
Index
第дёҖз« пјҡStateful and Stateless пјҢCookie and Session, е®һдҫӢжұ , Scope пјҢж•°жҚ®еә“иҝһжҺҘжұ
第дәҢз« пјҡMessaging , еҗҢжӯҘејӮжӯҘйҖҡдҝЎпјҢдёүз§Қи®ўйҳ…ж–№ејҸеҜ№жҜ” пјҢKafka
第дёүз« пјҡWebsocket
第еӣӣз« пјҡTransactionпјҲACID и„ҸиҜ»е№»иҜ»пјүпјҢдёӨйҳ¶ж®өжҸҗдәӨпјҢд№җи§Ӯ/жӮІи§ӮзҰ»зәҝрҹ”’
第дә”з« пјҡи°ғеәҰпјҲеҸҜдёІиЎҢеҢ–и°ғеәҰпјүпјҢеҗ„з§Қж—Ҙеҝ—пјҲйҖ»иҫ‘/зү©зҗҶ/redo/undo/redoundo/иЎҘеҒҝпјүпјҢзі»з»ҹеҙ©жәғжҒўеӨҚе®һзҺ°
第е…ӯз« пјҡзәҝзЁӢпјҲеӨҡзәҝзЁӢпјҢзәҝзЁӢжұ пјҢзәҝзЁӢе№Іжү°пјҢSynchronizedпјүпјҢй«ҳзә§е№¶еҸ‘зү№жҖ§пјҢFork/Join
第дёғз« пјҡCacheпјҢMemcacheпјҢRedisпјҢдёҖиҮҙжҖ§е“ҲеёҢ
з¬¬е…«з« пјҡеҸҚеҗ‘зҙўеј•пјҢLucene
第д№қз« пјҡSOAPпјҢRestfulпјҢWeb ServiceпјҢSOA
第еҚҒз« пјҡMicroServiceпјҢEurakaпјҢServerless
第еҚҒдёҖз« пјҡMysqlдјҳеҢ–1пјҲж–Ҫе·Ҙдёӯвҡ пёҸпјүIn a big mess , Who can help meрҹҳӯ
第еҚҒдәҢз« пјҡMysqlдјҳеҢ–2пјҲж–Ҫе·Ҙдёӯвҡ пёҸпјүIn a big mess , Who can help meрҹҳӯ
第еҚҒдёүз« пјҡMysqlж•°жҚ®еә“жҒўеӨҚдёҺеӨҮд»ҪпјҲйҖ»иҫ‘зү©зҗҶеӨҮд»ҪпјҢbinlogпјҢsnapshotпјү
第еҚҒеӣӣз« пјҡMySQLеҲҶеҢә
第еҚҒдә”з« пјҡNosqlпјҢMongoDBпјҢDAOе’ҢRepositoryе·®ејӮпјҢshardingиҝҮзЁӢ
第еҚҒе…ӯз« пјҡеӣҫж•°жҚ®еә“пјҢNeo4j
第еҚҒдёғз« пјҡLSM-Tree, ssTableпјҢеҗ‘йҮҸж•°жҚ®еә“
第еҚҒе…«з« пјҡж—¶еәҸж•°жҚ®еә“пјҢinfluxDB
第еҚҒд№қз« пјҡGaussDBпјҢдә‘ж•°жҚ®еә“
第дәҢеҚҒз« пјҡData WarehouseпјҢData Lake
第дәҢеҚҒдёҖз« пјҡClusterпјҢйӣҶзҫӨпјҢиҙҹиҪҪеқҮиЎЎпјҢsessionз»ҙжҠӨпјҢNginxпјҢеҸҚеҗ‘д»ЈзҗҶ
第дәҢеҚҒдәҢз« пјҡcloud computingпјҢMapReduceпјҢedge computing
第дәҢеҚҒдёүз« пјҡGraphQL(д»ҘеҸҠе’Ң RESTful APIпјүеҜ№жҜ”
第дәҢеҚҒеӣӣз« пјҡDockerпјҢImageпјҢVolumeпјҢmounts
第дәҢеҚҒдә”з« пјҡHadoopпјҢ Reducerж•°зӣ® пјҢYarn
第дәҢеҚҒе…ӯз« пјҡSpark
第дәҢеҚҒдёғз« пјҡStromпјҢHadoop е’Ң StormеҜ№жҜ”
第дәҢеҚҒе…«з« пјҡHdfs
第дәҢеҚҒд№қз« пјҡHbaseпјҢWeb Table
第дёүеҚҒз« пјҡHIVEпјҢETLпјҢHIVEе’Ңдј з»ҹж•°жҚ®еә“зҡ„еҜ№жҜ”
第дёүеҚҒдёҖз« пјҡFLINK
第дёүеҚҒдәҢз« пјҡAI
第дёҖз«
Stateful and Stateless
| еҜ№жҜ”з»ҙеәҰ | Stateful | Stateless |
|---|---|---|
| е®ҡд№ү | жңҚеҠЎеҷЁз»ҙжҠӨе®ўжҲ·з«ҜзҠ¶жҖҒ | жңҚеҠЎеҷЁдёҚз»ҙжҠӨе®ўжҲ·з«ҜзҠ¶жҖҒ |
| зҠ¶жҖҒеӯҳеӮЁ | жңҚеҠЎеҷЁдҝқеӯҳзҠ¶жҖҒпјҲдјҡиҜқгҖҒдёҠдёӢж–Үпјү | жңҚеҠЎеҷЁдёҚдҝқеӯҳзҠ¶жҖҒпјҢе®ўжҲ·з«ҜжҜҸж¬ЎеҸ‘йҖҒе®Ңж•ҙиҜ·жұӮдҝЎжҒҜ |
| иҜ·жұӮзӢ¬з«ӢжҖ§ | иҜ·жұӮд№Ӣй—ҙдҫқиө–еҺҶеҸІзҠ¶жҖҒ | жҜҸдёӘиҜ·жұӮзӢ¬з«ӢпјҢж— йңҖеҺҶеҸІдҝЎжҒҜ |
| иө„жәҗеҚ з”Ё | й«ҳпјҢеҚ з”ЁжңҚеҠЎеҷЁеҶ…еӯҳжҲ–еӯҳеӮЁиө„жәҗ | дҪҺпјҢжңҚеҠЎеҷЁж— зҠ¶жҖҒеӯҳеӮЁ |
| жү©еұ•жҖ§ | йҡҫд»Ҙжү©еұ•пјҢйңҖиҰҒеҗҢжӯҘзҠ¶жҖҒ | жҳ“дәҺжү©еұ•пјҢж— йңҖзҠ¶жҖҒеҗҢжӯҘ |
| е®№й”ҷжҖ§ | е®№й”ҷжҖ§дҪҺпјҢжңҚеҠЎеҷЁж•…йҡңдјҡеҜјиҮҙзҠ¶жҖҒдёўеӨұ | е®№й”ҷжҖ§й«ҳпјҢжңҚеҠЎеҷЁж— зҠ¶жҖҒеҪұе“Қ |
| еӨҚжқӮжҖ§ | жңҚеҠЎеҷЁи®ҫи®ЎеӨҚжқӮпјҢйңҖз»ҙжҠӨдјҡиҜқдҝЎжҒҜ | е®ўжҲ·з«Ҝи®ҫи®ЎеӨҚжқӮпјҢйңҖжҸҗдҫӣе®Ңж•ҙиҜ·жұӮдҝЎжҒҜ |
| зӨәдҫӢеҚҸи®®/жҠҖжңҜ | FTPгҖҒTelnetгҖҒWebSocket | HTTPгҖҒRESTful APIгҖҒDNS жҹҘиҜў |
| йҖӮз”ЁеңәжҷҜ | е®һж—¶дә’еҠЁгҖҒй•ҝж—¶й—ҙдјҡиҜқпјҲ银иЎҢгҖҒжёёжҲҸпјү | й«ҳ并еҸ‘гҖҒж— зҠ¶жҖҒдәӢеҠЎпјҲжҗңзҙўеј•ж“ҺгҖҒеҫ®жңҚеҠЎпјү |
| дјҳзӮ№ | дҫҝдәҺеӨ„зҗҶеӨҚжқӮдәӨдә’пјҢж”ҜжҢҒе®һж—¶зҠ¶жҖҒз®ЎзҗҶ | з®ҖеҢ–жңҚеҠЎеҷЁи®ҫи®ЎпјҢжҳ“жү©еұ• |
| зјәзӮ№ | й«ҳиө„жәҗеҚ з”ЁпјҢйҡҫд»Ҙжү©еұ• | зҪ‘з»ңејҖй”ҖеӨ§пјҢдёҚж”ҜжҢҒеӨҚжқӮдјҡиҜқ |
Cookie and Session
HttpеҚҸи®®жҳҜдёҖз§Қж— зҠ¶жҖҒзҡ„еҚҸи®®пјҢдҪҶжҳҜжңүж—¶йңҖиҰҒи®°еҪ•зҠ¶жҖҒпјҢиҫҫжҲҗStatefulгҖӮдёәжӯӨпјҢжңүдәҶCookieе’ҢSessionгҖӮ
- Cookieпјҡе®ўжҲ·з«ҜжөҸи§ҲеҷЁз”ЁжқҘдҝқеӯҳз”ЁжҲ·дҝЎжҒҜзҡ„дёҖз§ҚжңәеҲ¶пјӣеҪ“жҲ‘们йҖҡиҝҮжөҸи§ҲеҷЁиҝӣиЎҢзҪ‘йЎөи®ҝй—®зҡ„ж—¶еҖҷпјҢжңҚеҠЎеҷЁдјҡе°ҶдёҖдәӣж•°жҚ®д»ҘCookieзҡ„еҪўејҸдҝқеӯҳеңЁе®ўжҲ·з«ҜжөҸи§ҲеҷЁдёҠпјҢеҪ“дёӢж¬Ўе®ўжҲ·з«ҜжөҸи§ҲеҷЁеҶҚж¬Ўи®ҝй—®иҜҘзҪ‘з«ҷж—¶пјҢдјҡе°ҶCookieж•°жҚ®еҸ‘йҖҒз»ҷжңҚеҠЎеҷЁпјҢжңҚеҠЎеҷЁйҖҡиҝҮCookieж•°жҚ®жқҘиҫЁеҲ«з”ЁжҲ·иә«д»ҪгҖӮпјҲCookieеӯҳзҡ„жҳҜkey-valueй”®еҖјеҜ№пјү
- SessionпјҡиЎЁзӨәдёҖдёӘдјҡиҜқпјҢжҳҜеұһдәҺжңҚеҠЎеҷЁз«Ҝзҡ„дёҖз§Қе®№еҷЁеҜ№иұЎпјӣй»ҳи®Өжғ…еҶөдёӢпјҢй’ҲеҜ№жҜҸдёӘжөҸи§ҲеҷЁзҡ„иҜ·жұӮпјҢserverйғҪдјҡеҲӣе»әдёҖдёӘsessionеҜ№иұЎпјҢз”ҹжҲҗдёҖдёӘsessionIdпјҢз”ЁдәҺж ҮиҜҶиҜҘsessionеҜ№иұЎпјҢеҗҢж—¶е°Ҷ sessionIdд»Ҙcookieзҡ„еҪўејҸеҸ‘йҖҒз»ҷе®ўжҲ·з«ҜжөҸи§ҲеҷЁпјҢе®ўжҲ·з«ҜжөҸи§ҲеҷЁеҶҚж¬Ўи®ҝй—®иҜҘзҪ‘з«ҷж—¶пјҢдјҡе°Ҷcookieж•°жҚ®еҸ‘йҖҒз»ҷжңҚеҠЎеҷЁпјҢжңҚеҠЎеҷЁйҖҡиҝҮcookieж•°жҚ®жқҘиҫЁеҲ«з”ЁжҲ·иә«д»ҪпјҢд»ҺиҖҢжүҫеҲ°еҜ№еә”зҡ„sessionеҜ№иұЎпјҢеҰӮжһңжүҫдёҚеҲ°пјҢе°ұдјҡеҲӣе»әдёҖдёӘж–°зҡ„sessionеҜ№иұЎгҖӮз®ҖеҚ•жқҘиҜҙпјҢSessionзҡ„дҪңз”Ёе°ұжҳҜеё®еҠ©жҲ‘们е®һзҺ°дёҖдёӘжңүзҠ¶жҖҒзҡ„ HttpеҚҸи®®гҖӮ
е®һдҫӢжұ пјҲеҜ№иұЎжұ пјү
“еҜ№иұЎжұ ”пјҲObject PoolпјүжҳҜдёҖз§Қи®ҫи®ЎжЁЎејҸпјҢе®ғжҳҜдёҖз§Қз”ЁдәҺз®ЎзҗҶе’ҢйҮҚз”ЁеҜ№иұЎе®һдҫӢзҡ„жңәеҲ¶пјҢд»ҘжҸҗй«ҳжҖ§иғҪе’Ңиө„жәҗеҲ©з”ЁзҺҮзҡ„ж–№ејҸгҖӮеҜ№иұЎжұ йҖҡеёёз”ЁдәҺеҮҸе°‘еҲӣе»әе’Ңй”ҖжҜҒеҜ№иұЎзҡ„ејҖй”ҖпјҢзү№еҲ«жҳҜеңЁеҜ№иұЎзҡ„еҲӣе»әжҲҗжң¬иҫғй«ҳжҲ–йў‘з№ҒеҲӣе»әе’Ңй”ҖжҜҒеҜ№иұЎеҸҜиғҪеҜјиҮҙжҖ§иғҪдёӢйҷҚзҡ„жғ…еҶөдёӢгҖӮ
еңЁJavaдёӯпјҢеҜ№иұЎжұ йҖҡеёёжҳҜдёҖдёӘйӣҶеҗҲпјҢз”ЁдәҺеӯҳеӮЁе’Ңз®ЎзҗҶеӨҡдёӘеҜ№иұЎе®һдҫӢгҖӮеҪ“йңҖиҰҒдҪҝз”ЁеҜ№иұЎж—¶пјҢеҸҜд»Ҙд»ҺеҜ№иұЎжұ дёӯиҺ·еҸ–дёҖдёӘеҸҜз”Ёзҡ„еҜ№иұЎпјҢиҖҢдёҚжҳҜжҜҸж¬ЎйғҪеҲӣе»әж–°зҡ„еҜ№иұЎгҖӮдёҖж—ҰдҪҝз”Ёе®ҢжҲҗпјҢеҸҜд»Ҙе°ҶеҜ№иұЎиҝ”еӣһеҲ°еҜ№иұЎжұ дёӯпјҢд»ҘдҫҝзЁҚеҗҺйҮҚз”ЁпјҢиҖҢдёҚжҳҜз«ӢеҚій”ҖжҜҒе®ғгҖӮдҪҶжҳҜе®һдҫӢжұ ж•°йҮҸжҳҜжңүдёҠйҷҗзҡ„пјҢдёҚеҸҜиғҪж— йҷҗеҲ¶еҸҳеӨ§пјҲDDosж”»еҮ»еҶ…еӯҳзӣҙжҺҘзҲҶдәҶпјүгҖӮ
еӣ жӯӨпјҢдёәдәҶжңҚеҠЎеӨҡдёӘеҜ№иұЎпјҢеңЁе®һдҫӢжұ ж»ЎдәҶеҗҺпјҢеҸҜд»ҘжҠҠжңҖдёҚеёёз”Ёзҡ„еҜ№иұЎж”ҫеҲ°зЎ¬зӣҳдёҠгҖӮеҰӮжһңжңүйңҖиҰҒеҶҚжҚўеҮәгҖӮ
иҝҷжҳҜеӣ дёәStatefulеј•е…Ҙзҡ„й—®йўҳпјҢеӣ жӯӨзі»з»ҹиҰҒе°ҪйҮҸStatelessпјҢжҲ–иҖ…е°ҪеҸҜиғҪжҺ§еҲ¶е®һдҫӢпјҢд№ҹе°ұжңүдәҶScopeгҖӮ
Scopes
“scope”пјҲдҪңз”Ёеҹҹпјүз”ЁдәҺе®ҡд№үSpringе®№еҷЁеҰӮдҪ•з®ЎзҗҶbeanе®һдҫӢзҡ„з”ҹе‘Ҫе‘Ёжңҹе’ҢеҸҜи§ҒжҖ§гҖӮе…¶дёӯsingletonе’ҢprototypeеҸҜд»ҘеңЁжҜҸдёҖдёӘBeanеҜ№иұЎеүҚйғҪе®ҡд№үпјҢиҖҢе…¶дҪҷзҡ„дҪңз”ЁдәҺж•ҙдёӘWebгҖӮ
| Scope | Description | и§ЈйҮҠ |
|---|---|---|
| singleton | пјҲй»ҳи®Өпјүе°ҶеҚ•дёӘ Bean е®ҡд№үзҡ„дҪңз”ЁеҹҹйҷҗеҲ¶дёәжҜҸдёӘ Spring IoC е®№еҷЁзҡ„еҚ•дёӘеҜ№иұЎе®һдҫӢгҖӮ | ж•ҙдёӘ Spring е®№еҷЁдёӯеҸӘеҲӣе»әдёҖдёӘе®һдҫӢпјҢе…ЁеұҖе…ұдә« |
| prototype | е°ҶеҚ•дёӘ Bean е®ҡд№үзҡ„дҪңз”ЁеҹҹйҷҗеҲ¶дёәд»»ж„Ҹж•°йҮҸзҡ„еҜ№иұЎе®һдҫӢгҖӮ | жҜҸж¬ЎиҺ·еҸ– Bean ж—¶йғҪдјҡеҲӣе»әдёҖдёӘж–°е®һдҫӢпјҢжҜ”еҰӮcontrollerи°ғз”Ёserviceд№ҹдјҡеҲӣе»әж–°зҡ„гҖӮ |
| request | е°ҶеҚ•дёӘ Bean е®ҡд№үзҡ„дҪңз”ЁеҹҹйҷҗеҲ¶дёәеҚ•дёӘ HTTP иҜ·жұӮзҡ„з”ҹе‘Ҫе‘ЁжңҹгҖӮд»…еңЁж”ҜжҢҒ Web зҡ„ Spring ApplicationContext дёӯжңүж•ҲгҖӮ | жҜҸж¬ЎHTTPиҜ·жұӮйғҪдёҖдёӘж–°е®һдҫӢпјҢйҖӮеҗҲдёҺиҜ·жұӮзӣёе…ізҡ„ж•°жҚ®еӨ„зҗҶпјҢжҜ”еҰӮиҜ·жұӮеҸӮж•°ж ЎйӘҢзӯүгҖӮ |
| session | е°ҶеҚ•дёӘ Bean е®ҡд№үзҡ„дҪңз”ЁеҹҹйҷҗеҲ¶дёә HTTP дјҡиҜқзҡ„з”ҹе‘Ҫе‘ЁжңҹгҖӮд»…еңЁж”ҜжҢҒ Web зҡ„ Spring ApplicationContext дёӯжңүж•ҲгҖӮ | жҜҸдёӘ HTTP дјҡиҜқе‘ЁжңҹеҶ…йғҪдјҡжңүзӢ¬з«Ӣзҡ„ Bean е®һдҫӢпјҢйҖӮеҗҲз”ЁжҲ·зҷ»еҪ•зҠ¶жҖҒпјҢеңЁдёҖдёӘsessionеҶ…еӨҡдёӘhttpеҸӘжңүдёҖдёӘе®һдҫӢгҖӮ |
| application | е°ҶеҚ•дёӘ Bean е®ҡд№үзҡ„дҪңз”ЁеҹҹйҷҗеҲ¶дёә ServletContext зҡ„з”ҹе‘Ҫе‘ЁжңҹгҖӮд»…еңЁж”ҜжҢҒ Web зҡ„ Spring ApplicationContext дёӯжңүж•ҲгҖӮ | Bean зҡ„з”ҹе‘Ҫе‘ЁжңҹдёҺж•ҙдёӘ Web еә”з”Ёзҡ„з”ҹе‘Ҫе‘ЁжңҹдёҖиҮҙпјҢйҖӮеҗҲеӯҳеӮЁе…ЁеұҖй…ҚзҪ®гҖҒе…ұдә«иө„жәҗзӯүгҖӮе’ҢsingletonеҢәеҲ«жҳҜз”ЁеңЁwebгҖӮ |
| websocket | е°ҶеҚ•дёӘ Bean е®ҡд№үзҡ„дҪңз”ЁеҹҹйҷҗеҲ¶дёә WebSocket дјҡиҜқзҡ„з”ҹе‘Ҫе‘ЁжңҹгҖӮд»…еңЁж”ҜжҢҒ Web зҡ„ Spring ApplicationContext дёӯжңүж•ҲгҖӮ | жҜҸдёӘ WebSocket дјҡиҜқеҲӣе»әдёҖдёӘ Bean е®һдҫӢпјҢйҖӮеҗҲе®һж—¶йҖҡдҝЎеңәжҷҜдёӢдёҺеҚ•дёӘз”ЁжҲ·иҝһжҺҘзӣёе…ізҡ„ж•°жҚ®жҲ–зҠ¶жҖҒгҖӮ |
з”ЁдёӨдёӘжөҸи§ҲеҷЁпјҲжЁЎжӢҹ2дёӘйҡ”зҰ»зҡ„sessionпјүпјҢеҗ„иҮӘеҸ‘йҖҒ1дёӘrequest
| Controller | |||
| Prototype | session | ||
| Service | prototype | 4 service instances 4 controller instances | 4 service instances 2 controller instances |
| session | 2 service instances 4 controller instances | 2 service instances 2 controller instances | |
ж•°жҚ®еә“иҝһжҺҘжұ
иҝһжҺҘжұ пјҲConnection Poolпјүзҡ„жң¬иҙЁжҳҜзәҝзЁӢжұ пјҢжҳҜдёҖз§Қз”ЁдәҺз®ЎзҗҶе’ҢйҮҚз”Ёж•°жҚ®еә“иҝһжҺҘгҖҒзҪ‘з»ңиҝһжҺҘжҲ–е…¶д»–иө„жәҗиҝһжҺҘзҡ„жҠҖжңҜпјҢж—ЁеңЁжҸҗй«ҳеә”з”ЁзЁӢеәҸжҖ§иғҪе’Ңиө„жәҗеҲ©з”ЁзҺҮгҖӮиҝһжҺҘжұ йҖҡиҝҮз»ҙжҠӨдёҖз»„е·ІеҲӣе»әзҡ„иҝһжҺҘе®һдҫӢпјҢ并еңЁйңҖиҰҒж—¶еҲҶ й…ҚиҝҷдәӣиҝһжҺҘпјҢд»ҘеҮҸе°‘еҲӣе»әе’Ңй”ҖжҜҒиҝһжҺҘзҡ„ејҖй”ҖгҖӮ
иҝһжҺҘжұ ж•°йҮҸпјҲз»ҸйӘҢе…¬ејҸпјү
connections = ((core_count * 2) + effective_spindle_count)
- core_count: CPU ж ёеҝғж•°гҖӮ
- effective_spindle_count: жңүж•ҲзЈҒзӣҳж•°
еҪ“зәҝзЁӢж•°иҝҮеӨ§пјҢзәҝзЁӢдёҠдёӢж–ҮеҲҮжҚўдјҡйҷҚдҪҺж•ҲзҺҮгҖӮиҖҢйҖүжӢ©2еҖҚCPUж ёеҝғж•°жҳҜеӣ дёәиҝҷж ·дёҠдёӢж–ҮеҲҮжҚўжҜ”иҫғе°‘пјҲжңҖеҗҲзҗҶпјүпјҢиҖҢеҠ дёҠжңүж•ҲзЈҒзӣҳж•°жҳҜеӣ дёәеҫҖзЈҒзӣҳеҶҷж—¶и®ӨдёәCPUеҹәжң¬з©әй—ІпјҢдё»иҰҒеҚ з”ЁйҖҡйҒ“гҖӮ
иҝҷиҜҙжҳҺж•°жҚ®еә“иҝһжҺҘж•°е’Ңи®ҝй—®зҡ„ж•°йҮҸжІЎе…ізі»пјҢеҸӘе’ҢиҮӘе·ұ硬件еӣ зҙ жңүе…іпјҢзҗҶжғізҡ„иҝһжҺҘжұ жҳҜ вҖңе°Ҹжұ еӯҗпјҢеӨ§еҺӢеҠӣвҖқпјҡдҪ еёҢжңӣзәҝзЁӢзӯүеҫ…иҺ·еҸ–иҝһжҺҘпјҢиҖҢдёҚжҳҜиҝһжҺҘиҝҮеӨҡеҜјиҮҙз®ЎзҗҶжҲҗжң¬й«ҳгҖӮеӨ„зҗҶдёҚиҝҮжқҘж•°жҚ®еә”иҜҘжҚўеҘҪжңәеҷЁгҖӮ
第дәҢз«
Messaging – JMS
MessagingпјҡжҳҜдёҖз§ҚеңЁиҪҜ件组件жҲ–еә”з”ЁзЁӢеәҸд№Ӣй—ҙиҝӣиЎҢйҖҡдҝЎзҡ„ж–№жі•
жҳҜдёҖз§Қpeer-to-peerзҡ„ж–№ејҸпјҢеӨ§е®¶йғҪдёҖж ·еҸҜд»ҘжҺҘ收д№ҹеҸҜд»ҘеҸ‘йҖҒж¶ҲжҒҜпјҢжҜҸдёӘе®ўжҲ·з«ҜйғҪиҝһжҺҘеҲ°дёҖдёӘж¶ҲжҒҜд»ЈзҗҶпјҢиҜҘд»ЈзҗҶжҸҗдҫӣеҲӣе»әгҖҒеҸ‘йҖҒгҖҒжҺҘ收е’ҢиҜ»еҸ–ж¶ҲжҒҜзҡ„еҠҹиғҪпјҢиҝҷж ·е°ұеҸҜд»Ҙи§ЈеҶіжқҫж•ЈиҖҰеҗҲзҡ„й—®йўҳпјҢдҪҝеҫ—еҲҶеёғејҸжҲҗдёәеҸҜиғҪпјҲеҸҜд»ҘиҪ¬еҸ‘з»ҷе…¶е®ғжңҚеҠЎеҷЁж¶ҲжҒҜдәҶпјҢиҖҢдёҚжҳҜеҸӘеҸҜд»ҘеҺ»еӨ„зҗҶж¶ҲжҒҜ
JMSпјҲJava Mesage ServiceпјүпјҡжҳҜдёҖз§Қ Java APIпјҢе…Ғи®ёеә”з”ЁзЁӢеәҸеҲӣе»әгҖҒеҸ‘йҖҒгҖҒжҺҘ收е’ҢиҜ»еҸ–ж¶ҲжҒҜпјҢејҖжәҗзҡ„е®һзҺ°жңүkafkaпјҢJMSиҝҳе…·еӨҮд»ҘдёӢзү№зӮ№пјҡ
- ејӮжӯҘпјҲAsynchronousпјүпјҡ
- жҺҘ收客жҲ·з«ҜдёҚйңҖиҰҒеңЁеҸ‘йҖҒе®ўжҲ·з«ҜеҸ‘йҖҒж¶ҲжҒҜж—¶з«ӢеҚіжҺҘ收ж¶ҲжҒҜгҖӮеҸ‘йҖҒз«ҜеҸҜд»ҘеҸ‘йҖҒж¶ҲжҒҜ并继з»ӯжү§иЎҢе…¶д»–д»»еҠЎпјӣжҺҘ收з«ҜеҸҜд»ҘзЁҚеҗҺжҺҘ收иҝҷдәӣж¶ҲжҒҜгҖӮ
- еҸҜйқ пјҲReliableпјүпјҡ
- е®һзҺ° JMS API зҡ„ж¶ҲжҒҜжҸҗдҫӣиҖ…еҸҜд»ҘзЎ®дҝқж¶ҲжҒҜд»…иў«дј йҖ’дёҖж¬Ўдё”д»…дёҖж¬ЎгҖӮеҜ№дәҺдёҚйңҖиҰҒй«ҳеҸҜйқ жҖ§зҡ„еә”з”ЁпјҢд№ҹеҸҜд»ҘйҖүжӢ©иҫғдҪҺзҡ„еҸҜйқ жҖ§ж°ҙе№іпјҢжҜ”еҰӮе…Ғи®ёдёўеӨұж¶ҲжҒҜжҲ–жҺҘ收йҮҚеӨҚзҡ„ж¶ҲжҒҜгҖӮ
JMSж¶ҲжҒҜдј иҫ“жЁЎеһӢ
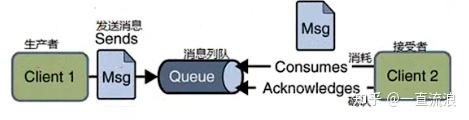
- зӮ№еҜ№зӮ№пјҲPoint-to-PointпјҢP2PпјүжЁЎеһӢпјҡ
- еңЁиҝҷдёӘжЁЎеһӢдёӯпјҢж¶ҲжҒҜз”ҹдә§иҖ…еҸ‘йҖҒж¶ҲжҒҜеҲ°йҳҹеҲ—пјҲQueueпјүпјҢж¶ҲжҒҜж¶Ҳиҙ№иҖ…д»ҺйҳҹеҲ—дёӯжҺҘ收ж¶ҲжҒҜгҖӮ
- жҜҸдёӘж¶ҲжҒҜеҸӘиғҪиў«дёҖдёӘж¶Ҳиҙ№иҖ…жҺҘ收пјҢдёҖж—Ұж¶ҲжҒҜиў«ж¶Ҳиҙ№пјҢе®ғе°ұдјҡд»ҺйҳҹеҲ—дёӯ移йҷӨпјҢзЎ®дҝқж¶ҲжҒҜдёҚдјҡйҮҚеӨҚеӨ„зҗҶгҖӮ
- иҝҷз§ҚжЁЎеһӢйҖӮз”ЁдәҺйңҖиҰҒзЎ®дҝқж¶ҲжҒҜеҸӘиў«еӨ„зҗҶдёҖж¬Ўзҡ„еңәжҷҜпјҢдҫӢеҰӮи®ўеҚ•еӨ„зҗҶгҖҒз”ЁжҲ·иҜ·жұӮеӨ„зҗҶзӯүгҖӮ
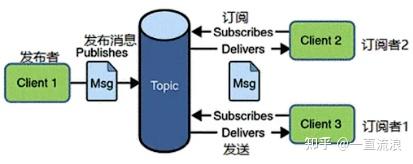
- еҸ‘еёғ/и®ўйҳ…пјҲPublish/SubscribeпјҢPub/SubпјүжЁЎеһӢпјҡ
- еңЁеҸ‘еёғ/и®ўйҳ…жЁЎеһӢдёӯпјҢж¶ҲжҒҜз”ҹдә§иҖ…пјҲеҸ‘еёғиҖ…пјүе°Ҷж¶ҲжҒҜеҸ‘йҖҒеҲ°дё»йўҳпјҲTopicпјүпјҢиҖҢж¶ҲжҒҜж¶Ҳиҙ№иҖ…пјҲи®ўйҳ…иҖ…пјүи®ўйҳ…ж„ҹе…ҙи¶Јзҡ„дё»йўҳгҖӮ
- дёҖдёӘеҸ‘еёғиҖ…еҸ‘йҖҒзҡ„ж¶ҲжҒҜеҸҜд»Ҙиў«еӨҡдёӘи®ўйҳ…иҖ…жҺҘ收пјҢиҝҷдҪҝеҫ—еҸ‘еёғ/и®ўйҳ…жЁЎеһӢйқһеёёйҖӮеҗҲйңҖиҰҒдёҖеҜ№еӨҡйҖҡдҝЎзҡ„еңәжҷҜгҖӮ
- и®ўйҳ…иҖ…еҸҜд»Ҙи®ҫзҪ®иҝҮж»ӨжқЎд»¶пјҢеҸӘжҺҘ收满足зү№е®ҡжқЎд»¶зҡ„ж¶ҲжҒҜпјҢиҝҷеўһеҠ дәҶж¶ҲжҒҜдј иҫ“зҡ„зҒөжҙ»жҖ§гҖӮ
дёӨз§ҚжЁЎеһӢзҡ„зү№зӮ№еҜ№жҜ”пјҡ
- дёҖеҜ№дёҖ vs дёҖеҜ№еӨҡпјҡ
- P2PжЁЎеһӢжҳҜдёҖеҜ№дёҖзҡ„ж¶ҲжҒҜдј иҫ“пјҢжҜҸжқЎж¶ҲжҒҜеҸӘжңүдёҖдёӘж¶Ҳиҙ№иҖ…гҖӮ
- Pub/SubжЁЎеһӢжҳҜдёҖеҜ№еӨҡзҡ„ж¶ҲжҒҜдј иҫ“пјҢдёҖжқЎж¶ҲжҒҜеҸҜд»Ҙиў«еӨҡдёӘи®ўйҳ…иҖ…жҺҘ收гҖӮ
- йҳҹеҲ— vs дё»йўҳпјҡ
- еңЁP2PжЁЎеһӢдёӯпјҢдҪҝз”ЁйҳҹеҲ—дҪңдёәж¶ҲжҒҜзҡ„е®№еҷЁпјҢйҳҹеҲ—дҝқиҜҒдәҶж¶ҲжҒҜзҡ„йЎәеәҸжҖ§е’ҢзӢ¬з«ӢжҖ§гҖӮ
- еңЁPub/SubжЁЎеһӢдёӯпјҢдҪҝз”Ёдё»йўҳдҪңдёәж¶ҲжҒҜзҡ„еҸ‘еёғзӮ№пјҢдё»йўҳе…Ғи®ёеӨҡдёӘи®ўйҳ…иҖ…жҺҘ收ж¶ҲжҒҜгҖӮ
- ж¶ҲжҒҜзЎ®и®Өпјҡ
- еңЁP2PжЁЎеһӢдёӯпјҢж¶Ҳиҙ№иҖ…йҖҡеёёйңҖиҰҒжҳҫејҸзЎ®и®Өж¶ҲжҒҜпјҢе‘ҠзҹҘж¶ҲжҒҜжңҚеҠЎеҷЁж¶ҲжҒҜе·Іиў«жҲҗеҠҹеӨ„зҗҶгҖӮ
- еңЁPub/SubжЁЎеһӢдёӯпјҢи®ўйҳ…иҖ…еҸҜиғҪйңҖиҰҒзЎ®и®Өж¶ҲжҒҜпјҢд№ҹеҸҜиғҪдёҚйңҖиҰҒпјҢиҝҷеҸ–еҶідәҺе…·дҪ“зҡ„е®һзҺ°е’Ңй…ҚзҪ®гҖӮ
- ж¶ҲжҒҜжҢҒд№…жҖ§пјҡ
- еңЁдёӨз§ҚжЁЎеһӢдёӯпјҢйғҪеҸҜд»Ҙй…ҚзҪ®ж¶ҲжҒҜзҡ„жҢҒд№…жҖ§пјҢзЎ®дҝқж¶ҲжҒҜдёҚдјҡеӣ дёәзі»з»ҹж•…йҡңиҖҢдёўеӨұгҖӮ
JMSзҡ„иҝҷдёӨз§Қж¶ҲжҒҜдј иҫ“жЁЎеһӢдёәдёҚеҗҢзҡ„еә”з”ЁеңәжҷҜжҸҗдҫӣдәҶзҒөжҙ»зҡ„ж¶ҲжҒҜдј йҖ’жңәеҲ¶пјҢе…Ғи®ёејҖеҸ‘иҖ…ж №жҚ®дёҡеҠЎйңҖжұӮйҖүжӢ©еҗҲйҖӮзҡ„жЁЎеһӢжқҘе®һзҺ°ж¶ҲжҒҜйҖҡдҝЎгҖӮ
JMSж¶ҲжҒҜж јејҸпјҲдёҚиҜҰз»Ҷеұ•ејҖдәҶпјҢж„ҹи§үдёҚйҮҚиҰҒпјү
- ж¶ҲжҒҜеӨҙ (Header)
- еҝ…йңҖйғЁеҲҶпјҢеҢ…еҗ«дёҺж¶ҲжҒҜзӣёе…ізҡ„еҹәжң¬дҝЎжҒҜпјҢжҜ”еҰӮж¶ҲжҒҜзҡ„зӣ®зҡ„ең°гҖҒж ҮиҜҶз¬ҰгҖҒж—¶й—ҙжҲізӯүгҖӮ
- дҪңз”Ёпјҡеё®еҠ©ж¶ҲжҒҜдј йҖ’е’Ңи·Ҝз”ұгҖӮ
- еұһжҖ§ (Properties)(еҸҜйҖү)
- з”ЁжҲ·жҲ–зі»з»ҹиҮӘе®ҡд№үзҡ„й”®еҖјеҜ№пјҲkey-value pairпјүгҖӮ
- дҪңз”ЁпјҡжҗәеёҰйўқеӨ–дҝЎжҒҜжҲ–е…ғж•°жҚ®пјҢеё®еҠ©ж¶ҲжҒҜжҺҘ收方зҗҶи§Јж¶ҲжҒҜеҶ…е®№жҲ–иҝӣиЎҢзӯӣйҖүгҖӮ
- ж¶ҲжҒҜдҪ“ (Body)(еҸҜйҖү)
- ж¶ҲжҒҜзҡ„дё»иҰҒеҶ…е®№пјҢйҖҡеёёеҢ…еҗ«дёҡеҠЎж•°жҚ®гҖӮ
- ж јејҸеҸҜд»ҘжҳҜ ж–Үжң¬пјҲеҰӮ JSONгҖҒXMLпјүгҖҒеӯ—иҠӮжөҒгҖҒеҜ№иұЎзӯүгҖӮ
еҗҢжӯҘе®ўжҲ·з«Ҝ-жңҚеҠЎеҷЁжЁЎеһӢй—®йўҳе’ҢеұҖйҷҗ
еҗҢжӯҘе®ўжҲ·з«Ҝ-жңҚеҠЎеҷЁжЁЎеһӢпјҲSynchronous client-server modelпјүпјҡе®ўжҲ·з«ҜеҸ‘йҖҒиҜ·жұӮеҗҺзӯүеҫ…жңҚеҠЎеҷЁе“Қеә”пјҢйҳ»еЎһејҸжү§иЎҢгҖӮеҹәжң¬зҡ„еҘҪеӨ„жҳҜеҫҲз®ҖеҚ•дҪҶеңЁй«ҳ并еҸ‘еңәжҷҜдёӢж•ҲзҺҮдҪҺдёӢгҖӮ
| зү№зӮ№ | жҸҸиҝ° | еҪұе“Қ |
|---|---|---|
| зҙ§иҖҰеҗҲпјҲTightly Coupledпјү | е®ўжҲ·з«Ҝе’ҢжңҚеҠЎеҷЁй«ҳеәҰдҫқиө–пјҢеҚҸи®®гҖҒж•°жҚ®ж јејҸйңҖе®Ңе…ЁдёҖиҮҙгҖӮ | зјәд№ҸзҒөжҙ»жҖ§пјҢйҡҫд»Ҙжү©еұ•пјҢдҝ®ж”№дёҖж–№йңҖж”№еҠЁеҸҰдёҖж–№гҖӮ |
| жІЎжңүдәӨд»ҳдҝқиҜҒпјҲNo Delivery Guaranteesпјү | ж¶ҲжҒҜдј йҖ’еҸҜиғҪеӨұиҙҘпјҢжңҚеҠЎеҷЁеҸҜиғҪдёўеӨұиҜ·жұӮпјҲжҜ”еҰӮжңҚеҠЎеҷЁдёҚеңЁзәҝпјүпјҢе®ўжҲ·з«ҜеҸҜиғҪжңӘ收еҲ°е“Қеә”пјҢж— еҶ—дҪҷдҝқиҜҒ | еўһеҠ ж•°жҚ®дёўеӨұзҡ„йЈҺйҷ©пјҢзі»з»ҹеҸҜйқ жҖ§йҷҚдҪҺгҖӮ |
| иҪҜ件зү©з§ҚеҢ–пјҲSoftware Speciationпјү | дёҚеҗҢзі»з»ҹйҡҫд»Ҙе…је®№жҲ–еҚҸеҗҢпјҢйҡҸзқҖйңҖжұӮеҸҳеҢ–пјҢе®ўжҲ·з«Ҝе’ҢжңҚеҠЎеҷЁйҖҗжёҗжј”еҢ–дёәзӢ¬з«Ӣзҡ„вҖңзү©з§ҚвҖқгҖӮ | еҘҪеӨ„жҳҜжҸҗй«ҳдәҶзҒөжҙ»жҖ§пјҢеҸҜд»Ҙи®©е…¶жӣҙдё“жіЁиҮӘе·ұзҡ„йңҖжұӮгҖӮдҪҶзі»з»ҹйҡҫд»ҘйӣҶжҲҗпјҢйҷҚдҪҺз»ҙжҠӨжҖ§е’Ңжү©еұ•жҖ§гҖӮ |
| жІЎжңүиҜ·жұӮзј“еҶІпјҲWithout a Request Bufferпјү | жңҚеҠЎеҷЁж”¶еҲ°иҜ·жұӮеҗҺйңҖз«ӢеҚіеӨ„зҗҶпјҢж— зј“еӯҳжңәеҲ¶гҖӮ | й«ҳ并еҸ‘жҲ–й«ҳиҙҹиҪҪж—¶пјҢе®№жҳ“еҮәзҺ°жҖ§иғҪ瓶йўҲжҲ–зі»з»ҹеҙ©жәғгҖӮ |
| иҝҮдәҺејәи°ғиҜ·жұӮе’Ңе“Қеә”пјҲToo Much Emphasis on Requests and Responsesпјү | ејәи°ғиҜ·жұӮдёҺе“Қеә”зҡ„дәӨдә’пјҢеҝҪз•ҘејӮжӯҘйҖҡдҝЎжҲ–дәӢ件й©ұеҠЁзӯүжӣҙй«ҳж•Ҳзҡ„жЁЎејҸгҖӮ | зі»з»ҹзҒөжҙ»жҖ§дёҚи¶іпјҢйҡҫд»Ҙеә”еҜ№еӨҚжқӮдёҡеҠЎйңҖжұӮгҖӮ |
| йҖҡдҝЎдёҚеҸҜйҮҚж”ҫпјҲCommunication is not Replayableпјү | ж¶ҲжҒҜдёўеӨұеҗҺж— жі•йҮҚж”ҫпјҢе®ўжҲ·з«ҜжҲ–жңҚеҠЎеҷЁж— жі•жҒўеӨҚд№ӢеүҚзҠ¶жҖҒгҖӮ | ж•°жҚ®еҸҜиғҪдёўеӨұпјҢзі»з»ҹе®№й”ҷжҖ§е·®пјҢеҪұе“Қз”ЁжҲ·дҪ“йӘҢгҖӮ |
и§ЈеҶіж–№жі•пјҡејӮжӯҘжЁЎеһӢ
еҠ дёҖдёӘж¶ҲжҒҜдёӯй—ҙ件пјҢжңҚеҠЎз«Ҝе’Ңе®ўжҲ·з«ҜйғҪдёҺдёӯй—ҙ件дәӨдә’пјҢеҶҚз”ұдёӯй—ҙ件иҪ¬еҸ‘гҖӮ жҜ”еҰӮcontroller收еҲ°ж¶ҲжҒҜпјҢз»ҷkafkaпјҢserviceзӣ‘еҗ¬kafkaеҺ»еӨ„зҗҶгҖӮиҝҷж ·е®һйҷ…дёҠеҸҢж–№йғҪжҳҜеҜ№зӯүзҡ„пјҢйғҪеҸҜд»ҘжҺҘ收еҸ‘йҖҒж¶ҲжҒҜгҖӮ
жӯӨж—¶ж¶ҲжҒҜеҸҜиғҪеҚҒеҲҶй’ҹеҗҺжүҚеӨ„зҗҶпјҲдёҡеҠЎз№ҒеҝҷдёӢпјүпјҢдё”еңЁcontrollerдёӢе·Із»Ҹиҝ”еӣһз»“жһңпјҢиҰҒе‘ҠиҜүеүҚз«ҜеӨ„зҗҶе®ҢжҲҗпјҢе°ұжңүдәҶдёүз§Қж–№ејҸпјҡ
| е®һзҺ°ж–№ејҸ | еҺҹзҗҶ | дјҳеҠЈеҠҝ |
| JavaScriptзӣ‘еҗ¬ | жҠҠеӨ„зҗҶе®ҢжҲҗзҡ„ж¶ҲжҒҜд№ҹжҺЁеҲ°TopicйҮҢйқўпјҢеҶҚз”ұеүҚз«ҜжҹҘиҜўпјҢеҺҹзҗҶеҰӮеҜ„дҝЎ | дјҳзӮ№пјҡзӣҙжҺҘдәӨдә’пјҢдёҚйңҖиҰҒеҚ•зӢ¬еҶҷж–°жҺҘеҸЈпјҲйғҪиҝҗиЎҢkafkaзӣ‘еҗ¬пјүпјҢеӨҚжқӮпјҢе®ўжҲ·з«ҜзӣҙжҺҘдёҺTopicиҝһжҺҘпјҢTopicзӣҙжҺҘжҡҙйңІпјҢйңҖиҰҒзЎ®дҝқж¶ҲжҒҜдј йҖ’зҡ„е®үе…ЁжҖ§пјҢйҳІжӯўжңӘжҺҲжқғзҡ„и®ўйҳ…е’Ңж¶ҲжҒҜзӘғеҸ–гҖӮ |
| Ajax | еүҚз«ҜеҶҚеҸ‘AjaxиҜ·жұӮпјҢиҪ®иҜўжңәеҲ¶жҹҘиҜў | ж— йңҖдёӯй—ҙ件жҜ”иҫғзҒөжҙ»пјҢдҪҶдёҘйҮҚеўһеҠ жңҚеҠЎеҷЁиҙҹиҪҪпјҢйҖ жҲҗдёҚеҝ…иҰҒзҡ„еёҰе®ҪжөӘиҙ№ |
| websocket | жңҚеҠЎеҷЁе®ўжҲ·з«Ҝwebsocketй“ҫжҺҘ | е®һж—¶жӣҙж–°пјҢеҸҢеҗ‘е·ҘдҪңпјҢиҠӮзңҒдәҶеёҰе®ҪйҖҡдҝЎйҮҸпјҢеҸҜд»ҘдҝқжҢҒжҢҒд№…иҝһжҺҘгҖӮдҪҶе®һзҺ°еӨҚжқӮеәҰй«ҳпјҢдҝқжҢҒиҝһжҺҘи®ІжҢҒз»ӯеҚ з”ЁжңҚеҠЎеҷЁиө„жәҗпјҢиҖҒжөҸи§ҲеҷЁдёҚе…је®№гҖӮ |
дәҢиҖ…并дёҚеӯҳеңЁз»қеҜ№зҡ„дјҳеҠҝеҠЈеҠҝпјҢдҫӢеҰӮзҷ»еҪ•йңҖиҰҒеҸҠж—¶зҡ„еҸҚйҰҲпјҢйӮЈд№ҲеҗҢжӯҘжЁЎеһӢжӣҙеҘҪгҖӮ
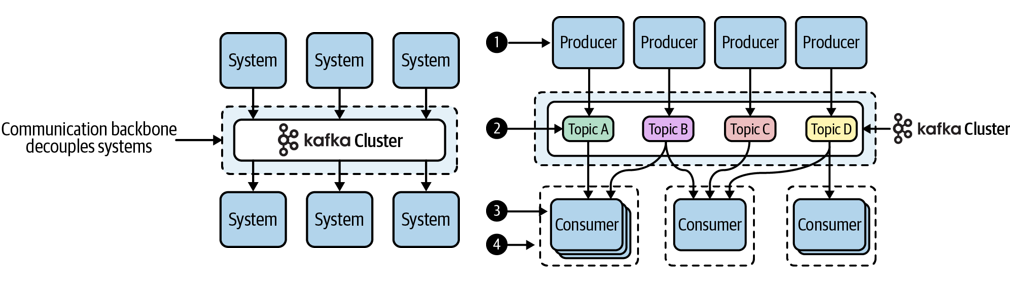
Kafka
дёҖз§Қж¶ҲжҒҜйҳҹеҲ—пјӣдё»иҰҒз”ЁжқҘеӨ„зҗҶеӨ§йҮҸж•°жҚ®зҠ¶жҖҒдёӢзҡ„ж¶ҲжҒҜйҳҹеҲ—пјҢдёҖиҲ¬з”ЁжқҘеҒҡж—Ҙеҝ—зҡ„еӨ„зҗҶгҖӮдё»иҰҒдҪңз”Ёжңүи§ЈиҖҰеҗҲпјҢејӮжӯҘеӨ„зҗҶпјҢжөҒйҮҸеүҠеі°гҖӮ
- kafkaзҡ„ж•°жҚ®еӯҳеӮЁеңЁlogйҮҢйқўпјҢж•°жҚ®еҫҖж–Ү件еҗҺйқўдёҚж–ӯиҝҪеҠ пјҢиҝҪеҠ зҡ„йҖҹеәҰжӣҙеҝ«
- logйҮҢйқўйғҪжҳҜжңүеәҸзҡ„дәӢ件пјҢжҜҸдёӘдәӢ件йғҪжңүдҪҚ移пјҢеҒҸ移йҮҸ
- еҪ“然жңүеҫҲеӨҡдёӘж¶Ҳиҙ№иҖ…пјҢжҠҠж¶Ҳиҙ№иҖ…еҲҶжҲҗдёҚеҗҢзҡ„з»„гҖӮеҪ“дёҖдёӘж¶ҲжҒҜиў«жүҖжңүзҡ„ж¶Ҳиҙ№иҖ…иҜ»иө°дәҶд№ӢеҗҺпјҢиҝҷдёӘж¶ҲжҒҜ жүҚдјҡиў«еҲ йҷӨжҺүпјӣеӨҡдёӘз”ЁжҲ·еҸҜд»ҘиҜ»еҸ–еҗҢдёҖдёӘlogпјҢ并且з»ҙжҠӨ他们еҗ„иҮӘзҡ„ж–Ү件дҪҚзҪ®пјҲйғҪеҲ°е“ӘйҮҢдәҶпјү
- иҝҷж ·е°ұиғҪдҝқиҜҒlogж–Ү件дёҚеҸҜиғҪж— йҷҗеҲ¶зҡ„еўһй•ҝ
- еҜ№дәҺйӣҶзҫӨзҡ„е®№зҒҫпјҢз”Ёз©әй—ҙжҚўеҸҜйқ жҖ§пјҢжҜ”еҰӮжҜҸдёӘж•°жҚ®еӯҳеӮЁдёӨдёӘеүҜжң¬пјҢиҝҷж ·жҜ”еҰӮжңүдёҖдёӘеҚЎеӨ«еҚЎжңҚеҠЎеҷЁеҙ©жәғдәҶпјҢиҝҳжңүдёҖдёӘеӨҮд»ҪиғҪеӨҹдҪҝз”ЁгҖӮеҜ№дәҺconsumerе®№зҒҫпјҢжӯӨж—¶е°ұйңҖиҰҒдёҖдёӘеҚҸи°ғеҷЁеңЁkafkaйӣҶзҫӨйҮҢйқўпјҢconsumerдёҖзӣҙеҸ‘еҝғи·іеҢ…з»ҷеҚҸи°ғеҷЁпјҢеҰӮжһңдёҚеҸ‘еҚҸи°ғеҷЁе°ұдёҚдјҡеҶҚжҠҠж¶ҲжҒҜз»ҷж•…йҡңзҡ„жңәеҷЁгҖӮ
第дёүз«
WebSocket
WebSocketжҳҜдёҖз§Қеә”з”ЁеҚҸи®®пјҢйҖҡиҝҮTCPеҚҸи®®еңЁдёӨдёӘеҜ№зӯүдҪ“д№Ӣй—ҙжҸҗдҫӣе…ЁеҸҢе·ҘпјҲеҸҢеҗ‘йғҪе·ҘдҪңпјүйҖҡдҝЎпјҢеҚіз”ЁжҲ·еҸҜд»Ҙдё»еҠЁз»ҷжңҚеҠЎеҷЁеҸ‘ж¶ҲжҒҜпјҢжңҚеҠЎеҷЁд№ҹеҸҜд»Ҙдё»еҠЁз»ҷз”ЁжҲ·дј йҖ’ж¶ҲжҒҜгҖӮ
- еңЁWebSocketеә”з”ЁзЁӢеәҸдёӯпјҢжңҚеҠЎеҷЁеҸ‘еёғWebSocketз«ҜзӮ№пјҢе®ўжҲ·з«ҜдҪҝз”Ёз«ҜзӮ№зҡ„URIиҝһжҺҘеҲ°жңҚеҠЎеҷЁгҖӮ
- WebSocketеҚҸи®®еңЁиҝһжҺҘе»әз«ӢеҗҺжҳҜеҜ№з§°зҡ„пјҡ
- е®ўжҲ·з«Ҝе’ҢжңҚеҠЎеҷЁеҸҜд»ҘеңЁиҝһжҺҘжү“ејҖж—¶йҡҸж—¶дә’зӣёеҸ‘йҖҒж¶ҲжҒҜпјҢд№ҹеҸҜд»ҘйҡҸж—¶е…ій—ӯиҝһжҺҘгҖӮ
- е®ўжҲ·з«ҜйҖҡеёёеҸӘиҝһжҺҘеҲ°дёҖдёӘжңҚеҠЎеҷЁпјҢжңҚеҠЎеҷЁжҺҘеҸ—жқҘиҮӘеӨҡдёӘе®ўжҲ·з«Ҝзҡ„иҝһжҺҘгҖӮ
WebSocketеҚҸи®®жңүдёӨйғЁеҲҶпјҡ
жҸЎжүӢпјҲhandshakeпјүе’Ңж•°жҚ®дј иҫ“пјҲdata transfer пјүгҖӮ
еҹәжң¬иҝҮзЁӢ
е®ўжҲ·з«ҜеҸ‘иө· WebSocket жҸЎжүӢиҜ·жұӮ
е®ўжҲ·з«ҜйҖҡиҝҮдҪҝз”Ёе…¶URIеҗ‘WebSocketз«ҜзӮ№еҸ‘йҖҒиҜ·жұӮжқҘеҗҜеҠЁжҸЎжүӢгҖӮ
жҸЎжүӢпјҲhandshakeпјүдёҺзҺ°жңүзҡ„еҹәдәҺHTTPзҡ„еҹәзЎҖи®ҫж–Ҫе…је®№пјҢWebжңҚеҠЎеҷЁи§ЈйҮҠе…¶дёәHTTPиҝһжҺҘеҚҮзә§иҜ·жұӮпјҢдёҖдёӘдҫӢеӯҗеҰӮдёӢпјҡ
GET /path/to/websocket/endpoint HTTP/1.1
Host: localhost
Upgrade: websocket
Connection: Upgrade
Sec-WebSocket-Key: xqBt3ImNzJbYqRINxEFlkg==
Origin: http://localhost
Sec-WebSocket-Version: 13жңҚеҠЎеҷЁе“Қеә” WebSocket жҸЎжүӢиҜ·жұӮ
HTTP/1.1 101 Switching Protocols
Upgrade: websocket
Connection: Upgrade
Sec-WebSocket-Accept: K7DJLdLooIwIG/MOpvWFB3y3FE8=Sec-WebSocket-Accept зҡ„з”ҹжҲҗ
- жңҚеҠЎеҷЁеҜ№Sec-WebSocket-Keyж ҮеӨҙзҡ„еҖјеә”з”Ёе·ІзҹҘж“ҚдҪңпјҢд»Ҙз”ҹжҲҗSec-WebSocket-Acceptж ҮеӨҙзҡ„еҖјгҖӮ
- е®ўжҲ·з«ҜеҜ№Sec-WebSocket-Keyж ҮеӨҙзҡ„еҖјеә”з”ЁзӣёеҗҢзҡ„ж“ҚдҪңпјҢеҰӮжһңз»“жһңдёҺд»ҺжңҚеҠЎеҷЁжҺҘ收еҲ°зҡ„еҖјеҢ№й…ҚпјҢеҲҷиҝһжҺҘжҲҗеҠҹе»әз«ӢгҖӮ
е»әз«Ӣ WebSocket иҝһжҺҘ
е®ўжҲ·з«Ҝ收еҲ°жңҚеҠЎеҷЁзҡ„е“Қеә”еҗҺпјҢйӘҢиҜҒ Sec-WebSocket-Accept жҳҜеҗҰжӯЈзЎ®гҖӮеҰӮжһңйӘҢиҜҒйҖҡиҝҮпјҢжңҚеҠЎеҷЁе’Ңе®ўжҲ·з«Ҝе°ұеҸҜд»Ҙдә’зӣёеҸ‘йҖҒж¶ҲжҒҜдәҶгҖӮ
ws://host:port/path?query
wss://host:port/path?query зӨәдҫӢе®һзҺ°
- еҲӣе»әз«ҜзӮ№зұ»пјҲendpointпјүгҖӮ
- е®һзҺ°з«ҜзӮ№зҡ„з”ҹе‘Ҫе‘Ёжңҹж–№жі•гҖӮ
- е°ҶжӮЁзҡ„дёҡеҠЎйҖ»иҫ‘ж·»еҠ еҲ°з«ҜзӮ№гҖӮ
- еңЁwebеә”з”ЁзЁӢеәҸеҶ…йғЁйғЁзҪІз«ҜзӮ№гҖӮ
еҜ№дәҺе…·дҪ“йҖ»иҫ‘е®һзҺ°пјҢз”ЁжҲ·еә”еҪ“е…ҲеҸ‘йҖҒйӘҢиҜҒпјҢжңҚеҠЎеҷЁиҝ”еӣһtokenпјҢеҶҚж №жҚ®tokenе»әз«ӢиҝһжҺҘдҝқиҜҒе”ҜдёҖжҖ§пјҲйҳІжӯўе…¶д»–дәәд№ҹеҸҜд»ҘиҝһжҺҘпјүгҖӮ
endpoint
еңЁWebSocketдёӯпјҢendpoint жҳҜжҢҮWebSocketйҖҡдҝЎзҡ„зӣ®ж ҮжҲ–з»ҲзӮ№гҖӮе®ғжҳҜWebSocketиҝһжҺҘзҡ„еҸҰдёҖз«ҜпјҢеҸҜд»Ҙ жҳҜжңҚеҠЎеҷЁжҲ–е®ўжҲ·з«ҜпјҢз”ЁдәҺжҺҘ收жҲ–еҸ‘йҖҒWebSocketж¶ҲжҒҜгҖӮ
е…ұжңүдёӨз§Қзұ»еһӢendpointпјҡ
- WebSocketжңҚеҠЎеҷЁз«Ҝ(endpoint)пјҡиҝҷжҳҜWebSocketйҖҡдҝЎзҡ„жңҚеҠЎеҷЁз«ҜпјҢе®ғзӯүеҫ…е®ўжҲ·з«Ҝзҡ„иҝһжҺҘиҜ·жұӮ并еӨ„зҗҶе®ғ们гҖӮдёҖж—ҰиҝһжҺҘе»әз«ӢпјҢжңҚеҠЎеҷЁз«Ҝе°ұдјҡзӣ‘еҗ¬жқҘиҮӘе®ўжҲ·з«Ҝзҡ„ж¶ҲжҒҜпјҢ并еҸҜд»Ҙеҗ‘е®ўжҲ·з«ҜеҸ‘йҖҒж¶ҲжҒҜгҖӮ WebSocketжңҚеҠЎеҷЁйҖҡеёёз”ЁдәҺе®һж—¶йҖҡдҝЎгҖҒеңЁзәҝжёёжҲҸгҖҒиҒҠеӨ©еә”з”ЁзӯүеңәжҷҜгҖӮ
- WebSocketе®ўжҲ·з«Ҝ(endpoint)пјҡиҝҷжҳҜWebSocketйҖҡдҝЎзҡ„е®ўжҲ·з«ҜпјҢе®ғдёҺWebSocketжңҚеҠЎеҷЁе»әз«ӢиҝһжҺҘпјҢ并еҸҜд»Ҙеҗ‘жңҚеҠЎеҷЁеҸ‘йҖҒж¶ҲжҒҜпјҢеҗҢж—¶жҺҘ收жңҚеҠЎеҷЁеҸ‘йҖҒзҡ„ж¶ҲжҒҜгҖӮWebSocketе®ўжҲ·з«ҜйҖҡеёёз”ЁдәҺдёҺжңҚеҠЎеҷЁиҝӣиЎҢеҸҢеҗ‘йҖҡдҝЎпјҢд»ҘиҺ·еҸ–е®һж—¶ж•°жҚ®жҲ–дёҺжңҚеҠЎеҷЁиҝӣиЎҢдәӨдә’гҖӮ
ж¶ҲжҒҜд»ЈзҗҶпјҲMessage Brokerпјү
еңЁWebSocketйҖҡдҝЎдёӯпјҢж¶ҲжҒҜд»ЈзҗҶжҳҜжҢҮWebSocketжңҚеҠЎеҷЁе’Ңе®ўжҲ·з«Ҝд№Ӣй—ҙзҡ„дёӯй—ҙ件пјҢз”ЁдәҺиҪ¬еҸ‘WebSocketж¶ҲжҒҜгҖӮе®ғе……еҪ“дәҶWebSocketжңҚеҠЎеҷЁе’Ңе®ўжҲ·з«Ҝд№Ӣй—ҙзҡ„жЎҘжўҒпјҢдҪҝе®ғ们еҸҜд»Ҙзӣёдә’йҖҡдҝЎгҖӮж¶ҲжҒҜд»ЈзҗҶеҸҜд»ҘжҳҜдёҖдёӘзӢ¬з«Ӣзҡ„жңҚеҠЎеҷЁпјҢд№ҹеҸҜд»ҘжҳҜWebSocketжңҚеҠЎеҷЁжң¬иә«гҖӮ
第еӣӣз«
Transaction
transactionжҳҜдёҖзі»еҲ—еҝ…йЎ»е…ЁйғЁжҲҗеҠҹе®ҢжҲҗзҡ„ж“ҚдҪңпјҢиҰҒд№ҲйғҪжү§иЎҢпјҢиҰҒд№ҲйғҪдёҚжү§иЎҢпјҲдәӢеҠЎеӣһж»ҡпјүпјҢдҝқиҜҒ ж•°жҚ®еә“ дёӯзҡ„ж•°жҚ®е§Ӣз»ҲеӨ„дәҺдёҖиҮҙзҡ„зҠ¶жҖҒгҖӮдәӢеҠЎзҡ„дё»иҰҒзӣ®ж ҮжҳҜзЎ®дҝқж•°жҚ®зҡ„дёҖиҮҙжҖ§гҖҒе®Ңж•ҙжҖ§е’ҢеҸҜйқ жҖ§пјҢе°Өе…¶жҳҜеңЁе№¶еҸ‘и®ҝй—®е’ҢејӮеёёжғ…еҶөдёӢгҖӮ
е®һзҺ°зҡ„жң¬иҙЁжҳҜдҫқиө–дәҺ ж—Ҙеҝ— е®һзҺ°зҡ„пјҢеҜ№дәҺеҶ…еӯҳеҸҳйҮҸжҜ”еҰӮдёҙж—¶еҸҳйҮҸint x пјҢ Int yпјҢдёҚдјҡи§ҰеҸ‘дәӢеҠЎеӣһж»ҡ
дәӢзү©еұһжҖ§
дәӢеҠЎеӨ„зҗҶзҡ„ACID
ACID жҳҜж•°жҚ®еә“дәӢеҠЎдёӯзҡ„еӣӣдёӘе…ій”®еұһжҖ§пјҢзЎ®дҝқж•°жҚ®еә“еңЁжү§иЎҢдәӢеҠЎж—¶иғҪеӨҹжӯЈзЎ®гҖҒе®үе…Ёең°еӨ„зҗҶж•°жҚ®гҖӮ
- еҺҹеӯҗжҖ§пјҡдёҚеҸҜеҲҶеүІпјҢзЎ®дҝқдәӢеҠЎдёӯзҡ„жҜҸдёҖжӯҘйғҪжү§иЎҢжҲҗеҠҹжҲ–дёҚжү§иЎҢпјҢйҒҝе…ҚйғЁеҲҶеӨұиҙҘгҖӮ
- дёҖиҮҙжҖ§пјҡжӯЈзЎ®дёҖиҮҙпјҢдҝқжҢҒж•°жҚ®еә“зҡ„е®Ңж•ҙжҖ§пјҢйҒҝе…ҚиҝқиғҢзәҰжқҹжқЎд»¶гҖӮ
- йҡ”зҰ»жҖ§пјҡдә’дёҚе№Іжү°пјҢйҒҝе…ҚдәӢеҠЎй—ҙзҡ„е№Іжү°пјҢзЎ®дҝқ并еҸ‘жү§иЎҢзҡ„дәӢеҠЎеҪјжӯӨзӢ¬з«ӢпјҢе’ҢдёІиЎҢеҫ—еҲ°зҡ„з»“жһңдёҖиҮҙгҖӮ
- жҢҒд№…жҖ§пјҡж°ёиҝңдҝқжҢҒпјҢдёҖж—ҰдәӢеҠЎжҸҗдәӨпјҢз»“жһңж°ёд№…з”ҹж•ҲпјҢйҒҝе…Қж•°жҚ®дёўеӨұгҖӮ
A – AtomicityпјҲеҺҹеӯҗжҖ§пјүпјҡ
- е®ҡд№үпјҡдәӢеҠЎдёӯзҡ„жүҖжңүж“ҚдҪңиҰҒд№Ҳе…ЁйғЁжҲҗеҠҹпјҢиҰҒд№Ҳе…ЁйғЁеӣһж»ҡгҖӮеҰӮжһңдәӢеҠЎдёӯзҡ„д»»дҪ•дёҖжӯҘж“ҚдҪңеӨұиҙҘпјҢеҲҷж•ҙдёӘдәӢеҠЎеӨұиҙҘпјҢж•°жҚ®еә“зҠ¶жҖҒдјҡеӣһеҲ°дәӢеҠЎејҖе§Ӣд№ӢеүҚзҡ„зҠ¶жҖҒпјҢзЎ®дҝқдёҚдјҡжңүйғЁеҲҶж“ҚдҪңжҲҗеҠҹзҡ„жғ…еҶөгҖӮ
- и§ЈйҮҠпјҡдәӢеҠЎиҰҒеғҸдёҖдёӘдёҚеҸҜеҲҶеүІзҡ„еҺҹеӯҗдёҖж ·жү§иЎҢгҖӮеҚідҫҝдәӢеҠЎдёӯеҢ…еҗ«еӨҡжӯҘж“ҚдҪңпјҢиҝҷдәӣж“ҚдҪңиҰҒд№Ҳе…ЁйғЁе®ҢжҲҗпјҢиҰҒд№Ҳе®Ңе…ЁдёҚжү§иЎҢгҖӮ
- дҫӢеӯҗпјҡ银иЎҢиҪ¬иҙҰж“ҚдҪңдёӯпјҢиҪ¬иҙҰзҡ„дёӨдёӘжӯҘйӘӨжҳҜд»ҺиҙҰжҲ·AжүЈй’ұгҖҒеҗ‘иҙҰжҲ·BеҠ й’ұгҖӮдәӢеҠЎзҡ„еҺҹеӯҗжҖ§зЎ®дҝқеҰӮжһңе…¶дёӯдёҖжӯҘеӨұиҙҘпјҢж•ҙдёӘиҪ¬иҙҰж“ҚдҪңе°ұдјҡеӣһж»ҡпјҢиҙҰжҲ·Aе’ҢиҙҰжҲ·Bзҡ„дҪҷйўқдҝқжҢҒдёҚеҸҳгҖӮ
C – ConsistencyпјҲдёҖиҮҙжҖ§пјүпјҡ
- е®ҡд№үпјҡдәӢеҠЎжү§иЎҢеҗҺпјҢж•°жҚ®еә“еҝ…йЎ»д»ҺдёҖдёӘдёҖиҮҙзҡ„зҠ¶жҖҒиҪ¬жҚўдёәеҸҰдёҖдёӘдёҖиҮҙзҡ„зҠ¶жҖҒгҖӮеңЁдёҖиҮҙжҖ§зәҰжқҹжқЎд»¶дёӢпјҢж•°жҚ®еә“дёӯзҡ„ж•°жҚ®дҝқжҢҒе®Ңж•ҙжҖ§гҖӮ
- и§ЈйҮҠпјҡдәӢеҠЎеңЁејҖе§Ӣе’Ңз»“жқҹж—¶пјҢж•°жҚ®еә“йғҪеҝ…йЎ»з¬ҰеҗҲжүҖжңүйў„и®ҫзҡ„规еҲҷгҖҒзәҰжқҹе’Ңж•°жҚ®е®Ңж•ҙжҖ§жқЎд»¶гҖӮдәӢеҠЎдёҚиғҪз ҙеқҸж•°жҚ®еә“зҡ„规еҲҷжҲ–е®Ңж•ҙжҖ§зәҰжқҹгҖӮ
- дҫӢеӯҗпјҡеҒҮи®ҫжңүдёҖдёӘж•°жҚ®еә“规еҲҷпјҢ规е®ҡ银иЎҢиҙҰжҲ·зҡ„дҪҷйўқдёҚиғҪдёәиҙҹж•°гҖӮдёҖж—ҰдәӢеҠЎжү§иЎҢе®ҢжҲҗпјҢж•°жҚ®еә“еҝ…йЎ»зЎ®дҝқиҝҷдёӘ规еҲҷдҫқж—§жҲҗз«ӢпјҢеҰӮжһңжҹҗдёӘж“ҚдҪңиҜ•еӣҫиҝқеҸҚ规еҲҷпјҢдәӢеҠЎе°Ҷиў«еӣһж»ҡгҖӮ
I – IsolationпјҲйҡ”зҰ»жҖ§пјүпјҡ
- е®ҡд№үпјҡеӨҡдёӘ并еҸ‘жү§иЎҢзҡ„дәӢеҠЎд№Ӣй—ҙеҪјжӯӨйҡ”зҰ»пјҢдёҖдёӘдәӢеҠЎзҡ„жү§иЎҢдёҚеә”еҪұе“Қ其他并еҸ‘дәӢеҠЎзҡ„жү§иЎҢз»“жһңгҖӮжҜҸдёӘдәӢеҠЎеә”иҜҘеҘҪеғҸжҳҜзӢ¬з«Ӣжү§иЎҢзҡ„пјҢеҚідҪҝеңЁеӨҡдәӢеҠЎе№¶еҸ‘зҡ„жғ…еҶөдёӢгҖӮ
- и§ЈйҮҠпјҡеҚідҪҝжңүеӨҡдёӘдәӢеҠЎе№¶еҸ‘иҝҗиЎҢпјҢзі»з»ҹд№ҹйңҖиҰҒзЎ®дҝқдёҖдёӘдәӢеҠЎдёӯзҡ„жңӘжҸҗдәӨж•°жҚ®дёҚдјҡиў«е…¶д»–дәӢеҠЎзңӢеҲ°жҲ–еҪұе“ҚпјҢйҳІжӯўвҖңи„ҸиҜ»вҖқгҖҒ”дёҚеҸҜйҮҚеӨҚиҜ»”гҖҒ”е№»иҜ»”зӯү并еҸ‘й—®йўҳгҖӮйҡ”зҰ»жҖ§йҖҡеёёйҖҡиҝҮдәӢеҠЎзҡ„йҡ”зҰ»зә§еҲ«жқҘе®һзҺ°пјҢеҰӮ
Read CommittedгҖҒRepeatable ReadзӯүгҖӮ - дҫӢеӯҗпјҡеҒҮи®ҫдәӢеҠЎAжӯЈеңЁдҝ®ж”№дёҖдёӘж•°жҚ®пјҢдҪҶе°ҡжңӘжҸҗдәӨпјҢдәӢеҠЎBдёҚеә”иҜҘиҜ»еҸ–еҲ°дәӢеҠЎAжңӘжҸҗдәӨзҡ„дёӯй—ҙзҠ¶жҖҒж•°жҚ®гҖӮ
D – DurabilityпјҲжҢҒд№…жҖ§пјүпјҡ
- е®ҡд№үпјҡдәӢеҠЎдёҖж—ҰжҸҗдәӨпјҢж•°жҚ®зҡ„дҝ®ж”№е°ұдјҡж°ёд№…дҝқеӯҳпјҢеҚідҪҝзі»з»ҹеҙ©жәғжҲ–ж•…йҡңпјҢе·ІжҸҗдәӨзҡ„дәӢеҠЎж•°жҚ®д№ҹдёҚдјҡдёўеӨұгҖӮ
- и§ЈйҮҠпјҡдәӢеҠЎжҸҗдәӨеҗҺпјҢзі»з»ҹдјҡзЎ®дҝқжүҖжңүж•°жҚ®зҡ„дҝ®ж”№жҢҒд№…еҢ–еӯҳеӮЁпјҢеҚідҪҝеҸ‘з”ҹ硬件жҲ–иҪҜ件故йҡңпјҢзі»з»ҹйҮҚеҗҜеҗҺж•°жҚ®д»Қ然еҸҜд»ҘжҒўеӨҚгҖӮйҖҡеёёйҖҡиҝҮеҶҷе…Ҙж—Ҙеҝ—жҲ–йҮҮз”Ёж•°жҚ®еә“еӨҮд»ҪжңәеҲ¶е®һзҺ°гҖӮ
- дҫӢеӯҗпјҡеҒҮи®ҫз”ЁжҲ·е®ҢжҲҗдәҶдёҖ次银иЎҢиҪ¬иҙҰж“ҚдҪң并жҸҗдәӨдәҶдәӢеҠЎпјҢеҚідҪҝзі»з»ҹеңЁиҪ¬иҙҰе®ҢжҲҗеҗҺ马дёҠеҙ©жәғпјҢиҪ¬иҙҰзҡ„ж•°жҚ®д№ҹеә”иҜҘж°ёд№…дҝқз•ҷпјҢ并еңЁзі»з»ҹжҒўеӨҚеҗҺеӯҳеңЁгҖӮ
еёёи§Ғж Үзӯҫи§ЈйҮҠ
Required
- иҜҙжҳҺпјҡй»ҳи®Өзҡ„дәӢеҠЎеұһжҖ§гҖӮеҰӮжһңеҪ“еүҚжІЎжңүдәӢеҠЎпјҢеҲҷж–°е»әдёҖдёӘдәӢеҠЎгҖӮеҰӮжһңи°ғз”Ёж—¶е·Із»ҸеӯҳеңЁдёҖдёӘдәӢеҠЎпјҢеҪ“еүҚж–№жі•е°ҶеҠ е…ҘеҲ°зҺ°жңүзҡ„дәӢеҠЎдёӯгҖӮжіЁж„ҸпјҒеңЁиҝӣе…Ҙе’ҢйҖҖеҮәж–№жі•зҡ„ж—¶еҖҷйғҪдјҡеҒҡжЈҖжҹҘпјҒ
- йҖӮз”ЁеңәжҷҜпјҡйҖӮз”ЁдәҺз»қеӨ§еӨҡж•°жғ…еҶөпјҢзЎ®дҝқжүҖжңүзӣёе…іж“ҚдҪңиҰҒд№ҲдёҖиө·жҸҗдәӨпјҢиҰҒд№ҲдёҖиө·еӣһж»ҡгҖӮ
- дј ж’ӯиЎҢдёәпјҡеҠ е…ҘзҺ°жңүдәӢеҠЎжҲ–еҲӣе»әдёҖдёӘж–°дәӢеҠЎгҖӮ
- е…·дҪ“дәӢдҫӢпјҡAдёӯжңүж–№жі•BпјҢиӢҘA,BеқҮдёәRequiredпјҢеҲҷеҸӘдјҡеҲӣе»әдёҖдёӘдәӢзү©
RequiresNew
- иҜҙжҳҺпјҡж— и®әи°ғз”Ёж—¶жҳҜеҗҰеӯҳеңЁдәӢеҠЎпјҢе§Ӣз»Ҳж–°е»әдёҖдёӘдәӢеҠЎгҖӮеҰӮжһңе·ІжңүдәӢеҠЎпјҢеҪ“еүҚдәӢеҠЎдјҡиў«жҢӮиө·пјҢеҫ…ж–°дәӢеҠЎз»“жқҹеҗҺжҒўеӨҚеҺҹжқҘзҡ„дәӢеҠЎгҖӮ
- йҖӮз”ЁеңәжҷҜпјҡз”ЁдәҺйңҖиҰҒж–№жі•зӢ¬з«Ӣжү§иЎҢгҖҒйҒҝе…ҚдёҺеӨ–йғЁдәӢеҠЎе№Іжү°зҡ„жғ…еҶөгҖӮ
- дј ж’ӯиЎҢдёәпјҡе§Ӣз»ҲеҲӣе»әж–°дәӢеҠЎпјҢеҺҹжңүдәӢеҠЎиў«жҡӮж—¶жҢӮиө·гҖӮ
- е…·дҪ“дәӢдҫӢпјҡLOGж“ҚдҪңдёҚеёҢжңӣиў«дёӯж–ӯпјҢеҸҜд»ҘеҚ•зӢ¬ејҖRequiresNewгҖӮиӢҘAдёӯжңүж–№жі•BпјҢиӢҘAдёәRequiredпјҢBдёәRequiresNew,йӮЈд№ҲBеҸ‘з”ҹй”ҷиҜҜдёҚдјҡеҪұе“ҚA
Supports
- иҜҙжҳҺпјҡж–№жі•еҸҜд»Ҙж”ҜжҢҒдәӢеҠЎпјҢдҪҶдёҚејәеҲ¶иҰҒжұӮгҖӮеҰӮжһңеҪ“еүҚжңүдәӢеҠЎпјҢж–№жі•е°ҶеҠ е…ҘзҺ°жңүдәӢеҠЎпјӣеҰӮжһңжІЎжңүдәӢеҠЎпјҢж–№жі•д№ҹеҸҜд»ҘйқһдәӢеҠЎжҖ§ең°жү§иЎҢгҖӮ
- йҖӮз”ЁеңәжҷҜпјҡз”ЁдәҺеҸҜйҖүжӢ©жҖ§зҡ„дәӢеҠЎж“ҚдҪңпјҢдәӢеҠЎжҖ§е№¶дёҚжҳҜеҝ…йңҖзҡ„гҖӮ
- дј ж’ӯиЎҢдёәпјҡеҰӮжһңжңүзҺ°жңүдәӢеҠЎеҲҷеҠ е…ҘпјҢеҗҰеҲҷйқһдәӢеҠЎжҖ§жү§иЎҢгҖӮ
- е…·дҪ“дәӢдҫӢпјҡиӢҘAдёӯжңүж–№жі•BпјҢдё”дәҢиҖ…еқҮдёәSupportsпјҢеҲҷжІЎжңүдәӢзү©гҖӮ
NotSupported
- иҜҙжҳҺпјҡеҪ“еүҚж–№жі•дёҚж”ҜжҢҒдәӢеҠЎгҖӮеҰӮжһңи°ғз”Ёж—¶жңүдәӢеҠЎеӯҳеңЁпјҢдәӢеҠЎдјҡиў«жҢӮиө·пјҢж–№жі•жү§иЎҢе®ҢжҲҗеҗҺеҶҚжҒўеӨҚеҺҹжқҘзҡ„дәӢеҠЎгҖӮ
- йҖӮз”ЁеңәжҷҜпјҡеҪ“дёҚеёҢжңӣж–№жі•еңЁдәӢеҠЎдёҠдёӢж–ҮдёӯиҝҗиЎҢж—¶пјҢжҜ”еҰӮдёҚйңҖиҰҒдәӢеҠЎдҝқиҜҒзҡ„дёҖдәӣеҸӘиҜ»ж“ҚдҪңгҖӮ
- дј ж’ӯиЎҢдёәпјҡжҢӮиө·зҺ°жңүдәӢеҠЎпјҢж— дәӢеҠЎж”ҜжҢҒгҖӮ
- е…·дҪ“дәӢдҫӢпјҡиӢҘAдёӯжңүж–№жі•BпјҢBдёәNotSupportedпјҢйӮЈд№ҲBдјҡдёҚеңЁдәӢзү©зҠ¶жҖҒжү§иЎҢ
Mandatory
- иҜҙжҳҺпјҡж–№жі•еҝ…йЎ»еңЁзҺ°жңүдәӢеҠЎдёҠдёӢж–Үдёӯжү§иЎҢгҖӮеҰӮжһңи°ғз”Ёж—¶жІЎжңүдәӢеҠЎеӯҳеңЁпјҢдјҡжҠӣеҮәејӮеёёгҖӮ
- йҖӮз”ЁеңәжҷҜпјҡејәеҲ¶иҰҒжұӮж–№жі•еҝ…йЎ»еңЁдәӢеҠЎдёӯжү§иЎҢгҖӮ
- дј ж’ӯиЎҢдёәпјҡеҝ…йЎ»жңүзҺ°жңүдәӢеҠЎпјҢеҰӮжһңжІЎжңүе°ұдјҡеӨұиҙҘгҖӮ
Never
- иҜҙжҳҺпјҡж–№жі•дёҚе…Ғи®ёеңЁдәӢеҠЎдёҠдёӢж–Үдёӯжү§иЎҢгҖӮеҰӮжһңи°ғз”Ёж—¶еӯҳеңЁдәӢеҠЎпјҢеҲҷжҠӣеҮәејӮеёёгҖӮ
- йҖӮз”ЁеңәжҷҜпјҡйңҖиҰҒзЎ®дҝқж–№жі•з»қеҜ№дёҚеңЁдәӢеҠЎдёӯжү§иЎҢж—¶гҖӮ
- дј ж’ӯиЎҢдёәпјҡдёҚиғҪжңүдәӢеҠЎпјҢеҰӮжһңжңүдәӢеҠЎеҲҷеӨұиҙҘгҖӮ
еӣһж»ҡпјҡжҠӣеҮә RuntimeException жҲ–иҖ… Error зҡ„ж—¶еҖҷпјҢspringдјҡиҮӘеҠЁеӣһж»ҡ
дәӢеҠЎйҡ”зҰ»зә§еҲ«
дәӢеҠЎйҡ”зҰ»зә§еҲ«жҺ§еҲ¶зҡ„жҳҜеҗҢдёҖж—¶й—ҙеҶ…еӨҡдёӘдәӢеҠЎеҰӮдҪ•зӣёдә’еҪұе“Қж•°жҚ®еҸҜи§ҒжҖ§зҡ„й—®йўҳгҖӮе®ғ规е®ҡдәҶдёҖдёӘдәӢеҠЎеҶ…зҡ„ж“ҚдҪңеңЁи®ҝй—®ж•°жҚ®ж—¶пјҢжҳҜеҗҰиғҪзңӢеҲ°е…¶д»–дәӢеҠЎеҜ№зӣёеҗҢж•°жҚ®зҡ„жӣҙж”№пјҢд»ҘеҸҠеҪ“еүҚдәӢеҠЎеҜ№е…¶д»–дәӢеҠЎжҳҜеҗҰеҸҜи§ҒгҖӮдёҚеҗҢзҡ„йҡ”зҰ»зә§еҲ«жҸҗдҫӣдәҶдёҚеҗҢзЁӢеәҰзҡ„ж•°жҚ®дёҖиҮҙжҖ§е’Ң并еҸ‘жҖ§дҝқжҠӨгҖӮ
йҡ”зҰ»жҖ§еҶІзӘҒжҖ»з»“
| иҜ»еҶҷеҶІзӘҒ | и„ҸиҜ» | дәӢеҠЎAиҜ»еҸ–дәҶдәӢеҠЎBдҝ®ж”№дҪҶжңӘжҸҗдәӨзҡ„ж•°жҚ®пјҲиҜ»еҲ°дәҶдәӢзү©еӨ„зҗҶзҡ„дёӯй—ҙзҠ¶жҖҒпјүпјҢдәӢеҠЎBйҡҸеҗҺеӣһж»ҡпјҢеҜјиҮҙAиҜ»зҡ„ж•°жҚ®ж— ж•ҲгҖӮ |
| иҜ»еҶҷеҶІзӘҒ | дёҚеҸҜйҮҚеӨҚиҜ» | дәӢеҠЎA第дёҖж¬ЎиҜ»еҸ–ж•°жҚ®еҗҺпјҢдәӢеҠЎBдҝ®ж”№е№¶жҸҗдәӨиҜҘж•°жҚ®пјҢдәӢеҠЎAеҶҚж¬ЎиҜ»еҸ–ж—¶ж•°жҚ®иў«дҝ®ж”№гҖӮ |
| иҜ»еҶҷеҶІзӘҒ | е№»иҜ» | дәӢеҠЎAжү§иЎҢиҢғеӣҙжҹҘиҜўеҗҺпјҢдәӢеҠЎBжҸ’е…Ҙ/еҲ йҷӨдәҶж»Ўи¶іжқЎд»¶зҡ„и®°еҪ•пјҢдәӢеҠЎAеҶҚж¬ЎжҹҘиҜўж—¶дёҚеҗҢгҖӮ |
| еҶҷеҶҷеҶІзӘҒ | и„ҸеҶҷ | дәӢеҠЎAе’ҢдәӢеҠЎBеҗҢж—¶дҝ®ж”№еҗҢдёҖжқЎи®°еҪ•пјҢдәӢеҠЎBзҡ„жҸҗдәӨиҰҶзӣ–дәҶдәӢеҠЎAзҡ„дҝ®ж”№гҖӮ |
дҪҝз”Ёж–№жі•
д»»еҠЎжң¬иә«жҳҜеңЁж•°жҚ®еә“е®ҢжҲҗпјҢеӣ жӯӨжҲ‘们йңҖиҰҒеңЁй“ҫжҺҘж•°жҚ®еә“зҡ„ж—¶еҖҷпјҢе‘ҠиҜүж•°жҚ®еә“жҲ‘们йңҖиҰҒд»Җд№Ҳйҡ”зҰ»пјҢж•°жҚ®еә“еҸҜд»Ҙеё®еҠ©е®ҢжҲҗеҠ й”Ғж“ҚдҪңгҖӮ
@Transactional(isolation = Isolation.READ_UNCOMMITTED)@Transactional(isolation = Isolation.READ_COMMITTED)@Transactional(isolation = Isolation.REPEATABLE_READ)@Transactional(isolation = Isolation.SERIALIZABLE)
еёёи§Ғж Үзӯҫи§ЈйҮҠ
Read Uncommittedпјҡ
- зү№жҖ§пјҡе…Ғи®ёдёҖдёӘдәӢеҠЎиҜ»еҸ–еҸҰдёҖдёӘжңӘжҸҗдәӨдәӢеҠЎзҡ„дҝ®ж”№пјҢеҸҜиғҪеҸ‘з”ҹи„ҸиҜ»пјҲDirty ReadпјүгҖӮ
- дјҳзӮ№пјҡ并еҸ‘жҖ§иғҪиҫғй«ҳгҖӮ
- зјәзӮ№пјҡжңҖдҪҺзҡ„йҡ”зҰ»зә§еҲ«пјҢеҸҜиғҪдјҡзңӢеҲ°жңӘжҸҗдәӨзҡ„ж•°жҚ®еҸҳеҢ–гҖӮ
- дҫӢеӯҗпјҡеҒҮи®ҫиҪҰзҘЁйў„и®ўдәҶпјҢжӯӨж—¶й”ҒдҪҸзҘЁпјҢйӮЈд№ҲеҰӮжһңжІЎжңүд№°жІЎйҖҖеҮәпјҢе…¶д»–дәәд№ҹд№°дёҚдәҶгҖӮ
Read Committedпјҡ
- зү№жҖ§пјҡеҸӘиғҪиҜ»еҸ–е·Із»ҸжҸҗдәӨзҡ„дәӢеҠЎдҝ®ж”№пјҢйҒҝе…ҚдәҶи„ҸиҜ»пјҢдҪҶеҸҜиғҪеҸ‘з”ҹдёҚеҸҜйҮҚеӨҚиҜ»пјҲNon-repeatable ReadпјүгҖӮ
- дјҳзӮ№пјҡеӨ§еӨҡж•°ж•°жҚ®еә“зҡ„й»ҳи®Өзә§еҲ«пјҢдҝқиҜҒжҜҸж¬ЎиҜ»еҸ–зҡ„ж•°жҚ®йғҪжҳҜе·ІжҸҗдәӨзҡ„гҖӮ
- зјәзӮ№пјҡеҗҢдёҖдәӢеҠЎдёӯпјҢиҝһз»ӯиҜ»еҸ–еҗҢдёҖжқЎж•°жҚ®еҸҜиғҪдјҡдёҚдёҖиҮҙгҖӮ
- дҫӢеӯҗпјҡеҗҢдёҖдёӘдәӢзү©еҶ…еӨҡж¬ЎеҜ№дёҖдёӘеҖјиҜ·жұӮпјҢ第дёҖж¬ЎGETдёәaпјҢ第дәҢж¬ЎGETе°ұеҸҜиғҪдёәbдәҶпјҢеӣ дёәжҜҸж¬ЎйғҪиҜ»еҸ–е·Із»ҸжҸҗдәӨзҡ„дәӢзү©дҝ®ж”№гҖӮ
Repeatable Readпјҡ
- зү№жҖ§пјҡдҝқиҜҒеҗҢдёҖдёӘдәӢеҠЎдёӯеӨҡж¬ЎиҜ»еҸ–зҡ„ж•°жҚ®жҳҜдёҖиҮҙзҡ„пјҢйҒҝе…ҚдёҚеҸҜйҮҚеӨҚиҜ»пјҢдҪҶеҸҜиғҪдјҡеҸ‘з”ҹе№»иҜ»пјҲPhantom ReadпјүгҖӮ
- дјҳзӮ№пјҡзЎ®дҝқиҜ»еҸ–зҡ„и®°еҪ•еңЁдәӢеҠЎжңҹй—ҙдёҚеҸ‘з”ҹеҸҳеҢ–гҖӮ
- зјәзӮ№пјҡд»ҚеҸҜиғҪжңүе№»иҜ»й—®йўҳпјҲеҚіжҸ’е…Ҙж–°ж•°жҚ®ж—¶зҡ„并еҸ‘й—®йўҳпјүгҖӮ
- и§ЈйҮҠпјҡдёҺдёҚеҸҜйҮҚеӨҚиҜ»зҡ„еҢәеҲ«еңЁдәҺпјҢдёҚеҸҜйҮҚеӨҚиҜ»жҳҜй’ҲеҜ№е·ІеӯҳеңЁзҡ„и®°еҪ•зҡ„дҝ®ж”№пјҢиҖҢе№»иҜ»еҲҷжҳҜеӣ дёә并еҸ‘дәӢеҠЎжҸ’е…ҘжҲ–еҲ йҷӨдәҶж–°зҡ„и®°еҪ•пјҢд»ҺиҖҢеҪұе“ҚдәҶжҹҘиҜўз»“жһңйӣҶзҡ„жқЎзӣ®ж•°йҮҸжҲ–еҶ…е®№гҖӮеҜ№дёҖдёӘеҗҢдёҖдёӘListеңЁеҗҢдёҖдәӢзү©иҜ»еҸ–пјҢ第дёҖж¬ЎиҜ»еҲ°10дёӘпјҢ第дәҢж¬ЎиҜ»еҲ°11дёӘпјҢеӣ дёәдёӯй—ҙжҸ’е…ҘдәҶдёҖдёӘж•°жҚ®гҖӮ
Serializableпјҡ
- зү№жҖ§пјҡжңҖй«ҳзә§еҲ«зҡ„йҡ”зҰ»пјҢдәӢеҠЎд№Ӣй—ҙе®Ңе…Ёйҡ”зҰ»пјҢд»ҝдҪӣдәӢеҠЎжҳҜдёҖдёӘжҺҘдёҖдёӘйЎәеәҸжү§иЎҢзҡ„пјҢи§ЈеҶідәҶе№»иҜ»й—®йўҳгҖӮ
- дјҳзӮ№пјҡжҸҗдҫӣдәҶжңҖй«ҳзҡ„дәӢеҠЎдёҖиҮҙжҖ§гҖӮ
- зјәзӮ№пјҡ并еҸ‘жҖ§е·®пјҢе®№жҳ“дә§з”ҹжҖ§иғҪ瓶йўҲгҖӮ
SpringдёӯеҜ№еә”дҪҝз”Ё
@Transactional(isolation = Isolation.READ_UNCOMMITTED)@Transactional(isolation = Isolation.READ_COMMITTED)@Transactional(isolation = Isolation.REPEATABLE_READ)@Transactional(isolation = Isolation.SERIALIZABLE)
еҲҶеёғејҸзі»з»ҹе®һзҺ°
еҸҜиғҪжңүеӨҡдёӘж•°жҚ®еә“пјҢжӯӨж—¶TransactionпјҲTomecat / SpringпјүдјҡиҮӘеҠЁеҚҸи°ғеӨҡдёӘж•°жҚ®жәҗ
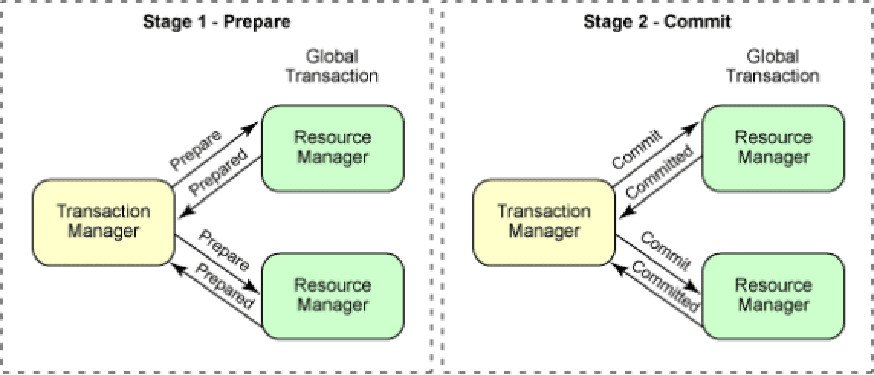
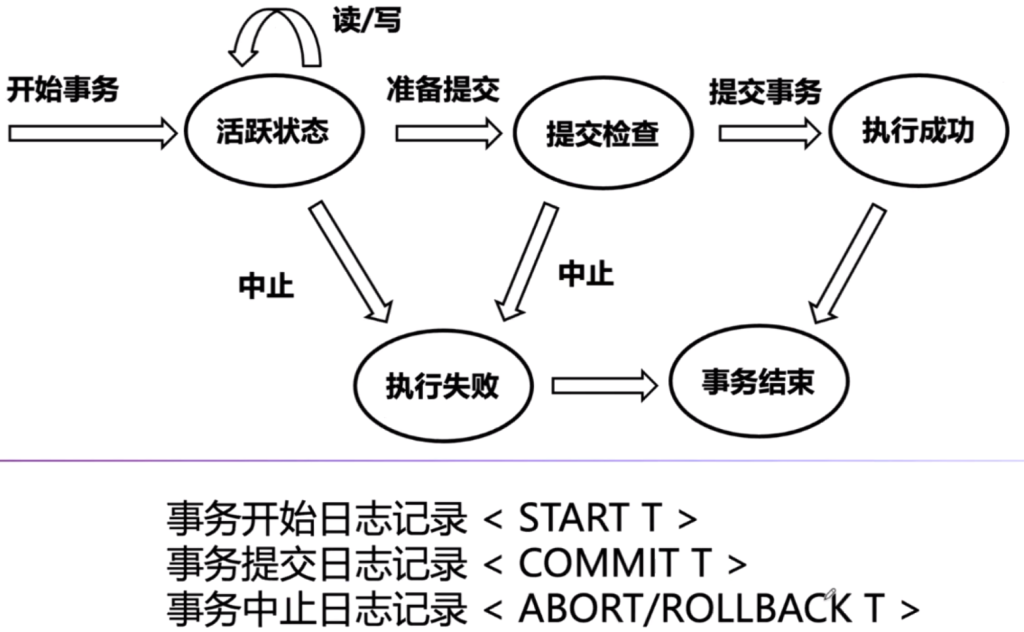
дёӨйҳ¶ж®өжҸҗдәӨ
第дёҖйҳ¶ж®өпјҡеә”з”ЁзЁӢеәҸпјҲUserпјүеҗ‘еҚҸи°ғиҖ…пјҲTransaction ManagerпјүеҸ‘йҖҒдёҖдёӘдәӢеҠЎиҜ·жұӮпјҢйҖҡзҹҘеҚҸи°ғиҖ…ејҖе§ӢдәӢеҠЎгҖӮеҚҸи°ғиҖ…еҗ‘жүҖжңүеҸӮдёҺиҖ…пјҲResource ManagerпјүпјҲеҸҜиғҪжҳҜеӨҡдёӘж•°жҚ®еә“гҖҒжңҚеҠЎзӯүпјүеҸ‘йҖҒдёҖдёӘвҖңеҮҶеӨҮжҸҗдәӨдәӢеҠЎвҖқзҡ„иҜ·жұӮпјҢиҜўй—®е®ғ们жҳҜеҗҰиғҪеӨҹжҲҗеҠҹжү§иЎҢдәӢеҠЎе№¶жҸҗдәӨз»“жһңгҖӮеҸӮдёҺиҖ…пјҲResource Managerпјүжү§иЎҢдәӢеҠЎе№¶еӣһеә”пјҲеҸӮдёҺиҖ…жү§иЎҢдәӢеҠЎпјҢдҪҶдёҚжҸҗдәӨпјҢиҖҢжҳҜе°ҶдәӢеҠЎж“ҚдҪңжҡӮж—¶дҝқеӯҳиө·жқҘпјҲдҫӢеҰӮй”ҒдҪҸзӣёе…іиө„жәҗпјүпјүгҖӮ
第дәҢйҳ¶ж®өпјҡжҸҗдәӨеүҚпјҢдёҖзҘЁеҗҰеҶіеҲ¶пјҢеҝ…йЎ»иҰҒйғҪеҸҜд»ҘжҸҗдәӨжүҚеҸҜд»ҘпјҢеҰӮжһңдёҖдёӘиҜҙеӣһж»ҡпјҢеҲҷйғҪйңҖиҰҒеӣһж»ҡпјӣжҺҘзқҖпјҢеҚҸи°ғиҖ…пјҲTransaction ManagerпјүеҸ‘йҖҒжҸҗдәӨжҲ–еӣһж»ҡиҜ·жұӮпјҢеҸӮдёҺиҖ…жү§иЎҢж“ҚдҪңпјҢжңҖеҗҺеҸӮдёҺиҖ…зЎ®и®Өз»“жһңгҖӮ
й—®йўҳпјҡеҸҜиғҪеӯҳеңЁж•°жҚ®дёҚдёҖиҮҙй—®йўҳпјҢеҰӮжһңеңЁжҸҗдәӨйҳ¶ж®өпјҢжңүеҸӮдёҺиҖ…жҸҗдәӨдәҶдәӢеҠЎпјҢдҪҶеҚҸи°ғиҖ…еҙ©жәғжҲ–жҹҗдәӣеҸӮдёҺиҖ…жІЎжңү收еҲ°жҸҗдәӨжҢҮд»ӨпјҢеҸҜиғҪеҜјиҮҙйғЁеҲҶжҸҗдәӨжҲҗеҠҹпјҢйғЁеҲҶжІЎжңүжҸҗдәӨпјҢеҮәзҺ°ж•°жҚ®дёҚдёҖиҮҙзҡ„жғ…еҶөпјҲйҖҡеёёйҖҡиҝҮдёүйҳ¶ж®өжҸҗдәӨеҚҸи®®зӯүж–№ејҸжқҘи§ЈеҶіпјүгҖӮ
зҰ»зәҝй”ҒпјҡжүҖи°“вҖңзҰ»зәҝвҖқжҢҮзҡ„жҳҜflushд№ӢеүҚпјҢж•°жҚ®иҜ»еҮәжқҘд№ӢеҗҺпјҢж”ҫеңЁдәҶtomcatзҡ„еҶ…еӯҳйҮҢпјӣиҝҷдёӘж—¶еҖҷжҳҜзҰ»зәҝзҡ„пјӣжүҖи°“вҖңеңЁзәҝвҖқпјҢе°ұжҳҜиҝҷдёӘеҜ№иұЎе®һж—¶еҸҚжҳ дәҶж•°жҚ®еә“зҡ„ж•°жҚ®пјӣдҪҶжҳҫ然ORжҳ е°„/JDBCйғҪжҳҜзҰ»зәҝзҡ„гҖӮ
жӮІи§ӮзҰ»зәҝй”Ғ
