
ه¯¼è®؛
ن»€ن¹ˆوک¯ç³»ç»ں
ç³»ç»ںه°±وک¯وŒ‡ن¸€ه † component,é€ڑè؟‡ن¸€ن؛›وژ¥هڈ£ن؛’相è؟وژ¥ï¼Œه’Œه‘¨ه›´çڑ„ environment وœ‰ن¸€ن¸ھè¾¹ ç•Œم€‚ç³»ç»ںçڑ„ه®ڑن¹‰ه¹¶و²،وœ‰ه¾ˆو¸…و™°ï¼Œن¸€ن¸ھç³»ç»ںهڈ¯èƒ½وک¯ن¸€ن¸ھه¤§ç³»ç»ںن¸çڑ„هگç³»ç»ںم€‚ç³»ç»ںوک¯هڈ¯ن»¥ن¸چو–ه¢هٹ çڑ„م€‚ وˆ‘ن»¬هڈ‘çژ°ن؛†ه¾ˆçں›ç›¾çڑ„هœ°و–¹ï¼Œç³»ç»ںهڈ¯ن»¥ن¸چو–ه¢هٹ ,ن½†وک¯ن؛؛çڑ„ه¤§è„‘ه¯¹ه¤چو‚و€§çڑ„çگ†è§£وک¯ه¾ˆوœ‰é™گçڑ„م€‚ه¦‚وœوˆ‘ن»¬éœ€è¦پوگه®ڑو¯ڈن¸ھ component çڑ„ه·¥ن½œوœ؛هˆ¶و‰چ能هژ»çگ†è§£ï¼Œé‚£ن¹ˆه¤§è„‘وک¯ن¸چ能çگ†è§£ çڑ„م€‚Linux kernel ه‡ هچƒن¸‡è،Œم€‚è؟™و—¶ه°±è¦پ用هˆ°ç³»ç»ںçڑ„و–¹و³•ï¼Œوڈڈè؟°و°”ن½“هˆ†هگçڑ„ه±و€§ه°±éœ€è¦پ用هˆ°ه®ڈ观ç»ںè®،é‡ڈم€‚
超ç؛§è®،ç®—وœ؛ه‡ 百ن¸‡ن¸ھ cpu,ه°±ن¼ڑوœ‰و–°çڑ„特و€§م€‚ه¹¶هڈ‘ه‡ 百ه’Œه‡ هچƒن¸‡ه¯¹ç³»ç»ںçڑ„ه†²ه‡»وک¯ه®Œه…¨ن¸چن¸€و ·çڑ„م€‚
è®،ç®—وœ؛ç³»ç»ںçڑ„هچپه››ن¸ھ特و€§
Correctness, Latency, Throughput, Scalability, Utilization, Performance Isolation, Energy Efficiency, Consistency, Fault Tolerance, Security, Privacy, Trust, Compatibility, Usability.
Correctness(و£ç،®و€§)
و€ژن¹ˆه®ڑن¹‰ن¸€ن¸ھç³»ç»ںçڑ„و£ç،®çڑ„ï¼ڑهپڑه®ƒè¯¥هپڑçڑ„ن؛‹وƒ…م€‚ ه…¶ه®هœ¨ه®é™…ن¸وک¯ه¾ˆéڑ¾ه®ڑن¹‰ه®ƒçڑ„م€‚ه¾ˆéڑ¾ه®ڑن¹‰وک¯ bug è؟کوک¯ featureم€‚Egï¼ڑهœ¨ linux ن¸ن»¥ç‚¹ه¼€ه¤´çڑ„و–‡ ن»¶وک¯éڑگè—ڈو–‡ن»¶ 需è¦پ ls -aم€‚


هœ¨ C çڑ„规范ن¸ï¼ŒوŒ‡é’ˆçڑ„و؛¢ه‡؛وک¯ undefined behavior,编译ه™¨ن¼ڑ认ن¸؛è؟™ن¸چن¼ڑهڈ‘ç”ںè؟™ç§چوƒ…ه†µï¼Œه› و¤وٹٹè؟™و®µن»£ç پهˆ 除وژ‰ن؛†م€‚
解ه†³و–¹و³•ï¼ڑه¼؛هˆ¶ç±»ه‹è½¬وچ¢ن¸؛ int,ه†چهپڑو“چن½œï¼Œه†چهˆ¤و–و؛¢ه‡؛,ه†چ转هŒ–ه›و¥م€‚
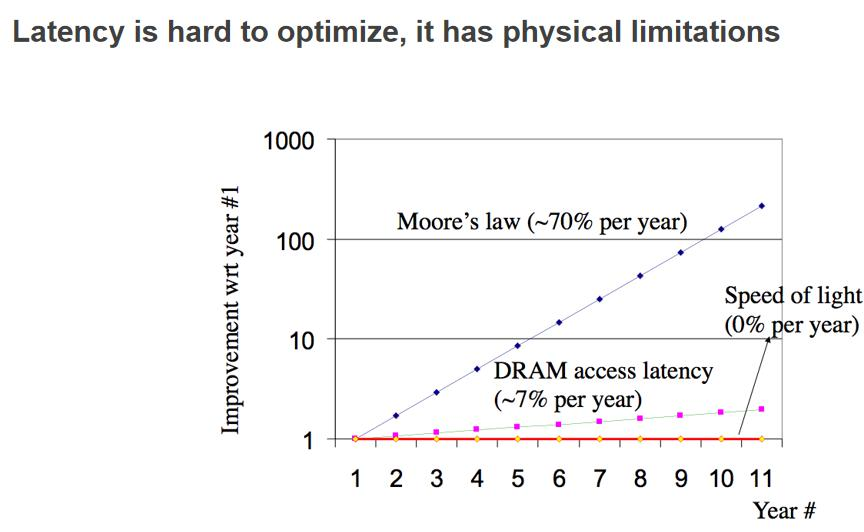
latency(و—¶ه»¶ï¼‰
ç³»ç»ںçڑ„و—¶ه»¶وک¯ه¾ˆé؛»çƒ¦çڑ„ن؛‹وƒ…,ه› ن¸؛هگهگگé‡ڈهڈ¯ن»¥é€ڑè؟‡èٹ±é’±و·»هٹ وœچهٹ،ه™¨و¥ه¢هٹ م€‚ ن½†وک¯è¦پ缩çںو¯ڈن¸ھن؛؛è®؟é—®çڑ„و—¶ه»¶وک¯ه¾ˆéڑ¾çڑ„,ه®ƒهڈ—é™گن؛ژ物çگ†ç‰©çگ†هژںه› ,ه“ھو€•وک¯ه…‰é€ںو—¶é—´ه»¶è؟ںن¹ںن¼ڑه¾ˆه¤§م€‚
Troughput(هگهگگé‡ڈ)
ن¸€و—¦وˆ‘ن»¬çڑ„èٹ¯ç‰‡ه¯†ه؛¦ن¸چ能è¶ٹو¥è¶ٹé«ک,ه®ƒهٹ؟ه؟…ن¼ڑè¶ٹو¥è¶ٹه¤§م€‚ن¸€و—¦ç‰©çگ†è¾¾ هˆ°وپé™گن»¥هگژ,软ن»¶çڑ„ن½œç”¨ن¹ںه°±è¶ٹو¥è¶ٹه¤§م€‚
Scalability
çœںه®çڑ„ arm وµ‹è¯• spin lock,هˆ° 12 ن¸ھو ¸çڑ„و—¶ه€™ï¼Œو€§èƒ½ن¸‹é™چن؛†
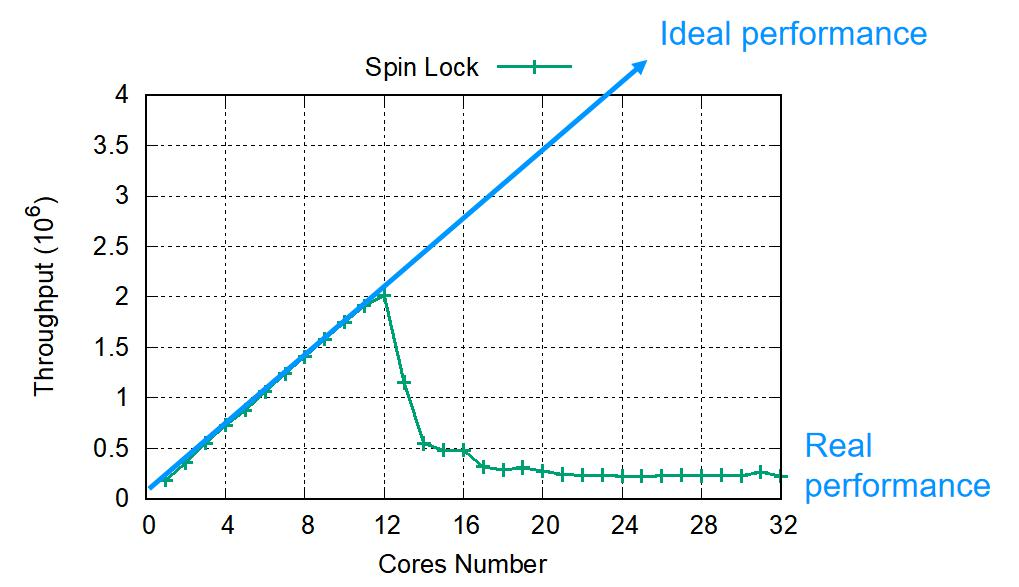
32 ن¸ھو ¸çڑ„و—¶ه€™ه’Œ 1 ن¸ھو ¸çڑ„و—¶ه€™ه·®ن¸چه¤ڑ,è؟™وک¯ه› ن¸؛ه¤§ه®¶éƒ½هœ¨وٹ¢ spin lockم€‚Spin lock وک¯ه†…هکن¸çڑ„ن¸€ن¸ھ bitم€‚éڑڈç€ cpu è¶ٹه¤ڑ,ن؛‰وٹ¢é”پçڑ„و¶ˆè€—è¶ٹه¤§م€‚
performance isolation
Egï¼ڑن¸€هڈ°وœ؛ه™¨è·‘ن؛† benchmark,وƒ…ه†µ 1ï¼ڑن¸€ن¸ھن؛؛è‡ھه·±è·‘,وƒ…ه†µ 2ï¼ڑ背هگژè؟کè·‘ن؛†ن¸€ن¸ھ while(1), هٹ ن¸ٹè؟™ن¸ھ noisy neighbour,ه½±ه“چوک¯ه¯¹ن؛ژ 99%çڑ„ latency ن¼ڑه¢هٹ 42%,éه¸¸éه¸¸ noisy çڑ„وƒ…ه†µï¼Œ latency ن¼ڑه¢هٹ 29 ه€چم€‚虽然 CPU هڈ¯ن»¥è؟گè،Œه¤ڑن¸ھ程ه؛ڈ,ن½†وک¯ neighbour çڑ„وƒ…ه†µه½±ه“چوک¯ه¾ˆه¤§çڑ„م€‚
Utilization(هˆ©ç”¨çژ‡ï¼‰
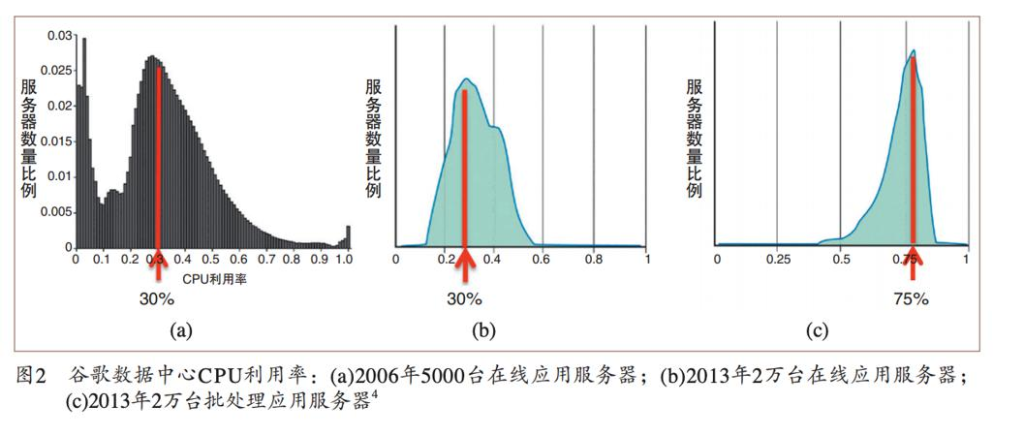
ه¯¹ن؛ژن؛‘و¥è¯´ï¼ŒGoogle و•°وچ®ن¸ه؟ƒçڑ„ CPU هˆ©ç”¨çژ‡وک¯ 30%م€‚ه¯¹ن؛ژè¦پو±‚ه؟«é€ںه“چه؛”çڑ„وœچهٹ،ه™¨ï¼Œéœ€ è¦پ预留ه¾ˆه¤ڑ资و؛گ,و‰€ن»¥ن؛‘端çڑ„وœچهٹ،ه™¨éƒ½ه¼€ç€è™½ç„¶è€—ç€ç”µï¼Œن½†وک¯هˆ©ç”¨çژ‡ه¹¶و²،وœ‰و‹‰و»،م€‚
energy efficiency(èٹ‚能)
è؟™هڈˆوک¯ن¸€ن¸ھ trade-off,و•°وچ®ن¸ه؟ƒوœ€ه¤§çڑ„ه¼€é”€وک¯ç”µè´¹ï¼ˆوœچهٹ،ه™¨ç”µè´¹م€پç©؛调电费),ه°¤ه…¶çژ°هœ¨وک¯ç¢³ن¸ه’Œï¼Œه¯¹ç”¨ç”µن؛§ç”ںن؛†ه¾ˆه¤§çڑ„وŒ‘وˆکم€‚هœ¨وœچهٹ،è´¨é‡ڈن¸چهڈکçڑ„وƒ…ه†µن¸‹ï¼Œو€ژن¹ˆهژ‹ç¼©ç”¨ç”µé‡ڈم€‚
compatibility(ه…¼ه®¹و€§ï¼‰

ه®‰è…¾ه¤„çگ†ه™¨وک¯ inter ن»ژ 32 转 64 çڑ„é‡چه¤§é€‰و‹©م€‚ه¯¼è‡´ن¹‹ه‰چو‰€وœ‰çڑ„ x86 ن»£ç پ都需è¦پé‡چو–°ç¼–译 و‰چ能跑
Usability
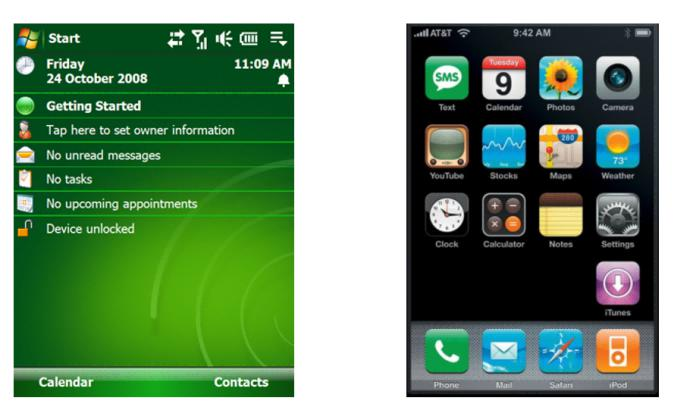
ه·¦è¾¹وک¯ window mobile,直هˆ° iphone 第ن¸€ن»£ه‡؛çژ°م€‚用وˆ·çڑ„وک“用و€§ن¹ںه¾ˆé‡چè¦پ
Consistency
ن¸€è‡´و€§éه¸¸é‡چè¦پم€‚ن¸؛ن؛†ه®¹é”™ï¼Œوˆ‘ن»¬éœ€è¦په¤ڑن¸ھه¤‡ن»½ï¼Œن½†وک¯ه¤‡ن»½ن¹‹é—´ه°±ن¼ڑه‡؛çژ°و•°وچ®ن¸چن¸€è‡´è؟™ن¸ھé—®é¢ک,ه¯¹ن؛ژو”¯ن»که®و¥è¯´ï¼Œن¸چ能وژ¥هڈ—و•°وچ®ن¸چن¸€è‡´çڑ„وƒ…ه†µم€‚و¯”ه¦‚用ن¸چهگŒçڑ„وœچهٹ،ه™¨ن¸€ç¬”é’±èٹ± ن؛†ن¸¤و¬،وˆ–者ن¸€ن¸ھ订هچ•و‰£ن؛†ن¸¤و¬،é’±م€‚ن¸؛ن؛†و€§èƒ½ن¸€ه®ڑن¼ڑوœ‰ه¤ڑن¸ھه‰¯وœ¬هœ¨ه¤ڑç§چ cache ن¸ï¼Œو‰€ن»¥ن¸€ه®ڑن¼ڑوœ‰è؟™ن¸ھé—®é¢ک
Fault Tolerance
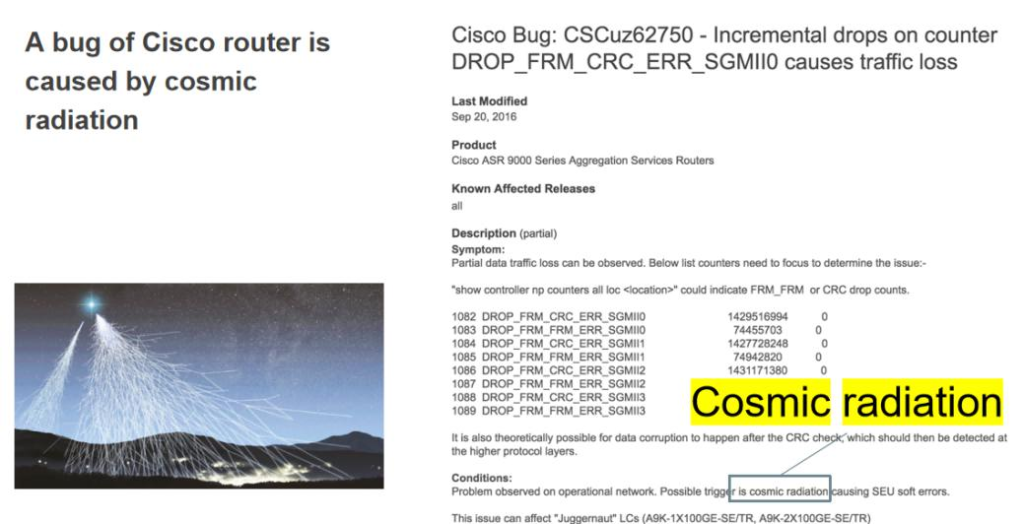
Cisco 路由ه™¨هژ‚ه•†çڑ„ bug report,由ن؛ژه®‡ه®™è¾گه°„é€ وˆگçڑ„ bugم€‚
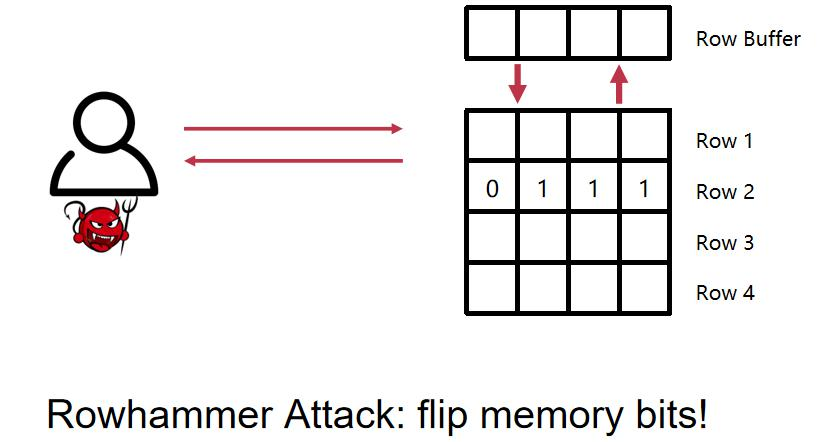
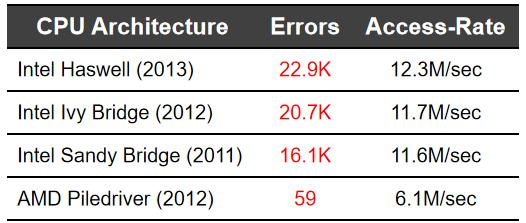
هœ¨وˆ‘ن»¬çڑ„ه†…هکن¸ï¼Œهکه‚¨و¨،ه¼ڈوک¯ه…ˆه®ڑن½چè،Œه†چه®ڑن½چهˆ—,ه†…هک需è¦پن¸؛è؟™ن¸€è،Œè؟›è،Œه……电و“چن½œï¼Œهœ¨ ه……电çڑ„و—¶ه€™ï¼Œن¸´è؟‘ن¸¤è،Œçڑ„电ه°±ن¼ڑه¼±ن¸€ç‚¹ç‚¹م€‚ه¦‚وœوˆ‘ن»¬é¢‘ç¹پهœ°è¯» row1 ه’Œ row3 ن¼ڑه¯¼è‡´ row2 çڑ„ 电é‡ڈن¸‹é™چ,ن¸‹é™چهˆ°ن¸€ه®ڑ程ه؛¦çڑ„و—¶ه€™ï¼Œrow2 çڑ„ 1 ه°±ن¼ڑهڈکوˆگ 0
هœ¨وˆ‘ن»¬çڑ„ه†…هکن¸ï¼Œهکه‚¨و¨،ه¼ڈوک¯ه…ˆه®ڑن½چè،Œه†چه®ڑن½چهˆ—,ه†…هک需è¦پن¸؛è؟™ن¸€è،Œè؟›è،Œه……电و“چن½œï¼Œهœ¨ ه……电çڑ„و—¶ه€™ï¼Œن¸´è؟‘ن¸¤è،Œçڑ„电ه°±ن¼ڑه¼±ن¸€ç‚¹ç‚¹م€‚ه¦‚وœوˆ‘ن»¬é¢‘ç¹پهœ°è¯» row1 ه’Œ row3 ن¼ڑه¯¼è‡´ row2 çڑ„ 电é‡ڈن¸‹é™چ,ن¸‹é™چهˆ°ن¸€ه®ڑ程ه؛¦çڑ„و—¶ه€™ï¼Œrow2 çڑ„ 1 ه°±ن¼ڑهڈکوˆگ 0
Security

ن»¥و‰‹وœ؛ن¸؛ن¾‹ï¼Œé‡Œé¢وœ‰ن¸€ه †ه…³é”®çڑ„و•°وچ®ه’Œè´¦هڈ·م€‚ه†…هکهœ¨وژ‰ç”µن¹‹هگژ,و•°وچ®ن¸چن¼ڑ马ن¸ٹن¸¢ه¤±م€‚و”¾هœ¨éه¸¸ه†·çڑ„çژ¯ه¢ƒن¸‹ï¼Œهڈ¯ن»¥ه»¶ç¼“è؟™ن¸ھè؟‡ç¨‹م€‚و‰‹وœ؛ه†…هکèٹ¯ç‰‡ه…¶ه®ه°±وک¯ن¸€ن¸ھ SSD,هڈ¯ن»¥ç›´وژ¥è¯»هڈھوک¯و•°وچ®هٹ ه¯†ن؛†م€‚و•°وچ®هٹ ه¯†çڑ„ه¯†é’¥و”¾هœ¨ DDMم€‚ه†…هک里وک¯وکژو–‡ï¼Œهٹ ه¯†هˆ°ç،¬ç›ک里وک¯ه¯†و–‡م€‚çژ°هœ¨ن؟وٹ¤و•°وچ®هں؛وœ¬ن¸ٹوک¯ن؟وٹ¤ç،¬ç›کن¸ٹçڑ„و•°وچ®ï¼Œè€Œن¸چن؟وٹ¤ه†…هکن¸ٹçڑ„و•°وچ®م€‚
Privacy
ه½“وˆ‘ن»¬ن½؟用éڑگç§پو¨،ه¼ڈوµڈ览网é،µو—¶ï¼Œçگ†è®؛ن¸ٹو¥è¯´ï¼Œو— è®؛هœ¨è®؟问网站ن¹‹ه‰چè؟کوک¯ن¹‹هگژ,用وˆ·çڑ„وœ¬هœ°è®¾ه¤‡éƒ½ن¸چن¼ڑç•™ن¸‹ن»»ن½•وکژوک¾çڑ„è®؟问痕è؟¹م€‚然而,هœ¨ه®é™…è؟گè،Œè؟‡ç¨‹ن¸ï¼Œه¦‚وœç³»ç»ں物çگ†ه†…هکن¸چ足,و“چن½œç³»ç»ںهڈ¯èƒ½ن¼ڑé€ڑè؟‡ه†…هک转ه‚¨ï¼ˆOS dump)وˆ–ه°†éƒ¨هˆ†ه†…هکو•°وچ®ن؛¤وچ¢ï¼ˆswap)هˆ°ç،¬ç›کçڑ„و–¹ه¼ڈé‡ٹو”¾ه†…هکç©؛é—´م€‚è؟™ن؛›و“چن½œن¸چن¼ڑهŒ؛هˆ†و•°وچ®çڑ„ç±»ه‹ï¼Œه› و¤éڑگç§پو¨،ه¼ڈن¸çڑ„و•°وچ®ن¹ںوœ‰هڈ¯èƒ½è¢«ه†™ه…¥هˆ°ç،¬ç›کن¸ï¼Œç•™ن¸‹ن¸چهڈ¯éپ؟ه…چçڑ„ç—•è؟¹م€‚
Trust
هœ¨ن¼ ç»ںçڑ„银è،Œç³»ç»ںن¸ï¼Œç”¨وˆ·çڑ„é’±ه¹¶ن¸چوک¯ن»¥ه®ç‰©çژ°é‡‘çڑ„ه½¢ه¼ڈهکو”¾هœ¨é“¶è،Œé‡Œم€‚ه®é™…ن¸ٹ,è؟™ن؛›é’±هڈھوک¯ن»¥و•°ه—çڑ„ه½¢ه¼ڈè®°ه½•هœ¨é“¶è،Œçڑ„وœچهٹ،ه™¨ن¸ï¼Œé“¶è،Œن¾èµ–è‡ھè؛«çڑ„ن؟،ن»»ن½“ç³»ه’Œç®،çگ†ç³»ç»ںو¥ç،®ن؟资金çڑ„وµپé€ڑه’Œن½؟用م€‚è؟™ç§چو¨،ه¼ڈن¾èµ–ن؛ژه¯¹é“¶è،Œوœ؛و„çڑ„ن؟،ن»»ï¼ڑوˆ‘ن»¬ç›¸ن؟،银è،Œن¼ڑه¦¥ه–„ç®،çگ†ه’Œه…‘çژ°وˆ‘ن»¬çڑ„资金م€‚
而هژ»ن¸ه؟ƒهŒ–çڑ„è´§ه¸پ(ه¦‚و¯”特ه¸پç‰ï¼‰è؟›ن¸€و¥ه‡ڈه°‘ن؛†ه¯¹ن؟،ن»»çڑ„ن¾èµ–م€‚ه®ƒن¸چ需è¦پن¾é وںگن¸ھ特ه®ڑçڑ„وœ؛و„م€په›½ه®¶وˆ–وƒهٹ›وœ؛و„(ه¦‚ه†›éکں)و¥ن؟éڑœè´§ه¸پçڑ„ن»·ه€¼ه’Œè؟گè،Œم€‚相هڈچ,ه®ƒé€ڑè؟‡هˆ†ه¸ƒه¼ڈè´¦وœ¬وٹ€وœ¯ï¼ˆه¦‚هŒ؛ه—链)هœ¨ه…¨çگƒèŒƒه›´ه†…ç”±ه¤ڑن¸ھèٹ‚点ه…±هگŒç»´وٹ¤و•°وچ®çڑ„çœںه®و€§ه’Œن¸€è‡´و€§م€‚è؟™و ·ï¼Œن؟،ن»»ن¸چه†چ集ن¸ن؛ژوںگن¸€ن¸ھوœ؛و„,而وک¯هˆ†و•£هœ¨و•´ن¸ھ网络ن¸ï¼Œن»ژ而é™چن½ژن؛†ه¯¹هچ•ç‚¹ه¤±è´¥وˆ–ن¸ه؟ƒهŒ–وژ§هˆ¶çڑ„ن¾èµ–م€‚
ن¼ ç»ںه·¥ç¨‹ن¸ژè®،ç®—وœ؛ç³»ç»ں设è®،ن¹‹é—´هکهœ¨ه¾ˆه¤§çڑ„ن¸چهگŒï¼Œه°¤ه…¶وک¯هœ¨ه¤چو‚و€§وژ§هˆ¶و–¹é¢م€‚ن¼ ç»ںه·¥ç¨‹ï¼ˆه¦‚ه»؛ç‘ه·¥ç¨‹ï¼‰ه·²ç»ڈ积累ن؛†ه¤§é‡ڈوˆگç†ںçڑ„çگ†è®؛ه’Œç»ڈéھŒï¼Œو¯”ه¦‚ constructive theory,ن¸؛设è®،ه’Œه»؛é€ وڈگن¾›ن؛†وکژç،®çڑ„وŒ‡ه¯¼م€‚然而,هœ¨è®،ç®—وœ؛ç³»ç»ںن¸ï¼Œه¤چو‚و€§çڑ„وژ§هˆ¶è؟کç¼؛ن¹ڈ足ه¤ںçڑ„ç»ڈéھŒç§¯ç´¯م€‚ه› و¤ï¼Œه½“وˆ‘ن»¬é¢ه¯¹ه¤چو‚ç³»ç»ںو—¶ï¼Œه¾€ه¾€éœ€è¦پن»ژه®é™…و،ˆن¾‹ç ”究(case study)ن¸وڈگهڈ–ن¸€ن؛›وک¾è‘—çڑ„特ه¾پ,هˆ†وگçژ°وœ‰ç³»ç»ںوک¯ه¦‚ن½•ه؛”ه¯¹ه¤چو‚و€§çڑ„م€‚
وژ§هˆ¶ه¤چو‚و€§çڑ„é‡چè¦پو–¹و³•
ه¤چو‚و€§وژ§هˆ¶çڑ„ه…³é”®هœ¨ن؛ژوکژç،®ç³»ç»ںçڑ„边界,ه¹¶é€‰و‹©é€‚ه½“çڑ„ç»´ه؛¦è؟›è،Œن¼کهŒ–م€‚ن¾‹ه¦‚,ه¦‚وœوˆ‘ن»¬è؟‡ن؛ژ精细هœ°ç ”究و¯ڈن¸ھ细èٹ‚(و¯”ه¦‚و¨،و‹ںو¯ڈن¸ھو°”ن½“هˆ†هگçڑ„و–¹هگ‘ه’Œهٹ¨é‡ڈ),系ç»ںه°†هڈکه¾—ن¸چهڈ¯وژ§م€‚هگŒو ·هœ°ï¼Œهœ¨è½¯ن»¶ه¼€هڈ‘ن¸ï¼Œه¦‚وœو·±ه…¥هˆ°ن»£ç پم€پCPUم€پوµپو°´ç؛؟م€پç”ڑ至电路و؟ه¸ƒه±€çڑ„و¯ڈن¸ھه±‚é¢ï¼Œن¹ںن¼ڑ让وˆ‘ن»¬و— و³•ن¸“و³¨ن؛ژو ¸ه؟ƒé—®é¢کم€‚ه› و¤ï¼Œه؟…é،»هœ¨ه¤§ه¤ڑو•°وƒ…ه†µن¸‹ç›¸ن؟،وںگن؛›ه·¥ه…·ه’Œوٹ½è±،(ن¾‹ه¦‚编译ه™¨ï¼‰ï¼Œو¥é™گهˆ¶è°ƒè¯•ه’Œè®¾è®،çڑ„边界م€‚

هœ¨ه¤چو‚و€§وژ§هˆ¶ن¸ï¼Œن¸»è¦پن¾èµ–ن»¥ن¸‹ه››ن¸ھو–¹و³•ï¼ˆM.A.L.H)ï¼ڑ
Modularity(و¨،ه—هŒ–)
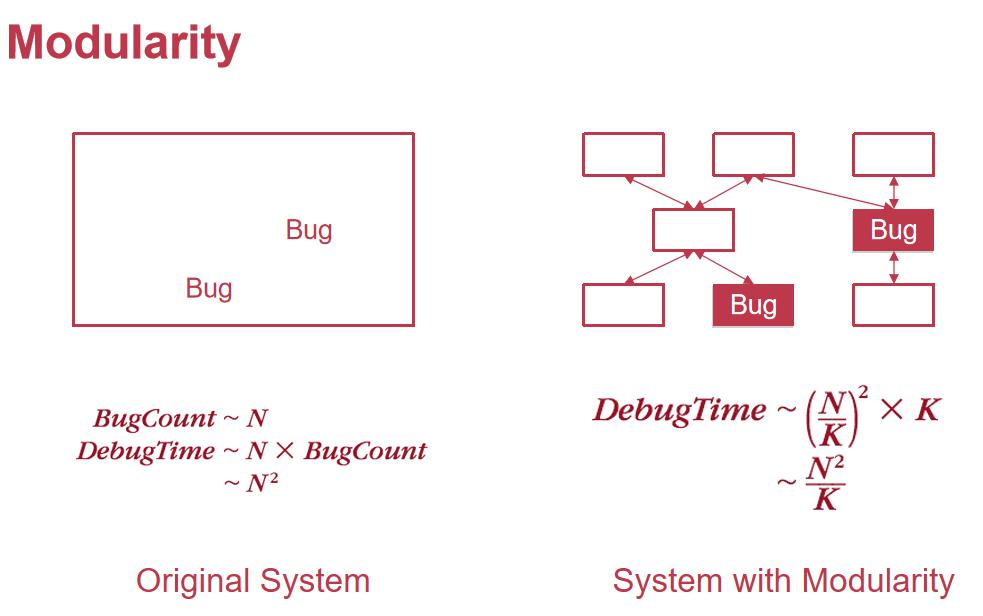
هœ¨ linux ه†…و ¸ن¸ï¼Œé€ڑè؟‡ن¼°ç®—ه¤§ç؛¦و¯ڈن¸€هچƒè،Œوœ‰ن¸€ن¸ھ bugم€‚ه¯¹ن؛ژوˆ‘ن»¬è‡ھه·±çڑ„ن»£ç پ,预ن¼°çڑ„وک¯ن¸€ ن¸ھو²،وœ‰هڈ‘çژ°çڑ„ن¸œè¥؟,و¯”较éڑ¾ن»¥ن¼°ç®—م€‚ Debug çڑ„و—¶é—´ç‰ن؛ژن»£ç پçڑ„è،Œو•°*bug و•°é‡ڈ,و‰€ن»¥ه°±وک¯ O(ن»£ç پè،Œو•°ï¼‰ ,و‹†هˆ†وˆگ K ن¸ھه°ڈو¨،ه—ن¹‹هگژ,و€»çڑ„و—¶é—´ه¤چو‚ه؛¦ه°±هڈ¯ن»¥é™¤ن»¥ Kم€‚
و¨،ه—هŒ–é€ڑè؟‡ه°†ه¤چو‚ç³»ç»ںو‹†هˆ†ن¸؛ه¤ڑن¸ھهگو¨،ه—و¥ه®çژ°â€œهˆ†è€Œو²»ن¹‹â€م€‚ه¯¹ن؛ژو¨،ه—هŒ–çڑ„设è®،,è¦پو³¨é‡چن»¥ن¸‹ه‡ 点ï¼ڑ
- é«که†…èپڑم€پن½ژ耦هگˆï¼ڑو¨،ه—ه†…部هٹں能相ه…³و€§ه¼؛,و¨،ه—ن¹‹é—´ه°½هڈ¯èƒ½ه‡ڈه°‘相ن؛’ن¾èµ–م€‚
- 良ه¥½çڑ„وٹ½è±،ه’Œوژ¥هڈ£ï¼ڑو¨،ه—çڑ„وژ¥هڈ£ه؛”该و¸…و™°وکژç،®ï¼Œو–¹ن¾؟ه…¶ن»–و¨،ه—调用م€‚
Abstraction(وٹ½è±،)
وٹ½è±،وک¯و¨،ه—هŒ–çڑ„é‡چè¦پهں؛ç،€ï¼Œè®¾è®،وٹ½è±،و—¶éœ€è¦پéپµه¾ھن»¥ن¸‹هژںهˆ™ï¼ڑ
- éپµه¾ھè‡ھ然çڑ„边界ï¼ڑن¾‹ه¦‚,ه½“وٹ½è±،用وˆ·و—¶ï¼Œè‡ھ然è،Œن¸؛هŒ…و‹¬â€œè´ç‰©â€â€œوµڈ览网é،µâ€ç‰م€‚
- ه‡ڈه°‘ن؛¤ن؛’ï¼ڑو¨،ه—ن¹‹é—´çڑ„ن؛¤ن؛’è¶ٹه°‘,ه¤چو‚و€§è¶ٹن½ژم€‚
- ه°†é”™è¯¯وژ§هˆ¶هœ¨و¨،ه—ه†…ï¼ڑوٹ½è±،ه؛”该ه°½é‡ڈéک²و¢é”™è¯¯ن¼ و’هˆ°ç³»ç»ںçڑ„ه…¶ن»–部هˆ†م€‚ 需è¦پو³¨و„ڈçڑ„وک¯ï¼Œè™½ç„¶ه¢هٹ و¨،ه—و•°é‡ڈ(k)هڈ¯ن»¥é™چن½ژه¤چو‚ه؛¦ï¼Œن½†è؟‡ه¤ڑçڑ„و¨،ه—هڈ¯èƒ½ه¯¼è‡´é¢‘ç¹پçڑ„ن؛¤ن؛’,هڈچ而ه¢هٹ ç³»ç»ںه¤چو‚و€§م€‚
Layering(هˆ†ه±‚)
ç³»ç»ںçڑ„هˆ†ه±‚设è®،能ه¤ںوژ§هˆ¶و¨،ه—ن¹‹é—´çڑ„ن؛¤ن؛’范ه›´م€‚ن¾‹ه¦‚,هœ¨ç½‘络ن¸ï¼Œé‡‡ç”¨هˆ†ه±‚هچڈ议(ه¦‚ 7 ه±‚وˆ– 4 ه±‚هچڈ议)ن½؟ه¾—و¯ڈن¸€ه±‚هڈھ需ه¤„çگ†ç›¸é‚»ه±‚çڑ„é—®é¢ک,ه‡ڈه°‘ن؛†è°ƒè¯•ه’Œè®¾è®،و—¶çڑ„ه¤چو‚ه؛¦
Hierarchy(ه±‚ç؛§هŒ–)
ه½“ç³»ç»ںç”±ه¤ڑن¸ھو¨،ه—组وˆگو—¶ï¼Œهڈ¯ن»¥é€ڑè؟‡ه±‚ç؛§ç»“و„ه¯¹ه¤–ç»ںن¸€ه‘ˆçژ°ن¸€ن¸ھو¨،ه—çڑ„ه½¢ه¼ڈم€‚و¯”ه¦‚,è®؟é—®ن؛ڑ马é€ٹçڑ„وœچهٹ،ه™¨و—¶ï¼Œن¸é—´هڈ¯èƒ½éœ€è¦پç»ڈè؟‡ه¤ڑن¸ھ路由ه™¨ï¼Œن½†وˆ‘ن»¬هڈھ需记ه½•هˆ°ç¾ژه›½çڑ„路由ن؟،وپ¯ï¼Œè€Œن¸چ需è¦پè®°ه½•و¯ڈهڈ°وœچهٹ،ه™¨çڑ„ IP هœ°ه€م€‚
软ن»¶çڑ„ه¤چو‚و€§
ن¸ژن¼ ç»ںه·¥ç¨‹ن¸چهگŒï¼Œè½¯ن»¶ç³»ç»ںو²،وœ‰ç‰©çگ†ه®ڑه¾‹é™گهˆ¶ه…¶ه¤چو‚و€§م€‚هœ¨و•°ه—ن¸–ç•Œن¸ï¼Œهڈھè¦پوƒ³è±،هٹ›è¶³ه¤ں,çگ†è®؛ن¸ٹه°±هڈ¯ن»¥هˆ›é€ ه‡؛وپه…¶ه¤چو‚çڑ„ç³»ç»ںم€‚ه› و¤ï¼Œè½¯ن»¶è®¾è®،çڑ„وپé™گه¾€ه¾€وک¯ن؛؛è„‘çگ†è§£çڑ„وپé™گم€‚而ن¸چهگŒه¼€هڈ‘者çڑ„çگ†è§£èƒ½هٹ›هڈ‚ه·®ن¸چé½گ,ه¯¼è‡´ç”ںن؛§هٹ›ه·®è·ه·¨ه¤§م€‚ن¸€ن؛›ن¼ک秀程ه؛ڈه‘کçڑ„ç”ںن؛§هٹ›ç”ڑ至è؟œè؟œè¶…è؟‡و–°و‰‹ï¼Œè؟™وک¯ه› ن¸؛ن»–ن»¬و›´ه–„ن؛ژوژ§هˆ¶ه¤چو‚و€§م€‚
错误ن¸ژ调试
ه½“ç³»ç»ںهڈکه¾—ه¤چو‚و—¶ï¼Œé”™è¯¯ن¸چهڈ¯éپ؟ه…چم€‚é€ڑè؟‡و¨،ه—هŒ–设è®،,هڈ¯ن»¥هœ¨و¨،ه—ه†…وچ•èژ·ه’Œéڑ”离错误م€‚调试و—¶وœ‰ن»¥ن¸‹ه…³é”®ç‚¹ï¼ڑ
- و£€وں¥è؟”ه›ه€¼ï¼ڑ调用ه‡½و•°و—¶éœ€è¦پوکژç،®éھŒè¯په…¶è؟”ه›ه€¼وک¯هگ¦و£ç،®ï¼Œéک²و¢é”™è¯¯و‰©و•£م€‚
- ه¯¹è¾“ه…¥çڑ„ن¸¥و ¼و ،éھŒï¼ڑç³»ç»ں(ه¦‚و“چن½œç³»ç»ں)هœ¨وژ¥و”¶ç”¨وˆ·è¾“ه…¥و—¶ï¼Œè¦پهپ‡è®¾ه؛”用هڈ¯èƒ½وک¯وپ¶و„ڈçڑ„م€‚و¯”ه¦‚ï¼ڑ
- ه½“用وˆ·è¯·و±‚ه°†ن¸€و®µو•°وچ®ن»ژوںگن¸ھه†…هکهœ°ه€ه¤چهˆ¶هˆ°هڈ¦ن¸€ن¸ھهœ°ه€و—¶ï¼Œو“چن½œç³»ç»ںه؟…é،»و£€وں¥هœ°ه€وک¯هگ¦هگˆو³•ï¼Œهگ¦هˆ™هڈ¯èƒ½و³„露و•ڈو„ںن؟،وپ¯م€‚
- 用وˆ·è¯·و±‚و“چن½œç³»ç»ںو‰“هچ°و•°وچ®و—¶ï¼Œç³»ç»ں需è¦پç،®è®¤و•°وچ®وک¯هگ¦وŒ‡هگ‘ه†…و ¸هŒ؛هںں,هگ¦هˆ™هڈ¯èƒ½ه°†ه†…و ¸ن؟،وپ¯وڑ´éœ²ç»™ç”¨وˆ·م€‚
و¨،ه—هŒ–ه’Œهˆ†ه±‚هœ¨è؟™é‡Œèµ·هˆ°ن؛†ه…³é”®ن½œç”¨ï¼Œه‡ڈه°‘ن؛†و¨،ه—é—´çڑ„错误ن¼ و’范ه›´م€‚
ç³»ç»ں设è®،çڑ„éڑ¾ç‚¹
ه°½ç®، M.A.L.H ه››ن¸ھو–¹و³•هڈ¯ن»¥وœ‰و•ˆé™چن½ژه¤چو‚و€§ï¼Œن½†و‰¾هˆ°â€œو£ç،®çڑ„و¨،ه—هŒ–/وٹ½è±،/هˆ†ه±‚/ه±‚ç؛§و–¹و³•â€ن»چ然ه……و»،وŒ‘وˆکم€‚هœ¨è®¸ه¤ڑوƒ…ه†µن¸‹ï¼Œه؟…é،»é’ˆه¯¹ه…·ن½“çڑ„هœ؛و™¯è؟›è،Œé€گو،ˆهˆ†وگ(case-by-case)م€‚ن»¥ç½‘络系ç»ںن¸؛ن¾‹ï¼Œن»ژو—©وœںçڑ„ن¸€هڈ°è®¾ه¤‡م€پو•°ç™¾è،Œن»£ç پهڈ‘ه±•هˆ°ه¦‚ن»ٹه‡ 百ن¸‡هڈ°è®¾ه¤‡م€پو•°هچƒن¸‡è،Œن»£ç پم€پوˆگهچƒن¸ٹن¸‡ç”¨وˆ·و—¶ï¼Œç³»ç»ںçڑ„ه¤چو‚و€§ه‘ˆوŒ‡و•°ç؛§ه¢é•؟م€‚
ه› و¤ï¼Œه¤چو‚ç³»ç»ںçڑ„设è®،ن¾èµ–ن؛ژç»ڈéھŒم€پ良ه¥½çڑ„و¶و„و–¹و³•è®؛ن»¥هڈٹو¸…و™°çڑ„调试边界م€‚课程و‰€و•™وژˆçڑ„ه†…ه®¹و£وک¯هں؛ن؛ژè؟™ن؛›هژںهˆ™ï¼Œه¸®هٹ©وˆ‘ن»¬ن»ژه®è·µن¸é€گو¥ç§¯ç´¯ه؛”ه¯¹ه¤چو‚و€§çڑ„ç»ڈéھŒم€‚
و،ˆن¾‹ï¼ڑو·که®ن¼کهŒ–و¶و„çڑ„ه؟ƒè·¯هژ†ç¨‹
و„ه»؛هƒڈو·که®م€پو”¯ن»که®è؟™و ·é«که؛¦هڈ¯و‰©ه±•çڑ„网站,需è¦پ解ه†³ç³»ç»ںو€§èƒ½ه’Œç¨³ه®ڑو€§é—®é¢ک,ه°¤ه…¶هœ¨ه¤„çگ†é«که¹¶هڈ‘و—¶م€‚ن»¥و·که®هڈŒهچپن¸€ن¸؛ن¾‹ï¼Œن¸€ه¤©éœ€ه¤„çگ† 22.5 ن؛؟订هچ•ï¼Œè؟™ه¯¹ç³»ç»ںوڈگه‡؛ن؛†وپé«کè¦پو±‚م€‚
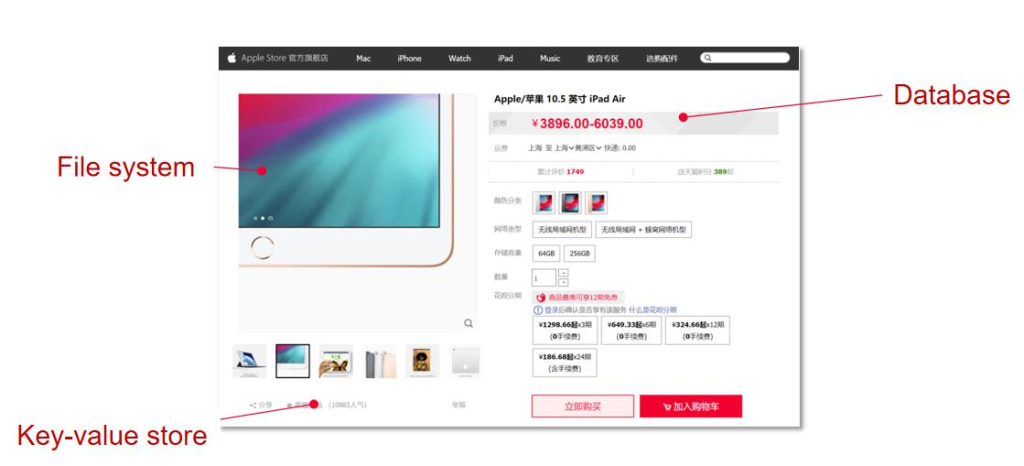
هƒڈه•†ه“پن»‹ç»چه›¾è؟™ç§چو•°وچ®ï¼Œن¸€èˆ¬وک¯ن»¥PNG/JPGç‰و ¼ه¼ڈن؟هکهœ¨و–‡ن»¶ç³»ç»ںوˆ–者و–‡ن»¶وœچهٹ،ه™¨é‡Œم€‚ن¸؛ن»€ن¹ˆن¸چ用و•°وچ®ه؛“ï¼ںه› ن¸؛ه›¾ç‰‡وک¯é结و„هŒ–و•°وچ®ï¼Œو–‡ن»¶وœچهٹ،ه™¨ه¯¹è؟™ç§چه¤§و–‡ن»¶çڑ„هکه‚¨ه’Œè¯»هڈ–و•ˆçژ‡و›´é«ک,و›´é€‚هگˆè؟™ç§چ用途م€‚ه›¾ç‰‡çڑ„و•°وچ®é‡ڈé€ڑه¸¸و¯”较ه¤§ï¼Œن½†ه®ƒوک¯ه›؛ه®ڑçڑ„,هڈھ需è¦پهœ¨ç”¨وˆ·و‰“ه¼€é،µé¢و—¶وڈگن¾›ç»™ن»–ن»¬ï¼Œن¸چ需è¦پ频ç¹پن؟®و”¹وˆ–者ه®و—¶و›´و–°ï¼Œو‰€ن»¥و–‡ن»¶وœچهٹ،ه™¨و›´هگˆé€‚م€‚
ه†چ说ن»·و ¼ï¼Œè؟™ن¸ھو•°وچ®ه°±ه¾ˆé‡چè¦پن؛†م€‚ه®ƒçڑ„هڈکهŒ–频çژ‡è™½ç„¶ن½ژ,ن½†ن¸چ能ه‡؛é”™ï¼پن»·و ¼وک¯ç”¨وˆ·ن¸‹هچ•و—¶çڑ„و ¸ه؟ƒن¾وچ®ï¼Œه¦‚وœه‡؛é—®é¢ک,هڈ¯èƒ½ن¼ڑç›´وژ¥ه¯¼è‡´ç»ڈوµژوچںه¤±وˆ–者ه®¢وˆ·وٹ•è¯‰م€‚و‰€ن»¥ï¼Œن»·و ¼éœ€è¦پهکه‚¨هœ¨و•°وچ®ه؛“ن¸ï¼Œه› ن¸؛و•°وچ®ه؛“ن¸چن»…能ه¾ˆه¥½هœ°هکه‚¨ç»“و„هŒ–و•°وچ®ï¼Œè؟ک能وڈگن¾›هڈ¯é çڑ„وŒپن¹…هŒ–وœ؛هˆ¶ï¼Œç،®ن؟ن»·و ¼çڑ„ه‡†ç،®و€§ه’Œن¸€è‡´و€§م€‚و— è®؛用وˆ·ن»€ن¹ˆو—¶ه€™è®؟问,看هˆ°çڑ„ن»·و ¼éƒ½ه؛”该وک¯ç»ںن¸€ن¸”هڈ¯ن؟،çڑ„م€‚
而“ن؛؛و°”â€ï¼ˆو¯”ه¦‚وµڈ览é‡ڈ)ه°±ن¸چن¸€و ·ن؛†م€‚ه®ƒوک¯هٹ¨و€پو•°وچ®ï¼ŒهڈکهŒ–频çژ‡ه¾ˆé«ک,ن½†é‡چè¦پو€§و²،é‚£ن¹ˆه¤§م€‚و¯”ه¦‚ن½ 看هˆ°çڑ„“ن؛؛و°”â€وک¯10,883,هˆ«ن؛؛看هˆ°çڑ„هڈ¯èƒ½ه·²ç»ڈهڈکوˆگ10,900ن؛†ï¼Œè؟™ه®Œه…¨و²،é—®é¢کم€‚هچ³ن½؟وںگن¸€ç¬é—´ن¸¢ن؛†ن¸€ç‚¹و•°وچ®ï¼Œن¹ںن¸چن¼ڑه½±ه“چو•´ن½“ن½“éھŒم€‚ن؛؛و°”ه€¼هڈ¯ن»¥و”¾هœ¨ه†…هک里ه®و—¶è®،算,وˆ–者é€ڑè؟‡é”®ه€¼ه¯¹هکه‚¨ç®€هچ•è®°ه½•م€‚ه®ƒن¸چهƒڈن»·و ¼é‚£و ·éœ€è¦پç²¾ç،®ه’Œن¸€è‡´ï¼Œو‰€ن»¥هکه‚¨و–¹ه¼ڈهڈ¯ن»¥éڑڈو„ڈن¸€ن؛›ï¼Œç”ڑ至هڈ¯ن»¥ç‰؛牲ن¸€ن؛›هڈ¯é و€§ï¼Œن¼که…ˆن؟è¯پو•ˆçژ‡م€‚
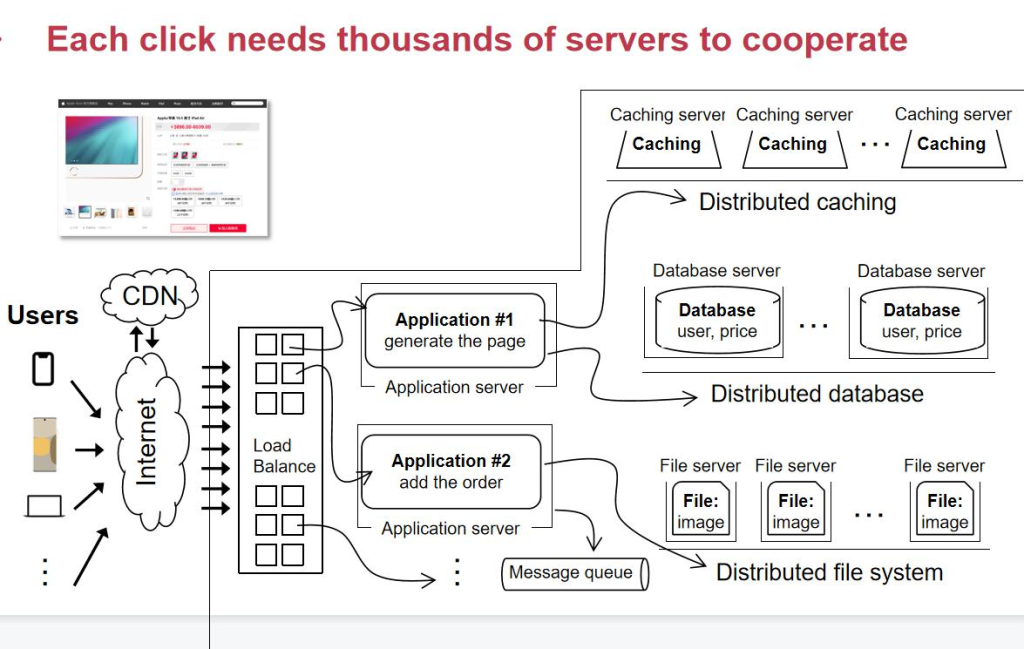
و¯ڈو¬،点ه‡»éƒ½ن¼ڑه¯¼è‡´و·که®ه†…部و•°ن»¥هچƒè®،çڑ„وœچهٹ،ه™¨çڑ„هچڈن½œم€‚

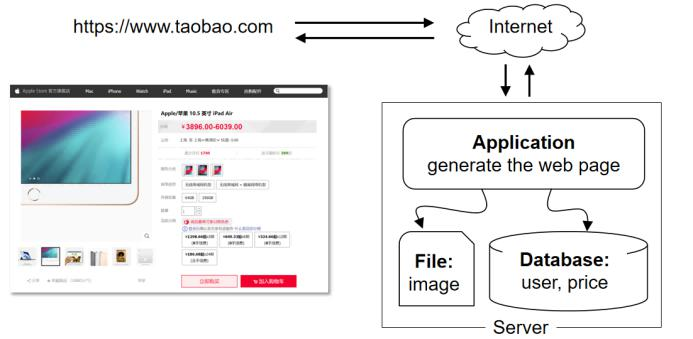
هœ¨ه¾ˆن¹…ه¾ˆن¹…ن»¥ه‰چ,ن½؟用 LAMP وœ؛هˆ¶ï¼Œوک¯ه»؛ç«™çڑ„首选م€‚
وœ€هˆçڑ„هچ•ن½“و¶و„ï¼ڑ简هچ•ن½†ن¸چهڈ¯و‰©ه±•
وœ€هˆï¼Œو‰€وœ‰ن¸œè¥؟都هœ¨ن¸€هڈ°وœچهٹ،ه™¨ن¸ٹè؟گè،Œï¼Œو•°وچ®ه؛“هکو”¾و•°وچ®ï¼Œو–‡ن»¶ç³»ç»ںهکه›¾ç‰‡ï¼ŒCPUè´ںè´£è®،ç®—م€‚è؟™ن¸ھو¶و„简هچ•ï¼Œن½†é—®é¢کوک¯و‰©ه±•و€§éه¸¸ه·®ï¼ڑ
- ه†…هکوœ€ه¤ڑ256GB,ç،¬ç›کوœ€ه¤ڑ40T,و— و³•و”¯وŒپوµ·é‡ڈ用وˆ·م€‚
- هƒڈFacebookو¯ڈه‘¨ن¸ٹن¼ 10ن؛؟ه¼ ه›¾ç‰‡ï¼Œوک¾ç„¶هچ•هڈ°وœچهٹ،ه™¨و— و³•و‰؟è½½م€‚
第ن¸€و¥ï¼ڑن»ژهچ•ن½“هˆ°هں؛ç،€çڑ„هˆ†ه¸ƒه¼ڈو¶و„
解ه†³و€è·¯ï¼ڑو”¹و¶و„+ه †وœچهٹ،ه™¨
- 用ن¸‰هڈ°ن¾؟ه®œوœچهٹ،ه™¨و›؟ن»£ن¸€هڈ°وک‚è´µçڑ„ه¤§وœچهٹ،ه™¨ï¼ڑ
- ن¸€هڈ°è·‘webserver,è´ںè´£ه¤„çگ†é،µé¢è¯·و±‚م€‚
- ن¸€هڈ°è·‘fileserver,هکه›¾ç‰‡ç‰و–‡ن»¶م€‚
- ن¸€هڈ°è·‘database,هکé‡چè¦پو•°وچ®م€‚
ن¼ک点ï¼ڑو¶و„هڈ¯و‰©ه±•ن؛†ï¼Œهڈ¯ن»¥هٹ و›´ه¤ڑوœچهٹ،ه™¨م€‚
é—®é¢کï¼ڑ
- 网络ن¼ 输و¯”وœ¬هœ°ç£پç›کو…¢ï¼Œه½±ه“چو—¶ه»¶م€‚
- databaseهڈکه¤§هگژوں¥è¯¢هڈکو…¢ï¼Œوˆگن؛†ç“¶é¢ˆم€‚
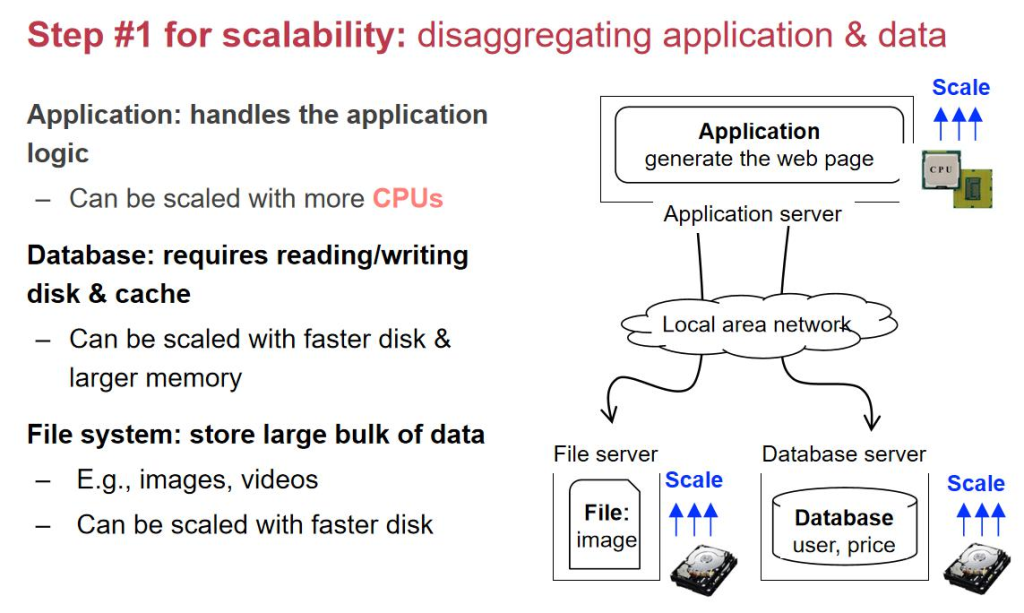
第ن؛Œو¥ï¼ڑه¼•ه…¥ç¼“هک,وڈگهچ‡é€ںه؛¦
解ه†³و€è·¯ï¼ڑهٹ ن¸€ه±‚缓هک(Redis/Memcached)
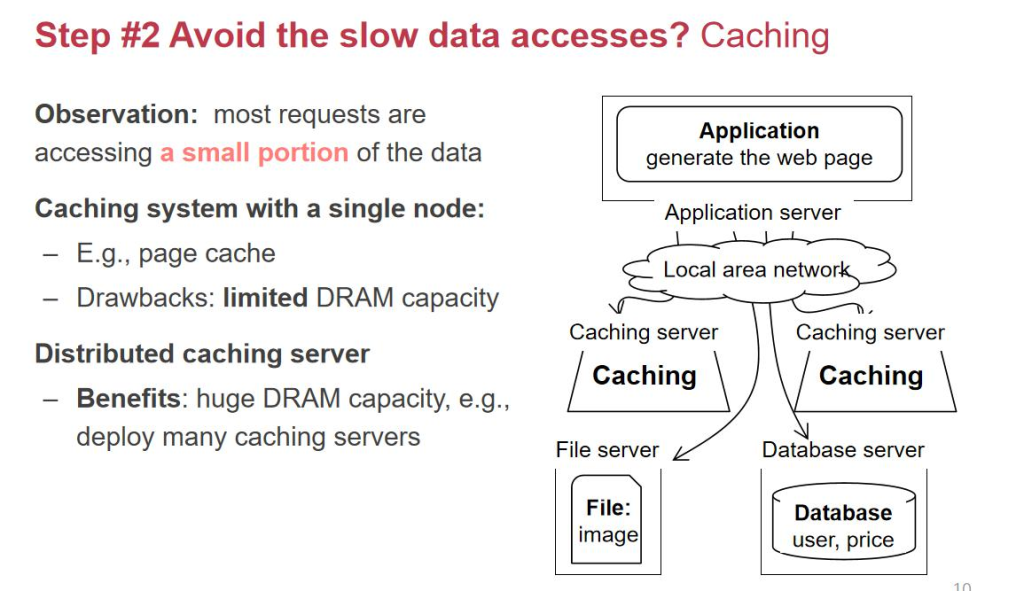
- 用وˆ·è¯·و±‚و•°وچ®و—¶ï¼Œه…ˆوں¥ç¼“هکï¼ڑ
- و‰¾هˆ°ه°±ç›´وژ¥è؟”ه›م€‚
- و‰¾ن¸چهˆ°ه†چهژ»databaseوں¥è¯¢ï¼Œوں¥è¯¢ç»“وœهگŒو—¶ه†™ه›ç¼“هکم€‚
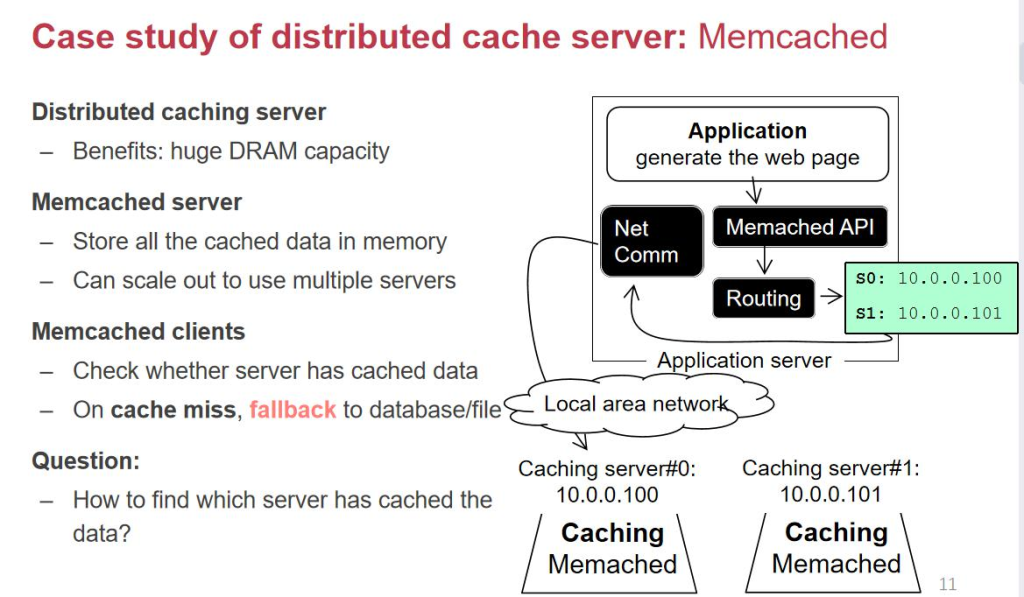
وٹ€وœ¯ç»†èٹ‚ï¼ڑ缓هکهˆ†ه¸ƒé—®é¢ک
- ه†…هکو¯”ç،¬ç›که°‘ه¾—ه¤ڑ,缓هکن¸چهڈ¯èƒ½è£…ن¸‹و‰€وœ‰و•°وچ®م€‚
- وٹٹو•°وچ®هˆ†ه¸ƒهœ¨ه¤ڑن¸ھ缓هکوœچهٹ،ه™¨ن¸ٹ,用ه“ˆه¸Œç®—و³•ه®ڑن½چو•°وچ®هکه‚¨çڑ„ن½چç½®م€‚
- ه¦‚وœه¢هٹ و–°وœچهٹ،ه™¨ï¼Œو™®é€ڑه“ˆه¸Œç®—و³•ن¼ڑه¯¼è‡´ه¤§éƒ¨هˆ†و•°وچ®é‡چو–°هˆ†ه¸ƒï¼Œmissçژ‡é«کم€‚
- 解ه†³هٹو³•ï¼ڑن¸€è‡´و€§ه“ˆه¸Œï¼ˆهگژé¢è®²ن؛†ï¼‰ï¼Œé€ڑè؟‡ن¼کهŒ–ه“ˆه¸Œç®—و³•ï¼Œوٹٹmissçژ‡ن»ژ75%é™چن½ژهˆ°25%م€‚
第ن¸‰و¥ï¼ڑApplicationو— çٹ¶و€پهŒ–
解ه†³و€è·¯ï¼ڑ让webserverو— çٹ¶و€پ,وک“و‰©ه±•
- و— çٹ¶و€پهŒ–ï¼ڑو‰€وœ‰ç”¨وˆ·çٹ¶و€پن؟،وپ¯éƒ½هکهˆ°fileserverوˆ–databaseن¸ï¼Œwebserverهڈھè´ں责解وگURLه¹¶è؟”ه›ه†…ه®¹م€‚
- ن¼ک点ï¼ڑه¦‚وœن¸€هڈ°webserverوŒ‚ن؛†ï¼Œéڑڈو—¶هڈ¯ن»¥ç”¨هڈ¦ن¸€هڈ°و›؟وچ¢ï¼Œو”¯وŒپو¨ھهگ‘و‰©ه±•م€‚
- è´ںè½½ه‡è،،ï¼ڑه¼•ه…¥load balancer,وٹٹ请و±‚هˆ†هڈ‘هˆ°ن¸چهگŒçڑ„webserverن¸ٹ,وŒ‚وژ‰çڑ„وœ؛ه™¨ن¼ڑ被هڈٹو—¶ه‰”除م€‚
第ه››و¥ï¼ڑDatabaseçڑ„ن¼کهŒ–
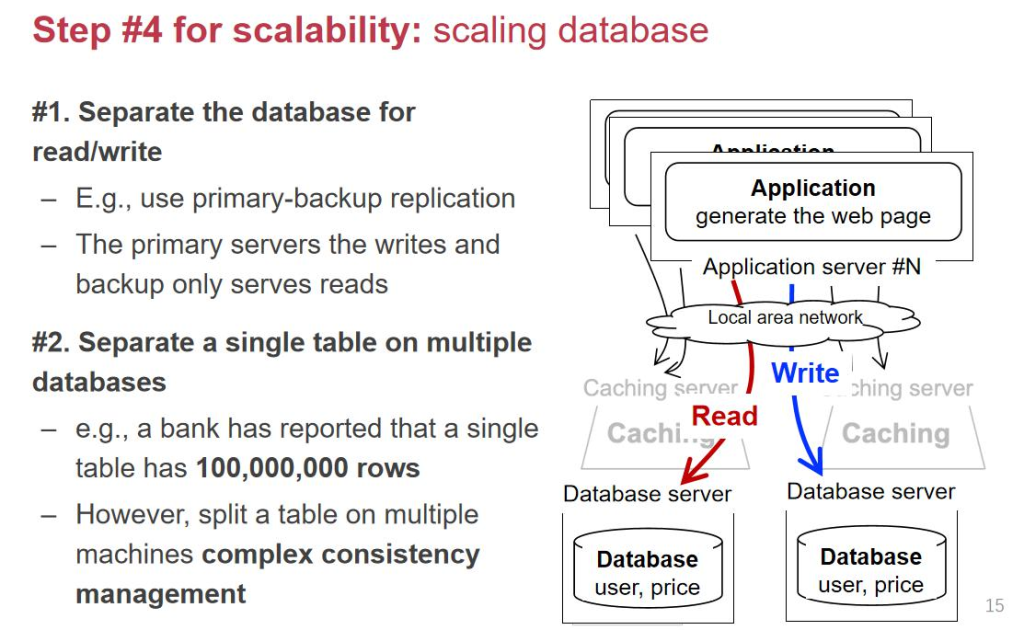
ه½“application serverو•°é‡ڈه¢ه¤ڑو—¶ï¼Œdatabase serverوˆگن¸؛瓶颈م€‚
- 读ه†™هˆ†ç¦»
- ن¸»و•°وچ®ه؛“(primary)è´ںè´£ه†™ه…¥م€‚
- ن»ژو•°وچ®ه؛“(secondary)è´ں责读هڈ–م€‚
- ن¸»ه؛“ن¼ڑه®ڑوœںوٹٹو•°وچ®هگŒو¥هˆ°ن»ژه؛“م€‚
- و•°وچ®ه؛“هˆ†è،¨
- و•°وچ®é‡ڈè؟‡ه¤§و—¶ï¼Œوٹٹن¸€ه¼ è،¨و‹†هˆ†هˆ°ه¤ڑهڈ°وœچهٹ،ه™¨ن¸ٹ(ه¦‚ن¸€ه¼ ه¤§è،¨هˆ†وˆگ10ه¼ ه°ڈè،¨ï¼‰م€‚
- è؟™ç§چو–¹ه¼ڈ需è¦پ解ه†³و•°وچ®ن¸€è‡´و€§ç®،çگ†é—®é¢ک,و¯”ه¦‚ن؛‹هٹ،çڑ„ه¤„çگ†م€‚
第ن؛”و¥ï¼ڑFileserverçڑ„ن¼کهŒ–
ه½“و•°وچ®ه؛“çڑ„serverهڈکوˆگه¤ڑهڈ°و—¶ï¼Œfileserverن¹ں需è¦پو‰©ه±•ï¼Œو¼”هڈکن¸؛هˆ†ه¸ƒه¼ڈو–‡ن»¶ç³»ç»ںï¼ڑ
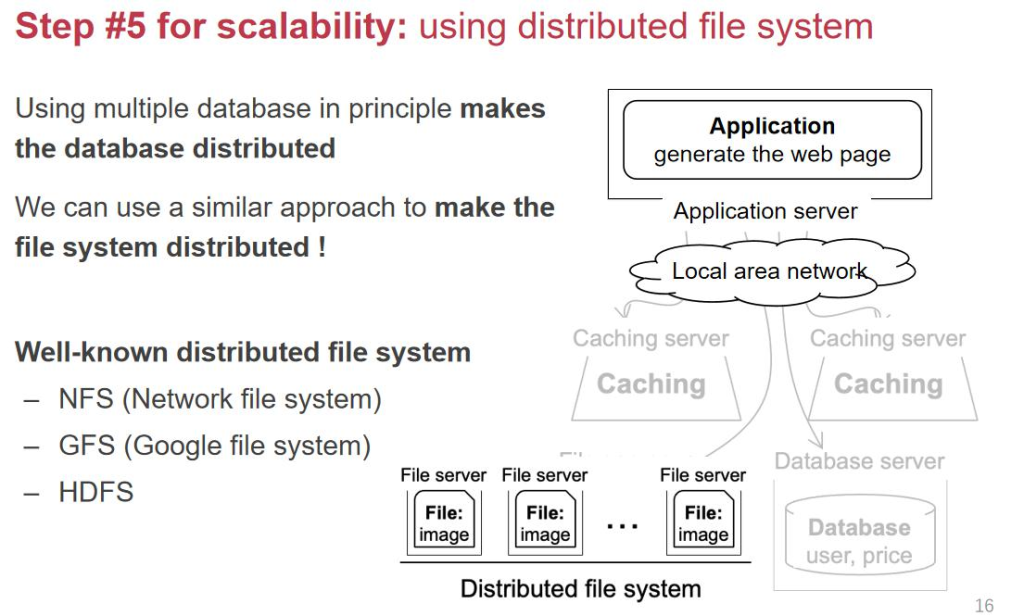
- ه…¸ه‹ن¾‹هگï¼ڑNFSم€پGFSم€پHDFSم€‚
- ه¤–部è،¨çژ°è؟کوک¯ن¸€ن¸ھç»ںن¸€çڑ„وژ¥هڈ£ï¼Œن½†ه†…部و•°وچ®هˆ†ه¸ƒهˆ°ه¤ڑهڈ°وœچهٹ،ه™¨ن¸ٹ,و”¯وŒپن»ژ1هڈ°و‰©ه±•هˆ°100هڈ°م€‚
第ه…و¥ï¼ڑه¼•ه…¥CDN,ه‡ڈه°‘و—¶ه»¶

ه½“用وˆ·هˆ†ه¸ƒهœ¨ه…¨ه›½و—¶ï¼Œè®؟é—®وœچهٹ،ه™¨çڑ„و—¶ه»¶ه¾ˆه¤§ï¼Œو¯”ه¦‚ه¹؟ه·ç”¨وˆ·è®؟é—®وه·وœچهٹ،ه™¨ن¼ڑه¾ˆو…¢م€‚
- 解ه†³و–¹و،ˆï¼ڑه¼•ه…¥CDN(ه†…ه®¹هˆ†هڈ‘网络)م€‚
- هœ¨ه…¨ه›½هگ„هœ°éƒ¨ç½²ç¼“هکوœچهٹ،ه™¨ï¼Œوٹٹ用وˆ·è®؟问频ç¹پçڑ„و•°وچ®ï¼ˆه¦‚ه›¾ç‰‡ï¼‰ç¼“هکهœ¨وœ¬هœ°م€‚
- 用وˆ·è®؟é—®و—¶ï¼Œç›´وژ¥ن»ژ离è‡ھه·±وœ€è؟‘çڑ„CDNèٹ‚点هڈ–و•°وچ®ï¼Œه‡ڈه°‘و—¶ه»¶م€‚
ه›¾ç‰‡ه¤„çگ†وµپ程ï¼ڑ
- ه›¾ç‰‡URLهکه‚¨هœ¨webserverن¸ï¼Œç”¨وˆ·è¯·و±‚و—¶è؟”ه›CDNçڑ„هœ°ه€م€‚
- 用وˆ·ن»ژCDNن¸‹è½½ه›¾ç‰‡م€‚
第ن¸ƒو¥ï¼ڑو‹†هˆ†ه¾®وœچهٹ،
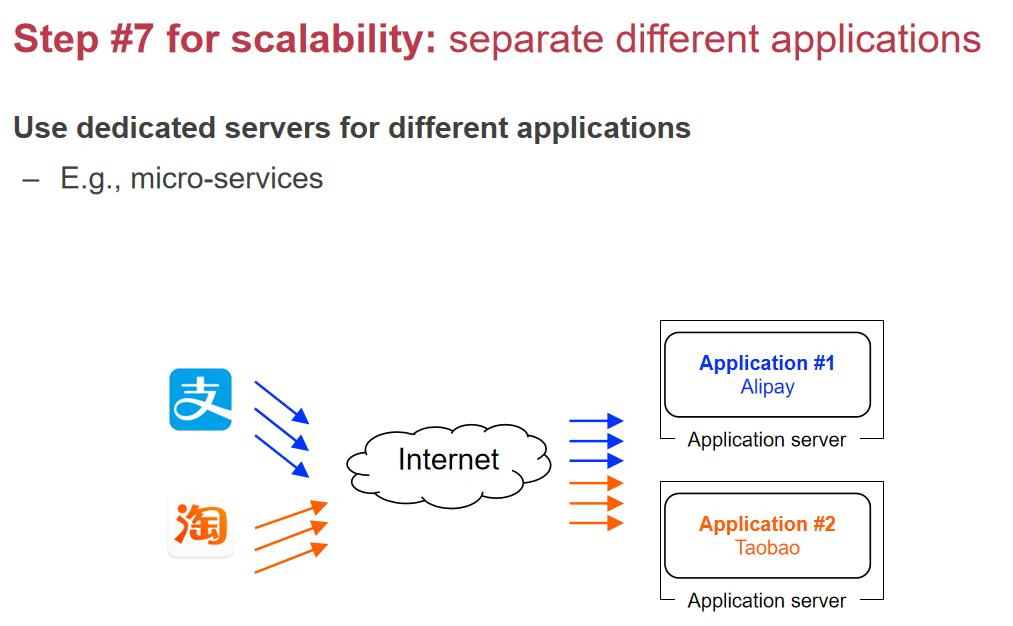
éڑڈç€ن¸ڑهٹ،هڈکه¤چو‚,هچ•ن¸€çڑ„webserverو¶و„ه·²ç»ڈو— و³•و»،足需و±‚,ه°¤ه…¶وک¯و·که®ه’Œو”¯ن»که®çڑ„هœ؛و™¯ه·®ه¼‚ه¾ˆه¤§ï¼ڑ
- و·که®éœ€è¦پوژ¨èچگç³»ç»ں(و¯”ه¦‚هچƒن؛؛هچƒé¢م€پçƒوگœï¼‰م€‚
- و”¯ن»که®éœ€è¦پé«که®‰ه…¨و€§ه’Œه®و—¶و€§ï¼ˆو¯”ه¦‚ن؟،用هچ،و¬؛诈و£€وµ‹ï¼‰م€‚
解ه†³و–¹و،ˆï¼ڑه¾®وœچهٹ،هŒ–
- وٹٹه¤§ه—çڑ„ن»£ç پو‹†هˆ†وˆگه¤ڑن¸ھه¾®وœچهٹ،,و¯ڈن¸ھه¾®وœچهٹ،هڈھè´ںè´£ن¸€ن¸ھهٹں能(و¯”ه¦‚وژ¨èچگç³»ç»ںم€پو”¯ن»کç³»ç»ں)م€‚
- وœچهٹ،ن¹‹é—´çڑ„ن؛¤ن؛’هڈ¯ن»¥ç”¨ï¼ڑ
- و¶ˆوپ¯éکںهˆ—(MQ)ï¼ڑ用ن؛ژه؟«é€ںم€پé«کو•ˆçڑ„ه¼‚و¥é€ڑن؟،م€‚
- و•°وچ®ه؛“وˆ–و–‡ن»¶ç³»ç»ںï¼ڑ用ن؛ژو…¢é€ںم€پ稳ه®ڑçڑ„é€ڑن؟،م€‚
Fault
ه¤§çڑ„و•°وچ®ن¸ه؟ƒçڑ„و•°وچ®ï¼Œهœ¨ه…¨çگƒن¸چهگŒçڑ„هœ°و–¹éƒ½ن¼ڑوœ‰و•°وچ®ن¸ه؟ƒم€‚ é‚£ن¹ˆè؟™ن¹ˆه¤چو‚çڑ„ç³»ç»ں组وˆگهœ¨ن¸€èµ·وœ€ه¤§çڑ„وŒ‘وˆکوک¯ن»€ن¹ˆه‘¢ï¼ں وœ€ه¤§çڑ„وŒ‘وˆکه°±وک¯ fault
Fault وک¯Errorçڑ„هژںه› م€‚Error وک¯ fault çڑ„结وœï¼Œfailure ه°±وک¯ه¾ˆه¤§çڑ„ه¤±è´¥م€‚ه½“وˆ‘ن»¬çڑ„ç³»ç»ںن¸چه‡؛é”™çڑ„وƒ…ه†µï¼Œن¸€ç™¾ن¸‡هڈ°وœ؛ه™¨éƒ½ن¸چه‡؛é”™وک¯ن¸چه¤ھهڈ¯èƒ½çڑ„م€‚ه› ن¸؛و€»ن½“ن¸وœ‰ن¸€هڈ°وœ؛ه™¨çڑ„ه‡؛é”™çژ‡وک¯éڑڈç€وœ؛ه™¨و•°é‡ڈوŒ‡و•°ه¢هٹ çڑ„م€‚
وˆ‘ن»¬ن¸چهڈ¯èƒ½و‰“é€ ن¸€ن¸ھو‰€وœ‰وœ؛ه™¨ن¸چه‡؛é”™هˆ†ه¸ƒه¼ڈç³»ç»ں,وˆ‘ن»¬ه¸Œوœ›ç”¨ن¸چهڈ¯é çڑ„组ن»¶ç»„هگˆهœ¨ن¸€èµ· 组وˆگن¸€ن¸ھهڈ¯é çڑ„هˆ†ه¸ƒه¼ڈç³»ç»ںم€‚وˆ‘ن»¬ه¸Œوœ›هگŒو—¶و–وژ‰ 90%وœ؛ه™¨çڑ„电,ه…¶ن»–çڑ„وœ؛ه™¨è؟ک能 workم€‚è؟™ه°±وک¯ه®¹é”™èƒ½هٹ›
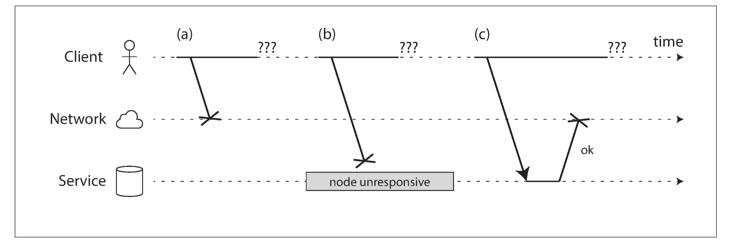
ه½“ن¸€ن¸ھ用وˆ·هڈ‘é€پو•°وچ®هˆ° service,هژںه›
- 1. 网络ن¸¢هŒ…
- 2. 请و±‚هœ¨ç½‘络ن¸ٹوژ’éکں(路由ه™¨هŒ…و»،ن؛†هœ¨وژ’éکں,ن½†وک¯ن½ çڑ„è€گه؟ƒهˆ°ن؛†ï¼‰
- 3. è؟œç«¯وœچهٹ،ه™¨هڈ¯èƒ½وŒ‚ن؛†
- 4. è؟œç«¯وœچهٹ،ه™¨و²،وŒ‚,ن½†وک¯وڑ‚و—¶هپœو¢ن؛†ه“چه؛”,java çڑ„ه†…هکه›و”¶وœ؛هˆ¶ jc,需è¦پ jvm وڑ‚هپœن½ڈم€‚
- 5. ه…¶ه®ه¤„çگ†ن؛†و“چن½œï¼Œن½†وک¯هœ¨è؟”ه›çڑ„و—¶ه€™وŒ‚ن؛†ï¼Œو¯”ه¦‚è؟点ن؛†ن¸¤و¬،ه¤„çگ†ن؛†ن¸¤ç¬”转账م€‚
Lamport وڈگه‡؛ن؛†ه¾ˆه¤ڑه¾ˆه¤ڑهˆ†ه¸ƒه¼ڈçگ†è®؛,2013 ه›¾çپµه¥–م€‚
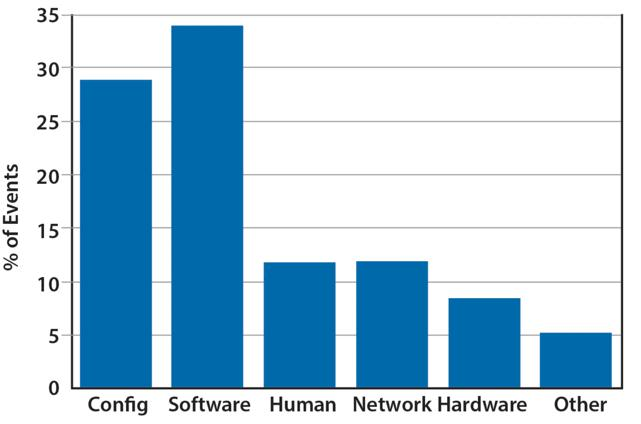
MTTFم€پMTTRم€پMTBF
- MTTFï¼ڑè؟ç»ه¤ڑن¹…ن¸چه®•وœ؛çڑ„ه¹³ه‡و—¶é—´م€‚
- MTTRï¼ڑه‡؛é”™ن»¥هگژن؟®ه¤چçڑ„ه¹³ه‡و—¶é—´م€‚
- MTBFï¼ڑن¸¤و¬،ه‡؛é”™çڑ„ه¹³ه‡é—´éڑ”و—¶é—´م€‚
MTBF = MTTF + MTTR
è®،ç®—و–¹و³•
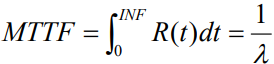
è؟™é‡Œçڑ„ خ» وک¯ه¤±و•ˆçژ‡ï¼ˆfailure rate),ن¹ں称ن¸؛و•…éڑœçژ‡م€‚ه®ƒè،¨ç¤؛ç³»ç»ںوˆ–و¨،ه—هœ¨هچ•ن½چو—¶é—´ه†…هڈ‘ç”ںو•…éڑœçڑ„و¦‚çژ‡
R(t) وک¯ç³»ç»ںهڈ¯é و€§ï¼ˆ system reliability)
ه¯¹ن؛ژن¸²èپ”çڑ„وƒ…ه†µï¼ڑMTTF وک¯هگ„é،¹ه€’و•°ه’Œçڑ„ه€’و•°
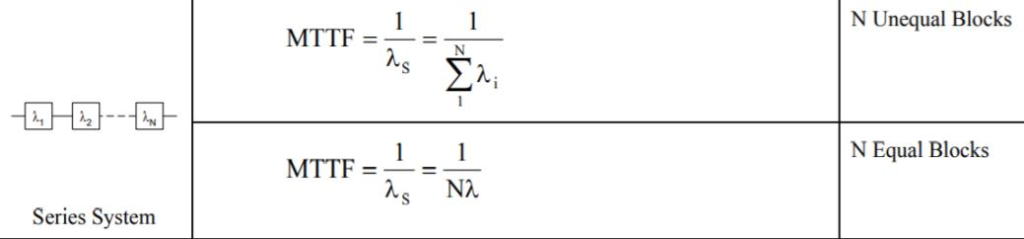
ه¯¹ن؛ژه¹¶èپ”,ه¯¹ن؛ژوœ€ن½ژو‰§è،Œè¦پو±‚وک¯ M ن¸ھ,目ه‰چوœ‰ N çڑ„组ن»¶çڑ„وƒ…ه†µ

MTBF çڑ„ن¸€ه¼ è،¨

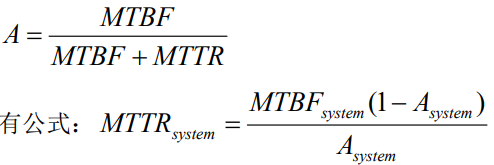
CAPه®ڑçگ†

CAP ه®ڑçگ†ï¼ڑن¸€è‡´و€§ï¼ˆConsistency)م€پهڈ¯ç”¨و€§ï¼ˆAvailability)م€پهˆ’هˆ†çڑ„ه®¹é”™ï¼ˆPartition)ن¸‰è€…هڈھ能选ن؛Œم€‚ Partition toleranceï¼ڑه°±ç®—网络被鲨鱼ه’¬ن؛†ï¼Œن¸€ن¸ھ网络هڈکن¸¤ن¸ھ网络ن؛†ï¼Œن¹ں能و£ه¸¸è؟گè،Œم€‚CAP è؟™ن¸‰ن¸ھهگŒو—¶هڈھ能و»،足ن¸¤ن¸ھم€‚
- CA(ن¸€è‡´و€§ + هڈ¯ç”¨و€§ï¼‰ï¼ڑهچ•ç‚¹و•°وچ®ه؛“,ه½“网络هˆ†هŒ؛و—¶و— و³•ه·¥ن½œï¼Œن½†ن؟è¯پو•°وچ®ن¸€è‡´ن¸”请و±‚هڈ¯ç”¨م€‚
- CP(ن¸€è‡´و€§ + هˆ†هŒ؛ه®¹é”™و€§ï¼‰ï¼ڑHBase,هœ¨ç½‘络هˆ†هŒ؛و—¶و‹’ç»è¯·و±‚,ن؟è¯پو•°وچ®ن¸€è‡´و€§ï¼Œن½†ç‰؛牲هڈ¯ç”¨و€§م€‚
- AP(هڈ¯ç”¨و€§ + هˆ†هŒ؛ه®¹é”™و€§ï¼‰ï¼ڑDNS,هچ³ن½؟网络هˆ†هŒ؛و—¶ن¾ç„¶è؟”ه›ç»“وœï¼Œن½†هڈ¯èƒ½و•°وچ®ن¸چن¸€è‡´م€‚
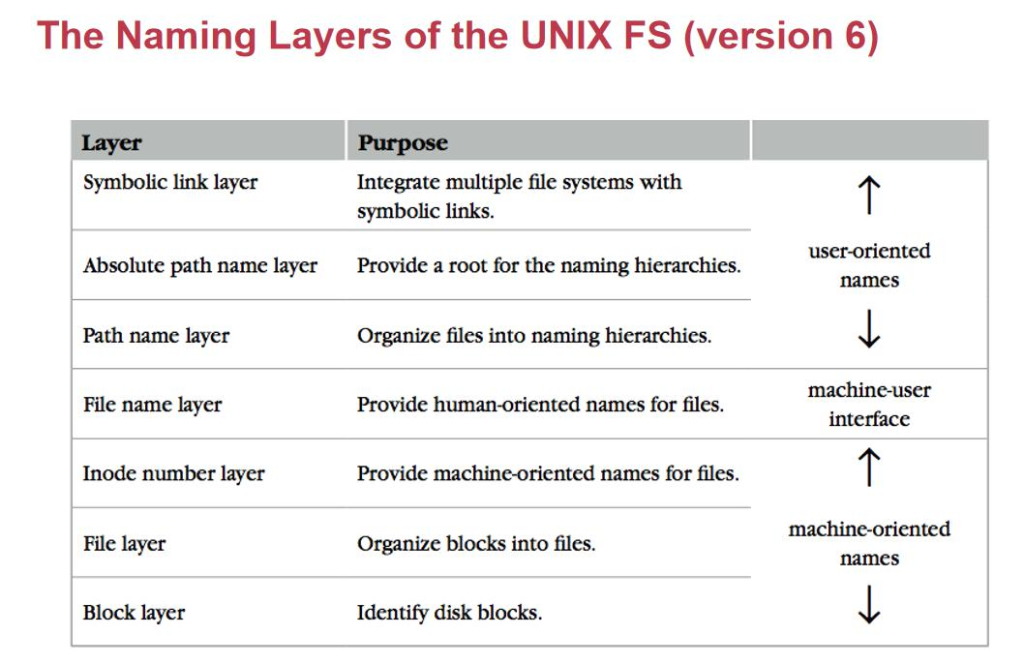
Inode-based file system
هœ¨هچ•وœ؛ن¸ٹو–‡ن»¶ç³»ç»ںçڑ„ه®çژ°وک¯ inode-base file system,وˆ‘ن»¬ه…ˆه¯¹هچ•ن½“و–‡ن»¶ç³»ç»ں解ه‰–,وœ€هگژه†چو‰©ه±•هˆ°هˆ†ه¸ƒه¼ڈو–‡ن»¶ç³»ç»ںم€‚
ن»€ن¹ˆوک¯ن¸€ن¸ھو–‡ن»¶ï¼ں
- 第ن¸€ن¸ھ特و€§ï¼ڑdurable,ه®ƒوک¯ن¸€و®µو”¾هœ¨هکه‚¨è®¾ه¤‡ن¸ٹçڑ„هڈ¯ن»¥ن؟هکçڑ„و•°وچ®م€‚ه®ƒن¸چن¼ڑه› ن¸؛ن½ ه…³وœ؛而و¶ˆه¤±م€‚
- 第ن؛Œن¸ھ特و€§ï¼ڑو–‡ن»¶وک¯وœ‰هگچه—çڑ„,وˆ‘ن»¬هڈ¯ن»¥هژ»ه‘½هگچن¸€ن¸ھو–‡ن»¶ï¼Œوˆ‘ن»¬ن¹ںهڈ¯ن»¥é€ڑè؟‡ن¸€ن¸ھهگچه—هژ» وŒ‡ه®ڑه¯¹ه؛”çڑ„و–‡ن»¶م€‚
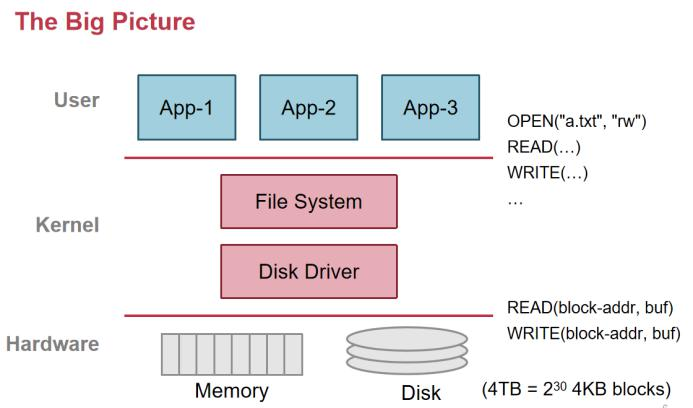
ç³»ç»ںه¯¹ن؛ژو–‡ن»¶و¥è¯´ï¼Œè؟™ن¸¤ن¸ھ特و€§éƒ½وک¯ن¸؛ن؛†è®©ç¨‹ه؛ڈه‘که’Œç”¨وˆ·هœ¨ن½؟用çڑ„و—¶ه€™و›´و–¹ن¾؟ن¸€ç‚¹م€‚هœ¨ ن¸€ن¸ھه¤§çڑ„ bigpicture 里é¢ï¼Œه†…و ¸هœ¨ç£پç›که’Œه†…هکن¹‹ن¸ٹ,وٹ½è±،ه‡؛و–‡ن»¶çڑ„ abstraction,ن¹ںه°±وک¯è¦پهڈ‘ وکژه‡؛و–‡ن»¶çڑ„وژ¥هڈ£م€‚وٹٹç،¬ن»¶وڈگن¾›çڑ„وژ¥هڈ£ï¼Œç»ڈè؟‡ os çڑ„组织ه’ŒهŒ…装هڈکوˆگن¸€ç»„و–°çڑ„وژ¥هڈ£ï¼Œç”¨وˆ·ن½؟用起و¥و›´ن¾؟وچ·çڑ„وژ¥هڈ£م€‚
و–‡ن»¶وڈگن¾›ن»€ن¹ˆ api ه‘¢ï¼ںOpen,读ه†™و–‡ن»¶ï¼Œه…³é—و–‡ن»¶ï¼ŒهگŒو¥و–‡ن»¶هˆ°ç£پç›ک,و–‡ن»¶çڑ„ه…ƒو•°وچ®ï¼Œ هڈ¯è¯»هڈ¯ه†™هڈ¯و‰§è،Œï¼Œو”¹هڈکو–‡ن»¶و‹¥وœ‰وƒï¼Œهˆ›ه»؛ç›®ه½•ï¼Œو”¹هڈکç›®ه½•ï¼Œmount (وŒ‚载)ه’Œ unamountم€‚
A Naive File System

وˆ‘ن»¬ه…ˆو¥çœ‹ن¸€ن¸ھ简هچ•çڑ„و–‡ن»¶ç³»ç»ںو€ژن¹ˆè®¾è®،م€‚ن¸€ن¸ھç£پç›که°±وک¯ن¸€ن¸ھه¾ˆه¤§çڑ„و•°ç»„م€‚و¯ڈن¸ھ block و—©وœںوک¯ 512 ه—èٹ‚,هگژو¥هڈکوˆگن؛† 4kم€‚ه¦‚وœوˆ‘çژ°هœ¨وœ‰ن¸€ن¸ھو–‡ن»¶è¦پو”¾هœ¨ç£پç›کن¸ٹ,و—¢ç„¶و”¾هœ¨ç£پç›کن¸ٹ ن؛†ï¼Œè‚¯ه®ڑه°±وœ‰ durable 特و€§ن؛†م€‚ هگچه—è؟™ن¹ˆè®¾ç½®ï¼ںوˆ‘ن»¬هڈ¯ن»¥وٹٹو–‡ن»¶é،؛ه؛ڈçڑ„و”¾هœ¨ç£پç›کن¸ٹ,هکو”¾çڑ„第ن¸€ن¸ھ block هکو”¾و–‡ن»¶çڑ„هگچه—م€‚è؟™ç§چ简هچ•çڑ„è®،وœ‰ن»€ن¹ˆé—®é¢که‘¢ï¼ں
- 1. ه› ن¸؛è؟ç»هکو”¾ï¼Œه¢هˆ هگژهکهœ¨ç¢ژ片
- 2. و–‡ن»¶ copy هˆ°هڈ¦ن¸€ن¸ھç£پç›کن»¥هگژ,هڈ¯èƒ½ه°±ن¸چوک¯ 107 ç¼–هڈ·ن؛†م€‚ه› ن¸؛هگچه—ه’Œç£پç›کوœ¬è؛«è€¦هگˆ çڑ„ه¤ھه¤ڑن؛†م€‚
وˆ‘ن»¬éœ€è¦پهœ¨ç£پç›کن¹‹ن¸ٹ,هپڑه±‚ه±‚软ن»¶çڑ„وٹ½è±،,وٹٹه®ƒهڈکوˆگه®¹وک“ن½؟用çڑ„م€‚
هˆ†ن¸؛ 3+3+1,ن¸ٹé¢ن¸‰ه±‚让ن؛؛و¥ç”¨
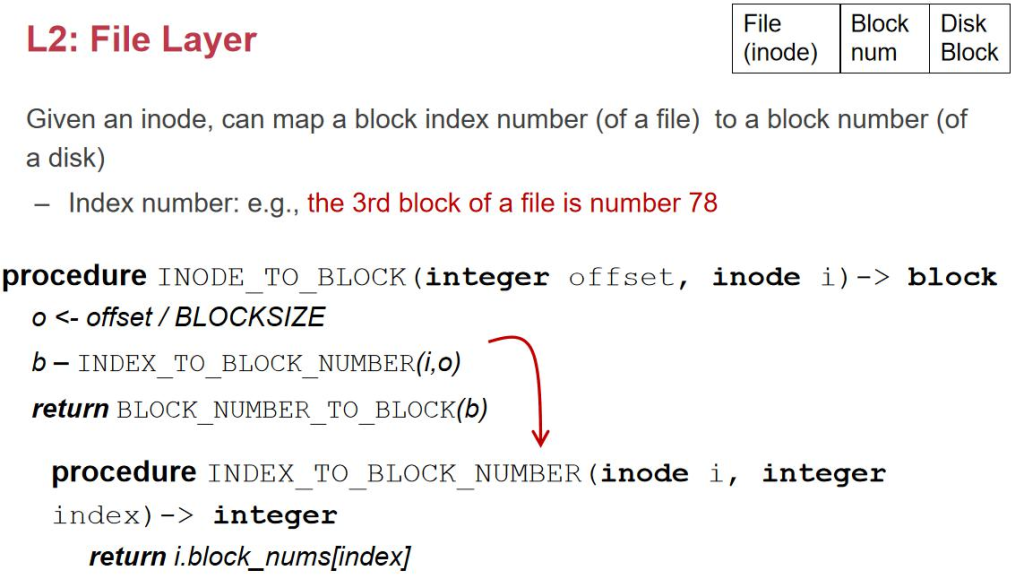
Block Layer
block layer,ن½ ç»™وˆ‘ن¸€ن¸ھ block number,وˆ‘ç»™ن½ ن¸€ن¸ھ block data,è؟™وک¯ç£پç›کوڈگن¾›çڑ„م€‚وˆ‘ن»¬32 è¦پ 107 هڈ·ï¼Œن½ ç»™وˆ‘ 4k و•°وچ®م€‚ن½†وک¯وک¾ç„¶ن¸چه¤ں,وˆ‘ن»¬éœ€è¦پçں¥éپ“و¯ڈن¸ھ block ه¤ڑه¤§ï¼Œوک¯ 4k è؟کوک¯ 512bï¼› ه“ھن؛› block 被用ن؛†ï¼Œه“ھن؛›وک¯ free çڑ„ï¼›وœ‰ç”¨çڑ„و•°وچ®ن»ژن»€ن¹ˆهœ°و–¹ه¼€ه§‹ï¼›

و‰€ن»¥وˆ‘ن»¬ه°±éœ€è¦پهœ¨ block è؟™ن¸€ه±‚و”¾ن¸€ن¸ھ特و®ٹçڑ„ superblock,ه®ƒن¸€èˆ¬و¥è¯´ç¬¬ن¸€ن¸ھوک¯ç”¨و¥هگ¯ هٹ¨çڑ„م€‚Superblock ن¸هŒ…هگ«ن؛† block çڑ„ه¤§ه°ڈ,free block çڑ„و•°é‡ڈ,و‰€ن»¥ superblock ن¸è®°ه½•ن؛†ه¾ˆه¤ڑ هژںن؟،وپ¯م€‚ه®ƒو€ژن¹ˆè®°ه½•ن¸€ن¸ھ block وک¯ç”¨ن؛†è؟کوک¯و²،用ه‘¢ï¼ںه®ƒن¼ڑ预留ن¸€ه—用و¥è®°ه½• bitmap,è؟™ه°±وک¯ ن¸€ن¸² 010101010,0 è،¨ç¤؛ free,1 è،¨ç¤؛ used,و¯ڈن¸ھ 01 ه°±وک¯é’ˆه¯¹ن؛†ن¸€ن¸ھهگژé¢çڑ„ block وک¯ç”¨ن؛†è؟کوک¯ و²،用م€‚Block size وک¯ن¸€ن¸ھ trade-off,软ن»¶هڈ¯ن»¥ن؟®و”¹ block size,ه¦‚وœè؟™ن¸ھ block size ه¤ھه°ڈن؛†م€‚è؟™ و„ڈه‘³ç€ç£پç›کهˆ†çڑ„ه¤ھç¢ژن؛†م€‚ه¤ھه¤§çڑ„è¯ه°±ه®¹وک“وµھè´¹وژ‰م€‚需è¦پهگˆçگ†è®¾ç½®é•؟ه؛¦م€‚

وژ¥ن¸‹و¥ه°±وک¯è®°ه½•ه“ھن؛›وک¯ free çڑ„م€‚ه¦‚وœوˆ‘ن»¬و¯ڈن¸ھ block ه‰چé¢هٹ ن؛†ن¸€ن½چ,وˆ‘ن»¬çڑ„ block وک¯ 4095 çڑ„ size,ه¯¼è‡´è¯»هڈ–هˆ°çڑ„و•°وچ®وک¯ن¸چه¯¹é½گçڑ„م€‚و‰€ن»¥وˆ‘ن»¬هœ¨è؟™ن¸ھو–‡ن»¶ç³»ç»ںه†…وˆ‘ن»¬وک¯ن½؟用 bitmap و¥ هکه‚¨è؟™ن¸ھن؟،وپ¯çڑ„م€‚4k çڑ„ block هڈ¯ن»¥هکو”¾ 8*4096=32K ن¸ھ block çڑ„وک¯هگ¦ن½؟用è؟‡م€‚و‰€ن»¥ن¸€ن¸ھ 4K çڑ„ bitmap ه°±هڈ¯ن»¥ه¯¹ه؛”هˆ° 32K*4K = 128M çڑ„ç£پç›کç©؛间,و•ˆçژ‡è؟کوک¯ه¾ˆé«کçڑ„م€‚وœ‰ن؛†è؟™ن؛›ن»¥هگژ,وˆ‘ن»¬ه°± وœ‰ن؛†ç¬¬ن¸€ه±‚م€‚
File Layer
File Layer è´ںè´£ه°†و–‡ن»¶çڑ„逻辑视ه›¾ن¸ژه؛•ه±‚هکه‚¨ه—çڑ„ه®é™…ن½چç½®وک ه°„,ه¹¶ç®،çگ†ه…ƒو•°وچ®ç´¢ه¼•ن¸ژè®؟é—®م€‚
第ن؛Œه±‚ï¼ڑن¸€و—¦وœ‰ن؛† block ن¹‹هگژ,ه¦‚وœوˆ‘ن»¬ن؟è¯پو¯ڈن¸ھو–‡ن»¶éƒ½ه°ڈن؛ژ 4k,وˆ‘ن»¬ه°±هڈ¯ن»¥ç›´وژ¥ن½؟用 block_id ن½œن¸؛و–‡ن»¶çڑ„ name,ن½†وک¯و–‡ن»¶ه؟…然و¯” 4k ه¤§ï¼Œن¸€ن¸ھو–‡ن»¶هچ block çڑ„و•°é‡ڈه°±ن¼ڑ超è؟‡ 1
planA:و–‡ن»¶è؟ç»هکو”¾

planBï¼ڑو–‡ن»¶ن¸چè؟ç»هکو”¾ï¼Œè؟™ن¸ھو•ˆçژ‡و›´é«کم€‚ن½†وک¯و€ژن¹ˆè®°ه½•ن¸چè؟ç»çڑ„ block number ه‘¢ï¼ںوˆ‘ ن»¬ه°±ه¼•ه…¥ن؛† index nodeم€‚هپ‡è®¾و–‡ن»¶هŒ…هگ«ن؛† 8 ن¸ھ block,ه¦‚وœوک¯è؟ç»çڑ„ه°±è®°ه½•ç¬¬ن¸€ن¸ھ id+é•؟ه؛¦ï¼Œ ه¦‚وœن¸چè؟ç»ï¼Œوˆ‘ن»¬وٹٹ 8 ن¸ھ block id è®°ه½•هœ¨ index node 里م€‚è؟™é‡Œé¢هŒ…هگ«ن؛† block number,è؟™ن¸ھ N çڑ„ه¤§ه°ڈه¾ˆوœ‰è®²ç©¶م€‚ه¦‚وœè؟™ن¸ھ size è®°ه½•çڑ„وک¯ block çڑ„و•°é‡ڈ,و–‡ن»¶çڑ„ه¤§ه°ڈه؟…é،»وک¯ 4k çڑ„و•´و•°ه€چ, 肯ه®ڑوœ‰é—®é¢کم€‚و‰€ن»¥è؟™ن¸ھ size وک¯و–‡ن»¶çڑ„ byte و•°é‡ڈ,وœ€هگژن¸€ن¸ھ block هڈ¯èƒ½و²،用ه®Œم€‚ ه¦‚وœوˆ‘ن»¬çڑ„ N وک¯ن¸€ن¸ھه®ڑه€¼ï¼Œé‚£ن¹ˆ Inode و”¯وŒپçڑ„و–‡ن»¶çڑ„وœ€ه¤§ه¤§ه°ڈوک¯ه¤ڑه°‘ه‘¢ï¼ںو€ژن¹ˆوڈگé«که‘¢ï¼ں
ه¦‚وœ N وک¯ 1000,و–‡ن»¶ه¤§ه°ڈوœ€ه¤ڑو‰چ 1000*4K,وک¾ç„¶وک¯ن¸چه¤ںçڑ„م€‚وˆ‘ن»¬ن¸چ能用ç؛؟و€§çڑ„و•°ç»„çڑ„è®°ه½• è؟™ن¸ھ block numberم€‚ه¦‚وœوˆ‘ن»¬وƒ³و”¯وŒپ 4G ه¤§ه°ڈçڑ„و–‡ن»¶ï¼Œé‚£ن¹ˆ 4G/4KB * 64B(ç£پç›کçڑ„ block_id çڑ„é•؟ه؛¦ï¼‰=8M,ن¸؛ن؛†و”¯وŒپن¸€ن¸ھ 4G çڑ„و–‡ن»¶ï¼Œه…‰وک¯هکه®ƒçڑ„ index ه°±è¦پ用هˆ° 8M,ه¦‚وœن¸€ن¸ھ Inode 8M, ه¦‚وœوˆ‘ن»¬ç”¨ن¸€هچٹçڑ„ç£پç›کهکè؟™ن¸ھ Inode,و¯”ه¦‚è؟™ن¸ھç£پç›ک 8T,用 4T و¥هک Inode,4T/8M = 50 ن¸‡ن¸ھ و–‡ن»¶م€‚وˆ‘ن»¬è®،ç®—وœ؛ن¸çڑ„و–‡ن»¶و¯«و— ç–‘é—®وک¯ç™¾ن¸‡ç؛§هˆ«ï¼Œوœ€ه¤§و”¯وŒپçڑ„و–‡ن»¶و‰چ 4G,è؟™ن؛›éƒ½و»،足ن¸چن؛† وˆ‘ن»¬çڑ„需و±‚م€‚
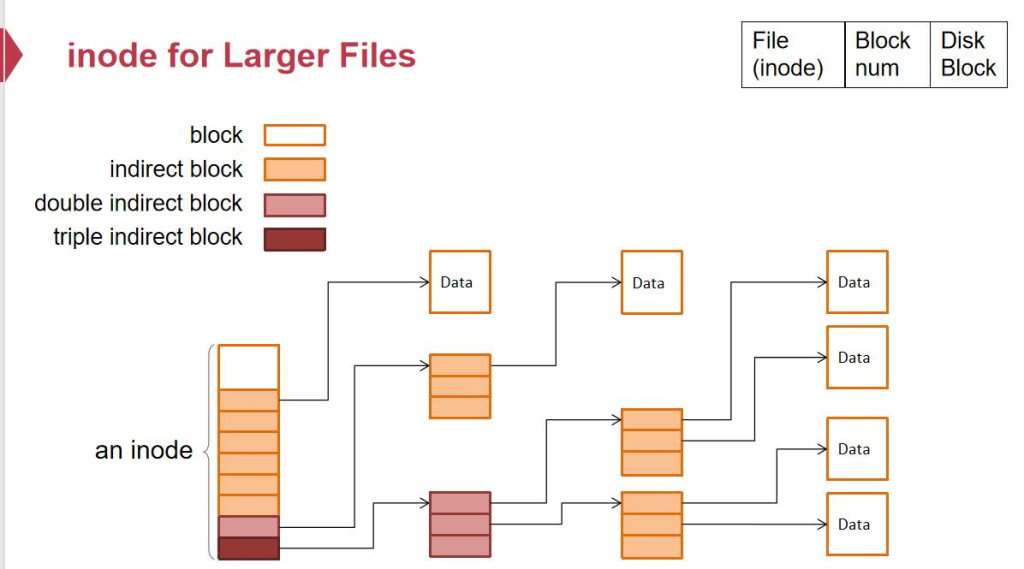
ه¦‚وœوˆ‘ن»¬çڑ„و–‡ن»¶و²،é‚£ن¹ˆه¤§ï¼Œوˆ‘ن»¬é¢„ç•™ن؛†ن¸€ن¸ھ 8M çڑ„ inode,ه°±وœ¬وœ«ه€’ç½®ن؛†م€‚وˆ‘ن»¬è¦پ预留 وˆگهڈ¯ن¼¸ç¼©çڑ„结و„م€‚وˆ‘ن»¬وٹٹو•°وچ®çڑ„ه‰چé¢ه‡ ن½چ设置وˆگوŒ‡هگ‘ block çڑ„م€‚هگژé¢ه‡ ن½چوŒ‡هگ‘ن¸€ن¸ھن؛Œç؛§çڑ„34 blockم€‚ه…¶ن¸و¯ڈن¸€é،¹éƒ½وک¯وŒ‡هگ‘ن¸€ن¸ھ block_indexم€‚ن؛Œç؛§çڑ„ block وک¯ 4k,و¯ڈن¸€é،¹وک¯ 8 ن¸ھ byte,هڈ¯ ن»¥وŒ‡هگ‘ 512 ن¸ھ blockم€‚è؟™ن¸ھه’Œé،µè،¨هپڑçڑ„ن؛‹وƒ…وک¯ه¾ˆهƒڈçڑ„م€‚ه¦‚وœن؛Œç؛§ن¹ں用و»،ن؛†ï¼Œوˆ‘ن»¬هڈ¯ن»¥ه†چهٹ ن¸€ ç؛§م€‚é‚£ن¹ˆه°±وک¯ 512*512 ن¸ھوŒ‡هگ‘ block çڑ„ block_indexم€‚è؟™و ·ه¯¹ن؛ژه°ڈو–‡ن»¶ï¼Œه°±هڈھ需è¦پ用هˆ°ه‰چé¢ه‡ ن¸ھم€‚ه¯¹ن؛ژه¤§و–‡ن»¶ه°±هڈ¯ن»¥ن¸€ç‚¹ç‚¹ه¢é•؟ه‡؛و¥م€‚
ه¯¹ن؛ژ layer2,ه…¶ن¸هڈ¯ن»¥ن½œن¸؛ double indirect block ه’Œ triple indirect block ه¯¹ن؛ژ第ن¸€ه±‚و¥è¯´ وک¯و— و‰€è°“çڑ„م€‚
وœ‰ن؛†ç¬¬ن؛Œه±‚ن¹‹هگژ,ه°±وœ‰ن؛† inodeم€‚é،µè،¨çڑ„è¯و‰€وœ‰ç»ںن¸€وک¯ 4 ç؛§é،µè،¨م€‚è¦پ解ه†³çڑ„وœ¬è´¨é—®é¢که…¶ ه®ه°±وک¯وک ه°„م€‚وœ‰ن؛†ç¬¬ن؛Œه±‚ن¹‹هگژ,هڈھè¦په‘ٹ诉وˆ‘ن»¬ inode هœ¨ه“ھ,ه’Œéœ€è¦پو•°وچ®هœ¨و–‡ن»¶ن¸çڑ„ offset, وˆ‘ن»¬ه°±هڈ¯ن»¥و‰¾هˆ°ه¯¹ه؛” block هœ¨ه“ھ,è؟”ه›ç»™ç”¨وˆ·م€‚
Inode Number Layer
ن»¥è®°ه½•ن¸€ن¸ھ free çڑ„ inode çڑ„链 è،¨ن¸²èµ·و¥م€‚
و‰€ن»¥ç»™ن؛†ن¸€ن¸ھ Inode number ه°±هڈ¯ن»¥ه¾—هˆ°و–‡ن»¶çڑ„و‰€وœ‰ن؟،وپ¯م€‚è؟™ه¯¹èژ·هڈ–و–‡ن»¶وک¯è¶³ه¤ںçڑ„,ن½†وک¯ه®ƒه¯¹ن؛ژن؛؛ç±»وک¯و¯”较éڑ¾çڑ„م€‚而ن¸” copy çڑ„و—¶ه€™ï¼Œinode-number وک¯ن¼ڑهڈکهٹ¨çڑ„
File Name Layer
第ه››ه±‚,وˆ‘ن»¬éœ€è¦پن¸€ن¸ھ user-friendly çڑ„ name,و€ژن¹ˆوٹٹه—符ن¸²ه’Œ inode-number هپڑن¸€ ن¸ھوک ه°„ه‘¢ï¼Œوœ€ç®€هچ•و•°وچ®ç»“و„ه°±وک¯ن¸€ن¸ھ dict وک ه°„م€‚
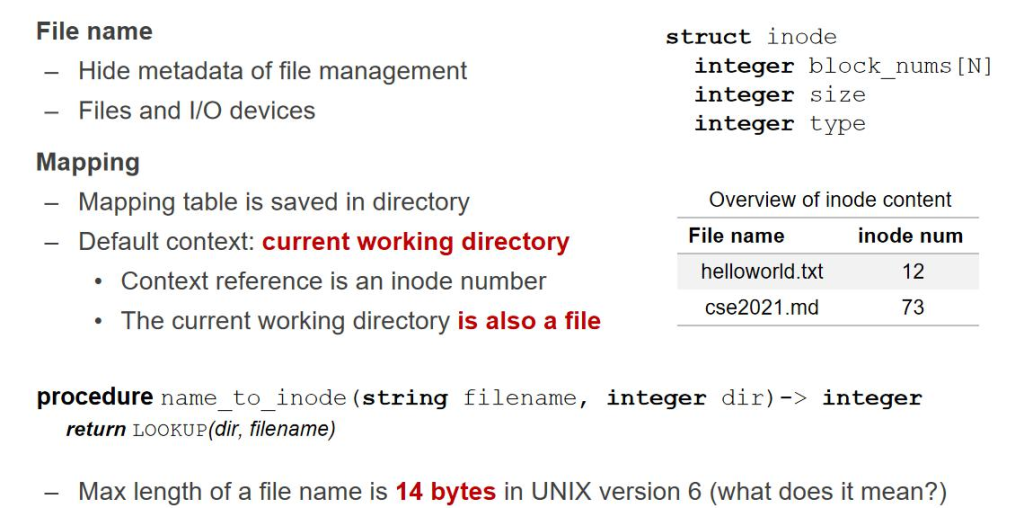
è؟™ن¸ھè،¨وœ€هگژهœ¨ç،¬ç›کن¸ٹه°±وک¯è؟™ن¹ˆهکçڑ„,ه®ƒهکهœ¨ن¸€ن¸ھو–‡ن»¶é‡Œï¼Œه®ƒوک¯و–‡ن»¶ç³»ç»ں规ه®ڑçڑ„و ¼ه¼ڈ,è؟™ ن¸ھو–‡ن»¶ه°±هڈ«هپڑç›®ه½•م€‚ن¹ںه°±وک¯é‡Œé¢و–‡ن»¶çڑ„هگچه—وک¯ن»€ن¹ˆï¼Œو–‡ن»¶çڑ„ inode-number وک¯ه¤ڑه°‘م€‚Foulder è؟™ن¸ھè¯چوک¯ه¾ˆè¯¯ه¯¼çڑ„,è؟™ن¸ھو–‡ن»¶ه¤¹هڈھوک¯هŒ…هگ«ن؛†ه…¶ن¸و–‡ن»¶çڑ„ inode-numer,而ن¸چوک¯هŒ…هگ«ن؛†و‰€وœ‰و–‡ ن»¶ه†…ه®¹م€‚و‰€ن»¥وˆ‘ن»¬ه€¾هگ‘用目ه½•è؟™ن¸ھè¯چ,و›´هٹ ه‡†ç،®م€‚
è®؟é—®و–‡ن»¶و–¹ه¼ڈï¼ڑç»™ن¸€ن¸ھو–‡ن»¶هگچ,给ن¸€ن¸ھç›®ه½•ï¼Œهژ»ç›®ه½•é‡Œو‰¾è؟™ن¸ھو–‡ن»¶هگچ,و‰¾هˆ°ه¯¹ه؛”çڑ„ Inode-number,ه°±هڈ¯ن»¥ه†چو‰¾هˆ°و–‡ن»¶ن؛†م€‚
è؟™و ·ه°±ن؛§ç”ںن؛† lookup çڑ„و–¹ه¼ڈï¼ڑ
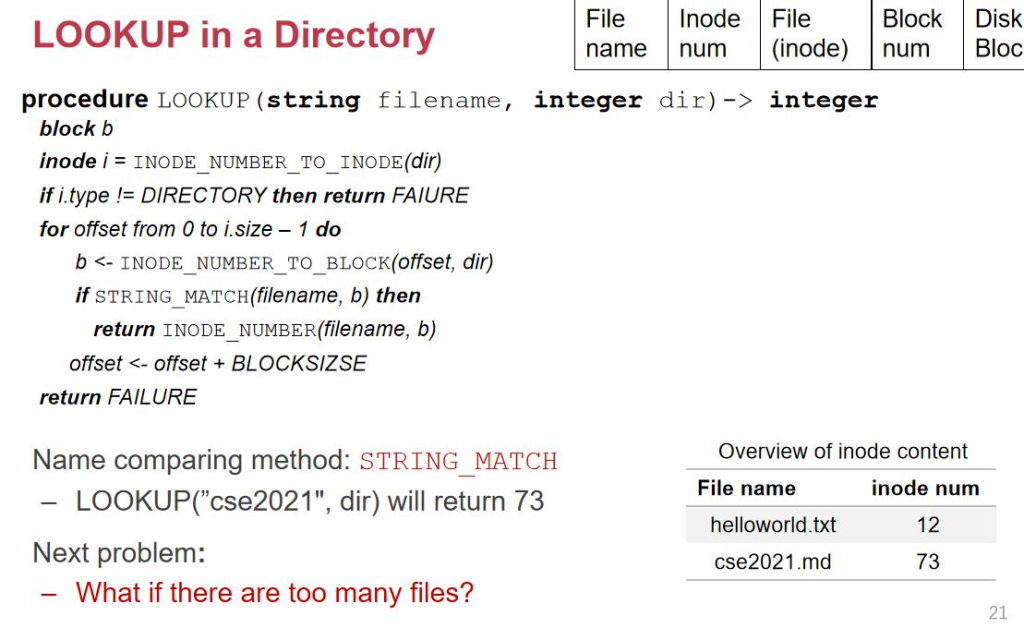
هˆ°è؟™ن¸€و¥ن¸؛و¢ï¼Œو•´ن¸ھو–‡ن»¶ç³»ç»ں都ه®Œه¤‡ن؛†ï¼Œو¯ڈن¸ھو–‡ن»¶éƒ½وœ‰ن¸€ن¸ھه—符ن¸²çڑ„و–‡ن»¶هگچم€‚ن½†وک¯è؟کوœ‰ ç¼؛点,وˆ‘ن»¬çژ°هœ¨هڈھوœ‰ن¸€ن¸ھç›®ه½•ï¼Œè؟™ن¸ھç›®ه½•ن¸‹وœ‰ه¾ˆه¤ڑه¾ˆه¤ڑو–‡ن»¶ï¼ˆه‡ 百ن¸‡ن¸ھ),ls وœ‰ه¥½ه‡ ن¸ھه±ڈه¹•ï¼Œ 都ن¸چ能é‡چهگچçڑ„م€‚و‰€ن»¥وˆ‘ن»¬ه؛”该وœ‰ن¸€ن¸ھ path name ه±‚,ه¦‚وœç›®ه½•ن¹ںه½“هپڑن¸€ن¸ھو–‡ن»¶ï¼Œé‚£ن¹ˆç›®ه½•ه°± هڈ¯ن»¥è¢«هŒ…هگ«هœ¨هڈ¦ن¸€ن¸ھو–‡ن»¶é‡Œé¢م€‚ç›®ه½•ن¹ںوœ‰ن¸€ن¸ھ Inode-number,目ه½•ه’Œو–‡ن»¶هœ¨ inode è؟™ن¸€ه±‚وک¯ و²،وœ‰هŒ؛هˆ«çڑ„م€‚ه°±هƒڈ inode ه’Œ data هœ¨ن¸‹ه±‚都وک¯ block ن¸€و ·م€‚
Path Name Layer

و—¢ç„¶ن¸چهŒ؛هˆ†ï¼Œوˆ‘ن»¬ه°±هڈ¯ن»¥وœ‰ن؛† path name,وˆ‘ن»¬هڈ¯ن»¥هˆ›ه»؛ projects/paper,وˆ‘ن»¬ه…ˆهژ»ه½“ه‰چ ç›®ه½•ن¸‹و‰¾ projects,و‰¾هˆ°ن»¥هگژه†چن»¥ projects ن¸؛ç›®ه½•و‰¾ paperم€‚
وژ¥ن¸‹و¥ن¸€ن¸ھé—®é¢که°±وک¯ç›®ه½•هگچه¤ھو·±ن؛†ï¼Œè¦پو‰“ه¥½ه‡ ه±‚ç›®ه½•م€‚هœ¨وˆ‘ن»¬ه‰چé¢è¯´çڑ„ç›®ه½•ç»“و„里é¢ï¼Œ ه¹¶و²،وœ‰ن»»ن½•هœ°و–¹ç»„织وˆ‘ن»¬وٹٹن¸€ن¸ھو–‡ن»¶هگچه¯¹ه؛”çڑ„ inode-number 设置وˆگهگŒن¸€ن¸ھم€‚ن¹ںه°±وک¯ن¸چهگŒو–‡ن»¶هگچه¯¹ه؛”هˆ°هگŒن¸€ن¸ھ inode-numberم€‚ه¦‚وœوˆ‘ن»¬ن¸؛ن¸€ن¸ھ inode هˆ›ه»؛ه¤ڑن¸ھ name,وˆ‘ن»¬ه°±هڈ¯ن»¥ن¸؛ن¸€ ن¸ھه¾ˆو·±ç›®ه½•çڑ„و–‡ن»¶هگچهˆ›ه»؛ن¸€ن¸ھه¾ˆçںçڑ„و–‡ن»¶هگچ,وœ€هگژه¯¹ه؛”çڑ„ inode وک¯ن¸€ن¸ھم€‚说وکژè؟™ن¸ھو–‡ن»¶هڈھوœ‰ن¸€ن¸ھم€‚
هپ‡è®¾ن¸€ن¸ھو–‡ن»¶وœ‰ن¸¤ن¸ھهگچه—,ه½“وˆ‘ن»¬هˆ وژ‰ن¸€ن¸ھهگچه—çڑ„و—¶ه€™ï¼Œç”¨هڈ¦ن¸€ن¸ھهژ»è®؟é—®وک¯èƒ½è®؟é—®è؟کوک¯ ن¸چ能è®؟é—®ه‘¢ï¼ں
ن»€ن¹ˆوک¯هˆ و–‡ن»¶ï¼ڑوœ¬è´¨و“چن½œهڈھوک¯هˆ 除目ه½•ن¸çڑ„helloworld.txt -> 12هˆ 除وژ‰ï¼Œه¹¶ن¸چوک¯هˆ 除block ن¸çڑ„و•°وچ®ï¼Œه› ن¸؛هڈ¯èƒ½هˆ«çڑ„هœ°و–¹è؟که¼•ç”¨ن؛†م€‚و‰€ن»¥وˆ‘ن»¬è¦پهœ¨ inode ن¸ç»´وٹ¤ن¸€ن¸ھ reference counter, ه¦‚وœهˆ 除ه®Œ reference counter == 0 ه°±هڈ¯ن»¥هˆ 除ن؛†م€‚هگŒو—¶وˆ‘ن»¬è؟ک需è¦پهٹ ن¸€ن¸ھ type و¥و ‡è¯†وک¯ن¸€ن¸ھ و™®é€ڑو–‡ن»¶è؟کوک¯ç›®ه½•م€‚
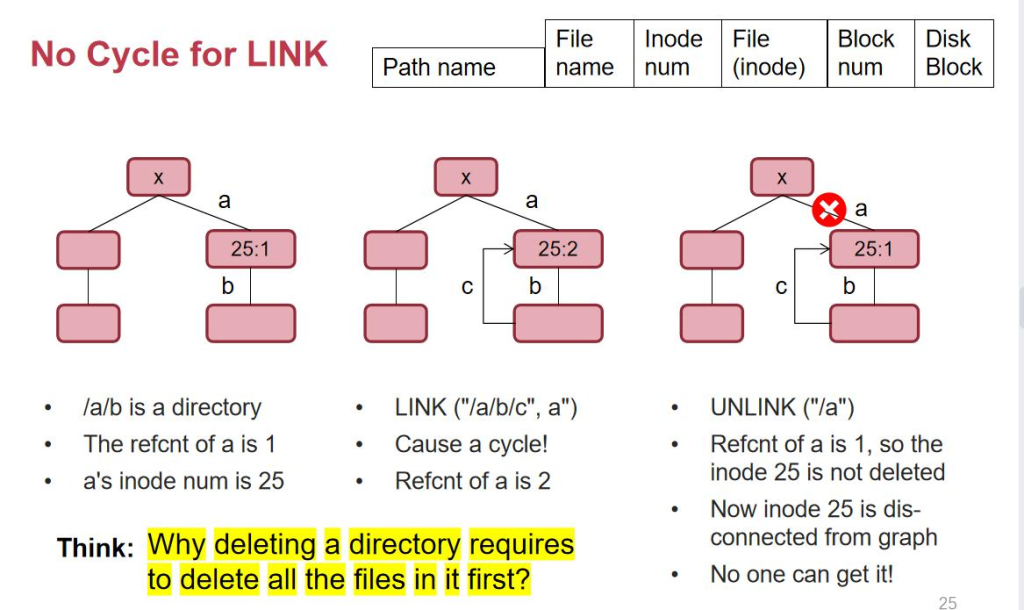
هپ‡è®¾ inode وœ‰ن¸ھ x,记ه½•ن؛†ç›®ه½• a,目ه½• a ن¸è®°ه½•ن؛†ç›®ه½• bم€‚هپ‡è®¾وˆ‘ن»¬çژ°هœ¨و¥ link وٹٹ/a/b/c ه¯¹ ه؛”هˆ°/a,ن¹ںه°±وک¯هœ¨ a çڑ„هگç›®ه½•ن¸‹ه»؛ç«‹ن؛†ن¸€ن¸ھوŒ‡هگ‘ a çڑ„ linkم€‚a çژ°هœ¨وœ‰ن¸¤ن¸ھن؛؛وŒ‡هگ‘ه®ƒï¼Œن¹ںه°±وک¯ /a ه’Œ/a/b/c,ه®ƒçڑ„ ref count وک¯ 2م€‚çژ°هœ¨وˆ‘ن»¬ه°è¯•هˆ 除/a,ه®ƒçڑ„ ref وک¯ 1,ن½†وک¯ن»ژ x ه†چن¹ںو‰¾ن¸چهˆ° a ن؛†م€‚ه› ن¸؛ه®ƒه”¯ن¸€çڑ„هگچه—被هˆ 除ن؛†م€‚ه®ƒو—¢و²،وœ‰è¢«هˆ وژ‰ï¼Œهڈˆن¸چ能被هڈ¦ه¤–çڑ„هœ°و–¹è®؟é—®هˆ°م€‚و‰€ن»¥ه°± ن¼ڑوˆگن¸؛ه†…هکهƒهœ¾م€‚و‰€ن»¥ç¦پو¢وŒ‡هگ‘ç›®ه½•م€‚
ه½“وˆ‘ن»¬هˆ 除ن¸€ن¸ھéç©؛ç›®ه½•çڑ„و—¶ه€™ï¼Œه…¶ه®وˆ‘ن»¬وک¯é€’ه½’هˆ 除çڑ„,هœ¨çœںه®çڑ„ linux 里é¢ï¼Œوˆ‘ن»¬ ه·²ç»ڈ考虑ن؛†è؟™ن¸ھé—®é¢کن؛†ï¼Œن½†è؟™ن¸ھ rm -r هœ¨ unix 第 6 版وک¯ن¸چهکهœ¨çڑ„م€‚
ه½“وˆ‘ن»¬هژ» rename çڑ„و—¶ه€™ï¼Œو”¹و–‡ن»¶هگچوک¯و–‡ن»¶ç³»ç»ںن¸éه¸¸ه¤چو‚çڑ„ن؛‹وƒ…م€‚هپ‡è®¾وˆ‘ن»¬è¦پهژ»هپڑو”¹ و–‡ن»¶هگچçڑ„و“چن½œï¼Œو¯”ه¦‚ mv (from,to),è؟™ن¸€ن¸ھوŒ‡ن»¤ç‰µو¶‰هˆ° 3 ن»¶ن؛‹وƒ…م€‚
- 1. وٹٹ to هˆ ن؛†ï¼Œto çڑ„ ref count هڈکوˆگ 0.
- 2. وٹٹ from هٹ ن¸€ن¸ھ to çڑ„هگچه—,from çڑ„ ref count هڈکوˆگ 2.
- 3. ه†چوٹٹ from çڑ„ ref count هڈکوˆگ 1
هœ¨è؟™ن¸ھè؟‡ç¨‹ن¸ن¸€و—¦هڈ‘ç”ںن؛†ن¸€و¬، crashم€‚و¯”ه¦‚هœ¨ 1 ه’Œ 2 ن¹‹é—´هڈ‘ç”ںن؛†و–电,وˆ‘ن»¬هڈ‘çژ°ه°‘ن؛† to è؟™ن¸ھو–‡ن»¶م€‚و‰€ن»¥è؟™ه°±وک¯وˆ‘ن»¬ atomic(هژںهگو€§ï¼‰çڑ„é—®é¢کم€‚هژںهگو€§ه°±وک¯ن¸چç®،ن¸é—´و–电çڑ„ن»€ن¹ˆوƒ…ه†µï¼Œ ه›ه¤چهˆ°و£ه¸¸وƒ…ه†µن»¥هگژ,è¦پن¹ˆه°±وک¯ه…¨هپڑ,è¦پن¹ˆه°±وک¯و²،هپڑ,ن¸چهکهœ¨ن¸é—´çڑ„وƒ…ه†µم€‚

Absolute Path Name Layer
وœ‰ن؛†è؟™ن¸ھن¹‹هگژ,وˆ‘ن»¬çژ°هœ¨وœ‰ن؛†ç›®ه½•ن؛†ï¼Œن¸€هڈ°وœ؛ه™¨وœ‰ه¾ˆه¤ڑن؛؛è¦پç™»ه½•ï¼Œوˆ‘ن»¬çœ‹هˆ°وˆ‘çڑ„و–‡ن»¶ï¼Œ38 ن½ 看هˆ°ن½ çڑ„و–‡ن»¶ï¼Œو–‡ن»¶ن¹‹é—´وک¯و²،وœ‰ن»»ن½•و–‡ن»¶و¸ éپ“هژ»و²ںé€ڑçڑ„م€‚ن¸؛ن؛†è§£ه†³è؟™ن¸ھé—®é¢ک,ه°±ه¼•ه…¥ن؛†و ¹ ç›®ه½•ï¼Œوœ‰ن؛†و ¹ç›®ه½•ن¹‹هگژ,ن¸€هڈ°وœ؛ه™¨ن¸ٹçڑ„و–‡ن»¶éƒ½هڈ¯ن»¥و ¹وچ®و ¹ç›®ه½•ه¼€ه§‹ç´¢ه¼•م€‚و ¹ç›®ه½•وœ€هگژه°±ه®ڑن¹‰ ن¸؛/,و ¹ç›®ه½•çڑ„.ه’Œ..都وŒ‡هگ‘ه®ƒè‡ھه·±م€‚
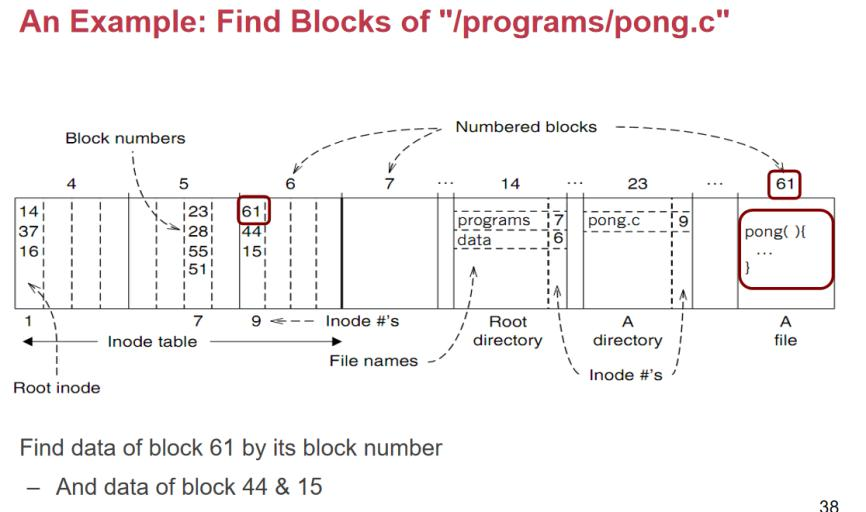
و•´ن¸ھè؟‡ç¨‹هˆ†ن¸؛ن»¥ن¸‹ه‡ ن¸ھو¥éھ¤ï¼Œو¸…و™°هœ°ه±•ç¤؛ن؛†ن»ژو ¹ç›®ه½•ه®ڑن½چهˆ° /programs/pong.c و–‡ن»¶çڑ„è·¯ه¾„解وگè؟‡ç¨‹ï¼ڑ
1. ه®ڑن½چو ¹ç›®ه½•
- و ¹ç›®ه½•çڑ„ç؛¦ه®ڑهœ°ه€ï¼ڑو ¹ç›®ه½•وک¯و–‡ن»¶ç³»ç»ںçڑ„起点,ه®ƒçڑ„ inode ç¼–هڈ·ç؛¦ه®ڑن¸؛ 1م€‚
- é€ڑè؟‡ super block و‰¾ inode tableï¼ڑو–‡ن»¶ç³»ç»ںçڑ„ super block ن¸è®°ه½•ن؛† inode table çڑ„èµ·ه§‹هœ°ه€م€‚وˆ‘ن»¬é€ڑè؟‡è؟™ن¸ھن؟،وپ¯و‰¾هˆ° inode tableم€‚
- و‰¾هˆ°و ¹ç›®ه½•çڑ„ inodeï¼ڑهœ¨ inode table ن¸ه®ڑن½چ inode ç¼–هڈ·ن¸؛ 1 çڑ„ inode و،目,读هڈ–ه…¶ه¯¹ه؛”çڑ„و•°وچ® blockم€‚
2. 解وگو ¹ç›®ه½•ه†…ه®¹
- 读هڈ– block 14ï¼ڑو ¹ç›®ه½•çڑ„ inode وŒ‡هگ‘çڑ„و•°وچ® block وک¯ block 14م€‚ه› و¤وˆ‘ن»¬è¯»هڈ– block 14 çڑ„ه†…ه®¹ï¼Œهڈ‘çژ°ه®ƒوک¯ن¸€ن¸ھç›®ه½•و–‡ن»¶م€‚
- ه®ڑن½چ
programsو،ç›®ï¼ڑهœ¨ block 14 ن¸ï¼Œو‰¾هˆ°هگچن¸؛programsçڑ„ç›®ه½•و،目,ه®ƒçڑ„ inode ç¼–هڈ·ن¸؛ 7م€‚
3. ه®ڑن½چ programs ç›®ه½•
- é€ڑè؟‡ inode table وں¥و‰¾ inode 7ï¼ڑه›هˆ° inode table,و‰¾هˆ°ç¬¬ 7 ن¸ھ inode و،ç›®م€‚
- 读هڈ– inode 7 وŒ‡هگ‘çڑ„و•°وچ®ه—ï¼ڑinode 7 وŒ‡هگ‘çڑ„و•°وچ®ه—وک¯ block 7,وˆ‘ن»¬è¯»هڈ–该 block çڑ„ه†…ه®¹م€‚
4. 解وگ programs ç›®ه½•
- ه®ڑن½چ
pong.cو،ç›®ï¼ڑهœ¨ block 7 çڑ„ه†…ه®¹ن¸ï¼Œو‰¾هˆ°هگچن¸؛pong.cçڑ„و–‡ن»¶و،目,ه®ƒçڑ„ inode ç¼–هڈ·ن¸؛ 9م€‚
5. ه®ڑن½چ pong.c و–‡ن»¶
- é€ڑè؟‡ inode table وں¥و‰¾ inode 9ï¼ڑه†چو¬،ه›هˆ° inode table,و‰¾هˆ°ç¬¬ 9 ن¸ھ inode و،ç›®م€‚
- 读هڈ– inode 9 وŒ‡هگ‘çڑ„و•°وچ®ه—ï¼ڑinode 9 وŒ‡هگ‘çڑ„و•°وچ®ه—وک¯ block 61م€‚
6. 读هڈ– pong.c و–‡ن»¶çڑ„ه†…ه®¹
- و‰¾هˆ° block 61ï¼ڑé€ڑè؟‡è¯»هڈ– block 61 çڑ„و•°وچ®ï¼Œوˆ‘ن»¬وœ€ç»ˆه¾—هˆ°ن؛†و–‡ن»¶
/programs/pong.cçڑ„ه†…ه®¹م€‚
و•´ن¸ھè·¯ه¾„解وگوک¯ن»ژو ¹ç›®ه½•ه¼€ه§‹ï¼Œن¾و¬،é€ڑè؟‡ inode ه’Œو•°وچ® block çڑ„وŒ‡é’ˆن¸چو–解وگو¯ڈن¸€ه±‚çڑ„ç›®ه½•ï¼Œç›´هˆ°وœ€ç»ˆه®ڑن½چهˆ°ç›®و ‡و–‡ن»¶çڑ„و•°وچ® block,ه®Œوˆگن؛†و–‡ن»¶è®؟é—®م€‚

وˆ‘ن»¬هڈ¯ن»¥هˆ—ه‡؛ temp ç›®ه½•çڑ„ inode هڈ·وک¯ه¤ڑه°‘م€‚وˆ‘ن»¬هڈکوˆگ 16 è؟›هˆ¶ن»¥هگژه°±وک¯è؟™ن¸ھم€‚وˆ‘ن»¬هڈ¯ن»¥ç”¨ debug çڑ„و–¹ه¼ڈو‰“ه‡؛è؟™ن¸ھو–‡ن»¶م€‚è؟™ه°±وک¯ç›®ه½•هœ¨ç£پç›کن¸ٹçڑ„و•°وچ®م€‚

وˆ‘ن»¬é‡چو–°وژ’ه؛ڈهگژه°±هڈ¯ن»¥çœ‹ه‡؛,و¯ڈن¸€è،Œه¯¹ه؛”çڑ„ه°±وک¯و–‡ن»¶هگچم€‚2e ه°±وک¯.,2e2e ه°±وک¯..م€‚ 0102 ه°±وک¯ç›®ه½•çڑ„و„ڈو€م€‚0c00 ه°±وک¯é•؟ه؛¦م€‚c40f ه°±وک¯وœ€هگژن¸€é،¹هˆ°ه¤´ن؛†م€‚ه‰چé¢ç؛¢è‰²çڑ„部هˆ†ه°±وک¯ inode-numberم€‚وˆ‘ن»¬ه°±é€ڑè؟‡è؟™ن¸ھه®éھŒçœ‹هˆ°ن؛†è؟™ن¸ھçœںçڑ„ç›®ه½•é•؟è؟™ن¸ھو ·هگم€‚
وœ‰ن؛†ن¸‹é¢ن¸‰ه±‚ن¹‹هگژ, و•´ن¸ھو–‡ن»¶ç³»ç»ںه·²ç»ڈوˆگç«‹ن؛†ï¼Œن½†وک¯ه…‰ç”¨ inode-number هپڑهگچه—ن¸چوک¯ه¾ˆهڈ‹ه¥½م€‚و‰€ن»¥éœ€è¦پ用 inode ه’Œو–‡ن»¶هگچه¯¹ه؛”,وˆ‘ن»¬è®°ه½•هœ¨هچ•ç‹¬çڑ„ن¸€ن¸ھو–‡ن»¶é‡Œم€‚è؟™ن¸ھو–‡ن»¶ن¸چوک¯وˆ‘ن»¬éڑڈو„ڈهڈ¯ن»¥é€ڑè؟‡read-write ن؟®و”¹çڑ„,ه› ن¸؛è؟™ن¸ھو–‡ن»¶وک¯ن¸€ن¸ھç›®ه½•و–‡ن»¶م€‚ه®ƒه¯¹ن؛ژو–‡ن»¶ç³»ç»ںو¥è¯´وک¯ه…ƒو•°وچ®م€‚ه¯¹ن؛ژ Inode و¥è¯´ï¼Œ ç›®ه½•و‰€وœ‰çڑ„و•°وچ®éƒ½ن؟هکهœ¨و•°وچ®هŒ؛,ه’Œن¸€èˆ¬çڑ„و–‡ن»¶و²،ن»€ن¹ˆهŒ؛هˆ«م€‚ن½†وک¯ن»ژ用وˆ·çڑ„角ه؛¦و¥çœ‹ï¼Œç›®ه½•ه°±وک¯ن¸€ن¸ھه…ƒو•°وچ®ï¼Œن¸چ能é€ڑè؟‡open/read/write و¥ن؟®و”¹ç›®ه½•ï¼Œهڈھ能é€ڑè؟‡ lsم€‚然هگژوœ‰ن؛†ç›®ه½•ن¹‹هگژ, ه†چه¾€ن¸ٹ递ه½’هœ°و ‘çٹ¶ç»„织结و„م€‚وژ¥ن¸‹و¥è؟کوœ‰ link çڑ„و¦‚ه؟µï¼Œlink ه…¶ه®ه°±وک¯و–‡ن»¶هگچم€‚

وˆ‘ن»¬هˆ›ه»؛ن¸€ن¸ھوŒ‡هگ‘ a.txt çڑ„ a.ln linkم€‚وˆ‘ن»¬هڈ‘çژ°çژ°هœ¨ه¤ڑن؛†ن¸€ن¸ھو–‡ن»¶ a.lnم€‚وˆ‘ن»¬هڈ‘çژ°ه®ƒن»¬çڑ„ و—¶é—´م€په¤§ه°ڈن¸€èµ·هڈکن؛†م€‚و‰€ن»¥ن¸ٹè؟°çڑ„ 2 وک¯ reference count,ه½“ ref cnt هڈکن¸؛ 0 çڑ„و—¶ه€™ï¼Œinode ه’Œ data ه°±ن¼ڑ被 free وژ‰م€‚6 ه°±وک¯و–‡ن»¶ size çڑ„ه¤§ه°ڈم€‚
ه½“وˆ‘ن»¬çں¥éپ“ link çڑ„و—¶ه€™ï¼Œه¦‚وœوˆ‘ن»¬çژ°هœ¨وڈ’ن؛†ن¸€ن¸ھ u ç›کهˆ°ن؛†ç”µè„‘ن¸م€‚ه¦‚وœوˆ‘ن»¬وƒ³هœ¨ن¸»وœ؛ن¸ هˆ›ه»؛ن¸€ن¸ھوŒ‡هگ‘ u ç›کçڑ„ link,è؟™وœ¬è؛«وک¯ن¸¤ن¸ھو–‡ن»¶ç³»ç»ں,inode-numberم€پspace 都وک¯ن¸چن¸€و ·çڑ„م€‚ وˆ‘ن»¬ن¸چ能直وژ¥ن½؟用 u ç›کو–‡ن»¶ç³»ç»ںن¸çڑ„ Inode-numberم€‚و‰€ن»¥ن¸چ能هˆ›ه»؛è·¨و–‡ن»¶ç³»ç»ںçڑ„ linkم€‚
Symbolic Link Layer
而第ن¸ƒه±‚ symbolic link layer,وˆ‘ن»¬هœ¨و–‡ن»¶ç³»ç»ںن¸هˆ›ه»؛ن؛†ن¸€ن¸ھو–°çڑ„و–‡ن»¶ï¼Œه†…ه®¹وک¯ن¸€ن¸ھه—符 ن¸²ï¼ŒوŒ‡هگ‘需è¦پ链وژ¥çڑ„و–‡ن»¶è·¯ه¾„ه’Œو–‡ن»¶هگچم€‚ه®ƒن¸چن¼ڑن»…ن»…هپœç•™هœ¨و‰“ه¼€ symbolic link وœ¬è؛«ï¼Œه®ƒن¼ڑ读 هڈ–ه‡؛و•°وچ®ï¼Œه¹¶ن¸”وŒ‡هگ‘è؟›ن¸€و¥çڑ„و“چن½œم€‚و‰€ن»¥هœ¨ inode_type ن¸è¦پو·»هٹ symbolic linkم€‚

وˆ‘ن»¬هˆ›ه»؛ s-link çڑ„ن؟،وپ¯çڑ„و—¶ه€™ï¼Œوˆ‘ن»¬هڈ‘çژ°وک¯وŒ‡هگ‘/tmp/abc çڑ„م€‚وˆ‘ن»¬هڈ¯ن»¥é€ڑè؟‡ه‘½ن»¤ readlink و¥è¯»ه‡؛ symbolic link و–‡ن»¶çڑ„ه†…ه®¹م€‚8 وک¯/tmp/abc çڑ„ه¤§ه°ڈ,ه®ƒه…¶ه®ن¸چ需è¦پهژ»هک/0م€‚ه¦‚وœوˆ‘ن»¬ه° 试ن½؟用 cat و¥è¯»هڈ–و•°وچ®çڑ„و—¶ه€™ï¼Œن¼ڑوٹ¥é”™م€‚ه½“وˆ‘ن»¬وٹٹ hello, world é‡چه®ڑهگ‘هˆ°/tmp/abc çڑ„و—¶ه€™ï¼Œ و‰چن¼ڑ读هˆ° hello, worldم€‚و‰€ن»¥è؟™ن¸ھه‘ٹ诉وˆ‘ن»¬ه“ھو€•هژںه…ˆçڑ„è·¯ه¾„çڑ„و–‡ن»¶ن¸چهکهœ¨çڑ„è¯ï¼Œوˆ‘ن»¬ن¹ںهڈ¯ن»¥ن¸؛ é‚£ن¸ھن¸چهکهœ¨çڑ„و–‡ن»¶هˆ›ه»؛ن¸€ن¸ھ symbolic link,ن½†وک¯ه¯¹ن؛ژ hard link و¥è¯´ï¼Œوˆ‘ن»¬ن¸چ能ن¸؛ن¸چهکهœ¨çڑ„و–‡ ن»¶هˆ›ه»؛ن¸€ن¸ھ hard link,ه› ن¸؛ inode 都ن¸چهکهœ¨م€‚
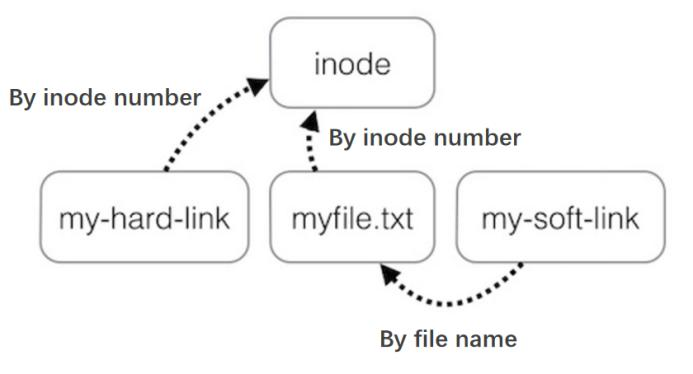
وˆ‘ن»¬هڈ¯ن»¥é€ڑè؟‡ن¸ٹه›¾و¥ه®،视ن¸€ن¸‹ hard link ه’Œ symbolic linkم€‚Hard link وک¯é€ڑè؟‡ inode-number 绑ه®ڑ,而 symbolic link(soft link)وک¯é€ڑè؟‡è·¯ه¾„ه’Œو–‡ن»¶هگچو¥ç»‘ه®ڑم€‚Symbolic link وک¯هڈ¯ن»¥وŒ‡هگ‘ç›®ه½•çڑ„, 而 hard link 除ن؛†.ه’Œ..وک¯ن¸چ能وŒ‡هگ‘ç›®ه½•çڑ„م€‚

وœ‰ن¸€ن¸ھ/Scholarly/programs/www,وˆ‘ن»¬è§‰ه¾—ه¤ھé•؟ن؛†ï¼Œوˆ‘ن»¬هˆ›ه»؛ن¸€ن¸ھ symbolic link /CSE-webم€‚ وˆ‘ن»¬ن½؟用 cd CSE-web; cd ..; وˆ‘ن»¬ه› ن¸؛ç”و،ˆوک¯/Scholarly/programsم€‚ن؛‹ه®ن¸ٹ,ç”و،ˆوک¯و ¹ç›®ه½•م€‚

è؟™وک¯ bash è‡ھه·±هپڑçڑ„ن¼کهŒ–,ه®ƒè®¤ن¸؛è؟™و ·è·ں符هگˆç›´è§‰م€‚
وˆ‘ن»¬ç®€هچ•هپڑن¸€ن¸ھو€»ç»“,ه‰چé¢ 7 ه±‚里é¢وœ‰ه‡ ن¸ھه’Œç›´è§‰ن¸چ符هگˆçڑ„هœ°و–¹م€‚
1.و–‡ن»¶هگچه’Œو–‡ن»¶وک¯و²،وœ‰ه…³ç³»çڑ„م€‚و–‡ن»¶ç›¸ه…³çڑ„و•°وچ®هˆ†ن¸؛ه…ƒو•°وچ®ï¼ˆهکهœ¨ inode 里)ه’Œو•°وچ® (inode وŒ‡هگ‘ block ن¸ï¼‰م€‚而و–‡ن»¶هگچوک¯هکهœ¨ç›®ه½•é‡Œçڑ„م€‚و‰€ن»¥و–‡ن»¶çڑ„و–‡ن»¶هگچه’Œو–‡ن»¶ه¹¶و²،وœ‰ç›´وژ¥ çڑ„ه…³ç³»ï¼Œè؟™ن¹ںوک¯وˆ‘ن»¬هڈ¯ن»¥é€ڑè؟‡ hardlink ç»™ن¸€ن¸ھو–‡ن»¶èµ‹ن؛ˆه¤ڑن¸ھو–‡ن»¶هگچم€‚و‰€ن»¥ن»»ن½•ن¸€ن¸ھوŒ‡هگ‘ Inode çڑ„و–‡ن»¶هگچوک¯ç‰ن»·çڑ„,و–°هˆ›ه»؛çڑ„ hard link ه’Œهژںه…ˆçڑ„و–‡ن»¶ç´¢ه¼•وک¯ç‰ن»·çڑ„م€‚
2.ن»¥هڈٹç›®ه½•çڑ„ه¤§ه°ڈوک¯ه¾ˆه°ڈçڑ„,هڈھه’Œو–‡ن»¶هگچçڑ„é•؟çںوœ‰ه…³ç³»م€‚
讲ه®Œو–‡ن»¶çڑ„结و„ن»¥هگژ,وˆ‘ن»¬ه·²ç»ڈçں¥éپ“ن؛†ç£پç›کن¸é™و€پو–‡ن»¶وک¯و€ژن¹ˆç»„织çڑ„م€‚وˆ‘ن»¬وژ¥ن¸‹و¥çœ‹و–‡ ن»¶وک¯و€ژن¹ˆè¢«è¯»ه†™م€پè®؟é—®م€پهگŒو¥çڑ„م€‚
è؟™ن؛›و“چن½œéƒ½وک¯é€ڑè؟‡ system call çڑ„و–¹ه¼ڈوڈگن¾›ç»™ç”¨وˆ·çڑ„ه؛”用程ه؛ڈçڑ„م€‚而用وˆ·é€ڑه¸¸è؟کè¦پé€ڑè؟‡ lib42 çڑ„ه°پ装و¥è°ƒç”¨م€‚
وˆ‘ن»¬ن¹‹ه‰چه¦è؟‡ C,C وک¯ن¸چوک¯ن¸€ن¸ھè·¨ه¹³هڈ°çڑ„è¯è¨€ه‘¢ï¼ںوˆ‘ن»¬ include ن¸چهگŒه¤´و–‡ن»¶çڑ„و—¶ه€™ن¼ڑوœ‰ن¸چ هگŒçڑ„çژ¯ه¢ƒم€‚وˆ‘ن»¬ç”¨ C çڑ„ lib وک¯ fopen,هœ¨ linux ن¸‹وک¯ه¯¹ه؛”çڑ„ open çڑ„ syscallم€‚Fopen وک¯è؟”ه›ن¸€ن¸ھ file*,而 open وک¯è؟”ه›ن¸€ن¸ھ int çڑ„ syscallم€‚

userid ه’Œ groupid هژ»هپڑè®؟é—®وژ§هˆ¶م€‚然هگژوک¯هڈ¯è¯»هڈ¯ه†™هڈ¯و‰§è،Œï¼Œè؟کè¦پن¸‰ن¸ھ time, last access, last modification, last change of inodeم€‚
Mtime 说çڑ„وک¯ data و”¹هٹ¨ï¼Œctime 说çڑ„وک¯ inode و”¹هٹ¨ï¼ˆlink و”¹هٹ¨ refcount,ن؟®و”¹وƒé™گ)م€‚

Open و–‡ن»¶çڑ„و—¶ه€™ï¼Œه…ˆè¦پ看و–‡ن»¶وک¯ه½’ه±ن؛ژه“ھن¸ھ用وˆ·çڑ„م€‚هŒ¹é…چ userid ه’Œ groupid,ه¦‚وœوƒ é™گن¸چهŒ¹é…چن¹ںن¸چن¼ڑ让ن½ و‰“ه¼€ï¼Œç„¶هگژو›´و–° last access timeم€‚然هگژè؟”ه›ن¸€ن¸ھ fd(و–‡ن»¶è¢«و‰“ه¼€ن¹‹هگژه°± ن¼ڑوœ‰ fd)م€‚

Fd هگŒو ·هڈ¯ن»¥è¢«ه‘½هگچو‰“ه¼€çڑ„设ه¤‡م€‚و¯”ه¦‚وˆ‘ن»¬و‰“ه¼€ن¸€ن¸ھé”®ç›کم€‚读çڑ„è¯ه°±وک¯ه¾—هˆ°é”®ç›کو£هœ¨è¾“ه…¥çڑ„ ه—و¯چم€‚و¯ڈن¸ھ process 都وœ‰وˆ‘ن»¬è‡ھه·±çڑ„ fd namesapceم€‚çژ°هœ¨وڈگن¸€ن¸ھé—®é¢کم€‚ن¸؛ن»€ن¹ˆوˆ‘ن»¬è¦پ用 fd و¥ ن½œن¸؛è؟”ه›çڑ„و–‡ن»¶ه‘¢ï¼ںن¸؛ن»€ن¹ˆن¸چè؟”ه› Inode 给用وˆ·ه‘¢ï¼ں

وˆ‘ن»¬ه¸Œوœ›ç”¨وˆ·ن¸چ能è®؟é—®ه†…و ¸çڑ„و•°وچ®ç»“و„,ه¦‚وœوˆ‘ن»¬ç›´وژ¥è؟”ه› inode çڑ„وŒ‡é’ˆï¼Œé‚£ن¹ˆه°±وٹٹه†… و ¸و•°وچ®ç›´وژ¥وڑ´éœ²ç»™ç”¨وˆ·ن؛†م€‚Non-byassability: inode وŒ‡é’ˆهڈ¯èƒ½ç»•è؟‡ open,ه› ن¸؛ open çڑ„و—¶ه€™و‹؟ هˆ°çڑ„وک¯ن¸€ن¸ھو–‡ن»¶هگچ,ن¹‹هگژه†چè؟”ه› fdم€‚ن½†وک¯ه¦‚وœوˆ‘ن»¬è؟”ه›çڑ„وک¯ inode,第ن؛Œو¬،ن¹‹هگژçڑ„ Open ه°± هڈ¯ن»¥éڑڈو—¶éڑڈهœ°و‹؟第ن¸€و¬،çڑ„ Inode è؟”ه›çڑ„وŒ‡é’ˆهژ»ç”¨ن؛†ï¼Œهڈ¯ن»¥ç»•è؟‡ OS هœ¨ open çڑ„و—¶ه€™çڑ„وƒé™گو£€وں¥م€‚ è؟™و ·ه؛”用程ه؛ڈه°±و²،وœ‰ن»»ن½•éƒ¨هˆ†ç»•è؟‡وƒé™گو£€وں¥م€‚

Fd è؟کè®°ه½•ن؛† cursor,ن¹ںه°±وک¯ه½“ه‰چçڑ„و–‡ن»¶م€‚

File_table وک¯و•´ن¸ھç³»ç»ںن¸€ه¼ è،¨ï¼Œè€Œ fd_table وک¯ن¸€ن¸ھè؟›ç¨‹ن¸€ه¼ è،¨م€‚
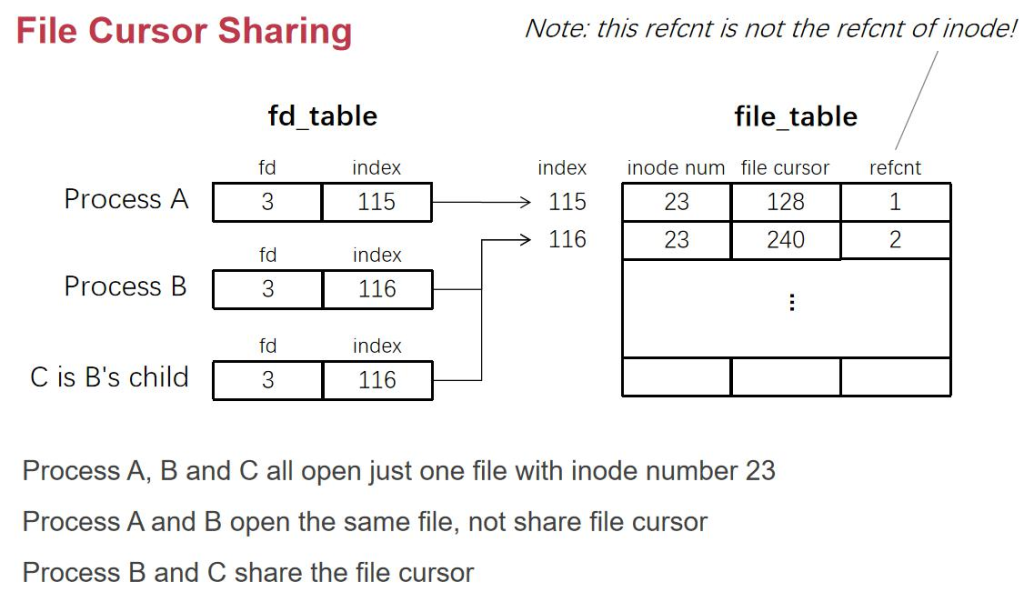
ن¸چهگŒè؟›ç¨‹ن¸çڑ„ fd_table,ه“ھو€• fd 相هگŒï¼ŒوŒ‡هگ‘çڑ„ file_table ن¸çڑ„ن½چç½®وک¯ن¸چن¸€و ·çڑ„م€‚C وک¯ B fork ه‡؛و¥çڑ„,继و‰؟ن؛†و‰€وœ‰و•°وچ®م€‚وچ¢هڈ¥è¯è¯´ï¼Œن¸¤ن¸ھè؟›ç¨‹و—¢هڈ¯ن»¥ه…±ن؛« fd_table(file cursor 相هگŒï¼‰ï¼Œن¹ں هڈ¯ن»¥ن¸چه…±ن؛«ï¼ˆç‹¬ç«‹ file_cursor)م€‚
ه®é™…ن¸ٹوˆ‘ن»¬هœ¨ print çڑ„و—¶ه€™ï¼Œه°±ن¼ڑéپ‡هˆ°ه…±ن؛« fd_table çڑ„وƒ…ه†µï¼Œه¦‚وœن¸چه…±ن؛«ï¼Œchild process هڈ¯èƒ½ه°±وٹٹ parent process çڑ„输ه‡؛覆盖وژ‰م€‚ و³¨و„ڈ file_table 里çڑ„ ref count وک¯è،¨ç¤؛ه¤ڑوœ‰ه°‘ن¸ھ fd وŒ‡هگ‘ه®ƒم€‚

و³¨و„ڈ FIND_UNUSED_ENTRY,وک¯é€‰و‹©ه½“ه‰چو²،وœ‰ç”¨è؟‡çڑ„ fd ن¸وœ€ه°ڈçڑ„ن¸€ن¸ھم€‚ وژ¥ن¸‹و¥وˆ‘ن»¬çœ‹ه®é™…çڑ„ç£پç›کن¸ٹçڑ„结و„ï¼ڑ
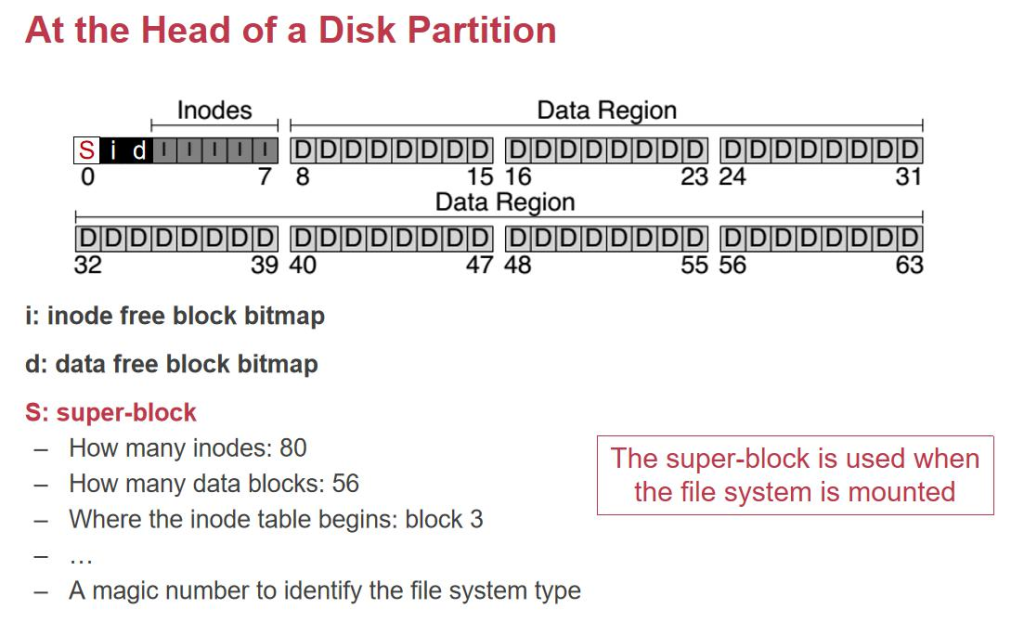
هœ¨ç£پç›کçڑ„ه¤´éƒ¨وˆ‘ن»¬و”¾ن¸€ن¸ھ:free inode bitmap,è؟کوœ‰ن¸€ن¸ھ data bitmap,وœ€ه¤´ن¸ٹوک¯ن¸€ن¸ھ Superblock,ه…¶ن¸è®°ه½•ن؛†ن¸€ن؛›ه…ƒو•°وچ®م€‚
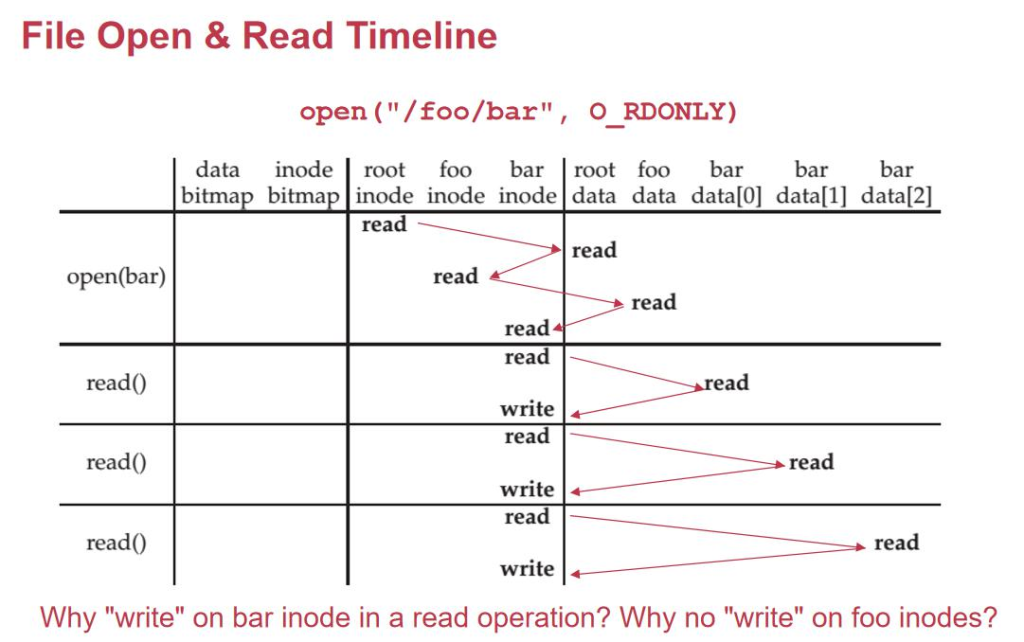
ه½“وˆ‘ن»¬هژ»و‰“ه¼€ن¸€ن¸ھو–‡ن»¶/foo/bar çڑ„و—¶ه€™ï¼Œوˆ‘ن»¬ه؛”该ه…ˆهژ»è¯» root_inode(ç؛¦ه®ڑن؟—وˆگçڑ„هœ°و–¹ï¼Œ 第ن¸€ن¸ھ inode çڑ„هœ°و–¹ï¼‰ï¼Œوˆ‘ن»¬ه°±هژ»è¯»و ¹ç›®ه½•ه¯¹ه؛”çڑ„ block number çڑ„ block,读هˆ°ن؛†و ¹ç›®ه½•ن¸‹ çڑ„و–‡ن»¶ï¼Œو‰¾هˆ°ن؛† foo çڑ„ inode,و‰¾هˆ° foo çڑ„و•°وچ®ï¼Œو‰¾هˆ°ن؛† bar çڑ„ inodeم€‚读çڑ„و—¶ه€™ï¼Œو‰¾هˆ° bar çڑ„ block 读,读ه®Œن؛†ن»¥هگژن؟®و”¹ن¸€ن¸‹ inode çڑ„ access timeم€‚
وˆ‘ن»¬هڈ‘çژ°هœ¨ read çڑ„و—¶ه€™ï¼Œوˆ‘ن»¬ن¸چه¾—ن¸چهژ» write ن¸€و¬،ç£پç›کن¸؛ن؛†و›´و–° access timeم€‚هœ¨ linux çڑ„و—¶ه€™ï¼Œهٹ è½½و–‡ن»¶ç³»ç»ںهگ¯هٹ¨çڑ„و—¶ه€™é»ک认ن¼ڑو·»هٹ noatime 选é،¹م€‚وˆ‘ن»¬ه¼±هŒ– atime çڑ„و›´و–°ï¼Œن¹ںه°± وک¯ه½“وˆ‘ن»¬ close çڑ„و—¶ه€™و‰چن¼ڑو›´و–° atime,而ن¸چè¦پ读ن¸€و¬،و›´و–°ن¸€و¬،,ه°½هڈ¯èƒ½ه‡ڈه°‘ç£پç›کçڑ„ه†™و“چن½œم€‚
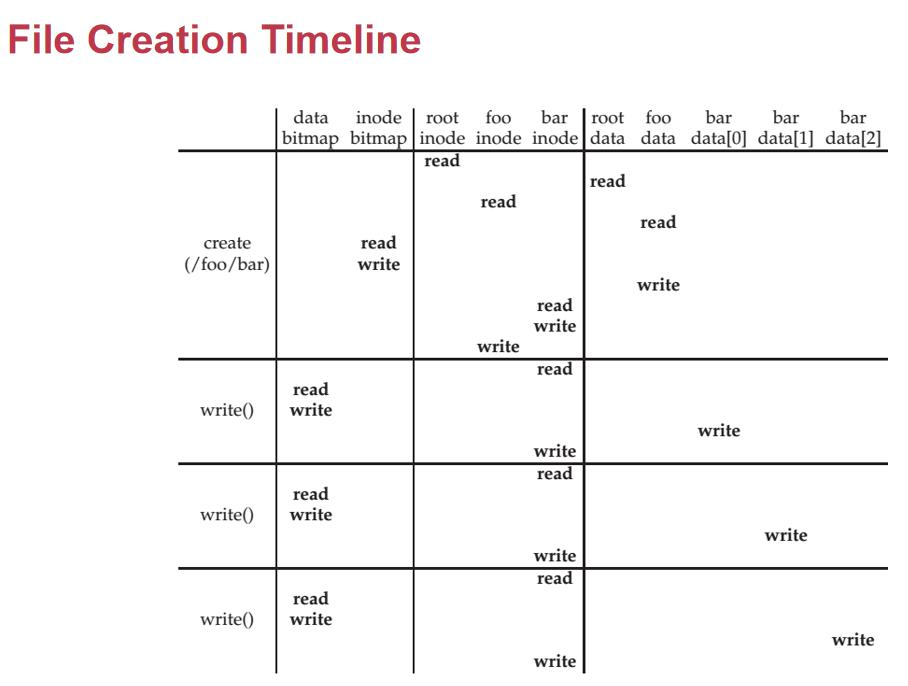
简هچ•è¯´ï¼Œè؟™ن¸ھè؟‡ç¨‹çڑ„و ¸ه؟ƒوک¯ه› ن¸؛ç£پç›کو“چن½œوک¯هں؛ن؛ژ ه—(block) 而ن¸چوک¯هچ•ç‹¬çڑ„ه—èٹ‚,و¶‰هڈٹهˆ°و–‡ن»¶ç³»ç»ںه¦‚ن½•é«کو•ˆç®،çگ†ه’Œو›´و–°و•°وچ®ه—م€‚
1. 首ه…ˆï¼ڑو‰¾هˆ° /foo çڑ„ن؟،وپ¯
- و–‡ن»¶è·¯ه¾„解وگه…ˆن»ژو ¹ç›®ه½•ه¼€ه§‹ï¼Œé€گه±‚وں¥و‰¾م€‚
- و‰¾هˆ°
/fooو—¶ï¼ڑ- 读
/fooçڑ„ inodeï¼ڑن»ژ inode ن¸çں¥éپ“/fooçڑ„و•°وچ®ه—ç¼–هڈ·م€‚ - 读
/fooçڑ„و•°وچ®ه—ï¼ڑèژ·هڈ–里é¢çڑ„ه†…ه®¹ï¼ˆه¦‚و–‡ن»¶هگچه’Œ inode ç¼–هڈ·çڑ„ه¯¹ه؛”ه…³ç³»ï¼‰م€‚
- 读
2. ه‡†ه¤‡هˆ›ه»؛ bar
- هˆ†é…چو–°çڑ„ inodeï¼ڑ
- 读 inode ن½چه›¾ï¼ˆinode bitmap)ï¼ڑو‰¾هˆ°ن¸€ن¸ھç©؛é—²çڑ„ inodeم€‚
- هˆ†é…چè؟™ن¸ھ inode ن½œن¸؛
barçڑ„ inodeم€‚
- و›´و–°
/fooçڑ„و•°وچ®ه—ï¼ڑ
- 读هڈ–
/fooçڑ„و•°وچ®ه—,و‰¾هˆ°هگˆé€‚ن½چç½®ه†™ه…¥barو–‡ن»¶هگچه’Œه®ƒçڑ„ inode ç¼–هڈ·م€‚
3. ن¸؛ن»€ن¹ˆهˆ›ه»؛و—¶è¦پ“读â€ï¼ں
è؟™ن¸ھ “读†و“چن½œن¸»è¦پوک¯ه› ن¸؛ç£پç›ک 物çگ†ه±‚ çڑ„特و€§ï¼ڑ
(1)ç£پç›کوŒ‰ه—و“چن½œ
- ç£پç›کçڑ„وœ€ه°ڈو“چن½œهچ•ن½چوک¯ ه—(block),é€ڑه¸¸وک¯ 4K ه¤§ه°ڈم€‚
- ه¦‚وœ
/fooçڑ„و•°وچ®ه—وک¯ 4K,ن½†وˆ‘ن»¬هڈھوƒ³ه¾€ه…¶ن¸ه†™ه…¥barçڑ„و،目(و¯”ه¦‚ه‡ هچپه—èٹ‚),ç£پç›کن¸چ能直وژ¥ه†™è؟™ه‡ هچپه—èٹ‚م€‚ - ه؟…é،»وٹٹ و•´ن¸ھ 4K ه—读ن¸ٹو¥ï¼Œن؟®و”¹ه…¶ن¸ن¸€éƒ¨هˆ†ï¼Œه†چه†™ه›ç£پç›کم€‚
(2)ه†™ه…¥و—¶ن؟وٹ¤هژںه§‹و•°وچ®
- ن¸؛ن؛†ن؟è¯پن¸چن¼ڑ覆盖وœھو”¹هڈکçڑ„部هˆ†ï¼Œه†™ç£پç›که‰چ需è¦پç،®ن؟ï¼ڑ
- و•°وچ®ه·²ç»ڈهœ¨ه†…هکن¸ه®Œو•´ن؟®و”¹ه¥½م€‚
- è؟™ه°±وک¯ “ه…ˆè¯»هگژه†™â€ çڑ„هژںه› م€‚
4. و›´و–° bar çڑ„ inode
- هˆ†é…چو•°وچ®ه—ï¼ڑ
- 读و•°وچ®ه—ن½چه›¾ï¼ˆdata bitmap)ï¼ڑو‰¾هˆ°ن¸€ن¸ھç©؛çڑ„ه—م€‚
- è؟™ن¸ھه—ه°†هکه‚¨
barçڑ„و–‡ن»¶ه†…ه®¹م€‚
- ه†™ inodeï¼ڑ
- هœ¨
barçڑ„ inode ن¸ï¼Œè®°ه½•ن¸‹è؟™ن¸ھو•°وچ®ه—ç¼–هڈ·م€‚
5. و€»ç»“ن¸؛ن»€ن¹ˆè¦پ读
- ç£پç›کوŒ‰ه—و“چن½œï¼ڑن¸چ能直وژ¥ه†™ه‡ ن¸ھه—èٹ‚,ه؟…é،»ه…ˆè¯»و•´ن¸ھه—م€‚
- 需è¦په®Œو•´و€§ï¼ڑن؟®و”¹ç›®ه½•و،目(ه¦‚
/fooçڑ„و•°وچ®ه—)و—¶ï¼Œه؟…é،»ç،®ن؟هژںو¥çڑ„ه…¶ن»–部هˆ†ن¸چن¸¢ه¤±م€‚ - ن½چه›¾çڑ„读هڈ–ï¼ڑن¸؛ن؛†و‰¾هˆ°ç©؛é—²çڑ„ inode ه’Œو•°وچ®ه—,ن¹ں需è¦پ读هڈ– inode ن½چه›¾ه’Œو•°وچ®ه—ن½چه›¾م€‚
و‰€ن»¥ï¼Œهˆ›ه»؛و–‡ن»¶çڑ„è؟‡ç¨‹è™½ç„¶çœ‹èµ·و¥وک¯â€œه†™â€ï¼Œن½†ه®é™…ن¸ٹ离ن¸چه¼€ 读و“چن½œï¼Œè؟™وک¯ن¸؛ن؛†هچڈè°ƒ ç£پç›ک物çگ†و“چن½œ ه’Œ و–‡ن»¶ç³»ç»ںçڑ„逻辑ç®،çگ†م€‚
وژ¥ن¸‹و¥وˆ‘ن»¬ه°±هڈ¯ن»¥و¥ه†™ن؛†ï¼Œن»ژ data_bit_map ن¸و‰¾ن¸€ن¸ھç©؛çڑ„ه†™ه›هژ»م€‚然هگژه†™ه›ه¯¹ه؛”çڑ„ block هگژه°±ه†چوٹٹ block number ه†™ه› inodeم€‚

è؟™é‡Œوˆ‘ن»¬هڈ‘çژ°هœ¨ه‰چé¢çڑ„è؟‡ç¨‹ن¸ï¼Œوœ€éڑ¾çڑ„ن؛‹وƒ…ن¹ںه°±وک¯ن¸€و—¦هڈ‘é€پن؛† failure ه°±ن¼ڑه¯¼è‡´ن¸¥é‡چçڑ„é—®é¢کم€‚
وˆ‘ن»¬ç›´وژ¥ه›هˆ°هˆڑو‰چè؟™ن¸ھ write و“چن½œï¼Œن¸€و¬، write 需è¦په†™ 3 و¬،ç£پç›ک(data_bit_map, inode, data)م€‚é‚£ن¹ˆé—®é¢کو¥ن؛†ï¼Œه½“وˆ‘ن»¬هœ¨هپڑè؟™ن¸ھو“چن½œçڑ„و—¶ه€™و–电ن؛†ï¼Œن¼ڑهڈ‘ç”ں 3 2 وƒ…ه†µï¼Œن¹ںه°±وک¯ 000,001,010,…,111,
- 1. data ه†™ن؛†ï¼Œè€Œ data_bit_map,inode و²،ه†™م€‚ه…ƒو•°وچ®ه•¥éƒ½و²،و›´و–°ï¼Œه±ن؛ژ nothing çڑ„وƒ…ه†µم€‚
- 2. Data_bit_map ه†™ن؛†ï¼Œè€Œه…¶ن»–ن¸¤ن¸ھو²،ه†™م€‚ه¼•ه…¥ن؛†هƒهœ¾ï¼Œو²،وœ‰ن»»ن½•و–‡ن»¶çڑ„ inode وŒ‡هگ‘è؟™ ه—هŒ؛هںںم€‚وˆ‘ن»¬هڈ¯ن»¥é€ڑè؟‡وٹٹو•´ن¸ھ inode و‰«وڈڈن¸€éپچه¾—هˆ° list,然هگژهپڑهŒ¹é…چ,و›´و–°ن¸€ن¸‹ bit mapم€‚
- 3. inode و›´و–°ن؛†ï¼Œè€Œ block ه’Œ data_bitmap و²،و›´و–°م€‚وˆ‘ن»¬هڈ‘çژ°و•°وچ®وک¯é”™çڑ„,وœ‰هڈ¯èƒ½è®؟é—® هˆ°وƒé™گو–‡ن»¶ه¼•هڈ‘ه®‰ه…¨é—®é¢ک,هڈ¯ç”¨و€§ن¹ںوœ‰é—®é¢کم€‚è؟™ن¸ھé—®é¢کوک¯وœ€ه¤§çڑ„م€‚
- 4. Data و²،ه†™ï¼Œن¼ڑه¯¼è‡´ه®‰ه…¨و€§é—®é¢کم€‚
- 5. Data_bitmap و²،ه†™ï¼Œن¼ڑ被هڈ¦ن¸€ن¸ھو–‡ن»¶ه…±ç”¨ن¸€ن¸ھ blockم€‚
- 6. Inode و²،ه†™ï¼Œن؛§ç”ںوµھè´¹م€‚
ه¦‚وœè®©وˆ‘ن»¬وژ’ه؛ڈçڑ„è¯ï¼Œوˆ‘ن»¬ن¼ڑه…ˆه†™ data,ه†چه†™ data_bit_map,ه†چه†™ inodeم€‚ه› ن¸؛ inode éه¸¸é‡چè¦پم€‚

Order و²،هٹو³•ن؟è¯پ,ه› ن¸؛وˆ‘ن»¬هڈ‘é€پو“چن½œçڑ„و•°وچ®هڈ¯èƒ½وک¯وŒ‰ç…§é،؛ه؛ڈçڑ„,ن½†وک¯ cache çڑ„وƒ…ه†µوˆ‘ ن»¬ن¸چهڈ¯وژ§م€‚

ن¸؛ن؛†éپ؟ه…چè؟™ن¸ھé—®é¢ک,è؟™و—¶ه€™وˆ‘ن»¬ه°±è¦پ用هˆ° SYNC,وٹٹه†…هکن¸çڑ„و‰€وœ‰ن¸œè¥؟ flush هˆ°ç›کن¸ٹم€‚
ه¦‚وœوˆ‘ن»¬وٹٹن¸€ن¸ھو‰“ه¼€çڑ„و–‡ن»¶هˆ وژ‰ن؛†ï¼Œه¦‚وœ file_table ن¸çڑ„ ref_cnt ن¸چن¸؛ 0,需è¦پç‰ه¾… inode هœ¨è؟›ç¨‹ close çڑ„و—¶ه€™وٹٹه®ƒهˆ وژ‰م€‚

除ن؛† inode,وˆ‘ن»¬è؟کهڈ¯ن»¥و€ژن¹ˆç»„织و•°وچ®ه‘¢ï¼ںن¸؛ن»€ن¹ˆوˆ‘ن»¬ن¸چ适用链è،¨ه‘¢ï¼ںFAS32 ه°±وک¯ ن¸€ن¸ھ链è،¨م€‚
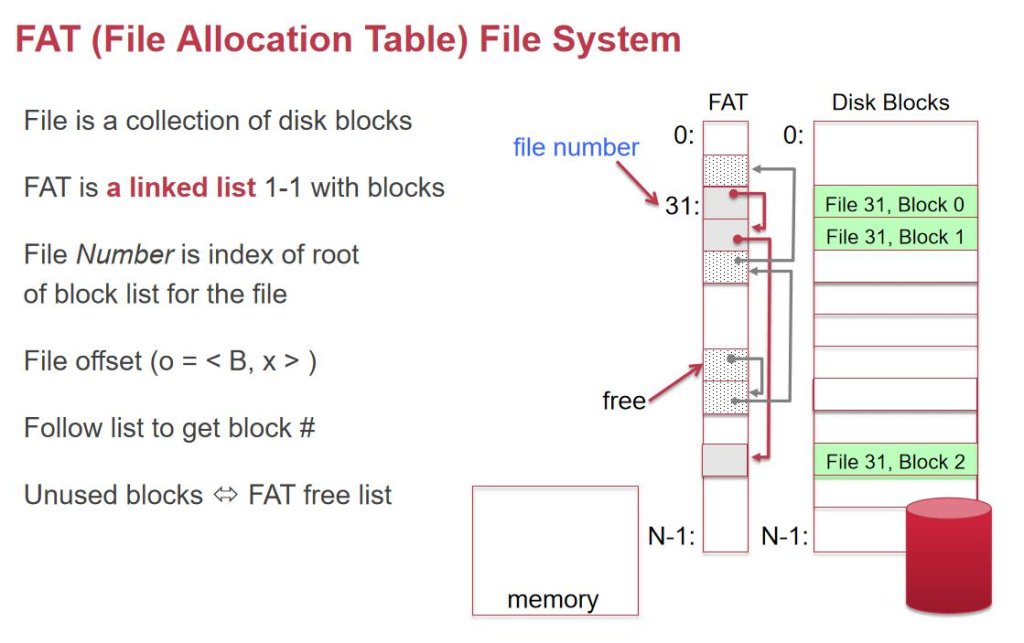
FAT32 ن½؟用 file allocation table و¥è®°ه½•و–‡ن»¶çڑ„第ن¸€ن¸ھ block-numberم€‚ه®ƒو²،وœ‰ Inode numberم€‚ FAT è،¨ه…¶ه®ه°±وک¯ن¸€ن¸ھ 64byte çڑ„è،¨م€‚ه½“وˆ‘ن»¬وٹٹè؟™ن¸ھè،¨ن¸²èµ·و¥ï¼Œوˆ‘ن»¬ه°±هڈ¯ن»¥وٹٹه¯¹ه؛”و•°وچ®ن¸²èµ·و¥م€‚ freelist ن¸€è·¯ن¸ٹوٹٹو‰€وœ‰ freeblock ن¸²هœ¨ن¸€èµ·م€‚وˆ‘ن»¬è¦پو–°هٹ ن¸€ن¸ھ block çڑ„و—¶ه€™ï¼Œوˆ‘ن»¬ه°±وٹٹ free_list وŒ‡هگ‘ه®ƒçڑ„ next,ه¤ڑه‡؛و¥ن¸€ن¸ھ free,然هگژو”¹ file32 çڑ„وœ€هگژن¸€ن¸ھوŒ‡هگ‘ free blockم€‚
é‚£ن¹ˆè؟™ن¹ˆن¸€ç§چ设è®،وœ‰ن»€ن¹ˆç‰¹ç‚¹ه‘¢ï¼ںه¯¹ن؛ژéڑڈوœ؛读ه†™ï¼Œéœ€è¦پéپچهژ†ن¸€éپچè؟™ن¸ھ linked_list,而وˆ‘ ن»¬çڑ„ Inode هڈھ需è¦پ读ن¸€éپچن¸‰ç؛§ç´¢ه¼•çڑ„链م€‚ه¦‚وœ linked_list وœ‰ن¸€ن¸ھهœ°و–¹هڈن؛†ï¼Œé‚£ن¹ˆه…¨éƒ¨éƒ½هڈن؛†م€‚ ن¸‰ç؛§é—´وژ¥ç´¢ه¼•هڈن؛†ن¹ںن¼ڑه¯¼è‡´ه¤§é‡ڈو•°وچ®و²،وœ‰ï¼Œن½†وک¯و¦‚çژ‡ه°ڈن¸€ç‚¹م€‚
NAT 适هگˆé،؛ه؛ڈ读ه†™م€‚و‰€ن»¥é€‚هگˆç”¨و¥هپڑو•°ç پ相وœ؛çڑ„هکه‚¨ن»‹è´¨م€‚
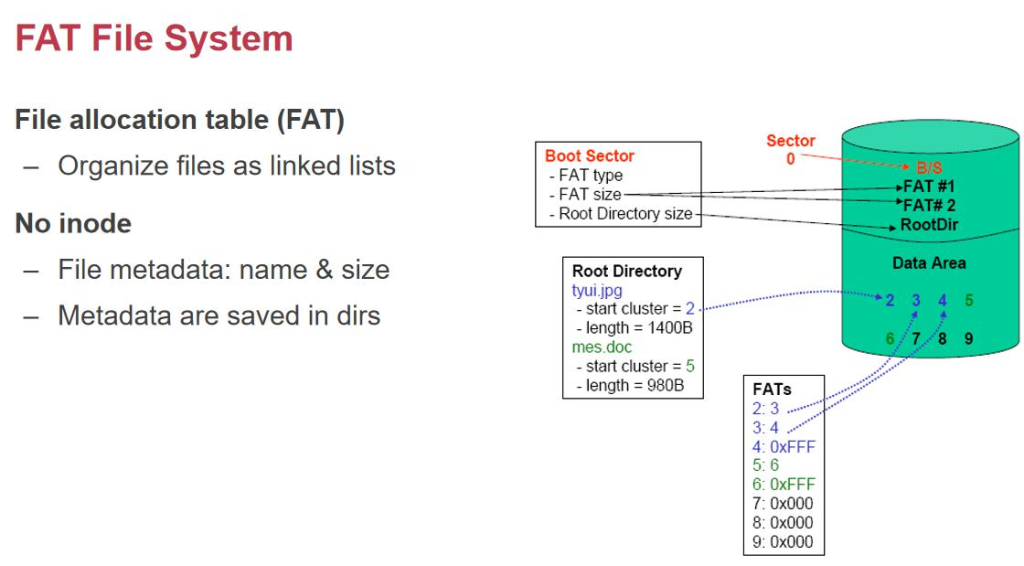
ç”±ن؛ژ fat è،¨و²،وœ‰ inode,و‰€ن»¥وˆ‘ن»¬è؟کوک¯è¦پè®°ه½•ن¸€ن؛›ه…ƒو•°وچ®م€‚وک¯è®°ه½•هœ¨ directory entry(目 ه½•é،¹ï¼‰ن¸م€‚inode çڑ„结و„وک¯ name: inode-numberم€‚而 FAT ن¸وک¯ name :第ن¸€ن¸ھ block çڑ„ number, size,….,هگ„ç§چه…ƒو•°وچ®çڑ„ن؟،وپ¯م€‚ه°±ç®—وœ‰ ref count,وˆ‘ن»¬ن¹ںن¸چçں¥éپ“هœ¨ه“ھ,需è¦پو‰«وڈڈن¸€éپچو‰€وœ‰çڑ„ ç›®ه½•م€‚و‰€ن»¥ FAT ن¸چو”¯وŒپ hard link çڑ„م€‚و ¸ه؟ƒه°±وک¯ name وک¯و–‡ن»¶çڑ„ه…ƒو•°وچ®çڑ„ن¸€éƒ¨هˆ†ï¼Œن؛ژوک¯وˆ‘ن»¬ه°±ن¸چ能让ن¸¤ن¸ھ name وŒ‡هگ‘ن¸€ن¸ھو•°وچ®م€‚

ه¦‚وœوˆ‘ن»¬وٹٹ U ç›کو ¼ه¼ڈهŒ–وˆگ FAT,وœ€ه¤§و”¯وŒپçڑ„ه¤§ه°ڈوک¯ 4G,è؟™ن¸ھ 4G وک¯ç”±ن»€ن¹ˆه†³ه®ڑçڑ„ï¼ںوک¯ه› ن¸؛ه…ƒو•°وچ®ن¸çڑ„ size هڈھوœ‰ 32 ن½چ,وœ€ه¤§هڈھ能è،¨ç¤؛ 4G çڑ„و–‡ن»¶م€‚而 Inode-based file system وک¯ç”±وœ‰ ه¤ڑه°‘ç؛§ indirect-block ه†³ه®ڑçڑ„م€‚ه¦‚وœوˆ‘ن»¬هœ¨ن¸€ن¸ھو–‡ن»¶ç³»ç»ں里é¢ï¼Œوˆ‘ن»¬çژ°هœ¨è¦پهکه¤§é‡ڈçڑ„و–‡ن»¶ï¼Œ ن½†و¯ڈن¸ھو–‡ن»¶ه°ڈن؛ژ 1k,ه¹³ه‡ 256byteم€‚而ن¸€ن¸ھ i-node ه°±وœ‰ 1k,ن؛ژوک¯وˆ‘ن»¬ن¸؛ن؛†è؟™ن¸ھو¯ڈن¸ھو–‡ن»¶çڑ„ هکه‚¨هˆ†é…چن¸€ن¸ھ 4k çڑ„ block ه’Œ 1k çڑ„ inodeم€‚ن؛‹ه®ن¸ٹوˆ‘ن»¬ن»ٹه¤©çڑ„ç£پç›کن¸ï¼Œوœ‰ه¾ˆه¤ڑ 4k çڑ„و•°وچ®و²،وœ‰ هکه®Œï¼Œè؟™ن¸ھهœ°و–¹وک¯ç”± size ه†³ه®ڑçڑ„م€‚وœ€هگژن¼ڑç•™ن¸‹ن¸€ن؛›ç©؛éڑ™çڑ„م€‚وˆ‘ن»¬وœ‰ن»€ن¹ˆهٹو³•وٹٹهˆ©ç”¨çژ‡وڈگé«که‘¢? ن¸€ن¸ھ简هچ•çڑ„هٹو³•وک¯ç›´وژ¥وٹٹو•°وچ®و”¾هœ¨ inode ن¸م€‚ن¸؛ن؛†éپ؟ه…چو–‡ن»¶ç³»ç»ں误解ن¸؛ blocknumber,ه†چهٹ ه‡ ن¸ھ flag ه°±è،Œن؛†م€‚è؟™و ·و–‡ن»¶هˆ©ç”¨çژ‡ ه°±وڈگé«کن؛†
هœ؛و™¯ï¼ڑوˆکهœ°è®°è€…ه¸¦و‰‹وœ؛,è؟›è؟‡ن¸€ن¸ھهŒ؛هںں,è؟›ه‡؛都وœ‰ن¸€ن¸ھه“¨ه…µم€‚è؟™ن¸ھه“¨ه…µéه¸¸و‡‚و–‡ن»¶ç³»ç»ں, 记者ن¸چ能让و–‡ن»¶ç³»ç»ںوœ‰ن»»ن½•çڑ„هڈکهŒ–,ه°±هڈ¯ن»¥ç”¨و–‡ن»¶ç³»ç»ںن¸و¯ڈن¸ھو–‡ن»¶çڑ„وœ€هگژن¸€ن¸ھ block ه¤ڑن½™çڑ„ ç©؛é—´م€‚è؟™ن¸ھو–¹و³•ن¸چن»…وˆکهœ°è®°è€…ن¹ںن¼ڑ用,黑ه®¢ن¹ںن¼ڑ用,病و¯’ه¦‚وœو”¾هœ¨è؟™ن¸ھهŒ؛هںںه°±و‰«وڈڈن¸چه‡؛و¥ن؛†م€‚ هٹ¨و€پهœ°ن؟®و”¹ inode ن¸çڑ„ size,ه°±هڈ¯ن»¥هœ¨وƒ³ç”¨çڑ„و—¶ه€™è°ƒç”¨هˆ°ç—…و¯’çڑ„ن»£ç پم€‚
هˆ†ه¸ƒه¼ڈو–‡ن»¶ç³»ç»ں
RPC
وˆ‘ن»¬ه¸Œوœ›وٹٹ file system ن»ژهچ•ن¸ھو‰©ه±•هˆ°ه¤ڑن¸ھم€‚è؟™ن¸ھهœ¨وژ¥è؟‘ 40 ه¹´ه‰چه°±وœ‰ن؛؛هپڑن؛†م€‚SUN ه…¬هڈ¸ ه¸Œوœ›ه¼€هڈ‘و²،وœ‰ç،¬ç›کçڑ„è®،ç®—وœ؛,و•°وچ®وک¯ن¸چوک¯éƒ½èƒ½ه…¨éƒ¨و¥è‡ھ网络م€‚ه¯¹ç”¨وˆ·وک¯é€ڈوکژçڑ„,وœ€ه؛•ه±‚çڑ„و ¸ ه؟ƒوٹ€وœ¯ه°±وک¯ RPCم€‚RPC ن¸چن»…ن»…وک¯ç”¨و¥وڈگن¾› Open,Write,Read وژ¥هڈ£ï¼ŒRPC è؟ک能ه®çژ°è·¨وœ؛ه™¨çڑ„ه‡½و•° 调用م€‚
ن¼ ç»ںçڑ„,ه¦‚وœوˆ‘ن»¬ن¸چ用 RPC,ه¤§ه®¶è¦پ调用网络çڑ„و—¶ه€™ï¼Œه°±è¦پن½؟用 socket,و‰“ه¼€ن¸€ن¸ھ socket, وœچهٹ،端è¦پ listen,然هگژهڈ¯ن»¥ accept ه¾—هˆ°ن¸€ن¸ھ fd,然هگژهœ¨هڈŒو–¹ن¹‹é—´هپڑن؛¤ن؛’,وˆ‘ن»¬éœ€è¦په†™ه¾ˆه¤ڑ glue code,ن¸چوک¯ه¾ˆو–¹ن¾؟,وˆ‘ن»¬ه¸Œوœ›وœ‰و›´هٹ 简هچ•çڑ„و“چن½œï¼Œclient çڑ„ن»£ç پهڈ¯ن»¥ç›´وژ¥ه†™ن¸€ن¸ھ fool()调用çڑ„ وک¯وœچهٹ،ه™¨ç«¯çڑ„ه‡½و•°ï¼Œè؟”ه›ه€¼ه°±وک¯ه¯¹ه؛”çڑ„è؟”ه›ه€¼م€‚وچ¢هڈ¥è¯è¯´وˆ‘ن»¬ه¸Œوœ› RPC ه’Œ PC(procedure call) وک¯ن¸€و ·çڑ„,وˆ‘ن»¬ن¸چ需è¦پ care ه®ƒوک¯ local è؟کوک¯ remote çڑ„م€‚除ن؛†هœ¨ framework ç؛§هˆ«ï¼Œهœ¨è¯è¨€ç؛§هˆ« ç”ڑ至都هŒ…هگ«ن؛† RPC 相ن¼¼çڑ„وœ؛هˆ¶ï¼Œو¯”ه¦‚ Java ن¸çڑ„ RMI(remote method invocation)م€‚说وکژ RPC وک¯ن¸€ن¸ھéه¸¸éه¸¸هں؛ç،€çڑ„ن½œç”¨م€‚

è؟™ن¸ھ mesure ه‡½و•°وک¯ç”¨و¥وµ‹é‡ڈ func çڑ„è؟گè،Œو—¶é—´م€‚Get_time ه°±وک¯و ¹وچ®ن¼ ه…¥çڑ„هچ•ن½چè؟”ه›ه¯¹ه؛” هچ•ن½چçڑ„و—¶é—´م€‚ه¦‚وœوˆ‘ن»¬وٹٹ GET_TIME و”¾هˆ°وœچهٹ،ه™¨ن¸ٹ,و¯”ه¦‚وˆ‘ن»¬وœ¬هœ°çڑ„و—¶é’ںن¸چو£ç،®ï¼Œè¯¥و€ژن¹ˆهژ» هپڑه‘¢ï¼ں
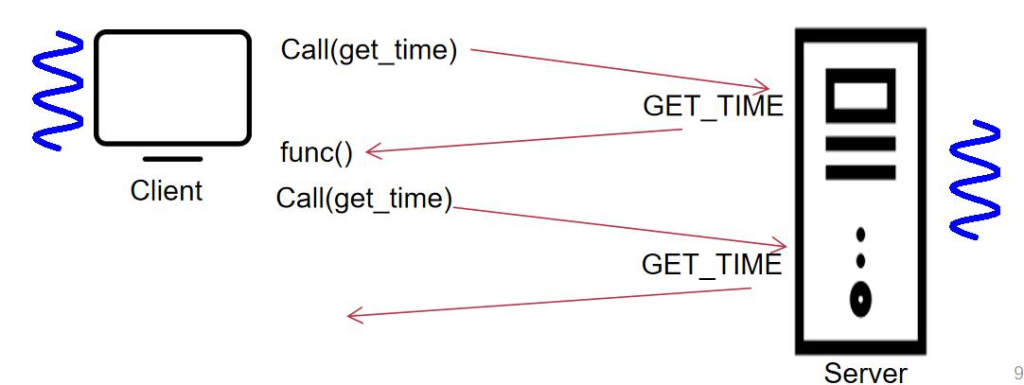
网络ه»¶è؟ں该و€ژن¹ˆهٹï¼ںوˆ‘ن»¬ن¹‹هگژن¼ڑ讨è®؛ه¯¹و—¶çڑ„ç®—و³•م€‚ وœ€ç®€هچ•çڑ„ه°±وک¯ه¤ڑ ping ه‡ و¬،,هڈ–ه‡ه€¼ï¼Œوˆ‘ن»¬هپ‡è®¾ن؛†ç½‘络و—¶ه»¶هں؛وœ¬ن¸ٹن¸چهڈک,ه¹¶ن¸”هپ‡è®¾ن؛†è؟‡ هژ»çڑ„و—¶é—´ç‰ن؛ژه›و¥çڑ„و—¶é—´م€‚ن¸€و—¦هœ¨è°ˆهˆ°هˆ†ه¸ƒه¼ڈçڑ„و—¶ه€™ï¼Œوˆ‘ن»¬ن¼ڑهڈ‘çژ°و—¶é’ںوک¯çœ‹èµ·و¥ç®€هچ•ن½†وک¯èƒŒ هگژوک¯ن¸€ن¸ھéه¸¸ه¤§çڑ„é—®é¢ک,ه› ن¸؛و²،وœ‰ن¸¤ن¸ھن؛؛çڑ„و—¶é’ںوک¯ن¸€و ·çڑ„م€‚

وˆ‘ن»¬éœ€è¦پوٹٹ second هڈ‚و•° convert ن¸€ن¸‹ï¼Œه› ن¸؛网络ن¸ٹçڑ„و•°وچ®وک¯ big-endian,然هگژن¼ ن¸€ن¸ھ Get time و‰“هŒ…وˆگن¸€ن¸ھ Message هڈ‘é€پç»™وœچهٹ،ه™¨ï¼Œه¾—هˆ° responseم€‚然هگژه†چ convert ه›و¥م€‚

ه¾—هˆ° request هگژ,ه¯¹ه…¶هپڑ解وگه¾—هˆ° opcode ه’Œ unitم€‚ه¾—هˆ°و•°وچ®ن»¥هگژ,è؟”ه›ن¸€ن¸ھ response(OK ه’Œ bad request ن¸¤ç§چهڈ¯èƒ½ï¼‰م€‚ وˆ‘ن»¬çœ‹هˆ°ه®ƒو¥و¥ه›ه›هپڑن؛†ه¾ˆه¤ڑهˆ«çڑ„ن؛‹وƒ…,ه¾ˆه¤ڑه†…ه®¹وک¯هڈ¯ن»¥و¨،ه—هŒ–çڑ„م€‚

è؟™ن؛›éƒ½وک¯هڈ¯ن»¥و”¾هœ¨ RPC çڑ„ stub(و،©ن»£ç پ,ن¸چ用程ه؛ڈه‘کç®،çڑ„)ن¸ï¼Œه…¨éƒ¨ç”¨ه؛“çڑ„و–¹ه¼ڈهژ»ه°پ装起 و¥م€‚
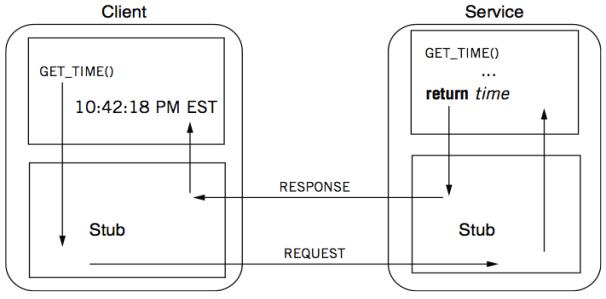

هœ¨ stub ن¸ن¼ڑه®çژ° GET_TIME ه¹¶ن¸”هڈ‘é€پç»™è؟œç«¯ه¾—هˆ° responseم€‚Stub ه°±ه¾ˆه¥½هœ°ه°پ装ن؛†ه؛•ه±‚网络é€ڑ 讯çڑ„细èٹ‚م€‚ه¯¹ن؛ژ server و¥è¯´ن¸€و ·ï¼Œوˆ‘ن»¬ه®çژ°ن؛†ه؛•ن¸‹çڑ„ن¸€ه±‚م€‚
è؟™وک¯éه¸¸ç»ڈه…¸çڑ„解耦و–¹ه¼ڈ,程ه؛ڈه‘کن¸چ用考虑ه‡½و•°وک¯هœ¨وœ¬هœ°è؟کوک¯هœ¨è؟œç«¯ï¼Œه½“然è؟™وک¯هœ¨ن¸چه‡؛ ه¼‚ه¸¸çڑ„وƒ…ه†µم€‚
وˆ‘ن»¬éœ€è¦پوٹٹو•°وچ®ç”¨هگˆçگ†çڑ„و–¹ه¼ڈ marshal وژ’éکںهڈ‘هˆ°ç½‘ن¸ٹهژ»ï¼ˆserialize)م€‚وˆ‘ن»¬و¥è¯¦ç»†çœ‹ن¸€ن¸‹ï¼Œ هœ¨ 1984 è؟™ç¯‡è®؛و–‡ن¸وڈگه‡؛çڑ„ RPC هŒ…هگ«ن؛†ن»€ن¹ˆه†…ه®¹:
- 1. Xid,X وک¯ transaction çڑ„缩ه†™ï¼Œه®ƒوک¯ç”¨ه‘ٹ诉 server 请و±‚وک¯هڈ‘è؟‡ن؛†è؟کوک¯و²،هڈ‘è؟‡ï¼Œهœ¨ه‡؛ é”™çڑ„و—¶ه€™éه¸¸وœ‰ç”¨
- 2. Call/reply53
- 3. RPC version,و„ڈه‘³ç€هڈ¯ن»¥و”¯وŒپه¤ڑن¸ھ version,ن¸€هڈ°هچ•وœ؛çڑ„ه؛”用程ه؛ڈه’Œه؛“é€ڑه¸¸وک¯هگˆهœ¨ن¸€ èµ·çڑ„,ن½†وک¯ client ه’Œ server çڑ„版وœ¬هڈ¯èƒ½ن¸چ相هگŒï¼Œè¦پ考虑هˆ°ه…¼ه®¹و€§
- 4. Program, program version, procedure,هڈ¯èƒ½è°ƒç”¨ن¸€ن¸ھهڈ¯و‰§è،Œو–‡ن»¶و‰€وڈگن¾›çڑ„ه‡½و•°
- 5. Auth stuff,و¥هپڑéھŒè¯پ
- 6. Arguments,هڈ‚و•°
هگŒو ·هœ¨ reply çڑ„و—¶ه€™ن¹ںوœ‰ه‡ ن¸ھن¸چهگŒçڑ„هڈ‚و•°
- 1. Accepted
- 2. Success,accepted ه’Œ success çڑ„هŒ؛هˆ«وک¯ن»€ن¹ˆه‘¢ï¼ںAccepted وک¯ه’Œ RPC 相ه…³çڑ„,而 Success وک¯ه’Œوˆ‘ن»¬è°ƒç”¨çڑ„ serveice 相ه…³çڑ„م€‚وچ¢هڈ¥è¯è¯´ه¦‚وœ accepted وک¯ false,说وکژ RPC éک¶و®µه°±é”™ن؛†ï¼Œ و²،وœ‰è°ƒç”¨هˆ°ç¨‹ه؛ڈ,而 success وک¯è¯´وکژ RPC ن¹‹é—´وک¯هڈ¯ن»¥و£ه¸¸ه¯¹è¯ï¼Œن½†وک¯ه…·ن½“و‰§è،Œçڑ„و—¶ه€™ه‡؛é”™ن؛†
- 3. Results
- 4. Auth stuff و€ژن¹ˆè®© client ه’Œ server ن؛’相绑ه®ڑه‘¢ï¼ں
Client 该و€ژن¹ˆçں¥éپ“è؟™ن¸ھ端هڈ£ه‘¢ï¼ںو‰€ن»¥هœ¨ç³»ç»ںن¸ï¼Œmain discovery وœچهٹ،و³¨ه†Œç«¯هڈ£ï¼Œهڈ¯ن»¥هˆ—ه‡؛ و‰€وœ‰ service çڑ„端هڈ£م€‚و‰€è°“çڑ„وœچهٹ،هڈ‘çژ°ن¹ںوک¯هœ¨هˆ†ه¸ƒه¼ڈç³»ç»ںوک¯ه¾ˆé‡چè¦پçڑ„组وˆگ部هˆ†م€‚وˆ‘ن»¬éœ€è¦پوٹٹ و•°وچ®هڈ‘é€پç»™ server,è؟™ن»¶ن؛‹وƒ…看ن¼¼ç®€هچ•è؟کوŒ؛ه¤چو‚çڑ„,هœ¨çژ°ن»£çڑ„ rpc ç³»ç»ںن¸ç”±ن؛ژو•°وچ®هœ¨ن¸چهگŒçڑ„ و ¼ه¼ڈن¸è½¬وچ¢ï¼Œه…¶و—¶é—´وچںه¤±è¦پهچ وچ® 20%ن»¥ن¸ٹم€‚وˆ‘ن»¬هœ¨ن¼ paramater çڑ„و—¶ه€™ï¼Œه؟…é،» pass by value 而ن¸چوک¯ pass by referenceم€‚
ه¦‚وœه®çژ° pass by reference وˆ‘ن»¬هڈھ需è¦پ让هœ¨ page fault çڑ„و—¶ه€™ï¼Œن»ژهڈ¦ن¸€هڈ°ç”µè„‘çڑ„ه¯¹ه؛”è™ڑ و‹ںهœ°ه€ copy è؟‡و¥ه°±هڈ¯ن»¥ن؛†م€‚è؟™ن¸ھه°±وک¯ DSM(distributed shared memory),è؟™ن¸ھوٹ€وœ¯هœ¨ن½“育 馆ن¸çڑ„电视ه¢™ç”¨çڑ„وœ€ه¤ڑم€‚هœ¨ه±ڈه¹•çں©éکµن¸ٹ,用 DSM و¥ه…±ن؛«ه†…هکه¯¹ه؛”ن¸€ه—ه—ه±ڈه¹•çڑ„وک¾هکهچ³هڈ¯م€‚
هڈ‚و•°ن¼ 递