е®ҡд№үпјҡжӮІи§Ӯй”ҒеҒҮе®ҡеңЁе№¶еҸ‘ж“ҚдҪңж—¶пјҢдјҡз»ҸеёёеҸ‘з”ҹж•°жҚ®еҶІзӘҒпјҢеӣ жӯӨжҜҸж¬ЎиҜ»еҸ–жҲ–дҝ®ж”№ж•°жҚ®ж—¶пјҢйғҪзӣҙжҺҘй”Ғе®ҡиө„жәҗпјҢдҪҝеҫ—е…¶д»–дәӢеҠЎдёҚиғҪеҗҢж—¶еҜ№е…¶иҝӣиЎҢж“ҚдҪңгҖӮд№ҹе°ұжҳҜиҜҙпјҢе®ғвҖңжӮІи§ӮвҖқең°и®ӨдёәдјҡеҸ‘з”ҹеҶІзӘҒпјҢжүҖд»ҘеңЁи®ҝй—®иө„жәҗж—¶дјҡе…ҲиҺ·еҸ–й”ҒпјҢзЎ®дҝқеҪ“еүҚдәӢеҠЎзӢ¬еҚ иө„жәҗгҖӮ
- еҪ“дёҖдёӘдәӢеҠЎиҰҒж“ҚдҪңжҹҗжқЎи®°еҪ•ж—¶пјҢе®ғдјҡеҜ№иҜҘи®°еҪ•еҠ й”ҒгҖӮе…¶д»–дәӢеҠЎжғіиҰҒж“ҚдҪңиҜҘи®°еҪ•ж—¶пјҢеҝ…йЎ»зӯүеҫ…иҜҘй”ҒйҮҠж”ҫгҖӮ
- е…ёеһӢеңәжҷҜдёӢпјҢжӮІи§Ӯй”ҒйҖҡеёёйҖҡиҝҮж•°жҚ®еә“зҡ„й”ҒжңәеҲ¶пјҲдҫӢеҰӮиЎЁй”ҒжҲ–иЎҢй”Ғпјүе®һзҺ°гҖӮ
- еңЁеҶІзӘҒиҫғеӨҡгҖҒ并еҸ‘дҝ®ж”№иҫғеӨҡзҡ„еңәжҷҜдёӢпјҢеҰӮйҮ‘иһҚдәӨжҳ“гҖҒеә“еӯҳз®ЎзҗҶзӯүпјҢеҸҜд»ҘзЎ®дҝқж•°жҚ®зҡ„е®үе…Ёе’ҢдёҖиҮҙжҖ§гҖӮ
д№җи§ӮзҰ»зәҝй”Ғ
е®ҡд№үпјҡ д№җи§Ӯй”ҒеҒҮи®ҫеңЁеӨ§еӨҡж•°жғ…еҶөдёӢпјҢеӨҡдёӘдәӢеҠЎе№¶еҸ‘ж“ҚдҪңж—¶дёҚдјҡеҸ‘з”ҹеҶІзӘҒпјҢеӣ жӯӨеңЁжү§иЎҢж“ҚдҪң时并дёҚдјҡеҜ№иө„жәҗеҠ й”ҒгҖӮеҪ“дәӢеҠЎеңЁжҸҗдәӨдҝ®ж”№ж—¶пјҢзі»з»ҹдјҡйҖҡиҝҮдёҖдәӣж–№ејҸпјҲеҰӮзүҲжң¬еҸ·жҲ–ж—¶й—ҙжҲіпјүжқҘжЈҖжҹҘеңЁжӯӨжңҹй—ҙжҳҜеҗҰжңүе…¶д»–дәӢеҠЎеҜ№ж•°жҚ®иҝӣиЎҢдәҶдҝ®ж”№гҖӮеҰӮжһңеҸ‘зҺ°еҶІзӘҒпјҢеҲҷжӢ’з»қжҸҗдәӨпјҢдәӢеҠЎеҝ…йЎ»йҮҚж–°е°қиҜ•ж“ҚдҪңгҖӮиҝҷз§Қж–№ејҸвҖңд№җи§ӮвҖқең°и®ӨдёәеҶІзӘҒдёҚдјҡз»ҸеёёеҸ‘з”ҹгҖӮ
- д№җи§Ӯй”ҒдёҚдҫқиө–ж•°жҚ®еә“зҡ„зү©зҗҶй”ҒжңәеҲ¶пјҢиҖҢжҳҜйҖҡиҝҮзүҲжң¬еҸ·пјҲжҲ–ж—¶й—ҙжҲіпјүжңәеҲ¶жқҘжҺ§еҲ¶гҖӮ
- жҜҸж¬ЎиҜ»еҸ–и®°еҪ•ж—¶пјҢиҜ»еҸ–иҜҘи®°еҪ•зҡ„зүҲжң¬еҸ·гҖӮ
- еҪ“иҝӣиЎҢжӣҙж–°ж“ҚдҪңж—¶пјҢдјҡжЈҖжҹҘи®°еҪ•зҡ„еҪ“еүҚзүҲжң¬еҸ·жҳҜеҗҰдёҺиҜ»еҸ–ж—¶дёҖиҮҙгҖӮеҰӮжһңдёҖиҮҙпјҢеҲҷжӣҙж–°жҲҗеҠҹпјӣеҰӮжһңзүҲжң¬еҸ·дёҚдёҖиҮҙпјҢиҜҙжҳҺеңЁжӯӨжңҹй—ҙе…¶д»–дәӢеҠЎдҝ®ж”№дәҶиҜҘи®°еҪ•пјҢеҪ“еүҚдәӢеҠЎеӨұиҙҘпјҢйңҖиҰҒйҮҚж–°е°қиҜ•гҖӮ
- йҖӮеҗҲдәҺиҜ»еӨҡеҶҷе°‘зҡ„еә”з”ЁеңәжҷҜпјҢеҰӮжҠҘиЎЁжҹҘиҜўгҖҒз”ЁжҲ·жҹҘзңӢж•°жҚ®зӯүж“ҚдҪңгҖӮеӣ дёәеңЁиҝҷз§ҚеңәжҷҜдёӢпјҢж•°жҚ®еҶІзӘҒзҡ„еҸҜиғҪжҖ§иҫғе°ҸпјҢд№җи§Ӯй”ҒеҸҜд»Ҙжңүж•ҲжҸҗеҚҮжҖ§иғҪгҖӮ
дёӨз§Қй”Ғз®ҖеҚ•еҜ№жҜ”жҖ»з»“
| зү№жҖ§ | зІ—зІ’еәҰй”Ғ | з»ҶзІ’еәҰй”Ғ |
|---|---|---|
| й”Ғе®ҡиҢғеӣҙ | й”Ғе®ҡиҫғеӨ§иҢғеӣҙзҡ„иө„жәҗпјҲеҰӮж•ҙеј иЎЁгҖҒж•ҙдёӘйӣҶеҗҲпјү | й”Ғе®ҡиҫғе°Ҹзҡ„иө„жәҗеҚ•е…ғпјҲеҰӮжҹҗиЎҢгҖҒжҹҗдёӘеҜ№иұЎпјү |
| 并еҸ‘жҖ§иғҪ | иҫғе·®пјҢе®№жҳ“еҜјиҮҙй”Ғз«һдәү | 并еҸ‘жҖ§иҫғеҘҪпјҢиө„жәҗеҶІзӘҒиҫғе°‘ |
| еӨҚжқӮеәҰ | з®ҖеҚ•пјҢй”Ғз®ЎзҗҶиҫғе°‘пјҢйҒҝе…ҚиҝҮеӨҡзҡ„й”ҒиҜ·жұӮ | еӨҚжқӮпјҢйңҖиҰҒз®ЎзҗҶжӣҙеӨҡзҡ„й”Ғ |
| йҖӮз”ЁеңәжҷҜ | 并еҸ‘иҫғдҪҺгҖҒж“ҚдҪңиҢғеӣҙиҫғеӨ§гҖҒжү№йҮҸж“ҚдҪң | 并еҸ‘иҫғй«ҳгҖҒиө„жәҗз»ҶеҲҶгҖҒйңҖиҰҒзІҫзЎ®жҺ§еҲ¶жҜҸдёӘж“ҚдҪңзҡ„й”Ғе®ҡ |
| й”ҒејҖй”Җ | иҫғе°ҸпјҢй”Ғз®ЎзҗҶејҖй”ҖиҫғдҪҺ | иҫғеӨ§пјҢй”Ғзҡ„з®ЎзҗҶе’Ңз»ҙжҠӨејҖй”Җжӣҙй«ҳ |
| жӯ»й”ҒйЈҺйҷ© | жӯ»й”ҒйЈҺйҷ©иҫғе°Ҹ | жӯ»й”ҒйЈҺйҷ©иҫғеӨ§ |
зІ—зІ’еәҰй”ҒпјҲCoarse-Grained Lockingпјү
жҢҮзҡ„жҳҜй”Ғе®ҡиҫғеӨ§иҢғеӣҙзҡ„иө„жәҗжҲ–ж•°жҚ®еҚ•е…ғпјҢд»ҘжҺ§еҲ¶е№¶еҸ‘и®ҝй—®гҖӮжҜ”еҰӮиҜҙжҲ‘дёҖеј иЎЁиҝҳжҺ§еҲ¶е…¶е®ғиЎЁпјҲеӨ–й”®е…іиҒ”пјүпјҢйңҖиҰҒеҜ№ж•ҙдёӘиЎЁиҝӣиЎҢжҺ§еҲ¶гҖӮе®һзҺ°еҺҹзҗҶпјҡдёӨз»„ж•°жҚ®йҖҡиҝҮеј•з”Ёе…ұдә«еҗҢдёҖдёӘзүҲжң¬еҸ·з ҒпјҢйҖҡиҝҮеј•з”Ёзҡ„ж–№жі•пјҢдёӨдёӘж•°жҚ®еј•з”Ёзҡ„ жҳҜеҗҢдёҖдёӘзүҲжң¬еҸ·з ҒпјҲжүҖи°“зҡ„зүҲжң¬еҸ·дёҚжҳҜдёҖдёӘж•°еӯ—пјҢиҖҢжҳҜдёҖдёӘеҜ№иұЎпјҢиҝҷдёӘеҜ№иұЎйҮҢйқўжңүдёҖдёӘж•°еӯ—еұһжҖ§пјҢ иҝҷдёӘж•°еӯ—е°ұжҳҜзүҲжң¬еҸ·з ҒпјүгҖӮ
第дә”з«
и°ғеәҰ
дҪңз”Ёпјҡи°ғеәҰдёәдәӢзү©зҡ„并еҸ‘еӨ„зҗҶиҝҮзЁӢдёӯпјҢеҶіе®ҡдәӢзү©дёӯжҜҸдёҖдёӘж“ҚдҪңзҡ„жү§иЎҢйЎәеәҸпјҢд»ҘжӯӨжқҘжҸҗй«ҳ并иЎҢж•ҲзҺҮгҖӮ

дёІиЎҢи°ғеәҰ
е®ҡд№үпјҡдәӢзү©дёІиЎҢжү§иЎҢ
еҸҜдёІиЎҢеҢ–и°ғеәҰ
з»ҷе®ҡдёҖдёӘ并еҸ‘и°ғеәҰSпјҢеӯҳеңЁдёҖдёӘдёІиЎҢи°ғеәҰSвҖҷпјҢеңЁд»»дҪ•ж•°жҚ®еә“зҠ¶жҖҒдёӢпјҢжҢүз…§и°ғеәҰSе’Ңи°ғеәҰS’жү§иЎҢеҗҺжүҖдә§з”ҹзҡ„з»“жһңйғҪжҳҜзӣёеҗҢзҡ„жӯӨж—¶и°ғеәҰSиў«з§°д№Ӣдёә еҸҜдёІиЎҢеҢ–и°ғеәҰ (serializable schedule)гҖӮ
еҸҜдёІиЎҢеҢ–и°ғеәҰзҡ„ж•°йҮҸеҚҒеҲҶе·ЁеӨ§пјҢдё”йҡҫд»Ҙж ЎйӘҢпјҢж•°жҚ®еә“дёӯдёҖиҲ¬йҖҡиҝҮжүҫеҲ°еҸҜдёІиЎҢеҢ–и°ғеәҰзҡ„еӯҗйӣҶ(е……еҲҶжқЎд»¶)пјҢеҚіжүҫеҲ°иғҪеӨҹжҸҗеүҚзЎ®и®ӨжҳҜеҸҜдёІиЎҢи°ғеәҰзҡ„并еҸ‘и°ғеәҰпјҲйғЁеҲҶи§ЈпјүпјҢиҝӣиҖҢжҸҗеҚҮи°ғеәҰж•ҲзҺҮгҖӮ
зӯүд»·ж“ҚдҪң
- дәӨжҚўиҝһз»ӯдёӨдёӘзӣёеҗҢж•°жҚ®иҜ»еҸ–ж“ҚдҪң
- дәӨжҚўиҝһз»ӯдёӨдёӘдёҚеҗҢж•°жҚ®иҜ»еҶҷж“ҚдҪң
йқһзӯүд»·ж“ҚдҪң
- дәӨжҚўиҝһз»ӯдёӨдёӘзӣёеҗҢж•°жҚ®зҡ„иҜ»еҶҷпјҢеҶҷеҶҷж“ҚдҪң
еҶІзӘҒеҸҜдёІиЎҢеҢ–и°ғеәҰзҡ„йӘҢиҜҒ


ж•°жҚ®еә“еҺҹеӯҗжҖ§е’ҢжҢҒд№…жҖ§е®һзҺ°
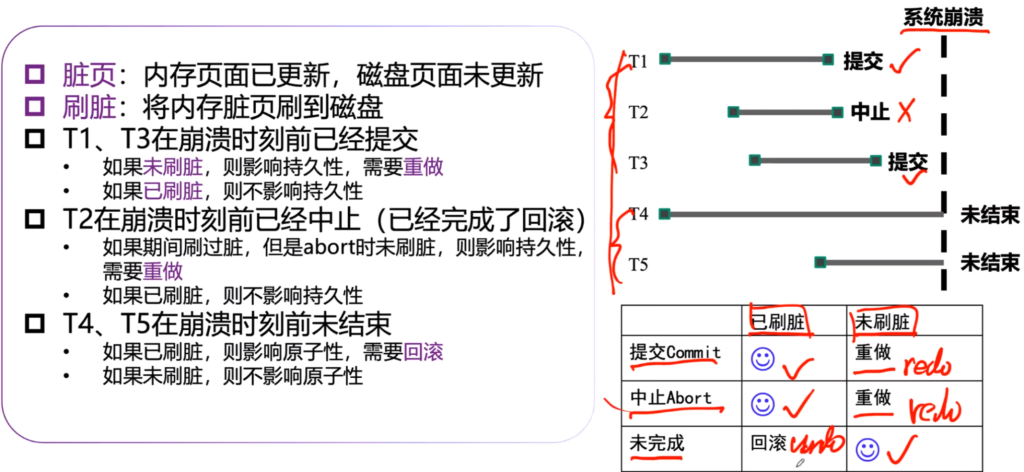
ж•…йҡңзі»з»ҹйҮҚеҗҜеҗҺпјҢеҶ…еӯҳж•°жҚ®дёўеӨұпјҢзЈҒзӣҳж•°жҚ®дёҚдёўеӨұ
еҺҹеӯҗжҖ§пјҲдәӢзү©иҝҗиЎҢдёӯпјү
- дәӢзү©иҝҗиЎҢжңҹй—ҙдёҚеҲ·зӣҳпјҢж•…йҡңзі»з»ҹйҮҚеҗҜеҗҺиҮӘеҠЁдҝқиҜҒеҺҹеӯҗжҖ§
- еӣ дёәж•ҙдёӘдәӢзү©иҝҳжІЎжңүиҝӣе…ҘзЎ¬зӣҳпјҢе°ұеҸҜд»ҘеҪ“жІЎжңүеӨ„зҗҶиҝҮиҝҷдёӘдәӢзү©пјҢзі»з»ҹйҮҚеҗҜеҗҺйҮҚж–°жү§иЎҢд»»еҠЎеҲҷе®№жҳ“дҝқжҢҒе…¶еҺҹеӯҗжҖ§
- еҚ з”ЁеҶ…еӯҳе®№жҳ“еҫҲеӨ§
- дәӢзү©иҝҗиЎҢжңҹй—ҙеҲ·зӣҳпјҢж•…йҡңзі»з»ҹйҮҚеҗҜйңҖиҰҒеӣһж»ҡдәӢеҠЎ
- йқўеҜ№йҮҚеҗҜжҜ”иҫғйә»зғҰпјҢиҖғиҷ‘еӣһж»ҡпјҲundoпјү
жҢҒд№…жҖ§пјҲдәӢзү©е·Із»Ҹе®ҢжҲҗпјү
- дәӢзү©е®ҢжҲҗж—¶еҲ·зӣҳпјҢж•…йҡңзі»з»ҹйҮҚеҗҜеҗҺиҮӘеҠЁдҝқиҜҒжҢҒд№…жҖ§
- дәӢзү©е®ҢжҲҗж—¶дёҚеҲ·зӣҳпјҢж•…йҡңзі»з»ҹйҮҚеҗҜеҗҺйңҖиҰҒйҮҚеҒҡиҜҘдәӢзү©(redo)
ж•°жҚ®еә“жҒўеӨҚеҹәжң¬еҺҹзҗҶ
- ж— ж•…йҡңдәӢеҠЎеӣһж»ҡ(дҫӢеҰӮиҙҰжҲ·е°ҸдәҺ0)пјҡеҪұе“ҚеҺҹеӯҗжҖ§пјҢж’Өй”ҖиҜҘдәӢеҠЎе·ІеҒҡж“ҚдҪң
- ж•…йҡңеӨұиҜҜеӣһж»ҡ(дҫӢеҰӮжӯ»й”ҒжқҖжӯ»дәӢеҠЎ)пјҡеҪұе“ҚеҺҹеӯҗжҖ§пјҢж’Өй”ҖиҜҘдәӢеҠЎе·ІеҒҡж“ҚдҪң
- зі»з»ҹж•…йҡң(дҫӢеҰӮйҮҚеҗҜ):еҶ…еӯҳж•°жҚ®дёўеӨұпјҢеҪұе“ҚеҺҹеӯҗжҖ§е’ҢжҢҒд№…жҖ§
- еҺҹеӯҗжҖ§пјҡж’Өй”ҖжңӘз»“жқҹ(дёҚеёҰCommitгҖҒAbortж Үи®°)зҡ„дәӢеҠЎ
- жҢҒд№…жҖ§пјҡйҮҚеҒҡе·Із»Ҹз»“жқҹ(еёҰCommitжҲ–Abortж Үи®°)зҡ„дәӢеҠЎ
- зі»з»ҹеҙ©жәғдёҚиғҪйҮҚеҗҜпјҡдёҚиғҪжҸҗдҫӣжңҚеҠЎпјҢеҪұе“ҚжҢҒд№…жҖ§
- дёҖдё»еӨҡеӨҮпјҡдё»еӨҮд№Ӣй—ҙйҖҡиҝҮж—Ҙеҝ—дҝқжҢҒдёҖиҮҙжҖ§пјҢеҸ‘з”ҹж•…йҡңеҗҺеҲҮжҚўеҲ°е…¶д»–зі»з»ҹ
- зЈҒзӣҳж•…йҡң:зЈҒзӣҳж•°жҚ®дёўеӨұпјҢеҪұе“ҚжҢҒд№…жҖ§
- зЈҒзӣҳж•°жҚ®еӨҡеүҜжң¬;ж•°жҚ®еӨҮд»ҪжңәеҲ¶:еҲӣе»әж•°жҚ®еӨҮд»ҪгҖҒж—Ҙеҝ—еӨҮд»Ҫ
- иҮӘ然зҒҫе®і:зі»з»ҹе®•жңәдёҚиғҪйҮҚеҗҜпјҢеҪұе“ҚжҢҒд№…жҖ§
- ејӮең°еӨҡжңәе®№зҒҫпјҡеӨҡжңәе®һж—¶дј иҫ“ж—Ҙеҝ—дҝқиҜҒдёҖиҮҙжҖ§пјҢеҸ‘з”ҹж•…йҡңеҗҺеҲҮжҚўеҲ°е…¶д»–зі»з»ҹ
й«ҳеҸҜз”ЁжҖ§жҢҮж Ү
йҖҡз”Ёй«ҳеҸҜз”ЁжҢҮж Ү:
- е№іеқҮж•…йҡңй—ҙйҡ”ж—¶й—ҙ MTBF(Mean Time between Failures):зі»з»ҹеңЁдёӨзӣёйӮ»ж•…йҡңй—ҙйҡ”жңҹеҶ…жӯЈзЎ®е·ҘдҪңзҡ„е№іеқҮж—¶й—ҙ
- е№іеқҮжҒўеӨҚж—¶й—ҙ MTTR(Mean Time to Repair):зі»з»ҹе№іеқҮд»Һж•…йҡңдёӯжҒўеӨҚйңҖиҰҒзҡ„ж—¶й—ҙ
- е№іеқҮжҚҹеқҸж—¶й—ҙ MTTF(Mean Time to Failure):зі»з»ҹеҮәзҺ°жҚҹеқҸзҡ„е№іеқҮж—¶й—ҙгҖӮ
ж•°жҚ®еә“е®№зҒҫжҢҮж Ү:
- жҒўеӨҚзӮ№зӣ®ж Ү RPO(Recovery Point Objective):дёҡеҠЎзі»з»ҹеңЁзі»з»ҹж•…йҡңеҗҺжүҖиғҪе®№еҝҚзҡ„ж•°жҚ®дёўеӨұйҮҸгҖӮ
- жҒўеӨҚж—¶й—ҙзӣ®ж Ү RTO(Recovery Time Objective):дёҡеҠЎзі»з»ҹжүҖиғҪе®№еҝҚзҡ„дёҡеҠЎеҒңжӯўжңҚеҠЎзҡ„жңҖй•ҝж—¶й—ҙгҖӮ
- дёҖиҲ¬з”ЁnдёӘ9жқҘиЎЁзӨә
- дҫӢеҰӮеӣӣдёӘд№қ99.99%иЎЁзӨәдёҖе№ҙ99.99%ж—¶й—ҙеҸҜз”ЁпјҢеҚідёҚеҸҜз”Ёж—¶й—ҙдёә365*24*60*0.01%=52.56еҲҶй’ҹ
зі»з»ҹеҙ©жәғеӨ„зҗҶж–№ејҸ
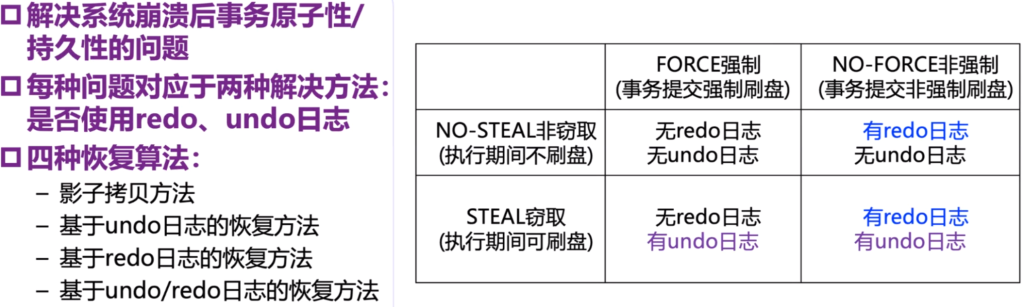
FORCEе’ҢNO-STEALж–№жЎҲйҖүжӢ©
| FORCE ејәеҲ¶ пјҲдәӢеҠЎжҸҗдәӨејәеҲ¶еҲ·зӣҳпјү | NO-FORCE ејәеҲ¶ пјҲдәӢеҠЎжҸҗдәӨдёҚејәеҲ¶еҲ·зӣҳпјү | |
| NO-STEALйқһзӘғеҸ– (жү§иЎҢжңҹй—ҙдёҚеҲ·зӣҳ) | ж— redoж—Ҙеҝ— | ж— undoж—Ҙеҝ— | жңүredoж—Ҙеҝ— | ж— undoж—Ҙеҝ— |
| STEALзӘғеҸ–(жү§иЎҢжңҹй—ҙеҸҜеҲ·зӣҳ) | ж— redoж—Ҙеҝ— | жңүundoж—Ҙеҝ— | жңүredoж—Ҙеҝ— | жңүundoж—Ҙеҝ— |
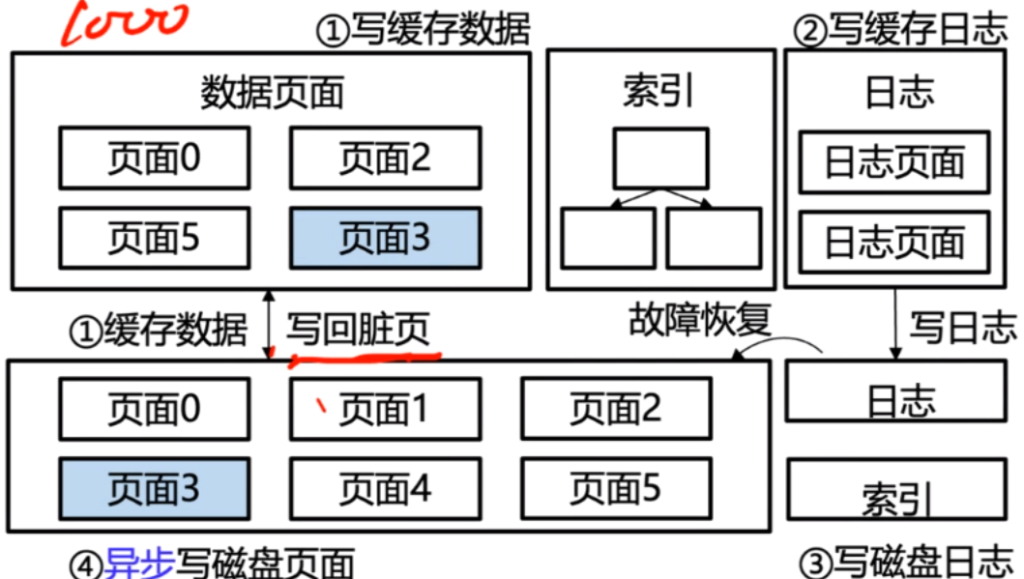
ж•°жҚ®еә“ж—Ҙеҝ—
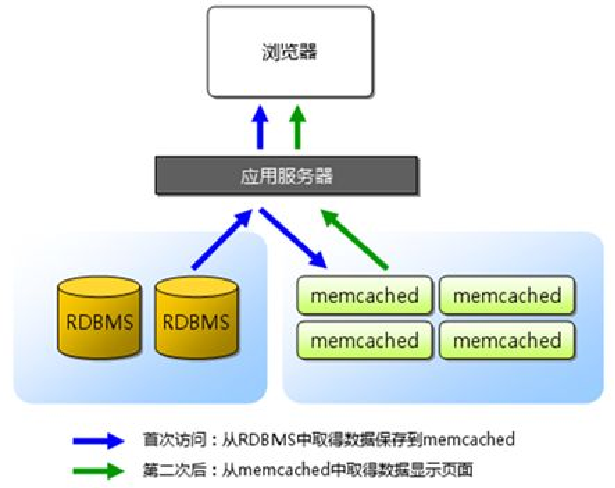
- ж•°жҚ®еә“ж—Ҙеҝ—жҳҜж•°жҚ®еә“зі»з»ҹеҶ…дёҖзі»еҲ—жү§иЎҢдәӢ件зҡ„и®°еҪ•пјҢе®ғдёҺж•°жҚ®еә“дәӢеҠЎжҳҜеҜҶеҲҮзӣёе…ізҡ„пјҢдәӢеҠЎзҡ„жү§иЎҢиҝҮзЁӢдјҡеҸҚжҳ еңЁж—Ҙеҝ—дёӯпјҢж•°жҚ®еә“еҸҜд»ҘйҖҡиҝҮеҜ№ж—Ҙеҝ—зҡ„еҲҶжһҗе®һзҺ°еҜ№дәӢеҠЎзҡ„еӣһж»ҡ(еҺҹеӯҗжҖ§)жҲ–йҮҚеҒҡ(жҢҒд№…жҖ§)
- ж—Ҙеҝ—жҳҜж—Ҙеҝ—и®°еҪ•(log record)зҡ„еәҸеҲ—гҖӮж—Ҙеҝ—и®°еҪ•жҳҜж•°жҚ®еә“зі»з»ҹжҙ»еҠЁи®°еҪ•зҡ„жңҖе°ҸеҚ•дҪҚпјҢжҜҸдёҖжқЎи®°еҪ•еҸҚжҳ дәҶж•°жҚ®еә“зі»з»ҹзҡ„дёҖж¬Ўж“ҚдҪңгҖӮж—Ҙеҝ—и®°еҪ•дёҚд»…еҢ…еҗ«дәҶж•°жҚ®зҡ„жӣҙж–°пјҢиҝҳеҢ…еҗ«дәҶж•°жҚ®еә“дәӢеҠЎејҖе§Ӣ/з»“жқҹзҡ„йҖ»иҫ‘гҖӮ
- ж—Ҙеҝ—зҡ„еҶ…е®№еңЁеҶҷе…ҘзЈҒзӣҳд»ҘеҗҺжҳҜдёҚдјҡиў«дҝ®ж”№зҡ„пјҢеӣ жӯӨжүҖжңүзҡ„ж—Ҙеҝ—еҶ…е®№еҸҜд»ҘйЎәеәҸеҶҷе…ҘзЈҒзӣҳпјҢиҝҷдҝқиҜҒдәҶй«ҳж•Ҳзҡ„еҶҷе…ҘйҖҹеәҰгҖӮиҜҘзү№жҖ§д№ҹжҳҜе»әз«Ӣй«ҳеҸҜз”ЁжҒўеӨҚжңәеҲ¶зҡ„еүҚжҸҗеҚіж•°жҚ®зҡ„йҡҸжңәиҜ»еҶҷиҪ¬жҚўдёәж—Ҙеҝ—зҡ„иҝһз»ӯиҜ»еҶҷгҖӮ
Undoеӣһж»ҡж—Ҙеҝ—
зү№зӮ№пјҡи®°еҪ•ж—§еҖј
- ж јејҸ < T , X , Vold >
- T : дәӢзү©е”ҜдёҖж ҮиҜҶз¬Ұ
- Xпјҡж•°жҚ®йЎ№
- Voldпјҡж•°жҚ®йЎ№дҝ®ж”№д»ҘеүҚзҡ„еҖј
- дә§з”ҹж—¶жңәпјҡеҪ“ж•°жҚ®Tдҝ®ж”№ж•°жҚ®йЎ№XпјҲWrite(X)пјүж—¶дә§з”ҹпјҢиҰҒеҜ№ж•°жҚ®ж“ҚдҪңж—¶еҖҷпјҢе…ҲеҶҷж—Ҙеҝ—пјҢж—Ҙеҝ—жҲҗеҠҹеҶҚж“ҚдҪңпјҢд№ҹеҸ«еҒҡ
WALпјҲWrite Ahead Logпјү - дҪңз”Ёпјҡе®һзҺ°дәӢзү©еӣһж»ҡ
- жіЁж„ҸпјҡдёҖиҲ¬иҝҳеҢ…жӢ¬дёҖдёӘж—Ҙеҝ—еәҸеҸ·log sequential number(LSN)пјҢдҫҝдәҺжӣҙеҝ«жүҫеҲ°дҪҚзҪ®
RedoйҮҚеҒҡж—Ҙеҝ—
- ж јејҸ < T , X , Vnew >
- T : дәӢзү©е”ҜдёҖж ҮиҜҶз¬Ұ
- Xпјҡж•°жҚ®йЎ№
- Vnewпјҡж•°жҚ®йЎ№дҝ®ж”№д»ҘеҗҺзҡ„еҖј
- дә§з”ҹж—¶жңәпјҡеҪ“ж•°жҚ®Tдҝ®ж”№ж•°жҚ®йЎ№XпјҲWrite(X)пјүж—¶дә§з”ҹпјҢеҗҢж ·д№ҹжҳҜ
WALпјҲWrite Ahead Logпјү - дҪңз”Ёпјҡе®һзҺ°дәӢзү©еӣһж»ҡ
- жіЁж„ҸпјҡдёҖиҲ¬иҝҳеҢ…жӢ¬дёҖдёӘж—Ҙеҝ—еәҸеҸ·log sequential number(LSN)пјҢдҫҝдәҺжӣҙеҝ«жүҫеҲ°дҪҚзҪ®
йҖ»иҫ‘ж—Ҙеҝ—
- и®°еҪ•дәӢеҠЎдёӯй«ҳеұӮжҠҪиұЎзҡ„йҖ»иҫ‘ж“ҚдҪң
- дёҫдҫӢпјҡи®°еҪ•ж—Ҙеҝ—дёӯUPDATEгҖҒDELETEе’ҢINSERTзҡ„ж–Үжң¬дҝЎжҒҜ
- дҫӢеҰӮе°ҸжҳҺзҡ„е№ҙйҫ„з”ұ20ж”№жҲҗ21гҖӮ
- еҘҪеӨ„пјҡж•°жҚ®еә“зүҲжң¬жӣҙж–°ж—¶еҖҷпјҢд№ҹе®№жҳ“жҒўеӨҚ
зү©зҗҶж—Ҙеҝ—
- и®°еҪ•ж•°жҚ®еә“е…·дҪ“зү©зҗҶеҸҳеҢ–
- дёҫдҫӢпјҡи®°еҪ•дёҖдёӘиў«жҹҘиҜўеҪұе“Қзҡ„ж•°жҚ®йЎ№еүҚеҗҺзҡ„еҖј
- дҫӢеҰӮ第10дёӘйЎөйқўз¬¬100еҒҸ移йҮҸзҡ„еҖјз”ұ20ж”№жҲҗ21гҖӮ
- еҘҪеӨ„пјҡ1. еҜ№дәҺInsertпјҢйҖ»иҫ‘ж—Ҙеҝ—дёҚиғҪжү§иЎҢ第дәҢж¬ЎпјҢиҖҢеҜ№дәҺзү©зҗҶж—Ҙеҝ—еҸҜд»ҘпјҲе№ӮзӯүжҖ§пјү 2. еҚ з”Ёе°Ҹ
зү©зҗҶйҖ»иҫ‘ж—Ҙеҝ—
- дёҖз§Қз»“еҗҲдәҶзү©зҗҶж—Ҙеҝ—е’ҢйҖ»иҫ‘ж—Ҙеҝ—ж··еҗҲж–№жі•
- ж—Ҙеҝ—и®°еҪ•дёӯеҢ…еҗ«дәҶж•°жҚ®йЎөйқўзҡ„зү©зҗҶдҝЎжҒҜпјҢдҪҶжҳҜйЎөйқўд»ҘеҶ…зӣ®ж Үж•°жҚ®йЎ№зҡ„дҝ®ж”№дҝЎжҒҜеҲҷжҳҜд»ҘйҖ»иҫ‘ж–№ејҸи®°еҪ•
- дҫӢеҰӮ第100дёӘйЎөйқў(зү©зҗҶ)зҡ„е°ҸжҳҺе№ҙйҫ„еҖјз”ұ20ж”№жҲҗ21(йҖ»иҫ‘)
ж•°жҚ®еә“ж—Ҙеҝ—жҖ§иҙЁ
- е№ӮзӯүжҖ§пјҡдёҖжқЎж—Ҙеҝ—и®°еҪ•ж— и®әжү§иЎҢдёҖж¬ЎжҲ–еӨҡж¬ЎпјҢеҫ—еҲ°зҡ„з»“жһңйғҪжҳҜдёҖиҮҙзҡ„гҖӮ
- дҫӢеҰӮ:x=x+1дёҚе№Ӯзӯүпјӣx=0е№Ӯзӯү
- зү©зҗҶж—Ҙеҝ—ж»Ўи¶іе№ӮзӯүжҖ§пјӣйҖ»иҫ‘ж—Ҙеҝ—дёҚж»Ўи¶і
- еӨұиҙҘеҸҜйҮҚеҒҡжҖ§пјҡдёҖжқЎж—Ҙеҝ—жү§иЎҢеӨұиҙҘеҗҺпјҢжҳҜеҗҰеҸҜдәәйҮҚеҒҡдёҖйҒҚиҫҫжҲҗжҒўеӨҚзӣ®зҡ„гҖӮ
- дҫӢеҰӮ:жҸ’е…ҘдёҖжқЎи®°еҪ•еӨұиҙҘпјҢеҶҚж¬ЎжҸ’е…ҘжҲҗеҠҹгҖӮ
- зү©зҗҶж—Ҙеҝ—ж»Ўи¶іеӨұиҙҘеҸҜйҮҚеҒҡжҖ§пјӣйҖ»иҫ‘ж—Ҙеҝ—дёҚж»Ўи¶іпјҡдҫӢеҰӮжҸ’е…Ҙж•°жҚ®йЎөйқўжҲҗеҠҹпјҢиҖҢжҸ’е…Ҙзҙўеј•еӨұиҙҘйҮҚеҒҡжҸ’е…ҘиҝҷдёӘйҖ»иҫ‘ж—Ҙеҝ—еӨұиҙҘгҖӮ
- ж“ҚдҪңеҸҜйҖҶжҖ§пјҡйҖҶеҗ‘жү§иЎҢж—Ҙеҝ—и®°еҪ•зҡ„ж“ҚдҪңпјҢеҸҜд»ҘеӨҚеҺҹжқҘзҠ¶жҖҒ(жңӘжү§иЎҢиҝҷжү№ж“ҚдҪңж—¶зҡ„зҠ¶жҖҒ)
- дҫӢеҰӮ第10дёӘйЎөйқўз¬¬100еҒҸ移йҮҸзҡ„еҖјз”ұ20ж”№жҲҗ21пјҢйҖҶж“ҚдҪңз”ұ21ж”№жҲҗ20
- зү©зҗҶж—Ҙеҝ—дёҚеҸҜйҖҶ(йЎөйқўеҒҸ移йҮҸдҪҚзҪ®еҸҜиғҪиў«еҗҺз»ӯи®°еҪ•дҝ®ж”№)пјҢйҖ»иҫ‘ж—Ҙеҝ—еҸҜйҖҶгҖӮ
йҖӮз”ЁжҖ§жҖ»з»“
| ж—Ҙеҝ—зұ»еһӢ | и§ЈжһҗйҖҹеәҰ | ж—Ҙеҝ—йҮҸ | еҸҜйҮҚеҒҡжҖ§ | е№ӮзӯүжҖ§ | еҸҜйҖҶжҖ§ | еә”з”ЁеңәжҷҜ |
|---|---|---|---|---|---|---|
| зү©зҗҶж—Ҙеҝ— | еҝ« | еӨ§ | жҳҜ | жҳҜ | еҗҰ | redoж—Ҙеҝ— |
| йҖ»иҫ‘ж—Ҙеҝ— | ж…ў | е°Ҹ | еҗҰ | еҗҰ | жҳҜ | undoж—Ҙеҝ— |
| зү©зҗҶйҖ»иҫ‘ж—Ҙеҝ— | иҫғеҝ« | дёӯ | жҳҜ | еҗҰ | еҗҰ | undoж—Ҙеҝ— |
ж•°жҚ®еә“жҒўеӨҚз®—жі•жҰӮиҝ°
еҺҹеӯҗжҖ§дҝқиҜҒ
- NO-STEALпјҡжү§иЎҢжңҹй—ҙдёҚеҲ·зӣҳпјҢдёҚеӯҳеңЁеҺҹеӯҗжҖ§й—®йўҳ
- й—®йўҳпјҡеҪ“дәӢзү©еҫҲеӨ§ж—¶пјҢMemеҚ з”ЁиҝҮеӨ§
- STEALпјҡжү§иЎҢжңҹй—ҙеҲ·зӣҳ
- й—®йўҳпјҡеӯҳеңЁеҺҹеӯҗжҖ§й—®йўҳпјҢеҰӮдёҠеӣҫзҡ„T4еҰӮжһңдәӢеҠЎжү§иЎҢжңҹй—ҙеҲ·зӣҳдәҶпјҢжӯӨж—¶йңҖиҰҒundoеӣһж»ҡ
жҢҒд№…жҖ§дҝқиҜҒ
- FORCEпјҡдәӢеҠЎжҸҗдәӨеҗҺе°ұејәеҲ¶еҲ·зӣҳпјҢдёҚеӯҳеңЁжҢҒд№…жҖ§й—®йўҳ
- й—®йўҳпјҡж•°жҚ®еә“IOдәӨдә’йў‘з№ҒпјҢеҚ з”ЁIOиө„жәҗиҝҮеӨҡ
- NO-FORCEпјҡдәӢеҠЎжҸҗдәӨдёҚејәеҲ¶еҲ·зӣҳ
- й—®йўҳпјҡеӯҳеңЁжҢҒд№…жҖ§й—®йўҳпјҢеҰӮз§Ҝж”’дәҶеҫҲеӨҡе·Із»ҸжҸҗдәӨзҡ„дәӢзү©жІЎеҒҡпјҢжӯӨж—¶е°ұйңҖиҰҒredoйҮҚеҒҡ
еҪұеӯҗжӢ·иҙқж–№жі•
еҺҹзҗҶпјҡдәӢзү©жү§иЎҢдёҚеҲ·зӣҳпјҢдәӢзү©дёҖжҸҗдәӨе°ұеҲ·зӣҳ
еҰӮжһңдәӢзү©AbortпјҢж•°жҚ®еә“жҢҮй’ҲдёҚеҸҳ
еҰӮжһңдәӢзү©жү§иЎҢе®ҢжҲҗпјҢж•°жҚ®еә“жҢҮй’Ҳе°ұеҲҮжҚўиҝҮжқҘ
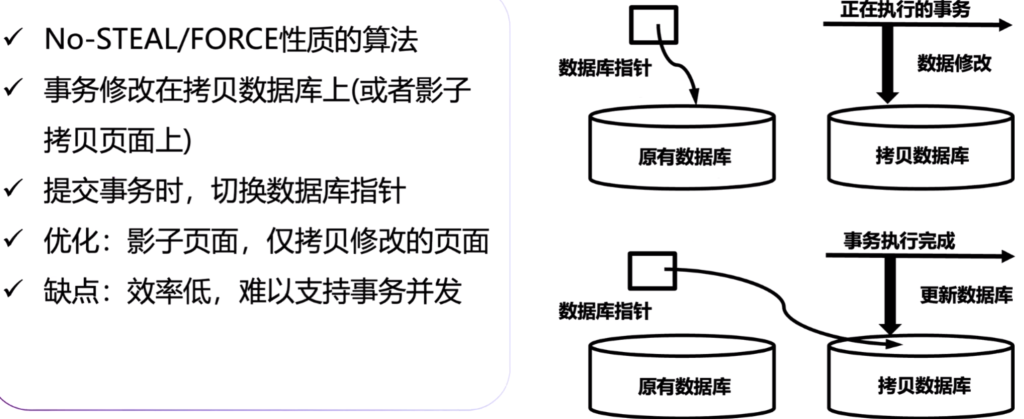
еҹәдәҺundoж—Ҙеҝ—зҡ„жҒўеӨҚж–№жі•
еҺҹзҗҶпјҡдәӢзү©жү§иЎҢжңҹй—ҙеҸҜд»ҘеҲ·зӣҳпјҲжҸҗдәӨйғЁеҲҶдәӢзү©пјүпјҢдё”дәӢзү©дёҖжҸҗдәӨе°ұеҲ·зӣҳ


жҒўеӨҚжөҒзЁӢ

дҫӢеӯҗ


й—®йўҳ
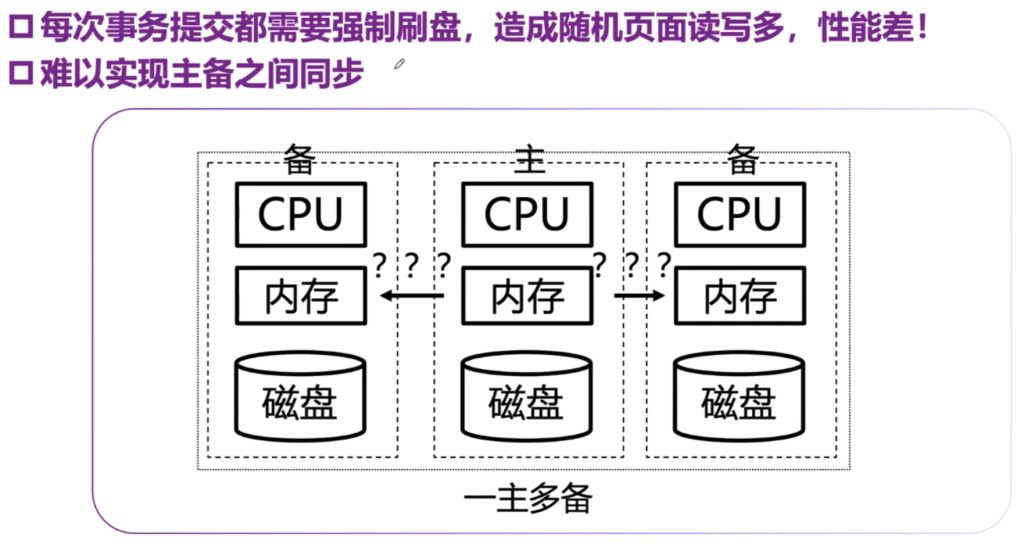
еҹәдәҺredoж—Ҙеҝ—зҡ„жҒўеӨҚж–№жі•
еҺҹзҗҶпјҡдәӢзү©жү§иЎҢдёҚеҲ·зӣҳпјҢжҸҗдәӨдәҶдәӢзү©еҸҜд»ҘдёҚеҲ·зӣҳгҖӮеӣ жӯӨеҜ№дәҺдёҖдәӣжІЎеҒҡзҡ„дәӢзү©redoжҒўеӨҚгҖӮ




й—®йўҳ

еҹәдәҺundo/redoж—Ҙеҝ—зҡ„жҒўеӨҚж–№жі•
еҺҹзҗҶпјҡдәӢзү©жү§иЎҢжңҹй—ҙеҲ·зӣҳпјҢдәӢзү©е®ҢжҲҗдёҚејәеҲ¶еҲ·зӣҳ

RedoжҳҜе№ӮзӯүжҖ§ж“ҚдҪңпјҢеӣ дёәredoжҳҜзү©зҗҶж—Ҙеҝ—пјҢе…·еӨҮзҡ„жҳҜе№ӮзӯүжҖ§пјҲи§ҒдёҠжңүд»Ӣз»Қпјү
иҖҢUndoдёҚжҳҜе№Ӯзӯүж“ҚдҪңпјҢеӣ дёәundoжҳҜйҖ»иҫ‘ж—Ҙеҝ—пјҢе…·еӨҮзҡ„жҳҜеҸҜйҖҶжҖ§


第е…ӯз«
Multithreading
еҹәжң¬зҹҘиҜҶ
иҝӣзЁӢ
иҝӣзЁӢжңүдёҖдёӘиҮӘеҢ…еҗ«зҡ„жү§иЎҢзҺҜеўғгҖӮиҝӣзЁӢйҖҡеёёе…·жңүдёҖз»„е®Ңж•ҙзҡ„гҖҒз§Ғжңүзҡ„еҹәжң¬иҝҗиЎҢж—¶иө„жәҗпјӣзү№еҲ«жҳҜпјҢжҜҸдёӘиҝӣзЁӢйғҪжңүиҮӘе·ұзҡ„еӯҳеӮЁз©әй—ҙгҖӮиҝӣзЁӢй—ҙйҖҡдҝЎпјҡRMI / HttpпјҢRMIйҖҡдҝЎж–№ејҸпјҡзұ»дјјдәҺServerе’ҢClientпјҢз”ЁSerializableпјҢжөҒзҡ„ж–№ејҸдј йҖ’
зәҝзЁӢ
зәҝзЁӢжңүж—¶иў«з§°дёәиҪ»йҮҸзә§иҝӣзЁӢгҖӮиҝӣзЁӢе’ҢзәҝзЁӢйғҪжҸҗдҫӣдәҶдёҖдёӘжү§иЎҢзҺҜеўғпјҢдҪҶеҲӣе»әж–°зәҝзЁӢжүҖйңҖзҡ„иө„жәҗжҜ”еҲӣе»әж–°иҝӣзЁӢе°‘гҖӮзәҝзЁӢеӯҳеңЁдәҺиҝӣзЁӢдёӯвҖ”вҖ”жҜҸдёӘиҝӣзЁӢиҮіе°‘жңүдёҖдёӘзәҝзЁӢгҖӮзәҝзЁӢе…ұдә«иҝӣзЁӢзҡ„иө„жәҗпјҢеҢ…жӢ¬еҶ…еӯҳе’Ңжү“ејҖзҡ„ж–Ү件гҖӮиҝҷжңүеҠ©дәҺй«ҳж•ҲдҪҶеҸҜиғҪеӯҳеңЁй—®йўҳзҡ„жІҹйҖҡгҖӮ
еӨҡзәҝзЁӢйҖҡдҝЎ
еҲӣе»әзәҝзЁӢ
ж–№жі•дёҖпјҡжүӢеҠЁеҲӣе»әдёҖдёӘзәҝзЁӢпјҢиҝҷдёӘзәҝзЁӢжү§иЎҢе®Ңе°ұз»“жқҹдәҶгҖӮпјҲдәәдёәзҡ„з®ЎзҗҶгҖҒжҺ§еҲ¶зәҝзЁӢпјү
- дёҖз§Қж–№жі•жҳҜ继жүҝThreadзұ»пјҲJavaжҳҜеҚ•ж №з»§жүҝпјҢе’ҢcppдёҚдёҖж ·пјҢжүҖд»Ҙиҝҷз§Қж–№жі•дёҚжҺЁиҚҗпјү
- дёҖз§Қж–№жі•жҳҜе®һзҺ°RunnableиҝҷдёӘжҺҘеҸЈпјҲжҺЁиҚҗдҪҝз”ЁиҝҷдёӘпјҢеӣ дёәJavaйҮҢйқўеҸӘиғҪ继жүҝдёҖдёӘзұ»пјҢдҪҶжҳҜе®һ зҺ°еҸҜд»Ҙе®һзҺ°еӨҡдёӘжҺҘеҸЈпјү
ж–№жі•дәҢпјҡйҖҡиҝҮзәҝзЁӢжұ пјҢеҰӮжһңжңүйңҖиҰҒиҺ·еҸ–зәҝзЁӢе°ұеңЁжұ еӯҗйҮҢйқўжүҫдёҖдёӘпјҢз”Ёе®Ңд№ӢеҗҺ收еӣһпјҢиҝҳжҳҜж”ҫеңЁеңЁзәҝзЁӢ жұ йҮҢйқўгҖӮиҠӮзәҰиө„жәҗпјҢеӣ дёәеҲӣе»әзәҝзЁӢзҡ„ж—¶еҖҷйңҖиҰҒж¶ҲиҖ—иө„жәҗгҖӮпјҲдёҚйңҖиҰҒиҖғиҷ‘зәҝзЁӢзҡ„з®ЎзҗҶпјҢзәҝзЁӢжҳҜж–°еҲӣе»ә зҡ„иҝҳжҳҜе·Іжңүзҡ„дҪҝз”ЁиҖ…дёҚйңҖиҰҒзҹҘйҒ“пјҢз”ұзәҝзЁӢжұ з®ЎзҗҶпјү
дёӯж–ӯдёҺеӯҳжҙ»еҮҪж•°
дёӯж–ӯдёҖдёӘзәҝзЁӢпјҢи°ғз”ЁThread.interruptпјҲпјүж–№жі•пјҢи®©е…¶жҠӣеҮәInterruptedExceptionејӮеёё
еҲӨж–ӯжҳҜеҗҰеӯҳжҙ»пјҢи°ғз”ЁThread.interrupted(пјү
join
joinж–№жі•е…Ғи®ёдёҖдёӘзәҝзЁӢзӯүеҫ…еҸҰдёҖдёӘзәҝзЁӢзҡ„е®ҢжҲҗгҖӮеҰӮжһңtжҳҜзәҝзЁӢеҪ“еүҚжӯЈеңЁжү§иЎҢзҡ„ThreadеҜ№иұЎпјҢt.joinпјҲпјү
дҪҝеҪ“еүҚзәҝзЁӢжҡӮеҒңжү§иЎҢпјҢзӣҙеҲ°tзҡ„зәҝзЁӢз»ҲжӯўгҖӮе’ҢsleepдёҖж ·пјҢjoinдҫқиө–дәҺж“ҚдҪңзі»з»ҹзҡ„ж—¶й—ҙпјҢи®ҫеӨҮеҘҪзҗҶи®әе°ұеҝ«пјҢжүҖд»ҘдҪ дёҚеә”иҜҘеҒҮи®ҫjoinдјҡзӯүеҫ…дҪ жҢҮе®ҡзҡ„ж—¶й—ҙгҖӮд№ҹе’ҢSleepзұ»дјјпјҢjoinйҖҡиҝҮеҸ‘еҮәInterruptedExceptionйҖҖеҮәжқҘе“Қеә”дёӯж–ӯгҖӮ
зәҝзЁӢй—ҙйҖҡдҝЎж–№жі•еҸҠй—®йўҳ
зәҝзЁӢд№Ӣй—ҙдё»иҰҒйҖҡиҝҮе…ұдә«еӯ—ж®өд»ҘеҸҠеӯ—ж®өеј•з”Ёзҡ„еҜ№иұЎжқҘиҝӣиЎҢйҖҡдҝЎгҖӮиҝҷз§ҚйҖҡдҝЎж–№ејҸйқһеёёй«ҳж•ҲпјҢдҪҶеҸҜиғҪдјҡеҜјиҮҙдёӨзұ»й”ҷиҜҜпјҡзәҝзЁӢе№Іжү°пјҲThread Interferenceпјүе’ҢеҶ…еӯҳдёҖиҮҙжҖ§й”ҷиҜҜпјҲMemory Consistency ErrorsпјүгҖӮйҳІжӯўиҝҷдәӣй”ҷиҜҜзҡ„е·Ҙе…·жҳҜеҗҢжӯҘжңәеҲ¶гҖӮ
然иҖҢпјҢдҪҝз”ЁеҗҢжӯҘжңәеҲ¶еҸҜиғҪдјҡеј•е…ҘзәҝзЁӢдәүз”ЁпјҢеҚіеҪ“дёӨдёӘжҲ–еӨҡдёӘзәҝзЁӢеҗҢж—¶е°қиҜ•и®ҝй—®еҗҢдёҖиө„жәҗж—¶пјҢдјҡеҜјиҮҙJavaиҝҗиЎҢж—¶д»Ҙжӣҙж…ўзҡ„йҖҹеәҰжү§иЎҢдёҖдёӘжҲ–еӨҡдёӘзәҝзЁӢпјҢз”ҡиҮіжҡӮеҒңе®ғ们зҡ„жү§иЎҢгҖӮзәҝзЁӢйҘҘйҘҝе’Ңжҙ»й”ҒжҳҜзәҝзЁӢдәүз”Ёзҡ„дёӨз§ҚеҪўејҸгҖӮ
дёҚеј•е…ҘеҗҢжӯҘжңәеҲ¶зҡ„й—®йўҳ
Thread InterferenceпјҲзәҝзЁӢе№Іжү°пјү
- If the initial value of c is 0, their interleaved actions might follow this sequence:
Thread A: Retrieve c.
Thread B: Retrieve c.
Thread A: Increment retrieved value; result is 1.
Thread B: Decrement retrieved value; result is -1.
Thread A: Store result in c; c is now 1.
Thread B: Store result in c; c is now -1.
зәҝзЁӢAзҡ„з»“жһңе°ұдёўеӨұдәҶ
Memory Consistency ErrorsпјҲеҶ…еӯҳдёҖиҮҙжҖ§й”ҷиҜҜпјү
еҒҮи®ҫе®ҡд№ү并еҲқе§ӢеҢ–дәҶдёҖдёӘз®ҖеҚ•зҡ„ int еӯ—ж®өпјҡ
int counter = 0;counter еӯ—ж®өиў«дёӨдёӘзәҝзЁӢ A е’Ң B е…ұдә«гҖӮеҒҮи®ҫзәҝзЁӢ A еҜ№ counter иҝӣиЎҢйҖ’еўһж“ҚдҪңпјҡ counter++;
йҡҸеҗҺдёҚд№…пјҢзәҝзЁӢ B жү“еҚ°еҮә counter зҡ„еҖјпјҡ System.out.println(counter);
еҰӮжһңиҝҷдёӨдёӘиҜӯеҸҘжҳҜеңЁеҗҢдёҖдёӘзәҝзЁӢдёӯжү§иЎҢзҡ„пјҢеҸҜд»Ҙе®үе…Ёең°еҒҮи®ҫиҫ“еҮәзҡ„еҖјжҳҜ “1”гҖӮдҪҶеҰӮжһңиҝҷдёӨдёӘиҜӯеҸҘжҳҜеңЁдёҚеҗҢзҡ„зәҝзЁӢдёӯжү§иЎҢпјҢжү“еҚ°еҮәжқҘзҡ„еҖјеҸҜиғҪд»Қ然жҳҜ “0”пјҢеӣ дёәзәҝзЁӢ A еҜ№ counter зҡ„дҝ®ж”№жңӘеҝ…еҜ№зәҝзЁӢ B еҸҜи§ҒвҖ”вҖ”йҷӨйқһзЁӢеәҸе‘ҳеңЁиҝҷдёӨдёӘиҜӯеҸҘд№Ӣй—ҙе»әз«ӢдәҶе…ҲиЎҢеҸ‘з”ҹе…ізі»пјҲhappens-beforeпјүгҖӮ
и§ЈеҶіж–№жі•
Synchronized
еҰӮжһң count жҳҜ SynchronizedCounter зҡ„дёҖдёӘе®һдҫӢпјҢйӮЈд№Ҳе°Ҷиҝҷдәӣж–№жі•и®ҫдёә synchronized дјҡжңүдёӨдёӘж•Ҳжһңпјҡ
- дә’ж–Ҙпјҡж— жі•и®©дёӨдёӘеҜ№еҗҢдёҖеҜ№иұЎзҡ„еҗҢжӯҘж–№жі•и°ғз”ЁдәӨй”ҷжү§иЎҢгҖӮеҪ“дёҖдёӘзәҝзЁӢжӯЈеңЁжү§иЎҢжҹҗдёӘеҜ№иұЎзҡ„еҗҢжӯҘж–№жі•ж—¶пјҢжүҖжңүе…¶д»–зәҝзЁӢи°ғз”ЁиҜҘеҜ№иұЎзҡ„еҗҢжӯҘж–№жі•йғҪдјҡиў«йҳ»еЎһпјҲжҡӮеҒңжү§иЎҢпјүпјҢзӣҙеҲ°з¬¬дёҖдёӘзәҝзЁӢжү§иЎҢе®ҢжҜ•гҖӮ
- е…ҲиЎҢеҸ‘з”ҹе…ізі»пјҡеҪ“дёҖдёӘеҗҢжӯҘж–№жі•йҖҖеҮәж—¶пјҢиҮӘеҠЁе»әз«ӢдёҖдёӘе…ҲиЎҢеҸ‘з”ҹе…ізі»пјҢдҝқиҜҒеҜ№еҜ№иұЎзҠ¶жҖҒзҡ„дҝ®ж”№еҜ№жүҖжңүзәҝзЁӢеҸҜи§ҒгҖӮ
еңЁ Java дёӯпјҢжҜҸдёӘеҜ№иұЎйғҪйҡҗеҗ«ең°жӢҘжңүдёҖдёӘеҶ…еңЁй”ҒпјҲд№ҹз§°дёәзӣ‘и§ҶеҷЁй”ҒпјүгҖӮеј•з”ЁеҸҳйҮҸе’ҢеӨ§еӨҡж•°еҺҹе§ӢеҸҳйҮҸпјҲйҷӨlongе’Ңdoubleд№ӢеӨ–зҡ„жүҖжңүзұ»еһӢпјүпјҢиҜ»еҸ–е’ҢеҶҷе…ҘйғҪжҳҜеҺҹеӯҗжҖ§зҡ„
еҜ№дәҺжүҖжңүеЈ°жҳҺдёәvolatileзҡ„еҸҳйҮҸпјҲеҢ…жӢ¬longе’ҢdoubleеҸҳйҮҸпјүпјҢиҜ»еҸ–е’ҢеҶҷе…ҘйғҪжҳҜеҺҹеӯҗжҖ§зҡ„гҖӮ
- жҢүз…§жғҜдҫӢпјҢдёҖдёӘзәҝзЁӢеңЁйңҖиҰҒеҜ№еҜ№иұЎзҡ„еӯ—ж®өиҝӣиЎҢзӢ¬еҚ дё”дёҖиҮҙзҡ„и®ҝй—®ж—¶пјҢеҝ…йЎ»иҺ·еҸ–иҜҘеҜ№иұЎзҡ„еҶ…еңЁй”ҒпјҢ并еңЁж“ҚдҪңе®ҢжҲҗеҗҺйҮҠж”ҫиҜҘеҶ…еңЁй”ҒгҖӮ
- дёҖдёӘзәҝзЁӢеңЁиҺ·еҸ–еҲ°й”ҒдёҺйҮҠж”ҫй”Ғд№Ӣй—ҙзҡ„ж—¶й—ҙж®өеҶ…иў«и®ӨдёәжӢҘжңүиҜҘеҶ…еңЁй”ҒгҖӮеҸӘиҰҒжҹҗдёӘзәҝзЁӢжӢҘжңүеҶ…еңЁй”ҒпјҢе…¶д»–д»»дҪ•зәҝзЁӢйғҪж— жі•иҺ·еҸ–зӣёеҗҢзҡ„й”ҒгҖӮеҪ“е…¶д»–зәҝзЁӢе°қиҜ•иҺ·еҸ–иҜҘй”Ғж—¶пјҢе®ғ们е°Ҷиў«йҳ»еЎһгҖӮ
еҪ“дёҖдёӘзәҝзЁӢйҮҠж”ҫеҶ…еңЁй”Ғж—¶пјҢйҮҠж”ҫеҠЁдҪңдёҺеҗҺз»ӯеҜ№иҜҘй”Ғзҡ„д»»дҪ•иҺ·еҸ–ж“ҚдҪңд№Ӣй—ҙдјҡиҮӘеҠЁе»әз«ӢдёҖдёӘе…ҲиЎҢеҸ‘з”ҹе…ізі»гҖӮ
еҰӮжһңи°ғз”Ёзҡ„жҳҜйқҷжҖҒеҗҢжӯҘж–№жі•
- йқҷжҖҒж–№жі•жҳҜдёҺзұ»зӣёе…ізҡ„пјҢиҖҢдёҚжҳҜдёҺеҜ№иұЎзӣёе…ізҡ„гҖӮstatic йқҷжҖҒж–№жі•иғҪдёҚиғҪдҪҝз”ЁеҗҢжӯҘж–№жі•е‘ўпјҹдёҚдјҡпјҢеӣ дёәжҜҸдёҖдёӘйқҷжҖҒж–№жі•е’Ңзұ»е…іиҒ”иҖҢдёҚжҳҜдёҖдёӘеҜ№иұЎ
- еңЁиҝҷз§Қжғ…еҶөдёӢпјҢзәҝзЁӢдјҡиҺ·еҸ–дёҺиҜҘзұ»е…іиҒ”зҡ„ Class еҜ№иұЎзҡ„еҶ…еңЁй”ҒгҖӮ
| ж–№жі•дёҖпјҡй’ҲеҜ№дәҺж•ҙдёӘеҮҪж•° | public class SynchronizedCounter { private int c = 0; public synchronized void increment() { c++; } public synchronized void decrement() { c–; } public synchronized int value() { return c;} } |
| ж–№жі•дәҢпјҡй’ҲеҜ№дәҺйғЁеҲҶ | public void addName(String name) { synchronized(this) { lastName = name; nameCount++; } nameList.add(name); } |
| ж–№жі•дёүпјҡеҜ№дәҺжҹҗдёҖдёӘйғЁеҲҶ иҝҷйҮҢй’ҲеҜ№дәҺ c1пјҢc2 еҠ ж“ҚдҪңеҲҶеҲ«дёҠй”ҒпјҢдёӨдёӘй”Ғд№Ӣй—ҙдёҚе№Іжү° | public class MsLunch { private long c1 = 0; private long c2 = 0; private Object lock1 = new Object(); private Object lock2 = new Object(); public void inc1() { synchronized(lock1) { c1++; } } public void inc2() { synchronized(lock2) { c2++; } } } |
еҸҜйҮҚе…Ҙзҡ„й”Ғпјҡ ReentrantLock
жҲ‘们жңүдёҖдёӘзұ» C пјҢе®ғжңүдёҖдёӘSynchronizedж–№жі• m пјҢ m йҮҢйқўи°ғз”ЁдәҶеҸҰеӨ–дёҖдёӘSynchronizedж–№жі• n пјҢ n д№ҹ еңЁ C йҮҢйқўпјӣ然иҖҢпјҢи°ғз”Ё n зҡ„ж—¶еҖҷпјҢеҸ‘зҺ°иҝҷдёӘеҜ№иұЎзҡ„й”Ғ еңЁ m жүӢйҮҢе‘ўпјҒ д№ҹжңүеҸҜиғҪ m жҳҜдёҖдёӘйҖ’еҪ’зҡ„ж–№жі•вҖҰвҖҰ
еј•е…ҘжҰӮеҝөпјҡеҸҜйҮҚе…Ҙзҡ„й”ҒгҖӮеҸҜйҮҚе…Ҙзҡ„й”Ғж„Ҹе‘ізқҖпјҡ дёҖдёӘзәҝзЁӢдёҚиғҪиҺ·еҫ—дёҖдёӘиў«е…¶д»–зәҝзЁӢеҚ жҚ®зҡ„lockпјӣдҪҶжҳҜе®ғиғҪеӨҹиҺ·еҫ—дёҖдёӘе®ғе·Із»ҸжӢҘжңүзҡ„й”ҒгҖӮ
еј•е…ҘеҗҢжӯҘжңәеҲ¶еёҰжқҘзҡ„й—®йўҳ
DeadlockпјҲжӯ»й”ҒпјүпјҡAзәҝзЁӢзӯүеҫ…BпјҢBзӯүеҫ…AпјҢиҝҷж ·е°ұдјҡйҷ·е…Ҙжӯ»й”Ғзҡ„еҫӘзҺҜгҖӮдёҖиҲ¬жҳҜз”ұдәҺиө„жәҗз«һдәүе’Ң并еҸ‘еӨ„зҗҶйЎәеәҸдёҚеҪ“еҜјиҮҙзҡ„гҖӮи§ЈеҶіж–№жі•пјҡи¶…ж—¶йҮҠж”ҫиө„жәҗ
StarvationпјҲйҘҝжӯ»пјүпјҡAжғіиҰҒи®ҝй—®дёҖдёӘе…ұдә«иө„жәҗпјҢдҪҶжҳҜдёҖзӣҙиҺ·еҸ–дёҚеҲ°пјҢе°ұеғҸиў«йҘҝжӯ»дәҶдёҖж ·гҖӮпјҲйңҖиҰҒж¶ҲйҷӨйӮЈдәӣиҙӘе©Әзҡ„ зәҝзЁӢпјҢйҒҝе…ҚдёҖдёӘзәҝзЁӢй•ҝжңҹиҙӘе©Әзҡ„еҚ з”Ёиө„жәҗпјӣжүҖд»ҘtomcatйҮҢйқўз”ЁдәҶиҝһжҺҘжұ пјҢйҒҝе…ҚдёҖдёӘиҝһжҺҘй•ҝжңҹеҚ з”Ёиө„ жәҗпјү
LivelockпјҲжҙ»й”Ғпјүпјҡжҙ»й”ҒжҳҜжҢҮдёҖдёӘзәҝзЁӢеҜ№еҸҰдёҖдёӘзәҝзЁӢзҡ„еҠЁдҪңеҒҡеҮәеҸҚеә”пјҢиҖҢеҰӮжһңеҸҰдёҖдёӘзәҝзЁӢзҡ„еҠЁдҪңд№ҹжҳҜеҜ№еүҚдёҖдёӘзәҝзЁӢеҠЁдҪңзҡ„еҸҚеә”пјҢйӮЈд№ҲеҸҜиғҪдјҡеҜјиҮҙжҙ»й”ҒгҖӮдёҺжӯ»й”Ғзұ»дјјпјҢжҙ»й”ҒзҠ¶жҖҒдёӢзҡ„зәҝзЁӢд№ҹж— жі•з»§з»ӯеҸ–еҫ—иҝӣеұ•гҖӮ然иҖҢпјҢзәҝзЁӢ并没жңүиў«йҳ»еЎһпјҢиҖҢжҳҜеҪјжӯӨдёҚеҒңең°е“Қеә”еҜ№ж–№пјҢеҜјиҮҙж— жі•жҒўеӨҚжӯЈеёёе·ҘдҪңгҖӮ
и§ЈеҶіж–№ејҸпјҡеҚҸи°ғиө„жәҗ
- еҸ—дҝқжҠӨзҡ„еқ—пјҲguarded blockпјүгҖӮ жңҖеёёи§Ғзҡ„ж–№ејҸпјҢwhile(!joy) {}з®ҖеҚ•зҡ„еҫӘзҺҜпјҢдҪҶжөӘиҙ№еӨ„зҗҶеҷЁж—¶й—ҙгҖӮдёҖиҲ¬дёҚжҺЁиҚҗиҝҷд№ҲеҒҡ
- и°ғз”Ё
waitж–№жі•дјҡжҡӮеҒңзәҝзЁӢпјҢзӣҙеҲ°еҸҰдёҖдёӘзәҝзЁӢеҸ‘еҮәйҖҡзҹҘпјҢиЎЁзӨәжҹҗдёӘзү№ж®ҠдәӢ件еҸ‘з”ҹпјҲдёҚдёҖе®ҡжҳҜеҪ“еүҚзәҝзЁӢжӯЈеңЁзӯүеҫ…зҡ„дәӢ件пјүгҖӮеңЁжңӘжқҘзҡ„жҹҗдёӘж—¶еҲ»пјҢеҸҰдёҖдёӘзәҝзЁӢе°ҶиҺ·еҸ–зӣёеҗҢзҡ„й”Ғ并и°ғз”ЁObject.notifyAllпјҢйҖҡзҹҘжүҖжңүзӯүеҫ…иҜҘй”Ғзҡ„зәҝзЁӢпјҢиЎЁзӨәжҹҗдёӘйҮҚиҰҒдәӢ件已з»ҸеҸ‘з”ҹгҖӮеңЁз¬¬дәҢдёӘзәҝзЁӢйҮҠж”ҫй”ҒеҗҺпјҢзӯүеҫ…зҡ„第дёҖдёӘзәҝзЁӢе°ҶйҮҚж–°иҺ·еҸ–й”Ғ并д»Һwaitж–№жі•зҡ„и°ғз”ЁдёӯжҒўеӨҚжү§иЎҢгҖӮ
дҪҝз”ЁеҸ—дҝқжҠӨеқ—еҲӣе»әз”ҹдә§иҖ…-ж¶Ҳиҙ№иҖ…еә”з”Ё
иҝҷз§Қеә”з”ЁеңЁдёӨдёӘзәҝзЁӢд№Ӣй—ҙе…ұдә«ж•°жҚ®пјҡ
- з”ҹдә§иҖ…пјҡеҲӣе»әж•°жҚ®гҖӮ
- ж¶Ҳиҙ№иҖ…пјҡдҪҝз”Ёж•°жҚ®гҖӮ
дёӨдёӘзәҝзЁӢйҖҡиҝҮдёҖдёӘе…ұдә«еҜ№иұЎиҝӣиЎҢйҖҡдҝЎгҖӮ
еҚҸи°ғжҳҜиҮіе…ійҮҚиҰҒзҡ„пјҡ
- ж¶Ҳиҙ№иҖ…зәҝзЁӢеҝ…йЎ»еңЁз”ҹдә§иҖ…зәҝзЁӢдәӨд»ҳж•°жҚ®д№ӢеҗҺжүҚиғҪжЈҖзҙўж•°жҚ®гҖӮ
- з”ҹдә§иҖ…зәҝзЁӢеҝ…йЎ»еңЁж¶Ҳиҙ№иҖ…зәҝзЁӢжЈҖзҙўе®Ңж—§ж•°жҚ®д№ӢеүҚпјҢдёҚиғҪдәӨд»ҳж–°ж•°жҚ®гҖӮ
дёҚеҸҜеҸҳеҜ№иұЎпјҲImmutable Objectпјү
- еҰӮжһңдёҖдёӘеҜ№иұЎзҡ„зҠ¶жҖҒеңЁжһ„йҖ д№ӢеҗҺдёҚиғҪжӣҙж”№пјҢйӮЈд№ҲиҜҘеҜ№иұЎиў«и®ӨдёәжҳҜдёҚеҸҜеҸҳзҡ„гҖӮ
- дҫқиө–дёҚеҸҜеҸҳеҜ№иұЎиў«е№ҝжіӣи®ӨдёәжҳҜзј–еҶҷз®ҖеҚ•гҖҒеҸҜйқ д»Јз Ғзҡ„дёҖз§Қжңүж•Ҳзӯ–з•ҘгҖӮ
- е·§еҰҷзҡ„йҒҝе…ҚдәҶзәҝзЁӢе№Іж¶үпјҲдёӨдёӘзәҝзЁӢйғҪеңЁеҶҷW/WпјүпјҢеҶ…еӯҳдёҚдёҖиҮҙпјҲдёҖдёӘеңЁеҶҷдёҖдёӘеңЁиҜ»W/Rпјү
дёҚеҸҜеҸҳеҜ№иұЎеңЁе№¶еҸ‘еә”з”Ёдёӯзү№еҲ«жңүз”ЁпјҡдёҚеҸҜеҸҳеҜ№иұЎзҡ„зҠ¶жҖҒдёҖж—ҰеҲӣе»әе°ұдёҚиғҪиў«ж”№еҸҳпјҢиҝҷдҪҝеҫ—е®ғ们йқһеёёйҖӮеҗҲеңЁе№¶еҸ‘зј–зЁӢдёӯдҪҝз”ЁпјҢеӣ дёәеӨҡдёӘзәҝзЁӢеҸҜд»Ҙе®үе…Ёең°и®ҝй—®дёҚеҸҜеҸҳеҜ№иұЎпјҢиҖҢдёҚеҝ…жӢ…еҝғж•°жҚ®з«һдәүжҲ–зҠ¶жҖҒдёҚдёҖиҮҙзҡ„й—®йўҳгҖӮиҝҷжңүеҠ©дәҺз®ҖеҢ–д»Јз Ғ并жҸҗй«ҳеҸҜйқ жҖ§гҖӮ
зЁӢеәҸе‘ҳеёёеёёдёҚж„ҝдҪҝз”ЁдёҚеҸҜеҸҳеҜ№иұЎпјҢеӣ дёә他们жӢ…еҝғеҲӣе»әж–°еҜ№иұЎзҡ„жҲҗжң¬пјҢиҖҢдёҚжҳҜзӣҙжҺҘеңЁеҺҹең°жӣҙж–°еҜ№иұЎгҖӮдҪҶеҜ№иұЎеҲӣе»әзҡ„еҪұе“Қеёёеёёиў«й«ҳдј°пјҢеӣ дёәеһғеңҫеӣһ收еёҰжқҘзҡ„ејҖй”ҖеҮҸе°‘е’Ңж— йңҖзј–еҶҷйўқеӨ–зҡ„д»Јз ҒжқҘдҝқжҠӨеҸҜеҸҳеҜ№иұЎдёҚеҸ—жҚҹеқҸпјҢдё”еҸҜд»ҘйҖҡиҝҮдёҚеҸҜеҸҳеҜ№иұЎеёҰжқҘзҡ„дёҖдәӣж•ҲзҺҮжқҘжҠөж¶ҲгҖӮ
й«ҳзә§е№¶еҸ‘зү№жҖ§
иҝҷдәӣзү№жҖ§еӨ§еӨҡж•°йғҪеңЁж–°зҡ„ java.util.concurrent еҢ…дёӯе®һзҺ°гҖӮ
Lock еҜ№иұЎпјҡ
LockеҜ№иұЎжҸҗдҫӣдәҶдёҖз§ҚжӣҙзҒөжҙ»зҡ„й”Ғе®ҡжңәеҲ¶гҖӮдёҺдј з»ҹзҡ„synchronizedж–№жі•жҲ–д»Јз Ғеқ—дёҚеҗҢпјҢLockжҸҗдҫӣдәҶжӣҙеӨҡеҠҹиғҪпјҢдҫӢеҰӮеҸҜйҮҚе…Ҙй”Ғе’ҢжқЎд»¶й”ҒпјҢе…Ғи®ёзЁӢеәҸеңЁдёҚеҗҢжқЎд»¶дёӢиҝӣиЎҢжӣҙз»ҶзІ’еәҰзҡ„жҺ§еҲ¶гҖӮдҪҝз”ЁLockпјҢејҖеҸ‘иҖ…еҸҜд»ҘжүӢеҠЁеҠ й”Ғе’Ңи§Јй”ҒпјҢиҝҷеңЁеӨҚжқӮзҡ„并еҸ‘еңәжҷҜдёӢе°Өе…¶жңүз”ЁгҖӮ- дҪңз”Ёпјҡ
LockжҸҗдҫӣдәҶеҜ№й”Ғзҡ„зІҫз»ҶжҺ§еҲ¶пјҢзү№еҲ«йҖӮз”ЁдәҺйңҖиҰҒеӨҚжқӮеҗҢжӯҘжҺ§еҲ¶зҡ„еңәжҷҜгҖӮ
Executorsпјҡ
Executorsзұ»жҸҗдҫӣдәҶзәҝзЁӢжұ з®ЎзҗҶзҡ„е®һзҺ°пјҢйҒҝе…ҚдәҶжүӢеҠЁеҲӣе»әе’Ңй”ҖжҜҒзәҝзЁӢзҡ„йә»зғҰпјҢе°Өе…¶йҖӮеҗҲйңҖиҰҒйў‘з№Ғи°ғеәҰд»»еҠЎзҡ„еә”з”ЁзЁӢеәҸгҖӮйҖҡиҝҮExecutorsпјҢеҸҜд»ҘеҲӣе»әеӣәе®ҡеӨ§е°Ҹзҡ„зәҝзЁӢжұ гҖҒзј“еӯҳзәҝзЁӢжұ жҲ–еҚ•зәҝзЁӢжү§иЎҢеҷЁгҖӮ- дҪңз”ЁпјҡзәҝзЁӢжұ еҸҜд»ҘеҮҸе°‘зі»з»ҹзҡ„ејҖй”ҖпјҢ并жҸҗй«ҳиө„жәҗеҲ©з”ЁзҺҮпјҢйҖӮеҗҲеӨ§и§„模并еҸ‘д»»еҠЎз®ЎзҗҶгҖӮ
并еҸ‘йӣҶеҗҲпјҡ
- 并еҸ‘йӣҶеҗҲзұ»пјҲеҰӮ
ConcurrentHashMapпјҡйҖҡиҝҮйҮҮз”ЁдәҶеҲҶж®өй”Ғзҡ„и®ҫи®ЎпјҢе…Ғи®ёеӨҡдёӘиҜ»зәҝзЁӢ并еҸ‘ең°и®ҝй—®mapпјҢ并且е…Ғи®ёеӨҡдёӘеҶҷзәҝзЁӢ并еҸ‘дҝ®ж”№дёҚеҗҢзҡ„ж®өгҖӮпјүе…Ғи®ёеӨҡдёӘзәҝзЁӢе®үе…Ёең°и®ҝй—®йӣҶеҗҲпјҢж— йңҖжүӢеҠЁж·»еҠ еҗҢжӯҘеқ—гҖӮйҖҡиҝҮеҲҶж®өй”Ғе®ҡжҠҖжңҜпјҢе®һзҺ°й«ҳж•Ҳзҡ„并еҸ‘ж“ҚдҪңпјҢеҮҸе°‘дәҶй”Ғз«һдәүгҖӮ - дҪңз”Ёпјҡ并еҸ‘йӣҶеҗҲйҖӮеҗҲиҜ»ж“ҚдҪңйў‘з№Ғзҡ„еңәжҷҜпјҢйҒҝе…ҚдәҶдј з»ҹеҗҢжӯҘйӣҶеҗҲдёӯзҡ„жҖ§иғҪ瓶йўҲгҖӮ
еҺҹеӯҗеҸҳйҮҸпјҡ
- еҺҹеӯҗеҸҳйҮҸпјҲеҰӮ
AtomicIntegerпјүе…Ғи®ёзәҝзЁӢе®үе…Ёзҡ„еҸҳйҮҸж“ҚдҪңпјҢж— йңҖжҳҫејҸдҪҝз”Ёй”ҒгҖӮйҖҡиҝҮ硬件ж”ҜжҢҒзҡ„еҺҹеӯҗж“ҚдҪңпјҲдҫӢеҰӮ CAS ж“ҚдҪңпјүжқҘдҝқиҜҒж•°жҚ®зҡ„е®үе…Ёдҝ®ж”№гҖӮ - дҪңз”ЁпјҡеҺҹеӯҗеҸҳйҮҸеңЁеӨҡзәҝзЁӢдёӢжҸҗдҫӣй«ҳж•ҲгҖҒж— й”Ғзҡ„ж“ҚдҪңпјҢеҮҸе°‘дәҶй”Ғзҡ„ејҖй”ҖпјҢйҖӮеҗҲз®ҖеҚ•зҡ„йҖ’еўһгҖҒйҖ’еҮҸж“ҚдҪңгҖӮ
ThreadLocalRandomпјҡ
ThreadLocalRandomжҸҗдҫӣдәҶдёҖз§ҚжҜҸдёӘзәҝзЁӢзӢ¬з«Ӣз”ҹжҲҗйҡҸжңәж•°зҡ„ж–№ејҸпјҢйҒҝе…ҚдәҶдј з»ҹRandomзұ»еңЁеӨҡзәҝзЁӢдёӢзҡ„з«һдәүй—®йўҳгҖӮ- дҪңз”Ёпјҡ
ThreadLocalRandomйҖҡиҝҮдёәжҜҸдёӘзәҝзЁӢеҚ•зӢ¬еҲҶй…ҚйҡҸжңәж•°з”ҹжҲҗеҷЁпјҢи§ЈеҶідәҶеӨҡзәҝзЁӢйҡҸжңәж•°з”ҹжҲҗдёӯзҡ„жҖ§иғҪ瓶йўҲй—®йўҳгҖӮ
Lock
- й”ҒеҜ№иұЎзҡ„е·ҘдҪңж–№ејҸдёҺеҗҢжӯҘд»Јз ҒдёӯдҪҝз”Ёзҡ„йҡҗејҸй”ҒйқһеёёзӣёдјјгҖӮ
- дёҺйҡҗејҸй”ҒдёҖж ·пјҢдёҖж¬ЎеҸӘжңүдёҖдёӘзәҝзЁӢеҸҜд»ҘжӢҘжңүдёҖдёӘй”ҒеҜ№иұЎгҖӮ
- й”ҒеҜ№иұЎиҝҳж”ҜжҢҒ
wait/notifyжңәеҲ¶пјҢйҖҡиҝҮе®ғ们关иҒ”зҡ„ConditionеҜ№иұЎжқҘе®һзҺ°гҖӮ
- й”ҒеҜ№иұЎзӣёеҜ№дәҺйҡҗејҸй”Ғзҡ„жңҖеӨ§дјҳеҠҝжҳҜиғҪеӨҹеңЁе°қиҜ•иҺ·еҸ–й”ҒеӨұиҙҘж—¶йҖҖеҮәгҖӮ
tryLockж–№жі•еңЁй”ҒдёҚеҸҜз”Ёж—¶з«ӢеҚійҖҖеҮәпјҢжҲ–иҖ…еңЁи¶…ж—¶д№ӢеүҚйҖҖеҮәпјҲеҰӮжһңжҢҮе®ҡдәҶи¶…ж—¶ж—¶й—ҙпјүгҖӮlockInterruptiblyж–№жі•еңЁеҸҰдёҖдёӘзәҝзЁӢеҸ‘йҖҒдёӯж–ӯдҝЎеҸ·ж—¶йҖҖеҮәпјҢеүҚжҸҗжҳҜй”Ғе°ҡжңӘиҺ·еҸ–гҖӮ
Executors
еҲҶзҰ»зәҝзЁӢз®ЎзҗҶдёҺд»»еҠЎжү§иЎҢпјҡеңЁе°Ҹ规模зЁӢеәҸдёӯпјҢд»»еҠЎе’ҢзәҝзЁӢд№Ӣй—ҙзҡ„зҙ§еҜҶиҖҰеҗҲжҳҜеёёи§Ғдё”еҸҜжҺҘеҸ—зҡ„гҖӮ然иҖҢпјҢеңЁеӨ§еһӢеә”з”ЁзЁӢеәҸдёӯпјҢе°ҶзәҝзЁӢзҡ„еҲӣе»әе’Ңз®ЎзҗҶзӢ¬з«ӢеҮәжқҘиғҪеӨҹжҸҗй«ҳд»Јз Ғзҡ„еҸҜз»ҙжҠӨжҖ§дёҺжү©еұ•жҖ§гҖӮ
жү§иЎҢеҷЁзҡ„дҪңз”Ёпјҡжү§иЎҢеҷЁжҳҜдёҖз§Қе·Ҙе…·пјҢеё®еҠ©ејҖеҸ‘иҖ…д»ҘжӣҙзҒөжҙ»зҡ„ж–№ејҸз®ЎзҗҶзәҝзЁӢпјҢйҒҝе…ҚжҳҫејҸеҲӣе»әе’ҢжҺ§еҲ¶зәҝзЁӢгҖӮйҖҡиҝҮдҪҝз”Ё Executor жҺҘеҸЈе’Ңе®һзҺ°пјҢжҜ”еҰӮзәҝзЁӢжұ пјҲThread PoolsпјүпјҢзі»з»ҹеҸҜд»Ҙжңүж•Ҳең°з®ЎзҗҶеӨҡдёӘзәҝзЁӢпјҢиҖҢ Fork/Join еҲҷеҸҜд»ҘеҲ©з”ЁеӨҡдёӘеӨ„зҗҶеҷЁжқҘеҠ йҖҹд»»еҠЎзҡ„并иЎҢеӨ„зҗҶгҖӮ
зәҝзЁӢжұ
е·ҘдҪңзәҝзЁӢпјҲWorker ThreadsпјүпјҡзәҝзЁӢжұ дёӯзҡ„зәҝзЁӢзӢ¬з«ӢдәҺд»»еҠЎпјҲRunnable жҲ– CallableпјүпјҢз”ЁдәҺжү§иЎҢеӨҡдёӘд»»еҠЎгҖӮдҪҝз”Ёе·ҘдҪңзәҝзЁӢеҸҜд»ҘеҮҸе°‘зәҝзЁӢйў‘з№ҒеҲӣе»әе’Ңй”ҖжҜҒеёҰжқҘзҡ„ејҖй”ҖпјҢжҸҗй«ҳзі»з»ҹжҖ§иғҪгҖӮ
еӣәе®ҡзәҝзЁӢжұ пјҲFixed Thread PoolпјүпјҡдёҖз§ҚзәҝзЁӢж•°йҮҸеӣәе®ҡзҡ„зәҝзЁӢжұ пјҢйҖҡиҝҮ Executors.newFixedThreadPool ж–№жі•еҲӣе»әгҖӮеӣәе®ҡзәҝзЁӢжұ зҡ„дјҳеҠҝжҳҜеҚідҪҝд»»еҠЎйҮҸеўһеҠ пјҢе®ғд№ҹиғҪйҖҡиҝҮеӣәе®ҡж•°йҮҸзҡ„зәҝзЁӢзЁіе®ҡиҝҗиЎҢпјҢйҒҝе…ҚжҖ§иғҪеӨ§е№…дёӢйҷҚпјҢзЎ®дҝқзі»з»ҹвҖңдјҳйӣ…йҖҖеҢ–вҖқгҖӮ
е…¶д»–зәҝзЁӢжұ зұ»еһӢпјҡ
- CachedThreadPoolпјҡеҠЁжҖҒжү©еұ•зҡ„зәҝзЁӢжұ пјҢйҖӮеҗҲеӨ§йҮҸзҹӯжңҹд»»еҠЎгҖӮ
- SingleThreadExecutorпјҡеҚ•зәҝзЁӢжү§иЎҢеҷЁпјҢдҝқиҜҒд»»еҠЎйҖҗдёӘжү§иЎҢпјҢйҖӮеҗҲдҫқж¬ЎеӨ„зҗҶд»»еҠЎзҡ„еңәжҷҜгҖӮ
еҲӣе»әдҪҝз”Ёеӣәе®ҡзәҝзЁӢжұ зҡ„жү§иЎҢеҷЁзҡ„з®ҖеҚ•ж–№жі•жҳҜи°ғз”Ё java.util.concurrent.Executors дёӯ зҡ„ newFixedThreadPool е·ҘеҺӮж–№жі•пјӣжӯӨзұ»иҝҳжҸҗдҫӣд»ҘдёӢе·ҘеҺӮж–№жі•пјҡ newCachedThreadPool ж–№жі•еҲӣе»әе…·жңү еҸҜжү©еұ•зәҝзЁӢжұ зҡ„жү§иЎҢеҷЁгҖӮжӯӨжү§иЎҢеҷЁйҖӮз”ЁдәҺеҗҜеҠЁи®ёеӨҡзҹӯжңҹд»»еҠЎзҡ„еә”з”ЁзЁӢ еәҸгҖӮ newSingleThreadExecutor ж–№жі•еҲӣе»әдёҖдёӘжү§иЎҢеҷЁпјҢдёҖж¬Ўжү§иЎҢдёҖдёӘд»»еҠЎгҖӮ
Fork/Join
- Fork/Join жҳҜдёҖз§Қ
ExecutorServiceзҡ„е®һзҺ°пјҢи®ҫи®Ўз”ЁдәҺеҸҜд»ҘйҖ’еҪ’жӢҶеҲҶдёәиҫғе°Ҹд»»еҠЎзҡ„е·ҘдҪңиҙҹиҪҪгҖӮ - зӣ®ж ҮжҳҜеҲ©з”Ёзі»з»ҹзҡ„жүҖжңүеӨ„зҗҶеҷЁпјҢжңҖеӨ§еҢ–зЁӢеәҸжҖ§иғҪгҖӮ
Fork/Join е·ҘдҪңж–№ејҸпјҡ
е·ҘдҪңжөҒзЁӢзұ»дјјдәҺпјҡеҰӮжһңд»»еҠЎи¶іеӨҹе°ҸпјҢзӣҙжҺҘжү§иЎҢпјҢеҗҰеҲҷе°Ҷд»»еҠЎжӢҶеҲҶдёәдёӨйғЁеҲҶпјҢеҲҶеҲ«жү§иЎҢ并зӯүеҫ…з»“жһңгҖӮиҝҷз§Қж–№ејҸйқһеёёйҖӮеҗҲ并иЎҢеӨ„зҗҶеӨҚжқӮд»»еҠЎпјҢе°Өе…¶еңЁеӨҡеӨ„зҗҶеҷЁзі»з»ҹдёӯеҸҜд»Ҙжҳҫи‘—жҸҗеҚҮжҖ§иғҪгҖӮ
if (my portion of the work is small enough)
do the work directly
else
split my work into two pieces
invoke the two pieces and wait for the results Fork/Join жЎҶжһ¶зҡ„д»Јз Ғе®һзҺ°пјҡ
- йҖҡиҝҮ ForkJoinTask зҡ„еӯҗзұ»е®һзҺ°пјҢйҖҡеёёдҪҝз”Ё RecursiveTaskпјҲеҸҜд»Ҙиҝ”еӣһз»“жһңпјүжҲ–иҖ… RecursiveActionпјҲж— иҝ”еӣһеҖјпјүжқҘеӨ„зҗҶд»»еҠЎгҖӮ
зӨәдҫӢ – еӣҫеғҸжЁЎзіҠеӨ„зҗҶпјҡ
- еӨ„зҗҶеӣҫеғҸж—¶пјҢжҜҸдёӘеғҸзҙ зҡ„йўңиүІеҖјйҖҡиҝҮе№іеқҮе‘ЁеӣҙеғҸзҙ еҖјжқҘжЁЎзіҠеҢ–гҖӮ
- з”ұдәҺеӣҫеғҸжҳҜдёҖз»ҙжҲ–дәҢз»ҙзҡ„еӨ§ж•°з»„пјҢиҝҷдёӘиҝҮзЁӢиҖ—ж—¶иҫғй•ҝгҖӮ
- дҪҝз”Ё Fork/Join жЎҶжһ¶еҸҜд»Ҙ并иЎҢеӨ„зҗҶжҜҸдёӘеғҸзҙ пјҢд»ҺиҖҢжҳҫи‘—еҮҸе°‘еӣҫеғҸеӨ„зҗҶзҡ„ж—¶й—ҙгҖӮ
иҷҡжӢҹзәҝзЁӢ
иҷҡжӢҹзәҝзЁӢжҳҜиҪ»йҮҸзә§зәҝзЁӢпјҢеҸҜд»ҘеҮҸе°‘зј–еҶҷгҖҒз»ҙжҠӨе’Ңи°ғиҜ•й«ҳеҗһеҗҗйҮҸ并еҸ‘еә”з”ЁзЁӢеәҸзҡ„е·ҘдҪңйҮҸгҖӮжӣҙеҠ иҪ»йҮҸеҢ–пјҢжҜ”еҰӮеңЁиў«IOйҳ»еЎһж—¶пјҢйӮЈд№Ҳе°ұжҠҠзәҝзЁӢи§Јз»‘пјӣзӯүIOз»“жқҹж—¶еҶҚз»‘е®ҡзәҝзЁӢпјҢдҪҶдёҚдёҖе®ҡжҳҜеҺҹе…Ҳзҡ„зәҝзЁӢгҖӮдҪҶеҜ№дәҺй•ҝж—¶й—ҙеҚ з”Ёcpuзҡ„д»»еҠЎдёҚеҸӢеҘҪгҖӮ
е№іеҸ°зәҝзЁӢпјҲPlatform Threadпјү
- е®ҡд№үпјҡе№іеҸ°зәҝзЁӢжҳҜдёҖдёӘеӣҙз»•ж“ҚдҪңзі»з»ҹпјҲOSпјүзәҝзЁӢзҡ„иҪ»йҮҸзә§е°ҒиЈ…зҡ„JavaзәҝзЁӢгҖӮ
- зү№зӮ№пјҡ
- е®ғеңЁеә•еұӮзҡ„ж“ҚдҪңзі»з»ҹзәҝзЁӢдёҠиҝҗиЎҢJavaд»Јз ҒгҖӮ
- еңЁе…¶ж•ҙдёӘз”ҹе‘Ҫе‘ЁжңҹдёӯпјҢе№іеҸ°зәҝзЁӢе§Ӣз»ҲеҚ з”ЁдёҖдёӘOSзәҝзЁӢгҖӮ
- еҸҜз”Ёзҡ„ж“ҚдҪңзі»з»ҹзәҝзЁӢж•°йҮҸеҶіе®ҡдәҶе№іеҸ°зәҝзЁӢзҡ„ж•°йҮҸйҷҗеҲ¶гҖӮ
- е№іеҸ°зәҝзЁӢйҖҡеёёе…·жңүиҫғеӨ§зҡ„зәҝзЁӢж ҲпјҲеӯҳеӮЁзәҝзЁӢжү§иЎҢзҠ¶жҖҒзҡ„еҶ…еӯҳпјүд»ҘеҸҠе…¶д»–з”ұж“ҚдҪңзі»з»ҹз®ЎзҗҶзҡ„иө„жәҗгҖӮ
- ж”ҜжҢҒзәҝзЁӢеұҖйғЁеҸҳйҮҸпјҲеҚізү№е®ҡдәҺжҹҗдёҖзәҝзЁӢзҡ„еҸҳйҮҸпјүгҖӮ
- дҪҝз”ЁеңәжҷҜпјҡйҖӮз”ЁдәҺиҝҗиЎҢжүҖжңүзұ»еһӢзҡ„д»»еҠЎпјҢдҪҶз”ұдәҺеҸ—йҷҗдәҺж“ҚдҪңзі»з»ҹзәҝзЁӢж•°йҮҸпјҢе№іеҸ°зәҝзЁӢжҳҜдёҖз§Қжңүйҷҗиө„жәҗгҖӮ
第дёғз«
еӣһйЎҫServletе’ҢTomcat
- ServletжҳҜJavaзј–еҶҷзҡ„жңҚеҠЎеҷЁз«ҜзЁӢеәҸпјҢз”ЁдәҺеӨ„зҗҶWebиҜ·жұӮе’Ңз”ҹжҲҗWebе“Қеә”гҖӮ
- TomcatжҳҜдёҖдёӘејҖжәҗзҡ„Java Servletе®№еҷЁпјҢд№ҹеҸҜд»Ҙз§°дёәWebжңҚеҠЎеҷЁпјҢз”ЁдәҺжүҳз®Ўе’ҢиҝҗиЎҢServletе’ҢJSPеә”з”ЁзЁӢеәҸгҖӮ
дёәд»Җд№ҲйңҖиҰҒзј“еӯҳ
Tomcatе’Ңж•°жҚ®еә“йғҪдёҚдёҖе®ҡжҳҜеңЁдёҖеҸ°жңәеҷЁдёҠйқўпјҢеҸҜиғҪжҳҜеҲҶеёғејҸзҡ„пјҢеҸҜиғҪжҳҜеӨҡеҸ°жңәеҷЁпјҢеҸҜиғҪжҳҜеӨҡдёӘ TomcatпјҢеҸҜиғҪжҳҜеӨҡдёӘж•°жҚ®еә“гҖӮеҰӮжһңз»қеӨ§еӨҡж•°жғ…еҶөйғҪжҳҜеҸӘиҜ»зҡ„пјҢеҗҺз«Ҝе’Ңж•°жҚ®еә“д№Ӣй—ҙзҡ„дәӨдә’пјҢзҪ‘з»ңејҖй”ҖеҫҲеӨ§пјҢжӯӨж—¶е°ұзӣҙжҺҘжҠҠж•°жҚ®зј“еӯҳеҲ°TomcatйӮЈйҮҢпјҢиҠӮзңҒдәҶеёҰе®ҪгҖӮ
- Qпјҡж•°жҚ®еә“йҮҢйқўжңүbufferгҖҒORMжҳ е°„йҮҢйқўд№ҹжңүbufferдҪңдёәзј“еҶІеҢәпјҢйӮЈдёәд»Җд№ҲиҰҒзј“еӯҳе‘ўпјҹ
- AпјҡдёҠйқўиҜҙзҡ„иҝҷдёӨдёӘзј“еӯҳйғҪдёҚжҳҜдҪ еҸҜд»ҘжҺ§еҲ¶зҡ„пјҢе®Ңе…ЁеҸ–еҶідәҺ他们иҮӘиә«пјҢжҲ‘们ејҖеҸ‘иҖ…з®ЎдёҚдәҶгҖӮиҖҢдҪҝз”Ё redisпјҢжҲ‘е°ұеҸҜд»ҘиҮӘе·ұзҡ„жҺ§еҲ¶зј“еӯҳпјҒ
дәӢе®һдёҠпјҢжҲ‘们еҗҺеҸ°зҡ„ж•°жҚ®еә“жңӘеҝ…жҳҜе…ізі»еһӢж•°жҚ®еә“пјҒжҲ‘们еҸҜиғҪиҝҳжҗһдәҶж–Ү件系з»ҹгҖҒmongoвҖҰвҖҰжңҖз»Ҳе®ғ们иҝҳжҳҜиЎЁзӨәдёәеҜ№иұЎпјҢзҗҶи®әдёҠжқҘиҜҙе®ғ们д№ҹеә”иҜҘиҝӣзј“еӯҳпјҒдҪҶжҳҜеғҸspring jpaйҮҢйқўзҡ„зј“еӯҳпјҢжҲ–иҖ…hanibatisйҮҢйқўзҡ„зј“еӯҳпјҢжҠҠж•°жҚ®еә“йҮҢйқўжҠ“еҸ–иҝҮжқҘзҡ„ж•°жҚ®е·Із»Ҹеј„жҲҗеҜ№иұЎзј“еӯҳдәҶпјҢе®ғд№ҹд»…д»…й’ҲеҜ№е…ізі»еһӢж•°жҚ®еә“пјҒпјҲиҝҳжңүпјҢжҲ‘жҠҠдёңиҘҝеҶҷеҲ°redisйҮҢйқўпјҢеҶҷе…Ҙзҡ„жҳҜе·Із»„иЈ…еҘҪзҡ„еҜ№иұЎпјӣеҺҹе§Ӣж•°жҚ®з»„иЈ…дёәеҜ№иұЎд№ҹйңҖиҰҒж¶ҲиҖ—е‘ўпјҒжүҖд»Ҙиҝҷд№ҹжҳҜredisиҠӮзңҒзҡ„ең°ж–№пјү
еҒҮеҰӮжҲ‘иҝҳжңүд»Һж–Ү件系з»ҹйҮҢйқўиҜ»еҸ–зҡ„пјҢnosqlж•°жҚ®еә“йҮҢйқўзҡ„иҜ»еҸ–зҡ„дёңиҘҝгҖҒеҠЁжҖҒз”ҹжҲҗзҡ„зҪ‘йЎөгҖҒеӣҫзүҮйғҪеҸҜд»Ҙ пјҢ жүҖд»ҘдҪҝз”Ёredisе°ұйғҪеҸҜд»ҘеӯҳеӮЁпјҢredisе®Ңе…ЁеңЁејҖеҸ‘иҖ…зҡ„жҺ§еҲ¶дёӢгҖӮжҜ”еҰӮеҸҢеҚҒдёҖзҡ„ж—¶еҖҷпјҢжҲ‘еҸҜд»Ҙи¶Ғз”ЁжҲ·и®ҝй—®йҮҸе°‘зҡ„ж—¶еҖҷжҸҗеүҚжҠҠеҸҜиғҪеҚ–зҲҶзҡ„зҪ‘йЎөзј“еӯҳеҮәжқҘпјҢиҝҷж ·жҸҗй«ҳи®ҝй—®зҡ„йҖҹеәҰгҖӮ redisз”ҡиҮіиҝҳеҸҜд»ҘдҪңдёәж¶ҲжҒҜдёӯй—ҙ件пјҢзұ»дјјkafkaзҡ„topicпјҢд»–е’ҢеҚЎеӨ«еҚЎзҡ„е·®еҲ«жҳҜredisйҮҢйқўзҡ„дёңиҘҝеңЁеҶ…еӯҳйҮҢйқўгҖӮ
ж•°жҚ®еә“жңҚеҠЎеҷЁеҜ№дәҺеҶ…еӯҳиҰҒжұӮжҜ”иҫғй«ҳпјҢиҖҢTomcatжңҚеҠЎеҷЁдё»иҰҒжҳҜCPUеҜҶйӣҶеһӢпјҲеӣ дёәиҰҒеӨ„зҗҶдёҖе ҶиҜ·жұӮпјүпјӣжүҖ д»ҘпјҢеҜ№дәҺдёҖдәӣеҸӘиҜ»зҡ„ж•°жҚ®пјҢжҲ‘д»Һж•°жҚ®еә“жӢҝеҲ°д№ӢеҗҺе°ұзј“еӯҳеңЁTomcatжң¬ең°пјҒ
Memory Caching
Memcached
з®Җд»Ӣ
Memcached жҳҜдёҖдёӘй«ҳж•Ҳзҡ„зј“еӯҳзі»з»ҹпјҢеё®еҠ©жҸҗй«ҳзҪ‘з«ҷзҡ„жҖ§иғҪгҖӮе®ғеӯҳеӮЁдёҖдәӣж•°жҚ®еңЁеҶ…еӯҳдёӯпјҢд»ҘеҮҸиҪ»ж•°жҚ®еә“зҡ„иҙҹжӢ…гҖӮиҝҷдёӘзі»з»ҹжҳ“дәҺдҪҝз”ЁпјҢж”ҜжҢҒеӨҡз§Қзј–зЁӢиҜӯиЁҖгҖӮ
- й«ҳжҖ§иғҪпјҡMemcached иғҪеӨҹеҝ«йҖҹеӨ„зҗҶж•°жҚ®иҜ·жұӮпјҢйҖӮеҗҲй«ҳжөҒйҮҸзҡ„зҪ‘з«ҷгҖӮ
- еҲҶеёғејҸпјҡе®ғеҸҜд»ҘеңЁеӨҡеҸ°жңҚеҠЎеҷЁдёҠиҝҗиЎҢпјҢдҫҝдәҺжү©еұ•гҖӮ
- еҶ…еӯҳеӯҳеӮЁпјҡж•°жҚ®иў«еӯҳеӮЁеңЁеҶ…еӯҳдёӯпјҢиҜ»еҸ–йҖҹеәҰеҫҲеҝ«пјҢйҖӮеҗҲйў‘з№Ғи®ҝй—®зҡ„ж•°жҚ®гҖӮ
- з®ҖеҚ•зҡ„й”®еҖјеӯҳеӮЁпјҡж•°жҚ®д»Ҙй”®еҖјеҜ№зҡ„еҪўејҸеӯҳеӮЁпјҢж–№дҫҝеҝ«йҖҹжҹҘжүҫе’ҢдҪҝз”ЁгҖӮ
еҺҹзҗҶпјҡеӯҳеӮЁеңЁеҶ…еӯҳдёӯзҡ„KV
memcachedйҮҢйқўпјҢеә”иҜҘдё»иҰҒж”ҫзҪ®иҰҒз»ҸеёёиҜ»зҡ„ж•°жҚ®пјҢеҸҜд»Ҙжӣҙеҝ«иҜ»еҲ°пјҢеҶҷжқҘиҜҙж„Ҹд№үдёҚеӨ§
дҪҝз”ЁCachingе’ҢдёҚдҪҝз”ЁCachingж—¶й—ҙеҜ№жҜ”пјҢдҪҝз”ЁеҗҺ第дәҢж¬ЎеҸҠд»ҘеҗҺжҹҘиҜўжҳҫи‘—еҠ еҝ«
еҶ…еӯҳз®ЎзҗҶ
еңЁжІЎжңүдҪҝз”Ё Memcached зҡ„жғ…еҶөдёӢпјҢжҜҸдёӘ Web жңҚеҠЎеҷЁзҡ„зј“еӯҳеҶ…еӯҳжҳҜзӢ¬з«Ӣзҡ„пјҢеҲҶеҲ«дёә 64MBпјҢжҖ»зј“еӯҳдёә 64MBгҖӮ
дҪҝз”Ё Memcached еҗҺпјҢеҗ„дёӘжңҚеҠЎеҷЁзҡ„еҶ…еӯҳеҸҜд»Ҙз»„еҗҲеңЁдёҖиө·пјҢеҪўжҲҗдёҖдёӘ 128MB зҡ„жҖ»зј“еӯҳжұ гҖӮMemcached еҸҜд»ҘйҖҡиҝҮеҲҶеёғејҸзј“еӯҳдҪҝеҗ„дёӘиҠӮзӮ№е…ұдә«еҶ…еӯҳпјҢд»ҺиҖҢжӣҙеҘҪең°еҲ©з”ЁеҶ…еӯҳиө„жәҗгҖӮ
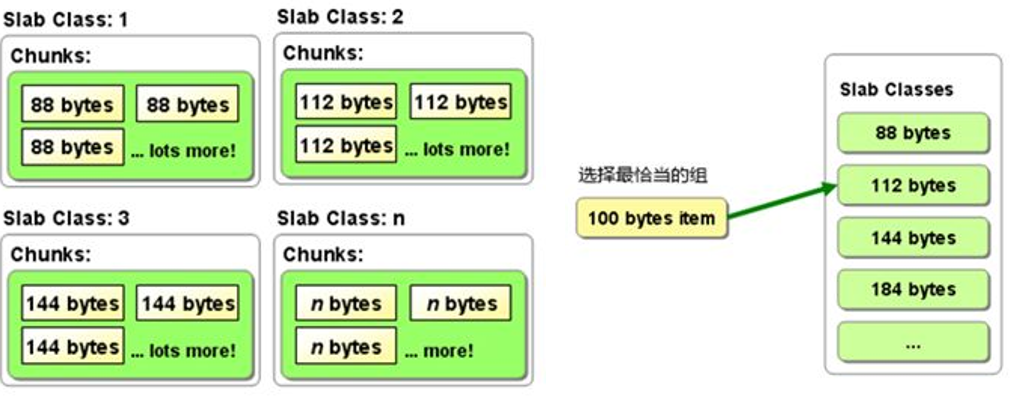
Memcached зҡ„ Slab еҲҶй…ҚжңәеҲ¶пјҢе®ғйҖҡиҝҮе°ҶеҶ…еӯҳеҲ’еҲҶжҲҗеӨҡдёӘвҖңSlab ClassвҖқжқҘз®ЎзҗҶдёҚеҗҢеӨ§е°Ҹзҡ„ж•°жҚ®гҖӮжҜҸдёӘ Slab Class еҢ…еҗ«еӨҡдёӘ ChunkпјҢжҜҸдёӘ Chunk зҡ„еӨ§е°ҸжҳҜзӣёеҗҢзҡ„гҖӮ
жҜҸдёӘ Slab Class еҜ№еә”дёҚеҗҢзҡ„ Chunk еӨ§е°ҸпјҢжҜ”еҰӮеӣҫзүҮдёӯзҡ„ Slab Class 1 зҡ„ Chunk еӨ§е°ҸжҳҜ 88 еӯ—иҠӮпјҢSlab Class 2 жҳҜ 112 еӯ—иҠӮпјҢдҫқж¬Ўзұ»жҺЁгҖӮ
дҫӢеҰӮеҪ“еӯҳеӮЁдёҖдёӘ 100 еӯ—иҠӮзҡ„йЎ№зӣ®ж—¶пјҢMemcached дјҡйҖүжӢ©дёҖдёӘжңҖйҖӮеҗҲзҡ„ Slab ClassпјҲжҜ”еҰӮеҢ…еҗ« 112 еӯ—иҠӮ Chunk зҡ„ Slab Class 2пјүжқҘеӯҳеӮЁиҜҘж•°жҚ®йЎ№гҖӮеҪ“然еҜ№дәҺvarcharиҝҳжҳҜдёӨз«Ҝж”ҫпјҢеӣ дёәдёҚзҹҘйҒ“ж•°жҚ®еӨҡй•ҝгҖӮ
еҪ“еӯҳж»Ўд№ӢеҗҺпјҢдјҡж”ҫеңЁзЎ¬зӣҳйҮҢйқўпјҲдёҖиҲ¬жҳҜеңЁжңҚеҠЎеҷЁзЎ¬зӣҳпјүпјҢзӣёжҜ”дәҺд»Һж•°жҚ®еә“иҜ»иҝҳжҳҜеҝ«дёҖдәӣгҖӮ
иҠӮзӮ№д№Ӣй—ҙдёҚйңҖиҰҒйҖҡдҝЎпјҢжү§иЎҢд»Јз Ғж—¶еҖҷдјҡиҮӘеҠЁеҸ–иҠӮзӮ№еҜ»жүҫпјҢи§ҒдёҖиҮҙжҖ§е“ҲеёҢ
дёҖиҮҙжҖ§е“ҲеёҢпјҲConsistent Hashingпјү
дёҖиҮҙжҖ§е“ҲеёҢжҳҜдёҖз§Қз”ЁдәҺеҲҶеёғејҸзј“еӯҳзі»з»ҹзҡ„ж•°жҚ®еҲҶеёғз®—жі•гҖӮе®ғйҖҡиҝҮе°ҶиҠӮзӮ№е’Ңж•°жҚ®йЎ№жҳ е°„еҲ°дёҖдёӘе“ҲеёҢзҺҜдёҠпјҢдҪҝеҫ—еҪ“иҠӮзӮ№еҸ‘з”ҹеўһеҮҸж—¶пјҢд»…дјҡеҪұе“ҚдёҖе°ҸйғЁеҲҶзҡ„ж•°жҚ®пјҢд»ҺиҖҢе®һзҺ°й«ҳж•Ҳзҡ„ж•°жҚ®еҲҶй…ҚдёҺз®ЎзҗҶгҖӮ
е·ҘдҪңеҺҹзҗҶ
- е“ҲеёҢзҺҜпјҲHash RingпјүпјҡдёҖиҮҙжҖ§е“ҲеёҢе°ҶжүҖжңүзҡ„иҠӮзӮ№е’Ңж•°жҚ®йЎ№ж №жҚ®е…¶е“ҲеёҢеҖјжҳ е°„еҲ°дёҖдёӘе“ҲеёҢзҺҜдёҠгҖӮе“ҲеёҢеҖјзҡ„иҢғеӣҙйҖҡеёёжҳҜ
[0, 2^32)гҖӮ - иҠӮзӮ№жҳ е°„пјҡжҜҸдёӘиҠӮзӮ№пјҲеҰӮзј“еӯҳжңҚеҠЎеҷЁпјүеңЁе“ҲеёҢзҺҜдёҠеҚ жҚ®зү№е®ҡзҡ„дҪҚзҪ®пјҢдҪҚзҪ®з”ұиҠӮзӮ№зҡ„е“ҲеёҢеҖјеҶіе®ҡгҖӮ
- ж•°жҚ®йЎ№жҳ е°„пјҡжҜҸдёӘж•°жҚ®йЎ№пјҲKeyпјүйҖҡиҝҮе“ҲеёҢеҮҪж•°и®Ўз®—еҮәе“ҲеёҢеҖјпјҢд»ҺиҖҢзЎ®е®ҡеңЁе“ҲеёҢзҺҜдёҠзҡ„дҪҚзҪ®гҖӮ
- ж•°жҚ®еӯҳеӮЁи§„еҲҷпјҡдёҖдёӘж•°жҚ®йЎ№дјҡеӯҳеӮЁеңЁвҖңйЎәж—¶й’Ҳж–№еҗ‘дёҠзҡ„第дёҖдёӘиҠӮзӮ№вҖқдёҠгҖӮеҚіпјҢе“ҲеёҢеҖјеңЁзҺҜдёҠйЎәж—¶й’ҲйҒҮеҲ°зҡ„第дёҖдёӘиҠӮзӮ№еҚідёәзӣ®ж ҮиҠӮзӮ№гҖӮ
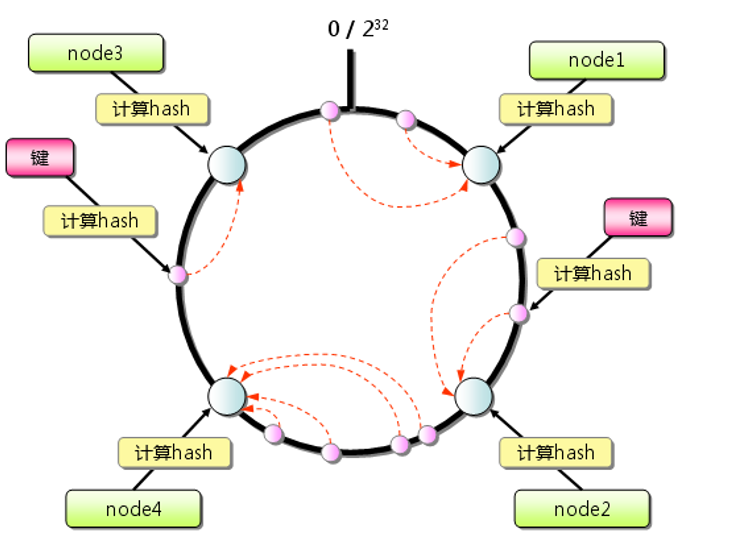
зү№зӮ№
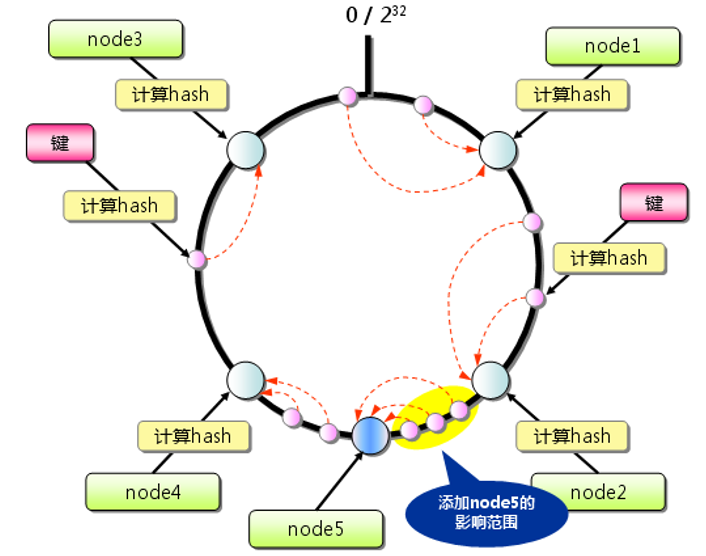
- еҮҸе°‘ж•°жҚ®иҝҒ移пјҡеңЁиҠӮзӮ№еўһеҠ жҲ–移йҷӨж—¶пјҢд»…еҪұе“ҚзҺҜдёҠдёҺиҜҘиҠӮзӮ№зӣёйӮ»зҡ„ж•°жҚ®йЎ№пјҢе…¶д»–ж•°жҚ®дёҚдјҡйҮҚж–°еҲҶй…ҚпјҢйҒҝе…ҚдәҶеӨ§и§„жЁЎзҡ„ж•°жҚ®иҝҒ移гҖӮиҝҷеңЁе®һйҷ…еә”з”ЁдёӯиғҪеӨҹжҳҫи‘—жҸҗй«ҳзі»з»ҹзҡ„зЁіе®ҡжҖ§е’Ңжү©еұ•жҖ§гҖӮ
- иҙҹиҪҪеқҮиЎЎпјҡдёҖиҮҙжҖ§е“ҲеёҢиғҪеӨҹе°Ҷж•°жҚ®еқҮеҢҖең°еҲҶеёғеңЁеӨҡдёӘиҠӮзӮ№дёҠпјҢд»ҺиҖҢе®һзҺ°иҙҹиҪҪеқҮиЎЎгҖӮ
- жү©еұ•жҖ§ејәпјҡж”ҜжҢҒеҠЁжҖҒж·»еҠ жҲ–移йҷӨиҠӮзӮ№пјҢ并且еҪұе“ҚиҢғеӣҙе°ҸпјҢж–№дҫҝзі»з»ҹзҡ„жЁӘеҗ‘жү©еұ•гҖӮ
еӣҫи§ЈиҜҙжҳҺ
- еҲқе§ӢзҠ¶жҖҒпјҡе·Ұеӣҫеұ•зӨәдәҶдёҖдёӘеҢ…еҗ«
node1гҖҒnode2гҖҒnode3е’Ңnode4зҡ„е“ҲеёҢзҺҜгҖӮж•°жҚ®йЎ№ж №жҚ®е“ҲеёҢеҖјеңЁзҺҜдёҠжүҫеҲ°жңҖжҺҘиҝ‘зҡ„иҠӮзӮ№иҝӣиЎҢеӯҳеӮЁгҖӮ - иҠӮзӮ№ж·»еҠ пјҡеҸіеӣҫеұ•зӨәдәҶеўһеҠ
node5еҗҺзҡ„еҸҳеҢ–гҖӮж–°иҠӮзӮ№node5еҠ е…ҘеҗҺпјҢд»…еҪұе“ҚдәҶйғЁеҲҶж•°жҚ®йЎ№зҡ„еӯҳеӮЁдҪҚзҪ®пјҲдҪҚдәҺ node4 е’Ң node2 д№Ӣй—ҙзҡ„ж•°жҚ®йЎ№пјүпјҢиҖҢе…¶д»–ж•°жҚ®йЎ№зҡ„дҪҚзҪ®дҝқжҢҒдёҚеҸҳгҖӮеҲ йҷӨд№ҹеҗҢзҗҶ
Redis
Redis жҳҜдёҖз§Қиў«з§°дёәй”®еҖјеӯҳеӮЁпјҲKey-Value Storeпјүзҡ„ж•°жҚ®еә“зұ»еһӢпјҢйҖҡеёёеҪ’зұ»дёә NoSQL ж•°жҚ®еә“гҖӮй”®еҖјеӯҳеӮЁзҡ„ж ёеҝғеңЁдәҺе°Ҷж•°жҚ®пјҲз§°дёәеҖјпјүеӯҳеӮЁеңЁдёҖдёӘе”ҜдёҖзҡ„й”®дёӢгҖӮ
- ејҖжәҗдёҺи®ёеҸҜпјҡRedis жҳҜдёҖдёӘејҖжәҗйЎ№зӣ®пјҢеҹәдәҺ BSD и®ёеҸҜиҜҒеҸ‘еёғгҖӮ
- й«ҳзә§й”®еҖјеӯҳеӮЁпјҡдёҺе…¶д»–й”®еҖјеӯҳеӮЁдёҚеҗҢпјҢRedis дёҚд»…еҸҜд»ҘеӯҳеӮЁеӯ—з¬ҰдёІзұ»еһӢзҡ„еҖјпјҢиҝҳж”ҜжҢҒдё°еҜҢзҡ„ж•°жҚ®з»“жһ„пјҢеҢ…жӢ¬пјҡ
| ж•°жҚ®з»“жһ„зұ»еһӢ | еҢ…еҗ«зҡ„еҶ…е®№ | з»“жһ„иҜ»/еҶҷиғҪеҠӣ |
|---|---|---|
| STRING | еӯ—з¬ҰдёІгҖҒж•ҙж•°жҲ–жө®зӮ№ж•°еҖј | еҜ№ж•ҙдёӘеӯ—з¬ҰдёІжҲ–йғЁеҲҶеӯ—з¬ҰдёІиҝӣиЎҢж“ҚдҪңпјҢеўһеҠ /еҮҸе°‘ж•ҙж•°е’Ңжө®зӮ№ж•°еҖј |
| LIST | еӯ—з¬ҰдёІзҡ„й“ҫиЎЁ | д»ҺдёӨз«ҜжҺЁйҖҒжҲ–еј№еҮәе…ғзҙ пјҢж №жҚ®еҒҸ移йҮҸиҝӣиЎҢдҝ®еүӘпјҢиҜ»еҸ–еҚ•дёӘжҲ–еӨҡдёӘе…ғзҙ пјҢжҢүеҖјжҹҘжүҫжҲ–еҲ йҷӨе…ғзҙ пјҢиҢғеӣҙжҹҘжүҫиҫғж…ў |
| SET | ж— еәҸзҡ„е”ҜдёҖеӯ—з¬ҰдёІйӣҶеҗҲ | ж·»еҠ гҖҒиҺ·еҸ–жҲ–еҲ йҷӨеҚ•дёӘе…ғзҙ пјҢжЈҖжҹҘжҲҗе‘ҳе…ізі»пјҢиҝӣиЎҢдәӨйӣҶгҖҒ并йӣҶгҖҒе·®йӣҶиҝҗз®—пјҢиҺ·еҸ–йҡҸжңәе…ғзҙ |
| HASH | ж— еәҸзҡ„й”®еҖјеҜ№е“ҲеёҢиЎЁ | ж·»еҠ гҖҒиҺ·еҸ–жҲ–еҲ йҷӨеҚ•дёӘе…ғзҙ пјҢиҺ·еҸ–ж•ҙдёӘе“ҲеёҢиЎЁ |
| ZSET (Sorted Set) | жңүеәҸзҡ„еӯ—з¬ҰдёІжҲҗе‘ҳеҲ°жө®зӮ№ж•°еҲҶж•°зҡ„жҳ е°„пјҢжҢүеҲҶж•°жҺ’еәҸ | ж·»еҠ гҖҒиҺ·еҸ–жҲ–еҲ йҷӨеҚ•дёӘе…ғзҙ пјҢж №жҚ®еҲҶж•°иҢғеӣҙжҲ–жҲҗе‘ҳеҖјиҺ·еҸ–е…ғзҙ |
еҶ…еӯҳдёҺжҢҒд№…еҢ–
Redis дё»иҰҒеңЁеҶ…еӯҳдёӯе·ҘдҪңпјҢд»ҘжӯӨжқҘе®һзҺ°еҮәиүІзҡ„жҖ§иғҪгҖӮиҝҷж„Ҹе‘ізқҖж•°жҚ®зҡ„и®ҝй—®йҖҹеәҰйқһеёёеҝ«гҖӮж №жҚ®дёҚеҗҢзҡ„еә”з”ЁйңҖжұӮпјҢRedis жҸҗдҫӣдәҶеӨҡз§ҚжҢҒд№…еҢ–ж–№ејҸпјҡ
- еҝ«з…§пјҲSnapshottingпјүпјҡе®ҡжңҹе°Ҷж•°жҚ®йӣҶеҝ«з…§пјҲdumpпјүдҝқеӯҳеҲ°зЈҒзӣҳдёӯгҖӮ
- AOF ж—Ҙеҝ—пјҲAppend-Only FileпјүпјҡжҜҸж¬Ўжү§иЎҢе‘Ҫд»Өж—¶пјҢе°Ҷе…¶йҷ„еҠ еҲ°ж—Ҙеҝ—ж–Ү件дёӯгҖӮ
Redis ж”ҜжҢҒз®ҖеҚ•й…ҚзҪ®зҡ„дё»д»ҺеӨҚеҲ¶пјҲMaster-Slave ReplicationпјүпјҲзј“еӯҳжҖҺд№Ҳдјҡжңүдё»д»ҺеӨҮд»Ҫпјҹеӣ дёәжңүдәәжҠҠе®ғеҪ“NoSQLж•°жҚ®еә“з”ЁвҖҰвҖҰпјүпјҢе…¶зү№жҖ§еҢ…жӢ¬пјҡ
- еҝ«йҖҹйқһйҳ»еЎһзҡ„еҲқж¬ЎеҗҢжӯҘпјҡдё»иҠӮзӮ№дёҺд»ҺиҠӮзӮ№зҡ„еҲқж¬Ўж•°жҚ®еҗҢжӯҘйқһеёёеҝ«йҖҹдё”дёҚйҳ»еЎһгҖӮ
- иҮӘеҠЁйҮҚиҝһпјҡеңЁзҪ‘з»ңеҲҶиЈӮпјҲеҰӮзҪ‘з»ңж•…йҡңпјүеҗҺпјҢRedis еҸҜд»ҘиҮӘеҠЁйҮҚиҝһ并继з»ӯеҗҢжӯҘгҖӮ
Redisдёӯеә”иҜҘж”ҫзҡ„жңүпјҡ1. з»Ҹеёёз”ЁеҲ°зҡ„дёңиҘҝ 2. з»Ҹеёёж¶үеҸҠеҲ°иҜ»еҸ–ж“ҚдҪңзҡ„пјҢиҖҢеҫҲе°‘ж¶үеҸҠеҲ°еҶҷзҡ„ж“ҚдҪңзҡ„ 3. дёӯй—ҙи®Ўз®—зҡ„з»“жһң 4. з»ҸеёёиҰҒеҶҷзҡ„дёңиҘҝдёҚиҰҒж”ҫе…Ҙзј“еӯҳ
еәҸеҲ—еҢ–пјҡдёӨдёӘиҝӣзЁӢд№Ӣй—ҙйҖҡдҝЎеҫҲйә»зғҰпјҢеҜ№дәҺTomcatе’ҢredisжҳҜдёӨдёӘиҝӣзЁӢгҖӮиҝӣзЁӢй—ҙжүҖи°“зҡ„йҖҡдҝЎе°ұжҳҜ дј иҫ“ж•°жҚ®пјӣжҜ”еҰӮжҲ‘иҰҒдј иҫ“дёҖдёӘobjectпјҢжҲ‘жҠҠе®ғиҪ¬еҢ–дёәдёҖдёӘеӯ—иҠӮж•°з»„ byte[] пјҢиҝҷе°ұжҳҜеәҸеҲ—еҢ–пјӣ然еҗҺдҪ 收еҲ°дәҶиҝҷдёӘеӯ—иҠӮж•°з»„пјҢдҪ е°ұжҠҠе®ғеҸҚеәҸеҲ—еҢ–пјҢе°ұеҸҳжҲҗдәҶдёҖдёӘobjectгҖӮ
еә”з”ЁеңәжҷҜпјҡRedis з”ұдәҺе…¶дё°еҜҢзҡ„ж•°жҚ®з»“жһ„гҖҒеҶ…еӯҳдёӯж“ҚдҪңзҡ„й«ҳжҖ§иғҪе’ҢжҢҒд№…еҢ–зү№жҖ§пјҢиў«е№ҝжіӣз”ЁдәҺзј“еӯҳгҖҒе®һж—¶еҲҶжһҗгҖҒж¶ҲжҒҜйҳҹеҲ—зӯүеңәжҷҜгҖӮ
| еҗҚз§° | зұ»еһӢ | ж•°жҚ®еӯҳеӮЁйҖүйЎ№ | жҹҘиҜўзұ»еһӢ | йҷ„еҠ еҠҹиғҪ |
|---|---|---|---|---|
| Redis | еҶ…еӯҳдёӯзҡ„йқһе…ізі»еһӢж•°жҚ®еә“ | еӯ—з¬ҰдёІгҖҒеҲ—иЎЁгҖҒйӣҶеҗҲгҖҒе“ҲеёҢгҖҒжңүеәҸйӣҶеҗҲ | й’ҲеҜ№жҜҸз§Қж•°жҚ®зұ»еһӢзҡ„еёёз”Ёи®ҝй—®жЁЎејҸе‘Ҫд»ӨгҖҒжү№йҮҸж“ҚдҪңе’ҢйғЁеҲҶдәӢеҠЎж”ҜжҢҒ | еҸ‘еёғ/и®ўйҳ…гҖҒдё»/д»ҺеӨҚеҲ¶гҖҒзЈҒзӣҳжҢҒд№…еҢ–гҖҒи„ҡжң¬пјҲеӯҳеӮЁиҝҮзЁӢпјү |
| Memcached | еҶ…еӯҳдёӯзҡ„й”®еҖјзј“еӯҳ | й”®еҲ°еҖјзҡ„жҳ е°„ | еҲӣе»әгҖҒиҜ»еҸ–гҖҒжӣҙж–°гҖҒеҲ йҷӨе‘Ҫд»Өд»ҘеҸҠе°‘ж•°е…¶д»–е‘Ҫд»Ө | еӨҡзәҝзЁӢжңҚеҠЎеҷЁд»ҘеўһејәжҖ§иғҪ |
| MySQL | е…ізі»еһӢж•°жҚ®еә“ | иЎҢиЎЁгҖҒиЎЁи§ҶеӣҫгҖҒз©әй—ҙж•°жҚ®е’Ң第дёүж–№жү©еұ•зҡ„ж•°жҚ®еә“ | SELECTгҖҒINSERTгҖҒUPDATEгҖҒDELETEгҖҒеҮҪж•°гҖҒеӯҳеӮЁиҝҮзЁӢ | з¬ҰеҗҲ ACIDпјҲдҪҝз”Ё InnoDBпјүгҖҒдё»/д»ҺеӨҚеҲ¶е’Ңдё»/дё»еӨҚеҲ¶ |
| PostgreSQL | е…ізі»еһӢж•°жҚ®еә“ | иЎҢиЎЁгҖҒиЎЁи§ҶеӣҫгҖҒз©әй—ҙж•°жҚ®гҖҒ第дёүж–№жү©еұ•гҖҒиҮӘе®ҡд№үзұ»еһӢзҡ„ж•°жҚ®еә“ | SELECTгҖҒINSERTгҖҒUPDATEгҖҒDELETEгҖҒеҶ…зҪ®еҮҪж•°гҖҒиҮӘе®ҡд№үеӯҳеӮЁиҝҮзЁӢ | з¬ҰеҗҲ ACIDпјҢдё»/д»ҺеӨҚеҲ¶пјҢеӨҡдё»еӨҚеҲ¶пјҲ第дёүж–№пјү |
| MongoDB | еҹәдәҺзЈҒзӣҳзҡ„йқһе…ізі»еһӢж–ҮжЎЈеӯҳеӮЁ | ж— жЁЎејҸ BSON ж–ҮжЎЈзҡ„иЎЁ | еҲӣе»әгҖҒиҜ»еҸ–гҖҒжӣҙж–°гҖҒеҲ йҷӨгҖҒжқЎд»¶жҹҘиҜўзӯүе‘Ҫд»Ө | ж”ҜжҢҒ Map-Reduce ж“ҚдҪңгҖҒдё»/д»ҺеӨҚеҲ¶гҖҒеҲҶзүҮгҖҒз©әй—ҙзҙўеј• |
жҹҘжүҫиҝҮзЁӢпјҡе…ҲеҺ»еҶ…еӯҳйҮҢйқўжҹҘжүҫпјҢжҹҘиҜўеӨұиҙҘеҗҺе°ұд»Һж•°жҚ®еә“йҮҢйқўиҜ»пјҢиҜ»еҮәжқҘеҗҺж”ҫеҲ°еҶ…еӯҳйҮҢйқўгҖӮдёӢж¬ЎиҜ»еҸ–зӣҙжҺҘд»ҺеҶ…еӯҳдёӯиҺ·еҸ–гҖӮеҪ“жӣҙж”№еҸҜд»ҘеңЁеҶ…еӯҳйҮҢйқўжӣҙж”№еҖјпјҢдҝқиҜҒжҹҘиҜўж—¶дёҖиҮҙжҖ§гҖӮ
еҲҶеёғејҸзј“еӯҳ
дёәд»Җд№ҲйңҖиҰҒеҲҶеёғејҸзј“еӯҳпјҡеӣ дёәдёҖдёӘжңәеҷЁзҡ„зј“еӯҳеҸҜиғҪдёҚеӨҹпјҢзү©зҗҶдёҠеӨҡдёӘжңәеҷЁпјҢе®һйҷ…йҖ»иҫ‘дёҠжҳҜдёҖдёӘеӨ§зҡ„ зј“еӯҳпјҢеҸҜд»Ҙе……еҲҶеҲ©з”ЁеӨҡдёӘжңәеҷЁзҡ„еҶ…еӯҳпјӣ зЁіе®ҡеҸҜд»ҘеӨҮд»ҪпјҢеҸҜйқ жҖ§еўһеҠ гҖӮ
第八з«
еҸҚеҗ‘зҙўеј•е’ҢжӯЈеҗ‘зҙўеј•
еҸҚеҗ‘зҙўеј•пјҢд№ҹз§°дёәвҖҢеҖ’жҺ’зҙўеј•пјҲInverted IndexпјүпјҢжҳҜдёҖз§Қзҙўеј•ж–№жі•пјҢз”ЁдәҺеӯҳеӮЁжҜҸдёӘиҜҚжҲ–зҹӯиҜӯеңЁж–ҮжЎЈдёӯзҡ„дҪҚзҪ®дҝЎжҒҜгҖӮеҖ’жҺ’зҙўеј•йҖҡиҝҮи®°еҪ•жҜҸдёӘиҜҚеҮәзҺ°зҡ„ж–ҮжЎЈеҲ—иЎЁжқҘе·ҘдҪңпјҢдҪҝеҫ—еңЁжҹҘиҜўж—¶еҸҜд»Ҙеҝ«йҖҹжүҫеҲ°еҢ…еҗ«зү№е®ҡиҜҚжұҮзҡ„жүҖжңүж–ҮжЎЈгҖӮиҝҷз§Қзҙўеј•ж–№жі•еңЁе…Ёж–Үжҗңзҙўдёӯйқһеёёжңүж•ҲпјҢеӣ дёәе®ғе…Ғи®ёз”ЁжҲ·еҝ«йҖҹжүҫеҲ°еҢ…еҗ«жҹҗдёӘе…ій”®иҜҚзҡ„жүҖжңүзӣёе…іж–ҮжЎЈгҖӮвҖҢ
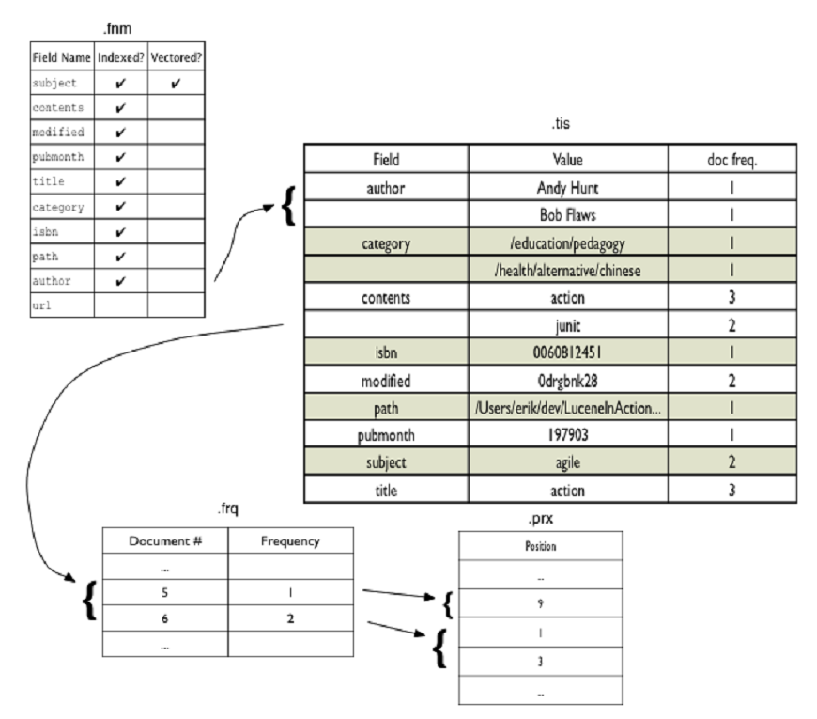
Luceneзҡ„termsзҙўеј•еұһдәҺиў«з§°дёәеҸҚеҗ‘зҙўеј•пјҢиҝҷжҳҜеӣ дёәе®ғеҸҜд»ҘеҲ—еҮәдёҖдёӘitemдёӯеҢ…еҗ«е®ғзҡ„ж–ҮжЎЈпјҢиҝҷдёҺж–ҮжЎЈеҲ—еҮәжңҜиҜӯзҡ„иҮӘ然关系зӣёеҸҚ
жӯЈеҗ‘зҙўеј•пјҲForward Indexпјүпјҡ жӯЈеҗ‘зҙўеј•жҳҜдёҖз§ҚжҢүж–ҮжЎЈжқҘз»„з»Үе’ҢеӯҳеӮЁж–Үжң¬ж•°жҚ®зҡ„зҙўеј•ж–№ејҸгҖӮжҜҸдёӘж–ҮжЎЈйғҪжңүдёҖдёӘеҜ№еә”зҡ„зҙўеј•йЎ№пјҢ иҝҷдёӘзҙўеј•йЎ№еҢ…еҗ«дәҶж–ҮжЎЈдёӯзҡ„жүҖжңүдҝЎжҒҜпјҢйҖҡеёёд»Ҙж–ҮжЎЈзҡ„ж ҮиҜҶз¬ҰпјҲеҰӮж–ҮжЎЈIDпјүдёәзҙўеј•зҡ„й”®гҖӮ жӯЈеҗ‘зҙўеј•йҖӮеҗҲдәҺйңҖиҰҒжҢүж–ҮжЎЈиҝӣиЎҢжЈҖзҙўзҡ„еңәжҷҜпјҢдҫӢеҰӮеңЁж–ҮжЎЈз®ЎзҗҶзі»з»ҹдёӯжҹҘжүҫзү№е®ҡж–ҮжЎЈжҲ–ж №жҚ®ж–ҮжЎЈеұһжҖ§иҝӣиЎҢиҝҮж»Өе’ҢжҺ’еәҸгҖӮ зјәзӮ№жҳҜеңЁеӨ„зҗҶеӨ§йҮҸж–Үжң¬ж•°жҚ®ж—¶пјҢжӯЈеҗ‘зҙўеј•еҸҜиғҪйңҖиҰҒеӨ§йҮҸзҡ„еӯҳеӮЁз©әй—ҙпјҢеӣ дёәжҜҸдёӘж–ҮжЎЈйғҪйңҖиҰҒдёҖдёӘ е®Ңж•ҙзҡ„зҙўеј•йЎ№гҖӮ
- жӯЈеҗ‘зҙўеј•йҖӮз”ЁдәҺйңҖиҰҒжҢүж–ҮжЎЈжЈҖзҙўзҡ„еә”з”ЁпјҢдҫӢеҰӮж–ҮжЎЈз®ЎзҗҶзі»з»ҹжҲ–еҶ…е®№еұ•зӨәгҖӮ
- еҸҚеҗ‘зҙўеј•йҖӮз”ЁдәҺйңҖиҰҒе…Ёж–Үжҗңзҙўе’Ңе…ій”®иҜҚжЈҖзҙўзҡ„еә”з”ЁпјҢдҫӢеҰӮжҗңзҙўеј•ж“Һе’ҢдҝЎжҒҜжЈҖзҙўзі»з»ҹгҖӮ
- жӯЈеҗ‘зҙўеј•йңҖиҰҒжӣҙеӨҡзҡ„еӯҳеӮЁз©әй—ҙпјҢдҪҶеңЁи®ҝй—®зү№е®ҡж–ҮжЎЈж—¶йҖҹеәҰиҫғеҝ«гҖӮ
- еҸҚеҗ‘зҙўеј•еҚ з”Ёиҫғе°‘зҡ„еӯҳеӮЁз©әй—ҙпјҢдҪҶеңЁе…Ёж–Үжҗңзҙўе’Ңе…ій”®иҜҚжЈҖзҙўж—¶йҖҹеәҰжӣҙеҝ«гҖӮ
йҖҡеёёпјҢжҗңзҙўеј•ж“Һдјҡз»“еҗҲдҪҝз”ЁжӯЈеҗ‘зҙўеј•е’ҢеҸҚеҗ‘зҙўеј•пјҢд»Ҙж»Ўи¶ідёҚеҗҢзҡ„жЈҖзҙўйңҖжұӮпјҢ并жҸҗдҫӣй«ҳж•Ҳзҡ„жҗңзҙўдҪ“ йӘҢгҖӮжӯЈеҗ‘зҙўеј•з”ЁдәҺеҝ«йҖҹиҺ·еҸ–ж–ҮжЎЈзҡ„иҜҰз»ҶдҝЎжҒҜпјҢиҖҢеҸҚеҗ‘зҙўеј•з”ЁдәҺй«ҳж•Ҳең°жүҫеҲ°еҢ…еҗ«жҹҘиҜўе…ій”®иҜҚзҡ„ж–ҮжЎЈгҖӮ
Lucene
LuceneжҳҜдёҖдёӘй«ҳжҖ§иғҪгҖҒеҸҜжү©еұ•зҡ„дҝЎжҒҜжЈҖзҙўпјҲIRпјүеә“гҖӮз”ЁжқҘе»әз«Ӣзҙўеј•пјҲеҰӮжһңдёҚе»әз«Ӣзҙўеј•пјҢжҜҸж¬ЎйғҪиҰҒжү«жҸҸжүҖжңүзҡ„ж–Ү件пјҢж•ҲзҺҮеӨӘдҪҺпјүе’ҢжҗңзҙўгҖӮ
йҖӮй…ҚиҢғеӣҙпјҡеӨ§йҮҸйқһз»“жһ„еҢ–зҡ„ж–Үжң¬пјҢдҫӢеҰӮжҗңзҙўеј•ж“ҺгҖӮ
еҒҮи®ҫйңҖиҰҒжҗңзҙўеӨ§йҮҸж–Ү件пјҢ并且еёҢжңӣиғҪеӨҹжүҫеҲ°еҢ…еҗ«жҹҗдёӘеҚ•иҜҚжҲ–зҹӯиҜӯзҡ„ж–Ү件пјҢи§ЈеҶіж–№жі•пјҡ
еҜ№иҜҘж–Үжң¬иҝӣиЎҢзҙўеј•пјҢ并е°Ҷе…¶иҪ¬жҚўдёәдёҖз§ҚеҸҜд»Ҙеҝ«йҖҹжҗңзҙўзҡ„ж јејҸпјҢд»ҺиҖҢж¶ҲйҷӨзј“ж…ўзҡ„йЎәеәҸжү«жҸҸиҝҮзЁӢгҖӮ
иҝҷз§ҚиҪ¬жҚўиҝҮзЁӢз§°дёәзҙўеј•пјҢе…¶иҫ“еҮәз§°дёәзҙўеј•гҖӮ
жҗңзҙўеҚіеңЁзҙўеј•дёӯжҹҘжүҫеҚ•иҜҚд»ҘжүҫеҲ°е®ғ们еҮәзҺ°зҡ„ж–ҮжЎЈзҡ„иҝҮзЁӢгҖӮ
жҗңзҙўзҡ„иҙЁйҮҸйҖҡеёёдҪҝз”ЁзІҫзЎ®еәҰе’ҢеҸ¬еӣһзҺҮжҢҮж ҮжқҘжҸҸиҝ°гҖӮеҪ“然д№ҹеҢ…жӢ¬йҖҹеәҰе’Ңеҝ«йҖҹжҗңзҙўеӨ§йҮҸж–Үжң¬зҡ„иғҪеҠӣпјҢж”ҜжҢҒеҚ•иҜҚе’ҢеӨҡиҜҚжҹҘиҜўгҖҒзҹӯиҜӯжҹҘиҜўгҖҒйҖҡй…Қз¬ҰгҖҒз»“жһңжҺ’еҗҚе’ҢжҺ’еәҸд№ҹеҫҲйҮҚиҰҒпјҢиҫ“е…ҘиҝҷдәӣжҹҘиҜўзҡ„еҸӢеҘҪиҜӯжі•д№ҹеҫҲйҮҚиҰҒгҖӮ
е…Ёж–Үжҗңзҙў
зұ»дјјзҷҫеәҰзҡ„зҪ‘з«ҷпјҢз”ЁжҲ·жҗңзҙўдёҖдёӘе…ій”®иҜҚпјҢж №жҚ®е»әз«Ӣзҡ„зҙўеј•пјҢжҹҘжүҫеҢ…жӢ¬е…ій”®иҜҚзҡ„зӣёе…ізҡ„йқһз»“жһ„еҢ–зҡ„ж•°жҚ®йҮҢйқўжңүе“ӘдәӣеҢ…еҗ«зӣ®ж Үе…ій”®иҜҚгҖӮ
з»“жһ„еҢ–пјҡеҰӮж•°жҚ®еә“пјҢжүҖжңүж•°жҚ®жҳҜschemaзҡ„пјҢж•°жҚ®жңүеӯ—ж®өпјҢеғҸиЎЁж јпјҢжҳҜжңүз»“жһ„зҡ„пјӣдҪҶиҝҷйҮҢ жҜ”еҰӮжҲ‘з»ҷдҪ дёҖдёӘhtmlпјҢжҲ–иҖ…дёҖж®өtxtпјҢиҝҷз§ҚдёңиҘҝжҳҜжІЎжңүз»“жһ„еҸҜеҜ»зҡ„гҖӮ
- з»“жһ„еҢ–ж•°жҚ®е»әз«Ӣзҙўеј•зҡ„ж–№ејҸпјҡB+ж ‘е°ұеҸҜд»Ҙ
- йӮЈйқһз»“жһ„еҢ–ж•°жҚ®жҖҺд№ҲеҠһе‘ўпјҹжҜ”еҰӮжңүдёҖдёӘdirзӣ®еҪ•пјҢйҮҢйқўжңүдёҖеӨ§е Ҷ.txtпјҢе’Ңhtmlж–Ү件пјҢжҲ‘иҰҒй—®иҝҷдёӘзӣ®еҪ•йҮҢйқўеҢ…еҗ«е…ій”®иҜҚjavaзҡ„ж–Ү件жңүе“Әдәӣпјҹ
е»әз«Ӣзҙўеј•
еҰӮжһңжҲ‘жҗңзҙўjavaпјҢдҪ иҰҒе‘ҠиҜүжҲ‘javaеҮәзҺ°еңЁе“ӘдәӣиЎҢпјҢд»ҘеҸҠе…·дҪ“зҡ„дҪҚзҪ®пјҹ
- 1. з”ЁжҹҗдёҖз§ҚtokenizerеӨ„зҗҶжәҗж–Ү件
- 2. preprocessпјҢжҜ”еҰӮжҠҠжүҖжңүзҡ„еӨ§еҶҷеӯ—жҜҚйғҪеҸҳжҲҗе°ҸеҶҷпјҢзӣёеҗҢзҡ„еҚ•иҜҚйғҪеҗҲ并еҲ°дёҖиө·пјҲжҜ”еҰӮжңүдәӣеҚ•иҜҚжҳҜ takeгҖҒtookгҖҒtakenйғҪжҳҜtakeзҡ„дёҚеҗҢеҪўејҸпјү
- 3. еҸҚеҗ‘зҙўеј•пјҡдёәд»Җд№ҲеҸ«еҸҚеҗ‘зҙўеј•е‘ўпјҢеӣ дёәдёҚжҳҜжҜҸдёҖиЎҢжҳ е°„еҲ°еҮ дёӘеҚ•иҜҚпјҢиҖҢжҳҜжҹҗдёҖдёӘе…ій”®иҜҚжҳ е°„еҲ°е“ӘеҮ иЎҢзҡ„е“ӘеҮ дёӘдҪҚзҪ®гҖӮ
Core Indexing Classes ж ёеҝғзҙўеј•зұ»
- IndexWriterпјҡ IndexWriter жҳҜзҙўеј•еҲӣе»әе’Ңз»ҙжҠӨзҡ„ж ёеҝғзұ»гҖӮе®ғиҙҹиҙЈе°Ҷж–ҮжЎЈж·»еҠ еҲ°зҙўеј•гҖҒжӣҙж–°зҙўеј•гҖҒеҲ йҷӨж–ҮжЎЈд»Ҙ еҸҠдјҳеҢ–зҙўеј•зӯүж“ҚдҪңгҖӮ IndexWriter жҳҜеңЁзҙўеј•е»әз«Ӣе’Ңжӣҙж–°иҝҮзЁӢдёӯзҡ„дё»иҰҒжҺҘеҸЈд№ӢдёҖгҖӮ
- Directoryпјҡ Directory жҳҜзҙўеј•ж–Ү件зҡ„еӯҳеӮЁе’Ңз®ЎзҗҶжҠҪиұЎгҖӮе®ғе®ҡд№үдәҶзҙўеј•ж–Ү件зҡ„дҪҚзҪ®е’Ңи®ҝй—®ж–№ејҸпјҢеҸҜд»ҘжҳҜеҹәдәҺ ж–Ү件系з»ҹзҡ„зӣ®еҪ•пјҢд№ҹеҸҜд»ҘжҳҜеҶ…еӯҳдёӯзҡ„ж•°жҚ®з»“жһ„гҖӮ Directory жҸҗдҫӣдәҶеҜ№зҙўеј•ж–Ү件зҡ„иҜ»еҶҷж“ҚдҪңпјҢдҪҝ еҫ—зҙўеј•еҸҜд»Ҙиў«жҢҒд№…еҢ–еӯҳеӮЁе’ҢжЈҖзҙўгҖӮ
- Analyzerпјҡ Analyzer жҳҜж–Үжң¬еҲҶжһҗзҡ„关键组件гҖӮе®ғе®ҡд№үдәҶеҰӮдҪ•е°Ҷж–Үжң¬ж•°жҚ®еҲҶеүІжҲҗеҚ•иҜҚжҲ–иҜҚз»„пјҢиҝӣиЎҢиҜҚе№І еҢ–гҖҒеҺ»йҷӨеҒңз”ЁиҜҚзӯүж–Үжң¬еӨ„зҗҶж“ҚдҪңгҖӮжӯЈзЎ®йҖүжӢ©е’Ңй…ҚзҪ®йҖӮеҪ“зҡ„еҲҶжһҗеҷЁеҜ№дәҺзҙўеј•зҡ„иҙЁйҮҸе’ҢжҖ§иғҪиҮіе…ійҮҚиҰҒгҖӮ
- Documentпјҡ Document иЎЁзӨәзҙўеј•дёӯзҡ„дёҖдёӘж–ҮжЎЈгҖӮж–ҮжЎЈйҖҡеёёз”ұдёҖз»„еӯ—ж®өпјҲ Field пјүз»„жҲҗпјҢжҜҸдёӘеӯ—ж®өеҢ…еҗ«дәҶж–Ү жЎЈзҡ„дёҖйғЁеҲҶдҝЎжҒҜпјҢеҰӮж ҮйўҳгҖҒжӯЈж–ҮгҖҒдҪңиҖ…зӯүгҖӮ Document з”ЁдәҺе°Ҷж–Үжң¬ж•°жҚ®ж·»еҠ еҲ°зҙўеј•гҖӮ
- Fieldпјҡ Field жҳҜж–ҮжЎЈдёӯзҡ„дёҖдёӘеӯ—ж®өжҲ–еұһжҖ§гҖӮе®ғеҢ…еҗ«дәҶеӯ—ж®өзҡ„еҗҚз§°гҖҒеҖјд»ҘеҸҠз”ЁдәҺжҢҮе®ҡеҰӮдҪ•еӨ„зҗҶиҜҘеӯ—ж®өзҡ„ й…ҚзҪ®йҖүйЎ№гҖӮеӯ—ж®өеҸҜд»ҘжҳҜж–Үжң¬гҖҒж•°еӯ—гҖҒж—ҘжңҹзӯүдёҚеҗҢзұ»еһӢзҡ„ж•°жҚ®пјҢж №жҚ®йңҖиҰҒиҝӣиЎҢзҙўеј•е’ҢжЈҖзҙўгҖӮ
FieldжҜҸдёӘеӯ—ж®өеҜ№еә”дәҺеңЁжҗңзҙўжңҹй—ҙж №жҚ®зҙўеј•жҹҘиҜўжҲ–д»Һзҙўеј•жЈҖзҙўзҡ„дёҖж®өж•°жҚ®гҖӮ
public abstract class BaseIndexTestCase extends TestCase {
protected String[] keywords = {"1","2"};
protected String[] unindexed = {"Netherlands","Italy"};
protected String[] unstored = {
"Amsterdam has lots of bridges",
"Venice has lots of canals"
};
protected String[] text = {"Amsterdam","Venice"};
protected Directory dir; ... }- Keyword пјҡе…ій”®еӯ—дёҚиў«еҲҶжһҗпјҲе°ұжҳҜдёҚдјҡиў«жӢҶејҖпјүпјҢиҖҢжҳҜиў«зҙўеј•е№¶йҖҗеӯ—еӯҳеӮЁеңЁзҙўеј•дёӯгҖӮ
- UnIndexed пјҡж—ўдёҚеҲҶжһҗд№ҹдёҚзҙўеј•пјҢдҪҶе…¶еҖјжҢүеҺҹж ·еӯҳеӮЁеңЁзҙўеј•дёӯгҖӮд№ҹе°ұжҳҜиҜҙдёҖж—ҰеҒҮеҰӮйҖҡиҝҮkeywordжҹҘ иҜўеҲ°дәҶпјҢиҰҒжҠҠunindexзҡ„йғЁеҲҶзҡ„еҶ…е®№иҰҒеёҰеҮәжқҘпјҢдҪҶжҳҜиҝҷйғЁеҲҶдёҚзҙўеј•гҖӮпјҲдҪ дёҚйңҖиҰҒжҠҠиҚ·е…°е’Ңж„ҸеӨ§еҲ©еҒҡ зҙўеј•пјҢжҲ‘еёҢжңӣзҡ„жҳҜжҲ‘жҹҘеҮәжқҘ1е’Ң2пјҢдҪ жҠҠиҚ·е…°е’Ңж„ҸеӨ§еҲ©зҡ„еҶ…е®№еёҰеҮәжқҘпјү
- UnStored пјҡжӯӨеӯ—ж®өзұ»еһӢиў«еҲҶжһҗе’Ңзҙўеј•пјҢиҰҒж”ҫеҲ°зҙўеј•йҮҢеҺ»е»әпјҢдҪҶдёҚеӯҳеӮЁеңЁзҙўеј•дёӯгҖӮеҪ“然жңүдёҖдәӣеҒңз”ЁиҜҚ еҲ—иЎЁпјҢжҜ”еҰӮдёҖдәӣйқһеёёеёёз”Ёзҡ„иҜҚпјҢиҝҷдәӣдёңиҘҝе°ұиў«еҝҪз•ҘгҖӮдёҖиҲ¬жҳҜжӯЈж–ҮпјҢйқһеёёй•ҝдёҚеә”иҜҘеӯҳеңЁзҙўеј•йҮҢйқўпјҢйқһ еёёжөӘиҙ№гҖӮпјҲжҜ”еҰӮиҝҷйҮҢжҲ‘们жҠҠAmsterdam,bridge,Venice,canalжқҘж”ҫе…Ҙзҙўеј•пјҢдҪ жҢүз…§bridgeжҹҘжҳҜеҸҜд»ҘжҹҘ еҲ°иҝҷдёӘж–Ү件зҡ„пјҢдҪҶжҳҜдҪ зҙўеј•йҮҢйқўжІЎжңүеӯҳеӮЁж•ҙдёӘе®Ңж•ҙзҡ„еҶ…е®№пјҢеӣ дёәе®Ңж•ҙзҡ„еҶ…е®№еҸҜиғҪеҫҲеӨ§пјҢжүҖд»ҘжҲ‘们зңҹ зҡ„иҰҒеҸ–иҰҒиҜ»зЎ¬зӣҳпјү
- Text пјҡиў«еҲҶжһҗ并被зҙўеј•пјҢеӯҳеӮЁеҲ°зҙўеј•йҮҢйқўгҖӮиҝҷж„Ҹе‘ізқҖеҸҜд»Ҙй’ҲеҜ№иҝҷз§Қзұ»еһӢзҡ„еӯ—ж®өиҝӣиЎҢжҗңзҙўпјҢдҪҶиҰҒжіЁ ж„Ҹеӯ—ж®өеӨ§е°ҸгҖӮеҸҜд»Ҙзұ»жҜ”keywordпјҢеҢәеҲ«жҳҜиҝҷдёӘtextдјҡиў«еҲҶжһҗдёҖдёӢпјҢиҖҢkeywordдёҚдјҡпјҲд№ҹе°ұжҳҜtextдјҡиў« ж–ӯејҖпјү
еӯ—ж®өзұ»еһӢ
еңЁLuceneдёӯпјҢеӯ—ж®өеҸҜд»Ҙиў«еӯҳеӮЁпјҢеңЁиҝҷз§Қжғ…еҶөдёӢпјҢе®ғ们зҡ„ж–Үжң¬д»ҘйқһеҸҚиҪ¬зҡ„ж–№ејҸжҢүеӯ—йқўж„ҸжҖқеӯҳеӮЁеңЁзҙўеј•дёӯгҖӮеҸҚиҪ¬зҡ„еӯ—ж®өз§°дёәзҙўеј•гҖӮ
дёҖдёӘеӯ—ж®өж—ўеҸҜд»Ҙиў«еӯҳеӮЁпјҢд№ҹеҸҜд»Ҙиў«зҙўеј•гҖӮ
еӯ—ж®өзҡ„ж–Үжң¬еҸҜд»Ҙиў«ж Үи®°дёәиҰҒзҙўеј•зҡ„жңҜиҜӯпјҢжҲ–иҖ…еӯ—ж®өзҡ„ж–Үжң¬д№ҹеҸҜд»ҘзӣҙжҺҘз”ЁдҪңиҰҒзҙўеј•зҡ„иҜҚжұҮгҖӮ
еӨ§еӨҡж•°еӯ—ж®өйғҪжҳҜж Үи®°еҢ–зҡ„пјҢдҪҶжңүж—¶еҜ№жҹҗдәӣж ҮиҜҶз¬Ұеӯ—ж®өиҝӣиЎҢеӯ—йқўзҙўеј•жҳҜжңүз”Ёзҡ„гҖӮ
еӯ—ж®өжҳҜж–ҮжЎЈзҡ„дёҖдёӘйғЁеҲҶпјҢжҜҸдёӘеӯ—ж®өжңүдёүдёӘз»„жҲҗйғЁеҲҶпјҡ
- еҗҚз§°пјҡеӯ—ж®өзҡ„ж ҮиҜҶз¬ҰгҖӮ
- зұ»еһӢпјҡеӯ—ж®өзҡ„ж•°жҚ®зұ»еһӢгҖӮ
- еҖјпјҡеӯ—ж®өзҡ„е®һйҷ…ж•°жҚ®пјҢеҸҜд»ҘжҳҜж–Үжң¬пјҲеҰӮ
StringгҖҒReaderжҲ–йў„еҲҶжһҗзҡ„TokenStreamпјүгҖҒдәҢиҝӣеҲ¶ж•°жҚ®пјҲеҰӮbyte[]пјүжҲ–ж•°еӯ—пјҲеҰӮNumberпјүгҖӮ
ж®өпјҲSegmentsпјү
Lucene зҙўеј•еҸҜд»Ҙз”ұеӨҡдёӘеӯҗзҙўеј•пјҲжҲ–з§°дёәж®өпјүз»„жҲҗгҖӮжҜҸдёӘж®өйғҪжҳҜдёҖдёӘе®Ңе…ЁзӢ¬з«Ӣзҡ„зҙўеј•пјҢеҸҜд»ҘеҚ•зӢ¬иҝӣиЎҢжҗңзҙўгҖӮзҙўеј•зҡ„жј”еҸҳж–№ејҸеҢ…жӢ¬пјҡ
- дёәж–°ж·»еҠ зҡ„ж–ҮжЎЈеҲӣе»әж–°зҡ„ж®өгҖӮ
- еҗҲ并зҺ°жңүзҡ„ж®өгҖӮ
- жҗңзҙўж“ҚдҪңеҸҜиғҪж¶үеҸҠеӨҡдёӘж®өе’Ң/жҲ–еӨҡдёӘзҙўеј•пјҢжҜҸдёӘзҙўеј•еҸҜиғҪз”ұдёҖз»„ж®өз»„жҲҗгҖӮ
ж–ҮжЎЈзј–еҸ·
еңЁеҶ…йғЁпјҢLucene дҪҝз”Ёж•ҙж•°ж–ҮжЎЈзј–еҸ·жқҘеј•з”Ёж–ҮжЎЈгҖӮ第дёҖдёӘж·»еҠ еҲ°зҙўеј•зҡ„ж–ҮжЎЈзј–еҸ·дёәйӣ¶пјҢйҡҸеҗҺзҡ„жҜҸдёӘж–ҮжЎЈзј–еҸ·дҫқж¬ЎеўһеҠ дёҖгҖӮ
еңЁLuceneдёӯеҜ»жүҫе’Ңжү“еҲҶ
Lucene жҸҗдҫӣдәҶеӨҡз§ҚдёҚеҗҢзҡ„ Query е®һзҺ°пјҢе…Ғи®ёжү§иЎҢеҗ„з§Қзұ»еһӢзҡ„жҹҘиҜўгҖӮ
жү§иЎҢжҗңзҙў
еә”з”ЁзЁӢеәҸйҖҡеёёдјҡи°ғз”Ё IndexSearcher.search(Query, int) жқҘжү§иЎҢжҗңзҙўж“ҚдҪңгҖӮдёҖж—Ұ Query еҲӣе»ә并жҸҗдәӨз»ҷ IndexSearcherпјҢLucene ејҖе§ӢиҝӣиЎҢиҜ„еҲҶиҝҮзЁӢгҖӮеңЁдёҖдәӣеҹәзЎҖи®ҫж–Ҫзҡ„и®ҫзҪ®е®ҢжҲҗеҗҺпјҢжҺ§еҲ¶жқғжңҖз»ҲдәӨз»ҷ Weight е®һзҺ°зұ»еҸҠе…¶ Scorer жҲ– BulkScorer е®һдҫӢгҖӮ
жҹҘиҜўзұ»
TermQuery
TermQuery жҳҜжңҖе®№жҳ“зҗҶи§Јдё”еә”з”ЁжңҖе№ҝжіӣзҡ„жҹҘиҜўзұ»гҖӮе®ғеҢ№й…ҚжүҖжңүеҢ…еҗ«жҢҮе®ҡжңҜиҜӯпјҲTermпјүзҡ„ж–ҮжЎЈпјҢTerm жҳҜеҮәзҺ°еңЁжҹҗдёӘзү№е®ҡеӯ—ж®өпјҲFieldпјүдёӯзҡ„дёҖдёӘеҚ•иҜҚгҖӮ
дҫӢеҰӮпјҢжһ„йҖ дёҖдёӘ TermQuery еҰӮдёӢпјҡ
TermQuery tq = new TermQuery(new Term("fieldName", "term"));жӯӨжҹҘиҜўдјҡиҜҶеҲ«жүҖжңү Field дёә "fieldName" 并еҢ…еҗ«жңҜиҜӯ "term" зҡ„ж–ҮжЎЈгҖӮ
BooleanQuery
BooleanQuery йҖҡиҝҮе°ҶеӨҡдёӘ TermQuery е®һдҫӢз»„еҗҲиө·жқҘпјҢеҸҜд»Ҙжһ„е»әжӣҙеӨҚжқӮзҡ„жҹҘиҜўгҖӮBooleanQuery еҢ…еҗ«еӨҡдёӘ BooleanClauseпјҢжҜҸдёӘеӯҗжҹҘиҜўйғҪжңүдёҖдёӘиҝҗз®—з¬ҰпјҲжқҘиҮӘ BooleanClause.OccurпјүпјҢиҜҘиҝҗз®—з¬ҰжҸҸиҝ°еӯҗжҹҘиҜўеҰӮдҪ•дёҺе…¶д»–еӯҗжҹҘиҜўз»„еҗҲгҖӮ
- SHOULDпјҡеӯҗжҹҘиҜўеҸҜд»ҘеҮәзҺ°еңЁз»“жһңйӣҶдёӯпјҢдҪҶдёҚжҳҜеҝ…йЎ»зҡ„гҖӮеҰӮжһңжүҖжңүеӯҗжҹҘиҜўйғҪжҳҜ
SHOULDпјҢеҲҷз»“жһңйӣҶдёӯзҡ„жҜҸдёӘж–ҮжЎЈиҮіе°‘еҢ№й…ҚдёҖдёӘеӯҗжҹҘиҜўгҖӮ - MUSTпјҡеӯҗжҹҘиҜўеҝ…йЎ»еҮәзҺ°еңЁз»“жһңйӣҶдёӯпјҢ并且дјҡеҪұе“ҚиҜ„еҲҶгҖӮз»“жһңйӣҶдёӯзҡ„жҜҸдёӘж–ҮжЎЈе°ҶеҢ№й…ҚжүҖжңүиҝҷж ·зҡ„еӯҗжҹҘиҜўгҖӮ
- FILTERпјҡеӯҗжҹҘиҜўеҝ…йЎ»еҮәзҺ°еңЁз»“жһңйӣҶдёӯпјҢдҪҶдёҚеҪұе“ҚиҜ„еҲҶгҖӮз»“жһңйӣҶдёӯзҡ„жҜҸдёӘж–ҮжЎЈе°ҶеҢ№й…ҚжүҖжңүиҝҷж ·зҡ„еӯҗжҹҘиҜўгҖӮ
- MUST NOTпјҡеӯҗжҹҘиҜўдёҚиғҪеҮәзҺ°еңЁз»“жһңйӣҶдёӯгҖӮз»“жһңйӣҶдёӯжІЎжңүж–ҮжЎЈдјҡеҢ№й…Қиҝҷж ·зҡ„еӯҗжҹҘиҜўгҖӮ
жһ„йҖ BooleanQuery ж—¶пјҢйҖҡиҝҮж·»еҠ дёӨдёӘжҲ–жӣҙеӨҡ BooleanClause е®һдҫӢжқҘе®һзҺ°гҖӮеҰӮжһңж·»еҠ зҡ„еӯҗжҹҘиҜўиҝҮеӨҡпјҢеңЁжҗңзҙўж—¶дјҡжҠӣеҮә TooManyClauses ејӮеёёгҖӮй»ҳи®ӨжңҖеӨҡе…Ғи®ё 1024 дёӘеӯҗжҹҘиҜўпјҢеҸҜд»ҘйҖҡиҝҮ IndexSearcher.setMaxClauseCount(int) дҝ®ж”№иҝҷдёӘеҖјгҖӮ
Phrase QueriesпјҲзҹӯиҜӯжҹҘиҜўпјү
зҹӯиҜӯжҹҘиҜўз”ЁдәҺжҹҘжүҫеҢ…еҗ«зү№е®ҡзҹӯиҜӯзҡ„ж–ҮжЎЈпјҢжңүд»ҘдёӢеҮ з§Қе®һзҺ°ж–№ејҸпјҡ
- PhraseQueryпјҡеҢ№й…ҚдёҖзі»еҲ—зҡ„жңҜиҜӯгҖӮ
PhraseQueryдҪҝз”Ё “slop” еӣ еӯҗжқҘзЎ®е®ҡзҹӯиҜӯдёӯзӣёйӮ»дёӨдёӘжңҜиҜӯд№Ӣй—ҙеҸҜд»Ҙе…Ғи®ёзҡ„жңҖеӨ§и·қзҰ»гҖӮй»ҳи®Өзҡ„slopеҖјдёә 0пјҢиЎЁзӨәзҹӯиҜӯеҝ…йЎ»е®Ңе…ЁеҢ№й…ҚгҖӮ - MultiPhraseQueryпјҡ
PhraseQueryзҡ„дёҖз§ҚйҖҡз”ЁеҪўејҸпјҢе…Ғи®ёдёәзҹӯиҜӯдёӯзҡ„жҹҗдёӘдҪҚзҪ®жҢҮе®ҡеӨҡдёӘжңҜиҜӯгҖӮдҫӢеҰӮпјҢеҸҜд»Ҙз”Ёе®ғжқҘжү§иЎҢеҢ…еҗ«еҗҢд№үиҜҚзҡ„зҹӯиҜӯжҹҘиҜўгҖӮ - Interval QueriesпјҡеңЁ
QueriesжЁЎеқ—дёӯд№ҹжҸҗдҫӣдәҶеҢәй—ҙжҹҘиҜўгҖӮ
PointRangeQuery
PointRangeQuery еҢ№й…ҚдҪҚдәҺж•°еҖјиҢғеӣҙеҶ…зҡ„жүҖжңүж–ҮжЎЈгҖӮиҰҒдҪҝз”Ё PointRangeQueryпјҢеҝ…йЎ»е°ҶеҖјзҙўеј•дёәж•°еҖјеӯ—ж®өпјҢдҫӢеҰӮ IntPointгҖҒLongPointгҖҒFloatPoint жҲ– DoublePointгҖӮ
PrefixQueryгҖҒWildcardQueryгҖҒRegexpQuery
- PrefixQueryпјҡз”ЁдәҺжҹҘжүҫжүҖжңүжңҜиҜӯд»ҘжҹҗдёӘеӯ—з¬ҰдёІејҖеӨҙзҡ„ж–ҮжЎЈгҖӮ
- WildcardQueryпјҡйҖҡй…Қз¬ҰжҹҘиҜўпјҢе…Ғи®ёдҪҝз”Ё
*пјҲеҢ№й…Қ 0 дёӘжҲ–еӨҡдёӘеӯ—з¬Ұпјүе’Ң?пјҲеҢ№й…Қ 1 дёӘеӯ—з¬ҰпјүйҖҡй…Қз¬ҰгҖӮ - RegexpQueryпјҡжҜ”
WildcardQueryжӣҙйҖҡз”ЁпјҢе…Ғи®ёеҢ№й…ҚжӯЈеҲҷиЎЁиҫҫејҸжЁЎејҸзҡ„жүҖжңүжңҜиҜӯгҖӮ
FuzzyQuery
FuzzyQuery еҢ№й…ҚеҢ…еҗ«дёҺжҢҮе®ҡжңҜиҜӯзӣёдјјзҡ„жңҜиҜӯзҡ„ж–ҮжЎЈпјҢзӣёдјјеәҰйҖҡиҝҮ Levenshtein и·қзҰ»жқҘзЎ®е®ҡгҖӮиҝҷз§ҚжҹҘиҜўеңЁеӨ„зҗҶжӢјеҶҷеҸҳдҪ“ж—¶йқһеёёжңүз”ЁгҖӮ
жү“еҲҶ
Lucene жү“еҲҶжңәеҲ¶
Lucene зҡ„жү“еҲҶжңәеҲ¶жҳҜе…¶еҸ—ж¬ўиҝҺзҡ„ж ёеҝғеҺҹеӣ д№ӢдёҖгҖӮLucene ж”ҜжҢҒеӨҡз§ҚеҸҜжҸ’жӢ”зҡ„дҝЎжҒҜжЈҖзҙўжЁЎеһӢпјҢеҢ…жӢ¬пјҡ
- еҗ‘йҮҸз©әй—ҙжЁЎеһӢ (Vector Space Model, VSM)
- жҰӮзҺҮжЁЎеһӢпјҢеҰӮ Okapi BM25 е’Ң DFR
- иҜӯиЁҖжЁЎеһӢ
жү“еҲҶе…¬ејҸдёӯзҡ„еӣ зҙ
дёәдәҶиҺ·еҫ—жӣҙй«ҳзҡ„еҫ—еҲҶпјҢе°ҪйҮҸеўһеҠ жҹҘиҜўиҜҚеңЁйҮҚиҰҒеӯ—ж®өпјҲеҰӮж Үйўҳпјүдёӯзҡ„йў‘зҺҮпјҢ并дҪҝз”ЁзЁҖжңүдё”зӣёе…ізҡ„е…ій”®иҜҚпјҢеҗҢж—¶дҝқжҢҒеӯ—ж®өеҶ…е®№з®ҖжҙҒд»ҘжҸҗй«ҳжқғйҮҚгҖӮ
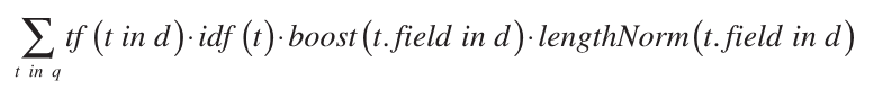
| еӣ зҙ | жҸҸиҝ° |
|---|---|
| tf(t in d) | жңҜиҜӯ (t) еңЁж–ҮжЎЈ (d) дёӯзҡ„иҜҚйў‘еӣ еӯҗгҖӮиЎЁзӨәиҜҘжңҜиҜӯеңЁж–ҮжЎЈдёӯеҮәзҺ°зҡ„йў‘зҺҮгҖӮ |
| idf(t) | жңҜиҜӯзҡ„йҖҶж–ҮжЎЈйў‘зҺҮгҖӮиЎЁзӨәиҜҘжңҜиҜӯеңЁж•ҙдёӘж–ҮжЎЈйӣҶеҗҲдёӯзҡ„зЁҖжңүзЁӢеәҰпјҢзЁҖжңүзҡ„жңҜиҜӯеҜ№еҫ—еҲҶеҪұе“ҚжӣҙеӨ§гҖӮ |
| boost(t.field in d) | еӯ—ж®өжҸҗеҚҮеӣ еӯҗпјҢйҖҡеёёеңЁзҙўеј•ж—¶и®ҫзҪ®пјҢз”ЁдәҺжҸҗеҚҮзү№е®ҡеӯ—ж®өзҡ„жқғйҮҚгҖӮ |
| lengthNorm(t.field in d) | еӯ—ж®өзҡ„й•ҝеәҰеҪ’дёҖеҢ–еҖјпјҢж №жҚ®еӯ—ж®өдёӯзҡ„иҜҚиҜӯж•°йҮҸиҝӣиЎҢеҪ’дёҖеҢ–гҖӮжӯӨеҖјеңЁзҙўеј•ж—¶и®Ўз®—пјҢ并еӯҳеӮЁеңЁзҙўеј•дёӯгҖӮ |
| coord(q, d) | еҚҸи°ғеӣ еӯҗпјҢеҹәдәҺж–ҮжЎЈдёӯеҢ№й…ҚжҹҘиҜўйЎ№зҡ„ж•°йҮҸжқҘи®Ўз®—гҖӮеҢ№й…Қзҡ„жҹҘиҜўйЎ№и¶ҠеӨҡпјҢеҫ—еҲҶи¶Ҡй«ҳгҖӮ |
| queryNorm(q) | жҹҘиҜўзҡ„еҪ’дёҖеҢ–еҖјпјҢж №жҚ®жҹҘиҜўйЎ№зҡ„еҠ жқғе№іж–№е’Ңи®Ўз®—гҖӮзЎ®дҝқжҹҘиҜўйЎ№жӣҙеӨҡзҡ„жҹҘиҜўдёҚдјҡдёҚе…¬е№іең°еҪұе“Қеҫ—еҲҶгҖӮ |
Solr
- жҳҜеҹәдәҺApache Luceneв„ўжһ„е»әзҡ„жөҒиЎҢгҖҒеҝ«йҖҹгҖҒејҖжәҗзҡ„дјҒдёҡжҗңзҙўе№іеҸ°гҖӮ
- е…·жңүй«ҳеәҰеҸҜйқ жҖ§гҖҒеҸҜжү©еұ•жҖ§е’Ңе®№й”ҷжҖ§пјҢжҸҗдҫӣеҲҶеёғејҸзҙўеј•гҖҒеӨҚеҲ¶е’ҢиҙҹиҪҪе№іиЎЎжҹҘиҜўгҖҒиҮӘеҠЁж•…йҡңиҪ¬з§»е’ҢжҒўеӨҚгҖҒйӣҶдёӯй…ҚзҪ®зӯүгҖӮ
- Solrдёәдё–з•ҢдёҠи®ёеӨҡжңҖеӨ§зҡ„дә’иҒ”зҪ‘зҪ‘з«ҷзҡ„жҗңзҙўе’ҢеҜјиҲӘеҠҹиғҪжҸҗдҫӣж”ҜжҢҒгҖӮ
SolrJ
- SolrJ жҳҜ Solr е®ҳж–№жҸҗдҫӣзҡ„ Java е®ўжҲ·з«Ҝеә“пјҢз”ЁдәҺдёҺ Solr жңҚеҠЎеҷЁиҝӣиЎҢдәӨдә’пјҢеҢ…жӢ¬зҙўеј•ж–ҮжЎЈгҖҒжү§иЎҢжҗңзҙўжҹҘиҜўгҖҒз®ЎзҗҶж ёеҝғпјҲcoresпјүзӯүж“ҚдҪңгҖӮ
第д№қз«
WebService
жҸҗдҫӣ跨硬件гҖҒж“ҚдҪңзі»з»ҹгҖҒзј–зЁӢиҜӯиЁҖе’Ңеә”з”ЁзЁӢеәҸе®һзҺ°зңҹжӯЈдә’ж“ҚдҪңжҖ§зҡ„жңәдјҡ
WebпјҡзӣёеҜ№дәҺIPCпјҲиҝӣзЁӢй—ҙйҖҡдҝЎпјүпјҢжҜ”еҰӮjavaдёӯзҡ„RMIпјҲremote method invocationпјүиҝңзЁӢж–№жі•и°ғз”ЁпјҢжҲ–иҖ…е…¶д»–иҜӯиЁҖдёӯзҡ„RPCпјҲиҝңзЁӢиҝҮзЁӢи°ғз”ЁпјүпјҢwebзҡ„и®ҝй—®иғҪеҠӣдјҡејәеҫ—еӨҡвҖ”вҖ”еҸӘжңүwebжүҚиғҪеҒҡеҲ°иҜҙжҜ”еҰӮзҫҺеӣҪеӨ§еӯҰжңүдёӘжңҚеҠЎеҷЁпјҢжҲ‘еңЁдёӯеӣҪд№ҹеҸҜд»Ҙи®ҝй—®еҫ—еҲ°гҖӮ
ServicesпјҡзӢ¬з«ӢдәҺе…·дҪ“зҡ„е®һзҺ°пјҢи§ЈеҶізҡ„жҳҜејӮжһ„зҡ„й—®йўҳпјҲж“ҚдҪңзі»з»ҹгҖҒзј–зЁӢиҜӯиЁҖзҡ„е·®ејӮпјүпјҢжҜ”еҰӮе®ўжҲ·з«ҜжҳҜC#ејҖеҸ‘зҡ„пјҢжңҚеҠЎз«ҜжҳҜjavaејҖеҸ‘зҡ„пјҢйӮЈдёәдәҶж–№дҫҝ他们д№Ӣй—ҙзҡ„дәӨдә’пјҢжҲ‘们е°ұиҰҒиө°зәҜж–Үжң¬зҡ„и·ҜзәҝпјҢеӨ§е®¶йғҪиғҪи®ӨиҜҶгҖӮ既然жҳҜзәҜж–Үжң¬пјҢйӮЈйңҖиҰҒдёҖе®ҡзҡ„ж јејҸпјҢSOAPдј зҡ„ж•°жҚ®йҮҢйқўеҢ…жӢ¬дәҶдёҖзі»еҲ—зҡ„operationгҖҒеҸӮж•°зҡ„еҗҚз§°зұ»еһӢпјҢдҪҶжҳҜж•°жҚ®й©ұеҠЁеһӢзҡ„гҖӮ
SOAP
SOAPпјҲSimple Object Access ProtocolпјҢз®ҖеҚ•еҜ№иұЎи®ҝй—®еҚҸи®®пјүжҳҜдёҖз§Қз”ЁдәҺзҪ‘з»ңжңҚеҠЎзҡ„еҚҸи®®пјҢе®ғе…Ғи®ёеә”з”ЁзЁӢеәҸд№Ӣй—ҙйҖҡиҝҮзҪ‘з»ңиҝӣиЎҢж•°жҚ®дәӨжҚўгҖӮSOAP жҳҜеҹәдәҺ XML зҡ„дёҖз§ҚеҚҸи®®пјҢеҸҜд»ҘеңЁдёҚеҗҢзҡ„ж“ҚдҪңзі»з»ҹе’Ңзј–зЁӢиҜӯиЁҖд№Ӣй—ҙдј йҖ’дҝЎжҒҜпјҢе…·жңүиүҜеҘҪзҡ„е…је®№жҖ§е’Ңжү©еұ•жҖ§гҖӮ
SOAP зҡ„еҹәжң¬жҰӮеҝө
SOAP жҳҜдёҖз§ҚеҹәдәҺж¶ҲжҒҜдј йҖ’зҡ„еҚҸи®®гҖӮжҜҸж¬ЎдәӨдә’йғҪжҳҜйҖҡиҝҮеҸ‘йҖҒвҖңиҜ·жұӮвҖқе’ҢжҺҘ收вҖңе“Қеә”вҖқзҡ„еҪўејҸиҝӣиЎҢгҖӮSOAP еҚҸ议规е®ҡдәҶж•°жҚ®еә”иҜҘеҰӮдҪ•еңЁиҜ·жұӮе’Ңе“Қеә”дёӯиў«ж јејҸеҢ–пјҢд»ҺиҖҢзЎ®дҝқдёҚеҗҢзҡ„зі»з»ҹеҸҜд»ҘзҗҶи§Је’ҢеӨ„зҗҶиҝҷдәӣж•°жҚ®гҖӮ
SOAP зҡ„з»„жҲҗйғЁеҲҶ
SOAP ж¶ҲжҒҜпјҡ
- SOAP ж¶ҲжҒҜйҖҡеёёжҳҜдёҖдёӘ XML ж–ҮжЎЈпјҢдё»иҰҒеҢ…жӢ¬еӣӣйғЁеҲҶпјҡ
- Envelopeпјҡж¶ҲжҒҜзҡ„еӨ–еұӮпјҢе®ҡд№үдәҶж¶ҲжҒҜжҳҜ SOAP ж¶ҲжҒҜгҖӮ
- HeaderпјҡеҸҜйҖүйғЁеҲҶпјҢйҖҡеёёеҢ…еҗ«дёҖдәӣжҺ§еҲ¶дҝЎжҒҜпјҢжҜ”еҰӮиә«д»ҪйӘҢиҜҒгҖҒдјҡиҜқдҝЎжҒҜзӯүгҖӮ
- Bodyпјҡдё»иҰҒеҶ…е®№йғЁеҲҶпјҢеҢ…еҗ«дәҶиҜ·жұӮжҲ–е“Қеә”зҡ„ж•°жҚ®гҖӮ
- FaultпјҡеҸҜйҖүйғЁеҲҶпјҢз”ЁдәҺиЎЁзӨәеҮәй”ҷдҝЎжҒҜпјҢжҜ”еҰӮжңҚеҠЎдёҚеҸҜз”ЁгҖҒжқғйҷҗдёҚи¶ізӯүгҖӮ
WSDLпјҲWeb Services Description LanguageпјүпјҡWSDL жҳҜдёҖз§ҚжҸҸиҝ° SOAP жңҚеҠЎзҡ„ XML ж–Ү件гҖӮе®ғе®ҡд№үдәҶжңҚеҠЎзҡ„жүҖжңүжҺҘеҸЈгҖҒж–№жі•гҖҒеҸӮж•°д»ҘеҸҠиҝ”еӣһеҖјзҡ„ж јејҸпјҢеё®еҠ©е®ўжҲ·з«ҜзҹҘйҒ“еҰӮдҪ•дҪҝз”ЁиҝҷдёӘжңҚеҠЎгҖӮеҸҜд»ҘзҗҶи§ЈдёәжңҚеҠЎзҡ„вҖңиҜҙжҳҺд№ҰвҖқгҖӮ
SOAP дј иҫ“еҚҸи®®пјҡSOAP йҖҡеёёдҪҝз”Ё HTTP жҲ– HTTPS дҪңдёәдј иҫ“еұӮеҚҸи®®пјҢд№ҹеҸҜд»Ҙз”Ёе…¶д»–еҚҸи®®пјҲеҰӮ SMTPпјүгҖӮHTTP жҳҜжңҖеёёи§Ғзҡ„пјҢеӣ дёәе®ғиғҪз©ҝйҖҸеӨ§еӨҡж•°йҳІзҒ«еўҷпјҢе®үе…ЁжҖ§й«ҳгҖӮ
SOAP зҡ„еҠҹиғҪе’Ңзү№зӮ№
- и·Ёе№іеҸ°пјҡSOAP дҪҝз”Ёж ҮеҮҶзҡ„ XML ж јејҸпјҢеҸҜд»ҘеңЁдёҚеҗҢзҡ„ж“ҚдҪңзі»з»ҹгҖҒзј–зЁӢиҜӯиЁҖд№Ӣй—ҙдј иҫ“ж•°жҚ®гҖӮжҜ”еҰӮпјҢдёҖдёӘ Java жңҚеҠЎз«Ҝзҡ„еә”з”ЁеҸҜд»ҘйҖҡиҝҮ SOAP е’Ң C# е®ўжҲ·з«Ҝзҡ„еә”з”ЁиҝӣиЎҢйҖҡдҝЎгҖӮ
- дёҘж јзҡ„ж ҮеҮҶеҢ–пјҡSOAP жңүдёҖеҘ—йқһеёёдёҘж јзҡ„ж ҮеҮҶе’Ңж јејҸгҖӮиҷҪ然иҝҷеҸҜиғҪдјҡеҜјиҮҙ SOAP ж¶ҲжҒҜзҡ„дҪ“з§ҜиҫғеӨ§пјҢдҪҶд№ҹзЎ®дҝқдәҶж•°жҚ®зҡ„еҮҶзЎ®жҖ§е’ҢдёҖиҮҙжҖ§гҖӮ
- е®үе…ЁжҖ§пјҡSOAP еҚҸи®®йҖҡеёёжҗӯй…Қ HTTPS дҪҝз”ЁпјҢж”ҜжҢҒ WS-SecurityпјҢеҸҜд»ҘеңЁ SOAP ж¶ҲжҒҜдёӯж·»еҠ ж•°еӯ—зӯҫеҗҚе’ҢеҠ еҜҶпјҢдҝқиҜҒж•°жҚ®зҡ„е®үе…Ёдј иҫ“гҖӮеӣ жӯӨпјҢSOAP йқһеёёйҖӮз”ЁдәҺ银иЎҢгҖҒйҮ‘иһҚзӯүйңҖиҰҒй«ҳе®үе…ЁжҖ§зҡ„еңәжҷҜгҖӮ
- еҸҜйқ жҖ§пјҡSOAP ж”ҜжҢҒ ACIDпјҲAtomicity, Consistency, Isolation, DurabilityпјүдәӢеҠЎзү№жҖ§пјҢеӣ жӯӨеҸҜд»ҘзЎ®дҝқж•°жҚ®зҡ„дј иҫ“е’Ңж“ҚдҪңзҡ„е®Ңж•ҙжҖ§пјҢйқһеёёйҖӮеҗҲйңҖиҰҒдҝқиҜҒж•°жҚ®еҮҶзЎ®жҖ§зҡ„дёҡеҠЎйҖ»иҫ‘гҖӮ
SOAP зҡ„е·ҘдҪңжөҒзЁӢ
еҒҮи®ҫжҲ‘们жңүдёҖдёӘеӨ©ж°”жҹҘиҜўжңҚеҠЎзҡ„ SOAP жңҚеҠЎпјҢе®ўжҲ·з«ҜеҸҜд»ҘиҜ·жұӮеӨ©ж°”дҝЎжҒҜпјҢжңҚеҠЎз«Ҝдјҡиҝ”еӣһзӣёеә”зҡ„з»“жһңгҖӮ
- е®ҡд№ү WSDLпјҡжңҚеҠЎжҸҗдҫӣж–№дјҡеҸ‘еёғ WSDLпјҢе®ҡд№үдәҶиҜҘжңҚеҠЎзҡ„жҺҘеҸЈгҖҒж–№жі•гҖҒеҸӮж•°зӯүдҝЎжҒҜгҖӮе®ўжҲ·з«ҜеҸҜд»ҘжҹҘзңӢ WSDL дәҶи§ЈжңҚеҠЎзҡ„дҪҝз”Ёж–№ејҸгҖӮ
- жһ„е»ә SOAP иҜ·жұӮпјҡе®ўжҲ·з«Ҝдјҡж №жҚ® WSDL жһ„е»әдёҖдёӘ SOAP иҜ·жұӮж¶ҲжҒҜгҖӮеҒҮи®ҫе®ўжҲ·з«ҜжғіжҹҘиҜўжҹҗдёӘеҹҺеёӮзҡ„еӨ©ж°”пјҢе®ғдјҡеҸ‘йҖҒеҢ…еҗ«еҹҺеёӮдҝЎжҒҜзҡ„ SOAP иҜ·жұӮж¶ҲжҒҜгҖӮ
- еҸ‘йҖҒиҜ·жұӮпјҡе®ўжҲ·з«Ҝе°Ҷ SOAP ж¶ҲжҒҜйҖҡиҝҮ HTTPпјҲжҲ– HTTPSпјүеҸ‘йҖҒз»ҷжңҚеҠЎз«ҜгҖӮ
- жңҚеҠЎз«ҜеӨ„зҗҶиҜ·жұӮпјҡжңҚеҠЎз«ҜжҺҘ收еҲ° SOAP ж¶ҲжҒҜеҗҺпјҢдјҡи§Јжһҗж¶ҲжҒҜеҶ…е®№пјҢжҸҗеҸ–еҮәиҜ·жұӮзҡ„еҹҺеёӮдҝЎжҒҜпјҢ然еҗҺжҹҘиҜўеӨ©ж°”ж•°жҚ®гҖӮ
- жһ„е»әе“Қеә”пјҡжңҚеҠЎз«Ҝе°ҶжҹҘиҜўеҲ°зҡ„еӨ©ж°”дҝЎжҒҜе°ҒиЈ…жҲҗ SOAP е“Қеә”ж¶ҲжҒҜпјҢ然еҗҺиҝ”еӣһз»ҷе®ўжҲ·з«ҜгҖӮ
- е®ўжҲ·з«Ҝи§Јжһҗе“Қеә”пјҡе®ўжҲ·з«ҜжҺҘ收еҲ°жңҚеҠЎз«Ҝзҡ„е“Қеә” SOAP ж¶ҲжҒҜеҗҺпјҢи§Јжһҗж¶ҲжҒҜдҪ“пјҢиҺ·еҸ–еӨ©ж°”дҝЎжҒҜ并жҳҫзӨәз»ҷз”ЁжҲ·гҖӮ
SOAP дёҺ REST зҡ„жҜ”иҫғ
SOAP е’Ң REST жҳҜдёӨз§Қеёёз”Ёзҡ„зҪ‘з»ңжңҚеҠЎеҚҸи®®пјҢе®ғ们зҡ„еҢәеҲ«еңЁдәҺпјҡ
- ж јејҸпјҡSOAP дҪҝз”Ё XMLпјҢж јејҸдёҘж јпјӣREST йҖҡеёёдҪҝз”Ё JSON жҲ– XMLпјҢж јејҸиҫғдёәзҒөжҙ»гҖӮ
- дј иҫ“еҚҸи®®пјҡSOAP еҸҜд»ҘдҪҝз”ЁеӨҡз§Қдј иҫ“еҚҸи®®пјҲеҰӮ HTTPгҖҒSMTPпјүпјҢиҖҢ REST йҖҡеёёеҸӘдҪҝз”Ё HTTPгҖӮ
- е®үе…ЁжҖ§пјҡSOAP жңүиҫғй«ҳзҡ„е®үе…ЁжҖ§пјҢйҖӮеҗҲй«ҳе®үе…ЁжҖ§зҡ„еә”з”ЁеңәжҷҜпјӣREST еңЁе®үе…ЁжҖ§дёҠеҲҷзӣёеҜ№з®ҖеҚ•дёҖдәӣгҖӮ
- жҖ§иғҪпјҡSOAP ж¶ҲжҒҜжҜ”иҫғеәһеӨ§пјҢжҖ§иғҪиҫғж…ўпјӣREST еӣ дёәж¶ҲжҒҜж јејҸзҒөжҙ»пјҢдј иҫ“ж•ҲзҺҮйҖҡеёёжӣҙй«ҳгҖӮ
йҖӮз”ЁеңәжҷҜ
- дјҒдёҡеә”з”ЁпјҡSOAP йҖӮеҗҲйӮЈдәӣйңҖиҰҒеӨҚжқӮдәӢеҠЎз®ЎзҗҶе’Ңй«ҳе®үе…ЁжҖ§зҡ„еә”з”ЁеңәжҷҜпјҢжҜ”еҰӮ银иЎҢгҖҒж”ҝеәңйғЁй—ЁзӯүгҖӮ
- и·Ёе№іеҸ°пјҡеңЁйңҖиҰҒж”ҜжҢҒеӨҡз§Қзј–зЁӢиҜӯиЁҖе’Ңе№іеҸ°зҡ„зҺҜеўғдёӯпјҢSOAP еҸҜд»ҘжҸҗдҫӣз»ҹдёҖзҡ„жҺҘеҸЈе’Ңж ҮеҮҶеҢ–зҡ„йҖҡдҝЎж–№ејҸгҖӮ
- й«ҳе®үе…ЁжҖ§йңҖжұӮпјҡеҰӮйҮ‘иһҚжңҚеҠЎгҖҒж”Ҝд»ҳзҪ‘е…ізӯүйңҖиҰҒеҠ еҜҶе’ҢзӯҫеҗҚзҡ„еңәжҷҜгҖӮ
SOAP жҳҜдёҖз§ҚеҹәдәҺ XML зҡ„зҪ‘з»ңжңҚеҠЎеҚҸи®®пјҢжҸҗдҫӣдәҶи·Ёе№іеҸ°гҖҒй«ҳе®үе…ЁжҖ§е’ҢеҸҜйқ зҡ„йҖҡдҝЎж–№ејҸпјҢзү№еҲ«йҖӮз”ЁдәҺдјҒдёҡзә§еә”з”Ёе’ҢйңҖиҰҒй«ҳж•°жҚ®е®Ңж•ҙжҖ§зҡ„еңәжҷҜгҖӮе°Ҫз®Ўе®ғзҡ„ж¶ҲжҒҜж јејҸжҜ”иҫғеӨҚжқӮпјҢдҪҶж ҮеҮҶеҢ–зҡ„ж јејҸд№ҹи®©е®ғжҲҗдёәдёҖз§ҚзЁіе®ҡе’Ңе®үе…Ёзҡ„зҪ‘з»ңжңҚеҠЎйҖүжӢ©гҖӮ
SOAP зјәзӮ№
- дёҺж¶ҲжҒҜж јејҸиҖҰеҗҲпјҡSOAP ејәеҲ¶дҪҝз”Ёзү№е®ҡзҡ„ XML ж¶ҲжҒҜж јејҸгҖӮз”ұдәҺдёҘж јзҡ„ж јејҸиҰҒжұӮпјҢдёҚеҗҢзі»з»ҹд№Ӣй—ҙзҡ„йҖҡдҝЎйңҖиҰҒеңЁж јејҸдёҠдҝқжҢҒдёҖиҮҙпјҢиҝҷеҜјиҮҙжңҚеҠЎе’Ңе®ўжҲ·з«ҜеңЁж•°жҚ®ж јејҸдёҠжңүеҫҲејәзҡ„иҖҰеҗҲжҖ§гҖӮ
- дёҺзј–з Ғж–№ејҸиҖҰеҗҲпјҡSOAP зҡ„ж¶ҲжҒҜзј–з Ғж–№ејҸд№ҹеҫҲеӣәе®ҡпјҢдёҚеҗҢзі»з»ҹй—ҙеҝ…йЎ»дҪҝз”ЁзӣёеҗҢзҡ„зј–з Ғж–№ејҸгҖӮиҝҷеўһеҠ дәҶеӨҚжқӮжҖ§пјҢд№ҹдҪҝеҫ—жңҚеҠЎеҸҳеҫ—жӣҙеҠ еғөеҢ–е’Ңйҡҫд»ҘйҖӮеә”дёҚеҗҢйңҖжұӮгҖӮ
- и§Јжһҗе’Ңз»„иЈ… SOAP ж¶ҲжҒҜпјҡSOAP ж¶ҲжҒҜжҳҜеҹәдәҺ XML зҡ„пјҢеӣ жӯӨйңҖиҰҒйўқеӨ–зҡ„и§Јжһҗе’Ңз»„иЈ…иҝҮзЁӢгҖӮиҝҷдәӣж“ҚдҪңдјҡж¶ҲиҖ—иө„жәҗпјҢеўһеҠ дәҶзі»з»ҹзҡ„иҙҹжӢ…пјҢзү№еҲ«жҳҜеҪ“ж¶ҲжҒҜеҶ…е®№иҫғеӨ§ж—¶пјҢж•ҲзҺҮй—®йўҳдјҡжӣҙеҠ зӘҒеҮәгҖӮ
- йңҖиҰҒ WSDL жқҘжҸҸиҝ°жңҚеҠЎз»ҶиҠӮпјҡWSDLпјҲWeb Services Description LanguageпјүжҳҜз”ЁжқҘжҸҸиҝ° SOAP жңҚеҠЎзҡ„жҺҘеҸЈгҖҒж–№жі•гҖҒеҸӮж•°зӯүдҝЎжҒҜзҡ„ XML ж–Ү件гҖӮдҪҝз”Ё SOAP жңҚеҠЎзҡ„е®ўжҲ·з«ҜйңҖиҰҒйҖҡиҝҮ WSDL жқҘдәҶи§ЈжңҚеҠЎзҡ„иҜҰз»ҶдҝЎжҒҜпјҢиҝҷдҪҝеҫ—ж•ҙдёӘжөҒзЁӢжӣҙдёәеӨҚжқӮе’Ңдҫқиө–ж–ҮжЎЈгҖӮ
- йңҖиҰҒз”ҹжҲҗд»ЈзҗҶпјҡеңЁеҹәдәҺ SOAP зҡ„зҪ‘з»ңжңҚеҠЎдёӯпјҢе®ўжҲ·з«ҜйҖҡеёёйңҖиҰҒз”ҹжҲҗд»ЈзҗҶпјҲProxyпјүжқҘдёҺжңҚеҠЎз«ҜдәӨдә’гҖӮд»ЈзҗҶжҳҜеҹәдәҺ WSDL иҮӘеҠЁз”ҹжҲҗзҡ„д»Јз ҒпјҢиҝҷдёҖиҝҮзЁӢж—ўеўһеҠ дәҶзі»з»ҹејҖеҸ‘зҡ„еӨҚжқӮжҖ§пјҢеҸҲеўһеҠ дәҶз»ҙжҠӨжҲҗжң¬гҖӮ
з”ұдәҺдёҠиҝ°иҝҷдәӣиҖҰеҗҲжҖ§е’ҢеӨҚжқӮжҖ§пјҢдҪҝз”Ё SOAP е®һзҺ°зҪ‘з»ңжңҚеҠЎдјҡиҖ—иҙ№иҫғеӨҡзҡ„ж—¶й—ҙе’ҢзІҫеҠӣпјҢеӣ жӯӨе»әи®®иҖғиҷ‘еҜ»жүҫж–°зҡ„ж–№ејҸжқҘе®һзҺ°зҪ‘з»ңжңҚеҠЎгҖӮиҝҷд№ҹжҳҜдёәд»Җд№Ҳиҝ‘е№ҙжқҘ RESTпјҲRepresentational State TransferпјүзӯүжӣҙиҪ»йҮҸзә§зҡ„зҪ‘з»ңжңҚеҠЎж–№ејҸйҖҗжёҗжөҒиЎҢзҡ„еҺҹеӣ пјҢREST жӣҙзҒөжҙ»гҖҒж јејҸжӣҙиҮӘз”ұпјҢ并且жӣҙе®№жҳ“зҗҶи§Је’Ңе®һзҺ°гҖӮеӣ жӯӨжҲ‘们йңҖиҰҒж•°жҚ®й©ұеҠЁеһӢзҡ„ж–№ејҸжқҘпјҢRestful Web Serviceеә”иҝҗиҖҢз”ҹгҖӮ
RESTпјҲRepresentational State Transferпјү
REST жҳҜдёҖз§ҚиҪ»йҮҸзә§зҡ„жһ¶жһ„йЈҺж јпјҢз”ЁдәҺи®ҫи®ЎзҪ‘з»ңжңҚеҠЎгҖӮе®ғеҹәдәҺ HTTP еҚҸи®®пјҢйҖҡиҝҮ URI и®ҝй—®иө„жәҗпјҢдҪҝз”Ёз»ҹдёҖзҡ„жҺҘеҸЈе®һзҺ°ж•°жҚ®зҡ„дј иҫ“е’Ңж“ҚдҪңгҖӮзӣёжҜ”дәҺ SOAPпјҢREST жӣҙеҠ зҒөжҙ»гҖҒй«ҳж•ҲпјҢжҳҜзҺ°д»Ј Web ејҖеҸ‘е’Ңеҫ®жңҚеҠЎжһ¶жһ„зҡ„йҰ–йҖүгҖӮ
- RepresentationalпјҲиЎЁиҝ°пјүпјҡжүҖжңүж•°жҚ®йғҪжҳҜиө„жәҗпјҢжҜҸдёӘиө„жәҗйғҪжңүе…¶дёҚеҗҢзҡ„иЎЁиҝ°гҖӮиө„жәҗеҸҜд»ҘжңүеӨҡз§ҚиЎЁзӨәж–№ејҸпјҢдҫӢеҰӮ JSONгҖҒXML зӯүгҖӮжҜҸдёӘиө„жәҗйғҪжңүдёҖдёӘе”ҜдёҖзҡ„ URI жқҘж ҮиҜҶпјҢйҖҡиҝҮ URIпјҢе®ўжҲ·з«ҜеҸҜд»Ҙи®ҝ问并ж“ҚдҪңиө„жәҗгҖӮ
- StateпјҲзҠ¶жҖҒпјүпјҡжҢҮе®ўжҲ·з«Ҝзҡ„зҠ¶жҖҒпјҢжңҚеҠЎеҷЁжҳҜж— зҠ¶жҖҒзҡ„гҖӮиө„жәҗзҡ„иЎЁиҝ°пјҲRepresentationпјүжҳҜе®ўжҲ·з«Ҝзҡ„зҠ¶жҖҒзҡ„дёҖйғЁеҲҶгҖӮжҜҸж¬ЎиҜ·жұӮеҗҺпјҢе®ўжҲ·з«ҜжҺҘ收еҲ°иө„жәҗзҡ„иЎЁиҝ°е№¶жӣҙж–°иҮӘиә«зҠ¶жҖҒпјҢиҖҢжңҚеҠЎеҷЁж— йңҖдҝқеӯҳиҜ·жұӮд№Ӣй—ҙзҡ„зҠ¶жҖҒгҖӮ
- TransferпјҲдј иҫ“пјүпјҡе®ўжҲ·з«ҜйҖҡиҝҮиҜ·жұӮ URI иҺ·еҸ–иө„жәҗзҡ„иЎЁиҝ°е№¶жӣҙж–°иҮӘиә«зҠ¶жҖҒгҖӮжҜҸеҪ“е®ўжҲ·з«ҜиҜ·жұӮдёҚеҗҢзҡ„иө„жәҗж—¶пјҢзҠ¶жҖҒдҝЎжҒҜйҖҡиҝҮиө„жәҗзҡ„иЎЁиҝ°иў«дј иҫ“еҲ°е®ўжҲ·з«ҜпјҢиҝҷе°ұжҳҜвҖңиЎЁиҝ°жҖ§зҠ¶жҖҒиҪ¬з§»вҖқгҖӮ
REST зҡ„ж ёеҝғжҰӮеҝө
- ж— зҠ¶жҖҒжҖ§пјҲStatelessпјүREST жҳҜж— зҠ¶жҖҒзҡ„пјҢжңҚеҠЎеҷЁдёҚдҝқеӯҳе®ўжҲ·з«Ҝзҡ„зҠ¶жҖҒгҖӮжҜҸдёӘиҜ·жұӮйғҪжҳҜзӢ¬з«Ӣзҡ„пјҢе®ўжҲ·з«Ҝеҝ…йЎ»еңЁиҜ·жұӮдёӯеҢ…еҗ«жүҖжңүеҝ…иҰҒзҡ„дҝЎжҒҜгҖӮж— зҠ¶жҖҒзҡ„и®ҫи®Ўи®©зі»з»ҹжӣҙжҳ“дәҺжү©еұ•е’Ңз»ҙжҠӨгҖӮ
- иө„жәҗеҜјеҗ‘пјҲResource-OrientedпјүеңЁ REST дёӯпјҢжҜҸдёӘ URL йғҪиЎЁзӨәдёҖдёӘиө„жәҗпјҢеҰӮз”ЁжҲ·гҖҒи®ўеҚ•гҖҒе•Ҷе“ҒзӯүгҖӮжҜҸдёӘиө„жәҗжңүдёҖдёӘе”ҜдёҖзҡ„ URIпјҲUniform Resource IdentifierпјүпјҢдҫӢеҰӮ
/users/123иЎЁзӨә ID дёә 123 зҡ„з”ЁжҲ·гҖӮ - ж ҮеҮҶзҡ„ HTTP ж–№жі•пјҡREST дҪҝз”Ё HTTP ж–№жі•жқҘе®ҡд№үж“ҚдҪңзұ»еһӢпјҢдё»иҰҒеҢ…жӢ¬пјҡ
- GETпјҡиҺ·еҸ–иө„жәҗ READ
- POSTпјҡеҲӣе»әиө„жәҗ CREATE
- PUTпјҡжӣҙж–°иө„жәҗ UPDATE
- DELETEпјҡеҲ йҷӨиө„жәҗ DELETE
- ж•°жҚ®ж јејҸзҒөжҙ»
- REST еҸҜд»ҘдҪҝз”ЁеӨҡз§Қж•°жҚ®ж јејҸпјҢжңҖеёёи§Ғзҡ„жҳҜ JSON е’Ң XMLпјҢдҪҶ JSON жӣҙиҪ»йҮҸпјҢдҫҝдәҺи§ЈжһҗпјҢеёёз”ЁдәҺеүҚеҗҺз«ҜдәӨдә’гҖӮ
- з»ҹдёҖжҺҘеҸЈпјҲUniform Interfaceпјү
- REST дҪҝз”Ёж ҮеҮҶеҢ–зҡ„жҺҘеҸЈпјҢжүҖжңүиө„жәҗи®ҝй—®е’Ңж“ҚдҪңйғҪйҖҡиҝҮж ҮеҮҶ HTTP ж–№жі•иҝӣиЎҢпјҢйҷҚдҪҺдәҶзі»з»ҹеӨҚжқӮжҖ§гҖӮ
REST зҡ„еҠҹиғҪе’Ңзү№зӮ№
- иҪ»йҮҸзә§е’Ңз®ҖеҚ•REST зҡ„ж¶ҲжҒҜж јејҸз®ҖеҚ•пјҢйҖҡеёёдёҚйңҖиҰҒеӨҚжқӮзҡ„ XML и§ЈжһҗпјҢдј иҫ“йҖҹеәҰжӣҙеҝ«пјҢиө„жәҗж¶ҲиҖ—жӣҙе°‘гҖӮ
- зҒөжҙ»жҖ§REST ж”ҜжҢҒеӨҡз§Қж•°жҚ®ж јејҸпјҢе…Ғи®ёж №жҚ®йңҖжұӮйҖүжӢ©жңҖеҗҲйҖӮзҡ„ж јејҸпјҲJSONгҖҒXMLгҖҒзәҜж–Үжң¬зӯүпјүгҖӮ
- жү©еұ•жҖ§REST жІЎжңүдёҘж јзҡ„ж ҮеҮҶе’ҢиҖҰеҗҲпјҢжңҚеҠЎз«Ҝе’Ңе®ўжҲ·з«ҜеҸҜд»ҘзӢ¬з«Ӣжј”еҢ–гҖӮж–°еҠҹиғҪеҸҜд»ҘйҡҸж—¶еўһеҠ пјҢдёҚеҪұе“ҚзҺ°жңүжҺҘеҸЈгҖӮ