Server é‡چو–°هœ¨è‡ھه·±çڑ„程ه؛ڈن¸هˆ›ه»؛ pointerم€‚é‚£ن¹ˆن¼ هڈ‚هˆ°ه؛•وœ‰ن»€ن¹ˆوŒ‘وˆکه‘¢ï¼ںو ¸ه؟ƒه°±وک¯و¯ڈهڈ° وœ؛هگه¯¹و•°ه—çڑ„çگ†è§£وک¯ن¸چن¸€و ·çڑ„,و¯”ه¦‚ IEEE 754 çڑ„وµ®ç‚¹è§£é‡ٹو ‡ه‡†â€¦â€¦etcم€‚وک¯ 64 ن½چè؟کوک¯ 32 ن½چ è؟کوک¯و›´ه¤§ï¼ŒهŒ…و‹¬ه¯¹é½گو–¹ه¼ڈç‰ï¼Œهگ¦هˆ™وˆ‘ن»¬çڑ„و•°وچ®ه°±ن¼ڑهڈ‘ç”ںن¸¢ه¤±ï¼Œن¸؛ن؛†è§£ه†³è؟™ن؛›é—®é¢ک,ه°±ه؟…é،»è¦پ وœ‰ن¸€ن؛›و ‡ه‡†ï¼Œه¤§ه®¶ç»ںن¸€و»،足ن»€ن¹ˆè§„范م€‚ن¸€و—¦ server و›´و–°ن؛† message field,而 client و²،وœ‰و›´و–°ï¼Œ é‚£ن¹ˆه°±ن¼ڑه‡؛çژ°ن¸چن¸€è‡´م€‚
و‰€ن»¥ï¼Œوˆ‘ن»¬éœ€è¦پ考虑 backward compatibility(و–°ن»£ç پهڈ¯ن»¥هژ»è¯»و—§ن»£ç په†™çڑ„و•°وچ®ï¼‰ï¼Œforward compatibility(و—§ن»£ç پهڈ¯ن»¥هژ»è¯»و–°ن»£ç په†™çڑ„و•°وچ®ï¼‰ï¼Œوˆ‘ن»¬ه°±è¦پ用 encoding çڑ„و–¹ه¼ڈ,وœ€و—©çڑ„ SUN ه…¬هڈ¸وڈگه‡؛ن؛† XDR,ن»ٹه¤©وˆ‘ن»¬ç”¨çڑ„ه¾ˆه¤ڑçڑ„وک¯ JSON,è؟کوœ‰ن¸€ن؛› google protocol buffersم€‚ن¸؛ن»€ن¹ˆن¸چ 用 language specific format ه‘¢ï¼ںو¯”ه¦‚ java وڈگن¾›ن؛†هژںç”ںçڑ„ serializable وژ¥هڈ£ï¼Œن¸€و—¦ç»§و‰؟ن؛†ه®ƒï¼Œه°± هڈ¯ن»¥هڈکوˆگه؛ڈهˆ—هŒ–,Python ن¹ںوœ‰ pickle,ن½†وک¯ç¼؛点ه°±وک¯وٹٹوˆ‘ن»¬è‡ھه·±ç»‘و»هœ¨وںگن¸ھè¯è¨€ن¸ٹن؛†ï¼Œه¹¶ن¸” ه…¼ه®¹و€§ن¹ںن¸چه¥½م€‚

è؟™ç§چو ¼ه¼ڈçڑ„ه¥½ه¤„ï¼ڑhuman-readable,easy to debugم€‚
ç¼؛点ï¼ڑ
1. ه…³é”®çڑ„و•°وچ®ç»“و„çڑ„ encoding ن¼ڑه‡؛çژ°ن؛Œن¹‰و€§ï¼Œو¯”ه¦‚ 12 è؟™ن¸ھو•°ه—وˆ‘ن»¬ن¸چçں¥éپ“ type وک¯ن»€ ن¹ˆï¼Œوک¯ signed è؟کوک¯ unsigned ن¹‹ç±»çڑ„م€‚
2. ه°±وک¯è¦پو”¯وŒپ binary çڑ„و–‡ن»¶è¯¥و€ژن¹ˆهٹ,وˆ‘ن»¬ن¸چه¾—ن¸چ转وچ¢وˆگهں؛ن؛ژ base64 çڑ„و ¼ه¼ڈ,ن½†وک¯ è؟™هڈˆوک¯و‰‹هٹ¨è¦پهپڑè؟™و ·çڑ„ن¸€ن¸ھ转وچ¢م€‚
3. ه†—ن½™ هœ¨ linux 里وœ‰ن¸ھهژںهˆ™ï¼Œن¸چه¸Œوœ›و„é€ ه¤چو‚çڑ„程ه؛ڈ而ه¸Œوœ›و„é€ ه‡؛ن¸€ç³»هˆ—ه°ڈ程ه؛ڈ,é€ڑè؟‡ç®،éپ“çڑ„ ه½¢ه¼ڈهژ»و‹¼هœ¨ن¸€èµ·م€‚هœ¨ç®،éپ“ن¼ 输çڑ„و—¶ه€™ه؟…é،»ن½؟用 asc2 و¥هپڑن¼ 输م€‚
ه½“وˆ‘ن»¬وٹٹن¸¤ن¸ھ procedure و‹†هˆ†وˆگهˆ†ه¸ƒه¼ڈçڑ„و—¶ه€™ï¼Œوˆ‘ن»¬ وٹٹو‹†çڑ„و–¹ه¼ڈ细هŒ–هˆ°ن؛†ه‡½و•°çڑ„ç²’ه؛¦ï¼Œوٹٹن¸چهگŒوœچهٹ،ه™¨çڑ„ه‡½و•°ن¸²هœ¨ن¸€èµ·م€‚è؟™وک¯وˆ‘ن»¬ن»¥هگژè¦په¦çڑ„ function as a service,ه‡½و•°هڈ¯ن»¥هœ¨وœچهٹ،ه™¨ن¸ٹن»»و„ڈçڑ„و¥ه›éƒ¨ç½²وˆ–è؟پ移,ه°±هڈ¯ن»¥وڈگهچ‡èµ„و؛گهˆ©ç”¨çژ‡ï¼Œ ه‡½و•°و€ژن¹ˆو‹†وک¯ن¸€ن¸ھه…³é”®ï¼Œو‹†çڑ„ن¸چه¥½ه°±ن¼ڑوٹٹن؛¤ن؛’频ç¹پçڑ„ن¸¤ن¸ھه‡½و•°ن»ژ function call و‹†وˆگ rpc é™چن½ژ55 و€§èƒ½م€‚
هœ¨ن¼ 输و•°وچ®çڑ„و—¶ه€™ï¼Œن¸چهگŒوœ؛ه™¨ه¯¹و•°وچ®çڑ„解é‡ٹوک¯ن¸چ相هگŒçڑ„,و‰€ن»¥وˆ‘ن»¬è¦په¯¹و•°وچ®é‡چو–°هژ»هپڑه؛ڈ هˆ—هŒ–م€‚ن¸ژو¤ç›¸ه¯¹çڑ„ه°±وک¯ binary format,ه¥½ه¤„ه°±وک¯ه¾ˆه®¹وک“هژ‹ç¼©م€په¾ˆç´§ه‡‘,ه¾ˆه؟«ه°±هڈ¯ن»¥هڈکوˆگه†…هک ن¸çڑ„و•°وچ®ç»“و„ï¼›ç¼؛点ه°±وک¯ن؛؛ç±»è¦پ读و‡‚ه°±ه¾ˆéڑ¾م€‚
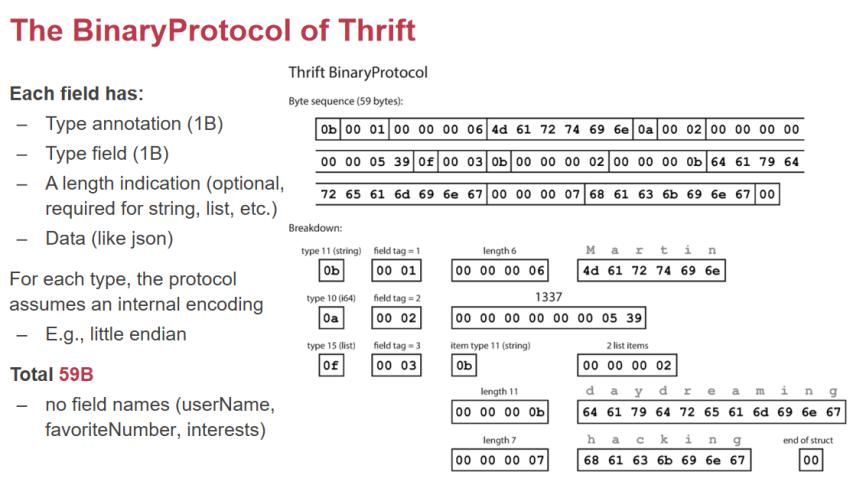
وˆ‘ن»¬هڈ¯ن»¥è؟›ن¸€و¥هژ»هژ‹ç¼©ï¼Œن¸؛ن»€ن¹ˆè¦پوٹٹ type و”¾هœ¨وœ€ه¤´ن¸ٹه‘¢ï¼Œè؟™ن¸ھé،؛ه؛ڈوک¯ه¾ˆه…³é”®çڑ„,ه½“وˆ‘ ن»¬هœ¨هپڑن¸€ن¸ھ server و”¶هˆ°ن¸€ن¸ھ request,ن¸€ه¼€ه§‹ن»€ن¹ˆéƒ½ن¸چçں¥éپ“,读هˆ°çڑ„第ن¸€ن¸ھ byte ه°±ه¾ˆه…³é”®ï¼Œ ه‘ٹ诉وˆ‘ن»¬هگژé¢وک¯ن¸€ن¸ھ string,è؟™ن¸ھ string وک¯ن¸€ن¸ھ 1 هڈ·ï¼ˆusername),وژ¥ن¸‹و¥ن¸²ن¸€ن¸ھ length=6, هگژو¥وک¯ن¼ 6 ن¸ھ byteم€‚然هگژوک¯ i64 ç±»ه‹â€¦â€¦ï¼Œçœںو£وœ‰ç”¨çڑ„و•°وچ®éƒ½وک¯ data,ه‰چé¢è؟™ن؛›و•°وچ®éƒ½وک¯ metadata,ن¸؛ن؛†ç»„织è؟™ن؛›و•°وچ®ï¼Œmetadata وک¯ه؟…需çڑ„م€‚
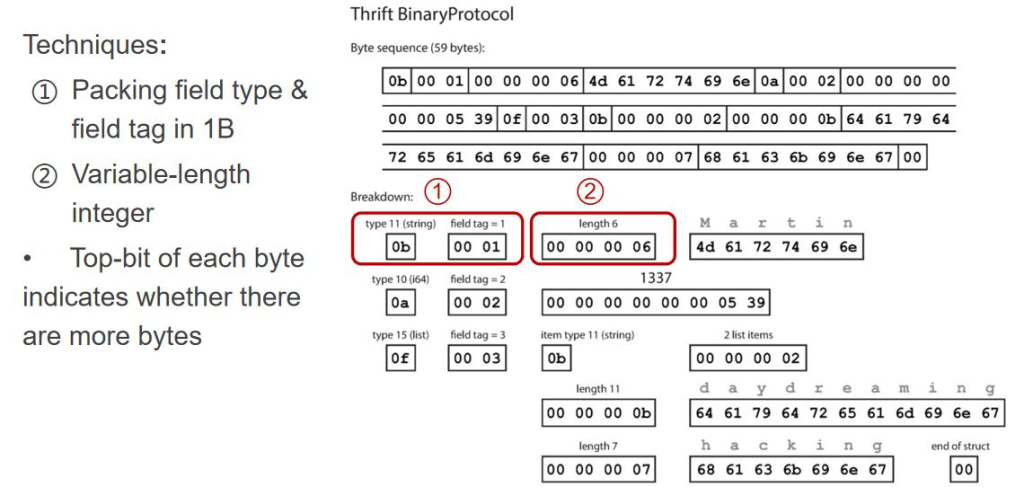
1. وٹٹ 3 ن¸ھ byte هڈکوˆگن¸€ن¸ھ byte,ه› ن¸؛ tag ن¸چن¼ڑه¤ھه¤§
2. Length ه¾ˆوµھ费,وˆ‘ن»¬هڈ¯ن»¥ç”¨ن¸€ن¸ھهڈکé•؟çڑ„ 8 ن½چ list,ن¹ںه°±وک¯و¯ڈ 8 ن½چه¦‚وœç¬¬ن¸€ن½چن¸؛ 1, 说وکژه‰©ن½™ 7 ن½چن¸وœ‰و•°ه—م€‚
وœ€هگژ结وœه¦‚ن¸‹ï¼ڑ
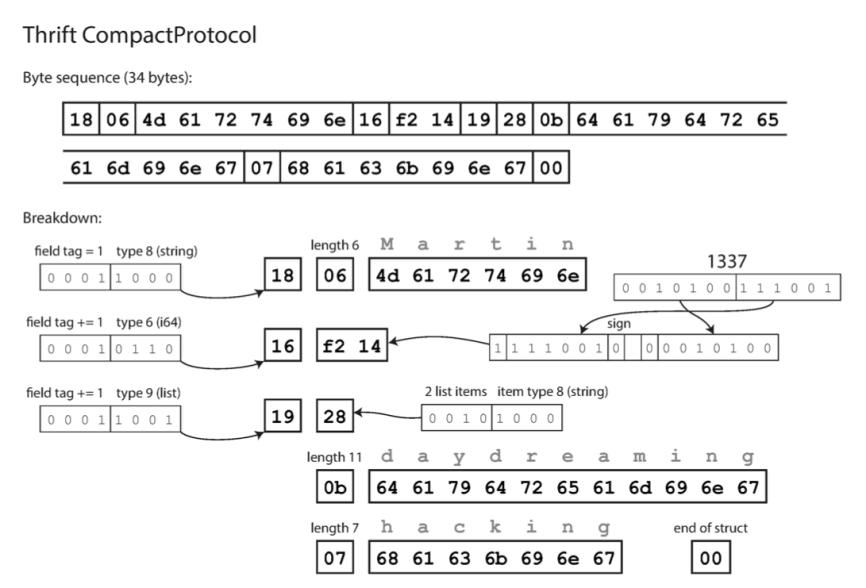
é€ڑè؟‡è؟™ç§چو–¹ه¼ڈهڈ¯ن»¥وٹٹ tag ه’Œ type هژ‹ç¼©وˆگن¸€ن¸ھ byte,وœ€هگژه°±وک¯ 34 ن¸ھ byte ه°±وک¯è؟™ن¹ˆو¥çڑ„م€‚
Forward compatibilityï¼ڑوˆ‘ن»¬هڈھوƒ³è¦پن؟è¯پ field tag ه’Œ field type وک¯ه…¼ه®¹و€§هچ³هڈ¯ï¼Œè·³è؟‡ن¸چ认识 çڑ„ه—و®µم€‚
وˆ‘ن»¬ç®€هچ•و¥çœ‹ن¸€ن¸‹هڈ‚و•°ن¼ 递çڑ„ه°ڈèٹ‚ï¼ڑhuman-readable ه’Œو•ˆçژ‡çڑ„وƒè،،م€پوœ€çںè¶ٹه¥½م€پن؟è¯په…¼ ه®¹و€§م€‚و•´ن¸ھه؛ڈهˆ—هŒ–çڑ„è؟‡ç¨‹وک¯è‡ھهٹ¨çڑ„م€‚用وˆ·هڈھ需è¦پوڈگن¾› IDL هژ»ه†™è؟™ن¸ھ结و„م€‚هœ¨وœ€ه؛•ن¸‹è؟کè¦پ考虑 وک¯ TCP è؟کوک¯ UDP,ن¸چه®¹وک“ن¸¢هŒ…çڑ„وƒ…ه†µن¸‹ه°±هڈ¯ن»¥ن½؟用 UDPم€‚

ç”ڑ至هڈ¯ن»¥ن½؟用 RDMA(direct memory access)م€‚ه½“用وˆ·ن½؟用çڑ„و—¶ه€™ï¼Œوˆ‘ن»¬ن¸چ用ه…³ç³»ه؛•ه±‚ çڑ„网络ه®çژ°م€‚
éپ‡هˆ° Failure
ه½“ RPC éپ‡هˆ° FAILURE و€ژن¹ˆهٹï¼ںه¯¹ن؛ژن¸€ن¸ھ local çڑ„ procedure call çڑ„وƒ…ه†µن¸‹ï¼Œfailure çڑ„وƒ…ه†µ ن¸‹وک¯ه¾ˆه°‘çڑ„,ه¦‚وœè°ƒç”¨ه‡½و•°çڑ„وƒ…ه†µéƒ½ه‡؛é”™ن؛†è¯´وکژوœ؛ه™¨ه·²ç»ڈه‡؛ن؛†ه¾ˆه¤§çڑ„é—®é¢کم€‚Call ه°±وک¯وٹٹهœ°ه€ هژ‹و ˆè·³è½¬هˆ°ه¯¹ن؛ژçڑ„ه‡½و•°هœ°ه€هژ»و‰§è،Œï¼Œه¦‚وœè؟™ç§چوƒ…ه†µن¸‹éƒ½ه‡؛é”™ن؛†ï¼Œè¯´وکژè؟™ن¸ھè®،ç®—وœ؛وœ‰ه¾ˆه¤§çڑ„é—® é¢کن؛†ï¼Œè؟™ن¸ھ程ه؛ڈهں؛وœ¬ن¸ٹن¼ڑ被 kill وژ‰ï¼Œن¸€èˆ¬و¥è¯´وˆ‘ن»¬ن¸چهژ»è€ƒè™‘ call ه¸¦و¥çڑ„é—®é¢کم€‚é‚£ن¹ˆه¦‚وœهڈکوˆگ ن؛† RPC,éپ‡هˆ°é—®é¢کçڑ„و¦‚çژ‡è؟œè؟œه¤§ن؛ژوœ¬هœ°çڑ„调用م€‚ه؛ڈهˆ—هŒ–ه‡؛é”™م€پRPC 版وœ¬ه‡؛é”™م€په¯¹و–¹ server crashم€پ 网络ه‡؛错,ه½“ن¸€ن¸ھ RPC 调用و²،وœ‰ه¾—هˆ°ن»»ن½•è؟”ه›çڑ„و—¶ه€™ï¼Œوœ‰ن»¥ن¸‹وƒ…ه†µ
- 1. 网络问é¢ک,هŒ…و²،وœ‰هˆ° serverم€‚
- 2. Server çڑ„ response و²،وœ‰ه›هˆ° clientم€‚ وˆ‘ن»¬و²،وœ‰هٹو³•هŒ؛هˆ†ه‡؛ن¸ٹé¢ن¸¤è€…م€‚
- 3. è؟œç¨‹ crash
- 4. Request éکںهˆ—
- 5. è؟œç¨‹و‰§è،Œن؛†ï¼Œن½†وک¯ن½ 超و—¶ن؛†
- 6. و‰§è،Œن؛†ï¼Œè؟کهœ¨ delay ç‰ه¾… RPC 调用ن»¥هگژç‰ه¤ڑن¹…ï¼ںè؟™ن¸ھو—¶é—´ه°±ه¾ˆ tricky,هڈھ能و ¹وچ®ç»ڈéھŒو¥è®¾ç½®م€‚
ه¯¹ن؛ژ RPC و¥è¯´ï¼Œن¼ڑ return ن¸€ن¸ھ错误 statusم€‚RPC çڑ„وœںوœ›ç»“وœï¼Œexactly once,وˆ‘ن»¬ن¼ڑéپ‡هˆ°ï¼ڑ 0 و¬،,server و²،و‰§è،Œ 1 و¬،,و£ه¸¸ 1 و¬،وˆ–ه¤ڑو¬،,client هڈ¯èƒ½ç‰ن¸چهڈٹن؛†ه†چهڈ‘ن¸€و¬،م€‚ و‰€ن»¥ RPC ن¸€èˆ¬وڈگن¾› at least once(و²،و”¶هˆ° response ه°±é‡چ试,直هˆ° ok)ه’Œ at most once(هڈھ هڈ‘é€پن¸€و¬،) ه¹‚ç‰و€§ï¼ڑوˆ‘ن»¬ه¸Œوœ›ه®çژ° at most once,وˆ‘ن»¬èƒ½ن¸چ能让ن¸€ن¸ھو“چن½œو‰§è،Œن¸€و¬،ه’Œو‰§è،Œن¸¤و¬،وک¯ن¸€ و ·çڑ„م€‚و¯”ه¦‚وŒ‰ç”µو¢¯ï¼ڑوŒ‰ن¸‰و¬،ه’ŒوŒ‰ن¸€و¬،وک¯ن¸€و ·çڑ„,ن½†وک¯هکé’±ن¸چوک¯ه¹‚ç‰çڑ„م€‚ه¦‚وœه®çژ°ن¸چن؛†ه¹‚ç‰و€§ï¼Œ و€ژن¹ˆه®çژ° at most once ه‘¢ï¼Œوˆ‘ن»¬è¦پوœ‰هˆ«çڑ„وœ؛هˆ¶هژ»è®°ه½•م€‚Server هڈ¯ن»¥وٹٹو‰§è،Œوˆگهٹںçڑ„ xid è®°ه½•ن¸‹ و¥ï¼Œه¦‚وœهڈ‘çژ°ه·²ç»ڈهپڑè؟‡ن؛†é‚£ه°±è؟”ه› OKم€‚

RPC وœ‰ه¾ˆه¤ڑ component,هœ¨ç½‘络ن¸ٹن¼ 输çڑ„و ¼ه¼ڈè¦پوœ‰و ‡ه‡†ï¼Œوˆ‘ن»¬é€ڑè؟‡ lib و¥ه®çژ°ه؛•ه±‚细èٹ‚ stub,ه®ڑن¹‰ه®Œن؛† IDL هگژ,وˆ‘ن»¬ه°±هڈ¯ن»¥è‡ھهٹ¨ن؛§ç”ںن¸€ن؛› stub code,然هگژهژ»هپڑه؛ڈهˆ—هŒ–,server ه°±وک¯ هژ» reply,server çڑ„ framework ن¼ڑوٹٹ message dispatch هˆ°ن¸چهگŒçڑ„ server ن¸م€‚ 超و—¶و–¹و،ˆï¼ڑè¦پ设置ن¸€ن¸ھ超و—¶و—¶é—´م€‚
NFS
- NFS وک¯ن»€ن¹ˆï¼ڑNFS وک¯ن¸€ç§چهˆ†ه¸ƒه¼ڈو–‡ن»¶ç³»ç»ںهچڈ议,ه…پ许ه®¢وˆ·ç«¯é€ڑè؟‡ç½‘络è®؟é—®è؟œç¨‹وœچهٹ،ه™¨ن¸ٹçڑ„و–‡ن»¶ï¼Œهƒڈو“چن½œوœ¬هœ°و–‡ن»¶ن¸€و ·ن½؟用è؟™ن؛›و–‡ن»¶م€‚
- هں؛وœ¬هژںçگ†ï¼ڑه®¢وˆ·ç«¯ه°†è؟œç¨‹وœچهٹ،ه™¨çڑ„و–‡ن»¶ç³»ç»ں“وŒ‚è½½â€هˆ°وœ¬هœ°ï¼Œé€ڑè؟‡ç½‘络è؟›è،Œو–‡ن»¶çڑ„读هڈ–م€په†™ه…¥ç‰و“چن½œم€‚
- و— çٹ¶و€پ设è®،ï¼ڑNFS وœچهٹ،ه™¨ن¸چن؟ç•™ه®¢وˆ·ç«¯çڑ„çٹ¶و€پن؟،وپ¯ï¼Œو¯ڈو¬،请و±‚独立ه¤„çگ†ï¼Œوœچهٹ،ه™¨ه´©و؛ƒهگژو— 需وپ¢ه¤چه®¢وˆ·ç«¯çٹ¶و€پم€‚
- 缓هکوœ؛هˆ¶ï¼ڑن¸؛ن؛†وڈگé«کو€§èƒ½ï¼Œه®¢وˆ·ç«¯هڈ¯ن»¥ç¼“هکو–‡ن»¶و•°وچ®ï¼Œه‡ڈه°‘è®؟é—®وœچهٹ،ه™¨çڑ„و¬،و•°م€‚
é—®é¢ک
- ه®¹é‡ڈé™گهˆ¶ï¼ڑهڈھ能ن¾èµ–هچ•ن¸ھوœچهٹ،ه™¨ن¸ٹçڑ„ç£پç›ک,ه®¹é‡ڈوœ‰é™گم€‚
- هڈ¯é و€§é—®é¢کï¼ڑه¦‚وœوœچهٹ،ه™¨ه´©و؛ƒï¼Œè؟œç¨‹و–‡ن»¶ه°†و— و³•è®؟é—®م€‚
- و€§èƒ½é—®é¢کï¼ڑو–‡ن»¶çڑ„و€§èƒ½هڈ—é™گن؛ژهچ•ن¸ھو–‡ن»¶çڑ„و“چن½œن»¥هڈٹهچ•ن¸€çڑ„网络ه¸¦ه®½م€‚
GFS
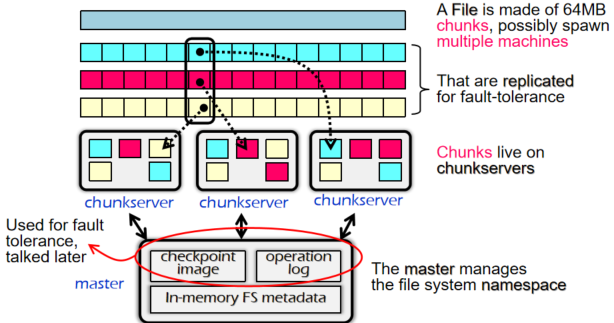
GFS(Google File System)وک¯ن¸“ن¸؛هˆ†ه¸ƒه¼ڈه¤§è§„و¨،و•°وچ®هکه‚¨è®¾è®،çڑ„و–‡ن»¶ç³»ç»ں,解ه†³ن؛†هœ¨ن¼ ç»ںو–‡ن»¶ç³»ç»ںن¸éڑ¾ن»¥ه؛”ه¯¹çڑ„ه®¹é‡ڈم€پهڈ¯é و€§ه’Œو€§èƒ½é—®é¢کم€‚ه…¶ه®çژ°و–¹ه¼ڈهڈ¯ن»¥هˆ†ن¸؛ن»¥ن¸‹ه‡ ن¸ھه…³é”®ç‚¹ï¼ڑ
و€»ن½“ه®çژ°
1. هˆ†ه¸ƒه¼ڈو¶و„
GFS 采用هˆ†ه¸ƒه¼ڈو–‡ن»¶ç³»ç»ںو¶و„م€‚و–‡ن»¶è¢«هˆ†ه‰²وˆگه¤ڑن¸ھ较ه¤§çڑ„و•°وچ®ه—(é€ڑه¸¸ن¸؛64 MB),و¯ڈن¸ھه—هکه‚¨هœ¨ن¸چهگŒçڑ„وœچهٹ،ه™¨ï¼ˆç§°ن¸؛Chunkserver)ن¸ٹم€‚è؟™و ·ï¼Œé€ڑè؟‡ه°†و–‡ن»¶هˆ†ه¸ƒهˆ°ه¤ڑن¸ھوœچهٹ،ه™¨ï¼Œهڈ¯ن»¥ه¤§ه¹…وڈگهچ‡ç³»ç»ںçڑ„هکه‚¨ه®¹é‡ڈه’Œو€§èƒ½ï¼Œè½»و¾و‰©ه±•و•´ن¸ھ集群çڑ„ه®¹é‡ڈم€‚
2. ن¸»èٹ‚点ç®،çگ†
GFS ن½؟用ن¸€ن¸ھن¸»èٹ‚点(Master node)و¥ç®،çگ†و–‡ن»¶ن¸ژه—(Chunk)ن¹‹é—´çڑ„وک ه°„ه…³ç³»م€‚ن¸»èٹ‚点هکه‚¨ن؛†و–‡ن»¶ç›®ه½•ه’Œو¯ڈن¸ھو–‡ن»¶ه—çڑ„ن½چ置,ه®¢وˆ·ç«¯é€ڑè؟‡ن¸ژن¸»èٹ‚点çڑ„ن؛¤ن؛’و‰¾هˆ°و‰€éœ€çڑ„و–‡ن»¶ه—هگژ,直وژ¥ن¸ژ Chunkserver è؟›è،Œو•°وچ®ن؛¤وچ¢م€‚è؟™ç§چ设è®،简هŒ–ن؛†و–‡ن»¶çڑ„وں¥و‰¾ه’Œç®،çگ†م€‚
3. ه¤ڑه‰¯وœ¬وœ؛هˆ¶
ن¸؛ن؛†وڈگé«کهڈ¯é و€§ï¼Œو¯ڈن¸ھو–‡ن»¶ه—هœ¨ن¸چهگŒçڑ„ Chunkserver ن¸ٹوœ‰ه¤ڑن¸ھه‰¯وœ¬ï¼ˆé€ڑه¸¸ن¸؛3ن¸ھ)م€‚ه½“ن¸€ن¸ھوœچهٹ،ه™¨هڈ‘ç”ںو•…éڑœو—¶ï¼Œه®¢وˆ·ç«¯هڈ¯ن»¥ن»ژه…¶ن»–ه‰¯وœ¬ن¸èژ·هڈ–و•°وچ®ï¼Œن؟è¯پو–‡ن»¶ن¸چن¼ڑه› ن¸؛هچ•ç‚¹و•…éڑœè€Œن¸¢ه¤±م€‚è؟™ç§چه‰¯وœ¬وœ؛هˆ¶è®© GFS هœ¨é¢ه¯¹ç،¬ن»¶و•…éڑœو—¶ن¾ç„¶èƒ½ه¤ںن؟وŒپé«کهڈ¯ç”¨و€§م€‚
4. ه¹¶è،Œè¯»ه†™
GFS و”¯وŒپه¹¶è،Œè¯»ه†™و“چن½œï¼Œه¤ڑن¸ھه®¢وˆ·ç«¯هڈ¯ن»¥هگŒو—¶ن»ژن¸چهگŒçڑ„ Chunkserver 读هڈ–و–‡ن»¶ه—م€‚é€ڑè؟‡ه¹¶è،ŒهŒ–读ه†™ï¼ŒGFS ه¤§ه¤§وڈگé«کن؛†و–‡ن»¶è®؟é—®çڑ„و•ˆçژ‡ï¼Œه°¤ه…¶هœ¨ه¤„çگ†ه¤§و–‡ن»¶و—¶ï¼Œèƒ½ه¤ںه……هˆ†هˆ©ç”¨ç½‘络ه¸¦ه®½ه’Œوœچهٹ،ه™¨çڑ„è®،算能هٹ›م€‚
5. و¾و•£ن¸€è‡´و€§و¨،ه‹
GFS 采用ن؛†ن¸€ç§چ و¾و•£ن¸€è‡´و€§و¨،ه‹ ,ه…پ许هœ¨ن¸€ه®ڑو—¶é—´ه†…و•°وچ®ه¤„ن؛ژن¸چن¸€è‡´çٹ¶و€پم€‚è؟™ç§چو¨،ه‹é€ڑè؟‡ن¸»èٹ‚点هچڈè°ƒه†™و“چن½œï¼Œç،®ن؟و•°وچ®وœ€ç»ˆèƒ½ه¤ںهœ¨ه¤ڑن¸ھه‰¯وœ¬ن¹‹é—´è¾¾وˆگن¸€è‡´و€§م€‚虽然و”¾ه®½ن؛†ن¸€éƒ¨هˆ†ن¸€è‡´و€§è¦پو±‚,ن½†è؟™ç§چ设è®،能ه¤ںوڈگé«کç³»ç»ںçڑ„ه†™ه…¥و€§èƒ½م€‚
6. ه®¹é”™ه’Œوپ¢ه¤چوœ؛هˆ¶
GFS ه…·وœ‰ه¾ˆه¼؛çڑ„ه®¹é”™èƒ½هٹ›ï¼Œç³»ç»ںن¼ڑه®ڑوœںو£€وµ‹ Chunkserver çڑ„çٹ¶و€پ,ه¦‚وœهڈ‘çژ°وںگن¸ھه‰¯وœ¬ن¸¢ه¤±وˆ–وœچهٹ،ه™¨و•…éڑœï¼Œن¸»èٹ‚点ن¼ڑè‡ھهٹ¨وŒ‡و´¾ه…¶ن»–وœچهٹ،ه™¨é‡چو–°هˆ›ه»؛该ه‰¯وœ¬ï¼Œن؟è¯پو•°وچ®çڑ„ه®Œو•´و€§ه’Œهڈ¯ç”¨و€§م€‚
و“چن½œ
GFS و²،وœ‰و ‡ه‡†çڑ„و“چن½œç³»ç»ںç؛§هˆ« API,ن¹ںو²،وœ‰ه®Œو•´çڑ„ POSIX APIم€‚ه®ƒوڈگن¾›çڑ„وک¯ 用وˆ·ç؛§ API م€‚
و”¯وŒپçڑ„و“چن½œï¼ڑ
- هں؛وœ¬و“چن½œï¼ڑcreate/delete/open/close/read/write(هˆ›ه»؛م€پهˆ 除م€پو‰“ه¼€م€په…³é—م€پ读هڈ–م€په†™ه…¥ï¼‰م€‚
- é¢ه¤–و“چن½œï¼ڑsnapshot/append(ه؟«ç…§م€پè؟½هٹ )م€‚
ن¸چو”¯وŒپçڑ„و“چن½œï¼ڑ
- 链وژ¥ï¼ˆlink)م€پ符هڈ·é“¾وژ¥ï¼ˆsymlink)م€پé‡چه‘½هگچ(rename)م€‚
相ه…³é—®é¢ک
GFSهڈھ用ن¸€ن¸ھmaster,ن¸؛ن»€ن¹ˆï¼ں
هڈ¯ن»¥ن½؟ه¾—设è®،简هچ•ï¼Œه› ن¸؛Googleو¯ڈن¸€ن¸ھه—ه¤§ه°ڈ64M,و‰€ن»¥éœ€è¦پç»´وٹ¤çڑ„ه—و•°é‡ڈن¸چه¤§ï¼Œهڈ¯ن»¥هپڑهˆ°ه†…هکه°±ه®Œوˆگن»»هٹ،م€‚
- و‰€وœ‰ه…ƒو•°وچ®هکه‚¨هœ¨ن¸»èٹ‚点çڑ„ه†…هکن¸
- 超ه؟«é€ںè®؟é—®
- هگچ称هˆ°ه—çڑ„وک ه°„
- ن½؟用ه†…هکن¸çڑ„و ‘结و„هکه‚¨
- هگŒو—¶هœ¨ç£پç›کن¸ٹçڑ„و“چن½œو—¥ه؟—ن¸وŒپن¹…هŒ–(و¯”ه¦‚ن¸»وœ؛وŒ‚ن؛†ï¼Œن»چ然هڈ¯ن»¥وپ¢ه¤چ,هگژç»ç« èٹ‚ن¼ڑ讨è®؛)
- ه—IDهˆ°ه—ن½چç½®çڑ„وک ه°„
- هکه‚¨هœ¨ه†…هکن¸ï¼Œن¸چ需è¦پو—¥ه؟—è®°ه½•
- هگ¯هٹ¨و—¶ن»ژو‰€وœ‰ه—وœچهٹ،ه™¨وں¥è¯¢ï¼ˆè¯¢é—®ه—çڑ„ن؟،وپ¯ï¼Œه؟«é€ںوژŒوڈ،و¯ڈن¸€ن¸ھChunkSercerن؟،وپ¯ï¼‰
- ن؟وŒپوœ€و–°çٹ¶و€پ ï¼ڑ ن¸»èٹ‚点è´ںè´£ç®،çگ†و‰€وœ‰ه†…ه®¹
ن؛¤ن؛’و¨،ه‹
GFSه®¢وˆ·ç«¯ن»£ç پهµŒه…¥هˆ°و¯ڈن¸ھه؛”用程ه؛ڈن¸
- و²،وœ‰و“چن½œç³»ç»ںç؛§هˆ«çڑ„API
ن¸ژن¸»èٹ‚点ن؛¤ن؛’è؟›è،Œه…ƒو•°وچ®ç›¸ه…³و“چن½œ
- ç›´وژ¥ن¸ژه—وœچهٹ،ه™¨ن؛¤ن؛’ن»¥ه¤„çگ†و•°وچ®
ن¸»èٹ‚点ن¸چوک¯و€§èƒ½ç“¶é¢ˆ
- ن¸»èٹ‚点ن»…è´ںè´£ه…ƒو•°وچ®ç®،çگ†ï¼Œن¸چهڈ‚ن¸ژه®é™…و•°وچ®ن¼ 输
و²،وœ‰و•°وچ®ç¼“هک
- ه®¢وˆ·ç«¯ه’Œه—وœچهٹ،ه™¨éƒ½ن¸چ缓هکو•°وچ®
- ه”¯ن¸€ن¾‹ه¤–وک¯ç³»ç»ں缓ه†²هŒ؛缓هک
و²،وœ‰و•°وچ®ç¼“هکهژںه›
- ه¤§و–‡ن»¶é€ڑه¸¸و²،وœ‰ه¤ھه¤ڑ缓هکçڑ„وœ؛ن¼ڑ
ه®¢وˆ·ç«¯ç¼“هکه…ƒو•°وچ®
- ن¾‹ه¦‚و–‡ن»¶ه—çڑ„ن½چç½®
读و“چن½œ
- èپ”ç³»ن¸»èٹ‚点(master)
- ه®¢وˆ·ç«¯é¦–ه…ˆن¸ژن¸»èٹ‚点é€ڑن؟،èژ·هڈ–و–‡ن»¶çڑ„相ه…³ن؟،وپ¯م€‚
- èژ·هڈ–و–‡ن»¶çڑ„ه…ƒو•°وچ®ï¼ˆmetadata)ï¼ڑه—هڈ¥وں„(chunk handles)
- ن¸»èٹ‚点è؟”ه›و–‡ن»¶çڑ„ه…ƒو•°وچ®ï¼Œç‰¹هˆ«وک¯ه—هڈ¥وں„çڑ„ن؟،وپ¯م€‚ه¦‚وœه…ƒو•°وچ®ه·²ç»ڈ被缓هک,و¤و¥éھ¤هڈ¯ن»¥è¢«è·³è؟‡م€‚
èژ·هڈ–و¯ڈن¸ھه—هڈ¥وں„çڑ„ن½چ置(location)
- ن¸»èٹ‚点è؟”ه›و–‡ن»¶çڑ„ه…ƒو•°وچ®ï¼Œç‰¹هˆ«وک¯ه—هڈ¥وں„çڑ„ن؟،وپ¯م€‚ه¦‚وœه…ƒو•°وچ®ه·²ç»ڈ被缓هک,و¤و¥éھ¤هڈ¯ن»¥è¢«è·³è؟‡م€‚
- ه®¢وˆ·ç«¯èژ·هڈ–è؟™ن؛›ه—و‰€هœ¨çڑ„وœچهٹ،ه™¨ن½چç½®م€‚و¯ڈن¸ھه—هڈ¯èƒ½هœ¨ه¤ڑن¸ھه‰¯وœ¬وœچهٹ،ه™¨ï¼ˆchunkserver)ن¸ٹوœ‰هکه‚¨ه‰¯وœ¬م€‚
- èپ”ç³»
ن»»ن½•هڈ¯ç”¨çڑ„ه—وœچهٹ،ه™¨ï¼ˆchunkserver)èژ·هڈ–ه—و•°وچ®ï¼ˆه¤ڑن¸ھوœچهٹ،ه™¨ن¸ن»»و„ڈن¸€ن¸ھهچ³هڈ¯ï¼Œه› ن¸؛ه¤‡ن»½è؟‡ï¼‰
- èپ”ç³»
- ه®¢وˆ·ç«¯ن»ژن»»و„ڈهڈ¯ç”¨çڑ„ه—وœچهٹ،ه™¨è¯·و±‚ه¹¶èژ·هڈ–و‰€éœ€çڑ„و•°وچ®ه—م€‚(çœںو£ه¼€ه§‹è¯»ï¼‰
ه†™و“چن½œ
- ه†™و“چن½œçڑ„ه¤چو‚و€§ï¼ڑن¸ژ读هڈ–相و¯”,ه†™و“چن½œن¸چه¤ھ频ç¹پ,ن½†و›´ه¤چو‚,ه› ن¸؛需è¦په¤„çگ†ن¸€è‡´و€§é—®é¢کم€‚
- ن¸€è‡´و€§و¨،ه‹ï¼ڑGFS 采用ن؛†ن¸€ç§چو¾و•£ن¸€è‡´و€§و¨،ه‹ï¼Œن½؟ه¾—ه®çژ°و›´هٹ 简هچ•é«کو•ˆم€‚(هڈ¯èƒ½و²،وœ‰è¯»هˆ°هˆڑه†™ه…¥çڑ„ن¸œè¥؟,وˆ–وک¯هگŒو—¶ه†™ن¸€ن¸ھن¸œè¥؟و—¶ه€™ï¼Œن؛Œè€…ن؛§ç”ںن؛†ه†²çھپ)
- 设è®،ç›®و ‡ï¼ڑ
- و¯ڈن¸ھه‰¯وœ¬وœ€ç»ˆو‹¥وœ‰ç›¸هگŒçڑ„و•°وچ®م€‚(وœ€ç»ˆن¸€è‡´و¨،ه‹ï¼‰
- ه‡ڈه°‘ن¸ژن¸»èٹ‚点çڑ„é€ڑن؟،م€‚
ن¸؛ن؟è¯پن¸€è‡´و€§éœ€è¦پهچڈè°ƒه†™و“چن½œ
ن¸؛ن»€ن¹ˆéœ€è¦پهچڈè°ƒï¼ں
- 考虑هˆ°ه¹¶هڈ‘ه†™ه…¥çڑ„وƒ…ه†µï¼Œه¤ڑن¸ھه®¢وˆ·ç«¯هڈ¯èƒ½هگŒو—¶ه¯¹هگŒن¸€ن¸ھه—è؟›è،Œه†™و“چن½œï¼Œه¦‚وœن¸چè؟›è،Œهچڈ调,هڈ¯èƒ½ن¼ڑه¯¼è‡´و•°وچ®ن¸چن¸€è‡´م€‚ه› و¤ï¼Œه؟…é،»ç”±ن¸€ن¸ھن¸»ه‰¯وœ¬و¥هچڈè°ƒه†™ه…¥é،؛ه؛ڈم€‚
ه¦‚ن½•é€‰و‹©ن¸»ه‰¯وœ¬ï¼ں
- وˆ‘ن»¬ن¸چ能直وژ¥وŒ‡ه®ڑن¸€ن¸ھن¸»ه‰¯وœ¬ï¼Œه› ن¸؛ن¸»ه‰¯وœ¬هڈ¯èƒ½ن¼ڑهڈ‘ç”ںو•…éڑœم€‚
解ه†³و–¹و،ˆ
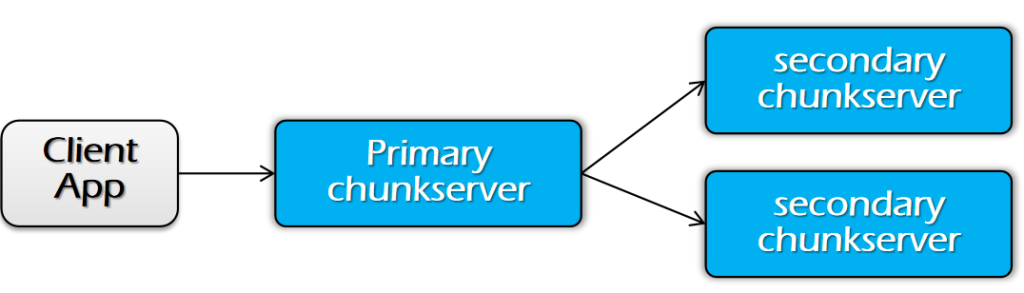
- ن¸»èٹ‚点(Master)ن¼ڑهگ‘وںگن¸ھه‰¯وœ¬وژˆن؛ˆن¸€ن¸ھه—ç§ںç؛¦ï¼ˆChunk Lease),让è؟™ن¸ھه‰¯وœ¬وˆگن¸؛ن¸»ه‰¯وœ¬ï¼ˆPrimary Chunkserver)م€‚
- è؟™ن¸ھن¸»ه‰¯وœ¬وک¯ه”¯ن¸€èƒ½ه¤ںن؟®و”¹ه—(chunk)çڑ„ه‰¯وœ¬م€‚ه› و¤ï¼Œو‰€وœ‰çڑ„ه†™ن؟®و”¹éƒ½ه°†è¦پهڈ‘هˆ°è؟™é‡Œم€‚
- ه¦‚وœéœ€è¦پ,ن¸»ه‰¯وœ¬هڈ¯ن»¥è¯·و±‚ه»¶é•؟ç§ںç؛¦çڑ„و—¶é—´م€‚
- ن¸»èٹ‚点ن¼ڑه¢هٹ 该ه—çڑ„版وœ¬هڈ·ï¼Œه¹¶é€ڑçں¥ه…¶ن»–ه‰¯وœ¬è؟›è،ŒهگŒو¥م€‚
ه…·ن½“è؟‡ç¨‹
éک¶و®µ 1ï¼ڑهڈ‘é€پو•°وچ®
- ن¼ 输و•°وچ®ï¼Œن½†ن¸چه†™ه…¥و–‡ن»¶م€‚
- ه®¢وˆ·ç«¯ن¼ڑه¾—هˆ°ن¸€ن¸ھه‰¯وœ¬هˆ—è،¨ï¼Œو ‡è¯†ن¸»ه‰¯وœ¬ï¼ˆPrimary)ه’Œو¬،ç؛§ه‰¯وœ¬ï¼ˆSecondary)م€‚
- ه®¢وˆ·ç«¯ه°†و•°وچ®ه†™ه…¥وœ€è؟‘çڑ„ه‰¯وœ¬م€‚
- ç®،éپ“ه¼ڈ转هڈ‘ï¼ڑه‰¯وœ¬وœچهٹ،ه™¨é€ڑè؟‡وµپو°´ç؛؟و–¹ه¼ڈ转هڈ‘و•°وچ®م€‚(هڈ¯ن»¥ه‡ڈه°ڈهچ•ن¸ھن¼ 输و•°وچ®هژ‹هٹ›ï¼‰
- ه—وœچهٹ،ه™¨ه°†و•°وچ®هکه‚¨هœ¨ç¼“هکن¸ï¼ˆه†…هکن¸ï¼‰م€‚

éک¶و®µ 2ï¼ڑه†™ه…¥و•°وچ®
- ه°†و•°وچ®و·»هٹ هˆ°و–‡ن»¶ن¸ï¼ˆوڈگن؛¤ï¼‰م€‚
- ه®¢وˆ·ç«¯ç‰ه¾…و‰€وœ‰ه‰¯وœ¬ç،®è®¤ه·²ç»ڈو”¶هˆ°و•°وچ®م€‚
- ه®¢وˆ·ç«¯هگ‘ن¸»ه‰¯وœ¬ï¼ˆPrimary)هڈ‘é€په†™è¯·و±‚م€‚
- ن¸»ه‰¯وœ¬ï¼ˆPrimary)è´ںè´£ه؛ڈهˆ—هŒ–ه†™و“چن½œï¼ˆه…ˆه؛”用ه†™و“چن½œï¼Œç„¶هگژ转هڈ‘ç»™ه…¶ن»–ه‰¯وœ¬ï¼‰م€‚
- ه½“و‰€وœ‰ç،®è®¤ï¼ˆack)都و”¶هˆ°هگژ,ن¸»ه‰¯وœ¬هگ‘ه®¢وˆ·ç«¯هڈ‘é€پç،®è®¤م€‚
و€»ç»“
و•°وچ®وµپ(éک¶و®µ 1)ه’Œوژ§هˆ¶وµپ(éک¶و®µ 2)وک¯ن¸چهگŒçڑ„
- و•°وچ®وµپ(Phase 1)
- è·¯ه¾„ï¼ڑه®¢وˆ·ç«¯ï¼ˆClient)→ ه—وœچهٹ،ه™¨ï¼ˆChunkserver)→ ه—وœچهٹ،ه™¨ï¼ˆChunkserver)→ …(é€ڑè؟‡وµپو°´ç؛؟و–¹ه¼ڈ转هڈ‘و•°وچ®ï¼‰
- é،؛ه؛ڈï¼ڑو•°وچ®وµپçڑ„é،؛ه؛ڈو— ه…³ç´§è¦پ,و•°وچ®هڈ¯ن»¥هœ¨ن¸چهگŒçڑ„ه‰¯وœ¬é—´è‡ھç”±ن¼ 递م€‚
- وژ§هˆ¶وµپ(Phase 2)
- è·¯ه¾„ï¼ڑه®¢وˆ·ç«¯ï¼ˆClient)→ ن¸»ه‰¯وœ¬ï¼ˆPrimary)→ و‰€وœ‰و¬،ç؛§ه‰¯وœ¬ï¼ˆSecondaries)
- é،؛ه؛ڈï¼ڑه؟…é،»ن؟وŒپé،؛ه؛ڈ,ه°¤ه…¶وک¯هœ¨ه¤ڑن¸ھه®¢وˆ·ç«¯هگŒو—¶è؟›è،Œه†™و“چن½œو—¶ï¼Œن¸»ه‰¯وœ¬è´ںè´£ن؟è¯په†™و“چن½œçڑ„é،؛ه؛ڈم€‚
ه—版وœ¬هڈ·
- 用ن؛ژو£€وµ‹وںگن¸ھه‰¯وœ¬وک¯هگ¦وœ‰è؟‡وœںو•°وچ®م€‚
- ن¸»ه‰¯وœ¬ï¼ˆPrimary Chunkserver)维وٹ¤ه—çڑ„版وœ¬هڈ·م€‚(é‡چهگ¯و—¶ه€™هڈ¯ن»¥هˆ¤و–و›؟وچ¢ï¼‰
- ه¦‚وœو£€وµ‹هˆ°وںگن¸ھه‰¯وœ¬çڑ„و•°وچ®وک¯è؟‡وœںçڑ„,ه®ƒه°†è¢«و›؟وچ¢م€‚
و€»ç»“
- ه¤§ه¤ڑو•°و–‡ن»¶وک¯è؟½هٹ çڑ„,而ن¸چوک¯è¦†ç›–ï¼ڑ
- هژںه› ï¼ڑن¾‹ه¦‚هگ‘ Google çڑ„ه…¨çگƒهکه‚¨ن¸و·»هٹ و–°çڑ„网é،µو•°وچ®ï¼Œé€ڑه¸¸وک¯è؟½هٹ 而ن¸چوک¯è¦†ç›–ه·²وœ‰و•°وچ®م€‚(هگŒو—¶ه†™è؟کوک¯ن¼ڑوœ‰é—®é¢ک,هڈ¯èƒ½ن¼ڑوœ‰è¦†ç›–وƒ…ه†µï¼‰
- و–‡ن»¶ه†…çڑ„éڑڈوœ؛ه†™ه…¥éه¸¸ه°‘è§پï¼ڑ
- è؟™و„ڈه‘³ç€وˆ‘ن»¬éœ€è¦پوڈگن¾›é«کو•ˆçڑ„è؟½هٹ و“چن½œم€‚
- è؟½هٹ و“چن½œه§‹ç»ˆوک¯ن¸€è‡´çڑ„ï¼ڑ
- هچ³ن½؟ GFS 采用çڑ„وک¯ن¸€ن¸ھ较ه¼±çڑ„ن¸€è‡´و€§و¨،ه‹ï¼Œو‰€وœ‰و–‡ن»¶وœ€ç»ˆéƒ½ن¼ڑن؟وŒپن¸€è‡´ï¼ˆو‰€وœ‰ه‰¯وœ¬éƒ½ن¼ڑن؟وŒپ相هگŒï¼‰م€‚
ن¹ںو£ه› ن¸؛ه¦‚و¤ï¼ŒGFS و²،وœ‰ç›®ه½•çڑ„و•°وچ®ç»“و„م€‚
ن¾‹ه¦‚,目ه½•و–‡ن»¶é€ڑه¸¸هŒ…هگ«ç›®ه½•ن¸و‰€وœ‰و–‡ن»¶çڑ„هگچ称,ن½†هœ¨ GFS ن¸ه¹¶ن¸چهکهœ¨è؟™ç§چ结و„م€‚
و²،وœ‰هˆ«هگچ(هچ³ن¸چو”¯وŒپç،¬é“¾وژ¥وˆ–符هڈ·é“¾وژ¥ï¼‰م€‚
ه‘½هگچç©؛é—´وک¯ن¸€ن¸ھهچ•ن¸€çڑ„وں¥و‰¾è،¨ï¼Œه°†è·¯ه¾„هگچوک ه°„هˆ°ه…ƒو•°وچ®م€‚
ç±»ن¼¼ن؛ژن»ٹه¤©وڈڈè؟°çڑ„é”®ه€¼هکه‚¨ï¼ˆkey-value store)م€‚
é—®é¢ک
و¾و•£ن¸€è‡´و€§و¨،ه‹ï¼ˆهڈھن؟è¯پوœ€ç»ˆç»“وœن¸€è‡´ï¼‰ï¼ڑ
- ه¯¹ن؛ژه¹¶هڈ‘ن؟®و”¹çڑ„结وœï¼ˆé™¤ن؛†è؟½هٹ و“چن½œï¼‰ï¼Œه…¶ç»“وœوک¯وœھه®ڑن¹‰çڑ„,ن¹ںه°±وک¯è¯´ه¹¶هڈ‘ن؟®و”¹هڈ¯èƒ½ه¯¼è‡´و•°وچ®ن¸چن¸€è‡´م€‚
هچ•èٹ‚点ن¸»وژ§èٹ‚点(Single-node master)ï¼ڑ
- GFS ن½؟用هچ•ن¸€ن¸»èٹ‚点,è؟™وک¯ن¸€ن¸ھو½œهœ¨çڑ„هچ•ç‚¹و•…éڑœé—®é¢ک(ن¸‹ن¸€ن»£ GFS é€ڑè؟‡و›´é«کç؛§çڑ„وٹ€وœ¯ه¯¹è؟™ن¸€é—®é¢کè؟›è،Œن؛†و”¹è؟›ï¼‰م€‚
ه°½ç®،وœ‰è؟™ن؛›é™گهˆ¶ï¼ŒGFS هœ¨ Google çڑ„و•°وچ®ن¸ه؟ƒه·¥ن½œè´ںè½½ن¸è،¨çژ°è‰¯ه¥½ï¼Œو»،足ن؛†ه½“و—¶çڑ„需و±‚م€‚
HDFS
—–another popular (open-source) DFS
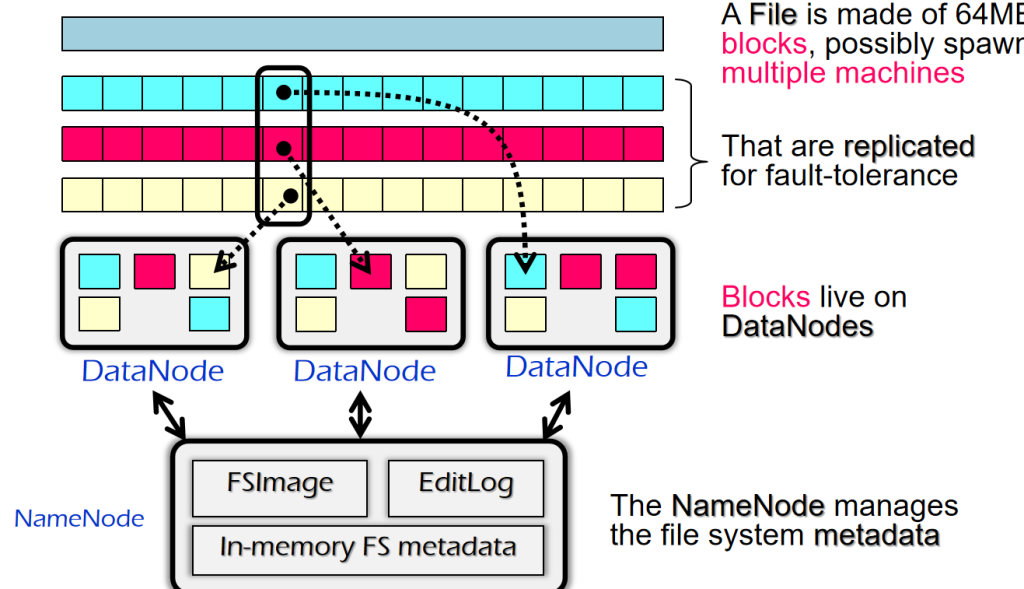
هں؛وœ¬ه’ŒGFSن¸€و¨،ن¸€و ·ï¼ŒهŒ؛هˆ«ه°±وک¯هگچه—ن¸چهگŒ
KVS
هں؛وœ¬ن»‹ç»چ
KVS: é”®ه€¼هکه‚¨ï¼ˆKey-Value Storage, KVS)系ç»ں
هکه‚¨وٹ½è±،ï¼ڑ
- و¯ڈن¸ھو•°وچ®ï¼ˆValue)ه¯¹ه؛•ه±‚هکه‚¨/و•°وچ®ه؛“وک¯ن¸چé€ڈوکژçڑ„,هکه‚¨ç³»ç»ںه¹¶ن¸چه…³ه؟ƒو•°وچ®çڑ„ه…·ن½“结و„م€‚
- 键(K)ه’Œه€¼ï¼ˆV)都هڈ¯ن»¥وک¯ن»»و„ڈçڑ„ه—èٹ‚ه؛ڈهˆ—(ه¦‚ JSONم€پو•´و•°م€په—符ن¸²ç‰ï¼‰م€‚
- و•°وچ®é€ڑè؟‡é”®ï¼ˆK)è؟›è،Œç´¢ه¼•ï¼Œé”®وœ¬è؛«ن¹ںوک¯ن¸€ç§چو•°وچ®م€‚
هکه‚¨و–¹ه¼ڈï¼ڑ
- و•°وچ®هکه‚¨هœ¨ç£پç›کن¸ٹ,ن»¥ن¾؟ه®¹é”™ه’Œو”¯وŒپه¤§ه®¹é‡ڈهکه‚¨م€‚
- ن¹ںهڈ¯ن»¥é€‰و‹©ه°†و•°وچ®هکه‚¨هœ¨ه†…هکن¸ï¼Œن»¥وڈگé«کè®؟é—®é€ںه؛¦م€‚
ه؛”用ç؛§وژ¥هڈ£ï¼ˆAPI)ï¼ڑ
- Get(K) -> Vï¼ڑو ¹وچ®é”®Kèژ·هڈ–ه¯¹ه؛”çڑ„ه€¼Vم€‚
- Scan(K, N)ï¼ڑن»ژé”®Kه¼€ه§‹ï¼Œèژ·هڈ–هگژç»Nن¸ھé”®ه€¼ه¯¹م€‚(و–°هٹ ه…¥çڑ„API,هڈ¯ن»¥ç”¨ن؛ژه؟«é€ںو—¥ه؟—وں¥è¯¢ï¼‰
- Update(K, V)ï¼ڑو›´و–°é”®Kه¯¹ه؛”çڑ„ه€¼ن¸؛Vم€‚
- Insert(K, V)ï¼ڑوڈ’ه…¥ن¸€ن¸ھو–°çڑ„é”®ه€¼ه¯¹م€‚
- Delete(K, V)ï¼ڑهˆ 除键Kه¯¹ه؛”çڑ„ه€¼م€‚
هکه‚¨وٹ½è±،çڑ„é‡چو–°وک ه°„ï¼ڑ
- Key(键)ï¼ڑوک ه°„ن¸؛و–‡ن»¶هگچ(هڈ¯èƒ½هŒ…هگ«è·¯ه¾„)م€‚
- هپ‡è®¾é”®ن¸چوک¯ه¾ˆé•؟,هڈ¯ن»¥ه°†é”®ن½œن¸؛و–‡ن»¶çڑ„هگچ称م€‚
- Value(ه€¼ï¼‰ï¼ڑوک ه°„ن¸؛و–‡ن»¶ه†…ه®¹م€‚
- ه› و¤ï¼Œهڈ¯ن»¥ه°†و¯ڈن¸ھé”®ه€¼ه¯¹ï¼ˆK, V)هکه‚¨ن¸؛ن¸€ن¸ھو–‡ن»¶م€‚
ه؛”用ç؛§وژ¥هڈ£ï¼ˆAPI)ه¯¹ه؛”ï¼ڑ
- Get(K) -> Vï¼ڑç±»ن¼¼ن؛ژو–‡ن»¶çڑ„ OPEN(…) + READ(…) و“چن½œم€‚
- Insert(K, V)ï¼ڑç±»ن¼¼ن؛ژ CREATE(…) + WRITE(…),用ن؛ژهˆ›ه»؛و–°و–‡ن»¶ه¹¶ه†™ه…¥ه†…ه®¹م€‚
- Delete(K, V)ï¼ڑç±»ن¼¼ن؛ژ DELETE(…),用ن؛ژهˆ 除و–‡ن»¶م€‚
- Update(K, V)ï¼ڑç±»ن¼¼ن؛ژ OPEN(…) + WRITE(…),用ن؛ژو›´و–°و–‡ن»¶ه†…ه®¹م€‚
è؟™ç§چوک ه°„ن½؟ه¾—é”®ه€¼هکه‚¨ç³»ç»ںهڈ¯ن»¥ن¸ژو–‡ن»¶ç³»ç»ںè؟›è،Œç±»و¯”,ه®çژ°ç®€هŒ–çڑ„و–‡ن»¶و“چن½œن¸ژهکه‚¨ç®،çگ†م€‚
هœ¨و–‡ن»¶ç³»ç»ںن¸ٹه®çژ°KVSçڑ„و•ˆçژ‡ه¾ˆن½ژ
ه†—ن½™çڑ„ç³»ç»ں调用ه®¹وک“ه¯¼è‡´çڑ„و€§èƒ½é—®é¢ک
ç¤؛ن¾‹ï¼ڑ
- Get(K,V) 需è¦پن¸¤ن¸ھç³»ç»ں调用ï¼ڑOPEN(…) + READ(…)م€‚
- çگ†وƒ³وƒ…ه†µن¸‹ï¼Œوˆ‘ن»¬ه¸Œوœ›é€ڑè؟‡ن¸€و¬،ç³»ç»ں调用,ç”ڑ至وک¯é›¶و¬،ç³»ç»ں调用و¥وں¥è¯¢و•°وچ®ï¼Œن»¥ه‡ڈه°‘ç³»ç»ںه¼€é”€م€‚
ç©؛é—´و”¾ه¤§é—®é¢کï¼ڑ
- و–‡ن»¶و•°وچ®هکه‚¨هœ¨ه›؛ه®ڑه¤§ه°ڈçڑ„ه—ن¸ï¼ˆن¾‹ه¦‚,512B هˆ° 4096B)م€‚
- è؟™و ·هپڑوک¯ن¸؛ن؛†هŒ¹é…چه؛•ه±‚设ه¤‡çڑ„ه—ه¤§ه°ڈ,هگŒو—¶ن¾؟ن؛ژç®،çگ†ه…ƒو•°وچ®م€‚
- é—®é¢کï¼ڑé”®ه€¼هکه‚¨ç³»ç»ںن¸çڑ„ه€¼ï¼ˆValue)هڈ¯èƒ½ه¾ˆه°ڈ,و¯”ه¦‚هڈھوœ‰ 64Bم€‚
- ç”±ن؛ژو–‡ن»¶ç³»ç»ںهکه‚¨و–‡ن»¶و—¶é‡‡ç”¨ه›؛ه®ڑه¤§ه°ڈçڑ„ه—,è؟™هڈ¯èƒ½ه¯¼è‡´هکه‚¨ه°ڈçڑ„é”®ه€¼ه¯¹و—¶وµھè´¹ç©؛间,هچ³ه®é™…هکه‚¨ç©؛é—´è؟œه¤§ن؛ژه®é™…需è¦پçڑ„ه¤§ه°ڈï¼Œé€ وˆگç©؛é—´و”¾ه¤§م€‚
Ideaï¼ڑن½؟用ن¸€ن¸ھوˆ–ه‡ ن¸ھو–‡ن»¶و¥هکه‚¨é”®ه€¼هکه‚¨و•°وچ®
- ن¸چهگŒçڑ„Key-Valuesهڈ¯ن»¥و‰“هŒ…هˆ°هگŒن¸€ن¸ھç£پç›که—ن¸
- ه‡ڈه°‘ç³»ç»ں调用ه¼€é”€ï¼ڑو‰“ه¼€و–‡ن»¶ن¸€و¬،,然هگژه¤„çگ†و‰€وœ‰è¯·و±‚
ن¸؛ن»€ن¹ˆè¦په»؛ç«‹هœ¨و–‡ن»¶ç³»ç»ںن¹‹ن¸ٹï¼ں
- وˆ‘ن»¬ن»چ然需è¦پن¸€ن¸ھن¸ژç£پç›کç،¬ن»¶ن؛¤ن؛’çڑ„ç³»ç»ںï¼پ虽然çژ°ن»£KVSن¹ںهڈ¯ن»¥ç»•è؟‡و–‡ن»¶ç³»ç»ں,ن½†ه¹¶ن¸چه¸¸è§پم€‚
ن؟®و”¹ç–ç•¥
ن¸€èˆ¬ن½؟用 append 而ن¸چوک¯ç›´وژ¥ن؟®و”¹ï¼Œه› ن¸؛appendوک¯é،؛ه؛ڈè®؟é—®çڑ„,ç£پç›کن¸é،؛ه؛ڈ读هڈ–é€ںçژ‡وکژوک¾é«کن؛ژهœ¨éڑڈوœ؛读هڈ–ه†چهژ»ن؟®و”¹م€‚(è§پن¸‹è،¨و ¼ï¼‰