- жөҸи§ҲеҷЁеҸӢеҘҪREST еҲ©з”Ё HTTP еҚҸи®®пјҢйҖӮеҗҲеңЁжөҸи§ҲеҷЁзҺҜеўғдёӯдҪҝз”ЁпјҢе°Өе…¶йҖӮз”ЁдәҺеүҚеҗҺз«ҜеҲҶзҰ»зҡ„еҚ•йЎөеә”з”ЁпјҲSPAпјүгҖӮ
RESTFulйЈҺж јзӨәдҫӢ
RESTfulйЈҺж јзҡ„WebжңҚеҠЎжҳҜдёҖз§ҚеҹәдәҺRESTпјҲRepresentational State TransferпјҢиЎЁзҺ°еұӮзҠ¶жҖҒиҪ¬з§»пјүжһ¶жһ„и®ҫи®Ўзҡ„WebжңҚеҠЎпјҢе®ғйҖҡиҝҮж ҮеҮҶзҡ„HTTPж–№жі•пјҲGETгҖҒPOSTгҖҒPUTгҖҒDELETEзӯүпјүжҸҗдҫӣWebиө„жәҗзҡ„ж“ҚдҪңжҺҘеҸЈпјҢеҲ©з”Ёз»ҹдёҖиө„жәҗж ҮиҜҶз¬ҰпјҲURIпјүиҝӣиЎҢиө„жәҗзҡ„е®ҡдҪҚгҖӮйҖҡиҝҮHttpзҡ„иҝ”еӣһз ҒиЎЁзӨәиҝ”еӣһзҡ„з»“жһңпјҢжҜ”еҰӮ201жҲҗеҠҹпјҢ404д»ЈиЎЁдёҚеӯҳеңЁпјҢ500д»ЈиЎЁжңҚеҠЎеҷЁеҶ…йғЁзҡ„й”ҷ иҜҜгҖӮRESTfulжңҚеҠЎд»ҘиҪ»йҮҸгҖҒж— зҠ¶жҖҒгҖҒз®ҖеҚ•дё”з¬ҰеҗҲHTTPеҚҸи®®дёәзү№зӮ№пјҢеңЁдә’иҒ”зҪ‘е’ҢзҺ°д»Јеә”з”ЁзЁӢеәҸзҡ„ејҖеҸ‘дёӯиў«е№ҝжіӣеә”з”ЁгҖӮ
еҒҮи®ҫжҲ‘们иҰҒи®ҫи®ЎдёҖдёӘRESTfulйЈҺж јзҡ„WebжңҚеҠЎжқҘз®ЎзҗҶвҖңд№ҰзұҚвҖқиө„жәҗпјҢиө„жәҗи·Ҝеҫ„пјҡ/books
| иҜ·жұӮж–№жі• | URI | ж“ҚдҪң |
|---|---|---|
| GET | /books | иҺ·еҸ–жүҖжңүд№ҰзұҚ |
| GET | /books/{id} | иҺ·еҸ–жҹҗдёҖжң¬д№ҰзұҚпјҲйҖҡиҝҮIDпјү |
| POST | /books | ж·»еҠ дёҖжң¬ж–°д№Ұ |
| PUT | /books/{id} | жӣҙж–°жҹҗдёҖжң¬д№ҰзұҚзҡ„дҝЎжҒҜ |
| DELETE | /books/{id} | еҲ йҷӨжҹҗдёҖжң¬д№ҰзұҚ |
REST дёҺ SOAP зҡ„еҜ№жҜ”
| зү№зӮ№ | REST | SOAP |
|---|---|---|
| ж¶ҲжҒҜж јејҸ | JSONпјҲеёёз”ЁпјүгҖҒXMLгҖҒзәҜж–Үжң¬зӯү | XML |
| еҚҸи®®дҫқиө– | еҹәдәҺ HTTPпјҢиҪ»йҮҸзә§ | еҹәдәҺ XMLпјҢеҚҸи®®еӨҚжқӮ |
| жҖ§иғҪ | й«ҳж•ҲпјҢж¶ҲжҒҜдҪ“з§Ҝе°Ҹ | ж¶ҲжҒҜеӨ§пјҢдј иҫ“йҖҹеәҰж…ў |
| зҒөжҙ»жҖ§ | зҒөжҙ»пјҢеҸҜд»ҘйҖӮеә”еӨҡз§ҚеңәжҷҜ | дёҘж јпјҢж јејҸе’ҢеҚҸи®®дёҚзҒөжҙ» |
| е®үе…ЁжҖ§ | HTTP иҮӘеёҰзҡ„ HTTPS еҠ еҜҶ | ж”ҜжҢҒ WS-SecurityпјҢй«ҳе®үе…ЁжҖ§ |
| йҖӮз”ЁеңәжҷҜ | 移еҠЁеә”з”ЁгҖҒWeb еә”з”ЁгҖҒеҫ®жңҚеҠЎзӯү | 银иЎҢгҖҒйҮ‘иһҚгҖҒдјҒдёҡзә§еә”з”Ё |
REST зҡ„йҖӮз”ЁеңәжҷҜ
- 移еҠЁеә”з”Ёе’Ң Web еә”з”ЁпјҡREST жҳҜиҪ»йҮҸзә§зҡ„пјҢйқһеёёйҖӮеҗҲйңҖиҰҒе®һж—¶ж•°жҚ®дәӨдә’зҡ„移еҠЁеә”з”Ёе’Ң Web еә”з”ЁгҖӮ
- еҫ®жңҚеҠЎжһ¶жһ„пјҡеҫ®жңҚеҠЎжһ¶жһ„дёӯеӨҡдёӘзӢ¬з«ӢжңҚеҠЎй—ҙйңҖиҰҒйў‘з№ҒдәӨдә’пјҢREST зҡ„зҒөжҙ»жҖ§е’ҢдҪҺиҖҰеҗҲйқһеёёйҖӮеҗҲгҖӮ
- е…¬е…ұ APIпјҡREST API еёёз”ЁдәҺе…¬ејҖзҡ„ж•°жҚ®жңҚеҠЎпјҢеҰӮеӨ©ж°”гҖҒең°еӣҫгҖҒзӨҫдәӨеӘ’дҪ“пјҢйҖӮеҗҲеӨ„зҗҶеӨ§йҮҸиҜ·жұӮгҖӮ
- зү©иҒ”зҪ‘пјҲIoTпјүпјҡREST зҡ„иҪ»йҮҸе’ҢзҒөжҙ»жҖ§дҪҝе…¶йҖӮеҗҲ IoT и®ҫеӨҮй—ҙзҡ„ж•°жҚ®дәӨжҚўгҖӮ
Restful Web Serviceзү№зӮ№пјҡ1. е…ёеһӢзҡ„е®ўжҲ·з«ҜгҖҒжңҚеҠЎз«Ҝжһ¶жһ„пјҢдҪҶжҳҜжҳҜж— зҠ¶жҖҒзҡ„гҖӮ2. е®ўжҲ·з«Ҝе’ҢжңҚеҠЎз«Ҝд№Ӣй—ҙдј йҖ’зҡ„йғҪжҳҜж•°жҚ®пјҲж•°жҚ®пјҒзәҜзҡ„пјҒпјү3. жңҚеҠЎз«ҜеҸӘеӨ„зҗҶж•°жҚ®пјҢж•°жҚ®зҡ„еұ•зӨәе®Ңе…Ёдҫқиө–дәҺе®ўжҲ·з«Ҝ
жҖ»з»“
REST жҳҜдёҖз§ҚеҹәдәҺ HTTP зҡ„ж— зҠ¶жҖҒжһ¶жһ„пјҢйҖҡиҝҮдј иҫ“иө„жәҗзҡ„дёҚеҗҢиЎЁиҝ°жқҘеё®еҠ©е®ўжҲ·з«ҜдҝқжҢҒзҠ¶жҖҒгҖӮе…¶зҒөжҙ»жҖ§гҖҒеҸҜжү©еұ•жҖ§е’Ңз®ҖеҚ•жҖ§дҪҝеҫ— REST жҲҗдёәзҺ°д»Ј Web ејҖеҸ‘гҖҒеҫ®жңҚеҠЎе’Ң移еҠЁеә”з”ЁејҖеҸ‘зҡ„йҰ–йҖүж–№жі•гҖӮ
WS зҡ„дјҳзјәзӮ№пјҲTrade-off of WSпјү
WS : web Service
дјҳзӮ№пјҲAdvantagesпјүпјҡ
- и·Ёе№іеҸ°пјҲAcross platformsпјүпјҡ
- еҹәдәҺ XMLпјҢдёҺдҫӣеә”е•Ҷж— е…іпјҲXML-based, independent of vendorsпјүгҖӮ
- иЎЁзӨә WS дёҚеҸ—зү№е®ҡе№іеҸ°жҲ–дҫӣеә”е•Ҷзҡ„йҷҗеҲ¶пјҢеӣ е…¶еҹәдәҺ XML ж јејҸпјҢеҸҜд»ҘеңЁдёҚеҗҢе№іеҸ°д№Ӣй—ҙдә’йҖҡгҖӮ
- иҮӘжҸҸиҝ°пјҲSelf-describedпјүпјҡ
- йҖҡиҝҮ WSDLпјҲWeb Services Description LanguageпјүжҸҸиҝ°ж“ҚдҪңгҖҒеҸӮж•°гҖҒзұ»еһӢе’Ңиҝ”еӣһеҖјгҖӮ
- WSDL жҳҜдёҖз§Қж ҮеҮҶеҢ–зҡ„ XML ж јејҸпјҢз”ЁдәҺжҸҸиҝ° Web жңҚеҠЎзҡ„жҺҘеҸЈпјҢеӣ жӯӨе®ўжҲ·з«ҜеҸҜд»ҘйҖҡиҝҮе®ғзҗҶи§ЈжңҚеҠЎзҡ„еҠҹиғҪе’ҢеҰӮдҪ•и°ғз”ЁгҖӮ
- Restfulе°ұжҳҜе®Ңе…ЁеҹәдәҺURL
- жЁЎеқ—еҢ–пјҲModulizationпјүпјҡ
- е°Ғ装组件пјҲEncapsulate componentsпјүгҖӮ
- Web жңҚеҠЎе…Ғи®ёе°ҶеҠҹиғҪеҲҶеүІжҲҗзӢ¬з«ӢжЁЎеқ—пјҢдҪҝдёҚеҗҢзҡ„组件еҸҜд»ҘзӢ¬з«ӢејҖеҸ‘гҖҒжөӢиҜ•е’Ңз»ҙжҠӨгҖӮ
- и·ЁйҳІзҒ«еўҷпјҲAcross Firewallпјүпјҡ
- дҪҝз”Ё HTTP еҚҸи®®гҖӮеӣ дёәеӨ§еӨҡж•°йҳІзҒ«еўҷе…Ғи®ё HTTP йҖҡдҝЎпјҢжүҖд»Ҙ Web жңҚеҠЎеҸҜд»ҘеҫҲе®№жҳ“ең°з©ҝйҖҸйҳІзҒ«еўҷиҝӣиЎҢж•°жҚ®дәӨжҚўгҖӮ
зјәзӮ№пјҲDisadvantagesпјүпјҡ
- иҫғдҪҺзҡ„з”ҹдә§еҠӣпјҲLower productivityпјүпјҡ
- дёҚйҖӮеҗҲзӢ¬з«Ӣеә”з”ЁпјҲNot suitable for stand-alone applicationsпјүгҖӮ
- иЎЁжҳҺ Web жңҚеҠЎеҸҜиғҪдёҚйҖӮеҗҲеҚ•жңәеә”з”ЁзЁӢеәҸзҡ„еңәжҷҜпјҢеӣ дёәе…¶и®ҫи®ЎжҳҜдёәдәҶи·Ёе№іеҸ°гҖҒеҲҶеёғејҸзҡ„жңҚеҠЎи°ғз”ЁпјҢиҖҢдёҚжҳҜжң¬ең°еә”з”Ёзҡ„ж•ҲзҺҮгҖӮ
- иҫғдҪҺзҡ„жҖ§иғҪпјҲLower performanceпјүпјҡ
- и§Јжһҗе’Ңз»„иЈ…пјҲParse and assemblyпјүпјҢйңҖиҰҒжҠҠjavaеҜ№иұЎиҪ¬еҢ–дёәдёҖдёӘзәҜж–Үжң¬зҡ„пјҢжҲ–иҖ…и§Јжһҗж–Үжң¬дҪңдёәдёҖдёӘjavaеҜ№иұЎгҖӮ
- з”ұдәҺ Web жңҚеҠЎеҹәдәҺ XML ж јејҸзҡ„ж•°жҚ®дәӨжҚўпјҢи§Јжһҗе’Ңз»„иЈ…ж•°жҚ®зҡ„иҝҮзЁӢзӣёеҜ№еӨҚжқӮпјҢеҸҜиғҪеҜјиҮҙжҖ§иғҪйҷҚдҪҺгҖӮ
- е®үе…ЁжҖ§пјҲSecurityпјүпјҡ
- дҫқиө–е…¶д»–жңәеҲ¶пјҢдҫӢеҰӮ HTTP е’Ң SSLпјҲDepend on other mechanism, such as HTTP+SSLпјүгҖӮ
- Web жңҚеҠЎиҮӘиә«жІЎжңүеҶ…е»әе®үе…ЁжңәеҲ¶пјҢйҖҡеёёйңҖиҰҒдҫқиө–е…¶д»–еҚҸи®®пјҲеҰӮ SSL/TLSпјүжқҘдҝқиҜҒж•°жҚ®дј иҫ“зҡ„е®үе…ЁжҖ§пјҢеӣ дёәwebServiceзҡ„ең°еҹҹжҖ§е№ҝпјҢе°ұжҜ”иҫғе®№жҳ“еҸ—еҲ°ж”»еҮ»пјҢжҲ–иҖ…дёӯй—ҙдәәжҲӘиҺ·дәҶгҖӮ
дҪҝз”ЁеңәжҷҜпјҡж”ҜжҢҒи·ЁйҳІзҒ«еўҷзҡ„йҖҡи®ҜгҖҒж”ҜжҢҒи·ЁйҳІзҒ«еўҷзҡ„йҖҡдҝЎгҖҒж”ҜжҢҒеә”з”ЁйӣҶжҲҗгҖҒж”ҜжҢҒB2BйӣҶжҲҗгҖҒйј“еҠұйҮҚз”ЁиҪҜ件пјӣ дёҚеә”иҜҘдҪҝз”ЁWSж—¶пјҡзӢ¬з«Ӣеә”з”ЁзЁӢеәҸгҖҒеҰӮMS OfficeпјҲи®ҝй—®иҢғеӣҙе°ҸпјүгҖҒеұҖеҹҹзҪ‘дёӯзҡ„еҗҢжһ„еә”з”ЁпјҲйғҪжҳҜjavaжҺҘ еҸЈпјҢзӣҙжҺҘдёҠjavaе°ұе®ҢдәӢдәҶпјүпјҡдҫӢеҰӮCOM+жҲ–EJBд№Ӣй—ҙзҡ„йҖҡдҝЎпјҲеҶҚжҜ”еҰӮspringи®ҝй—®mysqlгҖҒredisгҖҒkafkaгҖҒ elasticSearchпјү
SOAпјҡйқўеҗ‘жңҚеҠЎзҡ„жһ¶жһ„
SOAжҢҮзҡ„жҳҜService-oriented architecture пјҲйқўеҗ‘жңҚеҠЎзҡ„жһ¶жһ„пјүгҖӮжҲ‘们关注зҡ„й—®йўҳжҳҜпјҡжҲ‘们еңЁзі»з»ҹејҖеҸ‘зҡ„иҝҮзЁӢдёӯпјҢејӮжһ„жҖ§е’ҢйңҖжұӮзҡ„еҸҳеҢ–жҳҜжҲ‘们永иҝңйғҪдјҡйҒҮеҲ°зҡ„пјҢйӮЈд№ҲжҲ‘们еҰӮдҪ•и®©иҮӘе·ұзҡ„зі»з»ҹеҺ»еҝ«йҖҹе“Қеә”иҝҷдәӣй—®йўҳе‘ўпјҹе°ұжҳҜзҪ‘дёҠеҺ»жүҫеҲ«дәәеҶҷеҘҪзҡ„дёңиҘҝпјҢеҰӮжһңеҲ«дәәеҶҷзҡ„йғҪжҳҜе’ҢиҜӯиЁҖж— е…ізҡ„жңҚеҠЎпјҢжҲ‘们е°ұзӣҙжҺҘжӢҝжқҘйӣҶжҲҗпјҒ
еҒҮеҰӮжҲ‘иҰҒжһ„е»әдёҖдёӘз”өеӯҗд№Ұеә—гҖҒйҮҢйқўеҢ…жӢ¬дәҶи®ӨиҜҒзҷ»еҪ•зі»з»ҹгҖҒиҙўеҠЎзі»з»ҹгҖҒз»ҹи®Ўзі»з»ҹгҖҒи®ўеҚ•зі»з»ҹпјҢиҝҷд№ҲеӨҡзі»з»ҹејҖеҸ‘дёӢжқҘеҫҲеӨҚжқӮпјҢиҖҢдё”еҒҮеҰӮжҲ‘жҳҜеҚ–家пјҢеҚ–з»ҷдәҶ1000дёӘж–°еҚҺд№Ұеә—зҡ„з”ЁжҲ·пјҢ然еҗҺзӘҒ然еҸ‘зҺ°жҹҗдёӘзі»з»ҹеӯҳеңЁжјҸжҙһпјҢе°ұиҰҒе‘ҠиҜүдёҖеҚғдёӘз”ЁжҲ·пјҢиҝҷеҫҲйә»зғҰгҖӮ
жүҖд»Ҙе°ұжңүдёҖдёӘж–°ж–№жі•гҖҒзҷ»еҪ•зі»з»ҹ用第дёүж–№зҡ„жҜ”еҰӮзҷҫеәҰзҡ„пјҢи®ўеҚ•зі»з»ҹ用第дёүж–№зҡ„пјҢ然еҗҺжҲ‘иҮӘе·ұе°ұеҸӘеҒҡдёҖдёӘ йӣҶжҲҗгҖӮеҰӮжһңеҸ‘зҺ°зҷ»еҪ•зі»з»ҹжңүbugпјҢе°ұе‘ҠиҜүзҷҫеәҰзҡ„й—®йўҳпјҢзҷҫеәҰеҸӘиҰҒжӣҙж–°иҮӘе·ұзҡ„е°ұеҸҜд»ҘдәҶпјҢжҲ‘们дёҚз”ЁжҠҠжӣҙж–° еҢ…еҲҶеҸ‘з»ҷ1000дёӘз”ЁжҲ·пјҢеӣ дёәе®ғ们йғҪжҳҜзӣҙжҺҘи°ғз”ЁзҷҫеәҰзҡ„жңҚеҠЎпјҲжҜ”еҰӮдҪ и°ғзҷҫеәҰең°еӣҫпјҢдҪ еҪ“然дёҚжҳҜжҠҠзҷҫеәҰзҡ„еүҜ жң¬ж”ҫеҲ°жң¬ең°иҝҗиЎҢпјҢиҖҢжҳҜи°ғз”Ёдәә家зҡ„apiпјүгҖӮиҝҷж ·е°ұеҸҜд»Ҙеҝ«йҖҹжһ„е»әдёҖдёӘеә”з”ЁпјҢиҠӮзәҰејҖеҸ‘жҲҗжң¬гҖӮ
зү№зӮ№пјҡ
- жңҚеҠЎд№Ӣй—ҙжқҫж•ЈиҖҰеҗҲпјҢд№ҹе°ұжҳҜжҳҜзҷ»еҪ•зі»з»ҹгҖҒиҙўеҠЎзі»з»ҹгҖҒз»ҹи®Ўзі»з»ҹгҖҒи®ўеҚ•зі»з»ҹиҝҷдәӣзі»з»ҹйҖҡиҝҮжҲ‘ејҖеҸ‘зҡ„дёӯ й—ҙ件иҒ”зі»пјҢиҖҢдёҚжҳҜproducer&consumerд№Ӣй—ҙзӣҙжҺҘдә’зӣёйҖҡдҝЎпјҢиҝҷж ·зҡ„еҘҪеӨ„е°ұжҳҜеҒҮеҰӮжҲ‘еҸ‘зҺ°зҷ»еҪ•зі»з»ҹдёҚ еҘҪжҲ–иҖ…еӨӘиҙөдәҶпјҢжҲ‘еҸҜд»ҘжҚўдёҖдёӢпјҢжҚўд№ӢеҗҺеҲ«зҡ„зі»з»ҹд№ҹдёҚдјҡеҸ—еҲ°еҪұе“ҚпјҲеҪ“然жқҫиҖҰеҗҲзҡ„д»Јд»·е°ұжҳҜжҖ§иғҪдјҡе·® дёҖзӮ№пјү
- дҪҚзҪ®йҖҸжҳҺпјҢдёӯд»ӢиҖ…иҙҹиҙЈи·Ҝз”ұ
- еҚҸи®®зӢ¬з«ӢпјҢд»ҺhttpеҲҮжҚўеҲ°ftpпјҢдҪҶжҳҜдёҚиҰҒи®©е®ўжҲ·з«ҜжқҘе®һзҺ°
第еҚҒз«
Micorservice
еҫ®жңҚеҠЎпјҲMicroservicesпјүжҳҜдёҖз§Қжһ¶жһ„йЈҺж јпјҢе®ғе°Ҷеә”з”ЁзЁӢеәҸеҲҶи§ЈдёәдёҖзі»еҲ—е°Ҹзҡ„гҖҒзӢ¬з«Ӣзҡ„жңҚеҠЎпјҢжҜҸдёӘжңҚеҠЎйғҪжңүе…¶зү№е®ҡзҡ„дёҡеҠЎеҠҹиғҪе’Ңзӣ®ж ҮгҖӮиҝҷдәӣжңҚеҠЎзӣёеҜ№зӢ¬з«ӢпјҢеҸҜд»Ҙеҗ„иҮӘејҖеҸ‘гҖҒйғЁзҪІгҖҒжү©еұ•е’Ңз»ҙжҠӨгҖӮиҝҷз§Қжһ¶жһ„зҡ„ж ёеҝғзү№зӮ№еңЁдәҺеә”з”ЁзЁӢеәҸд»Јз Ғд»ҘзӢ¬з«Ӣзҡ„е°Ҹеқ—еҪўејҸдәӨд»ҳпјҢжҜҸдёӘеқ—йғҪеҸҜд»ҘеҚ•зӢ¬ејҖеҸ‘е’Ңз»ҙжҠӨпјҢдёҚдҫқиө–дәҺе…¶д»–йғЁеҲҶгҖӮиҝҷдёҺдј з»ҹзҡ„еҚ•дҪ“жһ¶жһ„еҪўжҲҗдәҶйІңжҳҺзҡ„еҜ№жҜ”пјҢеҗҺиҖ…жҳҜе°Ҷеә”з”ЁзЁӢеәҸзҡ„жүҖжңүйғЁеҲҶзҙ§еҜҶиҖҰеҗҲеңЁдёҖиө·гҖӮ
еҫ®жңҚеҠЎжһ¶жһ„зҡ„е…ій”®иҰҒзӮ№
- зӢ¬з«ӢйғЁзҪІпјҡжҜҸдёӘеҫ®жңҚеҠЎйғҪжҳҜдёҖдёӘзӢ¬з«Ӣзҡ„еә”з”ЁзЁӢеәҸжЁЎеқ—пјҢеҸҜд»ҘеҚ•зӢ¬иҝӣиЎҢйғЁзҪІе’Ңжү©еұ•пјҢиҖҢдёҚдјҡеҪұе“ҚеҲ°е…¶д»–жңҚеҠЎгҖӮиҝҷдҪҝеҫ—еӣўйҳҹеҸҜд»ҘеңЁдёҚе№Іжү°ж•ҙдҪ“зі»з»ҹзҡ„жғ…еҶөдёӢиҝӣиЎҢеҝ«йҖҹиҝӯд»ЈгҖӮ
- жқҫиҖҰеҗҲпјҡеҫ®жңҚеҠЎд№Ӣй—ҙйҖҡиҝҮAPIжҲ–ж¶ҲжҒҜдј йҖ’зі»з»ҹиҝӣиЎҢйҖҡдҝЎпјҢдҝқиҜҒдәҶжңҚеҠЎд№Ӣй—ҙзҡ„дҪҺиҖҰеҗҲжҖ§гҖӮиҝҷж ·пјҢеҚідҫҝдёҖдёӘеҫ®жңҚеҠЎеҮәзҺ°ж•…йҡңпјҢд№ҹдёҚдјҡеҪұе“ҚеҲ°е…¶д»–жңҚеҠЎзҡ„иҝҗиЎҢпјҢжҸҗй«ҳдәҶзі»з»ҹзҡ„е®№й”ҷжҖ§гҖӮ
- дёҡеҠЎзӢ¬з«ӢжҖ§пјҡжҜҸдёӘеҫ®жңҚеҠЎиҙҹиҙЈдёҖдёӘзү№е®ҡзҡ„дёҡеҠЎеҠҹиғҪпјҢеҸҜд»Ҙз”ұдёҚеҗҢзҡ„еӣўйҳҹиҝӣиЎҢејҖеҸ‘е’Ңз®ЎзҗҶгҖӮиҝҷдёҚд»…жҸҗй«ҳдәҶејҖеҸ‘ж•ҲзҺҮпјҢиҝҳи®©еӣўйҳҹеҸҜд»Ҙжӣҙеҝ«йҖҹең°е“Қеә”дёҡеҠЎйңҖжұӮзҡ„еҸҳеҢ–пјҢе®һзҺ°жӣҙеҘҪзҡ„дёҡеҠЎдёҺжҠҖжңҜзҡ„еҜ№йҪҗгҖӮ
- жҠҖжңҜеӨҡж ·жҖ§пјҡз”ұдәҺжҜҸдёӘжңҚеҠЎжҳҜзӢ¬з«Ӣзҡ„пјҢеӣўйҳҹеҸҜд»Ҙж №жҚ®е…·дҪ“зҡ„жңҚеҠЎйңҖжұӮйҖүжӢ©еҗҲйҖӮзҡ„жҠҖжңҜж Ҳе’ҢејҖеҸ‘иҜӯиЁҖпјҢиҖҢдёҚеҝ…еұҖйҷҗдәҺеҚ•дёҖзҡ„жҠҖжңҜйҖүжӢ©гҖӮ
еҫ®жңҚеҠЎзҡ„дјҳеҠҝ
- жӣҙе®№жҳ“з»ҙжҠӨпјҡз”ұдәҺжңҚеҠЎиў«еҲҶи§Јдёәе°ҸеһӢжЁЎеқ—пјҢд»Јз Ғеә“еҸҳеҫ—жӣҙе°ҸпјҢе®№жҳ“зҗҶи§Је’Ңз»ҙжҠӨгҖӮ
- з”ҹдә§еҠӣжҸҗеҚҮпјҡеӣўйҳҹеҸҜд»Ҙ并иЎҢең°ејҖеҸ‘е’ҢйғЁзҪІдёҚеҗҢзҡ„жңҚеҠЎпјҢеҮҸе°‘дәҶејҖеҸ‘е‘ЁжңҹгҖӮ
- е®№й”ҷжҖ§жӣҙй«ҳпјҡеҚ•дёӘжңҚеҠЎзҡ„ж•…йҡңдёҚдјҡеҜјиҮҙж•ҙдёӘзі»з»ҹзҳ«з—ӘпјҢзі»з»ҹе…·жңүжӣҙй«ҳзҡ„еҸҜйқ жҖ§гҖӮ
- жӣҙиҙҙиҝ‘дёҡеҠЎпјҡеӣўйҳҹеҸҜд»Ҙдёәзү№е®ҡзҡ„дёҡеҠЎйңҖжұӮеҲӣе»әе’ҢдјҳеҢ–еҫ®жңҚеҠЎпјҢдҪҝеҫ—жҠҖжңҜдёҺдёҡеҠЎжӣҙеҠ иҙҙеҗҲгҖӮ
зјәзӮ№пјҡ
- еҫ®жңҚеҠЎжһ¶жһ„ж•ҙдёӘеә”з”ЁеҲҶж•ЈжҲҗеӨҡдёӘжңҚеҠЎпјҢе®ҡдҪҚж•…йҡңзӮ№йқһеёёеӣ°йҡҫгҖӮ
- зЁіе®ҡжҖ§дёӢйҷҚгҖӮжңҚеҠЎж•°йҮҸеҸҳеӨҡеҜјиҮҙе…¶дёӯдёҖдёӘжңҚеҠЎеҮәзҺ°ж•…йҡңзҡ„жҰӮзҺҮеўһеӨ§пјҢ并且дёҖдёӘжңҚеҠЎж•…йҡңеҸҜиғҪеҜјиҮҙж•ҙдёӘзі»з»ҹжҢӮжҺүгҖӮдәӢе®һдёҠпјҢеңЁеӨ§и®ҝй—®йҮҸзҡ„з”ҹдә§еңәжҷҜдёӢпјҢж•…йҡңжҖ»жҳҜдјҡеҮәзҺ°зҡ„гҖӮдё”еҰӮжһңGateWayеҙ©жәғдәҶйӮЈд№Ҳе°ұжңүдәӣеӣ°йҡҫпјҢд»Җд№ҲдәӢжғ…йғҪеҒҡдёҚдәҶдәҶпјӣ
- жңҚеҠЎж•°йҮҸйқһеёёеӨҡпјҢйғЁзҪІгҖҒз®ЎзҗҶзҡ„е·ҘдҪңйҮҸеҫҲеӨ§гҖӮжҲҗжң¬еўһеҠ пјҢиҝҗз»ҙзҡ„еӨҚжқӮеәҰеўһеҠ гҖӮ
- ејҖеҸ‘ж–№йқўпјҡеҰӮдҪ•дҝқиҜҒеҗ„дёӘжңҚеҠЎеңЁжҢҒз»ӯејҖеҸ‘зҡ„жғ…еҶөдёӢд»Қ然дҝқжҢҒеҚҸеҗҢеҗҲдҪңгҖӮ
- жөӢиҜ•ж–№йқўпјҡжңҚеҠЎжӢҶеҲҶеҗҺпјҢеҮ д№ҺжүҖжңүеҠҹиғҪйғҪдјҡж¶үеҸҠеӨҡдёӘжңҚеҠЎгҖӮеҺҹжң¬еҚ•дёӘзЁӢеәҸзҡ„жөӢиҜ•еҸҳдёәжңҚеҠЎй—ҙи°ғз”Ёзҡ„жөӢиҜ•гҖӮжөӢиҜ•еҸҳеҫ—жӣҙеҠ еӨҚжқӮгҖӮ
еҫ®жңҚеҠЎжһ¶жһ„йҖӮеҗҲйӮЈдәӣйңҖиҰҒйў‘з№Ғжӣҙж–°е’Ңжү©еұ•зҡ„еӨ§еһӢеӨҚжқӮзі»з»ҹпјҢйҖҡиҝҮи§ЈиҖҰе’ҢжЁЎеқ—еҢ–пјҢеҫ®жңҚеҠЎеҸҜд»ҘеӨ§еӨ§жҸҗй«ҳзі»з»ҹзҡ„ж•ҸжҚ·жҖ§е’ҢеҸҜз»ҙжҠӨжҖ§гҖӮ然иҖҢпјҢеңЁе®һйҷ…еә”з”ЁдёӯпјҢдјҒдёҡйңҖиҰҒе№іиЎЎе…¶дјҳеҠҝе’Ңе®һж–ҪжҲҗжң¬пјҢзЎ®дҝқжҠҖжңҜжһ¶жһ„дёҺдёҡеҠЎйңҖжұӮеҢ№й…ҚгҖӮ
GateWay
дҪңдёәдёҖдёӘз»ҹдёҖи®ҝй—®зҡ„зҪ‘е…ігҖӮеә”з”ЁзЁӢеәҸпјҲеүҚз«ҜпјүдёҚйңҖиҰҒзҹҘйҒ“е…·дҪ“зҡ„жҳҜе“ӘдёӘжңҚеҠЎеҷЁеӨ„зҗҶеҜ№еә” зҡ„жңҚеҠЎпјҢеҸӘйңҖиҰҒеҜ№GateWayеҸ‘йҖҒиҜ·жұӮе°ұеҸҜд»ҘгҖӮжӯӨеӨ–пјҢGateWayиҝҳеҸҜд»Ҙиө·еҲ°иҙҹиҪҪеқҮиЎЎзҡ„дҪңз”ЁпјҢжҜ”еҰӮзҷ»еҪ•жңҚеҠЎжңүдёүдёӘжңҚеҠЎеҷЁпјҢ他们зҡ„keyеҗҚеӯ—йғҪжҳҜе®Ңе…ЁдёҖж ·зҡ„пјҢGateWayе°ұдјҡйҮҮз”Ёзӣёе…ізҡ„иҙҹиҪҪеқҮиЎЎзҡ„зӯ–з•ҘпјҢжҸҗй«ҳ并еҸ‘жҖ§иғҪгҖӮ
Gateway еҒҡзҡ„дәӢжғ…жҳҜпјҡ е®ўжҲ·з«ҜеҸ‘иҝҮжқҘзҡ„иҜ·жұӮпјҢжҜ”еҰӮ 8080/user/login пјҢжҲ–иҖ… 8080/book/buyBook пјҢ Gateway дјҡзҹҘйҒ“иҜҙж №жҚ® /user жҲ–иҖ… /book жқҘиҪ¬еҸ‘еҲ°еҜ№еә”зҡ„еҫ®жңҚеҠЎдёҠйқўеҺ»пјҢиҮідәҺйӮЈдёӘеҫ®жңҚеҠЎзҡ„ipе’Ңз«ҜеҸЈпјҢ Gateway дёҚйңҖиҰҒзҹҘйҒ“пјҢеӣ дёә Gateway дјҡеҺ» Eureka дёҠйқўеҺ»жүҫпјҢ然еҗҺиҪ¬еҸ‘иҝҮеҺ»гҖӮ
Eureka
Eureka жҳҜд»Җд№Ҳпјҹ
- Eureka жҳҜдёҖз§ҚеҹәдәҺ RESTпјҲиЎЁзҺ°еұӮзҠ¶жҖҒиҪ¬жҚўпјүзҡ„жңҚеҠЎпјҢдё»иҰҒз”ЁдәҺ AWS дә‘дёӯпјҢеё®еҠ©е®ҡдҪҚжңҚеҠЎпјҢе®һзҺ°дёӯй—ҙеұӮжңҚеҠЎеҷЁзҡ„иҙҹиҪҪеқҮиЎЎе’Ңж•…йҡңиҪ¬з§»гҖӮ
- ж ёеҝғ组件пјҡEureka ServerгҖӮ
Eureka зҡ„з”ЁйҖ”
- жңҚеҠЎеҸ‘зҺ°пјҡеё®еҠ©еҫ®жңҚеҠЎжһ¶жһ„дёӯзҡ„жңҚеҠЎжүҫеҲ°еҪјжӯӨгҖӮ
- еҹәзЎҖиҙҹиҪҪеқҮиЎЎпјҡй»ҳи®Өж”ҜжҢҒиҪ®иҜўиҙҹиҪҪеқҮиЎЎпјҢйҖӮеҗҲз®ҖеҚ•зҡ„иҙҹиҪҪеҲҶй…ҚйңҖжұӮгҖӮ
- й«ҳзә§иҙҹиҪҪеқҮиЎЎпјҲNetflixпјүпјҡж”ҜжҢҒж №жҚ®еӨҡз§ҚжқЎд»¶иҝӣиЎҢеҠ жқғеҲҶй…ҚпјҢзЎ®дҝқжӣҙе№ізЁізҡ„жңҚеҠЎе“Қеә”гҖӮ
Eureka жҳҜеҫ®жңҚеҠЎжһ¶жһ„дёӯз”ЁдәҺжңҚеҠЎеҸ‘зҺ°е’ҢиҙҹиҪҪеқҮиЎЎзҡ„йҮҚиҰҒ组件пјҢйҖҡиҝҮ Eureka Server жіЁеҶҢжңҚеҠЎгҖҒйҖҡиҝҮ Eureka Client иҝӣиЎҢдәӨдә’е’ҢеҲҶй…ҚгҖӮNetflix зҡ„зүҲжң¬иҝӣдёҖжӯҘеўһејәдәҶеј№жҖ§е’ҢзЁіе®ҡжҖ§гҖӮ
й«ҳеұӮжһ¶жһ„
жҜҸдёӘ regionпјҲеҢәеҹҹпјү жңүдёҖдёӘзӢ¬з«Ӣзҡ„ Eureka йӣҶзҫӨпјҢиҝҷдёӘйӣҶзҫӨеҸӘзҹҘйҒ“иҮӘе·ұеҢәеҹҹеҶ…зҡ„е®һдҫӢдҝЎжҒҜгҖӮжҜҸдёӘ zoneпјҲеҸҜз”ЁеҢәпјү иҮіе°‘жңүдёҖдёӘ Eureka жңҚеҠЎеҷЁпјҢд»Ҙеә”еҜ№еҢәеҹҹеҶ…зҡ„ж•…йҡңгҖӮ
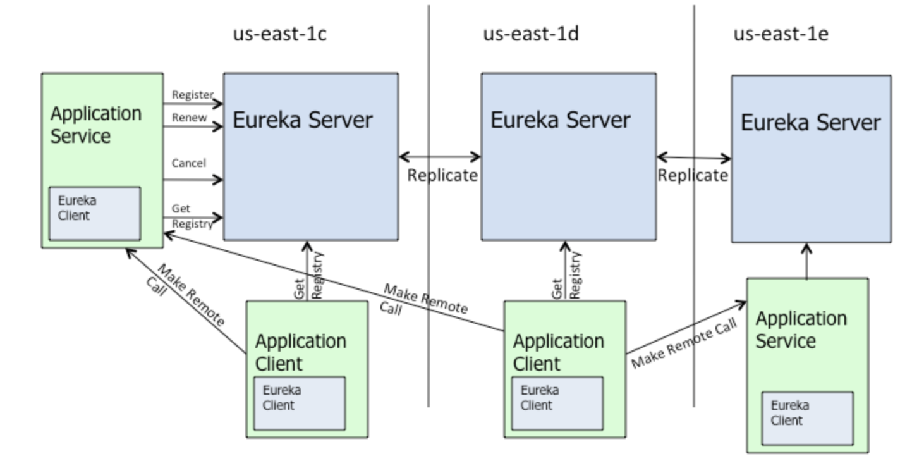
еңЁиҝҷдёӘй«ҳеұӮжһ¶жһ„дёӯпјҢEureka дҪңдёәжңҚеҠЎжіЁеҶҢдёӯеҝғпјҢз”ЁдәҺз®ЎзҗҶе’ҢеҸ‘зҺ°жңҚеҠЎе®һдҫӢгҖӮдё»иҰҒзҡ„и®ҫи®ЎеҺҹеҲҷеҢ…жӢ¬пјҡ
Eureka жңҚеҠЎеҷЁзҡ„еҢәеҹҹеҲ’еҲҶпјҡ
- Eureka иў«и®ҫи®ЎдёәеңЁдёҚеҗҢзҡ„ regionпјҲеҢәеҹҹпјү дёӯиҝҗиЎҢпјҢжҜҸдёӘеҢәеҹҹжңүдёҖдёӘзӢ¬з«Ӣзҡ„ Eureka йӣҶзҫӨгҖӮиҝҷж„Ҹе‘ізқҖжҹҗдёҖеҢәеҹҹеҶ…зҡ„ Eureka йӣҶзҫӨеҸӘе…іеҝғ并еӯҳеӮЁиҜҘеҢәеҹҹеҶ…зҡ„е®һдҫӢдҝЎжҒҜпјҢиҖҢдёҚдјҡж¶үеҸҠе…¶д»–еҢәеҹҹзҡ„жңҚеҠЎе®һдҫӢгҖӮ
ZoneпјҲеҸҜз”ЁеҢәпјүеҶ…зҡ„ж•…йҡңеӨ„зҗҶпјҡ
- дёәдәҶзЎ®дҝқжңҚеҠЎзҡ„й«ҳеҸҜз”ЁжҖ§пјҢжҜҸдёӘ zone иҮіе°‘жңүдёҖдёӘ Eureka жңҚеҠЎеҷЁгҖӮеҪ“жҹҗдёӘ zone еҸ‘з”ҹж•…йҡңж—¶пјҢе…¶д»– zone зҡ„ Eureka жңҚеҠЎеҷЁд»Қ然еҸҜд»ҘжӯЈеёёжҸҗдҫӣжңҚеҠЎгҖӮиҝҷз§Қи®ҫи®ЎеҲҶж•ЈдәҶеҚ•зӮ№ж•…йҡңзҡ„йЈҺйҷ©пјҢжҸҗй«ҳдәҶзі»з»ҹзҡ„еҸҜйқ жҖ§гҖӮ
жңҚеҠЎжіЁеҶҢдёҺеҸ‘зҺ°иҝҮзЁӢпјҡ
- Application ServiceпјҲеә”з”ЁжңҚеҠЎпјү дҪңдёә Eureka е®ўжҲ·з«ҜпјҢйҖҡиҝҮжіЁеҶҢе’Ңз»ӯзәҰзҡ„ж“ҚдҪңе°ҶиҮӘиә«е®һдҫӢдҝЎжҒҜеҸ‘йҖҒеҲ° Eureka жңҚеҠЎеҷЁгҖӮ
- Application ClientпјҲеә”з”Ёе®ўжҲ·з«Ҝпјү д»Һ Eureka жңҚеҠЎеҷЁиҺ·еҸ–жңҚеҠЎе®һдҫӢеҲ—иЎЁпјҢд»ҘдҫҝиҝӣиЎҢиҝңзЁӢи°ғз”ЁпјҲжҜ”еҰӮи®ҝй—®е…¶д»–жңҚеҠЎпјүгҖӮеә”з”Ёе®ўжҲ·з«Ҝе®ҡжңҹд»Һ Eureka жңҚеҠЎеҷЁиҺ·еҸ–жңҖж–°зҡ„жіЁеҶҢдҝЎжҒҜпјҢд»Ҙдҫҝе§Ӣз»ҲжӢҘжңүжңҖж–°зҡ„жңҚеҠЎе®һдҫӢеҲ—иЎЁгҖӮ
Eureka жңҚеҠЎеҷЁй—ҙзҡ„еӨҚеҲ¶пјҡ
- дёҚеҗҢзҡ„ Eureka жңҚеҠЎеҷЁд№Ӣй—ҙеӯҳеңЁж•°жҚ®еӨҚеҲ¶пјҲreplicateпјүжңәеҲ¶гҖӮдҫӢеҰӮпјҢеңЁ
us-east-1cгҖҒus-east-1dе’Ңus-east-1eиҝҷдёүдёӘ zone зҡ„ Eureka жңҚеҠЎеҷЁд№Ӣй—ҙпјҢжіЁеҶҢдҝЎжҒҜдјҡзӣёдә’еӨҚеҲ¶гҖӮиҝҷж ·зЎ®дҝқдәҶеҚідҪҝжҹҗдёҖеҸ° Eureka жңҚеҠЎеҷЁеҮәзҺ°й—®йўҳпјҢе…¶д»– Eureka жңҚеҠЎеҷЁд»Қ然еҸҜд»ҘжҸҗдҫӣжңҖж–°зҡ„жңҚеҠЎжіЁеҶҢдҝЎжҒҜгҖӮ
иҝҷз§Қжһ¶жһ„и®ҫи®Ўзҡ„е…ій”®еңЁдәҺеҲҶеҢәе’Ңй«ҳеҸҜз”ЁжҖ§пјҢзЎ®дҝқжҜҸдёӘеҢәеҹҹеҶ…зҡ„ Eureka йӣҶзҫӨзӣёдә’йҡ”зҰ»пјҢеҮҸе°‘ж•…йҡңзҡ„дј ж’ӯгҖӮеҗҢж—¶пјҢжҜҸдёӘеҢәеҹҹеҶ…жңүеӨҡдёӘеҸҜз”ЁеҢәзҡ„еҶ—дҪҷпјҢд»ҘдҝқиҜҒжңҚеҠЎзҡ„жҢҒз»ӯжҖ§гҖӮ
еңЁ Spring Boot дёӯйӣҶжҲҗе’ҢдҪҝз”Ё Eureka дҪңдёәжңҚеҠЎжіЁеҶҢдёҺеҸ‘зҺ°з»„件пјҢйҖҡеёёдҪҝз”Ё Spring Cloud Netflix жҸҗдҫӣзҡ„ж”ҜжҢҒгҖӮд»ҘдёӢжҳҜе®һзҺ°жӯҘйӘӨпјҡ
Serverless
д»Җд№ҲжҳҜж— жңҚеҠЎеҷЁпјҲServerlessпјүпјҹ
ж— жңҚеҠЎеҷЁжҳҜдёҖз§Қдә‘и®Ўз®—жЁЎејҸпјҢејҖеҸ‘иҖ…дё“жіЁдәҺзј–еҶҷеә”з”ЁйҖ»иҫ‘д»Јз ҒпјҢиҖҢдёҚйңҖиҰҒе…іеҝғеә•еұӮзҡ„жңҚеҠЎеҷЁеҹәзЎҖи®ҫж–Ҫз®ЎзҗҶгҖӮйҖҡиҝҮж— жңҚеҠЎеҷЁжһ¶жһ„пјҢеғҸеҮҪж•°еҚіжңҚеҠЎпјҲFunction as a Service, FaaSпјүиҝҷж ·зҡ„е№іеҸ°дјҡиҮӘеҠЁеӨ„зҗҶжү©еұ•гҖҒиҝҗиЎҢж—¶гҖҒиө„жәҗеҲҶй…ҚгҖҒе®үе…ЁжҖ§зӯүжңҚеҠЎеҷЁз»ҶиҠӮгҖӮ
еңЁж— жңҚеҠЎеҷЁзҺҜеўғдёӯпјҢеә”з”Ёзҡ„жү§иЎҢжҳҜдәӢ件й©ұеҠЁзҡ„пјҢеҚіж №жҚ®зү№е®ҡзҡ„и§ҰеҸ‘жқЎд»¶пјҲеҰӮHTTPиҜ·жұӮгҖҒж•°жҚ®еә“жӣҙж–°зӯүпјүжқҘеҗҜеҠЁд»Јз ҒпјҢиҖҢдёҚжҳҜйңҖиҰҒжҢҒз»ӯиҝҗиЎҢзҡ„жңҚеҠЎеҷЁгҖӮжӯӨеӨ–пјҢж— жңҚеҠЎеҷЁе·ҘдҪңиҙҹиҪҪеҸҜд»ҘзҗҶи§ЈдёәвҖңдёҚе…іжіЁйҖҡеёёз”ұжңҚеҠЎеҷЁеҹәзЎҖи®ҫж–ҪеӨ„зҗҶзҡ„ж–№йқўзҡ„дәӢ件й©ұеҠЁе·ҘдҪңиҙҹиҪҪвҖқпјҢжҜ”еҰӮвҖңиҰҒиҝҗиЎҢеӨҡе°‘е®һдҫӢвҖқе’ҢвҖңдҪҝз”Ёд»Җд№Ҳж“ҚдҪңзі»з»ҹвҖқзӯүй—®йўҳйғҪз”ұFaaSе№іеҸ°з®ЎзҗҶпјҢејҖеҸ‘иҖ…еҸӘйңҖдё“жіЁдәҺдёҡеҠЎйҖ»иҫ‘зҡ„е®һзҺ°гҖӮ
ж— жңҚеҠЎеҷЁеә”з”Ёзҡ„зү№зӮ№
- дәӢ件й©ұеҠЁзҡ„д»Јз Ғжү§иЎҢпјҡд»Јз Ғжү§иЎҢдҫқиө–зү№е®ҡзҡ„и§ҰеҸ‘жқЎд»¶пјҲеҰӮиҜ·жұӮгҖҒж•°жҚ®еә“еҸҳеҢ–гҖҒе®ҡж—¶д»»еҠЎзӯүпјүпјҢеҸӘжңүеңЁдәӢ件еҸ‘з”ҹж—¶жүҚдјҡиҝҗиЎҢпјҢиҝҷз§ҚжЁЎејҸжҸҗй«ҳдәҶиө„жәҗеҲ©з”ЁзҺҮгҖӮ
- е№іеҸ°иҮӘеҠЁз®ЎзҗҶж“ҚдҪңпјҡдә‘е№іеҸ°дјҡиҙҹиҙЈеә”з”Ёзҡ„еҗҜеҠЁгҖҒеҒңжӯўе’Ңжү©еұ•е·ҘдҪңпјҢд»ҺиҖҢеҮҸе°‘ејҖеҸ‘иҖ…еңЁжңҚеҠЎеҷЁз®ЎзҗҶдёҠзҡ„иҙҹжӢ…пјҢе…Ғ许他们专注дәҺд»Јз Ғзј–еҶҷгҖӮ
- еҸҜзј©ж”ҫиҮійӣ¶пјҡж— жңҚеҠЎеҷЁеә”з”ЁеңЁз©әй—Іж—¶еҸҜд»Ҙзј©ж”ҫеҲ°йӣ¶е®һдҫӢпјҢиҝҷж„Ҹе‘ізқҖеҪ“еә”з”ЁдёҚдҪҝз”Ёж—¶еҮ д№ҺдёҚдјҡдә§з”ҹиҙ№з”ЁгҖӮиҝҷз§Қзү№жҖ§дҪҝеҫ—ж— жңҚеҠЎеҷЁжһ¶жһ„еҜ№иҙҹиҪҪдёҚ规еҲҷжҲ–йңҖжұӮдёҚеҸҜйў„жөӢзҡ„еә”з”Ёйқһеёёз»ҸжөҺй«ҳж•ҲгҖӮ
- ж— зҠ¶жҖҒжҖ§пјҡжҜҸж¬ЎеҮҪж•°и°ғз”ЁйғҪжҳҜзӢ¬з«Ӣзҡ„пјҢдёҚдјҡеңЁдёҚеҗҢи°ғз”Ёд№Ӣй—ҙдҝқз•ҷзҠ¶жҖҒгҖӮж— зҠ¶жҖҒзҡ„зү№жҖ§з®ҖеҢ–дәҶжү©еұ•пјҢдҪҝе№іеҸ°еҸҜд»Ҙ并иЎҢжү§иЎҢеӨҡдёӘеҮҪж•°е®һдҫӢиҖҢдёҚдјҡдә§з”ҹеҶІзӘҒгҖӮ
зјәзӮ№пјҡ第дёҖж¬Ўе”ӨйҶ’并иҝ”еӣһе“Қеә”йңҖиҰҒдёҖзӮ№ж—¶й—ҙгҖӮеӣ дёәдёҖдәӣж— жңҚеҠЎеҷЁеҠҹиғҪдјҡжҢүйңҖиҝҗиЎҢпјҢи°ғиҜ•йӣҶжҲҗжҜ”иҫғеӣ°йҡҫгҖӮ
еҮҪж•°ејҸжңҚеҠЎпјҡзұ»жҜ” y = f(x)пјҢз»ҷе®ҡдёҖдёӘиҫ“е…ҘпјҢеҫ—еҲ°дёҖдёӘиҫ“еҮәз»“жһңгҖӮжӯӨеӨ–дёӨж¬ЎжҲ–иҖ…еӨҡж¬Ўзҡ„еҮҪж•°и®Ўз®—д№Ӣй—ҙжІЎжңүе…і зі»пјҢдёҠж¬ЎиҜ·жұӮи®Ўз®—зҡ„з»“жһңи®Ўз®—е®Ңиҝ”еӣһе°ұз»“жқҹпјҢи·ҹеҗҺйқўзҡ„жІЎжңүд»»дҪ•е…ізі»пјҢдҪ“зҺ°еҮәдёҖдёӘж— зҠ¶жҖҒгҖӮ
еӣҫзӨәи§ЈйҮҠж— жңҚеҠЎеҷЁдёҺдј з»ҹеҹәзЎҖи®ҫж–Ҫзҡ„еҢәеҲ«
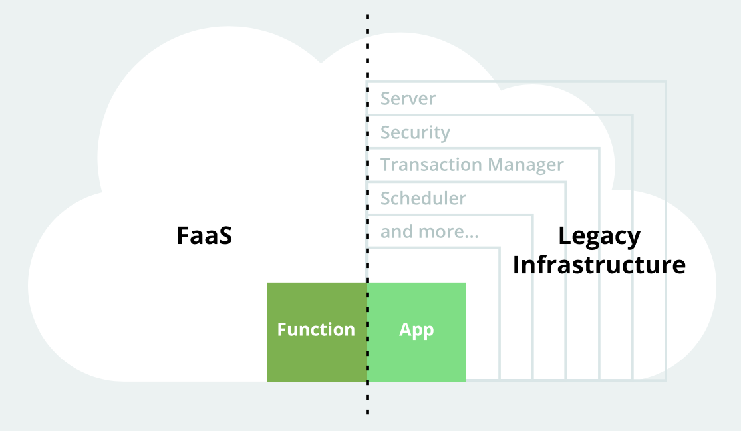
еӣҫдёӯзҡ„е·Ұдҫ§жҳҫзӨәдәҶж— жңҚеҠЎеҷЁпјҲFaaSпјүпјҢеҸідҫ§жҳҜдј з»ҹеҹәзЎҖи®ҫж–ҪгҖӮдј з»ҹзҡ„еҹәзЎҖи®ҫж–ҪйңҖиҰҒејҖеҸ‘иҖ…з®ЎзҗҶи®ёеӨҡзі»з»ҹж–№йқўпјҢжҜ”еҰӮпјҡ
- жңҚеҠЎеҷЁпјҡйңҖиҰҒз®ЎзҗҶе’Ңжү©еұ•зҡ„зү©зҗҶжҲ–иҷҡжӢҹжңәгҖӮ
- е®үе…ЁжҖ§пјҡзҪ‘з»ңе®үе…ЁгҖҒйҳІзҒ«еўҷзӯүдҝқжҠӨжңәеҲ¶гҖӮ
- дәӢеҠЎз®ЎзҗҶпјҡдҝқиҜҒдәӢеҠЎзҡ„е®Ңж•ҙжҖ§е’ҢдёҖиҮҙжҖ§гҖӮ
- и°ғеәҰеҷЁпјҡд»»еҠЎи°ғеәҰжҲ–йҳҹеҲ—з®ЎзҗҶгҖӮ
иҖҢеңЁFaaSзҡ„ж— жңҚеҠЎеҷЁжЁЎеһӢдёӯпјҢејҖеҸ‘иҖ…еҸӘйңҖдё“жіЁдәҺеҮҪж•°е’Ңеә”з”Ёзҡ„ејҖеҸ‘пјҢеә•еұӮзҡ„еҹәзЎҖи®ҫж–Ҫз”ұдә‘жҸҗдҫӣе•ҶиҮӘеҠЁз®ЎзҗҶпјҢеҢ…жӢ¬жү©еұ•е’Ңе®үе…ЁжҖ§гҖӮиҝҷз§Қж–№ејҸеҮҸе°‘дәҶз®ЎзҗҶзҡ„еӨҚжқӮеәҰпјҢдҪҝејҖеҸ‘иҖ…еҸҜд»Ҙеҝ«йҖҹйғЁзҪІе’Ңжү©еұ•еә”з”ЁгҖӮиҝҷз§ҚжЁЎејҸйқһеёёйҖӮеҗҲиҙҹиҪҪдёҚеҸҜйў„жөӢжҲ–дәӢ件й©ұеҠЁзҡ„еә”з”ЁпјҢиғҪеӨҹиҝ…йҖҹжү©еұ•пјҢ并且仅еңЁе®һйҷ…дҪҝз”Ёж—¶дә§з”ҹиҙ№з”ЁпјҢд»ҺиҖҢжҳҫи‘—йҷҚдҪҺдәҶжҲҗжң¬гҖӮ
Spring Cloud Function
Spring Cloud Function жҳҜдёҖдёӘеё®еҠ© Spring ејҖеҸ‘иҖ…дҪҝз”Ёж— жңҚеҠЎеҷЁжһ¶жһ„жҲ– FaaSпјҲFunction as a Serviceпјүе№іеҸ°зҡ„жЎҶжһ¶гҖӮйҖҡиҝҮ Spring Cloud FunctionпјҢејҖеҸ‘иҖ…еҸҜд»Ҙе°ҶдёҡеҠЎйҖ»иҫ‘д»ҘеҮҪж•°зҡ„еҪўејҸе®һзҺ°пјҢ并иғҪеӨҹеңЁеёёи§Ғзҡ„ FaaS жңҚеҠЎпјҲеҰӮ Amazon LambdaгҖҒApache OpenWhiskгҖҒMicrosoft AzureгҖҒProject Riff зӯүпјүдёҠиҝҗиЎҢиҝҷдәӣеҮҪж•°гҖӮ
Spring Cloud Function зҡ„дё»иҰҒзӣ®ж Ү
- жҺЁе№ҝйҖҡиҝҮеҮҪж•°е®һзҺ°дёҡеҠЎйҖ»иҫ‘пјҡе°ҶдёҡеҠЎйҖ»иҫ‘е°ҒиЈ…еңЁеҮҪж•°дёӯпјҢз®ҖеҢ–ејҖеҸ‘пјҢеўһејәзҒөжҙ»жҖ§гҖӮ
- и§ЈиҖҰдёҡеҠЎйҖ»иҫ‘зҡ„ејҖеҸ‘е’Ңзү№е®ҡиҝҗиЎҢж—¶зҺҜеўғпјҡзӣёеҗҢзҡ„д»Јз ҒеҸҜд»ҘдҪңдёә Web з«ҜзӮ№гҖҒжөҒеӨ„зҗҶеҷЁжҲ–д»»еҠЎиҝҗиЎҢпјҢзӢ¬з«ӢдәҺе…·дҪ“зҡ„жү§иЎҢзҺҜеўғгҖӮ
- жҸҗдҫӣз»ҹдёҖзҡ„зј–зЁӢжЁЎеһӢпјҡSpring Cloud Function ж”ҜжҢҒеӨҡз§Қж— жңҚеҠЎеҷЁжҸҗдҫӣе•ҶпјҢ并且еҸҜд»ҘеңЁжң¬ең°пјҲStandaloneпјүжҲ– PaaS зҺҜеўғдёӯиҝҗиЎҢпјҢе®һзҺ°дәҶи·Ёе№іеҸ°зҡ„дёҖиҮҙжҖ§гҖӮ
- еҗҜз”Ё Spring Boot зү№жҖ§пјҡеңЁж— жңҚеҠЎеҷЁзҺҜеўғдёӯд»Қ然еҸҜд»ҘдҪҝз”Ё Spring Boot зҡ„иҮӘеҠЁй…ҚзҪ®гҖҒдҫқиө–жіЁе…Ҙе’ҢжҢҮж Үзӣ‘жҺ§зӯүеҠҹиғҪгҖӮ
е…·дҪ“йғЁзҪІ
- еҗҜеҠЁжіЁеҶҢиЎЁпјҡе…¶д»–зҡ„жңҚеҠЎеҷЁеҗҜеҠЁзҡ„ж—¶еҖҷйғҪиҰҒеҲ°жңҚеҠЎжіЁеҶҢиҝҷйҮҢжқҘжіЁеҶҢдёҖдёӢпјҢжүҖд»Ҙеҝ…йЎ»иҰҒжңҖе…ҲеҗҜеҠЁEurekaзҡ„иҝҷдёӘжңҚеҠЎгҖӮ
- еҗҜеҠЁеҫ®жңҚеҠЎе…·дҪ“зҡ„жңҚеҠЎеҷЁпјҡеңЁиҝҷдёӘжңҚеҠЎеҷЁеҗҜеҠЁзҡ„ж—¶еҖҷдјҡиҮӘеҠЁеҲ°жіЁеҶҢиЎЁжңҚеҠЎеҷЁйҮҢйқўжіЁеҶҢдёҖдёӢпјҢдҫҝдәҺеҗҺйқўзҡ„GateWayиғҪеӨҹжүҫеҫ—еҲ°гҖӮ
- еҗҜеҠЁGateWayпјҢеӣ дёәе…·дҪ“зҡ„дёҡеҠЎжңҚеҠЎеҷЁе·Із»ҸеҗҜеҠЁдәҶпјҢеҗҜеҠЁGateWayд№ӢеҗҺпјҢз”ЁжҲ·зҡ„иҜ·жұӮе°ұеҸҜд»ҘиҪ¬еҸ‘еҲ°еҜ№еә”зҡ„еҫ®жңҚеҠЎпјҢеҰӮжһңе…ҲеҗҜеҠЁGateWayиҖҢжІЎжңүеҗҜеҠЁе…·дҪ“зҡ„дёҡеҠЎжңҚеҠЎеҷЁпјҢеҰӮжһңжңүиҜ·жұӮеҸ‘жқҘе°ұдјҡеҜјиҮҙGateWayжүҫдёҚеҲ°еҜ№еә”зҡ„еҫ®жңҚеҠЎзҡ„жңҚеҠЎеҷЁпјҢ然еҗҺеҮәзҺ°жҠҘй”ҷгҖӮ
еҫ®жңҚеҠЎзҠ¶жҖҒ
иӮҜе®ҡдёҚиғҪз”ЁsessionпјҢжҜ”еҰӮеҫ®жңҚеҠЎйӣҶзҫӨйҮҢйқўдёҖдёӘжңҚеҠЎеҷЁз”ЁжқҘзҷ»еҪ•пјҢеҰӮжһңз”ЁиҝҷдёӘжңҚеҠЎеҷЁеӯҳеӮЁsessionпјҢйӮЈд№Ҳд»–дёӢж¬ЎдёӢеҚ•зҡ„ж—¶еҖҷпјҢеҸҜиғҪжҳҜеҸҰеӨ–дёҖдёӘжңҚеҠЎеҷЁеӨ„зҗҶзҡ„пјҢиҖҢеҸҰеӨ–зҡ„жңҚеҠЎеҷЁдёҚзҹҘйҒ“з”ЁжҲ·зҡ„зҷ»еҪ•зҠ¶жҖҒпјҢеӣ жӯӨи§ЈеҶіж–№жЎҲе°ұжҳҜjwtгҖӮ
з”ЁжҲ·дҪҝз”ЁдёҖдёӘjwt tokenдј е…ҘпјҢжңҚеҠЎеҷЁзҡ„GateWayеҜ№дәҺйңҖиҰҒзҷ»еҪ•жҺҲжқғзҡ„иҜ·жұӮеҠ дёҖдёӘиҝҮж»ӨеҷЁпјҢ然еҗҺи§Јжһҗе’ҢиҝҷдёӘjwtпјҢеҶҚжҠҠи§ЈжһҗиҺ·еҸ–еҲ°зҡ„з”ЁжҲ·дҝЎжҒҜж”ҫе…ҘиҜ·жұӮзҡ„headerйҮҢйқўпјҢеҰӮжһңи§ЈжһҗеӨұиҙҘе°ұзӣҙжҺҘжӢҰжҲӘдёҚиҪ¬еҸ‘з»ҷеҗҺйқўзҡ„пјҢиҝҷж ·д№ҹеўһеҠ дәҶе®үе…ЁжҖ§гҖӮ
第еҚҒдёҖз«
MYSQLдјҳеҢ–
- иЎЁз»“жһ„жҳҜеҗҰеҗҲзҗҶпјҢиҢғејҸеҢ–пјҹж•°жҚ®зұ»еһӢпјҹ
- жӢҶиЎЁпјҹеҜ№дәҺдёҖеј иЎЁдёӯзҡ„ж•°жҚ®пјҢжҲ‘们жӣҙеёҢжңӣжҳҜж•ҙеј иЎЁдёӯзҡ„ж•°жҚ®е…ЁйғЁиў«и®ҝй—®жҲ–иҖ…е…ЁйғЁдёҚиў«и®ҝй—®пјӣиӢҘдёҚ然пјҢе°ұйңҖиҰҒиҖғиҷ‘жӢҶиЎЁгҖӮ
- varcharпјҲеҸҜеҸҳй•ҝпјҢдҫҝдәҺеҺӢзј©пјүе’ҢcharиҝҳжңүtextпјҲеӯҳеӮЁдёҖдёӘжҢҮй’ҲпјҢжү§иЎҢеӨ–йғЁеӯҳеӮЁзҡ„еҺҹж–Үпјүпјӣchar(N)еҚ з”Ёзҡ„еӯ—иҠӮеҫ—зңӢеӯ—з¬ҰйӣҶпјҢеҚ з”Ёзҡ„жҳҜеӯ—з¬ҰйӣҶдёӯжңҖй•ҝзҡ„еӯ—иҠӮж•°пјӣ
- иҜ»еҸ–и®°еҪ•зҡ„ж—¶еҖҷпјҢиҖғиҷ‘еҲ°pageзҡ„еӨ§е°ҸжңүйҷҗпјҢеҰӮжһңдёҖжқЎи®°еҪ•зҡ„еӨ§е°Ҹе°ұеҚ з”ЁдәҶеҘҪеҮ дёӘpageжҳҫ然жҳҜдёҚеҗҲзҗҶзҡ„пјҢжүҖд»Ҙзү№еҲ«й•ҝзҡ„ж–Үжң¬йңҖиҰҒдҪҝз”Ёtextзұ»еһӢпјҢиҝҷж ·иҜ»еҸ–еҮәжқҘзҡ„textйғЁеҲҶе°ұжҳҜдёҖдёӘжҢҮй’ҲпјҢжҖ§иғҪжӣҙеҘҪгҖӮ
- д»Җд№Ҳж ·зҡ„зҙўеј•з§‘еӯҰпјҹ д»Җд№Ҳж ·зҡ„еӯҳеӮЁеј•ж“ҺеҘҪпјҹпјҲжіЁпјҡMySQLе…¶е®һеҲҶдёәдёӨйғЁеҲҶпјҡServerеұӮе’ҢеӯҳеӮЁеј•ж“ҺеұӮпјҢServerеұӮзҡ„дҪңз”ЁжҳҜ и·ҹе®ўжҲ·з«ҜдәӨдә’пјҢи§ЈжһҗSQLпјҢиҝӣиЎҢжҹҘиҜўдјҳеҢ–пјҢеӯҳеӮЁеј•ж“ҺеұӮиҙҹиҙЈж•°жҚ®зҡ„еӯҳеӮЁе’ҢжҸҗеҸ–пјү
- й”ҒгҖҒйҡ”зҰ»жңәеҲ¶пјҹжүҖжңүзҡ„еҶ…еӯҳз”ЁеҲ°зј“еӯҳеҗҲйҖӮеҗ—пјҹ
- еҪ“硬件иө¶дёҚдёҠдёҡеҠЎзҡ„ж—¶еҖҷпјҢиҜҘжҖҺд№Ҳи°ғж•ҙжңҚеҠЎеҷЁжҖ§иғҪпјҹ
- еҲ—жңҖеҘҪзӣҙжҺҘи®ҫзҪ®дёәnot nullпјӣеҗҰеҲҷпјҢеңЁеӯҳеӮЁзҡ„ж—¶еҖҷпјҢеңЁиҝҷдёҖеҲ—дёҠеӨҡеҚ з”ЁдёҖдёӘbitпјҢжқҘиЎЁзӨәжҳҜеҗҰдёәnullпјҢ иҝҷж ·дјҡжөӘиҙ№з©әй—ҙпјӣеҗҢж—¶пјҢSQLеңЁжү§иЎҢзҡ„ж—¶еҖҷиҝҳдјҡеӨҡжү§иЎҢдёҖеҸҘжқҘеҲӨж–ӯдҪ иҝҷдёҖдёӘеӯ—ж®өеҲ°еә•жҳҜдёҚжҳҜз©әзҡ„пјҢ жөӘиҙ№ж—¶й—ҙгҖӮи§ЈеҶіж–№жЎҲпјҡеҚідҪҝжҳҜз©әзҡ„пјҢжҲ‘д№ҹеҶҷдёҖдёӘзү№ж®ҠеҖјиҝӣеҺ»пјҢе°ұдёҚдёәз©әдәҶгҖӮ
- иғҪйҖүж•°еӯ—е°ұйҖүж•°еӯ—пјҢж•°еӯ—зұ»еһӢе°‘еҫҲеӨҡеӯ—иҠӮпјҢиҖҢдёҚжҳҜйҖүжӢ©еӯ—з¬Ұзұ»еһӢпјҢиҝҷж ·жҖ§иғҪдјҡжӣҙеҘҪгҖӮ
- joinзҡ„ж—¶еҖҷиҰҒжіЁж„ҸпјҡдёӨдёӘиЎЁйҮҢйқўзҡ„йӮЈдёӨдёӘеҲ—пјҢйҰ–е…Ҳж•°жҚ®зұ»еһӢжңҖеҘҪдёҖиҮҙпјӣе…¶ж¬ЎдёӨдёӘеҲ—зҡ„еҗҚз§°жңҖеҘҪд№ҹжҳҜ дёҖиҮҙзҡ„пјҢдёҚиҰҒдёҖдёӘжҳҜвҖңstudent-idвҖқпјҢдёҖдёӘжҳҜвҖңstudent-numberвҖқгҖӮ
硬件еұӮзә§зҡ„дјҳеҢ–
йҡҸзқҖж•°жҚ®еә“иҙҹиҪҪзҡ„еўһеҠ пјҢд»»дҪ•ж•°жҚ®еә“еә”з”ЁжңҖз»ҲйғҪдјҡйҒҮеҲ°зЎ¬д»¶з“¶йўҲгҖӮж•°жҚ®еә“з®ЎзҗҶе‘ҳпјҲDBAпјүйңҖиҰҒиҜ„дј°жҳҜеҗҰеҸҜд»ҘйҖҡиҝҮи°ғдјҳеә”з”ЁзЁӢеәҸжҲ–йҮҚж–°й…ҚзҪ®жңҚеҠЎеҷЁжқҘйҒҝе…Қиҝҷдәӣ瓶йўҲпјҢжҲ–иҖ…жҳҜеҗҰйңҖиҰҒеўһеҠ 硬件иө„жәҗгҖӮ
еёёи§Ғзҡ„зі»з»ҹ瓶йўҲжқҘжәҗеҢ…жӢ¬пјҡ
- зЈҒзӣҳеҜ»йҒ“пјҡзЈҒзӣҳе®ҡдҪҚж•°жҚ®зҡ„йҖҹеәҰеҸ—йҷҗж—¶пјҢдјҡеҜјиҮҙжҖ§иғҪдёӢйҷҚгҖӮ
- зЈҒзӣҳиҜ»еҶҷпјҡйў‘з№Ғзҡ„ж•°жҚ®иҜ»еҶҷж“ҚдҪңдјҡеҜјиҮҙзЈҒзӣҳзҡ„иҙҹиҪҪиҝҮй«ҳпјҢеҪұе“Қж•°жҚ®и®ҝй—®йҖҹеәҰгҖӮ
- CPU е‘ЁжңҹпјҡеӨҚжқӮжҹҘиҜўе’Ңи®Ўз®—еҜҶйӣҶеһӢд»»еҠЎдјҡиҖ—иҙ№еӨ§йҮҸ CPU иө„жәҗгҖӮ
- еҶ…еӯҳеёҰе®ҪпјҡеҶ…еӯҳеёҰе®ҪдёҚи¶ідјҡеҪұе“Қж•°жҚ®д»ҺеҶ…еӯҳдёӯиҜ»еҸ–е’ҢеҶҷе…Ҙзҡ„ж•ҲзҺҮгҖӮ
дјҳеҢ–硬件иө„жәҗдҪҝз”ЁиғҪеӨҹеё®еҠ©зј“и§Јиҝҷдәӣ瓶йўҲпјҢжҸҗеҚҮж•°жҚ®еә“еә”з”Ёзҡ„ж•ҙдҪ“жҖ§иғҪгҖӮ
зҙўеј•
жҸҗй«ҳselectжҖ§иғҪжңҖеҘҪзҡ„еҠһжі•е°ұжҳҜеңЁз»ҸеёёжҹҘиҜўзҡ„еҲ—дёҠйқўе»әз«Ӣзҙўеј•гҖӮзҙўеј•жқЎзӣ®е……еҪ“жҢҮеҗ‘иЎЁиЎҢзҡ„жҢҮй’ҲпјҢе…Ғи®ёжҹҘиҜўеҝ«йҖҹзЎ®е®ҡе“ӘдәӣиЎҢз¬ҰеҗҲWHEREеӯҗеҸҘдёӯзҡ„жқЎд»¶пјҢ并жЈҖзҙўиҝҷдәӣиЎҢзҡ„ е…¶д»–еҲ—еҖјгҖӮ
зҙўеј•е°ҪеҸҜиғҪе»әз«ӢеңЁеҸ–еҖјдёәдёҚдёәз©әпјҲеҗҰеҲҷиҜ·з”ЁдёҖдёӘзү№ж®Ҡзҡ„еҖјеЎ«е……з©әеҖјпјүпјҢиҖҢдё”еҖје”ҜдёҖпјҲжҲ–иҖ…еҫҲе°‘жңүйҮҚеӨҚзҡ„пјүеҲ—дёҠйқўгҖӮ
并дёҚжҳҜзҙўеј•е»әз«Ӣзҡ„и¶ҠеӨҡи¶ҠеҘҪпјҢдёҚеҝ…иҰҒзҡ„зҙўеј•е»әз«ӢдјҡжөӘиҙ№ж—¶й—ҙжқҘеҶіе®ҡз”Ёд»Җд№Ҳзҙўеј•жҗңзҙўпјӣеҗҢж—¶зҙўеј•жң¬иә«еҚ жҚ®з©әй—ҙпјҒпјҲжҲ‘жҜҸе»әз«ӢдёҖдёӘзҙўеј•пјҢе°ұзӣёеҪ“дәҺз”ЁиҝҷдёӘkeyжқҘе»әз«ӢдәҶдёҖжЈөB+ж ‘пјү
- еҰӮжһңе»әз«ӢдәҶдёҖе Ҷзҙўеј•пјҢеҜ№дәҺж•°жҚ®жӣҙж–°зҡ„ж—¶еҖҷпјҢзҙўеј•ж”№еҸҳйңҖиҰҒи°ғж•ҙпјҢйӮЈд№Ҳз”ұдәҺеӨ§йҮҸзҡ„зҙўеј•е»әз«ӢпјҢеҜјиҮҙи°ғж•ҙb+ treeйңҖиҰҒж¶ҲиҖ—еӨ§йҮҸзҡ„ж—¶й—ҙпјҲжүҖд»ҘйңҖиҰҒз®ЎзҗҶиҖ…жқғиЎЎиҖғиҷ‘пјҒпјү
- зі»з»ҹдјҡиҮӘеҠЁеңЁиҮӘеўһзҡ„дё»й”®е»әз«Ӣзҙўеј•пјҲжҳҜиҒҡз°Үзҙўеј•пјҢд№ҹеҚізҙўеј•еңЁеҸ¶еӯҗиҠӮзӮ№зҡ„жҢҮй’ҲжҢҮеҗ‘зҡ„дҪҚзҪ®еңЁзЈҒзӣҳдёҠжҳҜиҝһз»ӯзҡ„пјүпјҢиҝҷж ·жңҖеӨ§зҡ„еҘҪеӨ„е°ұжҳҜеңЁjoinж“ҚдҪңзҡ„ж—¶еҖҷпјҢеҸҜд»Ҙеҝ«йҖҹе®ҡдҪҚеҲ°зӣ®ж ҮгҖӮ
- еҪ“иЎЁж јжҜ”иҫғе°Ҹзҡ„ж—¶еҖҷпјҢе»әз«Ӣзҙўеј•еҫҲжөӘиҙ№пјҢдёҚеҰӮе…ЁиЎЁжү«жҸҸгҖӮ
- иҺ·еҸ–иҰҒfind allзҡ„ж—¶еҖҷпјҢзҙўеј•д№ҹеҫҲжөӘиҙ№пјҢжң¬жқҘе°ұжҳҜиҰҒжҠҠж•ҙдёӘиЎЁж•°жҚ®иҜ»еҸ–еҮәжқҘпјҢзҙўеј•еӨұеҺ»ж„Ҹд№үгҖӮ
йҖүжӢ©иҮӘеўһдё»й”®еҒҡзҙўеј•зҡ„еҘҪеӨ„пјҡ
- еҰӮжһңиЎЁеҶ…зҡ„жҹҗеҮ еҲ—йғҪеҫҲйҮҚиҰҒпјҢдҪҶжҳҜжӢҝдёҚеҮҶе“ӘеҮ еҲ—еҒҡзҙўеј•зҡ„ж—¶еҖҷпјҢдёҚеҰЁзӣҙжҺҘдҪҝз”ЁиҮӘеўһдё»й”®
- иҮӘеўһдё»й”®зҡ„е”ҜдёҖжҖ§з”ұж•°жҚ®еә“дҝқиҜҒпјҢжӣҙеҠ еҸҜйқ
- еҗҢж—¶иҝҷдёӘдё»й”®дҪңдёәеӨ–й”®д№ҹжҜ”иҫғж–№дҫҝ
- еӣ дёәзҙўеј•жҳҜиҰҒжҠҠиҝҷеҲ—еӨҚеҲ¶еҮәжқҘзҡ„пјҢеӣ жӯӨз»“жһ„з®ҖеҚ•зҡ„иҜқпјҢз”ҹжҲҗзҡ„зҙўеј•жҜ”иҫғе°ҸпјҢеҗҢж—¶з”ҹжҲҗзҡ„B+ж ‘зҡ„ж•ҲзҺҮ д№ҹжҜ”иҫғй«ҳ
1. зҙўеј•зҡ„дҪңз”Ё
- еҝ«йҖҹжҹҘжүҫзү№е®ҡеҲ—еҖјзҡ„иЎҢпјҡеҰӮжһңжІЎжңүзҙўеј•пјҢMySQL йңҖиҰҒд»ҺеӨҙиҜ»еҸ–ж•ҙдёӘиЎЁпјҢеҜјиҮҙиЎЁи¶ҠеӨ§пјҢиҜ»еҸ–жҲҗжң¬и¶Ҡй«ҳгҖӮжңүдәҶзҙўеј•еҗҺпјҢMySQL еҸҜд»ҘзӣҙжҺҘе®ҡдҪҚеҲ°ж•°жҚ®ж–Ү件дёӯзҡ„дҪҚзҪ®пјҢиҖҢдёҚеҝ…иҜ»еҸ–жҜҸдёҖиЎҢгҖӮ
- дјҳеҢ– WHERE еӯҗеҸҘжҹҘиҜўпјҡзҙўеј•еҸҜд»Ҙеё®еҠ©еҝ«йҖҹжүҫеҲ°з¬ҰеҗҲ
WHEREжқЎд»¶зҡ„иЎҢгҖӮ - жҺ’йҷӨж— ж•ҲиЎҢпјҡйҖҡиҝҮзҙўеј•пјҢеҸҜд»ҘеңЁж—©жңҹзӯӣйҖүжҺүдёҚз¬ҰеҗҲжқЎд»¶зҡ„иЎҢпјҢеҠ йҖҹжҹҘиҜўгҖӮ
- еӨҡеҲ—зҙўеј•е’ҢеүҚзјҖдјҳеҢ–пјҡеҜ№дәҺеӨҡеҲ—зҙўеј•пјҢдјҳеҢ–еҷЁеҸҜд»ҘеҲ©з”Ёзҙўеј•зҡ„е·Ұдҫ§еүҚзјҖпјҲеҚіе·Ұиҫ№зҡ„дёҖдёӘжҲ–еӨҡдёӘеҲ—пјүпјҢзӣҙжҺҘжҹҘжүҫеҢ№й…Қзҡ„иЎҢгҖӮ
- иҝһжҺҘиЎЁж—¶еҝ«йҖҹжҹҘжүҫиЎҢпјҡзҙўеј•еҠ йҖҹдәҶиЎЁиҒ”жҺҘиҝҮзЁӢдёӯе…¶д»–иЎЁзҡ„иЎҢжЈҖзҙўгҖӮ
- жҹҘиҜўжңҖе°ҸеҖјжҲ–жңҖеӨ§еҖјпјҡеҜ№жҢҮе®ҡзҙўеј•еҲ—пјҲдҫӢеҰӮ
MIN(key_col)жҲ–MAX(key_col)пјүзҡ„еҖјжЈҖзҙўж—¶пјҢзҙўеј•еҸҜд»ҘжҸҗдҫӣеҝ«йҖҹи®ҝй—®гҖӮ - жҺ’еәҸе’ҢеҲҶз»„пјҡеҰӮжһңжҺ’еәҸжҲ–еҲҶз»„еҲ—жҳҜзҙўеј•зҡ„е·Ұдҫ§еүҚзјҖпјҢMySQL еҸҜд»ҘзӣҙжҺҘдҪҝз”Ёзҙўеј•пјҢд»ҺиҖҢдјҳеҢ–
ORDER BYе’ҢGROUP BYж“ҚдҪңгҖӮ - йҒҝе…Қи®ҝй—®ж•°жҚ®иЎҢпјҡеңЁжҹҗдәӣжғ…еҶөдёӢпјҢжҹҘиҜўеҸҜд»ҘзӣҙжҺҘд»Һзҙўеј•дёӯиҺ·еҸ–з»“жһңпјҢиҖҢдёҚеҝ…и®ҝй—®ж•°жҚ®иЎҢпјҢиҝҷжҸҗй«ҳдәҶж•ҲзҺҮгҖӮ
2. зҙўеј•зұ»еһӢ
- B-Tree зҙўеј•пјҡMySQL еӨ§еӨҡж•°зҙўеј•зұ»еһӢпјҲеҰӮ
PRIMARY KEYгҖҒUNIQUEгҖҒINDEXгҖҒFULLTEXTпјүеҹәдәҺ B ж ‘еӯҳеӮЁгҖӮ - R-Tree зҙўеј•пјҡз”ЁдәҺз©әй—ҙж•°жҚ®зұ»еһӢгҖӮ
- Hash зҙўеј•пјҡ
MEMORYиЎЁж”ҜжҢҒе“ҲеёҢзҙўеј•гҖӮ - еҖ’жҺ’зҙўеј•пјҡInnoDB зҡ„
FULLTEXTзҙўеј•дҪҝз”ЁеҖ’жҺ’еҲ—иЎЁжқҘеҠ йҖҹж–Үжң¬жҹҘиҜўгҖӮ
3. зҙўеј•зҡ„йҖӮз”ЁжҖ§
- е°ҸиЎЁжҲ–еӨ§иЎЁзҡ„жҠҘиЎЁжҹҘиҜўпјҡеҰӮжһңжҹҘиҜўйңҖиҰҒи®ҝй—®еӨ§йғЁеҲҶжҲ–е…ЁйғЁиЎҢпјҢйЎәеәҸиҜ»еҸ–дјҡжӣҙеҝ«гҖӮйЎәеәҸиҜ»еҸ–иғҪеҮҸе°‘зЈҒзӣҳеҜ»йҒ“ж¬Ўж•°пјҢз”ҡиҮіеңЁдёҚе®Ңе…ЁдҪҝз”ЁжүҖжңүиЎҢж—¶д№ҹжңүеҠ©дәҺжҸҗеҚҮжҖ§иғҪгҖӮ
- дё»й”®еҲ—пјҡдё»й”®еҲ—пјҲжҲ–еҲ—з»„еҗҲпјүдёҠиҮӘеҠЁеҲӣе»әзҙўеј•пјҢиҝҷдәӣзҙўеј•йҖҡиҝҮ
NOT NULLйҷҗеҲ¶дјҳеҢ–жҹҘиҜўжҖ§иғҪгҖӮдҪҝз”ЁInnoDBеӯҳеӮЁеј•ж“Һж—¶пјҢиЎЁж•°жҚ®дјҡжҢүз…§дё»й”®еҲ—йЎәеәҸиҝӣиЎҢзү©зҗҶеӯҳеӮЁпјҢд»ҺиҖҢеҠ йҖҹеҹәдәҺдё»й”®зҡ„жҹҘиҜўгҖӮ
4. жІЎжңүжҳҫи‘—дё»й”®ж—¶зҡ„и§ЈеҶіж–№жЎҲ
- иҮӘеҠЁйҖ’еўһдё»й”®пјҡеҪ“дёҖдёӘиЎЁжІЎжңүиҮӘ然主键时пјҢеҸҜд»ҘеҲӣе»әдёҖдёӘиҮӘеҠЁйҖ’еўһзҡ„еҲ—дҪңдёәдё»й”®гҖӮиҝҷж ·з”ҹжҲҗзҡ„е”ҜдёҖ ID еҸҜеңЁиЎЁиҒ”жҺҘж—¶дҪңдёәеӨ–й”®жҢҮй’ҲжҢҮеҗ‘е…¶д»–иЎЁдёӯзҡ„еҜ№еә”иЎҢгҖӮ
зҙўеј•жҳҜдјҳеҢ– MySQL жҹҘиҜўжҖ§иғҪзҡ„йҮҚиҰҒе·Ҙе…·пјҢдҪҶеңЁе°ҸиЎЁжҲ–йңҖеӨ§и§„жЁЎиҜ»еҸ–зҡ„еӨ§иЎЁдёӯж„Ҹд№үжңүйҷҗгҖӮйҖүжӢ©еҗҲйҖӮзҡ„зҙўеј•зұ»еһӢе’ҢеёғеұҖиғҪжҳҫи‘—жҸҗеҚҮж•°жҚ®еә“зҡ„жҹҘжүҫгҖҒжҺ’еәҸе’ҢиҒ”жҺҘжҖ§иғҪгҖӮ
MySQL зҙўеј•дјҳеҢ–
иҒҡз°Үзҙўеј•е’Ңж•°жҚ®еңЁзЈҒзӣҳдёҠеӯҳеӮЁзҡ„йЎәеәҸдёҖиҮҙпјҢжүҖд»ҘдјҡиҜ»дёҖж¬Ўе°ұжҳҜдёҖж•ҙйЎөпјҢдёҖдёӘиЎЁеҸӘиғҪжңүдёҖдёӘпјҢй»ҳи®Өдё»й”®дёҠе°ұжҳҜиҒҡз°Үзҙўеј•
еҰӮжһңе…Ғи®ёзҙўеј•дёәз©әпјҡжөӘиҙ№1bitпјӣиҝҗиЎҢж—¶дёҖзӣҙеҒҡжЈҖжҹҘпјӣж ‘йҖҖеҢ–жҲҗй“ҫиЎЁ
1. SPATIAL зҙўеј•дјҳеҢ–
- SPATIAL зҙўеј•иҰҒжұӮпјҡMySQL ж”ҜжҢҒеңЁ
NOT NULLзҡ„еҮ дҪ•еҖјеҲ—дёҠеҲӣе»әSPATIALзҙўеј•гҖӮдёәдәҶзЎ®дҝқжҜ”иҫғж“ҚдҪңжӯЈеёёпјҢжҜҸдёӘSPATIALзҙўеј•зҡ„еҲ—еҝ…йЎ»е…·жңүйҷҗе®ҡзҡ„ SRIDпјҲз©әй—ҙеҸӮиҖғзі»з»ҹж ҮиҜҶз¬ҰпјүгҖӮ - SRID йҷҗеҲ¶зҡ„дҪңз”ЁпјҡдјҳеҢ–еҷЁд»…еңЁ SRID йҷҗеҲ¶зҡ„еҲ—дёҠиҖғиҷ‘
SPATIALзҙўеј•гҖӮ- Cartesian SRID зҙўеј•пјҡж”ҜжҢҒз¬ӣеҚЎе°”иҫ№з•ҢжЎҶи®Ўз®—гҖӮ
- Geographic SRID зҙўеј•пјҡж”ҜжҢҒең°зҗҶиҫ№з•ҢжЎҶи®Ўз®—гҖӮ
2. еӨ–й”®дјҳеҢ–
- еҲҶиЎЁзӯ–з•ҘпјҡеҜ№дәҺжӢҘжңүеӨ§йҮҸеҲ—зҡ„иЎЁпјҢеҰӮжһңжҹҘиҜўж—¶ж¶үеҸҠеӨҡз§ҚеҲ—з»„еҗҲпјҢеҸҜд»Ҙе°ҶдёҚеёёз”Ёзҡ„ж•°жҚ®жӢҶеҲҶеҲ°е°‘еҲ—зҡ„зӢ¬з«ӢиЎЁдёӯпјҢеҗҢж—¶еңЁдё»иЎЁдёӯеӨҚеҲ¶иҜҘиЎЁзҡ„дё»й”® ID еҲ—жқҘе…іиҒ”иҝҷдәӣиЎЁгҖӮ
- жҖ§иғҪжҸҗеҚҮпјҡе°ҸиЎЁжӢҘжңүдё»й”®пјҢдҫҝдәҺеҝ«йҖҹжҹҘжүҫж•°жҚ®гҖӮйҖҡиҝҮиҒ”жҺҘж“ҚдҪңеҸҜд»ҘжҹҘиҜўжүҖйңҖзҡ„еҲ—з»„еҗҲпјҢд»ҺиҖҢеҮҸе°‘ I/O 并дјҳеҢ–зј“еӯҳеҲ©з”ЁзҺҮгҖӮе°ҸиЎЁеңЁжҜҸдёӘж•°жҚ®еқ—дёӯиғҪеӯҳеӮЁжӣҙеӨҡиЎҢпјҢиҝҷдҪҝжҹҘиҜўжӣҙй«ҳж•ҲгҖӮ
3. еҲ—зҙўеј•дјҳеҢ–
- зҙўеј•еүҚзјҖпјҡдҪҝз”Ё
col_name(N)иҜӯжі•пјҢеҸҜд»ҘеҜ№еӯ—з¬ҰдёІеҲ—зҡ„еүҚNдёӘеӯ—з¬ҰеҲӣе»әзҙўеј•гҖӮеҜ№иҫғй•ҝзҡ„еӯ—з¬ҰдёІеҲ—иҝӣиЎҢеүҚзјҖзҙўеј•пјҢиғҪжҳҫи‘—еҮҸе°‘зҙўеј•ж–Ү件еӨ§е°ҸгҖӮ- зӨәдҫӢпјҡ
CREATE TABLE test (blob_col BLOB, INDEX(blob_col(10))); - еүҚзјҖй•ҝеәҰйҷҗеҲ¶пјҡ
InnoDBиЎЁзҡ„REDUNDANTжҲ–COMPACTиЎҢж јејҸпјҡжңҖеӨҡ 767 еӯ—иҠӮгҖӮInnoDBиЎЁзҡ„DYNAMICжҲ–COMPRESSEDиЎҢж јејҸпјҡжңҖеӨҡ 3072 еӯ—иҠӮгҖӮMyISAMиЎЁпјҡжңҖеӨҡ 1000 еӯ—иҠӮгҖӮ
- и¶…еҮәеүҚзјҖй•ҝеәҰзҡ„жҗңзҙўпјҡиӢҘжҹҘиҜўжқЎд»¶и¶…еҮәзҙўеј•еүҚзјҖй•ҝеәҰпјҢзҙўеј•д»ҚеҸҜз”ЁдәҺжҺ’йҷӨдёҚеҢ№й…Қзҡ„иЎҢпјҢдҪҷдёӢиЎҢдјҡиҝӣдёҖжӯҘжЈҖжҹҘеҢ№й…ҚжҖ§гҖӮ
- зӨәдҫӢпјҡ
4. FULLTEXT зҙўеј•
- йҖӮз”ЁиҢғеӣҙпјҡ
FULLTEXTзҙўеј•з”ЁдәҺе…Ёж–ҮжҗңзҙўпјҢж”ҜжҢҒInnoDBе’ҢMyISAMеӯҳеӮЁеј•ж“ҺпјҢйҖӮз”ЁдәҺCHARгҖҒVARCHARе’ҢTEXTеҲ—гҖӮFULLTEXTзҙўеј•дҪңз”ЁдәҺж•ҙдёӘеҲ—пјҢдёҚж”ҜжҢҒеҲ—еүҚзјҖзҙўеј•гҖӮ - дјҳеҢ–жҹҘиҜўпјҡ
- жҹҘиҜўж–ҮжЎЈ ID жҲ–ж–ҮжЎЈ ID е’ҢжҺ’еәҸпјҡд»…иҝ”еӣһж–ҮжЎЈ ID жҲ–еёҰжҗңзҙўиҜ„еҲҶзҡ„ ID дјҡжӣҙй«ҳж•ҲгҖӮ
- йҷҗе®ҡз»“жһңзҡ„жҺ’еәҸпјҡ
FULLTEXTжҹҘиҜўжҢүеҫ—еҲҶйҷҚеәҸжҺ’еәҸпјҢдё”дҪҝз”ЁLIMITйҷҗеҲ¶иҝ”еӣһиЎҢж•°гҖӮ - д»…и®Ўж•°жҹҘиҜўпјҡеҰӮеҸӘйңҖиҝ”еӣһеҢ№й…ҚйЎ№зҡ„
COUNT(*)пјҢWHEREеӯҗеҸҘж јејҸеә”дёәWHERE MATCH(text) AGAINST ('search_text')гҖӮ
5. з©әй—ҙзҙўеј•
- ж”ҜжҢҒзҡ„еј•ж“ҺдёҺз»“жһ„пјҡ
MyISAMе’ҢInnoDBж”ҜжҢҒз©әй—ҙж•°жҚ®зұ»еһӢзҡ„R-Treeзҙўеј•гҖӮ- е…¶д»–еӯҳеӮЁеј•ж“ҺпјҲйҷӨ
ARCHIVEеӨ–пјүдҪҝз”ЁB-Treeзҙўеј•з©әй—ҙзұ»еһӢпјҢARCHIVEдёҚж”ҜжҢҒз©әй—ҙзұ»еһӢзҙўеј•гҖӮ
6. MEMORY еӯҳеӮЁеј•ж“Һдёӯзҡ„зҙўеј•
- й»ҳи®Өзҙўеј•зұ»еһӢпјҡ
MEMORYеӯҳеӮЁеј•ж“Һй»ҳи®ӨдҪҝз”ЁHASHзҙўеј•пјҢд№ҹж”ҜжҢҒBTREEзҙўеј•гҖӮ
7. еӨҡеҲ—еӨҚеҗҲзҙўеј•
ж №жҚ®еӨҡдёӘеҲ—е»әз«Ӣзҙўеј•пјҢдјҡжңүдёҚеҗҢеҲ—зҡ„дјҳе…Ҳзә§пјҢжҜ”еҰӮ姓еҗҚзӣёеҗҢжҢүз…§е№ҙйҫ„жҺ’еәҸпјҢе№ҙйҫ„зӣёеҗҢе®үиЈ…еӯҰеҸ·жҺ’еәҸгҖӮеӣ жӯӨпјҢзҙўеј•зҡ„йЎәеәҸйқһеёёйҮҚиҰҒпјҒ
- еӨҚеҗҲзҙўеј•зҡ„еҲӣе»әпјҡMySQL ж”ҜжҢҒеӨҡиҫҫ 16 еҲ—зҡ„еӨҚеҗҲзҙўеј•гҖӮ
- йҖӮз”ЁжҹҘиҜўзұ»еһӢпјҡMySQL еҸҜд»ҘеҜ№еҢ…еҗ«жүҖжңүеӨҚеҗҲзҙўеј•еҲ—гҖҒеүҚеҮ еҲ—гҖҒжҲ–еүҚеҮ дёӘиҝһз»ӯеҲ—зҡ„жҹҘиҜўдҪҝз”ЁеӨҚеҗҲзҙўеј•гҖӮ
- еҲ—йЎәеәҸдјҳеҢ–пјҡжҢүжӯЈзЎ®йЎәеәҸжҢҮе®ҡзҙўеј•еҲ—ж—¶пјҢеҚ•дёҖеӨҚеҗҲзҙўеј•еҸҜд»ҘеҠ йҖҹеӨҡдёӘдёҚеҗҢжҹҘиҜўгҖӮ
8. еӨҡеҲ—еӨҚеҗҲзҙўеј•зҡ„зү№жҖ§
- жң¬иҙЁпјҡеӨҡеҲ—еӨҚеҗҲзҙўеј•еҸҜд»Ҙи§ҶдҪңдёҖдёӘжңүеәҸж•°з»„пјҢе…¶дёӯжҜҸиЎҢжҳҜйҖҡиҝҮе°Ҷзҙўеј•еҲ—зҡ„еҖјдёІиҒ”еҲӣе»әзҡ„гҖӮдҫӢеҰӮпјҢдёӢиЎЁйҖҡиҝҮеңЁ
last_nameе’Ңfirst_nameдёҠе»әз«ӢеӨҚеҗҲзҙўеј•пјҡsql CREATE TABLE test ( id INT NOT NULL, last_name CHAR(30) NOT NULL, first_name CHAR(30) NOT NULL, PRIMARY KEY (id), INDEX name (last_name, first_name) ); - зҙўеј•дҪҝз”ЁеңәжҷҜпјҡеҜ№дәҺдҪҝз”Ё
nameзҙўеј•зҡ„жҹҘиҜўпјҢеҢ…жӢ¬дҪҶдёҚйҷҗдәҺд»ҘдёӢеҮ з§Қжғ…еҶөпјҡ- д»…жҢү
last_nameжҹҘиҜўпјҡSELECT * FROM test WHERE last_name='Jones'; - еҗҢж—¶жҢү
last_nameе’Ңfirst_nameжҹҘиҜўпјҡSELECT * FROM test WHERE last_name='Jones' AND first_name='John'; - дҪҝз”ЁеӨҡдёӘ
first_nameеҖјжҹҘиҜўпјҡSELECT * FROM test WHERE last_name='Jones' AND (first_name='John' OR first_name='Jon'); - иҢғеӣҙжҹҘиҜўпјҡ
SELECT * FROM test WHERE last_name='Jones' AND first_name >= 'M' AND first_name < 'N';
- д»…жҢү
- жңӘдҪҝз”Ёзҙўеј•еңәжҷҜпјҡиӢҘжҹҘиҜўжқЎд»¶дёҚз¬ҰеҗҲзҙўеј•зҡ„е·Ұдҫ§еүҚзјҖпјҢеҲҷж— жі•дҪҝз”Ёзҙўеј•гҖӮдҫӢеҰӮпјҡ
- д»…жҢү
first_nameжҹҘиҜўпјҡSELECT * FROM test WHERE first_name='John'; - дҪҝз”Ё OR жқЎд»¶пјҲж— жі•еҲ©з”Ёзҙўеј•пјүпјҡ
SELECT * FROM test WHERE last_name='Jones' OR first_name='John';
- д»…жҢү
9. е·ҰеүҚзјҖеҺҹеҲҷ
- иӢҘеӯҳеңЁеӨҚеҗҲзҙўеј•
(col1, col2, col3)пјҢеҲҷ MySQL д»…еңЁжҹҘиҜўжқЎд»¶дёӯеҢ…еҗ«зҙўеј•зҡ„е·Ұдҫ§еүҚзјҖж—¶дҪҝз”ЁиҜҘзҙўеј•гҖӮ - зӨәдҫӢжҹҘиҜўпјҡ
SELECT * FROM tbl_name WHERE col1=val1; -- дҪҝз”Ё (col1, col2, col3) зҙўеј•SELECT * FROM tbl_name WHERE col1=val1 AND col2=val2; -- дҪҝз”Ё (col1, col2, col3) зҙўеј•SELECT * FROM tbl_name WHERE col2=val2; -- дёҚдҪҝз”Ё (col1, col2, col3) зҙўеј•SELECT * FROM tbl_name WHERE col2=val2 AND col3=val3; -- дёҚдҪҝз”Ё (col1, col2, col3) зҙўеј•- з”ұдәҺ
(col2)е’Ң(col2, col3)дёҚжҳҜ(col1, col2, col3)зҡ„е·ҰеүҚзјҖпјҢеӣ жӯӨеҗҺдёӨз§ҚжҹҘиҜўдёҚиғҪеҲ©з”ЁиҜҘзҙўеј•гҖӮ
10. B-Tree зҙўеј•зҡ„зү№жҖ§
- ж”ҜжҢҒзҡ„жҜ”иҫғж“ҚдҪңпјҡB-Tree зҙўеј•ж”ҜжҢҒ
=гҖҒ>гҖҒ>=гҖҒ<гҖҒ<=гҖҒBETWEENзӯүиҝҗз®—з¬Ұзҡ„еҲ—жҜ”иҫғгҖӮ - LIKE иҝҗз®—ж”ҜжҢҒпјҡB-Tree зҙўеј•еңЁ