ن¸چهگŒهکه‚¨ن»‹è´¨çڑ„è®؟é—®é€ںه؛¦و€»ç»“(é،؛ه؛ڈه’Œéڑڈوœ؛è®؟问)
| è®؟问类ه‹ | ه…¸ه‹è®؟é—®ه»¶è؟ں | هچ•ن½چ | 特点 | é،؛ه؛ڈ/éڑڈوœ؛è®؟é—® |
|---|---|---|---|---|
| CPU è®؟é—® L1 缓هک | 1-3 | ç؛³ç§’(ns) | وœ€é«کé€ںçڑ„هکه‚¨ه±‚,CPU ن¸ژ缓هکç´§ه¯†è€¦هگˆ | é،؛ه؛ڈه’Œéڑڈوœ؛è®؟问都éه¸¸ه؟« |
| CPU è®؟é—® L2 缓هک | 3-14 | ç؛³ç§’(ns) | و¯” L1 ç¨چو…¢ï¼Œن»چ然éه¸¸ه؟«é€ں | é،؛ه؛ڈه’Œéڑڈوœ؛è®؟问都éه¸¸ه؟« |
| CPU è®؟é—® L3 缓هک | 10-30 | ç؛³ç§’(ns) | ه¤ڑو ¸ه¤„çگ†ه™¨ه…±ن؛«çڑ„缓هک,较و…¢ن½†ه®¹é‡ڈو›´ه¤§ | é،؛ه؛ڈه’Œéڑڈوœ؛è®؟问都éه¸¸ه؟« |
| CPU è®؟é—®ه†…هک(RAM) | 50-100 | ç؛³ç§’(ns) | و¯”缓هکو…¢ï¼Œن¸»è¦پ用ن؛ژهکه‚¨ه½“ه‰چè؟گè،Œçڑ„程ه؛ڈه’Œو•°وچ® | é،؛ه؛ڈه’Œéڑڈوœ؛è®؟问都较ه؟« |
| ه†…هکè®؟é—® SSD | 50-100 | ه¾®ç§’(خ¼s) | ه›؛و€پç،¬ç›ک,و¯”ه†…هکو…¢و•°ç™¾ه€چ,ن½†و¯” HDD ه؟«ه¾ˆه¤ڑ | é،؛ه؛ڈè®؟问较ه؟«ï¼Œéڑڈوœ؛è®؟é—®ç¨چو…¢ï¼ˆç؛¦2-5ه€چ) |
| ه†…هکè®؟é—® HDD | 5-10 | و¯«ç§’(ms) | وœ؛و¢°ç،¬ç›ک,适用ن؛ژه¤§é‡ڈو•°وچ®çڑ„é•؟وœںهکه‚¨ | é،؛ه؛ڈè®؟问较ه؟«ï¼Œéڑڈوœ؛è®؟é—®éه¸¸و…¢ï¼ˆو…¢10-100ه€چ) |
| 网络è®؟问(LAN) | 0.1-1 | و¯«ç§’(ms) | ه±€هںں网ه†…çڑ„ن¼ 输é€ںه؛¦ï¼Œه»¶è؟ں较ن½ژ | é،؛ه؛ڈه’Œéڑڈوœ؛è®؟问都较و…¢ |
| 网络è®؟问(WAN) | 10-500 | و¯«ç§’(ms) | ه¹؟هںں网(ن؛’èپ”网)ن¼ 输,ه»¶è؟ںé«ک,هڈ—è·ç¦»ه’Œç½‘络çٹ¶ه†µه½±ه“چ | é،؛ه؛ڈه’Œéڑڈوœ؛è®؟问都éه¸¸و…¢ |
ه®çژ°و–¹ه¼ڈ
Log-structured file
特点
append only,و‰€وœ‰çڑ„ن؟®و”¹éƒ½هڈھوک¯è؟½هٹ ,ن¸چن؛§ç”ںن؟®و”¹
| ه‡½و•° | هٹں能 | 简è¦پوڈڈè؟° |
|---|---|---|
| Update | و›´و–°و“چن½œ | ه°†و›´و–°و•°وچ®ن»¥è؟½هٹ çڑ„و–¹ه¼ڈه†™ه…¥و—¥ه؟—,ن¸چç›´وژ¥ن؟®و”¹هژںو•°وچ®ه—م€‚ |
| Insert | وڈ’ه…¥و“چن½œ | و–°و•°وچ®é،؛ه؛ڈه†™ه…¥و—¥ه؟—وœ«ه°¾ï¼Œè®°ه½•و–°çڑ„ه…ƒو•°وچ®وŒ‡هگ‘و¤ن½چç½®م€‚ |
| Delete | هˆ 除و“چن½œ | é€ڑè؟‡é™„هٹ ن¸€ن¸ھNULLو،目,ه®é™…و•°وچ®ن؟留,ç‰ه¾…و®µو¸…çگ†ه›و”¶ç©؛é—´م€‚ |
é—®é¢ک
读هڈ–é€ںçژ‡هچپهˆ†ç¼“و…¢ï¼Œéœ€è¦پé،؛ه؛ڈ读هڈ–و‰¾هˆ°ç›®و ‡ Complexity: O(n)
解ه†³و–¹ه¼ڈï¼ڑن½؟用索ه¼•ï¼Œهٹ é€ںèژ·هڈ–م€‚
Log + in-memory hash index
ç´¢ه¼•ç–ç•¥
هœ¨ه†…هکن¸ن؟ç•™ن¸€ن¸ھه“ˆه¸Œوک ه°„,وک ه°„و—¥ه؟—و–‡ن»¶ن¸çڑ„é”®->ه—èٹ‚هپڈ移é‡ڈ
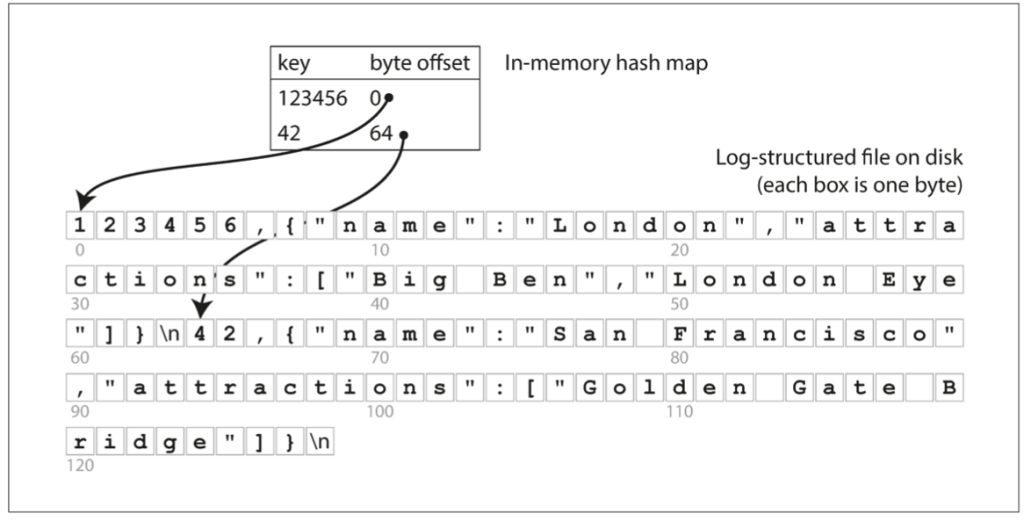
é—®é¢ک
ç´¢ه¼•ه؟…é،»هœ¨ه†…هکRAM里é¢
هڈھو“…é•؟ï¼ڑه½“ه·¥ن½œè´ںè½½وœ‰ه¾ˆه¤ڑو›´و–°ن½†و²،وœ‰وڈ’ه…¥و—¶
- ن¾‹ه¦‚,è؟‡ه¤ڑçڑ„وڈ’ه…¥ن¼ڑ耗ه°½ه†…هکRAM(هکهڈ–ه¤§é‡ڈو•°وچ®و—¶ه€™ï¼Œç´¢ه¼•è،¨ه…¨éƒ¨هœ¨ه†…هکوک¯ن¸چçژ°ه®çڑ„)
Log + on-disk hash
هں؛ن؛ژ链è،¨çڑ„ه“ˆه¸Œç´¢ه¼•ï¼ˆLinked-list based hash index)
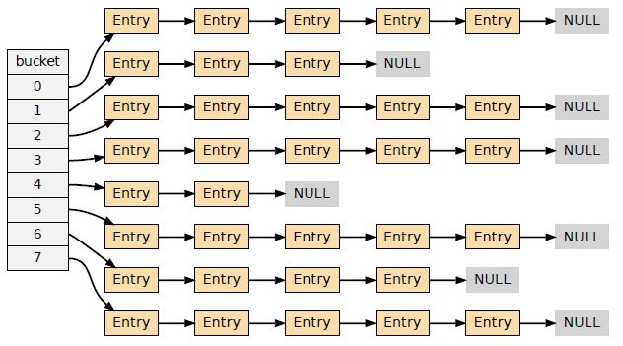
هژںçگ†ï¼ڑé€ڑè؟‡ه“ˆه¸Œوک ه°„,و ¹وچ®ه¯¹ه؛”çڑ„ه€¼هژ»و‰¾ه—,هڈ‘ç”ںه†²çھپه°±ن»ژه¤´ه¾€هگژه¯»و‰¾
- ن¼ک点ï¼ڑه®çژ°ç®€هچ•م€‚
- ç¼؛点(ه¯¹ن؛ژوœ€ç®€هچ•çڑ„ه®çژ°ï¼‰ï¼ڑ
- 读و€§èƒ½ه·®ï¼ڑهœ¨هڈ‘ç”ںه“ˆه¸Œه†²çھپو—¶ï¼Œè¯»هڈ–و€§èƒ½ه·®ï¼Œéœ€è¦پهœ¨éڑڈوœ؛ I/O ن¸éپچهژ†é“¾وژ¥çڑ„و،¶م€‚
- وڈ’ه…¥و€§èƒ½ه·®ï¼ڑهگŒو ·هœ¨ه“ˆه¸Œه†²çھپو—¶ï¼Œوڈ’ه…¥و€§èƒ½ن¹ںه¾ˆه·®ï¼Œé—®é¢کن¸ژ读هڈ–ç±»ن¼¼م€‚
é—®é¢کï¼ڑه¦‚ن½•و”¹è؟›ï¼ں
- 简هچ•çڑ„وƒ³و³•ï¼ڑه°†هگŒن¸€ن¸ھه“ˆه¸Œو،¶çڑ„و،ç›®و”¾هœ¨هگŒن¸€ن¸ھو–‡ن»¶ه—ن¸ï¼Œن»¥ه‡ڈه°‘链çڑ„é•؟ه؛¦م€‚
Cuckoo hashing
Get()
هœ¨ Cuckoo Hashing ن¸ï¼ŒGet(key) و“چن½œéه¸¸é«کو•ˆï¼Œه› ن¸؛و¯ڈن¸ھé”®هڈھ能هکه‚¨هœ¨ن¸¤ن¸ھن½چç½®ن¹‹ن¸€ï¼ڑ
- ن½؟用ه“ˆه¸Œه‡½و•° H0 ه’Œ H1 هˆ†هˆ«è®،ç®—ه‡؛é”®çڑ„ن¸¤ن¸ھهڈ¯èƒ½ن½چç½®ï¼ڑ
- Buckets0[H0(key)] وˆ–
- Buckets1[H1(key)]
- ه…ˆو£€وں¥ Buckets0[H0(key)] وک¯هگ¦هŒ…هگ«è¯¥é”®ï¼ڑ
- ه¦‚وœو‰¾هˆ°ï¼Œهˆ™è؟”ه›ه¯¹ه؛”çڑ„ه€¼م€‚
- ه¦‚وœ Buckets0 ن¸و²،وœ‰و‰¾هˆ°è¯¥é”®ï¼Œهˆ™و£€وں¥ Buckets1[H1(key)]ï¼ڑ
- ه¦‚وœو‰¾هˆ°ï¼Œهˆ™è؟”ه›ه¯¹ه؛”çڑ„ه€¼م€‚
- ه¦‚وœن¸¤ن¸ھن½چ置都و²،وœ‰و‰¾هˆ°è¯¥é”®ï¼Œè؟”ه›é”®ن¸چهکهœ¨çڑ„结وœم€‚
Insert()
è®،ç®—é”®çڑ„ن¸¤ن¸ھه“ˆه¸Œه€¼ï¼Œو‰¾هˆ°ه®ƒهڈ¯ن»¥هکو”¾çڑ„ن½چç½®ï¼ڑBuckets0[H0(key)] وˆ– Buckets1[H1(key)]م€‚
ه¦‚وœه…¶ن¸ن¸€ن¸ھو،¶وک¯ç©؛çڑ„,ه°†é”®وڈ’ه…¥è¯¥ن½چç½®م€‚
ه¦‚وœç›®و ‡ن½چç½®ه·²ç»ڈ被هچ 用,هˆ™ه°†هژںوœ‰çڑ„键“踢ه‡؛â€ï¼Œه¹¶ه°è¯•ه°†è¢«è¸¢ه‡؛çڑ„é”®é‡چو–°وڈ’ه…¥هˆ°ه®ƒçڑ„هڈ¦ن¸€ن¸ھه“ˆه¸Œو،¶ن¸ï¼ˆç›¸ه½“ن؛ژوگ¬è؟پ键)م€‚
è؟™ن¸ھè؟‡ç¨‹ن¼ڑن¸چو–é‡چه¤چ,直هˆ°و‰¾هˆ°ç©؛ن½چوˆ–者达هˆ°é‡چو–°ه“ˆه¸Œçڑ„é™گهˆ¶م€‚
Update()
- ن½؟用ه“ˆه¸Œه‡½و•° H0 ه’Œ H1 وں¥و‰¾é”®çڑ„ن½چç½®م€‚
- ه¦‚وœهœ¨ن»»و„ڈن¸€ن¸ھو،¶ن¸و‰¾هˆ°è¯¥é”®ï¼Œç›´وژ¥و›´و–°ه…¶ه¯¹ه؛”çڑ„ه€¼هچ³هڈ¯م€‚
- ه¦‚وœو²،وœ‰و‰¾هˆ°é”®ï¼Œهˆ™éœ€è¦پو‰§è،Œوڈ’ه…¥و“چن½œم€‚
ن¼ک点
- وں¥و‰¾و—¶é—´ن¸؛ه¸¸و•° O(1),ه› ن¸؛é”®وœ€ه¤ڑهڈھ能هœ¨ن¸¤ن¸ھن½چç½®ن¹‹ن¸€م€‚
- ه‡ڈه°‘ه“ˆه¸Œه†²çھپçڑ„链é•؟ه؛¦é—®é¢کم€‚
ç¼؛点
- وڈ’ه…¥è؟‡ç¨‹ن¸هڈ¯èƒ½ن¼ڑهڈ‘ç”ں“وگ¬è؟پâ€و“چن½œï¼Œه¯¼è‡´و€§èƒ½ن¸چ稳ه®ڑم€‚
- ه¦‚وœه†²çھپè؟‡ه¤ڑ,هڈ¯èƒ½éœ€è¦پé‡چو–°è°ƒو•´ه“ˆه¸Œè،¨çڑ„ه¤§ه°ڈ(rehashing)م€‚
| Method | Update/Insert efficient | Get efficient | Range Query | Support large dataset |
| Log | Yes | No | No | Yes |
| Log + in-memory hash index | Yes | Yes | No | No |
| Log + on-disk hash | No | Medium | No | Yes |
| B+Tree | No | Medium | Yes | Yes |
| LSM tree | Yes | Yes | Medium | Yes |
é—®é¢ک
- هڈ¯ن»¥و”¾هœ¨ç£پç›کن¸ٹ,ن½†éœ€è¦پè°¨و…ژé‡چو–°è®¾è®،ه“ˆه¸Œو–¹و،ˆï¼Œوˆ–者ن»”细选و‹©هگˆé€‚çڑ„ه“ˆه¸Œو–¹و،ˆï¼Œوƒè،،هˆ©ه¼ٹم€‚
- و—¥ه؟—و–‡ن»¶ن¸چو–ه¢é•؟ -> هڈ¯èƒ½ه¯¼è‡´ç£پç›کç©؛间耗ه°½é—®é¢کم€‚
- ç¼؛ن¹ڈ范ه›´وں¥è¯¢و”¯وŒپ(و•ˆçژ‡وپن½ژ)
- ن¾‹ه¦‚,و— و³•é«کو•ˆهœ°و‰«وڈڈوںگن¸ھ范ه›´ه†…çڑ„و‰€وœ‰é”®ï¼ˆه¦‚ن»ژ “kitty00000” هˆ° “kitty99999” çڑ„键)م€‚
ه¦‚ن½•éک²و¢و—¥ه؟—و–‡ن»¶و— é™گه¢é•؟ï¼ں
Log-structured 设è®،ن½؟و›´و–°و“چن½œéه¸¸ه؟«é€ں,ه› ن¸؛هڈھ需è¦په°†و•°وچ®è؟½هٹ هˆ°و–‡ن»¶ن¸م€‚然而,و–‡ن»¶ن¼ڑن¸چو–ه¢é•؟,وœ€ç»ˆن¼ڑ耗ه°½ç£پç›کç©؛é—´م€‚
- é—®é¢کï¼ڑو—¥ه؟—و–‡ن»¶ن¸ن¼ڑوœ‰è®¸ه¤ڑé‡چه¤چè®°ه½•ï¼Œه¯¼è‡´وµھè´¹ç©؛é—´م€‚هگŒو—¶ï¼Œهˆ 除çڑ„و•°وچ®ن»چ然ن؟ç•™هœ¨و–‡ن»¶ن¸م€‚
解ه†³و–¹و،ˆï¼ڑهژ‹ç¼©ï¼ˆCompaction)
- هژ‹ç¼©è؟‡ç¨‹ï¼ڑو‰«وڈڈو•´ن¸ھو–‡ن»¶ï¼Œهˆ 除é‡چه¤چè®°ه½•ï¼Œه°†ه‰©ن½™çڑ„و•°وچ®ه†™ه…¥ن¸€ن¸ھو–°و–‡ن»¶م€‚
- é—®é¢کï¼ڑه¦‚وœو–‡ن»¶ه¤ھه¤§ï¼Œهژ‹ç¼©و•´ن¸ھو–‡ن»¶ن¼ڑéه¸¸è€—و—¶م€‚
و”¹è؟›و–¹و،ˆï¼ڑهˆ†و®µهژ‹ç¼©ï¼ˆCompaction with Segmentation)
- هˆ†و®µï¼ڑه°†و–‡ن»¶هˆ†ن¸؛ه›؛ه®ڑه¤§ه°ڈçڑ„و®µï¼ˆsegments)م€‚
- ه†™ه…¥و–°و®µï¼ڑه¦‚وœوںگن¸ھو®µه·²و»،,ه°±هˆ›ه»؛ن¸€ن¸ھو–°çڑ„و–‡ن»¶و¥è؟›è،Œوڈ’ه…¥و“چن½œم€‚
- وژ§هˆ¶هژ‹ç¼©ç²’ه؛¦ï¼ڑé€ڑè؟‡è°ƒو•´و®µçڑ„ه¤§ه°ڈ,هڈ¯ن»¥وژ§هˆ¶هژ‹ç¼©و“چن½œçڑ„ç²’ه؛¦ï¼Œéپ؟ه…چن¸€و¬،ه¤„çگ†è؟‡ه¤§çڑ„و–‡ن»¶م€‚
ه¦‚ن½•ه¤„çگ†هˆ 除
- appendن¸€ن¸ھNULLçڑ„entry
- Garbage-collected هœ¨ compaction وœںé—´
LSM_TREE
ç´¢ه¼•ç»“و„Bو ‘و€»ç»“
- 1.هڈ¯ن»¥و”¯وŒپ范ه›´وں¥و‰¾
- 2.Get(K), Insert(K,V) and Update(K,V) are relative slow
LSMن¼کهٹ؟
- 1. Searching a given key in a SSTable is efficient (no brute force)
- 2.
هˆ†ه¸ƒه¼ڈç³»ç»ں
Consistency model
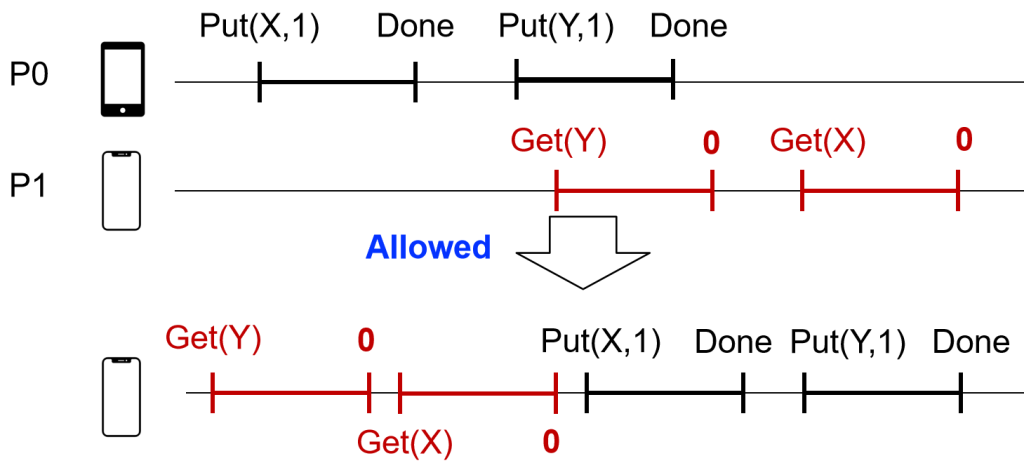
ه¼؛ن¸€è‡´و€§و¨،ه‹
It’s easy for users to reason about correctness assuming(هœ¨ç¨‹ه؛ڈه‘ک视角ç‰ن»·ن؛ژن¸€ن¸ھهچ•ç؛؟程)
- Everything has only one-copy(هڈھوœ‰ن¸€ن¸ھو‹·è´ï¼‰
- The overall behavior is equivalent to some serial behavior(ç‰ن»·ن؛ژهچ•ç؛؟程è،Œن¸؛)
- The overall behavior can be viewed as a system that never fails
ç‰ن»·ن؛ژç؛؟و€§ï¼Œن½†ن¸چ符هگˆن؛؛类直觉
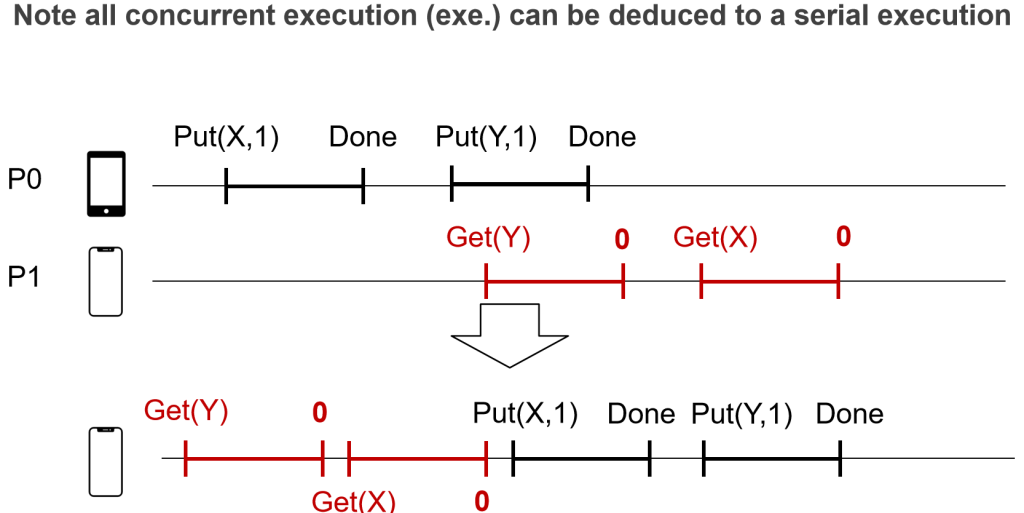
global issuing order
ه¼؛ن¸€è‡´و€§و¨،ه‹ï¼Œن¸¥و ¼وŒ‰ç…§و“چن½œو—¶é—´é،؛ه؛ڈ
- All the concurrent execution is equivalent to a serial execution
- The order of each op matches the global wall clock time
é—®é¢کï¼ڑو²،وœ‰هٹو³•هœ¨هˆ†ه¸ƒه¼ڈç³»ç»ںه®è،Œ
و— و³•ç،®ه®ڑP0,P1ه…·ن½“ه¼€ه§‹و—¶é—´ï¼Œه¯¼è‡´و— و³•ه…·ن½“و‰§è،ŒوŒ‡ن»¤ï¼ŒهگŒو—¶ن¸چهگŒè®¾ه¤‡و—¶é—´وˆ³ن¹ںن¸چهگŒ
Per-process issuing/completion order
- All the concurrent execution is equivalent to a serial execution
- The order of each op matches per-process issuing/completion order(وŒ‰ç…§هˆ°è¾¾و—¶é—´ï¼‰
Primary-backup model
- Primary forwards writes to all the replicas
M0 executes writes locally (in order)
Respond OK
ن¸€è‡´و€§و¨،ه‹ه’Œوœ€ç»ˆن¸€è‡´و€§
逻辑و€§ن؟وŒپو£ç،®و€§çڑ„هژںه›
- و¯ڈن¸ھو•°وچ®é،¹هڈھوœ‰ن¸€ن¸ھه‰¯وœ¬م€‚
- و•´ن¸ھç³»ç»ںçڑ„è،Œن¸؛ç‰هگŒن؛ژوںگç§چن¸²è،Œè،Œن¸؛م€‚
- و•´ن¸ھç³»ç»ںçڑ„è،Œن¸؛هڈ¯ن»¥è¢«è§†ن¸؛ن¸€ن¸ھن»ژن¸چه¤±è´¥çڑ„ç³»ç»ں
è؟™ن¸‰ç§چن¸€è‡´و€§و¨،ه‹هœ¨هˆ†ه¸ƒه¼ڈç³»ç»ںن¸ه®ڑن¹‰ن؛†ن¸چهگŒçڑ„é،؛ه؛ڈه…³ç³»
1. ه…¨ه±€هڈ‘èµ·é،؛ه؛ڈ(ن¸¥و ¼ن¸€è‡´و€§ï¼‰
- ه®ڑن¹‰ï¼ڑو‰€وœ‰و“چن½œهœ¨ه…¨ه±€ن¸ٹوŒ‰ç…§و—¶é—´é،؛ه؛ڈè؟›è،Œï¼Œو‰€وœ‰è؟›ç¨‹éƒ½ه¯¹و“چن½œçڑ„é،؛ه؛ڈوœ‰ه®Œه…¨ن¸€è‡´çڑ„视ه›¾م€‚
- 特点ï¼ڑن»»ن½•ن¸€ن¸ھو“چن½œçڑ„结وœه؟…é،»هœ¨و‰€وœ‰هگژç»و“چن½œن¹‹ه‰چهڈ¯è§پ,ç،®ن؟ç³»ç»ںçٹ¶و€پهœ¨و‰€وœ‰ç”¨وˆ·çœ‹و¥وک¯ه®Œه…¨ن¸€è‡´çڑ„م€‚
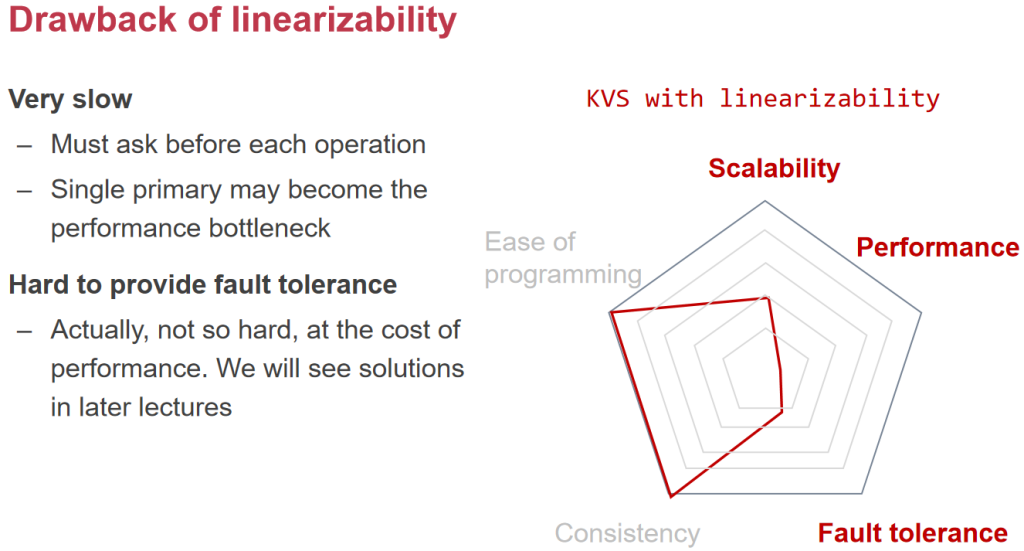
- ه±€é™گو€§ï¼ڑه®çژ°ن¸¥و ¼ن¸€è‡´و€§é€ڑه¸¸éœ€è¦پ较é«کçڑ„ه»¶è؟ںه’Œه¤چو‚çڑ„هچڈè°ƒوœ؛هˆ¶م€‚
2. و¯ڈن¸ھè؟›ç¨‹çڑ„هڈ‘èµ·/ه®Œوˆگé،؛ه؛ڈ(é،؛ه؛ڈن¸€è‡´و€§ sequential consistency)
- ه®ڑن¹‰ï¼ڑو¯ڈن¸ھè؟›ç¨‹çڑ„و“چن½œهœ¨وœ¬هœ°وک¯وŒ‰ç…§ه…¶هڈ‘èµ·çڑ„é،؛ه؛ڈهڈ¯è§پ,ن½†ن¸چهگŒè؟›ç¨‹ن¹‹é—´çڑ„é،؛ه؛ڈهڈ¯èƒ½ن¸چن¸€è‡´م€‚
- 特点ï¼ڑ用وˆ·هڈ¯ن»¥çœ‹هˆ°è‡ھه·±هڈ‘èµ·çڑ„و“چن½œçڑ„é،؛ه؛ڈ,ن½†ه¯¹ن؛ژه…¶ن»–è؟›ç¨‹çڑ„و“چن½œçڑ„é،؛ه؛ڈو²،وœ‰ه…¨ه±€è§†ه›¾م€‚
- ه±€é™گو€§ï¼ڑه…پ许وںگن؛›و“چن½œçڑ„ه¹¶è،Œو€§ï¼Œن½†هڈ¯èƒ½ه¯¼è‡´ن¸چهگŒè؟›ç¨‹çœ‹هˆ°çڑ„ç³»ç»ںçٹ¶و€پن¸چن¸€è‡´م€‚
3. ه…¨ه±€â€œه®Œوˆگ-هڈ‘èµ·â€é،؛ه؛ڈ(ç؛؟و€§هŒ– linearizability)
- ه®ڑن¹‰ï¼ڑهœ¨ن¸€ن¸ھ逻辑و—¶é—´ç‚¹ن¸ٹ,و‰€وœ‰و“چن½œçڑ„ه®Œوˆگو—¶é—´ن¸ژهڈ‘èµ·و—¶é—´éƒ½وœ‰ن¸€ن¸ھن¸€è‡´çڑ„é،؛ه؛ڈ,هچ³و¯ڈن¸ھو“چن½œéƒ½وœ‰ن¸€ن¸ھه”¯ن¸€çڑ„و—¶é—´وˆ³ï¼Œن¸”و‰€وœ‰و“چن½œهœ¨و—¶é—´ن¸ٹوک¯é،؛ه؛ڈوژ’هˆ—çڑ„م€‚
- 特点ï¼ڑ用وˆ·هœ¨ن»»ن½•و—¶ه€™çœ‹هˆ°çڑ„ç³»ç»ںçٹ¶و€پ都وک¯ن¸€è‡´çڑ„,ن¸”هڈ¯ن»¥é€ڑè؟‡ن¸€ن¸ھè™ڑو‹ںçڑ„ç؛؟و€§هŒ–و—¶é—´è½´و¥çگ†è§£م€‚
- ه±€é™گو€§ï¼ڑو¯”ن¸¥و ¼ن¸€è‡´و€§ه®½و¾ï¼Œه…پ许و›´é«کçڑ„ه¹¶هڈ‘و€§ï¼Œن½†ن»چ然è¦پو±‚ç³»ç»ں能ه¤ںهœ¨é€»è¾‘ن¸ٹè؟›è،Œن¸€è‡´çڑ„و“چن½œé،؛ه؛ڈم€‚
ه®çژ°ç؛؟و€§هŒ– linearizability
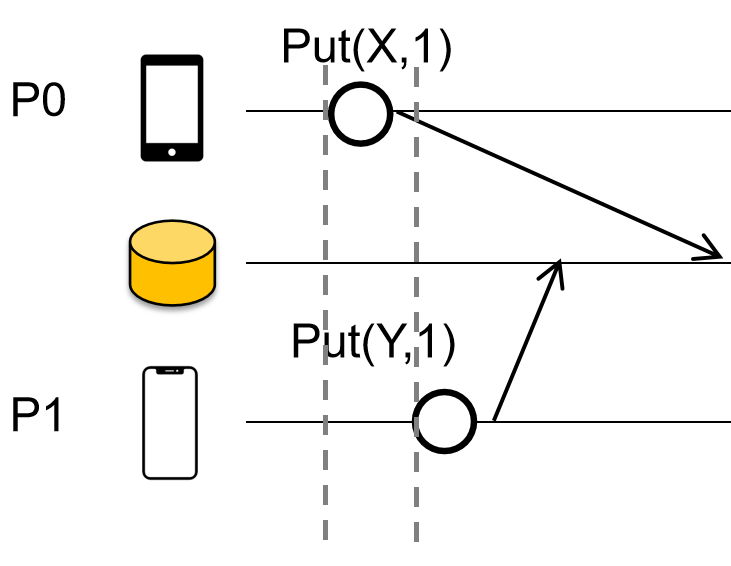
ه¯¹ن؛ژه†™و“چن½œï¼ڑ
ن¸»èٹ‚点(Primary)ه°†ه†™و“چن½œè½¬هڈ‘ç»™و‰€وœ‰ه‰¯وœ¬ï¼ˆReplicas)م€‚
ن¸»èٹ‚点هœ¨وœ¬هœ°وŒ‰é،؛ه؛ڈو‰§è،Œه†™و“چن½œم€‚
و‰§è،Œه®Œهگژ,ن¸»èٹ‚点è؟”ه›â€œOKâ€ç»™ه®¢وˆ·ç«¯م€‚
ه¯¹ن؛ژ读و“چن½œï¼ڑ
ن¸»èٹ‚点直وژ¥è؟”ه›ه…¶وœ¬هœ°و•°وچ®çڑ„ه‰¯وœ¬ç»™ه®¢وˆ·ç«¯م€‚
Implementing linearizability: Primary-backup approach
Primary-Backup Modelçڑ„ç¼؛点
و€§èƒ½é—®é¢کï¼ڑ
读هڈ–و€§èƒ½ï¼ڑو¯ڈو¬،读هڈ–و“چن½œéƒ½éœ€è¦پé¢ه¤–çڑ„ه¾€è؟”و—¶é—´ï¼ˆRTT)و¥èپ”ç³»ن¸»èٹ‚点(Primary)م€‚è؟™ه¢هٹ ن؛†ه»¶è؟ں,ه°¤ه…¶وک¯هœ¨é«کè´ںè½½çڑ„وƒ…ه†µن¸‹م€‚
ه†™ه…¥و€§èƒ½ï¼ڑه†™و“چن½œن¸چن»…需è¦پن¸ژن¸»èٹ‚点è؟›è،Œé€ڑن؟،,è؟ک需è¦پن¸ژو‰€وœ‰ه‰¯وœ¬ï¼ˆBackups)èپ”系,è؟™ه¯¼è‡´و›´ه¤ڑçڑ„RTT,è؟›ن¸€و¥ه¢هٹ ن؛†ه»¶è؟ںم€‚
هڈ¯و‰©ه±•و€§é—®é¢کï¼ڑ
ن¸»èٹ‚点هڈ¯èƒ½وˆگن¸؛و€§èƒ½ç“¶é¢ˆم€‚éڑڈç€ه®¢وˆ·ç«¯è¯·و±‚çڑ„ه¢هٹ ,ن¸»èٹ‚点需è¦په¤„çگ†و‰€وœ‰çڑ„读ه†™و“چن½œï¼Œهڈ¯èƒ½ه¯¼è‡´è´ںè½½è؟‡é‡چ,ه½±ه“چو•´ن½“ç³»ç»ںçڑ„ه“چه؛”و—¶é—´ه’Œهگهگگé‡ڈم€‚
هڈ¯é و€§é—®é¢کï¼ڑ
ه¦‚وœن¸»èٹ‚点وˆ–وںگن¸ھه‰¯وœ¬ه´©و؛ƒï¼Œç³»ç»ںçڑ„هڈ¯é و€§ن¼ڑهڈ—هˆ°ه½±ه“چم€‚虽然هڈ¯ن»¥è®¾è®،ه†—ن½™وœ؛هˆ¶ï¼Œن½†هœ¨ن¸»èٹ‚点ه´©و؛ƒçڑ„وƒ…ه†µن¸‹ï¼Œç³»ç»ںهڈ¯èƒ½ن¼ڑهڈکه¾—ن¸چهڈ¯ç”¨ï¼Œه°¤ه…¶وک¯ه¦‚وœو²،وœ‰وœ‰و•ˆçڑ„و•…éڑœè½¬ç§»وœ؛هˆ¶م€‚
وˆ‘ن»¬هڈ¯ن»¥ه…پ许read读هڈ–ن»»و„ڈه‰¯وœ¬هگ—ï¼ں
ه¯¹ن؛ژه†™و“چن½œï¼ڑ
- ن¸»èٹ‚点(Primary)转هڈ‘ه†™è¯·و±‚ï¼ڑن¸»èٹ‚点ه°†ه†™و“چن½œè½¬هڈ‘ç»™و‰€وœ‰ه‰¯وœ¬ï¼ˆReplicas)م€‚
- وœ¬هœ°و‰§è،Œï¼ڑن¸»èٹ‚点(M0)هœ¨وœ¬هœ°وŒ‰é،؛ه؛ڈو‰§è،Œه†™و“چن½œم€‚
- ه“چه؛”ï¼ڑو‰§è،Œه®Œهگژ,ن¸»èٹ‚点è؟”ه›â€œOKâ€ç»™ه®¢وˆ·ç«¯ï¼Œè،¨ç¤؛ه†™ه…¥وˆگهٹںم€‚
ه¯¹ن؛ژ读و“چن½œï¼ڑ
è؟”ه›ه‰¯وœ¬و•°وچ®ï¼ڑن»»ن½•ه‰¯وœ¬éƒ½هڈ¯ن»¥è؟”ه›ه…¶وœ¬هœ°و•°وچ®çڑ„ه‰¯وœ¬ç»™ه®¢وˆ·ç«¯م€‚è؟™ç§چ设è®،ه…پ许ن»ژه¤ڑن¸ھه‰¯وœ¬è؟›è،Œè¯»هڈ–,ن»¥وڈگé«کهڈ¯ç”¨و€§ه’Œو€§èƒ½م€‚
é—®é¢ک,و¤و—¶P0éک…读ن؛§ç”ںé—®é¢ک
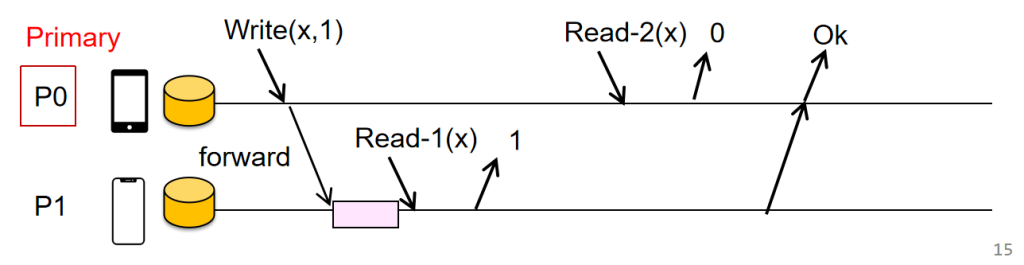
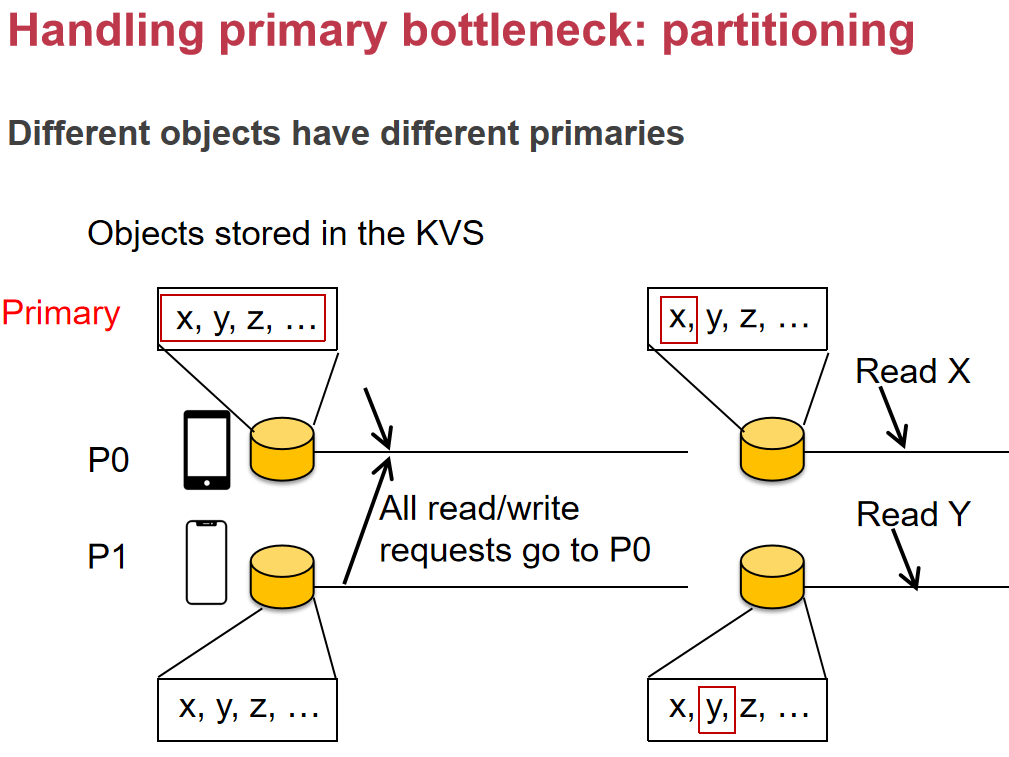
é€ڑè؟‡هˆ†هŒ؛و¥ن¼کهŒ–Primary-Backupç³»ç»ںçڑ„و€§èƒ½ï¼Œç‰¹هˆ«وک¯è§£ه†³ن؛†هڈ¯و‰©ه±•و€§é—®é¢کم€‚و¯ڈن¸ھPrimaryèٹ‚点ه¤„çگ†ن¸چهگŒه¯¹è±،çڑ„读ه†™è¯·و±‚,وœ‰و•ˆهˆ†و•£ن؛†è´ں载,ه‡ڈه°‘ن؛†هچ•èٹ‚点وˆگن¸؛瓶颈çڑ„é£ژ险م€‚
Eventual consistency
特点ï¼ڑ
وœ€ç»ˆن¸€è‡´و€§ï¼ˆEventual consistency )ï¼ڑو‰€وœ‰وœچهٹ،ه™¨وœ€ç»ˆéƒ½ن¼ڑو”¶هˆ°و‰€وœ‰ه†™و“چن½œï¼Œو‹¥وœ‰ç›¸هگŒه†™و“چن½œçڑ„وœچهٹ،ه™¨ه°†وœ‰ن¸€è‡´çڑ„و•°وچ®ه†…ه®¹م€‚ه› و¤ï¼Œه¦‚وœو•°وچ®و²،وœ‰و–°çڑ„و›´و–°و“چن½œï¼Œوœ€ç»ˆو‰€وœ‰çڑ„è®؟问都ن¼ڑè؟”ه›وœ€هگژن¸€و¬،و›´و–°çڑ„ه€¼م€‚
ن¼کهŒ–çڑ„读ه†™و“چن½œï¼ڑ
读و“چن½œï¼ڑè؟”ه›وœچهٹ،ه™¨ن¸ٹçڑ„وœ€و–°وœ¬هœ°ه‰¯وœ¬و•°وچ®ï¼Œè؟™و ·هڈ¯ن»¥وڈگé«ک读و“چن½œçڑ„و€§èƒ½ï¼Œه‡ڈه°‘ه»¶è؟ںم€‚
ه†™و“چن½œï¼ڑه†™و“چن½œé¦–ه…ˆهœ¨وœ¬هœ°و‰§è،Œه¹¶ç›´وژ¥è؟”ه›ï¼Œه†™ه…¥çڑ„و•°وچ®ن¼ڑهœ¨هگژهڈ°ن¼ و’هˆ°و‰€وœ‰وœچهٹ،ه™¨ï¼ˆن¾‹ه¦‚é€ڑè؟‡هگŒو¥و“چن½œï¼‰م€‚è؟™وک¯و€§èƒ½وœ€ن¼کçڑ„ه®çژ°و–¹ه¼ڈ,ه› ن¸؛ه†™و“چن½œن¸چن¼ڑه› ن¸؛ç‰ه¾…هگŒو¥è€Œه»¶è؟ںم€‚
GFS çڑ„وœ€ç»ˆن¸€è‡´و€§و¨،ه‹
GFS ن½؟用ن¸€ç§چç±»ن¼¼وœ€ç»ˆن¸€è‡´و€§çڑ„و¨،ه‹ï¼Œهچ³â€œو¯ڈن¸ھه‰¯وœ¬وœ€ç»ˆن¼ڑوœ‰ç›¸هگŒçڑ„و•°وچ®â€م€‚GFS é€ڑè؟‡ن½؟用ن¸»èٹ‚点و¥هچڈè°ƒه†™و“چن½œï¼Œه®çژ°وœ€ç»ˆن¸€è‡´و€§م€‚è؟™ç§چو–¹ه¼ڈ适用ن؛ژو•°وچ®ن¸ه؟ƒçڑ„هœ؛و™¯م€‚
GFS 适هگˆèپٹه¤©ه؛”用هگ—ï¼ں
وک¾ç„¶ن¸چ适هگˆï¼Œهژںه› ه¦‚ن¸‹ï¼ڑ
- é«که»¶è؟ںï¼ڑGFS çڑ„ن¸»èٹ‚点هچڈè°ƒه’ŒهگŒو¥è؟‡ç¨‹هڈ¯èƒ½ه¯¼è‡´è¾ƒé«که»¶è؟ں,و— و³•و»،足èپٹه¤©ه؛”用çڑ„ه®و—¶و€§éœ€و±‚م€‚
- ه‰¯وœ¬هگŒو¥é—®é¢کï¼ڑèپٹه¤©ه؛”用需è¦په؟«é€ںهگŒو¥و•°وچ®ï¼ŒGFS çڑ„وœ€ç»ˆن¸€è‡´و€§و¨،ه‹هڈ¯èƒ½ه¯¼è‡´و¶ˆوپ¯ن¸چهگŒو¥م€‚
- 设è®،ç›®و ‡ن¸چهگŒï¼ڑGFS ن¸»è¦پن¸؛ه¤§è§„و¨،هکه‚¨è®¾è®،,ن¸چ适هگˆéœ€è¦پن½ژه»¶è؟ںم€پé«کن¸€è‡´و€§çڑ„èپٹه¤©ه؛”用هœ؛و™¯م€‚
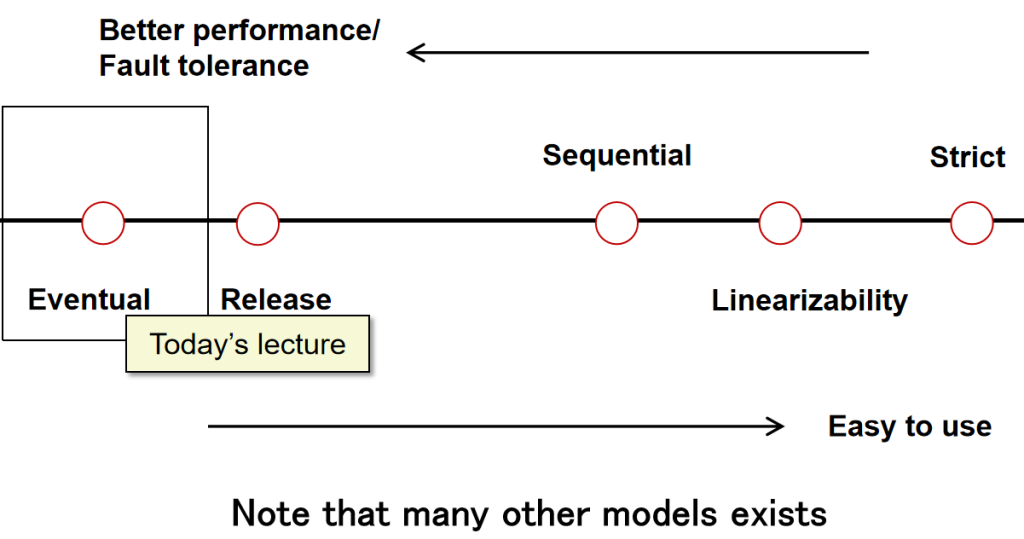
وˆ‘ن»¬وƒ³هœ¨èپٹه¤©ç±»ه؛”用程ه؛ڈن¸è¯»/ه†™ن»€ن¹ˆ
و–¹و³•ï¼ڑç›´وژ¥ه†™ه…¥ç¦»ه®¢وˆ·ç«¯وœ€è؟‘çڑ„وœچهٹ،ه™¨ï¼Œوœچهٹ،ه™¨ç،®è®¤ه†™ه…¥هگژ,ه†چه°†و›´و–°ن¼ و’ç»™ه…¶ن»–وœچهٹ،ه™¨م€‚وœچهٹ،ه™¨هڈ¯ن»¥ه’Œه®¢وˆ·ç«¯هœ¨هگŒن¸€ن½چç½®م€‚
é—®é¢کï¼ڑ
هœ¨è؟™ç§چ设置ن¸‹ï¼Œهڈ¯èƒ½ه‡؛çژ°çڑ„é—®é¢کï¼ڑ
ن¸€ن¸ھه¸¸è§پçڑ„ه¼‚ه¸¸çژ°è±،هڈ«هپڑه†™-ه†™ه†²çھپم€‚ه½“ه¤ڑن¸ھوœچهٹ،ه™¨هœ¨ن¸چçں¥éپ“ه½¼و¤çڑ„وƒ…ه†µن¸‹هگŒو—¶و›´و–°ç›¸هگŒçڑ„و•°وچ®و—¶ï¼Œن¼ڑهڈ‘ç”ںè؟™ç§چوƒ…ه†µم€‚
结وœï¼ڑو•°وچ®ه‡؛çژ°هˆ†و§م€‚ن¾‹ه¦‚,ن¸€ن¸ھوœچهٹ،ه™¨ه…ˆو·»هٹ X هگژو·»هٹ Y,而هڈ¦ن¸€ن¸ھوœچهٹ،ه™¨é،؛ه؛ڈ相هڈچ,وœ€ç»ˆçڑ„و•°وچ®ه°±ن¸چن¸€è‡´ï¼Œو— و³•ن؟è¯پهڈھوœ‰ن¸€ن¸ھو£ç،®çڑ„版وœ¬م€‚
Linearizability vs. Eventual Consistency ه¯¹و¯”è،¨
| 特و€§ | ç؛؟و€§هŒ–(Linearizability) | وœ€ç»ˆن¸€è‡´و€§ï¼ˆEventual Consistency) |
|---|---|---|
| ه†²çھپه¤„çگ†و–¹ه¼ڈ | و‚²è§‚çڑ„ه†²çھپه¤„çگ† | ن¹گ观çڑ„ه†²çھپه¤„çگ† |
| ه†²çھپه†™ه…¥çڑ„ه¸¸è§پو€§ | ه†²çھپه†™ه…¥وک¯ه¸¸è§پوƒ…ه†µ | ه†²çھپه†™ه…¥وک¯ç½•è§پوƒ…ه†µ |
| و›´و–°ç”ںو•ˆو—¶é—´ | و›´و–°هœ¨ه؛ڈهˆ—هŒ–ن¹‹ه‰چن¸چن¼ڑç”ںو•ˆ | ه…پ许و›´و–°هڈ‘ç”ں,ç¨چهگژه†چه¯¹و•°وچ®è؟›è،Œه؛ڈهˆ—هŒ– |
| وœ€ç»ˆç›®و ‡ | و•°وچ®éœ€è¦پهœ¨ه¤ڑن¸ھ设ه¤‡ن¹‹é—´ن؟وŒپن¸€è‡´ | وœ€ç»ˆç›®و ‡ç›¸هگŒï¼ڑو•°وچ®هœ¨ه¤ڑن¸ھ设ه¤‡ن¹‹é—´ن؟وŒپن¸€è‡´ |
需è¦په¤„çگ†çڑ„ه¼‚ه¸¸ï¼ڑ
1.ه†™-ه†™ه†²çھپ(Write-write conflict)ï¼ڑ
解ه†³و–¹و³•ï¼ڑهœ¨وœ¬هœ°ه†™ه…¥هگژ,ه°†ه†™و“چن½œن»¥هگژهڈ°ن»»هٹ،çڑ„و–¹ه¼ڈهڈ‘é€پهˆ°و‰€وœ‰وœچهٹ،ه™¨م€‚و¯ڈن¸ھوœچهٹ،ه™¨ن¼ڑه؛”用è؟™ن؛›ه†™و“چن½œï¼Œه¹¶هœ¨ه؟…è¦پو—¶è§£ه†³ه†²çھپم€‚
é—®é¢ک #1ï¼ڑه¦‚ن½•ه؛”用و›´و–°ï¼ں
وک¯هگ¦هڈ¯ن»¥ç›´وژ¥è¦†ç›–هژںه§‹ه†…ه®¹ï¼ںن¾‹ه¦‚,ن½؟用键ه€¼هکه‚¨ï¼ˆKVS)çڑ„ put() و“چن½œو¥è¦†ç›–ï¼ں
èپٹه¤©و•°وچ®ن؟هکهœ¨ن¸€ن¸ھé”®ه€¼هکه‚¨ن¸ï¼Œه€¼وک¯ن¸€ن¸ھهگ‘é‡ڈم€‚
- 覆盖هژںه§‹ه†…ه®¹ï¼ڑن¾‹ه¦‚
chat[cid] = [ …, new_sid],直وژ¥ه°†و–°çڑ„ه†…ه®¹ه†™ه…¥ï¼Œè¦†ç›–و—§çڑ„ه†…ه®¹م€‚ن¼ڑه¯¼è‡´و•°وچ®ن¸¢ه¤±
هˆو¥و–¹و،ˆï¼ڑç›´وژ¥ç”¨و–°çڑ„ه†™ه…¥و›؟وچ¢و—§çڑ„ه€¼
- ن¸چ能م€‚è؟™و ·هپڑن¼ڑن¸¢ه¤±ه؛”用è¯ن¹‰ï¼Œن»ژ而ه¯¼è‡´â€œن¸چن¸€è‡´â€م€‚虽然وœ€ç»ˆçڑ„ه€¼هڈ¯èƒ½çœ‹èµ·و¥ç›¸هگŒï¼Œن½†ه®ƒن¸چن¼ڑ符هگˆه؛”用程ه؛ڈçڑ„预وœں逻辑وˆ–و„ڈه›¾م€‚
解ه†³و–¹و،ˆï¼ڑه°†و›´و–°و“چن½œه®ڑن¹‰ن¸؛ه‡½و•°
و›´و–°و“چن½œوک¯ن¸€ن¸ھه‡½و•°ï¼Œè€Œن¸چوک¯ن¸€ن¸ھو–°ه€¼ï¼ڑهœ¨ه¤„çگ†ه†™و“چن½œو—¶ï¼Œç”¨وˆ·وڈگن¾›ن¸€ن¸ھه‡½و•°و¥و›´و–°و•°وچ®ï¼Œè€Œن¸چوک¯ç›´وژ¥وڈگن؛¤و–°çڑ„ه€¼م€‚(1. allocate a sid; 2. chat[cid].append(sid))
هگŒو—¶ه‡½و•°ه؟…é،»وک¯ç،®ه®ڑو€§çڑ„ï¼ڑه‡½و•°çڑ„و‰§è،Œç»“وœه؟…é،»وک¯ç،®ه®ڑو€§çڑ„(هچ³ç›¸هگŒè¾“ه…¥ه؟…é،»ه¾—هˆ°ç›¸هگŒçڑ„输ه‡؛),ن»¥ç،®ن؟و‰€وœ‰وœچهٹ،ه™¨هœ¨ه؛”用و¤ه‡½و•°و—¶ه¾—هˆ°ç›¸هگŒçڑ„结وœم€‚
و–°çڑ„é—®é¢ک,é،؛ه؛ڈه¦‚ن½•ن؟è¯پ
e.g. Clientهڈ‘é€پX , iPhoneهڈ‘é€پY , و²،وœ‰ن؟è¯پن؛Œè€…相هگŒçڑ„é،؛ه؛ڈ
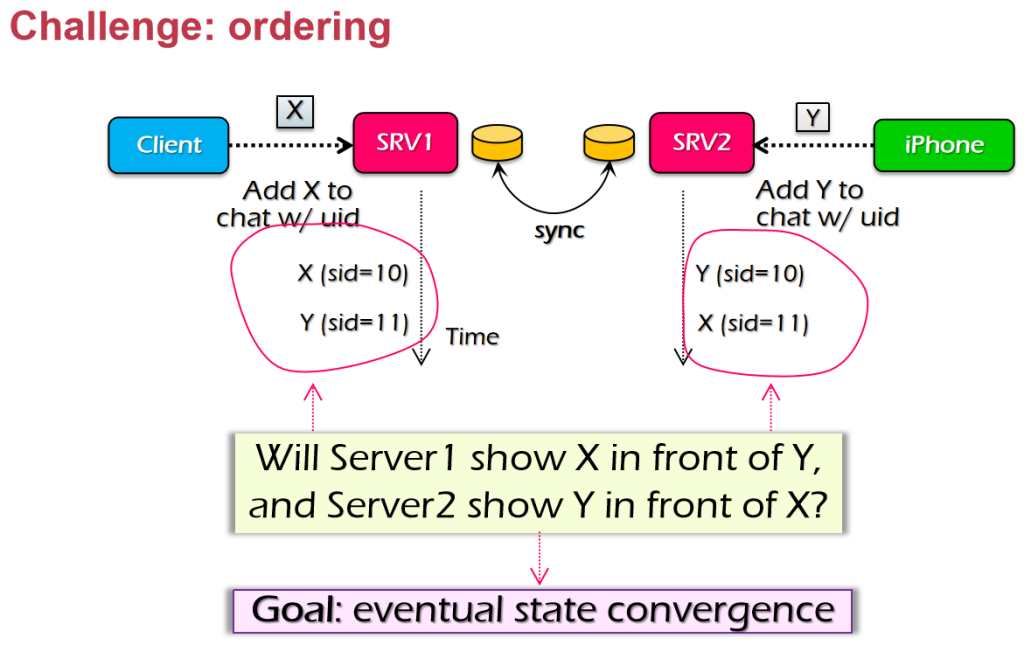
وœ‰ه؛ڈو›´و–°هˆ—è،¨ه¤„çگ†و–¹و،ˆ
- è®°ه½•و›´و–°و“چن½œï¼ڑو¯ڈن¸ھèٹ‚点ه°†و›´و–°و“چن½œè®°ه½•هœ¨و—¥ه؟—ن¸م€‚
- و›´و–°وژ’ه؛ڈï¼ڑو ¹وچ®وںگç§چ规هˆ™ï¼ˆه¦‚و—¶é—´وˆ³ï¼‰ه¯¹و—¥ه؟—ن¸çڑ„و›´و–°è؟›è،Œوژ’ه؛ڈم€‚
- ه»¶è؟ںو›´و–°ï¼ڑهœ¨ç،®ه®ڑو›´و–°èƒ½وŒ‰و£ç،®é،؛ه؛ڈو‰§è،Œه‰چ,وڑ‚缓ه؛”用و›´و–°و“چن½œم€‚
- هگŒو¥وœ؛هˆ¶ï¼ڑç،®ن؟و‰€وœ‰èٹ‚点çڑ„و—¥ه؟—ن¸€è‡´ï¼Œن؟è¯پو¯ڈن¸ھèٹ‚点都وœ‰ç›¸هگŒçڑ„و›´و–°م€‚
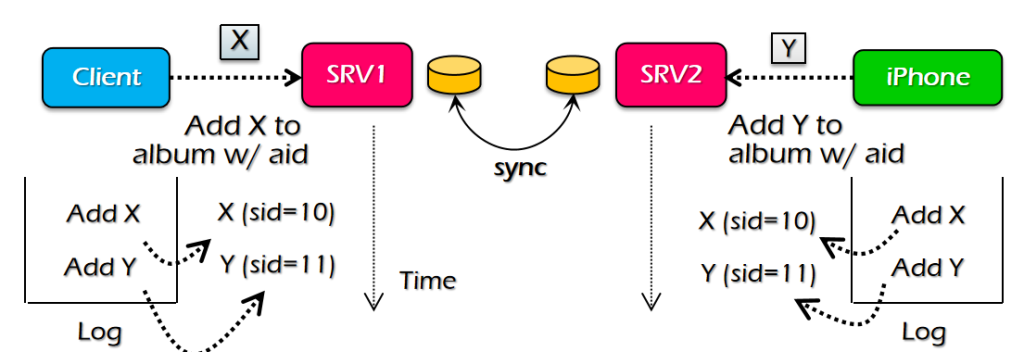
و¤و—¶çڑ„è¦پ点وک¯ï¼Œن؟è¯پ第ن؛Œو¥çڑ„规هˆ™ه‡؛و¥çڑ„é،؛ه؛ڈوک¯ن¸€è‡´çڑ„م€‚
é—®é¢کï¼ڑن؛Œè€…çڑ„و—¶é—´وˆ³وپ°ه¥½ه°±وک¯ç›¸ç‰
解ه†³و–¹و،ˆï¼ڑن¸؛و›´و–°هˆ†é…چه”¯ن¸€ID
- و›´و–°IDï¼ڑو¯ڈو¬،و›´و–°هˆ†é…چن¸€ن¸ھه”¯ن¸€çڑ„ID,و ¼ه¼ڈن¸؛
<و—¶é—´ T, èٹ‚点 ID>م€‚- و—¶é—´ Tï¼ڑè،¨ç¤؛هˆ›ه»؛و›´و–°و—¶çڑ„و—¶é—´وˆ³م€‚
- èٹ‚点 IDï¼ڑè،¨ç¤؛هˆ›ه»؛该و›´و–°çڑ„èٹ‚点,用ن؛ژهœ¨و—¶é—´وˆ³ç›¸هگŒو—¶و‰“ç ´ه¹³ه±€م€‚
- و›´و–°IDçڑ„هˆ†é…چï¼ڑ
- و¯ڈن¸ھو›´و–°ç”±هˆ›ه»؛该و›´و–°çڑ„èٹ‚点هˆ†é…چه”¯ن¸€çڑ„IDم€‚
- و›´و–°وژ’ه؛ڈï¼ڑ
- ه¦‚وœوœ‰ن¸¤ن¸ھو›´و–°ï¼ˆX ه’Œ Y),وˆ‘ن»¬هڈ¯ن»¥é€ڑè؟‡و—¶é—´وˆ³
Tو¥وژ’ه؛ڈï¼› - ه¦‚وœو—¶é—´ç›¸هگŒï¼Œهˆ™ن½؟用èٹ‚点IDو¥ه†³ه®ڑن¼که…ˆé،؛ه؛ڈ,ç،®ن؟و›´و–°وœ‰ه”¯ن¸€çڑ„é،؛ه؛ڈم€‚
- ه¦‚وœوœ‰ن¸¤ن¸ھو›´و–°ï¼ˆX ه’Œ Y),وˆ‘ن»¬هڈ¯ن»¥é€ڑè؟‡و—¶é—´وˆ³
é—®é¢ک1ï¼ڑوˆ‘ن»¬èƒ½هگ¦ن½؟用 <èٹ‚点 ID, و—¶é—´ T> ن½œن¸؛ه”¯ن¸€IDï¼ں
- وژ’ه؛ڈو›´و–°ï¼ڑو²،وœ‰é—®é¢ک,ن»چ然هڈ¯ن»¥و ¹وچ®و—¶é—´وˆ³وژ’ه؛ڈم€‚
- 用وˆ·ن½“éھŒï¼ˆه› وœه…³ç³»ن؟留)ï¼ڑن¸چه¤ھه¥½م€‚و¯”ه¦‚,ه¦‚وœوˆ‘هœ¨iPhoneن¸ٹو¯”iPadن¸ٹو›´و—©هڈ‘ه¸ƒن¸€و،و¶ˆوپ¯ï¼Œن½؟用
<èٹ‚点 ID, و—¶é—´ T>ن¼ڑه¯¼è‡´وˆ‘و€»وک¯ه…ˆçœ‹هˆ°iPhoneçڑ„و•°وچ®ï¼Œه“ھو€•ه®é™…ن¸ٹiPadن¸ٹçڑ„و¶ˆوپ¯و›´و—©م€‚
é—®é¢ک2ï¼ڑ<و—¶é—´ T, èٹ‚点 ID> 能éک²و¢ن¸ٹè؟°ç”¨وˆ·ن½“éھŒé—®é¢کهگ—ï¼ں
- 能هگ¦è§£ه†³é—®é¢کï¼ڑهڈ–ه†³ن؛ژèٹ‚点çڑ„و—¶é’ںو—¶é—´م€‚ه¦‚وœو‰€وœ‰èٹ‚点çڑ„و—¶é’ںهگŒو¥è‰¯ه¥½ï¼Œ
<و—¶é—´ T, èٹ‚点 ID>هڈ¯ن»¥éپ؟ه…چه› وœه…³ç³»é”™ن¹±çڑ„é—®é¢کم€‚ - وŒ‘وˆکï¼ڑهœ¨هˆ†ه¸ƒه¼ڈç³»ç»ںن¸ï¼Œن¼ ç»ںç³»ç»ں组ن»¶çڑ„و—¶é’ںن¸چهگŒو¥ï¼Œه¯¼è‡´و—¶é’ںهپڈه·®م€‚ه› و¤ï¼Œهں؛ن؛ژو—¶é’ںو—¶é—´çڑ„و–¹و،ˆن¼ڑé¢ن¸´و—¶é—´ن¸چن¸€è‡´çڑ„é—®é¢ک,هڈ¯èƒ½و— و³•ه®Œه…¨è§£ه†³ç”¨وˆ·ن½“éھŒن¸ٹçڑ„ه› وœه…³ç³»é—®é¢کم€‚
è؟™و ·ه°±هڈ¯ن»¥ن؟وŒپ结وœن¸€è‡´و€§
é—®é¢ک,ن»€ن¹ˆو—¶ه€™ه†چو›´و–°هˆ°و•°وچ®ه؛“ن¸ٹ
1.و¯ڈن¸€و¬،و›´و–°ه°±ç›´وژ¥ن¸ٹن¼ هˆ°و•°وچ®ه؛“,问é¢کوک¯ه› ن¸؛وœچهٹ،ه™¨çڑ„هˆه§‹çٹ¶و€پن¸چهگŒï¼پ
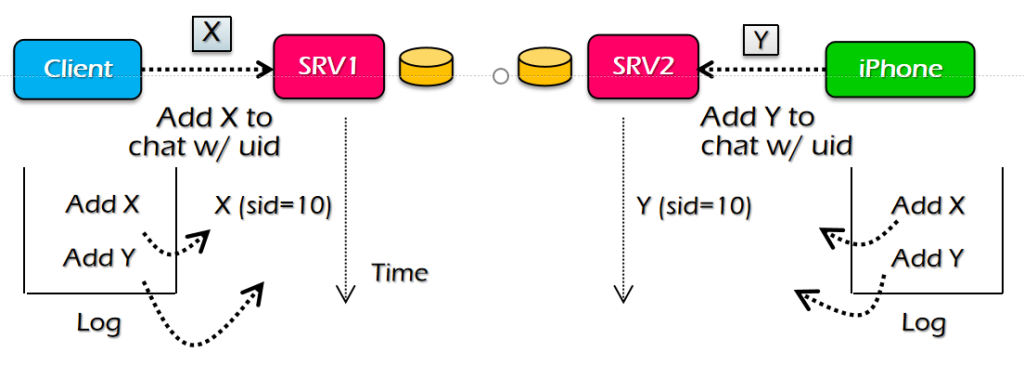
ه›و»ڑهگŒو¥ه‰چçڑ„و‰€وœ‰و›´و–°
- و¸…ç©؛هکه‚¨ï¼ڑه°†هکه‚¨é‡چç½®ن¸؛ç©؛çٹ¶و€پم€‚
- é‡چو–°è؟گè،Œو‰€وœ‰و›´و–°ه‡½و•°ï¼ڑن»ژç©؛çڑ„هکه‚¨çٹ¶و€په¼€ه§‹ï¼Œé‡چو–°ه؛”用و‰€وœ‰و›´و–°م€‚
- هگŒو¥هگژï¼ڑSrv1 ه’Œ Srv2 ه…·وœ‰ç›¸هگŒçڑ„و›´و–°é›†هگˆï¼ˆوœ‰ه؛ڈو—¥ه؟—),ه¹¶è¾¾وˆگ相هگŒçڑ„وœ€ç»ˆçٹ¶و€پم€‚
ç›®و ‡ï¼ڑو—¶é’ںو—¶é—´هڈچوک çœںه®çڑ„(ه¢™ن¸ٹو—¶é’ں)و›´و–°é،؛ه؛ڈ
وˆ‘ن»¬ه¸Œوœ›و›´و–°é،؛ه؛ڈ能ه¤ںن¸ژçœںه®çڑ„ه¢™ن¸ٹو—¶é’ںو—¶é—´ن¸€è‡´م€‚ن¹ںه°±وک¯è¯´ï¼Œه¦‚وœن½ ه…ˆهœ¨iPhoneن¸ٹهڈ‘ه¸ƒن¸€و،و¶ˆوپ¯ï¼Œç„¶هگژهœ¨iPadن¸ٹهڈ‘ه¸ƒهڈ¦ن¸€و،و¶ˆوپ¯ï¼ŒiPhoneن¸ٹçڑ„و—¶é—´ه؛”该ه°ڈن؛ژiPadçڑ„و—¶é—´م€‚然而,çژ°ه®ن¸çڑ„è®،ç®—وœ؛èٹ‚点ن¹‹é—´çڑ„و—¶é’ںه¹¶ن¸چوک¯ه®Œه…¨هگŒو¥çڑ„,è؟™ن¼ڑه¯¼è‡´é—®é¢کم€‚
و›´و–°é،؛ه؛ڈوک¯هگ¦èƒ½ن¸ژه¢™ن¸ٹو—¶é’ںو—¶é—´ن¸€è‡´ï¼ں
- çگ†وƒ³وƒ…ه†µï¼ڑه¦‚وœو‰€وœ‰èٹ‚点çڑ„و—¶é’ںه®Œه…¨هگŒو¥ï¼Œé‚£ن¹ˆو›´و–°çڑ„é،؛ه؛ڈن¼ڑن¸ژçœںه®çڑ„و—¶é—´ن؟وŒپن¸€è‡´م€‚iPhoneçڑ„و¶ˆوپ¯ن¼ڑه…ˆن؛ژiPadçڑ„و¶ˆوپ¯م€‚
- ه®é™…وƒ…ه†µï¼ڑهœ¨هˆ†ه¸ƒه¼ڈç³»ç»ںن¸ï¼Œèٹ‚点çڑ„و—¶é’ںهڈ¯èƒ½ن¸چهگŒو¥ï¼Œه¯¼è‡´و—¶é—´وˆ³ن¸چه‡†ç،®م€‚هچ³ن½؟iPhoneه…ˆهڈ‘ه¸ƒو¶ˆوپ¯ï¼Œç”±ن؛ژو—¶é’ں误ه·®ï¼ŒiPadçڑ„و¶ˆوپ¯هڈ¯èƒ½ن¼ڑوœ‰و›´و—©çڑ„و—¶é—´وˆ³ï¼Œن»ژ而و‰“ن¹±ن؛†é،؛ه؛ڈم€‚
ç¤؛ن¾‹
- هœ؛و™¯ï¼ڑن½ هœ¨iPhoneن¸ٹه…ˆهڈ‘é€پن؛†ن¸€و،و¶ˆوپ¯ï¼Œç„¶هگژهœ¨iPadن¸ٹهڈ‘é€پن؛†هڈ¦ن¸€و،و¶ˆوپ¯م€‚
- 预وœںè،Œن¸؛ï¼ڑiPhoneçڑ„و¶ˆوپ¯ه؛”该ه…ˆوک¾ç¤؛,iPadçڑ„و¶ˆوپ¯هگژوک¾ç¤؛م€‚
- ه®é™…è،Œن¸؛ï¼ڑç”±ن؛ژiPhoneه’ŒiPadçڑ„و—¶é’ںن¸چهگŒو¥ï¼ŒiPadçڑ„و—¶é’ںهڈ¯èƒ½و¯”iPhoneه؟«م€‚ه› و¤ï¼ŒiPadçڑ„و¶ˆوپ¯هڈ¯èƒ½ن¼ڑ被认ن¸؛ه…ˆهڈ‘ç”ں,هچ³ن½؟ه®ƒه®é™…ن¸ٹوک¯هœ¨iPhoneن¹‹هگژهڈ‘ه¸ƒçڑ„م€‚è؟™ه¯¼è‡´ن؛†ن¸چ符هگˆه› وœه…³ç³»çڑ„و›´و–°é،؛ه؛ڈم€‚
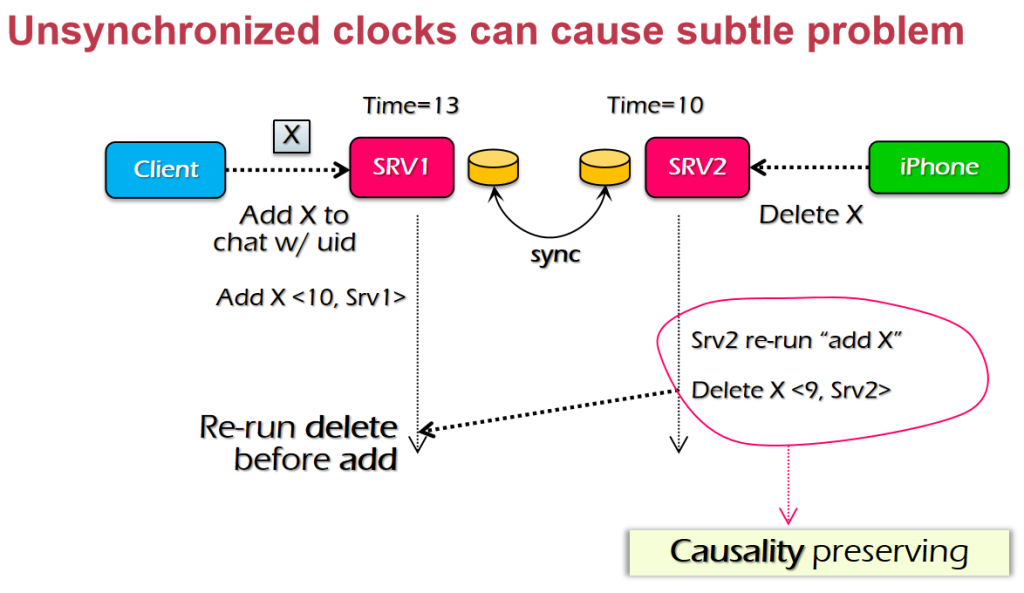
ن¾‹ه¦‚و¤ه¤„,add<X,Srv1>ه…ˆه‡؛و¥ï¼Œن½†و—¶é—´وˆ³ه¤§ï¼Œهˆ 除Xهگژهڈ‘ç”ں,ن½†و—¶é—´وˆ³ه°ڈ,هگŒو¥و—¶ه€™ه°±ن¼ڑه‡؛çژ°é—®é¢کم€‚
ه› وœه…³ç³»çڑ„ه®ڑن¹‰ï¼ڑ
هœ¨هˆ†ه¸ƒه¼ڈç³»ç»ںن¸ï¼Œن؛‹ن»¶ X ه’Œن؛‹ن»¶ Y هکهœ¨ه› وœه…³ç³»ï¼ˆX -> Y)ه½“ن¸”ن»…ه½“ï¼ڑ
- هچ•èٹ‚点ن¸ٹçڑ„é،؛ه؛ڈï¼ڑX ه’Œ Y هœ¨هگŒن¸€ن¸ھèٹ‚点ن¸ٹهˆ›ه»؛,ه¹¶ن¸” X هڈ‘ç”ںهœ¨ Y ن¹‹ه‰چ(هچ•ç؛؟程و‰§è،Œï¼‰م€‚
- è·¨èٹ‚点çڑ„ه› وœه…³ç³»ï¼ڑX ه’Œ Y ç”±ن¸چهگŒèٹ‚点(ه¦‚èٹ‚点 i ه’Œèٹ‚点 j)هˆ›ه»؛,ن¸” X “ه¼•هڈ‘” ن؛† Y çڑ„هڈ‘ç”ںم€‚
- è؟™و„ڈه‘³ç€ X çڑ„结وœه½±ه“چن؛† Yم€‚
ç¤؛ن¾‹ï¼ڑ
- X وک¯و·»هٹ ن¸€و،èپٹه¤©و¶ˆوپ¯ï¼ˆadd chat),Y وک¯هˆ 除该èپٹه¤©و¶ˆوپ¯ï¼ˆdelete chat)م€‚
- ه› وœé“¾ï¼ڑه¦‚وœهکهœ¨ن¸€ن¸ھن؛‹ن»¶ Z,ن½؟ه¾— X -> Z -> Y(هچ³ X ه¯¼è‡´ Z,Z ه†چه¯¼è‡´ Y),那ن¹ˆ X ه’Œ Y ن¹‹é—´هکهœ¨ه› وœه…³ç³»م€‚
é—®é¢کï¼ڑ<و—¶é—´, ID> ن¸چ能ن؟وŒپه› وœé،؛ه؛ڈ
- هژںه› ï¼ڑç”±ن؛ژèٹ‚点çڑ„و—¶é’ںن¸چهگŒو¥ï¼Œç›´وژ¥ن½؟用物çگ†و—¶é’ں(هچ³
<و—¶é—´, ID>)و¥وژ’ه؛ڈو— و³•ن؟è¯په› وœه…³ç³»çڑ„و£ç،®é،؛ه؛ڈم€‚ن¾‹ه¦‚,وںگن¸ھن؛‹ن»¶çڑ„ه®é™…هڈ‘ç”ںو—¶é—´هڈ¯èƒ½و¯”هڈ¦ن¸€ن¸ھو™ڑ,ن½†ç”±ن؛ژو—¶é’ںن¸چهگŒو¥ï¼Œو—¶é—´وˆ³هڈ¯èƒ½ن¼ڑ错误هœ°هڈچوک é،؛ه؛ڈ,ه¯¼è‡´ه› وœه…³ç³»و··ن¹±م€‚
ç›®و ‡
- ç›®و ‡ï¼ڑو—¶é’ںه؛”ه½“هڈچوک ه› وœé،؛ه؛ڈ,ن¹ںه°±وک¯è¯´ï¼Œه¦‚وœن؛‹ن»¶ X ه¯¼è‡´ن؛†ن؛‹ن»¶ Y,那ن¹ˆ X çڑ„و—¶é—´وˆ³ه؛”该ه°ڈن؛ژ Y çڑ„و—¶é—´وˆ³ï¼Œن؟وŒپن؛‹ن»¶çڑ„ه› وœه…³ç³»م€‚
و€è·¯ï¼ڑن½؟用逻辑و—¶é’ں
Lamport clock algorithms
- و¯ڈن¸ھوœچهٹ،ه™¨ç»´وٹ¤ن¸€ن¸ھو—¶é’ںTم€‚
- éڑڈç€ه®é™…و—¶é—´çڑ„وژ¨ç§»ï¼ŒT递ه¢ï¼Œن¾‹ه¦‚و¯ڈ秒ه¢هٹ 1م€‚
- ه¦‚وœن»ژه…¶ن»–وœچهٹ،ه™¨çœ‹هˆ°T’,هˆ™و›´و–°Tن¸؛
T = Max(T, T' + 1)م€‚
Lamport clockçڑ„é—®é¢ک
Lamportو—¶é’ں能给و‰€وœ‰ن؛‹ن»¶ن¸€ن¸ھه…¨ه؛ڈهگ—ï¼ں
- ن¸چ能,ه› ن¸؛ن¼ڑوœ‰ç›¸هگŒçڑ„و—¶é—´وˆ³م€‚
ه¦‚ن½•è§£ه†³ه¹³ه±€ï¼ں
- وˆ‘ن»¬هڈ¯ن»¥é€ڑè؟‡و·»هٹ é¢ه¤–çڑ„é،؛ه؛ڈو¥è§£ه†³ï¼Œو¯”ه¦‚ن½؟用
<逻辑و—¶é—´, èٹ‚点ID>م€‚ - è؟™و ·هڈ¯ن»¥ن؟è¯په…¨ه؛ڈن؟وŒپه› وœه…³ç³»م€‚
ن¸؛ن»€ن¹ˆه…¨ه؛ڈçگ†وƒ³ï¼ں
- ه¦‚وœه‰¯وœ¬وŒ‰ç…§ه…¨ه؛ڈه؛”用ه†™و“چن½œï¼Œé‚£ن¹ˆه®ƒن»¬çڑ„çٹ¶و€پن¼ڑوœ€ç»ˆن¸€è‡´ï¼ˆو”¶و•›ï¼‰م€‚
ه¯¹ن؛ژو¯ڈن¸€ه¯¹ن؛‹ن»¶ï¼Œوˆ‘ن»¬éƒ½هڈ¯ن»¥و¯”较ه®ƒن»¬çڑ„و—¶é—´وˆ³ï¼Œن¾‹ه¦‚ T(e1) < T(e2) وˆ– T(e1) > T(e2)م€‚
é—®é¢کï¼ڑè؟™ç§چé،؛ه؛ڈهڈ¯èƒ½è؟‡ن؛ژن¸¥و ¼م€‚
ه¯¹ن؛ژن¸چ相ه…³çڑ„ن؛‹ن»¶ï¼Œé،؛ه؛ڈهڈ¯èƒ½ن¸ژه¤–部观ه¯ں者çڑ„é،؛ه؛ڈن¸چن¸€è‡´م€‚
ن¾‹ه¦‚ï¼ڑوˆ‘ه…ˆç»™Aliceو·»هٹ ن؛†ن¸€هڈ¥è¯ï¼Œç„¶هگژ独立هœ°ç»™Bobو·»هٹ ن؛†ن¸€هڈ¥è¯ï¼Œç³»ç»ںهڈ¯èƒ½ç”¨Lamportو—¶é’ںه°†Bobçڑ„ن؛‹ن»¶وژ’هœ¨ه‰چé¢ï¼Œه°½ç®،ه®ƒن»¬وک¯و— ه…³çڑ„م€‚
و—¶é’ںè،¨ç¤؛ن¸؛ن¸€ن¸ھهگ‘é‡ڈ(و¯ڈن¸ھوœچهٹ،ه™¨ن¸€ن¸ھو،目)م€‚
- و¯ڈن¸ھو،ç›®ه¯¹ه؛”وœچهٹ،ه™¨ن¸ٹçڑ„وœ¬هœ°Lamportو—¶é’ںم€‚
- éڑڈç€ه®é™…و—¶é—´çڑ„وژ¨ç§»ï¼Œوœ¬هœ°و—¶é’ںT递ه¢ï¼Œن¾‹ه¦‚و¯ڈ秒ه¢هٹ 1م€‚
- ه¦‚وœن»ژه…¶ن»–وœچهٹ،ه™¨çœ‹هˆ°و—¶é—´وˆ³T,هˆ™و›´و–°
Ti = Max(Ti, Ti' + 1)م€‚
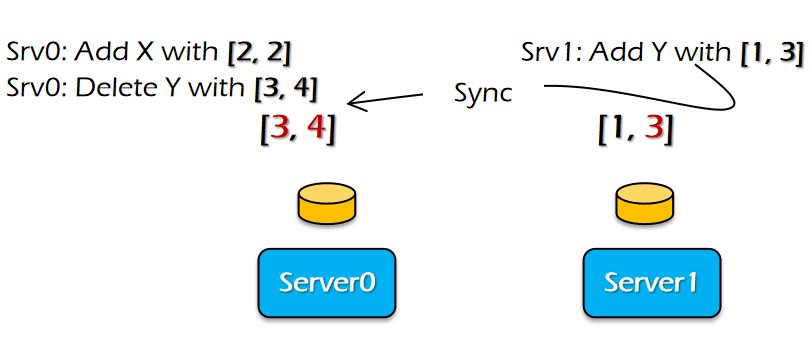
Lamport و—¶é’ں vs. Vectorو—¶é’ں ه¯¹و¯”è،¨
| 特و€§ | Lamport و—¶é’ں | Vectorو—¶é’ں |
|---|---|---|
| ه› وœه…³ç³»وچ•èژ· | وچ•èژ·ه› وœه…³ç³» | وچ•èژ·ه› وœه…³ç³» |
| é،؛ه؛ڈç±»ه‹ | ه…¨ه؛ڈ(Total Order) | 部هˆ†ه؛ڈ(Partial Order) |
| ن½؟用هœ؛و™¯ | 适用ن؛ژه¤§ه¤ڑو•°هœ؛و™¯ | 用ن؛ژ需è¦پو›´ن¸¥و ¼ه› وœه…³ç³»çڑ„هœ؛و™¯ |
| ن؛‹ن»¶وژ’ه؛ڈ | 能ه¤ںن¸؛و‰€وœ‰ن؛‹ن»¶وڈگن¾›é،؛ه؛ڈ | وڈگن¾›éƒ¨هˆ†ن؛‹ن»¶çڑ„ه› وœé،؛ه؛ڈ |
| هکه‚¨éœ€و±‚ | èٹ‚çœپç©؛间,ن»…需هکه‚¨هچ•ن¸ھو—¶é—´وˆ³ | 需è¦پو›´ه¤ڑهکه‚¨ç©؛间,و¯ڈن¸ھèٹ‚点ن¸€ن¸ھو،ç›® |
| ه¤چو‚و€§ | 较ن½ژ | 较é«ک |
و€»ç»“ï¼ڑ
- Lamport و—¶é’ںï¼ڑهœ¨è®¸ه¤ڑهœ؛و™¯ن¸‹ه·²è¶³ه¤ں,能ه¤ںن¸؛ن؛‹ن»¶وژ’ه؛ڈ,ه¹¶èٹ‚çœپهکه‚¨ç©؛é—´م€‚
- Vectorو—¶é’ںï¼ڑوڈگن¾›و›´ç»†ç²’ه؛¦çڑ„ه› وœه…³ç³»è·ںè¸ھ,ن½†éœ€è¦پو›´ه¤ڑçڑ„هکه‚¨ç©؛é—´ه’Œه¤چو‚و€§م€‚
é—®é¢که›é،¾
ن¸؛ن؛†وڈگهچ‡و€§èƒ½ï¼Œوˆ‘ن»¬ن¼ڑç«‹هچ³هœ¨وœ¬هœ°èٹ‚点و‰§è،Œه†™و“چن½œم€‚然而,è؟™ن؛›ه†™و“چن½œهڈ¯èƒ½وک¯ن¸چ稳ه®ڑçڑ„(وˆ‘ن»¬ç§°ن¸؛وڑ‚ه®ڑه†™ه…¥ï¼‰م€‚ن¹‹ه‰چçڑ„解ه†³و–¹و،ˆوک¯é‡چو–°ن»ژç©؛هکه‚¨çٹ¶و€په¼€ه§‹ï¼Œé‡چو–°è؟گè،Œو‰€وœ‰و›´و–°ه‡½و•°ï¼Œن½†è؟™ç§چهپڑو³•و•ˆçژ‡ن½ژن¸‹م€‚
ç›®و ‡
- éپ؟ه…چé‡چو–°è؟گè،Œو‰€وœ‰و›´و–°ه‡½و•°ï¼ڑوˆ‘ن»¬ه¸Œوœ›éپ؟ه…چو¯ڈو¬،都ن»ژه¤´é‡چو–°و‰§è،Œو‰€وœ‰çڑ„و›´و–°و“چن½œï¼Œè؟™و ·هڈ¯ن»¥ه‡ڈه°‘ن¸چه؟…è¦پçڑ„è®،ç®—ه¼€é”€م€‚
- ه‡ڈه°‘و—¥ه؟—çڑ„ه¤§ه°ڈï¼ڑن¼کهŒ–و—¥ه؟—ç³»ç»ں,ه‡ڈه°‘و—¥ه؟—و–‡ن»¶çڑ„هکه‚¨ه¤§ه°ڈ,ن»¥وڈگé«کç³»ç»ںçڑ„و•´ن½“و€§èƒ½ه’Œèµ„و؛گهˆ©ç”¨çژ‡م€‚
ن¸‹ن¸€و¥çڑ„و–¹و،ˆهڈ¯èƒ½و¶‰هڈٹه¢é‡ڈو›´و–°م€پو£€وں¥ç‚¹وœ؛هˆ¶وˆ–هژ‹ç¼©و—¥ه؟—و¥وڈگé«کو•ˆçژ‡م€‚
و–¹و،ˆï¼ڑهŒ؛هˆ†وڑ‚ه®ڑه†™ه…¥ه’Œç¨³ه®ڑه†™ه…¥
و¯ڈن¸ھوœچهٹ،ه™¨çڑ„و—¥ه؟—ç”±ن¸¤éƒ¨هˆ†ç»„وˆگï¼ڑ
- 稳ه®ڑه†™ه…¥ï¼ˆStable writes)
- وڑ‚ه®ڑه†™ه…¥ï¼ˆTentative writes)
稳ه®ڑه†™ه…¥هœ¨هگŒو¥و—¶ن¸چن¼ڑ被ه›و»ڑ,而وڑ‚ه®ڑه†™ه…¥هڈ¯èƒ½هœ¨هگŒو¥و—¶è¢«ن؟®و”¹وˆ–ه›و»ڑم€‚
é—®é¢کï¼ڑه¦‚ن½•ç،®ه®ڑه“ھن؛›ه†™ه…¥وک¯ç¨³ه®ڑçڑ„ï¼ں
- ç”و،ˆï¼ڑن½؟用Lamportو—¶é’ںو¥هˆ¤و–ه†™ه…¥وک¯هگ¦ç¨³ه®ڑم€‚
- ن¸€ن¸ھو›´و–° WWW وک¯ç¨³ه®ڑçڑ„,ه½“ن¸”ن»…ه½“و²،وœ‰ن»»ن½•و،ç›®çڑ„Lamportو—¶é—´وˆ³ه°ڈن؛ژ WWW çڑ„و—¶é—´وˆ³م€‚è؟™و„ڈه‘³ç€هœ¨و‰€وœ‰èٹ‚点çڑ„ن؛‹ن»¶ه؛ڈهˆ—ن¸ï¼Œه·²ç»ڈو²،وœ‰و–°çڑ„ن؛‹ن»¶هڈ¯èƒ½ن¼ڑهœ¨ WWW ن¹‹ه‰چهڈ‘ç”ں,ن؟è¯پن؛†ه› وœه…³ç³»م€‚
وڈگن؛¤ï¼ˆه†™ه…¥ï¼‰و–¹و،ˆ
- و›´و–°
<10, A>وک¯ç¨³ه®ڑçڑ„,ه‰چوڈگوک¯و‰€وœ‰èٹ‚点都ه·²çœ‹هˆ°ن؛†و‰€وœ‰و—¶é—´وˆ³ه°ڈن؛ژç‰ن؛ژ 10 çڑ„و›´و–°م€‚- ه› ن¸؛و ¹وچ® Lamport و—¶é’ںçڑ„规هˆ™ï¼Œه®ƒو°¸è؟œن¸چن¼ڑه†چ看هˆ°و—¶é—´وˆ³ه°ڈن؛ژ 10 çڑ„و›´و–°م€‚
é—®é¢کï¼ڑ
هچ³ن½؟ه¦‚و¤ï¼Œهœ¨é‡چو–°è؟وژ¥و—¶ï¼Œن»چ然وœ‰è®¸ه¤ڑه†™و“چن½œهڈ¯èƒ½ن¼ڑ被ه›و»ڑم€‚
解ه†³و–¹و³•و–¹هگ‘ï¼ڑ
ن¸؛ن؛†ه‡ڈه°‘ه›و»ڑو¬،و•°ï¼Œهڈ¯ن»¥è؟›ن¸€و¥ن¼کهŒ–هگŒو¥ç–略,ه¦‚ن½؟用ه¢é‡ڈهگŒو¥م€پن¼کهŒ–وڑ‚ه®ڑه†™ه…¥çڑ„ه¤„çگ†وœ؛هˆ¶ç‰ï¼Œن»¥ه‡ڈه°‘و–è؟هگژçڑ„ه›و»ڑو“چن½œم€‚
و–¹و،ˆ
- ن¸»èٹ‚点ï¼ڑوŒ‡ه®ڑن¸€ن¸ھوœچهٹ،ه™¨ن¸؛“ن¸»èٹ‚点â€و¥ç®،çگ†ه†™ه…¥و“چن½œçڑ„وڈگن؛¤م€‚
- هˆ†é…چه…¨ه±€وڈگن؛¤é،؛ه؛ڈ(CSN)ï¼ڑن¸؛و¯ڈن¸ھه†™و“چن½œهˆ†é…چن¸€ن¸ھه…¨ه±€çڑ„وڈگن؛¤é،؛ه؛ڈç¼–هڈ·ï¼ˆCSN)م€‚
- ه®Œو•´و—¶é—´وˆ³ï¼ڑو¯ڈن¸ھه†™و“چن½œçڑ„ه®Œو•´و—¶é—´وˆ³ç”±
<CSN, وœ¬هœ°و—¶é—´وˆ³, وœچهٹ،ه™¨ID>组وˆگم€‚
- ه®Œو•´و—¶é—´وˆ³ï¼ڑو¯ڈن¸ھه†™و“چن½œçڑ„ه®Œو•´و—¶é—´وˆ³ç”±
- 稳ه®ڑه†™ه…¥ï¼ڑن»»ن½•و‹¥وœ‰ه·²çں¥CSNçڑ„ه†™ه…¥و“چن½œéƒ½وک¯ç¨³ه®ڑçڑ„م€‚
- é،؛ه؛ڈ规هˆ™ï¼ڑو‰€وœ‰ç¨³ه®ڑه†™ه…¥éƒ½ن¼ڑوژ’هˆ—هœ¨وڑ‚ه®ڑه†™ه…¥ن¹‹ه‰چم€‚
- CSNن؛¤وچ¢ï¼ڑوœچهٹ،ه™¨ن¹‹é—´ن؛¤وچ¢CSNن»¥ه…±ن؛«وڈگن؛¤é،؛ه؛ڈن؟،وپ¯م€‚
- CSNه®ڑن¹‰ه…¨ه±€é،؛ه؛ڈï¼ڑCSNه®ڑن¹‰ن؛†ه·²وڈگن؛¤و›´و–°çڑ„ه…¨ه±€é،؛ه؛ڈ,ç،®ن؟و‰€وœ‰ه·²وڈگن؛¤çڑ„ه†™و“چن½œهœ¨هگ„ن¸ھوœچهٹ،ه™¨ن¸ٹوŒ‰ç…§ن¸€è‡´çڑ„é،؛ه؛ڈه؛”用م€‚
课ه ‚é—®é¢ک
If TS(event #1) < TS(event #2), what does it say about event #1 (create on node #1) and event #2 (created on node #2)?
Event #1 occurred at a physical time earlier than event #2
Node #1 must have communicated with Node #2
If event #1 has been synced to node #2, then event #1 must have occurred at a physical time earlier than event #2
ه†²çھپن¸‹ن؟è¯پهژںهگو€§
Consistency under crashï¼ڑAll-or-nothing atomicity
Centralized approach
ن¸€هڈ°وœچهٹ،ه™¨è¢«وŒ‡ه®ڑن¸؛“ن¸»وœچهٹ،ه™¨â€م€‚
- ن¸؛و¯ڈو¬،ه†™و“چن½œهˆ†é…چن¸€ن¸ھو€»çڑ„وڈگن؛¤é،؛ه؛ڈهڈ·ï¼ˆCSN)م€‚
- ه®Œو•´çڑ„و—¶é—´وˆ³و ¼ه¼ڈن¸؛ï¼ڑ<CSN, local-TS, SrvID>
- ن»»ن½•ه…·وœ‰ه·²çں¥CSNçڑ„ه†™و“چن½œéƒ½وک¯ç¨³ه®ڑçڑ„م€‚
و‰€وœ‰ç¨³ه®ڑçڑ„ه†™و“چن½œéƒ½وژ’هœ¨ن¸´و—¶ه†™و“چن½œن¹‹ه‰چم€‚
CSNهœ¨وœچهٹ،ه™¨ن¹‹é—´ن؛¤وچ¢م€‚
- CSNه®ڑن¹‰ن؛†ه·²وڈگن؛¤و›´و–°çڑ„ه…¨ه±€é،؛ه؛ڈم€‚
ن¸€هڈ°وœچهٹ،ه™¨è¯·و±‚ن¸»وœچهٹ،ه™¨ن¸؛و‰€وœ‰ن¸´و—¶ه†™و“چن½œهˆ†é…چCSN(هŒ…و‹¬ن»ژه…¶ن»–وœچهٹ،ه™¨وژ¥و”¶هˆ°çڑ„ه†™و“چن½œï¼‰م€‚
هچ³ï¼Œن¸»وœچهٹ،ه™¨هڈ¯ن»¥ن¸؛ن¾èµ–çڑ„ه†™و“چن½œهˆ†é…چو›´ه¤§çڑ„CSNم€‚
é—®é¢کï¼ڑ
ه®Œو•´و—¶é—´وˆ³وک¯هگ¦و€»وک¯ن¸ژن¸´و—¶é،؛ه؛ڈهŒ¹é…چï¼ں
ن¸چه…¨وک¯م€‚ه¦‚وœن؟،وپ¯çڑ„و›´و–°ن¸¤è€…ن¹‹é—´و²،وœ‰ن¾èµ–ه…³ç³»ï¼Œه°±هڈ¯èƒ½ن¼ڑن¸چهگŒم€‚
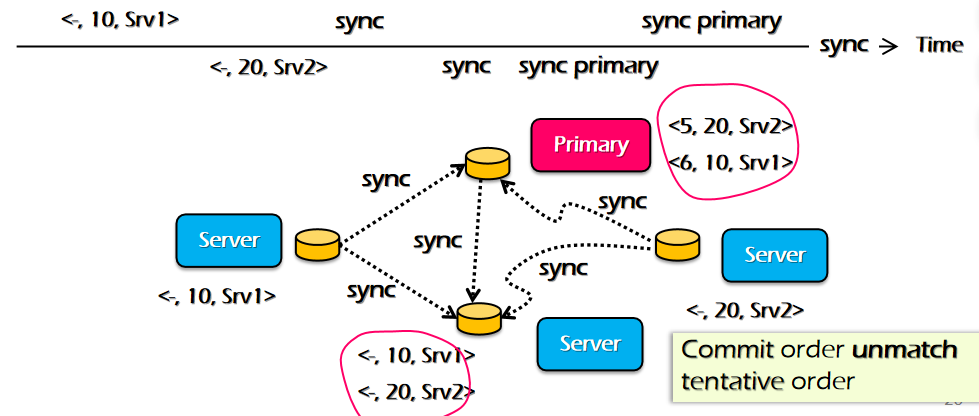
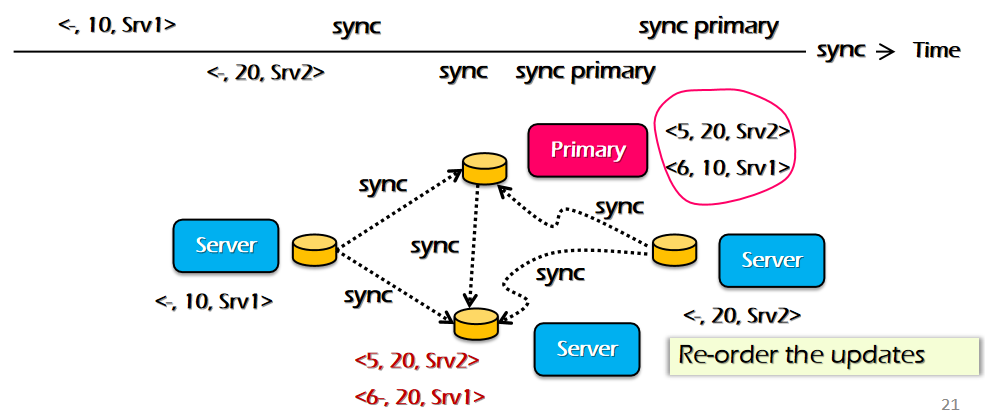
و—¥ه؟—هڈ¯ن»¥é•؟و—¶é—´ن؟留而و— 需ن؟®ه‰ھم€‚
ه½“èٹ‚点وژ¥و”¶هˆ°و–°çڑ„CSNو—¶ï¼Œهڈ¯ن»¥ن¸¢ه¼ƒو‰€وœ‰ه·²وڈگن؛¤çڑ„و—¥ه؟—و،目,直هˆ°è¯¥ç‚¹ن¸؛و¢م€‚
结وœï¼ڑن¸چ需è¦پن؟ç•™ه¤ڑه¹´çڑ„و—¥ه؟—و•°وچ®م€‚
ه¼؛ن¸€è‡´و€§و¨،ه‹ï¼ˆ strong consistency model )
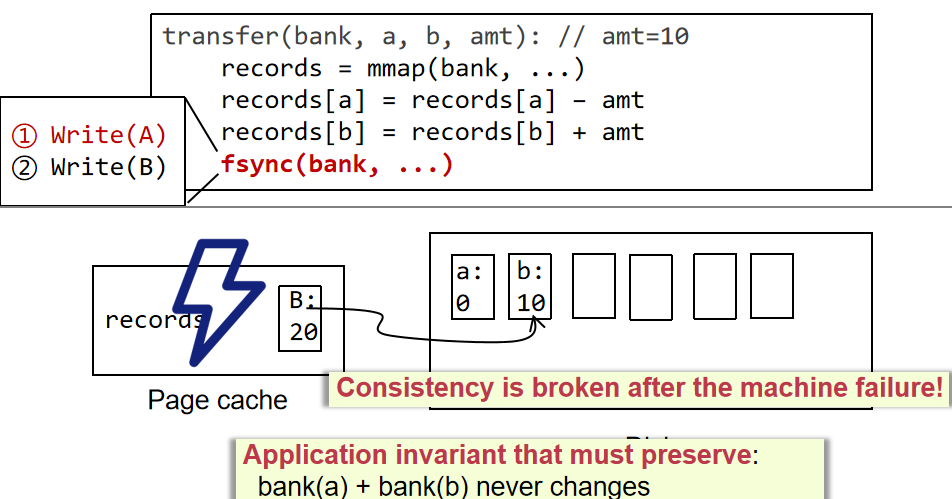
هœ¨ه‡؛é”™وƒ…ه†µن¸‹ï¼Œè¦پن؟وŒپه‡½و•°è¦پن¹ˆه…¨و‰§è،Œï¼Œè¦پن¹ˆه…¨éƒ½ن¸چو‰§è،Œï¼ˆall-or-nothing)
ه¯¹ن؛ژ用وˆ·و¥è¯´ï¼Œوژ¨çگ†ç³»ç»ںçڑ„و£ç،®و€§ه¾ˆه®¹وک“,هپ‡è®¾ï¼ڑ
- و‰€وœ‰و•°وچ®هڈھوœ‰ن¸€ن¸ھه‰¯وœ¬م€‚
- و•´ن½“è،Œن¸؛ç‰ن»·ن؛ژوںگç§چن¸²è،Œè،Œن¸؛م€‚
- 需è¦پهœ¨هژںهگهچ•ه…ƒن¸و‰§è،Œçڑ„و“چن½œï¼ˆé€ڑه¸¸ç§°ن¸؛ن؛‹هٹ،ن¸çڑ„و“چن½œï¼‰هœ¨ن¸€هڈ°وœ؛ه™¨ن¸ٹو‰§è،Œï¼Œه¹¶ن¸”è¦پن¹ˆه®Œه…¨هڈ‘ç”ں,è¦پن¹ˆه®Œه…¨ن¸چهڈ‘ç”ں(ه…¨وœ‰وˆ–ه…¨و— çڑ„هژںهگو€§ï¼‰م€‚
ه…¨وœ‰وˆ–ه…¨و— (all-or-nothing)çڑ„هژںهگو€§ن½؟ه¾—وژ¨çگ†ه¤±è´¥وƒ…ه†µهڈکه¾—و›´هٹ ه®¹وک“م€‚
- هڈھ需考虑و“چن½œهڈ‘ç”ںوˆ–ن¸چهڈ‘ç”ںçڑ„هگژوœï¼Œè€Œن¸چ需è¦پ考虑و“چن½œéƒ¨هˆ†هڈ‘ç”ںçڑ„وƒ…ه†µم€‚
ه®çژ°و–¹و³•
shadow copy
ç،®ن؟ن¸€ç»„ه†™ه…¥و–‡ن»¶çڑ„و“چن½œوک¯ه…¨وœ‰وˆ–ه…¨و— çڑ„,ن¾‹ه¦‚ه°†è®°ه½•aه’Œbه†™ه…¥é“¶è،Œو–‡ن»¶م€‚
é«کç؛§و€è·¯ï¼ˆه†™و—¶ه¤چهˆ¶ï¼‰ï¼ڑ
- ن¸چè¦پن؟®و”¹و—§ه‰¯وœ¬ï¼ˆه§‹ç»ˆن؟ç•™ن¸€ن¸ھن¸€è‡´çڑ„ه‰¯وœ¬ï¼‰م€‚
- هڈھوœ‰ه½“و‰€وœ‰ه†™ه…¥و“چن½œوˆگهٹںو—¶ï¼Œو‰چ用و›´و–°و›؟وچ¢هژںه§‹و–‡ن»¶م€‚

é—®é¢کï¼ڑه¦‚وœهœ¨fcopyوˆ–fsyncè؟‡ç¨‹ن¸هڈ‘ç”ںه´©و؛ƒï¼Œن¼ڑهڈ‘ç”ںن»€ن¹ˆï¼ں
- هژںه§‹bankو–‡ن»¶ه§‹ç»ˆن؟وŒپن¸€è‡´
- وˆ‘ن»¬هڈ¯ن»¥هˆ 除bank_temp,è؟™و ·è½¬è´¦ه°±ن¸چن¼ڑهڈ‘ç”ںن؛†
é—®é¢کï¼ڑه¦‚وœé‡چه‘½هگچè؟‡ç¨‹ن¸هڈ‘ç”ںه´©و؛ƒï¼Œن¼ڑهڈ‘ç”ںن»€ن¹ˆï¼ں
- ه¯¹ن؛ژ银è،Œè½¬è´¦ï¼Œه®ƒوک¯ن¸€è‡´çڑ„(ن»»هٹ،و²،وˆگهٹں,ه›é€€ï¼‰
و–‡ن»¶ç³»ç»ںçٹ¶و€په¦‚ن½•ï¼ں
- هڈ–ه†³ن؛ژو–‡ن»¶ç³»ç»ںçڑ„ه†…部ه®çژ°ï¼Œه¦‚ن¸‹ه›¾و‰€ç¤؛

简هچ•çڑ„解ه†³و–¹و³•ï¼ڑ
è¦پو±‚ه؛”用程ه؛ڈهˆ 除ن¸چه؟…è¦پçڑ„ç´¢ه¼•èٹ‚点
ه؛”用程ه؛ڈçں¥éپ“ه؛”该هˆ 除“bank_tempâ€
é—®é¢کï¼ڑ1.وپ¶و„ڈو”»ه‡»و— و³•éپ؟ه…چ 2.ه¤چو‚و–‡ن»¶ç³»ç»ںéڑ¾ن»¥ه®çژ°
ه¥½çڑ„解ه†³و–¹و³•ï¼ڑJournaling
و€»ç»“
ه°†و•°وچ®ه†™ه…¥و–°ه‰¯وœ¬ï¼Œç„¶هگژهڈ¯ن»¥هژںهگو€§هœ°هˆ‡وچ¢هˆ°و–°ه‰¯وœ¬م€‚
转وچ¢وک¯ن¸€ن¸ھall-or-nothingçڑ„و“چن½œ
- ن½؟用و—¥ه؟—è®°ه½•é‡چه‘½هگچو–‡ن»¶م€‚
ن»…需و–‡ن»¶ç³»ç»ںçڑ„简هچ•وپ¢ه¤چè؟‡ç¨‹
- وپ¢ه¤چهگژهˆ 除ن¸´و—¶و–‡ن»¶م€‚
- و–‡ن»¶ç³»ç»ںé€ڑè؟‡و—¥ه؟—è®°ه½•ن؟وŒپن¸€è‡´و€§م€‚
- هچ³ï¼Œو–‡ن»¶ç³»ç»ںوœ¬è؛«وœ‰وپ¢ه¤چè؟‡ç¨‹م€‚
ه½±هگه¤چهˆ¶çڑ„ç¼؛点
- هڈھ能ن¸€و¬،è؟›è،Œن¸€ن¸ھو“چن½œم€‚
- è½»çژ‡هœ°و‰§è،Œه¹¶هڈ‘ن¼ 输هڈ¯èƒ½ن¼ڑه¯¼è‡´ن¸€è‡´و€§é—®é¢کم€‚
- هچ³ن½؟è؟™ن؛›و“چن½œçگ†è®؛ن¸ٹهڈ¯ن»¥ه¹¶è،Œè؟گè،Œم€‚
- ه¾ˆéڑ¾وژ¨ه¹؟هˆ°ه¤ڑن¸ھو–‡ن»¶وˆ–ç›®ه½•م€‚
- ه؟…é،»ه°†و‰€وœ‰و–‡ن»¶و”¾هœ¨ن¸€ن¸ھç›®ه½•ن¸ï¼Œوˆ–者é‡چه‘½هگچهگç›®ه½•م€‚
- ن»»ن½•ï¼ˆه°ڈçڑ„)و›´و”¹éƒ½éœ€è¦په¤چهˆ¶و•´ن¸ھو–‡ن»¶م€‚
Journaling
ه®çژ°è؟‡ç¨‹ï¼ڑ
و›´و–°ه‰چçڑ„è®°ه½•è؟‡ç¨‹ï¼ڑ
- è®°ه½•و›´و”¹هˆ°و—¥ه؟—(Journal)م€‚
- وڈگن؛¤و—¥ه؟—م€‚
- و‰§è،Œو›´و–°م€‚
ه´©و؛ƒه‰چçڑ„وƒ…ه†µï¼ڑ
- وڈگن؛¤ه‰چه´©و؛ƒï¼ڑو²،وœ‰و•°وچ®è¢«و›´و”¹ï¼Œن¸¢ه¼ƒو—¥ه؟—م€‚
ه´©و؛ƒهگژçڑ„وƒ…ه†µï¼ڑ
- وڈگن؛¤هگژه´©و؛ƒï¼ڑو—¥ه؟—ه®Œو•´ï¼Œé‡چهپڑو—¥ه؟—ن¸çڑ„و›´و”¹م€‚
Journalingçڑ„ç¼؛点
و‰€وœ‰ه†…ه®¹éƒ½éœ€è¦په†™ه…¥ç£پç›کن¸¤و¬،ï¼ڑ
- ن¸€و¬،ه†™ه…¥و—¥ه؟—(journal)م€‚
- هڈ¦ن¸€و¬،ه†™ه…¥وœ€ç»ˆهکه‚¨ن½چ置(home location)م€‚
ه½“و–‡ن»¶è¾ƒه¤§و—¶ï¼Œè؟™ç§چو–¹ه¼ڈن¼ڑهڈکه¾—é—®é¢کé‡چé‡چم€‚
Logging for atomicity
ه…³é”®و€وƒ³ï¼ˆن¸ژو—¥ه؟—è®°ه½•éه¸¸ç›¸ن¼¼ï¼‰ï¼ڑ
- éپ؟ه…چو›´و–°ç£پç›کçٹ¶و€پ,直هˆ°وˆ‘ن»¬هڈ¯ن»¥هœ¨و•…éڑœهگژوپ¢ه¤چه®ƒم€‚
ه¦‚ن½•هœ¨ه½±هگه¤چهˆ¶وˆ–و—¥ه؟—è®°ه½•ن¸ه®çژ°è؟™ن¸€ç‚¹ï¼ں
- ه½±هگه¤چهˆ¶ه°†و›´و–°ç¼“ه†²هœ¨هژںه§‹و–‡ن»¶çڑ„ه‰¯وœ¬ن¸م€‚
- و—¥ه؟—è®°ه½•ه°†و›´و–°ç¼“ه†²هœ¨و‰‡هŒ؛ن¸ï¼ˆهڈ¯ن»¥çœ‹ن½œوک¯ن¸€ن¸ھه°ڈو—¥ه؟—)م€‚
وˆ‘ن»¬هڈ¯ن»¥é€ڑè؟‡ه°†و‰€وœ‰و›´و–°هکه‚¨هœ¨و—¥ه؟—ن¸و¥وژ¨ه¹؟و—¥ه؟—è®°ه½•ï¼ڑ
- و—¥ه؟—و–‡ن»¶ï¼ڑن¸€ن¸ھن»…هŒ…هگ«و›´و–°ç»“وœçڑ„و–‡ن»¶م€‚
- و—¥ه؟—و،ç›®ï¼ڑهŒ…هگ«ن¸€ن¸ھهژںهگهچ•ه…ƒçڑ„و›´و–°ه€¼ï¼ˆن¾‹ه¦‚,ن¼ 输)م€‚
و—¥ه؟—è®°ه½•ه’Œه½±هگه¤چهˆ¶çڑ„ن¸»è¦پو€وƒ³وک¯ï¼Œهœ¨و“چن½œه®Œوˆگن¹‹ه‰چن¸چè¦پç›´وژ¥ن؟®و”¹ç£پç›کçٹ¶و€پ,ن»¥ç،®ن؟و•…éڑœوپ¢ه¤چو—¶çڑ„هڈ¯é و€§م€‚ه½±هگه¤چهˆ¶é€ڑè؟‡هœ¨هژںه§‹و–‡ن»¶çڑ„ه‰¯وœ¬ن¸ٹè؟›è،Œو›´و”¹ï¼Œè€Œو—¥ه؟—è®°ه½•é€ڑè؟‡ه°†و›´و”¹ç¼“هکهœ¨ن¸€ن¸ھه°ڈçڑ„و—¥ه؟—(é€ڑه¸¸وک¯و‰‡هŒ؛)ن¸م€‚هœ¨و—¥ه؟—è®°ه½•çڑ„é€ڑ用و–¹و³•ن¸ï¼Œو‰€وœ‰çڑ„و›´و–°éƒ½هکه‚¨هœ¨و—¥ه؟—و–‡ن»¶ن¸ï¼Œن؟è¯پç³»ç»ںن¸€è‡´و€§
ن؛‹هٹ،ه’Œوڈگن؛¤ç‚¹
وˆ‘ن»¬ç§°ن¸€ç»„需è¦پهژںهگو€§çڑ„و“چن½œن¸؛“ن؛‹هٹ،â€م€‚
ن؛‹هٹ،é€ڑه¸¸ن¸؛ه؛”用程ه؛ڈوڈگن¾›وژ¥هڈ£ï¼Œن»¥و ‡è®°و“چن½œçڑ„هژںهگو€§ç²’ه؛¦ï¼ڑ
TX.begin()(ن؛‹هٹ،ه¼€ه§‹ï¼‰TX.commit()(ن؛‹هٹ،وڈگن؛¤ï¼‰
هœ¨begin()ه’Œcommit()ن¹‹é—´çڑ„و¯ڈو¬،و›´و–°éƒ½هکه‚¨هœ¨و—¥ه؟—و،ç›®ن¸ï¼ڑ
- هڈ¯ن»¥é€ڑè؟‡é‡چو”¾و—¥ه؟—ن¸çڑ„و¯ڈن¸ھو،ç›®و¥é‡چو–°و‰§è،Œم€‚
وڈگن؛¤ç‚¹
- وڈگن؛¤ç‚¹وک¯وˆ‘ن»¬ç،®ه®ڑو“چن½œه·²ç»ڈ“ه…¨éƒ¨ه®Œوˆگâ€çڑ„و—¶هˆ»م€‚
ن؛‹هٹ،وک¯ن¸€ç§چç،®ن؟ن¸€ç»„و“چن½œè¦پن¹ˆه…¨éƒ¨ه®Œوˆگ,è¦پن¹ˆه…¨éƒ¨ن¸چه®Œوˆگçڑ„وœ؛هˆ¶ï¼Œç»´وٹ¤ن؛†و“چن½œçڑ„هژںهگو€§م€‚é€ڑè؟‡ن؛‹هٹ،ه¼€ه§‹ (TX.begin()) ه’Œوڈگن؛¤ (TX.commit()) و¥ه®ڑن¹‰و“چن½œçڑ„范ه›´ï¼Œو—¥ه؟—è®°ه½•ن؛†è؟™وœںé—´çڑ„و‰€وœ‰و›´و”¹ï¼Œن¾؟ن؛ژهœ¨ه‡؛çژ°و•…éڑœو—¶é€ڑè؟‡و—¥ه؟—é‡چو”¾وپ¢ه¤چو•°وچ®م€‚ه½“ن؛‹هٹ،هˆ°è¾¾وڈگن؛¤ç‚¹و—¶ï¼Œو“چن½œè¢«è®¤ن¸؛ه·²ç»ڈه®Œو•´و‰§è،Œم€‚

Redo-only
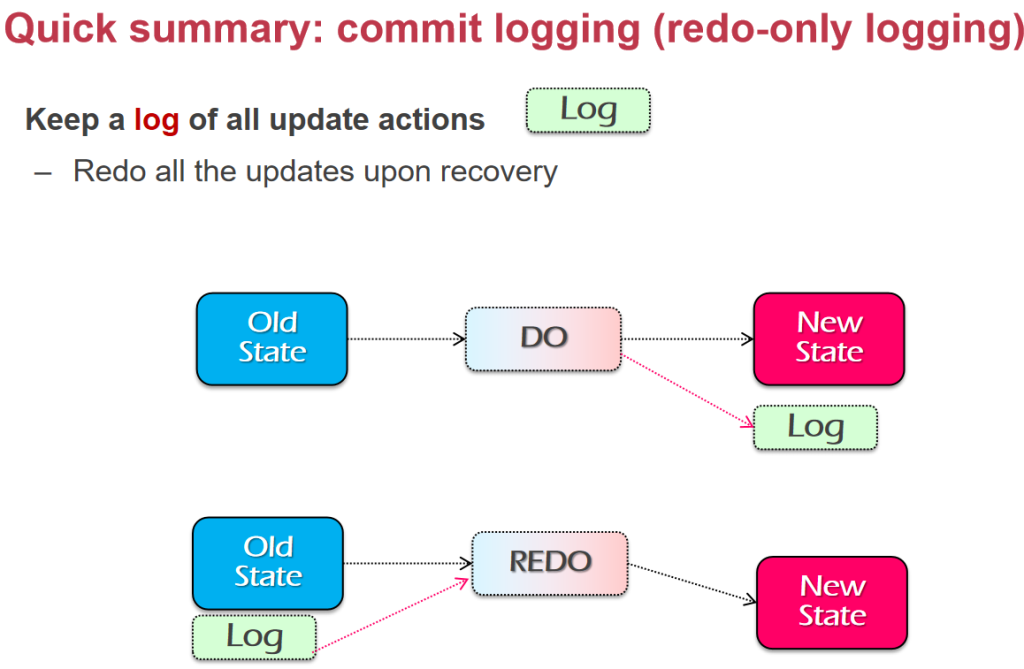
هœ¨و›´و–°و–°çٹ¶و€په‰چ,记ه½•è¦پو›´و–°çڑ„ه€¼هˆ°و—¥ه؟—
é‡چهگ¯هگژ,وˆ‘ن»¬éœ€è¦په°†ç³»ç»ںوپ¢ه¤چهˆ°ن¸€è‡´çٹ¶و€پ
- هں؛ن؛ژهکه‚¨هœ¨و—¥ه؟—و–‡ن»¶ن¸çڑ„و—¥ه؟—و،ç›®è؟›è،Œوپ¢ه¤چم€‚
و–¹و³•
- ن»ژه¤´هˆ°ه°¾éپچهژ†و—¥ه؟—م€‚
- é‡چو–°ه؛”用ه®Œو•´و—¥ه؟—و،ç›®ن¸è®°ه½•çڑ„و›´و–°م€‚
هˆ°ç›®ه‰چن¸؛و¢ï¼Œredo-onlyو—¥ه؟—è®°ه½•çڑ„ن¼کç¼؛点
ن¼ک点
- وڈگن؛¤و“چن½œéه¸¸é«کو•ˆï¼ڑهڈھوœ‰ن¸€ن¸ھو–‡ن»¶é™„هٹ و“چن½œï¼ˆه¸¦وœ‰و›´و–°çڑ„و•°وچ®ï¼‰م€‚
- ه…¶ن»–و–¹و³•ï¼Œه¦‚ه½±هگه¤چهˆ¶ï¼Œن¼ڑه¤چهˆ¶و•´ن¸ھو–‡ن»¶م€‚
ç¼؛点
- وµھè´¹ç£پç›کI/Oï¼ڑو‰€وœ‰ç£پç›کو“چن½œه؟…é،»هœ¨وڈگن؛¤ç‚¹è؟›è،Œم€‚
- و‰€وœ‰و›´و–°ه؟…é،»هœ¨ن؛‹هٹ،وڈگن؛¤ن¹‹ه‰چ缓هکهœ¨ه†…هکن¸م€‚
- و—¥ه؟—و–‡ن»¶ن¼ڑوŒپç»ه¢é•؟,虽然ه¤§ه¤ڑو•°و›´و–°ه·²ç»ڈ被هˆ·و–°هˆ°ç£پç›کن¸ٹ(除éوœ؛ه™¨é‡چهگ¯وˆ–ه´©و؛ƒï¼Œوˆ‘ن»¬éœ€è¦پè؟›è،Œوپ¢ه¤چ)م€‚
هں؛وœ¬è§£ه†³و–¹و،ˆ
- وˆ‘ن»¬ه…پ许ن؛‹هٹ،ç›´وژ¥ه°†وœھوڈگن؛¤çڑ„ه€¼ه†™ه…¥ç£پç›کم€‚
- هœ¨وڈگن؛¤ç‚¹ن¹‹ه‰چ,è؟™هڈ¯ن»¥é‡ٹو”¾ه†…هکç©؛é—´ه¹¶هˆ©ç”¨ç£پç›کI/Oم€‚

ه¦‚ن½•éک²و¢وœھوڈگن؛¤ن؛‹هٹ،çڑ„部هˆ†و›´و–°ï¼ں
- ن½؟用و—¥ه؟—è®°ه½•و¥و’¤é”€وœھوڈگن؛¤ن؛‹هٹ،çڑ„و›´و–°ï¼پ
Undo-Redo
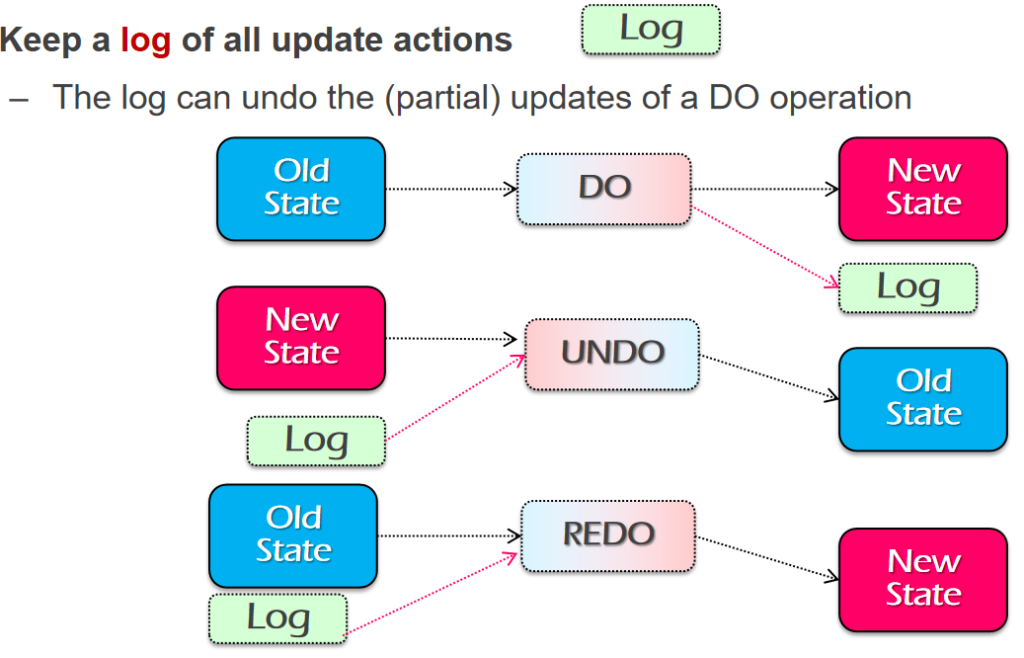
é—®é¢کï¼ڑوˆ‘ن»¬وک¯هگ¦éœ€è¦پredoو،ç›®ï¼ں
- هڈ–ه†³ن؛ژوˆ‘ن»¬وک¯هگ¦ç‰ه¾…è®°ه½•
[a]ه†™ه…¥ç£پç›ک(ن¾‹ه¦‚,sync)م€‚ - é€ڑه¸¸وک¯çڑ„ï¼ڑç‰ه¾…ن¸¤و¬،ç£پç›کهگŒو¥ه¾ˆو…¢ï¼پ
- ه°¤ه…¶وک¯ه¯¹ن؛ژéو—¥ه؟—ه†™ه…¥ï¼ڑو—¥ه؟—وک¯ه؟«é€ںçڑ„é،؛ه؛ڈç£پç›که†™ه…¥م€‚

و—¥ه؟—و،ç›® vs. و—¥ه؟—è®°ه½•
Redo-onlyو—¥ه؟—è®°ه½•ه°†و—¥ه؟—و،目附هٹ هˆ°و—¥ه؟—و–‡ن»¶ن¸ï¼ڑ
- هŒ…هگ«ن؛‹هٹ،çڑ„و‰€وœ‰و›´و–°م€‚
Undo-redoو—¥ه؟—è®°ه½•ه°†و—¥ه؟—è®°ه½•é™„هٹ هˆ°و—¥ه؟—و–‡ن»¶ن¸ï¼ڑ
- هŒ…هگ«هچ•ن¸ھو“چن½œçڑ„و›´و–°م€‚
- و¥è‡ھن¸چهگŒن؛‹هٹ،(TX)çڑ„و—¥ه؟—è®°ه½•هڈ¯èƒ½ن؛¤é”™ه‡؛çژ°م€‚
- ن¾‹ه¦‚,و“چن½œç³»ç»ںهڈ¯èƒ½ه°†ن؛‹هٹ،è°ƒه؛¦وڑ‚هپœم€‚
- ه› و¤ï¼Œوˆ‘ن»¬éœ€è¦پوŒ‡é’ˆو¥è؟½è¸ھهگŒن¸€ن؛‹هٹ،çڑ„و“چن½œم€‚
وپ¢ه¤چè؟‡ç¨‹è¯»هڈ–و—¥ه؟—ه¹¶و ¹وچ®ه…¶ه†…ه®¹وپ¢ه¤چçٹ¶و€پم€‚
وپ¢ه¤چ规هˆ™
- ن»ژوœ«ه°¾ه¼€ه§‹هگ‘ه‰چéپچهژ†م€‚
- و ‡è®°و‰€وœ‰و²،وœ‰وڈگن؛¤و—¥ه؟—(CMT)çڑ„ن؛‹هٹ،è®°ه½•ï¼Œه¹¶è؟½هٹ ن¸و¢و—¥ه؟—(ABORT)م€‚
- ن»ژوœ«ه°¾ه¼€ه§‹هگ‘ه‰چو’¤é”€ï¼ˆUNDO)ن¸و¢و—¥ه؟—م€‚
- ن»ژه¤´هˆ°ه°¾é‡چهپڑ(REDO)وڈگن؛¤و—¥ه؟—م€‚
解é‡ٹï¼ڑ هœ¨ه´©و؛ƒوپ¢ه¤چè؟‡ç¨‹ن¸ï¼Œç³»ç»ںé€ڑè؟‡è¯»هڈ–و—¥ه؟—و¥ç،®ه®ڑه“ھن؛›و“چن½œه·²ç»ڈه®Œوˆگ,ه“ھن؛›وœھه®Œوˆگم€‚é€ڑè؟‡è؟™ن؛›وپ¢ه¤چ规هˆ™ï¼Œوœھه®Œوˆگçڑ„ن؛‹هٹ،ن¼ڑ被و ‡è®°ه¹¶و’¤é”€ï¼Œè€Œه·²ه®Œوˆگçڑ„ن؛‹هٹ،هˆ™ن¼ڑ被é‡چهپڑ,ن»¥ç،®ن؟ç³»ç»ںçڑ„ن¸€è‡´و€§م€‚
و£€وں¥ç‚¹ï¼ˆCheckpoint)
ن½œç”¨ï¼ڑç،®ه®ڑه“ھن؛›و—¥ه؟—هڈ¯ن»¥ن¸¢ه¼ƒï¼Œç„¶هگژن¸¢ه¼ƒه®ƒن»¬م€‚
é—®é¢کï¼ڑ
- redo-onlyو—¥ه؟—è®°ه½•ه’Œundo-redoو—¥ه؟—è®°ه½•ن¼ڑه°†و‰€وœ‰و›´و–°è؟½هٹ هˆ°و—¥ه؟—و–‡ن»¶ن¸ï¼Œه¯¼è‡´و—¥ه؟—و–‡ن»¶ن¸چو–ه¢é•؟,ه°½ç®،ه¤§ه¤ڑو•°و›´و–°ه·²ç»ڈهˆ·و–°هˆ°ç£پç›کن¸ٹم€‚
- ه¤§ه‹و—¥ه؟—و–‡ن»¶ن¸چن»…وµھè´¹هکه‚¨ç©؛间,è؟کن¼ڑن½؟ç³»ç»ںوپ¢ه¤چهڈکو…¢م€‚
وŒ‘وˆکن¸ژ观ه¯ںï¼ڑ
- 简هچ•و–¹و³•çڑ„é—®é¢کï¼ڑç›´وژ¥è؟گè،Œrecovery process虽然هڈ¯ن»¥ن¸¢ه¼ƒو—¥ه؟—و–‡ن»¶ï¼Œن½†é€ںه؛¦ه¤ھو…¢ï¼Œه½±ه“چç³»ç»ںو€§èƒ½م€‚
- 观ه¯ںï¼ڑوœھوڈگن؛¤çڑ„و›´و–°é€ڑه¸¸هڈھهکهœ¨ن؛ژه†…هکن¸çڑ„é،µç¼“هکن¸م€‚ه¦‚وœه°†ç¼“هکه†…ه®¹هˆ·و–°هˆ°ç£پç›ک,هڈ¯ن»¥ه®‰ه…¨هœ°ن¸¢ه¼ƒè؟™ن؛›و—¥ه؟—م€‚
- ه…³é”®é—®é¢کï¼ڑه¦‚وœوœ‰و£هœ¨è؟›è،Œçڑ„ن؛‹هٹ،(TX)و€ژن¹ˆهٹï¼ں需è¦پç،®ن؟و£هœ¨è؟›è،Œçڑ„ن؛‹هٹ،çڑ„و—¥ه؟—被ن؟留,ن»¥ه…چن¸¢ه¤±وœھه®Œوˆگçڑ„و“چن½œم€‚
و”¹è؟›و–¹و،ˆï¼ڑ
- هœ¨è؟›è،Œو£€وں¥ç‚¹و—¶ï¼Œه†™ه…¥ن¸€ن¸ھهŒ…هگ«و‰€وœ‰و£هœ¨è؟›è،Œن؛‹هٹ،هڈٹه…¶و—¥ه؟—çڑ„و£€وں¥ç‚¹è®°ه½•ï¼ˆCKPT),ç،®ن؟وپ¢ه¤چو—¶èƒ½ه¤ںن؟ç•™è؟™ن؛›وœھه®Œوˆگçڑ„ن؛‹هٹ،,éک²و¢و•°وچ®ن¸¢ه¤±م€‚
解ه†³و–¹و،ˆï¼ڑو£€وں¥ç‚¹ï¼ˆCheckpoint)
- ç›®çڑ„ï¼ڑé€ڑè؟‡و£€وں¥ç‚¹وœ؛هˆ¶ï¼Œç،®ه®ڑه“ھن؛›و—¥ه؟—ه·²ç»ڈن¸چه†چ需è¦پ,ه‡ڈه°‘و—¥ه؟—و–‡ن»¶çڑ„ه¤§ه°ڈم€‚
- و£€وں¥ç‚¹çڑ„هں؛وœ¬و¥éھ¤ï¼ڑ
- ç‰ه¾…و²،وœ‰و“چن½œهœ¨è؟›è،Œم€‚
- ه°†و£€وں¥ç‚¹ï¼ˆCKPT)记ه½•ه†™ه…¥و—¥ه؟—,هŒ…هگ«و‰€وœ‰و£هœ¨è؟›è،Œن؛‹هٹ،هڈٹه…¶و—¥ه؟—çڑ„هˆ—è،¨م€‚
- هˆ·و–°é،µç¼“هک,ه°†وœھوڈگن؛¤çڑ„و›´و–°ه†™ه…¥ç£پç›کم€‚
- ن¸¢ه¼ƒé™¤و£€وں¥ç‚¹è®°ه½•ه¤–çڑ„و‰€وœ‰و—¥ه؟—è®°ه½•م€‚
وپ¢ه¤چè؟‡ç¨‹
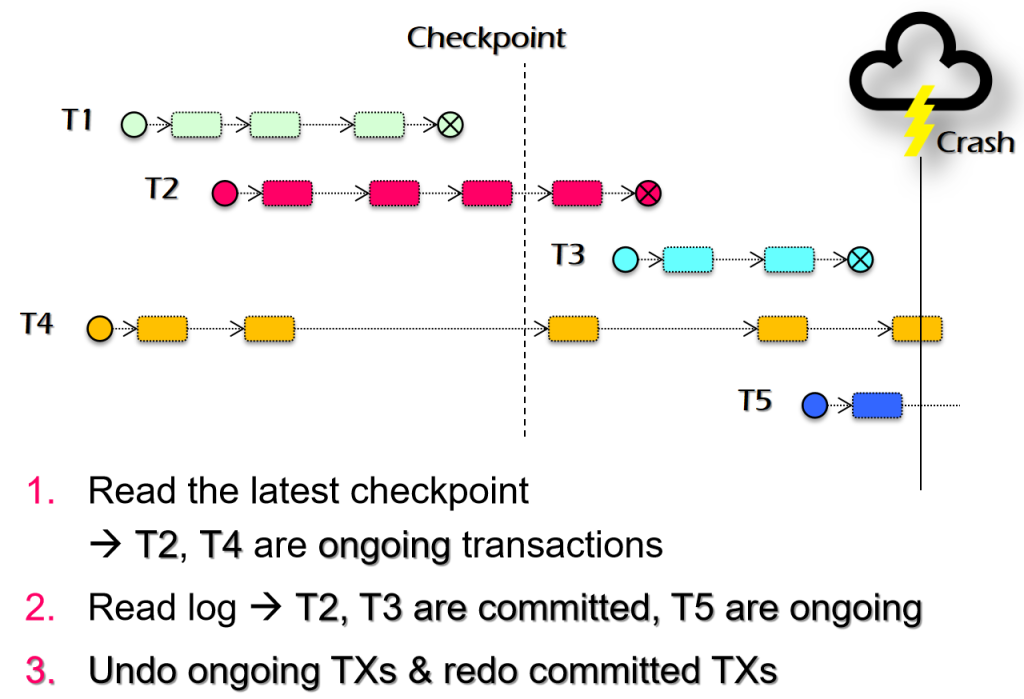
- ه¯¹ن؛ژT1ه·²ç»ڈه®Œوˆگ,都ن¸چ需è¦پهپڑ
- T2,需è¦په¯¹checkpointن»¥هگژçڑ„部هˆ†ï¼Œè؟›è،Œوپ¢ه¤چ
- T3,ن»ژè‡ھه·±çڑ„log entriesé‡چو–°وپ¢ه¤چ
- T4,و ¹وچ®CKPه’ŒLog entriesن¸€èµ·وپ¢ه¤چ
- T5,直وژ¥ن»ژlog里é¢
- T1: do nothing
T2: redo its update based on the log in its checkpoint
T3: redo its updates based on the log entries
T4: undo its updates based on the log in both CKP & log entries
T5: undo its updates based on the log entries
ه¯¹و¯”و€»ç»“
Redo-onlyو—¥ه؟—è®°ه½•ï¼ڑ
- و‰§è،Œوœںé—´ï¼ڑ相و¯”ن؛ژUndo-redoو—¥ه؟—è®°ه½•ï¼ŒRedo-onlyو—¥ه؟—è®°ه½•éœ€è¦پçڑ„ç£پç›کو“چن½œو›´ه°‘,ه› و¤و›´ه؟«م€‚
- وپ¢ه¤چوœںé—´ï¼ڑهڈھ需è¦پن¸€و¬،و‰«وڈڈو•´ن¸ھو—¥ه؟—و–‡ن»¶ï¼Œوپ¢ه¤چé€ںه؛¦ن¹ں相ه¯¹è¾ƒه؟«م€‚
- ه؛”用هœ؛و™¯ï¼ڑRedo-onlyو—¥ه؟—è®°ه½•é€ڑه¸¸وک¯é¦–选,除ééپ‡هˆ°هŒ…هگ«ه¤§é‡ڈه†…هکçٹ¶و€پçڑ„ن؛‹هٹ،م€‚
Undo-onlyو—¥ه؟—è®°ه½•ï¼ڑ
- و—¥ه؟—规هˆ™ï¼ڑ
- هœ¨ن؟®و”¹وŒپن¹…çٹ¶و€پن¹‹ه‰چ,ه…ˆè؟½هٹ Undoو—¥ه؟—è®°ه½•م€‚
- çٹ¶و€پن؟®و”¹ه؟…é،»هœ¨ن؛‹هٹ،وڈگن؛¤ن¹‹ه‰چ被هˆ·و–°هˆ°ç£پç›کم€‚
- و²،وœ‰Redoéک¶و®µم€‚
- ه؛”用频çژ‡ï¼ڑه¾ˆه°‘ن½؟用م€‚
- و‰§è،Œوœںé—´ï¼ڑو¯”Undo-Redoو—¥ه؟—è®°ه½•و…¢ه¾—ه¤ڑم€‚
- وپ¢ه¤چوœںé—´ï¼ڑوپ¢ه¤چé€ںه؛¦è¾ƒه؟«م€‚
Before-or-after atomicity
The overall behavior is equivalent to some serial behavior
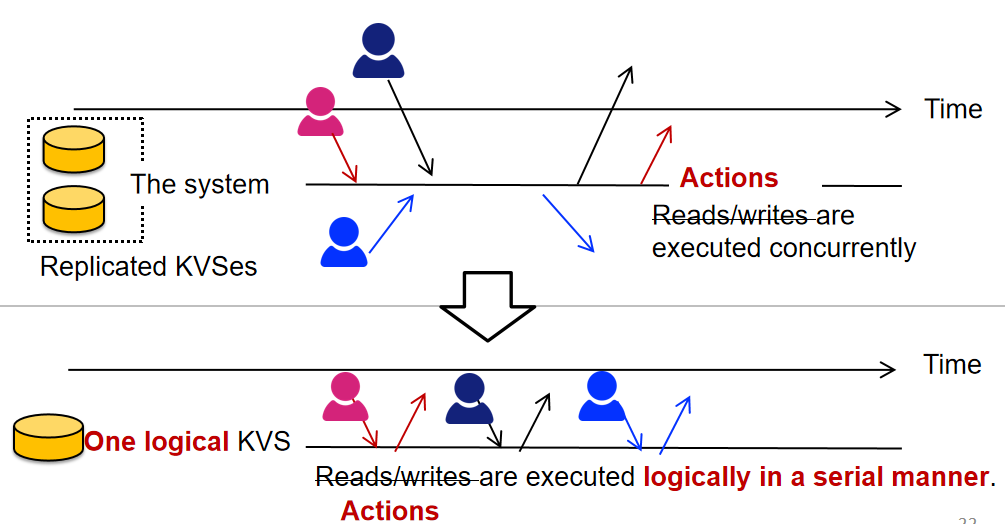
ه¯¹ن؛ژه¤ڑç؛؟程,هڈ¯ن»¥ç‰ن»·وˆگن¸؛ن¸€ن¸ھهچ•ç؛؟程,ن¸چن»…وک¯è¯»ه†™م€‚
race conditioné—®é¢ک
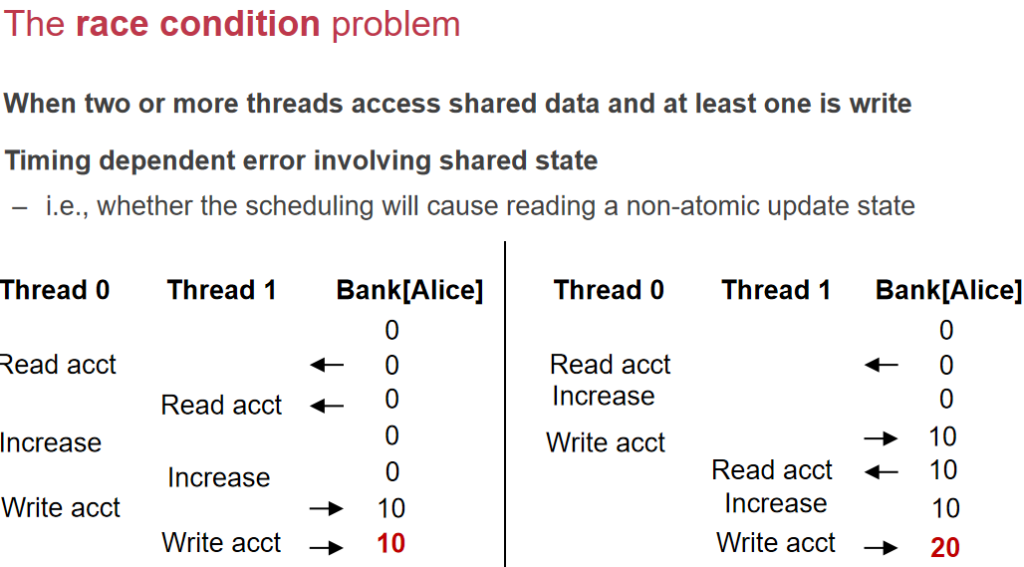
ç»ڈه…¸é—®é¢ک,ه¤ڑن¸ھن؛؛ه¯¹ن¸€ن¸ھه€¼هگŒو—¶هٹ ,ن¸”و²،وœ‰و³¨و„ڈهˆ°هڈ¦ن¸€ن¸ھن؛؛ن؟®و”¹ï¼Œو²،وœ‰ن؟è¯پهٹ çڑ„هژںهگو€§م€‚و¯”ه¦‚说ه¾®ن؟،وژ¥é¾™ï¼Œن¹ںوœ‰è؟™و ·çڑ„é—®é¢کم€‚
- ه؟…é،»ç،®ن؟و‰€وœ‰هڈ¯èƒ½çڑ„è°ƒه؛¦éƒ½وک¯ه®‰ه…¨çڑ„م€‚
- هڈ¯èƒ½çڑ„è°ƒه؛¦وژ’هˆ—و•°é‡ڈه·¨ه¤§م€‚
- وœ‰ن؛›ن¸چ良调ه؛¦ن¼ڑه¯¼è‡´ç³»ç»ںه´©و؛ƒï¼Œوœ‰ن؛›هˆ™ن¸چن¼ڑ,وƒ…ه†µوœ‰و—¶وک¯ن¸چ稳ه®ڑçڑ„م€‚
- هœ¨è°ƒç”¨ن¹‹é—´çڑ„ه°ڈو—¶é—´هڈکهŒ–هڈ¯èƒ½ه¯¼è‡´ن¸چهگŒçڑ„è،Œن¸؛,è؟™هڈ¯èƒ½éڑگè—ڈن؛†é”™è¯¯ï¼ˆن¾‹ه¦‚,Therac-25ن؛‹و•…)م€‚
- è؟™ن؛›é”™è¯¯ن¹ں被称ن¸؛“وµ·و£®bugâ€ï¼ˆHeisenbugs),و؛گè‡ھوµ·و£®ه ،çڑ„ن¸چç،®ه®ڑو€§هژںçگ†م€‚
- هڈ¯èƒ½çڑ„ç³»ç»ں解ه†³و–¹و،ˆ-1ï¼ڑDMT(ç،®ه®ڑو€§ه¤ڑç؛؟程)م€‚
- هڈ¯èƒ½çڑ„ç³»ç»ں解ه†³و–¹و،ˆ-2ï¼ڑè®°ه½•ه’Œé‡چو”¾م€‚
- è؟™ن¸¤ç§چ解ه†³و–¹و،ˆهœ¨و£ç،®و€§وˆ–وˆگوœ¬و–¹é¢éƒ½ه¾ˆéڑ¾ه®çژ°ï¼Œوˆ–者ن¸¤è€…都وœ‰é—®é¢کم€‚
before-or-after atomictity
ن¸؛ن؛†éک²و¢ç”±ç«و€پو،ن»¶ï¼ˆrace condition)ه¼•هڈ‘çڑ„هچ±é™©ï¼Œوˆ‘ن»¬éœ€è¦پن¸€ç»„读/ه†™و“چن½œوک¯هژںهگçڑ„م€‚
- ن¾‹ه¦‚,ن¸چ能看هˆ°وˆ–覆盖ه¹¶هڈ‘و“چن½œçڑ„ن¸é—´çٹ¶و€پم€‚
- ن¸€ن¸ھه¹¶هڈ‘و“چن½œهڈ¯èƒ½هŒ…هگ«ه¤ڑن¸ھهڈ¯ن»¥ç؛؟و€§هŒ–çڑ„读/ه†™م€‚
ه¹¶هڈ‘و“چن½œه…·وœ‰ه‰چهگژه±و€§ï¼Œه¦‚وœن»ژ调用者çڑ„视角و¥çœ‹ï¼Œو“چن½œçڑ„و•ˆوœه°±هƒڈوک¯ه®Œه…¨هœ¨هڈ¦ن¸€ن¸ھو“چن½œن¹‹ه‰چوˆ–ن¹‹هگژهڈ‘ç”ںçڑ„,而ن¸چوک¯éƒ¨هˆ†é‡چهڈ م€‚
ن¸ژLinearizabilityهŒ؛هˆ«
符هگˆLinearizability,ن½†ن¸چ符هگˆbefore-or-after
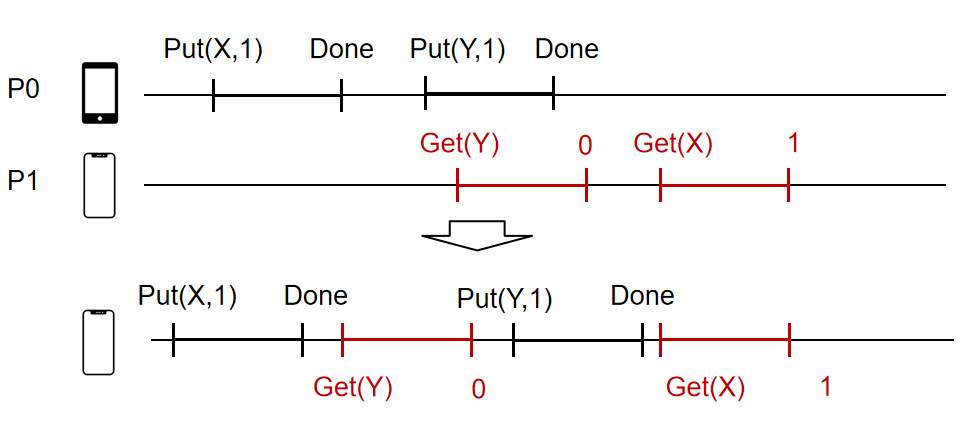
وˆ‘ن»¬ه°†ن¸€ç»„需è¦پهژںهگهŒ–çڑ„و“چن½œç§°ن¸؛“ن؛‹هٹ،â€م€‚
ن؛‹هٹ،é€ڑه¸¸ن¸؛ه؛”用程ه؛ڈوڈگن¾›وژ¥هڈ£ï¼Œن»¥و ‡è®°و“چن½œçڑ„هژںهگو€§ç²’ه؛¦ï¼ڑ
- TX.begin()
- TX.commit()
ه› و¤ï¼Œé€ڑه¸¸وƒ…ه†µن¸‹ï¼Œن؛‹هٹ،ه؟…é،»هگŒو—¶وڈگن¾›â€œه…¨وœ‰وˆ–ه…¨و— â€ï¼ˆall-or-nothing)ه’Œâ€œه‰چهگژهژںهگو€§â€ï¼ˆbefore-or-after)çڑ„特و€§ï¼Œن¹ںه°±وک¯ ACIDم€‚
解ه†³و–¹ه¼ڈ
ن½؟用é”پو¥ه®çژ°ه‰چهگژهژںهگو€§ï¼ڑه…¨ه±€é”پ
é”پï¼ڑن¸€ç§چو•°وچ®ç»“و„,ه…پ许هœ¨ن»»و„ڈو—¶هˆ»هڈھوœ‰ن¸€ن¸ھCPUèژ·هڈ–该é”پم€‚
- 程ه؛ڈهڈ¯ن»¥èژ·هڈ–(acquire)ه’Œé‡ٹو”¾ï¼ˆrelease)é”پم€‚
- ه¦‚وœèژ·هڈ–ه¤±è´¥ï¼Œهˆ™CPUه°†ç‰ه¾…ç›´هˆ°وˆگهٹںèژ·هڈ–é”پم€‚
- ç¤؛ن¾‹ï¼ڑ
pthread_mutexم€‚
ه…¨ه±€é”پï¼ڑ
- و“چن½œهœ¨و‰§è،Œه‰چه؟…é،»èژ·هڈ–ه…¨ه±€é”پ,ه®Œوˆگهگژé‡ٹو”¾ه…¨ه±€é”پم€‚
ن»£ç پç¤؛ن¾‹
ه·¦ن¾§وک¯هژںه§‹çڑ„depositه‡½و•°ن»£ç پï¼ڑ
plaintextه¤چهˆ¶ن»£ç پDeposit(bank, acct, amt):
bank[acct] += amt
هڈ³ن¾§وک¯و·»هٹ ه…¨ه±€é”پهگژçڑ„ن»£ç پï¼ڑ
plaintextه¤چهˆ¶ن»£ç پDeposit(bank, lock, acct, amt):
acquire(lock)
bank[acct] += amt
release(lock)
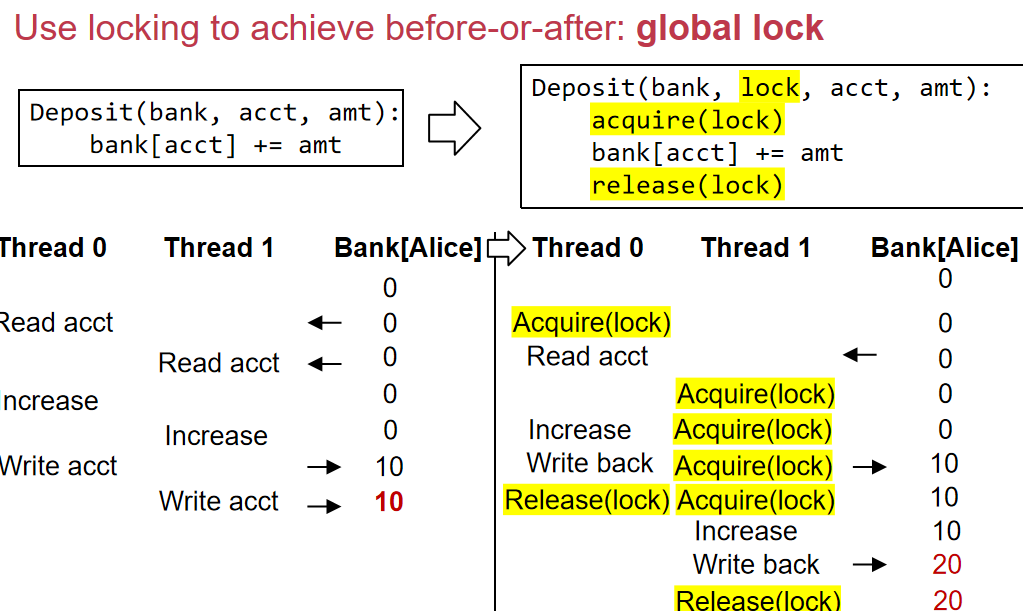
و¯ڈن¸ھه…±ن؛«و•°وچ®éƒ½وœ‰ن¸€ن¸ھé”پ,称ن¸؛fine-grained locking
ن½†ه¯¹ن؛ژن¸é—´وƒ…ه†µï¼Œن¸چهڈ¯ن»¥è¯»ï¼Œن¸چ然è؟کوک¯ن¼ڑوœ‰é—®é¢ک

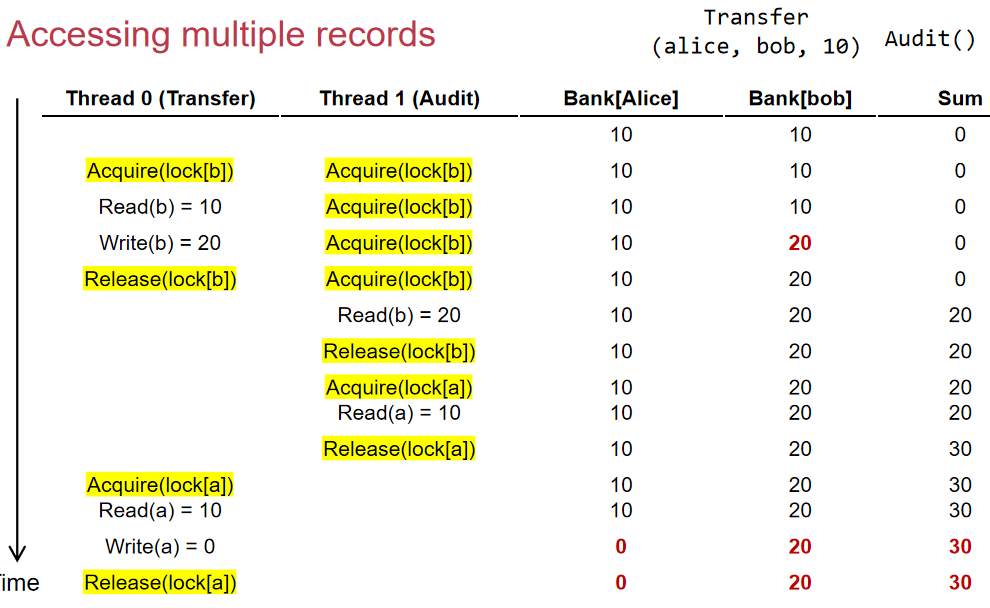
و ¸ه؟ƒé—®é¢کï¼ڑ
- 简هچ•çڑ„细粒ه؛¦é”په¹¶ن¸چ能éک²و¢ن¸é—´ç»“وœçڑ„وڑ´éœ²م€‚
è§پ解ï¼ڑ
- وˆ‘ن»¬éœ€è¦په»¶è؟ںو¯ڈن¸ھه…±ن؛«و•°وچ®çڑ„é”پé‡ٹو”¾و—¶é—´ï¼Œç›´هˆ°و‰€وœ‰ن؛‹هٹ،çڑ„و›´و–°ه®Œوˆگم€‚
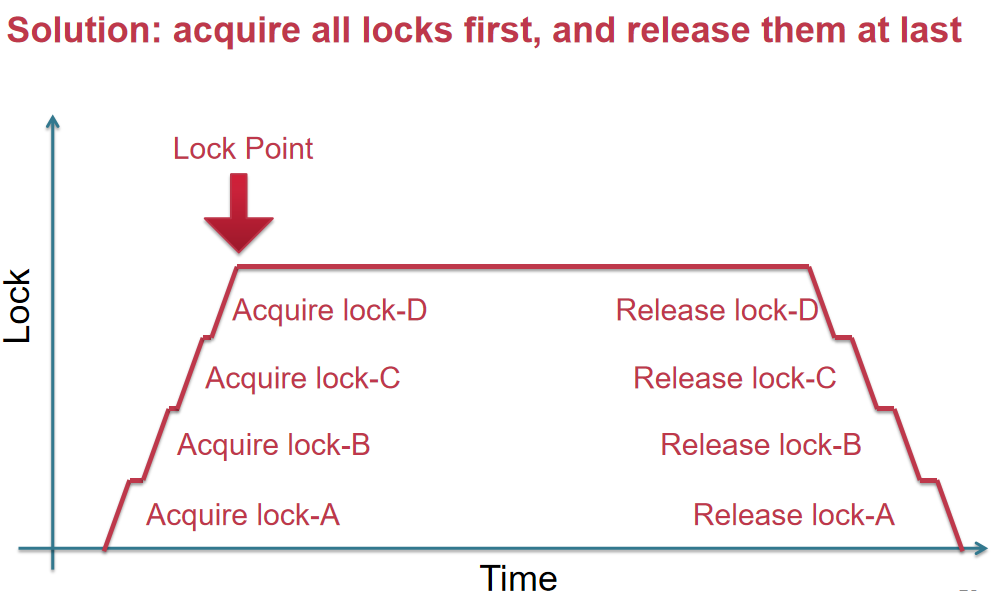
Two-phase locking (2PL)
2PLé”پèژ·هڈ–规هˆ™ï¼ڑ
该و“چن½œه؟…é،»هœ¨è®؟é—®ه…±ن؛«و•°وچ®ن¹‹ه‰چèژ·هڈ–ه…¶é”پ,ه¹¶é‡ٹو”¾ه®ƒï¼Œç›´هˆ°و‰€وœ‰و“چن½œه®Œوˆگ
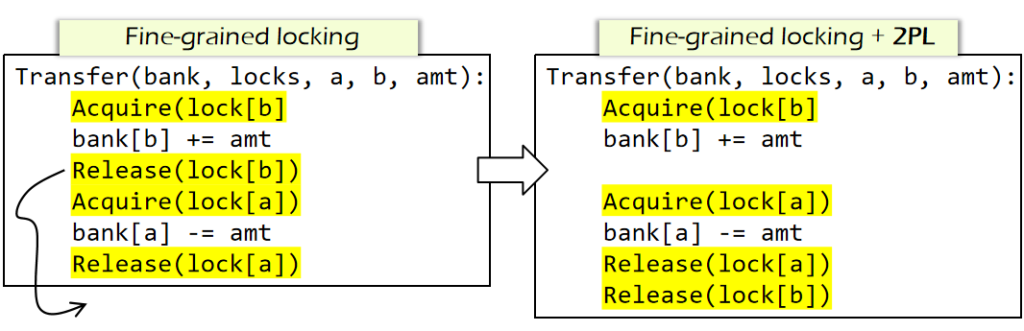
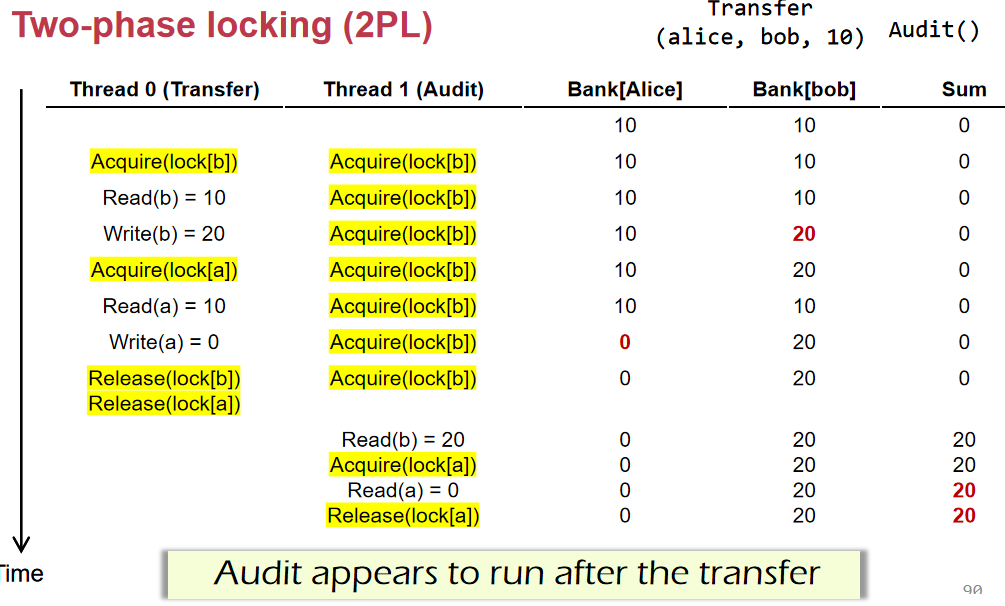
و€»هچ 用é”پو—¶é—´وکژوک¾ه‡ڈه°‘


ه؛ڈهˆ—


ه°½ç®،وœ€ç»ˆç»“وœوک¯ه¯¹çڑ„,ن½†وک¯ن¸é—´ç»“وœن¸چن¸€ه®ڑه¯¹ï¼Œه…·ن½“è؟کوک¯è¦پ看用وˆ·ï¼Œè¦پ符هگˆن¸²è،Œçڑ„结وœï¼Œن¸؛ن؛†هŒ؛هˆ«ن¸چهگŒçڑ„,ه®ڑن¹‰ن؛†ن¸‰ç§چSerializabilityو¨،ه‹
Final-state serializability
ه¦‚وœن¸€ن¸ھè°ƒه؛¦çڑ„وœ€ç»ˆه†™ه…¥çٹ¶و€پن¸ژوںگن¸ھن¸²è،Œè°ƒه؛¦çڑ„وœ€ç»ˆçٹ¶و€پ相هگŒï¼Œé‚£ن¹ˆè؟™ن¸ھè°ƒه؛¦وک¯وœ€ç»ˆçٹ¶و€پن¸²è،ŒهŒ–çڑ„م€‚
Conflict serializability(وœ€ه¸¸ç”¨ï¼‰
هœ¨ن»¥ن¸‹وƒ…ه†µن¸‹ï¼Œن¸¤ن¸ھو“چن½œن¼ڑهڈ‘ç”ںه†²çھپï¼ڑ
- ه®ƒن»¬ه¯¹هگŒن¸€و•°وچ®ه¯¹è±،è؟›è،Œو“چن½œï¼Œن»¥هڈٹ
- ه…¶ن¸è‡³ه°‘وœ‰ن¸€ن¸ھوک¯ه†™çڑ„,ه¹¶ن¸”
- ه®ƒن»¬ه±ن؛ژن¸چهگŒçڑ„ن؛¤وک“
ه†²çھپهڈ¯ن¸²è،ŒهŒ–
ه¦‚وœن¸€ن¸ھè°ƒه؛¦çڑ„ه†²çھپé،؛ه؛ڈ(هچ³ه†²çھپو“چن½œهڈ‘ç”ںçڑ„é،؛ه؛ڈ)ن¸ژوںگن¸ھن¸²è،Œè°ƒه؛¦ن¸çڑ„ه†²çھپé،؛ه؛ڈ相هگŒï¼Œé‚£ن¹ˆè؟™ن¸ھè°ƒه؛¦وک¯ه†²çھپهڈ¯ن¸²è،ŒهŒ–çڑ„م€‚

conflictه…³ç³»ï¼Œé€ڑè؟‡conflictه…³ç³»ï¼Œهڈ¯ن»¥و„ه»؛ن¸€ن¸ھه›¾
ه†²çھپه›¾
- èٹ‚点è،¨ç¤؛ن؛‹هٹ،,边وک¯وœ‰هگ‘çڑ„م€‚
- ه¦‚وœن¸”ن»…ه¦‚وœن»¥ن¸‹ن¸¤ç‚¹éƒ½وˆگ立,هˆ™هœ¨Tiه’ŒTjن¹‹é—´هکهœ¨ن¸€و،è¾¹ï¼ڑ
- Ti​ه’ŒTj​ن¹‹é—´هکهœ¨ه†²çھپم€‚
- ه†²çھپçڑ„第ن¸€ن¸ھو¥éھ¤هڈ‘ç”ںهœ¨Tiن¸م€‚
ن¸€ن¸ھè°ƒه؛¦وک¯ه†²çھپهڈ¯ن¸²è،ŒهŒ–çڑ„,ه½“ن¸”ن»…ه½“ï¼ڑ
- ه®ƒçڑ„ه†²çھپه›¾وک¯و— çژ¯çڑ„م€‚
ه†²çھپç‰ن»·
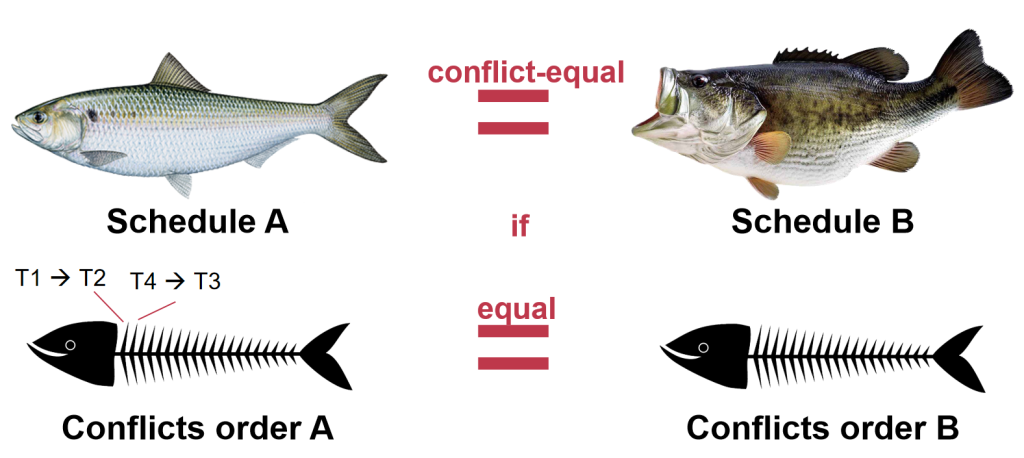
ه†²çھپç‰ن»·çڑ„و ¸ه؟ƒوک¯و¯”较ن¸¤ن¸ھè°ƒه؛¦ن¸ه†²çھپو“چن½œçڑ„相ه¯¹é،؛ه؛ڈ,而ن¸چوک¯و“چن½œçڑ„ه…·ن½“ه†…ه®¹م€‚هڈھè¦پن¸¤ن¸ھè°ƒه؛¦çڑ„ه†²çھپé،؛ه؛ڈن¸€è‡´ï¼Œه®ƒن»¬ه°±هڈ¯ن»¥è¢«è®¤ن¸؛وک¯ç‰ن»·çڑ„
View serializability
ه‡ ن¹ژو²،ن؛؛用,و¯”较éڑ¾هˆ¤هˆ«
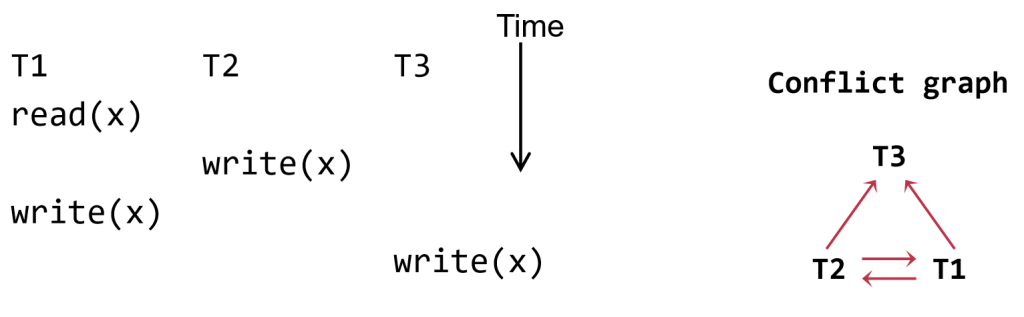
T1م€پT2 ه’Œ T3 ن¹‹é—´çڑ„ه†²çھپه…³ç³»م€‚ç”±ن؛ژن¾èµ–ه…³ç³»ه½¢وˆگن؛†ن¸€ن¸ھه¾ھçژ¯ï¼ˆcyclic),ه› و¤è؟™ن¸ھè°ƒه؛¦ ن¸چوک¯ه†²çھپهڈ¯ن¸²è،ŒهŒ–çڑ„,ه› ن¸؛و— و³•و‰¾هˆ°ن¸€ن¸ھو— ه¾ھçژ¯çڑ„é،؛ه؛ڈو¥è§£ه†³ه†²çھپم€‚
ه¦‚وœن¸€ن¸ھè°ƒه؛¦çڑ„وœ€ç»ˆه†™ه…¥çٹ¶و€پن»¥هڈٹن¸é—´çڑ„读هڈ–و“چن½œن¸ژوںگن¸ھن¸²è،Œè°ƒه؛¦ç›¸هگŒï¼Œé‚£ن¹ˆè؟™ن¸ھè°ƒه؛¦وک¯è§†ه›¾هڈ¯ن¸²è،ŒهŒ–çڑ„م€‚
و£ه¼ڈه®ڑن¹‰ï¼ڑ
- ن¸¤ن¸ھè°ƒه؛¦ S ه’Œ S′ وک¯è§†ه›¾ç‰ن»·çڑ„(View Equivalent),ه½“ن»¥ن¸‹و،ن»¶و»،足ï¼ڑ
- هœ¨è°ƒه؛¦ S ن¸ï¼Œه¦‚وœن؛‹هٹ، Ti 读هڈ–ن؛†وںگن¸ھو•°وچ®é،¹ X çڑ„هˆه§‹ه€¼ï¼Œé‚£ن¹ˆهœ¨ S′ن¸ Tiن¹ںè¦پ读هڈ–Xçڑ„هˆه§‹ه€¼م€‚
- هœ¨è°ƒه؛¦ S ن¸ï¼Œه¦‚وœن؛‹هٹ، Ti读هڈ–ن؛†ç”±ن؛‹هٹ، Tjه†™ه…¥çڑ„و•°وچ®é،¹ X,那ن¹ˆهœ¨ S′ ن¸ Ti ن¹ںه؟…é،»è¯»هڈ–ç”± Tj​ ه†™ه…¥çڑ„ Xم€‚
- هœ¨è°ƒه؛¦ S ن¸ï¼Œه¦‚وœن؛‹هٹ، Tiوک¯ه¯¹ X هپڑه‡؛وœ€ç»ˆه†™ه…¥çڑ„ن؛‹هٹ،,那ن¹ˆهœ¨ S′ ن¸ن¹ںè¦پوک¯ Ti ه¯¹ X هپڑوœ€ç»ˆه†™ه…¥م€‚

Proof of 2PL
هپ‡è®¾ï¼ڑ
- هپ‡è®¾ 2PL ن¸چ能ç”ںوˆگه†²çھپهڈ¯ن¸²è،ŒهŒ–çڑ„è°ƒه؛¦م€‚
ه†²çھپه›¾ï¼ˆConflict Graph)ï¼ڑ
- هپ‡è®¾هœ¨و‰§è،Œ 2PL çڑ„è؟‡ç¨‹ن¸ن؛§ç”ںن؛†ن¸€ن¸ھه¾ھçژ¯ه†²çھپه›¾م€‚
- هپ‡è®¾وœ‰ن¸€ç»„ن؛‹هٹ، T1→T2→…→Tk→T1 و„وˆگن¸€ن¸ھه¾ھçژ¯ن¾èµ–ه…³ç³»م€‚
ه…±ن؛«هڈکé‡ڈ(ه†²çھپ资و؛گ)ï¼ڑ
- و¯ڈن¸¤ن¸ھ相邻çڑ„ن؛‹هٹ، Ti​ ه’Œ Ti+1​ ن¹‹é—´هکهœ¨ن¸€ن¸ھه…±ن؛«هڈکé‡ڈ xi ه¼•هڈ‘ن؛†ه†²çھپم€‚
- è؟™ن؛›ه…±ن؛«هڈکé‡ڈ用 x1,x2,…,xk​ è،¨ç¤؛م€‚
é”پèژ·هڈ–è؟‡ç¨‹ï¼ڑ
- و¯ڈن¸ھن؛‹هٹ،ن¾و¬،èژ·هڈ–ه…±ن؛«هڈکé‡ڈçڑ„é”پم€‚ن¾‹ه¦‚ï¼ڑ
T1èژ·هڈ– x1​ çڑ„é”پم€‚T2èژ·هڈ– x1ه’Œ x2​ çڑ„é”پم€‚T3èژ·هڈ– x2​ ه’Œ x3​ çڑ„é”پم€‚- ن»¥و¤ç±»وژ¨ï¼Œç›´هˆ°
T_kèژ·هڈ– xk−1​ ه’Œ xk​ çڑ„é”پم€‚
è؟هڈچ 2PL çڑ„وƒ…ه†µï¼ڑ
- ه¦‚وœ
T1هœ¨ه®Œوˆگوںگن؛›و“چن½œهگژé‡ٹو”¾ن؛† x1​ çڑ„é”پ(ه¦‚ه›¾و‰€ç¤؛),è؟™ه°±ن¼ڑè؟هڈچ 2PL,ه› ن¸؛هœ¨ن¸¤éک¶و®µé”پهچڈè®®ن¸ï¼Œن؛‹هٹ،هœ¨é‡ٹو”¾ن»»ن½•é”پن¹‹هگژ,ن¸چه…پ许ه†چèژ·هڈ–و–°çڑ„é”پم€‚ - è؟™é‡Œ
T1é‡ٹو”¾ن؛† x1 çڑ„é”پ,ن½†ن¹‹هگژهڈˆه°è¯•èژ·هڈ– xkx_kxk​ çڑ„é”پ,è؟™è؟هڈچن؛† 2PL çڑ„规هˆ™م€‚
结è®؛ï¼ڑ
- ه› و¤ï¼Œè؟™ç§چوƒ…ه†µن¸چهڈ¯èƒ½هڈ‘ç”ں,ه› ن¸؛ه®ƒن¼ڑه¯¼è‡´ 2PL هچڈè®®çڑ„è؟هڈچم€‚
- ç”±ن؛ژ 2PL ن؟è¯پن¸چن¼ڑن؛§ç”ںè؟™ç§چه¾ھçژ¯çڑ„ه†²çھپه›¾ï¼Œو‰€ن»¥هڈ¯ن»¥ه¾—ه‡؛结è®؛ï¼ڑ 2PL ه®é™…ن¸ٹهڈ¯ن»¥ç”ںوˆگه†²çھپهڈ¯ن¸²è،ŒهŒ–çڑ„è°ƒه؛¦ï¼Œن»ژ而هڈچè¯پن؛†وœ€هˆçڑ„هپ‡è®¾وک¯é”™è¯¯çڑ„م€‚
ه¹»è¯»é—®é¢ک(Phantom Problem)ï¼ڑ
- é—®é¢کوڈڈè؟°ï¼ڑ
- 虽然é”پن½ڈن؛†و•°وچ®ï¼Œو— و³•ن؟®و”¹ï¼Œن½†وک¯ه¦‚وœوڈ’ه…¥éکںهˆ—,هœ¨èژ·هڈ–éکںهˆ—و—¶ه€™ه°±ن¼ڑوœ‰é—®é¢ک
- ه†²çھپه®ڑن¹‰ï¼ڑ
- ن¸¤ن¸ھو“چن½œهڈ‘ç”ںه†²çھپçڑ„و،ن»¶وک¯ه®ƒن»¬è®؟问相هگŒçڑ„و•°وچ®é،¹ï¼Œن¸”至ه°‘ه…¶ن¸ن¸€ن¸ھوک¯ه†™و“چن½œم€‚
- و•°وچ®é،¹ çڑ„ه®ڑن¹‰وک¯وٹ½è±،çڑ„,ه®ƒهڈ¯ن»¥وک¯وںگن¸ھه…·ن½“و•°وچ®ï¼Œن¹ںهڈ¯ن»¥وک¯و•´ن¸ھو•°وچ®ه؛“م€‚ه› و¤ï¼Œé”په®ڑوœ؛هˆ¶ه؛”ه½“能ه¤ںوچ•وچ‰و‰€وœ‰هڈ¯èƒ½çڑ„ه†²çھپ,ç،®ن؟ن؛‹هٹ،çڑ„ه…ˆهگژé،؛ه؛ڈن¸چ被و‰“ç ´م€‚
- 解ه†³و–¹و،ˆï¼ڑ
- è°“è¯چé”پ(Predicate Locking)ï¼ڑهں؛ن؛ژو،ن»¶é”په®ڑو»،足特ه®ڑè°“è¯چçڑ„و•°وچ®é،¹م€‚ن¾‹ه¦‚,é”په®ڑو‰€وœ‰â€œه·¥èµ„ > 5000â€çڑ„è®°ه½•ï¼Œéک²و¢ه…¶ن»–ن؛‹هٹ،وڈ’ه…¥و–°çڑ„符هگˆو،ن»¶çڑ„و•°وچ®é،¹م€‚
- B-و ‘ç´¢ه¼•ن¸çڑ„范ه›´é”پ(Range Locks in a B-tree index)ï¼ڑهپ‡è®¾هœ¨وںگن¸ھه±و€§ï¼ˆه¦‚“ه·¥èµ„â€ï¼‰ن¸ٹوœ‰ç´¢ه¼•ï¼Œهڈ¯ن»¥é”په®ڑن¸€ن¸ھ范ه›´ï¼Œéک²و¢ه…¶ن»–ن؛‹هٹ،هœ¨و¤èŒƒه›´ه†…وڈ’ه…¥و–°çڑ„و•°وچ®ï¼›وˆ–者,直وژ¥é”په®ڑو•´ن¸ھè،¨م€‚
- وœ‰و—¶هœ¨ه®è·µن¸è¢«ه؟½ç•¥ï¼ڑهœ¨ه®é™…ه؛”用ن¸ï¼Œه¹»ه½±é—®é¢کوœ‰و—¶ن¼ڑ被ه؟½è§†ï¼Œه°¤ه…¶وک¯هœ¨ن¸€ن؛›ه¯¹ن¸€è‡´و€§è¦پو±‚较ن½ژçڑ„هœ؛و™¯ن¸م€‚
2PL هڈ¯ن»¥ن؟è¯په†²çھپهڈ¯ن¸²è،ŒهŒ–,ن½†ه؟…é،»ç،®ن؟ه†²çھپé€ڑè؟‡é”پوœ؛هˆ¶ه¾—هˆ°ه¦¥ه–„هچڈè°ƒم€‚
Deadlock
هœ¨ç»§ç»و‰§è،Œن¹‹ه‰چ,و¯ڈن¸ھن؛‹هٹ،(TX)ه؟…é،»ç‰ه¾…ه†²çھپçڑ„ن؛‹هٹ،é‡ٹو”¾é”پم€‚
ç”±ن؛ژ 2PL çڑ„و‚²è§‚特و€§ï¼Œهœ¨ن¸¤ن¸ھو“چن½œé—´ï¼Œه¦‚وœن¸€ن¸ھن؛‹هٹ،هœ¨ç‰ه¾…هڈ¦ن¸€ن¸ھن؛‹هٹ،é‡ٹو”¾é”پ(ن¾‹ه¦‚,ن¸¤ن¸ھن؛‹هٹ،都试ه›¾هگŒو—¶è®؟é—® a ه’Œ b,ن½†é،؛ه؛ڈن¸چهگŒï¼‰ï¼Œهڈ¯èƒ½ن¼ڑه‡؛çژ° و»é”پ çڑ„وƒ…ه†µم€‚
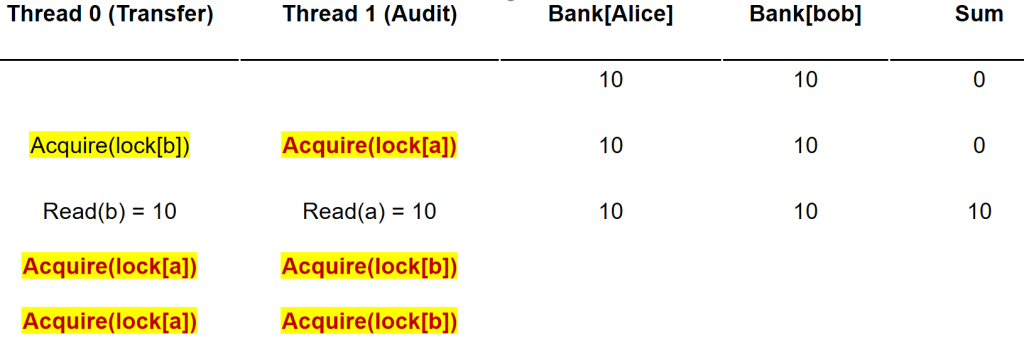
解ه†³و–¹و³•
- وŒ‰ç…§é¢„ه®ڑن¹‰é،؛ه؛ڈèژ·هڈ–é”پ(预éک²و–¹و³•ï¼‰
- ن¸چو”¯وŒپé€ڑ用çڑ„ن؛‹هٹ،ï¼ڑن؛‹هٹ،هœ¨و‰§è،Œه‰چه؟…é،»çں¥éپ“ه…¶è¯»/ه†™çڑ„集هگˆï¼Œه› ن¸؛é™چن½ژن؛†é€ںçژ‡
- é€ڑè؟‡è®،ç®—ه†²çھپه›¾و¥و£€وµ‹و»é”پ(و£€وµ‹و–¹و³•ï¼‰
- ه¦‚وœهکهœ¨ه¾ھçژ¯ï¼Œé‚£ن¹ˆن¸€ه®ڑوœ‰و»é”پم€‚
- 终و¢ن¸€ن¸ھن؛‹هٹ،و¥و‰“ç ´ه¾ھçژ¯م€‚
- ن¸€èˆ¬ن½؟用و¯”较ه°‘,ه› ن¸؛و£€وµ‹çڑ„وˆگوœ¬è¾ƒé«کم€‚
- ن½؟用هگ¯هڈ‘ه¼ڈ(heuristics)و–¹و³•ï¼ˆن¾‹ه¦‚و—¶é—´وˆ³ï¼‰é¢„ه…ˆن¸و¢ن؛‹هٹ،(é‡چ试و–¹و³•ï¼‰
- هڈ¯èƒ½ن¼ڑه‡؛çژ°è¯¯هˆ¤وˆ–و´»é”پçڑ„وƒ…ه†µم€‚
و»é”پï¼ڑهœ¨ه®é™…ن¸ï¼Œو»é”پé€ڑه¸¸ه¾ˆéڑ¾é¢„éک²ه’Œو£€وµ‹م€‚
é”په¼€é”€ï¼ڑé”په¸¦و¥çڑ„é¢ه¤–ه¼€é”€ï¼ˆهŒ…و‹¬èژ·هڈ–é”په’Œç‰ه¾…é”پé‡ٹو”¾çڑ„و—¶é—´ï¼‰م€‚
ن¸ٹè؟° 2PL(ن¸¤éک¶و®µé”پهچڈ议)问é¢کçڑ„و ¹وœ¬هژںه› وک¯ï¼ڑ
- 2PL é€ڑè؟‡ن¸€ç§چو‚²è§‚çڑ„و–¹ه¼ڈو¥éپ؟ه…چç«ن؛‰و،ن»¶ï¼ˆRace Conditions)م€‚
Optimistic concurrency control
OCC(ن¹گ观ه¹¶هڈ‘وژ§هˆ¶ï¼‰ن»¥ن¸‰ن¸ھéک¶و®µو‰§è،Œن؛‹هٹ،
- 第ن¸€éک¶و®µï¼ڑه¹¶هڈ‘çڑ„وœ¬هœ°ه¤„çگ†
- ه°†è¯»هڈ–çڑ„و•°وچ®هکه…¥â€œè¯»هڈ–集â€م€‚
- ه°†ه†™ه…¥و“چن½œوڑ‚هکهˆ°â€œه†™ه…¥é›†â€ن¸م€‚
- 第ن؛Œéک¶و®µï¼ڑهœ¨ه…³é”®هŒ؛ن¸éھŒè¯پن¸²è،ŒهŒ–
- éھŒè¯پوک¯هگ¦ن؟è¯پن؛†ن¸²è،ŒهŒ–(ن؛‹هٹ،独立و€§ï¼‰م€‚
- و£€وں¥â€œè¯»هڈ–集â€ن¸çڑ„و•°وچ®وک¯هگ¦è¢«ن؟®و”¹è؟‡م€‚
- 第ن¸‰éک¶و®µï¼ڑهœ¨ه…³é”®هŒ؛ن¸وڈگن؛¤ç»“وœوˆ–ن¸و¢
- ه¦‚وœéھŒè¯په¤±è´¥ï¼Œهˆ™ن¸و¢ن؛‹هٹ،م€‚
- ه¦‚وœéھŒè¯پé€ڑè؟‡ï¼Œهˆ™ه°†â€œه†™ه…¥é›†â€ن¸çڑ„و•°وچ®ه†™ه…¥و•°وچ®ه؛“,ه¹¶وڈگن؛¤ن؛‹هٹ،م€‚
ن¼کهٹ؟
OCC(ن¹گ观ه¹¶هڈ‘وژ§هˆ¶ï¼‰هˆ†ن¸؛ن¸‰ن¸ھو¥éھ¤ï¼Œç،®ن؟ن؛‹هٹ،هœ¨و— é”پçڑ„وƒ…ه†µن¸‹ه¹¶هڈ‘و‰§è،Œï¼Œéپ؟ه…چن؛†é”په¸¦و¥çڑ„ه¼€é”€ه’Œو»é”پé—®é¢کï¼ڑ
- 第ن¸€éک¶و®µï¼ڑن؛‹هٹ،ه¼€ه§‹و—¶ï¼Œهœ¨وœ¬هœ°è؟›è،Œو•°وچ®è¯»هڈ–ه’Œه†™ه…¥çڑ„وڑ‚هک,ن¸چه¯¹ه®é™…و•°وچ®ه؛“هپڑو”¹هٹ¨ï¼Œه‡ڈه°‘ن؛†é”پçڑ„ن½؟用م€‚
- 第ن؛Œéک¶و®µï¼ڑهœ¨ن؛‹هٹ،وڈگن؛¤ن¹‹ه‰چ,è؟›ه…¥ه…³é”®هŒ؛è؟›è،Œو£€وں¥ï¼Œç،®ن؟读هڈ–çڑ„و•°وچ®و²،وœ‰è¢«ه…¶ن»–ن؛‹هٹ،ن؟®و”¹ï¼Œن»ژ而ن؟è¯پن¸€è‡´و€§م€‚ه¦‚وœو£€وµ‹هˆ°ه†²çھپ,هˆ™ه›و»ڑ该ن؛‹هٹ،م€‚
- 第ن¸‰éک¶و®µï¼ڑو ¹وچ®éھŒè¯پ结وœï¼Œه†³ه®ڑوڈگن؛¤وˆ–ن¸و¢ن؛‹هٹ،م€‚ه¦‚وœé€ڑè؟‡éھŒè¯پ,ه°†وڑ‚هکçڑ„و•°وچ®ه†™ه…¥و•°وچ®ه؛“,هگ¦هˆ™و”¾ه¼ƒè¯¥ن؛‹هٹ،م€‚
è؟™ç§چو–¹و³•é€‚用ن؛ژن½ژه†²çھپçڑ„çژ¯ه¢ƒï¼Œé€ڑè؟‡وژ¨è؟ںé”پو“چن½œو¥وڈگé«کç³»ç»ںو€§èƒ½م€‚
第ن¸€éک¶و®µï¼ڑه¹¶هڈ‘çڑ„وœ¬هœ°ه¤„çگ†
- 读هڈ–و“چن½œï¼ڑه°†è¯»هڈ–çڑ„و•°وچ®هٹ ه…¥â€œè¯»هڈ–集â€م€‚
- ه†™ه…¥و“چن½œï¼ڑه°†ه†™ه…¥و“چن½œوڑ‚هکهˆ°â€œه†™ه…¥é›†â€ن¸م€‚
é—®é¢کï¼ڑه¦‚وœهœ¨هگŒن¸€ن؛‹هٹ،ن¸ç¬¬ن؛Œو¬،读هڈ–هگŒن¸€ن¸ھو•°وچ®é،¹ï¼ˆه¦‚ A)و€ژن¹ˆهٹï¼ں
- ç”و،ˆï¼ڑç›´وژ¥ن»ژ读هڈ–集ن¸è¯»هڈ–,ه› ن¸؛读هڈ–集ن¸هڈ¯èƒ½ه·²ç»ڈهŒ…هگ«ن؛†ه½“ه‰چن؛‹هٹ،çڑ„ن؟®و”¹ه€¼م€‚
- ن¾‹ه¦‚,ه¦‚وœن؛‹هٹ،ه…ˆه†™ه…¥
A,然هگژه†چ读هڈ–A,系ç»ںن¼ڑن»ژ读هڈ–集ن¸èژ·هڈ–وœ€و–°ه€¼ï¼Œن»¥ç،®ن؟读هڈ–çڑ„وک¯è¯¥ن؛‹هٹ،ه†™ه…¥çڑ„ه€¼م€‚
第ن؛Œéک¶و®µï¼ڑهœ¨ه…³é”®هŒ؛ه†…éھŒè¯پن¸²è،ŒهŒ–
و¯”ه¦‚éپ‡هˆ°ABAé—®é¢ک,و•°وچ®è¢«ه…¶ن»–ç؛؟程ن؟®و”¹هگژهڈˆن؟®و”¹ه›و£ç،®çڑ„ه€¼ï¼Œè؟™و—¶ه€™éœ€è¦پ读هڈ–هڈکهŒ–
- ن؛‹هٹ،è؟›ه…¥ه…³é”®هŒ؛,éھŒè¯په…¶و“چن½œçڑ„ن¸²è،ŒهŒ–,ç،®ن؟و²،وœ‰ه†²çھپم€‚
- و£€وں¥â€œè¯»هڈ–集â€ن¸çڑ„و‰€وœ‰و•°وچ®é،¹وک¯هگ¦هœ¨ن؛‹هٹ،و‰§è،Œوœں间被ه…¶ن»–ن؛‹هٹ،ن؟®و”¹è؟‡م€‚
- ه¦‚وœن»»ن½•و•°وچ®هœ¨è¯»هڈ–集ن¸هڈ‘ç”ںن؛†هڈکهŒ–,هˆ™è¯¥ن؛‹هٹ،و— و³•ن؟è¯پن¸²è،ŒهŒ–,需è¦پن¸و¢م€‚
第ن¸‰éک¶و®µï¼ڑهœ¨ه…³é”®هŒ؛ه†…وڈگن؛¤وˆ–ن¸و¢ن؛‹هٹ،
- ن¸و¢ï¼ڑه¦‚وœç¬¬ن؛Œéک¶و®µçڑ„éھŒè¯په¤±è´¥ï¼Œهˆ™ن¸و¢è¯¥ن؛‹هٹ،م€‚
- وڈگن؛¤ï¼ڑه¦‚وœéھŒè¯پوˆگهٹں,هˆ™ه°†ه†™ه…¥é›†ن¸çڑ„و•°وچ®ه†™ه…¥و•°وچ®ه؛“,وڈگن؛¤è¯¥ن؛‹هٹ،م€‚
و³¨و„ڈï¼ڑ第ن؛Œéک¶و®µه’Œç¬¬ن¸‰éک¶و®µه؟…é،»هœ¨ه…³é”®هŒ؛ه†…و‰§è،Œم€‚
é—®é¢کن¸ژ解ه†³و–¹ه¼ڈ
第ن؛Œéک¶و®µه’Œç¬¬ن¸‰éک¶و®µه؟…é،»هœ¨ه…³é”®هŒ؛ه†…و‰§è،Œم€‚هگ¦هˆ™ï¼Œه¦‚وœهœ¨éھŒè¯په’Œوڈگن؛¤ن¹‹é—´وœ‰ه…¶ن»–ن؛‹هٹ،ن؟®و”¹ن؛†و•°وچ®ï¼Œهڈ¯èƒ½ه¯¼è‡´و•°وچ®ن¸چن¸€è‡´م€‚

ه…¨ه±€é”پ
- 第ن؛Œéک¶و®µه’Œç¬¬ن¸‰éک¶و®µçڑ„و‰§è،Œو—¶é—´é€ڑه¸¸ه¾ˆçںم€‚
- è؟™ن¸¤ن¸ھéک¶و®µن»…هŒ…هگ«éھŒè¯پ逻辑,而ن¸چو¶‰هڈٹن؛‹هٹ،çڑ„ه®é™…و‰§è،Œé€»è¾‘م€‚
ن»£ç پç¤؛ن¾‹ï¼ڑ
pythonه¤چهˆ¶ن»£ç پdef validate_and_commit(): # 第ن؛Œéک¶و®µه’Œç¬¬ن¸‰éک¶و®µ
global_lock.lock() # èژ·هڈ–ه…¨ه±€é”پ
for d in read_set:
if d has changed:
abort() # ه¦‚وœè¯»هڈ–çڑ„و•°وچ®هڈ‘ç”ںو”¹هڈک,هˆ™ن¸و¢
for d in write_set:
write(d) # ه°†ه†™ه…¥é›†çڑ„و•°وچ®ه†™ه…¥و•°وچ®ه؛“
global_lock.unlock() # é‡ٹو”¾ه…¨ه±€é”پ
ن½؟用ن¸¤éک¶و®µé”په®çژ°ه…³é”®هŒ؛(Phase 2 & 3)
ن½؟用ن¸¤éک¶و®µé”پ(2PL)ï¼ڑé€ڑè؟‡ن¸¤éک¶و®µé”پهڈ¯ن»¥ه¢هٹ ه¹¶هڈ‘و€§م€‚
é—®é¢کï¼ڑن½؟用ن¸¤éک¶و®µé”پهڈ¯èƒ½ن¼ڑه¸¦و¥و»é”پé—®é¢کم€‚
ن»£ç پç¤؛ن¾‹ï¼ڑ
pythonه¤چهˆ¶ن»£ç پdef validate_and_commit(): # Phase 2 & 3
for d in read_set:
d.lock() # ه¯¹è¯»هڈ–集ن¸çڑ„و¯ڈن¸ھو•°وچ®é،¹هٹ é”پ
if d has changed:
abort() # ه¦‚وœو•°وچ®ه·²هڈکو›´ï¼Œهˆ™ن¸و¢ن؛‹هٹ،ه¹¶é‡ٹو”¾و‰€وœ‰ه·²èژ·هڈ–çڑ„é”پ
for d in write_set:
d.lock() # ه¯¹ه†™ه…¥é›†ن¸çڑ„و¯ڈن¸ھو•°وچ®é،¹هٹ é”پ
write(d) # و‰§è،Œه†™و“چن½œ
# é‡ٹو”¾و‰€وœ‰é”پ
é€ڑè؟‡وژ’ه؛ڈو¥éپ؟ه…چو»é”پ
ن½؟用وژ’ه؛ڈو–¹و³•و¥éپ؟ه…چو»é”پï¼ڑهœ¨هٹ é”پن¹‹ه‰چ,ه°†è¯»هڈ–集ه’Œه†™ه…¥é›†هگˆه¹¶ه¹¶وژ’ه؛ڈ,然هگژوŒ‰ç…§é،؛ه؛ڈن¾و¬،هٹ é”پ,è؟™و ·هڈ¯ن»¥ه‡ڈه°‘و»é”پçڑ„é£ژ险م€‚
è؟›ن¸€و¥ن¼کهŒ–çڑ„و€è€ƒï¼ڑوک¯هگ¦éœ€è¦په¯¹è¯»هڈ–集çڑ„و¯ڈن¸ھو•°وچ®é،¹éƒ½هٹ é”پï¼ں
pythonه¤چهˆ¶ن»£ç پdef validate_and_commit(): # Phase 2 & 3
for d in sorted(read_set + write_set):
d.lock() # وŒ‰é،؛ه؛ڈهٹ é”پ,ه‡ڈه°‘و»é”پهڈ‘ç”ںçڑ„هڈ¯èƒ½و€§
for d in read_set:
if d has changed:
abort() # ه¦‚وœè¯»هڈ–çڑ„و•°وچ®هڈ‘ç”ںو”¹هڈک,هˆ™ن¸و¢ن؛‹هٹ،
for d in write_set:
write(d) # و‰§è،Œه†™و“چن½œ
# é‡ٹو”¾و‰€وœ‰é”پ
ن¸¤éک¶و®µé”پ + 读هڈ–éھŒè¯پ
ه¦‚ن½•ه®çژ°ç¬¬ن؛Œه’Œç¬¬ن¸‰éک¶و®µçڑ„ه…³é”®هŒ؛ï¼ں
观ه¯ں(ه…³ن؛ژ读هڈ–集)ï¼ڑ
ه¦‚وœéھŒè¯پé€ڑè؟‡ï¼Œé‚£ن¹ˆن¼¼ن¹ژن¸چ需è¦پهœ¨è¯»هڈ–集ن¸وŒپوœ‰é”پم€‚
pythonه¤چهˆ¶ن»£ç پdef validate_and_commit(): # Phase 2 & 3
for d in sorted(write_set):
d.lock() # ن»…ه¯¹ه†™ه…¥é›†ن¸çڑ„و•°وچ®é،¹هٹ é”پ
for d in read_set:
if d has changed:
abort() # ه¦‚وœè¯»هڈ–çڑ„و•°وچ®é،¹هڈ‘ç”ںهڈکهŒ–,هˆ™ن¸و¢ن؛‹هٹ،
for d in write_set:
write(d) # و‰§è،Œه†™و“چن½œ
# é‡ٹو”¾و‰€وœ‰é”پ

هœ¨è¯¥ç¤؛ن¾‹ن¸ï¼Œن؛‹هٹ، T1 ه’Œ T2 هœ¨ه¹¶هڈ‘و‰§è،Œè؟‡ç¨‹ن¸ه±•ç¤؛ن؛†é”پç¼؛ه¤±çڑ„é—®é¢کم€‚
- éک¶و®µ 1ï¼ڑ
T1读هڈ–و•°وچ®é،¹A_T0ه’ŒB_T0م€‚T2ن¹ں读هڈ–و•°وچ®é،¹A_T0ه’ŒB_T0م€‚
- éک¶و®µ 2ï¼ڑ
T1ه¯¹و•°وچ®é،¹Aهٹ é”په¹¶éھŒè¯پB_T0م€‚T2ه¯¹و•°وچ®é،¹Bهٹ é”په¹¶éھŒè¯پA_T0م€‚ è؟™é‡Œçڑ„ç¼؛é™·وک¯ï¼ŒT1ه’ŒT2ن¹‹é—´çڑ„é”پو²،وœ‰ç›¸ن؛’هچڈ调,ه¯¼è‡´هڈ¯èƒ½çڑ„و•°وچ®ه†²çھپم€‚特هˆ«وک¯ï¼ŒT1و²،وœ‰é”په®ڑB,而T2و²،وœ‰é”په®ڑA,ن»ژ而ه¼•هڈ‘ه¹¶هڈ‘ه†²çھپم€‚
ن¸؛ن؛†è§£ه†³ن¸ٹè؟°é—®é¢ک,هڈ¯ن»¥é‡‡ç”¨ن¸¤éک¶و®µé”پن¸ژ读هڈ–éھŒè¯پ相结هگˆçڑ„و–¹و³•ï¼ڑ
- ç–ç•¥ï¼ڑ
- ن»…é”په®ڑه†™ه…¥é›†ï¼ڑه¯¹
write_setن¸çڑ„و¯ڈن¸ھو•°وچ®é،¹هٹ é”پم€‚ - 读هڈ–éھŒè¯پï¼ڑو£€وں¥è¯»هڈ–集ن¸و•°وچ®é،¹çڑ„çٹ¶و€پ,ç،®ن؟و²،وœ‰è¢«ن؟®و”¹وˆ–هٹ é”پم€‚
- ن»…é”په®ڑه†™ه…¥é›†ï¼ڑه¯¹
ن»£ç پç¤؛ن¾‹ï¼ڑ
def validate_and_commit(): # Phase 2 & 3 with before-or-after
for d in sorted(write_set):
d.lock() # ه¯¹ه†™ه…¥é›†وژ’ه؛ڈهگژé€گن¸ھهٹ é”پ
for d in read_set:
if d has changed or d has been locked:
abort() # ه¦‚وœو•°وچ®é،¹ه·²هڈکو›´وˆ–被هٹ é”پ,هˆ™ن¸و¢ن؛‹هٹ،
for d in write_set:
write(d) # و‰§è،Œه†™و“چن½œ
# é‡ٹو”¾و‰€وœ‰é”پ- é”په®ڑه†™ه…¥é›†ï¼ڑهڈھه¯¹
write_setن¸çڑ„و•°وچ®é،¹هٹ é”پ,è؟™و ·هڈ¯ن»¥ه‡ڈه°‘é”پçڑ„و•°é‡ڈ,وڈگé«که¹¶هڈ‘و€§م€‚ - 读هڈ–éھŒè¯پï¼ڑهœ¨ه†™ه…¥ن¹‹ه‰چ,و£€وں¥
read_setن¸çڑ„و¯ڈن¸ھو•°وچ®é،¹ï¼Œç،®ن؟è؟™ن؛›و•°وچ®é،¹هœ¨ه½“ه‰چن؛‹هٹ،و‰§è،Œوœںé—´و²،وœ‰è¢«ه…¶ن»–ن؛‹هٹ،ن؟®و”¹وˆ–هٹ é”پم€‚è؟™و ·هڈ¯ن»¥éپ؟ه…چو•°وچ®ن¸چن¸€è‡´çڑ„وƒ…ه†µم€‚
و€»ç»“ï¼ڑè؟™ç§چو–¹و³•é€ڑè؟‡é”په®ڑه†™ه…¥é›†ه¹¶éھŒè¯پ读هڈ–集,و—¢ن؟è¯پن؛†و•°وچ®ن¸€è‡´و€§ï¼Œهڈˆه‡ڈه°‘ن؛†é”پçڑ„ن½؟用,وڈگé«کن؛†ç³»ç»ںçڑ„ه¹¶هڈ‘و€§ه’Œو•ˆçژ‡م€‚
结è®؛
OCC çڑ„ن¼کهٹ؟
- ن¸»è¦پهœ؛و™¯ï¼ڑ适هگˆهڈھ读و•°وچ®è®؟é—®ه¤ڑن؛ژه†™و“چن½œçڑ„وƒ…ه†µم€‚
OCC(ن¹گ观ه¹¶هڈ‘وژ§هˆ¶ï¼‰هœ¨çگ†وƒ³وƒ…ه†µن¸‹ï¼ˆهچ³و²،وœ‰ن¸و¢ï¼‰çڑ„و“چن½œï¼ڑ
- 1و¬،读هڈ–ï¼ڑ读هڈ–و•°وچ®ه€¼م€‚
- 1و¬،éھŒè¯پ读هڈ–ï¼ڑéھŒè¯پو•°وچ®ه€¼وک¯هگ¦ه·²è¢«و›´و”¹ï¼ˆن»¥هڈٹوک¯هگ¦è¢«هٹ é”پ)م€‚
2PL(ن¸¤éک¶و®µé”پ)çڑ„و“چن½œï¼ڑ
- 1و¬،و“چن½œï¼ڑèژ·هڈ–é”پ(é€ڑه¸¸وک¯ن¸€ن¸ھهژںهگ CAS و“چن½œï¼‰م€‚
- 1و¬،读هڈ–ï¼ڑ读هڈ–و•°وچ®ه€¼م€‚
- 1و¬،ه†™ه…¥ï¼ڑé‡ٹو”¾é”پم€‚
- ç”±ن؛ژهچ•ن¸ھ CPU ه†™ه…¥وک¯هژںهگçڑ„,ه› و¤ن¸چ需è¦پè؟›è،Œé¢ه¤–çڑ„هژںهگ CAS و“چن½œم€‚
و€»ç»“
- é”په®ڑو“چن½œçڑ„وˆگوœ¬è¾ƒé«ک,特هˆ«وک¯ن¸ژ读هڈ–و“چن½œç›¸و¯”م€‚
- OCC çڑ„ن¼کهٹ؟هœ¨ن؛ژه‡ڈه°‘é”پو“چن½œï¼Œو›´é€‚هگˆè¯»هڈ–ه¤ڑن؛ژه†™ه…¥çڑ„هœ؛و™¯ï¼Œه› ن¸؛ه®ƒن»…هœ¨وڈگن؛¤و—¶و‰چ需è¦پéھŒè¯په†²çھپ,ه¤§ه¤§é™چن½ژن؛†é”پçڑ„ه¼€é”€م€‚相و¯”ن¹‹ن¸‹ï¼Œ2PL 需è¦پو¯ڈو¬،èژ·هڈ–ه’Œé‡ٹو”¾é”پ,ه¸¦و¥é¢ه¤–çڑ„و€§èƒ½ه¼€é”€م€‚
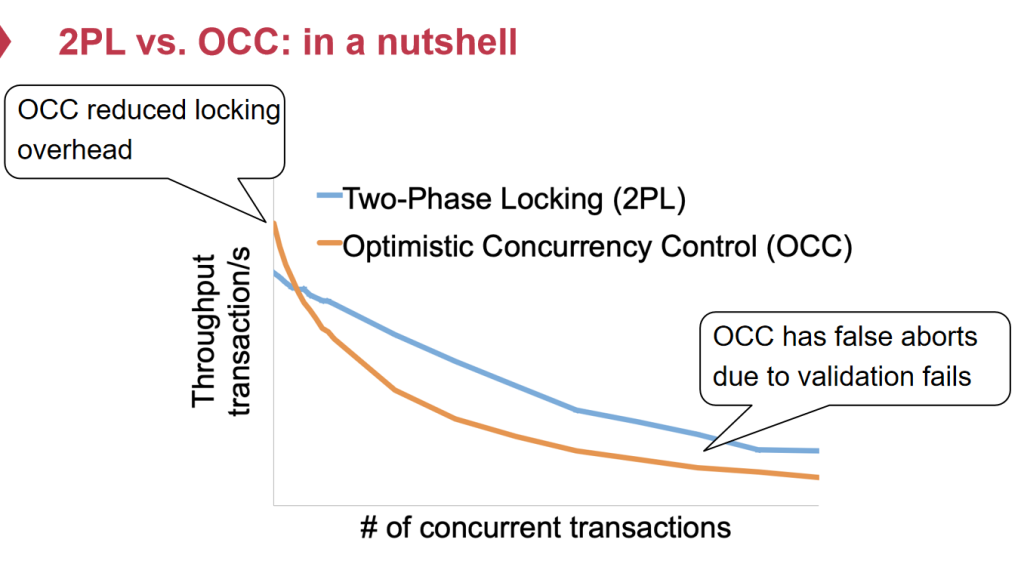
é”پوœ؛هˆ¶هˆو¥
1. é”پçڑ„设è®،ç›®و ‡ن¸ژç ”ç©¶èƒŒو™¯
- ه¤ڑç؛؟程çژ¯ه¢ƒن¸‹çڑ„é”پوœ؛هˆ¶ه®çژ°ç›®و ‡وک¯ن¼کهŒ–و€§èƒ½ه’Œو‰©ه±•و€§ï¼Œè؟™وک¯ç³»ç»ںç ”ç©¶ن¸çڑ„و´»è·ƒè¯¾é¢کم€‚
- 许ه¤ڑن¸چهگŒçڑ„ه®çژ°و–¹ه¼ڈن¸چو–هڈ‘ه±•ï¼Œن»¥وڈگé«کç³»ç»ںçڑ„ه¹¶هڈ‘ه¤„çگ†èƒ½هٹ›م€‚
2. هں؛ç،€é”پوœ؛هˆ¶è®¾è®،
- ن½؟用ن¸€ن¸ھ简هچ•çڑ„و ‡ه؟—ن½چ(flag)و¥è،¨ç¤؛é”پçڑ„çٹ¶و€پ(وک¯هگ¦è¢«وŒپوœ‰ï¼‰م€‚
- èژ·هڈ–é”پçڑ„هں؛وœ¬و¥éھ¤ï¼ڑ
- ه½“ç؛؟程ه°è¯•èژ·هڈ–é”پو—¶ï¼Œé¦–ه…ˆè¯»هڈ–و ‡ه؟—ن½چم€‚
- ه¦‚وœو ‡ه؟—ن½چوک¾ç¤؛é”پوœھ被هچ 用,هˆ™ç؛؟程ه°†ه…¶è®¾ç½®ن¸؛“é”په®ڑâ€çٹ¶و€پ,ن»¥وŒپوœ‰é”پم€‚
3. هگŒو¥é—®é¢کن¸ژç«ن؛‰و،ن»¶
- هœ¨ه¤ڑç؛؟程çژ¯ه¢ƒن¸ï¼Œه¦‚وœن¸¤ن¸ھç؛؟程هگŒو—¶è¯»هڈ–هˆ°é”پوœھ被وŒپوœ‰çڑ„çٹ¶و€پ,هˆ™ن¼ڑن؛§ç”ںç«ن؛‰و،ن»¶م€‚
- é—®é¢کï¼ڑن¸¤ن¸ھç؛؟程هڈ¯èƒ½هگŒو—¶ه°è¯•èژ·هڈ–é”پ,ه¯¼è‡´é”پçٹ¶و€پçڑ„ن¸چن¸€è‡´م€‚
- 解ه†³و–¹و³•ï¼ڑ需è¦پç،®ن؟و“چن½œçڑ„ه‰چهگژé،؛ه؛ڈ,ن½؟ه¾—هڈھوœ‰ن¸€ن¸ھç؛؟程وˆگهٹںèژ·هڈ–é”پم€‚简هچ•çڑ„و ‡ه؟—ن½چن¸چ足ن»¥ه؛”ه¯¹ه¤ڑç؛؟程ه¹¶هڈ‘ç«ن؛‰ï¼Œéœ€è¦پو›´é«کç؛§çڑ„هگŒو¥وœ؛هˆ¶م€‚
4. ç،¬ن»¶و”¯وŒپçڑ„هژںهگو€§و“چن½œï¼ڑCompare and Swap
- ç،¬ن»¶هژںè¯وڈگن¾›ن؛†ن؟éڑœو“چن½œهژںهگو€§ï¼ˆن¸چهڈ¯هˆ†ه‰²ï¼‰çڑ„وœ؛هˆ¶ï¼Œن½؟ه¾—é”پçٹ¶و€پçڑ„و›´و–°و“چن½œهڈ¯ن»¥هژںهگو€§ه®Œوˆگم€‚
- ه¸¸ç”¨çڑ„ç،¬ن»¶هژںهگو“چن½œï¼ڑ
- Compare-and-swap(هœ¨ SPARC و¶و„ن¸ٹ)
- Compare-and-exchange(هœ¨ x86 و¶و„ن¸ٹ)
- é”په‰چ缀(Lock prefix)ï¼ڑهœ¨ x86 ن¸ï¼Œن½؟用é”په‰چç¼€هڈ¯ن»¥ç،®ن؟وŒ‡ن»¤هœ¨ç‰¹ه®ڑه†…هکهœ°ه€ن¸ٹçڑ„هژںهگو‰§è،Œï¼Œéپ؟ه…چو•°وچ®ç«ن؛‰م€‚
5. CompareAndSwap ه‡½و•°ç¤؛ن¾‹
- ه‡½و•°
CompareAndSwap(int *ptr, int expected, int new)çڑ„هں؛وœ¬é€»è¾‘ï¼ڑ- 读هڈ–وŒ‡é’ˆه½“ه‰چه€¼ه¹¶هکه‚¨ن¸؛
actualم€‚ - ه¦‚وœ
actualç‰ن؛ژexpected,هˆ™ه°†*ptrو›´و–°ن¸؛new,ه¹¶è؟”ه›actualه€¼م€‚
- 读هڈ–وŒ‡é’ˆه½“ه‰چه€¼ه¹¶هکه‚¨ن¸؛
- ç،¬ن»¶é€ڑè؟‡é”په‰چ缀(Lock prefix)ن؟è¯پو¤و“چن½œçڑ„هژںهگو€§ï¼Œن»ژ而ç،®ن؟ç«ن؛‰و،ن»¶ن¸‹çڑ„ه®‰ه…¨و€§م€‚
int CompareAndSwap(int *ptr, int expected, int new) { // ن½؟用é”په‰چç¼€
int actual = *ptr;
if (actual == expected)
*ptr = new;
return actual;
} // ç،¬ن»¶é€ڑè؟‡é”په‰چç¼€ç،®ن؟هژںهگو€§é”په‰چç¼€çڑ„ن½؟用ن½؟ه¾—وŒ‡ن»¤و‰§è،Œو—¶ن¸چن¼ڑهڈ—هˆ°ه…¶ن»–ç؛؟程çڑ„ه¹²و‰°ï¼Œن»ژ而ç،®ن؟ن؛†é”په®ڑو“چن½œçڑ„هژںهگو€§م€‚
// ه®ڑن¹‰è‡ھو—‹é”پ结و„ن½“
typedef struct __lock_t {
int flag; // 0 è،¨ç¤؛é”پهڈ¯ç”¨ï¼Œ1 è،¨ç¤؛é”په·²è¢«وŒپوœ‰
} lock_t;
// هˆه§‹هŒ–é”پ,ه°† flag 设ن¸؛ 0 è،¨ç¤؛é”پهڈ¯ç”¨
void init(lock_t *lock) {
lock->flag = 0;
}
// èژ·هڈ–é”پ,ن½؟用 CompareAndSwap ه®çژ°è‡ھو—‹é”پ
void lock(lock_t *lock) {
while (CompareAndSwap(&lock->flag, 0, 1) == 1)
; // è‡ھو—‹ç‰ه¾…,直هˆ°é”پهڈ¯ç”¨
}
// é‡ٹو”¾é”پ,ه°† flag 设ن¸؛ 0
void unlock(lock_t *lock) {
lock->flag = 0;
}Hardware Transactional Memory
- CPUن؟è¯پن؛†è¯»/ه†™ه†…هکو“چن½œçڑ„“ه…ˆوˆ–هگژهژںهگو€§â€ï¼ڑ
- ن¹ںه°±وک¯è¯´ï¼Œو“چن½œن¹‹é—´و²،وœ‰ç«و€پو،ن»¶ï¼ˆهچ³ن¸چن¼ڑه‡؛çژ°ه¹¶هڈ‘ه†²çھپ),ن¹ںن¸چ需è¦پ“ن؛Œéک¶و®µé”پâ€ï¼ˆ2PL)وˆ–软ن»¶ه®çژ°çڑ„“ن¹گ观ه¹¶هڈ‘وژ§هˆ¶â€ï¼ˆOCC)م€‚
- Intelçڑ„HTM(ç،¬ن»¶ن؛‹هٹ،ه†…هک)被称ن¸؛RTM(é™گهˆ¶و€§ن؛‹هٹ،ه†…هک)ï¼ڑ
- RTMوک¯ن¸€ç§چé™گهˆ¶و€§ن؛‹هٹ،ه†…هک(Restricted Transactional Memory)وٹ€وœ¯م€‚
- è؟™ç§چوٹ€وœ¯é¦–و¬،هœ¨Haswellه¤„çگ†ه™¨ن¸ه¼•ه…¥م€‚
ن½؟用و–¹ه¼ڈ
- ISAه¯¹ن؛‹هٹ،ه†…هکçڑ„و”¯وŒپï¼ڑ
- ISA(وŒ‡ن»¤é›†و¶و„)ه¯¹ن؛‹هٹ،çڑ„و”¯وŒپه’Œن¹‹ه‰چوڈڈè؟°çڑ„ن؛‹هٹ،(TX)ه¾ˆç›¸ن¼¼م€‚
- ه›é،¾ï¼ڑهœ¨è½¯ن»¶ن¸ç¼–ه†™ن؛‹هٹ،ï¼ڑ
- ن½؟用
TX.beginو¥و ‡è®°ن؛‹هٹ،çڑ„ه¼€ه§‹م€‚ - ن½؟用
TX.commitو¥وڈگن؛¤ن؛‹هٹ،م€‚
- ن½؟用
- هœ¨RTMن¸çڑ„و¦‚ه؟µوک¯ç±»ن¼¼çڑ„(و–°çڑ„و±‡ç¼–ن»£ç پ)ï¼ڑ
- ن½؟用
xbeginو¥و ‡è®°RTMو‰§è،Œçڑ„ه¼€ه§‹م€‚ - ن½؟用
xendو¥و ‡è®°RTMçڑ„结وںم€‚
- ن½؟用
ن½؟用ç¤؛ن¾‹
- ه¦‚وœن؛‹هٹ،وˆگهٹںهگ¯هٹ¨ï¼ڑ
- و‰§è،Œهڈ—RTMن؟وٹ¤çڑ„ه·¥ن½œï¼Œç„¶هگژه°è¯•وڈگن؛¤ن؛‹هٹ،م€‚
- CPUو£€وµ‹ç«و€پو،ن»¶ه¹¶هœ¨ه؟…è¦پو—¶ن¸و¢ï¼ڑ
- ه¦‚وœن؛‹هٹ،被ن¸و¢ï¼ŒCPUن¼ڑه›و»ڑهˆ°
xbeginè،Œï¼Œه¹¶è؟”ه›ن¸€ن¸ھن¸و¢ن»£ç پم€‚
- ه¦‚وœن؛‹هٹ،被ن¸و¢ï¼ŒCPUن¼ڑه›و»ڑهˆ°
- هœ¨ن؛‹هٹ،ه†…و‰‹هٹ¨ن¸و¢ï¼ڑ
- هœ¨ن»£ç پç¤؛ن¾‹ن¸ï¼Œن½؟用
_xbegin()و¥ه¼€ه§‹ن؛‹هٹ،م€‚ه¦‚وœو،ن»¶و»،足,هڈ¯ن»¥ن½؟用_xabort()و‰‹هٹ¨ن¸و¢ن؛‹هٹ،م€‚ن؛‹هٹ،çڑ„ه…³é”®ن»£ç پهœ¨_xend()ن¹‹ه‰چè؟گè،Œï¼Œن»¥ç،®ن؟هœ¨و•´ن¸ھè؟‡ç¨‹ن¸ن؛‹هٹ،çڑ„هژںهگو€§م€‚ - ه¦‚وœن؛‹هٹ،و²،وœ‰وˆگهٹںه¼€ه§‹ï¼Œو‰§è،Œه¤‡ç”¨ن»£ç پè·¯ه¾„(fallback routine)م€‚
- هœ¨ن»£ç پç¤؛ن¾‹ن¸ï¼Œن½؟用
if (_xbegin() == _XBEGIN_STARTED) {
if (condition) {
_xabort(); // و‰‹هٹ¨ن¸و¢
}
// ه…³é”®ن»£ç پ
_xend(); // 结وںن؛‹هٹ،
} else {
// ه¤‡ç”¨ن»£ç پ
}ن¼کç¼؛点
RTMçڑ„ن¼ک点
هœ¨xbegin()ه’Œxend()ن¹‹é—´çڑ„ه†…هکو“چن½œو»،足“ه…ˆوˆ–هگژâ€هژںهگو€§ï¼ڑ
- è؟™و„ڈه‘³ç€هœ¨ن؛‹هٹ،ه†…çڑ„و“چن½œè¦پن¹ˆه…¨éƒ¨ه®Œوˆگ,è¦پن¹ˆه…¨éƒ¨ه›و»ڑ,ç،®ن؟و•°وچ®ن¸€è‡´و€§ï¼Œéپ؟ه…چه¹¶هڈ‘ه†²çھپم€‚
و¯”起“ن¸¤éک¶و®µé”پ(2PL)â€وˆ–“ن¹گ观ه¹¶هڈ‘وژ§هˆ¶ï¼ˆOCC)â€ï¼Œç¼–程و›´ن¸؛简هچ•ï¼ˆهœ¨ه¤§ه¤ڑو•°وƒ…ه†µن¸‹ï¼‰ï¼ڑ
- ن½؟用RTMهڈ¯ن»¥ه‡ڈه°‘ه¤چو‚çڑ„é”پوœ؛هˆ¶ه’Œه†²çھپه¤„çگ†ن»£ç پ,让编程هڈکه¾—و›´ç›´وژ¥م€‚
هœ¨وںگن؛›وƒ…ه†µن¸‹ï¼Œو€§èƒ½و›´ه¥½ï¼ڑ
- RTMهڈ¯ن»¥ه‡ڈه°‘é”پçڑ„ن½؟用,ن»ژ而ه‡ڈه°‘ç؛؟程间çڑ„ç‰ه¾…ه’Œèµ„و؛گن؛‰ç”¨ï¼Œوڈگهچ‡ه¹¶هڈ‘و€§èƒ½م€‚
ç¤؛ن¾‹ن»£ç پ
extern std::vector<u64> data; // ه¤ڑç؛؟程ه…±ن؛«çڑ„و•°وچ®
if (_xbegin() == _XBEGIN_STARTED) {
data.push(12); // ه°†و•°وچ®هٹ ه…¥ه…±ن؛«هگ‘é‡ڈ
} else {
// ه¦‚وœن؛‹هٹ،ه¼€ه§‹ه¤±è´¥ï¼Œهœ¨è؟™é‡Œه¤„çگ†ه›é€€و“چن½œ
}- ن»£ç پ解é‡ٹï¼ڑè؟™é‡Œه°è¯•ç”¨
_xbegin()ه¼€هگ¯ن¸€ن¸ھن؛‹هٹ،,ه¹¶هœ¨ن؛‹هٹ،ه†…ه°†و•°وچ®12وژ¨ه…¥ه…±ن؛«çڑ„dataهگ‘é‡ڈم€‚è‹¥ن؛‹هٹ،هگ¯هٹ¨ه¤±è´¥ï¼Œهڈ¯ن»¥é€ڑè؟‡elseè¯هڈ¥ه¤„çگ†ه¤±è´¥çڑ„وƒ…ه†µï¼ˆو¯”ه¦‚é”په®ڑو“چن½œç‰ï¼‰م€‚
ç¼؛点
ن¸چ能ن؟è¯پن؛‹هٹ،وˆگهٹںو‰§è،Œï¼ڑ
- RTMن¸چ能ç،®ن؟ن؛‹هٹ،هœ¨و‰€وœ‰وƒ…ه†µن¸‹éƒ½èƒ½وˆگهٹںه®Œوˆگم€‚ن؛‹هٹ،هڈ¯èƒ½ه› ن¸؛资و؛گه†²çھپم€پç،¬ن»¶é™گهˆ¶وˆ–ه…¶ن»–هژںه› 被ن¸و¢ï¼Œéœ€è¦پç¼–ه†™ه¤‡ç”¨é€»è¾‘ه¤„çگ†è؟™ç§چوƒ…ه†µم€‚
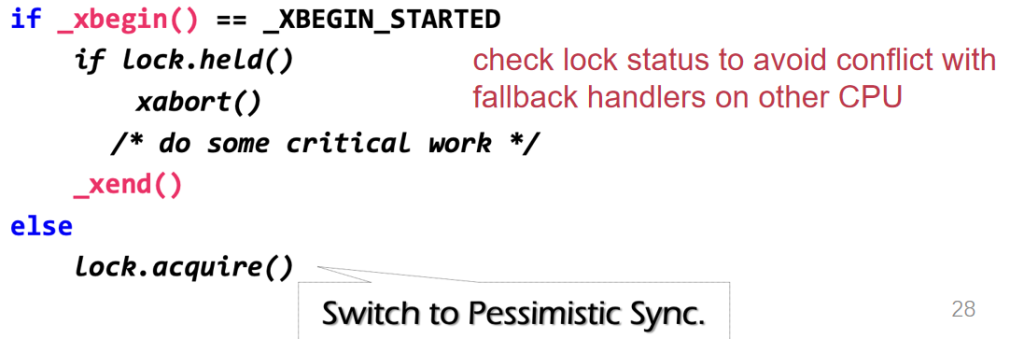
ه…³ن؛ژRTMه®çژ°çڑ„ن؛‹ه®
- Intelé€ڑè؟‡ن¹گ观ه¹¶هڈ‘وژ§هˆ¶ï¼ˆOCC)ه®çژ°RTMï¼ڑ
- OCCوœ¬è؛«و— و³•ن؟è¯پوˆگهٹںو‰§è،Œن؛‹هٹ،,ه› و¤هœ¨ç«ن؛‰و؟€çƒˆوˆ–ه†²çھپ频ç¹پçڑ„çژ¯ه¢ƒن¸ï¼Œن؛‹هٹ،هڈ¯èƒ½ن¼ڑ被ن¸و¢م€‚
- RTMçڑ„OCCهœ¨CPUç،¬ن»¶ن¸ٹه®çژ°ï¼Œوœ‰ن¸€ه®ڑé™گهˆ¶ï¼ڑ
- ن½؟用CPU缓هکو¥è؟½è¸ھCPU读/ه†™é›†هگˆï¼Œç›‘وµ‹ه“ھن؛›ه†…هکهŒ؛هںں被ن؛‹هٹ،è®؟é—®م€‚
- ن½؟用缓هکن¸€è‡´و€§هچڈè®®و¥و£€وµ‹ه†²çھپ,ç،®ن؟ه¤ڑن¸ھç؛؟程è®؟é—®ه…±ن؛«èµ„و؛گو—¶çڑ„ن¸€è‡´و€§م€‚
RTMçڑ„هڈ—é™گه·¥ن½œé›†
- CPU缓هکه®¹é‡ڈوœ‰é™گï¼ڑ
- ه¦‚وœن؛‹هٹ،çڑ„读/ه†™é›†هگˆè¶…è؟‡ن؛†ç¼“هکه¤§ه°ڈ,RTMن¼ڑو— و،ن»¶ن¸و¢ن؛‹هٹ،م€‚
- RTMçڑ„读/ه†™é›†هگˆوœ‰ه¤ڑه¤§ï¼ں
- 读/ه†™é›†هگˆه¤§ه°ڈهڈ–ه†³ن؛ژç،¬ن»¶è®¾ç½®ï¼ˆه¦‚缓هکه¤§ه°ڈ)م€پè®؟é—®و¨،ه¼ڈ(读وˆ–ه†™ï¼‰م€‚
- L1缓هکè·ںè¸ھو‰€وœ‰ه†™و“چن½œï¼ŒL2وˆ–L3缓هکè·ںè¸ھو‰€وœ‰è¯»و“چن½œم€‚
- ه›¾ن¸وک¾ç¤؛ن؛†ه·¥ن½œé›†ه¤§ه°ڈن¸ژن¸و¢çژ‡çڑ„ه…³ç³»ï¼ڑéڑڈç€ه·¥ن½œé›†ه¤§ه°ڈçڑ„ه¢هٹ ,ن¸و¢çژ‡وک¾è‘—ن¸ٹهچ‡م€‚ن¾‹ه¦‚,ه†™é›†هگˆçڑ„وœ€ه¤§و”¯وŒپه¤§ه°ڈن¸؛31KB,而读集هگˆçڑ„وœ€ه¤§و”¯وŒپه¤§ه°ڈن¸؛4MBم€‚
RTMوœ‰ه…¶ç‹¬ç‰¹çڑ„ه¹¶هڈ‘وژ§هˆ¶ن¼کهٹ؟,ن½†هکهœ¨ç،¬ن»¶é™گهˆ¶ه’Œوˆگهٹںçژ‡é—®é¢کم€‚ه¤§ه‹ه·¥ن½œé›†وˆ–频ç¹په†²çھپو—¶ï¼Œن؛‹هٹ،هڈ¯èƒ½ن¸و¢ï¼Œه› و¤هœ¨ç¼–ه†™RTMن»£ç پو—¶ï¼Œéœ€è¦پ特هˆ«è€ƒè™‘è؟™ن؛›ç،¬ن»¶ç‰¹و€§ه’Œé™گهˆ¶ï¼Œن»¥éپ؟ه…چو´»é”په’Œé«کن¸و¢çژ‡م€‚
RTM çڑ„وœ‰é™گو‰§è،Œو—¶é—´
ن؛‹هٹ،و‰§è،Œو—¶é—´è¶ٹé•؟,ن؛‹هٹ،ن¸و¢çڑ„و¦‚çژ‡è¶ٹé«کï¼ڑ
- è؟™وک¯ه› ن¸؛CPUن¸و–ن¼ڑو— و،ن»¶ن¸و¢ن؛‹هٹ،م€‚
ن¸و–ن¸؛ن»€ن¹ˆن¼ڑه¯¼è‡´RTMن¸و¢ï¼ں
- CPUن¸و–ه¯¼è‡´ن¸ٹن¸‹و–‡هˆ‡وچ¢ï¼Œè؟™ن¼ڑو±،وں“缓هک,ن»ژè€Œç ´هڈن؛‹هٹ،çڑ„éڑ”离و€§م€‚
ç¤؛ن¾‹و•°وچ®ï¼ڑ
- ه›¾ن¸ه±•ç¤؛ن؛†ن؛‹هٹ،و‰§è،Œو—¶é—´ن¸ژن¸و¢çژ‡çڑ„ه…³ç³»ï¼ڑوœ€ه¤§و‰§è،Œو—¶é—´ن¸؛3.9و¯«ç§’,éڑڈç€و‰§è،Œو—¶é—´ه¢هٹ ,ن¸و¢çژ‡è؟…é€ںن¸ٹهچ‡م€‚
و€»ç»“ï¼ڑ
RTMن؛‹هٹ،需è¦پهœ¨وœ‰é™گçڑ„و—¶é—´ه†…ه®Œوˆگ,ه› ن¸؛较é•؟çڑ„ن؛‹هٹ،و‰§è،Œو—¶é—´و›´ه®¹وک“ه¯¼è‡´ن¸و¢ï¼Œن¸»è¦پهژںه› وک¯CPUن¸و–ن¼ڑç ´هڈن؛‹هٹ،çڑ„هژںهگو€§م€‚è؟™و„ڈه‘³ç€RTM适用ن؛ژ较çںçڑ„ن؛‹هٹ،,é•؟و—¶é—´ن؛‹هٹ،需è¦پ特هˆ«ه°ڈه؟ƒم€‚
ه¤‡ç”¨è·¯ه¾„ï¼ڑن½؟RTMوœ€ç»ˆوڈگن؛¤
é—®é¢کï¼ڑRTMن¸چ能ن؟è¯پن؛‹هٹ،وˆگهٹںï¼ڑ
- ç±»ن¼¼ن؛ژن¹گ观ه¹¶هڈ‘وژ§هˆ¶ï¼ˆOCC),RTMن¸çڑ„ن؛‹هٹ،ن»£ç پç”±ن؛ژه†²çھپهڈ¯èƒ½ن¼ڑ频ç¹پن¸و¢م€‚
- ç،¬ن»¶é™گهˆ¶ن¹ںوک¯ن¸و¢çڑ„و½œهœ¨هژںه› م€‚
ه؟…é،»هœ¨ه¤ڑو¬،é‡چ试هگژهˆ‡وچ¢هˆ°ه¤‡ç”¨è·¯ه¾„ï¼ڑ
- ن¾‹ه¦‚,ن½؟用è®،و•°ه™¨è®°ه½•é‡چ试و¬،و•°ï¼Œه½“超è؟‡وںگن¸ھو¬،و•°هگژ,و”¹ç”¨é”پç‰و‚²è§‚هگŒو¥وœ؛هˆ¶م€‚
- ه¦‚وœé¢‘ç¹پن½؟用ه¤‡ç”¨è·¯ه¾„,ن¼ڑه¯¼è‡´و€§èƒ½ن¸‹é™چم€‚
ن»£ç پç¤؛ن¾‹ï¼ڑ
- ن½؟用
_xbegin()ه°è¯•هگ¯هٹ¨ن؛‹هٹ،,ه¦‚وœه½“ه‰چوœ‰é”پ被وŒپوœ‰ï¼Œهˆ™ن¸و¢ن؛‹هٹ،(xabort()),هگ¦هˆ™و‰§è،Œه…³é”®ن»£ç پ,وœ€هگژ用_xend()结وںن؛‹هٹ،م€‚ - ه¦‚وœن؛‹هٹ،و— و³•وˆگهٹں,هˆ™è؟›ه…¥
elseهˆ†و”¯ï¼Œèژ·هڈ–é”پو‰§è،Œه¤‡ç”¨ن»£ç پم€‚

هœ¨RTM编程ن¸ï¼Œن؛‹هٹ،ن¸و¢وک¯ن¸چهڈ¯éپ؟ه…چçڑ„م€‚ن¸؛ن؛†ç،®ن؟程ه؛ڈ稳ه®ڑè؟گè،Œï¼Œé€ڑه¸¸éœ€è¦پهœ¨ه¤ڑو¬،é‡چ试هگژهˆ‡وچ¢هˆ°ه¤‡ç”¨è·¯ه¾„(ن¾‹ه¦‚é”پ)م€‚è؟™وک¯ن¸€ç§چه¹³è،،و€§èƒ½ه’Œهڈ¯é و€§çڑ„ç–略,ن½†ه¦‚وœé¢‘ç¹پن¸و¢ï¼ŒRTMçڑ„و€§èƒ½ن¼کهٹ؟ه°†ن¸چه¤چهکهœ¨م€‚
ن»¥ن¸‹وک¯ه¯¹ن¸¤ه¼ ه›¾çڑ„简هچ•ç؟»è¯‘ه’Œè§£é‡ٹم€‚
OCC ه’Œ RTM çڑ„简è¦پو€»ç»“
- OCC(ن¹گ观ه¹¶هڈ‘وژ§هˆ¶ï¼‰ï¼ڑ
- OCCوک¯ن¸€ç§چç»ڈه…¸çڑ„هچڈ议,用ن؛ژه®çژ°â€œه…ˆوˆ–هگژâ€هژںهگو€§ï¼ˆهچ³ن؛‹هٹ،è¦پن¹ˆه…¨éƒ¨ه®Œوˆگ,è¦پن¹ˆن¸چه®Œوˆگ)م€‚
- OCCçڑ„çگ†ه؟µç”ڑ至被ç،¬ن»¶è®¾è®،者采用,用ن؛ژن¼کهŒ–ه¹¶هڈ‘وژ§هˆ¶م€‚
- ن؛‹هٹ،ه†…هکçڑ„ç،¬ن»¶و”¯وŒپï¼ڑ
- ن¸؛程ه؛ڈه‘کوڈگن¾›ن؛†ç®€ن¾؟çڑ„编程و¨،ه‹ï¼Œو— 需ن½؟用é”پم€‚
- هڈھè¦پ程ه؛ڈه‘کهœ¨ه†…هکن¸è؟›è،Œè®،算(ه¦‚ه†…هکو•°وچ®ه؛“و“چن½œï¼‰ï¼Œه°±èƒ½èژ·ه¾—良ه¥½çڑ„و€§èƒ½م€‚
- ن½؟用ه¾—ه½“و—¶و€§èƒ½è‰¯ه¥½ï¼Œéپ؟ه…چن؛†é”په’Œهژںهگو“چن½œçڑ„需و±‚م€‚
- 然而,程ه؛ڈه‘کن»چ需谨و…ژه¤„çگ†هڈ¯èƒ½هکهœ¨çڑ„é™·éک±ï¼Œه¦‚ه¤„çگ†ن¸و¢ه’Œه›و»ڑم€‚
و€»ç»“
OCCه’ŒRTM都ن¸؛ه¹¶هڈ‘وژ§هˆ¶وڈگن¾›ن؛†و–°çڑ„途ه¾„م€‚OCCن¸»è¦پوک¯è½¯ن»¶ه®çژ°çڑ„و€وƒ³ï¼Œن½†ن¹ںه½±ه“چن؛†ç،¬ن»¶è®¾è®،ï¼›RTMهˆ™وک¯ç،¬ن»¶ه®çژ°ï¼Œç®€هŒ–ن؛†ه¹¶هڈ‘编程,ن½†ç¨‹ه؛ڈه‘ک需و³¨و„ڈه…¶ن½؟用é™گهˆ¶م€‚
ه½“ن؛‹هٹ،هŒ…هگ«ه¤§é‡ڈé•؟و—¶é—´è؟گè،Œçڑ„读و“چن½œو—¶ï¼ŒOCC ه’Œ 2PL è،¨çژ°ن¸چن½³
- OCCï¼ڑه¦‚وœè¯»éھŒè¯په¤±è´¥ï¼Œن؛‹هٹ،ن¼ڑن¸و¢ï¼Œè؟™ه¯¹é•؟و—¶é—´çڑ„读و“چن½œن¸چهڈ‹ه¥½م€‚
- 2PL(ن¸¤éک¶و®µé”پهچڈ议)ï¼ڑ读و“چن½œه°†وŒپوœ‰é”پ,éک»ه،ه…¶ن»–و“چن½œï¼Œé™چن½ژç³»ç»ںçڑ„ه¹¶هڈ‘و€§èƒ½م€‚
- هœ¨ه®é™…ه؛”用ن¸ï¼Œè¯»و“چن½œéه¸¸و™®éپچï¼ڑ
- ن¾‹ه¦‚,هœ¨و·که®ç‰ç”µه•†ه¹³هڈ°ï¼Œç”¨وˆ·و“چن½œه¾€ه¾€ن»¥ه¤§é‡ڈçڑ„读و“چن½œن¸؛ن¸»ï¼Œو·»هٹ é،¹ç›®çڑ„و“چن½œç›¸ه¯¹è¾ƒه°‘م€‚
- هœ؛و™¯ç¤؛ن¾‹ï¼ڑهœ¨è؟گè،Œé•؟و—¶é—´çڑ„هˆ†وگن»»هٹ،وˆ–读هڈ–ه¤§و•°وچ®é›†و—¶ï¼Œهپ¶ه°”需è¦پو›´و–°ن¸€ه°ڈ部هˆ†و•°وچ®م€‚
结è®؛
OCCه’Œ2PLهœ¨ه¤„çگ†é•؟و—¶é—´è؟گè،Œçڑ„هڈھ读وˆ–读ن¸؛ن¸»çڑ„ن؛‹هٹ،و—¶è،¨çژ°ن¸چن½³ï¼Œه®¹وک“ه¯¼è‡´ن¸و¢وˆ–éک»ه،م€‚ه¯¹ن؛ژè؟™ç§چهœ؛و™¯ï¼Œهڈ¯èƒ½éœ€è¦پ采用ه…¶ن»–و›´é€‚هگˆه¹¶هڈ‘读و“چن½œçڑ„وژ§هˆ¶و–¹و³•ï¼Œن»¥وڈگé«کç³»ç»ںو€§èƒ½ه’Œه“چه؛”é€ںه؛¦م€‚
multi-versioning concurrency control
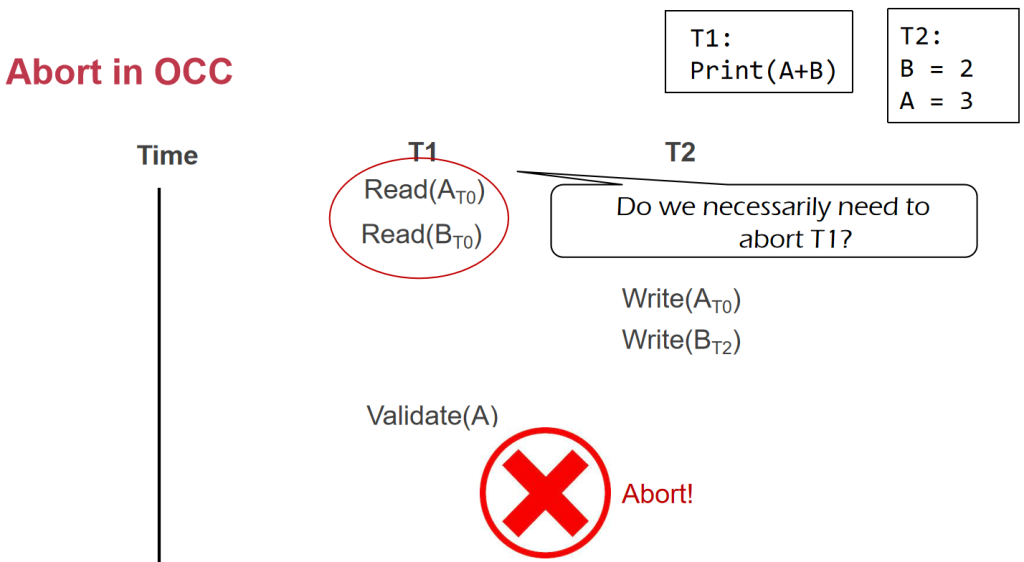
ه¤ڑ版وœ¬ه¹¶هڈ‘وژ§هˆ¶çڑ„çگ†ه؟µ
ه¤ڑ版وœ¬ه¹¶هڈ‘وژ§هˆ¶ï¼ˆMVCC)ï¼ڑ
MVCCçڑ„و ¸ه؟ƒو€وƒ³وک¯ن؟ç•™و•°وچ®çڑ„ه¤ڑن¸ھهژ†هڈ²ç‰ˆوœ¬ï¼Œو–¹ن¾؟ه¹¶هڈ‘ن؛‹هٹ،读هڈ–ن¸€è‡´و€§è§†ه›¾ï¼Œه¹¶éپ؟ه…چه› و›´و–°ه¼•هڈ‘çڑ„ه†²çھپم€‚
- و¯ڈن¸ھو•°وچ®éƒ½وœ‰ه¤ڑن¸ھ版وœ¬ï¼Œè€Œن¸چوک¯هڈھوœ‰هچ•ن¸€ç‰ˆوœ¬م€‚
- ن¸€ç»„版وœ¬ن»£è،¨و•°وچ®ه؛“çڑ„ن¸€ن¸ھه؟«ç…§ï¼ˆsnapshot),ن¾‹ه¦‚ ( A_{T0} ) ه’Œ ( B_{T0} ) è،¨ç¤؛هœ¨و—¶é—´ç‚¹ ( T0 ) çڑ„و•°وچ®ه؟«ç…§م€‚
- 版وœ¬هڈ·وژ¥è؟‘ن؛ژن؛‹هٹ،(TX)è؟›è،Œو›´و–°çڑ„و—¶é—´م€‚
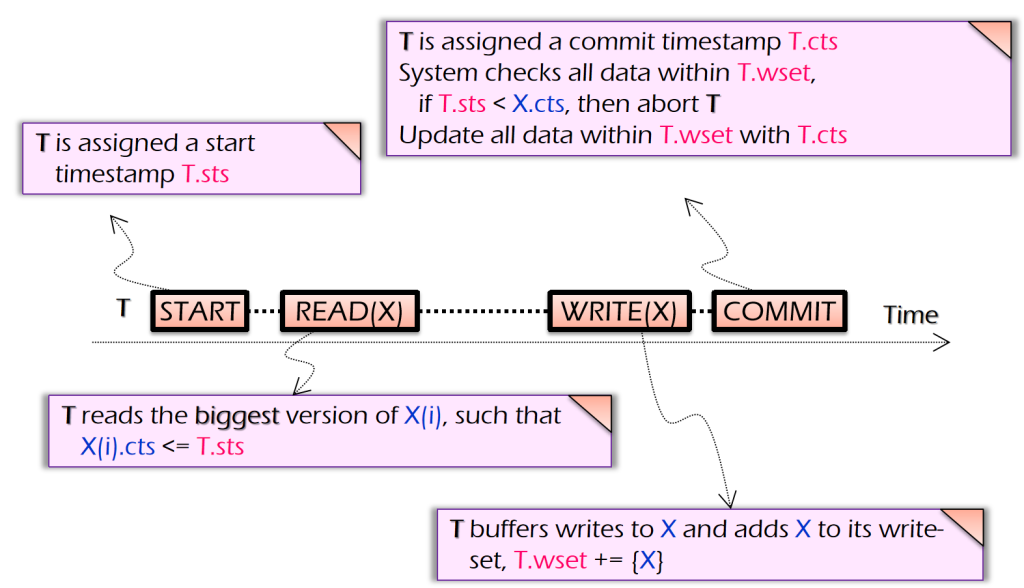
و•°وچ®ç»“و„ç¤؛ن¾‹ï¼ڑ
- Dataï¼ڑهŒ…هگ«ن¸€ن¸ھه€¼ه’Œن¸€ن¸ھé”پم€‚
- VersionedDataï¼ڑهŒ…هگ«ه¤ڑن¸ھو•°وچ®ç‰ˆوœ¬çڑ„هˆ—è،¨ن»¥هڈٹن¸€ن¸ھé”پم€‚
- و¯ڈن¸ھ版وœ¬çڑ„و•°وچ®ï¼ˆه¦‚ ( X_0 ) ه’Œ ( X_1 ))ن¼ڑوœ‰ن¸€ن¸ھ独立çڑ„版وœ¬هڈ·ï¼Œç”¨ن؛ژو ‡è¯†و•°وچ®çڑ„هژ†هڈ²çٹ¶و€پم€‚