LIKEиҝҗз®—дёӯд»…еңЁLIKEжЁЎејҸдёәеёёйҮҸеӯ—з¬ҰдёІдё”дёҚд»ҘйҖҡй…Қз¬ҰејҖеӨҙж—¶з”ҹж•ҲпјҲжң¬иҙЁд»Қ然жҳҜleftmostпјүгҖӮ- зӨәдҫӢпјҲдҪҝз”Ёзҙўеј•пјүпјҡ
sql SELECT * FROM tbl_name WHERE key_col LIKE 'Patrick%'; SELECT * FROM tbl_name WHERE key_col LIKE 'Pat%_ck%'; - йқһеёёйҮҸеӯ—з¬ҰдёІжҲ–д»ҘйҖҡй…Қз¬ҰејҖеӨҙзҡ„
LIKEжЁЎејҸж— жі•дҪҝз”Ёзҙўеј•пјҡsql SELECT * FROM tbl_name WHERE key_col LIKE '%Patrick%'; -- дёҚдҪҝз”Ёзҙўеј• SELECT * FROM tbl_name WHERE key_col LIKE other_col; -- дёҚдҪҝз”Ёзҙўеј•
- зӨәдҫӢпјҲдҪҝз”Ёзҙўеј•пјүпјҡ
дјҳеҢ–е»әи®®
- дҪҝз”Ёе·ҰеүҚзјҖ规еҲҷпјҡеҲӣе»әеӨҚеҗҲзҙўеј•ж—¶пјҢжҢүеёёз”ЁжҹҘиҜўжқЎд»¶зҡ„е·ҰеүҚзјҖйЎәеәҸжҺ’еҲ—еҲ—пјҢд»ҘжҸҗй«ҳзҙўеј•еҲ©з”ЁзҺҮгҖӮ
- йҒҝе…Қ OR жқЎд»¶пјҡеңЁеӨҚеҗҲзҙўеј•жҹҘиҜўдёӯпјҢе°ҪйҮҸйҒҝе…Қ OR жқЎд»¶пјҢеӣ е…¶ж— жі•жңүж•ҲеҲ©з”Ёзҙўеј•гҖӮ
- еҪ“whereиҜӯеҸҘдёӯдҪҝз”Ёorж“ҚдҪңз¬Ұ并且orдёӨиҫ№зҡ„жқЎд»¶ж¶үеҸҠеҲ°иҮіе°‘дёӨдёӘеӯ—ж®өж—¶пјҢMySQLж— жі•дҪҝз”Ёзҙўеј•пјҢдјҡиҪ¬еҗ‘е…ЁиЎЁжү«жҸҸгҖӮеӣ жӯӨпјҢеә”е°ҪйҮҸйҒҝе…ҚдҪҝз”Ёorж“ҚдҪңз¬ҰгҖӮ
- еҺҹеӣ пјҡеӣ дёәMySQLдёӯзҡ„зҙўеј•жҳҜж №жҚ®жҹҗдёӘеӯ—ж®өиҝӣиЎҢжҺ’еәҸе»әз«Ӣзҡ„гҖӮеҪ“дҪҝз”Ёorж“ҚдҪңз¬ҰпјҢиҜҙжҳҺжңүдёӨдёӘжқЎд»¶е…¶дёӯжҹҗдёӘжқЎд»¶жҲҗз«ӢеҚіеҸҜпјҢиҖҢжҲ‘们дҪҝз”ЁжҹҗдёӘзҙўеј•ж—¶еҸӘиғҪеҲӨж–ӯеҮәеҜ№еә”еӯ—ж®өзҡ„жқЎд»¶жҳҜеҗҰжҲҗз«ӢпјҢеҚідҪҝдёҚжҲҗз«ӢпјҢеҸҰдёҖдёӘжқЎд»¶жҲҗз«Ӣж—¶иҜҘи®°еҪ•д№ҹз¬ҰеҗҲжҲ‘们иҰҒжҹҘиҜўзҡ„з»“жһңгҖӮжүҖд»ҘдҪҝз”Ёзҙўеј•ж— жі•еҒҡеҮәеҲӨж–ӯгҖӮ
- еҗҲзҗҶдҪҝз”Ё LIKEпјҡеҜ№еӯ—з¬ҰдёІеҢ№й…ҚжҹҘиҜўпјҢзЎ®дҝқ LIKE жЁЎејҸеёёйҮҸдёҚд»ҘйҖҡй…Қз¬ҰејҖеӨҙд»Ҙе……еҲҶеҲ©з”Ё B-Tree зҙўеј•гҖӮ
- еҰӮжһңдҪҝз”ЁдәҶlikeдё”д»Ҙ%ејҖеӨҙпјҢеҲҷзҙўеј•дјҡеӨұж•ҲгҖӮпјҲеҸіжЁЎзіҠеӨұж•Ҳпјү
- еҰӮжһңдҪҝз”ЁдәҶlikeдё”д»Ҙ%з»“жқҹпјҢеҲҷзҙўеј•з”ҹж•ҲгҖӮпјҲе·ҰжЁЎзіҠз”ҹж•Ҳпјү
B-ж ‘Treeеј•зү№зӮ№
- еҸҜд»ҘеҲ©з”Ёзҙўеј•зҡ„WHEREеӯҗеҸҘпјҡ
WHERE index_part1=1 AND index_part2=2 AND other_column=3WHERE index_part1='hello' AND index_part3=5- еӨҚеҗҲзҙўеј•д»ҺжңҖе·ҰйғЁеҲҶејҖе§Ӣж—¶жңҖжңүж•ҲгҖӮ
ORиҜӯеҸҘеҸҜиғҪдјҡеҜјиҮҙйғЁеҲҶжҲ–е®Ңе…ЁдёҚдҪҝз”Ёзҙўеј•гҖӮ- дёҚеҲ©з”Ёзҙўеј•зҡ„WHEREеӯҗеҸҘпјҡ
- йқһжңҖе·ҰеүҚзјҖпјҢеҰӮ
index_part2=1 AND index_part3=2 ORжқЎд»¶дёҚеңЁжңҖе·ҰеүҚзјҖзҡ„зҙўеј•дёҠгҖӮ
е“ҲеёҢзҙўеј•зү№зӮ№
- д»…ж”ҜжҢҒзӯүеҖјжҹҘиҜўпјҢйҖӮз”ЁдәҺ
=жҲ–<=>ж“ҚдҪңз¬ҰпјҢдёҚж”ҜжҢҒиҢғеӣҙжҹҘиҜўгҖӮ - ж— жі•дјҳеҢ–ORDER BYпјҢеҸӘиғҪз”ЁдәҺе®Ңж•ҙй”®еҖјзҡ„жҹҘжүҫпјҢе…ёеһӢдәҺвҖңй”®еҖјеӯҳеӮЁвҖқеңәжҷҜгҖӮ
MySQLйҷҚеәҸзҙўеј•
- ж”ҜжҢҒDESCе®ҡд№үпјҢжҸҗеҚҮжҢүйҷҚеәҸжү«жҸҸзҡ„ж•ҲзҺҮгҖӮ
- еӨҡеҲ—дјҳеҢ–пјҡж”ҜжҢҒж··еҗҲеҚҮеәҸе’ҢйҷҚеәҸзҡ„зҙўеј•жү«жҸҸпјҢжҸҗй«ҳжЈҖзҙўж•ҲзҺҮгҖӮ
иЎЁи®ҫи®ЎдјҳеҢ–зӯ–з•Ҙ
иЎЁеҲ—и®ҫи®Ў
- ж•°жҚ®зұ»еһӢжңҖе°ҸеҢ–пјҡдјҳйҖүжӣҙе°Ҹзҡ„ж•°жҚ®зұ»еһӢпјҢдҫӢеҰӮз”Ё
MEDIUMINTжӣҝд»ЈINTгҖӮ - е°ҪйҮҸйҒҝе…ҚNULLеҖјпјҢеҸҜд»ҘжҸҗеҚҮзҙўеј•ж•ҲзҺҮ并иҠӮзңҒеӯҳеӮЁз©әй—ҙгҖӮ
иЎҢж јејҸ
- дҪҝз”Ёзҙ§еҮ‘иЎҢж јејҸпјҲеҰӮ
DYNAMICгҖҒCOMPACTпјүпјҢеҮҸе°‘CHARеҲ—зҡ„еӯҳеӮЁеҚ з”ЁгҖӮVARCHARпјҲеҸҜеҺӢзј©пјҢеҜ№дәҺеҸҳй•ҝеҸҠеҸҜдёәз©әж•°жҚ®жӣҙеҘҪпјү - еҺӢзј©еӯҳеӮЁпјҡеҸҜд»ҘдҪҝз”Ё
ROW_FORMAT=COMPRESSEDжқҘеҮҸе°‘еӯҳеӮЁз©әй—ҙгҖӮ
зҙўеј•и®ҫи®Ў
- дё»й”®и®ҫи®Ўпјҡдё»й”®и¶Ҡзҹӯи¶ҠеҘҪпјҢиҠӮзңҒж¬Ўзә§зҙўеј•зҡ„з©әй—ҙгҖӮ
- еӨҚеҗҲзҙўеј•пјҡж №жҚ®жҹҘиҜўйў‘зҺҮи®ҫи®ЎеӨҚеҗҲзҙўеј•пјҢжңҖеёёз”Ёзҡ„еҲ—ж”ҫеңЁеүҚйқўгҖӮ
- йғЁеҲҶеүҚзјҖзҙўеј•пјҡеҜ№дәҺй•ҝеӯ—з¬ҰдёІеҲ—пјҢеҸҜдҪҝз”ЁеүҚзјҖзҙўеј•пјҢжҸҗй«ҳзҙўеј•е‘ҪдёӯзҺҮгҖӮ
иҝһжҺҘдёҺ规иҢғеҢ–
- жӢҶиЎЁпјҡе°ҶдёҚеёёз”Ёзҡ„ж•°жҚ®еҲҶиЎЁеӯҳеӮЁпјҢжҸҗеҚҮжҹҘиҜўж•ҲзҺҮгҖӮ
- 规иҢғеҢ–пјҡеҮҸе°‘ж•°жҚ®еҶ—дҪҷпјҢдҝқжҢҒ第дёүиҢғејҸпјӣдҪҶеңЁзү№е®ҡеңәжҷҜеҸҜеҸҚ规иҢғеҢ–жҸҗй«ҳжҖ§иғҪгҖӮ
ж•°еҖјдјҳеҢ–
- дјҳе…ҲдҪҝз”Ёж•°еӯ—IDпјҢеҮҸе°‘еӯҳеӮЁе’ҢеҶ…еӯҳеҚ з”ЁпјҢжҸҗеҚҮеҜ№жҜ”йҖҹеәҰгҖӮ
еӯ—з¬ҰдёІдјҳеҢ–
- дҪҝз”ЁдәҢиҝӣеҲ¶жҺ’еәҸеҠ еҝ«еӯ—з¬ҰдёІжҜ”иҫғгҖӮ
- еҲҶзҰ»й•ҝеӯ—з¬ҰдёІеҲ—еҲ°зӢ¬з«ӢиЎЁдёӯпјҢеҮҸе°‘дё»иЎЁзҡ„иЎҢеӨ§е°ҸпјҢжҸҗй«ҳеёёз”ЁжҹҘиҜўжҖ§иғҪгҖӮ
еӨ§ж•°жҚ®зұ»еһӢдјҳеҢ–
- BLOBеҺӢзј©пјҡиҖғиҷ‘еҜ№еӨ§еқ—ж–Үжң¬ж•°жҚ®еҺӢзј©еӯҳеӮЁгҖӮ
- еҲҶзҰ»BLOBеҲ—еҲ°еҚ•зӢ¬иЎЁдёӯпјҢйҖҡиҝҮиҝһжҺҘжҹҘиҜўж—¶жүҚиҜ»еҸ–пјҢеҮҸе°‘еҶ…еӯҳе’ҢI/OиҙҹжӢ…гҖӮ
еңЁжҸ’е…ҘеӨ§йҮҸж•°жҚ®ж—¶пјҢеҸҜд»Ҙе…ій—ӯе”ҜдёҖй”®жЈҖжҹҘпјҲдҪҶжҳҜиҰҒдәәдёәдҝқиҜҒпјүпјҢд№ҹеҸҜд»Ҙи®ҫзҪ®е”ҜдёҖй”®дёҚдёҘж јжҢүйЎәеәҸйҖ’еўһпјҢиҝҷж ·mysqlдјҡдёәжҜҸдёӘзәҝзЁӢеҲҶй…ҚдёҖеқ—иҮӘеўһidпјӣжүҖд»Ҙе°ұдёҚиғҪйҖҡиҝҮжңҖеҗҺдёҖдёӘidеҲӨж–ӯж•°жҚ®еә“зҡ„еӨ§е°Ҹ
й»ҳи®ӨжҜҸжқЎиҜӯеҸҘйғҪеңЁдёҖдёӘдәӢеҠЎдёӯжү§иЎҢпјҢжүҖд»ҘеҸҜд»Ҙи®ҫзҪ®жҳҜеҗҰз«ӢеҲ»жҸҗдәӨпјӣд№ҹеҸҜд»Ҙи®ҫзҪ®еӨҡжқЎиҜӯеҸҘдҪҝз”ЁдёҖдёӘдәӢеҠЎпјҢдҪҶжҳҜиҰҒйҒҝе…ҚеӨ§дәӢеҠЎпјҲеӣһж»ҡиҖ—ж—¶й•ҝпјүпјӣзј“еӯҳеҲ·зӣҳи®ҫзҪ®гҖҒйҖүжӢ©жҖ§еҲ·зӣҳгҖҒеӨ§дәӢеҠЎжӢҶеҲҶпјӣдәӢеҠЎйҡ”зҰ»зә§еҲ«и®ҫзҪ®пјӣеҸӘиҜ»ж“ҚдҪңдёҚдёҠй”Ғ
MySQL еҰӮдҪ•жү“ејҖе’Ңе…ій—ӯиЎЁ
иҝҗиЎҢ mysqladmin status зӨәдҫӢ
жү§иЎҢ mysqladmin status е‘Ҫд»Өж—¶пјҢдјҡжҳҫзӨәзұ»дјјеҰӮдёӢеҶ…е®№пјҡ
Uptime: 426 Running threads: 1 Questions: 11082 Reloads: 1 Open tables: 12Open tables ж•°еҖјеҸҜиғҪдјҡеӨ§дәҺе®һйҷ…иЎЁзҡ„ж•°йҮҸпјҢеӣ дёә MySQL жҳҜеӨҡзәҝзЁӢзҡ„гҖӮеӨҡдёӘе®ўжҲ·з«ҜеҸҜд»ҘеҗҢж—¶жҹҘиҜўеҗҢдёҖдёӘиЎЁпјҢжҜҸдёӘ并еҸ‘дјҡиҜқдјҡзӢ¬з«Ӣжү“ејҖиЎЁпјҢд»ҘдҫҝдҝқжҢҒеҗ„дёӘдјҡиҜқзҠ¶жҖҒдёҖиҮҙгҖӮ
иҝҷз§Қж–№ејҸж¶ҲиҖ—йўқеӨ–еҶ…еӯҳпјҢдҪҶйҖҡеёёжҸҗй«ҳдәҶжҖ§иғҪгҖӮеңЁ MyISAM иЎЁдёӯпјҢжҜҸдёӘе®ўжҲ·з«ҜйңҖиҰҒдёҖдёӘйўқеӨ–зҡ„ж–Ү件жҸҸиҝ°з¬ҰжқҘжү“ејҖж•°жҚ®ж–Ү件гҖӮ
жү“ејҖе’Ңе…ій—ӯиЎЁзҡ„жңәеҲ¶
table_open_cacheе’Ңmax_connectionsпјҡжҺ§еҲ¶жңҚеҠЎеҷЁеҸҜд»ҘдҝқжҢҒжү“ејҖж–Ү件зҡ„жңҖеӨ§ж•°йҮҸгҖӮ- иӢҘеўһеҠ е…¶дёӯд»»дҪ•дёҖйЎ№пјҢеҸҜиғҪдјҡеҸ—еҲ°ж“ҚдҪңзі»з»ҹеҜ№еҚ•иҝӣзЁӢж–Ү件жҸҸиҝ°з¬Ұж•°йҮҸзҡ„йҷҗеҲ¶гҖӮ
- и®Ўз®—зј“еӯҳеӨ§е°ҸпјҡеҜ№ 200 дёӘ并еҸ‘иҝһжҺҘпјҢжҺЁиҚҗи®ҫзҪ®
table_open_cacheиҮіе°‘дёә200 * NпјҢе…¶дёӯNжҳҜжҹҘиҜўдёӯжҜҸдёӘиҝһжҺҘжүҖз”Ёзҡ„жңҖеӨ§иЎЁж•°йҮҸгҖӮ - ж–Ү件жҸҸиҝ°з¬ҰйҷҗеҲ¶пјҡж“ҚдҪңзі»з»ҹеҝ…йЎ»ж”ҜжҢҒжүҖйңҖзҡ„ж–Ү件жҸҸиҝ°з¬Ұж•°йҮҸпјҢеҗҰеҲҷ MySQL еҸҜиғҪеҮәзҺ°жӢ’з»қиҝһжҺҘжҲ–жҹҘиҜўеӨұиҙҘзҡ„жғ…еҶөгҖӮ
иЎЁзј“еӯҳз®ЎзҗҶжңәеҲ¶
- MySQL е…ій—ӯжңӘдҪҝз”Ёзҡ„表并е°Ҷ其移еҮәзј“еӯҳзҡ„жғ…еҶөпјҡ
- еҪ“зј“еӯҳе·Іж»Ўдё”зәҝзЁӢе°қиҜ•жү“ејҖдёҚеңЁзј“еӯҳдёӯзҡ„иЎЁгҖӮ
- еҪ“зј“еӯҳдёӯзҡ„иЎЁж•°йҮҸи¶…иҝҮ
table_open_cacheдё”жҹҗдәӣиЎЁжңӘиў«д»»дҪ•зәҝзЁӢдҪҝз”ЁгҖӮ - еҪ“жү§иЎҢ
FLUSH TABLESгҖҒmysqladmin flush-tablesжҲ–mysqladmin refreshж—¶еҸ‘з”ҹиЎЁеҲ·ж–°гҖӮ
зј“еӯҳз®ЎзҗҶжөҒзЁӢ
- зј“еӯҳж»Ўж—¶пјҡMySQL дјҳе…ҲйҮҠж”ҫеҪ“еүҚжңӘдҪҝз”Ёзҡ„иЎЁпјҢд»ҺжңҖд№…жңӘдҪҝз”Ёзҡ„иЎЁејҖе§ӢгҖӮ
- еҰӮжһңйңҖиҰҒжү“ејҖж–°зҡ„иЎЁдё”зј“еӯҳж»Ўдё”ж— еҸҜйҮҠж”ҫиЎЁж—¶пјҢзј“еӯҳе°ҶжҡӮж—¶жү©еұ•гҖӮ
- зј“еӯҳжү©еұ•жңҹй—ҙпјҡиӢҘжҹҗиЎЁд»ҺвҖңе·Із”ЁвҖқиҪ¬дёәвҖңжңӘз”ЁвҖқзҠ¶жҖҒпјҢиҜҘиЎЁе°Ҷиў«е…ій—ӯ并д»Һзј“еӯҳдёӯ移йҷӨгҖӮ
жЈҖжөӢзј“еӯҳеӨ§е°ҸжҳҜеҗҰдёҚи¶і
- йҖҡиҝҮ
Opened_tablesзҠ¶жҖҒеҸҳйҮҸпјҢжҹҘзңӢиҮӘжңҚеҠЎеҷЁеҗҜеҠЁд»ҘжқҘзҡ„иЎЁжү“ејҖж¬Ўж•°пјҡ
mysql> SHOW GLOBAL STATUS LIKE 'Opened_tables';еҰӮжһңиҜҘеҖјйқһеёёеӨ§жҲ–еўһеҠ иҝ…йҖҹпјҢеҚідҪҝжңӘжү§иЎҢиҝҮеӨҡзҡ„ FLUSH TABLES ж“ҚдҪңпјҢе»әи®®еңЁжңҚеҠЎеҷЁеҗҜеҠЁж—¶еўһеҠ table_open_cacheгҖӮ
еҗҢдёҖж•°жҚ®еә“дёӯеҲӣе»әеӨҡдёӘиЎЁзҡ„зјәзӮ№
- еңЁеҗҢдёҖж•°жҚ®еә“зӣ®еҪ•дёӯеҢ…еҗ«еӨ§йҮҸ MyISAM иЎЁдјҡеҜјиҮҙ жү“ејҖгҖҒе…ій—ӯе’ҢеҲӣе»әж“ҚдҪңеҸҳж…ўгҖӮ
- жү§иЎҢеӨҡдёӘиЎЁзҡ„
SELECTиҜӯеҸҘж—¶пјҢиӢҘиЎЁзј“еӯҳе·Іж»ЎпјҢеҲҷдјҡжңүйўқеӨ–зҡ„ејҖй”ҖпјҢеӣ дёәжҜҸж¬Ўжү“ејҖдёҖдёӘж–°иЎЁйғҪеҸҜиғҪеҜјиҮҙе…ій—ӯеҸҰдёҖдёӘиЎЁгҖӮ - дјҳеҢ–ж–№жі•пјҡеўһеҠ иЎЁзј“еӯҳдёӯзҡ„жқЎзӣ®ж•°д»ҘеҮҸе°‘йў‘з№ҒејҖе…іиЎЁзҡ„ејҖй”ҖгҖӮ
Limits
MySQL ж•°жҚ®еә“е’ҢиЎЁж•°йҮҸзҡ„йҷҗеҲ¶
ж•°жҚ®еә“ж•°йҮҸ
MySQL жң¬иә«жІЎжңүж•°жҚ®еә“ж•°йҮҸзҡ„йҷҗеҲ¶пјҢдҪҶеә•еұӮзҡ„ж–Ү件系з»ҹеҸҜиғҪдјҡеҜ№зӣ®еҪ•ж•°йҮҸжңүйҷҗеҲ¶гҖӮ
иЎЁж•°йҮҸ
- MySQL жң¬иә«д№ҹжІЎжңүиЎЁж•°йҮҸзҡ„йҷҗеҲ¶пјҢдҪҶж–Ү件系з»ҹеҸҜиғҪдјҡйҷҗеҲ¶з”ЁдәҺиЎЁзӨәиЎЁзҡ„ж–Ү件数йҮҸгҖӮ
- дёҚеҗҢзҡ„еӯҳеӮЁеј•ж“ҺеҸҜиғҪдјҡжңүдёҚеҗҢзҡ„йҷҗеҲ¶пјҢдҫӢеҰӮпјҡ
- InnoDB ж”ҜжҢҒжңҖеӨҡ 40 дәҝеј иЎЁгҖӮ
иЎЁеӨ§е°ҸйҷҗеҲ¶
- иЎЁзҡ„жңҖеӨ§жңүж•ҲеӨ§е°ҸйҖҡеёёз”ұж“ҚдҪңзі»з»ҹзҡ„ж–Ү件еӨ§е°ҸйҷҗеҲ¶еҶіе®ҡпјҢиҖҢдёҚжҳҜ MySQL зҡ„еҶ…йғЁйҷҗеҲ¶гҖӮ
- ж“ҚдҪңзі»з»ҹж–Ү件еӨ§е°ҸйҷҗеҲ¶зҡ„жңҖж–°дҝЎжҒҜпјҢеҸӮиҖғж“ҚдҪңзі»з»ҹзҡ„е®ҳж–№ж–ҮжЎЈгҖӮ
- Windows з”ЁжҲ·жіЁж„ҸпјҡFAT е’Ң VFAT (FAT32) дёҚйҖӮеҗҲз”ҹдә§зҺҜеўғпјҢе»әи®®дҪҝз”Ё NTFS ж–Ү件系з»ҹгҖӮ
йҒҮеҲ°вҖңиЎЁе·Іж»ЎвҖқй”ҷиҜҜзҡ„еҺҹеӣ
- зЈҒзӣҳе·Іж»ЎгҖӮ
- дҪҝз”Ё InnoDB иЎЁпјҢдё” InnoDB иЎЁз©әй—ҙж–Ү件已满гҖӮиЎЁз©әй—ҙзҡ„жңҖеӨ§еӨ§е°ҸеҚіжҳҜеҚ•иЎЁзҡ„жңҖеӨ§еӨ§е°ҸпјҢжҺЁиҚҗе°ҶеӨ§дәҺ 1TB зҡ„иЎЁеҲ’еҲҶдёәеӨҡдёӘиЎЁз©әй—ҙж–Ү件гҖӮ
- ж“ҚдҪңзі»з»ҹж–Ү件еӨ§е°ҸйҷҗеҲ¶гҖӮдҫӢеҰӮпјҢдҪҝз”Ё MyISAM иЎЁпјҢж“ҚдҪңзі»з»ҹж”ҜжҢҒзҡ„жңҖеӨ§ж–Ү件еӨ§е°Ҹдёә 2GBпјҢйӮЈд№ҲеҪ“ж•°жҚ®ж–Ү件жҲ–зҙўеј•ж–Ү件иҫҫеҲ°жӯӨйҷҗеҲ¶ж—¶е°ұдјҡеҮәй”ҷгҖӮ
- дҪҝз”Ё MyISAM иЎЁпјҢдё”иЎЁз©әй—ҙеӨ§е°Ҹи¶…иҝҮдәҶеҶ…йғЁжҢҮй’ҲжүҖе…Ғи®ёзҡ„жңҖеӨ§з©әй—ҙгҖӮ
- й»ҳи®Өжғ…еҶөдёӢпјҢMyISAM ж”ҜжҢҒж•°жҚ®ж–Ү件е’Ңзҙўеј•ж–Ү件зҡ„жңҖеӨ§е°әеҜёдёә 256TBпјҢеҸҜд»ҘеўһеӨ§еҲ°жңҖеӨ§ 65,536TBпјҲ256\^7 вҲ’ 1 еӯ—иҠӮпјүгҖӮ
еҲ—ж•°йҷҗеҲ¶
жҜҸиЎЁзҡ„жңҖеӨ§еҲ—ж•°
- MySQL еҜ№еҚ•иЎЁзҡ„жңҖеӨ§еҲ—ж•°йҷҗеҲ¶дёә 4096 еҲ—пјҢдҪҶе…·дҪ“йҷҗеҲ¶еӣ дёҚеҗҢеӣ зҙ иҖҢејӮпјҡ
- иЎҢзҡ„жңҖеӨ§еӨ§е°ҸйҷҗеҲ¶дәҶеҲ—зҡ„жҖ»ж•°е’ҢеӨ§е°ҸгҖӮжүҖжңүеҲ—зҡ„й•ҝеәҰжҖ»е’ҢдёҚиғҪи¶…иҝҮиҜҘйҷҗеҲ¶гҖӮ
- еҚ•еҲ—зҡ„еӯҳеӮЁйңҖжұӮеҪұе“ҚдәҶз»ҷе®ҡжңҖеӨ§иЎҢеӨ§е°ҸеҶ…еҸҜд»Ҙе®№зәізҡ„еҲ—ж•°гҖӮ
- еӯҳеӮЁеј•ж“ҺйҷҗеҲ¶пјҡдҫӢеҰӮпјҢInnoDB иЎЁжҜҸиЎЁжңҖеӨ§еҲ—ж•°дёә 1017гҖӮ
- еҠҹиғҪй”®йғЁеҲҶдҪңдёәиҷҡжӢҹз”ҹжҲҗзҡ„йҡҗи—ҸеҲ—е®һзҺ°пјҢеӣ жӯӨиЎЁдёӯжҜҸдёӘеҠҹиғҪй”®йғЁеҲҶйғҪи®Ўз®—еңЁеҲ—жҖ»ж•°йҷҗеҲ¶еҶ…гҖӮ
иЎҢеӨ§е°ҸйҷҗеҲ¶
иЎҢеӨ§е°Ҹзҡ„йҷҗеҲ¶еӣ зҙ
- еҶ…йғЁиЎЁзӨәпјҡMySQL иЎЁзҡ„еҶ…йғЁиЎЁзӨәжңҖеӨ§иЎҢеӨ§е°ҸйҷҗеҲ¶дёә 65,535 еӯ—иҠӮпјҢеҚідҪҝеӯҳеӮЁеј•ж“ҺиғҪж”ҜжҢҒжӣҙеӨ§иЎҢж•°гҖӮ
- BLOB е’Ң TEXT еҲ—еҸӘеҚ з”Ё 9 еҲ° 12 еӯ—иҠӮпјҢеӣ дёәе…¶еҶ…е®№еӯҳеӮЁеңЁиЎҢеӨ–гҖӮ
- InnoDB иЎҢеӨ§е°ҸпјҡInnoDB иЎЁзҡ„ж•°жҚ®еңЁжң¬ең°ж•°жҚ®еә“йЎөдёӯеӯҳеӮЁпјҢеҜ№дәҺ 4KBгҖҒ8KBгҖҒ16KB е’Ң 32KB йЎөеӨ§е°ҸпјҢиЎҢеӨ§е°ҸйҷҗеҲ¶з•Ҙе°ҸдәҺдёҖйЎөзҡ„дёҖеҚҠгҖӮ
- дёҚеҗҢеӯҳеӮЁж јејҸеҚ з”ЁдёҚеҗҢзҡ„йЎөеӨҙе’ҢйЎөе°ҫз©әй—ҙпјҢеҪұе“ҚеҸҜз”ЁдәҺиЎҢеӯҳеӮЁзҡ„з©әй—ҙгҖӮ
CHARдёҚеҸҜеҺӢзј©пјҢе»әиЎЁж—¶и¶…иҝҮpageзҡ„дёҖеҚҠе°ұжҠҘй”ҷпјӣVARCHARеҸҜеҺӢзј©пјҢжүҖд»ҘVARCHARиҝҳдјҡеҮәзҺ°е»әиЎЁдёҚжҠҘй”ҷдҪҶжҸ’е…ҘжҠҘй”ҷзҡ„жғ…еҶөпјҢжҲ‘们еҸҜд»ҘйҖҡиҝҮVARCHARе»әдёҖдёӘеӨ§е°ҸжҺҘиҝ‘64KBзҡ„иЎЁпјҢдҪҶжҳҜжҸ’е…Ҙж•°жҚ®еҲ°иҫҫpageеӨ§е°Ҹзҡ„дёҖеҚҠж—¶е°ұдјҡжҠҘй”ҷ
иЎҢеӨ§е°ҸйҷҗеҲ¶зӨәдҫӢ
зӨәдҫӢ 1: з”ұдәҺиЎҢеӨ§е°Ҹи¶…иҝҮйҷҗеҲ¶пјҢйңҖе°ҶжҹҗдәӣеҲ—жӣҙж”№дёә TEXT жҲ– BLOB зұ»еһӢгҖӮ
mysql> CREATE TABLE t (
a VARCHAR(10000), b VARCHAR(10000),
c VARCHAR(10000), d VARCHAR(10000),
e VARCHAR(10000), f VARCHAR(10000),
g VARCHAR(6000)
) ENGINE=InnoDB CHARACTER SET latin1;- й”ҷиҜҜ: и¶…еҮә InnoDB иЎЁзұ»еһӢзҡ„жңҖеӨ§иЎҢеӨ§е°ҸйҷҗеҲ¶пјҲ65535 еӯ—иҠӮпјүпјҢе»әи®®е°ҶйғЁеҲҶеҲ—жӣҙж”№дёә
TEXTжҲ–BLOBзұ»еһӢгҖӮ
зӨәдҫӢ 2: жӣҙж”№ g еҲ—дёә TEXTпјҢи§ЈеҶідәҶиЎҢеӨ§е°Ҹи¶…йҷҗзҡ„й—®йўҳгҖӮ
mysql> CREATE TABLE t (
a VARCHAR(10000), b VARCHAR(10000),
c VARCHAR(10000), d VARCHAR(10000),
e VARCHAR(10000), f VARCHAR(10000),
g TEXT(6000)
) ENGINE=InnoDB CHARACTER SET latin1;зӨәдҫӢ 3: иЎҢеӨ§е°ҸйҷҗеҲ¶зҡ„иҝӣдёҖжӯҘжөӢиҜ•гҖӮ
mysql> CREATE TABLE t1 (
c1 VARCHAR(32765) NOT NULL,
c2 VARCHAR(32766) NOT NULL
) ENGINE=InnoDB CHARACTER SET latin1;- жҲҗеҠҹ: жІЎжңүи¶…иҝҮ InnoDB зҡ„иЎҢеӨ§е°ҸйҷҗеҲ¶пјҢеҲҡеҘҪеү©дёӨдёӘеӯ—иҠӮз”ЁдәҺеӯҳеӮЁејҖй”ҖгҖӮ
зӨәдҫӢ 4: еҪ“жҠҠйқһз©әж”№дёәз©ә
mysql> CREATE TABLE t3 (
c1 VARCHAR(32765) NULL,
c2 VARCHAR(32766) NULL
) ENGINE = MyISAM CHARACTER SET latin1; - еӨұиҙҘ: еҪ“еҸҜд»Ҙдёәз©әж—¶йңҖиҰҒжңүйўқеӨ–зҡ„ејҖй”ҖгҖӮ
зӨәдҫӢ 5: е°қиҜ•е®ҡд№үеҚ•еҲ—зҡ„и¶…еӨ§ VARCHAR еӯ—з¬ҰдёІгҖӮ
mysql> CREATE TABLE t2 (
c1 VARCHAR(65535) NOT NULL
) ENGINE=InnoDB CHARACTER SET latin1;- й”ҷиҜҜ: иЎҢеӨ§е°Ҹи¶…йҷҗпјҢеӣ дёәеҢ…еҗ«дәҶеӯҳеӮЁејҖй”ҖпјҢе»әи®®ж”№з”Ё
TEXTжҲ–BLOBзұ»еһӢгҖӮ
зӨәдҫӢ 6: MyISAM еӯҳеӮЁж јејҸзҡ„иЎҢеӨ§е°ҸжөӢиҜ•гҖӮ
mysql> CREATE TABLE t4 (
c1 CHAR(255), c2 CHAR(255), ..., c33 CHAR(255)
) ENGINE=InnoDB ROW_FORMAT=DYNAMIC DEFAULT CHARSET latin1;- й”ҷиҜҜ: 255 * 33 = 8415иЎҢеӨ§е°Ҹи¶…йҷҗ (>8126 еӯ—иҠӮ)пјҢе»әи®®е°ҶйғЁеҲҶеҲ—ж”№дёә
TEXTжҲ–BLOBзұ»еһӢгҖӮCHARжҳҜеҜ№йҪҗзҡ„пјҢVARCHARжҳҜеҺӢзј©зҡ„
дјҳеҢ– InnoDB иЎЁ
еӯҳеӮЁеёғеұҖдјҳеҢ–
- еҪ“ж•°жҚ®йҮҸзЁіе®ҡжҲ–еўһй•ҝиҮідёҖе®ҡ规模时пјҢеҸҜдҪҝз”Ё
OPTIMIZE TABLEиҜӯеҸҘйҮҚж–°з»„з»ҮиЎЁе’ҢеҺӢзј©з©әй—ҙпјҢеҮҸе°‘зҙўеј•зҡ„зўҺзүҮеҢ–пјҢд»ҺиҖҢжҸҗеҚҮжҖ§иғҪгҖӮ - еҰӮжһңдё»й”®иҝҮй•ҝпјҲеҰӮз»„еҗҲеӨҡдёӘеҲ—з»„жҲҗеӨҚжқӮдё»й”®пјүпјҢе°ҶжөӘиҙ№еӨ§йҮҸзЈҒзӣҳз©әй—ҙгҖӮжҺЁиҚҗдҪҝз”ЁиҮӘеўһеҲ— (
AUTO_INCREMENT) дҪңдёәдё»й”®пјҢжҲ–д»…зҙўеј•VARCHARеҲ—зҡ„еүҚзјҖд»ҘиҠӮзңҒз©әй—ҙгҖӮ CHARеӣәе®ҡй•ҝеәҰдјҡеҚ з”ЁжӣҙеӨҡеӯҳеӮЁз©әй—ҙпјҢиҖҢVARCHARйҖӮеҗҲеӯҳеӮЁеҸҜеҸҳй•ҝеәҰеӯ—з¬ҰдёІпјҢе°Өе…¶жҳҜеҢ…еҗ«еӨ§йҮҸNULLеҖјзҡ„еҲ—гҖӮ- еҜ№дәҺеҢ…еҗ«еӨ§йҮҸйҮҚеӨҚж–Үжң¬жҲ–ж•°еӯ—зҡ„иЎЁпјҢеҸҜиҖғиҷ‘дҪҝз”Ё
COMPRESSEDиЎҢж јејҸжқҘеҺӢзј©ж•°жҚ®гҖӮдҫӢеҰӮеӯҰеҸ·5220319еҸҜд»ҘеҺӢзј©гҖӮ
дәӢеҠЎз®ЎзҗҶдјҳеҢ–
AUTOCOMMIT=1жҳҜ MySQL й»ҳи®Өи®ҫзҪ®пјҢдҪҶеңЁз№ҒеҝҷжңҚеҠЎеҷЁдёҠеҸҜиғҪйҖ жҲҗжҖ§иғҪ瓶йўҲгҖӮе»әи®®е°ҶеӨҡдёӘзӣёе…ізҡ„ж•°жҚ®ж“ҚдҪңж”ҫе…ҘеҚ•дёӘдәӢеҠЎпјҢ并еңЁж“ҚдҪңз»“жқҹж—¶жү§иЎҢCOMMITгҖӮ- еҜ№дәҺд»…еҢ…еҗ«
SELECTжҹҘиҜўзҡ„дәӢеҠЎпјҢеҸҜд»ҘејҖеҗҜAUTOCOMMITд»ҘиҜҶеҲ«дёәеҸӘиҜ»дәӢеҠЎпјҢд»ҺиҖҢжҸҗй«ҳжҖ§иғҪгҖӮ - йҒҝе…ҚеңЁжҸ’е…ҘгҖҒжӣҙж–°жҲ–еҲ йҷӨеӨ§йҮҸж•°жҚ®еҗҺжү§иЎҢеӣһж»ҡпјҢиҝҷж ·дјҡдёҘйҮҚеҪұе“ҚжҖ§иғҪпјҢ并еҸҜиғҪеҜјиҮҙжҜ”еҺҹе§Ӣж“ҚдҪңжӣҙй•ҝзҡ„еӣһж»ҡж—¶й—ҙгҖӮеҚідҪҝеңЁеӣһж»ҡиҝҮзЁӢдёӯз»Ҳжӯўж•°жҚ®еә“иҝӣзЁӢпјҢжңҚеҠЎеҷЁйҮҚеҗҜж—¶д№ҹдјҡйҮҚж–°ејҖе§Ӣеӣһж»ҡгҖӮ
иҜ»дәӢеҠЎдјҳеҢ–
- еҜ№дәҺеҸӘиҜ»дәӢеҠЎпјҢеҸҜдҪҝз”Ё
START TRANSACTION READ ONLYиҜӯеҸҘпјҢеҮҸе°‘дәӢеҠЎеӨ„зҗҶзҡ„ејҖй”ҖгҖӮ - еҰӮжһңдәӢеҠЎеҸӘеҢ…еҗ«йқһй”Ғе®ҡзҡ„
SELECTиҜӯеҸҘпјҢеҸҜд»ҘејҖеҗҜAUTOCOMMITи®ҫзҪ®пјҢд»Ҙз®ҖеҢ–дәӢеҠЎз®ЎзҗҶ并жҸҗеҚҮжҹҘиҜўж•ҲзҺҮгҖӮ
жү№йҮҸж•°жҚ®еҜје…Ҙ
- еңЁеҜје…Ҙж•°жҚ®ж—¶е…ій—ӯ
autocommitжЁЎејҸпјҢеӣ дёәжҜҸж¬ЎжҸ’е…ҘйғҪдјҡеҲ·ж–°ж—Ҙеҝ—гҖӮ
SET autocommit=0;
-- жү№йҮҸеҜје…Ҙ SQL иҜӯеҸҘ
COMMIT;- еҜ№дәҺе…·жңү
UNIQUEзәҰжқҹзҡ„дәҢзә§зҙўеј•пјҢеҜје…ҘеүҚеҸҜжҡӮж—¶е…ій—ӯе”ҜдёҖжҖ§жЈҖжҹҘпјҢйҒҝе…ҚеӨ§йҮҸзЈҒзӣҳ I/OгҖӮ
SET unique_checks=0;
-- жү№йҮҸеҜје…Ҙ SQL иҜӯеҸҘ
SET unique_checks=1;- еҰӮжһңжңүеӨ–й”®зәҰжқҹпјҢеҜје…Ҙж—¶еҸҜе…ій—ӯеӨ–й”®жЈҖжҹҘпјҢиҠӮзңҒзЈҒзӣҳ I/OгҖӮ
SET foreign_key_checks=0;
-- жү№йҮҸеҜје…Ҙ SQL иҜӯеҸҘ
SET foreign_key_checks=1;InnoDB жҹҘиҜўдјҳеҢ–
- жҜҸдёӘ
InnoDBиЎЁйғҪйңҖиҰҒдё»й”®пјҢдёҚеә”еҢ…еҗ«иҝҮеӨҡжҲ–иҝҮй•ҝзҡ„еҲ—пјҢд»Ҙе…ҚйҮҚеӨҚеҖјеңЁдәҢзә§зҙўеј•дёӯеҚ з”ЁиҝҮеӨҡз©әй—ҙгҖӮ - дёҚиҰҒдёәжҜҸеҲ—еҲӣе»әеҚ•зӢ¬зҡ„дәҢзә§зҙўеј•пјҢеӣ дёәжҹҘиҜўеҸӘиғҪдҪҝз”ЁдёҖдёӘзҙўеј•гҖӮеҜ№дәҺеёёз”Ёз»„еҗҲжҹҘиҜўпјҢеҸҜд»ҘдҪҝз”ЁеӨҡеҲ—з»„еҗҲзҙўеј•пјҢиҖҢйқһеҚ•еҲ—зҙўеј•гҖӮ
- иӢҘеҲ—дёҚеҸҜеҢ…еҗ«
NULLеҖјпјҢе»әи®®еңЁеҲӣе»әиЎЁж—¶еЈ°жҳҺдёәNOT NULLпјҲеҚ з”Ёз©әй—ҙпјүгҖӮ
еңЁ MySQL дёӯпјҢеҰӮжһңиҰҒдёҖж¬ЎжҸ’е…ҘеӨҡиЎҢж•°жҚ®пјҢеҸҜд»ҘдҪҝз”ЁеӨҡиЎҢ INSERT иҜӯжі•пјҢиҝҷз§Қж–№ејҸдёҚд»…иғҪеҮҸе°‘дёҺжңҚеҠЎеҷЁзҡ„йҖҡдҝЎејҖй”ҖпјҢиҝҳеҸҜд»ҘжҸҗй«ҳжҸ’е…Ҙж•ҲзҺҮгҖӮиҜӯжі•еҰӮдёӢпјҡ
INSERT INTO yourtable VALUES (1,2), (5,5), ...;еӨҡиЎҢ INSERT иҜӯжі•зҡ„е·ҘдҪңеҺҹзҗҶ
еңЁдёҖж¬Ў INSERT ж“ҚдҪңдёӯжҸ’е…ҘеӨҡиЎҢпјҢе®ўжҲ·з«ҜдёҺж•°жҚ®еә“жңҚеҠЎеҷЁд№Ӣй—ҙзҡ„йҖҡдҝЎдјҡеҮҸе°‘пјҢеҸӘйңҖиҰҒдёҖж¬Ўе‘Ҫд»ӨеҚіеҸҜжҸ’е…ҘеӨҡиЎҢж•°жҚ®гҖӮиҝҷз§Қж–№жі•иғҪеҮҸе°‘ SQL иҜӯеҸҘзҡ„еӨ„зҗҶејҖй”ҖпјҢиҠӮзңҒйҖҡдҝЎж—¶й—ҙпјҢжҸҗеҚҮжҸ’е…ҘйҖҹеәҰгҖӮиҝҷз§ҚдјҳеҢ–еҜ№дәҺ д»»дҪ•еӯҳеӮЁеј•ж“ҺпјҲдёҚд»…йҷҗдәҺ InnoDBпјү йғҪйҖӮз”ЁгҖӮ
innodb_autoinc_lock_mode и®ҫзҪ®
еҜ№дәҺеҢ…еҗ«иҮӘеўһеҲ—пјҲauto-incrementпјүзҡ„иЎЁпјҢеңЁжү§иЎҢжү№йҮҸжҸ’е…Ҙж—¶пјҢinnodb_autoinc_lock_mode и®ҫзҪ®дёә 2пјҲinterleaved жЁЎејҸпјүжҜ”й»ҳи®Өзҡ„ 1пјҲconsecutive жЁЎејҸпјүжӣҙй«ҳж•ҲпјҢе°Өе…¶еңЁе№¶еҸ‘зҺҜеўғдёӢгҖӮ
еҗ„дёӘжЁЎејҸзҡ„и§ЈйҮҠпјҡ
- жЁЎејҸ 1пјҲconsecutiveпјүпјҡеңЁй»ҳи®ӨжЁЎејҸдёӢпјҢInnoDB дёәжҜҸж¬ЎиҮӘеўһеҖјеҲҶй…ҚдёҖдёӘе…ЁеұҖй”ҒгҖӮиҝҷж„Ҹе‘ізқҖеҚідҫҝжҳҜеңЁжү№йҮҸжҸ’е…ҘдёӯпјҢжңҚеҠЎеҷЁд№ҹдјҡд»ҘйҖ’еўһзҡ„йЎәеәҸеҲҶй…ҚжҜҸдёҖдёӘиҮӘеўһ IDпјҢзЎ®дҝқйЎәеәҸиҝһз»ӯгҖӮиҝҷз§Қй”Ғзҡ„ж–№ејҸеҮҸе°‘дәҶжҸ’е…Ҙж—¶зҡ„еҶІзӘҒпјҢйҖӮз”ЁдәҺеҚ•зәҝзЁӢжҲ–дёҚеӨӘйў‘з№Ғзҡ„иҮӘеўһж“ҚдҪңеңәжҷҜгҖӮ
- жЁЎејҸ 2пјҲinterleavedпјүпјҡеңЁ interleaved жЁЎејҸдёӢпјҢInnoDB еҸӘдјҡеңЁиҺ·еҸ–иҮӘеўһеҖјж—¶з”іиҜ·дёҖж¬Ўй”ҒпјҢ然еҗҺз«ӢеҚійҮҠж”ҫгҖӮиҝҷз§Қж–№ејҸжӣҙйҖӮеҗҲ并еҸ‘жҸ’е…Ҙж“ҚдҪңпјҢеӣ дёәдёҚйңҖиҰҒдёҘж јжҢүз…§йЎәеәҸеҲҶй…ҚиҮӘеўһеҖјпјҢеҸӘиҰҒ ID жҳҜе”ҜдёҖзҡ„еҚіеҸҜгҖӮиҝҷз§Қж–№ејҸе…Ғи®ёжү№йҮҸжҸ’е…Ҙж—¶еҗҢж—¶еҲҶй…ҚеӨҡдёӘиҮӘеўһеҖјпјҢеҮҸе°‘й”Ғз«һдәүгҖӮ
дёәд»Җд№ҲйҖүжӢ©жЁЎејҸ 2пјҲinterleavedпјү
еңЁжү№йҮҸжҸ’е…ҘдёӯпјҢеҰӮжһңдҪҝз”Ёй»ҳи®Өзҡ„жЁЎејҸ 1пјҲconsecutiveпјүпјҢзі»з»ҹдјҡйҖҗдёӘй”Ғе®ҡжҜҸдёӘиҮӘеўһеҖјпјҢеҚідҫҝжҳҜжү№йҮҸжҸ’е…ҘпјҢд»Қ然дјҡйЎәеәҸеҲҶй…ҚпјҢиҝҷдјҡеј•е…ҘйўқеӨ–зҡ„й”Ғз«һдәүгҖӮжЁЎејҸ 2пјҲinterleavedпјүеҲҷе…Ғи®ёжү№йҮҸжҸ’е…Ҙзҡ„иҮӘеўһеҖје№¶иЎҢеҲҶй…ҚпјҢдёҚиҰҒжұӮйЎәеәҸдёҖиҮҙпјҢеӣ жӯӨжҸ’е…ҘйҖҹеәҰжӣҙеҝ«гҖҒж•ҲзҺҮжӣҙй«ҳгҖӮ
InnoDB зҡ„зЈҒзӣҳ I/O дјҳеҢ–
зј“еҶІжұ зҡ„дҪҝз”Ё
- еўһеҠ зј“еҶІжұ еӨ§е°Ҹе°Ҷж•°жҚ®зј“еӯҳпјҢйҒҝе…ҚжҜҸж¬ЎжҹҘиҜўйғҪи®ҝй—®зЈҒзӣҳгҖӮ
- дҪҝз”Ё
innodb_buffer_pool_sizeйҖүйЎ№жҢҮе®ҡзј“еҶІжұ еӨ§е°ҸгҖӮ
еҲ·ж–°ж–№жі•зҡ„и°ғж•ҙ:иӢҘж•°жҚ®еә“еҶҷе…ҘжҖ§иғҪдёҚи¶іпјҢи°ғж•ҙ innodb_flush_method д»ҘдјҳеҢ–еҶҷе…ҘжҖ§иғҪгҖӮ
й…ҚзҪ® fsync йҳҲеҖјпјҡinnodb_fsync_threshold еҸҜи®ҫзҪ®и§ҰеҸ‘йҳҲеҖјпјҢд»ҘдҫҝеҲҶж•ЈеҲ·ж–°еҶҷе…ҘпјҢйҒҝе…ҚеҗҢдёҖж—¶еҲ»еӨ§йҮҸ I/O ж“ҚдҪңгҖӮ
иҖғиҷ‘йқһж—ӢиҪ¬еӯҳеӮЁ
- еҜ№дәҺйҡҸжңә I/O ж“ҚдҪңпјҢе»әи®®дҪҝз”Ёйқһж—ӢиҪ¬еӯҳеӮЁпјҲеҰӮ SSDпјүпјҢиҖҢж—ӢиҪ¬еӯҳеӮЁжӣҙйҖӮеҗҲйЎәеәҸ I/O ж“ҚдҪңгҖӮдёҚз”Ёжңәжў°зЎ¬зӣҳ
- дёҚеҗҢж–Ү件зұ»еһӢеҸҜеҲҶеёғеңЁдёҚеҗҢзҡ„еӯҳеӮЁи®ҫеӨҮдёҠпјҢеҰӮ
file-per-tableиЎЁз©әй—ҙж–Ү件йҖӮеҗҲйҡҸжңә I/OпјҢиҖҢзі»з»ҹиЎЁз©әй—ҙгҖҒеҸҢеҶҷзј“еҶІе’ҢйҮҚеҒҡж—Ҙеҝ—ж–Ү件йҖӮеҗҲйЎәеәҸ I/OгҖӮ
еўһеҠ I/O е®№йҮҸ:иӢҘз”ұдәҺжЈҖжҹҘзӮ№ж“ҚдҪңеҜјиҮҙеҗһеҗҗйҮҸе®ҡжңҹдёӢйҷҚпјҢеўһеӨ§ innodb_io_capacity зҡ„еҖјпјҢеҸҜйҒҝе…Қз§ҜеҺӢйҖ жҲҗзҡ„жҖ§иғҪдёӢйҷҚгҖӮ
InnoDB зҡ„ DDL ж“ҚдҪңдјҳеҢ–
- дҪҝз”Ё
TRUNCATE TABLEиҖҢйқһDELETE FROMжё…з©әиЎЁпјҢдҪҶиӢҘеӯҳеңЁеӨ–й”®зәҰжқҹпјҢTRUNCATEдјҡйҖҖеҢ–дёәDELETEгҖӮ - дё»й”®еңЁ InnoDB дёӯжҳҜиЎЁз»“жһ„зҡ„ж ёеҝғпјҢеӣ жӯӨеә”еңЁеҲӣе»әиЎЁж—¶зЎ®е®ҡдё»й”®пјҢе°ҪйҮҸйҒҝе…ҚеҗҺз»ӯзҡ„дё»й”®дҝ®ж”№гҖӮ
дјҳеҢ– MEMORY иЎЁ
- MEMORY иЎЁйҖӮз”ЁдәҺеӯҳеӮЁйқһе…ій”®жҖ§ж•°жҚ®пјҡеҸҜд»Ҙдёәйў‘з№Ғи®ҝй—®дҪҶдёҚйңҖиҰҒжҢҒд№…еҢ–зҡ„дёҙж—¶ж•°жҚ®жҸҗдҫӣй«ҳйҖҹеӯҳеӮЁгҖӮз”ұдәҺж•°жҚ®еӯҳеӮЁеңЁеҶ…еӯҳдёӯпјҢеӣ жӯӨеңЁж•°жҚ®еә“йҮҚеҗҜжҲ–ж–ӯз”өж—¶е°ҶдјҡдёўеӨұгҖӮ
MyISAM иЎЁдјҳеҢ–
MyISAM еј•ж“ҺиҷҪ然йҖҗжёҗиў« InnoDB жӣҝд»ЈпјҢдҪҶд»Қ然еңЁдёҖдәӣзү№е®ҡеңәжҷҜдёӢеә”з”ЁпјҲеҰӮе…Ёж–ҮжЈҖзҙўе’ҢеҸӘиҜ»иЎЁпјүпјҢеӣ жӯӨдјҳеҢ–зӯ–з•Ҙдҫқ然жңүз”Ёпјҡ
иЎЁзўҺзүҮж•ҙзҗҶ
- дҪҝз”Ё
OPTIMIZE TABLEиҜӯеҸҘж•ҙзҗҶ MyISAM иЎЁд»ҘеҮҸе°‘зўҺзүҮпјҢзү№еҲ«жҳҜйў‘з№ҒеҲ йҷӨе’Ңжӣҙж–°зҡ„иЎЁдјҡдә§з”ҹзўҺзүҮгҖӮ
延иҝҹеҶҷе…Ҙ
- и®ҫзҪ®
delay_key_writeдёәONеҸҜеҮҸе°‘й”®зј“еӯҳзҡ„зЈҒзӣҳ I/OпјҢдҪҶеңЁж•°жҚ®еә“еҙ©жәғж—¶жңүдёўеӨұж•°жҚ®зҡ„йЈҺйҷ©пјҢеӣ жӯӨд»…йҖӮеҗҲйқһе…ій”®ж•°жҚ®гҖӮ
зҙўеј•зј“еӯҳ
- дҪҝз”Ё
key_buffer_sizeеҸӮж•°еўһеҠ й”®зј“еҶІеҢәеӨ§е°ҸпјҢеҸҜеҠ йҖҹзҙўеј•ж“ҚдҪңпјҢзү№еҲ«йҖӮз”ЁдәҺд»Ҙ MyISAM дёәдё»зҡ„иҜ»еҜҶйӣҶеһӢеә”з”ЁеңәжҷҜгҖӮ
иҜ»еҶҷй”ҒжңәеҲ¶
- MyISAM дёҚж”ҜжҢҒиЎҢзә§й”ҒпјҢеҸӘж”ҜжҢҒиЎЁзә§й”ҒпјҢе®№жҳ“еңЁй«ҳ并еҸ‘дёӢеҸ‘з”ҹй”Ғдәүз”ЁгҖӮиӢҘиЎЁдёҚеҶҚжӣҙж–°пјҢеҸҜд»ҘеңЁеә”з”ЁеұӮйҖҡиҝҮеҗҲйҖӮзҡ„еҲҶеҢәзӯ–з•ҘжқҘйҷҚдҪҺй”Ғз«һдәүгҖӮ
еҶ…еӯҳдјҳеҢ– (MEMORY) иЎЁзҡ„дјҳеҢ–
зҙўеј•йҖүжӢ©
- MEMORY иЎЁж”ҜжҢҒе“ҲеёҢзҙўеј•е’Ң BTree зҙўеј•гҖӮеҜ№дәҺзӯүеҖјжҹҘиҜўпјҲдҫӢеҰӮ
=пјүпјҢе“ҲеёҢзҙўеј•иҫғ BTree зҙўеј•жӣҙеҝ«пјҢдҪҶеңЁиҢғеӣҙжҹҘиҜўж—¶ж•ҲзҺҮдҪҺдәҺ BTree зҙўеј•гҖӮ - иӢҘ MEMORY иЎЁйў‘з№ҒиҝӣиЎҢиҢғеӣҙжҹҘиҜўпјҲдҫӢеҰӮ
<гҖҒ>пјүпјҢе»әи®®дҪҝз”Ё BTree зҙўеј•гҖӮ
ж•°жҚ®зұ»еһӢзҡ„йҖүжӢ©пјҡMEMORY иЎЁзҡ„жҜҸиЎҢж•°жҚ®дјҡдҝқеӯҳеңЁеҶ…еӯҳдёӯпјҢеӣ жӯӨиҰҒеҗҲзҗҶи®ҫи®Ўж•°жҚ®зұ»еһӢд»ҘиҠӮзңҒз©әй—ҙгҖӮдҫӢеҰӮпјҢдҪҝз”Ё VARCHAR иҖҢйқһ CHAR еӯҳеӮЁеҸҜеҸҳй•ҝеәҰеӯ—з¬ҰдёІгҖӮ
е®ҡжңҹеҲ·ж–°е’Ңжё…з©әпјҡз”ұдәҺеҶ…еӯҳиЎЁдёҚдјҡжҢҒд№…еҢ–пјҢе»әи®®еңЁйқһе…ій”®ж•°жҚ®дҪҝз”Ёе®ҢжҜ•еҗҺе®ҡжңҹжё…з©әжҲ–еҲ·ж–°иЎЁпјҢд»ҘйҮҠж”ҫеҶ…еӯҳгҖӮ
еҲҶеҢәжҠҖжңҜпјҡеҪ“ж•°жҚ®йҮҸеәһеӨ§ж—¶пјҢеҸҜд»ҘйҖҡиҝҮеҲҶеҢәжқҘз®ЎзҗҶеӨҡдёӘ MEMORY иЎЁпјҢе°ҶдёҚеҗҢеҲҶеҢәж•°жҚ®ж”ҫеңЁдёҚеҗҢзҡ„жңҚеҠЎеҷЁеҶ…еӯҳдёӯпјҢеҮҸиҪ»еҚ•дёҖжңҚеҠЎеҷЁзҡ„иҙҹиҪҪгҖӮ
йў„иҜ»пјҡиҜ»еҸ–е°‘зҡ„ж—¶еҖҷеӨҡиҜ»дёҖдәӣж”ҫеңЁеҶ…еӯҳйҮҢ
иҗҪзӣҳзәҝзЁӢж•°пјҲе°ҸдәҺе®һдҫӢж•°йҮҸпјүпјҢиҗҪзӣҳйҳҲеҖј
жҡ–еҗҜеҠЁпјҡеҚідҪҝе…іжңәпјҢд№ҹжҠҠйғЁеҲҶзј“еӯҳиҗҪзӣҳпјҢ然еҗҺжҒўеӨҚзј“еӯҳ
зј“еҶІдёҺзј“еӯҳдјҳеҢ–
зј“еӯҳи®ҫзҪ®
и®ҫзҪ®Buffer sizeж—¶пјҢй»ҳи®ӨChunksizeжҳҜ128гҖӮжҢҮд»ӨйңҖиҰҒжҢҮе®ҡBuffer sizeеӨ§е°Ҹе’Ңе®һдҫӢж•°йҮҸпјҢеҰӮжһңи®ҫ8GпјҢ16дёӘе®һдҫӢпјҢе®һйҷ…bufferжҳҜ8GпјӣдҪҶеҰӮжһңж”№жҲҗ9GпјҢе®һйҷ…дјҡеҲҶй…Қ10GпјҢеӣ дёә9G/16дёҚжҳҜ128Mзҡ„ж•ҙж•°еҖҚгҖӮпјҢе®һдҫӢжңҖеӨҡжҳҜ64дёӘпјҢBuffer sizeжңҖе°‘жҳҜ1G
зј“еҶІжұ еӨ§е°Ҹи°ғж•ҙ
- еҜ№дәҺ InnoDB иЎЁпјҢйҖҡиҝҮи°ғж•ҙ
innodb_buffer_pool_sizeеҸҜд»Ҙзј“еӯҳжӣҙеӨҡж•°жҚ®пјҢеҮҸе°‘зЈҒзӣҳ I/O ж“ҚдҪңпјҢжҸҗй«ҳжҖ§иғҪгҖӮ
жҹҘиҜўзј“еӯҳ
- еҜ№дәҺйў‘з№ҒйҮҚеӨҚзҡ„зӣёеҗҢжҹҘиҜўпјҢејҖеҗҜ
query_cacheеҸҜжҳҫи‘—жҸҗеҚҮжҹҘиҜўжҖ§иғҪгҖӮдҪҶжҳҜпјҢеңЁй«ҳ并еҸ‘еҶҷж“ҚдҪңеңәжҷҜдёӢдёҚжҺЁиҚҗеҗҜз”ЁжҹҘиҜўзј“еӯҳпјҢеӣ дёәж•°жҚ®жӣҙж–°дјҡеҜјиҮҙзј“еӯҳеӨұж•ҲпјҢеўһеҠ зі»з»ҹиҙҹжӢ…гҖӮ
зҙўеј•зј“еӯҳ
key_buffer_sizeеҸӮж•°з”ЁдәҺжҺ§еҲ¶ MyISAM иЎЁзҡ„зҙўеј•зј“еӯҳеӨ§е°ҸгҖӮеҜ№дәҺдё»иҰҒдҪҝз”Ё MyISAM иЎЁзҡ„еә”з”ЁпјҢеҸҜд»ҘйҖӮеҪ“еўһеҠ жӯӨеҸӮж•°д»ҘдјҳеҢ–зҙўеј•жҹҘиҜўгҖӮ
дёҙж—¶иЎЁе’ҢиҝһжҺҘзј“еӯҳ
tmp_table_sizeе’Ңmax_heap_table_sizeеҸӮж•°жҺ§еҲ¶дёҙж—¶иЎЁзҡ„еӨ§е°ҸгҖӮеңЁйңҖиҰҒеӨ§ж•°жҚ®йӣҶиҝһжҺҘж“ҚдҪңзҡ„еңәжҷҜдёӢпјҢеҸҜд»ҘеўһеҠ иҝҷдәӣеҸӮж•°д»ҘйҳІжӯўдёҙж—¶иЎЁеҶҷе…ҘзЈҒзӣҳгҖӮtable_open_cacheеҸӮж•°жҺ§еҲ¶иЎЁзј“еӯҳж•°йҮҸгҖӮеҜ№йў‘з№Ғи®ҝй—®зҡ„иЎЁеўһеӨ§жӯӨеҸӮж•°еҸҜеҮҸе°‘иЎЁжү“ејҖе’Ңе…ій—ӯзҡ„ж“ҚдҪңж¬Ўж•°пјҢжҸҗеҚҮжҖ§иғҪгҖӮ
InnoDBзҡ„зј“еҶІжұ з®ЎзҗҶ并дёҚе®Ңе…ЁйҒөеҫӘдј з»ҹзҡ„жңҖиҝ‘жңҖе°‘дҪҝз”ЁпјҲLRUпјүз®—жі•пјҢиҖҢжҳҜйҮҮз”ЁдәҶдёҖз§Қж”№иҝӣзҡ„LRUзӯ–з•ҘпјҢд»ҘеҮҸе°‘йӮЈдәӣд»…и®ҝй—®дёҖж¬Ўзҡ„ж•°жҚ®еңЁзј“еҶІжұ дёӯзҡ„еҚ з”ЁгҖӮиҝҷз§Қж–№жі•её®еҠ©йў‘з№Ғи®ҝй—®зҡ„вҖңзғӯвҖқж•°жҚ®з•ҷеңЁеҶ…еӯҳдёӯпјҢеҗҢж—¶и®©дёҚеёёи®ҝй—®зҡ„ж•°жҚ®жӣҙеҝ«ең°иў«жӣҝжҚўжҺүгҖӮ
InnoDB дјҡеңЁеҗҺеҸ°жү§иЎҢдёҖдәӣд»»еҠЎпјҢеҢ…жӢ¬е°Ҷзј“еҶІжұ дёӯзҡ„и„ҸйЎөпјҲеҚіе·Ідҝ®ж”№дҪҶе°ҡжңӘеҶҷе…ҘзЈҒзӣҳзҡ„ж•°жҚ®йЎөпјүеҲ·ж–°еҲ°ж•°жҚ®ж–Ү件гҖӮеңЁ MySQL 8.0 дёӯпјҢзј“еҶІжұ зҡ„еҲ·ж–°ж“ҚдҪңз”ұйЎөйқўжё…зҗҶзәҝзЁӢиҙҹиҙЈпјҢе…¶ж•°йҮҸз”ұ innodb_page_cleaners еҸӮж•°жҺ§еҲ¶пјҢй»ҳи®ӨеҖјдёә 4гҖӮ然иҖҢпјҢеҰӮжһңйЎөйқўжё…зҗҶзәҝзЁӢж•°и¶…иҝҮдәҶзј“еҶІжұ е®һдҫӢж•°пјҢеҲҷ innodb_page_cleaners дјҡиҮӘеҠЁи°ғж•ҙдёәдёҺ innodb_buffer_pool_instances зӣёеҗҢзҡ„еҖјгҖӮ
еҪ“и„ҸйЎөзҡ„жҜ”дҫӢиҫҫеҲ° innodb_max_dirty_pages_pct_lwm еҸӮж•°и®ҫзҪ®зҡ„дҪҺж°ҙдҪҚеҖјж—¶пјҢе°ұдјҡи§ҰеҸ‘зј“еҶІжұ еҲ·ж–°гҖӮй»ҳи®ӨдҪҺж°ҙдҪҚеҖјдёәзј“еҶІжұ йЎөжҖ»ж•°зҡ„ 10%гҖӮеҰӮжһңе°Ҷ innodb_max_dirty_pages_pct_lwm и®ҫзҪ®дёә 0пјҢеҲҷдјҡзҰҒз”ЁжӯӨж—©жңҹеҲ·ж–°иЎҢдёәгҖӮ
е·ҘдҪңжңәеҲ¶
- дёӯй—ҙжҸ’е…ҘзӮ№пјҡж–°иҜ»е…Ҙзҡ„йЎөйқўдёҚдјҡзӣҙжҺҘиў«жҸ’е…ҘеҲ°LRUеҲ—иЎЁзҡ„еӨҙйғЁпјҲеҚіжңҖиҝ‘дҪҝз”Ёзҡ„йғЁеҲҶпјүпјҢиҖҢжҳҜиў«жҸ’е…ҘеҲ°и·қе°ҫйғЁ3/8дҪҚзҪ®гҖӮиҝҷз§ҚжҸ’е…Ҙж–№ејҸиғҪеӨҹйҳІжӯўйӮЈдәӣд»…и®ҝй—®дёҖж¬Ўзҡ„йЎөйқўпјҲйҖҡеёёз”ұйў„иҜ»жҲ–е…ЁиЎЁжү«жҸҸеј•е…ҘпјүжҢӨеҚ зј“еҶІжұ дёӯзҡ„йў‘з№Ғж•°жҚ®гҖӮ
- LRUеҲ—иЎЁзҡ„еҸҢж®өз»“жһ„пјҡ
- ж–°йЎөйқўпјҡж–°иҜ»е…Ҙзҡ„йЎөйқўйҰ–е…Ҳиҝӣе…Ҙзј“еҶІжұ зҡ„3/8жҸ’е…ҘзӮ№дҪҚзҪ®пјҢеӨ„дәҺвҖңеҶ·вҖқзҠ¶жҖҒгҖӮ
- зғӯйЎөйқўпјҡеҰӮжһңиҝҷдәӣйЎөйқўеҶҚж¬Ўиў«и®ҝй—®пјҢе®ғ们дјҡиў«жҸҗеҚҮеҲ°LRUеҲ—иЎЁзҡ„еӨҙйғЁпјҲжңҖиҝ‘дҪҝз”Ёз«ҜпјүпјҢиЎЁжҳҺе®ғ们зҡ„йҮҚиҰҒжҖ§пјҢд»ҺиҖҢеңЁеҶ…еӯҳдёӯдҝқз•ҷжӣҙй•ҝж—¶й—ҙгҖӮ
- ж·ҳжұ°зӯ–з•ҘпјҡLRUеҲ—иЎЁе°ҫйғЁйқ иҝ‘жң«з«Ҝзҡ„дҪҚзҪ®пјҲеңЁжҸ’е…ҘзӮ№д№ӢеҗҺпјүзҡ„йЎөйқўиў«и®ӨдёәжҳҜвҖңж—§зҡ„вҖқпјҢеңЁйңҖиҰҒз©әй—ҙж—¶дјҳе…Ҳиў«ж·ҳжұ°гҖӮиҝҷж ·пјҢдёҚйў‘з№Ғи®ҝй—®зҡ„ж•°жҚ®иў«жӣҙеҝ«ең°ж·ҳжұ°пјҢдјҳеҢ–дәҶзј“еҶІжұ дёӯйў‘з№Ғж•°жҚ®зҡ„дҝқз•ҷгҖӮ
иҝҷз§Қж”№иҝӣзҡ„LRUи®ҫи®ЎиғҪжңүж•ҲйҳІжӯўзј“еҶІжұ иў«еҸҜиғҪеҸӘдҪҝз”ЁдёҖж¬Ўзҡ„ж•°жҚ®еЎ«ж»ЎпјҢд»ҺиҖҢдҝқз•ҷи¶іеӨҹзҡ„з©әй—ҙз»ҷзңҹжӯЈзҡ„вҖңзғӯвҖқйЎөйқўпјҢжҸҗеҚҮзј“еӯҳж•ҲзҺҮгҖӮиҝҷз§Қж–№жі•еҜ№дәҺй«ҳеҗһеҗҗйҮҸзі»з»ҹе°ӨдёәйҮҚиҰҒпјҢеӣ дёәеңЁиҝҷдәӣзі»з»ҹдёӯпјҢйҒҝе…Қзј“еҶІжұ жұЎжҹ“еҜ№дәҺз»ҙжҢҒжҖ§иғҪиҮіе…ійҮҚиҰҒгҖӮ
ж—Ҙеҝ—зј“еҶІ
innodb_log_buffer_sizeжҺ§еҲ¶дәӢеҠЎж—Ҙеҝ—зј“еҶІеҢәеӨ§е°ҸпјҢйҖӮеҗҲжңүеӨ§йҮҸдәӢеҠЎзҡ„еңәжҷҜгҖӮиҫғеӨ§зҡ„ж—Ҙеҝ—зј“еҶІеҢәеҸҜд»ҘеҮҸе°‘зЈҒзӣҳеҶҷе…Ҙйў‘зҺҮпјҢдҪҶд№ҹдјҡеўһеҠ еҙ©жәғж—¶зҡ„жҒўеӨҚж—¶й—ҙгҖӮ
жҖ»дҪ“дјҳеҢ–е»әи®®
- йҖӮй…ҚдёҚеҗҢж•°жҚ®еј•ж“Һпјҡж №жҚ®еә”з”ЁеңәжҷҜйҖүжӢ©йҖӮеҗҲзҡ„еј•ж“ҺпјҢдҫӢеҰӮдәӢеҠЎеһӢеә”з”ЁжҺЁиҚҗдҪҝз”Ё InnoDBпјҢиҖҢиҜ»еҜҶйӣҶеһӢе’Ңе…Ёж–ҮжЈҖзҙўеҸҜйҖүз”Ё MyISAMгҖӮ
- зҙўеј•зӯ–з•ҘпјҡеҗҲзҗҶи®ҫи®Ўдё»й”®е’Ңзҙўеј•пјҢйҒҝе…ҚиҝҮй•ҝжҲ–еҶ—дҪҷзҡ„дё»й”®гҖӮеҜ№й«ҳжҹҘиҜўжҖ§иғҪиҰҒжұӮзҡ„еә”з”ЁпјҢйҮҮз”Ёз»„еҗҲзҙўеј•жҲ–иҰҶзӣ–зҙўеј•гҖӮ
- еҲҶеҢәе’ҢеҲҶиЎЁзӯ–з•ҘпјҡеҜ№дәҺеӨ§иЎЁпјҢйҖҡиҝҮж°ҙе№іеҲҶеҢәе’ҢеҲҶиЎЁзӯ–з•ҘжқҘеҮҸе°‘й”Ғдәүз”Ёе’ҢжҸҗй«ҳжҹҘиҜўж•ҲзҺҮгҖӮ
- дәӢеҠЎз®ЎзҗҶпјҡеҗҲзҗҶдҪҝз”ЁдәӢеҠЎжҺ§еҲ¶иҜӯеҸҘпјҢеҮҸе°‘й•ҝдәӢеҠЎпјҢе°ҪйҮҸйҒҝе…ҚеӨ§жү№йҮҸж•°жҚ®зҡ„еӣһж»ҡж“ҚдҪңгҖӮ
- зӣ‘жҺ§дёҺи°ғж•ҙпјҡе®ҡжңҹдҪҝз”ЁжҖ§иғҪеҲҶжһҗе·Ҙе…·пјҲеҰӮ
EXPLAINпјүеҲҶжһҗжҹҘиҜўжҖ§иғҪпјҢ并жҢҒз»ӯи°ғж•ҙж•°жҚ®еә“еҸӮж•°пјҢд»ҘйҖӮеә”дёҡеҠЎйңҖжұӮзҡ„еҸҳеҢ–гҖӮ
第еҚҒдёүз«
MySQL еӨҮд»ҪдёҺжҒўеӨҚжҰӮиҝ°
дёәд»Җд№ҲйңҖиҰҒеӨҮд»ҪдёҺжҒўеӨҚпјҹ
дҝқжҠӨж•°жҚ®е…ҚеҸ—пјҡзі»з»ҹеҙ©жәғгҖӮ硬件故йҡңпјҢж–ӯз”өгҖӮз”ЁжҲ·иҜҜж“ҚдҪңпјҲеҰӮиҜҜеҲ ж•°жҚ®пјүгҖӮе…ёеһӢеә”з”ЁеңәжҷҜпјҡе®үе…ЁеҚҮзә§гҖӮж•°жҚ®иҝҒ移жҲ–еӨҚеҲ¶зҺҜеўғжҗӯе»әгҖӮ
еӨҮд»ҪдёҺжҒўеӨҚзұ»еһӢ
1. зү©зҗҶеӨҮд»Ҫ vs. йҖ»иҫ‘еӨҮд»Ҫ
- зү©зҗҶеӨҮд»ҪпјҡеӨҚеҲ¶ж•°жҚ®еә“ж–Ү件еҸҠзӣ®еҪ•гҖӮйҖӮеҗҲйңҖиҰҒеҝ«йҖҹжҒўеӨҚзҡ„еӨ§еһӢж•°жҚ®еә“пјҢзӣёеҜ№е®үе…ЁпјҢдҪҶеҝ…йЎ»жҳҜеҗҢдёҖз§Қж•°жҚ®еә“гҖӮ
- йҖ»иҫ‘еӨҮд»ҪпјҡдҪҝз”Ё
CREATE DATABASEе’ҢINSERTзӯүйҖ»иҫ‘з»“жһ„дҝқеӯҳж•°жҚ®гҖӮйҖӮеҗҲж•°жҚ®йҮҸе°ҸжҲ–йңҖиҰҒи·Ёе№іеҸ°иҝҒ移зҡ„еңәжҷҜгҖӮжү§иЎҢж…ўпјҢе®үе…Ёе·®гҖҒ
2. еңЁзәҝеӨҮд»Ҫ vs. зҰ»зәҝеӨҮд»Ҫ
- еңЁзәҝеӨҮд»ҪпјҲзғӯеӨҮд»Ҫпјүпјҡ
- еңЁж•°жҚ®еә“жңҚеҠЎеҷЁиҝҗиЎҢжңҹй—ҙеӨҮд»ҪгҖӮ
- еҜ№е®ўжҲ·з«ҜеҪұе“Қиҫғе°ҸпјҢдҪҶйңҖзЎ®дҝқйҖӮеҪ“зҡ„й”Ғе®ҡжңәеҲ¶гҖӮз®ЎзҗҶеҫҲеӨҚжқӮпјҢж¶үеҸҠеҲ°еҗ„з§ҚеҠ й”ҒгҖӮ
- зҰ»зәҝеӨҮд»ҪпјҲеҶ·еӨҮд»Ҫпјүпјҡ
- еңЁж•°жҚ®еә“жңҚеҠЎеҷЁеҒңжӯўж—¶еӨҮд»ҪгҖӮ
- ж“ҚдҪңз®ҖеҚ•пјҢеҝ«пјҢдҪҶдјҡдёӯж–ӯжңҚеҠЎгҖӮ
- жё©еӨҮд»Ҫпјҡ
- еҶҷж“ҚдҪңдёӯжӯўпјҢиҜ»ж“ҚдҪңжӯЈеёё
- жңҚеҠЎеҷЁиҝҗиЎҢдҪҶй”Ғе®ҡж•°жҚ®пјҢйҳІжӯўдҝ®ж”№гҖӮ
3. жң¬ең°еӨҮд»Ҫ vs. иҝңзЁӢеӨҮд»Ҫ
- жң¬ең°еӨҮд»ҪпјҡеңЁ MySQL жңҚеҠЎеҷЁжүҖеңЁдё»жңәдёҠжү§иЎҢгҖӮ
- иҝңзЁӢеӨҮд»Ҫпјҡд»Һе…¶д»–дё»жңәиҝӣиЎҢеӨҮд»ҪгҖӮ
4. еҝ«з…§еӨҮд»Ҫ
- еҖҹеҠ©з¬¬дёүж–№е·Ҙе…·пјҲеҰӮ VeritasгҖҒLVM жҲ– ZFSпјүз”ҹжҲҗж–Ү件系з»ҹеҝ«з…§гҖӮ
- зү№зӮ№пјҡ
- еҝ«йҖҹи®°еҪ•ж–Ү件系з»ҹжҲ–еӯҳеӮЁзҠ¶жҖҒзҡ„ж–№жі•пјҢйҖҡиҝҮеҶҷж—¶еӨҚеҲ¶жҠҖжңҜжҚ•иҺ·жҹҗдёҖж—¶й—ҙзӮ№зҡ„ж•°жҚ®пјҢдёҚеӨҚеҲ¶е®һйҷ…ж•°жҚ®пјҢеҲӣе»әйҖҹеәҰеҝ«гҖҒжҖ§иғҪеҪұе“Қе°ҸпјҢйҖӮеҗҲй«ҳйў‘еӨҮд»Ҫе’Ңеҝ«йҖҹжҒўеӨҚгҖӮ
- дҪҶдҫқиө–зү№е®ҡеӯҳеӮЁзі»з»ҹпјҢ并йңҖдҝқйҡңж•°жҚ®дёҖиҮҙжҖ§гҖӮ
- еҝ«з…§еҲӣе»әеҗҺпјҢд»»дҪ•еҜ№ж–Ү件系з»ҹзҡ„дҝ®ж”№пјҢйғҪдјҡе°ҶеҺҹе§Ӣж•°жҚ®дҝқз•ҷеңЁеҝ«з…§дёӯпјҢж–°зҡ„ж•°жҚ®еҶҷе…ҘеҸҰдёҖдёӘдҪҚзҪ®гҖӮе®һйҷ…дёҠпјҢз”ұдәҺcopy-on-writeжҠҖжңҜпјҢеҒҮеҰӮеңЁжҹҗдёӘж—¶й—ҙжҲ‘们еҒҡдәҶдёҖдёӘе…ЁйҮҸеӨҮд»ҪпјҢйӮЈд№Ҳд№ӢеҗҺз”ұдәҺж•°жҚ®еә“зҡ„еўһеҲ ж”№пјҢ然еҗҺеҮәзҺ°дәҶж–Ү件数жҚ®зҡ„еҸҳеҢ–пјҢж–Ү件зӣёеҜ№дәҺж—§жңүзҡ„ж–Ү件дјҡжңүдёҖйғЁеҲҶеҸҳеҢ–пјҢиҝҷйғЁеҲҶеҸҳеҢ–е°ұеҸ«еҒҡеҝ«з…§пјҒ
- жң¬иә«е°ұжҳҜеўһйҮҸејҸеӨҮд»Ҫ
- жіЁж„ҸпјҡMySQL жң¬иә«дёҚж”ҜжҢҒеҝ«з…§еҠҹиғҪгҖӮ
5. е®Ңж•ҙеӨҮд»Ҫ vs. еўһйҮҸеӨҮд»Ҫ
- е®Ңж•ҙеӨҮд»ҪпјҡеҢ…еҗ«жҹҗдёҖж—¶еҲ»зҡ„жүҖжңүж•°жҚ®гҖӮ
- еўһйҮҸеӨҮд»ҪпјҡдҝқеӯҳиҮӘдёҠж¬ЎеӨҮд»Ҫд»ҘжқҘзҡ„еҸҳжӣҙж•°жҚ®пјҲдҫқиө–дәҢиҝӣеҲ¶ж—Ҙеҝ—пјүгҖӮ
ж•°жҚ®еә“еӨҮд»Ҫж–№жі•
иғҢжҷҜзҹҘиҜҶпјҡMySQLзҡ„з»“жһ„е…¶е®һжҳҜеҲҶдёӨеұӮзҡ„пјҢдёҖеұӮжҳҜдёҠйқўзҡ„ServerпјҢиҝҷжҳҜйқўеҗ‘з”ЁжҲ·зҡ„пјҢз”ЁжҲ·еҸ‘иҝҮжқҘзҡ„SQLиҜ·жұӮпјҢдҪ жқҘеҒҡеӨ„зҗҶпјӣ第дәҢеұӮжҳҜеј•ж“ҺпјҢInnoDB or MyISAMпјҢй»ҳи®ӨзҺ°еңЁз”Ёзҡ„жҳҜInnoDBгҖӮеј•ж“ҺеңЁиҝҷйҮҢиҙҹиҙЈзҡ„жҳҜе’Ңж–Ү件系з»ҹдәӨдә’гҖӮжңүдёҖдёӘеҫҲеӨ§зҡ„bufferзј“еӯҳгҖӮжңүеҫҲеӨҡlogпјҡundo logпјҢredo logпјҢж•ҙдёӘиҝҷдёҖеұӮж“ҚдҪңзҡ„ж—¶еҖҷе®ғзңӢдёҚеҲ°SQLпјҢеҸӘзңӢеҲ°ж–Ү件гҖӮ
дёҠйқўзҡ„SQLжҳҜеңЁеӨ„зҗҶSQLзҡ„пјҢе®ғеҜ№еә”зҡ„logе°ұжҳҜbin-logпјҢе®ғи®°дҪҸдҪ жү§иЎҢзҡ„жүҖжңүзҡ„SQLж“ҚдҪңгҖӮиҝҷдёӨеұӮд№Ӣй—ҙжҳҜеҸҜд»Ҙи§ЈиҖҰзҡ„гҖӮи§ЈиҖҰзҡ„еҘҪеӨ„е°ұжҳҜпјҢжҲ‘еңЁlinuxжҲ–иҖ…windowsдёҠйқўе®үиЈ…MySQLпјҢжҲ‘еҸӘйңҖиҰҒж”№engineиҝҷдёҖеұӮе°ұеҸҜд»ҘдәҶгҖӮ
Mysqldump
mysqldump жҳҜ MySQL жҸҗдҫӣзҡ„дёҖдёӘеӨҮд»Ҫе·Ҙе…·пјҢз”ЁдәҺеҜјеҮәж•°жҚ®еә“зҡ„з»“жһ„е’Ңж•°жҚ®пјҢеёёз”ЁдәҺж•°жҚ®иҝҒ移жҲ–еӨҮд»ҪгҖӮ
ж ёеҝғеҠҹиғҪ
- ж•°жҚ®еә“еӨҮд»Ҫпјҡж”ҜжҢҒе°ҶдёҖдёӘжҲ–еӨҡдёӘж•°жҚ®еә“еҜјеҮәдёә SQL ж–Ү件пјҢеҢ…еҗ«иЎЁз»“жһ„е’Ңж•°жҚ®гҖӮ
- иЎЁз»“жһ„еҜјеҮәпјҡд»…еҜјеҮәиЎЁзҡ„еҲӣе»әиҜӯеҸҘиҖҢдёҚеҢ…еҗ«ж•°жҚ®гҖӮ
- ж•°жҚ®жҒўеӨҚпјҡз”ҹжҲҗзҡ„ SQL ж–Ү件еҸҜд»ҘйҖҡиҝҮ
mysqlе‘Ҫд»ӨеҜје…ҘпјҢе®ҢжҲҗжҒўеӨҚгҖӮ - зҒөжҙ»зҡ„иҝҮж»Өпјҡж”ҜжҢҒжҢүиЎЁгҖҒжҢүжқЎд»¶еҜјеҮәзү№е®ҡж•°жҚ®гҖӮ
жҒўеӨҚж–№жі•
- 1. жҒўеӨҚе®Ңж•ҙеӨҮд»ҪпјҡзӣҙжҺҘд»ҺжңҖиҝ‘зҡ„е®Ңж•ҙеӨҮд»ҪжҒўеӨҚж•°жҚ®гҖӮ
- 2. ж—¶й—ҙзӮ№жҒўеӨҚпјҡз»“еҗҲе®Ңж•ҙеӨҮд»Ҫе’ҢдәҢиҝӣеҲ¶ж—Ҙеҝ—пјҲbin-logпјүпјҢжҒўеӨҚеҲ°зү№е®ҡж—¶й—ҙзӮ№гҖӮпјҲе…Ҳд»Һе…ЁйҮҸеӨҮд»ҪиҺ·еҸ–пјҢжҺҘзқҖbin logйҮҢйқўжҒўеӨҚеҲ°зү№зӮ№ж—¶й—ҙпјү
еҒҮи®ҫжҲ‘们зҡ„еӨҮд»Ҫзӯ–з•ҘжҳҜжҜҸдёӘе‘Ёж—ҘдёӢеҚҲдёҖзӮ№иҝӣиЎҢдёҖж¬Ўе…ЁйҮҸеӨҮд»ҪпјҢд№ҹе°ұжҳҜжҠҠж•°жҚ®еә“йҮҢйқўзҡ„жүҖжңүж•°жҚ®е…ЁеӨҮд»ҪдёҖж¬ЎгҖӮйӮЈд№ҲпјҢеңЁдёӨж¬Ўе…ЁйҮҸеӨҮд»Ҫд№Ӣй—ҙпјҢж•°жҚ®еә“жҜҸж¬Ўжү§иЎҢеҶҷе…Ҙж“ҚдҪңзҡ„ж—¶еҖҷпјҢйғҪдјҡеҜ№bin-logж–Ү件иҝӣиЎҢж“ҚдҪңпјҢеҶҷе…ҘеўһйҮҸеӨҮд»ҪгҖӮд№ҹе°ұжҳҜи®°еҪ•з”ЁжҲ·еҜ№ж•°жҚ®еә“зҡ„жүҖжңүзҡ„ж“ҚдҪңеҸҳжӣҙгҖӮзҺ°еңЁеҒҮеҰӮеңЁе‘Ёдёүзҡ„дёӯеҚҲпјҢж•°жҚ®еә“дё»жңәзӘҒ然еҙ©дәҶпјҢйӮЈд№ҲжҲ‘们йҰ–е…ҲиҰҒжҒўеӨҚеҲ°жңҖиҝ‘дёҖж¬ЎеҒҡзҡ„е…ЁйҮҸеӨҮд»ҪпјҡеҘҪдәҶпјҢзҺ°еңЁе°ұе·Із»ҸжҒўеӨҚеҲ°жңҖиҝ‘дёҖж¬Ўе…ЁйҮҸеӨҮд»Ҫзҡ„зҠ¶жҖҒйҮҢпјҢ然еҗҺиҰҒд»ҺдёҠж¬Ўе…ЁйҮҸеӨҮд»ҪеҲ°еҙ©жәғжңҹй—ҙзҡ„binlogж–Ү件全йғЁиҜ»еҸ–еҮәжқҘпјҢ然еҗҺжҒўеӨҚгҖӮеҰӮжһңжҜҸж¬ЎзЈҒзӣҳеқҸжӯ»жҲ–иҖ…зЈҒзӣҳй”ҷиҜҜпјҢеҹәжң¬дёҠе°ұиғҪжҒўеӨҚеҲ°еҺҹжқҘзҡ„зҠ¶жҖҒгҖӮдҪҶжҳҜеҰӮжһңжңүдёҖдёӘbinlogж–Ү件еҙ©жәғдәҶжҲ–иҖ…еҜ„дәҶпјҢйӮЈе°ұеҸҜиғҪжҒўеӨҚдёҚеҲ°е‘Ёдёүеҙ©жәғзҡ„ж—¶еҖҷзҡ„зҠ¶жҖҒдәҶпјҢеҸҜиғҪеҸӘиғҪжҒўеӨҚеҲ°е‘ЁдәҢзҡ„дёӢеҚҲжҲ–иҖ…жҹҗдёӘзЁҚеҫ®жӣҙж—©зҡ„ж—¶й—ҙзӮ№гҖӮ
еӨҮд»Ҫзӯ–з•Ҙ
- е®ҡжңҹеӨҮд»Ҫпјҡж №жҚ®ж•°жҚ®йҮҚиҰҒжҖ§е’Ңи®ҝй—®йў‘зҺҮи®ҫзҪ®еӨҮд»Ҫйў‘зҺҮгҖӮ
- йӘҢиҜҒеӨҮд»ҪпјҡзЎ®дҝқеӨҮд»Ҫж–Ү件е®Ңж•ҙпјҢйҡҸж—¶еҸҜжҒўеӨҚгҖӮ
- еӨҮд»ҪеӯҳеӮЁе®үе…ЁпјҡдҪҝз”ЁеҠ еҜҶжҠҖжңҜ并еӯҳеӮЁеңЁе®үе…ЁгҖҒеҶ—дҪҷзҡ„зҺҜеўғдёӯгҖӮ
BinlogгҖҒRedo Log е’Ң Undo Log еҜ№жҜ”иЎЁ
| зү№жҖ§ | BinlogпјҲеҪ’жЎЈж—Ҙеҝ—пјү | Redo LogпјҲйҮҚеҒҡж—Ҙеҝ—пјү | Undo LogпјҲеӣһж»ҡж—Ҙеҝ—пјү |
|---|---|---|---|
| дё»иҰҒз”ЁйҖ” | и®°еҪ•жүҖжңүеҜ№ж•°жҚ®еә“зҡ„жӣҙж”№пјҢз”ЁдәҺдё»д»ҺеӨҚеҲ¶е’Ңж•°жҚ®жҒўеӨҚ | зЎ®дҝқе·ІжҸҗдәӨдәӢеҠЎзҡ„жҢҒд№…жҖ§пјҲеҙ©жәғжҒўеӨҚпјү | ж”ҜжҢҒдәӢеҠЎеӣһж»ҡе’ҢеӨҡзүҲжң¬е№¶еҸ‘жҺ§еҲ¶пјҲMVCCпјү |
| ж јејҸ | дәҢиҝӣеҲ¶ж јејҸпјҲдёҚеҸҜиҜ»пјү | дәҢиҝӣеҲ¶ж јејҸпјҲдёҚеҸҜиҜ»пјү | дәҢиҝӣеҲ¶ж јејҸпјҲдёҚеҸҜиҜ»пјү |
| еӯҳеӮЁдҪҚзҪ® | еӯҳеӮЁдәҺзЈҒзӣҳпјҢеҸҜиҪ®жҚўжҲ–еҪ’жЎЈ | еӯҳеӮЁдәҺ MySQL ж•°жҚ®зӣ®еҪ• | еӯҳеӮЁдәҺ InnoDB иЎЁз©әй—ҙдёӯ |
| дҪҝз”ЁиҢғеӣҙ | ж•°жҚ®еә“е…ЁеұҖдәӢеҠЎзә§еҲ«жӣҙж”№ | д»…йҖӮз”ЁдәҺ InnoDB зҡ„ж•°жҚ®йЎөжӣҙж”№ | д»…йҖӮз”ЁдәҺ InnoDB зҡ„дәӢеҠЎеӣһж»ҡж“ҚдҪң |
| жҒўеӨҚи§’иүІ | з”ЁдәҺзӮ№ж—¶й—ҙжҒўеӨҚе’Ңдё»д»ҺеӨҚеҲ¶ | з”ЁдәҺеҙ©жәғжҒўеӨҚж—¶йҮҚеҒҡе·ІжҸҗдәӨзҡ„дәӢеҠЎ | з”ЁдәҺеҙ©жәғжҒўеӨҚж—¶еӣһж»ҡжңӘжҸҗдәӨзҡ„дәӢеҠЎ |
| еә”з”ЁеңәжҷҜ | дё»д»ҺеӨҚеҲ¶гҖҒж•…йҡңеҗҺзҡ„ж•°жҚ®жҒўеӨҚ | ж•°жҚ®еә“еҙ©жәғеҗҺзҡ„дәӢеҠЎжҒўеӨҚпјҢзЎ®дҝқж•°жҚ®жҢҒд№…жҖ§ | дәӢеҠЎеӣһж»ҡгҖҒеӨҡзүҲжң¬е№¶еҸ‘жҺ§еҲ¶дёӢзҡ„дёҖиҮҙжҖ§иҜ»еҸ–пјҲMVCCпјү |
| зұ»еһӢ | йҖ»иҫ‘ж—Ҙеҝ— | зү©зҗҶж—Ҙеҝ— | йҖ»иҫ‘ж—Ҙеҝ— |
第еҚҒеӣӣз«
MySQL еҲҶеҢә
дёҖгҖҒз®Җд»Ӣ
еҪ“дёҖдёӘиЎЁйҮҢйқўзҡ„ж•°жҚ®еӨӘеӨҡдәҶзҡ„ж—¶еҖҷпјҢеҚ з”Ёзҡ„з©әй—ҙеӨӘеӨ§пјҢеҸҜиғҪе°ұжҺҘиҝ‘зЈҒзӣҳзҡ„еӯҳеӮЁз©әй—ҙпјҢиҝҷж—¶еҖҷе°ұйңҖиҰҒеҲҶеҢәпјҢжҠҠиЎЁзҡ„ж•°жҚ®жӢҶејҖпјҲеҲҶеҢәпјүпјҢ然еҗҺи®©дёҚеҗҢеҲҶеҢәзҡ„ж•°жҚ®еӯҳеӮЁеҲ°дёҚеҗҢзҡ„зЈҒзӣҳдёҠйқўгҖӮжҲ‘们иҰҒеҒҡзҡ„дәӢжғ…е°ұжҳҜпјҢи®©иҝҷдәӣеӨҡдёӘиҠӮзӮ№дёҠеӯҳеӮЁзҡ„дёңиҘҝеңЁйҖ»иҫ‘дёҠжҳҜдёҖеј иЎЁпјҒ
еҲҶеҢәжҳҜе°ҶиЎЁдёӯзҡ„ж•°жҚ®еҲ’еҲҶеҲ°дёҚеҗҢзҡ„еӯҳеӮЁеҢәеҹҹпјҢд»ҘдјҳеҢ–еӯҳеӮЁе’ҢжҹҘиҜўжҖ§иғҪзҡ„жҠҖжңҜгҖӮMySQL д»Һ 8.0 ејҖе§Ӣж”ҜжҢҒеҲҶеҢәеҠҹиғҪпјҢдё»иҰҒйҖҡиҝҮ InnoDB е’Ң NDB еӯҳеӮЁеј•ж“Һе®һзҺ°гҖӮ
еҲҶеҢәзҡ„еҹәжң¬жҰӮеҝө
- ж°ҙе№іеҲҶеҢәпјҲHorizontal Partitioningпјүпјҡ е°ҶиЎЁзҡ„иЎҢж•°жҚ®еҲҶеёғеҲ°еӨҡдёӘеҲҶеҢәдёӯгҖӮ
- еһӮзӣҙеҲҶеҢәпјҲVertical Partitioningпјүпјҡ е°ҶиЎЁзҡ„еҲ—ж•°жҚ®еҲҶеёғеҲ°еӨҡдёӘеҲҶеҢәдёӯгҖӮпјҲMySQL дёҚж”ҜжҢҒпјү
дәҢгҖҒеҲҶеҢәзҡ„зұ»еһӢ
MySQL ж”ҜжҢҒд»ҘдёӢ еҲҶеҢәзұ»еһӢпјҢж №жҚ®еңәжҷҜйҖүжӢ©йҖӮеҗҲзҡ„ж–№жЎҲпјҡ
1. иҢғеӣҙRANGE еҲҶеҢә
- жҢҮе®ҡдәҶжҹҗдёҖеҲ—жҲ–иҖ…жҹҗеҮ еҲ—пјҢж №жҚ®д»–们еҖјзҡ„иҢғеӣҙпјҢ然еҗҺжқҘеҲҶеҢәгҖӮеҢәеҹҹеә”иҜҘжҳҜиҝһз»ӯиҖҢдё”дёҚиғҪйҮҚеӨҚзҡ„пјҢйҖҡеёёйғҪжҳҜз”Ёзҡ„LESS THENпјҲйғҪжҳҜе°ҸдәҺе•ҠпјҒжІЎжңүзӯүдәҺпјүпјҢжҜ”еҰӮ<0зҡ„еҲҶдёӘеҢәпјҢ<50зҡ„еҲҶдёӘеҢәпјҢ< MAX_VALUEпјҲиҝҷзҺ©ж„Ҹе°ұжҳҜдҝқиҜҒжңҖеҗҺжүҖжңүжңҖеӨ§еҖјйғҪз»ҷдҪ еҢ…е®№иҝӣеҺ»пјүеҲҶдёӘеҢәгҖӮ
- дёҚе…Ғи®ёз”Ёfloatжө®зӮ№ж•°гҖӮиҮ§иҖҒеёҲзҡ„ICSе‘ҠиҜүжҲ‘们пјҢжө®зӮ№ж•°зҡ„й—®йўҳжҳҜеҫҲеӨҡзҡ„пјҒеӣ дёәжө®зӮ№ж•°жҳҜиҝ‘дјјиЎЁзӨәгҖӮеҰӮжһңеҲ¶е®ҡдәҶеӨҡеҲ—пјҢжҜ”еҰӮaгҖҒbгҖҒcпјҢиғҪдёҚиғҪжҠҠaзҡ„еҲ—еҒҡдёҖдёӘе№іж–№жҲ–иҖ…еҮҪж•°и®Ўз®—дёҖдёӢеӨ„зҗҶпјҹдёҚиЎҢпјҒдёҚжҺҘеҸ—иЎЁиҫҫејҸгҖӮ