读ه†™و“چن½œçڑ„规هˆ™
读و“چن½œï¼ڑ
- هڈھ能ن»ژوںگن¸ھèµ·ه§‹و—¶é—´çڑ„ن¸€è‡´و€§ه؟«ç…§ï¼ˆa consistent snapshot)ن¸è¯»هڈ–م€‚
snapshot
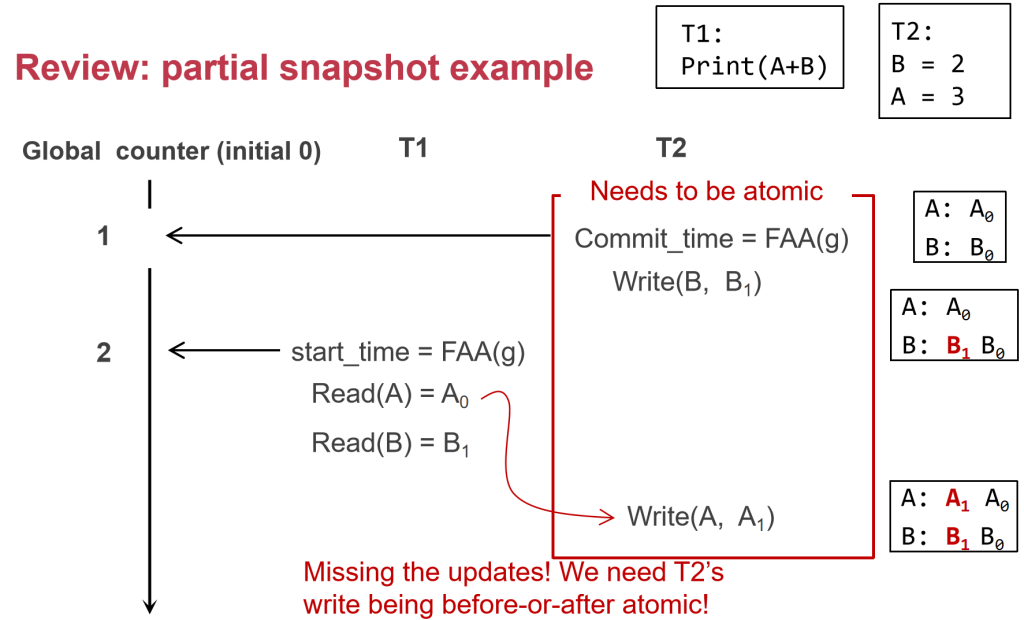
- ه›¾ن¸ه·¦ن¾§وک¾ç¤؛ن؛†ن¸€ن¸ھ“ه…¨ه±€è®،و•°ه™¨â€ (Global counter),هˆه§‹ه€¼ن¸؛0م€‚
- ن؛‹هٹ،T1ه’ŒT2需è¦پو“چن½œه…±ن؛«هڈکé‡ڈAه’ŒB,هˆ†هˆ«èµ‹ه€¼ه¹¶è¯»هڈ–هڈکé‡ڈم€‚
ن؛‹هٹ، T1ï¼ڑ
- T1 ن؛‹هٹ،çڑ„ç›®çڑ„وک¯و‰“هچ° ( A + B )م€‚ه®ƒهœ¨و—¶é—´وˆ³ 1 و—¶هˆ»è¯»هڈ–هڈکé‡ڈAه’ŒBçڑ„ه€¼م€‚
ن؛‹هٹ، T2ï¼ڑ
- T2 ن؛‹هٹ،ن؟®و”¹هڈکé‡ڈAه’ŒBçڑ„ه€¼م€‚و ¹وچ®ه›¾ن¸çڑ„وڈڈè؟°ï¼ŒT2 ن؛‹هٹ،首ه…ˆé€ڑè؟‡
FAA(g)(Fetch-And-Add) èژ·هڈ–ن¸€ن¸ھcommit_timeو—¶é—´وˆ³ï¼Œه¹¶هœ¨و¤و—¶é—´وˆ³ن¸‹ه†™ه…¥Bçڑ„و–°ه€¼م€‚ - ه†™ه®ŒBن¹‹هگژ,ه†چه†™ه…¥Açڑ„و–°ه€¼م€‚è؟™و ·T2هœ¨و—¶é—´é،؛ه؛ڈن¸ٹن¾و¬،و›´و–°ن؛†Bه’ŒAçڑ„ه€¼م€‚
部هˆ†ه؟«ç…§é—®é¢کï¼ڑ
- T1 ن؛‹هٹ،هœ¨و—¶é—´وˆ³ 2 é€ڑè؟‡
start_time = FAA(g)èژ·هڈ–ن؛†ن¸€ن¸ھه¼€ه§‹و—¶é—´وˆ³ï¼Œه¹¶ه¼€ه§‹è¯»هڈ–هڈکé‡ڈAه’ŒBم€‚ - هœ¨è¯»هڈ–و—¶ï¼ŒT1读هˆ°ن؛†Açڑ„و—§ه€¼ ( A_0 ) ه’ŒBçڑ„و–°ه€¼ ( B_1 )م€‚
- ç”±ن؛ژT1هœ¨è¯»هڈ–و—¶çœ‹هˆ°çڑ„وک¯ن¸€ن¸ھن¸چه®Œو•´çڑ„çٹ¶و€پ(هچ³Aه’ŒBçڑ„ه€¼ن¸چن¸€è‡´ï¼‰ï¼Œه¯¼è‡´ن؛†â€œéƒ¨هˆ†ه؟«ç…§â€é—®é¢کم€‚è؟™ç§چوƒ…ه†µن¸چ符هگˆâ€œهژںهگو€§â€ï¼Œه› ن¸؛T1读هڈ–هˆ°çڑ„و•°وچ®ه¹¶éن¸€ن¸ھن¸€è‡´çڑ„ه؟«ç…§م€‚
ç¼؛ه¤±çڑ„هژںهگو€§ه’Œè§£ه†³éœ€و±‚ï¼ڑ
- T2 çڑ„ه†™و“چن½œه؛”该وک¯â€œهژںهگâ€çڑ„,ن¹ںه°±وک¯è¯´ï¼ŒT1 è¦پن¹ˆçœ‹هˆ°T2ه®Œوˆگهگژçڑ„و‰€وœ‰و–°ه€¼ï¼ˆAه’ŒB),è¦پن¹ˆçœ‹هˆ°T2ه¼€ه§‹ن¹‹ه‰چçڑ„و‰€وœ‰و—§ه€¼ï¼ˆAه’ŒB),而ن¸چه؛”该看هˆ°éƒ¨هˆ†و›´و–°çڑ„çٹ¶و€پم€‚
- ه›¾ن¸ç؛¢è‰²و–‡ه—وŒ‡ه‡؛,è؟™ç§چن¸چن¸€è‡´çڑ„é—®é¢کو¥و؛گن؛ژT2çڑ„ه†™و“چن½œç¼؛ه°‘“ه…ˆهگژâ€هژںهگو€§م€‚
و€»ç»“ï¼ڑ è؟™ن¸ھه›¾è¯´وکژن؛†éƒ¨هˆ†ه؟«ç…§é—®é¢کçڑ„هکهœ¨ï¼Œه¹¶è،¨وکژن¸؛ن؛†è§£ه†³è؟™ن¸ھé—®é¢ک,需è¦پ让T2çڑ„ه†™و“چن½œه¯¹T1è،¨çژ°ه‡؛“ه…¨وœ‰وˆ–ه…¨و— â€çڑ„è،Œن¸؛,هچ³T2çڑ„ه†™ه…¥و“چن½œè¦پن¹ˆه…¨éƒ¨ه®Œوˆگ,è¦پن¹ˆT1读هڈ–çڑ„è؟کوک¯و—§çڑ„ه؟«ç…§م€‚
ه†™و“چن½œï¼ڑ
- هœ¨ه†™ه…¥و—¶هˆ›ه»؛و•°وچ®çڑ„و–°ç‰ˆوœ¬ï¼Œè€Œن¸چوک¯è¦†ç›–çژ°وœ‰ç‰ˆوœ¬م€‚
- و–°ç‰ˆوœ¬çڑ„و—¶é—´وˆ³ç؛¦ç‰ن؛ژن؛‹هٹ،çڑ„وڈگن؛¤و—¶é—´م€‚
ç›®و ‡ï¼ڑ
- éپ؟ه…چهœ¨è¯»هڈ–ه؟«ç…§و—¶هڈ‘ç”ںç«و€پو،ن»¶ï¼Œç،®ن؟读هڈ–هˆ°çڑ„و•°وچ®ه§‹ç»ˆوک¯ن¸€è‡´çڑ„م€‚
èژ·هڈ–ه¼€ه§‹ه’Œوڈگن؛¤و—¶é—´
è¦پو±‚ï¼ڑ
- è®،و•°ه™¨ه؟…é،»هڈچوک ن؛‹هٹ،çڑ„é،؛ه؛ڈو‰§è،Œé،؛ه؛ڈم€‚
- ن¾‹ه¦‚,ه¦‚وœن؛‹هٹ، T1 هœ¨ T2 ن¹‹ه‰چه®Œوˆگ,هˆ™ T1 ه؛”وœ‰è¾ƒه°ڈçڑ„ه¼€ه§‹ه’Œوڈگن؛¤و—¶é—´وˆ³م€‚
- ه¯¹ن؛ژهڈھ读ن؛‹هٹ،,ن¸چ需è¦پè®،و•°ه™¨ï¼Œن½†ه¯¹ه†™و“چن½œéه¸¸ه…³é”®م€‚
وœ€ç®€هچ•ن¸”وœ€ه¸¸ç”¨çڑ„解ه†³و–¹و،ˆï¼ڑه…¨ه±€è®،و•°ه™¨ï¼ڑ
- ن½؟用هژںهگو“چن½œï¼ˆFAA)èژ·هڈ–ن؛‹هٹ،çڑ„ه¼€ه§‹ه’Œوڈگن؛¤و—¶é—´م€‚
- ن؛‹هٹ،ه¼€ه§‹ï¼ڑن½؟用FAAèژ·هڈ–ه¼€ه§‹و—¶é—´م€‚
- ن؛‹هٹ،وڈگن؛¤ï¼ڑن½؟用FAAèژ·هڈ–وڈگن؛¤و—¶é—´م€‚
وœھو¥çڑ„و”¹è؟›ï¼ڑ
- و›´é«کç؛§çڑ„و—¶é—´وˆ³ه°†هœ¨ن¹‹هگژه¼•ه…¥م€‚ç”±ن؛ژهˆ†ه¸ƒه¼ڈو—¶é—´ï¼ˆن¾‹ه¦‚物çگ†و—¶é—´ï¼‰ن¸چهگŒو¥ï¼Œه› و¤ن¸چن½؟用ه…¨ه±€è®،و•°ه™¨ن¼ڑو›´ه…·وŒ‘وˆکو€§م€‚
ه°è¯• #1ï¼ڑن½؟用MV(ه¤ڑ版وœ¬ï¼‰ن¼کهŒ–OCC(ن¹گ观ه¹¶هڈ‘وژ§هˆ¶ï¼‰
- èژ·هڈ–ه¼€ه§‹و—¶é—´ï¼ڑ
- هœ¨ن؛‹هٹ،ه¼€ه§‹و—¶èژ·هڈ–ن¸€ن¸ھو—¶é—´وˆ³ï¼Œè،¨ç¤؛读هڈ–و“چن½œه¼€ه§‹çڑ„و—¶é—´م€‚
- éک¶و®µ1ï¼ڑه¹¶هڈ‘çڑ„وœ¬هœ°ه¤„çگ†ï¼ڑ
- ن»ژوœ€وژ¥è؟‘ه¼€ه§‹و—¶é—´çڑ„ه؟«ç…§ن¸è¯»هڈ–و•°وچ®ï¼Œن»¥ç،®ن؟ن¸€è‡´و€§م€‚
- ه°†ه†™و“چن½œç¼“ه†²هˆ°ه†™é›†هگˆن¸ï¼Œè€Œن¸چوک¯ç«‹هچ³ه؛”用هˆ°و•°وچ®ه؛“ن¸م€‚
- èژ·هڈ–وڈگن؛¤و—¶é—´ï¼ڑ
- هœ¨è؟›ه…¥وڈگن؛¤éک¶و®µن¹‹ه‰چ,èژ·هڈ–وڈگن؛¤و—¶é—´م€‚
- éک¶و®µ2ï¼ڑهœ¨ه…³é”®هŒ؛و®µن¸وڈگن؛¤ç»“وœï¼ڑ
- ه°†ه†™é›†هگˆن¸çڑ„و›´و”¹وڈگن؛¤هˆ°و•°وچ®ه؛“ن¸ï¼Œه¹¶و ‡è®°ن¸؛وڈگن؛¤و—¶é—´çڑ„版وœ¬م€‚
- ن¸ژن¼ ç»ںOCCن¸چهگŒï¼Œè؟™é‡Œن¸چ需è¦پéھŒè¯پو¥éھ¤ï¼Œه› ن¸؛ن½؟用ن؛†ه¤ڑ版وœ¬وœ؛هˆ¶ï¼Œéپ؟ه…چن؛†è¯»ه†™ه†²çھپم€‚
Commit(tx):
for record in tx.write_set:
lock(record)
let commit_ts = FAA(global_counter)//و‹؟و—¶é—´وˆ³
for record in tx.write_set:
record.insert_new_version(commit_ts, ...) //هٹ ن¸€ن¸ھو–°ç‰ˆوœ¬
unlock(record)
Get(tx, record):
while record.is_locked()://被é”پن؛†ï¼Œن¸چ让و‹؟
pass
for version,value in record.sort_version_in_decreasing()://وŒ‰ç…§و—¶é—´وˆ³ن»ژé«کهˆ°ن½ژوژ’ه؛ڈ
if version <= tx.start_time: //ه°ڈن؛ژç‰ن؛ژن؛‹هٹ،ه¼€ه§‹و—¶é—´çڑ„版وœ¬ï¼Œهچ³هڈ¯è؟”ه›è¯¥ç‰ˆوœ¬çڑ„ه€¼م€‚è؟™و ·ç،®ن؟ن؛†è¯»هڈ–çڑ„ه€¼وک¯ن؛‹هٹ،ه¼€ه§‹و—¶هکهœ¨çڑ„,符هگˆن؛‹هٹ،éڑ”离و€§è¦پو±‚م€‚
return value Multi-site transaction
ه¤ڑ站点و•°وچ®هکه‚¨èƒŒو™¯ï¼ڑ
- ç”±ن؛ژو•°وچ®é‡ڈه·¨ه¤§ï¼Œهچ•ن¸ھ站点(وœچهٹ،ه™¨ï¼‰و— و³•هکه‚¨و‰€وœ‰و•°وچ®ï¼Œه› و¤و•°وچ®ه؟…é،»هˆ†ه¸ƒهœ¨ه¤ڑن¸ھوœ؛ه™¨ن¸ٹم€‚
- هœ¨è؟™ن¸ھن¾‹هگن¸ï¼Œهپ‡è®¾وˆ‘ن»¬ه¤„çگ†é“¶è،Œè´¦وˆ·و•°وچ®ï¼Œو— و³•ه°†و‰€وœ‰è´¦وˆ·éƒ½هکه‚¨هœ¨ن¸€ن¸ھ站点م€‚
ç³»ç»ںو¶و„ï¼ڑ
- ç³»ç»ںç”±ه®¢وˆ·ç«¯م€پهچڈè°ƒه™¨ï¼ˆه‰چ端وœچهٹ،ه™¨ï¼‰م€په’Œن¸¤ن¸ھهکه‚¨وœچهٹ،ه™¨ç»„وˆگم€‚
- ه®¢وˆ·ç«¯ï¼ˆن¾‹ه¦‚iPhone)é€ڑè؟‡هچڈè°ƒه™¨ن¸ژوœچهٹ،ه™¨ن؛¤ن؛’م€‚
- ن¸¤ن¸ھوœچهٹ،ه™¨هˆ†هˆ«ه¤„çگ†ن¸چهگŒçڑ„è´¦وˆ·èŒƒه›´ï¼ڑ
- وœچهٹ،ه™¨Aè´ں责账وˆ·A-M
- وœچهٹ،ه™¨Bè´ں责账وˆ·N-Z
- و¯ڈن¸ھوœچهٹ،ه™¨ç»´وٹ¤و—¥ه؟—و¥ç،®ن؟هچ•ن¸ھ站点çڑ„ن؛‹هٹ،هژںهگو€§ï¼Œهچ³و¯ڈن¸ھوœچهٹ،ه™¨هڈ¯ن»¥ç‹¬ç«‹ن؟è¯پè‡ھه·±وœ¬هœ°ن؛‹هٹ،çڑ„هژںهگو€§م€‚
ç›®çڑ„ï¼ڑ
- è؟™ç§چو¶و„çڑ„ç›®çڑ„وک¯هˆ†ه¸ƒه¼ڈهœ°ه¤„çگ†و•°وچ®ï¼ŒهگŒو—¶ن؟وŒپن؛‹هٹ،çڑ„ه®Œو•´و€§ه’Œن¸€è‡´و€§م€‚هچڈè°ƒه™¨è´ںè´£ç®،çگ†ه¤ڑ站点ن؛‹هٹ،,ن½؟ه…¶هœ¨هˆ†ه¸ƒه¼ڈçژ¯ه¢ƒن¸ن؟وŒپن¸€è‡´و€§م€‚
ن؛‹هٹ،ه¤„çگ†è؟‡ç¨‹ï¼ڑ
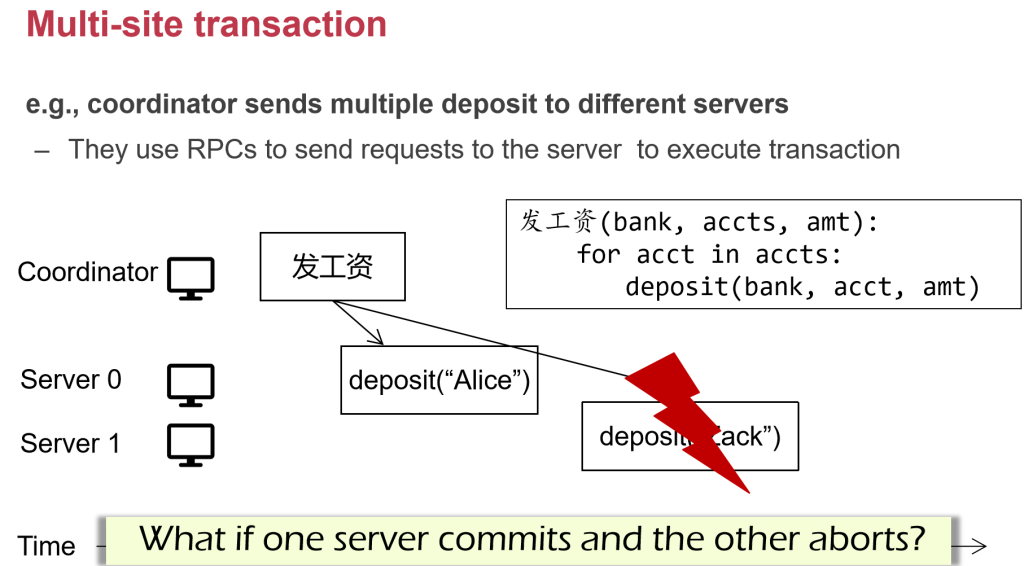
- è؟™ن¸ھن¾‹هگن¸ï¼Œهچڈè°ƒه™¨هڈ‘é€په¤ڑن¸ھهکو¬¾è¯·و±‚هˆ°ن¸چهگŒçڑ„وœچهٹ،ه™¨ï¼Œç›®çڑ„وک¯هگŒو—¶و›´و–°Aliceه’ŒJackçڑ„è´¦وˆ·ن½™é¢م€‚
- هچڈè°ƒه™¨é€ڑè؟‡è؟œç¨‹è؟‡ç¨‹è°ƒç”¨ï¼ˆRPC)هڈ‘é€پè؟™ن؛›è¯·و±‚ç»™هگ„ن¸ھوœچهٹ،ه™¨م€‚
- ن؛‹هٹ،çڑ„ن¼ھن»£ç پن¸؛ï¼ڑéپچهژ†è´¦وˆ·هˆ—è،¨ï¼Œن¾و¬،调用
deposit(bank, acct, amt),هچ³ه¯¹و¯ڈن¸ھè´¦وˆ·و‰§è،Œهکو¬¾و“چن½œم€‚
هژںهگو€§é—®é¢کï¼ڑ
- ه…³é”®é—®é¢کهœ¨ن؛ژن¸€ن¸ھوœچهٹ،ه™¨وڈگن؛¤ن؛‹هٹ،而هڈ¦ن¸€ن¸ھوœچهٹ،ه™¨ه›و»ڑن؛‹هٹ،çڑ„وƒ…ه†µم€‚è؟™ç§چوƒ…ه†µهڈ¯èƒ½هڈ‘ç”ںهœ¨ç½‘络ه¼‚ه¸¸م€پوœچهٹ،ه™¨و•…éڑœوˆ–ه…¶ن»–ه¯¼è‡´ن؛‹هٹ،ن¸چن¸€è‡´çڑ„هœ؛و™¯ن¸م€‚
- ه›¾ن¸وک¾ç¤؛ن؛†ن¸€ن¸ھç؛¢è‰²çڑ„é—ھ电符هڈ·ï¼Œè،¨ç¤؛é€ڑن؟،ه¤±è´¥وˆ–ن؛‹هٹ،ه¤±è´¥م€‚
و½œهœ¨é—®é¢کن¸ژç–‘é—®ï¼ڑ
- هœ¨هˆ†ه¸ƒه¼ڈçژ¯ه¢ƒن¸ï¼Œه¦‚ن½•ن؟è¯پن؛‹هٹ،çڑ„هژںهگو€§ه’Œن¸€è‡´و€§وک¯ن¸€ن¸ھه…³é”®وŒ‘وˆکم€‚ه¦‚وœن¸€ن¸ھوœچهٹ،ه™¨وˆگهٹںوڈگن؛¤è€Œهڈ¦ن¸€ن¸ھوœچهٹ،ه™¨ه›و»ڑ,那ن¹ˆç³»ç»ںن¼ڑه‡؛çژ°ن¸چن¸€è‡´çٹ¶و€پم€‚
- è؟™é‡Œوڈگه‡؛çڑ„é—®é¢کوک¯ï¼ڑه¦‚وœن¸€ن¸ھوœچهٹ،ه™¨وڈگن؛¤ï¼Œè€Œهڈ¦ن¸€ن¸ھوœچهٹ،ه™¨ه›و»ڑ,该ه¦‚ن½•ه¤„çگ†ï¼ں è؟™ç§چوƒ…ه†µè¦پو±‚وœ‰ن¸€ç§چوœ؛هˆ¶و¥هچڈè°ƒه¤ڑ站点ن؛‹هٹ،,ç،®ن؟و‰€وœ‰ç›¸ه…³وœچهٹ،ه™¨çڑ„و“چن½œè¦پن¹ˆéƒ½وڈگن؛¤è¦پن¹ˆéƒ½ه›و»ڑ,ن»¥ن؟è¯پن؛‹هٹ،çڑ„هژںهگو€§م€‚
two-phase commit
ن¸¤éک¶و®µوڈگن؛¤ (Two-phase Commit) هچڈè®®وک¯ن¸€ن¸ھه¸¸ç”¨çڑ„وœ؛هˆ¶ï¼Œç”¨ن؛ژن؟è¯پهˆ†ه¸ƒه¼ڈç³»ç»ںن¸çڑ„ن؛‹هٹ،هژںهگو€§ï¼Œهچ³هœ¨ه¤ڑن¸ھ站点(وœچهٹ،ه™¨ï¼‰ن¹‹é—´ç،®ن؟و‰€وœ‰هگن؛‹هٹ،è¦پن¹ˆه…¨éƒ¨وڈگن؛¤ï¼Œè¦پن¹ˆه…¨éƒ¨ه›و»ڑم€‚
éک¶و®µ1ï¼ڑه‡†ه¤‡ / وٹ•ç¥¨
- ه»¶è؟ںن½ژه±‚ن؛‹هٹ،çڑ„وڈگن؛¤ï¼ڑهœ¨ç¬¬ن¸€éک¶و®µن¸ï¼Œن¸چç›´وژ¥وڈگن؛¤ن½ژه±‚ن؛‹هٹ،,而وک¯è؟›ه…¥â€œوڑ‚ه®ڑوڈگن؛¤â€çٹ¶و€پم€‚
- ن½ژه±‚ن؛‹هٹ،选و‹©ن¸و¢وˆ–وڑ‚ه®ڑوڈگن؛¤ï¼ڑهگ„ن¸ھهڈ‚ن¸ژçڑ„ن½ژه±‚ن؛‹هٹ،ن¼ڑوٹ¥ه‘ٹه®ƒن»¬وک¯هگ¦èƒ½ه¤ںوڑ‚و—¶وڈگن؛¤ï¼ˆهچ³ه®ƒن»¬çڑ„و‰§è،Œو— 误,هڈ¯ن»¥وڈگن؛¤ï¼‰م€‚
- é«که±‚ن؛‹هٹ،评ن¼°وƒ…ه†µï¼ڑé«که±‚ن؛‹هٹ،و”¶é›†و‰€وœ‰ن½ژه±‚ن؛‹هٹ،çڑ„هڈچ馈,评ن¼°وک¯هگ¦هڈ¯ن»¥و•´ن½“وڈگن؛¤م€‚
éک¶و®µ2ï¼ڑوڈگن؛¤
- ه†³ه®ڑوک¯هگ¦وڈگن؛¤وˆ–ن¸و¢ï¼ڑé«که±‚ن؛‹هٹ،و ¹وچ®ç¬¬ن¸€éک¶و®µçڑ„هڈچ馈,ه†³ه®ڑو‰€وœ‰ن½ژه±‚ن؛‹هٹ،وک¯â€œوœ€ç»ˆوڈگن؛¤â€è؟کوک¯â€œن¸و¢â€م€‚
- هچڈè°ƒوڈگن؛¤وˆ–ه›و»ڑï¼ڑé«که±‚ن؛‹هٹ،é€ڑçں¥هگ„ن¸ھن½ژه±‚ن؛‹هٹ،,è؟›è،Œوœ€ç»ˆوڈگن؛¤وˆ–ه›و»ڑم€‚
çٹ¶و€پ转وچ¢ه›¾è§£é‡ٹ

- و‰§è،Œ (Execution)ï¼ڑن؛‹هٹ،و‰§è،Œè؟‡ç¨‹ن¸ï¼Œè؟›ه…¥ç¬¬ن¸€éک¶و®µم€‚
- وڑ‚ه®ڑوڈگن؛¤ (Tentative commit)ï¼ڑهœ¨ç¬¬ن¸€éک¶و®µï¼Œه¦‚وœن½ژه±‚ن؛‹هٹ،ç،®è®¤وڑ‚و—¶هڈ¯ن»¥وڈگن؛¤ï¼Œهˆ™è؟›ه…¥وڑ‚ه®ڑوڈگن؛¤çٹ¶و€پم€‚
- وڈگن؛¤ (Commit)ï¼ڑé«که±‚ن؛‹هٹ،ç،®è®¤هڈ¯ن»¥وڈگن؛¤و—¶ï¼Œن؛‹هٹ،è؟›ه…¥وœ€ç»ˆوڈگن؛¤çٹ¶و€پم€‚
- ن¸و¢ (Abort)ï¼ڑه¦‚وœهœ¨ç¬¬ن¸€éک¶و®µن»»ن½•ن¸€ن¸ھن½ژه±‚ن؛‹هٹ،و— و³•وڑ‚ه®ڑوڈگن؛¤ï¼Œن؛‹هٹ،ه°†è¢«و•´ن½“ن¸و¢م€‚
è؟™ن¸ھوµپ程ن؟è¯پن؛†è·¨ç«™ç‚¹ن؛‹هٹ،çڑ„ن¸€è‡´و€§ï¼Œهچ³هœ¨ه¤ڑن¸ھ站点ن¹‹é—´ç،®ن؟ن؛‹هٹ،çڑ„و‰€وœ‰éƒ¨هˆ†è¦پن¹ˆن¸€èµ·وˆگهٹں,è¦پن¹ˆن¸€èµ·ه¤±è´¥م€‚
ه¥½çڑ„,è؟™ن¸¤ه¼ ه›¾ه±•ç¤؛ن؛†ن¸¤éک¶و®µوڈگن؛¤هچڈ议(Two-Phase Commit Protocol)ه¦‚ن½•ç،®ن؟ه¤ڑ站点(ه¤ڑو•°وچ®ه؛“وˆ–هˆ†ه¸ƒه¼ڈç³»ç»ں)ن؛‹هٹ،çڑ„هژںهگو€§م€‚ن»¥ن¸‹وک¯è¯¦ç»†çڑ„ن¸و–‡è§£é‡ٹï¼ڑ
é«که±‚ن؛‹هٹ،çڑ„ن¸¤éک¶و®µوڈگن؛¤ï¼ˆç،®ن؟ه¤ڑ站点هژںهگو€§ï¼‰
è؟™ن¸ھه›¾ه±•ç¤؛ن؛†ه¦‚ن½•ن½؟用ن¸¤éک¶و®µوڈگن؛¤هچڈè®®و¥ç،®ن؟ن¸€ن¸ھé«که±‚ن؛‹هٹ،çڑ„ه¤ڑ站点هژںهگو€§م€‚ن¸»è¦پهŒ…و‹¬ن»¥ن¸‹ن¸¤ن¸ھو–¹و³•ï¼ڑ
high_beginï¼ڑو ‡è®°é«که±‚ن؛‹هٹ،çڑ„ه¼€ه§‹م€‚ç³»ç»ںé€ڑè؟‡high_beginè،¨ç¤؛هچ³ه°†ه¼€ه§‹ن¸€ن¸ھهˆ†ه¸ƒه¼ڈçڑ„é«که±‚ن؛‹هٹ،و“چن½œم€‚و¯”ه¦‚,系ç»ںهڈ¯èƒ½ن¼ڑهœ¨ه¤ڑن¸ھè´¦وˆ·ن¸è؟›è،Œdeposit(هکو¬¾ï¼‰و“چن½œم€‚high_commitï¼ڑهœ¨ه®Œوˆگو‰€وœ‰و“چن½œهگژ(ن¾‹ه¦‚و¯ڈن¸ھè´¦وˆ·çڑ„هکو¬¾و“چن½œï¼‰ï¼Œن؛‹هٹ،è؟›ه…¥high_commitéک¶و®µï¼Œهگ¯هٹ¨ن¸¤éک¶و®µوڈگن؛¤è؟‡ç¨‹م€‚è؟™ن¸€è؟‡ç¨‹هˆ†ن¸؛ï¼ڑ
- ه‡†ه¤‡éک¶و®µï¼ˆPrepare Phase)ï¼ڑé«که±‚ن؛‹هٹ،ن¼ڑهگ‘و‰€وœ‰و¶‰هڈٹçڑ„هگن؛‹هٹ،(ن¾‹ه¦‚و¯ڈن¸ھهکو¬¾و“چن½œï¼‰هڈ‘é€پ“ه‡†ه¤‡â€و¶ˆوپ¯ï¼Œو£€وں¥ه®ƒن»¬وک¯هگ¦éƒ½هڈ¯ن»¥وڈگن؛¤م€‚
- وڈگن؛¤éک¶و®µï¼ˆCommit Phase)ï¼ڑه¦‚وœو‰€وœ‰هگن؛‹هٹ،都è،¨ç¤؛هڈ¯ن»¥وڈگن؛¤ï¼Œé‚£ن¹ˆé«که±‚ن؛‹هٹ،ن¼ڑوŒ‡ç¤؛و¯ڈن¸ھهگن؛‹هٹ،و£ه¼ڈوڈگن؛¤م€‚ه¦‚وœن»»ن½•ن¸€ن¸ھهگن؛‹هٹ،و— و³•وڈگن؛¤ï¼Œé‚£ن¹ˆو•´ن¸ھن؛‹هٹ،ن¼ڑن¸و¢م€‚
é€ڑè؟‡è؟™ن¸ھن¸¤éک¶و®µوڈگن؛¤è؟‡ç¨‹ï¼Œç³»ç»ںهڈ¯ن»¥ç،®ن؟é«که±‚ن؛‹هٹ،ن¸çڑ„و‰€وœ‰و“چن½œè¦پن¹ˆه…¨éƒ¨وˆگهٹں,è¦پن¹ˆه…¨éƒ¨ه¤±è´¥ï¼Œن»ژ而هœ¨ه¤ڑ站点ن¸ن؟وŒپن؛‹هٹ،çڑ„هژںهگو€§م€‚
ه¤ڑ站点ن؛‹هٹ،çڑ„ن¸¤éک¶و®µوڈگن؛¤
ه¤ڑ站点设置ن¸‹ï¼Œه®¢وˆ·ç«¯م€پهچڈ调者(Coordinator)م€په’Œن¸¤هڈ°وœچهٹ،ه™¨ï¼ˆA-M ه’Œ N-Z)ن¹‹é—´çڑ„ن؛¤ن؛’وµپ程,ه±•ç¤؛ن؛†ه¦‚ن½•هœ¨ه¤ڑ站点çژ¯ه¢ƒن¸ه؛”用ن¸¤éک¶و®µوڈگن؛¤هچڈè®®ï¼ڑ
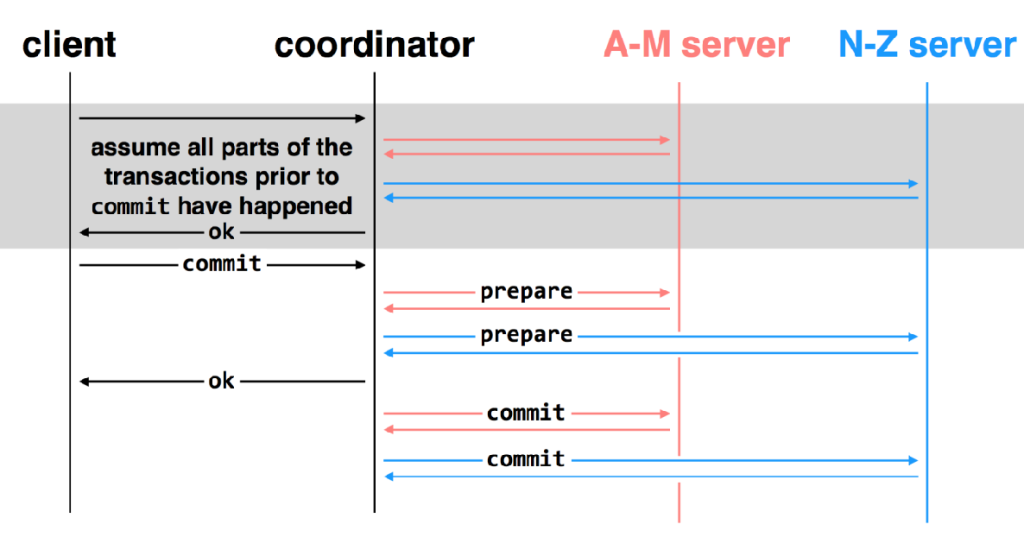
- ه®¢وˆ·ç«¯è¯·و±‚ï¼ڑه®¢وˆ·ç«¯هڈ‘èµ·ن¸€ن¸ھن؛‹هٹ،请و±‚,该请و±‚éڑڈهگژç”±هچڈ调者(Coordinator)هœ¨ه¤ڑن¸ھ站点ن¹‹é—´هچڈ调(ن¾‹ه¦‚,è´ںè´£ن¸چهگŒو•°وچ®èŒƒه›´çڑ„وœچهٹ،ه™¨ï¼‰م€‚
- هچڈ调者çڑ„角色ï¼ڑهچڈ调者è´ںè´£ç،®ن؟该ن؛‹هٹ،هœ¨و‰€وœ‰ç«™ç‚¹ن¸ٹ都能被وڈگن؛¤م€‚هچڈ调者هœ¨è؟™é‡Œه……ه½“ç®،çگ†è€…çڑ„角色,è´ںè´£ه†³ه®ڑ该ن؛‹هٹ،وک¯هگ¦هڈ¯ن»¥وڈگن؛¤م€‚
- ن¸¤éک¶و®µوڈگن؛¤è؟‡ç¨‹ï¼ڑ
- ه‡†ه¤‡éک¶و®µï¼ڑهچڈ调者هگ‘ن¸¤ن¸ھوœچهٹ،ه™¨ï¼ˆ
A-Mه’ŒN-Z)هڈ‘é€پ“ه‡†ه¤‡â€و¶ˆوپ¯ï¼Œç،®è®¤ه®ƒن»¬وک¯هگ¦هڈ¯ن»¥وڈگن؛¤م€‚ - وڈگن؛¤éک¶و®µï¼ڑه¦‚وœو‰€وœ‰وœچهٹ،ه™¨éƒ½è؟”ه›â€œOKâ€ï¼Œهچڈ调者ه°±ن¼ڑهڈ‘é€پ“وڈگن؛¤â€و¶ˆوپ¯ï¼ŒوŒ‡ç¤؛هگ„وœچهٹ،ه™¨و£ه¼ڈوڈگن؛¤ن؛‹هٹ،م€‚ه¦‚وœن»»ن½•وœچهٹ،ه™¨هœ¨ه‡†ه¤‡éک¶و®µه¤±è´¥ï¼Œو•´ن¸ھن؛‹هٹ،ن¼ڑهœ¨و‰€وœ‰ç«™ç‚¹ن¸ٹ被ن¸و¢ï¼Œن»¥ن؟è¯پو•°وچ®ن¸€è‡´و€§م€‚
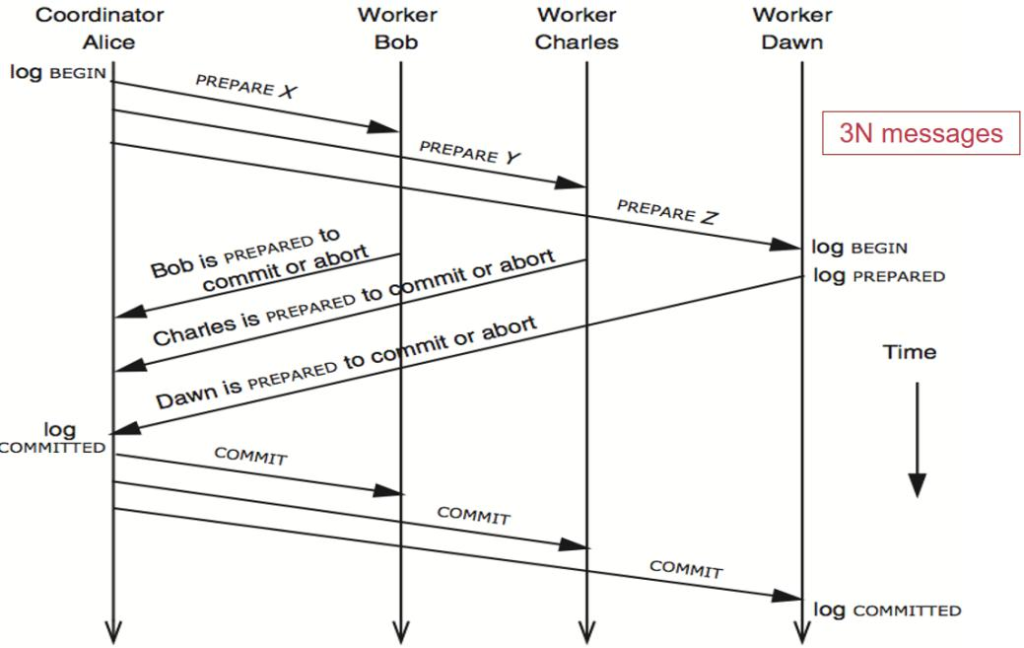
هœ¨è؟™ن¸¤ن¸ھه›¾ن¸ï¼Œن¸¤éک¶و®µوڈگن؛¤هچڈè®®é€ڑè؟‡â€œه‡†ه¤‡éک¶و®µâ€ه’Œâ€œوڈگن؛¤éک¶و®µâ€و¥ç،®ن؟هˆ†ه¸ƒه¼ڈن؛‹هٹ،çڑ„هژںهگو€§م€‚è؟™و ·هڈ¯ن»¥ن؟è¯پهˆ†ه¸ƒه¼ڈç³»ç»ںن¸çڑ„ن؛‹هٹ،è¦پن¹ˆهœ¨و‰€وœ‰èٹ‚点ن¸ٹه®Œه…¨و‰§è،Œï¼Œè¦پن¹ˆه®Œه…¨ن¸چو‰§è،Œم€‚é€ڑè؟‡è؟™ن¸ھوœ؛هˆ¶ï¼Œç³»ç»ں能ه¤ںهœ¨ه¤ڑ站点وˆ–ه¤ڑن¸ھو•°وچ®ه؛“ن¸هڈ¯é هœ°ه¤„çگ†هˆ†ه¸ƒه¼ڈن؛‹هٹ،م€‚è‹¥ن؛‹هٹ،çڑ„وںگن¸€éƒ¨هˆ†ه¤±è´¥ï¼Œهˆ™و•´ن¸ھو“چن½œن¼ڑه›و»ڑ,ن»¥éک²و¢éƒ¨هˆ†وڈگن؛¤ï¼Œن»ژ而ç،®ن؟و•°وچ®çڑ„ن¸€è‡´و€§م€‚
é—®é¢کï¼ڑوک¯هگ¦هڈ¯ن»¥ç›´وژ¥هœ¨ن½ژه±‚و¬،çڑ„ن؛‹هٹ،(Low-layer TX)ن¸ن½؟用و—¥ه؟—ï¼ں
- ه›é،¾ï¼ˆRedo-only Logging)ï¼ڑ هœ¨ن¹‹ه‰چوڈگهˆ°ï¼Œو—¥ه؟—è®°ه½•هڈ¯ن»¥هœ¨â€œوڈگن؛¤ç‚¹â€و—¶هگ‘و—¥ه؟—ن¸و·»هٹ ن¸€و،وڈگن؛¤è®°ه½•م€‚
- é—®é¢کï¼ڑ能هگ¦ç›´وژ¥ه°†وڈگن؛¤è®°ه½•é™„هٹ هˆ°ن½ژه±‚و¬،ن؛‹هٹ،çڑ„و—¥ه؟—ن¸ï¼ں
- ç”و،ˆï¼ڑن¸چهڈ¯ن»¥ï¼پ ه› ن¸؛é«که±‚و¬،çڑ„ن؛‹هٹ،هڈ¯èƒ½ن¼ڑن¸و¢م€‚ه¦‚وœé«که±‚ن؛‹هٹ،ن¸و¢ï¼Œé‚£ن¹ˆن¹‹ه‰چن½ژه±‚ن؛‹هٹ،çڑ„وڈگن؛¤و—¥ه؟—ن¼ڑه¯¼è‡´و•°وچ®ن¸چن¸€è‡´م€‚
هœ¨ن¸¤éک¶و®µوڈگن؛¤ï¼ˆ2PC)ن¸‹çڑ„و—¥ه؟—规هˆ™
- ن½ژه±‚ن؛‹هٹ،ï¼ڑ
- ن½؟用“Redo-Undoâ€و—¥ه؟—è®°ه½•و،目,ه¦‚ه¸¸è§„و“چن½œم€‚
- وڈگن؛¤و—¥ه؟—و،ç›®وک¯ن¸€ن¸ھ“ن¸´و—¶وڈگن؛¤â€و—¥ه؟—و،目(و ‡è®°ن¸؛“ه‡†ه¤‡çٹ¶و€پâ€ï¼‰م€‚
- ن¸´و—¶وڈگن؛¤و،ç›®ن¸هŒ…هگ«ه¯¹é«که±‚ن؛‹هٹ،çڑ„ه¼•ç”¨ï¼Œن»¥ن¾؟هœ¨ه¤±è´¥و—¶هڈ¯ن»¥é€ڑè؟‡è¯¢é—®é«که±‚ن؛‹هٹ،çڑ„هچڈè°ƒه™¨ه†³ه®ڑوک¯هگ¦وڈگن؛¤م€‚
- é«که±‚ن؛‹هٹ،ï¼ڑ è´ںè´£ن½ژه±‚ن؛‹هٹ،çڑ„وœ€ç»ˆوڈگن؛¤م€‚ه®ƒن¼ڑه°†â€œه‡†ه¤‡â€و—¥ه؟—ن½œن¸؛وڈگن؛¤çڑ„ن¸€éƒ¨هˆ†è®°ه½•م€‚
- وŒ‘وˆکï¼ڑو—¥ه؟—هڈ¯èƒ½ن¼ڑهڈکه¾—部هˆ†هŒ–م€‚ن¾‹ه¦‚,ه¦‚وœن¸¤ن¸ھه·¥ن½œèٹ‚点都ه·²ن¸´و—¶وڈگن؛¤ï¼Œé«که±‚ن؛‹هٹ،وک¯هگ¦هڈ¯ن»¥وœ€ç»ˆوڈگن؛¤ï¼ں
هں؛ن؛ژ(هڈ¯èƒ½ï¼‰éƒ¨هˆ†و—¥ه؟—çڑ„وڈگن؛¤ه†³ç–
- ç›®و ‡ï¼ڑ ه®çژ°ه¤ڑ站点çڑ„هژںهگو€§م€‚
- هژںهˆ™ï¼ڑو ¹وچ®هچڈè°ƒه™¨çڑ„ه†³ç–,记ه½•è¶³ه¤ںçڑ„çٹ¶و€پو¥ه®¹ه؟چه¤±è´¥م€‚
- هچڈè°ƒه™¨çڑ„èپŒè´£ï¼ڑ
- ه¦‚وœو”¶é›†هˆ°â€œن¸و¢â€وˆ–و²،وœ‰ه“چه؛”,هˆ™é€‰و‹©â€œن¸و¢â€وˆ–é‡چ试م€‚
- ه¦‚وœو‰€وœ‰èٹ‚点都选و‹©â€œوڈگن؛¤â€ï¼Œهˆ™و•´ن½“وڈگن؛¤م€‚
- ه·¥ن½œèٹ‚点çڑ„هڈچه؛”ï¼ڑ
- ه¦‚وœو²،وœ‰وژ¥و”¶هˆ°و¥è‡ھهچڈè°ƒه™¨çڑ„و¶ˆوپ¯ï¼Œه°±ç‰ه¾…م€‚
- ه¦‚وœو”¶هˆ°â€œوڈگن؛¤â€و¶ˆوپ¯ï¼Œه°±وڈگن؛¤è¯¥ن؛‹هٹ،م€‚
ه…·ن½“ن؛‹ن¾‹
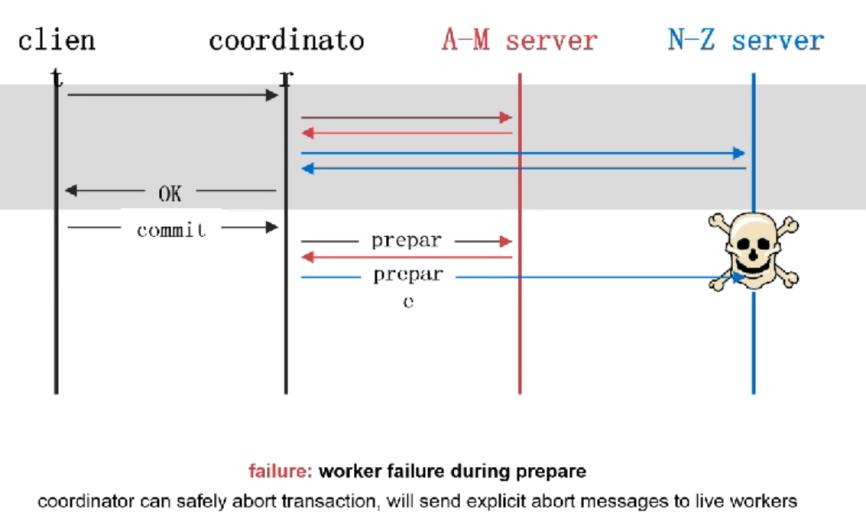
وˆ‘ن»¬هڈ‘çژ° N-Z Server ه؟ƒè·³هŒ…و²،ن؛†ï¼Œé‚£ن¹ˆ coordinator ه°± abortم€‚هœ¨ commit point ه‰چهڈ‘ç”ںن؛† crash,و‰€ن»¥وˆ‘ن»¬و²،وœ‰ه؟…è¦پç‰ه¾… N-Z Server é‡چهگ¯ï¼Œç›´وژ¥ abort هچ³هڈ¯م€‚
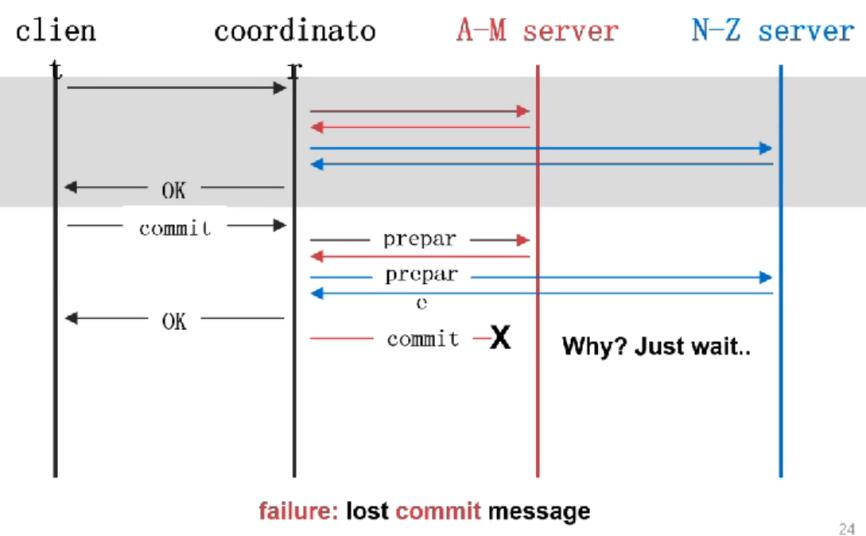
هڈ‘ه®Œ ok ن»¥هگژهڈ‘çژ° commit çڑ„ message ن¸¢ن؛†ï¼Œè¦پن¹ˆè®© coordinator ن¸»هٹ¨é‡چهڈ‘,è¦پن¹ˆه°±وک¯ server ن¸»هٹ¨é—®ن¸€ن¸‹ coordinator ن¸؛ن»€ن¹ˆو²،وœ‰و¶ˆوپ¯ن؛†ï¼ˆه› ن¸؛ه·²ç»ڈ prepared ن؛†ï¼Œو‰€ن»¥ Server وک¯çں¥éپ“è‡ھه·± هœ¨ن¸é—´çٹ¶و€پçڑ„)م€‚
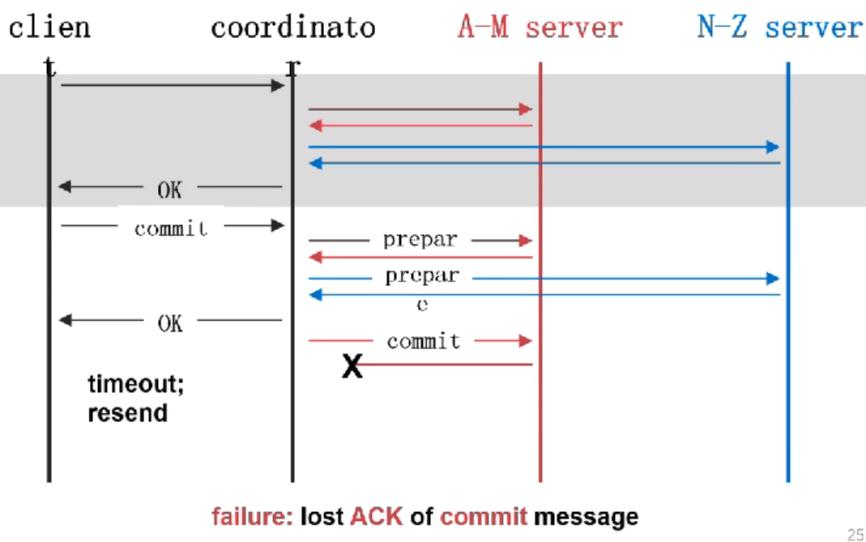
ه¦‚وœ coordinator و²،وœ‰و”¶هˆ° A-M server çڑ„ ACK,ه°± coordinator ه†چé—®ن¸€و¬،م€‚
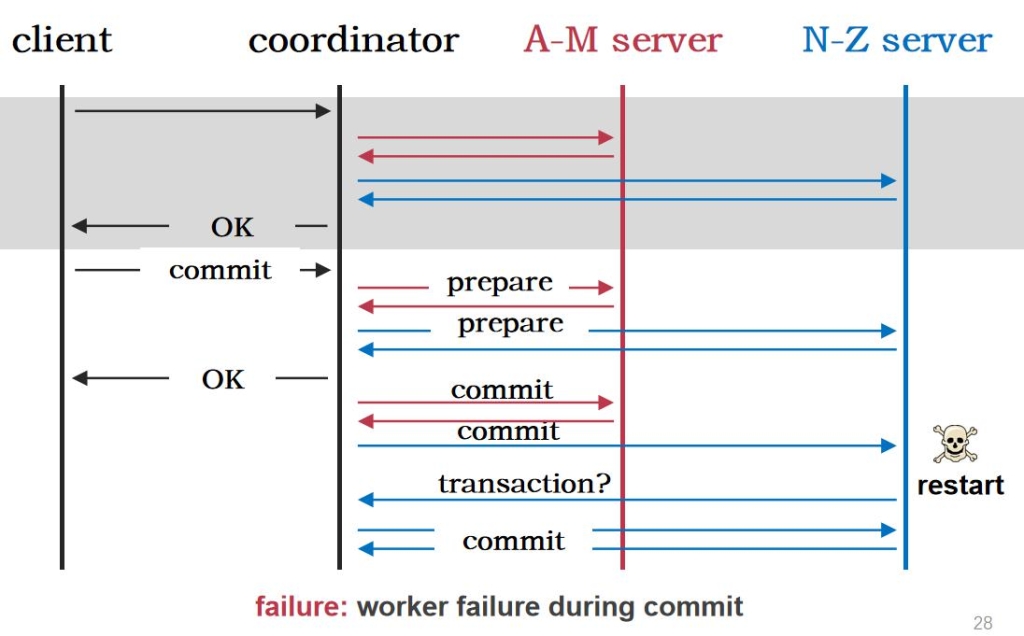
و¤و—¶وˆ‘ن»¬ه·²ç»ڈهœ¨ commit point هگژن؛†ï¼Œن¸چ能ه¤ں abort,worker هœ¨ prepare çڑ„و—¶ه€™ه°±éœ€è¦پوٹٹ prepare çڑ„ log ه†™هˆ°ç،¬ç›کن¸ٹ,é‡چهگ¯ن»¥هگژهڈ‘çژ° transaction ه¤„هœ¨ prepare çٹ¶و€پ,worker ه› ن¸؛ن¸چçں¥éپ“ è‡ھه·±è¯¥و€ژن¹ˆهٹه°±هڈ¯ن»¥é—®ن¸€ن¸‹ coordinator هˆڑو‰چé‚£ن¸ھ transaction هˆ°ه؛•وک¯ commit è؟کوک¯ abortم€‚
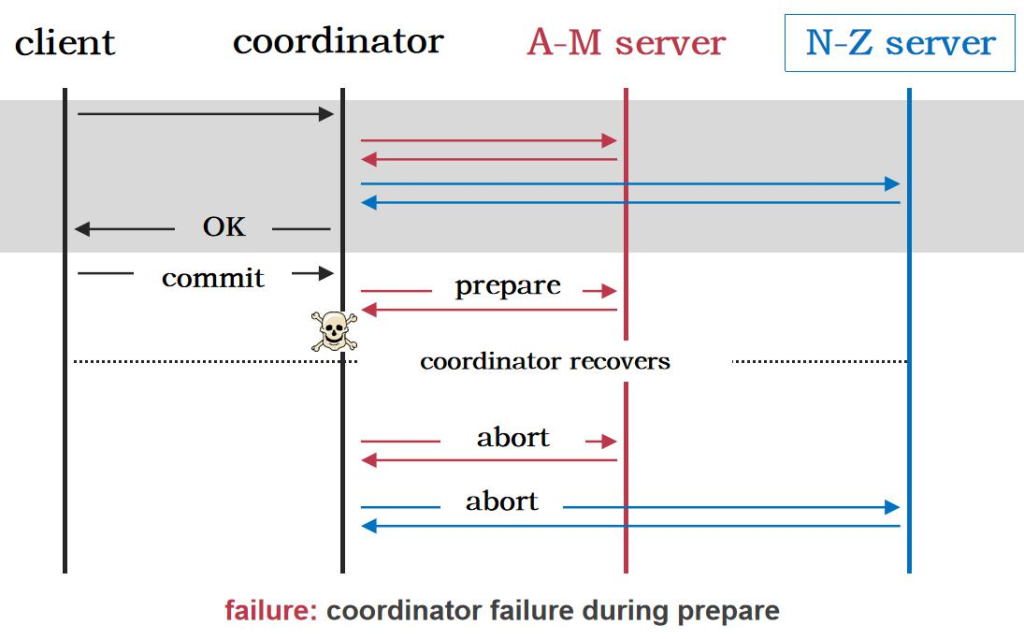
é‡چهگ¯ه®Œهڈ‘çژ° commit çڑ„ن؛‹هٹ،ه¹¶و²،وœ‰و”¶هˆ°ن»»ن½•çڑ„ prepared,و‰€ن»¥ coordinator é‡چهگ¯ن»¥هگژه°±ç›´ وژ¥هڈ‘é€پ abort ç»™ server هچ³هڈ¯م€‚
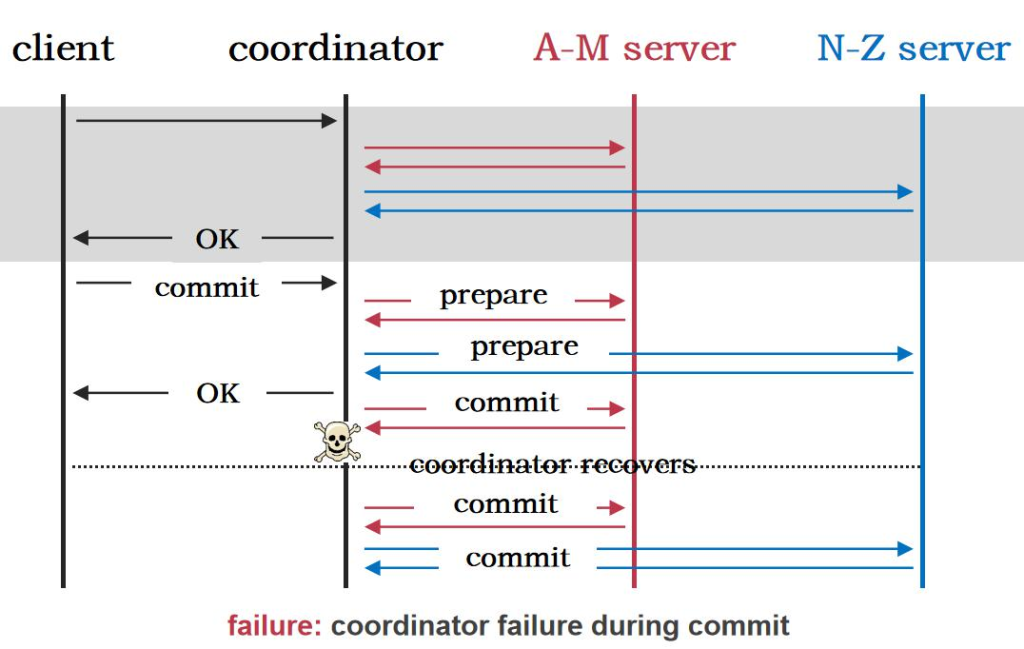
é‡چهگ¯ن»¥هگژه†چهڈ‘ن¸€éپچ commit هˆ°ن¸¤ن¸ھ server هچ³هڈ¯
ن¸¤éک¶و®µوڈگن؛¤çڑ„و€»ç»“
- ن¸¤éک¶و®µوڈگن؛¤ï¼ˆ2PC)ï¼ڑه®çژ°ه¤ڑ站点هژںهگو€§م€‚هچ³ن½؟ن؛‹هٹ،需è¦پن¸ژه¤ڑن¸ھوœ؛ه™¨é€ڑن؟،,ن¹ںهڈ¯ن»¥ن؟وŒپهژںهگو€§م€‚
- هœ¨ن¸¤éک¶و®µوڈگن؛¤è؟‡ç¨‹ن¸ï¼Œه¦‚وœهœ¨وڈگن؛¤ç‚¹ن¹‹ه‰چهڈ‘ç”ںو•…éڑœï¼Œن؛‹هٹ،هڈ¯ن»¥è¢«ن¸و¢م€‚ه¦‚وœه·¥ن½œèٹ‚点(وˆ–هچڈè°ƒه™¨ï¼‰هœ¨وڈگن؛¤ç‚¹ن¹‹هگژهڈ‘ç”ںو•…éڑœï¼Œé‚£ن¹ˆه®ƒن»¬ن¼ڑوپ¢ه¤چهˆ°ه‡†ه¤‡ï¼ˆPREPARED)çٹ¶و€پ,ه¹¶ه®Œوˆگن؛‹هٹ،م€‚
- ه‰©ن½™وŒ‘وˆکï¼ڑهچڈè°ƒه™¨و•…éڑœن¸‹çڑ„هڈ¯ç”¨و€§ï¼ڑ
- éپµه¾ھهچڈè°ƒه™¨çڑ„ه†³ç–هڈ¯ن»¥ç®€هŒ–ه®çژ°ه¤ڑ站点هژںهگو€§ï¼Œن½†ه¦‚وœهچڈè°ƒه™¨é•؟و—¶é—´ه®•وœ؛该و€ژن¹ˆهٹï¼ں
- وˆ‘ن»¬ه°†هœ¨ن¸‹ن¸€è®²ن¸وژ¢è®¨ه¦‚ن½•وڈگé«کهچڈè°ƒه™¨çڑ„هڈ¯ç”¨و€§م€‚
و‚²è§‚ه¤چهˆ¶ (Pessimistic Replication)
- وœ‰ن؛›ه؛”用程ه؛ڈهڈ¯èƒ½ن¸چو„؟و„ڈه®¹ه؟چن¸چن¸€è‡´و€§ï¼ڑ
- و¯”ه¦‚,ن¸€ن¸ھه¤چهˆ¶çڑ„é”پوœچهٹ،ه™¨ï¼Œوˆ–用ن؛ژن¸¤éک¶و®µوڈگن؛¤ï¼ˆ2PC)çڑ„ه¤چهˆ¶هچڈè°ƒه™¨م€‚
- وœ€ه¥½ن¸چè¦پن¸¤و¬،هˆ†é…چهگŒن¸€ن¸ھé”پم€‚
- و¯”ه¦‚,وœ€ه¥½هœ¨ن؛‹هٹ،وڈگن؛¤ن¸ٹوœ‰ن¸€ن¸ھن¸€è‡´çڑ„ه†³ç–م€‚
- وƒè،،ï¼ڑ
- و‚²è§‚ه¤چهˆ¶وڈگن¾›و›´ه¼؛çڑ„ن¸€è‡´و€§ï¼Œن½†ن¼ڑه¯¼è‡´ï¼ڑ
- هڈ¯ç”¨و€§و¯”ن¹گ观ه¤چهˆ¶و›´ن½ژم€‚
- ç‰ه¾…ن¸ژه…¶ن»–ه‰¯وœ¬هگŒو¥çڑ„و€§èƒ½ه¼€é”€و›´ه¤§م€‚
ن¹گ观çڑ„وƒ…ه†µï¼ڑه…پ许ه‡؛çژ° out-of-sync çڑ„وƒ…ه†µï¼Œè®©ن؛؛ه’Œوœ؛ه™¨هژ»هˆ¤ه®ڑ,简هچ•çڑ„و–¹و³•ه°±وک¯و—¶é—´وˆ³ï¼Œن½†وک¯ه¸¦و¥çڑ„é—®é¢که°±وک¯و€ژن¹ˆهژ»ç»´وٹ¤وœ؛ه™¨é—´çڑ„و—¶é—´وˆ³ï¼Œé‚£ن¹ˆوˆ‘ن»¬هڈ¯ن»¥ç”¨ن¸€ن¸ھ vector هژ»ç»´وٹ¤ ن¸چهگŒوœ؛ه™¨é—´çڑ„و—¶é—´وˆ³ï¼Œه¦‚وœهکهœ¨هپڈه؛ڈه…³ç³»ï¼Œé‚£ن¹ˆوˆ‘ن»¬هڈ¯ن»¥ç›´وژ¥è¦†ç›–ï¼›ه¦‚وœن¸چهکهœ¨هپڈه؛ڈه…³ç³»çڑ„وƒ…ه†µï¼Œه°±ن؛§ç”ںن؛† conflict,需è¦پوˆ‘ن»¬و‰‹هٹ¨ merge çڑ„وƒ…ه†µم€‚
و‚²è§‚çڑ„وƒ…ه†µï¼ڑوˆ‘ن»¬ن¸چه…پ许ه‡؛çژ°ن»»ن½• conflict çڑ„وƒ…ه†µï¼Œsingle-copy(ه¯¹ه¤–ن؛§ç”ںçڑ„و•ˆوœه’Œن¸€ن¸ھ copy وک¯ن¸€و ·çڑ„م€‚)وˆ‘ن»¬وƒ³ن؛†ن¸€ن¸ھهٹو³•هڈ«هپڑ Quorum,و¯ڈو¬،ه†™çڑ„و—¶ه€™éƒ½ç‰هˆ°وœ‰è‹¥ه¹²ن¸ھ请و±‚è؟”ه› و‰چوˆگهٹںم€‚وˆ‘ن»¬è¯»ه†™éƒ½وک¯ n و¬،,ن½†وک¯وˆ‘ن»¬ç‰هˆ°ه¯¹ه؛”و•°é‡ڈçڑ„请و±‚è؟”ه›هچ³è®¤ن¸؛ ACK ن؛†م€‚و¯”ه¦‚وˆ‘ن»¬ ه†™ن؛†ن¸‰هڈ°ï¼Œه…¶ن»–ن¸¤هڈ°و²،وœ‰ه›ه¤چ,وˆ‘ن»¬ن¹ں继ç»ه¾€ن¸‹èµ°م€‚وˆ‘ن»¬هڈھ需è¦پن؟è¯پQr+Qw > replica هچ³ هڈ¯ï¼Œه¦‚وœن¸€ن¸ھوœچهٹ،ه™¨ه‘ٹ诉وˆ‘ن»¬ه€¼وک¯ 2,ن¸¤ن¸ھوœچهٹ،ه™¨ه‘ٹ诉وˆ‘ن»¬ه€¼وک¯ 3,و€ژن¹ˆهٹï¼ںو¯”ه¦‚هژںو¥çڑ„ه€¼ وک¯ 3,وˆ‘ن»¬è¦په†™ 2 è؟›هژ»م€‚读 3 ن¸ھçڑ„وƒ…ه†µوˆ‘ن»¬è¯»هˆ°ن؛†â€œ2,3,3â€ï¼Œوˆ‘ن»¬ن¸چن¼ڑ认ن¸؛وک¯ 3.è؟™ه’Œوٹ•ç¥¨و²، وœ‰ه…³ç³»ï¼Œه؟…é،»è¦پن¸‰ن¸ھ相هگŒçڑ„وƒ…ه†µن¸‹ï¼Œوˆ‘ن»¬و‰چ能认ن¸؛读هˆ°ن؛†و£ç،®çڑ„و•°وچ®م€‚ه› ن¸؛وœ؛ه™¨ن¼ڑ recovery, و‰€ن»¥ 3 وœ€ç»ˆوک¯ن¼ڑهڈکوˆگ 2 çڑ„,و‰€ن»¥وˆ‘ن»¬çڑ„ client 需è¦په†چهژ»è¯»ه®ƒï¼Œç›´هˆ°è¯»هˆ°çڑ„و•°وچ®ç¬¦هگˆو،ن»¶م€‚
ç›®و ‡ï¼ڑهچ•ن¸€ه‰¯وœ¬ن¸€è‡´و€§ (ç؛؟و€§هŒ–)
- ن¹گ观و–¹ه¼ڈçڑ„é—®é¢کï¼ڑ ه‰¯وœ¬ن¹‹é—´هڈ¯èƒ½ن¸چهگŒو¥م€‚
- ن¸€ن¸ھه‰¯وœ¬ه†™ه…¥و•°وچ®ï¼Œن½†هڈ¦ن¸€ن¸ھه‰¯وœ¬هڈ¯èƒ½çœ‹ن¸چهˆ°è؟™ن¸ھهڈکهŒ–م€‚
- هœ¨هچ•ن¸€وœچهٹ،ه™¨ن¸ن¸چهڈ¯èƒ½ه‡؛çژ°è؟™ç§چوƒ…ه†µم€‚
- çگ†وƒ³ç›®و ‡ï¼ڑهچ•ن¸€ه‰¯وœ¬ن¸€è‡´و€§
- وŒ‡çڑ„وک¯ï¼ڑç³»ç»ںه¤–部هڈ¯è§پçڑ„è،Œن¸؛è،¨çژ°ه¾—هƒڈهڈھوœ‰ن¸€ن¸ھو•°وچ®ه‰¯وœ¬م€‚
- و“چن½œçœ‹èµ·و¥ه¥½هƒڈوک¯هœ¨هچ•ن¸€ه‰¯وœ¬ن¸ٹو‰§è،Œçڑ„م€‚
- ه†…部هڈ¯èƒ½ن¼ڑوœ‰و•…éڑœوˆ–ن¸چن¸€è‡´و€§ï¼Œن½†éœ€è¦پوˆ‘ن»¬ه±ڈ蔽è؟™ن؛›وƒ…ه†µم€‚
و—¶é—´هگŒو¥
وˆ‘ن»¬هœ¨ç”ںو´»ن¸وœ‰ه¾ˆه¤ڑ设ه¤‡ï¼Œو¯”ه¦‚وˆ‘ن»¬هپڑن؛†ن¸€ن¸ھ PPT,è؟™ه°±و¶‰هڈٹهˆ°هœ¨هڈ°ه¼ڈوœ؛ه’Œç¬”è®°وœ¬ن¸ٹو€ژ ن¹ˆç،®ه®ڑو–‡ن»¶çڑ„و–°و—§ï¼Œن¸€ن¸ھوœ€ç®€هچ•çڑ„و–¹و³•ه°±وک¯é€ڑè؟‡و–‡ن»¶çڑ„و—¶é—´وˆ³م€‚و—¶é—´هœ¨هˆ†ه¸ƒه¼ڈç³»ç»ںن¸è¢«ç”¨هˆ° çڑ„وک¯éه¸¸ه¤ڑçڑ„,و¯”ه¦‚ DNS cache çڑ„وœ‰و•ˆوœںوک¯ 24 ه°ڈو—¶ï¼Œç™¾ه؛¦ه¦‚وœè¦پوچ¢ ip çڑ„و—¶ه€™ï¼Œéœ€è¦پن؟è¯پهژں ه…ˆ ip هڈ¯ن»¥ه·¥ن½œ 24 ه°ڈو—¶م€‚è؟کوœ‰ن¸€ç§چوک¯هپڑè®،é‡ڈ,è®،ç®—ن¸€ن¸ھو“چن½œèٹ±ن؛†ه¤ڑن¹…م€‚و—¥هژ†و—¶é—´ï¼ڑه½“ه‰چçڑ„و—¶é—´وک¯ه¤ڑه°‘,给ن؛‹ن»¶و‰“ن¸ٹو—¶é—´وˆ³هپڑوژ’ه؛ڈم€‚ و—¢ç„¶و—¶é—´ه¾ˆé‡چè¦پ,那ن¹ˆو€ژن¹ˆو ·وµ‹é‡ڈو—¶é—´ه‘¢ï¼ں

çں³è‹±هڈ¯ن»¥éه¸¸ç¨³ه®ڑهœ°ن؛§ç”ںه›؛ه®ڑ频çژ‡çڑ„و™¶وŒ¯ï¼Œو¯”ه¦‚ 1MHz çڑ„وŒ¯èچ،ه™¨ن؛§ç”ں 1000 ن¸ھ cycle çڑ„و—¶ é—´ه°±وک¯ 1 و¯«ç§’م€‚و‰€ن»¥وˆ‘ن»¬هœ¨è®،ç®—وœ؛ن¸ه°±هڈ¯ن»¥وٹٹو—¶é—´è®°ه½•وˆگن»ژ 1970.1.1 هˆ°çژ°هœ¨è؟™ن¸ھو—¶هˆ»ç»ڈè؟‡ن؛† ه¤ڑه°‘秒م€‚ه½“وˆ‘ن»¬وٹٹè®،ç®—وœ؛ه…³وژ‰çڑ„و—¶ه€™ï¼Œè؟™ن¸ھو—¶é—´ه¹¶ن¸چن¼ڑو¶ˆه¤±م€‚هœ¨وˆ‘ن»¬ن¸»و؟ن¸ٹوœ‰ن¸€ن¸ھه°ڈ电و± و”¯ و’‘è؟™ن¸ھو—¶é—´ن¸چو–ه¾€ه‰چèµ°م€‚è؟™ن¸ھو—¶é—´ه¹¶ن¸چوک¯éه¸¸çڑ„ه‡†ï¼Œو™¶وŒ¯ن¸چوک¯ن؛؛ç±»وƒ³çڑ„é‚£ن¹ˆه®Œç¾ژ,وŒ¯هٹ¨çڑ„و¬، و•°وک¯هکهœ¨è¯¯ه·®ه’Œهپڈ移çڑ„م€‚ NTP ه¯¹ه¤–وڈگن¾›ه¯¹و—¶وœچهٹ،م€‚

è؟‡هژ»çڑ„و—¶é—´ه’Œه›و¥çڑ„و—¶é—´هڈ¯èƒ½وک¯ن¸چن¸€و ·çڑ„,è؟™و ·وˆ‘ن»¬è®،ç®—çڑ„و—¶é—´ه°±ن¸چه‡†ن؛†م€‚

و“چن½œç³»ç»ںه†…部维وٹ¤çڑ„ه°±وک¯è؟™ن¹ˆن¸€و®µن»£ç پ,ن½†وک¯وک¯وœ‰é—®é¢کçڑ„م€‚ه¦‚وœè°ƒو—¶é—´è؟™ن¹ˆè°ƒن¼ڑوœ‰ن»€ن¹ˆ هگژوœï¼ںو¯”ه¦‚وˆ‘ن»¬و—¶é—´و…¢ن؛†هچپ秒é’ںم€‚t_end هڈ¯èƒ½و¯” t_begin ه°ڈ,delay هڈ¯èƒ½هڈکوˆگè´ںو•°وˆ–者ه·¨ه¤§çڑ„ و•°ه—م€‚

ه؛”用程ه؛ڈهپ‡è®¾و—¶é—´وک¯ن¸چن¼ڑه¾€ه›èµ°çڑ„م€‚

وˆ‘ن»¬هœ¨و›´و–°و—¶é’ںçڑ„وƒ…ه†µن¸‹ï¼Œوˆ‘ن»¬و¯ڈو¬،و›´و–°çڑ„و—¶ه€™ه°‘هٹ ن¸€ç‚¹ï¼Œè؟™و ·وˆ‘ن»¬çڑ„و—¶é’ںه°±و…¢ن¸‹و¥ن؛†م€‚ وˆ‘ن»¬ن¸چ能ن¸€و¬،و€§هœ°هژ»è°ƒو•´ï¼Œéœ€è¦پو¸گو¸گهœ°هژ»è°ƒو•´م€‚ وœ‰ن؛†è؟™ن¸ھو—¶é—´وˆ³ن»¥هگژ,وˆ‘ن»¬ه°±هڈ¯ن»¥و‹؟هˆ°ن¸€ن¸ھو¯”较ه‡†çڑ„و—¶é—´م€‚ Reconciliation ه°±وک¯è§£ه†³ه†²çھپه’Œن¸و–م€‚و–‡ن»¶ن؛§ç”ںه†²çھپçڑ„و ¸ه؟ƒهژںه› ه°±وک¯ç‰ˆوœ¬ن¸چن¸€و ·ï¼Œوœ€ç®€هچ•çڑ„و–¹و³•ه°±وک¯و–‡ن»¶ inode ن¸çڑ„ m_timeم€‚

ه¦‚وœن¸¤هڈ°وœ؛ه™¨ه¼€ه§‹و—¶é—´وک¯ن¸€و ·çڑ„,ه¦‚وœه¯¹هگŒن¸€ن¸ھو–‡ن»¶هœ¨ن¸¤هڈ°وœ؛ه™¨ن؟®و”¹ï¼Œهچ•ç؛¯çœ‹ m_time وک¯ن¸چه¤ںçڑ„,وˆ‘ن»¬ن¸چ能用 m_time و¥è¦†ç›–هڈ¦ن¸€هڈ°ç”µè„‘ن¸ٹçڑ„و–‡ن»¶çڑ„ن؟®و”¹م€‚وˆ‘ن»¬çڑ„ç›®و ‡وک¯ه†™çڑ„و•°وچ® ن¸چ能ن¸¢ï¼Œè§£ه†³è؟™ن¸ھé—®é¢کçڑ„و–¹و³•ه°±وک¯ vector_timestamp,و¯ڈن¸ھو–‡ن»¶ن¸ç»´وٹ¤ن؛†ن¸€ن¸ھو—¶é—´وˆ³هگ‘é‡ڈ, è®°ه½•ن؛†هœ¨و¯ڈهڈ°وœ؛ه™¨ن¸ٹçڑ„و—¶é—´وˆ³م€‚هڈھوœ‰هœ¨و—¶é—´هگ‘é‡ڈهڈ¯ن»¥و¯”较çڑ„و—¶ه€™ï¼Œو‰چهژ»هپڑو¯”较م€‚هœ¨ن¸€ن¸ھèٹ‚点 ن¸ٹçڑ„و—¶é—´وˆ³و°¸è؟œهڈھه’Œè‡ھه·±و¯”较م€‚


è؟™ه°±وک¯ن¹گ观ه¸¦و¥çڑ„é—®é¢کم€‚
Quorum
و‚²è§‚çڑ„وƒ…ه†µو€ژن¹ˆه¤„çگ†ï¼ںوˆ‘ن»¬ن¸چه¸Œوœ›ن؛§ç”ںن»»ن½• conflictم€‚وˆ‘ن»¬وœ€هگژçڑ„ç›®و ‡وƒ³هˆ°è¾¾ single-copy-consistencyم€‚ 1. هٹ é”پ,هگŒو—¶هڈھوœ‰ن¸€ن¸ھن؛؛هڈ¯ن»¥و”¹ï¼Œن½†وک¯و€§èƒ½ن¼ڑهڈ—هˆ°ه½±ه“چ ن¸€ن¸ھ client ç»™هگ‘ن¸¤ن¸ھ server هڈ‘请و±‚,ن¸€و—¦ن¸€ن¸ھوŒ‚ن؛†ï¼Œé‚£ن¹ˆه°±هڈ‘ç»™هڈ¦ن¸€ن¸ھم€‚ن½†وک¯ه› ن¸؛网络 ه…³ç³»هڈ¯èƒ½ه¯¼è‡´ network partition

وˆ‘ن»¬çژ°هœ¨وœ‰ن¸‰ن¸ھوœچهٹ،ه™¨ï¼Œه†™çڑ„و—¶ه€™وˆ‘ن»¬هگŒو—¶ه†™ن¸‰ن»½ï¼Œن¸€و—¦ن¸¤ن¸ھوœچهٹ،ه™¨ه›ه¤چه†™ه®Œن؛†ï¼Œé‚£ن¹ˆ وˆ‘ن»¬ه°±è®¤ن¸؛ه†™ه®Œن؛†م€‚هœ¨è¯»çڑ„و—¶ه€™ï¼Œه¦‚وœن»ژو£ه¥½وŒ‚ن؛†çڑ„وœچهٹ،ه™¨è¯»ï¼Œé‚£ن¹ˆه°±وœ‰é—®é¢کن؛†ï¼Œو‰€ن»¥وˆ‘ن»¬ ن¹ںè¦پهڈ‘ 3 ن¸ھ请و±‚,و”¶هˆ°ن¸¤ن¸ھو•°وچ®وک¯ç›¸هگŒçڑ„,那ن¹ˆه°±è®¤ن¸؛读هˆ°ن؛†م€‚ هœ¨è؟™ç§چوƒ…ه†µن¸‹ï¼Œوˆ‘ن»¬هڈ¯ن»¥ن؟è¯پ读هˆ°çڑ„ن¸€ه®ڑوک¯وœ€è؟‘ه†™è؟›هژ»çڑ„و•°وچ®ï¼Œè؟™هڈ¯ن»¥ه®¹ه؟چن¸€ن¸ھ server هڈ‘é€پ failure çڑ„وƒ…ه†µم€‚è؟™ه°±وک¯ Quorum,è¦پو±‚读è؟›هژ»çڑ„و•°é‡ڈ(Qr)ه’Œه†™è؟›هژ»çڑ„و•°é‡ڈ(Qw)ه؟…é،»ه¤§ن؛ژ replica و•°é‡ڈ N(2+2>3)م€‚è؟™و ·ن؟è¯پوˆ‘ن»¬è¯»هˆ°çڑ„ replica ن¸€ه®ڑوœ‰و–°çڑ„م€‚

ه†™ 4 读 2 وک¾ç„¶وک¯ه¯¹è¯»هڈ‹ه¥½ï¼Œوˆ‘ن»¬هڈ¯ن»¥ه¾ˆه؟«هœ°è¯»م€‚ه†™çڑ„و—¶ه€™هڈھه…پ许 1 ن¸ھ crash,读çڑ„و—¶ه€™ وˆ‘ن»¬ه…پ许 3 ن¸ھ crashم€‚
و³¨و„ڈ Qw = 2ه¹¶ن¸چوک¯è¯´هڈھه†™ن¸¤ن¸ھ,而وک¯ 5 ن¸ھ都è¦په†™ï¼Œن½†وک¯وœ‰ 2 ن¸ھè؟”ه›ه†™ه®Œه°±ç»§ç»ه¾€ن¸‹èµ°ن؛†م€‚ه†™ن¸¤ن¸ھçڑ„è¯ï¼Œlatency و¯”ه†™ 5 ن¸ھو”¶هˆ° 4 ن¸ھçڑ„ latency è¦پن½ژم€‚ é‚£ن¹ˆه¦‚وœوˆ‘ن»¬é€ڑè؟‡è؟™ç§چو–¹و³•ï¼Œن¹ںهڈ¯ن»¥ن¼کهŒ– availability,ن¹ںه°±وک¯و¯ڈو¬،ه†™éƒ½و”¶هˆ°ه“چه؛”,è؟™ه°± è¦پو±‚ه†™çڑ„و“چن½œç›¸ه¯¹و¯”较ه°‘م€‚ Quorum çڑ„و€è·¯وک¯éه¸¸ç®€هچ•çڑ„,ن½†وک¯ه†™éƒ½è¦په†™ 5,读çڑ„و—¶ه€™ه°±هڈ¯ن»¥è¯» 2 ن¸ھن¹‹ç±»çڑ„م€‚
RSM
ه¦‚وœوœ؛ه™¨ه¼€ه§‹وک¯ن¸€و ·çڑ„,输ه…¥م€پ输ه…¥çڑ„é،؛ه؛ڈ都وک¯ن¸€ و ·çڑ„,و“چن½œéƒ½وک¯ deterministic çڑ„,那ن¹ˆوœ€ç»ˆç»“وœوک¯ن¸€و ·çڑ„م€‚
وˆ‘ن»¬é€ڑè؟‡ç½‘络هڈ‘è؟‡هژ»è¯·و±‚,وˆ‘ن»¬è®¤ن¸؛输ه…¥وک¯هڈ¯ن»¥ن¸€و ·çڑ„م€‚ن½†وک¯é،؛ه؛ڈه¾ˆéڑ¾ن؟è¯پم€‚
Deterministic ه‘¢ï¼ں相هگŒçڑ„ن»£ç په¦‚وœé‡Œé¢وœ‰é”پم€پCPU ه¤ڑو ¸è°ƒه؛¦ç‰éƒ½ن¼ڑه½±ه“چ deterministicم€‚و‰€ن»¥ ç،®ن؟ the same order وک¯و ¹و¤چن؛ژهˆ†ه¸ƒه¼ڈçڑ„é—®é¢کم€‚ و—¢ç„¶ه®ƒé—®é¢کçڑ„و ¹و؛گهœ¨هˆ†ه¸ƒه¼ڈ,وˆ‘ن»¬هڈ¯ن»¥و”¹ن¸؛ن¸€هڈ°وœ؛ه™¨ coordinator-worker çڑ„ه½¢ه¼ڈ,وˆ‘ن»¬ وƒ³ن؟è¯پ input çڑ„ order,وˆ‘ن»¬ن¸چ需è¦پ让ن¸€هڈ°وœ؛ه™¨çڑ„ coordinator هژ»و‰§è،Œè؟™ن¸ھ input,ه®ƒهڈھ被用و¥ ç»™ input و‰“ن¸ٹ order و ‡è®°م€‚

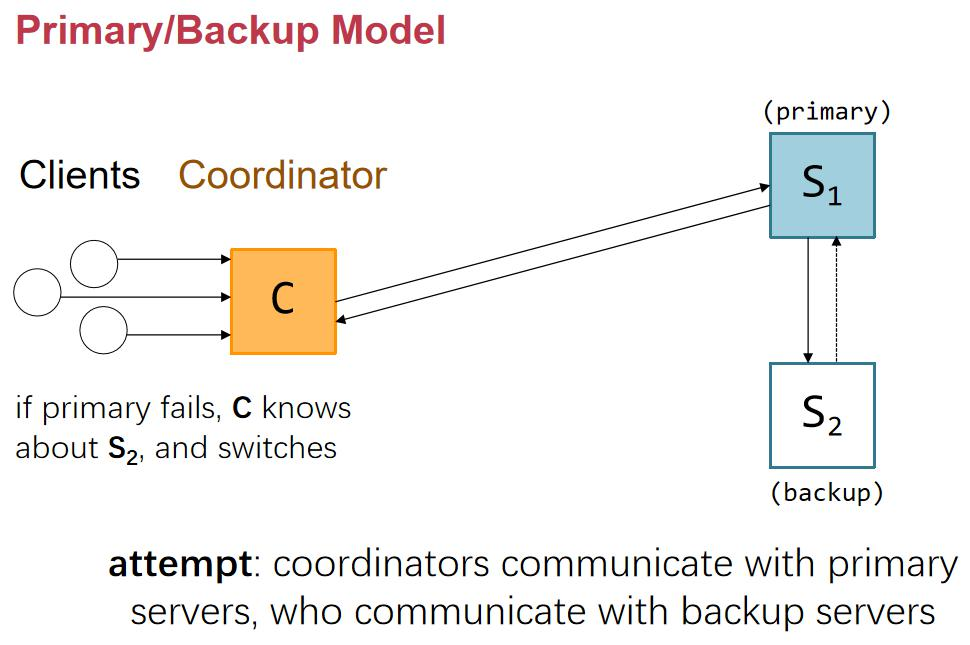
ه¦‚وœه‡؛çژ°ن؛†ن¸€ن¸ھ network partition,ن¹ںه°±وک¯ه¯¹ن؛ژ coordinator2 و¥è¯´ï¼Œه®ƒè®¤ن¸؛ primary server S1 وŒ‚ن؛†ï¼Œcoordinator2 è¦پç«‹هچ³وٹٹ S2 هڈکوˆگ primary serverم€‚
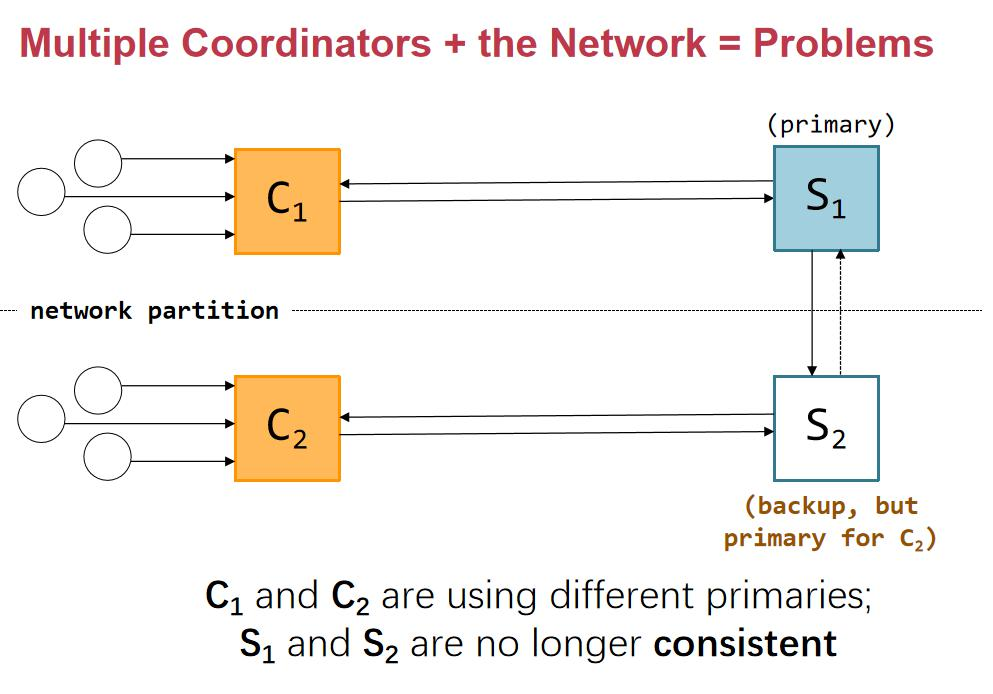
و¤و—¶ S1 ه’Œ S2 ن¹‹é—´ن¸€ه®ڑو•°وچ®ن¸چن¸€è‡´ن؛†ï¼ŒS1 ه’Œ S2 ن؟،وپ¯ن¸چن¸€و ·ه¹¶ن¸”ن¸چ能覆盖م€‚è¦پ解ه†³è؟™ن¸ھ, وˆ‘ن»¬ه°±è¦پهٹ ن¸€ن¸ھ view server,ه®ƒè®°ه½•è°پوک¯ primary,è°پوک¯ backupم€‚View server ن¼ڑé€ڑçں¥وœچهٹ،, ن½ وک¯ backup è؟کوک¯ primaryم€‚View server هڈھوœ‰ن¸€ن¸ھ,و¥éپ؟ه…چن¸چن¸€è‡´çڑ„وƒ…ه†µم€‚
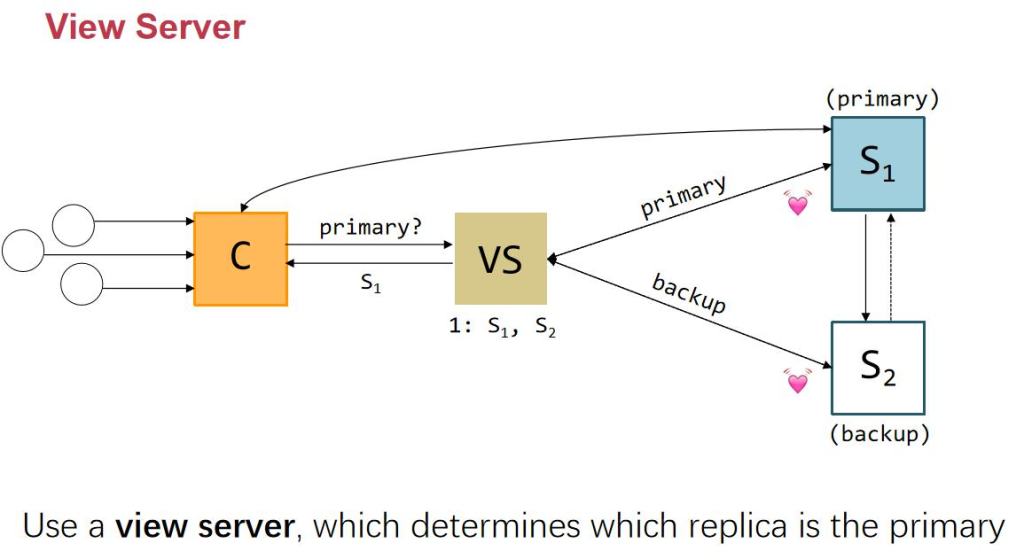
Coordinator ه¼€ه§‹é—® view server çژ°هœ¨è°پوک¯ primary,ه›ç”وک¯ S1,那ن¹ˆ coordinator ه°±ç›´وژ¥ ه’Œ S1 و‰“ن؛¤éپ“م€‚S1 ه’Œ S2 ه®ڑوœںهœ°هگ‘ View server هڈ‘é€په؟ƒè·³م€‚è؟™ن¸ھ view server هڈھوœ‰ن¸€هڈ°وœ؛ه™¨ï¼Œن¹ں ن¼ڑé¢ن¸´هگ„ç§چهگ„و ·çڑ„é—®é¢کم€‚
1. S1 وŒ‚ن؛†ï¼Œview server ç«‹هچ³هڈ‘çژ° S1 çڑ„ه؟ƒè·³و²،ن؛†م€‚é‚£ن¹ˆ view server ن»»ه‘½ S2 هڈکوˆگ primaryم€‚ 然هگژ coordinator é—®çڑ„و—¶ه€™ï¼Œè؟”ه› S2,è؟™وک¯ view server çڑ„و£ه¸¸ه®¹é”™م€‚هœ¨ S2 هڈھè¦پè‡ھه·±وک¯ primary ن¹‹ه‰چ,ه®ƒن¼ڑ reject و¥è‡ھ client ه’Œ coordinator çڑ„ن»»ن½•è¯·و±‚,ن¸؛ن؛†éک²و¢ن¸¤ن¸ھ primary هگŒو—¶ه‡؛çژ°çڑ„ وƒ…ه†µم€‚
2. Network partition failure,S1 ه…¶ه®و²،وŒ‚,ن½†وک¯ه؟ƒè·³و²،وœ‰هˆ° view server,و‰€ن»¥ view server 误ن»¥ن¸؛ primary server S1 وŒ‚ن؛†م€‚هœ¨è؟™ç§چوƒ…ه†µن¸‹ï¼Œه®ƒه°±هڈھ能认ن¸؛ S1 وŒ‚ن؛†ï¼Œه®ƒن¼ڑوٹٹ S2 设ن¸؛ primaryم€‚ ه®ƒè®¾ç½® primary S2 çڑ„و¶ˆوپ¯ï¼Œè؟کهœ¨ fly çڑ„و—¶ه€™م€‚Coordinator ç»™ S1 هڈ‘é€پو¶ˆوپ¯ï¼Œه®ƒè؟کن¼ڑ继ç»ه¾€ن¸‹و‰§ è،Œï¼Œè؟کن¼ڑه’Œ S2 هگŒو¥ï¼Œه¹¶ن¸” S2 هگŒو¥وˆگهٹںم€‚هœ¨è؟کهœ¨ fly çڑ„و—¶ه€™ï¼Œcoordinator çں¥éپ“ primary S2 ن؛†ï¼Œ è؟کوک¯ه› ن¸؛ن»»ه‘½çٹ¶è؟کو²،هˆ° S2 ن¼ڑ reject وژ‰ coordinator çڑ„请و±‚م€‚ن»»ه‘½çٹ¶هˆ° S2 ن»¥هگژ,و¤و—¶ S1 ه’Œ S2 都وک¯ primaryم€‚虽然و¤و—¶ coordinator وœ€و–°çڑ„请و±‚都ن¼ڑهڈ‘هˆ° S2,ه¦‚وœ coordinator و²،و”¶هˆ°و–°çڑ„ وک¯ S2,è؟کوک¯ç»™ S1 هڈ‘ن؛†ه°±ن¼ڑه¯¼è‡´ن¸چن¸€è‡´م€‚
و‰€ن»¥وˆ‘ن»¬çژ°هœ¨هٹ ن¸€و،و–°çڑ„规هˆ™ï¼Œéœ€è¦پç‰هˆ°ه…¶ن»– backup server هڈ‘é€پ ACK ç»™ primary server و‰چ继ç»و‰§è،Œو“چن½œم€‚S2 ه› ن¸؛ه½“ه‰چو²،وœ‰ backup,ه› ن¸؛ S1 è؟کن¸چçں¥éپ“è‡ھه·±ن¸چوک¯ primary,و‰€ن»¥ S2 هœ¨ è؟™ن¸ھçںوڑ‚و—¶é—´ه†…وک¯و²،وœ‰ backup çڑ„,è؟™ç§چوƒ…ه†µن¹ںوک¯ه…پ许çڑ„م€‚و‰€ن»¥و¤و—¶ S2 ن½œن¸؛ primary server, ه®ƒçں¥éپ“ه½“ه‰چè‡ھه·±و²،وœ‰ه°ڈه¼ں(backup-server),و‰€ن»¥ S2 ن¸چ需è¦پو”¶هˆ°هˆ«ن؛؛çڑ„ ACK ه°±هڈ¯ن»¥ç»§ç»و‰§ è،Œهˆ«çڑ„و“چن½œم€‚ è؟™é‡Œé¢وœ€ه¤§çڑ„è–„ه¼±çڑ„点ه°±وک¯ VS,ن؛ژوک¯وˆ‘ن»¬ه°±éœ€è¦په¤ڑهڈ° VS,ن½†وک¯وˆ‘ن»¬ن¸؛ن؛†è§£ه†³و•°وچ®çڑ„ن¸€ 致و€§ï¼Œوˆ‘ن»¬و‰چه¸Œوœ› view server وک¯ن¸€هڈ°ï¼Œçژ°هœ¨ه¤ڑهڈ°هڈˆن¸چ能ن؟è¯پن¸€è‡´و€§ن؛†ï¼Œè؟™و—¶ه€™وˆ‘ن»¬ه°±ه¼•ه…¥ ن؛† paxosم€‚
Paxos
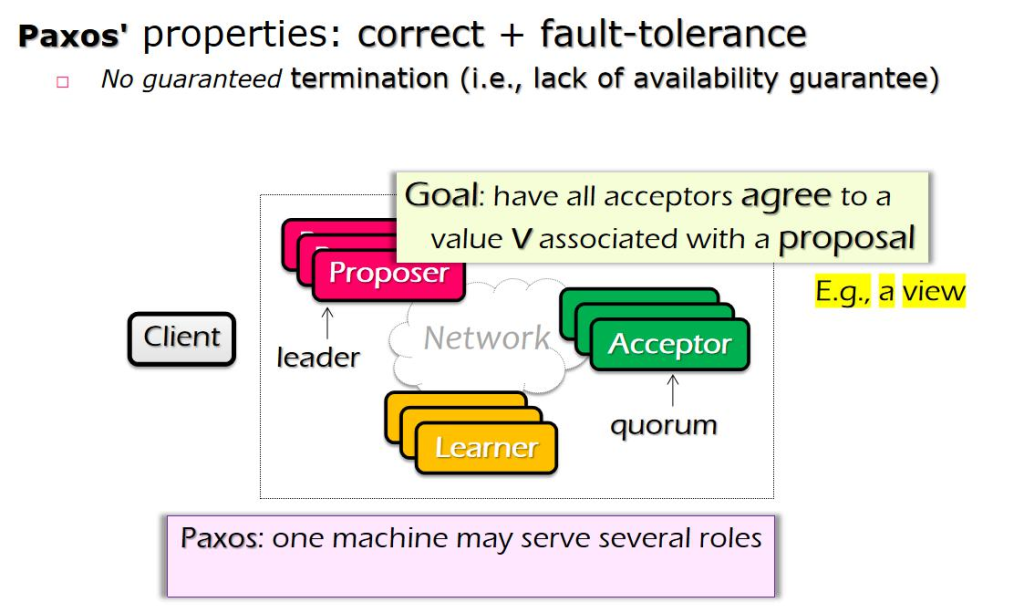
Paxos è¦پن؟è¯پوک¯و•°وچ®وک¯ه¯¹çڑ„,و‰€وœ‰هڈ‚ن¸ژçڑ„ viewserver è¦پ讨è®؛ه‡؛ن¸€ن¸ھن¸€è‡´çڑ„结وœم€‚第ن؛Œن¸ھ ç›®و ‡ه°±وک¯ fault-tolerance,è؟™ن¸ھç³»ç»ںن¸ن¸چن¾èµ–وںگن¸ھèٹ‚点وŒ‚ن؛†ن¸ژهگ¦éƒ½هڈ¯ن»¥و£ه¸¸è؟گè،Œم€‚
PAXOS ن¸چ能ن؟è¯پ termination,ن¹ںه°±وک¯ه®ƒهڈ¯èƒ½ن¸چ能讨è®؛ه‡؛وœ€ç»ˆçڑ„结وœï¼Œه¦‚وœè®¨è®؛ن¸چه‡؛结وœï¼Œ é‚£ه°±ه†چ讨è®؛ن¸€و¬،,ن½†وک¯هœ¨ه®é™…ه®è·µن¸ï¼Œè؟کوک¯هڈ¯ن»¥ن؟è¯پ termination çڑ„م€‚
هˆ†وˆگè‹¥ه¹²ن¸ھ角色,وœ‰ Proposerï¼ڑوڈگè®®وٹٹ S2 هڈکوˆگ primary,acceptor 说هگŒو„ڈ,而 learner ه°±وک¯ه¦ن¹ وœ€و–°çڑ„èٹ‚点م€‚ن¸€هڈ°وœ؛ه™¨هœ¨ن¸چهگŒ round 里é¢هڈ¯èƒ½و‰®و¼”ن¸چهگŒçڑ„角色م€‚Paxos وœ€éڑ¾çڑ„وک¯ن¸چ هگŒè½®هڈ¯èƒ½هµŒه¥—هœ¨ن¸€èµ·ï¼Œه› ن¸؛و¯ڈن¸ھن؛؛é€ڑè؟‡ç½‘络è؟وژ¥ï¼Œو‰€ن»¥ه®ƒç›´وژ¥ه¯¼è‡´ن؛†ن¸چهگŒè½®هڈ¯èƒ½هµŒه¥—هœ¨ن¸€èµ·م€‚ è؟™وک¯ Paxos ه¾ˆه¤ڑن؛؛هگگو§½ه¤ھéڑ¾و‡‚ن؛†çڑ„وƒ…ه†µم€‚
ç›®و ‡ï¼ڑو‰€وœ‰çڑ„ acceptor هگŒو„ڈن¸€ن¸ھ proposal çڑ„ value وک¯ (v proposal: 2:S2),و¯”ه¦‚ S2 وک¯ primary serverم€‚
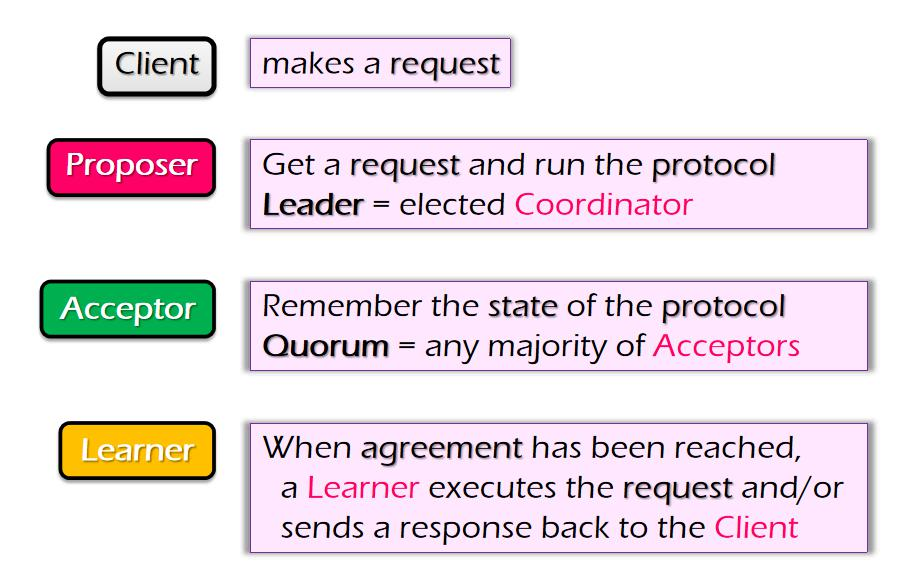
وˆ‘ن»¬ç›´وژ¥çœ‹è؟™ن¸ھن¾‹هگ,و•´ن¸ھè؟‡ç¨‹é¦–ه…ˆوœ‰ن¸€ن¸ھ proposer,ه®ƒوƒ³وˆگن¸؛ن¸€ن¸ھ leaderم€‚Leader ن¼ڑ proposal ن¸€ن¸ھ value v هڈ‘ç»™و‰€وœ‰ن؛؛,و”¶é›†و‰€وœ‰ن؛؛وک¯ن¸چوک¯ agree,ه¦‚وœ major çڑ„ acceptor agree ن»¥هگژه°±ه®£ه¸ƒ resultم€‚
2-phase-commit è¦پو”¶é›†و‰€وœ‰ن؛؛çڑ„ commit و‰چ commit,而è؟™é‡Œ leader هڈھ需è¦پو”¶é›†هˆ° majority çڑ„ acceptor çڑ„ agree,ه°±هڈ¯ن»¥ announceم€‚ه¦‚وœن¸چوک¯ majority,ن؛”ن¸ھوœ؛ه™¨è¯´ç‰ن؛ژ v1 ه’Œن؛”ن¸ھوœ؛ه™¨ 说ç‰ن؛ژ v2,那ه°±ن¸چه¥½è§£ه†³م€‚
ه¦‚وœوœ‰ه¤ڑن½™ن¸€ن¸ھن؛؛ه¸Œوœ›هڈکوˆگ leader و€ژن¹ˆهٹه‘¢ï¼ںوˆ‘ن»¬éœ€è¦پ让و‰€وœ‰ن؛؛هگŒو„ڈن½ هڈکوˆگ leader,è؟™ وœ¬è؛«ه°±وک¯وˆ‘ن»¬éœ€è¦پ解ه†³çڑ„é—®é¢کم€‚و‰€ن»¥وœ€ç»ˆن¸€ن¸ھه±‹هگ里ن¹±ç³ںç³ںçڑ„,ه¾ˆه¤ڑهœ°و–¹éƒ½هœ¨ propose ه‡؛و–° çڑ„ proposalم€‚ه¹¶ن¸”و•°وچ®هŒ…ن¹ںن¼ڑن¸¢ï¼Œleader ن¹ں crash ن؛†و€ژن¹ˆهٹه‘¢ï¼ں
ه¦‚وœن¸€ن¸ھ leader و”¶é›†هˆ° majority, هˆڑوƒ³ه’Œه¤§ه®¶è¯´è‡ھه·±وک¯ leader,ن½†وک¯è‡ھه·±وŒ‚ن؛†و€ژن¹ˆهٹï¼ں ن¸؛ن»€ن¹ˆهڈ« PAXOS,è؟™وک¯ن¸€ن¸ھه¸Œè…ٹçڑ„ه°ڈه²›ï¼Œن¸ٹé¢ن½ڈن؛†ه¾ˆه¤ڑن؛؛选 leader,وœ‰ن¸€ن؛›ن؛؛ه‡؛و¥ proposal,ه¤§ه®¶ه°±éھ‘ç€ه°ڈ车é€پو¶ˆوپ¯م€‚ه®ƒوک¯وœ‰ round çڑ„,轮ه’Œè½®ن¹‹é—´وک¯ه¼‚و¥çڑ„,第ن؛Œè½®ن¸چ需è¦پ ç‰ç¬¬ن¸€è½®ç»“وںو‰چه¼€ه§‹ï¼Œه› ن¸؛ه¤§ه®¶ن¸چçں¥éپ“第ن¸€è½®ن»€ن¹ˆو—¶ه€™ç®—结وں,و¯ڈن¸€è½®هڈˆهˆ†وˆگè‹¥ه¹²ن¸ھه¼‚و¥çڑ„éک¶و®µم€‚
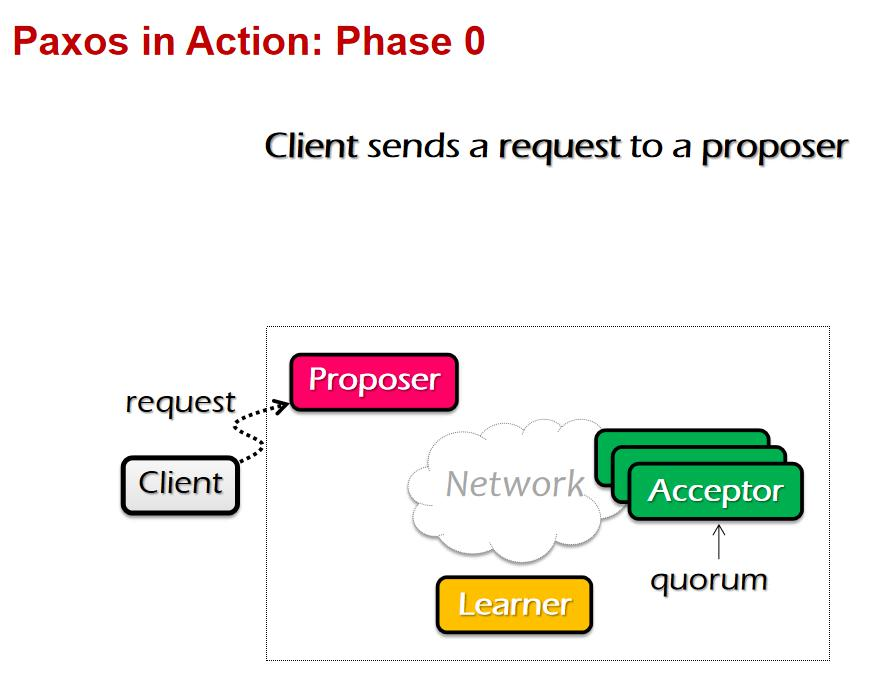
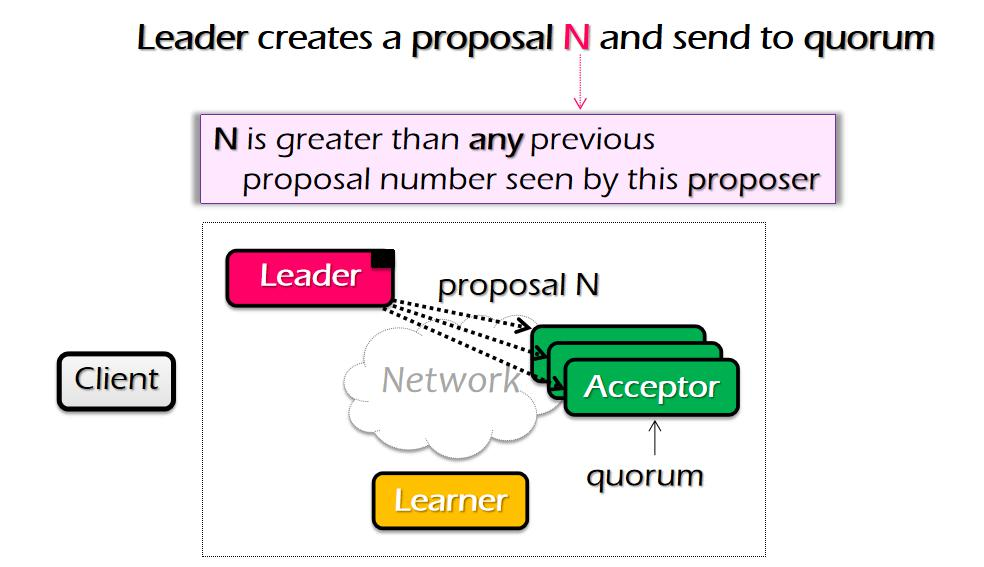
Client 让 proposer ه¼€ه§‹ï¼Œç„¶هگژوœ‰ن¸€ن¸ھ proposer هڈکوˆگن؛† leader,ه®ƒéœ€è¦پ说“وˆ‘ه°±وک¯ leaderâ€ï¼Œ ن¸چ需è¦پç‰هˆ«ن؛؛هگŒو„ڈ,ن»–هڈ¯ن»¥هˆ›ه»؛ن¸€ن¸ھ proposal هڈ«هپڑ N,N çڑ„特点ه°±وک¯و¯”ه®ƒè§پè؟‡çڑ„و‰€وœ‰ proposal 都è¦په¤§م€‚然هگژه°±وٹٹ proposal N هڈ‘ç»™ه…¶ن»–ن؛؛م€‚
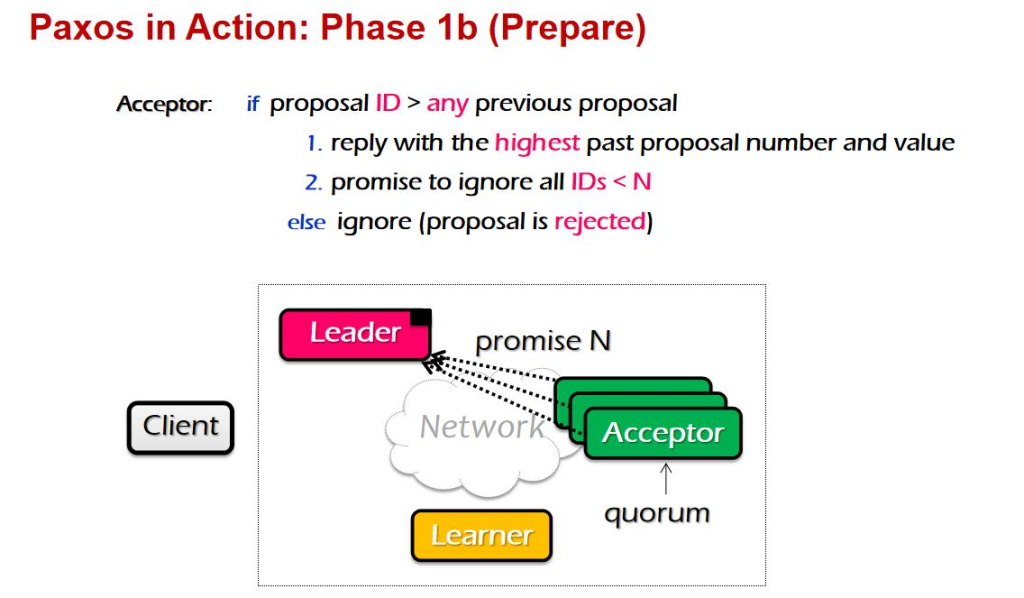
ه¯¹ن؛ژ acceptor,ه¦‚وœو”¶هˆ°çڑ„ proposal ه¤§ن؛ژه®ƒè§پè؟‡çڑ„و‰€وœ‰ proposal,那ن¹ˆه®ƒه°±وٹٹن¹‹ه‰چè§پè؟‡ çڑ„وœ€ه¤§çڑ„ proposal çڑ„è®°ه½•هڈ‘ç»™ Leaderم€‚و¯”ه¦‚ه®ƒçژ°هœ¨و”¶هˆ°çڑ„وک¯ 5 هڈ·ï¼Œè€Œن¹‹ه‰چو”¶هˆ°çڑ„وک¯ 4 هڈ·+value çڑ„,ه®ƒه°±ن¼ڑوٹٹ 4 هڈ·+value هڈ‘ç»™ leader,ه®ƒن¼ڑو‰؟è¯؛وœھو¥ه؟½ç•¥وژ‰وژ¥و”¶هˆ°çڑ„و‰€وœ‰ه°ڈن؛ژ N çڑ„è؟™ن؛› proposalم€‚
و‰€ن»¥ acceptor ه°±هپڑè؟™ن¸ھن؛‹وƒ…م€‚
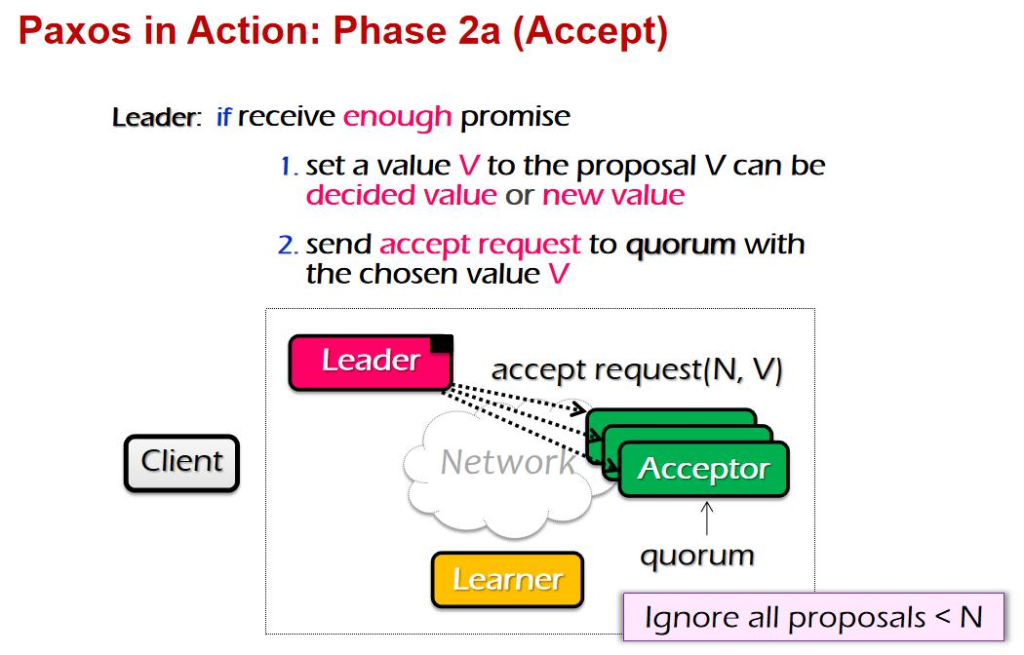
ه¦‚وœ leader و”¶هˆ°ن؛†è¶³ه¤ںه¤ڑ(majority)çڑ„ promise,ه®ƒه°±ن¼ڑ选و‹©ن¸€ن¸ھ value V هڈ‘ç»™و‰€وœ‰çڑ„ promise ç»™ه®ƒçڑ„ acceptor çڑ„èٹ‚点م€‚هœ¨è؟™é‡Œéœ€è¦پو³¨و„ڈçڑ„وک¯ï¼Œه¦‚وœو”¶هˆ°çڑ„و‰€وœ‰ promise 里é¢وک¯و²، وœ‰ value çڑ„,那ه°±è‡ھه·±وŒ‘ن¸€ن¸ھو–°çڑ„ vم€‚ه¦‚وœه¸¦ن؛† value,那ن¹ˆه®ƒه°±ن¼ڑç›´وژ¥é€‰è؟™ن¸ھ valueم€‚
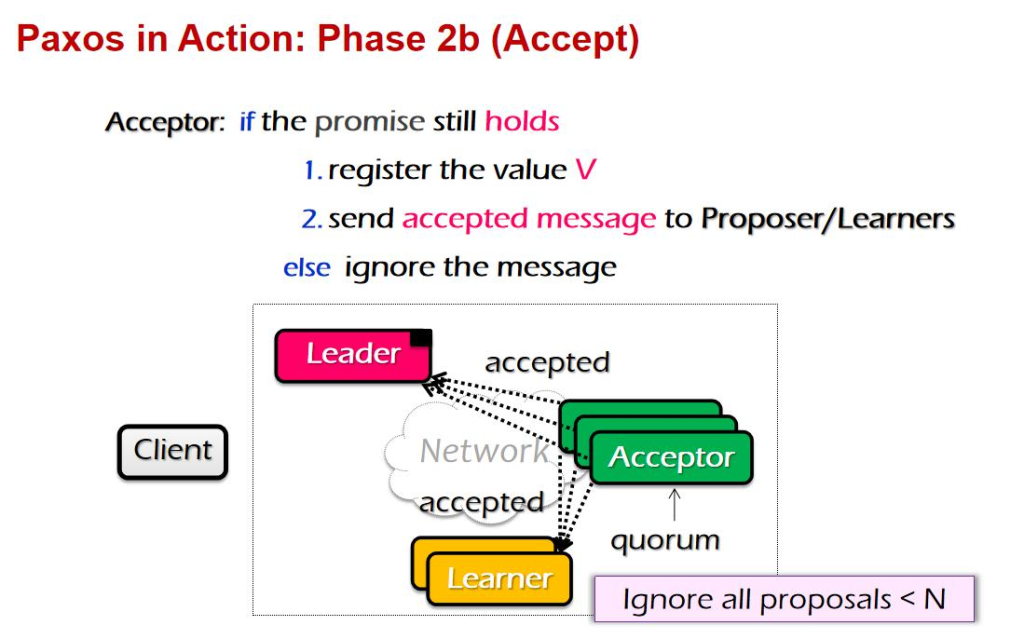
Acceptor و”¶هˆ°è؟™ن¸ھو–°çڑ„و¶ˆوپ¯ن¹‹هگژ,ه¦‚وœ promise ن¾ç„¶وک¯ï¼Œé‚£ن¹ˆه®ƒه°±è®°ه½•وœ€و–°çڑ„ N ه’Œ value, è®°ن¸‹و¥ن»¥هگژ,ه°±ç»™ leader هڈ‘ن¸€ن¸ھ acceptم€‚è®°ن¸‹و¥ن¸€ن¸ھè؟™ن¸ھ leader ه°±ه®ڑن¸‹و¥ن؛†ï¼Œè؟™ن¸ھ learner ه°±هڈ¯ن»¥ه›ه¤چç»™ client وˆ‘ن»¬ه®ڑن¸‹و¥çڑ„ view server وک¯è°پم€‚
هœ¨و•´ن¸ھ paxos çڑ„èٹ‚点ن¸ï¼Œو¯ڈن¸ھèٹ‚点都هڈ¯ن»¥هگŒو—¶ه……ه½“ه¤ڑن¸ھè؛«ن»½ï¼Œéœ€è¦پç»´وٹ¤ن¸€ن؛›و•°وچ®م€‚
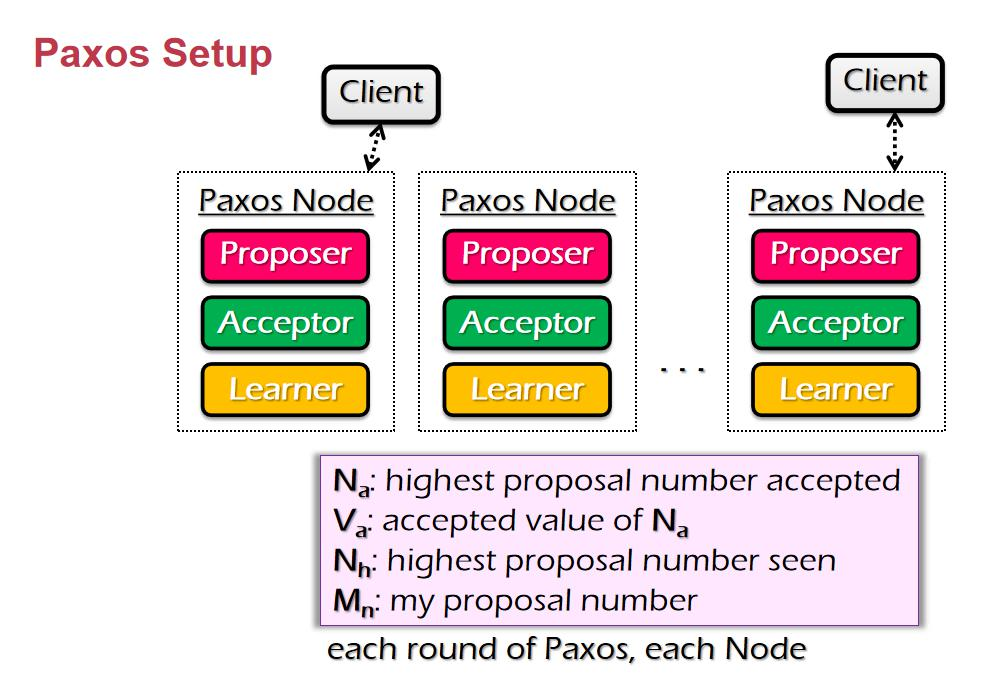
Na ه’Œ Va ه°±وک¯وژ¥و”¶هˆ°çڑ„وœ€ه¤§çڑ„ n ه’Œ v وک¯ه¤ڑه°‘,è؟کوœ‰è§پè؟‡çڑ„وœ€ه¤§çڑ„ n وک¯ه¤ڑه°‘,è؟کوœ‰ه°±وک¯è‡ھ ه·±çڑ„ proposal number وک¯ه¤ڑه°‘م€‚
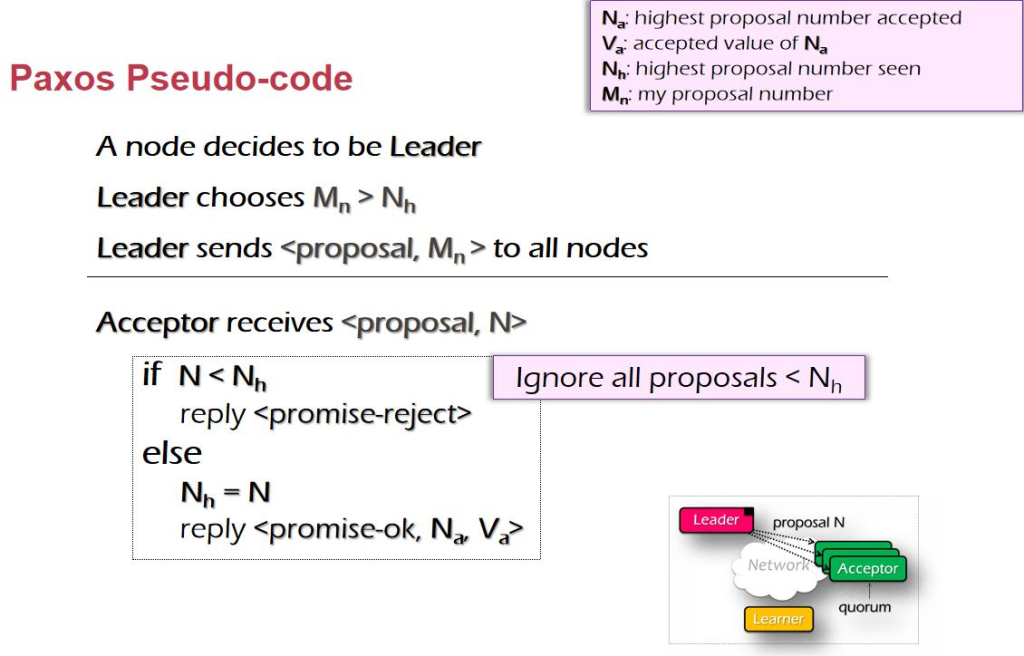
ه®ƒé€‰و‹©ن¸€ن¸ھو¯”è§پè؟‡çڑ„و‰€وœ‰ proposal 都ه¤§çڑ„ proposal number هڈ‘ç»™ه…¶ن»–و‰€وœ‰èٹ‚点م€‚ه¯¹ن؛ژ acceptor و¥è¯´ï¼Œه¦‚وœو¯”è§پè؟‡çڑ„و‰€وœ‰ proposal number 都ه¤§ï¼Œé‚£ن¹ˆه°±è؟”ه› < Na , Va >
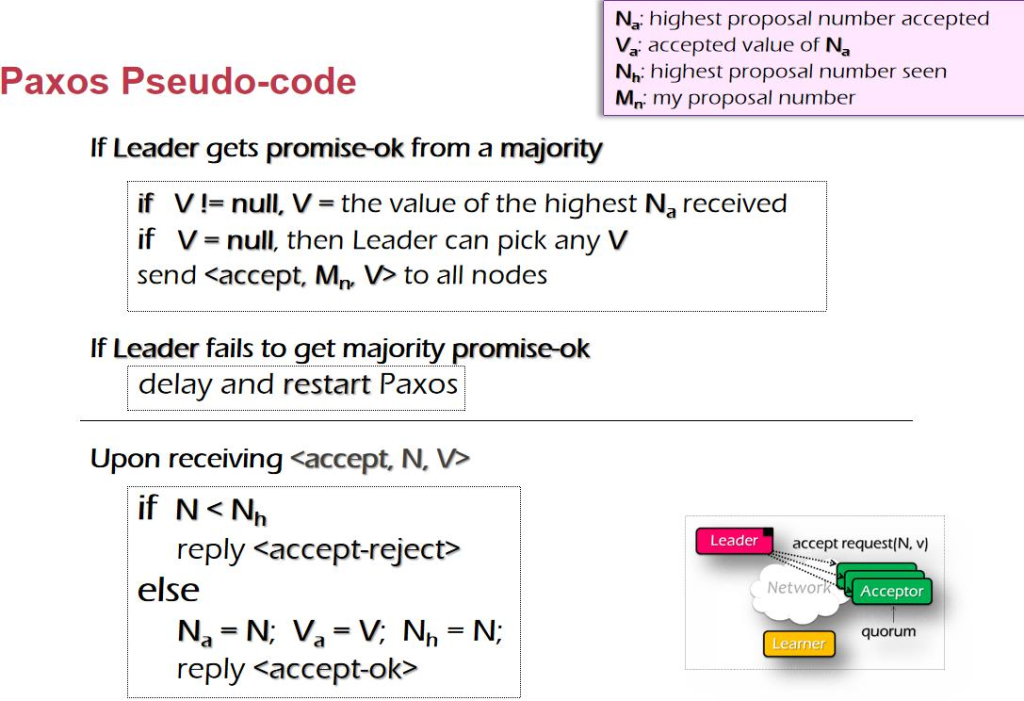