- еӨҡеҲ—жҜ”иҫғзҡ„жҳҜеҗ‘йҮҸпјҢжҜ”еҰӮиҰҒжҜ”иҫғпјҲa,b,cпјү(d,e,f)пјҢе°ұжҜ”иҫғaе’ҢdпјҢжҜ”иҫғеҮәжқҘе°ҸдәҺзҡ„иҜқе°ұе°ҸдәҺпјҢжҜ”иҫғдёҚ еҮәжқҘе°ұжҳҜжҜ”иҫғbе’ҢeпјҢ然еҗҺеҗҢзҗҶжҜ”иҫғcе’Ңf
дёҫдҫӢпјҡ е®ҡд№үдёҖдёӘе‘ҳе·ҘиЎЁпјҢж №жҚ®е‘ҳе·ҘIDеҲҶеҢәпјҢ1~10еҸ·е‘ҳе·ҘдёҖдёӘеҲҶеҢәпјҢ11~20еҸ·е‘ҳе·ҘдёҖдёӘеҲҶеҢәпјҢдҫқж¬Ўзұ»жҺЁпјҢе…ұе»әз«Ӣ4дёӘеҲҶеҢәгҖӮ
2. еҲ—иЎЁLIST еҲҶеҢә
еҹәдәҺзҰ»ж•ЈеҖјеҲ—иЎЁзҡ„еҢ№й…ҚгҖӮеҲ—иЎЁеҲҶеҢәе’ҢиҢғеӣҙеҲҶеҢәзұ»дјјпјҢдё»иҰҒеҢәеҲ«жҳҜlist partitionзҡ„еҲҶеҢәиҢғеӣҙжҳҜйў„е…Ҳе®ҡд№үеҘҪзҡ„дёҖзі»еҲ—еҖјпјҢиҖҢдёҚжҳҜиҝһз»ӯзҡ„иҢғеӣҙгҖӮжҜ”еҰӮдәӨеӨ§жңүй—өиЎҢгҖҒдёғе®қж ЎеҢәзӯүзӯүе°ұеҸҜд»Ҙж №жҚ®иҝҷдәӣж ЎеҢәзҡ„еҖјжқҘзЎ®е®ҡеҲҶеҢәгҖӮ
CREATE TABLE members (
firstname VARCHAR(25) NOT NULL,
lastname VARCHAR(25) NOT NULL,
username VARCHAR(16) NOT NULL,
email VARCHAR(35),
joined DATE NOT NULL
)
PARTITION BY LIST (YEAR(joined)) (
PARTITION p0 VALUES IN (2000, 2001, 2002),
PARTITION p1 VALUES IN (2003, 2004, 2005),
PARTITION p2 VALUES IN (2006, 2007, 2008)
);- е®ҡд№үжҹҗдёӘеҲ—зҡ„еҸ–еҖјиҢғеӣҙпјҢж №жҚ®еҸ–еҖјиҢғеӣҙжқҘеҲҶеҢәгҖӮйҖӮз”ЁдәҺеҲ—еҖјеңЁеӨҡдёӘзҰ»ж•ЈйӣҶеҗҲдёӯзҡ„жғ…еҶөгҖӮйҖӮз”ЁдәҺеҲ—еҖјеңЁеӨҡдёӘзҰ»ж•ЈйӣҶеҗҲдёӯзҡ„жғ…еҶөгҖӮеҰӮжһңйҮҮз”ЁIgnoreж ҮиҜҶз¬ҰпјҢжҸ’е…ҘеӨҡдёӘиЎҢпјҢжңүзҡ„еҗҲжі•жңүзҡ„дёҚеҗҲжі•пјҢзі»з»ҹдјҡжҸ’е…ҘеҗҲжі•зҡ„пјҢдёўејғдёҚеҗҲжі•гҖӮ
3. HASH еҲҶеҢә
еҹәдәҺз”ЁжҲ·е®ҡд№үзҡ„иЎЁиҫҫејҸиҝ”еӣһзҡ„ж•ҙж•°еҖјпјҢе°Ҷж•°жҚ®еҲҶж•ЈеҲ°дёҚеҗҢеҲҶеҢәдёӯпјҢ然еҗҺеҶіе®ҡжҳҜе“ӘдёҖеҸ°жңҚеҠЎеҷЁеӯҳеӮЁпјҢдёҖиҲ¬еңЁйқһиҙҹзҡ„еҖјдёҠйқўеӨ„зҗҶгҖӮ
- еҲҶеҢәзҡ„ж•°йҮҸйҖҡиҝҮ
PARTITIONSжҢҮе®ҡгҖӮ
4. KEY еҲҶеҢә
зұ»дјјдәҺ HASH еҲҶеҢәпјҢдҪҶдҪҝз”Ё MySQL еҶ…зҪ®зҡ„е“ҲеёҢеҮҪж•°пјҢMysqlиҮӘеҠЁж №жҚ®дё»й”®ж•ЈеҲ—пјҢдё”ж”ҜжҢҒйқһж•ҙж•°еҲ—гҖӮ
- йҖӮеҗҲйңҖиҰҒз®ҖеҚ•е®ҡд№үеҲҶеҢә规еҲҷдё”ж— йңҖиҮӘе®ҡд№үиЎЁиҫҫејҸзҡ„еңәжҷҜгҖӮ
дёүгҖҒеҲҶеҢәзҡ„дјҳеҠҝ
1. жҸҗеҚҮжҹҘиҜўжҖ§иғҪ
- WHERE еӯҗеҸҘиҝҮж»Өпјҡ жҹҘиҜўеҸӘи®ҝй—®ж»Ўи¶іжқЎд»¶зҡ„еҲҶеҢәпјҢеӨ§е№…еҮҸе°‘ж— ж•Ҳжү«жҸҸгҖӮ
- жҳҫејҸеҲҶеҢәйҖүжӢ©пјҡ йҖҡиҝҮжҳҫејҸеҲҶеҢәйҖүжӢ©пјҢз”ЁжҲ·еҸҜд»ҘжҢҮе®ҡжҹҘиҜўи®ҝй—®зү№е®ҡзҡ„еҲҶеҢәпјҢд»ҺиҖҢжҳҫи‘—жҸҗеҚҮжҹҘиҜўйҖҹеәҰгҖӮдҫӢеҰӮпјҡ
SELECT * FROM employees PARTITION (p0, p1) WHERE job_code < 1000;еңЁиҝҷдёӘдҫӢеӯҗдёӯпјҢMySQL дјҡд»…жҹҘиҜў p0 е’Ң p1 еҲҶеҢәзҡ„ж•°жҚ®пјҢиҖҢеҝҪз•Ҙе…¶д»–еҲҶеҢәпјҢиҝҷеңЁе·ІзҹҘеҲҶеҢәдҪҚзҪ®зҡ„жғ…еҶөдёӢйқһеёёй«ҳж•ҲгҖӮ
2. ж–№дҫҝзҡ„ж•°жҚ®з®ЎзҗҶ
- еҲ йҷӨеҲҶеҢәпјҡ еҪ“жҹҗдәӣж•°жҚ®еӨұеҺ»ж•Ҳз”Ёж—¶пјҢеҸҜд»ҘзӣҙжҺҘеҲ йҷӨеҢ…еҗ«иҝҷдәӣж•°жҚ®зҡ„еҲҶеҢәгҖӮдҫӢеҰӮпјҢеҲ йҷӨеҢ…еҗ«еҺҶеҸІж•°жҚ®зҡ„еҲҶеҢәжҜ”еҲ йҷӨеҚ•зӢ¬зҡ„иЎҢжӣҙеҠ й«ҳж•ҲгҖӮ
- ж·»еҠ ж–°еҲҶеҢәпјҡ еҜ№дәҺжҢҒз»ӯеўһй•ҝзҡ„ж•°жҚ®пјҢж·»еҠ ж–°зҡ„еҲҶеҢәеҸҜд»ҘйҒҝе…ҚиҝҒ移еӨ§йҮҸж•°жҚ®пјҢжҸҗй«ҳжү©еұ•жҖ§гҖӮдҫӢеҰӮпјҢеҪ“йңҖиҰҒдёәж–°зҡ„е№ҙд»Ҫж•°жҚ®еҲӣе»әдёҖдёӘж–°еҲҶеҢәж—¶пјҢеҸӘйңҖж·»еҠ дёҖдёӘеҲҶеҢәиҖҢж— йңҖйҮҚе»әж•ҙдёӘиЎЁгҖӮ
3. еўһејәзҡ„ж•°жҚ®з»ҙжҠӨ
- еҲҶеҢәжҠҖжңҜдҪҝеҫ—ж•°жҚ®еә“з»ҙжҠӨеҸҳеҫ—жӣҙеҠ зҒөжҙ»е’Ңй«ҳж•ҲгҖӮдҫӢеҰӮпјҢеҸҜд»ҘйҖҡиҝҮе®ҡжңҹз»ҙжҠӨеҲҶеҢәжқҘжҸҗеҚҮж•°жҚ®еә“жҖ§иғҪпјҢжҲ–иҖ…еңЁйңҖиҰҒж—¶йҖҡиҝҮж•°жҚ®зҡ„з”ҹе‘Ҫе‘Ёжңҹз®ЎзҗҶеҜ№еҲҶеҢәиҝӣиЎҢжё…зҗҶе’ҢеҪ’жЎЈгҖӮж•°жҚ®еҸҜд»Ҙи·ЁзЈҒзӣҳ/ж–Ү件系з»ҹеӯҳеӮЁпјҢйҖӮеҗҲеӯҳеӮЁеӨ§йҮҸж•°жҚ®гҖӮ
еҜ№дәҺеә”з”ЁжқҘиҜҙпјҢиЎЁдҫқ然жҳҜдёҖдёӘйҖ»иҫ‘ж•ҙдҪ“пјҢдҪҶж•°жҚ®еә“еҸҜд»Ҙй’ҲеҜ№дёҚеҗҢзҡ„ж•°жҚ®еҲҶеҢәзӢ¬з«Ӣжү§иЎҢз®ЎзҗҶж“ҚдҪңпјҢдёҚеҪұе“Қе…¶д»–еҲҶеҢәзҡ„иҝҗиЎҢгҖӮиҖҢж•°жҚ®еҲ’еҲҶзҡ„规еҲҷеҚіз§°дёәеҲҶеҢәеҮҪж•°пјҢж•°жҚ®еҶҷе…ҘиЎЁж—¶пјҢдјҡж №жҚ®иҝҗз®—з»“жһңеҶіе®ҡеҶҷе…Ҙе“ӘдёӘеҲҶеҢәгҖӮ
еӣӣгҖҒжіЁж„ҸдәӢйЎ№
- еҲҶеҢәй”®зҡ„йҖүжӢ©пјҡ
йҖүжӢ©еҲҶеҢәй”®ж—¶иҰҒи°Ёж…ҺпјҢеә”иҜҘйҖүжӢ©жҹҘиҜўж—¶еёёз”ЁдҪңиҝҮж»ӨжқЎд»¶зҡ„еҲ—гҖӮеҲҶеҢәй”®зҡ„йҖүжӢ©дјҡеҪұе“ҚжҖ§иғҪпјҢеӣ жӯӨйңҖиҰҒж №жҚ®е…·дҪ“зҡ„жҹҘиҜўеңәжҷҜжқҘеҶіе®ҡеҲҶеҢәзӯ–з•ҘгҖӮ - жҹҘиҜўдјҳеҢ–пјҡ
еҲҶеҢәиҷҪ然еҸҜд»ҘжҸҗеҚҮжҖ§иғҪпјҢдҪҶд№ҹйңҖиҰҒи°Ёж…Һи®ҫи®ЎгҖӮдҫӢеҰӮпјҢWHEREеӯҗеҸҘдёӯж¶үеҸҠеҲҶеҢәй”®зҡ„жҹҘиҜўеҸҜд»Ҙе……еҲҶеҲ©з”ЁеҲҶеҢәдјҳеҢ–пјҢдҪҶеҰӮжһңжҹҘиҜўжқЎд»¶жІЎжңүж¶үеҸҠеҲҶеҢәй”®пјҢеҲҷеҸҜиғҪж— жі•иҺ·еҫ—йў„жңҹзҡ„жҖ§иғҪжҸҗеҚҮгҖӮ - жҖ§иғҪзҡ„е№іиЎЎпјҡ
еҲҶеҢәеҸҜиғҪеёҰжқҘйўқеӨ–зҡ„з®ЎзҗҶејҖй”ҖпјҢзү№еҲ«жҳҜеңЁеҲҶеҢәж•°зӣ®иҫғеӨҡж—¶пјҢMySQL еңЁеӨ„зҗҶеӨ§йҮҸеҲҶеҢәж—¶еҸҜиғҪдјҡеҮәзҺ°жҖ§иғҪ瓶йўҲгҖӮеӣ жӯӨпјҢеңЁи®ҫи®ЎеҲҶеҢәж—¶пјҢиҰҒиҖғиҷ‘еҗҲйҖӮзҡ„еҲҶеҢәж•°йҮҸе’Ңж•°жҚ®зҡ„еҲҶеёғж–№ејҸгҖӮ - ж— жі•и·ЁеҲҶеҢә JOINпјҡ
еҲҶеҢәиЎЁеҶ…зҡ„ JOIN ж“ҚдҪңйҖҡеёёдјҡеҸ—еҲ°йҷҗеҲ¶пјҢзү№еҲ«жҳҜеңЁи·ЁеӨҡдёӘеҲҶеҢәжҹҘиҜўж—¶гҖӮеҰӮжһң JOIN иҜӯеҸҘзҡ„иЎЁжҲ–жқЎд»¶дёҚж¶үеҸҠеҲҶеҢәй”®пјҢеҸҜиғҪдјҡеҜјиҮҙжҖ§иғҪдёӢйҷҚгҖӮ - еҲҶеҢәзҡ„з»ҙжҠӨпјҡ
иҷҪ然еҲҶеҢәеҸҜд»Ҙз®ҖеҢ–ж•°жҚ®з®ЎзҗҶе’ҢжҹҘиҜўдјҳеҢ–пјҢдҪҶд№ҹйңҖиҰҒе®ҡжңҹеҜ№еҲҶеҢәиҝӣиЎҢз»ҙжҠӨгҖӮж•°жҚ®иҝҒ移гҖҒеҲҶеҢәжү©еұ•гҖҒеҲ йҷӨдёҚеҶҚйңҖиҰҒзҡ„еҲҶеҢәзӯүе·ҘдҪңйғҪйңҖиҰҒе®ҡжңҹиҝӣиЎҢгҖӮ - еӯҳеӮЁеј•ж“ҺйҷҗеҲ¶пјҡ
еҲҶеҢәиЎЁйҖҡеёёдҫқиө–дәҺ InnoDB жҲ– NDB еӯҳеӮЁеј•ж“ҺпјҢдё”жҹҗдәӣж“ҚдҪңпјҲеҰӮе…Ёж–Үзҙўеј•гҖҒеӨ–й”®зәҰжқҹзӯүпјүеҸҜиғҪдёҚе®Ңе…Ёж”ҜжҢҒеҲҶеҢәиЎЁгҖӮеӣ жӯӨпјҢеңЁдҪҝз”ЁеҲҶеҢәеҠҹиғҪж—¶пјҢйңҖзЎ®и®ӨеӯҳеӮЁеј•ж“Һзҡ„ж”ҜжҢҒжғ…еҶөе’ҢдёҡеҠЎйңҖжұӮгҖӮ
- NULLеӨ„зҗҶпјҡеҰӮжһңйҒҮеҲ°дәҶNULLж•°еҖјпјҢиҝҷз§ҚжҸ’е…Ҙзҡ„дёңиҘҝдјҡиў«ж”ҫеҲ°жңҖе°Ҹзҡ„дёҖдёӘеҲҶеҢәйҮҢйқўпјҲиҢғеӣҙжңҖдҪҺзҡ„дёҖдёӘеҲҶеҢәпјүиҖҢеҜ№дәҺListеҲҶеҢәпјҢе…Ғи®ёin Nullдё“й—ЁеҲӣе»әдёҖдёӘеҲҶеҢәпјӣеҜ№дәҺHashеҲҶеҢәпјҢnullйғҪдјҡиў«еҪ“еҒҡ0然еҗҺйҖҒеҲ°hashеҮҪж•°йҮҢйқў
- и°ғж•ҙеҲҶеҢәпјҲйҮҚж–°з»„з»ҮеҲҶеҢәпјүпјҡжҜ”иҫғиҖ—ж—¶й—ҙпјҢи°ғж•ҙж¶үеҸҠеҲ°ж•ҙдёӘиЎЁж ј
- еҲ йҷӨеҲҶеҢәпјҡеҰӮжһңз”Ёзҡ„еҲҶеҢә规еҲҷе…ЁжҳҜе°ҸдәҺпјҢйӮЈд№ҲеҲ йҷӨдёҖдёӘеҲҶеҢәе°ұдјҡеҜјиҮҙеҺҹжқҘеӯҳеӮЁзҡ„ж•°жҚ®еҲ йҷӨпјҢдҪҶжҳҜеҗҺйқўж–°зҡ„иҫ“е…ҘжҸ’е…ҘиҝӣжқҘзҡ„ж—¶еҖҷе°ұдјҡиҝӣе…ҘжӯЈзЎ®зҡ„еҲҶеҢәгҖӮ
- зү№еҲ«жҸҗзӨәпјҡдёҚе…Ғи®ёdrop еҲҶеҢәпјҲйҖҡиҝҮHashеҲҶеҢәжҲ–иҖ…keyж•ЈеҲ—зҡ„пјүпјҒдёҖж—ҰdropпјҢйӮЈд№Ҳж•ҙдёӘеҲҶеҢәзҡ„ж•°йҮҸе°ұеҸ‘з”ҹеҸҳеҢ–пјҢйӮЈд№ҲеҒҮеҰӮд№ӢеүҚжҳҜеҸ–жЁЎиҝҗз®—пјҢзҺ°еңЁеҲҶеҢәж•°йҮҸж”№еҸҳпјҢжүҖжңүзҡ„еӯҳеӮЁйғҪиҰҒеҸ‘з”ҹеӨ§еҸҳеҢ–пјҒйҷӨйқһйҮҚж–°и°ғж•ҙпјҢиҖҢдё”дёҚжҳҜз”ЁreorginazeпјҢз”Ёзҡ„иҜӯжі•жҳҜcoalesceпјҒдҪҶжҳҜиҝҪеҠ еҸҜд»ҘзӣҙжҺҘиҝӣиЎҢпјҒе…·дҪ“еҺҹеӣ жІЎжңүи®ІпјҢжңүиҮӘе·ұзҡ„е®һзҺ°пјҒ
第еҚҒдә”з«
NOSQL
1. еӨ§ж•°жҚ®иғҢжҷҜ
- еӨ§ж•°жҚ®зҺ°зҠ¶пјҡ
- еҘҪж¶ҲжҒҜпјҡеӨ§ж•°жҚ®е·ІжҲҗдёәзҺ°е®һгҖӮ
- еқҸж¶ҲжҒҜпјҡеҰӮдҪ•еӯҳеӮЁе’ҢеҲҶжһҗеӨ§ж•°жҚ®жҳҜе·ЁеӨ§зҡ„жҢ‘жҲҳгҖӮ
- ж•°жҚ®зұ»еһӢпјҡ
- з»“жһ„еҢ–ж•°жҚ®пјҡжңүжҳҺзЎ®ж јејҸпјҲеҰӮ XML ж–ҮжЎЈгҖҒж•°жҚ®еә“иЎЁзӯүпјүпјҢдј з»ҹе…ізі»еһӢж•°жҚ®еә“пјҲRDBMSпјүж“…й•ҝеӨ„зҗҶгҖӮ
- еҚҠз»“жһ„еҢ–ж•°жҚ®пјҡжңүдёҖе®ҡзҡ„з»“жһ„пјҢдҪҶеҸҜиғҪдјҡиў«еҝҪз•ҘпјҲеҰӮз”өеӯҗиЎЁж јпјүгҖӮ
- йқһз»“жһ„еҢ–ж•°жҚ®пјҡж— еҶ…йғЁз»“жһ„пјҲеҰӮзәҜж–Үжң¬гҖҒеӣҫеғҸж•°жҚ®пјүгҖӮ
2. NoSQL ж•°жҚ®еә“
- е®ҡд№ү(Not only SQL)пјҡ
- дј з»ҹ RDBMS ж— жі•й«ҳж•ҲеӯҳеӮЁе’ҢеӨ„зҗҶжө·йҮҸж•°жҚ®пјҢйқһз»“жһ„еҢ–ж•°жҚ®пјҢNoSQL ж•°жҚ®еә“дҪңдёәиЎҘе……жҠҖжңҜеә”иҝҗиҖҢз”ҹгҖӮ
- еҸӘиҰҒж•°жҚ®еҲҶеёғејҸеӯҳеӮЁпјҢйңҖиҰҒеўһеҠ еҸҜйқ жҖ§пјҢе°ұйңҖиҰҒеүҜжң¬replication
- еҲҶеёғејҸеӯҳеӮЁпјҢдҪҝз”Ёе…ізі»еһӢиЎҢдёҚиЎҢпјҹжҲ‘们еңЁеҲҶеҢәзҡ„ж—¶еҖҷи®ІеҲ°дәҶпјҢеҰӮжһңдёҖеј иЎЁж•°жҚ®йҮҸеҫҲеӨ§пјҢжҲ‘е°ұиҰҒжӢҶпјҢ然еҗҺиҝҷз§Қж“ҚдҪңеҸҜиғҪеҸҲйңҖиҰҒеҠ й”ҒгҖӮ
- зӨәдҫӢпјҡMapReduce жЎҶжһ¶гҖӮ
| з»ҙеәҰ | дј з»ҹ RDBMS | MapReduce |
|---|---|---|
| ж•°жҚ®и§„жЁЎ | GigabytesпјҲеҚғе…Ҷеӯ—иҠӮзә§еҲ«пјү | PetabytesпјҲPB зә§еҲ«пјҢи¶…еӨ§и§„жЁЎпјү |
| и®ҝй—®ж–№ејҸ | ж”ҜжҢҒдәӨдә’ејҸе’Ңжү№йҮҸпјҲInteractive and batchпјү | д»…ж”ҜжҢҒжү№йҮҸпјҲBatchпјү |
| жӣҙж–°жЁЎејҸ | иҜ»еҶҷеӨҡж¬ЎпјҲRead and write many timesпјү | еҶҷе…ҘдёҖж¬ЎпјҢиҜ»еҸ–еӨҡж¬ЎпјҲWrite once, read many timesпјү |
| ж•°жҚ®з»“жһ„ | йқҷжҖҒжЁЎејҸпјҲStatic schemaпјү | еҠЁжҖҒжЁЎејҸпјҲDynamic schemaпјү |
| ж•°жҚ®е®Ңж•ҙжҖ§ | й«ҳе®Ңж•ҙжҖ§пјҲHighпјү | е®Ңж•ҙжҖ§иҫғдҪҺпјҲLowпјү |
| жү©еұ•жҖ§ | йқһзәҝжҖ§жү©еұ•пјҲNonlinearпјү | зәҝжҖ§жү©еұ•пјҲLinearпјү |
DAOе’ҢRepositoryе·®ејӮ
- дёҖиҲ¬жқҘиҜҙпјҢдёҖдёӘRepositoryеҜ№еә”зҡ„дёҖдёӘзұ»еһӢзҡ„ж•°жҚ®еә“йҮҢйқўзҡ„дёҖдёӘиЎЁгҖӮ
- DAOзҡ„д»»еҠЎжҳҜйңҖиҰҒеұҸи”ҪдёҚеҗҢж•°жҚ®еә“е·®ејӮпјҢи®©жңҚеҠЎеұӮзҡ„зңјйҮҢеҸӘжңүдёҖдёӘдёҖдёӘзҡ„еҜ№иұЎгҖӮжҜ”еҰӮеҜ№дәҺвҖңз”ЁжҲ·вҖқпјҢз”ЁжҲ·зҡ„еӨҙеғҸеҸҜиғҪеӯҳеңЁMongoDBпјҢе…¶д»–зҡ„з”ЁжҲ·еҗҚйӮ®з®ұеӯҳеңЁSQLйҮҢйқўпјҢDAOе°ұиҰҒе®ҢжҲҗз»„иЈ…гҖӮ
MongoDB
- MongoDB жҳҜд»Җд№Ҳпјҹ
- дёҖз§Қж–ҮжЎЈеһӢ NoSQL ж•°жҚ®еә“пјҢејҖжәҗпјҢC++зј–еҶҷгҖӮ
- еҗҚеӯ—жқҘжәҗдәҺвҖңhumongousвҖқпјҲеәһеӨ§пјүгҖӮ
зү№зӮ№пјҡ
- ж–ҮжЎЈејҸ(Document-Oriented)еӯҳеӮЁ
- е…Ёзҙўеј•ж”ҜжҢҒ(2D)пјҢж”ҜжҢҒең°зҗҶз©әй—ҙзҙўеј•
- й«ҳеҸҜз”ЁжҖ§пјҲйҖҡиҝҮеӨҚеҲ¶е’ҢиҮӘеҠЁеҲҶзүҮpartitionпјү
- MapReduce ж”ҜжҢҒ
- еҶ…еөҢж–Ү件系з»ҹпјҲGridFSпјү
- ж”ҜжҢҒMap Reduce
- collectionжҳҜжЁЎејҸиҮӘз”ұпјҲschema freeпјүзҡ„
- жқғйҷҗжҺ§еҲ¶пјҲе°ұдёҚеҗҢзҡ„дәәеҸҜд»Ҙи®ҝй—®дёҚеҗҢзҡ„ж•°жҚ®еә“пјүпјҢжҜҸдёӘж•°жҚ®еә“еӯҳеӮЁеңЁеҚ•зӢ¬зҡ„ж–Ү件
еңЁдёҖдёӘйӣҶеҗҲпјҲCollectionпјүдёӯеҸҜд»Ҙж”ҫзҪ®дёҚеҗҢзҡ„ж–ҮжЎЈпјҲDocumentпјүпјҢ并且е®ғжҳҜж— жЁЎејҸпјҲSchema-Freeпјүзҡ„гҖӮд»ҺзҗҶи®әдёҠжқҘиҜҙпјҢзЎ®е®һеҸҜд»Ҙе°ҶжүҖжңүж•°жҚ®йғҪеӯҳеӮЁеҲ°дёҖдёӘйӣҶеҗҲдёӯгҖӮ然иҖҢпјҢиҝҷд№ҲеҒҡжҳҜеҗҰеҗҲзҗҶйңҖиҰҒе…·дҪ“й—®йўҳе…·дҪ“еҲҶжһҗгҖӮ
е…ізі»еһӢж•°жҚ®еә“е’Ңйқһе…ізі»еһӢж•°жҚ®еә“зҡ„еҢәеҲ«
еңЁе…ізі»еһӢж•°жҚ®еә“дёӯпјҢдёҚеҗҢзҡ„иЎЁйҖҡеёёеҜ№еә”дёҚеҗҢзҡ„ж•°жҚ®з»“жһ„гҖӮдҫӢеҰӮпјҡ
- дәәе‘ҳдҝЎжҒҜдјҡеӯҳеӮЁеңЁвҖңдәәе‘ҳиЎЁвҖқдёӯ
- и®ўеҚ•дҝЎжҒҜдјҡеӯҳеӮЁеңЁвҖңи®ўеҚ•иЎЁвҖқдёӯ
- д№ҰзұҚдҝЎжҒҜдјҡеӯҳеӮЁеңЁвҖңд№ҰзұҚиЎЁвҖқдёӯ
еҺҹеӣ жҳҜиҝҷдәӣж•°жҚ®зҡ„з»“жһ„дёҚдёҖж ·пјҢиҖҢеңЁе…ізі»еһӢж•°жҚ®еә“дёӯпјҢиЎЁжҳҜдёҘж јеҸ—жЁЎејҸзәҰжқҹзҡ„пјҢжүҖд»ҘдҪ йңҖиҰҒе°Ҷж•°жҚ®жҢүз»“жһ„жӢҶеҲҶеҲ°дёҚеҗҢзҡ„иЎЁдёӯгҖӮиҖҢеңЁеғҸ MongoDB иҝҷж ·зҡ„йқһе…ізі»еһӢж•°жҚ®еә“дёӯпјҢж–ҮжЎЈжң¬иә«жҳҜеҸҜд»Ҙе…·жңүдёҚеҗҢеӯ—ж®өзҡ„пјҢеӣ жӯӨд»ҺжҠҖжңҜдёҠи®ІпјҢдҪ зЎ®е®һеҸҜд»ҘжҠҠжүҖжңүзұ»еһӢзҡ„ж•°жҚ®йғҪж”ҫеңЁдёҖдёӘйӣҶеҗҲйҮҢгҖӮ
дёәд»Җд№Ҳд»Қ然йңҖиҰҒеӨҡдёӘйӣҶеҗҲпјҹ
е°Ҫз®Ў MongoDB жҳҜж— жЁЎејҸзҡ„пјҢдҪҶе°ҶжүҖжңүж•°жҚ®ж”ҫеҲ°дёҖдёӘйӣҶеҗҲдёӯеңЁе®һйҷ…ејҖеҸ‘дёӯдјҡеёҰжқҘи®ёеӨҡй—®йўҳпјҡ
- ејҖеҸ‘дёҺз»ҙжҠӨзҡ„еӨҚжқӮжҖ§
- еңЁдёҖдёӘйӣҶеҗҲдёӯеӯҳж”ҫдёҚеҗҢзұ»еһӢзҡ„ж–ҮжЎЈдјҡи®©ејҖеҸ‘дәәе‘ҳе’Ңз®ЎзҗҶе‘ҳзҡ„е·ҘдҪңеҸҳеҫ—еӨҚжқӮгҖӮеӣ дёәйңҖиҰҒйўқеӨ–зҡ„йҖ»иҫ‘жқҘеҢәеҲҶе’ҢеӨ„зҗҶдёҚеҗҢзұ»еһӢзҡ„ж•°жҚ®пјҢе®№жҳ“еҮәй”ҷдё”йҡҫд»Ҙз»ҙжҠӨгҖӮ
- ж•ҲзҺҮй—®йўҳ
- иҺ·еҸ–йӣҶеҗҲзҡ„еҲ—иЎЁиҰҒжҜ”д»ҺдёҖдёӘйӣҶеҗҲдёӯжҸҗеҸ–жүҖжңүж•°жҚ®зұ»еһӢзҡ„еҲ—иЎЁеҝ«еҫ—еӨҡгҖӮ
- е°ҶеҗҢзұ»ж–ҮжЎЈеҲҶз»„еӯҳеӮЁеңЁеҗҢдёҖдёӘйӣҶеҗҲдёӯпјҢжңүеҠ©дәҺе®һзҺ°ж•°жҚ®зҡ„еұҖйғЁжҖ§пјҲData LocalityпјүпјҢд»ҺиҖҢжҸҗй«ҳжҹҘиҜўж•ҲзҺҮгҖӮ
- зҙўеј•зҡ„дҪңз”Ё
- еҪ“дёәйӣҶеҗҲеҲӣе»әзҙўеј•ж—¶пјҢе°ұејҖе§ӢеҜ№ж–ҮжЎЈз»“жһ„ж–ҪеҠ дәҶдёҖе®ҡзҡ„зәҰжқҹгҖӮ
- еҰӮжһңйӣҶеҗҲдёӯеҢ…еҗ«еӨҡз§Қзұ»еһӢзҡ„ж–ҮжЎЈпјҢзҙўеј•зҡ„и®ҫи®ЎдјҡеҸҳеҫ—еӨҚжқӮпјҢжҖ§иғҪд№ҹдјҡеҸ—еҲ°еҪұе“ҚгҖӮ
иҷҪ然зҗҶи®әдёҠеҸҜд»Ҙе°ҶжүҖжңүж•°жҚ®еӯҳеӮЁеҲ°дёҖдёӘйӣҶеҗҲдёӯпјҢдҪҶеңЁе®һйҷ…еә”з”ЁдёӯпјҢж №жҚ®ж–ҮжЎЈзұ»еһӢжӢҶеҲҶдёәдёҚеҗҢзҡ„йӣҶеҗҲжҳҜдёҖз§ҚжӣҙеҗҲзҗҶзҡ„и®ҫи®Ўж–№ејҸпјҢиҝҷж ·еҸҜд»ҘеҮҸе°‘еӨҚжқӮжҖ§пјҢжҸҗй«ҳжҖ§иғҪе’ҢеҸҜз»ҙжҠӨжҖ§гҖӮ
еҹәжң¬жңҜиҜӯ
- ж–ҮжЎЈ (Document)пјҡ
- ж•°жҚ®зҡ„еҹәжң¬еҚ•е…ғпјҢзӣёеҪ“дәҺе…ізі»еһӢж•°жҚ®еә“дёӯзҡ„дёҖиЎҢгҖӮ
- ж јејҸпјҡ
{"key": "value"}пјҢеҸҜеөҢеҘ—гҖӮ- й”®дёҚиғҪеҢ…еҗ«з©әеӯ—з¬Ұ
\0гҖӮ - зү№ж®Ҡеӯ—з¬ҰеҰӮ
.е’Ң$еә”йҒҝе…ҚдҪҝз”ЁгҖӮ - й”®еҗҚеҢәеҲҶеӨ§е°ҸеҶҷпјҢдё”ж–ҮжЎЈдёӯй”®еҗҚдёҚиғҪйҮҚеӨҚгҖӮ
- й”®дёҚиғҪеҢ…еҗ«з©әеӯ—з¬Ұ
- йӣҶеҗҲ (Collection)пјҡ
- ж–ҮжЎЈзҡ„еҲҶз»„пјҢзӣёеҪ“дәҺе…ізі»еһӢж•°жҚ®еә“дёӯзҡ„иЎЁгҖӮ
- ж— еӣәе®ҡжЁЎејҸ (Schema-free)пјҢйӣҶеҗҲдёӯзҡ„ж–ҮжЎЈеҸҜд»ҘжңүдёҚеҗҢзҡ„з»“жһ„гҖӮ
- з»„ж–ҮжЎЈиҖҢжҲҗпјҢе‘ҪеҗҚ规еҲҷпјҡ
- дёҚиғҪдҪҝз”Ёз©әеӯ—з¬ҰдёІгҖӮ
- дёҚе»әи®®д»Ҙ
system.ејҖеӨҙгҖӮ - еҸҜд»ҘйҖҡиҝҮ
.иЎЁзӨәеӯҗйӣҶеҗҲгҖӮ
- ж•°жҚ®еә“ (Database)пјҡ
- MongoDB дёӯзҡ„ж•°жҚ®еә“з”ұеӨҡдёӘйӣҶеҗҲз»„жҲҗпјҢжҜҸдёӘж•°жҚ®еә“зӢ¬з«ӢеӯҳеӮЁгҖҒе…·жңүзӢ¬з«ӢжқғйҷҗгҖӮ
- зү№ж®Ҡж•°жҚ®еә“пјҡ
adminпјҡз”ЁдәҺжқғйҷҗз®ЎзҗҶгҖӮlocalпјҡдёҚиў«еӨҚеҲ¶пјҢйҖӮз”ЁдәҺжң¬ең°еӯҳеӮЁгҖӮconfigпјҡз”ЁдәҺеӯҳеӮЁеҲҶзүҮй…ҚзҪ®гҖӮ
MongoDB зҡ„еӨҚеҲ¶дёҺеҲҶзүҮ
еӨҚеҲ¶ (Replication)пјҡ
- жҸҗдҫӣй«ҳеҸҜз”ЁжҖ§пјҢйҖҡиҝҮдё»д»ҺеӨҚеҲ¶е®һзҺ°гҖӮ
- дё»иҠӮзӮ№жҺҘеҸ—еҶҷж“ҚдҪңпјҢд»ҺиҠӮзӮ№еҗҢжӯҘж•°жҚ®гҖӮ
еҲҶзүҮ (Sharding)пјҡ
- з”ЁдәҺеӨ§и§„жЁЎж•°жҚ®еҲҶеёғејҸеӯҳеӮЁгҖӮ
- ж•°жҚ®еҲҶеҢәеҲҶеёғеңЁеӨҡдёӘиҠӮзӮ№пјҲShardпјүдёҠгҖӮ
Shard
иҮӘеҠЁеҲҶзүҮ
- ShardingжҢҮзҡ„жҳҜеҲҶзүҮпјҢMongoDBж”ҜжҢҒиҮӘеҠЁеҲҶзүҮпјӣеҒҮеҰӮдёҖдёӘcollectionжҜ”иҫғеӨ§пјҢд»–е°ұдјҡжҠҠcollectionеҲҮжҲҗеҮ дёӘshardпјҢshardе…¶е®һиҝҳжңүжӣҙе°Ҹзҡ„еҚ•дҪҚе°ұжҳҜchunkпјҢжҠҠиҝҷдәӣchunkеҲҶеёғеҲ°еӨҡеҸ°жңәеҷЁдёҠйқўеӯҳеӮЁгҖӮ
- жӯӨеӨ–MongoDBдјҡиҮӘеҠЁдҝқиҜҒдёҚеҗҢзҡ„жңәеҷЁд№Ӣй—ҙпјҢchunkзҡ„ж•°йҮҸе·®ејӮе°ҸдәҺзӯүдәҺ2
- еҲҶеҢәд№ӢеҗҺпјҢиҝҳжңүдёҖдәӣй…ҚзҪ®зҡ„е…ғж•°жҚ®йңҖиҰҒи®°еҪ•пјҢеңЁconfigй…ҚзҪ®жңҚеҠЎеҷЁеӯҳеӮЁпјҢе®ғзӣёеҪ“дәҺдёҖдёӘи·Ҝз”ұеҷЁпјҢй’ҲеҜ№и®ҝй—®зҡ„иҜ·жұӮз»“еҗҲе…ғж•°жҚ®пјҢжҠҠиҜ·жұӮиҪ¬еҸ‘еҲ°еҜ№еә”зҡ„еҲҶзүҮеӯҳеӮЁзҡ„ж•°жҚ®жңҚеҠЎеҷЁжқҘиҺ·еҫ—з»“жһң
- иҝҷж ·зҡ„еҘҪеӨ„е°ұжҳҜеӯҳеӮЁзҡ„еҺӢеҠӣжҜ”иҫғе№іиЎЎпјҢеҪ“然д№ҹж”ҜжҢҒдәәе·Ҙзҡ„з®ЎзҗҶпјҢеӣ дёәжңүж—¶еҖҷж•°жҚ®зҡ„еҶ·зғӯжңүе·®еҲ«пјҢж•°жҚ®и®ҝй—®зҡ„йў‘зҺҮжңүе·®еҲ«пјҢиҝҷз§Қжғ…еҶөе°ұдјҡжүӢеҠЁеҲҶзүҮпјҢжҠҠдёҖдәӣз»Ҹеёёи®ҝй—®зҡ„ж•°жҚ®еқҮиЎЎж”ҫзҪ®пјҢеӣ жӯӨиҝҷз§Қжғ…еҶөдёӢпјҢеҸҜиғҪжҹҗдёҖеҸ°жңәеҷЁеӯҳеӮЁзҡ„еӨ§е°ҸжҜ”иҫғеӨ§пјҢдёҚеҗҢжңәеҷЁд№Ӣй—ҙchunkж•°йҮҸзҡ„е·®и·қеҸҜиғҪи¶…иҝҮдәҶ2пјҲдёәд»Җд№Ҳжңүж—¶еҖҷд№ҹйңҖиҰҒдәәе·Ҙз®ЎзҗҶshardingеҲҶзүҮпјү
shardзҡ„дҫқжҚ®пјҡйңҖиҰҒйҖүжӢ©дёҖеҲ—пјҢдҪңдёәдёҖдёӘkeyпјҢиҝҷдёӘkeyе°ұеҸ«еҒҡshard keyгҖӮдҫӢеҰӮA-FејҖеӨҙеӯҰз”ҹ姓еҗҚдҪңдёәдёҖдёӘеҲҶзүҮпјҢдҫӢеҰӮG-PејҖеӨҙеӯҰз”ҹ姓еҗҚдҪңдёәдёҖдёӘеҲҶзүҮгҖӮ
shardingж—¶жңәпјҡ1.еҪ“еүҚи®Ўз®—жңәдёҠзҡ„зЈҒзӣҳз©әй—ҙе·Із”Ёе®ҢгҖӮ2.еёҢжңӣеҶҷе…Ҙж•°жҚ®зҡ„йҖҹеәҰеҝ«дәҺеҚ•дёӘmongodbжүҖиғҪеӨ„зҗҶзҡ„йҖҹеәҰгҖӮпјҲжҜ”еҰӮеӨ§йҮҸзҡ„дј ж„ҹеҷЁеҫҖж•°жҚ®еә“1sеҸҜиғҪиҰҒеҶҷе…Ҙ1GBзҡ„ж•°жҚ®пјҢеҰӮжһңжқҘдёҚеҸҠеҶҷпјҢе°ұйңҖиҰҒеӨҡдёӘMongoDBжқҘеҶҷе…Ҙпјү3.еёҢжңӣеңЁеҶ…еӯҳдёӯдҝқз•ҷжӣҙеӨ§жҜ”дҫӢзҡ„ж•°жҚ®д»ҘжҸҗй«ҳжҖ§иғҪпјҢеҲҶеёғејҸзј“еӯҳ
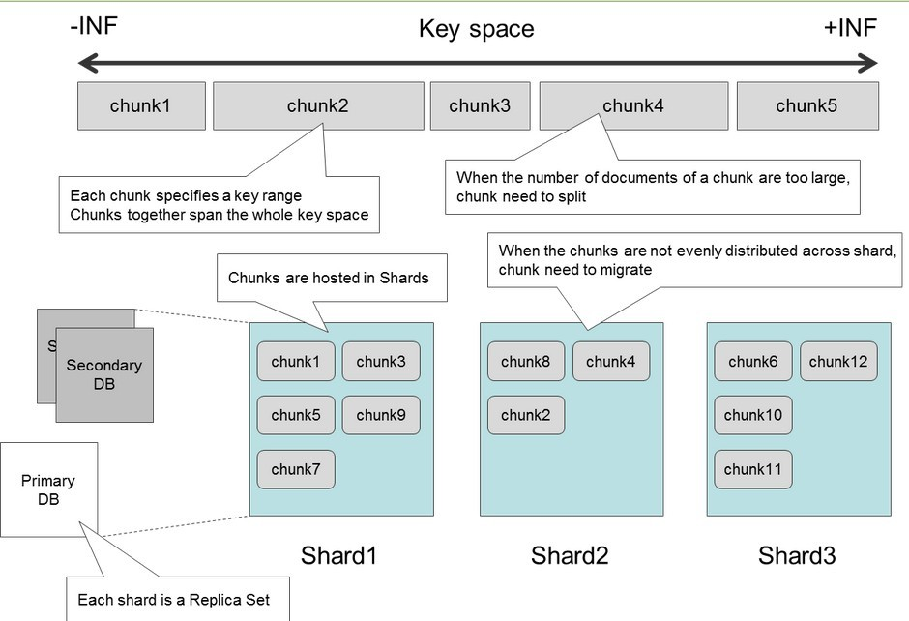
еҒҮи®ҫејҖе§Ӣзҡ„ж—¶еҖҷеҲҶзүҮпјҢжҜҸдёӘchunkд»ЈиЎЁзҡ„жҳҜжҹҗдёҖдёӘиҢғеӣҙзҡ„ж•°жҚ®пјҢchunkе°ұдјҡиў«еҲҶеёғејҸзҡ„еӯҳеӮЁеңЁshardжңҚеҠЎеҷЁйҮҢйқўгҖӮеҪ“еҫҖдёҖдёӘchunkйҮҢйқўдёҚж–ӯжҸ’е…Ҙж•°жҚ®зҡ„ж—¶еҖҷпјҢиҝҷдёӘchunkеҸҜиғҪе°ұдјҡеҲҶиЈӮпјҢеҲҶиЈӮжҲҗеӨҡдёӘchunkгҖӮиҖғиҷ‘еҲ°еүҚйқўжүҖиҜҙзҡ„дёҚеҗҢзҡ„shardжңҚеҠЎеҷЁд№Ӣй—ҙchunkзҡ„ж•°йҮҸе·®ејӮдёҚиғҪи¶…иҝҮ2дёӘпјҢйӮЈд№ҲдёҖж—ҰеҲҶиЈӮд№ӢеҗҺж•°йҮҸиҝқеҸҚдәҶиҝҷдёӘ规е®ҡпјҢMongoDBе°ұдјҡиҮӘеҠЁзҡ„и°ғж•ҙchunkеңЁжңҚеҠЎеҷЁд№Ӣй—ҙзҡ„дҪҚзҪ®пјҢдҝқиҜҒеқҮиЎЎгҖӮ
дҝқиҜҒдәҶеӯҳеӮЁж•°жҚ®иҙҹиҪҪе№іиЎЎпјҢеқҮеҢҖеҲҶеёғпјҲзұ»дјјдәҺBж ‘пјҢдёҚеҗҢshardзҡ„chunkе·®еҖји¶…иҝҮдёҖе®ҡиҢғеӣҙе°ұеҲҶиЈӮпјү
д»Җд№Ҳж—¶еҖҷз”ЁMongoDB
дёәд»Җд№ҲжҲ‘们йңҖиҰҒmongoDBпјҹиҝҷдёӘдёҖе®ҡиҰҒд»Һе®ғжҳҜschema freeзҡ„иҝҷдёҖзӮ№жқҘеҮәеҸ‘гҖӮ
дёүжҳҹе’ҢиӢ№жһңзҡ„жүӢжңәпјҢе°ұе®ғдҝ©зҡ„еұһжҖ§дёҚе®Ңе…ЁдёҖж ·пјҢд№ҹе°ұжҳҜиҜҙеӨ§е®¶жҳҜ schema free зҡ„пјҢе°ұдҪ жңүдҪ зҡ„еұһжҖ§пјҢжҲ‘ жңүжҲ‘зҡ„еұһжҖ§пјҢеңЁиҝҷз§Қжғ…еҶөдёӢпјҢйӮЈжҲ‘жҠҠе®ғеӯҳеҲ°дёҖиө·йғҪеңЁиҝҷдёӘ mobile иҝҷдёӘ collection йҮҢгҖӮ
дҪ еҰӮжһңз”ЁдёүжҳҹйҮҢйқўе®ғзү№жңүзҡ„пјҢжҜ”еҰӮиҜҙе®ғд»·ж јжҜ”иҫғдҫҝе®ңпјҢз”Ёе®ғзү№жңүзҡ„д»·ж јеҺ»жҗңзҙўпјҢе°Ҫз®Ў apple йҮҢйқўжІЎжңү price иҝҷдёҖдёӘеұһжҖ§пјҢдҪ иҝҷдёӘжҗңзҙўзҡ„иҜӯеҸҘдёҖе®ҡиғҪжҗңеҮәжқҘз¬ҰеҗҲиҰҒжұӮзҡ„дёңиҘҝгҖӮжүҖд»ҘдҪ жҳҜеңЁ schema free зҡ„иҝҷж · дёҖдёӘж•°жҚ®еә“дёҠеҺ»еӯҳдәҶеӨ§е®¶дёҚдёҖж ·зҡ„ж•°жҚ®пјҢ然еҗҺжҲ‘зҡ„жҗңзҙўиҝҳеҸҜд»ҘжҢүз…§дёҚдёҖж ·зҡ„еұһжҖ§еҺ»з»ҷе®ғжүҫеҮәжқҘпјҢдёҚжҳҜиҜҙ еӨ§е®¶йғҪиҰҒжңүзӣёеҗҢзҡ„иҝҷдёӘеұһжҖ§пјҢжүҖд»ҘиҝҷдёӘеңәеҗҲжүҚжҳҜmongoDBеҫҲжңүз”Ёзҡ„ең°ж–№гҖӮ
иҝҳжңүд»Җд№ҲжҳҜ schema free зҡ„пјҹе…¶е®һжңүдёҖдёӘдёңиҘҝжҳҜпјҢе°ұжҳҜеҰӮжһңжҲ‘еҜ№д№ҰжңүдёҖдәӣиҜ„и®әгҖӮйӮЈжҳҜдёҚжҳҜе°ұжҳҜж ‘еҪўзҡ„пјҹ е°ұжҳҜиҜҙиҝҷжң¬д№ҰиҝҳжңүдёҖдёӘиҜ„и®әпјҢе®ғиҝҳеҸҜд»Ҙжңүи·ҹеё–пјҢе®ғзҡ„и·ҹеё–иҝҳеҸҜд»Ҙжңүи·ҹеё–пјҢе®ғзҡ„и·ҹеё–еҸҜиғҪжңүеҘҪеҮ дёӘпјҢи·ҹеё–зҡ„и·ҹеё–д№ҹеҸҜд»Ҙ继з»ӯдёӢеҺ»гҖӮ然еҗҺеҸҰеӨ–дёҖжң¬д№Ұе®ғд№ҹжңүпјҢдҪҶжҳҜе®ғеҲ°еә•жңүеҮ еұӮпјҹ然еҗҺжҜҸдёҖеұӮзҡ„и·ҹеё–жңүеӨҡе°‘дёӘпјҹиҝҷжҳҜдёҚдёҖе®ҡдәҶгҖӮ
е°ұеӨ§е®¶иҝҷдёӘжҳҜжІЎжңүд»Җд№ҲиҜҙпјҢеӨ§е®¶зҡ„и·ҹеё–жңҖеӨҡеҲ°дёүеұӮпјҢжҜҸдёҖеұӮжңҖеӨҡ 5 дёӘпјҢ然еҗҺжҲ‘е°ұеҒҡдәҶдёӘиЎЁпјҢжІЎжңүзҡ„пјҢйӮЈ иҝҷж—¶еҖҷдҪ зңӢеҲ°дҪ иҰҒд»Һиҝҷз§Қд№ҰиҜ„зҡ„иҜқпјҢйӮЈе®ғзЎ®е®һе°ұжҳҜ schema free зҡ„пјҢ然еҗҺдҪ е°ұеҸҜд»ҘжҠҠиҝҷдәӣдёңиҘҝе°ұеӯҳжҲҗдёҖ жң¬д№Ұзҡ„жҹҗдёҖдёӘеұһжҖ§еҫҖйҮҢйқўеҺ»иҝҪеҠ гҖӮ йӮЈеҰӮжһңдҪ иҰҒеңЁ MySQL йҮҢеҺ»еӯҳпјҢйӮЈе®ғжңҖеёҰжқҘзҡ„жңҖеӨ§й—®йўҳе°ұжҳҜпјҢйӮЈдҪ иҰҒеҺ»жүҫиҝҷдёӘд№ҰиҜ„зҡ„ж—¶еҖҷпјҢдҪ иҝҷд№Ҳиҝҷд№ҲеӨҡеұӮпјҢдҪ жҖҺд№ҲеҺ»еӨ„зҗҶпјҹдҪ жҳҜжҠҠеҲ—иҪ¬жҲҗиЎҢеӯҳе‘ўпјҹиҝҳжҳҜиҜҙдҪ жҖҺд№Ҳз”Ёе…¶д»–зҡ„ ж–№жі•пјҹеҸҚжӯЈе°ұжҜ”иҫғйә»зғҰпјҢжүҖд»ҘиҝҷдёӘжҳҜжғіз»ҷеӨ§е®¶и§ЈйҮҠдёҖдёӢпјҢе°ұжҳҜдҪ иҰҒз”Ё mongoDBпјҢдҪ еҚғдёҮеҲ«и§үеҫ—д»–еҸӘжҳҜжӢҝжқҘеӯҳеӣҫзүҮз”Ёзҡ„гҖӮ
第еҚҒе…ӯз«
Neo4J е’Ңеӣҫи®Ўз®—
дёҖгҖҒеӣҫж•°жҚ®еә“з®Җд»Ӣ
- д»Җд№ҲжҳҜеӣҫ (Graph)
еӣҫжҳҜз”ұйЎ¶зӮ№пјҲvertices/nodesпјүе’Ңиҫ№пјҲedges/relationshipsпјүз»„жҲҗзҡ„ж•°жҚ®з»“жһ„гҖӮ
- иҠӮзӮ№иЎЁзӨәе®һдҪ“пјҲеҰӮдәәгҖҒзү©дҪ“пјүгҖӮ
- иҫ№иЎЁзӨәе®һдҪ“д№Ӣй—ҙзҡ„е…ізі»гҖӮ еӣҫзҡ„зү№жҖ§пјҡ
- иҠӮзӮ№е…·жңүеұһжҖ§пјҲkey-value еҜ№пјүгҖӮ
- иҫ№д№ҹеҸҜд»ҘеҢ…еҗ«еұһжҖ§пјҲдҫӢеҰӮжқғйҮҚгҖҒж—¶й—ҙжҲізӯүпјүгҖӮ
- иҫ№жңүж–№еҗ‘жҖ§пјҢдё”е§Ӣз»ҲиҝһжҺҘдёӨдёӘиҠӮзӮ№гҖӮ
- д»Җд№ҲжҳҜеӣҫж•°жҚ®еә“ (Graph Database)
еӣҫж•°жҚ®еә“жҳҜдёҖз§Қж”ҜжҢҒеӣҫжЁЎеһӢеӯҳеӮЁе’Ңж“ҚдҪңзҡ„еңЁзәҝж•°жҚ®еә“пјҢжҸҗдҫӣж ҮеҮҶзҡ„CRUDж“ҚдҪңпјҡеҲӣе»әпјҲCreateпјүгҖҒиҜ»еҸ–пјҲReadпјүгҖҒжӣҙж–°пјҲUpdateпјүгҖҒеҲ йҷӨпјҲDeleteпјүгҖӮ
- дјҳеҢ–зӣ®ж ҮпјҡдәӢеҠЎжҖ§иғҪпјҲOLTPпјүе’Ңж“ҚдҪңеҸҜз”ЁжҖ§гҖӮ
- дёӨеӨ§ж ёеҝғ组件пјҡ
- еә•еұӮеӯҳеӮЁпјҲUnderlying StorageпјүпјҡеҶіе®ҡеҰӮдҪ•еӯҳеӮЁж•°жҚ®гҖӮ
- еӨ„зҗҶеј•ж“ҺпјҲProcessing EngineпјүпјҡеҶіе®ҡеҰӮдҪ•жҹҘиҜўе’Ңж“ҚдҪңж•°жҚ®гҖӮ
- дј з»ҹе…ізі»еһӢж•°жҚ®еә“пјҲRDBMSпјүе’ҢNoSQLж•°жҚ®еә“еӨ„зҗҶе…ізі»еӨҚжқӮжҖ§ж•ҲзҺҮиҫғдҪҺгҖӮ
- еӣҫж•°жҚ®еә“еӨ©з„¶ж”ҜжҢҒеӨҚжқӮе…ізі»е»әжЁЎе’Ңй«ҳж•Ҳзҡ„е…ізі»жҹҘиҜўгҖӮ
дәҢгҖҒеӣҫж•°жҚ®еә“дёҺе…¶д»–еӯҳеӮЁж–№ејҸзҡ„жҜ”иҫғ
- е…ізі»еһӢж•°жҚ®еә“зҡ„зјәзӮ№пјҡ
- еӨҡиЎЁ JOIN ж“ҚдҪңеӨҚжқӮдё”дҪҺж•ҲпјҢйҡҸзқҖе…ізі»ж·ұеәҰеўһеҠ жҖ§иғҪдёӢйҷҚгҖӮ
- зӨәдҫӢпјҡиҺ·еҸ– Bob зҡ„жңӢеҸӢзҡ„ SQL жҹҘиҜўпјҡ
sql SELECT p1.Person FROM Person p1 JOIN PersonFriend ON PersonFriend.FriendID = p1.ID JOIN Person p2 ON PersonFriend.PersonID = p2.ID WHERE p2.Person = 'Bob';
- NoSQL ж•°жҚ®еә“зҡ„зјәзӮ№пјҡ
- зјәд№Ҹе…ізі»жЁЎеһӢпјҢдё»иҰҒйҖӮеҗҲйқһз»“жһ„еҢ–жҲ–ејұе…ізі»ж•°жҚ®гҖӮеңЁйӮЈз§Қе…ізі»жҜ”иҫғеӨҚжқӮзҡ„е…ізі»еӯҳеӮЁзҡ„ж—¶еҖҷпјҢжҹҘиҜўзҡ„д»Јд»·д№ҹдјҡйқһеёёеӨ§гҖӮ
- еӣҫж•°жҚ®еә“зҡ„дјҳеҠҝпјҡ
- зӣҙжҺҘиЎЁиҫҫе®һдҪ“дёҺе…ізі»гҖӮ
- й«ҳж•ҲжҹҘиҜўж·ұеәҰе…ізі»пјҢдҫӢеҰӮжңӢеҸӢзҡ„жңӢеҸӢпјҲFriends-of-FriendsпјүгҖӮеҰӮжһңз”ЁmysqlеӯҳеӮЁзҡ„иҜқпјҢеңЁжҹҘжүҫдёҖдёӘдәәеҘҪеҸӢзҡ„еҘҪеҸӢзҡ„еҘҪеҸӢйңҖиҰҒз»ҸиҝҮеӨҡж¬Ў joinиҝһжҺҘж“ҚдҪңпјҲиҰҒе…ҲеҒҡз¬ӣеҚЎе°”з§ҜпјҢ然еҗҺж №жҚ®жҹҗдёӘжқЎд»¶иҝӣиЎҢиҝӣдёҖжӯҘзӯӣйҖүпјүпјҢиҝҷз§ҚеңЁеӨҚжқӮзҡ„жҹҘиҜўзҡ„жғ…еҶө дёӢпјҢmysqlзҡ„жҹҘиҜўзҡ„ж•ҲзҺҮе°ұйқһеёёдҪҺгҖӮ
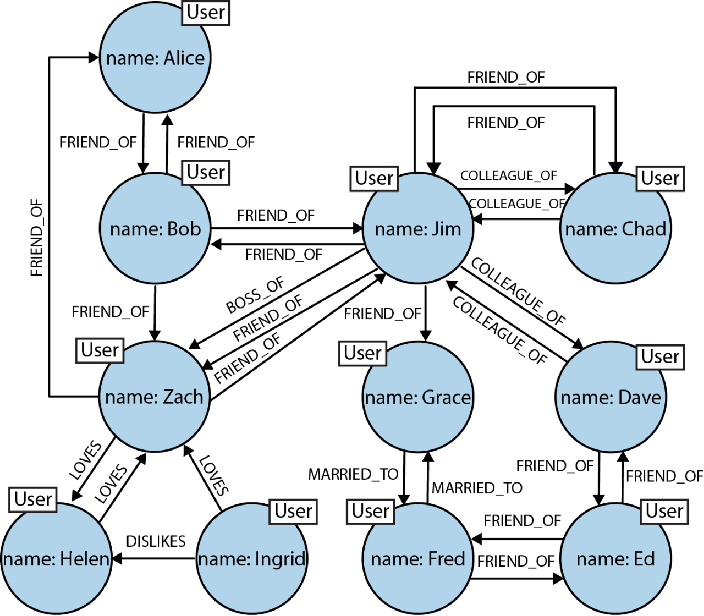
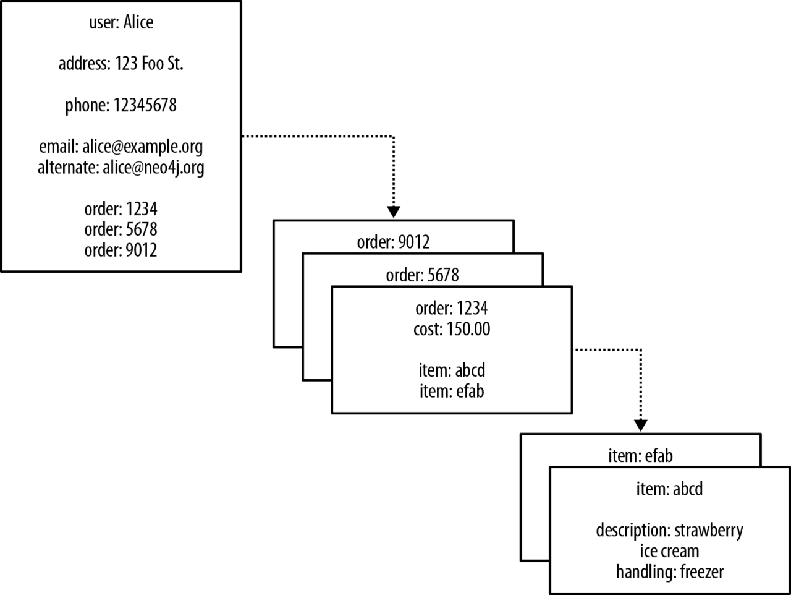
дёүгҖҒNeo4J зҡ„еӣҫжЁЎеһӢ
- ж ҮжіЁеұһжҖ§еӣҫжЁЎеһӢ (Labeled Property Graph Model)
- иҠӮзӮ№ (Node)пјҡиЎЁзӨәе®һдҪ“пјҢеӯҳеӮЁеұһжҖ§гҖӮ
- еұһжҖ§жҳҜй”®еҖјеҜ№пјҲKey-ValueпјүеҪўејҸпјҢж”ҜжҢҒеӯ—з¬ҰдёІгҖҒж•°з»„зӯүзұ»еһӢгҖӮ
- е…ізі» (Relationship)пјҡиҝһжҺҘиҠӮзӮ№пјҢеёҰжңүж–№еҗ‘жҖ§гҖҒеҗҚз§°е’ҢеұһжҖ§гҖӮ
- дҫӢеҰӮпјҡ
(Alice)-[:KNOWS]->(Bob)иЎЁзӨә Alice зҹҘйҒ“ BobгҖӮ
- дҫӢеҰӮпјҡ
- ж Үзӯҫ (Label)пјҡдёәиҠӮзӮ№еҲҶзұ»пјҢиЎЁзӨәи§’иүІжҲ–зҫӨз»„гҖӮ
- жҹҘиҜўиҜӯиЁҖ Cypher
Cypher жҳҜ Neo4j зҡ„жҹҘиҜўиҜӯиЁҖпјҢиҜӯжі•з®ҖжҙҒзӣҙи§ӮпјҢзұ»дјј ASCII иүәжңҜгҖӮ
- еҹәжң¬иҜӯжі•пјҡ
MATCH (a:Person)-[:KNOWS]->(b)-[:KNOWS]->(c) WHERE a.name = 'Jim' RETURN b, c;
еӣӣгҖҒж•°жҚ®е»әжЁЎдёҺеӣҫеә”з”ЁејҖеҸ‘
- ж•°жҚ®е»әжЁЎ
- иҠӮзӮ№иЎЁзӨәдәӢзү©пјҡдҪҝз”ЁиҠӮзӮ№д»ЈиЎЁж„ҹе…ҙи¶Јзҡ„е®һдҪ“пјҢеҰӮз”ЁжҲ·гҖҒи®ҫеӨҮзӯүгҖӮ
- е…ізі»иЎЁзӨәз»“жһ„пјҡз”Ёж–№еҗ‘жҖ§е…ізі»иЎЁиҫҫе®һдҪ“й—ҙзҡ„е…іиҒ”гҖӮ
- еұһжҖ§еӯҳеӮЁзү№жҖ§пјҡиҠӮзӮ№е’Ңе…ізі»еҸҜеёҰжңүеұһжҖ§пјҢз”ЁдәҺи®°еҪ•зӣёе…ідҝЎжҒҜпјҲеҰӮжқғйҮҚгҖҒж—¶й—ҙжҲізӯүпјүгҖӮ
- иҜӯд№үжё…жҷ°пјҡйҖҡиҝҮе…ізі»ж–№еҗ‘жҳҺзЎ®е®һдҪ“й—ҙзҡ„иҜӯд№үгҖӮ
- еә”з”ЁзӨәдҫӢпјҡд№ҰзұҚжҺЁиҚҗзі»з»ҹ
- йңҖжұӮпјҡдҪңдёәиҜ»иҖ…пјҢжҲ‘еёҢжңӣзҹҘйҒ“е–ңж¬ўжҹҗд№Ұзҡ„е…¶д»–иҜ»иҖ…иҝҳе–ңж¬ўе“Әдәӣд№ҰпјҢд»ҘдҫҝеҜ»жүҫйҳ…иҜ»е»әи®®гҖӮ
- е®һзҺ°жҹҘиҜўпјҡ
cypher MATCH (:Reader {name: 'Alice'})-[:LIKES]->(:Book {title: 'Dune'}) <-[:LIKES]-(:Reader)-[:LIKES]->(books:Book) RETURN books.title;
- дәӢе®һе»әжЁЎдёәиҠӮзӮ№
зӨәдҫӢпјҡжҸҸиҝ°дёҖдҪҚе‘ҳе·Ҙзҡ„иҒҢдҪҚдҝЎжҒҜгҖӮ
CREATE (:Person {name: 'Ian'})
-[:EMPLOYMENT]->(:Job {start_date: '2011-01-05'})
-[:EMPLOYER]->(:Company {name: 'Neo'}),
(:Job)-[:ROLE]->(:Role {name: 'Engineer'});дә”гҖҒNeo4J йғЁзҪІдёҺиҝҗиЎҢ
- иҝҗиЎҢ Neo4Jпјҡ
- жҺ§еҲ¶еҸ°жЁЎејҸпјҡ
<NEO4J_HOME>/bin/neo4j console - еҗҺеҸ°иҝҗиЎҢпјҡ
<NEO4J_HOME>/bin/neo4j start
- жҺ§еҲ¶еҸ°жЁЎејҸпјҡ
- еөҢе…ҘејҸжЁЎејҸпјҡдёҺеә”з”ЁзЁӢеәҸеҗҢиҝӣзЁӢиҝҗиЎҢгҖӮ
- жңҚеҠЎеҷЁжЁЎејҸпјҡзӢ¬з«ӢйғЁзҪІпјҢйҖҡиҝҮе®ўжҲ·з«Ҝи®ҝй—®гҖӮ
е…ӯгҖҒNeo4J еҶ…йғЁеӯҳеӮЁжңәеҲ¶
- еӯҳеӮЁж–Ү件пјҡж•°жҚ®еҲҶеқ—еӯҳеӮЁеҲ°дёҚеҗҢж–Ү件дёӯпјҲиҠӮзӮ№гҖҒе…ізі»гҖҒж ҮзӯҫгҖҒеұһжҖ§еҲҶеҲ«еӯҳеӮЁпјүгҖӮ
- е…ізі»еӯҳеӮЁзҡ„еҸҢеҗ‘й“ҫиЎЁпјҡиҠӮзӮ№дёҺе…ізі»й—ҙдҪҝз”ЁеҸҢеҗ‘й“ҫиЎЁиҝһжҺҘпјҢеҝ«йҖҹйҒҚеҺҶе…ізі»зҪ‘з»ңгҖӮ
- иҠӮзӮ№зҡ„еӯҳеӮЁеҚ з”Ё15byteпјҡ第дёҖдёӘдҪҚжҳҜдёҖдёӘж Үеҝ—дҪҚпјҢжҳҜеҗҰжңүе…іиҒ”зҡ„иҫ№жҳҜеҗҰжӯЈеңЁдҪҝз”ЁпјҢ然еҗҺпјҲеҒҸ移йҮҸ 1пјүжҳҜеӯҳеӮЁдёӢдёҖдёӘиҫ№зҡ„IDе…ізі»пјҢ然еҗҺеӯҳеӮЁдёӢдёҖдёӘеұһжҖ§зҡ„idпјҢ然еҗҺеӯҳеӮЁlabelsпјҢжңҖеҗҺеӯҳеӮЁе…¶д»–зҡ„еҶ…е®№
- иҫ№зҡ„еӯҳеӮЁеҚ з”Ё34byteпјҢ第дёҖдёӘдҪҚжҳҜдёҖдёӘж Үеҝ—дҪҚпјҢеӯҳеӮЁжҳҜеҗҰжӯЈеңЁдҪҝз”Ёпјӣд№ӢеҗҺеӯҳеӮЁиҝҷдёӘе…ізі»зҡ„иө·е§ӢиҠӮзӮ№ жҳҜи°ҒпјҢз»ҲжӯўиҠӮзӮ№жҳҜи°ҒгҖҒе…ізі»зҡ„зұ»еһӢпјӣ然еҗҺеӯҳеӮЁз¬¬дёҖдёӘиҠӮзӮ№пјҲиҫ№зҡ„иө·е§ӢиҠӮзӮ№пјүзҡ„еүҚдёҖдёӘе…ізі»жҳҜи°ҒпјҢеҗҺ дёҖдёӘе…ізі»жҳҜи°ҒпјҢ第дәҢдёӘиҠӮзӮ№зҡ„еүҚдёҖдёӘе…ізі»жҳҜи°ҒпјҢеҗҺдёҖдёӘе…ізі»жҳҜи°ҒпјҢеҗҺйқўе°ұжҳҜдҝқз•ҷеӯ—ж®ө
- жҳҜйҖҡиҝҮй“ҫиЎЁиҝһиө·жқҘзҡ„
第еҚҒдёғз«
ж—Ҙеҝ—з»“жһ„ж•°жҚ®еә“ (Log-Structured Database)
LSM-TreeпјҲLog-Structured Merge Treeпјү
е®ҡд№үпјҡLSM-Tree жҳҜдёҖз§Қ еҲҶеұӮгҖҒжңүеәҸгҖҒйқўеҗ‘зЈҒзӣҳ зҡ„ж•°жҚ®з»“жһ„гҖӮе…¶ж ёеҝғжҖқжғіжҳҜеҲ©з”ЁзЈҒзӣҳ йЎәеәҸеҶҷжҖ§иғҪиҝңй«ҳдәҺйҡҸжңәеҶҷжҖ§иғҪ зҡ„зү№зӮ№жқҘдјҳеҢ–еҶҷе…ҘгҖӮ
зү№зӮ№пјҡ
- ж•°жҚ®еҶҷе…Ҙпјҡд»Ҙ Append жЁЎејҸеҶҷе…ҘпјҢйҒҝе…ҚеҲ йҷӨе’Ңдҝ®ж”№пјҢжҸҗеҚҮеҶҷжҖ§иғҪгҖӮ
- йҖӮз”ЁеңәжҷҜпјҡеҶҷеӨҡиҜ»е°‘ зҡ„еңәжҷҜпјҢеҰӮж—Ҙеҝ—зі»з»ҹе’Ңж—¶еәҸж•°жҚ®еә“гҖӮ
дјҳзӮ№пјҡ
- жҳҫи‘—жҸҗеҚҮ жҸ’е…ҘгҖҒдҝ®ж”№гҖҒеҲ йҷӨ жҖ§иғҪгҖӮ
- йҖӮз”ЁдәҺ е®һж—¶гҖҒж—¶еәҸж•°жҚ®еӯҳеӮЁгҖӮ
- ж•°жҚ®зғӯеәҰдёҺ еұӮзә§пјҲlevelпјү зӣёе…ігҖӮжҳҫ然иҜ»ж–°ж•°жҚ®дјҡжӣҙеҝ«гҖӮ
зјәзӮ№пјҡ
- зүәзүІйғЁеҲҶ иҜ»еҸ–жҖ§иғҪпјҡдёҖж¬ЎиҜ»еҸ–еҸҜиғҪйңҖиҰҒи®ҝй—®еӨҡдёӘеұӮгҖӮ
- иҜ»ж”ҫеӨ§ е’Ң еҶҷж”ҫеӨ§ й—®йўҳпјҡж•°жҚ®еӨҡеұӮз®ЎзҗҶеҸҜиғҪеҜјиҮҙеӨҡдҪҷзҡ„ I/O ж“ҚдҪңгҖӮ
- еҶҷж”ҫеӨ§ пјҡдёәдәҶе®ҢжҲҗдёҖйЎ№еҶҷж“ҚдҪңпјҢж•°жҚ®еә“зі»з»ҹйңҖиҰҒеңЁеә•еұӮеӯҳеӮЁдёӯеҶҷе…Ҙзҡ„еӯ—иҠӮйҮҸеӨ§дәҺе®һйҷ…зҡ„ж•°жҚ®йҮҸгҖӮжҜ”еҰӮиҜҙLSMTreeеҗҲ并пјҢCompactionе°ұжңүгҖӮ
- иҜ»ж”ҫеӨ§пјҡдёәдәҶе®ҢжҲҗдёҖж¬ЎиҜ»ж“ҚдҪңпјҢзі»з»ҹйңҖиҰҒйўқеӨ–иҜ»еҸ–еӨ§йҮҸзҡ„ж— е…іж•°жҚ®гҖӮжҜ”еҰӮиҜҙLSMTreeиҜ»еҸ–жҹҗдёӘеҖјпјҢе®һйҷ…иҰҒиҜ»еҸ–еҫҲеӨҡеқ—гҖӮ
SSTable (Sorted String Table)
е®ҡд№үпјҡSSTable жҳҜдёҖз§Қ <й”®, еҖј> зҡ„еӯҳеӮЁж јејҸпјҢж”ҜжҢҒжңүеәҸеӯҳеӮЁгҖӮ
зү№зӮ№пјҡж•°жҚ®йЎәеәҸеҶҷе…ҘпјҢжҸҗеҚҮзЈҒзӣҳжҖ§иғҪгҖӮж”ҜжҢҒй«ҳж•Ҳзҡ„йҡҸжңәиҜ»еҸ–гҖӮ
йҷҗеҲ¶пјҡ
- еҶҷе…ҘзЈҒзӣҳеҗҺдёҚеҸҜеҸҳпјҢдҝ®ж”№жҲ–еҲ йҷӨйңҖиҰҒеӨ§йҮҸ I/O ж“ҚдҪңгҖӮ
- дёҚйҖӮеҗҲйҡҸжңәеҶҷе…ҘгҖӮ
еҶҷйҳ»еЎһпјҡеҶҷе…Ҙзҡ„ж—¶еҖҷеҸҜиғҪжңүдёӘйҳ»еЎһй—®йўҳпјҢдёәе•Ҙпјҹеӣ дёәе®ғеҶҷе…Ҙзҡ„ж—¶еҖҷе®ғжңүеҸҜиғҪйңҖиҰҒеҺ»еҒҡиҝҷдёӘеҗҲ并пјҢжҜ”еҰӮ L0 еұӮж»ЎдәҶ д№ӢеҗҺпјҢе®ғиҰҒеҫҖ L1 еұӮеҺ»иҗҪпјҢйӮЈд№ҲжҲ‘еҲҡжүҚи®ІдәҶдёҖдёӘжһҒз«Ҝжғ…еҶөжҳҜ L1 еұӮдҪ иҗҪдёӢжқҘд№ӢеҗҺд№ҹж»ЎдәҶпјҢеҸҲиҰҒеҫҖ L2 еұӮ иҗҪпјҢд»ҘжӯӨзұ»жҺЁпјҢжҜҸдёҖеұӮеҸҜиғҪйғҪдјҡж»ЎгҖӮ
зў°еҲ°иҝҷз§Қжғ…еҶөжҖҺд№ҲеҠһпјҹд»–е°ұиҜҙиҝҷж ·еңЁеҒҡ compaction зҡ„ж—¶еҖҷпјҢжҠҠеҶ…еӯҳйҮҢзҡ„иҗҪдёӢжқҘиҝҷдёӘеҠЁдҪңзӣҙжҺҘеҒҡдәҶд»Ҙ еҗҺпјҢеҰӮжһңи§ҰеҸ‘дәҶд»Һ L 0 еҲ° L1 еұӮзҡ„иҝҷдёӘеҠЁдҪңпјҢе°ұиҪ¬з§»еҲ°еҗҺеҸ°еҺ»еҒҡејӮжӯҘзҡ„еҶҷе…ҘзЎ¬зӣҳе°ұдёҚиҰҒеңЁеүҚеҸ°пјҢе°ұжҳҜиҜҙ е®ғеҸӘиҰҒиҗҪдёӢжқҘ马дёҠе°ұз»ҷз”ЁпјҢе°ұеҸҜд»ҘеҺ»еҸҳжҲҗдёҖдёӘеҸҜеҶҷзҡ„дёҖдёӘеҶ…еӯҳиЎЁпјҢ马дёҠе°ұеҸҜд»ҘжҺҘ收新зҡ„иҜ·жұӮиҝӣеҺ»пјҢеҗҺйқў е°ұж”ҫеҲ°иҝҷйҮҢйқўпјҢиҝҷе°ұжүҖи°“зҡ„еҶҷйҳ»еЎһпјҢе°ұжҳҜиҜҙдҪ еңЁеҶҷзҡ„иҝҮзЁӢеҪ“дёӯе°ұеҫҲе®№жҳ“дёҚж–ӯзҡ„еҫҖдёӢиҗҪпјҢ然еҗҺе°ұзңӢеҲ°иҝҷдёӘ ж”ҫеӨ§е°ұеҫҲдёҘйҮҚпјҢе°ұиҝҷдёҖж¬Ўе…¶ж“ҚдҪңе…¶е®һжү§иЎҢдәҶеҫҲеӨҡеҶҷзҡ„еҠЁдҪңпјҢ然еҗҺиҝҳжңүеҸҜиғҪжҲҗдёәиҝҷдёӘ瓶йўҲпјҢиҝҷж ·е°ұйҳ»зўҚдәҶ иҝҷдёӘдәӢзү©зҡ„еӨ„зҗҶзҡ„еҸҜз”ЁжҖ§гҖӮ
иҜ»ж”ҫеӨ§пјҡйӮЈиҜ»е‘ўпјҹжҳҜеӯҳеңЁиҝҷд№ҲдёҖдёӘй—®йўҳпјҢе°ұжҳҜжҲ‘еңЁжүҫдёҖдёӘж•°жҚ®зҡ„ж—¶еҖҷпјҢжҲ‘е…ҲеҲ°еҶ…еӯҳиЎЁйҮҢпјӣжүҫдёҚеҲ°пјҢжҲ‘еҶҚеҲ°иҝҷдёӘ L0 еұӮжүҫпјҢжүҫдёҚеҲ°жҲ‘д№ҹдёҚиғҪиҜҙиҝҷж•°жҚ®дёҚеӯҳеңЁпјҢжңүеҸҜиғҪе®ғеӨӘиҖҒпјҢе®ғиҗҪеҲ°еә•дёӢеҺ»дәҶпјҢдәҺжҳҜжҲ‘дёҖеұӮеұӮжүҫпјҢжһҒжңү еҸҜиғҪе°ұжҳҜжңҖеҗҺдҪ еңЁеҫҲжүҫдәҶеҫҲеӨҡеұӮдҪ жүҚжүҫеҲ°гҖӮиҖҢдё”дҪ еңЁдёҚеҗҢзҡ„еұӮйҮҢйқўеҸҜиғҪиҝҳеӯҳзқҖдёҚеҗҢзҡ„зүҲжң¬гҖӮеӣ дёәжҲ‘们еҲҡ жүҚиҜҙдәҶпјҢе®ғзҡ„ж”№еҶҷжҳҜйҖҡиҝҮиҝҪеҠ еҫ—еҲ°зҡ„пјҢйӮЈд№ҹе°ұжҳҜиҜҙдҪ еҰӮжһңжңүиҖҒзүҲжң¬зҡ„иҜқпјҢе®ғдјҡеңЁжӣҙдҪҺзҡ„еұӮйҮҢйқўпјҢеҰӮжһңжІЎжңүз»ҸиҝҮcompactionпјҢиҝҷдёӘж•°жҚ®иҝҳжҳҜеңЁзҡ„пјҢеҸӘжңү compact жүҚжңүдёҖж¬ЎжңәдјҡеҸҜиғҪжҠҠе®ғз»ҷеҲ жҺүгҖӮйҷҗеҲ¶дәҶAPжҹҘиҜў зҡ„жҖ§иғҪгҖӮ
и§ЈеҶіж–№жЎҲпјҡ
LevelDB е’Ң RocksDB
LevelDBпјҡеҹәдәҺ LSM-TreeпјҢж”ҜжҢҒеұӮзә§еҺӢзј©пјҲCompactionпјүд»ҘдјҳеҢ–зЈҒзӣҳз©әй—ҙдҪҝз”ЁгҖӮ
RocksDBпјҡ
- з”ұ Facebook ејҖеҸ‘пјҢдҪңдёә LevelDB зҡ„жү©еұ•гҖӮ
- ж”ҜжҢҒжӣҙй«ҳжҖ§иғҪпјҢе°Өе…¶йҖӮз”ЁдәҺ ж··еҗҲдәӢеҠЎеҲҶжһҗеӨ„зҗҶпјҲHTAPпјүгҖӮ
- жҸҗдҫӣеөҢе…ҘејҸгҖҒжҢҒд№…еҢ–зҡ„й”®еҖјеӯҳеӮЁпјҢдјҳеҢ–дәҶж—Ҙеҝ—з»“жһ„ж•°жҚ®еә“зҡ„жҖ§иғҪгҖӮ
RocksDB зҡ„дјҳеҢ–
еҶҷе…ҘжөҒзЁӢпјҡ
- ж•°жҚ®е…ҲеҶҷе…ҘеҶ…еӯҳпјҢеҶҚеҗҺеҸ°ејӮжӯҘеҶҷе…ҘзЈҒзӣҳпјҢйҷҚдҪҺеҶҷ延иҝҹгҖӮ
- й—®йўҳпјҡ
- еҶ…еӯҳеҶҷж»Ўж—¶еҸҜиғҪеј•еҸ‘йҳ»еЎһгҖӮ
- еҗҺеҸ°д»»еҠЎпјҲCompactionпјүеҸҜиғҪжҲҗдёәжҖ§иғҪ瓶йўҲгҖӮ
иҜ»еҸ–жөҒзЁӢпјҡйңҖиҰҒи®ҝй—®еӨҡеұӮж•°жҚ®ж–Ү件пјҢеҜјиҮҙ иҜ»ж”ҫеӨ§й—®йўҳгҖӮ
и§ЈеҶіж–№жЎҲпјҡ
- еҶҷйҳ»еЎһпјҡйҖҡиҝҮдёӯй—ҙзј“еӯҳеұӮеҲҶеҸ‘еҶҷе…Ҙд»»еҠЎпјҢзј“и§ЈеҶҷе…ҘеҺӢеҠӣгҖӮ
- иҜ»ж”ҫеӨ§пјҡеј•е…Ҙ еҲ—ејҸеӯҳеӮЁ дјҳеҢ–еҲҶжһҗжҖ§иғҪгҖӮ
ж··еҗҲеӯҳеӮЁ (HTAP)

OLTP е’Ң OLAPпјҡ
- OLTPпјҡ
- еңЁзәҝдәӢеҠЎеӨ„зҗҶпјҢзү№зӮ№жҳҜдҪҺ延иҝҹгҖҒй«ҳ并еҸ‘гҖӮ
- йҖӮеҗҲ иЎҢејҸеӯҳеӮЁгҖӮ
- OLAPпјҡ
- еңЁзәҝеҲҶжһҗеӨ„зҗҶпјҢзү№зӮ№жҳҜй«ҳ延иҝҹгҖҒдҪҺ并еҸ‘гҖҒеӨ§ж•°жҚ®йҮҸгҖӮ
- йҖӮеҗҲ еҲ—ејҸеӯҳеӮЁгҖӮ
ж··еҗҲеӯҳеӮЁзӯ–з•Ҙпјҡ
- иЎҢејҸеӯҳеӮЁйҖӮеҗҲдәӢеҠЎж•°жҚ®пјҢеҲ—ејҸеӯҳеӮЁйҖӮеҗҲеҲҶжһҗж•°жҚ®гҖӮ
- йҖҡиҝҮ еҠЁжҖҒж јејҸиҪ¬жҚў йҷҚдҪҺзЈҒзӣҳејҖй”ҖгҖӮ
еҗ‘йҮҸж•°жҚ®еә“ (Vector Database)
еҗ‘йҮҸеҢ–пјҡеҗ‘йҮҸпјҲembeddingпјүз”ұ AI жЁЎеһӢпјҲеҰӮеӨ§еһӢиҜӯиЁҖжЁЎеһӢпјҢLLMпјүз”ҹжҲҗпјҢеҢ…еҗ«еӨ§йҮҸз»ҙеәҰдҝЎжҒҜгҖӮеҗ‘йҮҸзҡ„з»ҙеәҰиЎЁзӨәж•°жҚ®зҡ„зү№еҫҒпјҢеҸҜз”ЁдәҺжҚ•иҺ·жЁЎејҸе’Ңе…ізі»гҖӮ
з”ЁйҖ”пјҡз®ЎзҗҶе’ҢеӯҳеӮЁй«ҳз»ҙзү№еҫҒж•°жҚ®пјҢж”ҜжҢҒеҹәдәҺзӣёдјјжҖ§зҡ„жҹҘиҜўгҖӮ
еҗ‘йҮҸж•°жҚ®еә“зҡ„е·ҘдҪңеҺҹзҗҶ
ж ёеҝғпјҡеҹәдәҺ иҝ‘дјјжңҖиҝ‘йӮ»пјҲApproximate Nearest Neighbor, ANNпјү жҗңзҙўз®—жі•жүҫеҲ°дёҺжҹҘиҜўеҗ‘йҮҸжңҖзӣёдјјзҡ„еҗ‘йҮҸгҖӮ
дё»иҰҒз®—жі•пјҡйҡҸжңәжҠ•еҪұпјҲRandom Projectionпјүпјҡе°Ҷй«ҳз»ҙж•°жҚ®жҠ•еҪұеҲ°дҪҺз»ҙз©әй—ҙпјҢеҮҸе°‘и®Ўз®—еӨҚжқӮеәҰгҖӮ
жқғиЎЎпјҡеҮҶзЎ®жҖ§ vs. йҖҹеәҰпјҡеҗ‘йҮҸж•°жҚ®еә“йҖҡеёёжҸҗдҫӣиҝ‘дјјз»“жһңпјҢйңҖеңЁжҖ§иғҪе’ҢеҮҶзЎ®зҺҮд№Ӣй—ҙеҒҡеҮәеҸ–иҲҚгҖӮ
еҗ‘йҮҸж•°жҚ®еә“зҡ„еә”з”Ё
е…ёеһӢе·Ҙе…·пјҡPinecone зӯүгҖӮ
еңәжҷҜпјҡAI жҺЁиҚҗзі»з»ҹгҖҒеӣҫеғҸ/ж–Үжң¬жЈҖзҙўзӯүгҖӮ
ж ёеҝғз®—жі•
- 欧еҮ йҮҢеҫ—и·қзҰ»пјҲL2 и·қзҰ»пјү
е®ҡд№үпјҡи®Ўз®—дёӨзӮ№д№Ӣй—ҙзҡ„зӣҙзәҝи·қзҰ»пјҢе…¬ејҸдёә (d = \sqrt{\sum (x_i – y_i)^2})гҖӮ
зү№зӮ№пјҡеҜ№з»қеҜ№ж•°еҖјж•Ҹж„ҹпјҢйҖӮз”ЁдәҺж•°еҖјзү№еҫҒгҖӮ
йҖӮз”ЁеңәжҷҜпјҡеңЁзү№еҫҒеҲҶеёғиҫғдёәеқҮеҢҖпјҢдё”еҜ№е…·дҪ“ж•°еҖјеҸҳеҢ–иҫғдёәж•Ҹж„ҹзҡ„еңәжҷҜпјҢдҫӢеҰӮжҺЁиҚҗзі»з»ҹдёӯзҡ„з”ЁжҲ·еҒҸеҘҪгҖӮ - дҪҷејҰзӣёдјјеәҰ
е®ҡд№үпјҡи®Ўз®—дёӨеҗ‘йҮҸеӨ№и§’зҡ„дҪҷејҰеҖјпјҢе…¬ејҸдёә ( \text{cosine}(A, B) = \frac{A \cdot B}{||A|| \cdot ||B||} )гҖӮ
зү№зӮ№пјҡеҸӘе…іжіЁеҗ‘йҮҸзҡ„ж–№еҗ‘пјҢеҝҪз•ҘдәҶеӨ§е°ҸпјҢйҖӮеҗҲж–Үжң¬ж•°жҚ®гҖӮ
йҖӮз”ЁеңәжҷҜпјҡж–Үжң¬зӣёдјјеәҰи®Ўз®—пјҢеҰӮдҝЎжҒҜжЈҖзҙўгҖҒж–ҮжЎЈиҒҡзұ»пјҢе°Өе…¶еңЁзү№еҫҒиЎЁзӨәдёәиҜҚеҗ‘йҮҸж—¶гҖӮ - жӣје“ҲйЎҝи·қзҰ»пјҲL1 и·қзҰ»пјү
е®ҡд№үпјҡи®Ўз®—дёӨзӮ№д№Ӣй—ҙеңЁеҗ„дёӘз»ҙеәҰдёҠзҡ„з»қеҜ№и·қзҰ»д№Ӣе’ҢпјҢе…¬ејҸдёә (d = \sum |x_i – y_i|)гҖӮ
зү№зӮ№пјҡеҜ№ејӮеёёеҖјиҫғдёәзЁіеҒҘгҖӮ
йҖӮз”ЁеңәжҷҜпјҡзү№еҫҒз©әй—ҙзЁҖз–Ҹзҡ„жғ…еҶөпјҢжҲ–иҖ…еҪ“зү№еҫҒд№Ӣй—ҙжңүжҳҺзЎ®зҡ„з»қеҜ№еҖјж„Ҹд№үж—¶гҖӮ - жқ°еҚЎеҫ·зӣёдјјеәҰ
е®ҡд№үпјҡи®Ўз®—дёӨдёӘйӣҶеҗҲзҡ„дәӨйӣҶдёҺ并йӣҶзҡ„жҜ”зҺҮпјҢе…¬ејҸдёә ( J(A, B) = \frac{|A \cap B|}{|A \cup B|} )гҖӮ
зү№зӮ№пјҡйҖӮз”ЁдәҺйӣҶеҗҲж•°жҚ®пјҢејәи°ғе…ғзҙ зҡ„еӯҳеңЁдёҺеҗҰгҖӮ
йҖӮз”ЁеңәжҷҜпјҡжҺЁиҚҗзі»з»ҹдёӯзҡ„з”ЁжҲ·иЎҢдёәзӣёдјјеәҰгҖҒж–ҮжЎЈеҺ»йҮҚзӯүгҖӮ - зҡ®е°”йҖҠзӣёе…ізі»ж•°
е®ҡд№үпјҡиЎЎйҮҸдёӨдёӘеҸҳйҮҸд№Ӣй—ҙзҡ„зәҝжҖ§е…ізі»ејәеәҰпјҢи®Ўз®—е…¬ејҸдёә ( r = \frac{cov(X, Y)}{\sigma_X \sigma_Y} )гҖӮ
зү№зӮ№пјҡеҜ№еқҮеҖје’Ңж ҮеҮҶе·®иҝӣиЎҢдәҶеҪ’дёҖеҢ–еӨ„зҗҶпјҢйҖӮеҗҲиЎЎйҮҸзәҝжҖ§е…ізі»гҖӮ
йҖӮз”ЁеңәжҷҜпјҡз”ЁжҲ·иҜ„еҲҶж•°жҚ®зҡ„зӣёе…іжҖ§еҲҶжһҗпјҢйҖӮз”ЁдәҺжҺЁиҚҗзі»з»ҹдёӯзҡ„еҚҸеҗҢиҝҮж»ӨгҖӮ
第еҚҒе…«з«
TSDB
д»Җд№ҲжҳҜж—¶еәҸж•°жҚ®еә“пјҲTSDBпјүпјҹ
ж—¶еәҸж•°жҚ®еә“пјҲTSDBпјүжҳҜдё“й—ЁдёәеӨ„зҗҶеёҰжңүж—¶й—ҙжҲізҡ„ж•°жҚ®пјҲеҚіж—¶еәҸж•°жҚ®пјүиҖҢдјҳеҢ–зҡ„ж•°жҚ®еә“гҖӮж—¶еәҸж•°жҚ®жҢҮзҡ„жҳҜйҡҸж—¶й—ҙеҸҳеҢ–зҡ„жөӢйҮҸжҲ–дәӢ件гҖӮдҫӢеҰӮпјҢжңҚеҠЎеҷЁзҡ„жҖ§иғҪзӣ‘жҺ§гҖҒзҪ‘з»ңж•°жҚ®гҖҒдј ж„ҹеҷЁж•°жҚ®гҖҒзӮ№еҮ»дәӢ件гҖҒеёӮеңәдәӨжҳ“зӯүпјҢйғҪжҳҜж—¶еәҸж•°жҚ®зҡ„е…ёеһӢдҫӢеӯҗгҖӮж—¶еәҸж•°жҚ®еә“дё»иҰҒз”ЁдәҺеӨ„зҗҶиҝҷдәӣдёҺж—¶й—ҙзӣёе…ізҡ„еәҰйҮҸе’ҢдәӢ件数жҚ®гҖӮ
зү№зӮ№пјҡ
- ж—¶еәҸж•°жҚ®зҡ„з”ҹе‘Ҫе‘Ёжңҹз®ЎзҗҶгҖҒж•°жҚ®жҖ»з»“е’ҢеҜ№еӨ§йҮҸи®°еҪ•зҡ„жү«жҸҸпјҢдҪҝеҫ—ж—¶еәҸж•°жҚ®дёҚеҗҢдәҺе…¶д»–ж•°жҚ®зұ»еһӢгҖӮ
- TSDB дјҳеҢ–дәҶеҜ№ж—¶й—ҙзӣёе…іж•°жҚ®зҡ„з®ЎзҗҶпјҢиғҪеӨҹй«ҳж•ҲеӨ„зҗҶйҡҸж—¶й—ҙеҸҳеҢ–зҡ„ж•°жҚ®гҖӮ
е…·дҪ“иҖҢиЁҖпјҡ
- жңүеӯҳжҙ»зҠ¶жҖҒпјҢи®ҫзҪ®дәҶеӯҳжҙ»ж—¶й—ҙ
- ж јејҸз®ҖеҚ•
- еӯҳеӮЁж—¶ж №жҚ®е·®еҖјпјҢиҝӣдёҖжӯҘеҺӢзј©
- жүҖжңүж•°жҚ®йғҪжңүж—¶й—ҙжҲі
ж—¶еәҸж•°жҚ®еә“зҡ„йҮҚиҰҒжҖ§
еҰӮд»ҠпјҢеҮ д№ҺжүҖжңүзү©зҗҶдё–з•Ңзҡ„иЎЁйқўйғҪжңүдј ж„ҹеҷЁпјҢеҹҺеёӮзҡ„иЎ—йҒ“гҖҒе·ҘеҺӮгҖҒеҚ«жҳҹгҖҒиЎЈзү©гҖҒжүӢжңәзӯүйғҪеңЁдёҚж–ӯең°дә§з”ҹж—¶еәҸж•°жҚ®гҖӮиҝҷдәӣж•°жҚ®йҮҸеӨ§гҖҒжқҘжәҗеӨҡгҖҒзӣ‘жҺ§йңҖжұӮејәпјҢдј з»ҹж•°жҚ®еә“еҫҲйҡҫеә”еҜ№еҰӮжӯӨеәһеӨ§зҡ„ж•°жҚ®еӨ„зҗҶйңҖжұӮгҖӮдёәжӯӨпјҢйңҖиҰҒдёҖз§Қе…·жңүй«ҳжҖ§иғҪгҖҒеҸҜжү©еұ•гҖҒдё“дёәж—¶еәҸж•°жҚ®и®ҫи®Ўзҡ„ж—¶еәҸж•°жҚ®еә“гҖӮ
ж—¶еәҸж•°жҚ®пјҡжҜ”еҰӮиҜҙдёҖдёӘең°еӣҫпјҢжҲ‘иҝҷжҳҜдёҖдёӘпјҢжҜ”еҰӮиҜҙдёҖдёӘиҠұеӣӯпјҢжҲ‘еңЁйҮҢйқўеёғдәҶеҫҲеӨҡзҡ„дј ж„ҹеҷЁпјҢиҝҷдәӣдј ж„ҹеҷЁе°ұжҳҜе®ғзҡ„жё©еәҰе’Ңж№ҝеәҰпјҢжҲ‘жқҘеҒҡиҝҷдёӘиҮӘеҠЁжөҮзҒҢпјҢ然еҗҺ他们е°ұдјҡжәҗжәҗдёҚж–ӯзҡ„дә§з”ҹж•°жҚ®пјҢжҲ‘иҰҒжҠҠе®ғеӯҳ иө·жқҘпјҢйӮЈеҸҜд»ҘзңӢеҲ°е®ғ们жәҗжәҗдёҚж–ӯдә§з”ҹж•°жҚ®пјҢдәҺжҳҜжҲ‘们зңӢеҲ°иҝҷж•°жҚ®жңүеҮ дёӘзү№еҫҒгҖӮ
- 第дёҖдёӘпјҡиҝҷдёӘж•°жҚ®еҸӘиҰҒдҪ еҫҖдёҠеҸ‘пјҢе®ғдёҖе®ҡеёҰдёҖдёӘж—¶й—ҙжҲіпјҢжҲ‘иҰҒзҹҘйҒ“дҪ иҝҷдёӘж•°жҚ®жҳҜд»Җд№Ҳж—¶й—ҙеҸ‘дёҠ жқҘпјҹиҝҷжҳҜ第дёҖдёӘй—®йўҳгҖӮ
- 第дәҢдёӘпјҡдҪ дёҖе®ҡдјҡжңүеӨ§йҮҸзҡ„иҝҷз§Қдј ж„ҹеҷЁеңЁдј ж•°жҚ®пјҢжүҖд»Ҙе®ғеҝ…йЎ»иҰҒж”ҜжҢҒиҝҷз§Қй«ҳ并еҸ‘пјҢе°ұеҗһеҗҗйҮҸиҰҒ еӨ§пјҢиҝҷз§ҚеҗһеҗҗйҮҸеҝ…йЎ»иҰҒеӨ§жүҚиғҪж”ҜжҢҒй«ҳ并еҸ‘гҖӮ
- 第дёүдёӘпјҡдҪ иҜҙдј ж„ҹеҷЁеҰӮжһңд»–еңЁжҠҘж•°жҚ®пјҢд»–еҒ¶е°”дёўжҺүдёҖдёӨдёӘжҲ–иҖ…дёҖдёӨдёӘдёҚеӨӘеҮҶпјҢе®ғдјҡдёҚдјҡеҪұе“ҚдҪ зҡ„иҝҷдёӘж•°жҚ®ж•ҙдҪ“зҡ„ж•Ҳжһңпјҹ е°ұжҳҜд»–еҰӮжһңиҜҙжҜҸдёҖз§’й’ҹйғҪжҠҘдёҖдёӘж•°жҚ®пјҢеңЁжҹҗдёҖз§’д»–зӘҒ然丢дәҶдёҖдёӘж•°жҚ®пјҢе®ғдјҡдёҚдјҡеҪұе“ҚдҪ еҒҡз»ҹи®Ў зҡ„ж•Ҳжһңпјҹе°ұзҗҶи®әдёҠжқҘиҜҙпјҢе®ғйҮҢйқўзҡ„ж•°жҚ®е…Ғи®ёе°‘йҮҸзҡ„дёҚеҮҶзЎ®жҲ–иҖ…жҳҜзјәеӨұпјҢд№ҹе°ұжҳҜиҜҙе®ғзҡ„ж•°жҚ®е’ҢйӮЈ з§Қ transaction зҡ„ж•°жҚ®е°ұеҪўжҲҗдәҶйІңжҳҺзҡ„еҜ№жҜ”гҖӮ
- 第еӣӣдёӘпјҡе°ұжҳҜе…¶е®һжҲ‘们еҜ№еҚ•зӮ№зҡ„ж•°жҚ®жҳҜдёҚж„ҹе…ҙи¶Јзҡ„пјҢдҪ иҜҙжҲ‘иҰҒзҹҘйҒ“жҹҗдёҖдёӘж—¶й—ҙзӮ№пјҢиҝҷйҮҢйқўжҜҸдёҖ з§’йғҪиҰҒеҸ‘ж•°жҚ®пјҢжҲ‘иҰҒзҹҘйҒ“еңЁжҹҗдёҖз§’зҡ„ж•°жҚ®пјҢиҝҷдёӘиӮҜе®ҡдҪ дёҚеӨӘе…іеҝғпјҢдҪ е…іеҝғзҡ„жҳҜдёҖдёӘж—¶й—ҙеҢәй—ҙ еҶ…пјҢжҜ”еҰӮиҜҙеңЁдёҖе°Ҹж—¶еҶ…е®ғзҡ„ж•°жҚ®д»Җд№Ҳж ·зҡ„пјҢжҲ‘иҰҒеҺ»жұӮе’ҢгҖӮжүҖд»ҘеңЁжҢҒз»ӯж•°жҚ®еә“йҮҢпјҢд»–еҜ№еҚ•зӮ№ж•°жҚ® зҡ„и®ҝй—®дёҚдјҡзү№еҲ«еӨҡпјҢд»–з»ҸеёёеҒҡзҡ„жҳҜеҜ№дёҖеқ—ж•°жҚ®пјҢе°Өе…¶жҳҜж—¶й—ҙзүҮеҲ’еҲҶеҮәжқҘзҡ„дёҖж®өж•°жҚ®пјҢд»–иҰҒеҺ»еҒҡ дёҖдёӘи®ҝй—®гҖӮ
- ж•ҙдҪ“зҡ„еӯҳж”ҫжҳҜз”ЁдәҶзұ»дјјlsmж—Ҙеҝ—з»“жһ„еҗҲе№¶ж ‘зҡ„з»“жһ„пјӣж—¶еәҸж•°жҚ®еә“зҡ„з”ҹе‘Ҫе‘ЁжңҹдёҖиҲ¬жҜ”иҫғзҹӯпјҢжҜ”еҰӮдёҖдёӘ дј ж„ҹеҷЁпјҢеҸҜиғҪжҲ‘们еҸӘе…іеҝғжңҖиҝ‘дёҖе‘Ёзҡ„жҲ–иҖ…дёҖдёӘжңҲзҡ„ж•°жҚ®пјҢи¶…иҝҮзҡ„ж—¶й—ҙзҡ„ж•°жҚ®е°ұеҸҜд»ҘеҲ йҷӨпјҲжҜ”еҰӮеҪ“жҺү еҲ°L0д»ҘдёӢпјҢжҲ‘们е°ұе°Ҷе…¶еҺӢзј©пјҢз”ҡиҮіеҲ йҷӨпјүгҖӮпјҲзұ»жҜ”е…ізі»еһӢж•°жҚ®еә“зҡ„и®ўеҚ•ж•°жҚ®пјҢи®ўеҚ•ж•°жҚ®еҝ…йЎ»иҰҒжҢҒд№… еҢ–дҝқеӯҳпјҢдҪҶжҳҜиҝҷз§Қж—¶еәҸж•°жҚ®еә“еҸҜд»ҘйҖҡиҝҮж‘ҳиҰҒеҺӢзј©дёҖдёӢпјҢжҲ–иҖ…зӣҙжҺҘеҲ жҺүпјү
- дёҚеӨӘеҸҜиғҪдјҡе»әз«Ӣзҙўеј•пјҢдҫӢеҰӮи®°еҪ•жё©еәҰйҡҸж—¶й—ҙзҡ„еҸҳеҢ–пјҢдёҖиҲ¬дёҚдјҡжңүеҝ…иҰҒе»әз«Ӣзҙўеј•пјҲжҜ”еҰӮе»әдёӘжё©еәҰеңЁж—¶ й—ҙзҡ„зҙўеј•пјҢиҝҷжІЎжңүж„Ҹд№үпјү
- еҜ№дәҺж—¶еәҸж•°жҚ®еә“жҺҘеҸ—зҡ„ж•°жҚ®зҡ„зү№зӮ№пјҡжӣҙеӨҡзҡ„ж•°жҚ®зӮ№пјҢжӣҙеӨҡзҡ„ж•°жҚ®жәҗпјҢжӣҙеӨҡзҡ„зӣ‘жҺ§пјҢжӣҙеӨҡзҡ„жҺ§еҲ¶.