ه¦‚وœ V ن¸چç‰ن؛ژ null,那ن¹ˆه°±è®¾ç½®ن¸؛وœ€ه¤§çڑ„ Na ه¯¹ه؛”çڑ„ Vaم€‚然هگژهڈ‘ç»™و‰€وœ‰ acceptorم€‚ه¯¹ن؛ژ acceptor,ه¦‚وœوœ‰ه¤§çڑ„,那ن¹ˆه°±و‹’ç»ï¼Œهگ¦هˆ™ه°±ç›´وژ¥è®¾ç½®وˆگ leader هڈ‘è؟‡و¥çڑ„ه€¼م€‚
ه¦‚وœ leader و”¶ن¸چهˆ° majority,那ن¹ˆه°±è¦پç‰ن¸€è½®وœںه¾…ن¸‹è½®èƒ½ه¤ںو”¶هˆ°م€‚
ن¸€و¬،و²،وœ‰ه‡؛çژ°ن»»ن½•وƒ…ه†µçڑ„ paxos
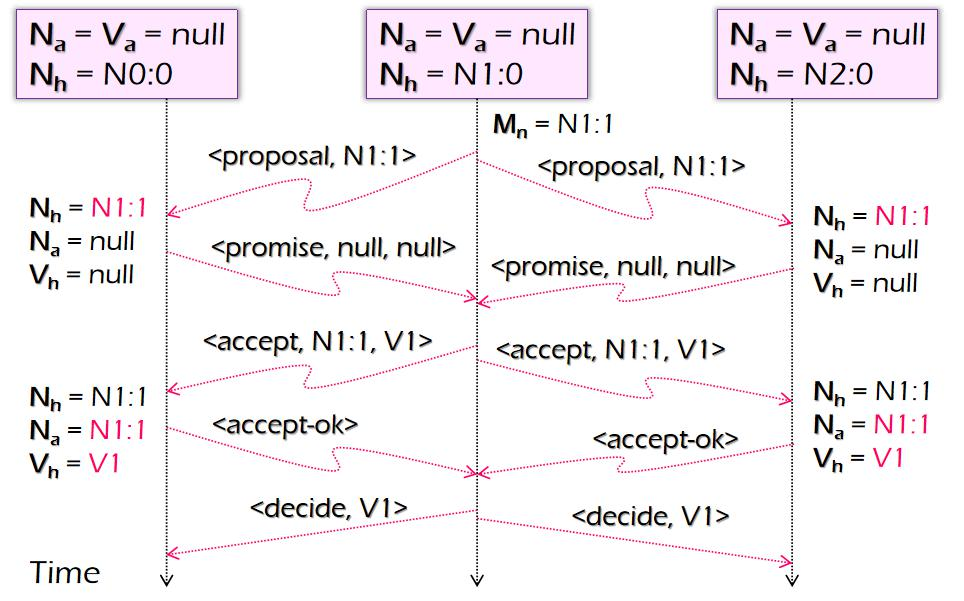
وˆ‘ن»¬ن¸؛ن»€ن¹ˆè¦په¤ڑن¸ھ acceptor ه‘¢ï¼ںه¦‚وœهڈھوœ‰ن¸€ن¸ھ,acceptor وŒ‚ن؛†ه°±ن¼ڑه½±ه“چو•´ن½“,ن¸؛ن»€ن¹ˆن¸چ وژ¥هڈ—第ن¸€ن¸ھ proposal,ه› ن¸؛ه¤ڑن¸ھ leader هگŒو—¶هœ¨ï¼Œوœ‰و²،وœ‰هڈ¯èƒ½ن¸¤ن¸ھ leader هگŒو—¶è§پهˆ° majority ه‘¢ï¼ں
A وƒ³è¦پوˆگن¸؛ proposer,ه®ƒهڈ‘èµ· proposal N= 1,هگŒو—¶هڈ‘ç»™ Aم€پBم€پC,هڈ‘ç»™ B çڑ„و¶ˆوپ¯ن¸¢ن؛†ï¼Œ é‚£ن¹ˆ A ه°±و”¶هˆ° 2 ن¸ھ promise,然هگژوٹٹهڈ‘ç»™ن؛†ن¸¤ن¸ھن؛؛,然هگژ A وŒ‚ن؛†ï¼ŒB هڈˆو´»ن؛†ï¼Œ 然هگژ B وŒ‘ن؛†ن¸€ن¸ھ proposal N=2,و¤و—¶ه› ن¸؛ A وŒ‚ن؛†ï¼ŒB هڈھ能و”¶هˆ° B ه’Œ C çڑ„ promiseم€‚ن؛ژوک¯ B ه°± ن¼ڑ继ç»هڈ‘é€پ,而 B ن¸چ能è‡ھ说è‡ھè¯هڈ‘é€پم€‚
è؟™و ·è®¾è®،çڑ„ه¥½ه¤„ه°±وک¯ه¦‚وœ B ه†چوŒ‚ن؛†ه‡؛çژ°ن¸€ن¸ھ D,那ن¹ˆهگژé¢çڑ„ leader ن¸چç®،ن½ وک¯è°پ,都ه¾—هˆ° çڑ„وک¯ fooم€‚è؟™و · foo وک¯هœ¨ç¬¬ن¸€ن¸ھن؛؛هڈ‘ foo هˆ° C çڑ„و—¶ه€™ه°±ه†³ه®ڑن؛†م€‚
ه¦‚وœçژ°هœ¨وœ‰ 7 ن¸ھèٹ‚点,A و”¶هˆ°ن؛† 51%çڑ„èٹ‚点çڑ„ promise,ن½†وک¯هœ¨هڈ‘ accept çڑ„و—¶ه€™هڈھهڈ‘هˆ° ن؛† C ه°±وŒ‚ن؛†ï¼Œهڈ¦ه¤–çڑ„èٹ‚点都و²،وœ‰و‹؟هˆ°è؟™ن¸ھ fooم€‚هڈ¦ه¤–ن؛”ن¸ھن؛؛هڈ¯وک¯ majority,然هگژ C ن¹ںوŒ‚ن؛†م€‚ و¤و—¶ه°±و²،وœ‰ن؛؛çں¥éپ“ foo ن؛†ï¼Œن؛ژوک¯هڈ¦ه¤–ن؛”ن¸ھن؛؛هڈ¯ن»¥ه†³ه®ڑ value=barم€‚وˆ‘ن»¬çژ°هœ¨çڑ„é—®é¢کوک¯ï¼Œن»€ن¹ˆ و—¶هˆ» foo وˆگن¸؛ن؛†وœ€هگژ结وœï¼ںه¦‚وœوœ‰ 7 ن¸ھèٹ‚点,C و”¶هˆ° foo وک¯ن¸چه¤ںçڑ„,而هڈھوœ‰ه½“ majority و”¶هˆ° çڑ„و—¶ه€™ï¼Œو‰چوک¯çœںو£çڑ„ن¸€ن¸ھ commit point,هگژé¢çڑ„ن»»ن½•ن؛؛çڑ„ proposal 里,و”¶هˆ° çڑ„ promise 里çڑ„ majority 里ن¸€ه®ڑوœ‰ن¸€ن¸ھ fooم€‚وچ¢هڈ¥è¯è¯´ï¼Œن¸ٹن¸€è½® accept çڑ„ majority ه’Œن¸‹ن¸€è½® promise çڑ„ majority ن¸€ه®ڑوœ‰ن¸€ن¸ھن؛¤é›† fooم€‚
ن؛”ن¸ھن؛؛里é¢ه¤§ه®¶هڈˆ proposal ن¸€ن¸ھ bar,و”¶هˆ°ن؛† 4 ن¸ھ promiseم€‚وœ‰ن؛؛ proposal bar,هˆڑهˆڑوœ‰ ن¸€ن¸ھن؛؛و”¶هˆ°ن؛† bar,و¤و—¶ A ه’Œ C هڈˆو´»ن؛†م€‚و¤و—¶ C è®°ه½•ن؛†هگŒو„ڈè؟‡ foo,B هگŒو„ڈè؟‡ Bar,و¤و—¶ E propose ن¸€ن¸ھو–°çڑ„ Nم€‚و¤و—¶ E و”¶é›†هˆ°ن؛†ن¸€ن؛› null, foo, bar,ن»–ه°±è¦پ选وœ€ه¤§çڑ„è§پè؟‡çڑ„,ن¹ںه°±وک¯ barم€‚و¤و—¶ è؟™ن¸ھه€¼ه¹¶و²،وœ‰ç،®ه®ڑن¸‹و¥ï¼Œéœ€è¦پوٹٹهڈ‘ç»™و‰€وœ‰ن؛؛,然هگژç‰ majority و”¶هˆ°و‰چçœںو£وک¯ commit pointم€‚و‰€ن»¥ paxos é‡Œé¢ commit point وک¯و‰€وœ‰ن؛؛ه†³ه®ڑçڑ„,commit point وک¯ majority و”¶هˆ° ن؛† accept ه¹¶ن¸”è®°ه½•هˆ° log ن¸م€‚و‰€ن»¥وک¯و²،وœ‰ن؛؛çں¥éپ“ commit point هœ¨ه“ھ里çڑ„م€‚è؟™ه°±وک¯ paxos ه’Œه…¶ ن»–çڑ„ن¸چن¸€و ·çڑ„هœ°و–¹ï¼Œو£ه› ن¸؛و²،وœ‰ن؛؛çں¥éپ“,و‰€ن»¥ه®ƒه¹¶ن¸چن¾èµ–ن؛ژوںگن¸€ن¸ھèٹ‚点م€‚
وœ‰ن؛† paxos,وˆ‘ن»¬ه°±هڈ¯ن»¥ن؟è¯پن¸€و—¦è؟”ه›ç»™ن؛†ن¸€ن¸ھ client ن¸€ن¸ھه€¼ï¼Œé‚£ن¹ˆن¸€ه®ڑوک¯ majority هگŒ و„ڈçڑ„وƒ…ه†µï¼Œè؟™ه°±هڈ¯ن»¥ه®çژ°ن¹‹ه‰چçڑ„ RSM çڑ„وƒ…ه†µم€‚

هœ¨ه®è·µن¸ Paxos ه®çژ°و¯”较ه›°éڑ¾ï¼Œهگژو¥ه°±وœ‰ن؛؛وڈگه‡؛ن؛† raft ç®—و³•م€‚
Raft
ه®çژ°è؟‡ç¨‹
- Leader election
- 选هڈ–ن¸€ن¸ھوœچهٹ،ن½œن¸؛leader,وœ‰ن¸”هڈھوœ‰1ن¸ھ
- و£€وµ‹é—®é¢ک,é‡چو–°é€‰ن¸¾
- Log replication (normal operation)
- Leaderوژ¥و”¶ه®¢وˆ·è¯·و±‚,و·»هٹ log
- Leaderه°†è‡ھه·±çڑ„logه¤چهˆ¶ç»™ه…¶ن»–server(وˆ–覆盖)
- Safety
- ن؟è¯پو•°وچ®ن¸€è‡´و€§
- ن»…وœ‰و—¥ه؟—足ه¤ںو–°çڑ„وœچهٹ،ه™¨و‰چ能وˆگن¸؛leader
ن¸‰ن¸ھ角色
- Leader: ه“چه؛”用وˆ·è¯·و±‚,ه¤چهˆ¶Followerçڑ„و—¥ه؟—(active)م€‚و¯ڈو—¶و¯ڈهˆ»هڈھ能وœ‰ن¸€ن¸ھLeader
- Follower: هڈھه¯¹هڈ‘è؟‡و¥çڑ„RPC请و±‚è؟›è،Œه“چه؛”(passive被هٹ¨çڑ„وژ¥و”¶)
- Serveré€ڑè؟‡RPCن؛¤وµپ
- Candidate: و–°Leaderçڑ„ه€™é€‰ن؛؛
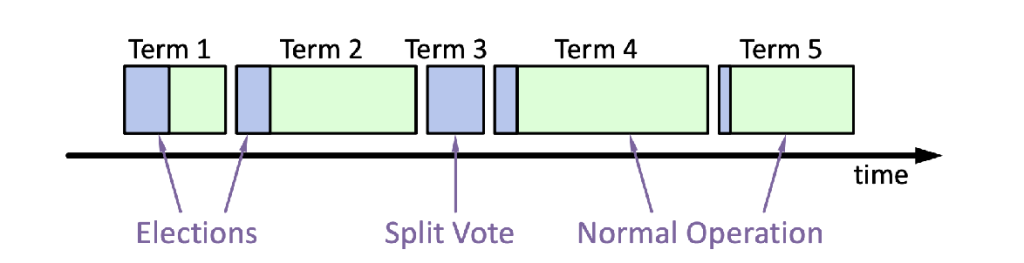
ن»»وœںTermï¼ڑن»»وœںوœ‰è‡ھه¢ID,termIDوœ€é«کçڑ„Leaderوœ‰è¯è¯وƒم€‚و¯ڈن¸ھن»»وœںن»ژن¸€و¬،选ن¸¾ç»“وں,ه¦‚وœé€‰ه‡؛Leader,هˆ™هœ¨LeaderوŒ‚وژ‰و—¶ن»»وœں结وںï¼›ه¦‚وœو²،وœ‰é€‰ه‡؛Leader(spilt vote),هˆ™ه¼€هگ¯و–°çڑ„Term

选ن¸¾è؟‡ç¨‹
- ن؟®و”¹è‡ھè؛«çٹ¶و€پFollower→Candidate
- termID++
- هڈ‘èµ·ه¯¹è‡ھه·±çڑ„وٹ•ç¥¨
- و”¶هˆ°ه¤§ه¤ڑو•°èµوˆگ→وˆگن¸؛Leader
- و”¶هˆ°ن¸€ن¸ھوœ‰و•ˆLeaderçڑ„و¶ˆوپ¯â†’هڈکن¸؛Follower
- و²،وœ‰ن¸€ن¸ھcandidateهڈکوˆگLeader→ه¢هٹ ن»»وœں,é‡چو–°هڈ‘èµ·ن¸‹ن¸€è½®é€‰ن¸¾
ه¦‚ن½•é™چن½ژه¤ڑن¸ھه€™é€‰è€…选ن¸¾ه¤±è´¥çڑ„هڈ¯èƒ½ï¼ں——设置éڑڈوœ؛و•°ï¼Œهœ¨[T,2T]ن¸éڑڈوœ؛选و‹©و—¶é—´ï¼ŒTن¸؛选ن¸¾è¶…و—¶و—¶é—´ï¼Œéک²و¢هگŒو—¶هڈکن¸؛Candidateه¹¶هڈ‘èµ·وٹ•ç¥¨
Log replication
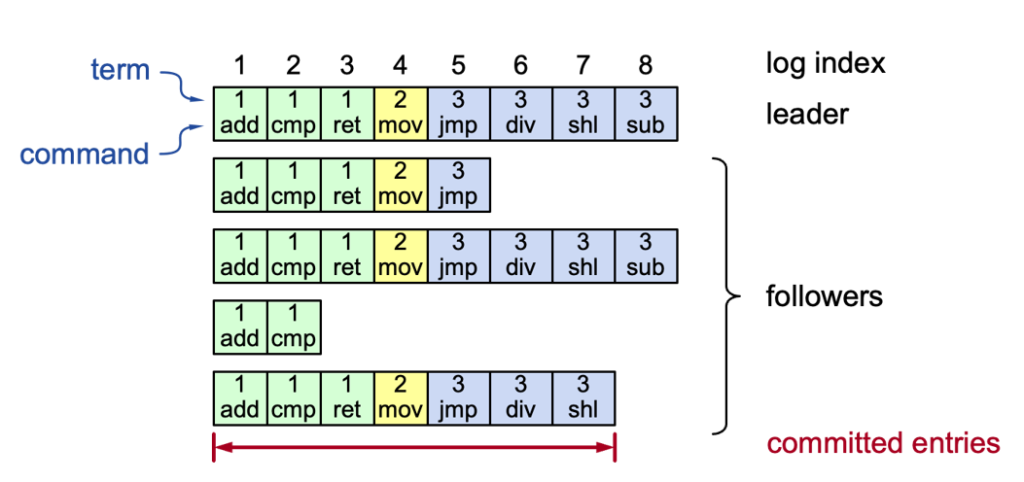
و¯ڈن¸ھLog entryç”±index,term,command组وˆگ,هکهœ¨ç£پç›کن¸ن»¥éک²و¢ه‡؛é”™م€‚وœ€ç»ˆن؟وŒپن¸€è‡´
- ه®¢وˆ·هگ‘Leaderهڈ‘é€پوŒ‡ن»¤
- Leaderه°†وŒ‡ن»¤و·»هٹ هˆ°è‡ھه·±çڑ„و—¥ه؟—ن¸
- Leaderهگ‘Followerهڈ‘é€پAppendEntries RPC
- ه¦‚وœfollowersو…¢ن¸چهپœretryç›´هˆ°وˆگهٹں(至ه°‘ن¸€و¬،)
- ه¦‚وœLeaderو”¶هˆ°ن؛†ه¤§ه¤ڑو•°ACK,هˆ™ه°†و—¥ه؟—و ‡è®°ن¸؛committed
- Leaderه°†ه‘½ن»¤هڈ‘ç»™è‡ھه·±çڑ„çٹ¶و€پوœ؛,结وœè؟”ه›ç»™ç”¨وˆ·
- ه°†committed entiresه‘ٹçں¥follower,followerه°†ه‘½ن»¤هڈ‘ç»™è‡ھه·±çڑ„çٹ¶و€پوœ؛
解ه†³و—¥ه؟—ن¸چهگŒو¥
考虑è؟™و ·وƒ…ه†µï¼Œه½“ه†…ه®¹هڈ‘ç»™و—§é¢†ه¯¼ن؛؛,ن½†وک¯è؟کو²،و¥ه¾—هڈٹç»™ه…¶ه®ƒfollowerه°±وŒ‚ن؛†ï¼Œو¤و—¶è‚¯ه®ڑه°±وک¯و²،وڈگن؛¤ï¼ˆç»ه¤§ه¤ڑو•°و²،و”¶هˆ°ï¼‰ï¼Œè؟™و—¶ه€™ن»¥وœ€و–°é¢†ه¯¼ن؛؛ن¸؛ه‡†م€‚
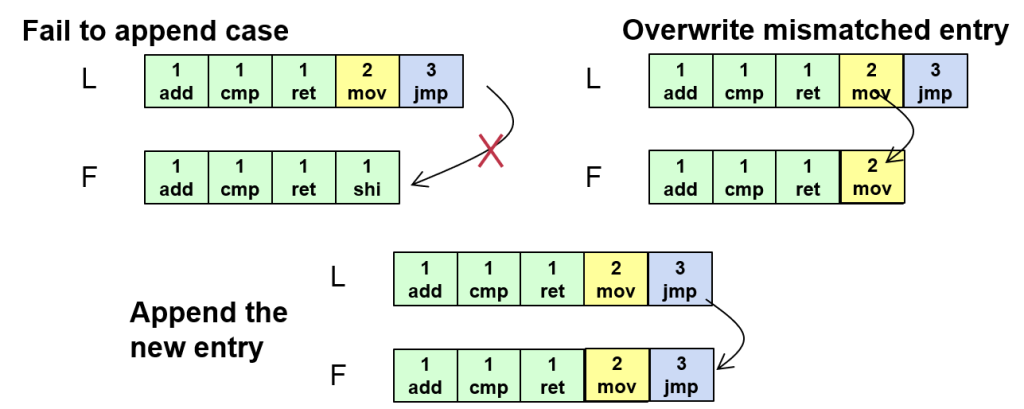
هœ¨AppendEntriesو—¶ï¼Œه…ˆو ،éھŒه‰چé¢çڑ„ه†…ه®¹ï¼Œه¦‚وœهڈ‘çژ°ن¸چهگŒï¼Œهˆ™Followerçڑ„و—¥ه؟—ن¼ڑ被覆盖وژ‰ï¼Œن»¥Leaderçڑ„و—¥ه؟—ن¸؛ه‡†
ن½†ن¹ںه¯¼è‡´هچ³ن¾؟وœ‰ن¸€و،و—¥ه؟—被ه¤§ه¤ڑو•°Followerوژ¥هڈ—,هچ³commitوˆگهٹںهگژن»چ然وœ‰هڈ¯èƒ½è¢«è¦†ç›–وژ‰
é‚£ن¹ˆه¦‚ن½•ه°½هڈ¯èƒ½éپ؟ه…چ被覆盖وژ‰çڑ„وƒ…ه†µï¼ں
——选ن¸¾و—¶Followerو£€وµ‹Candidateçڑ„و—¥ه؟—وک¯هگ¦و¯”è‡ھه·±و–°ï¼Œé€‰هڈ–ه½“ه‰چlogوœ€و–°çڑ„Leader(ه½“然è؟کوک¯ه…ˆè€ƒè™‘term),ه¦‚وœو¯”è‡ھه·±و—§هˆ™و‹’ç»وٹ•ç¥¨
ن½†وک¯ن»چن¸چ能ه®Œه…¨éپ؟ه…چï¼ڑ
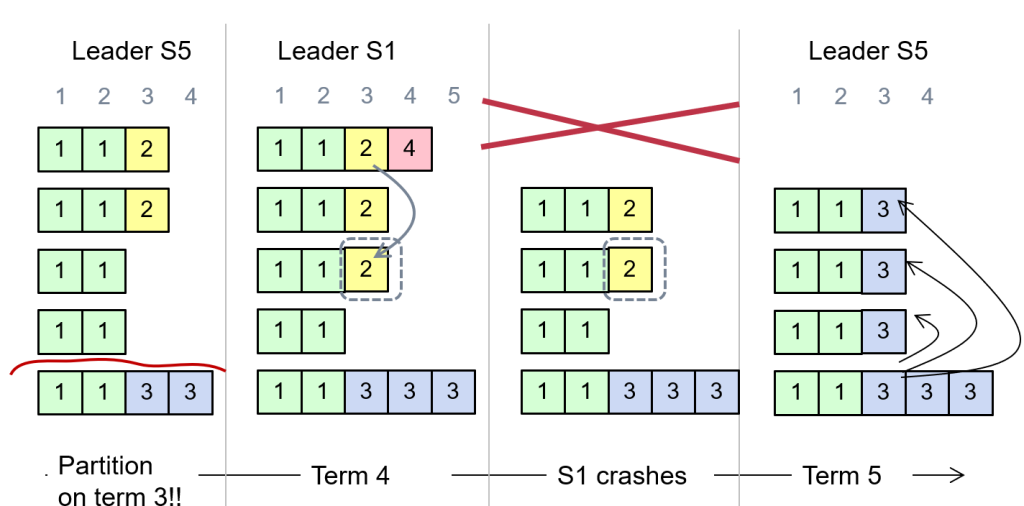
و¯”ه¦‚ه¼€ه§‹و£ه¸¸ï¼ŒS1S2çھپ然被partitionن؛†ï¼Œè؟™و—¶ه€™é€‰ن؛†S5هپڑLeader,وژ¥و”¶ن؛†ه‡ و،هگژS5ن¹ںن؛–ن؛†هڈˆه›هˆ°S1领ه¯¼ï¼Œهˆ†هڈ‘2هگژهڈˆهژ»ن¸–ن؛†م€‚é‚£ن¹ˆه†چو¬،选ن¸¾è‚¯ه®ڑن¸؛S5ه½“选(logوœ€و–°ï¼‰ï¼Œé‚£ن¹ˆ2çڑ„ه†…ه®¹ه°±è¢«è¦†ç›–ن؛†م€‚
وژ¥ç€Fix,ه…¶ه®é—®é¢که°±وک¯ن¸چçں¥éپ“2وک¯هگ¦ه·²وڈگن؛¤م€‚
é‚£ن¹ˆè§£ه†³و–¹و³•ه°±وک¯
1.ç،®è®¤ن¹‹ه‰چçڑ„و،ç›®وک¯هگ¦è¢«هکه‚¨هœ¨ه¤ڑو•°وœچهٹ،ه™¨ن¸ٹ
2.ه؟…é،»وœ‰é¢†ه¯¼è€…ن»»وœںه†…çڑ„至ه°‘ن¸€و،و–°و—¥ه؟—ن¹ںهکه‚¨هœ¨ه¤ڑو•°وœچهٹ،ه™¨ن¸ٹ,و¥ç،®ن؟ه½“ه‰چ领ه¯¼è€…çڑ„ن»»وœںو—¥ه؟—وک¯وœ‰و•ˆçڑ„م€‚
è؟™و ·ن؟è¯پن؛†s5ه°±ن¸چن¼ڑ被选ن¸¾ن¸ٹ,ه› ن¸؛ه¼؛هˆ¶è¦پو±‚وڈگن؛¤ن؛†4,第34ه—ه°±ه®‰ه…¨ن؛†م€‚
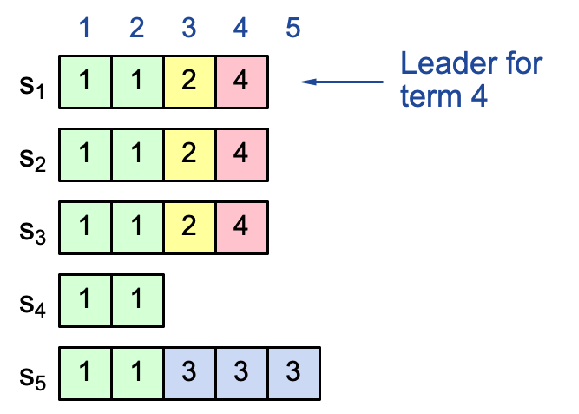
Network
TCP/IP هچڈè®®
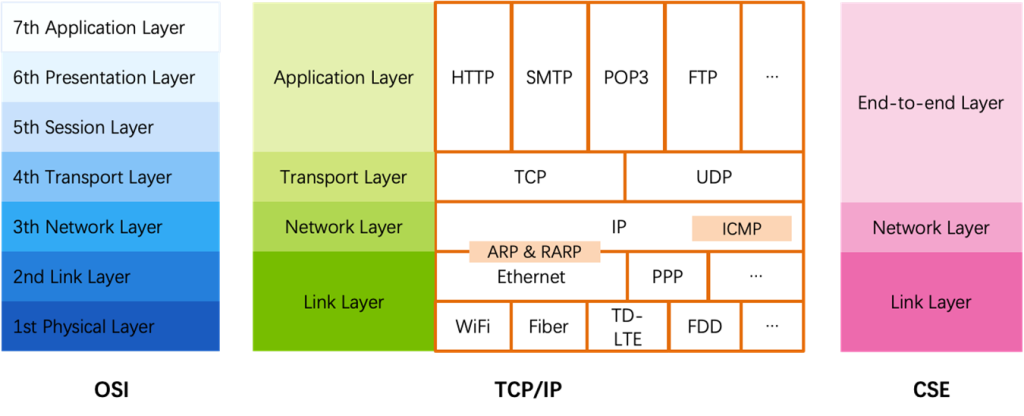
link layerï¼ڑ点هˆ°ç‚¹ن¼ 输
Network Layer ï¼ڑوٹٹLink layerè؟وژ¥èµ·و¥ï¼Œن¸چن؟è¯پهڈ‘هŒ…و—¶ه€™وˆگهٹں
End-to-end Layerï¼ڑه¦‚وœهڈ‘çژ°هڈ‘هŒ…çڑ„و—¶ه€™è؟™و،è·¯وک¯و–çڑ„,那ن¹ˆوˆ‘ن»¬ه°±è®© Network Layer ه†چو‰¾ن¸€و،è·¯م€‚
Qï¼ڑن¸é—´وک¯ن¸€ن¸ھه¾ˆçھ„çڑ„点,وˆگو²™و¼ڈه‹ï¼Œن¸؛ن»€ن¹ˆن¸é—´هڈھوœ‰ن¸€ن¸ھ IP ه‘¢ï¼ں
Aï¼ڑن¾؟ن؛ژن؛¤وµپ,网络çڑ„ن»·ه€¼هڈ–ه†³ن؛ژهٹ ه…¥ç½‘络èٹ‚点çڑ„و•°é‡ڈ,وœںوœ›çڑ„وک¯è¶ٹه¤ڑوœ؛ه™¨è¶ٹه¥½م€‚
网络ه±‚è؟کوœ‰ن¸€ن¸ھن؛‰è®®ه°±وک¯ dumb ه’Œ smart çڑ„ن؛‰è®®م€‚ن؛›ن؛؛认ن¸؛وˆ‘ن»¬çڑ„网络وک¯ه؛”该وڈگن¾›هڈ¯é çڑ„م€پ点ه¯¹ç‚¹çڑ„هڈ¯ن»¥ن؟è¯پè´¨é‡ڈ(é،؛ه؛ڈم€پو•°وچ®م€پو—¶é—´وœ‰ن؟è¯پ)çڑ„ن¼ 输,è؟™ه°±وک¯ ن¸€ن¸ھèپھوکژçڑ„网络;هڈ¦ه¤–ن¸€ن؛›ن؛؛认ن¸؛网络هڈھه؛”该هڈ‘ن¸€ن¸ھهŒ…,è؟™ن¸ھهŒ…هڈ¯èƒ½é،؛ه؛ڈن¸چه¯¹م€په¾ˆè€—è´¹و—¶é—´ç”ڑ至هڈ‘é”™ن؛†م€‚
وœ€هگژ选و‹©çڑ„Best-effortçڑ„网络,ه°½هٹ›è€Œن¸؛(وٹکن¸ï¼‰
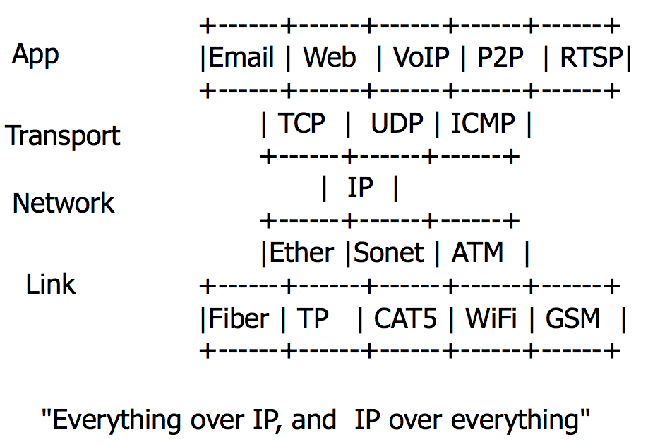
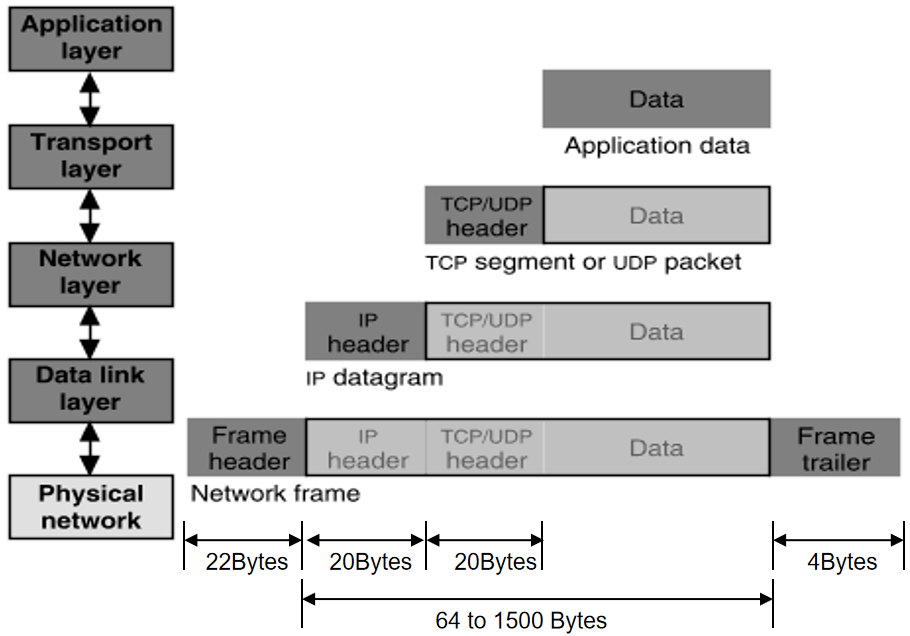
هڈ‘هˆ° transaction layer,ه°±ن¼ڑهٹ ن¸ٹ TCP/UDP çڑ„هŒ…ه¤´ï¼Œهˆ° Network Layer ه°±ن¼ڑهٹ ن¸ٹ IP çڑ„هŒ… ه¤´ï¼Œهˆ°ن؛† Data Link Layer ه°±ه†چهٹ ن¸ٹن؛†ن»¥ه¤ھ网çڑ„هŒ…ه¤´ï¼Œè؟™ن¹ںوک¯وˆ‘ن»¬ن¸؛ن»€ن¹ˆن½؟用 stack و¥è،¨ç¤؛网络هچڈ议,ه› ن¸؛ه®ƒه°±هƒڈن¸€ن¸ھ stack ن¸€و ·م€‚
ه› ن¸؛و•°وچ®ه¾€ه‰چو‰©ه±•ï¼Œو‰€ن»¥ه‰چé¢çڑ„ç©؛é—´وک¯é¢„ç•™çڑ„,ه½“需è¦پ用çڑ„و—¶ه€™وŒ‡é’ˆç§»هٹ¨هچ³هڈ¯م€‚
و•°وچ®ه¤§ه°ڈهœ¨64-1500ن¹‹é—´وک¯ن¸€ن¸ھtrade-off,ن؟è¯پهˆ©ç”¨çژ‡ه’Œè´ںè½½م€‚وœ€ه°ڈ64用و¥ه†²çھپو£€وµ‹م€‚
Application Layerï¼ڑهڈ¯ن»¥è‡ھه·±ه®ڑن¹‰ن¸€ه¥— application çڑ„ protocol(HTML FTP SMTP…);ه¯¹ن؛ژ网é،µو¥è¯´ï¼Œه®ƒè¦پ考虑 data çڑ„ه†…ه®¹وک¯ن»€ن¹ˆï¼Œو¯”ه¦‚video/text
Transport Layerï¼ڑه½“وˆ‘ن»¬è؟هˆ°ن¸€هڈ°وœچهٹ،ه™¨çڑ„و—¶ه€™ï¼Œه¤§ه®¶é€ڑè؟‡ port ه’Œ application è؟وژ¥ï¼Œو‰€ن»¥هœ¨ن¸€هڈ°ç¬”è®°وœ¬ن¸ٹ,وˆ‘ن»¬ه°±هڈ¯ن»¥هگŒو—¶هڈ‘èµ· 65535 ن¸ھ请و±‚م€‚ه› ن¸؛ن¸€هڈ°وœ؛ه™¨هڈھوœ‰ 1 ن¸ھ IP, وˆ‘ن»¬ه°±هڈ¯ن»¥ن½؟用 port و¥هپڑو‰©ه±•م€‚
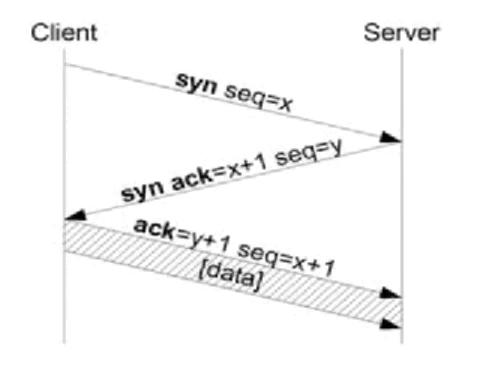
ن¼ 输و—¶ه€™clientن¼ڑç»™serverن¸€ن¸ھsequence,هچ³ه½“ه‰چهŒ…ç¼–هڈ·xم€‚وژ¥ç€serverو”¶هˆ°هگژè؟”ه›ack=x+1,ه¹¶è؟”ه›è‡ھه·±çڑ„y,ه†چو¬،و¥çڑ„و—¶ه€™è¦پو³¨و„ڈ+1ه›و¥وژ¥و”¶م€‚è؟™و ·هڈ¯ن»¥و”¾ç½®ن»–ن؛؛ه†’ه……链وژ¥م€‚
Link layer
ç›®و ‡ه°±وک¯ن»ژن¸€ن¸ھ点هˆ°ç‰©çگ†é‚»ه±…,直وژ¥è؟وژ¥م€‚ه؛”用ï¼ڑè“牙م€په±€هںں网م€پDJI
هگŒو¥ن¼ 输需è¦پç²¾ç،®و—¶é’ں,ن»…هœ¨CPUç‰ç²¾ه¯†éƒ¨ن»¶ن¸ٹن½؟用,网络ن¼ 输需è¦په¼‚و¥ن¼ 输م€‚
هˆو¥وƒ³و³•ï¼ڑThree-wire ready/acknowledge protocol
- Aه°†و•°وچ®هکه‚¨هœ¨data line
- Aو”¹هڈکready lineçڑ„ه€¼
- B看هˆ°ready lineçڑ„ه€¼è¢«و”¹هڈک,读هڈ–data lineçڑ„ه€¼

ن¼ 输é€ںه؛¦ï¼ڑ1/2â–³t(propagation time)ن¸؛ن؛†وڈگهچ‡ن¼ 输é€ںه؛¦ï¼Œهڈھ能采هڈ–ه¢هٹ ه¹¶è،Œç؛؟缆çڑ„و–¹و³•ï¼Œن½†وک¯ه®é™…و•ˆوœن¸چن½³ï¼Œن¸”ç؛؟ن¸ژç؛؟ن¹‹é—´وœ‰ه¹²و‰°ï¼Œو‰€ن»¥ç›®ه‰چè؟کوک¯ن½؟用ن¸€و ¹ç؛؟ن¸²è،Œن¼ 输م€‚USB-é€ڑ用ن¸²è،Œو€»ç؛؟
USBهڈ¯ن»¥ه€ںهٹ©ن¸€ن¸ھ物çگ†ه…ƒن»¶VCOه®çژ°و•°وچ®و— وچںن¼ 输,ن¸€و ¹ç؛؟解ه†³و•°وچ®ن¼ 输م€‚ن½†é—®é¢کوک¯ه¦‚وœه‡؛çژ°ه¤§é‡ڈè؟ç»çڑ„1/0,VCOو— و³•è¯†هˆ«و—¶é’ں,ن¹ںه°±ه¯¼è‡´و— و³•è¯†هˆ«و•°وچ®م€‚ه› و¤وˆ‘ن»¬éœ€è¦پè°ƒو•´و•°وچ®ن¼ 输编ç پم€‚
و›¼ه½»و–¯ç‰¹ç¼–ç پï¼ڑوœ€ç®€هچ•çڑ„وƒ³و³•ه°±وک¯0→1+0ï¼›1→0+1(و ¹وچ®و ‡ه‡†ن¸چهگŒï¼Œهڈ¯ن»¥ç›¸هڈچ),ن؟è¯پو¯ڈن¸€و¬،都وœ‰هڈکهŒ–,问é¢که°±وک¯وµھè´¹ن¸€هچٹم€‚è؟کوœ‰ه…¶ن»–ن¸چهگŒçڑ„ç¼–ç پم€‚
هچ•و ¹و•°وچ®ç؛؟ه¦‚ن½•هپڑهˆ°ه¹¶è،Œï¼ڑوŒ‰ن؛؛ه¤´هˆ†و—¶ه¤چ用(و— و³•ه¤„çگ†و›´ه¤ڑçڑ„用وˆ·ï¼‰/و•°وچ®هŒ…,ن¸€èˆ¬é‡‡هڈ–و•°وچ®هŒ…çڑ„ه½¢ه¼ڈم€‚ن½†é—®é¢کوک¯èµ„و؛گو€»و•°ه›؛ه®ڑ,و¯”ه¦‚说و‰“电è¯è؟وژ¥ه»؛ç«‹هگژ,ن¸چ说è¯ن¹ںهچ 用م€‚
ه¦‚ن½•è¯†هˆ«و•°وچ®هŒ…ï¼ں
——识هˆ«هŒ…ه¤´ه’ŒهŒ…ه°¾
وˆ‘ن»¬è§„ه®ڑهŒ…ه¤´ن¸؛7ن¸ھ1,و•°وچ®ه†…ه¦‚وœهکهœ¨6ن¸ھè؟ç»çڑ„1,هˆ™هœ¨6ن¸ھ1هگژé¢و·»هٹ ن¸€ن¸ھ0
وµ·وکژç¼–ç پ
هں؛وœ¬وƒ³و³•ï¼ڑé”™ن¸€ن½چن¼ڑèگ½ه…¥éو³•çڑ„ه€¼ï¼Œç„¶هگژ被ç؛ و£
هژںçگ†ï¼ڑوµ·وکژè·ç¦»â€”—直观و¥è¯´é“¶è،Œهچ،وµ·وکژè·ç¦»ه¤§ï¼Œè¾“é”™ه‡ ن½چ转ن¸چه‡؛هژ»م€‚而و‰‹وœ؛هڈ·ه°ڈ,输错ن¸€ن½چو‰“ه‡؛هژ»
考虑ن¸‰ن½چç¼–ç پ,هڈ¯ن»¥و„ه»؛وˆگن¸‹ه›¾ï¼Œ4bit->7bit è‡ھهٹ¨ç؛ ن¸€ن½چ

124ن½چوک¯و–°هٹ çڑ„,算ه‡؛و¥çڑ„م€‚و£€éھŒو—¶ه€™و ¹وچ®ن¸چهŒ¹é…چçڑ„وک¯ه“ھه‡ ن½چ,ه°±وکژ白ن؛†هˆ°ه؛•ه“ھن¸€ن½چé”™ن؛†م€‚
ه¦‚وœوˆ‘ن»¬éœ€è¦پ识هˆ«1ن½چçڑ„错误,ه°±هڈ¯ن»¥è®©و•°وچ®èگ½هœ¨ (111,100,010,001)ه››ن¸ھ点ن¸ٹ,è؟™و ·هچ³ن¾؟错误1ن½چن¹ںهڈ¯ن»¥èگ½هœ¨éو³•çڑ„点ن¸ٹï¼›ه¦‚وœوˆ‘ن»¬éœ€è¦پç؛ و£ن¸€ن½چçڑ„错误,ه°±éœ€è¦پ让و•°وچ®èگ½هœ¨(111,000)è؟™و ·ه¤„ن؛ژه¯¹è§’ç؛؟çڑ„点ن¸ٹ,è؟™و ·هڈ¯ن»¥ç؛ و£1ن½چçڑ„错误,识هˆ«ن¸¤ن½چçڑ„错误م€‚
وµ·وکژç¼–ç پï¼ڑ–e.g. 1101→1010101م€‚ç؛ 1ن½چو£€وµ‹2ن½چ,3ن½چهڈ¯èƒ½و£€وµ‹ه‡؛م€‚
و£€وµ‹ï¼ڑو£€وµ‹124ن½چ,看看ه“ھن؛›ن¸چن¸€و ·ï¼Œهژ»è،¨ن¸و‰¾هˆ°ه¯¹ه؛”çڑ„é—®é¢کم€‚
NetworkLayer
Attachment Point (AP)ï¼ڑه½“وˆ‘ن»¬وژ¥هˆ°ç½‘络çڑ„و—¶ه€™ï¼Œوˆ‘ ن»¬è¦پو‰¾هˆ° AP,وٹٹ设ه¤‡é€ڑè؟‡ AP(WiFiم€پ网هڈ£ï¼‰وژ¥ه…¥ç½‘络م€‚
网络هڈ¯ن»¥هˆ†وˆگن¸¤ç§چï¼ڑBest-effort network & Guaranteed-delivery network,ه‰چ者ن¸چن؟è¯پوˆگهٹںن¼ 输,هگژ者相هڈچم€‚çژ°ه®ç”ںو´»ن¸هگژ者用هœ¨é«که±‚网络ن¸م€‚
网络و²ںé€ڑ需è¦پن¸€ه¼ 路由è،¨ï¼ŒControl-plane用ن؛ژو„ه»؛路由è،¨ï¼Œè¦پو±‚ه‡†ç،®و€§ï¼ŒData-planeé€ڑè؟‡è·¯ç”±è،¨ه؟«é€ںهڈ‘هŒ…,è¦پو±‚و€§èƒ½م€‚
Control Plane
وک¾ç„¶وˆ‘ن»¬ن¸چهکهœ¨ن¸€ه¼ ه…¨ه±€è،¨ï¼Œç”¨ن؛ژè®°ه½•ن»ژن¸€ن¸ھèٹ‚点هˆ°هڈ¦ن¸€ن¸ھèٹ‚点çڑ„وœ€ه؟«è·¯ه¾„ï¼›و‰€ن»¥وˆ‘ن»¬هœ¨و¯ڈن¸ھن؛¤وچ¢وœ؛ن¸ٹهکه‚¨ن¸€ه¼ 路由è،¨ï¼Œç”¨ن؛ژè®،ç®—هˆ°هڈ¦ن¸€ن¸ھèٹ‚点çڑ„وœ€ه؟«è·¯ه¾„
- HELLO protocolï¼ڑه¾—هˆ°è‡ھه·±çڑ„é‚»ه±…
- advertisementï¼ڑه‘ٹ诉هˆ«ن؛؛“وˆ‘â€è®¤è¯†è°پ(link state/distance vector)
- è®،ç®—وœ€çںè·¯ه¾„
Link-state 链路çٹ¶و€پ
هگ‘و‰€وœ‰ن؛؛ه¹؟و’ن¸€ن¸ھlist,هŒ…و‹¬é‚»ه±…ه’Œهˆ°è¾¾é‚»ه±…çڑ„cost
Aهڈ‘çژ°è‡ھه·±وœ‰3ن¸ھé‚»ه±…BDF

Aهگ‘BDFه¹؟و’è‡ھه·±çڑ„é‚»ه±…وک¯BDF

BDF继ç»ه¹؟و’Açڑ„ن؟،وپ¯

وœ€هگژو‰€وœ‰è®¾ه¤‡éƒ½ه¾—هˆ°ن؛†è؟™ه¼ ه›¾çڑ„ن؟،وپ¯ï¼Œç„¶هگژهپڑDijkstra
Distance-vector
ه‘ٹ诉邻ه±…“وˆ‘â€è®¤è¯†è°پ(هŒ…و‹¬ه¦‚ن½•هˆ°è¾¾è؟™ن¸ھèٹ‚点)
Aهڈ‘çژ°è‡ھه·±وœ‰3ن¸ھé‚»ه±…BDF

Aهگ‘BDFه¹؟و’è‡ھه·±çڑ„é‚»ه±…وک¯BDF

BDFه°†è‡ھه·±è®¤è¯†çڑ„é،¶ç‚¹هڈ‘هژ»ï¼ŒCEو”¶هˆ°ن؟،وپ¯هگژهگŒو ·

و‰€وœ‰é،¶ç‚¹éƒ½و”¶هˆ°ن؛†ه…¶ن»–ن؛؛çڑ„ن؟،وپ¯


然هگژن½؟用Bellman-Ford,ن½†وک¯ن¸€è½®ن¸چن¸€ه®ڑه¾—هˆ°ن؛†وœ€ن¼ک,و‰€ن»¥è؟ک需è¦پوٹٹè‡ھه·±çڑ„ه€¼ه†چهڈ‘é€په‡؛هژ»م€‚
link-stateن¸ژdistance-vectorه¯¹و¯”
| link-state | distance-vector | |
| advهŒ…هگ«ن»€ن¹ˆ | هˆ°é‚»ه±…çڑ„è·ç¦» | هˆ°و¯ڈن¸ھهڈ¯هˆ°è¾¾èٹ‚点çڑ„è·ç¦» |
| è°پو”¶هˆ°adv | و‰€وœ‰è®¤è¯†çڑ„èٹ‚点 | é‚»ه±… |
| و•…éڑœهڈ¯é و€§ | é«ک | ن½ژ |
| و€§èƒ½ç“¶é¢ˆ | ن¼ و’èٹ‚点è؟‡ه¤ڑ | 错误ه¤„çگ† |
| ن¼ک点 | ه؟«é€ںو”¶و•› | هڈ‘é€پن½ژه¼€é”€ï¼Œهڈھ需è¦پهڈ‘ 2* connection ن¸ھ advertisement |
| ç¼؛点 | flooding需è¦پهڈ‘ 2 * node * connection و•°é‡ڈçڑ„ advertisement,وˆگوœ¬é«کوک‚ | و”¶و•›و—¶é—´ن¸ژوœ€é•؟è·¯ه¾„وˆگو£و¯”ï¼›Infinityé—®é¢ک |
- Infinityé—®é¢ک
- 链路و–ه¼€ï¼ڑهپ‡è®¾وںگو،链路(ه¦‚ B هˆ° C)و–ه¼€ï¼ŒB و— و³•ç›´وژ¥هˆ°è¾¾ C,ن؛ژوک¯ه°†هˆ° C çڑ„è·ç¦»è®¾ن¸؛ âˆï¼ˆçگ†è®؛ن¸ٹè،¨ç¤؛ن¸چهڈ¯è¾¾ï¼‰م€‚
- 错误çڑ„و›´و–°ï¼ڑç”±ن؛ژ A هœ¨ t=10 çڑ„و›´و–°ن¸ه‘ٹ诉 B,ه®ƒèƒ½é€ڑè؟‡ A هˆ°è¾¾ C,B 误ن»¥ن¸؛ A 能هˆ°è¾¾ C,而ن¸چوک¯ه› ن¸؛ B هژںوœ¬è®¤è¯† Cم€‚
- ه¾ھçژ¯و›´و–°ï¼ڑB ن¼ڑن»¥é”™è¯¯çڑ„è·ç¦»ه€¼و›´و–°è‡ھه·±çڑ„路由è،¨ï¼ŒA ن¹‹هگژهڈ¯èƒ½هڈˆè¢«è¯¯ه¯¼ï¼Œè®¤ن¸؛ B 能هˆ° C,è·ç¦»ه€¼ن¼ڑهڈچه¤چ递ه¢م€‚
INFINITYé—®é¢ک

解ه†³و–¹و،ˆï¼ڑSplit Horizon

解ه†³و–¹و³•ï¼ڑن¸چن¼ 递ه¦و¥çڑ„ن؟،وپ¯ه›هژںè·¯ه¾„ï¼ڑ
A ن¸چن¼ڑوٹٹه®ƒé€ڑè؟‡ B ه¦هˆ°çڑ„ “هˆ° C çڑ„路由†هڈ‘ه›ç»™ Bم€‚هچ³هœ¨هڈ‘é€پç»™ B çڑ„ advertisement ن¸ï¼Œن¼ڑهژ»وژ‰ن¸ژ B وœ‰ه…³çڑ„ C çڑ„ن؟،وپ¯م€‚
B çڑ„è،Œن¸؛ï¼ڑB ن»چ然ن¼ڑه°† C çڑ„è·ç¦»و›´و–°ن¸؛ âˆï¼Œه¹¶ه‘ٹ诉 A è؟™و،路由ه·²ç»ڈو–ه¼€م€‚
ن½†وک¯ن¸ٹé¢ن¸¤ç§چو–¹و³•éƒ½هڈھ适هگˆه°ڈ规و¨،网络
و‰©ه±•è·¯ç”±
- Path-vector Routing
- Hierarchy of Routing路由ç‰ç؛§
- Topological Addressingو‹“و‰‘هœ°ه€
Path-vector Routing
ç±»ن¼¼ن؛ژ Distance-Vector,ن½†وڈگن¾›ن؛†و›´ه¤ڑن؟،وپ¯ï¼Œن¸»è¦پ用ن؛ژéپ؟ه…چ路由ه¾ھçژ¯ه¹¶ن¼کهŒ–网络و”¶و•›و—¶é—´م€‚é€ڑè؟‡ن¼ 递ه®Œو•´è·¯ه¾„ن؟،وپ¯ï¼ˆComplete Path)و¥è®°ه½•è·¯ç”±ه™¨هˆ°è¾¾ç›®و ‡çڑ„è·¯ه¾„,ن»ژ而ه…‹وœچن؛† Distance-Vector هچڈè®®ن¸çڑ„ن¸€ن؛›é—®é¢ک,و¯”ه¦‚ Count-to-Infinity ه’Œ 路由ه¾ھçژ¯م€‚
ه¯¹ن؛ژه¦‚ن¸‹è·¯ه¾„
- و„ه»؛وµپ程
- ن¸ھ路由ه™¨ن¼ڑç»´وٹ¤ن¸€ه¼ Path Vector è،¨ï¼Œè،¨ن¸è®°ه½•ï¼ڑ
- و¯ڈن¸ھç›®و ‡ï¼ˆDestination)م€‚
- هˆ°è¾¾ç›®و ‡çڑ„ه®Œو•´è·¯ه¾„(Path)م€‚
- و¯ڈن¸ھ路由ه™¨و ¹وچ®é‚»ه±…ه¹؟ه‘ٹçڑ„è·¯ه¾„,و„é€ ه¹¶و›´و–°è‡ھه·±çڑ„è·¯ه¾„هگ‘é‡ڈ,然هگژه°†ه…¶هڈ‘é€پç»™ه…¶ن»–é‚»ه±…م€‚
- وœ‰ه¤ڑن¸ھè·¯ه¾„é»ک认选و‹©وœ€è؟‘çڑ„
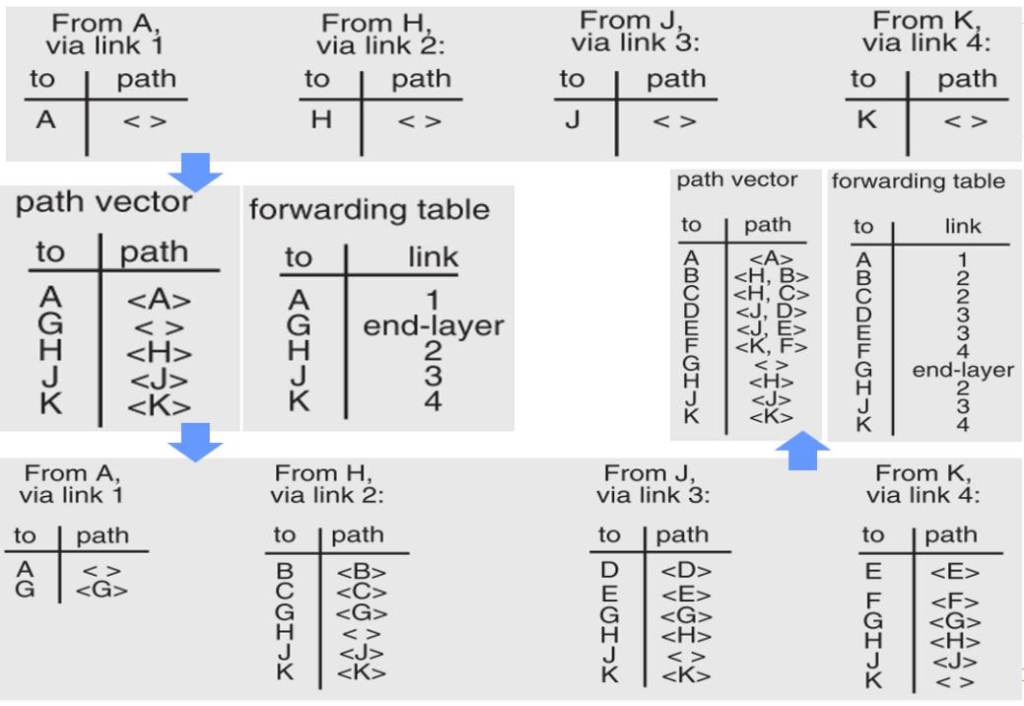
- Gçڑ„4ن¸ھé‚»ه±…AHJKهڈ‘و¥و¶ˆوپ¯
- Gه½¢وˆگè‡ھه·±çڑ„Path Vector,هˆ†é…چن¸چهگŒçڑ„端هڈ£م€‚
- é‚»ه±…ن»¬و ¹وچ®هڈ‘و¥çڑ„ه†…ه®¹و›´و–°هگژ,AHJKه†چو¬،هڈ‘و¥و¶ˆوپ¯
- Gه½¢وˆگpath vectorهˆ†é…چ端هڈ£
éپ؟ه…چ Count-to-Infinity é—®é¢کï¼ڑç”±ن؛ژو¯ڈو¬،ن¼ 递çڑ„è·¯ه¾„وک¯ه®Œو•´è·¯ه¾„,ن¸چن¼ڑه‡؛çژ°و— ç©·ه¤§و›´و–°çڑ„é—®é¢کم€‚
و›´ه؟«çڑ„و”¶و•›ï¼ڑPath Vector çڑ„è·¯ه¾„ن؟،وپ¯و›´ه…¨é¢ï¼Œéپ؟ه…چن؛†ه†—ن½™ن¼ و’,ه‡ڈه°‘ن؛†ç½‘络çڑ„و”¶و•›و—¶é—´م€‚
ه¦‚ن½•éپ؟ه…چçژ¯è·¯ï¼ں路由ه™¨و‹’ç»ن»»ن½•هŒ…هگ«è‡ھè؛«çڑ„è·¯ه¾„م€‚
ه¦‚ن½•é€‰و‹©ه¤ڑو،è·¯ه¾„ن¸çڑ„وœ€ن¼کè·¯ه¾„ï¼ںو ¹وچ®è·¯ه¾„çڑ„ و€»وˆگوœ¬ï¼ˆCost) è؟›è،Œé€‰و‹©ï¼Œن¾‹ه¦‚è·³و•°وœ€ه°‘وˆ–ه»¶è؟ںوœ€ن½ژم€‚
网络و‹“و‰‘هڈکهŒ–و—¶و€ژن¹ˆهٹï¼ںو–°é“¾è·¯ï¼ڑه°†ه…¶هٹ ه…¥è·¯ه¾„هگ‘é‡ڈه¹¶é‡چو–°è®،ç®—م€‚ه¤±و•ˆé“¾è·¯ï¼ڑ移除邻ه±…هپœو¢ه¹؟ه‘ٹçڑ„è·¯ه¾„م€‚
Hierachical
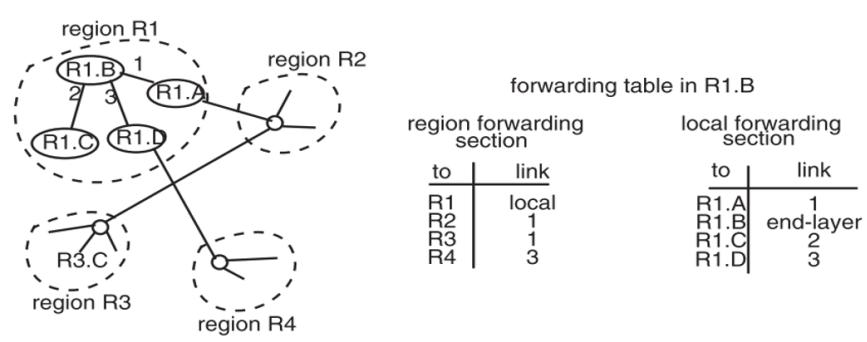
وˆ‘ن»¬çڑ„路由è،¨هڈھ需è¦پè®°ه½• 4 ن¸ھ region,و¯”ه¦‚و‰¾هˆ°R1,هœ¨ن؛¤ç»™R1çڑ„ه¤„çگ†ï¼Œو‰¾هˆ°R1.B
ç¼؛点ï¼ڑAddressه’Œlocation需è¦پ绑ه®ڑم€‚ه¦‚ن»ٹهڈ¯ن»¥é€ڑè؟‡ipوں¥هˆ°هœ°ه€ï¼Œوœ‰è؟™و–¹é¢هژںه›
è·¨è¶ٹRgion路由需è¦پBGP
Addressing
ه¦‚ن½•ç®€و´پهœ°è،¨ç¤؛è؟ç»çڑ„IPهœ°ه€ï¼ں
——CIDR Notationï¼ڑ(18.0.0.0)→(18.0.0.255)都هڈ¯ن»¥è،¨ç¤؛وˆگ(18.0.0.0)/24,/24ن»£è،¨ه‰چ24ن½چ,و³¨و„ڈوک¯ه€’ç€çœ‹
Data Plane
ن؛¤وچ¢وœ؛ه¦‚ن½•هœ¨ه‡ 百ن¸ھCycleه†…ه®Œوˆگن¸€ن¸ھو•°وچ®هŒ…çڑ„转هڈ‘ï¼ں
——ç”ڑ至ن¸چ能è®؟é—®ه†…هک
ن¸€و¬،需è¦پهپڑçڑ„ن؛‹وƒ…
- وں¥è،¨ï¼Œهœ¨è½¬هڈ‘è،¨ن¸وں¥و‰¾و•°وچ®هŒ…çڑ„ç›®çڑ„هœ°ï¼Œه…¨éƒ¨è؟›cache
- çں¥éپ“ه°±و‰¾ه‡؛هڈ£هœ¨ه“ھه°±و‰¾ï¼Œو‰¾ن¸چهˆ°ه°±و”¾ه¼ƒ
- و›´و–°TTL,ن½؟用ن¸“é—¨çڑ„ç،¬ن»¶è؟›è،Œو›´و–°ن»¥وڈگé«کé€ںه؛¦
- TTL (能被转هڈ‘ه¤ڑه°‘و¬،timeToLive)ï¼ڑوک¯و•°وچ®هŒ…ه¤´éƒ¨ن¸çڑ„ن¸€ن¸ھه—و®µï¼Œç”¨و¥éک²و¢و•°وچ®هŒ…هœ¨ç½‘络ن¸و— é™گه¾ھçژ¯م€‚و¯ڈç»ڈè؟‡ن¸€ن¸ھ路由ه™¨ï¼ŒTTL ن¼ڑه‡ڈه°‘ 1م€‚ه¦‚وœه‡ڈه°‘هˆ° 0,و•°وچ®هŒ…ه°†è¢«ن¸¢ه¼ƒم€‚
- هڈ‘é€پهˆ°ه¯¹ه؛”端هڈ£ï¼Œن¼ 输链路
ن¸چè¦پن½؟用sleep,ن¸€ç›´è½®è¯¢
NAT
NAT(network address translation)وک¯ه› ن¸؛电脑ه¤ھه¤ڑن؛†ï¼Œç½‘络ه¤ھه°‘ن؛†ï¼Œو‰€ن»¥è¦پهˆ†ن¸؛ه†…网ه’Œه¤–网م€‚ه†…网ه¼€ه¤´وک¯ 10.ه’Œ 192.م€‚ه†…网ipو— و³•è¢«ه¤–部è®؟问,ه†…网è®؟é—®ه¤–网需è¦پç»ڈè؟‡Netgate,هچ 用ن¸€ن¸ھه¯¹ه¤–端هڈ£ï¼Œه¹¶ن»¥ن¸€ن¸ھç»ںن¸€çڑ„ipه¯¹ه¤–è®؟é—®
و¯”ه¦‚è®؟é—®baidu,هپڑن؛†ن¸€ن¸ھtranslation,转وچ¢è؟‡هژ»è½¬وچ¢ه›و¥م€‚需è¦پو ¹وچ®ه®é™…çڑ„端هڈ£ه†چ转وچ¢ن¸؛ه›و¥ç»™ه†…网用م€‚
- é—®é¢ک
- NAT Port çڑ„و•°é‡ڈوک¯وœ‰é™گçڑ„م€‚
- è؟™وک¯ه…¸ه‹çڑ„ç ´هڈن؛†ه±‚ç؛§çڑ„设è®،م€‚Ip هœ°ه€ن¸چه¤ںن؛†ï¼Œوˆ‘ن»¬ç”¨هˆ°ن؛†ن¸ٹه±‚ end-to-end layer çڑ„ port çڑ„و¦‚ه؟µم€‚网络ه±‚ن؟®و”¹ن؛†ç«¯هڈ£م€‚用ن¸ٹه±‚çڑ„و¦‚ه؟µè§£ه†³ن؛†ن¸‹ه±‚çڑ„é—®é¢ک,و‰€ن»¥è؟™ه¹¶ن¸چوک¯ن¸€ن¸ھه¾ˆو¼‚ن؛®çڑ„设è®،م€‚而ن¸”ه؟…é،»è¦پو±‚ن¸ٹه±‚ه؟…é،»وک¯ port,ه¦‚وœوˆ‘ن»¬ç”¨çڑ„ن¸چوک¯ TCP/UDP çڑ„ port و¦‚ه؟µï¼Œé‚£ن¹ˆ NAT ه°±ن¸چ能用ن؛†م€‚
- ç ´هڈ端هˆ°ç«¯é€ڑن؟،,ه¢هٹ ه»¶è؟ںم€‚ن¸چ适هگˆه¤§é‡ڈه¹¶هڈ‘è؟وژ¥ï¼ˆç«¯هڈ£è€—ه°½é—®é¢ک)م€‚
- وœ¬è´¨ه°±وک¯ipه°‘ن؛†ï¼Œé‚£ن¹ˆIPV6هڈ¯ن»¥è§£ه†³ï¼Œوپ¢ه¤چ简و´پم€‚
ن»¥ه¤ھ网
ن»¥ه¤ھ网(Ethernet)وک¯ن¸€ç§چه±€هںں网(LAN)وٹ€وœ¯çڑ„ç»ں称,هں؛ن؛ژه¹؟و’çڑ„é€ڑن؟،و–¹ه¼ڈم€‚و‰€وœ‰è؟وژ¥هœ¨ه…±ن؛«çڑ„电缆وˆ–ه…‰ç؛¤é“¾è·¯ن¸ٹçڑ„设ه¤‡éƒ½هڈ¯ن»¥وژ¥و”¶هˆ°ه½¼و¤çڑ„ن¼ 输ن؟،وپ¯م€‚ن¸؛ç®،çگ†ç½‘络ن¸çڑ„é€ڑن؟،,ن»¥ه¤ھ网采用ن؛†ن¸€ç§چ“هڈ‘é€په‰چ监هگ¬â€ï¼ˆcarrier sense)çڑ„规هˆ™ï¼Œç،®ن؟هœ¨هڈ‘é€پو•°وچ®ن¹‹ه‰چ,设ه¤‡ن¼ڑو£€وں¥é“¾è·¯وک¯هگ¦ç©؛é—²م€‚ه¦‚وœن¸¤هڈ°è®¾ه¤‡هگŒو—¶ه¼€ه§‹هڈ‘é€پو•°وچ®ï¼Œه°±ن¼ڑهڈ‘ç”ںن¸€ç§چ称ن¸؛“碰و’â€çڑ„错误م€‚ن¸؛ن؛†ه‡ڈه°‘ه› 碰و’ه¯¼è‡´çڑ„ن¼ 输و—¶é—´وµھ费,ن»¥ه¤ھ网è؟که¼•ه…¥ن؛†â€œهڈ‘é€پن¸ç›‘هگ¬â€çڑ„规هˆ™ï¼Œç”¨ن»¥و£€وµ‹ç¢°و’ه¹¶هڈٹو—¶é‡‡هڈ–وژھو–½م€‚è؟™ن¸ھهچڈ议被称ن¸؛è½½و³¢ç›‘هگ¬ه¤ڑè·¯è®؟é—®هڈٹ碰و’و£€وµ‹ï¼ˆCarrier Sense Multiple Access with Collision Detection,简称 CSMA/CD)م€‚
ç±»هˆ«ï¼ڑهچٹهڈŒه·¥ï¼ˆهڈ‘و”¶هˆ†ه¼€ï¼‰ï¼Œه…¨هڈŒه·¥ï¼ˆè؟وژ¥هگژهڈˆهڈ¯ن»¥وژ¥و”¶هڈˆهڈ¯ن»¥هڈ‘),ن»¥ه¤ھ网çڑ„و•°وچ®هŒ…و ¼ه¼ڈه¦‚ن¸‹

- Hubو¨،ه¼ڈï¼ڑو‰€وœ‰è®¾ه¤‡é€ڑè؟‡é›†ç؛؟ه™¨ (Hub) è؟وژ¥ï¼Œن½؟用ه¹؟و’çڑ„و–¹ه¼ڈهڈ‘é€پو•°وچ®هŒ…,و•°وچ®ن¼ڑن¼ é€پ给网络ن¸و‰€وœ‰è®¾ه¤‡م€‚éه¸¸ن¸چه®‰ه…¨
- Switch و¨،ه¼ڈï¼ڑن؛¤وچ¢وœ؛ (Switch) و ¹وچ®MACهœ°ه€è،¨ه°†و•°وچ®هŒ…ه®ڑهگ‘هڈ‘é€پ给目و ‡è®¾ه¤‡ï¼Œه‡ڈه°‘ه¹؟و’م€‚
ن»¥ه¤ھ网çڑ„هڈ‘é€پ-وژ¥و”¶

هœ¨هڈ‘é€پ端,ETHERNET_SEND هڈھه°†è°ƒç”¨ن¼ 递هˆ°é“¾è·¯ه±‚م€‚هœ¨وژ¥و”¶ç«¯ï¼Œو£€وµ‹هŒ…çڑ„ç›®و ‡وک¯هگ¦ن¸؛è‡ھه·±ï¼Œه¦‚وœوک¯è‡ھه·±هˆ™è؟›è،Œه¤„çگ†ï¼Œهگ¦هˆ™ه؟½ç•¥
Layer Mapping
ه°†ن»¥ه¤ھ网è؟وژ¥هˆ°Network Layerçڑ„转هڈ‘网络
考虑ن¸‹é¢çڑ„ن»¥ه¤ھ网و¶و„(LMN…ن¸؛ipهœ°ه€ï¼›17/15/18ن¸؛macهœ°ه€ï¼‰

ه†…网è®؟é—®ï¼ڑL→N,Nن¼ڑ监هگ¬هˆ°و¶ˆوپ¯ï¼Œهڈ‘çژ°و•°وچ®هŒ…çڑ„macهœ°ه€وک¯è‡ھه·±ï¼Œç„¶هگژوژ¥و”¶هˆ°ن؛†و¶ˆوپ¯
ه¤–网è®؟é—®ï¼ڑL→E,由ن؛ژEن¸چهœ¨ن»¥ه¤ھ网ه†…,هŒ…ه¤´ن¸éœ€è¦پهŒ…و‹¬ipهœ°ه€â€œEâ€ه’Œè·¯ç”±ه™¨Kçڑ„macهœ°ه€â€œ19â€ï¼Œç„¶هگژ路由ه™¨ن¼ڑن»ژ4هڈ·هڈ£ه°†و¶ˆوپ¯هڈ‘é€پهˆ°ه…¶ن»–路由ه™¨ï¼Œن¸؛ن؛†éک²و¢ه¯¹é¢çڑ„路由ه™¨ن¹ںوک¯ن»¥ه¤ھ网,è؟ک需è¦پوٹٹmacهœ°ه€ن»ژ“19â€و”¹وˆگEهœ¨è‡ھè؛«ه†…网ن¸çڑ„macهœ°ه€م€‚macهڈ¯èƒ½ç›¸هگŒï¼Œن½†ه®é™…هœ¨هگŒن¸€ن»¥ه¤ھ网ن¸‹و¦‚çژ‡و¯”较ه°ڈم€‚
هœ°ه€è§£وگهچڈè®®ARP
ن¸€ن¸ھو–°هٹ ه…¥ç½‘络çڑ„Lه¦‚ن½•çں¥éپ“ه…¶ن»–ن؛؛çڑ„هœ°ه€ï¼ں
ه†…网ï¼ڑLçں¥éپ“Mçڑ„IPهœ°ه€ï¼Œه¸Œوœ›é€ڑè؟‡ن»¥ه¤ھ网è®؟问,هˆ™ن¼ڑهڈ‘é€پن¸€ن¸ھç±»ه‹ن¸؛ARPçڑ„و¶ˆوپ¯ï¼Œه¹؟و’هˆ°ن»¥ه¤ھ网ن¸ٹçڑ„设ه¤‡ن¸ٹهژ»é—®ï¼Œه¦‚وœè¯·و±‚هŒ…ن¸çڑ„ç›®و ‡ IP هœ°ه€آ ه’Œè‡ھه·±çڑ„相هگŒï¼Œه°±ن¼ڑه°†è‡ھه·±ن¸»وœ؛çڑ„ MAC هœ°ه€ه†™ه…¥ه“چه؛”هŒ…è؟”ه›ن¸»وœ؛
ه¤–网ï¼ڑLçں¥éپ“Eçڑ„IPهœ°ه€ï¼Œه¸Œوœ›é€ڑè؟‡ن»¥ه¤ھ网è®؟问,路由ه™¨ن¼ڑوژ¥و”¶هˆ°è؟™ن¸ھو¶ˆوپ¯ï¼Œه‘ٹ诉Lه°†ه‡†ه¤‡هڈ‘ç»™Eçڑ„و¶ˆوپ¯هڈ‘é€پç»™è‡ھه·±ï¼ŒهگŒو—¶هœ¨ه¤–网ن¸ٹو‰¾ه¯»Eçڑ„ن½چ置(وˆ–者هژںوœ¬ه°±çں¥éپ“Eçڑ„ن½چ置)
é—®é¢کï¼ڑه› ن¸؛é—®macهœ°ه€وک¯è°پçں¥éپ“都هڈ¯ن»¥ه›ï¼Œé‚£ن¹ˆhackerه°±هڈ¯ن»¥ه›è‡ھه·±çڑ„,ه°±هڈ¯èƒ½è¢«hackerن¸é—´هˆ©ç”¨م€‚و— و³•éک²ه¾،,و‰€ن»¥éƒ¨éکںن¸ٹarp绑ه®ڑو»ن؛†ï¼Œو‰‹هٹ¨هٹ ه…¥éک²و¢وœ‰ن؛؛ه…¥ن¾µم€‚
End to End Layer
ن¸‰ç§چهچڈè®®
- UDP(User Datagram Protocol)ï¼ڑن»…ن»…هڈھوک¯وٹٹو•°وچ®هŒ…هڈ‘ه‡؛هژ»ï¼Œو²،ن؟éڑœé€ںه؛¦ه؟«
- TCP(Transmission Control Protocol)ï¼ڑن؟وŒپé،؛ه؛ڈ,ن¸چن¼ڑن¸¢هŒ…,ن¸چن¼ڑوœ‰é‡چه¤چهŒ…ï¼›و”¯وŒپوµپه¼ڈوژ§هˆ¶ï¼ˆوژ§هˆ¶ç½‘络وµپé‡ڈ)
- RTP(Real-time Transport Protocol)ï¼ڑن¸»è¦پ用ن؛ژéں³è§†é¢‘ç‰وµپه¼ڈو•°وچ®
çگ†وƒ³çڑ„端هˆ°ç«¯ç½‘络çڑ„è¦پو±‚ï¼ڑ
- ن؟è¯پat-least-once(至ه°‘و”¶هˆ°ن¸€و¬،)
- ن؟è¯پat-most-once
- ن؟è¯پو•°وچ®و£ç،®
- ن؟è¯پو•°وچ®وµپçڑ„é،؛ه؛ڈ
- 网络و³¢هٹ¨وژ§هˆ¶(Jitter control)(ن¸چه‡؛çژ°ه¤§çڑ„و³¢هٹ¨ï¼‰
- وژˆوƒç®،çگ†هڈٹéڑگç§پو€§
- ن؟è¯پ端هˆ°ç«¯çڑ„و€§èƒ½ï¼ˆوœ€éڑ¾ï¼‰
ن»¥ن¸ٹن¸‰ç§چهچڈ议都و— و³•ه…¨éƒ¨و»،足7ن¸ھ需و±‚
At-least-once
هں؛وœ¬ç–ç•¥ï¼ڑهڈ‘é€پهŒ…ن¹‹هگژ,ه¦‚وœن¸€و®µو—¶é—´هگژه¯¹و–¹وœھهڈ‘é€پACKو¶ˆوپ¯ï¼Œه°±ه†چهڈ‘ن¸€و¬،
“ن¸€و®µو—¶é—´â€çڑ„ç،®ه®ڑ——RTT
RTT(Round Trip time)=ن¹‹ه‰چهڈ‘هŒ…çڑ„ه¹³ه‡و—¶ه»¶+ه†—ن½™é‡ڈ
ه®çژ°ï¼ڑ
- هڈ‘هŒ…و—¶هŒ…و‹¬nonce(id)
- senderن؟هکن¸€ن»½هŒ…çڑ„و•°وچ®
- ه¦‚وœè¶…و—¶هˆ™é‡چهڈ‘nonceه¯¹ه؛”çڑ„هŒ…
- ç›´هˆ°receiverè؟”ه›ن¸€ن¸ھهŒ…و‹¬nonceçڑ„ACK
- ه¦‚وœretryè؟‡ه¤ڑهˆ™و”¾ه¼ƒ
ç،®ه®ڑRTTçڑ„ن¸‰ç§چو–¹و³•ï¼ڑ
- 首ه…ˆç»ن¸چ能用ه›؛ه®ڑو—¶é—´ï¼Œè؟‡é•؟è؟‡çں都ن¸چه¥½
- ن½؟用Adaptive timerï¼ڑو¯ڈéپ‡هˆ°ن¸€و¬،超و—¶ï¼Œهˆ™ه°†RTTهڈکن¸؛1.5ه€چï¼›ه½“然è؟کوœ‰ن¸€ن؛›و”¹è؟›çڑ„و–¹و³•ï¼ˆç»ڈéھŒï¼‰
- NAK(Negative Acknowledgment)ï¼ڑreceiverهœ¨و”¶هˆ°و‰€وœ‰هŒ…ن¹‹هگژه‘ٹ诉senderè‡ھه·±ç¼؛ه¤±ن؛†ه“ھن؛›هŒ…,需è¦پreceiverç»´وٹ¤ن¸€ن¸ھTimer
At-most-once
ه‡ ç§چو–¹و³•ï¼ڑ
- وœ€هں؛وœ¬çڑ„ه®çژ°ï¼ڑreceiverè®°ن¸‹وœ€è؟‘çڑ„nonce,ه¦‚وœsenderé‡چهڈ‘,هˆ™ن¸چه†چه¤„çگ†
——ن½†وک¯و— و³•ç•Œه®ڑن»€ن¹ˆو—¶ه€™هˆ 除nonce,هڈ¯èƒ½هˆ ن؛†è؟کو”¶هˆ°ï¼Œهڈکوˆگن¸€ن¸ھه¢“碑 - 请و±‚ن؟è¯په¹‚ç‰و€§ï¼Œه®¹ه؟چé‡چو–°هڈ‘هŒ…
- nonceè‡ھه¢ï¼Œè®°ن¸‹è§پهˆ°çڑ„وœ€é«کnonce,ه؟½ç•¥nonceن½ژçڑ„请و±‚م€‚——ه¦‚وœن¹±ه؛ڈو€ژن¹ˆهٹم€‚هگŒو ·هڈ¯èƒ½ن¼ڑوˆگن¸؛ه¢“碑,ن½†ه› ن¸؛هڈھوœ‰ن¸€ن¸ھهŒ…ن¸چهچ 用هœ°و–¹
- و¯ڈن¸ھ端هڈ£هڈھوœچهٹ،ن¸€و¬،请و±‚,ه¦‚وœç«¯هڈ£10000و”¶هˆ°ن؛†ن¸€ن¸ھهŒ…,ن¸‹ن¸€و¬،ن½؟用10001,ن½†وک¯ن»€ن¹ˆو—¶ه€™èƒ½ه¤چ用端هڈ£ï¼ں端هڈ£ن¸ھو•°هڈ¯èƒ½ن¸چه¤ں
Anyway,و²،وœ‰ه®Œç¾ژçڑ„و–¹و³•
و•°وچ®و£ç،®
هں؛وœ¬وƒ³و³•ï¼ڑchecksumو ،éھŒï¼Œن½†وک¯و€»وœ‰و•°وچ®ه’Œو ،éھŒهگŒو—¶ه‡؛é”™çڑ„وƒ…ه†µ
هڈ‘é€پé،؛ه؛ڈ
senderه‘ٹ诉receiverن¸€ه…±وœ‰ه‡ ن¸ھهŒ…,ه¹¶ن¸”و¯ڈن¸ھهŒ…و¶µç›–ç´¢ه¼•
ه‡ ç§چو–¹و³•ï¼ڑ
- و”¶هˆ°3هڈ·هŒ…هگژ,هڈھو”¶4هڈ·هŒ…,وٹ›ه¼ƒو›´ه¤§çڑ„هŒ…
- ç»´وٹ¤ن¸€ن¸ھbuffer,ن½†وک¯ه¦‚وœç½‘络ه‡؛é—®é¢ک,ن¼ڑن½؟bufferهچ 用وپه¤§çڑ„ç©؛é—´
- bufferو»،ن؛†ن»¥هگژ,و¸…ç©؛buffer,ه…¨éƒ¨é‡چن¼
- receiverهڈ‘é€پNAK,ه‘ٹçں¥senderç¼؛ه°‘ه“ھن¸ھهŒ…
و³¢هٹ¨وژ§هˆ¶
解ه†³و–¹و³•ï¼ڑ视频缓ه†²هŒ؛,é€ڑè؟‡و—¶ه»¶ç،®ه®ڑ需è¦په¤ڑه¤§çڑ„缓ه†²هŒ؛
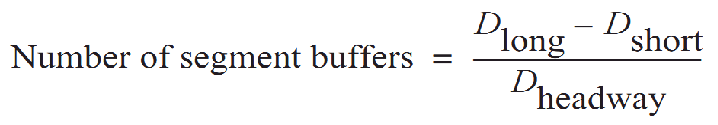
هˆ†هˆ«وک¯99é•؟و—¶ه»¶ï¼Œوœ€ن½ژو—¶ه»¶ï¼Œه¹³ه‡ه»¶è؟ں
وژˆوƒç®،çگ†هڈٹéڑگç§پو€§
解ه†³ï¼ڑه…¬é’¥هڈٹç§پ钥,ç§پé’¥ن¸چ能و³„露
端هˆ°ç«¯çڑ„و€§èƒ½
- وœ€هں؛وœ¬çڑ„ه®çژ°ï¼ڑهڈ‘هŒ…→ACK→هڈ‘هŒ…→ACK…و”¶هˆ°هگژو‰چè؟”ه›
- è؟™و ·ن¸€ه®ڑé،؛ه؛ڈ,و£ç،®و€§ن¹ںوœ€ه¥½
- é—®é¢کوک¯و—¶ه»¶ï¼Œé€ڑ讯و•ˆçژ‡ه¾ˆن½ژ
- و”¹è؟›ï¼ڑsenderن¸€ç›´هڈ‘هŒ…,receiverو”¶هˆ°هگژهڈ‘ACKه›و¥
- هڈ¯èƒ½هڈ‘ه¤ھه؟«ن؛†ï¼Œن¸¢هŒ…
- é—®é¢کï¼ڑsenderن¸€ç›´هڈ‘هŒ…ن¼ڑهچ 用ه¤§é‡ڈçڑ„ه¸¦ه®½ï¼Œو‰€ن»¥هڈ¯ن»¥هڈ‘nن¸ھ,هپœن¸€ن¼ڑ,ه†چهڈ‘nن¸ھ
ه¦‚ن½•ç،®ه®ڑn——需è¦پ考虑ه¸¦ه®½ه’Œreceiverçڑ„ه¤„çگ†èƒ½هٹ›
ه¦‚وœه¸¦ه®½ه……足,那ن¹ˆوˆ‘ن»¬هڈھ需è¦پç‰receiverه¤„çگ†ه®Œnن¸ھ,è؟”ه›ن¸€ç»„ACK,ه†چ继ç»هڈ‘هŒ… م€‚(ه›؛ه®ڑçھ—هڈ£ï¼‰

ن½†وک¯ç‰ه¾…ACKçڑ„و—¶é—´ن»چ然وک¯è¢«وµھè´¹وژ‰çڑ„,需è¦پTCPن¸çڑ„“و»‘هٹ¨çھ—هڈ£â€و¥è§£ه†³م€‚و”¶هˆ°1هڈ‘3,و”¶2هڈ‘4ن»¥و¤ç±»وژ¨

ه¼‚ه¸¸ه¤„çگ†

ن¸؛ن؛†èژ·ه¾—وœ€ه¥½çڑ„è،¨çژ°ï¼ڑwindow sizeçڑ„设置ï¼ڑwindow size ≥ round-trip time(ه¾€è؟”و—¶é—´ï¼‰أ— bottleneck(瓶颈) data rate
ه¦‚ï¼ڑsenderé€ںçژ‡1MBps,receiveré€ںçژ‡500kBps,RTT=70ms,هچ•ن¸ھهŒ…ه¤§ه°ڈ5kB
هˆ™Sliding window size=500kB*70ms=35kB(ن¸€ن¸ھçھ—هڈ£هڈ‘7ن¸ھهŒ…)
é—®é¢کوک¯ç½‘络çٹ¶ه†µن¼ڑو”¹هڈک,ه¦‚ن½•è§£ه†³ï¼ں
TCPه µه،وژ§هˆ¶
è°پو¥è´ںè´£ه†²çھپوژ§هˆ¶
network layerï¼ڑهڈ¯ن»¥ç›´وژ¥و„ںçں¥هˆ°ه µه،ï¼›وœ€ç»ˆه†³ه®ڑه¦‚ن½•ه¤„çگ†è¶…é¢و•°وچ®هŒ…
end to end layerï¼ڑهڈ¯ن»¥é€ڑè؟‡و”¶هˆ°ACKهˆ¤و–,ن½†وک¯ه¹¶ن¸چé«کو•ˆ
ن¸؛ن؛†éک²و¢و‹¥ه µï¼Œوˆ‘ن»¬ن¸چ能و— é™گهœ°هڈ‘هŒ…,è؟ک需è¦پç»™Sliding window size设ه®ڑن¸€ن¸ھن¸ٹç•Œ
ن¸؛ن؛†éک²و¢و‹¥ه µï¼ڑwindow sizeçڑ„设置ï¼ڑwindow size ≤ min(RTT أ— bottleneck data rate, Receiver buffer),وک¾ç„¶و€§èƒ½ه’Œéک²و¢و‹¥ه µوک¯çں›ç›¾çڑ„م€‚
ه µه،وژ§هˆ¶
- 缓و…¢ه¢هٹ هŒ…çڑ„و•°é‡ڈ
- ه¦‚وœو²،وœ‰هڈ‘çژ°ن¸¢هŒ…,هˆ™ç»§ç»ه¢هٹ
- ه¦‚وœهڈ‘çژ°ن¸¢هŒ…,هˆ™ه؟«é€ںé™چن½ژهŒ…çڑ„و•°é‡ڈ(ن؟ه®ˆçڑ„و–¹ه¼ڈ)
需è¦پ考虑çڑ„é—®é¢کï¼ڑ
و€§èƒ½ï¼ڑهچ³ن¾؟é™چن½ژهŒ…çڑ„و•°é‡ڈ,ن¹ںن¸چ能è؟‡ن؛ژن½ژ,需è¦په°½هڈ¯èƒ½هچ و»،瓶颈وµپé‡ڈ
ه…¬ه¹³و€§ï¼ڑه…±ن؛«ç“¶é¢ˆçڑ„هڈ‘ن»¶ن؛؛需è¦پèژ·ه¾—相ç‰çڑ„هگهگگé‡ڈ
AIMD(Additive Increase, Multiplicative Decrease)
و¯ڈن¸ھRTTن¸:
- 网络çٹ¶ه†µه¥½: cwnd = cwnd + 1
- 部هˆ†ن¸¢هŒ…ï¼ڑ cwnd = cwnd / 2
- ه…¨éƒ¨ن¸¢هŒ…ï¼ڑن»ژه¤´ه¼€ه§‹
é—®é¢کï¼ڑهˆه§‹ه€¼وک¯1,هˆه§‹ه¢é•؟è؟‡و…¢ï¼Œè§£ه†³و–¹و،ˆوک¯ç¬¬ن¸€و¬،ه¢é•؟وŒ‰وŒ‡و•°ç؛§ï¼Œcwnd=2*cwnd,ن¹‹هگژ都وک¯هٹ و³•

è؟™é‡Œوک¯ن¸€ن¸ھو¯”较ن؟ه®ˆçڑ„هپڑو³•ï¼Œه°½هڈ¯èƒ½هœ°ن¸چه¯¹ç½‘络ن؛§ç”ںهژ‹هٹ›ï¼›ه¦‚وœوک¯و•°وچ®ن¸ه؟ƒç‰ç½‘络çٹ¶ه†µè‰¯ه¥½çڑ„و–¹و³•ï¼Œé™چن½ژçڑ„ه¹…ه؛¦هڈ¯ن»¥هڈکه°ڈم€‚
AIMDهڈ¯ن»¥ن؟è¯په¸¦ه®½هˆ†é…چه…¬ه¹³و€§ï¼Œهژںçگ†ه¦‚ن¸‹ه›¾ï¼Œé€ڑè؟‡ن¸چو–ن؟®و£ï¼Œهژںçگ†وک¯و–œçژ‡ن¸چهگŒ

TCPçڑ„ç¼؛点
- 路由ه™¨éœ€è¦پbuffer,è؟‡ه¤§ه°±ن¼ڑه½±ه“چو€§èƒ½م€‚وژ’éکںو—¶é—´ن¼ڑه¾ˆé•؟
- هœ¨و— ç؛؟网ن¸ï¼Œéپ‡هˆ°ç½‘络ن؟،هڈ·é—®é¢کن¸چه؛”该ه‡ڈه°‘هڈ‘هŒ…و•°é‡ڈ,而ه؛”该ه¢ه¤§ï¼ˆه› ن¸؛ن¸چوک¯ç½‘络وµپé‡ڈ瓶颈)
- هœ¨و•°وچ®ن¸ه؟ƒن¸è،¨çژ°ن¸چه¥½ï¼Œه‰چé¢وڈگè؟‡ï¼Œن¸چè¦پو¯ڈو¬،وٹکهچٹ
- ه¯¹ن؛ژRTT较ه¤§çڑ„وƒ…ه†µوœ‰â€œهپڈè§پâ€
DNSهںںهگچç³»ç»ں
ه¦‚وœو²،وœ‰هںںهگچ,ه¯¹ن؛ژ程ه؛ڈن¸چن¼ڑوœ‰ن»»ن½•ه½±ه“چ,ن½†وک¯ه¯¹ن؛ژ用وˆ·ن¸چهڈ‹ه¥½م€‚
ن¸€ن¸ھهںںهگچهڈ¯ن»¥ه…·وœ‰ه¤ڑن¸ھIPهœ°ه€ï¼Œو–¹ن¾؟è´ںè½½ه‡è،،م€پوڈگé«ک用وˆ·و‰؟è½½
ن¸€ن¸ھIPهœ°ه€هڈ¯ن»¥وœ‰ه¤ڑن¸ھهںںهگچ,هڈھ需è¦په¤ڑن¸ھ端هڈ£
هںںهگچن¸ژIPهœ°ه€çڑ„绑ه®ڑهڈ¯ن»¥و”¹هڈک
é€ڑè؟‡هںںهگچو‰¾هˆ°IP
èµ·هˆوک¯و”¾هœ¨ن¸€ن¸ھtxtو–‡ن»¶ن¸ï¼Œن½†وک¯ه¾ˆن¸چو–¹ن¾؟
BINDç³»ç»ں
ه°†هںںهگچهˆ†ه±‚م€‚.com;.cnç‰و ¹هںںهگچهˆ†هˆ«ç”±ن¸چهگŒçڑ„DNSوœچهٹ،ه™¨ç®،辖,ه¦‚se.sjtu.edu.cn,و¯ڈن¸ھهگژç¼€ه±‚ه±‚ن¸‹و”¾ï¼Œو¯ڈن؛؛هڈھç®،çگ†è‡ھه·±ه’Œن¸‹ن¸€ه±‚(类ن¼¼و–‡ن»¶ç³»ç»ں)
ن؛ژوک¯وˆ‘ن»¬هڈ¯ن»¥وŒ‰ن¸‹é¢çڑ„è؟‡ç¨‹èژ·ه¾—ن¸€ن¸ھهںںهگچçڑ„ipهœ°ه€

ن½†وک¯وˆ‘ن»¬è®¤ن¸؛è؟™و ·é€ وˆگçڑ„网络请و±‚è؟‡ه¤ڑ,وœ‰ن¸¤ç§چو”¹è‰¯و–¹ه¼ڈ
- ن½؟用è‡ھه·±çڑ„DNSوœچهٹ،ه™¨/هœ¨وœ¬هœ°هکه‚¨ç»“وœï¼Œن¼که…ˆن»ژوŒ‡ه®ڑçڑ„وœچهٹ،ه™¨/وœ¬هœ°èژ·هڈ–هںںهگچهˆ°IPçڑ„وک ه°„
- Recursionï¼ڑç”±و ¹èٹ‚点èژ·هڈ–ه…¨éƒ¨هںںهگچ,ه†چè؟”ه›ç»™ç”¨وˆ·م€‚وœچهٹ،ه™¨é—´ç½‘络ه¸¦ه®½و™®éپچé«ک,能èژ·ه¾—و›´ه¥½çڑ„و€§èƒ½
- Cacheï¼ڑRecursionه¯¹rootçڑ„è¦پو±‚وپé«کم€‚و‰€ن»¥ه®é™…ن¸ٹه¹¶ن¸چوک¯éه¸¸çڑ„“ç‰ç؛§هˆ†وکژâ€ï¼Œن¸‹ه±‚DNSوœچهٹ،ه™¨ن¼ڑن½؟用cache,هکه‚¨ن¸€ه®ڑé‡ڈçڑ„ه…¶ن»–“هںںهگچ-ipâ€وک ه°„,وœ‰ç½‘络请و±‚و—¶ن¼ڑه…ˆè®؟é—®ن¸‹ه±‚DNSوœچهٹ،ه™¨ï¼Œه¦‚وœو‰¾ن¸چهˆ°ه†چهژ»root询问,需è¦پ设置ن¸€ن¸ھهگˆçگ†çڑ„è؟‡وœںو—¶é—´م€‚(é•؟ه‡ڈه°ڈè´ںو‹…,ن½†ه¯¼è‡´و›´و–°ن¸چهڈٹو—¶ï¼Œçںهڈچن¹‹ï¼‰

DNSçڑ„ن¼کç¼؛点
ن¼ک点ï¼ڑه±‚ç؛§و¶و„هژ»ن¸ه؟ƒهŒ–ï¼›هںںهگچه…¨çگƒهڈ¯ç”¨ï¼›و€§èƒ½هڈ¯و‰©ه±•ï¼›ç®،çگ†هڈ¯و‰©ه±•ï¼›ه®¹é”™ï¼›é€ںه؛¦ه؟«
ç¼؛点ï¼ڑهڈ—هˆ°ه½“هœ°و”؟ç–ه½±ه“چwww.baidu.comï¼›و ¹وœچهٹ،ه™¨è´ںè½½è؟‡é‡چï¼›ه®‰ه…¨و€§ (وپ¶و„ڈçڑ„DNSوœچهٹ،ه™¨)آ
ه’Œو–‡ن»¶ç³»ç»ںه¯¹و¯”
| و¯”较é،¹ | و–‡ن»¶هگچ (File-name) | ن¸»وœ؛هگچ (Host-name) |
|---|---|---|
| ن½œç”¨ | و›´هٹ 用وˆ·هڈ‹ه¥½ | و›´هٹ 用وˆ·هڈ‹ه¥½ |
| 绑ه®ڑç›®و ‡ | و–‡ن»¶هگچ -> inodeç¼–هڈ· | ن¸»وœ؛هگچ -> IPهœ°ه€ |
| 结و„ | و–‡ن»¶هگچوک¯هˆ†ه±‚结و„ | ن¸»وœ؛هگچوک¯هˆ†ه±‚结و„ |
| 绑ه®ڑç›®و ‡çڑ„结و„ | inodeç¼–هڈ·وک¯ه¹³é¢ç»“و„ | IPهœ°ه€وک¯ه¹³é¢ç»“و„ |
| وک¯هگ¦وک¯ه¯¹è±،çڑ„ن¸€éƒ¨هˆ† | و–‡ن»¶هگچن¸چوک¯و–‡ن»¶çڑ„ن¸€éƒ¨هˆ†ï¼ˆهکه‚¨هœ¨ç›®ه½•ن¸ï¼‰ | ن¸»وœ؛هگچن¸چوک¯ç½‘ç«™çڑ„ن¸€éƒ¨هˆ†ï¼ˆهکه‚¨هœ¨هگچ称وœچهٹ،ه™¨ن¸ï¼‰ |
| هگچ称ن¸ژه€¼çڑ„绑ه®ڑه…³ç³» | 1-هگچ称 -> ه¤ڑه€¼ (هگ¦)ï¼›ه¤ڑهگچ称 -> 1-ه€¼ (وک¯) | 1-هگچ称 -> ه¤ڑه€¼ (وک¯)ï¼›ه¤ڑهگچ称 -> 1-ه€¼ (وک¯) |
Naming
ن½œç”¨ï¼ڑو£€ç´¢ï¼ˆURL),ه…±ن؛«ï¼ˆه¼•ç”¨ï¼‰ï¼Œèٹ‚çœپç©؛间(هگچ称وŒ‡ن»£ه¯¹è±،),éڑگè—ڈ(و“چن½œه¯¹è±،ن¸چ用çں¥éپ“ه؛•ه±‚),و”¯وŒپè®؟é—®وژ§هˆ¶ï¼ˆçں¥éپ“هگچ称و‰چهڈ¯ن»¥ï¼‰ï¼Œهڈ‹ه¥½è®؟问(هںںهگچو¯”ipه¥½è®؟问),间وژ¥è®؟é—®
ه‘½هگچو–¹و،ˆï¼ڑهگچ称集هگˆï¼ˆو‰€وœ‰هگˆو³•çڑ„هگچ称),ه€¼é›†هگˆï¼ˆهگچ称ه¯¹ه؛”çڑ„و‰€وœ‰هڈ¯èƒ½ه€¼ï¼‰ï¼Œوں¥و‰¾ç®—و³•ï¼ˆç”¨ن؛ژه°†هگچ称解وگن¸؛ه€¼ï¼‰
وں¥و‰¾و–¹ه¼ڈï¼ڑè،¨وں¥و‰¾ï¼ˆç”µè¯ç°؟),递ه½’(Recursiveآ )وں¥و‰¾ï¼ˆ/usr/bin/rm),ه¤ڑé‡چوں¥و‰¾ï¼ˆو²،وœ‰ç»ه¯¹è·¯ه¾„و—¶ï¼ŒوŒ‰é¢„ه®ڑن¹‰هˆ—è،¨وں¥و‰¾ e.g. $PATH)
è¦پ点ï¼ڑه‘½هگچè¯و³•ï¼ˆو¯”ه¦‚c++ن¸چ能用forه‘½هگچ),هڈ¯ه¯¹ه؛”çڑ„ه€¼ï¼Œه¦‚ن½•è§£وگ,وک¯هگ¦وک¯ه…¨ه±€
ن¸€ن؛›FAQ:
- و¯ڈن¸ھهگچ称وک¯هگ¦éƒ½وœ‰ه€¼ï¼ں(و‚¬ç©؛هگچ称,و— 绑ه®ڑه€¼ï¼‰
- هگچ称وک¯هگ¦هڈ¯ن»¥وœ‰ه¤ڑن¸ھه€¼ï¼ں(ه¤ڑو’هœ°ه€وœ‰ه¤ڑن¸ھوژ¥و”¶è€…)
- و¯ڈن¸ھه€¼وک¯هگ¦éƒ½وœ‰هگچ称ï¼ں(هŒ؟هگچه€¼ه¦‚ن¸´و—¶و–‡ن»¶ï¼‰
- ه€¼وک¯هگ¦هڈ¯ن»¥وœ‰ه¤ڑن¸ھهگچ称ï¼ں(هگŒن¹‰è¯چه¦‚软链وژ¥ï¼‰
- هگچ称ه¯¹ه؛”çڑ„ه€¼وک¯هگ¦ن¼ڑéڑڈو—¶é—´هڈکهŒ–ï¼ں(DNSè®°ه½•ipن¼ڑ)
ه†…ه®¹هˆ†هڈ‘网络CDN
dockeré•œهƒڈم€پb站视频ç‰ه†…ه®¹ï¼Œهœ¨هˆ†هڈ‘و—¶هڈ¯èƒ½ن¼ڑé€ وˆگه¾ˆه¤§çڑ„网络هژ‹هٹ›ï¼Œé‚£ن¹ˆوˆ‘ن»¬èƒ½هپڑن؛›ن»€ن¹ˆ
——ه†…ه®¹هˆ†هڈ‘,ه°†هگŒو ·çڑ„ه†…ه®¹هœ¨ه…¨çگƒهگ„هœ°çڑ„وœچهٹ،ه™¨ن¸ٹه»؛ç«‹ه¤ڑن¸ھه‰¯وœ¬ï¼Œن»¥è¾¾هˆ°وœ€ن½³çڑ„è®؟é—®و€§èƒ½م€‚
用وˆ·é€ڑè؟‡ه¤ڑو¬،DNSوگœç´¢ï¼Œه¾—هˆ°وœ€è؟‘çڑ„وœچهٹ،ه™¨ï¼Œه¦‚وœوœچهٹ،ه™¨ه†…و²،وœ‰è¯¥ه†…ه®¹ï¼Œوœچهٹ،ه™¨ن¼ڑن»ژن¸ه؟ƒوœچهٹ،ه™¨èژ·هڈ–,هڈ‘给用وˆ·çڑ„هگŒو—¶ï¼Œهکه‚¨هˆ°è‡ھه·±çڑ„cacheه†….
ه¼€ه§‹هڈ¯èƒ½é—®ï¼ڑوœ€è؟‘çڑ„و·که®ه›¾ç‰‡ه“ھ里و¥çڑ„م€‚é‚£ن¸€ه®ڑن¸چوک¯ن¸ه؟ƒوœچهٹ،ه™¨ï¼Œè€Œوک¯وœ€و–°çڑ„CDNوœچهٹ،ه™¨ن؟هک
P2P(Peer to Peer) Network
——No Central Server
BitTorrentو¯”特و´ھوµپ
特点ï¼ڑ
- هˆ†ه¸ƒه¼ڈ资و؛گه…±ن؛«ï¼ڑ用وˆ·ن»ژه…¶ن»–ن؛؛那里ن¸‹è½½و–‡ن»¶çڑ„片و®µï¼Œè€Œن¸چوک¯ن»ژهچ•ن¸€çڑ„و¥و؛گم€‚
- è¾¹ن¸‹è½½è¾¹ن¸ٹن¼ ï¼ڑ用وˆ·هœ¨ن¸‹è½½و–‡ن»¶çڑ„هگŒو—¶ï¼ŒBitTorrent ن¼ڑه°†ه·²ç»ڈن¸‹è½½çڑ„部هˆ†هˆ†ن؛«ç»™ه…¶ن»–用وˆ·م€‚
- وŒپç»هˆ†ن؛«ï¼ˆç§چهگن؟وŒپو´»è·ƒï¼‰ï¼ڑو–‡ن»¶ن¸‹è½½ه®Œوˆگهگژ,BitTorrent ه®¢وˆ·ç«¯ن¼ڑ继ç»è؟گè،Œن¸€و®µو—¶é—´ï¼ˆوˆگن¸؛“ç§چهگâ€ï¼‰ï¼Œه°†و–‡ن»¶هˆ†ن؛«ç»™ه…¶ن»–用وˆ·م€‚
ن¸‰ن¸ھ角色ï¼ڑ
- trackerï¼ڑè®°ه½•و¯ڈن¸ھو–‡ن»¶çڑ„و¯ڈ部هˆ†هœ¨ه“ھ里
- seederï¼ڑوœ‰و•´ن¸ھو–‡ن»¶
- peerï¼ڑوœ‰ن¸€éƒ¨هˆ†و–‡ن»¶
و‰§è،Œè؟‡ç¨‹
- و–‡ن»¶هڈ‘ه¸ƒè€…ه°†و–‡ن»¶çڑ„هں؛ç،€ن؟،وپ¯(.torrentو–‡ن»¶)هڈ‘ه¸ƒهˆ°ن¸€ن¸ھ网站ن¸ٹ(trackerçڑ„url,و–‡ن»¶هگچهڈٹه¤§ه°ڈ,hashو ،éھŒç پ)
- è؟™ن¸€و¥وک¯ن¸ه؟ƒهŒ–çڑ„
- tracker组织ن¸€ن¸ھpeerçڑ„群,هˆ†هˆ«و‹¥وœ‰و–‡ن»¶çڑ„ن¸چهگŒéƒ¨هˆ†ï¼ˆوœ‰é‡چه¤چ)
- Seederه°†و–‡ن»¶çڑ„ç§چهگهڈ‘ه¸ƒه‡؛هژ»ï¼ˆوŒ‡هگ‘网站ن¸ٹçڑ„.torrentو–‡ن»¶ï¼‰
- ن¸‹è½½è€…ه…ˆé€ڑè؟‡ç§چهگèژ·هڈ–.torrentو–‡ن»¶ï¼Œه†چèژ·هڈ–هˆ°trackerçڑ„url
- trackerè؟”ه›ن¸€ن¸ھpeerçڑ„هˆ—è،¨
- ن¸‹è½½è€…ن»ژpeerه¤„è؟›è،Œن¸‹è½½
BitTorrentçڑ„ç¼؛点ï¼ڑن¾èµ–tracker;规و¨،ه¾ˆéڑ¾و‰©ه¤§(tracker需è¦پè·ںè¸ھو¯ڈن¸ھ用وˆ·çڑ„هٹ ه…¥م€پ离ه¼€ï¼Œو¥ن؟è¯پو•°وچ®ه®Œو•´و€§)
ن¸؛ن؛†è§£ه†³é—®é¢ک,وˆ‘ن»¬ه°†trackerçڑ„و•°وچ®هکه‚¨هœ¨ن¸€ن¸ھهˆ†ه¸ƒه¼ڈه“ˆه¸Œè،¨ن¸ٹ
DHTهˆ†ه¸ƒه¼ڈه“ˆه¸Œè،¨
- 用ن؛ژه؟«é€ںوں¥و‰¾è´ںè´£çڑ„peer
- و¯ڈن¸ھèٹ‚点هکه‚¨ن¸€éƒ¨هˆ†ه“ˆه¸Œè،¨
- ن¸چن¸¥و ¼ن؟è¯پو•°وچ®çڑ„و—¶و•ˆو€§
ه¦‚ن½•ç،®ه®ڑ需è¦پçڑ„keyهœ¨ه“ھن¸ھوœچهٹ،ه™¨ن¸ٹï¼ڑ
وˆ‘ن»¬ه¯¹keyهپڑن¸€و¬،ه“ˆه¸Œï¼Œه†چه¯¹وœچهٹ،ه™¨çڑ„ipهœ°ه€هپڑن¸€و¬،ه“ˆه¸Œï¼Œه¾—هˆ°ن¸‹è،¨

ه°†ه“ˆه¸Œه€¼و„ه»؛وˆگن¸€ن¸ھçژ¯ï¼Œو¯ڈن¸ھوœچهٹ،ه™¨è´ں责那ن؛›ه“ˆه¸Œه€¼èگ½هœ¨è‡ھه·±é€†و—¶é’ˆو–¹هگ‘çڑ„keyم€‚ه½“وˆ‘ن»¬è®؟é—®keyçڑ„ه€¼ï¼Œهڈھ需è¦پè®،ç®—ن¸€و¬،ه“ˆه¸Œه€¼ï¼Œç„¶هگژن¸چو–é،؛و—¶é’ˆو—‹è½¬ï¼Œه°±èƒ½و‰¾هˆ°وœ€ç»ˆçڑ„وœچهٹ،ه™¨م€‚
çژ°هœ¨وˆ‘ن»¬ه°†O(n)çڑ„ç®—و³•وڈگهچ‡هˆ°O(log n)ï¼ڑو¯ڈن¸ھوœچهٹ،ه™¨ن؟هکه…¶é،؛و—¶é’ˆو–¹هگ‘çڑ„ه¤ڑن¸ھوœچهٹ،ه™¨هœ°ه€ï¼Œوˆ‘ن»¬ن¸چ需è¦پن¸€ن¸ھن¸€ن¸ھو‰¾ه¯»وœچهٹ،ه™¨ï¼Œهڈ¯ن»¥ç›´وژ¥é€ڑè؟‡ه½“ه‰چوœچهٹ،ه™¨ن؟هکçڑ„èٹ‚点,跳è؟‡ن¸چه±ن؛ژه“ˆه¸ŒèŒƒه›´çڑ„وœچهٹ،ه™¨

Finger i points to successor of n+2i,è؟™و ·و¯ڈن¸ھهکçڑ„èٹ‚点ن¹ںه°‘,وڈگé«کن؛†و•ˆçژ‡
joinç±»ن¼¼ن؛ژ链è،¨و·»هٹ ,询问هگژé¢è‡ھه·±è¦په¤چو‚çڑ„ه€¼م€‚
ه¦‚وœوœچهٹ،ه™¨وŒ‚ن؛†و€ژن¹ˆهٹï¼ڑ
- ن¸€ن¸ھkeyن؟هکهœ¨ه…¶é،؛و—¶é’ˆو–¹هگ‘ن¸ٹçڑ„ه¤ڑن¸ھوœچهٹ،ه™¨ï¼Œè؟™و ·هڈ¯ن»¥ن؟è¯پو•°وچ®ن¸چن¼ڑن¸¢ه¤±
- هگŒو—¶ï¼Œو¯ڈن¸ھèٹ‚点هگŒو—¶ن¹ںن؟هکه…¶هگژو–¹ه‡ ن¸ھèٹ‚点(successor list),هڈ¯ن»¥و–¹ن¾؟è·³è؟‡وچںهڈèٹ‚点
ه¦‚وœه“ˆه¸Œه€¼هˆ†ه¸ƒن¸چه‡هŒ€ï¼ڑو„ه»؛ه‡؛hashه€¼ن¸چهگŒçڑ„è™ڑو‹ںèٹ‚点,هˆ†é…چهˆ°ن¸چهگŒوœچهٹ،ه™¨ن¸ٹ,ه°±ه‡è،،ن؛†م€‚
و€»ç»“
Distributed Computing
çں©éکµن¹کو³•ï¼ڑ
è®،ç®—ه…¬ه¼ڈï¼ڑY = Wآ°X (آ° è،¨ç¤؛çں©éکµن¹کو³•ï¼‰
- W: ( m أ— k ) (وƒé‡چçں©éکµï¼‰
- X: ( k أ—B ) (输ه…¥çں©éکµï¼‰
- k: 特ه¾پç»´ه؛¦ï¼Œm: و؟€و´»و•°é‡ڈ,B: و‰¹و¬،ه¤§ه°ڈ
و¯ڈن¸€ه±‚ï¼ڑè®،ç®—é‡ڈ ≈ ( 2k – 1) أ— m أ— B ≈ 2 أ— Size(W) أ—B
ه¯¹ن؛ژو‰€وœ‰ه±‚ï¼ڑو€»è®،ç®—é‡ڈ ≈ 2 أ— B أ— #parameters
هڈچهگ‘ن¼ و’
و¢¯ه؛¦è®،ç®—ه…¬ه¼ڈ
- dX = W آ° dY ((k أ—m ) آ° ( m أ—B ))
- dW = dY آ° Xلµ€ (( m أ—B ) آ° ( B أ— k ))
è؟‘ن¼¼è®،ç®—é‡ڈï¼ڑ
- dXï¼ڑ ( (2m – 1) أ—k أ— B ≈ 2 أ—{Size(W)} أ—B )
- dWï¼ڑ ( (2B – 1) أ—m أ—k ≈ 2 أ—{Size(W)} أ—B )
و€»è®،ç®—é‡ڈ(考虑و‰€وœ‰ه±‚)ï¼ڑ
- و€»é‡ڈ ≈ ( 2 أ— 2 أ— {Size(W0)} أ— B + 2 أ—2 أ— {Size(W1)} أ— B + ……= 4 أ—B أ— {#parameters} )
و€»è®،ï¼ڑè®ç»ƒن¸€ن¸ھه¤§و¨،ه‹و‰€éœ€è¦پçڑ„و€»ç®—هٹ›ه¤§è‡´وک¯6 * #parameters * Batch size
ه¦‚ن½•وڈگهچ‡ç®—هٹ›ï¼ڑ
- هچ•و ¸è®¾ه¤‡ç®—هٹ›وڈگهچ‡ï¼ڑوµپو°´ç؛؟م€پ超و ‡é‡ڈ(و¯ڈن¸ھcycleه¤ڑو،,هژںçگ†é¢„وµ‹وŒ‡ن»¤ ن¸€èˆ¬4-8وœ€ه¤ڑ)م€پ 超频
- هچ•و ¸è®¾ه¤‡ç®—هٹ›ه†چوڈگهچ‡ï¼ڑSIMDï¼ڑن¸€ن¸ھوŒ‡ن»¤و‰§è،Œه¤ڑن¸ھوµ®ç‚¹و“چن½œï¼ˆوœ‰ç‰©çگ†ن¸ٹ界)
- و–°وŒ‡ن»¤é›†و¶و„(ISA)ï¼ڑSIMDه¤„çگ†ï¼ڑ
- هچ•وŒ‡ن»¤م€په¤ڑو•°وچ®ï¼ˆSIMD)ن¸€و،وŒ‡ن»¤ï¼ˆن¾‹ه¦‚读هڈ–وˆ–هٹ و³•ï¼‰هڈ¯ن»¥هگŒو—¶ن½œç”¨ن؛ژه¤ڑن¸ھو•°وچ®م€‚
- هگŒن¸€وŒ‡ن»¤ن¼ڑ被ه¹؟و’هˆ°ه¤ڑن¸ھç®—وœ¯é€»è¾‘هچ•ه…ƒï¼ˆALUs),ه¹¶è،Œو‰§è،Œم€‚
- ن¸؛ن»€ن¹ˆن¸چن½؟用ن¸چهگŒçڑ„وŒ‡ن»¤ï¼ںç®،çگ†و¯ڈن¸ھALU独立çڑ„وŒ‡ن»¤وµپçڑ„وˆگوœ¬ه¤ھé«ک,ن¼ڑه¢هٹ ه¤چو‚و€§ه¹¶é™چن½ژو•ˆçژ‡م€‚
- هگŒو—¶ن¼ڑهچ 用ه¾ˆه¤§ç¼“هکن»¥هڈٹè®؟هکه¯¼è‡´ه®é™…وڈگهچ‡ه¹¶و²،وœ‰é¢„وœںه؟«م€‚
- ن¸؛ن»€ن¹ˆن¸چه،ه‡ هچƒن¸ھALU(ï¼ں)物çگ†ن؟،هڈ·ن¼ 递é™گهˆ¶/ه·¥è‰؛é™گهˆ¶ï¼ŒهگŒو¥ن¹ںèٹ±ه¾ˆه¤ڑو—¶é—´م€‚
- SIMTï¼ڑهچ•وŒ‡ن»¤ه¤ڑç؛؟程,وک¯ن¸€ç§چه¹¶è،Œç¼–程çڑ„وٹ½è±،و¨،ه‹ï¼Œن¸چوک¯ه…·ن½“çڑ„ç،¬ن»¶ه®çژ°ï¼ŒSIMDو€وƒ³و‰©ه±•م€‚
- 编译ه™¨ن¼ڑه°†è؟™ن؛›ن»£ç پ转هŒ–ن¸؛ه؛•ه±‚(و،ن»¶ï¼‰SIMD و“چن½œ
- ه¼€هڈ‘者需è¦پ考虑ç،¬ن»¶ç»†èٹ‚,و‰چ能ه……هˆ†هˆ©ç”¨ç،¬ن»¶و€§èƒ½م€‚
- ه¤ڑو ¸
- 缓هکن¸€è‡´و€§هچڈè®®ï¼ڑ
- ç›®çڑ„ï¼ڑç،®ن؟ن¸چهگŒو ¸ه؟ƒه¯¹ç¼“هکو•°وچ®وœ‰ن¸€è‡´çڑ„视ه›¾م€‚ه¦‚وœو ¸ه؟ƒ1و›´و–°ن؛†ç¼“هکè،ŒL1,那ن¹ˆL1çڑ„ه€¼ن¼ڑهڈٹو—¶ه¯¹و ¸ه؟ƒ2هڈ¯è§پم€‚
- 监هگ¬هچڈè®®ï¼ڑو¯ڈن¸ھ缓هکوژ§هˆ¶ه™¨ن¼ڑ监هگ¬ه…¶ن»–و ¸ه؟ƒçڑ„و‰€وœ‰ه†…هک读/ه†™و“چن½œم€‚
- ç›®ه½•هچڈè®®ï¼ڑهڈ¯èƒ½é€ڑè؟‡ن¸€ن¸ھه…¨ه±€ç›®ه½•و¥ه®çژ°ï¼ˆç”¨ن؛ژè®°ه½•ç¼“هکçڑ„çٹ¶و€پ)م€‚
- 监هگ¬هچڈ议(Snoop-based protocols)监هگ¬ه¼€é”€ï¼Œç›®ه½•هچڈ议(Directory-based protocols)ن¸€è‡´و€§ه¼€é”€ï¼Œو‰©ه±•ه¼€é”€م€‚
- çژ°ن»£CPUï¼ڑهچ•ن¸ھèٹ¯ç‰‡ن¸ٹçڑ„و ¸ه؟ƒو•°é‡ڈوœ‰é™گ(20-100ن¸ھ)م€‚
- çژ°ن»£GPUï¼ڑو ¸ه؟ƒو•°é‡ڈه¾ˆه¤ڑ,ن½†ه®Œه…¨و²،وœ‰ç¼“هکن¸€è‡´و€§وœ؛هˆ¶م€‚
- 缓هکن¸€è‡´و€§هچڈè®®ï¼ڑ
- ه¯¹ن؛ژوںگن؛›è®،ç®—هپڑن¸“é—¨çڑ„ç،¬ن»¶
roofline modelï¼ڑ用ن؛ژç،®ه®ڑو€§èƒ½ç“¶é¢ˆهœ¨è®،ç®—/è®؟هک
- yè½´ï¼ڑè،¨ç¤؛وµ®ç‚¹ç®—هٹ›ï¼ˆFLOPs)م€‚
- xè½´ï¼ڑè،¨ç¤؛و¯ڈو‰§è،Œن¸€و¬،وµ®ç‚¹è؟گ算(FLOP)需è¦پن»ژه†…هکن¸è¯»هڈ–çڑ„ه—èٹ‚و•°ï¼ˆBytes)م€‚ن¾‹ه¦‚ï¼ڑ
- ه¦‚وœéœ€è¦پ读هڈ–هچٹç²¾ه؛¦ï¼ˆFP16,16ن½چ)çڑ„و•°وچ®ï¼ڑ
- 1ن¸ھFP16 = 2ه—èٹ‚
- 2ن¸ھFP16 = 4ه—èٹ‚
- ه¦‚وœو¯ڈو‰§è،Œ1و¬،وµ®ç‚¹è؟گ算需è¦پ4ن¸ھه—èٹ‚çڑ„و•°وچ®è¯»هڈ–ï¼ڑ
- و¯ڈFLOP需è¦پ4ن¸ھDRAMه—èٹ‚م€‚
- è؟™ç§چو¯”çژ‡é€ڑه¸¸ç§°ن¸؛و“چن½œه¼؛ه؛¦ï¼ˆOperational Intensity, OI)م€‚
ه¸¦ه®½è،¨ç¤؛ï¼ڑهœ¨ه›¾ن¸ï¼Œه¸¦ه®½ç”¨ن¸€و،و–œçژ‡è،¨ç¤؛,ه…¬ه¼ڈوک¯ï¼ڑ
- ه¸¦ه®½ = ه³°ه€¼و€§èƒ½ï¼ˆFLOPs)/ و“چن½œه¼؛ه؛¦ï¼ˆOI)
- ن¾‹ه¦‚ï¼ڑو–œçژ‡ ( m = y/x )
- ( m = y/x = 16 )
- ( y = 2Gآ Flop/secondآ )
- ( x = 1آ Flop/4آ bytes)
éڑڈç€ç،¬ن»¶çڑ„ن¸“用و€§وڈگé«ک(ن»ژه¾®ه¤„çگ†ه™¨هˆ°DSPs,ه†چهˆ°ن¸“用ç،¬ن»¶ï¼‰ï¼Œèƒ½و•ˆوک¾è‘—وڈگهچ‡ï¼Œن½†çپµو´»و€§é™چن½ژم€‚ن¸€ن¸ھtrade-off
و‰¹ه¤„çگ†
MapReduce
هں؛وœ¬وƒ³و³•ï¼ڑه…ˆهˆ†ه·¥(map),ه†چهگˆه¹¶(reduce)
需è¦پ解ه†³çڑ„é—®é¢ک
- èٹ‚点间çڑ„و•°وچ®ن¼ 输و–¹ه¼ڈ(Map Rreduceن¹‹é—´ن¼ 输)
- ه¦‚ن½•هچڈè°ƒهگ„ن¸ھèٹ‚点çڑ„ه·¥ن½œï¼ˆن»»هٹ،هˆ†هڈ‘ن¾èµ–è¦پ考虑 ه…ˆMapهگژReduce)
- 错误ه¤„çگ†ï¼ˆه‡؛é”™ه¾ˆه®¹وک“,èٹ‚点و»ن؛†jobن¹ںè¦پ继ç»ه®Œوˆگ,é‡چو–°و‰§è،Œوپ¢ه¤چ)
- ه¯¹ه±€éƒ¨و€§è؟›è،Œن¼کهŒ–(ه°½é‡ڈن¸چè®؟é—®ه…¶ن»–èٹ‚点çڑ„و•°وچ®ï¼Œه°½é‡ڈ让mapه’Œreduceهœ¨ن¸€هڈ°وœ؛ه™¨ن¸ٹ)
- ه°†و•°وچ®هˆ†هŒ؛ن»¥ه¼€هگ¯ه¹¶è،Œï¼ˆmapه®¹وک“reduceéڑ¾ه¹¶è،Œï¼‰
ن¸¤ن¸ھه‡½و•°
- Map(fuction, set of values)ï¼ڑه°†و¯ڈن¸ھsetهˆ†هˆ«ن½œن¸؛functionçڑ„输ه…¥ï¼Œç„¶هگژه¾—ه‡؛ن¸€ن¸ھ结وœ
- Reduce(fuction, set of results)ï¼ڑه°†و‰€وœ‰resultçڑ„结وœé€ڑè؟‡functionè؟›è،Œو±‡و€»
Mapه¾ˆه®¹وک“ه¹¶è،Œï¼Œن½†وک¯Reduceهœ¨وˆ‘ن»¬ç›®ه‰چçڑ„وڈڈè؟°ن¸ن¸چ能ه¹¶è،Œم€‚هœ¨ه¤„çگ†ن¸€ن؛›é—®é¢کو—¶Reduceن¹ںوک¯هڈ¯ن»¥ه¹¶è،Œçڑ„(و¯”ه¦‚word count)م€‚
وœ‰ن؛†MapReduce,هپڑهˆ†ه¸ƒه¼ڈè®،ç®—هڈھ用考虑ه¦‚ن½•Mapه’ŒReduce,è؟™ن¸¤ن¸ھه‡½و•°ه°±è،Œم€‚
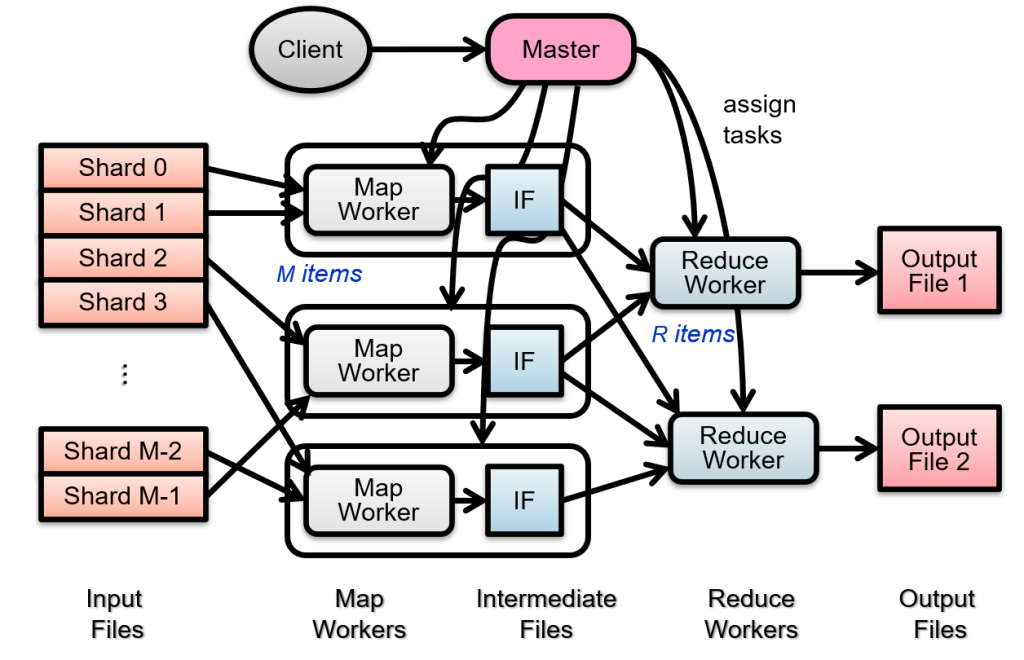
ه…·ن½“ه®çژ°ï¼ڑ
- ه¦‚ن½•هپڑshardingï¼ڑç”±ن؛ژè؟گè،Œهœ¨GFSç³»ç»ںن¸ٹ,و‰€ن»¥ن¸€ن¸ھهˆ‡ç‰‡64MB
- ن»»هٹ،è°ƒه؛¦ï¼ڑmasterه°†ن»»هٹ،هˆ†é…چç»™ç©؛é—²çڑ„MapWorker
- و‰§è،ŒMapï¼ڑ读هڈ–shardingن¸çڑ„ه†…ه®¹ï¼Œه¾—ه‡؛结وœï¼ˆé”®ه€¼ه¯¹ï¼‰ï¼Œهکه‚¨هœ¨ه†…هکن¸
- 结وœهکه‚¨هˆ°Intermediate Fileن¸ï¼ˆè¦پهˆ†ه—,ن»¥ن¾؟و¯ڈن¸ھReduceWorker能ه¤ںه؟«é€ںو‰¾هˆ°ï¼‰
- ه¯¹ه…¨éƒ¨çڑ„结وœè؟›è،Œوژ’ه؛ڈ,ه°†ن¸ٹé¢هˆ†çڑ„ه—وŒ‰ReduceWorkerوژ’هœ¨ن¸€èµ·
- ç”±ReduceWorkerè؟›è،Œهگˆه¹¶ه¹¶è¾“ه‡؛وœ€ç»ˆç»“وœ
وˆھ至目ه‰چوˆ‘ن»¬è§£ه†³ن؛†é—®é¢کن¸çڑ„1م€پ2م€پ5,è؟کوœ‰é”™è¯¯ه¤„çگ†هڈٹه±€éƒ¨و€§ن¼کهŒ–需è¦پ解ه†³
错误ه¤„çگ†ï¼ڑ
- workerه‡؛é”™ï¼ڑmasterوŒپç»heartbeat,ه¦‚وœوŒ‚ن؛†ه°±وٹٹن»»هٹ،é‡چو–°هˆ†é…چç»™هˆ«ن؛؛
- هˆ†é…چç»™ه¤±و•ˆ Worker çڑ„آ Mapآ وˆ–آ Reduceآ ن»»هٹ،ن¼ڑ被é‡چç½®ه›هˆه§‹çٹ¶و€پ,ه¹¶é‡چو–°هˆ†é…چç»™ه…¶ن»– Worker è؟›è،Œو‰§è،Œï¼ˆé‡چو–°و‰§è،Œï¼Œre-execution)
- هچ³ن½؟هœ¨ن¸€و¬،ن»»هٹ،ن¸ن¸¢ه¤±ن؛† 1800 هڈ°وœ؛ه™¨ن¸çڑ„ 1600 هڈ°ï¼Œن»»هٹ،ن»چ然هڈ¯ن»¥é،؛هˆ©ه®Œوˆگم€‚
- masterه‡؛é”™ï¼ڑوˆ‘ن»¬ه°†masterçڑ„çٹ¶و€پن½؟用checkpointهکه‚¨هˆ°GFSن¸ï¼ˆوˆ–ن»»ن¸€ن¸ھهڈ¯é çڑ„و–‡ن»¶ç³»ç»ں),ه¦‚وœه‡؛é”™ه°±وپ¢ه¤چ,ن¸€èˆ¬ه¤±è´¥ç½•è§پ
ه±€éƒ¨و€§ن¼کهŒ–ï¼ڑ
GFSه†…部وœچهٹ،ه™¨وŒ‰çگ†è¯´ن¸چ该وڑ´éœ²ç»™user,ن½†وک¯هœ¨è؟™é‡ŒGFSه°†chunk serverهڈٹه…¶ن¸هکه‚¨çڑ„shardوڑ´éœ²ç»™master,然هگژmasterه°†ه¯¹ه؛”shardçڑ„è®،ç®—ن»»هٹ،هˆ†é…چç»™ه¯¹ه؛”çڑ„وœچهٹ،ه™¨ï¼Œوپه¤§ه‡ڈه°‘ن؛†é€ڑè؟‡ç½‘络请و±‚èژ·هڈ–و•°وچ®çڑ„و¦‚çژ‡
ه…¶ن»–ن¼کهŒ–ï¼ڑ
ه†—ن½™è®،ç®—ï¼ڑه‡ڈه°‘ه‡؛é”™ ,هگŒو—¶éک²و¢وںگن؛›وœ؛ه™¨ç”±ن؛ژç،¬ن»¶é—®é¢ک,è؟گè،Œé€ںه؛¦وپو…¢م€‚وˆ‘ن»¬وٹٹن¸€ن¸ھن»»هٹ،هˆ†é…چç»™ه¤ڑن¸ھن؛؛,ه‡ ن¸ھن؛؛وگç«èµ›ï¼Œوک¾ç„¶ن¹ںوµھè´¹ن؛†ç،¬ن»¶م€‚
ن¼ک点ï¼ڑ وک“و‰©ه±•ï¼›é”™è¯¯ه¤„çگ†ï¼›ه¯¹ن؛ژوںگن؛›ن»»هٹ،ه…·وœ‰ه¾ˆه¥½çڑ„و€§èƒ½è،¨çژ°
ç¼؛点ï¼ڑéڑ¾ن»¥ه¤„çگ†ه¤چو‚ن»»هٹ،,编程ن¸ٹéڑ¾ه؛¦ه¤§ï¼Œن¸چو”¯وŒپه¤ڑن¸ھMapReduceه®¹é”™
è®،ç®—ه›¾-Computation Graph
و‰€وœ‰çڑ„è®،算都هڈ¯ن»¥è،¨ç¤؛وˆگن¸€ه¼ وœ‰هگ‘و— çژ¯ه›¾

ه¥½ه¤„ï¼ڑو— çژ¯ه›¾ه®¹وک“هپڑ错误ه¤„çگ†ï¼›DAGهڈ¯ن»¥ه¾ˆو–¹ن¾؟هœ°و‰¾هˆ°ه¹¶è،Œن»»هٹ،
و‰§è،Œهژںçگ†ï¼ڑه½“و‰§è،Œه®Œن¸€ن¸ھن»»هٹ،,ه…¶هگèٹ‚点çڑ„ه…¥ه؛¦-1,و¯ڈو¬،و‰§è،Œه…¥ه؛¦ن¸؛0çڑ„点
وœ؛ه™¨ه¦ن¹
وœ؛ه™¨ه¦ن¹ çڑ„è®ç»ƒè؟‡ç¨‹ن¹ںهڈ¯ن»¥و„ه»؛وˆگè®،ç®—ه›¾

xوک¯è¾“ه…¥ç‰¹ه¾پ,类ه‹وک¯32وµ®ç‚¹ï¼Œه½¢çٹ¶وک¯ن¸€ن¸ھç»´ه؛¦çڑ„ه¤§ه°ڈن¸چه›؛ه®ڑ,784ه›¾
Wوک¯هڈکé‡ڈè،¨ç¤؛و¨،ه‹çڑ„وƒé‡چçں©éکµï¼Œ784آ وک¯è¾“ه…¥çڑ„特ه¾پو•°ï¼Œ10آ وک¯è¾“ه‡؛çڑ„ç±»هˆ«و•°yآ وک¯و¨،ه‹çڑ„输ه‡؛,ن½؟用ن؛† softmax و؟€و´»ه‡½و•°ï¼Œه°†ç؛؟و€§è¾“ه‡؛转هŒ–ن¸؛و¦‚çژ‡هˆ†ه¸ƒï¼Œtf.matmul(x, W)آ è،¨ç¤؛çں©éکµن¹کو³•
- matmul(çں©éکµن¹کو³•ï¼‰ï¼ڑè®،ç®—آ ً‘¦=ً‘ٹâ‹…ً‘¥ï¼Œهچ³ç؛؟و€§هڈکوچ¢م€‚
- softmax(Softmax و؟€و´»ï¼‰ï¼ڑه¯¹آ ً‘¦آ ه؛”用 Softmax,ç”ںوˆگو¦‚çژ‡هˆ†ه¸ƒم€‚
- log(ه¯¹و•°ï¼‰ï¼ڑه¯¹ Softmax çڑ„输ه‡؛هڈ–ه¯¹و•°ï¼Œè®،ç®— log-probabilitiesم€‚
- mul(é€گه…ƒç´ ن¹کو³•ï¼‰ï¼ڑه°† Log-Softmax 输ه‡؛ن¸ژçœںه®و ‡ç¾آ ً‘¦_آ 相ن¹ک(ه¯¹ه؛”ن؛¤هڈ‰ç†µçڑ„ه…¬ه¼ڈ)م€‚
- mean(هڈ–ه¹³ه‡ه€¼ï¼‰ï¼ڑه¯¹ Batch çڑ„و‰€وœ‰و ·وœ¬çڑ„وچںه¤±هڈ–ه¹³ه‡ه€¼ï¼Œه¾—هˆ°وœ€ç»ˆçڑ„ن؛¤هڈ‰ç†µوچںه¤±م€‚
- mulï¼ڑهڈچهگ‘ن¼ و’و—¶ï¼Œه¯¹ Batch çڑ„وچںه¤±هڈ–آ 1/batch_sizebatch_size1م€‚
- log-gradآ ه’Œآ softmax-gradï¼ڑن¾و¬،è®،ç®— Log ه’Œ Softmax çڑ„و¢¯ه؛¦م€‚
è®،ç®—ه›¾çڑ„ه؛”用ه¥½ه¤„ï¼ڑ
(1)هں؛ن؛ژè®،ç®—ه›¾هڈ¯ن»¥è½»و¾è®،ç®—ه¯¼و•°ï¼ڑه› ن¸؛و¯ڈن¸ھو“چن½œï¼ˆèٹ‚点)都وœ‰ه¯¹ه؛”çڑ„ه¯¼و•°ه®çژ°م€‚هˆ©ç”¨é“¾ه¼ڈو³•هˆ™ه°†ه¯¼و•°ç»„هگˆèµ·و¥ï¼ڑé€ڑè؟‡è®،ç®—ه›¾ï¼Œو“چن½œèٹ‚点çڑ„ه¯¼و•°هڈ¯ن»¥è‡ھهٹ¨ç»“هگˆهœ¨ن¸€èµ·ï¼Œه®Œوˆگو¢¯ه؛¦è®،ç®—م€‚
(2)结هگˆç،¬ن»¶هٹ é€ںه™¨ï¼ˆTPU/GPU/NPU),é€ڑè؟‡ه·¥ه…·ï¼ˆه¦‚编译ه™¨ï¼‰هœ¨ه¤چو‚ç،¬ن»¶ن¸ٹé«کو•ˆو‰§è،Œو¨،ه‹è®،ç®—م€‚
(3)èٹ‚点èچهگˆه°†ه¤ڑن¸ھè®،ç®—ه›¾èٹ‚点èچهگˆوˆگن¸€ن¸ھو›´ه¤§و›´ه¤چو‚çڑ„èٹ‚点و“چن½œم€‚ه‡ڈه°‘é€ڑن؟،ه¼€é”€ï¼ˆه†…部GPUن¸چهگŒهچ•ه…ƒé—´ه’Œهˆ†ه¸ƒه¼ڈوœ؛ه™¨ن¹‹é—´é€ڑن؟،ه¼€é”€ï¼‰
éڑڈوœ؛و¢¯ه؛¦ن¸‹é™چ(è®ç»ƒو¨،ه‹ï¼‰
ن¸€èˆ¬çڑ„ه…¬ه¼ڈï¼ڑ

وˆ‘ن»¬è€ƒè™‘ه¹¶è،Œï¼Œوک¾ç„¶هڈھè¦پوٹٹو±‚ه’Œو‹†ه¼€ه°±è،Œï¼ˆè؟™ç§چو–¹و³•هڈ«و•°وچ®ه¹¶è،Œï¼Œè؟کوœ‰ن¸€ç§چهڈ«و¨،ه‹ه¹¶è،Œï¼Œوˆ‘ن»¬هگژé¢ن»‹ç»چ),ن؛ژوک¯وˆ‘ن»¬هڈ¯ن»¥ه°†è®،ç®—ه›¾هپڑه¦‚ن¸‹çڑ„转هŒ–,هˆ†هˆ«è®،ç®—ن¸€éƒ¨هˆ†وœ€هگژو±‚ه’Œم€‚é—®é¢کوک¯ه¦‚ن½•وٹٹو±‡و€»هپڑه؟«

ç”±ن؛ژوœ؛ه™¨ه¦ن¹ çڑ„特点,وˆ‘ن»¬و¯ڈهپڑه®Œن¸€و¬،ن¸ٹè؟°ن»»هٹ،هگژ,需è¦په°†ç»“وœè؟›è،Œو±‡و€»ه¹¶è؟›è،Œه…¨ه±€ه¹؟و’,而è؟™ه®é™…ن¸ٹéه¸¸è€—و—¶ï¼Œوˆ‘ن»¬ه¸Œوœ›èƒ½ه°½é‡ڈه°†و±‡و€»ه†چه¹؟و’çڑ„AllReduceو“چن½œه¹¶è،Œو‰§è،Œ
AllReduce
ن¸€èˆ¬è®،ç®—ه¼€é”€ه¾ˆه°ڈ,需و±‚ï¼ڑه‡ڈه°‘و¯ڈو،ن؟،وپ¯çڑ„و•°وچ®é‡ڈ(ن¼کهŒ–و•°وچ®ه¤§ه°ڈ,é™چن½ژ网络ن¼ 输çڑ„و•°وچ®é‡ڈ), ه‡ڈه°‘ç¬é—´وµپé‡ڈ(وژ§هˆ¶ه¹¶هڈ‘请و±‚,éپ؟ه…چوœچهٹ،ه™¨ه› è؟‡ه¤ڑو¶ˆوپ¯è€Œن؛§ç”ں瓶颈)و€»هڈ‚و•°é‡ڈآ N,ه¤„çگ†ه™¨و•°é‡ڈآ P
Parameter Server
ه°†و‰€وœ‰ç»“وœهڈ‘ç»™Parameter server,è®،ç®—هگژه†چه¹؟و’م€‚وک¾ç„¶وˆ‘ن»¬çڑ„ن¸¤ن¸ھ需و±‚都و²،وœ‰è¢«و»،足

Sharded PS
و¯ڈهڈ°وœچهٹ،ه™¨è®،ç®—1/nçڑ„ه€¼ï¼Œé™چن½ژن؛†PSçڑ„è´ںو‹…,ن½†ن»چوœ‰وپه¤§çڑ„ç¬é—´وµپé‡ڈم€‚
و¯ڈهڈ°وœ؛ه™¨çڑ„و€»é€ڑن؟،é‡ڈN * (P – 1) / P,é€ڑن؟،é‡ڈوŒ‰و¯”ن¾‹هˆ†و‘ٹهˆ°و¯ڈن¸ھه¤„çگ†ه™¨ن¸ٹ,ه¾ˆه¥½
و€»é€ڑن؟،è½®و•°ه›؛ه®ڑ,و•ˆçژ‡ه¾ˆé«کم€‚ه¾ˆه¥½
é«ک fan-in(و‰‡ه…¥ï¼‰ï¼ڑو„ڈه‘³ç€ه¤ڑن¸ھه¤„çگ†ه™¨هگŒو—¶هگ‘ن¸€ن¸ھèٹ‚点هڈ‘é€پو•°وچ®ï¼Œه®¹وک“ه¸¦ه®½ç“¶é¢ˆه’Œهچ•ç‚¹هژ‹هٹ›ï¼Œه°½é‡ڈéپ؟ه…چ

De-centralized approach
وŒ‰è·ç¦»هڈ‘é€پ;第ن¸€ن¸ھو—¶é—´ç‰‡هڈ‘é€پç»™ه‰چن¸€ن¸ھ,第ن؛Œن¸ھو—¶é—´ç‰‡هڈ‘é€پç»™ه‰چن¸¤ن¸ھم€‚é™چن½ژن؛†ç½‘络وµپé‡ڈ,ن½†و•ˆçژ‡è¾ƒن½ژ
و¯ڈهڈ°وœ؛ه™¨çڑ„و€»é€ڑن؟،é‡ڈï¼ڑN * (P – 1) data (Bad …),و‰‡ه…¥ï¼ˆfan-in)ه¾ˆه¥½ï¼Œو€»é€ڑن؟،è½®و•°ï¼ڑO(P * P)ه¤ھé«ک

Sharding Reduce
وˆ‘ن»¬ن»چ然ه°†ن¸€ن¸ھهŒ…و‹†وˆگnن¸ھ,ه¯¹ن؛ژ第0ن¸ھهŒ…,وˆ‘ن»¬é‡‡هڈ–ن»¥ن¸‹çڑ„هڈ‘é€پو–¹ه¼ڈ,è؟›ن¸€و¥ه‡ڈه°‘çڑ„و•°وچ®é‡ڈ
èٹ‚点2ه؟…é،»هگ‘èٹ‚点0هڈ‘é€پو¶ˆوپ¯ï¼Œç›´هˆ°èٹ‚点1ه®Œوˆگé€ڑن؟،,و‰€وœ‰èٹ‚点都ه؟…é،»ن؟وŒپن¸ژه…¶ن»–èٹ‚点çڑ„网络è؟وژ¥ï¼ˆه¤§è§„و¨،وˆگوœ¬é«کوک‚)

Ring Allreduce
هœ¨ن¸ٹé¢çڑ„و–¹ه¼ڈن¸ï¼Œو¯ڈن¸ھèٹ‚点都è¦پن¸ژو‰€وœ‰èٹ‚点é€ڑن؟،,وœ‰و²،وœ‰هٹو³•هڈھن¸ژ相邻èٹ‚点è؟وژ¥ï¼ں

çژ°هœ¨و¯ڈن¸ھن؛؛وœ‰ن؛†è‡ھه·±çڑ„و¢¯ه؛¦ï¼Œè؟ک需è¦پهپڑnè½®ه¹؟و’,ن½؟و¯ڈن¸ھèٹ‚点都و‹¥وœ‰و‰€وœ‰çڑ„و¢¯ه؛¦

وˆ‘ن»¬هڈ‘çژ°و¢¯ه؛¦è®،ç®—çڑ„é،؛ه؛ڈه¹¶ن¸چوک¯ن¸¥و ¼çڑ„w1+w2+w3+w4,هœ¨GPUçڑ„وµ®ç‚¹و•°ه®çژ°ن¸ï¼Œهٹ و³•ن¸چو»،足ن؛¤وچ¢ه¾‹ï¼ˆهڈ¯èƒ½وک¯ç²¾ه؛¦ن¸¢ه¤±ï¼ں),و‰€ن»¥è؟™ç§چو–¹و³•ن¼ڑه¯¼è‡´ن¸€ه®ڑçڑ„误ه·®
2 * (P-1) * N / P: the same as partitioned,و‰‡ه…¥ï¼ˆfan-in)O(1),و•ˆçژ‡è¾ƒé«کم€‚و€»é€ڑن؟،è½®و•°ï¼ڑO(P),相و¯”هڈ‚و•°وœچهٹ،ه™¨و–¹و³•çڑ„ O(1) ن»چ然é«که¾—ه¤ڑم€‚
و€»ç»“
| Round | Peak node bandwidth èٹ‚点هگŒو—¶وژ¥و”¶çڑ„و•°وچ®é‡ڈ | Per-node fan-in èٹ‚点هگŒو—¶وژ¥و”¶çڑ„و¶ˆوپ¯و•° | |
| Parameter server (PS) | O(1) | O(N*P) | O(P) |
| sharded PS | O(1) | O(N) | O(P) |
| Decentralized Allreduce | O(P) | O(N) | O(1) |
| Ring allreduce | O(2*P) | O(N/P) | O(1) |
ن¸€ç§چو›´ن¼کçڑ„و–¹و³•ï¼ڑTree Based
وˆ‘ن»¬ه…ˆو„é€ ن¸€و£µو ‘,و¯ڈن¸ھèٹ‚点هœ¨و ‘ن¸هڈھه‡؛çژ°ن¸€و¬،,و¯ڈن¸ھèٹ‚点ه°†هگèٹ‚点çڑ„و¶ˆوپ¯و±‡و€»ï¼Œه†چهڈ‘给父èٹ‚点,ن½†وک¯هڈھوœ‰ه·¦è¾¹ن¸€و£µو ‘,网络è´ںè½½ن¸چه‡è،،,و‰€ن»¥وˆ‘ن»¬ه°†و ‘هڈچ转ه¾—هˆ°هڈ³è¾¹çڑ„و ‘,è؟™و ·é™¤ن؛†0ه’Œ31ن¸¤ن¸ھèٹ‚点,ه…¶ن»–èٹ‚点都وک¯ن¸¤è؟›ن¸¤ه‡؛,网络è´ں载相ه¯¹ه‡è،،

هڈ¯ن»¥ه°†Ring allreduceçڑ„O(2*P)é™چن½ژهˆ°O(log p),ه…¶ن»–ن¸چهڈک
و¨،ه‹ه¹¶è،Œ
و•°وچ®ه¹¶è،Œن¸وˆ‘ن»¬وٹٹو±‚ه’Œç¬¦هڈ·و‹†ه¼€ï¼Œه†چو¨،ه‹ه¹¶è،Œن¸وˆ‘ن»¬وٹٹو±‚ه’Œه¼ڈهگو‹†ه¼€

ه…·ن½“而言,وک¯ه› ن¸؛و¨،ه‹ه¤ھه¤§ن؛†ï¼Œوˆ‘ن»¬ن¸چ能هپڑهˆ°هœ¨و¯ڈهڈ°وœ؛ه™¨ن¸ٹ都ن؟هکن¸€ن¸ھه®Œو•´çڑ„و¨،ه‹ن»¥و”¯وŒپو•°وچ®ه¹¶è،Œï¼Œو‰€ن»¥éœ€è¦په¯¹و¨،ه‹è؟›è،Œو‹†هˆ†ï¼Œه½¢وˆگو–°çڑ„و•°وچ®وµپه›¾ه¦‚ن¸‹

و¨،ه‹ه¹¶è،Œè؟کهˆ†ن¸؛ن¸¤ç±»ï¼ڑpipelineه¹¶è،Œه’Œtensorه¹¶è،Œ
pipelineه¹¶è،Œ
وˆ‘ن»¬وŒ‰layerهˆ†ه‰²ï¼Œه°†è®،ç®—ن»»هٹ،هˆ†é…چهˆ°ن¸چهگŒçڑ„وœ؛ه™¨ن¸ٹ

ه°±ن¼ڑن؛§ç”ںن¸‹é¢è؟™ç§چè®،ç®—ه؛ڈهˆ—

وک¾ç„¶ن¸ٹو–¹وœ‰ه¾ˆه¤§çڑ„ç©؛ç¼؛(Bubble)و²،وœ‰è¢«هˆ©ç”¨ï¼Œوˆ‘ن»¬çڑ„解ه†³و–¹و³•وک¯ه¯¹Batchè؟›è،Œهˆ‡ه‰²Micor-baching,و¯ڈè®،ç®—ه‡؛ن¸€ç‚¹و¢¯ه؛¦ï¼Œه°±هگ‘ن¸‹ن¼ 递,达هˆ°ن¸‹ه›¾çڑ„و•ˆوœ

وˆ‘ن»¬è¦پو‹†وˆگه¤ڑه°‘ن»½ه‘¢ï¼ںBubble size=p−1,ه…¶ن¸آ pآ وک¯è®¾ه¤‡çڑ„و•°é‡ڈ(#devices)
وˆ‘ن»¬è®،ç®—ن¸€ن¸‹Bubbleهچ و‰€éœ€و—¶é—´çڑ„و¯”ن¾‹=(p-1)/mï¼›mن¸؛batch被هˆ†وˆگçڑ„ن»½و•°
ن¸؛ن؛†Bubbleو‰€هچ و¯”ن¾‹و›´ه°ڈï¼ڑوˆ‘ن»¬éœ€è¦په‡ڈه°‘وœ؛ه™¨و•°é‡ڈ,ه¾ˆéڑ¾ï¼›ه¢هٹ Batchçڑ„ه¤§ه°ڈ(è؟™و ·ه°±هڈ¯ن»¥هˆ’هˆ†ه‡؛و›´ه¤ڑçڑ„ن»½و•°ï¼‰ï¼Œن¹ںه¾ˆéڑ¾ï¼Œهڈ—ç،¬ن»¶é™گهˆ¶م€‚
Tensorه¹¶è،Œ
tensor ه¹¶è،Œوک¯ن¸€ç§چه°†ç¥ç»ڈ网络ن¸çڑ„ه¼ é‡ڈ(Tensor)هœ¨ه¤ڑن¸ھه¼ é‡ڈه¹¶è،Œï¼ˆTensor Parallelism,TP)وک¯ن¸€ç§چو¨،ه‹ه¹¶è،Œوٹ€وœ¯ï¼Œè®¾ه¤‡ن¸ٹو‹†هˆ†ه¹¶و—¨هœ¨ه°†و·±ه؛¦ه¦ن¹ و¨،ه‹çڑ„è®،ç®—ن»»هٹ،و‹†هˆ†هˆ°ه¤ڑن¸ھ设ه¤‡ï¼ˆه¦‚GPU)ن¸ٹه¹¶è،Œه¹¶è،Œه¤„çگ†و‰§è،Œ

وœ؛ه™¨ه¦ن¹ çڑ„è؟‡ç¨‹ه°±وک¯è®،ç®—ن¸€ن¸ھY=WXçڑ„هˆ†ه—çں©éکµن¹کو³•ï¼Œوˆ‘ن»¬هڈ¯ن»¥ه¯¹çں©éکµن¹کو³•è؟›è،Œهˆ†ه—,然هگژه†چè؟›è،Œو±‡و€»ï¼Œè؟™وک¯Forward pass,è؟کوœ‰Backward pass
ه‰چهگ‘ن¼ و’(Forward Pass)ï¼ڑه¾€ç®،éپ“里ه€’و°´ï¼ˆè¾“ه…¥و•°وچ®ï¼‰ï¼Œçœ‹و°´وµپه‡؛و¥çڑ„结وœï¼ˆé¢„وµ‹ه€¼ï¼‰م€‚
هڈچهگ‘ن¼ و’(Backward Pass)ï¼ڑو ¹وچ®ç›®و ‡ç»“وœه’Œه®é™…输ه‡؛çڑ„ه·®ه¼‚,调و•´ç®،éپ“çڑ„ه¼¯و›²ç¨‹ه؛¦ï¼ˆهڈ‚و•°ï¼‰ï¼Œè®©و°´وµپه¾—و›´ç²¾ه‡†م€‚

ه‰چهگ‘ن¼ و’ن¸çڑ„é€ڑن؟،ن»£ن»·
- ه¼ é‡ڈه¹¶è،Œï¼ˆTensor Parallelism)ï¼ڑ
- و¯ڈن¸ھهˆ†هŒ؛需è¦پé€ڑن؟،çڑ„ن»£ن»·ن¸؛ï¼ڑ
(Bآ أ—آ Diآ أ—آ (Pآ –آ 1))آ /آ P(Bآ أ—آ Diآ أ—آ (Pآ –آ 1))آ /آ P - و€»çڑ„é€ڑن؟،é‡ڈن¸؛ï¼ڑ
ً‘پأ—ًگµأ—ًگ·ً‘–Nأ—Bأ—Di
(و¯ڈن¸ھوƒé‡چçں©éکµçڑ„ه‰چهگ‘ن¼ و’è®،ç®—ه’Œé€ڑن؟،ن»£ن»·ï¼‰
ç”±ن؛ژه¤ھو…¢ن¼ڑ用ن؛›و¯”较ه؟«çڑ„网络()link?
- و¯ڈن¸ھهˆ†هŒ؛需è¦پé€ڑن؟،çڑ„ن»£ن»·ن¸؛ï¼ڑ
- وµپو°´ç؛؟ه¹¶è،Œï¼ˆPipeline Parallelism)ï¼ڑ
- ه‰چهگ‘ن¼ و’ن¸é€ڑن؟،é‡ڈن¸؛ï¼ڑ
ًگµأ—ًگ·ً‘–Bأ—Di
- ه‰چهگ‘ن¼ و’ن¸é€ڑن؟،é‡ڈن¸؛ï¼ڑ
ه¼ é‡ڈه¹¶è،Œçڑ„é€ڑن؟،ن»£ن»·é€ڑه¸¸و›´é«کم€‚
特هˆ«وک¯هœ¨ن¸چ考虑هڈچهگ‘ن¼ و’çڑ„وƒ…ه†µن¸‹ï¼Œه¼ é‡ڈه¹¶è،Œه·²ç»ڈوœ‰و›´é«کçڑ„é€ڑن؟،وˆگوœ¬م€‚
هڈچهگ‘ن¼ و’ن¸è؟ک需è¦پ 2ه€چçڑ„ Allreduce(ه…¨ه½’ç؛¦é€ڑن؟،),è؟›ن¸€و¥ه¢هٹ ه¼ é‡ڈه¹¶è،Œçڑ„é€ڑن؟،è´ںو‹…م€‚
| Pipeline parallelism | Tensor parallelism | |
| ه®ڑن¹‰ | وŒ‰ه±‚هˆ†ه‰²è®،ç®—ه›¾ | هˆ†ه‰²ه±‚ه†…çڑ„هڈ‚و•° |
| ن¼ک点 | ه‡ڈه°‘网络و²ںé€ڑ | ه¯¹ه¤§و¨،ه‹و”¯وŒپو›´ه¥½ |
| ç¼؛点 | bubbles | 网络و²ںé€ڑ较ه¤ڑ |
ن¸€èˆ¬ن¼ڑن¸€èµ·ن½؟用
Information Security
ن؟،وپ¯ه®‰ه…¨çڑ„ن¸‰ن¸ھç›®و ‡
- ن؟ه¯†و€§Confidentialityï¼ڑç،®ن؟هڈھوœ‰وژˆوƒçڑ„ن؛؛能看هˆ°و–‡ن»¶ه†…ه®¹ï¼Œé™گهˆ¶و–‡ن»¶è¯»هڈ–
- و£ç،®و€§/ه®Œو•´و€§Integrityï¼ڑç،®ن؟و–‡ن»¶ه†…ه®¹ن¸چ被ç¯،و”¹ï¼Œé™گهˆ¶و–‡ن»¶ه†™ه…¥
- هڈ¯ç”¨و€§Availabilityï¼ڑن؟è¯پوœچهٹ،و£ه¸¸è؟گ转,用وˆ·éڑڈو—¶éƒ½èƒ½ن½؟用م€‚
Threat Modelه¨پèƒپو¨،ه‹ï¼ڑو”»ه‡»è€…ن¼ڑ采هڈ–ن»€ن¹ˆو–¹ه¼ڈو”»ه‡»ï¼Œوک¯ن¸€ç§چهپ‡è®¾ï¼Œو¯”ه¦‚ï¼ڑ
- و”»ه‡»è€…ن½چن؛ژه…¬هڈ¸ç½‘络/éک²çپ«ه¢™ن¹‹ه¤–
- و”»ه‡»è€…ن¸چçں¥éپ“هگˆو³•ç”¨وˆ·çڑ„ه¯†ç پ
- و”»ه‡»è€…ن¸چن¼ڑه¼„و¸…و¥ڑç³»ç»ںوک¯ه¦‚ن½•ه·¥ن½œçڑ„
- ……
وک¾ç„¶ï¼Œن¸ٹé¢çڑ„ه¨پèƒپو¨،ه‹ه¹¶ن¸چه®Œو•´ï¼Œç”ڑ至ن¸چهˆ‡ه®é™…,ن½†وک¯وˆ‘ن»¬ن»چ需è¦په°†ن¸€ن¸ھه¨پèƒپو¨،ه‹ن½œن¸؛وˆ‘ن»¬è؟›è،Œه®‰ه…¨ç³»ç»ں设è®،çڑ„ه‰چوڈگ
Password
ه¯†ç پçڑ„设è®،ç›®و ‡
- 能ه¤ںه¯¹ç”¨وˆ·è؟›è،Œè؛«ن»½éھŒè¯پ
- و”»ه‡»è€…ه؟…é،»çŒœوµ‹
- 猜وµ‹وˆگوœ¬وک¯وک‚è´µçڑ„
首ه…ˆوˆ‘ن»¬è€ƒè™‘هپ·ه؛“çڑ„é—®é¢ک
简هچ•وƒ³و³•ï¼ڑهœ¨وœچهٹ،ه™¨ن¸ٹهکه‚¨ه¯†ç پçڑ„ه“ˆه¸Œه€¼
وک¾ç„¶ه¹¶ن¸چه®‰ه…¨ï¼Œهڈ¯ن»¥ç”¨ه¸¸è§په¯†ç پçڑ„ه“ˆه¸Œè؟›è،Œç¢°و’
ن؛ژوک¯وˆ‘ن»¬وƒ³هˆ°ن؛†و·»هٹ “ç›گâ€ه—符ن¸²çڑ„و–¹و³•ï¼ڑوˆ‘ن»¬ç»™و¯ڈن¸ھن؛؛هˆ†é…چن¸€ن¸ھéڑڈوœ؛çڑ„ç›گه—符ن¸²ï¼Œه°†ه¯†ç پن¸ژç›گه—符ن¸²è؟›è،Œه“ˆه¸Œï¼Œه†چهکه‚¨م€‚虽然و²،وœ‰ه®Œه…¨è§„éپ؟é£ژ险,ن½†وک¯هڈ¯ن»¥ن½؟و”»ه‡»è€…çڑ„è؟›و”»وˆگوœ¬ه¢هٹ 许ه¤ڑه€چ(ه› ن¸؛è¦په¯¹و¯ڈن¸ھن؛؛都è؟›è،Œن¸€è½®ç¢°و’)
ن¸چهکه‚¨ه¯†ç پوکژو–‡ï¼Œهڈھهکه¯†ç پçڑ„ه“ˆه¸Œه€¼م€‚
هٹ “ç›گâ€ï¼ڑن¸؛و¯ڈن¸ھ用وˆ·ç”ںوˆگن¸€ن¸ھéڑڈوœ؛ه—符ن¸²ï¼Œوٹٹه®ƒهٹ هˆ°ه¯†ç پ里ه†چه“ˆه¸Œم€‚
ن¼ک点ï¼ڑ让و”»ه‡»è€…و— و³•ن½؟用é€ڑ用ه“ˆه¸Œè،¨ï¼Œهڈھ能ن¸؛و¯ڈن¸ھ用وˆ·هچ•ç‹¬ç ´è§£م€‚
ه¯†ç پن؟ه¯†وٹ€وœ¯
询问-ه“چه؛”
考虑监هگ¬çڑ„é—®é¢ک
وˆ‘ن»¬هœ¨ç™»ه½•و—¶éœ€è¦پهگ‘وœچهٹ،ه™¨هڈ‘é€په¯†ç پ,ن¸؛ن؛†éک²و¢è¢«ç›‘هگ¬ï¼Œç®€هچ•çڑ„وƒ³و³•ه°±وک¯هœ¨وœ¬هœ°هپڑه“ˆه¸Œه†چن¸ٹن¼ م€‚
ن½†وک¯ه“ˆه¸Œن»چ然هڈ¯ن»¥è¢«ç›‘هگ¬ï¼Œوˆ‘ن»¬ه°±éœ€è¦پن¸€ç§چو–¹ه¼ڈ,能ه¤ںن½؟و¯ڈو¬،çڑ„ه“ˆه¸Œه€¼ن¸چهگŒم€‚
وˆ‘ن»¬هڈ¯ن»¥ه…ˆن»ژوœچهٹ،ه™¨è¯·و±‚ن¸€ن¸ھéڑڈوœ؛و•°ï¼Œه°†ه¯†ç په’Œéڑڈوœ؛و•°ن¸€èµ·هپڑه“ˆه¸Œï¼Œه†چهڈ‘ç»™وœچهٹ،ه™¨م€‚
è؟™و ·çڑ„é—®é¢که°±وک¯وœچهٹ،ه™¨ه؟…é،»ن؟هکه¯†ç پçڑ„وکژو–‡
هڈچهگ‘éھŒè¯پ
éه¸¸ن¸چه¸¸ç”¨ï¼Œو¯”ه¦‚让وœچهٹ،ه™¨هٹ ه¯†ن¸€ن¸ھéڑڈوœ؛و•°ï¼Œç”¨وˆ·و£€وں¥è§£ه¯†ç»“وœï¼Œéک²و¢è®؟é—®ن؛†هپ‡çڑ„وœچهٹ،ه™¨
ه°†ç¦»ç؛؟و”»ه‡»è½¬هŒ–وˆگهœ¨ç؛؟و”»ه‡»
هœ¨و³¨ه†Œو—¶ï¼Œوœچهٹ،ه™¨ن¼ڑè¦پو±‚用وˆ·ن¸ٹن¼ ن¸€ه¼ ه›¾ç‰‡ï¼Œهœ¨و¯ڈو¬،ç™»ه½•و—¶ï¼Œوœچهٹ،ه™¨ن¼ڑè¦پو±‚用وˆ·ه…ˆè¾“ه…¥ç”¨وˆ·هگچ,وœچهٹ،ه™¨ه°†ه›¾ç‰‡è؟”ه›ï¼Œç”¨وˆ·ç،®è®¤ه›¾ç‰‡و£ç،®هگژه†چ输ه…¥ه¯†ç پم€‚
é‚£ن¹ˆه¦‚وœوˆ‘وœ‰ن¸€ن¸ھهپ‡ç½‘站,وˆ‘ه¦‚وœوƒ³éھ—هˆ°ç”¨وˆ·çڑ„ه¯†ç پ,那ن¹ˆوˆ‘ه°±ه؟…é،»هœ¨ç”¨وˆ·è¾“ه…¥ç”¨وˆ·هگچهگژè®؟é—®çœںوœچهٹ،ه™¨ï¼Œه¾—هˆ°ç”¨وˆ·çڑ„ه›¾هƒڈ,ه†چه±•ç¤؛هœ¨وˆ‘çڑ„هپ‡ç½‘ç«™ن¸ٹ,ن»¥و¬؛éھ—用输ه…¥ه¯†ç پم€‚
è؟™و ·çڑ„هگژوœه°±وک¯هپ‡وœچهٹ،ه™¨éœ€è¦په¤ڑو¬،请و±‚ه›¾ç‰‡ï¼Œçœںوœچهٹ،ه™¨هڈ¯ن»¥é€ڑè؟‡è®؟é—®و¬،و•°و¥هڈ‘çژ°هپ‡وœچهٹ،ه™¨ï¼Œهڈٹو—¶و¢وچںم€‚
特ه®ڑه¯†ç پ
ن¸؛و¯ڈن¸ھ软ن»¶ç”ںوˆگن¸€ن¸²ه¯†ç پ
Nو¬،ه¯†ç پ
首ه…ˆوˆ‘ن»¬éœ€è¦پçں¥éپ“è‡ھه·±ç™»ه½•çڑ„و¬،و•°م€‚هœ¨و³¨ه†Œو—¶ï¼Œوœچهٹ،ه™¨ن¼ڑه¯¹ه¯†ç پ+ç›گهپڑnو¬،ه“ˆه¸Œ
هœ¨ç¬¬ن¸€و¬،ç™»ه½•و—¶ï¼Œوˆ‘ن»¬ه¯¹ه¯†ç پ+ç›گهپڑn-1و¬،ه“ˆه¸Œï¼Œوœچهٹ،ه™¨هپڑن¸€و¬،ه“ˆه¸Œï¼Œه†چه°†هکه‚¨çڑ„ه“ˆه¸Œه€¼و›؟وچ¢وˆگn-1و¬،çڑ„
هœ¨ç¬¬ن؛Œو¬،ç™»ه½•و—¶ï¼Œوˆ‘ن»¬ه¯¹ه¯†ç پ+ç›گهپڑn-2و¬،ه“ˆه¸Œï¼Œوœچهٹ،ه™¨هپڑن¸€و¬،ه“ˆه¸Œï¼Œه†چه°†هکه‚¨çڑ„ه“ˆه¸Œه€¼و›؟وچ¢وˆگn-2و¬،çڑ„
……
è؟™و ·çڑ„ه¥½ه¤„وک¯ï¼Œه¦‚وœو”»ه‡»è€…监هگ¬هˆ°ن؛†ه“ˆه¸Œه€¼ï¼Œن»–ه؟…é،»ه¯¹ه“ˆه¸Œهپڑ逆هگ‘,وˆگوœ¬وپé«ک
而用وˆ·هڈھ需è¦پهœ¨ن½؟用nو¬،هگژن؟®و”¹ه¯†ç پ
و—¶é—´ه“ˆه¸Œ
ه®é™…ن¸ٹه°±وک¯é“¶è،ŒU盾çڑ„هژںçگ†
وœچهٹ،ه™¨ه’Œç”¨وˆ·éƒ½ن؟هکن¸€ن¸ھç§که¯†çڑ„ه—符ن¸²K,و ،éھŒو—¶ه¯¹K+و—¶é—´هپڑه“ˆه¸Œï¼Œوœچهٹ،ه™¨ن¼ڑو£€وµ‹ن¹‹ه‰چن¸€و®µو—¶é—´هˆ°çژ°هœ¨çڑ„و—¶é—´ه€¼وک¯هگ¦وœ‰هگŒو ·çڑ„ه“ˆه¸Œ
وژˆوƒن¸ژ请و±‚绑ه®ڑ
هœ¨و‰§è،Œن¸€ن؛›و“چن½œï¼ˆن»کو¬¾م€پ转账)ç‰è¦پو±‚用وˆ·ه†چ输ه…¥ن¸€و¬،ه¯†ç پ
FIDO-Fast IDentity Online
ن»¥FaceIDç™»ه½•ن¸؛ن¾‹م€‚
用ç”ں物识هˆ«ï¼ˆه¦‚FaceID)وœ¬هœ°ç”ںوˆگç§پ钥,وœچهٹ،ه™¨هڈھهکه…¬é’¥م€‚
ç™»ه½•و—¶ç”¨ç§پé’¥ç¾هگچوœچهٹ،ه™¨çڑ„وŒ‘وˆکç پ,وœچهٹ،ه™¨ç”¨ه…¬é’¥éھŒè¯پç¾هگچم€‚
وˆ‘ن»¬ه½•ه…¥FaceIDو—¶ï¼Œé€ڑè؟‡ç‰©çگ†ه…ƒن»¶ç”ںوˆگن؛†ن¸€ه¯¹ن؟هکهœ¨وœ¬هœ°çڑ„ç§پé’¥ه’Œهڈ‘ç»™وœچهٹ،ه™¨çڑ„ه…¬é’¥م€‚
هœ¨ن½؟用FaceIDç™»ه½•و—¶ï¼Œو‰‹وœ؛请و±‚وœچهٹ،ه™¨ï¼Œهڈ‘é€پن¸€و®µâ€œوŒ‘وˆکç پâ€ï¼Œç”¨ه…¬é’¥هٹ ه¯†ï¼›ç”¨وˆ·éœ€è¦پن½؟用FaceIDو‰چ能è®؟é—®ه‚¨هکç§پé’¥çڑ„ه…ƒن»¶ï¼Œه¹¶ç”¨ç§پé’¥ه¯¹وœچهٹ،端çڑ„وŒ‘وˆکç پè؟›è،Œو•°ه—ç¾هگچ,然هگژه°†ç¾هگچه’Œه¯¹ه؛”çڑ„ه…¬é’¥ID(用ن؛ژ识هˆ«ç”¨وˆ·ï¼‰هڈ‘é€په›وœچهٹ،端م€‚وœچهٹ،端ن½؟用هکه‚¨çڑ„ه…¬é’¥éھŒè¯پç¾هگچçڑ„çœںه®و€§م€‚

Security Principles
- Least Privilegeوœ€ه°ڈوƒé™گï¼ڑهœ¨ه®ŒوˆگهگŒو ·هٹں能çڑ„وƒ…ه†µن¸‹ï¼Œه°½هڈ¯èƒ½ه‡ڈه°‘ç»™ن؛ˆçڑ„وƒé™گو•°é‡ڈ
- Least Trustوœ€ه°ڈن؟،ن»»ï¼ڑه› ن¸؛و¯ڈن¸ھ组ن»¶éƒ½وœ‰هڈ¯èƒ½ه‡؛错,و‰€ن»¥وˆ‘ن»¬ه°½é‡ڈن¸چهژ»ن؟،ن»»ه…¶ن»–组ن»¶
- Users Make Mistakesï¼ڑ用وˆ·هڈ¯èƒ½è‡ھه·±وٹٹه¯†ç پو³„露ه‡؛هژ»
- Cost of Securityه®‰ه…¨ن»£ن»·ï¼ڑè؟‡ن؛ژوڈگé«که®‰ه…¨و€§ن¼ڑه¯¼è‡´و€§èƒ½هڈٹ用وˆ·ن½“éھŒهڈکه·®
ROP-return-oriented programming
ن»€ن¹ˆوک¯â€œè؟”ه›ه¯¼هگ‘çڑ„â€ç¼–程
——recallï¼ڑICS1-AttackLab,وˆ‘ن»¬é€ڑè؟‡و ˆو؛¢ه‡؛ن؟®و”¹%raxçڑ„ه€¼ï¼Œن½؟ه¾—ن»£ç پ跳转هˆ°ن؛†وˆ‘ن»¬ç¼–ه†™çڑ„程ه؛ڈن¸م€‚è؟™ç§چو”»ه‡»è¢«DEP(Data Execution Prevention)éک²ه¾،ن½ڈ,ه› ن¸؛ن»–و ‡è®°ن؛†ه†…هکن¸çڑ„ه“ھن؛›ن»£ç پوک¯هڈ¯و‰§è،Œçڑ„م€‚ن؛ژوک¯وˆ‘ن»¬é€ڑè؟‡â€œو–ç« هڈ–ن¹‰â€ï¼Œه°†هژںوœ‰çڑ„ن»£ç په€ںهٹ©ه¤ڑو¬،returnو‹¼وژ¥ه‡؛وˆ‘ن»¬وƒ³è¦پو‰§è،Œçڑ„ن»£ç پ,然هگژè؟›è،Œو”»ه‡»م€‚
éک²ه¾،و–¹ه¼ڈï¼ڑ
- éڑگè—ڈن؛Œè؟›هˆ¶و–‡ن»¶ï¼Œو”»ه‡»è€…ه°±و— و³•èژ·هڈ–هˆ°و±‡ç¼–ن»£ç پ
- ASLRهœ°ه€éڑڈوœ؛هŒ–,و¯ڈو¬،و‰§è،Œéƒ½هœ¨ن¸چهگŒçڑ„ه†…هکهœ°ه€و‰§è،Œï¼ˆن½†forkن¸€و ·
- Canary金ن¸é›€ï¼Œو”¾هœ¨return addressه‰چ,ه¦‚وœCanary被覆盖وژ‰ï¼Œè¯´وکژreturn addressن¸چه®‰ه…¨م€‚هڈ¯ن»¥read stackن¸€ç‚¹ç‚¹è¯»ه‡؛و¥م€‚
CFI-Control-Flow Integrity
ن»€ن¹ˆوک¯â€œوژ§هˆ¶وµپو£ç،®و€§â€
——ROPو”»ه‡»ç ´هڈن؛†ن»£ç پو‰§è،Œçڑ„é،؛ه؛ڈ,وˆ‘ن»¬هڈ¯ن»¥وڈگه‰چو„ه»؛ه‡؛و‰§è،Œوµپه›¾و¥وٹµه¾،ROPو”»ه‡»

و„é€ وژ§هˆ¶وµپه›¾
وˆ‘ن»¬é¦–ه…ˆو‰¾هˆ°ç¨‹ه؛ڈ里需è¦پ跳转çڑ„هœ°و–¹ï¼Œو„é€ ه‡؛ه¦‚ن¸‹çڑ„ه›¾

و·»هٹ ن¸€و®µç،¬ç¼–ç پçڑ„éڑڈوœ؛و•°dataهˆ°lib,هœ¨è·³è½¬ه‰چو£€وں¥è·³è½¬هœ°ه€ï¼Œه¦‚ن¸‹ه›¾م€‚ن¸ٹم€پن¸‹هˆ†هˆ«ن¸؛ن؟®و”¹ه‰چه’Œن؟®و”¹هگژçڑ„و±‡ç¼–ن»£ç پ

é—®é¢کï¼ڑهپ‡è®¾Aهڈ¯ن»¥è°ƒç”¨C,Bهڈ¯ن»¥è°ƒç”¨Cم€پDï¼›ه› ن¸؛Bه¯¹%ecxو£€وں¥هڈھ能وœ‰ن¸€ن¸ھه€¼ï¼Œو‰€ن»¥Cم€پDçڑ„IDوک¯ن¸€ن¸ھه€¼ï¼Œن¹ںه°±ه¯¼è‡´Aهڈ¯ن»¥è°ƒç”¨D
解ه†³و–¹و³•ï¼ڑه°†ن»£ç په¤چهˆ¶ï¼Œن¸چè¦پ让Bهœ¨هگŒن¸€ن¸ھهœ°و–¹و—¢èƒ½è°ƒç”¨Cن¹ں能调用Dï¼›ه¤ڑن¸ھID
é—®é¢کï¼ڑA调用F,Bن¹ں调用F,那ن¹ˆFçڑ„returnن¼ڑه‡؛çژ°ه’Œن¸ٹé¢ن¸€و ·çڑ„é—®é¢ک
解ه†³ï¼ڑshadow stack,ن¸؛è؟”ه›ه€¼ç»´وٹ¤هڈ¦ن¸€ن¸ھو ˆï¼Œç”¨ن؛ژو£€وں¥è؟”ه›çڑ„ه‡†ç،®و€§م€‚
ه®é™…ن¸ٹCFIن¸چ能ه½»ه؛•éک²ه¾،é’ˆه¯¹ن؛ژوژ§هˆ¶وµپه›¾çڑ„و”»ه‡»ï¼Œن½†ه·²ç»ڈه¾—هˆ°ن؛†ه¾ˆه¥½çڑ„و•ˆوœ

Blind ROP(盲è؟”ه›ه¯¼هگ‘编程)
هپ‡è®¾هڈھçں¥éپ“وœچهٹ،ه™¨وœ‰و ˆو؛¢ه‡؛é—®é¢ک,ن¸چçں¥éپ“ن؛Œè؟›هˆ¶و–‡ن»¶ï¼Œن¸چçں¥éپ“ه†…هکهœ°ه€ç©؛é—´
هڈ‘é€پن¸€ن¸ھHTTP请و±‚,ه¾—هˆ°çڑ„è؟”ه›ه€¼ن¸‰ç§چوƒ…ه†µï¼ڑو£ه¸¸è؟”ه›ï¼ˆو— è®؛وک¯ç½‘é،µor404,هڈچو£وک¯و²،ه´©ï¼‰/è؟وژ¥و–ه¼€/kale
هپ‡è®¾وˆ‘ن»¬é€ڑè؟‡و ˆو؛¢ه‡؛,覆盖هˆ°ن¸€éƒ¨هˆ†return addressو—¶ï¼Œوˆ‘ن»¬هڈ¯ن»¥é€ڑè؟‡nو¬،ه°è¯•ï¼Œه¾—هˆ°return addressçڑ„ه‰چه‡ ن½چ(错çڑ„都ه´©ن؛†ï¼Œو²،ه´©و„ڈه‘³ç€وک¯و£ç،®çڑ„),هگŒو ·çڑ„و”»ه‡»و–¹و³•هڈ¯ن»¥و”»ç ´é‡‘ن¸é›€
ن¸؛ن»€ن¹ˆو¯ڈو¬،هœ°ه€éƒ½ن¸€و ·â€”—ه› ن¸؛nginxçڑ„وœچهٹ،è؟›ç¨‹وک¯ن»ژ父è؟›ç¨‹forkه‡؛و¥çڑ„


ه¦‚وœوˆ‘ن»¬éœ€è¦پè؟›è،Œو”»ه‡»ï¼Œه°±è¦په¾—هˆ°ن؛Œè؟›هˆ¶و–‡ن»¶ï¼›ن»چ然هپڑه°è¯•ï¼Œوˆ‘ن»¬é€ڑè؟‡ن»…ن؟®و”¹return addressçڑ„هگژن¸¤ن½چ(ن¸€èˆ¬ن¸چن¼ڑوٹ¥é”™ï¼‰ï¼ŒهگŒو ·هڈ¯ن»¥ه¾—هˆ°ن¸‰ç§چوƒ…ه†µï¼ˆو£ه¸¸è؟”ه›/è؟وژ¥و–ه¼€/kale)
و‰¾هˆ°returnï¼ڑ
- وˆ‘ن»¬è¦†ç›–ن¸¤ن¸ھهœ°ه€ï¼Œé‚£ن¹ˆreturnهگژه°±ن¼ڑè·³هˆ°ç¬¬ن؛Œن¸ھهœ°ه€
- هپ‡è®¾وˆ‘ن»¬ه…ˆه°†ç¬¬ن؛Œن¸ھهœ°ه€è®¾ç½®وˆگو–ه¼€è؟وژ¥çڑ„هœ°ه€ï¼Œè؟گè،Œï¼Œهڈ‘çژ°è؟وژ¥و–ه¼€
- ه†چه°†ç¬¬ن؛Œن¸ھهœ°ه€و”¹وˆگkaleçڑ„هœ°ه€ï¼Œè؟گè،Œï¼Œهڈ‘çژ°kale,说وکژ第ن¸€ن¸ھهœ°ه€و‰§è،Œن؛†return
然هگژوˆ‘ن»¬éœ€è¦پو‰¾هˆ°èƒ½ه¤ںن؟®و”¹ه†…هکçڑ„ن»£ç پ,ه…·ن½“而言ه°±وک¯éœ€è¦پو‰¾هˆ°pop %rdi; return; ن¹‹ç±»çڑ„ن»£ç پ,وک¾ç„¶وک¯ه¾ˆéڑ¾çڑ„,وˆ‘ن»¬ن»ژ简هچ•çڑ„ه¼€ه§‹م€‚
وˆ‘ن»¬çژ°هœ¨éœ€è¦پ调用writeه‡½و•°ï¼Œé‚£ن¹ˆوˆ‘ن»¬éœ€è¦پن؟®و”¹rdi/rsi/rdxن¸‰ن¸ھه¯„هکه™¨çڑ„ه€¼ï¼Œه¤–هٹ 调用+return

而x86و±‡ç¼–هœ¨ه‡½و•°وœ«ه°¾ه¸¸وœ‰ن»¥ن¸‹çڑ„ن»£ç پو®µï¼Œه› ن¸؛è؟™ن؛›ه¯„هکه™¨وک¯callee saveه¯„هکه™¨ï¼Œو‰€ن»¥ه‡½و•°ه‰چن¼ڑوœ‰ه¤§و®µpush,ه‡½و•°هگژن¼ڑوœ‰ه¤§و®µpop

وˆ‘ن»¬هڈ¯ن»¥é€ڑè؟‡è؟ç»ن؟®و”¹8ن¸ھreturn address,然هگژن؟®و”¹وœ€هگژن¸€ن¸ھ,看能هگ¦ه¼•هڈ‘结وœçڑ„هڈکهŒ–,و¥هˆ¤و–وک¯ن¸چوک¯و‰§è،Œن؛†ن»¥ن¸ٹ6ن¸ھpop
而ن¸ٹé¢è؟™و®µن»£ç پهڈ¯ن»¥é€ڑè؟‡و–ç« هڈ–ن¹‰و‰§è،Œpop rdiه’Œpop rsi

وˆ‘ن»¬ه†چه°è¯•ن؟®و”¹rdxï¼›ه› ن¸؛rdxوک¯caller saveه¯„هکه™¨ï¼Œه°±هڈ¯ن»¥é€ڑè؟‡è°ƒç”¨ه…¶ن»–ه‡½و•°ن؟®و”¹rdx,而è؟™و ·çڑ„能ن؟®و”¹rdxçڑ„ه‡½و•°هŒ…و‹¬ç³»ç»ںه‡½و•°strcmp,而è؟™ç§چه‡½و•°ن¼ڑهکه‚¨هœ¨PLTن¸
PLTè،¨وœ‰ن¸¤ن¸ھ特点ï¼ڑهœ°ه€8ه¯¹é½گï¼›ه…¶ن¸ه…¨éƒ¨وک¯هڈ¯و‰§è،Œçڑ„هœ°ه€ï¼Œن¸چن¼ڑه¯¼è‡´ه´©و؛ƒ
ه½“وˆ‘ن»¬و‰¾هˆ°PLTè،¨ï¼Œه°±هڈ¯ن»¥é€ڑè؟‡ن؟®و”¹rdiم€پrsiو¥و‰¾هˆ°strcmp,و–¹و³•وک¯é€ڑè؟‡ن¸‹é¢è؟™ç§چو–¹ه¼ڈوµ‹è¯•ç»“وœ

وœ€هگژوˆ‘ن»¬éœ€è¦پو‰¾هˆ°write,هگŒو ·ن½؟用PLTè،¨ï¼Œو£€وں¥وک¯هگ¦èƒ½و”¶هˆ°ن¸€ن؛›ن¹±ç پم€‚
و•°وچ®وµپè·ںè¸ھ
وˆ‘ن»¬وœ€هˆçڑ„ç›®و ‡وک¯ن؟وٹ¤و•°وچ®ï¼Œé‚£ن¹ˆèƒ½ن¸چ能é€ڑè؟‡è·ںè¸ھو•°وچ®وµپهٹ¨ï¼Œé™گهˆ¶éڑگç§پو•°وچ®هڈ‘é€پï¼ں
هژںçگ†ï¼ڑé€ڑè؟‡è®،算,ç¦پو¢jmpهˆ°ن¸€ن¸ھ被وں“色(taintن¸؛true)(用وˆ·هڈ¯وژ§هˆ¶ï¼‰çڑ„هœ°ه€ï¼Œوک¯هٹ¨و€پوژ§هˆ¶çڑ„

هژںçگ†ه°±وک¯هœ¨ه†…هکç؛§هˆ«هپڑن¸€ن¸ھtaintè،¨ï¼Œç¦پو¢ه°†taintن¸؛trueçڑ„ه€¼هڈ‘é€په‡؛هژ»م€‚ن½†وک¯taintن¹ںوک¯èƒ½é€ڑè؟‡وژ§هˆ¶وµپ被و´—وژ‰çڑ„م€‚
Secure Channelه®‰ه…¨é€ڑéپ“
ه¦‚ن½•ن؟è¯پ设ه¤‡ن¸ژ设ه¤‡é—´çڑ„ه®‰ه…¨
- ن¸¤è¾¹ه…±ن؛«ن¸€ن¸ھه¯†é’¥key(除ééپچهژ†keyهگ¦هˆ™ه¾—ن¸چهˆ°ه†…ه®¹ï¼‰
- هڈŒو–¹ه…±ن؛«ن¸€ن¸ھه¯†é’¥ï¼ˆkey),用ه®ƒهٹ ه¯†ه’Œè§£ه¯†و¶ˆوپ¯م€‚
- ه®‰ه…¨و€§ï¼ڑه¦‚وœن¸é—´è€…ن¸چçں¥éپ“ه¯†é’¥ï¼Œه°±و— و³•è§£ه¯†ه†…ه®¹ï¼Œن½†ه¯†é’¥ن¸€و—¦و³„露,و¶ˆوپ¯ه°±ن¸چه®‰ه…¨ن؛†م€‚
- macï¼ڑkeyه’Œmessageن¸€èµ·هٹ ه¯†ه¾—هˆ°token,token用ن؛ژو ،éھŒï¼Œéک²و¢è¢«ç¯،و”¹ï¼ˆن¸é—´è€…هڈ¯ن»¥و‹¦وˆھAهˆ°Bçڑ„و¶ˆوپ¯ï¼Œه¹¶ن¸چو–ç»™Bé‡چهڈ‘,هڈ¯ن»¥هڈچه¤چ让Bو‰§è،ŒهگŒو ·çڑ„و“چن½œï¼Œو¯”ه¦‚解é”پ车门)
- 用keyه’Œو¶ˆوپ¯ن¸€èµ·ç”ںوˆگن¸€ن¸ھtoken,هڈ‘é€پç»™وژ¥و”¶و–¹م€‚
- وژ¥و”¶و–¹ç”¨هگŒو ·çڑ„و–¹و³•ç”ںوˆگtoken,و¯”ه¯¹وک¯هگ¦ن¸€è‡´م€‚
- هœ¨و¶ˆوپ¯ن¸هٹ ه…¥ن¸€ن¸ھهڈکهŒ–çڑ„seq,用ن؛ژéک²و¢هڈچه¤چوµ‹è¯•ï¼ˆéپ؟ه…چن؛†é‡چهڈ‘,ن½†وک¯ن¸¤è¾¹çڑ„seqوک¯ن¸€و ·çڑ„,ن¸é—´è€…هڈ¯ن»¥وˆھهڈ–Aç»™Bçڑ„seq,و‹¼وژ¥هˆ°è‡ھه·±çڑ„هپ‡و¶ˆوپ¯ن¸ٹ,ه†’ه……Bç»™Aهڈ‘)
- Diffie-Hellmanï¼ڑن¸¤è¾¹ن؛¤وچ¢ه…¬é’¥ï¼Œç„¶هگژهˆ†هˆ«ç”¨ه¯¹و–¹çڑ„ه…¬é’¥هٹ ه¯†ï¼Œç”¨è‡ھه·±çڑ„ç§پ钥解ه¯†ï¼ˆن¸é—´è€…هڈ¯ن»¥هœ¨ه¯†é’¥ن؛¤وچ¢و—¶و‹¦وˆھ,然هگژن¸€ç›´هœ¨ن¸é—´è½¬هڈ‘و¶ˆوپ¯ï¼‰
- هڈŒو–¹ن؛¤وچ¢ه…¬é’¥ï¼Œهگ„è‡ھ用ه¯¹و–¹çڑ„ه…¬é’¥ه’Œè‡ھه·±çڑ„ç§پé’¥è®،ç®—ن¸€ن¸ھ“ه…±ن؛«ه¯†é’¥â€م€‚
- ن¸é—´è€…هڈ¯ن»¥و‹¦وˆھه¹¶و›؟وچ¢ه…¬é’¥ï¼Œه’ŒهڈŒو–¹هˆ†هˆ«ه»؛ç«‹ن¸چهگŒçڑ„“ه…±ن؛«ه¯†é’¥â€ï¼Œè®©è‡ھه·±هڈکوˆگن¸é—´ن»£çگ†م€‚
- RSAه…¬ç§پé’¥هٹ ه¯†ï¼ڑAن»ژ网络ن¸ٹçڑ„وƒه¨پوœ؛و„ه¾—هˆ°Bçڑ„ه…¬é’¥ï¼ˆوˆ–者Bç»™Aهڈ‘é€په…¬é’¥ه’Œوƒه¨پوœ؛و„هڈ‘و”¾çڑ„è¯پن¹¦ï¼‰
- Aé€ڑè؟‡وƒه¨پوœ؛و„èژ·هڈ–Bçڑ„ه…¬é’¥ï¼ˆوˆ–Bوڈگن¾›ه…¬é’¥ه’Œوœ؛و„ç¾هڈ‘çڑ„è¯پن¹¦ï¼‰م€‚
- A用Bçڑ„ه…¬é’¥هٹ ه¯†و¶ˆوپ¯ï¼Œهڈھوœ‰Bçڑ„ç§پ钥能解ه¯†م€‚
- ن¼ک点ï¼ڑه…¬é’¥وک¯ه…¬ه¼€çڑ„,ن¸چو€•و³„露,ç§پé’¥هœ¨è‡ھه·±و‰‹ن¸ه®‰ه…¨م€‚
Data Privacyو•°وچ®éڑگç§پ
| وٹ€وœ¯ | و ¸ه؟ƒé—®é¢ک | و ¸ه؟ƒç‰¹ç‚¹ |
|---|---|---|
| OT(éپ—ه؟کن¼ 输) | éڑگè—ڈو•°وچ®éœ€و±‚ | و•°وچ®é€‰و‹©è؟‡ç¨‹ن¸چوڑ´éœ² |
| DP(ه·®هˆ†éڑگç§پ) | éک²و¢ن¸ھن؛؛و•°وچ®و³„露 | و·»هٹ ه™ھه£°وˆ–é™گهˆ¶وں¥è¯¢ |
| Secret Sharing(ç§که¯†ه…±ن؛«ï¼‰ | ه¤ڑن؛؛èپ”هگˆوپ¢ه¤چو•°وچ® | ه®‰ه…¨هˆ†هڈ‘و•°وچ®ï¼Œن½†éœ€è¦پkن¸ھن»¥ن¸ٹèپ”هگˆ |
| HE(هگŒو€پهٹ ه¯†ï¼‰ | و•°وچ®éڑگç§پن¸ژè®،算需و±‚ | ه¯†و–‡ç›´وژ¥è®،算,ن؟وٹ¤و•°وچ®éڑگç§پ |
| TEE(هڈ¯ن؟،و‰§è،Œçژ¯ه¢ƒï¼‰ | و•°وچ®è؟گè،Œçژ¯ه¢ƒçڑ„ه®‰ه…¨ | ç،¬ن»¶éڑ”离ه’Œه†…هکهٹ ه¯†ï¼Œéک²و¢وپ¶و„ڈ程ه؛ڈو”»ه‡» |
OT-Oblivious Transfer
Aوœ‰ن¸¤ن¸ھو•°وچ®ï¼›Bوƒ³è¦پن¸€ن¸ھ,ن½†وک¯Bن¸چوƒ³è®©Açں¥éپ““وˆ‘â€وƒ³è¦په“ھن¸ھ
Aç”ںوˆگن¸¤ه¯¹ه…¬ç§پ钥,هˆ†هˆ«ه¯¹ه؛”ن¸€ن¸ھو•°وچ®ï¼›Bç”ںوˆگن¸€ن¸ھéڑڈوœ؛و•°r,ه¹¶é€ڑè؟‡وƒ³è¦پçڑ„و•°وچ®çڑ„ه…¬é’¥هٹ ه¯†ï¼Œهڈ‘ç»™Aï¼›Aه¾—هˆ°و¶ˆوپ¯هگژ用ن¸¤ن¸ھç§پ钥解ه¯†ه¾—هˆ°k0,k1(ه…¶ن¸وœ‰ن¸€ن¸ھوک¯r),然هگژه°†ن¸¤ن¸ھو•°وچ®هˆ†هˆ«ن¸ژk0,k1,هپڑه¼‚وˆ–,ه…¨éƒ¨هڈ‘ç»™Bï¼›Bه†چه’Œrهپڑن¸€و¬،ه¼‚وˆ–,ه°±èƒ½ه¾—هˆ°è‡ھه·±è¦پçڑ„و•°وچ®
Aن¸چو¸…و¥ڑBهˆ°ه؛•è¦په“ھن¸€ن¸ھو•°وچ®م€‚
Bن؟è¯پè‡ھه·±هڈھو‹؟هˆ°éœ€è¦پçڑ„و•°وچ®ï¼Œن¸چو³„露و„ڈه›¾م€‚
DP-Differencial Privacyه·®هˆ†éڑگç§پ
Bو•°وچ®ه؛“ن¸وœ‰هگ„ç§چو•°وچ®ï¼Œهڈھو”¯وŒپه¤ڑو،و•°وچ®ن¸€èµ·è؟”ه›ï¼›ن½†وک¯Aوƒ³ه¾—هˆ°ن¸€ن¸ھن؛؛çڑ„و•°وچ®م€‚وک¾ç„¶Aهڈ¯ن»¥é€ڑè؟‡ه¤ڑو¬،هڈچه¤چç›é€‰ه¾—هˆ°وƒ³è¦پوک¯و•°وچ®م€‚و‰€ن»¥Bçڑ„ه¤„çگ†و–¹ه¼ڈوک¯ï¼ڑè؟”ه›ه€¼هˆ†و®µï¼ˆè؟”ه›ن¸€ن¸ھè؟‘ن¼¼ه€¼è€Œéç²¾ç،®ه€¼ï¼Œوœ‰وچںçڑ„);设ه®ڑ询问预算(هœ¨و•°وچ®ه؛“وœھو›´و–°ه‰چ,Bهڈھ能询问ه‡ و¬،)è؟™و ·هچ³ن½؟و•°وچ®è¢«ه¤ڑو¬،وں¥è¯¢ï¼Œن»چ然و— و³•ه¾—هˆ°ç²¾ç،®çڑ„ن¸ھن؛؛ن؟،وپ¯م€‚
Secret Sharing
هپ‡è®¾nن¸ھن؛؛ه…±ن؛«ن¸€ن¸ھو•°وچ®ï¼Œهˆ†وˆگnن»½ï¼Œè€Œهڈھè¦پوœ‰ن»»و„ڈkن¸ھن؛؛ه°±èƒ½وپ¢ه¤چه‡؛و•°وچ®
هژںçگ†ï¼ڑSن¸؛هٹ ه¯†و•°وچ®ï¼Œf(x) = S + a1x + a2x + … + ak-1xk-1,nن¸ھن؛؛و‹؟ن¸چهگŒçڑ„x,kن¸ھن؛؛ه°±èƒ½è§£ه‡؛ه…¨éƒ¨ai
ن¼ک点ï¼ڑوک¯ن¸€ن¸ھن؟،وپ¯çگ†è®؛ن¸ٹه®‰ه…¨çڑ„هچڈè®®
ç¼؛点ï¼ڑçگ†وƒ³هپ‡è®¾ï¼ˆè‡³ه°‘ k ن¸ھ部هˆ†و°¸è؟œن¸چن¼ڑن¸²é€ڑ) é€ڑن؟،ه¼€é”€
HE–Homomorphic EncryptionهگŒو€پهٹ ه¯†
能هگ¦ه®çژ°ه¯†و–‡هٹ ه‡ڈن¹ک除ه¾—هˆ°çڑ„结وœï¼Œن¹ںوک¯هژںو–‡هٹ ه‡ڈن¹ک除ه¾—هˆ°çڑ„结وœه¯¹ه؛”çڑ„ه¯†و–‡ï¼ˆç”¨ن؛ژن؛‘ن¸ٹè؟گ算)
SWHE(SomeWhat Homomorphic Encryption)部هˆ†هگŒو€پهٹ ه¯†ï¼ڑو”¯وŒپ部هˆ†و“چن½œçڑ„هگŒو€پهٹ ه¯†
FHE(Full Homomorphic Encryption)ه…¨هگŒو€پهٹ ه¯†ï¼ڑو‰€وœ‰è؟گ算都و”¯وŒپï¼›هپڑن¸چهˆ°
و•°وچ®هœ¨هٹ ه¯†çٹ¶و€پن¸‹هڈ¯ن»¥è®،算,ن؟وٹ¤éڑگç§پم€‚
ç¼؛点ï¼ڑه…¨هگŒو€پهٹ ه¯†ç›®ه‰چو•ˆçژ‡è¾ƒن½ژم€‚هپڑن¸چهˆ°
TEE-Trusted Execution Environmentهڈ¯ن؟،و‰§è،Œçژ¯ه¢ƒ
هژںçگ†ï¼ڑه†…هکهٹ ه¯†ï¼Œهٹ è½½هˆ°cacheن¸هڈکوˆگوکژو–‡

TEE هڈ¯ن»¥è®؟é—®و‰€وœ‰ DRAM ه’Œه¤–ه›´è®¾ه¤‡ï¼›REE و— و³•è®؟é—® TEE çڑ„资و؛گ
ç¼؛点ï¼ڑه؟…é،»ن؟،ن»»ç،¬ن»¶هژ‚ه•†