дјҳеҢ–пјҡ1.еҸҜд»ҘдёҚи®°еҪ•ж—¶й—ҙжҲіпјҡеҰӮжһңдј иҫ“жқҘзҡ„ж•°жҚ®жҜ”иҫғзЁіе®ҡзҡ„иҜқпјҢдҫӢеҰӮжҜҸз§’1дёӘж•°жҚ®пјҢжҲ‘еҸҜд»Ҙи®°еҪ•жҹҗдёҖдёӘзү№е®ҡ ж•°жҚ®пјҲжҜ”еҰӮејҖе§Ӣзҡ„ж•°жҚ®зҡ„ж—¶й—ҙжҲіпјү然еҗҺеҗҺйқўжҜҸз§’и®°еҪ•дёҖдёӘж•°жҚ®е°ұеҘҪгҖӮ2.еҸҜд»Ҙи®°еҪ•ж•°жҚ®зҡ„еўһйҮҸпјҡжҜ”еҰӮи®°еҪ•жё©еәҰпјҢеҸҳеҢ–жҜ”иҫғе°ҸгҖӮжҲ‘е°ұи®°еҪ•зӣёжҜ”дёҠдёҖдёӘж•°жҚ®еўһеҠ жҲ–иҖ…еҮҸе°‘дәҶеӨҡе°‘ еәҰгҖӮиҝҷж ·еӯҳеӮЁзҡ„ж•°жҚ®зҡ„з©әй—ҙеҫ—д»ҘиҠӮзңҒдәҶпјҢжүҖд»ҘеҸҜд»ҘеӯҳжӣҙеӨҡзҡ„ж•°жҚ®гҖӮ
InfluxDB
InfluxDB жҳҜдёҖдёӘдё“й—Ёдёәж—¶еәҸж•°жҚ®жһ„е»әзҡ„е№іеҸ°пјҢж—ЁеңЁеӨ„зҗҶз”ұдј ж„ҹеҷЁгҖҒеә”з”ЁзЁӢеәҸе’ҢеҹәзЎҖи®ҫж–Ҫз”ҹжҲҗзҡ„еӨ§йҮҸж—¶й—ҙжҲіж•°жҚ®гҖӮе®ғеё®еҠ©ејҖеҸ‘иҖ…еҝ«йҖҹжһ„е»әз”ЁдәҺеҲҶжһҗгҖҒзү©иҒ”зҪ‘пјҲIoTпјүе’Ңдә‘еҺҹз”ҹжңҚеҠЎзҡ„е®һж—¶еә”з”ЁзЁӢеәҸгҖӮ
ж ёеҝғзү№жҖ§пјҡ
- еӨ„зҗҶеӨ§и§„жЁЎгҖҒй«ҳйў‘зҺҮзҡ„ж—¶еәҸж•°жҚ®гҖӮ
- йҖӮз”ЁдәҺйңҖиҰҒй«ҳжҖ§иғҪе’ҢеҸҜжү©еұ•жҖ§зҡ„еә”з”ЁеңәжҷҜпјҢеҰӮ IoTгҖҒдә‘и®Ўз®—зӯүгҖӮ
InfluxDB зҡ„ж ёеҝғжҰӮеҝө
InfluxDB дҪҝз”ЁеӨҡдёӘе…ғзҙ жқҘеӯҳеӮЁе’Ңз®ЎзҗҶж•°жҚ®гҖӮдё»иҰҒеҢ…жӢ¬пјҡ
- ж—¶й—ҙжҲіпјҲTimestampпјүпјҡжүҖжңүж•°жҚ®йғҪеҢ…еҗ«ж—¶й—ҙжҲіпјҢиЎЁзӨәж•°жҚ®и®°еҪ•зҡ„ж—¶й—ҙгҖӮInfluxDB дҪҝз”Ё RFC3339 UTC ж јејҸжҳҫзӨәж—¶й—ҙпјҢ并ж”ҜжҢҒзәіз§’зә§еҲ«зҡ„зІҫеәҰгҖӮ
- жөӢйҮҸпјҲMeasurementпјүпјҡжөӢйҮҸжҳҜж•°жҚ®зҡ„е®№еҷЁпјҢеҢ…еҗ«ж—¶й—ҙжҲігҖҒж ҮзӯҫгҖҒеӯ—ж®өзӯүдҝЎжҒҜгҖӮйҖҡиҝҮжөӢйҮҸеҗҚз§°еҸҜд»Ҙжё…жҷ°ең°жҸҸиҝ°ж•°жҚ®зҡ„еҶ…е®№пјҲдҫӢеҰӮ “census” и®°еҪ•зҡ„жҳҜе…ідәҺиңңиңӮе’ҢиҡӮиҡҒзҡ„ж•°йҮҸпјүгҖӮ
- еӯ—ж®өпјҲFieldsпјүпјҡеӯ—ж®өеҢ…жӢ¬еӯ—ж®өй”®пјҲfield keyпјүе’ҢеҖјпјҲfield valueпјүгҖӮеӯ—ж®өеҖјеҸҜд»ҘжҳҜеӯ—з¬ҰдёІгҖҒжө®еҠЁеҖјгҖҒж•ҙж•°жҲ–еёғе°”еҖјгҖӮ
- еӯ—ж®өй”®пјҲField Keyпјүпјҡеӯ—ж®өзҡ„еҗҚз§°гҖӮ
- еӯ—ж®өеҖјпјҲField Valueпјүпјҡеӯ—ж®өзҡ„еҖјгҖӮ
- ж ҮзӯҫпјҲTagsпјүпјҡж ҮзӯҫжҳҜе…ғж•°жҚ®зҡ„йӣҶеҗҲпјҢеҢ…жӢ¬ж Үзӯҫй”®пјҲtag keyпјүе’Ңж ҮзӯҫеҖјпјҲtag valueпјүгҖӮж Үзӯҫиў«зҙўеј•пјҢеӣ жӯӨеңЁжҹҘиҜўж—¶йҖҹеәҰиҫғеҝ«пјҢйҖӮеҗҲеӯҳеӮЁеёёжҹҘиҜўзҡ„е…ғж•°жҚ®гҖӮ
- ж Үзӯҫй”®пјҲTag KeyпјүпјҡиЎЁзӨәж Үзӯҫзҡ„зұ»еҲ«пјҢеҰӮ “location” е’Ң “scientist”гҖӮ
- ж ҮзӯҫеҖјпјҲTag Valueпјүпјҡж Үзӯҫй”®зҡ„е…·дҪ“еҖјпјҢеҰӮ “klamath” е’Ң “portland”гҖӮ
InfluxDB зҡ„и®ҫи®ЎеҺҹеҲҷ
InfluxDB еңЁи®ҫи®Ўж—¶иҖғиҷ‘дәҶд»ҘдёӢеҮ дёӘеҺҹеҲҷпјҢж—ЁеңЁдјҳеҢ–ж—¶еәҸж•°жҚ®зҡ„еӨ„зҗҶпјҡ
- ж—¶й—ҙйЎәеәҸзҡ„ж•°жҚ®еҶҷе…ҘпјҡдёәдәҶжҸҗй«ҳжҖ§иғҪпјҢInfluxDB ејәеҲ¶ж•°жҚ®жҢүж—¶й—ҙеҚҮеәҸеҶҷе…ҘгҖӮ
- дёҘж јзҡ„жӣҙж–°е’ҢеҲ йҷӨжқғйҷҗпјҡдёәжҸҗй«ҳжҹҘиҜўе’ҢеҶҷе…ҘжҖ§иғҪпјҢInfluxDB йҷҗеҲ¶дәҶеҜ№ж•°жҚ®зҡ„жӣҙж–°е’ҢеҲ йҷӨж“ҚдҪңгҖӮж—¶еәҸж•°жҚ®йҖҡеёёжҳҜдёҖж¬ЎжҖ§еҶҷе…ҘпјҢдёҚйңҖиҰҒйў‘з№Ғжӣҙж–°гҖӮ
- дјҳе…ҲеӨ„зҗҶиҜ»еҶҷиҜ·жұӮпјҡInfluxDB дјҳе…ҲеӨ„зҗҶиҜ»еҶҷиҜ·жұӮпјҢиҖҢдёҚжҳҜејәдёҖиҮҙжҖ§дҝқиҜҒгҖӮиҝҷж„Ҹе‘ізқҖжҹҘиҜўеҸҜиғҪдёҚдјҡеҢ…жӢ¬жңҖж–°зҡ„ж•°жҚ®пјҢдҪҶжңҖз»Ҳж•°жҚ®дјҡиҫҫеҲ°дёҖиҮҙжҖ§гҖӮ
- ж— жЁЎејҸи®ҫи®ЎпјҲSchemaless DesignпјүпјҡInfluxDB йҮҮз”Ёж— жЁЎејҸи®ҫи®ЎпјҢжӣҙзҒөжҙ»ең°з®ЎзҗҶдёҚиҝһз»ӯзҡ„ж•°жҚ®гҖӮ
- ж•°жҚ®йӣҶдјҳдәҺеҚ•дёӘзӮ№пјҡз”ұдәҺж—¶еәҸж•°жҚ®зҡ„жҜҸдёӘзӮ№еңЁж•ҙдҪ“ж•°жҚ®йӣҶдёӯзҡ„дҪңз”Ёиҫғе°ҸпјҢеӣ жӯӨ InfluxDB жҸҗдҫӣдәҶејәеӨ§зҡ„иҒҡеҗҲе·Ҙе…·жқҘеӨ„зҗҶеӨ§йҮҸж•°жҚ®пјҢжүҖд»ҘжІЎжңүIDиҝҷдёӘжҰӮеҝөпјҢе°ұжҳҜжҢүз…§ж—¶й—ҙжҲіеҺ»жӢҝпјӣеҜ№дәҺеӨҡдёӘж—¶й—ҙзӮ№йҮҚеӨҚж•°жҚ®пјҢдёҚдјҡеӯҳдёӨж¬ЎпјҲеҮҸе°‘еҚ з”Ёпјү
- е№ӮзӯүжҖ§гҖӮеә”з”ЁеңәжҷҜйҮҢйқўе°ұжҳҜеӨ§йҮҸзҡ„дј ж„ҹеҷЁпјҢдјҡжҠҠеӨ§йҮҸзҡ„ж•°жҚ®йҖҡиҝҮдёҚеҸҜйқ зҡ„жҲ–иҖ…дёҚйӮЈд№ҲеҸҜйқ зҡ„зҪ‘з»ңдј йҖ’иҝҮжқҘпјҢйӮЈжҲ‘е°ұдёҚиғҪдҝқиҜҒе®ғжІЎжңүиў«еҸ‘йҖҒеӨҡж¬ЎпјҢдҪҶжҳҜе®ғеҸ‘йҖҒеӨҡж¬Ўе®ғд№ҹдёҚиғҪеҜ№жҲ‘зҡ„ж•°жҚ®еә“дә§з”ҹеҪұе“ҚпјҢжҲ‘ еҸӘеӯҳдёҖдёӘпјҲж №жҚ®ж—¶й—ҙжҲіпјүгҖӮжҜ”еҰӮйҷӨдәҶvalueд№ӢеӨ–зҡ„йғЁеҲҶж•°жҚ®йғҪжҳҜзӣёеҗҢзҡ„пјҢиҝҷж ·зҡ„ж•°жҚ®жҸҗдәӨдәҶдёүж¬ЎпјҢ дёҚдјҡеғҸmysqlдёҖж ·жҸ’е…ҘдёүиЎҢзӣёеҗҢзҡ„ж•°жҚ®пјҢInluxDBдјҡз”ЁжңҖж–°зҡ„дёҖдёӘж•°жҚ®еӯҳеӮЁгҖӮ
InfluxDB зҡ„еӯҳеӮЁеј•ж“Һ
InfluxDB зҡ„еӯҳеӮЁеј•ж“ҺзЎ®дҝқж•°жҚ®е®үе…ЁгҖҒжҹҘиҜўз»“жһңеҮҶ确并且具жңүиҫғеҘҪзҡ„жҖ§иғҪгҖӮеӯҳеӮЁеј•ж“Һзҡ„з»„жҲҗйғЁеҲҶеҢ…жӢ¬пјҡ
- еҶҷеүҚж—Ҙеҝ—пјҲWALпјүпјҡз”ЁдәҺзЎ®дҝқж•°жҚ®зҡ„жҢҒд№…жҖ§гҖӮ
- зј“еӯҳпјҲCacheпјүпјҡж•°жҚ®йҰ–е…ҲеҶҷе…ҘеҶ…еӯҳзј“еӯҳпјҢ并且еҸҜд»Ҙз«ӢеҚіиҝӣиЎҢжҹҘиҜўгҖӮ
- ж—¶й—ҙз»“жһ„еҗҲе№¶ж ‘пјҲTSMпјүпјҡз”ЁдәҺеӯҳеӮЁе’ҢеҺӢзј©ж•°жҚ®пјҢд»ҘжҸҗй«ҳжҹҘиҜўж•ҲзҺҮгҖӮ
- еӯҳеӮЁзҡ„жҳҜе·®еҖјпјҢdeltaеҸҳеҢ–пјҲй’ҲеҜ№дәҺжҹҗдёҖдёӘзӮ№зҡ„еҲқе§ӢеҖјпјү
- жҢүз…§ж—¶еәҸзҡ„keyеҺ»жүҫ
- ж—¶еәҸзҙўеј•пјҲTSIпјүпјҡз”ЁдәҺеҠ йҖҹж—¶еәҸж•°жҚ®зҡ„зҙўеј•е’ҢжҹҘиҜўгҖӮ
InfluxDB ж•°жҚ®еҶҷе…ҘиҝҮзЁӢ
еҪ“ж•°жҚ®йҖҡиҝҮ API иў«еҶҷе…Ҙ InfluxDB ж—¶пјҲз”ЁпјүпјҢж•°жҚ®йҰ–е…Ҳиў«еҶҷе…ҘеҲ° WAL дёӯпјҢ然еҗҺиў«еҺӢ缩并еҶҷе…ҘзЈҒзӣҳгҖӮеңЁеҶ…еӯҳзј“еӯҳдёӯпјҢж•°жҚ®жҳҜз«ӢеҚіеҸҜжҹҘиҜўзҡ„пјҢзј“еӯҳе®ҡжңҹеҶҷе…ҘзЈҒзӣҳгҖӮйҡҸзқҖ TSM ж–Ү件зҡ„з§ҜзҙҜпјҢе®ғ们дјҡиў«еҗҲ并е’ҢеҺӢзј©жҲҗжӣҙй«ҳеұӮж¬Ўзҡ„ TSM ж–Ү件гҖӮ
InfluxDB зҡ„ж•°жҚ®з»“жһ„дјҳеҢ–
InfluxDB жҸҗдҫӣдәҶй’ҲеҜ№ж•°жҚ®жЁЎеһӢдјҳеҢ–зҡ„е·Ҙе…·пјҡ
- SeriesпјҡдёҖдёӘзі»еҲ—жҳҜе…·жңүзӣёеҗҢжөӢйҮҸгҖҒж ҮзӯҫйӣҶе’Ңеӯ—ж®өй”®зҡ„зӮ№йӣҶеҗҲгҖӮзі»еҲ—её®еҠ©еҲҶз»„е…·жңүзӣёдјјеұһжҖ§зҡ„ж•°жҚ®гҖӮ
- PointпјҡдёҖдёӘж•°жҚ®зӮ№еҢ…жӢ¬зі»еҲ—й”®гҖҒеӯ—ж®өеҖје’Ңж—¶й—ҙжҲігҖӮ
ж•°жҚ®еӯҳеӮЁдёҺз»„з»Ү
- BucketпјҲжЎ¶пјүпјҡInfluxDB зҡ„ж•°жҚ®еӯҳеӮЁеҚ•дҪҚпјҢз»“еҗҲдәҶж•°жҚ®еә“е’Ңж•°жҚ®дҝқз•ҷжңҹзҡ„жҰӮеҝөгҖӮжҜҸдёӘжЎ¶йғҪжңүдёҖдёӘз»„з»Үе’Ңдҝқз•ҷжңҹи®ҫзҪ®гҖӮ
- OrganizationпјҲз»„з»Үпјүпјҡз»„з»ҮжҳҜдёҖдёӘз”ЁжҲ·з»„зҡ„е·ҘдҪңеҢәпјҢжүҖжңүзҡ„д»ӘиЎЁзӣҳгҖҒд»»еҠЎгҖҒжЎ¶е’Ңз”ЁжҲ·йғҪеұһдәҺеҗҢдёҖдёӘз»„з»ҮгҖӮ
SchemaдјҳеҢ–
locationе’ҢscientistйғҪжҳҜtagпјҢ_fieldе’Ң_valueйғҪжҳҜfieldгҖӮ
- FieldsдёҚеҸӮдёҺзҙўеј•пјҢеҝ…йЎ»жү«жҸҸе…ЁиЎЁпјӣеҰӮжһңз»Ҹеёёиў«и®ҝй—®пјҢдёҚйҖӮеҗҲд»Ҙиҝҷз§ҚеҪўејҸеӯҳеӮЁпјҢе°ұеә”иҜҘд»Ҙtagзҡ„еҪўејҸ еӯҳеӮЁгҖӮ
- TagsеҸӮдёҺзҙўеј•пјҢеҪ“然жҹҘиҜўиө·жқҘе°ұдјҡжӣҙеҝ«гҖӮеҪ“然зҙўеј•жң¬иә«жҳҜжңүејҖй”Җзҡ„пјҢ并且еҰӮжһңдҪ иҝӣиЎҢеҶҷж“ҚдҪңпјҢзҙўеј• д№ҹдјҡжӣҙж–°пјҢеёҰжқҘжӣҙеӨҡејҖй”ҖгҖӮ
influxзҡ„ж•°жҚ®йғҪжҳҜд»Ҙappendзҡ„ж–№ејҸеҫҖйҮҢеҠ пјҲзұ»жҜ”lsmпјҢдҪҶжҳҜе®һйҷ…дёҠеҸ«еҒҡж—¶й—ҙеәҸеҲ—еҗҲе№¶ж ‘пјүгҖӮ
Storage Engine еӯҳеӮЁеј•ж“Һ
ж•ҙдҪ“жҳҜTSMпјҲTime Structured Merge Treeпјүз»“жһ„пјҢзұ»дјјдәҺLSMзҡ„з»“жһ„гҖӮ иҗҪеҲ°жҜ”иҫғдёӢйқўзҡ„еұӮе°ұжҢүз…§еҲ—еҺӢзј©гҖӮдёәд»Җд№ҲжҢүз…§еҲ—еӯҳпјҹжҲ‘们关еҝғзҡ„жҳҜз»ҷе®ҡж—¶й—ҙж®өеҶ…еҲ—зҡ„valueпјҢжҢүз…§еҲ— еӯҳпјҢиҝҷдәӣи®ҜжҒҜе°ұеҸҜд»Ҙиҝһз»ӯеӯҳеӮЁдәҶгҖӮ
Shard
ж•°жҚ®йҮҸеӨ§дәҶпјҢmongoDBдёӯе°ұжҳҜжҠҠж•°жҚ®еҺӢжҲҗеҫҲеӨҡshardпјҢneo4jд№ҹжҳҜгҖӮж—¶еәҸж•°жҚ®еә“жҳҜжңҖз®ҖеҚ•зҡ„зәҝжҖ§иЎЁпјҢеӣ дёә并дёҚеӯҳеңЁд»Җд№ҲиҜЎејӮзҡ„еӨ–й”®е…іиҒ”иҝҷз§ҚпјҢзӣҙжҺҘеҲҮе°ұе®ҢдәӢдәҶгҖӮ
1 дёӘ bucket еҸҜд»ҘеҲҶжҲҗиӢҘе№ІдёӘ shard groupпјҢиҝҷдёӘ shard group йҮҢйқўеҸҲеҲҶжҲҗиӢҘе№ІдёӘshardгҖӮж„Ҹд№үпјҹйҰ–е…ҲжҳҜжҲ‘们еҸҜд»ҘеҒҡеҲҶеёғејҸеӯҳеӮЁгҖӮиҝҳжңүпјҢзұ»жҜ”жҲ‘们еңЁе…ізі»еһӢж•°жҚ®еә“йҮҢзңӢеҲ°йӮЈдёӘpartitionпјҢе°ұжҳҜжҲ‘еҰӮжһңиҰҒжҹҘжҹҗдёҖеӨ©зҡ„ж•°жҚ®пјҢдҪ дёҚз”ЁеҺ»еҒҡе…ЁиЎЁжү«жҸҸпјҢжҲ–иҖ…е»әдёҖдёӘе…ЁиЎЁзҡ„зҙўеј•еҺ»еҒҡеӨ„зҗҶпјҢжҲ‘е°ұе®ҡдҪҚеҲ°иҝҷдёӘ shard groupйҮҢеҺ»жҹҘжүҫгҖӮеҰӮжһңи·Ёи¶ҠеҮ еӨ©пјҢжҲ‘е°ұжҹҘз¬ҰеҗҲзҡ„дёӨдёӘдёүдёӘshard groupгҖӮ
第еҚҒд№қз«
дә‘ж•°жҚ®еә“зҡ„жҰӮеҝөе’Ңзү№зӮ№
дә‘ж•°жҚ®еә“зҡ„дёҖдёӘжңҖеӨ§зҡ„зү№зӮ№жҳҜд»Җд№ҲпјҹжҜ”еҰӮиҜҙеңЁеҚҺдёәзҡ„жңәжҲҝйҮҢжңүеҫҲеӨҡеҫҲеӨҡзҡ„жңҚеҠЎеҷЁжӢҝеҮәжқҘеҺ»з»ҷдҪ з”ЁдәҶпјҢ然 еҗҺдҪ д№ҹеҲ«з®Ўе®ғжңүеӨҡе°‘зү©зҗҶжңҚеҠЎеҷЁпјҢдҪ е°ұиҜҙжҲ‘йңҖиҰҒдёҖеҸ°иҷҡжӢҹжңәпјҢйӮЈзҗҶи®әдёҠе°ұжҳҜиҝҷдёӘжңәжҲҝйҮҢжүҖжңүзҡ„жңәеҷЁе…ЁйғЁ еҸҜд»Ҙз»ҷдҪ жӢҝжқҘз”ЁпјҲжҜ”еҰӮж”ҜжҢҒеңЁзәҝеј№жҖ§дјёзј©пјүпјҢдҪ еҸӘиҰҒжңүй’ұе°ұеҸҜд»ҘвҖ”вҖ”еҜ№дҪ жқҘиҜҙе°ұжҳҜдҪ дёҚиҰҒз®ЎиҝҷдёӘжңәжҲҝйҮҢ жңүеӨҡе°‘жңәеҷЁпјҢдҪ зңјзқӣйҮҢзңӢеҲ°зҡ„жҳҜдёҖеҸ°и¶…зә§и®Ўз®—жңәгҖӮжҲ‘жҠҠжүҖжңүзҡ„зЎ¬зӣҳеҗҲеҲ°дёҖиө·пјҢеҪўжҲҗдәҶдёҖдёӘзҪ‘з»ңж–Ү件系 з»ҹпјҢжҲ‘еҶҚжҠҠжңәеҷЁдёҠиҝҗиЎҢзҡ„иҝҷдәӣ CPU йҖҡиҝҮзҪ‘з»ңеҗҲеңЁдёҖиө·пјҢеҪўжҲҗдәҶдёҖдёӘи¶…зә§CPUгҖӮ
然еҗҺжҲ‘жүҖжңүзҡ„д»»еҠЎжқҘдәҶд№ӢеҗҺпјҢе°ұеңЁиҝҷдәӣ CPU дёҠеҺ»и°ғеәҰпјҢеҲ©з”Ёеә•дёӢжүҖжңүзҡ„зЎ¬зӣҳеҗҲиө·жқҘжһ„жҲҗзҡ„зҪ‘з»ңж–Ү件系 з»ҹеҺ»еӯҳеӮЁж•°жҚ®пјҢиҝҷе°ұжҳҜеӯҳеӮЁе’Ңи®Ўз®—зҡ„еҲҶзҰ»гҖӮ
иҝҷе°ұе’ҢеӨ§е®¶зңӢеҲ°зҡ„жң¬ең°зҡ„и®Ўз®—жңәдёҚдёҖж ·пјҢз”ҡиҮіи·ҹдҪ жң¬ең°жҗһдәҶ 5 еҸ°и®Ўз®—жңәпјҢеӨ§е®¶е»әдёҖдёӘйӣҶзҫӨд№ҹдёҚдёҖж ·гҖӮйӣҶ зҫӨзҡ„зӣ®зҡ„жҳҜеҒҡдё»д»ҺеӨҮд»ҪвҖ”вҖ”дёҖдё»еӣӣд»ҺпјҢеҒҡиҜ»еҶҷеқҮиҙҹиҪҪеқҮиЎЎпјҢдҪҶжҳҜдҪ йғЁзҪІдёәдёҖдёӘдә‘зҡ„иҜқпјҢеңЁжҲ‘зңјйҮҢзңӢеҲ°зҡ„ дёҚжҳҜдә”еҸ°жңәеҷЁпјҢжҳҜдёҖеҸ°жңәеҷЁпјҢжүҖжңүзҡ„д»»еҠЎеҸҜд»ҘеңЁиҝҷдёҠйқўеҺ»иҝӣиЎҢи°ғеәҰпјҢиҝҷи·ҹдҪ дә”еҸ°жңәеҷЁеҪјжӯӨд№Ӣй—ҙйҡ”зҰ»пјҢ然 еҗҺеӨ§е®¶дә’зӣёд№Ӣй—ҙеҺ»еҒҡеӨҮд»ҪжҳҜдёҚдёҖж ·зҡ„гҖӮжүҖд»Ҙд»–иҝҷйҮҢе°ұи®ІдәҶжҲ‘们жҳҜдёҖдёӘеҲҶеёғејҸзҡ„е…ұдә«еӯҳеӮЁгҖӮ
дёәд»Җд№ҲжҳҜе…ұдә«еӯҳеӮЁпјҹе°ұеҲҡжүҚи®Іе®ғжҳҜдёҖдёӘи¶…еӨ§зҡ„дёҖдёӘеӯҳеӮЁпјҢдёҖдёӘзҪ‘зӣҳпјҢ然еҗҺеңЁиҝҷдёӘеҹәзЎҖд№ӢдёҠиҰҒеҒҡй«ҳеҸҜз”Ёзҡ„ е®№зҒҫпјҢе°ұжҳҜжҲ‘жүҖжңүзҡ„жңҚеҠЎеҷЁжңүеҸҜиғҪдјҡеҮәй”ҷпјҢдёҖж—ҰеҮәй”ҷ马дёҠе°ұжңүе…¶д»–зҡ„йЎ¶дёҠжқҘпјҢ然еҗҺжҲ‘д»»еҠЎе’Ңж•°жҚ®е°ұеҒҡдёҖ ж¬ЎиҝҒ移гҖӮ
GaussDB
GaussDBжҳҜдёҖдёӘеҲҶеёғејҸзҡ„ж•°жҚ®еә“гҖӮ
- еҚҺдёәзҡ„openGaussдёҚжҳҜдә‘ж•°жҚ®еә“пјҢжҗ¬дёҠдә‘GaussDBжүҚжҳҜдә‘ж•°жҚ®еә“гҖӮ
- openGaussжҳҜдёҖдёӘй«ҳжҖ§иғҪгҖҒй«ҳе®үе…ЁгҖҒй«ҳеҸҜйқ жҖ§зҡ„дјҒдёҡзә§ејҖжәҗе…ізі»еһӢж•°жҚ®еә“
- openGaussжҳҜдёҖдёӘеҚ•иҝӣзЁӢеӨҡзәҝзЁӢзҡ„жһ¶жһ„пјҢдҪҶжҳҜmySQLжҳҜдёҖдёӘеӨҡиҝӣзЁӢзҡ„жһ¶жһ„пјҢеҫҲеҸҜиғҪдёҖдёӘж•°жҚ®еә“иҝһ жҺҘе°ұеҜ№еә”дёҖдёӘиҝӣзЁӢгҖӮдҪҝз”ЁеҚ•иҝӣзЁӢзҡ„иҜқеҸҜд»ҘйҷҚдҪҺйҖҡдҝЎзҡ„ејҖй”ҖгҖӮеӨҡиҝӣиЎҢйңҖиҰҒдҪҝз”ЁеҲ°иҝӣзЁӢй—ҙйҖҡи®ҜпјҢиҖҢеҚ•иҝӣ зЁӢзҡ„иҜқеҸҜд»ҘдҪҝз”Ёе…ұдә«еҶ…еӯҳзҡ„ж–№жі•гҖӮ
- еҚ•иЎЁеӨ§е°Ҹ32TBпјҢеҚ•иЎҢж•°жҚ®йҮҸж”ҜжҢҒ1GB
еҲҶеёғејҸзҡ„еӣ°йҡҫпјҹдёҖдёӘе…ізі»еһӢж•°жҚ®еә“пјҢиҰҒжғіеҒҡеҲҶеёғејҸе°ұеҫҲжҒ¶еҝғдәҶпјҢе°ұеӣ°йҡҫеңЁдҪ жҠҠж•°жҚ®жҖҺд№ҲеӯҳеӮЁжүҚиғҪи®©иҝҷдёӘ ж•°жҚ®еә“е®ғзҡ„жҖ§иғҪдјҡжҜ”иҫғй«ҳпјҢжҜ”еҰӮиҜҙиҰҒеҒҡдёҖдёӘжҹҘиҜўпјҢжӯЈеҘҪиҝҷдёӘжҹҘиҜўж¶үеҸҠеҲ°ж•°жҚ®е…ЁйғЁеӯҳеңЁдёҚеҗҢзҡ„иҠӮзӮ№дёҠпјҢйӮЈ дҪ иҰҒжҠҠж•°жҚ®е…ЁйғЁзҡ„жұҮиҒҡеҲ°дёҖдёӘең°ж–№пјҢиҝҷе°ұеҫҲжҒ¶еҝғгҖӮ
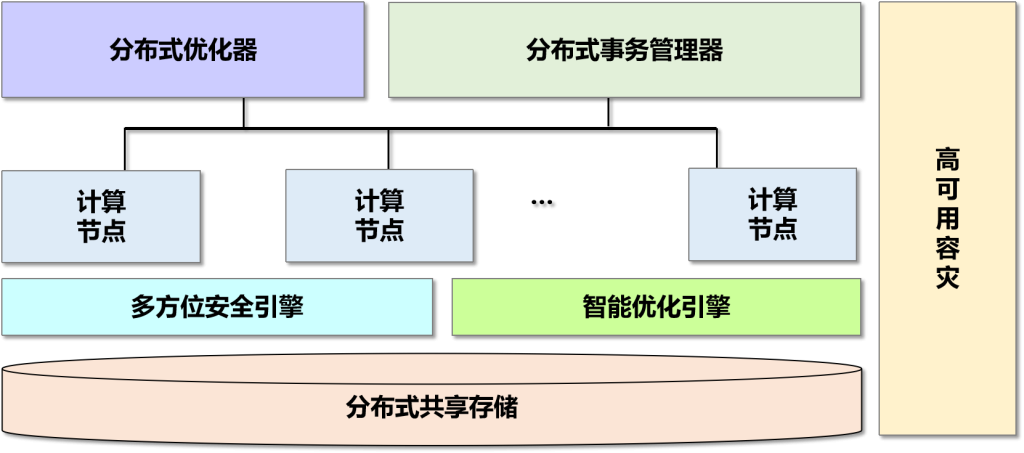
GaussDBзҡ„еҲҶеёғејҸдјҳеҢ–еҷЁ
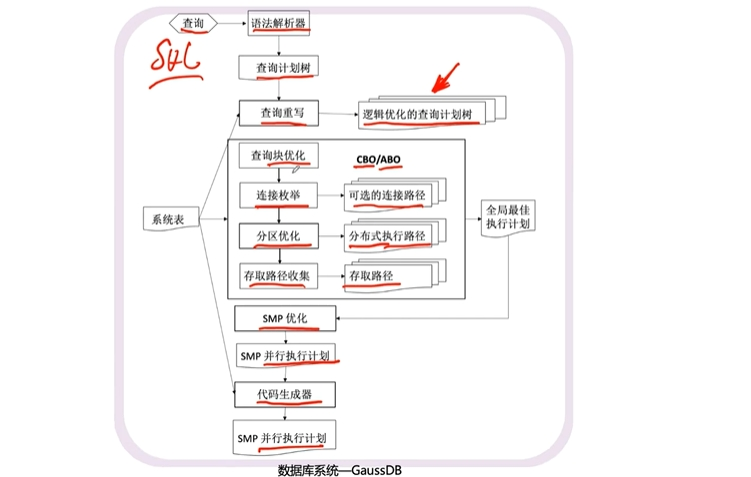
дҪ еҶҷдәҶдёҖдёӘ SQL зҡ„жҹҘиҜўпјҢд»–е°ұе…ҲеҒҡиҜӯжі•е’Ңи§ЈжһҗпјҢе°ұзңӢдҪ иҰҒе№Іе•ҘпјҢ然еҗҺз”ҹжҲҗдёҖжЈөжҹҘиҜўи®ЎеҲ’ж ‘гҖӮе®ғзҡ„жү§иЎҢ ж•ҲзҺҮе°ұеҸҜиғҪдёҚй«ҳпјҢжүҖд»Ҙе°ұж №жҚ®жҲ‘йў„е…Ҳе®ҡд№үеҘҪзҡ„дёҖдәӣ规еҲҷеҺ»дјҳеҢ–гҖӮ
дјҳеҢ–зҡ„дёңиҘҝжңүеҢ…жӢ¬д»Җд№Ҳе‘ўпјҹжҜ”еҰӮеңЁеҲҶеёғејҸеңәжҷҜдёӢпјҢжҜ”еҰӮиҜҙжҲ‘жңүдёӨеј иЎЁеҺ»иҝһжҺҘпјҢйӮЈдҪ еҸҜд»ҘT1 иҝһжҺҘT2пјҢ T2 еҸҜд»ҘиҝһжҺҘT1гҖӮ
жүҖд»Ҙз»ҸиҝҮиҝҷдёҖзі»еҲ—зҡ„дёңиҘҝпјҢжңҖеҗҺдҪ дјҡеҸ‘зҺ°дҪ еҶҷзҡ„иҝҷдёӘ SQL иҜӯеҸҘпјҢдҪ еҸҜиғҪеҺӢж №йғҪжІЎжғіиҝҮж•°жҚ®жҳҜеҲҶеёғзҡ„пјҢ 然еҗҺиҝҳжңүд»Җд№Ҳе°ҶжқҘиғҪ并иЎҢзҡ„гҖӮдҪҶжҳҜз»ҸиҝҮиҝҷдёҖзі»еҲ—зҡ„еӨ„зҗҶпјҢжңҖеҗҺе®ғдә§з”ҹзҡ„жҳҜеңЁеӨҡдёӘжңәеҷЁдёҠпјҢиҖҢдё”жҳҜ并иЎҢеҺ» жү§иЎҢзҡ„пјҢиҝҷж ·зҡ„йҖ»иҫ‘е°ұи·ҹдҪ еҶҷзҡ„дёҚдёҖж ·дәҶпјҢдёӯй—ҙз»ҸиҝҮдәҶдёҖзі»еҲ—зҡ„дјҳеҢ–пјҢе°ұеңЁйҳІжӯўдҪ еҶҷзҡ„дёңиҘҝеҫҲзғӮгҖӮ
GaussDBеӨҡз§ҹжҲ·
еҰӮжһңеӯҳзҡ„ж—¶еҖҷжҜҸдёҖдёӘж•°жҚ®еә“йғҪжҳҜжүҖжңүдәәеҗ„иҮӘзӢ¬еҚ пјҢе®Ңе…ЁдёҚдёҖж ·пјҢйӮЈд№ҲеёҰжқҘзҡ„дёҖдёӘй—®йўҳжҳҜжҲ‘иҝҷдёӘеҫҲйҡҫеҺ»з»ҙ жҠӨгҖӮеҫ®дҝЎе°ҸзЁӢеәҸе®ғзҡ„дёҖдёӘеҹәжң¬зҡ„еҺҹзҗҶжҳҜпјҡе®ғиҰҒз”ЁеҲ°еҫ®дҝЎжң¬иә«иҮӘе·ұжҸҗдҫӣзҡ„йӮЈдәӣжңҚеҠЎеҺ»ејҖеҸ‘д»–иҮӘе·ұзҡ„дёңиҘҝгҖӮ йӮЈд№ҲеҰӮжһңжҲ‘иҰҒжҳҜзңӢеҲ°жүҖжңүзҡ„иҝҷдәӣе°ҸзЁӢеәҸпјҢ他们йғҪжңүеҗ„иҮӘе®Ңе…ЁдёҚеҗҢзҡ„ж•°жҚ®з»“жһ„еҺ»еӯҳеӮЁпјҢ然еҗҺиҝҳиҰҒжҲ‘еҜ№д»–们 еҺ»иҝӣиЎҢж”Ҝж’‘пјҢжҲ‘е°ұдёҖдёӘж•°жҚ®еә“пјҢжҲ‘еҰӮдҪ•дёәжүҖжңүзҡ„е°ҸзЁӢеәҸжңҚеҠЎпјҹ
жҚўеҸҘиҜқиҜҙпјҢдҪ жңүдёҖдёӘж•°жҚ®еә“жңҚеҠЎеҷЁзҡ„е®һдҫӢпјҢдҪ зҡ„дёңиҘҝеҺ»з»ҷдёҚеҗҢзҡ„з§ҹжҲ·пјҢ他们жҜҸдёҖдёӘдәәйғҪеңЁдёҠйқўеҸҜд»Ҙеӯҳ他们зҡ„ж•°жҚ®пјҢдҪҶжҳҜ他们еҪјжӯӨд№Ӣй—ҙйғҪи®ӨдёәиҮӘе·ұжҳҜжңүдёҖдёӘзӢ¬еҚ зҡ„ж•°жҚ®еә“гҖӮ
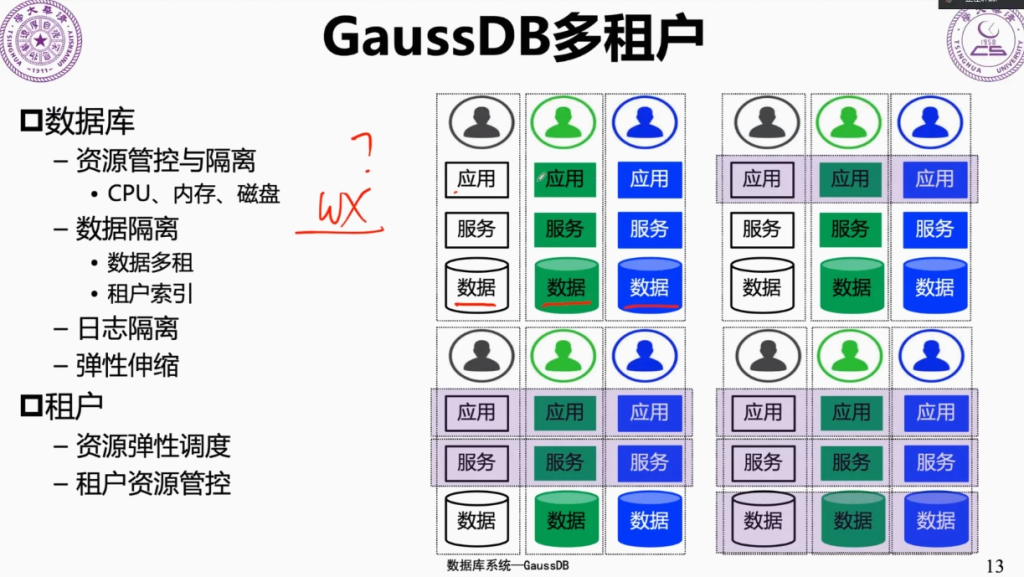
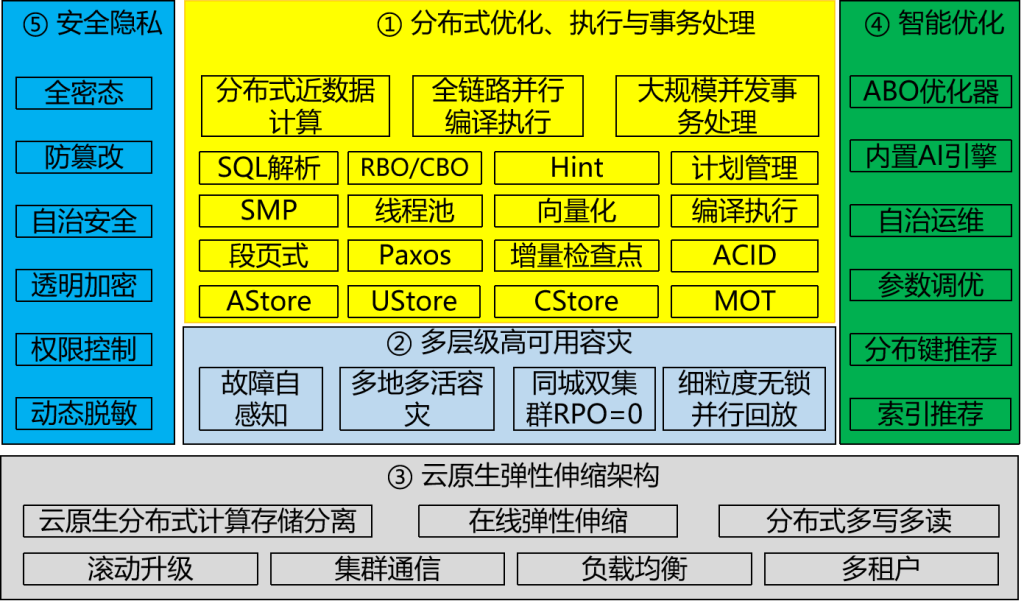
и®ҫжҲ‘зҺ°еңЁжңүдёӨдёӘеә”з”ЁпјҢдёҖдёӘеә”з”ЁиҜҙжҲ‘иҝҷдёӘж•°жҚ®еә“йҮҢйқўиҝҷдёӘиЎЁпјҢе®ғе°ұдёҖеј иЎЁпјҢд»–иҜҙжҲ‘зҡ„еӯ—ж®өеҲҶеҲ«жҳҜaгҖҒbгҖҒ cгҖҒdгҖҒeгҖӮйӮЈжңүеҸҰеӨ–дёҖдёӘз”ЁжҲ·пјҢд»–иҜҙжҲ‘зҡ„еӯ—ж®өжҳҜиҝҷж ·зҡ„пјҡaгҖҒbгҖҒcгҖҒdгҖҒfгҖӮеҰӮдҪ•жңҚеҠЎиҝҷдёӨдёӘз”ЁжҲ·пјҹ
- 第дёҖз§Қж–№жі•пјҡsingle tableпјҢжҲ‘еҸӘжңүдёҖеј иЎЁпјҢжІЎжңүдёӘжҖ§еҢ–зҡ„дёңиҘҝпјҢжңҖеҗҺиЎЁжңүдёӘиЎЁзӨәoidпјҲowner idпјүпјҢ з”ЁиҝҷдёӘж ҮиҜҶжқҘеҢәеҲҶж•°жҚ®жҳҜи°Ғзҡ„пјҢжҲ‘们е°ұеҸҜд»ҘзӣҙжҺҘйҡ”зҰ»дәҶгҖӮзјәзӮ№пјҡschemaиҰҒжұӮжҳҜдёҖж ·зҡ„пјҢдёҚж”ҜжҢҒдёӘ жҖ§еҢ–дәҶпјҢдәӢеҠЎзҡ„з®ЎзҗҶд№ҹдјҡжҜ”иҫғеӨҚжқӮпјҢ并еҸ‘йҮҸй«ҳпјҢи®ҝй—®жҖ§иғҪе°ұдјҡдёӢйҷҚгҖӮ
- 第дәҢз§Қж–№жі•пјҡдёҚжҳҜдёҖеј иЎЁгҖӮ第дёҖеј иЎЁжҜ”еҰӮжҲ‘еӯҳabcd+oidпјҢ第дәҢеј иЎЁеӯҳoid+дё»й”®пјҲе…іиҒ”еҲ°з¬¬дёҖеј иЎЁпјү +жү©еұ•key+жү©еұ•valueгҖӮиҝҷйҮҢе…¶е®һе°ұжҳҜжҠҠиҮӘе·ұзү№жңүзҡ„еҲ—иҪ¬дёәдәҶиЎҢжқҘеӯҳеӮЁгҖӮ
- 第дёүз§Қж–№жі•пјҡз®—дәҶпјҢеӨ§е®¶иҝҳжҳҜеҲ«еӯҳеңЁдёҖиө·дәҶгҖӮ第дёҖдёӘеә”з”ЁжңүиҮӘе·ұзҡ„иЎЁпјҢ第дәҢдёӘеә”з”ЁжңүиҮӘе·ұзҡ„иЎЁпјҢдҪҶ жҳҜеӨ§е®¶иҝҳжҳҜж”ҫеңЁдёҖдёӘdbйҮҢйқўгҖӮ
- 第еӣӣз§Қж–№жі•пјҡе№Іи„ҶдёҖдёӘдәәдёҖдёӘdbпјҢеҪ»еә•еҲҶејҖгҖӮпјҲжңҖдёҚеҘҪпјҢжңҖжөӘиҙ№иө„жәҗзҡ„ж–№жі•пјүгҖӮ
з«ҷеңЁж•°жҚ®еә“зҡ„и§’еәҰжқҘзңӢпјҡ
1. schema еҰӮжһңжңүдёҖдәӣеҸҜд»Ҙе…ұдә«пјҢйӮЈд№ҲжҲ‘иҝҷдёӘж•°жҚ®еә“е°ұеҘҪз®ЎзҗҶпјҢжҲ‘ж—ўеҸҜд»Ҙж”ҜжҢҒдҪ жңүиҝҷдёӘе…ұеҗҢзҡ„дёңиҘҝпјҢ д№ҹеҸҜд»Ҙж”ҜжҢҒдҪ дёӘжҖ§еҢ–дёңиҘҝгҖӮ 2. 硬件зҡ„иө„жәҗиҰҒйҡ”зҰ»ејҖпјҢжҹҗдёҖдёӘз§ҹжҲ·жҢӮдәҶдёҚдјҡеҪұе“Қе…¶д»–дәәгҖӮ
openGaussзҡ„жҹҘиҜўдјҳеҢ–
еӣ дёәж•°жҚ®йҮҸе·ЁеӨ§пјҢжүҖд»ҘдјҳеҢ–жҳҜеҖјеҫ—зҡ„пјҢеҗҰеҲҷж•°жҚ®йҮҸе°ҸпјҢжҜ”еҰӮеҲ«еҒҡдјҳеҢ–пјҢдјҳеҢ–еҸҚиҖҢиҠұж—¶й—ҙгҖӮе…·дҪ“дјҳеҢ–зңӢдёҠйқўзҡ„еӣҫгҖӮ
- еҹәдәҺ规еҲҷзҡ„жҹҘиҜўдјҳеҢ–пјҲRBOпјү
- ж №жҚ®йў„е®ҡд№үзҡ„еҗҜеҸ‘ејҸ规еҲҷеҜ№SQLиҜӯеҸҘиҝӣиЎҢдјҳеҢ–
- еҹәдәҺд»Јд»·зҡ„жҹҘиҜўдјҳеҢ–пјҲCBOпјү
- еҲ©з”Ёз»ҹи®ЎдҝЎжҒҜпјҢйҖҡиҝҮеҹәзЎҖе’Ңд»Јд»·дј°и®ЎеҜ№SQLиҜӯеҸҘеҜ№еә”зҡ„еҖҷйҖүзү©зҗҶи®ЎеҲ’иҝӣиЎҢд»Јд»·дј°з®—пјҢ并д»ҺеҖҷйҖүи®ЎеҲ’дёӯйҖүжӢ©д»Јд»·жңҖдҪҺзҡ„зү©зҗҶи®ЎеҲ’дҪңдёәжңҖз»Ҳзҡ„жү§иЎҢи®ЎеҲ’
- еҹәдәҺдәәе·ҘжҷәиғҪзҡ„жҹҘиҜўдјҳеҢ–пјҲABOпјү
- 收йӣҶжү§иЎҢи®ЎеҲ’зҡ„зү№еҫҒз»ҹи®ЎдҝЎжҒҜпјҢеҖҹеҠ©дәәе·ҘжҷәиғҪжЁЎеһӢдј°и®Ўеҹәж•°е’Ңд»Јд»·пјҢ并йҖүжӢ©й«ҳж•Ҳзҡ„жү§иЎҢи®ЎеҲ’
- жҷәиғҪеҹәж•°дј°и®Ўе’Ңд»Јд»·дј°и®Ў
- жҷәиғҪи®ЎеҲ’йҖүжӢ©е’Ңз”ҹжҲҗ
иЎҢеӯҳеӮЁе’ҢеҲ—еӯҳеӮЁ
- иЎҢеӯҳеӮЁпјҡйҖӮеҗҲдёҡеҠЎж•°жҚ®зҡ„йў‘з№Ғжӣҙж–°пјҢжҜ”еҰӮжҸ’е…Ҙжӣҙж–°дёҖжқЎж•°жҚ®пјҢзұ»жҜ”еҸҢеҚҒдёҖејҖеҚ–зҡ„ж—¶еҖҷи®ўеҚ•еҫҲеӨҡжқЎзӣ®иҰҒжҸ’е…ҘиҝӣжқҘ
- еҲ—еӯҳеӮЁпјҡж”ҜжҢҒдёҡеҠЎж•°жҚ®зҡ„иҝҪеҠ е’ҢеҲҶжһҗеңәжҷҜпјҢзұ»жҜ”еҸҢеҚҒдёҖз»“жқҹзҡ„зҡ„ж—¶еҖҷйңҖиҰҒз»ҹи®Ўй”Җе”®йўқгҖҗжіЁж„ҸпјҡеңЁжү№йҮҸеҠ иҪҪзҡ„ж—¶еҖҷдёәд»Җд№ҲжӣҙйҖӮеҗҲеҲ—еӯҳеӮЁе‘ўпјҹеӣ дёәеҲ—еӯҳеӮЁзҡ„ж—¶еҖҷеҺӢзј©зҺҮй«ҳпјҢжҜ”еҰӮжҹҗдёҖеҲ—иҝһз»ӯдёӢжқҘеӯҳзҡ„жҳҜ5дёӘиҝһз»ӯзҡ„1пјҢжҲ‘е°ұеҸҜд»ҘеҺӢзј©дёҖдёӢпјҢжҲ–иҖ…жҲ‘ж—¶й—ҙжҲізҡ„иҜқеҸ‘зҺ°еҸҜд»Ҙи®°еҪ•дёҖдёӘеўһйҮҸпјҢиҝҷж ·е°ұеӨ§еӨ§зҡ„дјҳеҢ–дәҶеӯҳеӮЁзҡ„з©әй—ҙпјҢдҪҝз”ЁеҲ—еӯҳеӮЁзҡ„иҜқжӣҙеҠ зҡ„й«ҳж•ҲгҖ‘
- openGaussзҡ„еј•ж“Һдјҡж №жҚ®жү§иЎҢзҡ„SQLиҜӯеҸҘеҲӨж–ӯжҳҜеңЁиЎҢиҝҳжҳҜеҲ—еӯҳеӮЁдёҠиҝӣиЎҢжҹҘжүҫ
- еҗҢж—¶еҒҡиЎҢеӯҳеӮЁе’ҢеҲ—еӯҳеӮЁзҡ„зјәзӮ№жҳҜжөӘиҙ№дәҶз©әй—ҙпјҢдҪҶжҳҜеҘҪеӨ„жҳҜйҖӮеҗҲзҡ„SQLдјҡеҸ‘еҲ°еҜ№еә”зҡ„еӯҳеӮЁдёҠпјҢйҖҹеәҰдјҡжҳҺжҳҫжҸҗй«ҳгҖӮ
- еҶ…еӯҳиЎЁпјҡж•°жҚ®ж•ҙдёӘеңЁеҶ…еӯҳйҮҢйқўпјҢеӨ§йҮҸзҡ„ж•°жҚ®дёҖж¬ЎжҖ§еҠ иҪҪеҲ°еҶ…еӯҳйҮҢйқўпјҢд»ҘеҗҺзҡ„жүҖжңүж“ҚдҪңе…ЁйғЁйғҪеңЁеҶ…еӯҳйҮҢйқўпјҢеҸҜиғҪеҸӘиҰҒжҲ‘дёҚе…іжңәпјҢжҲ‘еҸҜиғҪж•°жҚ®дёҖзӣҙйғҪдёҚз”ЁиҗҪзЎ¬зӣҳпјҢжҜҸеӨ©еҸҜиғҪдёәдәҶеӨҮд»ҪпјҢжҠҠж•°жҚ®иҗҪдёҖж¬ЎзЎ¬зӣҳгҖӮпјҲйӮЈе’ҢжҲ‘们д№ӢеүҚиҜҙзҡ„mysqlжңүд»Җд№ҲеҢәеҲ«е‘ўпјҹд№ӢеүҚжүҖиҜҙзҡ„bufferжҜ”иҫғе°ҸпјҢжҲ‘们еҸӘиғҪжҠҠжӯЈеңЁж“ҚдҪңжҲ–йңҖиҰҒж“ҚдҪңзҡ„ж•°жҚ®еҠ иҪҪеҲ°bufferйҮҢйқўпјҢдҪҶжҳҜеҶ…еӯҳиЎЁиҰҒжұӮеҫҲеӨ§зҡ„зј“еӯҳпјҢејҖжңәзҡ„дёҖеҲ»е°ұжҠҠж•°жҚ®еҠ иҪҪеҲ°еҶ…еӯҳдёӯпјү
- еә”з”ЁеңәжҷҜпјҡжҜ”еҰӮеӯҳеӮЁдёҖзі»еҲ—йЈҺеҠӣеҸ‘з”өжңәзҡ„еҺӮ家гҖҒеһӢеҸ·гҖҒйЈҺеңәдҝЎжҒҜз”ЁиЎҢеӯҳеӮЁпјҢдҪҶжҳҜеҰӮжһңйЈҺеҠӣеҸ‘з”өжңәдёҚж–ӯзҡ„еҸ‘ж—¶еәҸж•°жҚ®зҡ„иҜқпјҢиҝҷдәӣж•°жҚ®еә”иҜҘжӣҙйҖӮеҗҲеҲ—еӯҳеӮЁгҖӮеҗҢж—¶йңҖиҰҒиЎҢгҖҒеҲ—еӯҳеӮЁзҡ„еңәжҷҜе°ұжҳҜиҝҷж ·
ORMж•ҲзҺҮ
жңүдәәеҸҜиғҪжңүз–‘й—®пјҡORMжҳ е°„жҳҜйҖҡиҝҮжҠҠеҜ№иұЎзҡ„ж“ҚдҪңйҖҡиҝҮJPAе·Ҙе…·з”ҹжҲҗSQLиҜӯеҸҘпјҢ然еҗҺеҸ‘йҖҒз»ҷж•°жҚ®еә“иҝӣиЎҢж“Қ дҪңзҡ„пјҢйӮЈеҰӮжһңжҲ‘иҮӘе·ұзӣҙжҺҘеҶҷSQLиҜӯеҸҘзҡ„иҜқдёҚжҳҜйҒҝе…ҚдәҶиҝҷдёӘиҪ¬жҚўзҡ„иҝҮзЁӢпјҢдёҖе®ҡдјҡжңүжӣҙй«ҳзҡ„ж•ҲзҺҮеҗ—пјҹ
еӣһзӯ”пјҡй”ҷиҜҜзҡ„гҖӮJPAе·Ҙе…·йҮҢйқўжңүеӨ§йҮҸз§ҜзҙҜзҡ„дјҳеҢ–зҡ„SQLзҡ„з»ҸйӘҢпјҢдјҡжҠҠеҜ№иұЎзҡ„ж“ҚдҪңиҪ¬жҚўдёәеҹәжң¬дёҠиҜҙжҳҜжңҖдјҳж•ҲзҺҮзҡ„SQLж“ҚдҪңиҜӯеҸҘгҖӮдҪҶжҳҜеҰӮжһңдҪ иҮӘе·ұеҶҷSQLиҜӯеҸҘеҸҜиғҪж•ҲзҺҮиҝңиҝңжҜ”дёҚдёҠгҖӮдҪҶжҳҜжңүдәәиҜҙж•°жҚ®еә“дёҚжҳҜжңүжҹҘиҜўдјҳеҢ–еҗ—пјҹе®һйҷ…дёҠж•°жҚ®еә“зҡ„жҹҘиҜўдјҳеҢ–еҫҲжңүйҷҗпјҲиҜҫдёҠзҡ„дёҫдҫӢе°ұжҳҜеә•жқҝдёҚиЎҢжҖҺд№Ҳжү“жү®йғҪдёҚеҘҪзңӢпјүжүҖд»ҘиҜҙйҖҡиҝҮORMжҳ е°„дә§з”ҹзҡ„SQLеҹәжң¬е°ұжҳҜжңҖдјҳи§ЈгҖӮжӯӨеӨ–иҝҳжңүдёҖз§Қжғ…еҶөпјҢжҜ”еҰӮж•°жҚ®еә“йҮҢйқўжңүдёҖдәӣеҮҪж•°йңҖиҰҒиў«и°ғз”ЁпјҢд»– 们дә§з”ҹзҡ„жҳҜдёҖдёӘз»“жһңиҝ”еӣһжҲ‘пјҢж•°жҚ®зҡ„еӨ„зҗҶе°ұжҳҜеңЁж•°жҚ®еә“йҮҢйқўе®һзҺ°зҡ„пјҢеҰӮжһңз”ЁORMзҡ„иҜқеҸҜиғҪдјҡеҶҷдёҖдёӘйҒҚеҺҶпјҢйӮЈиҝҷж ·зҡ„жғ…еҶөеҸҜиғҪORMе°ұжҜ”иҫғе·®гҖӮ
GaussDBзҡ„еҲҶеёғејҸдәӢеҠЎ
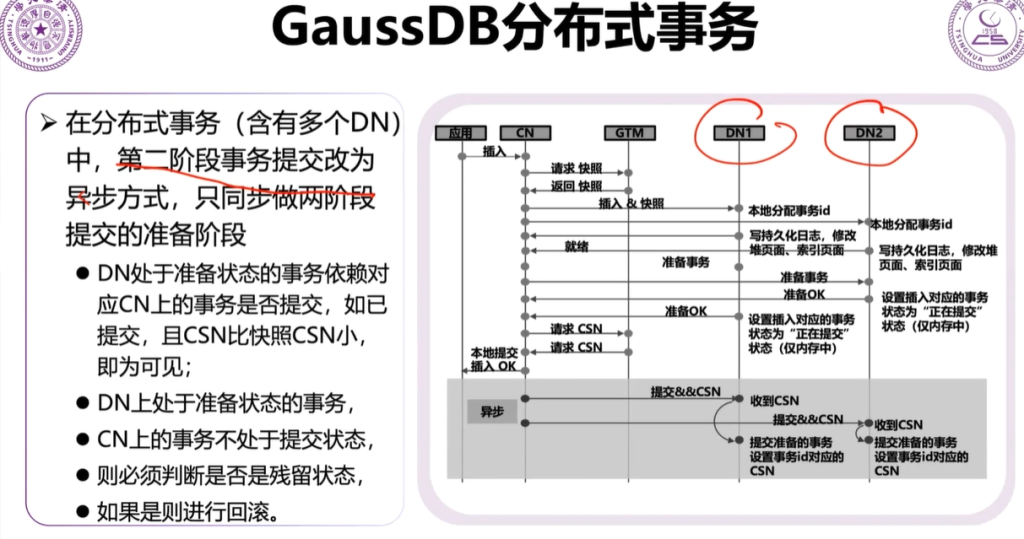
еҰӮжһңдҪ еҸӘж¶үеҸҠеҲ°дёҖдёӘж•°жҚ®иҠӮзӮ№пјҢйӮЈиҝҷжҳҜдёҖз§Қжғ…еҶөпјҢеҰӮжһңдҪ ж¶үеҸҠеҲ°дёӨдёӘж•°жҚ®иҠӮзӮ№пјҢйӮЈе°ұдјҡжңүдёҖдёӘдёӨйҳ¶ж®өжҸҗ дәӨеҚҸи®®гҖӮ
дјҳеҢ–жҳҜиҜҙеңЁз¬¬дәҢдёӘйҳ¶ж®өе®ғжҳҜејӮжӯҘзҡ„пјӣд»–еҸ‘иҜ·жұӮеҮәеҺ»пјҢ然еҗҺд»–д№ҹжІЎжңүеҺ»зӯүзқҖ他们пјӣеӣһжІЎжңүеӣһжқҘзҡ„иҝҷдёӘзәҝгҖӮ д№ҹе°ұжҳҜиҜҙиҝҷдёӘзҒ°иүІзҡ„йғЁеҲҶзӣёеҪ“дәҺеңЁеҗҺеҸ°ж…ўж…ўеҺ»еӨ„зҗҶпјҢеүҚз«Ҝиҝҷз«Ҝ他马дёҠе°ұеҲ° OK дәҶпјҢе°ұжӯӨеӨ„еҗҺйқўиҝҷз«Ҝд»–дјҡ жғіеҠһжі•еҺ»и®©д»–дёҖе®ҡиғҪжҸҗдәӨзҡ„пјҢйӮЈд№ҲиҝҷжҳҜд»–еҒҡзҡ„дёҖдёӘдјҳеҢ–гҖӮ
дёәд»Җд№ҲиҰҒжңүејӮжӯҘпјҹдёҫдёӘдҫӢеӯҗпјҡ жҜ”еҰӮиҜҙжңүдёҖдёӘж•°жҚ®йҮҮйӣҶеҷЁпјҢе®ғжҜҸйҡ”дёҖж®өж—¶й—ҙе°ұдјҡеҺ»йҮҮйӣҶдёҖдёӢж•°жҚ®пјҢ然еҗҺжҠҠж•°жҚ®еҶҷеҲ°ж•°жҚ®еә“йҮҢйқўеҺ»гҖӮ дҪҶеҸҜиғҪж•°жҚ®еҸ‘иҝҮжқҘйқһеёёзҡ„еҝ«пјҢ第дёҖдёӘж•°жҚ®иҝҳжІЎеӨ„зҗҶе®ҢпјҢ第дәҢдёӘж•°жҚ®е°ұеҸ‘иҝҮжқҘдәҶгҖӮеҗҢжӯҘзҡ„жғ…еҶөдёӢпјҢеҝ… йЎ»жҳҜеүҚз«ҜеҸ‘иҝҮжқҘдёҖдёӘж•°жҚ®пјҢеҗҺз«ҜserverеҺ»еӨ„зҗҶпјҢеӨ„зҗҶе®ҢдәҶе’ҢеүҚз«ҜиҜҙе“ҰжҲ‘еӨ„зҗҶе®ҢдәҶпјҢеүҚз«ҜеҶҚжқҘдёӢдёҖ дёӘгҖӮиҝҷе°ұдјҡеҮәзҺ°й—®йўҳгҖӮ д»Җд№Ҳж„ҸжҖқпјҹе°ұжҳҜеңЁзҺ°еңЁиҝҷдёӘеңәжҷҜд№ӢдёӢпјҢжҳҜжҲ‘们дёҚж–ӯзҡ„жқҘдәӢ件пјҢдәӢ件еңЁжІЎжңүиў«еӨ„зҗҶе®Ңд№ӢеүҚдјҡжңүж–°зҡ„дәӢ 件иҝӣжқҘпјҢжҲ‘们иҰҒдҫқж¬ЎиҰҒеҺ»еӨ„зҗҶпјҢе®ғдёҚиғҪдёўгҖӮдҪҶжҳҜжҲ‘жҜҸдёҖдёӘеӨ„зҗҶд№ӢеҗҺдёҚжҳҜеҗҢжӯҘеңЁеӨ„зҗҶпјҢдёҚжҳҜиҜҙ第дёҖдёӘ еӨ„зҗҶе®ҢдәҶпјҢ第дәҢдёӘжүҚиғҪжқҘпјҢйӮЈиҝҷз§ҚдёңиҘҝеҸ«е•Ҙе‘ўпјҹеҸ«жөҒејҸж•°жҚ®гҖӮ
GaussDBзүҲжң¬жӣҙж–°
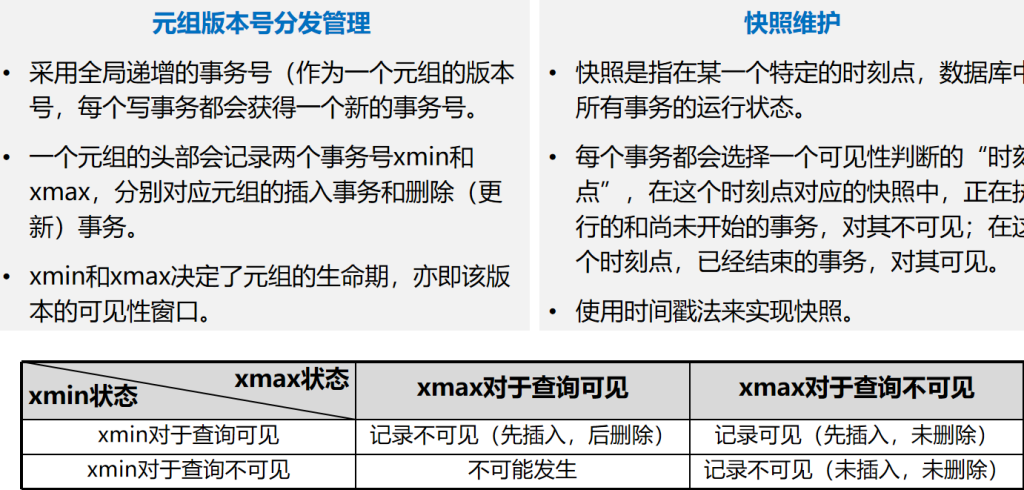
з®ҖеҚ•жқҘиҜҙеҸӘжңүxminе’Ңxmaxд№Ӣй—ҙзҡ„жҳҜеҸҜи§ҒеҸҜз”Ёзҡ„гҖӮ
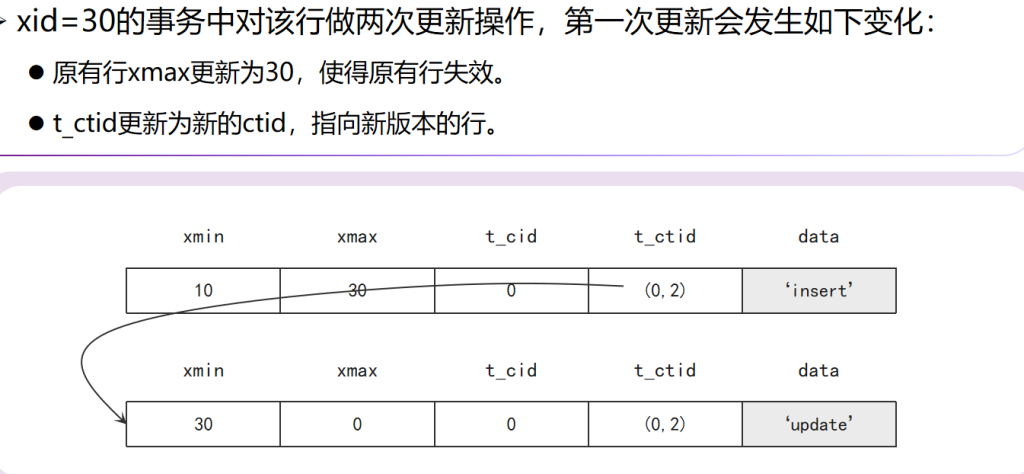
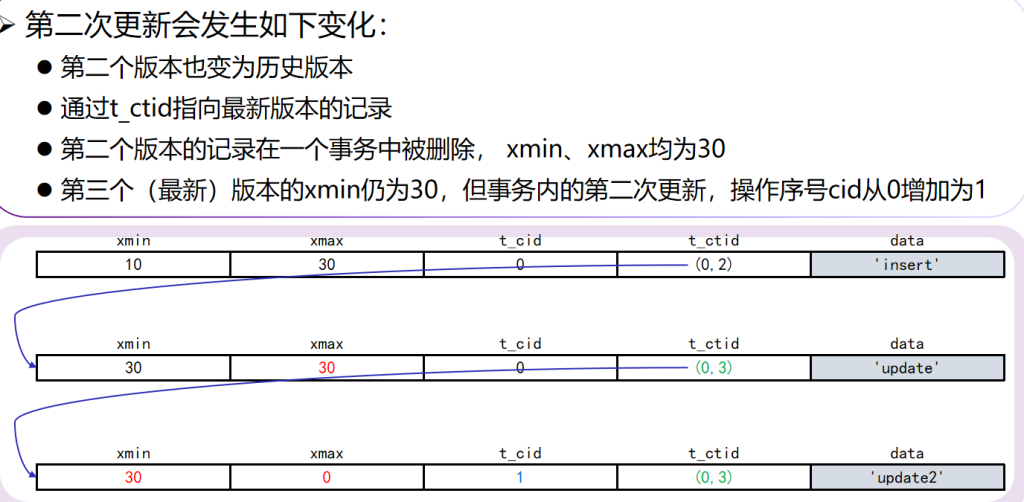
第дәҢеҚҒз«
Data Warehouse ж•°жҚ®д»“еә“
- еӨҡе…ғзҡ„ж•°жҚ®еҰӮдҪ•иһҚеҗҲеӨ„зҗҶпјҹж•°жҚ®д»“еә“пјҡжҠҠеҫҲеӨҡжқҘжәҗзҡ„ж•°жҚ®еҠ иҪҪд№ӢеҗҺпјҢжҠҠ他们е®үиЈ…еҗҢдёҖдёӘж–№ејҸеӯҳеӮЁгҖӮ
- жҜ”еҰӮдәӨеӨ§зҡ„ж•°жҚ®гҖҒеӨҚж—ҰгҖҒеҗҢжөҺзҡ„ж•°жҚ®пјҢеҸҜиғҪеҲҶеҲ«жңү10гҖҒ11гҖҒ12дёӘеӯ—ж®өзҡ„ж•°жҚ®пјҢйңҖиҰҒжҠҠиҝҷдәӣж•°жҚ®вҖңжҠҪеҸ–гҖҒиҪ¬жҚўгҖҒеӯҳеӮЁвҖқпјҢйҖҡеёёжқҘиҜҙжҠҠдёҚеҗҢзҡ„ж–Ү件иҪ¬еӯҳеӮЁеҲ°Parquet/RC Fileзҡ„ж–Үд»¶ж јејҸ
- RC Fileзҡ„ж–Ү件пјҡжҠҠеҺҹе§Ӣзҡ„е…ізі»жҠҪеҸ–жҹҗдёҖеҲ—жҲ–иҖ…еҮ еҲ—гҖҒз”ҡиҮіжҠҠж•ҙдёӘиЎЁеӯҳеӮЁиө·жқҘгҖӮеҗҢж—¶ж–Ү件жңҖеүҚйқўиҝҳжңүжңүдёҖдәӣе…ғж•°жҚ® иЎЁиҫҫзҡ„иЎҢеҸ·жҳҜе“ӘеҮ иЎҢгҖҒжҲ–иҖ…жҳҜеҗҰжңүеҺӢзј©пјҢеҺӢзј©еҗҺkeyй•ҝеәҰгҖӮ然еҗҺиҝҷдәӣж–Ү件被е»әжҲҗHDFSзҡ„еқ—гҖӮ
- Parquetпјҡзұ»дјјRC FileгҖӮ
- еӯҳеңЁзҡ„й—®йўҳпјҡйңҖиҰҒETLпјҲжҠҪеҸ–гҖҒиҪ¬жҚўгҖҒеӯҳеӮЁпјү然еҗҺеҶҷе…ҘеҲ°Parquetзҡ„дёӯй—ҙж–Үд»¶ж јејҸпјҢиҝҷдёӘзҡ„д»Јд»·жҳҜеҫҲеӨ§зҡ„гҖӮиҖҢиҝҷдәӣж–Ү件еңЁд№ӢеҗҺеҰӮжһңзӣҙжҺҘеҒҡSQLзҡ„ж—¶еҖҷж•ҲзҺҮеҫҲдҪҺгҖӮжүҖд»ҘжңҖз»ҲиҝҳжҳҜиҰҒиҪ¬еҲ°SQLзҡ„ж•°жҚ®еә“дёӯпјҲзӣҙжҺҘеҜ№ж•°жҚ®еә“еӨ„зҗҶпјүйӮЈжҲ‘们 е°ұжғіпјҡеҰӮжһңж•°жҚ®жқҘдәҶпјҢжҲ‘们еҸҜдёҚеҸҜд»Ҙе…ҲжҠҠж•°жҚ®жҢүз…§еҺҹе§Ӣзҡ„ж јејҸеӯҳеӮЁпјҢеҪ“жҲ‘зңҹжӯЈйңҖиҰҒзҡ„ж—¶еҖҷпјҢеҶҚжҠҠж•°жҚ®еҜје…ҘиҝӣжқҘгҖӮ жүҖд»Ҙиҝҷе°ұжҳҜж•°жҚ®ж№–гҖӮ
Data Lake ж•°жҚ®ж№–
- д»ҘиҮӘ然/еҺҹе§Ӣж јејҸеӯҳеӮЁж•°жҚ®зҡ„зі»з»ҹжҲ–еӯҳеӮЁеә“пјҢйҖҡеёёжҳҜеҜ№иұЎblobжҲ–ж–Ү件
- ж•°жҚ®ж№–йҖҡеёёжҳҜдёҖдёӘеҚ•дёҖзҡ„ж•°жҚ®еӯҳеӮЁпјҢеҢ…жӢ¬жәҗзі»з»ҹж•°жҚ®гҖҒдј ж„ҹеҷЁж•°жҚ®гҖҒзӨҫдәӨж•°жҚ®зӯүзҡ„еҺҹе§ӢеүҜжң¬пјҢд»ҘеҸҠз”ЁдәҺжҠҘе‘ҠгҖҒеҸҜ и§ҶеҢ–гҖҒй«ҳзә§еҲҶжһҗе’ҢжңәеҷЁеӯҰд№ зӯүд»»еҠЎзҡ„иҪ¬жҚўж•°жҚ®гҖӮ
- ж•°жҚ®ж№–еҸҜд»ҘеҢ…жӢ¬жқҘиҮӘе…ізі»ж•°жҚ®еә“зҡ„з»“жһ„еҢ–ж•°жҚ®пјҲиЎҢе’ҢеҲ—пјүгҖҒеҚҠз»“жһ„еҢ–ж•°жҚ®пјҲCSVгҖҒж—Ҙеҝ—гҖҒXMLгҖҒJSONпјүгҖҒйқһз»“ жһ„еҢ–ж•°жҚ®пјҲз”өеӯҗйӮ®д»¶гҖҒж–ҮжЎЈгҖҒpdfпјүе’ҢдәҢиҝӣеҲ¶ж•°жҚ®пјҲеӣҫеғҸгҖҒйҹійў‘гҖҒи§Ҷйў‘пјүгҖӮж•°жҚ®ж№–еҸҜд»Ҙе»әз«ӢеңЁвҖңжң¬ең°вҖқпјҲеңЁз»„з»Үзҡ„ж•° жҚ®дёӯеҝғеҶ…пјүжҲ–вҖңдә‘дёӯвҖқпјҲдҪҝз”Ёдәҡ马йҖҠгҖҒеҫ®иҪҜгҖҒз”ІйӘЁж–Үдә‘жҲ–и°·жӯҢзӯүдҫӣеә”е•Ҷзҡ„дә‘жңҚеҠЎпјүгҖӮ
- 1. еңЁеҝ…иҰҒзҡ„ж—¶еҖҷдјҡйҖҡиҝҮETLзҡ„ж–№жі•пјҢжҠҠж•°жҚ®еҜје…ҘеҲ°ж•°жҚ®д»“еә“зҡ„йҮҢйқў
- 2. ж•°жҚ®ж№–иҰҒи§ЈеҶізҡ„й—®йўҳе°ұжҳҜпјҡйқўдёҙеӨ§йҮҸзҡ„ж•°жҚ®иҰҒеҜје…Ҙзҡ„ж—¶еҖҷжҖҺд№ҲжҠҠеҺҹе§Ӣж•°жҚ®еҝ«йҖҹжҺҘеҸ—дёӢжқҘ
Data Lake vs Data Warehouse
| Data Lake | Data Warehouse | |
| Data Structure | Raw | Processed |
| Purpose of Data | Not yet defined | Currently in use |
| Users | Data Scientistsпјҡ й’ҲеҜ№еҺҹе§Ӣж•°жҚ®иҝӣиЎҢеӨ„зҗҶ | Business Professionalsпјҡ дё»иҰҒй’ҲеҜ№е•ҶдёҡйҮ‘иһҚзҡ„еҲҶжһҗгҖҒз»ҹ |
| Accessibility | Highly accessible and quick to updateпјҡеӣ дёәдёҚйңҖиҰҒеҺ»еҒҡetlиҝҷж ·зҡ„еҠЁдҪң | More complicated and costly to make changesпјҡ еҸҜд»ҘзҗҶи§Јдёәдё»иҰҒжҳҜж•°жҚ®зҡ„дёҖж¬ЎеҜје…ҘпјҢ д»ҘеҗҺеҸӘжҳҜеҒҡеҲҶжһҗзҡ„ |
| зү№зӮ№ | ж•°жҚ®д»“еә“ | ж•°жҚ®ж№– |
| ж•°жҚ® | е…ізі»ж•°жҚ® | еҗ„з§Қж•°жҚ®пјҲеӣ дёәе®ғжҳҜзӣҙжҺҘеӯҳеӮЁзҡ„еҺҹе§Ӣж•°жҚ®пјҡ з»“жһ„еҢ–еҚҠз»“жһ„еҢ–зӯүзӯүйғҪеҸҜд»Ҙпјү |
| schema жЁЎејҸ | жҜ”иҫғдёҘж јзҡ„жЁЎејҸпјҢ ж•°жҚ®еңЁиҜ»еҸ–зҡ„ж—¶еҖҷжҲ–иҖ…еҶҷе…Ҙзҡ„ж—¶еҖҷеҒҡдёҖдёӘж ЎйӘҢ пјҲschema-on-writeжҲ–иҖ…readпјү | schema-on-readпјҲеҸӘжңүеңЁж•°жҚ®еҲҶжһҗзҡ„ж—¶еҖҷпјҢ д№ҹе°ұжҳҜд»ҺиҜ»иө°ж•°жҚ®зҡ„ж—¶еҖҷж ЎйӘҢж•°жҚ®зҡ„жЁЎејҸжҳҜеҗҰеҗҲжі•пјҢ еӣ дёәе®ғжҳҜзӣҙжҺҘеӯҳеӮЁзҡ„еҺҹе§Ӣж•°жҚ®пјҢеӯҳеӮЁзҡ„ж—¶еҖҷдёҚж ЎйӘҢпјү |
| жҖ§иғҪ | жң¬ең°еӯҳеӮЁзҡ„ж—¶еҖҷйқһеёёеҝ« | з”ЁдҪҺжҲҗжң¬зҡ„еӯҳеӮЁжҠҠеӨ§йҮҸзҡ„ж•°жҚ®еӯҳеӮЁиҝӣжқҘпјҢ еҪ“жҗңзҙўзҡ„ж—¶еҖҷеҸҜиғҪжҜ”иҫғж…ў |
| ж•°жҚ®иҙЁйҮҸ | schema-on-writeпјҢиҝҮж»ӨдәҶдёҚеҗҲ规е®ҡзҡ„ж•°жҚ® | еӣ дёәжүҖжңүж•°жҚ®зӣҙжҺҘжҺҘеҸ—пјҢиҙЁйҮҸж— дҝқиҜҒ |
ж№–д»“дёҖдҪ“пјҡдёҚз®ЎжҳҜи°ҒиҰҒжқҘжҹҘж•°жҚ®пјҢйғҪеҲ°еә•еұӮеҺ»жҠ“ж•°жҚ®пјҢеҰӮжһңжҳҜе…ізі»еһӢзҡ„е°ұеҺ»е…ізі»еһӢзҡ„жүҫж•°жҚ®пјҢйқһе…ізі»еһӢзҡ„е°ұеҲ°йқһе…ізі»еһӢзҡ„еҺ»жүҫе°ұеҘҪдәҶпјҢдёҚдёҘж јеҢәеҲҶж•°жҚ®ж№–е’Ңж•°жҚ®д»“еә“гҖӮ
第дәҢеҚҒдёҖз«
йӣҶзҫӨ
- жңүи®ёеӨҡз”ЁжҲ·пјҢеҸҜиғҪеңЁи®ёеӨҡдёҚеҗҢзҡ„ең°ж–№пјҲй«ҳжҖ§иғҪпјү
- зі»з»ҹжҳҜй•ҝж—¶й—ҙиҝҗиЎҢзҡ„пјҢдёҚиғҪз»Ҳз«ҜжңҚеҠЎпјҲеҸҜйқ жҖ§пјү
- жҜҸз§’еӨ„зҗҶеӨ§йҮҸдәӢеҠЎ
- з”ЁжҲ·ж•°йҮҸе’Ңзі»з»ҹиҙҹиҪҪеҸҜиғҪдјҡеўһеҠ пјҲжҜ”еҰӮopen aiпјү
- д»ЈиЎЁеҸҜи§Ӯзҡ„е•Ҷдёҡд»·еҖј(жҜ”еҰӮж”Ҝд»ҳзі»з»ҹжҳҜдёҖдёӘеҫҲе…ій”®зҡ„зі»з»ҹпјҢдҪҶжҳҜзұ»жҜ”з”өеӯҗд№Ұеә—зҡ„жөҸи§ҲеҠҹиғҪе°ұжҳҜдёӘеҫҲйҡҸ дҫҝзҡ„еҠҹиғҪпјҢеӣ жӯӨдёәдәҶдҝқиҜҒж”Ҝд»ҳзҡ„еҸҜйқ жҖ§пјҢеҫҲеҸҜиғҪйңҖиҰҒжҠҠ常规зҡ„дёҡеҠЎжңҚеҠЎе’Ңж”Ҝд»ҳжңҚеҠЎеҲҶејҖпјҢдҝқиҜҒе®үе…Ё е’ҢеҸҜйқ жҖ§)
- з”ұеӨҡдәәж“ҚдҪңе’Ңз®ЎзҗҶ
Nginx
йӣҶзҫӨ
- йӣҶзҫӨпјҲClusteringпјүжҳҜз”ұдёҖз»„жқҫж•ЈиҖҰеҗҲзҡ„жңҚеҠЎеҷЁз»„жҲҗпјҢеҗ‘е®ўжҲ·з«ҜжҸҗдҫӣз»ҹдёҖзҡ„жңҚеҠЎгҖӮ
- д»Һе®ўжҲ·з«Ҝи§Ҷи§’пјҢйӣҶзҫӨиЎЁзҺ°дёәеҚ•дёҖзі»з»ҹпјҲеҚ•дёҖзі»з»ҹи§ҶеӣҫжҲ–еҚ•дёҖзі»з»ҹй•ңеғҸпјүгҖӮ
- иҠӮзӮ№пјҲNodesпјүпјҡ йӣҶзҫӨдёӯзҡ„и®Ўз®—жңәз§°дёәиҠӮзӮ№гҖӮ
RAS еұһжҖ§
- еҸҜйқ жҖ§пјҲReliabilityпјүпјҡ ж¶ҲйҷӨеҚ•зӮ№ж•…йҡңгҖӮ
- еҸҜз”ЁжҖ§пјҲAvailabilityпјүпјҡ зЎ®дҝқжҖ»дҪ“еҸҜз”ЁжҖ§пјҢи®Ўз®—е…¬ејҸдёәпјҡ 1вҲ’(1вҲ’рқ‘“%)^nгҖӮ
- еҸҜз»ҙжҠӨжҖ§пјҲServiceabilityпјүпјҡ
- еӨҚжқӮжҖ§жҜ”еҚ•дёҖжңҚеҠЎеҷЁжӣҙй«ҳпјҢдҪҶж”ҜжҢҒзғӯеҚҮзә§гҖӮ
еҸҜжү©еұ•жҖ§пјҲScalabilityпјүпјҡ
- еҸҜеңЁзі»з»ҹиҝҗиЎҢжңҹй—ҙеўһеҠ жңҚеҠЎеҷЁпјҢеҮҸе°‘дёӯж–ӯгҖӮ
- еҲ©з”Ёж ҮеҮҶ硬件жһ„е»әйӣҶзҫӨжҜ”дҪҝз”ЁеӨҡеӨ„зҗҶеҷЁжңәеҷЁжӣҙдҫҝе®ңгҖӮ
иҙҹиҪҪеқҮиЎЎдёҺж•…йҡңиҪ¬з§»
иҙҹиҪҪеқҮиЎЎпјҡ
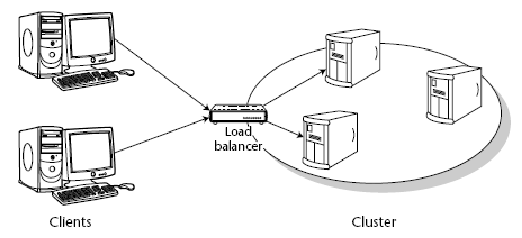
- е®ҡд№үпјҡе°ҶиҜ·жұӮеҲҶй…Қз»ҷйӣҶзҫӨдёӯзҡ„дёҚеҗҢиҠӮзӮ№пјҢд»ҘдјҳеҢ–ж•ҙдҪ“жҖ§иғҪгҖӮ
- ж–№жі•пјҡ
- зі»з»ҹеҢ–пјҲйЎәеәҸеҲҶй…ҚпјүжҲ–йҡҸжңәеҲҶй…ҚгҖӮ
- зӣ‘жҺ§иҠӮзӮ№иҙҹиҪҪпјҢйҖүжӢ©иҙҹиҪҪиҫғдҪҺзҡ„иҠӮзӮ№гҖӮ
- дјҡиҜқзІҳжҖ§пјҲSession Stickinessпјүпјҡ
- й—®йўҳпјҡsessionдјҡеӯҳеңЁдәҺжҹҗдёҖеҸ°зү№е®ҡзҡ„жңҚеҠЎеҷЁдёҠпјҢеҜјиҮҙеҗҺз»ӯдјҡиҜқеҸӘиғҪдёҺзү№е®ҡжңҚеҠЎеҷЁдәӨдә’
- и§ЈеҶіпјҡ
- broadcast е°Ҷsessionе№ҝж’ӯз»ҷжүҖжңүжңҚеҠЎеҷЁгҖӮзјәзӮ№жөӘиҙ№гҖӮ
- жүҫдё“й—Ёзҡ„sessionжңҚеҠЎеҷЁпјҢеӨ„зҗҶsessionгҖӮеҘҪеӨ„жҳҜжүҖжңүжңҚеҠЎеҷЁйғҪж— зҠ¶жҖҒдәҶпјҢеқҸеӨ„жҳҜиҝҷеҸ°жңҚеҠЎеҷЁеҸҳжҲҗдәҶеҚ•дёҖзҠ¶жҖҒиҠӮзӮ№пјҢеҸҜиғҪиҰҒеҜ№е…¶еӨҮд»ҪгҖӮпјҲиҝҷдёӘbugеңЁдәҺеҚ•зӮ№ж•…йҡңпјҢеҰӮжһңredisжҢӮдәҶйә»зғҰе°ұеӨ§дәҶпјү
- з”Ёip-hashпјҢдҝқиҜҒеҜ№дәҺеҗҢдёҖдёӘз”ЁжҲ·зҡ„и®ҝй—®пјҢз”ЁеҗҢдёҖеҸ°жңәеҷЁеӨ„зҗҶгҖӮ
ж•…йҡңиҪ¬з§»пјҲFailoverпјүпјҡ
- иҜ·жұӮзә§ж•…йҡңиҪ¬з§»пјҡ жҹҗиҠӮзӮ№ж— жі•жңҚеҠЎж—¶пјҢе°ҶиҜ·жұӮйҮҚе®ҡеҗ‘еҲ°еҸҰдёҖиҠӮзӮ№гҖӮ
- дјҡиҜқзә§ж•…йҡңиҪ¬з§»пјҡ еҰӮжһңдјҡиҜқзҠ¶жҖҒеңЁе®ўжҲ·з«Ҝе’ҢжңҚеҠЎеҷЁй—ҙе…ұдә«пјҢйңҖеңЁж–°иҠӮзӮ№дёҠйҮҚе»әзҠ¶жҖҒгҖӮ
е№ӮзӯүжҖ§пјҲIdempotenceпјү
е®ҡд№үпјҡе№Ӯзӯүж“ҚдҪңжҳҜжҢҮеҜ№еҗҢдёҖиҜ·жұӮйҮҚеӨҚжү§иЎҢпјҢе§Ӣз»ҲиҺ·еҫ—зӣёеҗҢз»“жһңзҡ„ж“ҚдҪңгҖӮеҰӮпјҡHTTP зҡ„ GET иҜ·жұӮйҖҡеёёжҳҜе№Ӯзӯүзҡ„гҖӮ
еӨұиҙҘеҸҜиғҪзӮ№пјҡ
- иҜ·жұӮеҸ‘еҮәеҗҺпјҢжңҚеҠЎж–№жі•жү§иЎҢеүҚеӨұиҙҘгҖӮи§ЈеҶіпјҡжҚўдёҖеҸ°жңҚеҠЎеҷЁгҖӮ
- жңҚеҠЎж–№жі•жү§иЎҢдёӯйҖ”еӨұиҙҘгҖӮи§ЈеҶіпјҡйҮҚж–°жҚўжңҚеҠЎеҷЁпјҢйҮҚж–°жӢҝsessionжү§иЎҢгҖӮ
- жңҚеҠЎж–№жі•жү§иЎҢе®ҢжҲҗеҗҺпјҢе“Қеә”дј иҫ“еӨұиҙҘгҖӮи§ЈеҶіпјҡдҝқиҜҒзі»з»ҹдёҘж је№Ӯзӯүзҡ„жғ…еҶөдёӢжҚўжңҚеҠЎеҷЁжү§иЎҢгҖӮ
Nginx
дёҖдёӘй«ҳжҖ§иғҪзҡ„ејҖжәҗWebжңҚеҠЎеҷЁе’ҢеҸҚеҗ‘д»ЈзҗҶжңҚеҠЎеҷЁпјҢеҗҢж—¶иҝҳеҸҜд»Ҙз”ЁдҪңйӮ®д»¶д»ЈзҗҶе’ҢиҙҹиҪҪеқҮиЎЎеҷЁгҖӮWordPressдҪҝз”ЁжӯӨжҠҖжңҜгҖӮ
еҸҚеҗ‘д»ЈзҗҶпјҡпјҲreverse proxyпјүпјҢжҢҮзҡ„жҳҜд»ЈзҗҶеӨ–зҪ‘з”ЁжҲ·зҡ„иҜ·жұӮеҲ°еҶ…йғЁзҡ„жҢҮе®ҡзҡ„жңҚеҠЎеҷЁпјҢ并е°Ҷж•°жҚ®иҝ”еӣһз»ҷз”Ё жҲ·зҡ„дёҖз§Қж–№ејҸпјӣе®ўжҲ·з«ҜдёҚзӣҙжҺҘдёҺеҗҺз«ҜжңҚеҠЎеҷЁиҝӣиЎҢйҖҡдҝЎпјҢиҖҢжҳҜдёҺеҸҚеҗ‘д»ЈзҗҶжңҚеҠЎеҷЁиҝӣиЎҢйҖҡдҝЎ,йҡҗи—ҸдәҶеҗҺз«ҜжңҚеҠЎеҷЁзҡ„ IP ең°еқҖгҖӮ еҸҚеҗ‘д»ЈзҗҶзҡ„дё»иҰҒдҪңз”ЁжҳҜжҸҗдҫӣиҙҹиҪҪеқҮиЎЎе’Ңй«ҳеҸҜз”ЁжҖ§гҖӮ
- иҙҹиҪҪеқҮиЎЎпјҡNginxеҸҜд»Ҙе°Ҷдј е…Ҙзҡ„иҜ·жұӮеҲҶеҸ‘з»ҷеӨҡдёӘеҗҺз«ҜжңҚеҠЎеҷЁпјҢд»Ҙе№іиЎЎжңҚеҠЎеҷЁзҡ„иҙҹиҪҪпјҢжҸҗй«ҳзі»з»ҹжҖ§иғҪ е’ҢеҸҜйқ жҖ§гҖӮ
- зј“еӯҳеҠҹиғҪпјҡNginxеҸҜд»Ҙзј“еӯҳйқҷжҖҒж–Ү件жҲ–еҠЁжҖҒйЎөйқўпјҢеҮҸиҪ»жңҚеҠЎеҷЁзҡ„иҙҹиҪҪпјҢжҸҗй«ҳе“Қеә”йҖҹеәҰгҖӮ
- еҠЁйқҷеҲҶзҰ»пјҡе°ҶеҠЁжҖҒз”ҹжҲҗзҡ„еҶ…е®№пјҲеҰӮ PHPгҖҒPythonгҖҒNode.js зӯүпјүе’ҢйқҷжҖҒиө„жәҗпјҲеҰӮ HTMLгҖҒCSSгҖҒ JavaScriptгҖҒеӣҫзүҮгҖҒи§Ҷйў‘зӯүпјүеҲҶеҲ«еӯҳж”ҫеңЁдёҚеҗҢзҡ„жңҚеҠЎеҷЁжҲ–и·Ҝеҫ„дёҠгҖӮ
- еӨҡз«ҷзӮ№д»ЈзҗҶпјҡNginxеҸҜд»Ҙд»ЈзҗҶеӨҡдёӘеҹҹеҗҚжҲ–иҷҡжӢҹдё»жңәпјҢе°ҶдёҚеҗҢзҡ„иҜ·жұӮиҪ¬еҸ‘еҲ°дёҚеҗҢзҡ„еҗҺз«ҜжңҚеҠЎеҷЁдёҠпјҢе®һ зҺ°еӨҡдёӘз«ҷзӮ№зҡ„е…ұдә«з«ҜеҸЈгҖӮ
| еұһжҖ§ | д»ЈзҗҶпјҲProxyпјү | еҸҚеҗ‘д»ЈзҗҶпјҲReverse Proxyпјү |
|---|---|---|
| жңҚеҠЎеҜ№иұЎ | е®ўжҲ·з«ҜпјҲз”ЁжҲ·пјү | зӣ®ж ҮжңҚеҠЎеҷЁпјҲжңҚеҠЎз«Ҝпјү |
| дё»иҰҒеҠҹиғҪ | её®еҠ©е®ўжҲ·з«Ҝи®ҝй—®зӣ®ж ҮжңҚеҠЎеҷЁ | её®еҠ©жңҚеҠЎеҷЁеӨ„зҗҶжқҘиҮӘе®ўжҲ·з«Ҝзҡ„иҜ·жұӮпјҢеҸ‘йҖҒз»ҷеӨ„зҗҶиҜ·жұӮжңҚеҠЎеҷЁ |
| йҡҗи—ҸдҝЎжҒҜ | йҡҗи—Ҹе®ўжҲ·з«Ҝзҡ„IPе’Ңиә«д»ҪдҝЎжҒҜ | йҡҗи—ҸеҗҺз«ҜжңҚеҠЎеҷЁзҡ„IPе’Ңз»“жһ„дҝЎжҒҜ |
| е…ёеһӢз”ЁйҖ” | дёҠзҪ‘д»ЈзҗҶгҖҒеҢҝеҗҚжөҸи§ҲгҖҒеҶ…е®№иҝҮж»Ө | иҙҹиҪҪеқҮиЎЎгҖҒе®үе…ЁйҳІжҠӨгҖҒзј“еӯҳеҠ йҖҹ |
| еёёи§Ғе·Ҙе…· | SquidгҖҒShadowsocksгҖҒHTTP Proxy | NginxгҖҒHAProxyгҖҒApache Traffic Server |
иҙҹиҪҪеқҮиЎЎж–№ејҸ
- иҪ®иҜўпјҲRound-robinпјүпјҡ иҜ·жұӮжҢүйЎәеәҸеҲҶй…Қз»ҷжңҚеҠЎеҷЁгҖӮ(дјҳзӮ№пјҡиҙҹиҪҪ еқҮиЎЎзҡ„ж•ҲжһңжҜ”иҫғеҘҪпјҢдёҚеҗҢзҡ„жңәеҷЁиҪ®жөҒжқҘеӨ„зҗҶпјҢдёҖиҲ¬жқҘиҜҙжҜ”ж–№жі•дёүзҡ„ж•ҲжһңеҘҪпјӣзјәзӮ№пјҡsessionйңҖиҰҒеҚ• зӢ¬з»ҙжҠӨпјҢд»ҘеҸҠжІЎжңүж–№жі•дәҢзҡ„дјҳзӮ№)
- жңҖе°‘иҝһжҺҘпјҲLeast-connectedпјүпјҡ еҲҶй…Қз»ҷеҪ“еүҚжҙ»еҠЁиҝһжҺҘж•°жңҖе°‘зҡ„жңҚеҠЎеҷЁгҖӮ
- IP е“ҲеёҢпјҲIP-hashпјүпјҡ дҪҝз”Ёе“ҲеёҢеҮҪж•°ж №жҚ®е®ўжҲ·з«Ҝ IP ең°еқҖйҖүжӢ©жңҚеҠЎеҷЁгҖӮдјҳзӮ№пјҡдҝқиҜҒдәҶдјҡиҜқзҡ„зІҳеҲ¶жҖ§пјҢеҸӘиҰҒз”ЁжҲ·зҡ„IPдёҚеҸҳпјҢйӣҶзҫӨдёӯеӨ„зҗҶз”ЁжҲ·иҜ·жұӮзҡ„жңәеҷЁ е°ұдёҚдјҡеҸҳпјҢзјәзӮ№пјҡиҝҷжҳҜдёүз§Қж–№жі•йҮҢйқўиҙҹиҪҪеқҮиЎЎж•ҲжһңжңҖе·®зҡ„дёҖз§ҚпјҢеҰӮжһңhashеҮҪж•°йҖүжӢ©зҡ„дёҚеҘҪзҡ„иҜқпјҢжңҖз»Ҳзҡ„з»“жһңеҫҲеҸҜиғҪжҳҜеҜјиҮҙйӣҶзҫӨйҮҢйқўзҡ„з»ҸеёёжҳҜдёҖеҸ°жңәеҷЁеңЁеӨ„зҗҶиҜ·жұӮпјӣеҪ“然иҝҳжңүдёҖдёӘзјәзӮ№е°ұжҳҜеҰӮжһңз”ЁжҲ·ж”№еҸҳдәҶIPпјҢжҜ”еҰӮдёҠзҪ‘йҖ”дёӯејҖеҗҜдәҶжҲ–иҖ…е…ій—ӯдәҶVPNжҲ–иҖ…д»ЈзҗҶжңҚеҠЎеҷЁпјҢеҜјиҮҙз”ЁжҲ·ipж”№еҸҳпјҢиҝҷж—¶еҖҷsessionе°ұеҸҜиғҪдёўеӨұпјү
MysqlйӣҶзҫӨ
з»„жҲҗпјҡдёҖдёӘзұ»дјјGateWayзҡ„MySQL RouterпјҢиҙҹиҙЈиҪ¬еҸ‘иҜ·жұӮгҖӮ
ж•°жҚ®еә“з»„жҲҗеҸҜиғҪжҳҜдёҖдёӘдё»MySQLжңҚеҠЎеҷЁпјҢдёӨдёӘд»ҺMySQLжңҚеҠЎеҷЁпјҢдё»жңҚеҠЎеҷЁиҙҹиҙЈиҜ»еҶҷж“ҚдҪңпјҢеҗҺйқўдёӨдёӘд»ҺжңҚеҠЎеҷЁеҸӘиғҪиҜ»пјҢ然еҗҺеҗҢжӯҘдё»жңҚеҠЎеҷЁзҡ„еҶ…е®№гҖӮ
MySQL RouterпјҢиҙҹиҙЈиҪ¬еҸ‘иҜ·жұӮд№ҹдјҡдҝқиҜҒиҙҹиҪҪеқҮиЎЎпјҢеҜ№дәҺиҜ»зҡ„ж“ҚдҪңеқҮиЎЎеҲҶй…ҚпјҲеҪ“然主жңҚеҠЎеҷЁеҸҜиғҪдјҡе°‘дёҖзӮ№пјүеҜ№дәҺеҶҷзҡ„ж“ҚдҪңеҲҶй…Қз»ҷдё»жңҚеҠЎеҷЁгҖӮ
第дәҢеҚҒдәҢз«
Cloud Computting
дә‘и®Ўз®—жҳҜдёҖз§ҚйҖҡиҝҮиҷҡжӢҹеҢ–жҠҖжңҜпјҢе®һзҺ°иө„жәҗеҠЁжҖҒеҲҶй…Қе’Ңз®ЎзҗҶзҡ„и®Ўз®—жЁЎеһӢгҖӮз”ЁжҲ·жҢүйңҖиҺ·еҸ–иө„жәҗпјҢйҷҚдҪҺдәҶ硬件жҠ•иө„жҲҗжң¬гҖӮжҠҠжүҖжңүдёңиҘҝеҸҳжҲҗдә’иҒ”зҪ‘дёҠйқўиғҪеӨҹи®ҝй—®зҡ„жңҚеҠЎпјҢжҡҙйңІеҮәжқҘгҖӮ
зү№зӮ№
- еј№жҖ§дјёзј© (Elastic Scaling)пјҡ
дә‘и®Ўз®—жңҚеҠЎеҸҜд»Ҙж №жҚ®йңҖжұӮж— йҷҗжү©еұ•жҲ–зј©еҮҸпјҢж»Ўи¶іе®ўжҲ·еј№жҖ§зҡ„йңҖжұӮгҖӮ - жҢүйңҖд»ҳиҙ№ (Pay-as-you-go)пјҡ
з”ЁжҲ·еҸӘйңҖдёәе®һйҷ…дҪҝз”Ёзҡ„иө„жәҗд»ҳиҙ№пјҢж— йңҖйў„д»ҳеӨ§йўқиҙ№з”ЁгҖӮ - еҝ«йҖҹйғЁзҪІ (Rapid Provisioning)пјҡ
йғЁзҪІжңҚеҠЎзҡ„ж—¶й—ҙд»Һдј з»ҹзҡ„ж•°е‘ЁжҲ–ж•°жңҲзј©зҹӯиҮіеҮ з§’жҲ–еҮ еҲҶй’ҹгҖӮ - й«ҳзә§иҷҡжӢҹеҢ–жҠҖжңҜ (Advanced Virtualization)пјҡ
дә‘и®Ўз®—йҖҡиҝҮиҷҡжӢҹеҢ–е®һзҺ°иө„жәҗжұ еҢ–е’Ңй«ҳж•ҲеҲҶй…ҚгҖӮ
ж ёеҝғжҠҖжңҜ
MapReduce
MapReduce жҳҜдёҖз§Қе…ёеһӢзҡ„жү№еӨ„зҗҶжЎҶжһ¶пјҢйҖӮеҗҲеӨ§и§„жЁЎж•°жҚ®зҡ„еҲҶеёғејҸи®Ўз®—д»»еҠЎпјҢи§ЈеҶіжө·йҮҸж•°жҚ®зҡ„并иЎҢеӨ„зҗҶе’Ңе®№й”ҷй—®йўҳгҖӮ
- дҪҝз”Ё Map е’Ң Reduce зҡ„еҲҶйҳ¶ж®өеӨ„зҗҶжЁЎеһӢгҖӮ
- йҖҡиҝҮеҲҮеҲҶд»»еҠЎе®һзҺ°е№¶иЎҢеҢ–и®Ўз®—гҖӮ
- йҖҡиҝҮд»»еҠЎйҮҚиҜ•е’Ңдёӯй—ҙж–Ү件жңәеҲ¶е®һзҺ°е®№й”ҷгҖӮ
- йҖӮеҗҲзҰ»зәҝж•°жҚ®еӨ„зҗҶпјҢдҪҶзЎ¬зӣҳиҜ»еҶҷеҸҜиғҪеҜјиҮҙжҖ§иғҪ瓶йўҲгҖӮ
дёӨдёӘйҳ¶ж®ө
Mapйҳ¶ж®өпјҡе°Ҷиҫ“е…Ҙж•°жҚ®еҲҶзүҮпјҢжҳ е°„дёәй”®еҖјеҜ№пјҲkey-valueпјүпјҢ并з”ҹжҲҗдёӯй—ҙз»“жһңгҖӮ
Reduceйҳ¶ж®өпјҡеҜ№дёӯй—ҙз»“жһңзҡ„й”®еҖјеҜ№иҝӣиЎҢеҪ’并е’ҢиҒҡеҗҲпјҢз”ҹжҲҗжңҖз»Ҳзҡ„иҫ“еҮәз»“жһңгҖӮ
жөҒзЁӢеҲҶи§Ј
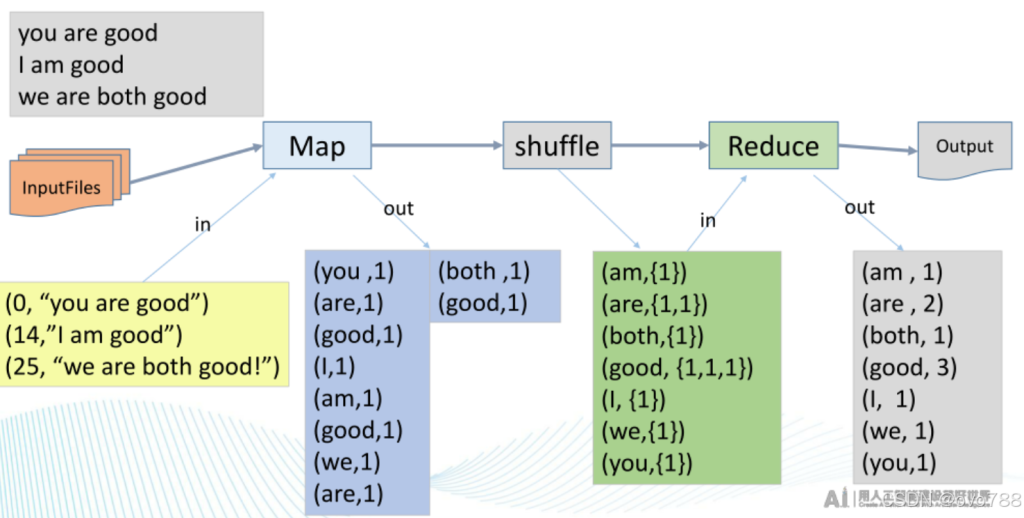
- з”ЁжҲ·зЁӢеәҸпјҲUser Programпјү
- з”ЁжҲ·зј–еҶҷ MapReduce зЁӢеәҸгҖӮ
- зЁӢеәҸйҖҡиҝҮе®ўжҲ·з«ҜжҸҗдәӨеҲ°йӣҶзҫӨпјҢз”ұ Master иҝӣиЎҢи°ғеәҰгҖӮ
- Master и°ғеәҰд»»еҠЎ
- Master иҙҹиҙЈпјҡ
- е°Ҷиҫ“е…Ҙж–Ү件еҲҮеҲҶжҲҗеӨҡдёӘйҖ»иҫ‘еҲҶзүҮпјҲsplitпјүгҖӮ
- е°Ҷ Map е’Ң Reduce д»»еҠЎеҲҶй…Қз»ҷз©әй—Ізҡ„ Worker иҠӮзӮ№гҖӮ
- иҫ“е…Ҙж–Ү件зҡ„еҲҶзүҮеӨ§е°ҸйҖҡеёёзӯүдәҺеҲҶеёғејҸж–Ү件系з»ҹпјҲеҰӮ HDFSпјүзҡ„ block еӨ§е°ҸгҖӮ
- Master иҙҹиҙЈпјҡ
- Map йҳ¶ж®ө
- жҜҸдёӘ Map Worker еӨ„зҗҶдёҖдёӘжҲ–еӨҡдёӘеҲҶзүҮпјҲsplitпјүпјҢд»Һжң¬ең°зЈҒзӣҳиҜ»еҸ–ж•°жҚ®гҖӮ
- Map Worker жү§иЎҢз”ЁжҲ·е®ҡд№үзҡ„
map()еҮҪж•°пјҢе°Ҷж•°жҚ®иҪ¬еҢ–дёәй”®еҖјеҜ№пјҲkey-valueпјүгҖӮ- дҫӢеҰӮпјҢиҜ»еҸ–дёҖж¬ЎвҖңamвҖқпјҢиҫ“еҮә
{am: 1}гҖӮ
- дҫӢеҰӮпјҢиҜ»еҸ–дёҖж¬ЎвҖңamвҖқпјҢиҫ“еҮә
- дёӯй—ҙз»“жһңеҶҷе…Ҙжң¬ең°зЈҒзӣҳпјҢз”ҹжҲҗдёӯй—ҙж–Ү件пјҲIntermediate FilesпјүгҖӮ
- Shuffle йҳ¶ж®ө
- Reduce йҳ¶ж®өејҖе§ӢеүҚпјҢжүҖжңүдёӯй—ҙж–Ү件дјҡйҖҡиҝҮзҪ‘з»ңдј иҫ“пјҲhttpпјүеҲ° Reduce WorkerгҖӮ
- пјҲsortпјүMaster жҢүз…§й”®еҖјеҜ№зҡ„й”®пјҲ
keyпјүеҜ№дёӯй—ҙж–Ү件еҲҶеҢәпјҢ并еҲҶй…ҚеҲ°дёҚеҗҢзҡ„ Reduce WorkerгҖӮ- дҫӢеҰӮпјҢй”®еҖјеҜ№
{A-N}еҸ‘йҖҒеҲ° Reduce Worker 1пјҢ{O-Z}еҸ‘йҖҒеҲ° Reduce Worker 2гҖӮ
- дҫӢеҰӮпјҢй”®еҖјеҜ№
- пјҲSecondary SortпјүеҰӮжһңйңҖиҰҒеҜ№ key зҡ„еҲҶ组规еҲҷе’ҢжҺ’еәҸ规еҲҷиҝӣиЎҢеҢәеҲҶпјҢеҸҜд»ҘйҖҡиҝҮ
Job.setSortComparatorClass(Class)жқҘжҢҮе®ҡиҮӘе®ҡд№үзҡ„жҺ’еәҸ规еҲҷпјҢеҸҜд»ҘжҺ§еҲ¶ key еҰӮдҪ•еҲҶз»„пјҢд»ҺиҖҢе®һзҺ°еҹәдәҺ value зҡ„дәҢж¬ЎжҺ’еәҸгҖӮ
- Reduce йҳ¶ж®ө
- Reduce Worker иҜ»еҸ–еҲҶй…Қзҡ„дёӯй—ҙж–Ү件гҖӮ
- жү§иЎҢз”ЁжҲ·е®ҡд№үзҡ„
reduce()еҮҪж•°пјҢеҜ№й”®еҖјеҜ№иҝӣиЎҢеҪ’并е’ҢиҒҡеҗҲпјҢз”ҹжҲҗжңҖз»Ҳз»“жһңгҖӮ- дҫӢеҰӮпјҢе°Ҷ
{are: 1, are: 1}еҪ’并дёә{are: 2}гҖӮ
- дҫӢеҰӮпјҢе°Ҷ
- жңҖз»Ҳз»“жһңеҶҷе…Ҙиҫ“еҮәж–Ү件пјҲOutput FilesпјүгҖӮжіЁж„ҸпјҡReducer зҡ„иҫ“еҮәж•°жҚ®дёҚжҳҜжҺ’еәҸзҡ„гҖӮ
- иҫ“еҮәз»“жһң
- Reduce Worker зҡ„иҫ“еҮәж–Ү件еӯҳеӮЁеңЁеҲҶеёғејҸж–Ү件系з»ҹдёӯпјҢдҫӣз”ЁжҲ·дҪҝз”ЁгҖӮ
еҗҺеҮ дёӘйҳ¶ж®өйғҪеұһдәҺreduceпјҢд»ҺShuffle з®—иө·гҖӮеҰӮжһңжҢүз…§иҜҫ件пјҢreduceеҲҶдёәдёүдёӘйҳ¶ж®өsuffle пјҢsortпјҢreduce
е®№й”ҷжңәеҲ¶
- д»»еҠЎйҮҚиҜ•пјҡеҰӮжһңжҹҗдёӘ Worker иҠӮзӮ№е·ҘдҪңзј“ж…ўжҲ–е®•жңәпјҢMaster дјҡе°ҶжңӘе®ҢжҲҗзҡ„д»»еҠЎеҲҶй…Қз»ҷе…¶д»–з©әй—Ізҡ„ WorkerгҖӮдҫӢеҰӮпјҢеҪ“еӨ„зҗҶ第 100 еқ—ж•°жҚ®зҡ„ Worker еҮәзҺ°й—®йўҳпјҢMaster дјҡе°Ҷд»»еҠЎеҲҶй…Қз»ҷеҸҰдёҖдёӘз©әй—ІиҠӮзӮ№гҖӮ
- дёӯй—ҙж–Ү件зҡ„еҶ—дҪҷпјҡдёӯй—ҙж–Ү件еӯҳеӮЁеңЁжң¬ең°зЈҒзӣҳдёӯпјҢд»»еҠЎеӨұиҙҘж—¶еҸҜд»Ҙиў«е…¶д»– Worker йҮҚж–°иҜ»еҸ–е’ҢеӨ„зҗҶгҖӮ
жү№еӨ„зҗҶзү№зӮ№
- жү№еӨ„зҗҶпјҡжүҖжңүж•°жҚ®еӨ„зҗҶеҝ…йЎ»жҢүз…§йҳ¶ж®өпјҲMap -> Shuffle -> Reduceпјүе®ҢжҲҗпјҢж•°жҚ®д»Ҙжү№ж¬ЎжөҒеҠЁгҖӮ
- Reduce йҳ¶ж®өејҖе§ӢеүҚпјҢжүҖжңү Map йҳ¶ж®өеҝ…йЎ»е®ҢжҲҗгҖӮ
- ж•°жҚ®еӨ„зҗҶжҳҜзҰ»зәҝзҡ„пјҢйҖӮеҗҲйңҖиҰҒе…ЁйҮҸж•°жҚ®еҲҶжһҗзҡ„еңәжҷҜгҖӮ
- жөҒејҸеӨ„зҗҶпјҡдёҺжү№еӨ„зҗҶдёҚеҗҢпјҢжөҒејҸеӨ„зҗҶпјҲеҰӮ Spark StreamingпјүеҸҜд»Ҙиҫ№жҺҘ收数жҚ®иҫ№еӨ„зҗҶгҖӮ
жҖ§иғҪдјҳеҢ–
- зЎ¬зӣҳиҜ»еҶҷзҡ„瓶йўҲпјҡMapReduce дёӯй—ҙз»“жһңеӯҳеӮЁеңЁжң¬ең°зЈҒзӣҳпјҢеҜ№жҖ§иғҪжңүдёҖе®ҡеҪұе“ҚгҖӮ
- еҶ…еӯҳдјҳеҢ–пјҡдёәжҸҗй«ҳжҖ§иғҪпјҢеҸҜд»Ҙе°Ҷдёӯй—ҙз»“жһңеӯҳеӮЁеңЁеҶ…еӯҳдёӯпјҲеҰӮ Spark дҪҝз”Ё RDD ж•°жҚ®з»“жһ„е®һзҺ°пјүпјҢеҶ…еӯҳдјҳеҢ–йңҖиҰҒй«ҳж•Ҳзҡ„ж•°жҚ®з»“жһ„ж”ҜжҢҒгҖӮ
GoogleеҲҶеёғејҸж–Ү件系з»ҹ (GFS):
еҲ©з”ЁзҺ°жңүзҡ„ж–Ү件系з»ҹе®һзҺ°ж–Ү件管зҗҶпјҢеңЁдёҠйқўеҶҚеҠ дёҖеұӮпјҢе®һзҺ°еҲҶеёғејҸгҖӮ
- и®ҫи®Ўз”ЁдәҺж»Ўи¶іеӨ§и§„жЁЎж•°жҚ®еӨ„зҗҶйңҖжұӮгҖӮ
- дҪҝз”Ёж—Ҙеҝ—и®°еҪ•жҸҗдәӨзҡ„жӣҙж–°пјҢ并йҖҡиҝҮеҶ…еӯҳе’ҢжҢҒд№…еҢ–еӯҳеӮЁз»“еҗҲе®һзҺ°й«ҳж•Ҳи®ҝй—®гҖӮ
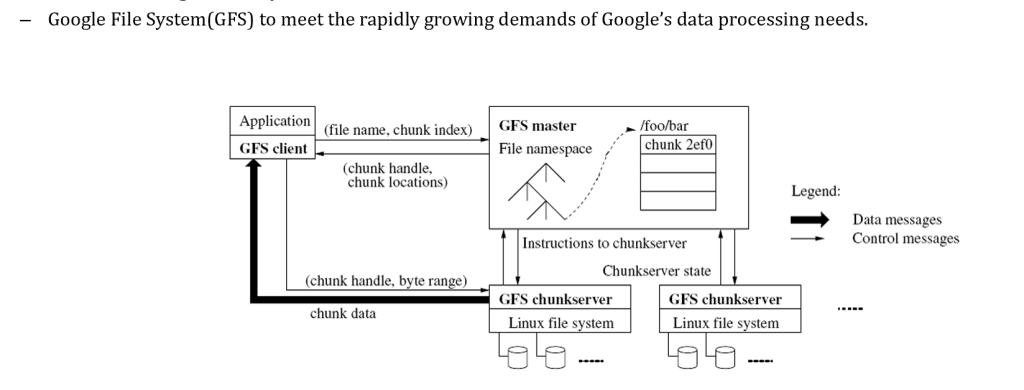
Bigtable:
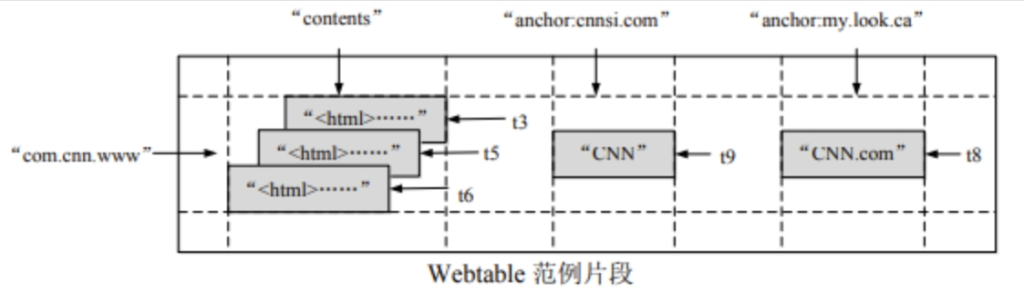
- GoogleејҖеҸ‘зҡ„еҲҶеёғејҸеӯҳеӮЁзі»з»ҹпјҢз”ЁдәҺз®ЎзҗҶз»“жһ„еҢ–ж•°жҚ®гҖӮ
- ж•°жҚ®д»ҘиЎҢй”®гҖҒеҲ—й”®е’Ңж—¶й—ҙжҲізҡ„еҪўејҸзҙўеј•пјҢйҖӮз”ЁдәҺеӨ„зҗҶжө·йҮҸж•°жҚ®гҖӮ
- 1. йҰ–е…Ҳе’ҢmongoDBдёҖж ·пјҢдёҚеӯҳеңЁд»Җд№Ҳд№ұдёғе…«зіҹзҡ„еӨ–й”®е…іиҒ”гҖӮ
- 2. Column Family еҲ—ж—ҸпјҡеғҸдәҢзә§еҲҶзұ»дёҖж ·пјҢжҜ”еҰӮдҪ жңүеҚҒдёӘеӯ—ж®өпјҢжҲ‘们еҲҶдёә3+3+4пјҢ3пјҢ3пјҢ4е°ұеҲҶеҲ«жҲҗ дёәеҲ—ж—ҸгҖӮеҗҺйқўз»“жһ„д№ҹеҸҜд»ҘжҜ”иҫғиҮӘз”ұең°еҸҳеҢ–пјҢжІЎжңүйӮЈд№ҲдёҘж јзҡ„schemaгҖӮ
- 3. TimeStampпјҡеҹәдәҺж—¶й—ҙжҲізҡ„ж•°жҚ®еӯҳеӮЁгҖӮдёҠеӣҫдёӯеұ•зӨәеҮәдәҶдёҖдёӘз«ӢдҪ“зҡ„з»“жһ„гҖӮ
жҖ»з»“пјҡж•°жҚ®йҮҸйқһеёёеӨ§гҖҒschemaжІЎйӮЈд№ҲдёҘж јгҖҒеёҢжңӣеӯҳеӮЁеӨҡдёӘзүҲжң¬гҖӮ
- Apache Hadoop:
- дёҖз§ҚејҖжәҗжЎҶжһ¶пјҢж”ҜжҢҒеҸҜйқ гҖҒеҸҜжү©еұ•зҡ„еҲҶеёғејҸи®Ўз®—гҖӮ
- еҢ…жӢ¬ж ёеҝғ组件пјҡ
- HDFSпјҡй«ҳеҗһеҗҗйҮҸзҡ„еҲҶеёғејҸж–Ү件系з»ҹгҖӮ
- MapReduceпјҡеӨ§ж•°жҚ®еҲҶеёғејҸеӨ„зҗҶжЎҶжһ¶гҖӮ
Edge Computing
иҫ№зјҳи®Ўз®—жҳҜдёҖз§ҚдјҳеҢ–дә‘и®Ўз®—зҡ„ж–№ејҸгҖӮ
еҹәжң¬еҺҹзҗҶпјҡ
- ж ёеҝғжҖқжғіпјҡе°Ҷж•°жҚ®еӨ„зҗҶд»Һдә‘з«ҜвҖңдёӯеҝғеҢ–вҖқеҗ‘вҖңеҺ»дёӯеҝғеҢ–вҖқиҪ¬еҸҳпјҢйҖҡиҝҮе°ұиҝ‘еӨ„зҗҶдјҳеҢ–жҖ§иғҪе’Ңж•ҲзҺҮгҖӮеҪ“ж— жі•еӨ„зҗҶж—¶еҖҷеҗ‘дёҠеҚёиҪҪеҲ°и®Ўз®—иғҪеҠӣжӣҙејәиҠӮзӮ№гҖӮ
- зҪ‘з»ңиҫ№зјҳпјҡжҳҜжҢҮйқ иҝ‘ж•°жҚ®жәҗпјҲеҰӮдј ж„ҹеҷЁгҖҒзү©иҒ”зҪ‘и®ҫеӨҮгҖҒжҷәиғҪз»Ҳз«Ҝзӯүпјүзҡ„йғЁеҲҶпјҢиҖҢдёҚжҳҜдҫқиө–дәҺиҝңзЁӢдә‘ж•°жҚ®дёӯеҝғгҖӮ
зү№зӮ№
- еҮҸе°‘еёҰе®ҪйңҖжұӮпјҡ
ж•°жҚ®ж— йңҖе…ЁйғЁдёҠдј еҲ°дә‘з«ҜпјҢиҠӮзңҒзҪ‘з»ңдј иҫ“жҲҗжң¬гҖӮ - жң¬ең°еӨ„зҗҶиғҪеҠӣпјҡ
еңЁи®ҫеӨҮжң¬ең°е®ҢжҲҗеӨ§йғЁеҲҶи®Ўз®—д»»еҠЎпјҢдҫӢеҰӮжҷәиғҪжүӢжңәгҖҒдј ж„ҹеҷЁгҖҒе№іжқҝз”өи„‘гҖӮ - ж–ӯзҪ‘иҝҗиЎҢпјҡ
иҫ№зјҳи®ҫеӨҮеҸҜд»ҘеңЁзҪ‘з»ңдёҚзЁіе®ҡжҲ–ж–ӯзҪ‘时继з»ӯиҝҗиЎҢгҖӮ
еә”з”ЁеңәжҷҜ
- и§Ҷйў‘еҲҶжһҗпјҡ
- дј з»ҹдә‘и®Ўз®—еӣ 延иҝҹе’Ңйҡҗз§Ғй—®йўҳдёҚйҖӮеҗҲеӨ„зҗҶи§Ҷйў‘ж•°жҚ®гҖӮ
- иҫ№зјҳи®Ўз®—еҸҜд»ҘеңЁжң¬ең°и®ҫеӨҮеҲҶжһҗи§Ҷйў‘пјҢ并仅дёҠдј з»“жһңеҲ°дә‘з«ҜгҖӮ
- жҷәиғҪ家еұ…пјҡ
- еңЁе®¶дёӯжң¬ең°еӨ„зҗҶж•°жҚ®пјҢеҮҸе°‘йҡҗз§Ғжі„йңІе’ҢеёҰе®ҪеҺӢеҠӣгҖӮ
- иҫ№зјҳзҪ‘е…іпјҲеҰӮEdgeOSпјүеҸҜд»Ҙе®һзҺ°и®ҫеӨҮзҡ„й«ҳж•Ҳз®ЎзҗҶе’ҢжңҚеҠЎйғЁзҪІгҖӮ
移еҠЁиҫ№зјҳи®Ўз®— (MEC)
- дә‘еҚёиҪҪпјҲCloud Offloading пјү
- иҫ№зјҳжңҚеҠЎеҷЁжңүж—¶ж— жі•еӨ„зҗҶиҝҮеӨҡзҡ„иҜ·жұӮжҲ–и®Ўз®—пјҢжӯӨж—¶еҸҜд»Ҙеҗ‘дёҠеҚёиҪҪеҲ°и®Ўз®—иғҪеҠӣжӣҙејәзҡ„иҠӮзӮ№еӨ„зҗҶгҖӮ
- и®Ўз®—еҚёиҪҪ (Computation Offloading)пјҡ
- е°ҶеӨҚжқӮи®Ўз®—д»»еҠЎд»Һз»Ҳз«Ҝи®ҫеӨҮиҪ¬з§»еҲ°иҫ№зјҳжңҚеҠЎеҷЁпјҢиҠӮзңҒи®ҫеӨҮиғҪиҖ—пјҢжҸҗй«ҳи®Ўз®—йҖҹеәҰгҖӮ
- еҪўејҸеҢ…жӢ¬жң¬ең°жү§иЎҢгҖҒе®Ңе…ЁеҚёиҪҪе’ҢйғЁеҲҶеҚёиҪҪгҖӮ
第дәҢеҚҒдёүз«
GraphQL
- APIзҡ„жҹҘиҜўиҜӯиЁҖпјҡ
- GraphQLжҳҜдёҖз§Қз”ЁдәҺAPIзҡ„жҹҘиҜўиҜӯиЁҖгҖӮ
- е®ғе…Ғи®ёе®ўжҲ·з«ҜеҸӘиҜ·жұӮжүҖйңҖзҡ„ж•°жҚ®пјҢеҰӮжҢҮе®ҡзҡ„Order_idиҖҢйқһе…ЁйғЁOrderпјҢйҒҝе…ҚдәҶдј з»ҹREST APIеҶ—дҪҷж•°жҚ®зҡ„й—®йўҳгҖӮ
- зұ»еһӢзі»з»ҹ (Type System)пјҡ
- GraphQLеҹәдәҺдёҖдёӘз”ЁжҲ·е®ҡд№үзҡ„зұ»еһӢзі»з»ҹжқҘиҝҗиЎҢпјҢиғҪе…је®№зҺ°жңүзҡ„ж•°жҚ®е’Ңд»Јз ҒгҖӮ
- йҖҡиҝҮе®ҡд№үж•°жҚ®зұ»еһӢе’Ңеӯ—ж®өпјҢжҸҗдҫӣзҒөжҙ»дё”ејәеӨ§зҡ„ж•°жҚ®жҹҘиҜўж–№ејҸгҖӮ
еҠҹиғҪ
- жҹҘиҜўе’ҢеҸҳжӣҙ (Queries and Mutations)пјҡ
- жҹҘиҜў (Query)пјҡз”ЁдәҺиҺ·еҸ–ж•°жҚ®гҖӮ
- еҸҳжӣҙ (Mutation)пјҡз”ЁдәҺжӣҙж–°жҲ–еҶҷе…Ҙж•°жҚ®гҖӮ
- еӯ—ж®өе’ҢеҸӮж•° (Fields and Arguments)пјҡ
- GraphQLж”ҜжҢҒдёәжҜҸдёӘеӯ—ж®өе®ҡд№үеҸӮж•°пјҢе®һзҺ°зІҫзЎ®жҹҘиҜўгҖӮеҰӮжҹҘжүҖжңүheroзҡ„nameпјҢжҢҮе®ҡж•°жҚ®иҪ¬жҚўдёәиӢұе°әгҖӮ
- еҲ«еҗҚ (Aliases)пјҡ
- е…Ғи®ёз»ҷеӯ—ж®өи®ҫзҪ®еҲ«еҗҚпјҢи§ЈеҶіж•°жҚ®еҶІзӘҒй—®йўҳгҖӮеҰӮдёҚеҗҢfieldйҮҢзҡ„idпјҢиө·еҲ«еҗҚеҢәеҲҶ
- зүҮж®ө (Fragments)пјҡ
- ж”ҜжҢҒеңЁеӨҡдёӘжҹҘиҜўдёӯеӨҚз”Ёеӯ—ж®өйӣҶеҗҲпјҢжҸҗй«ҳејҖеҸ‘ж•ҲзҺҮгҖӮ
- еҸҳйҮҸ (Variables)пјҡ
- еҠЁжҖҒеҖјеҸҜд»Ҙд»ҺжҹҘиҜўдёӯжҸҗеҸ–пјҢйҖҡиҝҮеӯ—е…ёж–№ејҸдј йҖ’гҖӮ
GraphQL е’Ң RESTful API еҜ№жҜ”
- GraphQL дјҳеҠҝпјҡзҒөжҙ»зҡ„ж•°жҚ®иҺ·еҸ–ж–№ејҸгҖҒйҒҝе…ҚеӨҡдҪҷжҲ–дёҚи¶іж•°жҚ®дј иҫ“гҖҒж”ҜжҢҒе®һж—¶ж•°жҚ®жҺЁйҖҒгҖҒеҮҸе°‘иҜ·жұӮж¬Ўж•°пјҢйҖӮеҗҲеӨҚжқӮе’ҢзҺ°д»ЈеҢ–еә”з”ЁгҖӮ
- RESTful API дјҳеҠҝпјҡи®ҫи®Ўз®ҖеҚ•гҖҒз”ҹжҖҒжҲҗзҶҹгҖҒйҖӮеҗҲиө„жәҗз»“жһ„жё…жҷ°гҖҒжҺҘеҸЈзЁіе®ҡзҡ„еңәжҷҜгҖӮ
| еҜ№жҜ”з»ҙеәҰ | GraphQL | RESTful API |
|---|---|---|
| з«ҜзӮ№ж•°йҮҸ | еҚ•дёҖз«ҜзӮ№пјҢжүҖжңүжҹҘиҜўйҖҡиҝҮдёҖдёӘ /graphql з«ҜзӮ№е®ҢжҲҗгҖӮ | еӨҡдёӘз«ҜзӮ№пјҢжҜҸдёӘз«ҜзӮ№д»ЈиЎЁдёҖдёӘиө„жәҗжҲ–дёҖз»„зӣёе…іиө„жәҗгҖӮ |
| жҹҘиҜўиҜӯиЁҖ | дҪҝз”ЁејәеӨ§зҡ„жҹҘиҜўиҜӯиЁҖпјҢе®ўжҲ·з«ҜеҸҜд»ҘзІҫзЎ®иҜ·жұӮжүҖйңҖзҡ„ж•°жҚ®еӯ—ж®өгҖӮ | дёҚж”ҜжҢҒжҹҘиҜўиҜӯиЁҖпјҢе®ўжҲ·з«ҜеҸӘиғҪиҺ·еҸ–жңҚеҠЎеҷЁйў„е®ҡд№үзҡ„ж•°жҚ®з»“жһ„гҖӮ |
| ж•°жҚ®иҺ·еҸ–ж–№ејҸ | е®ўжҲ·з«ҜеҶіе®ҡж•°жҚ®з»“жһ„пјҢеҸҜд»ҘжҢүйңҖиҺ·еҸ–йңҖиҰҒзҡ„ж•°жҚ®пјҢйҒҝе…ҚиҝҮеӨҡжҲ–иҝҮе°‘зҡ„ж•°жҚ®дј иҫ“гҖӮ | жңҚеҠЎеҷЁеҶіе®ҡиҝ”еӣһзҡ„ж•°жҚ®з»“жһ„пјҢе®ўжҲ·з«ҜйңҖиҰҒж №жҚ®жңҚеҠЎеҷЁз«Ҝзҡ„и®ҫи®Ўи®ҝй—®иө„жәҗи·Ҝеҫ„иҺ·еҸ–ж•°жҚ®гҖӮ |
| зүҲжң¬з®ЎзҗҶ | дёҚйңҖиҰҒдёҘж јзҡ„зүҲжң¬з®ЎзҗҶгҖӮж–°еўһжҲ–дҝ®ж”№еӯ—ж®өдёҚдјҡеҪұе“ҚзҺ°жңүе®ўжҲ·з«ҜгҖӮ | йҖҡеёёйңҖиҰҒйҖҡиҝҮеўһеҠ API зүҲжң¬пјҲеҰӮ /v1/resourceпјүжқҘз®ЎзҗҶжӣҙж–°пјҢзЎ®дҝқе…је®№жҖ§гҖӮ |
| е®һж—¶ж•°жҚ®ж”ҜжҢҒ | ж”ҜжҢҒе®һж—¶ж•°жҚ®жҺЁйҖҒпјҢйҖҡиҝҮи®ўйҳ…пјҲSubscriptionпјүжңәеҲ¶е®һзҺ°гҖӮ | дёҚзӣҙжҺҘж”ҜжҢҒе®һж—¶ж•°жҚ®пјҢйҖҡеёёйңҖиҰҒйҖҡиҝҮиҪ®иҜўжҲ– WebSocket зӯүжңәеҲ¶е®һзҺ°гҖӮ |
| иө„жәҗиЎЁзӨә | е…Ғи®ёе®ўжҲ·з«Ҝж №жҚ®йңҖжұӮз»„еҗҲиө„жәҗпјҢе®ўжҲ·з«ҜеҸҜд»ҘзҒөжҙ»еҶіе®ҡеҰӮдҪ•иҺ·еҸ–е’Ңз»„еҗҲж•°жҚ®гҖӮ | д»Ҙиө„жәҗдёәдёӯеҝғпјҢжҜҸдёӘиө„жәҗжңүе”ҜдёҖзҡ„ URIпјҢиө„жәҗиЎЁзӨәеӣәе®ҡпјҢзјәд№ҸзҒөжҙ»жҖ§гҖӮ |
| иҝҮеӨҡж•°жҚ®дј иҫ“ | йҒҝе…ҚиҝҮеӨҡж•°жҚ®дј иҫ“пјҢе®ўжҲ·з«ҜеҸӘдјҡжҺҘ收еҲ°жҳҺзЎ®иҜ·жұӮзҡ„ж•°жҚ®еӯ—ж®өгҖӮ | еҸҜиғҪдјҡиҝ”еӣһе®ўжҲ·з«ҜдёҚйңҖиҰҒзҡ„ж•°жҚ®пјҢйҖ жҲҗж•°жҚ®жөӘиҙ№гҖӮ |
| дёҚи¶іж•°жҚ®дј иҫ“ | йҒҝе…ҚдёҚи¶іж•°жҚ®дј иҫ“пјҢе®ўжҲ·з«ҜеҸҜд»ҘеңЁдёҖж¬ЎиҜ·жұӮдёӯиҺ·еҸ–жүҖжңүйңҖиҰҒзҡ„ж•°жҚ®пјҢйҒҝе…ҚеӨҡж¬ЎиҜ·жұӮгҖӮ | еҰӮжһңдёҖдёӘиө„жәҗдёҚеҢ…еҗ«е®ўжҲ·з«ҜйңҖиҰҒзҡ„е…ЁйғЁж•°жҚ®пјҢеҸҜиғҪйңҖиҰҒеӨҡж¬ЎиҜ·жұӮдёҚеҗҢзҡ„з«ҜзӮ№жқҘиҺ·еҸ–е®Ңж•ҙж•°жҚ®гҖӮ |
| еӨҚжқӮжҹҘиҜўж”ҜжҢҒ | ж”ҜжҢҒеӨҚжқӮжҹҘиҜўпјҢеҸҜд»ҘеңЁеҚ•дёӘиҜ·жұӮдёӯиҺ·еҸ–еӨҡдёӘзӣёе…іиө„жәҗзҡ„ж•°жҚ®гҖӮ | еӨҚжқӮжҹҘиҜўйңҖиҰҒеӨҡдёӘз«ҜзӮ№иҜ·жұӮпјҢжҲ–иҖ…йҖҡиҝҮжңҚеҠЎеҷЁз«Ҝи®ҫи®Ўдё“й—Ёзҡ„жҹҘиҜўжҺҘеҸЈгҖӮ |
| е®һж—¶жҖ§ | еҺҹз”ҹж”ҜжҢҒи®ўйҳ…жңәеҲ¶пјҢйҖӮеҗҲйңҖиҰҒе®һж—¶жӣҙж–°ж•°жҚ®зҡ„еңәжҷҜгҖӮ | дёҚж”ҜжҢҒеҺҹз”ҹе®һж—¶жӣҙж–°пјҢйҖҡеёёйңҖиҰҒйўқеӨ–е®һзҺ°пјҲеҰӮиҪ®иҜўжҲ– WebSocketпјүгҖӮ |
| еӯҰд№ жӣІзәҝ | йңҖиҰҒеӯҰд№ GraphQL зҡ„жҹҘиҜўиҜӯиЁҖе’Ңжһ¶жһ„и®ҫи®ЎпјҢеҲқжңҹеӯҰд№ жӣІзәҝиҫғйҷЎгҖӮ | дҪҝз”Ё HTTP еҚҸи®®зҡ„ж ҮеҮҶж–№жі•пјҢеӯҰд№ жӣІзәҝиҫғе№ізј“пјҢејҖеҸ‘иҖ…иҫғдёәзҶҹжӮүгҖӮ |
| е·Ҙе…·ж”ҜжҢҒ | жңүдё°еҜҢзҡ„е·Ҙе…·ж”ҜжҢҒпјҲеҰӮ ApolloгҖҒRelay зӯүпјүпјҢеҸҜд»Ҙеё®еҠ©еҝ«йҖҹејҖеҸ‘е’Ңи°ғиҜ•гҖӮ | жңүе№ҝжіӣзҡ„е·Ҙе…·е’Ңеә“ж”ҜжҢҒпјҲеҰӮ PostmanгҖҒSwagger зӯүпјүпјҢз”ҹжҖҒжҲҗзҶҹгҖӮ |
| жҖ§иғҪдјҳеҢ– | еҸҜд»ҘеҮҸе°‘е®ўжҲ·з«Ҝе’ҢжңҚеҠЎеҷЁд№Ӣй—ҙзҡ„иҜ·жұӮж¬Ўж•°пјҢдјҳеҢ–жҖ§иғҪпјҲзү№еҲ«жҳҜеңЁйңҖиҰҒеӨҚжқӮжҹҘиҜўж—¶пјүгҖӮ | еҸҜиғҪйңҖиҰҒеӨҡж¬ЎиҜ·жұӮжқҘе®ҢжҲҗеӨҚжқӮжҹҘиҜўпјҢеўһеҠ зҪ‘з»ңејҖй”ҖгҖӮ |
| й”ҷиҜҜеӨ„зҗҶ | й”ҷиҜҜдҝЎжҒҜйҖҡеёёйӣҶдёӯеңЁе“Қеә”зҡ„ errors еӯ—ж®өдёӯпјҢдҫҝдәҺе®ўжҲ·з«ҜеӨ„зҗҶгҖӮ | й”ҷиҜҜдҝЎжҒҜйҖҡиҝҮ HTTP зҠ¶жҖҒз Ғе’Ңе“Қеә”дҪ“иҝ”еӣһпјҢйңҖиҰҒе®ўжҲ·з«Ҝи§Јжһҗе’ҢеӨ„зҗҶгҖӮ |
| з”ҹжҖҒжҲҗзҶҹеәҰ | ж–°е…ҙжҠҖжңҜпјҢз”ҹжҖҒзі»з»ҹжӯЈеңЁеҝ«йҖҹеҸ‘еұ•пјҢйҖӮеҗҲзҺ°д»ЈеҢ–еә”з”ЁејҖеҸ‘гҖӮ | жҲҗзҶҹзҡ„жҠҖжңҜпјҢе№ҝжіӣеә”з”ЁдәҺеҗ„з§ҚйЎ№зӣ®пјҢзү№еҲ«жҳҜдј з»ҹзі»з»ҹе’Ңз®ҖеҚ•еә”з”ЁеңәжҷҜгҖӮ |
| йҖӮз”ЁеңәжҷҜ | йҖӮеҗҲйңҖиҰҒзҒөжҙ»ж•°жҚ®иҺ·еҸ–гҖҒе®һж—¶жҖ§ејәгҖҒеӨҚжқӮжҹҘиҜўзҡ„еңәжҷҜпјҲеҰӮ移еҠЁз«ҜгҖҒеүҚз«Ҝеә”з”ЁпјүгҖӮ | йҖӮеҗҲиө„жәҗз®ҖеҚ•гҖҒжҺҘеҸЈзЁіе®ҡгҖҒдј з»ҹйЎ№зӣ®дёӯпјҢзү№еҲ«жҳҜ CRUD ж“ҚдҪңиҫғеӨҡзҡ„еңәжҷҜгҖӮ |
| зј“еӯҳж”ҜжҢҒ | е®ўжҲ·з«ҜйңҖиҰҒиҮӘиЎҢе®һзҺ°зј“еӯҳйҖ»иҫ‘пјҲеҰӮ Apollo Client жҸҗдҫӣзҡ„зј“еӯҳеҠҹиғҪпјүгҖӮ | еҹәдәҺ HTTP зҡ„зј“еӯҳжңәеҲ¶пјҲеҰӮ ETagгҖҒLast-Modifiedпјүж”ҜжҢҒеҺҹз”ҹзј“еӯҳеҠҹиғҪ |
第дәҢеҚҒеӣӣз«
Container
е®№еҷЁжҳҜдёҖдёӘжІҷзӣ’еҢ–зҡ„иҝӣзЁӢпјҢиҝҗиЎҢеңЁдё»жңәзі»з»ҹдёӯпјҢдёҺе…¶д»–иҝӣзЁӢе®Ңе…Ёйҡ”зҰ»гҖӮ
е®№еҷЁеҲ©з”ЁдәҶLinuxеҶ…ж ёдёӯзҡ„д»ҘдёӢеҠҹиғҪпјҡ
- NamespacesпјҲе‘ҪеҗҚз©әй—ҙпјүпјҡ
- жҸҗдҫӣиҝӣзЁӢгҖҒзҪ‘з»ңгҖҒж–Ү件系з»ҹзӯүйҡ”зҰ»зҺҜеўғгҖӮ
- cgroupsпјҲжҺ§еҲ¶з»„пјүпјҡ
- жҺ§еҲ¶иө„жәҗеҲҶй…ҚпјҢеҰӮCPUгҖҒеҶ…еӯҳзӯүгҖӮ
Docker
Docker жҳҜдёҖз§Қе®№еҷЁеҢ–жҠҖжңҜпјҢйҖҡиҝҮж“ҚдҪңзі»з»ҹзә§зҡ„иҷҡжӢҹеҢ–пјҢе°Ҷеә”з”ЁзЁӢеәҸеҸҠе…¶дҫқиө–жү“еҢ…еҲ°дёҖдёӘе®№еҷЁдёӯгҖӮе®№еҷЁжҸҗдҫӣдәҶдёҖдёӘзӢ¬з«Ӣзҡ„иҝҗиЎҢзҺҜеўғпјҢеҸҜд»ҘеңЁд»»дҪ•ең°ж–№иҝҗиЎҢпјҲејҖеҸ‘гҖҒжөӢиҜ•гҖҒз”ҹдә§зҺҜеўғдёҖиҮҙпјүгҖӮдёҺдј з»ҹиҷҡжӢҹжңәзӣёжҜ”пјҢе®№еҷЁжӣҙеҠ иҪ»йҮҸзә§пјҢеӣ дёәе®ғ们зӣҙжҺҘдёҺж“ҚдҪңзі»з»ҹеҶ…ж ёдәӨдә’пјҢж— йңҖиҷҡжӢҹеҢ–硬件гҖӮ
DockerдҪҝиҝҷдәӣжҠҖжңҜеҸҳеҫ—жӣҙеҠ жҳ“дәҺдҪҝз”ЁгҖӮжҖ»з»“жқҘиҜҙпјҡ
- е®№еҷЁжҳҜдёҖз§ҚеҸҜиҝҗиЎҢзҡ„й•ңеғҸе®һдҫӢпјҡеҸҜд»ҘйҖҡиҝҮDocker APIжҲ–CLIеҲӣе»әгҖҒеҗҜеҠЁгҖҒеҒңжӯўгҖҒ移еҠЁжҲ–еҲ йҷӨгҖӮ
- и·Ёе№іеҸ°пјҡеҸҜд»ҘеңЁжң¬ең°гҖҒиҷҡжӢҹжңәжҲ–дә‘з«ҜиҝҗиЎҢгҖӮ
- й«ҳеәҰйҡ”зҰ»пјҡе®№еҷЁжңүиҮӘе·ұзҡ„иҪҜ件гҖҒдәҢиҝӣеҲ¶ж–Ү件гҖҒй…ҚзҪ®зӯүпјҢеҪјжӯӨзӢ¬з«ӢгҖӮе®№еҷЁеҪјжӯӨзӢ¬з«ӢпјҢдә’дёҚе№Іжү°пјҲйҖҡиҝҮ cgroup е’Ң namespace е®һзҺ°иө„жәҗйҡ”зҰ»пјүгҖӮ
- еҸҜ移жӨҚпјҡеҸҜд»ҘиҝҗиЎҢеңЁдёҚеҗҢзҡ„ж“ҚдҪңзі»з»ҹдёҠгҖӮ
Image
й•ңеғҸжҳҜжһ„е»әе®№еҷЁзҡ„еҹәзЎҖпјҢжҜҸдёӘй•ңеғҸзұ»дјјдәҺж“ҚдҪңзі»з»ҹеҝ«з…§пјҢжҳҜдёҖдёӘеҸӘиҜ»жЁЎжқҝпјҢз”ЁжқҘеҲӣе»әе®№еҷЁгҖӮе®№еҷЁеҗҜеҠЁж—¶д»Һй•ңеғҸиҺ·еҸ–ж–Ү件系з»ҹгҖӮ
- й•ңеғҸжҸҗдҫӣдәҶе®№еҷЁжүҖйңҖзҡ„йҡ”зҰ»ж–Ү件系з»ҹгҖӮ
- й•ңеғҸеҢ…еҗ«пјҡ
- еә”з”ЁиҝҗиЎҢжүҖйңҖзҡ„жүҖжңүдҫқиө–гҖҒй…ҚзҪ®гҖҒи„ҡжң¬гҖҒдәҢиҝӣеҲ¶ж–Ү件зӯүгҖӮ
- е®№еҷЁзҡ„е…ғж•°жҚ®пјҲеҰӮзҺҜеўғеҸҳйҮҸгҖҒй»ҳи®ӨиҝҗиЎҢе‘Ҫд»ӨзӯүпјүгҖӮ
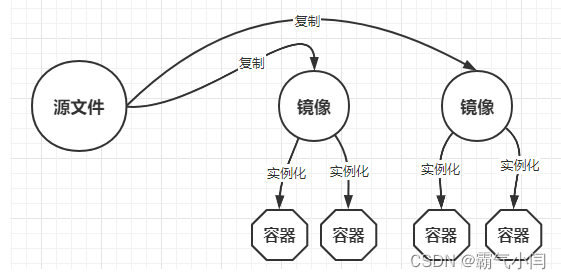
иҷҡжӢҹжңәйңҖиҰҒдёҖдёӘе®Ңж•ҙзҡ„ж“ҚдҪңзі»з»ҹжқҘиҝҗиЎҢпјҢиө„жәҗејҖй”ҖиҫғеӨ§гҖӮиҖҢе®№еҷЁе…ұдә«е®ҝдё»жңәзҡ„ж“ҚдҪңзі»з»ҹеҶ…ж ёпјҢеҗҜеҠЁйҖҹеәҰеҝ«гҖҒиө„жәҗеҚ з”ЁдҪҺгҖӮ
| зү№жҖ§ | е®№еҷЁ | иҷҡжӢҹжңә |
|---|---|---|
| еҗҜеҠЁйҖҹеәҰ | жһҒеҝ«пјҲйҖҡеёёеңЁеҮ з§’еҶ…пјү | иҫғж…ўпјҲйҖҡеёёйңҖиҰҒеҮ еҲҶй’ҹпјү |
| иө„жәҗеҚ з”Ё | иҪ»йҮҸпјҲе…ұдә«дё»жңәеҶ…ж ёпјү | йҮҚпјҲжҜҸдёӘVMжңүзӢ¬з«ӢOSпјҢиө„жәҗж¶ҲиҖ—еӨ§пјү |
| йҡ”зҰ»жҖ§ | дёӯзӯүпјҲе…ұдә«еҶ…ж ёпјҢдҪҶиҝӣзЁӢйҡ”зҰ»пјү | й«ҳпјҲе®Ңе…Ёйҡ”зҰ»пјҢжҜҸдёӘVMзӢ¬з«ӢиҝҗиЎҢпјү |
| 移жӨҚжҖ§ | й«ҳпјҲиғҪеңЁдёҚеҗҢзҺҜеўғдёӯдёҖиҮҙиҝҗиЎҢпјү | дёӯзӯүпјҲдҫқиө–дәҺhypervisorеҸҠOSпјү |
| з®ЎзҗҶе·Ҙе…· | Docker, Kubernetesзӯү | VMware, Hyper-V, KVMзӯү |
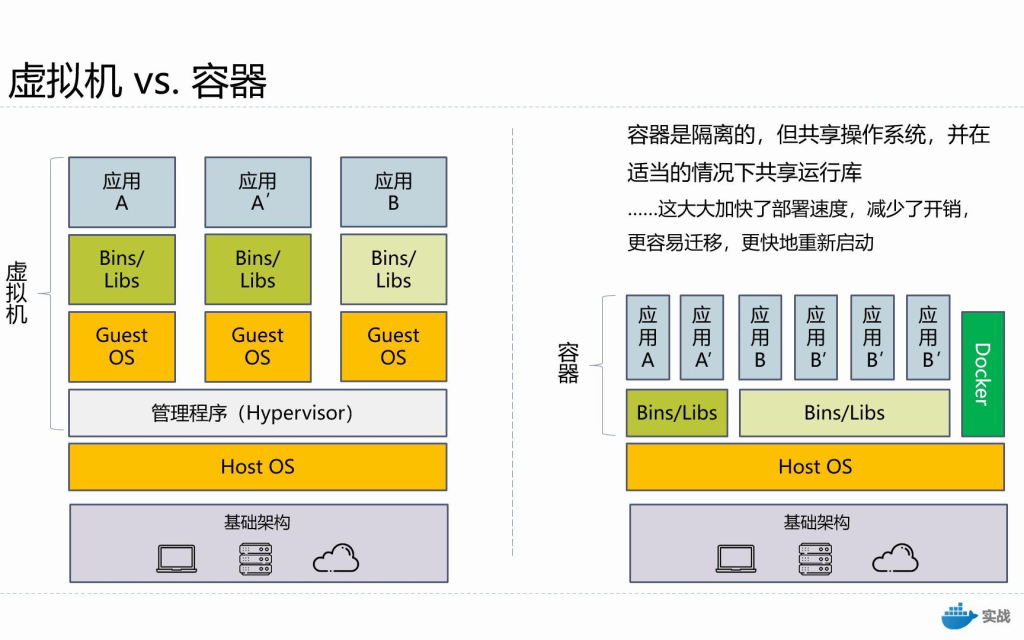
Dockerжһ„е»ә
жһ„е»әй•ңеғҸпјҡ
- еҲӣе»әдёҖдёӘеҗҚдёә
Dockerfileзҡ„ж–Ү件пјҲж— еҗҺзјҖпјү
FROM node:18-alpine #жҢҮе®ҡй•ңеғҸзҡ„еҹәзЎҖзҺҜеўғ
WORKDIR /app #е·ҘдҪңзӣ®еҪ•дҪҚзҪ®
COPY . . #е°Ҷе®ҝдё»жңәпјҲеҚіејҖеҸ‘зҺҜеўғпјүеҪ“еүҚзӣ®еҪ•зҡ„жүҖжңүеҶ…е®№пјҲ.пјүеӨҚеҲ¶еҲ°е®№еҷЁзҡ„е·ҘдҪңзӣ®еҪ•пјҲ/appпјүгҖӮ
RUN yarn install --production #еңЁе®№еҷЁдёӯиҝҗиЎҢ yarn install е‘Ҫд»Ө
CMD ["node", "src/index.js"] #nodeеҗҜеҠЁ
EXPOSE 3000 #3000з«ҜеҸЈжҡҙйңІ- жү§иЎҢе‘Ҫд»Өжһ„е»әй•ңеғҸпјҡ
$ docker build -t getting-started .
еҗҜеҠЁе®№еҷЁпјҡ
- дҪҝз”Ёд»ҘдёӢе‘Ҫд»ӨеҗҜеҠЁе®№еҷЁпјҡ
$ docker run -dp 3000:3000 getting-started - еҸӮж•°иҜҙжҳҺпјҡ
-dпјҡеҗҺеҸ°иҝҗиЎҢе®№еҷЁгҖӮ-p 3000:3000пјҡе°Ҷдё»жңәзҡ„3000з«ҜеҸЈжҳ е°„еҲ°е®№еҷЁзҡ„3000з«ҜеҸЈгҖӮ
Mount
еҪ“йңҖиҰҒеҜ№еҶ…е®№дҝ®ж”№пјҢжҲ‘们еҸҜд»Ҙе°Ҷж•°жҚ®еҶҷеҲ°е®№еҷЁзҡ„еҸҜеҶҷе…ҘеұӮпјҢдҪҶеҪ“е®№еҷЁеҒңжӯўиҝҗиЎҢж—¶пјҢеҶҷе…Ҙзҡ„ж•°жҚ®дјҡдёўеӨұгҖӮиҰҒд№ҲйҮҚж–°жү“еҢ…пјҢиҝҮзЁӢеҚҒеҲҶз№ҒзҗҗгҖӮ
иҝҷж—¶еҖҷеҸҜд»Ҙз”Ёж•°жҚ®жҢӮиҪҪпјҢжҢҮзҡ„жҳҜе°Ҷдё»жңәж–Ү件系з»ҹдёӯзҡ„жҹҗдёӘйғЁеҲҶпјҲж–Ү件жҲ–зӣ®еҪ•пјүдёҺе®№еҷЁеҶ…зҡ„жҹҗдёӘи·Ҝеҫ„е…іиҒ”иө·жқҘпјҢдҪҝе®№еҷЁеҸҜд»Ҙи®ҝй—®дё»жңәзҡ„ж•°жҚ®пјҢжҲ–иҖ…дё»жңәеҸҜд»Ҙж–№дҫҝзҡ„дҝ®ж”№ж–Ү件жҲ–ж•°жҚ®пјҢд»ҘдёӢжҳҜдёӨз§ҚжҢӮиҪҪж–№ејҸпјҡ
| еҜ№жҜ”йЎ№ | Bind Mount | Volume |
|---|---|---|
| SourceдҪҚзҪ® | з”ЁжҲ·жҢҮе®ҡ | зі»з»ҹжҢҮе®ҡ |
| Sourceдёәз©ә | иҰҶзӣ– dest дёәз©ә | дҝқз•ҷ dest еҶ…е®№ |
| Sourceйқһз©ә | иҰҶзӣ– dest еҶ…е®№ | иҰҶзӣ– dest еҶ…е®№ |
| Sourceз§Қзұ» | ж–Ү件жҲ–зӣ®еҪ• | еҸӘиғҪжҳҜзӣ®еҪ• |
| еҸҜ移жӨҚжҖ§ | дёҖиҲ¬пјҲиҮӘиЎҢз»ҙжҠӨпјү | ејәпјҲDocker жүҳз®ЎпјүеҸҜд»ҘйҖҡиҝҮ docker run жҲ– docker-compose ж–Ү件иҪ»жқҫ移жӨҚеҲ°дёҚеҗҢзҡ„дё»жңәгҖӮ |
| е®ҝдё»зӣҙжҺҘи®ҝй—® | е®№жҳ“пјҲд»…йңҖ chownпјү | еҸ—йҷҗпјҲйңҖзҷ»еҪ• root з”ЁжҲ·пјү |
йҖҡиҝҮ nicolaka/netshoot е’Ң dig е‘Ҫд»ӨпјҢжҲ‘们еҸҜд»Ҙеҝ«йҖҹжЈҖжҹҘ Docker зҪ‘з»ңжҳҜеҗҰй…ҚзҪ®жӯЈзЎ®гҖӮеҰӮжһңеҸ‘зҺ°й—®йўҳпјҢеҸҜд»ҘиҝӣдёҖжӯҘдҪҝз”Ёе…¶д»–е·Ҙе…·пјҲеҰӮ ping, tcpdumpпјүиҝӣиЎҢж·ұе…ҘжҺ’жҹҘгҖӮ
docker compose
Docker Compose жҳҜ Docker е®ҳж–№жҸҗдҫӣзҡ„дёҖдёӘе·Ҙе…·пјҢдё»иҰҒз”ЁдәҺз®ЎзҗҶе’ҢйғЁзҪІз”ұеӨҡдёӘе®№еҷЁз»„жҲҗзҡ„еә”з”ЁзЁӢеәҸ(pod)гҖӮ
йҖҡиҝҮдёҖдёӘ YAML ж јејҸзҡ„ж–Ү件пјҲйҖҡеёёе‘ҪеҗҚдёә docker-compose.ymlпјүпјҢеҸҜд»Ҙе®ҡд№үжүҖжңүйңҖиҰҒзҡ„жңҚеҠЎпјҲе®№еҷЁпјү
第дәҢеҚҒдә”з«
Hadoop
HadoopжҳҜдёҖдёӘз”ұApacheеҹәйҮ‘дјҡжүҖејҖеҸ‘зҡ„еҲҶеёғејҸзі»з»ҹеҹәзЎҖжһ¶жһ„гҖӮз”ЁжҲ·еҸҜд»ҘеңЁдёҚдәҶи§ЈеҲҶеёғејҸеә•еұӮз»ҶиҠӮзҡ„жғ…еҶөдёӢпјҢејҖеҸ‘еҲҶеёғејҸзЁӢеәҸгҖӮе……еҲҶеҲ©з”ЁйӣҶзҫӨзҡ„еЁҒеҠӣпјҢи§ЈеҶіжө·йҮҸж•°жҚ®зҡ„еӯҳеӮЁеҸҠжө·йҮҸж•°жҚ®зҡ„еҲҶжһҗи®Ўз®—й—®йўҳгҖӮ
е№ҝд№үдёҠзҡ„HadoopжҳҜжҢҮHadoopзҡ„ж•ҙдёӘжҠҖжңҜз”ҹжҖҒеңҲпјӣзӢӯд№үдёҠзҡ„HadoopжҢҮзҡ„жҳҜе…¶ж ёеҝғдёүеӨ§з»„件пјҢеҢ…жӢ¬HDFSгҖҒYARNеҸҠMapReduce.
- Hadoop Common: еҶ…ж ё
- HDFS: еҲҶеёғејҸж–Ү件系з»ҹ
- YARN: иө„жәҗз®ЎзҗҶпјҢMapReduce: еҲҶеёғејҸи®Ўз®—пјӣ
- MapReduce并иЎҢеӨ„зҗҶзҡ„ж—¶еҖҷдјҡеҮәзҺ°дёҖдёӘй—®йўҳпјҢе°ұжҳҜеҚ•дёҖж•…йҡңиҠӮзӮ№пјҢ еҸҜиғҪеҜјиҮҙж•ҙдёӘзі»з»ҹеҙ©дәҶпјҢжҲ–иҖ…жҲҗдёәbottleneckпјҢжүҖд»ҘиҰҒжңүYARNгҖӮ й’ҲеҜ№еӨ§ж•°жҚ®жү№еӨ„зҗҶиҜ·жұӮпјҢи®ҫи®ЎеҹәдәҺMapReduce/YARNзҡ„并иЎҢеӨ„зҗҶж–№жЎҲгҖӮ
- Clinent node : е®ўжҲ·з«ҜпјҢиҝҗиЎҢMapReduceзЁӢеәҸзҡ„ең°ж–№пјҢз”ұдҪ зј–еҶҷзҡ„д»Јз Ғз»„жҲҗпјҲMapReduce ProgramпјүгҖӮ
- JobClientпјҡжҳҜе®ўжҲ·з«ҜдёҠзҡ„дёҖдёӘ组件пјҢиҙҹиҙЈе°Ҷз”ЁжҲ·зҡ„MapReduceдҪңдёҡжҸҗдәӨеҲ°йӣҶзҫӨдёӯиҝҗиЎҢгҖӮе®ғжҳҜз”ЁжҲ·зЁӢеәҸдёҺHadoopйӣҶзҫӨдәӨдә’зҡ„жҺҘеҸЈгҖӮ
- JobIDпјҡжҜҸдёӘдҪңдёҡеңЁHadoopйӣҶзҫӨдёӯйғҪжңүдёҖдёӘе”ҜдёҖзҡ„ж ҮиҜҶз¬ҰгҖӮJobClientдјҡеҗ‘JobTrackerиҜ·жұӮдёҖдёӘJobIDпјҢд»Ҙж ҮиҜҶиҝҷдёӘдҪңдёҡгҖӮJobIDзұ»дјјдәҺд»»еҠЎзҡ„вҖңиә«д»ҪиҜҒвҖқпјҢз”ЁдәҺеңЁйӣҶзҫӨдёӯи·ҹиёӘд»»еҠЎзҡ„зҠ¶жҖҒгҖӮ
- JobTrackerпјҲиҙҹиҙЈд»»еҠЎзҡ„и°ғеәҰе’Ңи·ҹиёӘпјҢдҪҶе®ғжҳҜдёҖдёӘеҚ•зӮ№з»„件пјҢе®№жҳ“жҲҗдёәжҖ§иғҪ瓶йўҲпјҲYarnи§ЈеҶіпјүпјүпјҡ收еҲ°дҪңдёҡеҗҺпјҢж №жҚ®HDFSдёӯиҫ“е…Ҙзӣ®еҪ•жүҫеҲ°йңҖиҰҒеӨ„зҗҶзҡ„ж–Ү件гҖӮHDFSдёӯзҡ„ж–Ү件йҖҡеёёдјҡиў«еҲҮеҲҶжҲҗеӨҡдёӘж•°жҚ®еқ—пјҲblockпјүпјҢжҜҸдёӘж•°жҚ®еқ—еҸҜиғҪиў«иҝӣдёҖжӯҘеҲ’еҲҶжҲҗеӨҡдёӘsplitпјҲйҖ»иҫ‘дёҠзҡ„иҫ“е…ҘеҲҶзүҮпјүгҖӮжҜҸдёӘsplitеҜ№еә”дёҖдёӘMapд»»еҠЎгҖӮJobTrackerдјҡж №жҚ®д»»еҠЎзҡ„splitдҝЎжҒҜе’ҢйӣҶзҫӨдёӯеҗ„иҠӮзӮ№зҡ„зҠ¶жҖҒпјҢеҶіе®ҡе°Ҷд»»еҠЎеҲҶй…Қз»ҷе“ӘдәӣиҠӮзӮ№дёҠзҡ„TaskTrackerжү§иЎҢгҖӮеҗҢж—¶жЈҖжөӢйӣҶзҫӨж•…йҡңе’ҢеҒҘеә·зҠ¶жҖҒпјҢеҰӮжһңд»»еҠЎеӨұиҙҘиҰҒйҮҚж–°и°ғеәҰд»»еҠЎгҖӮ
- TaskTrackerпјҲиҝҗиЎҢеңЁйӣҶзҫӨдёҠпјҢиҙҹиҙЈжҺҘ收任еҠЎеҲҶй…ҚиҜ·жұӮпјҢ并жҠҘе‘ҠзҠ¶жҖҒпјүпјҡжҺҘ收еҲ°д»»еҠЎеҗҺпјҢдјҡж №жҚ®д»»еҠЎзҡ„йңҖжұӮпјҲжҜ”еҰӮйңҖиҰҒеӨ„зҗҶзҡ„splitпјүд»ҺHDFSдёӯиҜ»еҸ–зӣёе…іж•°жҚ®гҖӮдёәдәҶдҝқиҜҒд»»еҠЎзҡ„йҡ”зҰ»жҖ§е’ҢзӢ¬з«ӢжҖ§пјҢTaskTrackerдјҡеңЁиҠӮзӮ№дёҠеҲӣе»әдёҖдёӘж–°зҡ„JVMпјҲJavaиҷҡжӢҹжңәпјүеӯҗиҝӣзЁӢпјҢеңЁиҝҷдёӘеӯҗиҝӣзЁӢдёӯиҝҗиЎҢз”ЁжҲ·зҡ„MapReduceзЁӢеәҸгҖӮ
- жү§иЎҢзҡ„иҝҮзЁӢдёӯпјҢTaskTrackerдёҚж–ӯеҸ‘еҝғи·із»ҷJobTrackerпјҢдҝқиҜҒеӯҳжҙ»гҖӮ
- MapReduceзЁӢеәҸдјҡеңЁTaskTrackerеҲӣе»әзҡ„JVMдёӯиҝҗиЎҢгҖӮ
дёәи§ЈеҶідёҠйқўжҗңиҜҙзҡ„жҖ§иғҪ瓶йўҲпјҢдҪҝз”ЁYARNйҖҡиҝҮе°Ҷиө„жәҗз®ЎзҗҶе’Ңд»»еҠЎи·ҹиёӘеҲҶејҖпјҢи§ЈеҶідәҶJobTrackerзҡ„жҖ§иғҪ瓶йўҲе’ҢеҚ•зӮ№ж•…йҡңй—®йўҳпјҢеҗҢж—¶ж”ҜжҢҒжӣҙеӨҡзҡ„и®Ўз®—жЎҶжһ¶пјҢдҪҝHadoopжӣҙеҠ зҒөжҙ»е’Ңй«ҳж•Ҳ
Reducerж•°зӣ®
number.of.nodes вҲ— number.of.max.containers.per.node вҲ— 0.95or1.75пјҢжіЁж„ҸдёҚжҳҜиҢғеӣҙпјҢеҸӘжңүдёӨдёӘеҖј
- number.of.nodesпјҡйӣҶзҫӨдёӯжңәеҷЁзҡ„ж•°йҮҸгҖӮ
- number.of.max.containers.per.nodeпјҡжҜҸеҸ°жңәеҷЁдёҠеҸҜд»ҘиҝҗиЎҢзҡ„жңҖеӨ§е®№еҷЁж•°гҖӮ
- 0.95пјҡдҝқе®Ҳдј°з®—пјҢReducer ж•°йҮҸз•Ҙе°‘дәҺйӣҶзҫӨзҡ„жңҖеӨ§е№¶иЎҢиғҪеҠӣгҖӮ
- зү№зӮ№пјҡReducer зҡ„ж•°йҮҸе°ҸдәҺйӣҶзҫӨзҡ„жңҖеӨ§е№¶иЎҢиғҪеҠӣпјҢжүҖжңү Reducer еҸҜд»ҘеҗҢж—¶иҝҗиЎҢгҖӮ
- дјҳзӮ№пјҡ
- з®ҖеҚ•пјҡжүҖжңү Reducer дёҖж¬ЎжҖ§и°ғеәҰе’ҢиҝҗиЎҢпјҢи°ғеәҰејҖй”ҖдҪҺгҖӮ
- жІЎжңүд»»еҠЎзӯүеҫ…пјҡжүҖжңүе®№еҷЁйғҪеҸҜд»ҘеҗҢж—¶е·ҘдҪңпјҢдёҚйңҖиҰҒеҲҮжҚўд»»еҠЎгҖӮ
- зјәзӮ№пјҡ
- иҙҹиҪҪдёҚеқҮиЎЎпјҡеҰӮжһңжҹҗдәӣ Reducer еӨ„зҗҶзҡ„ж•°жҚ®йҮҸзү№еҲ«еӨ§пјҲж•°жҚ®еҖҫж–ңпјүпјҢиҝҷдәӣд»»еҠЎдјҡжӢ–ж…ўж•ҙдҪ“иҝӣеәҰпјҢеҜјиҮҙйғЁеҲҶе®№еҷЁз©әй—ІиҖҢжөӘиҙ№иө„жәҗгҖӮ
- йҖӮз”ЁеңәжҷҜпјҡж•°жҚ®еҲҶеёғиҫғеқҮеҢҖпјҢReducer зҡ„иҙҹиҪҪе·®ејӮдёҚеӨ§гҖӮд»»еҠЎи°ғеәҰз®ҖеҚ•пјҢеҮҸе°‘и°ғеәҰејҖй”ҖгҖӮ
- 1.75пјҡжҝҖиҝӣдј°з®—пјҢReducer ж•°йҮҸи¶…иҝҮйӣҶзҫӨзҡ„жңҖеӨ§е№¶иЎҢиғҪеҠӣпјҢд»»еҠЎеҲҶжү№жү§иЎҢгҖӮ
- зү№зӮ№пјҡReducer зҡ„ж•°йҮҸи¶…иҝҮйӣҶзҫӨзҡ„жңҖеӨ§е№¶иЎҢиғҪеҠӣпјҢд»»еҠЎйңҖиҰҒеҲҶжү№ж¬ЎиҝҗиЎҢгҖӮ
- дјҳзӮ№пјҡ
- иҙҹиҪҪеқҮиЎЎпјҡд»»еҠЎиў«еҲҮеҫ—жӣҙз»ҶпјҢжүҖжңү Reducer зҡ„е·ҘдҪңйҮҸжӣҙеҠ еқҮеҢҖпјҢеҮҸе°‘ж•°жҚ®еҖҫж–ңеёҰжқҘзҡ„еҪұе“ҚгҖӮ
- иө„жәҗеҲ©з”ЁзҺҮй«ҳпјҡеҚідҪҝжҹҗдәӣ Reducer еӨ„зҗҶйҖҹеәҰж…ўпјҢе…¶д»–д»»еҠЎд№ҹеҸҜд»Ҙеҝ«йҖҹе®ҢжҲҗ并继з»ӯе·ҘдҪңпјҢйҒҝе…Қиө„жәҗй—ІзҪ®гҖӮ
- зјәзӮ№пјҡ
- и°ғеәҰејҖй”Җй«ҳпјҡйңҖиҰҒйў‘з№ҒеҲҮжҚўд»»еҠЎпјҢеӯҳеңЁйўқеӨ–зҡ„и°ғеәҰе’Ңж•°жҚ®дј иҫ“ејҖй”ҖгҖӮ
жңүе…іReduceеҶ…е®№еҫҖеӣһжүҫMapreduce
第дәҢеҚҒе…ӯз«
Spark
Spark з®Җд»Ӣ
Spark зҡ„дјҳеҠҝпјҡ
- зӣёжҜ” Hadoop MapReduceпјҢSpark жҖ§иғҪжҸҗеҚҮеҸҜиҫҫдёҠзҷҫеҖҚгҖӮ
- д»ҘеҶ…еӯҳдёәж ёеҝғиҝӣиЎҢи®Ўз®—пјҢйҒҝе…Қйў‘з№Ғзҡ„зЈҒзӣҳ I/O ж“ҚдҪңгҖӮ
- ж”ҜжҢҒ жү№еӨ„зҗҶ е’Ң жөҒеӨ„зҗҶпјҢеҸҜд»ҘйҖӮеә”еӨҡз§ҚеңәжҷҜпјҲеҰӮж•°жҚ®з§‘еӯҰгҖҒжңәеҷЁеӯҰд№ зӯүпјүгҖӮ
- еҸҜиҝҗиЎҢеңЁ еҚ•жңә жҲ– йӣҶзҫӨ зҺҜеўғдёӯгҖӮ
жү№еӨ„зҗҶе’ҢжөҒеӨ„зҗҶзҡ„еҢәеҲ«пјҡ
- жү№еӨ„зҗҶпјҡж•°жҚ®д»Ҙжү№ж¬Ўзҡ„еҪўејҸдёҖж¬ЎжҖ§еӨ„зҗҶе®ҢгҖӮдҫӢеҰӮпјҢе…Ҳ收йӣҶдёҖжү№ж•°жҚ®пјҢеӨ„зҗҶеҗҺжүҚиғҪиҝӣе…ҘдёӢдёҖйҳ¶ж®өгҖӮ
- жөҒеӨ„зҗҶпјҡж•°жҚ®жәҗжәҗдёҚж–ӯең°еҲ°жқҘпјҢжқҘдёҖзӮ№еӨ„зҗҶдёҖзӮ№гҖӮдҫӢеҰӮпјҢдј ж„ҹеҷЁжҢҒз»ӯеҸ‘йҖҒж•°жҚ®пјҢжңҚеҠЎеҷЁйңҖиҰҒж №жҚ®ж•°жҚ®е®һж—¶еӨ„зҗҶгҖӮ
жөҒеӨ„зҗҶзҡ„зү№зӮ№пјҡ
- ж•°жҚ®жҳҜжҢҒз»ӯдә§з”ҹзҡ„пјҲдҫӢеҰӮдј ж„ҹеҷЁдј иҫ“зҡ„жё©еәҰж•°жҚ®пјүгҖӮ
- жөҒејҸеӨ„зҗҶ并йқһ иҜ·жұӮ-е“Қеә”жЁЎејҸпјҲеҰӮ HTTPпјүгҖӮжөҒж•°жҚ®еҸҜд»ҘйҖҡиҝҮж¶ҲжҒҜдёӯй—ҙ件пјҲеҰӮ Kafkaпјүзј“еҶІпјҢйҒҝе…ҚеӨ„зҗҶйҖҹеәҰи·ҹдёҚдёҠж•°жҚ®дә§з”ҹйҖҹеәҰгҖӮ
Spark зҡ„ж ёеҝғдјҳеҠҝпјҡеҶ…еӯҳи®Ўз®—
Hadoop зҡ„зјәзӮ№пјҡ
- Hadoop MapReduce дҪҝз”ЁеҲҶеёғејҸж–Ү件系з»ҹпјҲHDFSпјүиҝӣиЎҢдёӯй—ҙз»“жһңзҡ„жұҮиҒҡпјҢйў‘з№Ғзҡ„зЈҒзӣҳ I/O ж“ҚдҪңдјҡеҜјиҮҙжҖ§иғҪ瓶йўҲпјҡ
- иҜ»еҸ–ж•°жҚ®еҲ°еҶ…еӯҳпјҲI/O ж“ҚдҪңпјүгҖӮ
- дёӯй—ҙз»“жһңеҶҷе…ҘзЈҒзӣҳпјҲI/O ж“ҚдҪңпјүгҖӮ
- Reduce йҳ¶ж®өеҶҚж¬ЎиҜ»еҸ–е’ҢеҶҷе…ҘпјҲI/O ж“ҚдҪңпјүгҖӮ
Spark зҡ„дјҳеҢ–пјҡ
- Spark иҜ»еҸ–ж•°жҚ®еҗҺпјҢеҲ©з”Ё еҶ…еӯҳи®Ўз®— жқҘеӨ„зҗҶж•°жҚ®пјҢеҮҸе°‘зЈҒзӣҳ I/O ж“ҚдҪңгҖӮ
- жҸҗдҫӣ зј“еӯҳжңәеҲ¶пјҲcacheпјүпјҡ
- еҪ“еҶ…еӯҳдёҚи¶іж—¶пјҢSpark дјҳе…Ҳдҝқз•ҷзј“еӯҳзҡ„ж•°жҚ®пјҢе°ҪйҮҸйҒҝе…Қе°Ҷж•°жҚ®еҶҷе…ҘзЈҒзӣҳгҖӮ
- жіЁж„Ҹпјҡзј“еӯҳжҳҜз”ЁжҲ·зҡ„вҖңж„ҝжңӣвҖқпјҢе…·дҪ“жҳҜеҗҰзј“еӯҳз”ұ Spark ж №жҚ®иө„жәҗжғ…еҶөеҶіе®ҡгҖӮ
Spark ж ёеҝғ组件
| жңҜиҜӯ | еҗ«д№ү |
|---|---|
| Application | Spark еә”з”ЁзЁӢеәҸпјҢз”ұдёҖдёӘ Driver е’ҢеӨҡдёӘ Executor з»„жҲҗгҖӮ |
| Driver | еә”з”ЁзЁӢеәҸзҡ„дё»иҠӮзӮ№пјҢиҙҹиҙЈиҝҗиЎҢ main() ж–№жі•пјҢеҲӣе»ә SparkContextпјҢеҲ’еҲҶд»»еҠЎе№¶и°ғеәҰ Executor жү§иЎҢгҖӮ |
| Cluster Manager | йӣҶзҫӨиө„жәҗз®ЎзҗҶеҷЁпјҢж”ҜжҢҒеӨҡз§ҚжЁЎејҸпјҲеҰӮ Hadoop YARNгҖҒMesosгҖҒStandaloneпјүгҖӮ |
| Worker Node | жү§иЎҢи®Ўз®—д»»еҠЎзҡ„е·ҘдҪңиҠӮзӮ№гҖӮ |
| Executor | е·ҘдҪңиҠӮзӮ№дёҠзҡ„иҝӣзЁӢпјҢиҙҹиҙЈжү§иЎҢ TaskпјҢ并е°Ҷз»“жһңдҝқеӯҳеҲ°еҶ…еӯҳжҲ–зЈҒзӣҳдёӯпјҢеҗҢж—¶еҗ‘ Driver жұҮжҠҘзҠ¶жҖҒгҖӮ |
| Task | еҸ‘йҖҒеҲ° Executor зҡ„е·ҘдҪңеҚ•е…ғгҖӮ |
| Job | еӨҡдёӘ并иЎҢжү§иЎҢзҡ„ Task з»„жҲҗдёҖдёӘ JobгҖӮ |
Spark жү§иЎҢжөҒзЁӢ
SparkContextпјҡ
- Spark еә”з”ЁзЁӢеәҸзҡ„е…ҘеҸЈпјҢе…Ғи®ёз”ЁжҲ·йҖҡиҝҮ SparkContext и®ҝй—®йӣҶзҫӨиө„жәҗгҖӮ
- з”ЁжҲ·зЁӢеәҸйҖҡиҝҮ SparkContext иҝһжҺҘеҲ°йӣҶзҫӨиө„жәҗз®ЎзҗҶеҷЁпјҢз”іиҜ·и®Ўз®—иө„жәҗ并еҗҜеҠЁ ExecutorгҖӮ
Driver зҡ„иҒҢиҙЈпјҡ
- е°Ҷи®Ўз®—д»»еҠЎеҲ’еҲҶдёәжү§иЎҢйҳ¶ж®өпјҲstageпјүе’ҢеӨҡдёӘ TaskгҖӮ
- е°Ҷ Task еҲҶеҸ‘з»ҷ Executor жү§иЎҢгҖӮ
- жұҮжҖ» Executor зҡ„жү§иЎҢзҠ¶жҖҒгҖӮ
Executor зҡ„иҒҢиҙЈпјҡ
- жү§иЎҢ TaskгҖӮ
- е°Ҷжү§иЎҢз»“жһңдҝқеӯҳеҲ°еҶ…еӯҳжҲ–иҖ…зЈҒзӣҳгҖӮ
- е®ҡжңҹеҗ‘ Driver е’ҢйӣҶзҫӨиө„жәҗз®ЎзҗҶеҷЁжұҮжҠҘзҠ¶жҖҒгҖӮ
Spark RDDпјҲResilient Distributed Datasetпјү
жҳҜдёҖдёӘеҲҶеёғејҸгҖҒдёҚеҸҜеҸҳзҡ„еј№жҖ§ж•°жҚ®йӣҶеҗҲпјҢж”ҜжҢҒеҹәдәҺеҶ…еӯҳзҡ„并иЎҢи®Ўз®—пјҢ并йҖҡиҝҮе®№й”ҷжңәеҲ¶иҮӘеҠЁйҮҚе»әдёўеӨұзҡ„еҲҶеҢәж•°жҚ®гҖӮ
RDD зҡ„зү№зӮ№пјҡ
- ResilientпјҲеј№жҖ§пјүпјҡ
- RDD д№Ӣй—ҙеҪўжҲҗжңүеҗ‘ж— зҺҜеӣҫпјҲDAGпјүгҖӮ
- еҰӮжһңжҹҗдёӘеҲҶеҢәдёўеӨұпјҢеҸҜд»ҘйҖҡиҝҮзҲ¶ RDD йҮҚж–°и®Ўз®—з”ҹжҲҗпјҢеҚіе…·еӨҮе®№й”ҷжҖ§гҖӮ
- DistributedпјҲеҲҶеёғејҸпјүпјҡ
- RDD зҡ„ж•°жҚ®д»ҘйҖ»иҫ‘еҲҶеҢәзҡ„еҪўејҸеҲҶеёғеңЁйӣҶзҫӨзҡ„дёҚеҗҢиҠӮзӮ№дёҠпјҢж”ҜжҢҒ并иЎҢи®Ўз®—гҖӮ
- DatasetпјҲж•°жҚ®йӣҶпјүпјҡ
- еӯҳеӮЁзҡ„ж•°жҚ®еҸҜд»ҘжқҘиҮӘеӨ–йғЁж•°жҚ®жәҗпјҢеҰӮ JSON ж–Ү件гҖҒCSV ж–Ү件гҖҒж•°жҚ®еә“зӯүгҖӮ
RDD зҡ„ж“ҚдҪңзұ»еһӢпјҡ
- Transformationпјҡ
- иҪ¬жҚўж“ҚдҪңпјҢиҝ”еӣһдёҖдёӘж–°зҡ„ RDDгҖӮ
- жғ°жҖ§жү§иЎҢпјҡеҸӘжңүйҒҮеҲ° Action ж“ҚдҪңж—¶пјҢTransformation жүҚдјҡзңҹжӯЈжү§иЎҢгҖӮ
- зӨәдҫӢпјҡ
mapгҖҒfilterгҖӮ
- Actionпјҡ
- жү§иЎҢж“ҚдҪңпјҢиҝ”еӣһз»“жһңжҲ–е°Ҷз»“жһңдҝқеӯҳеҲ°еӨ–йғЁеӯҳеӮЁзі»з»ҹгҖӮ
- зӨәдҫӢпјҡ
reduceгҖҒcollectгҖӮ
жғ°жҖ§жү§иЎҢзҡ„дјҳеҠҝпјҡ
- Transformation ж“ҚдҪңдёҚдјҡз«ӢеҚіжү§иЎҢпјҢиҖҢжҳҜжһ„е»әдёҖдёӘжңүеҗ‘ж— зҺҜеӣҫпјҲDAGпјүгҖӮ
- еҸӘжңүеҪ“ Action ж“ҚдҪңи§ҰеҸ‘ж—¶пјҢжүҚдјҡж №жҚ® DAG еӣҫеҗ‘еүҚжҺЁеҜје№¶жү§иЎҢ TransformationгҖӮ
- еҘҪеӨ„пјҡиҠӮзңҒеҶ…еӯҳз©әй—ҙпјҢйҒҝе…ҚдёҚеҝ…иҰҒзҡ„и®Ўз®—гҖӮ
Spark еҲҶеҢәпјҲPartitionпјү
еҲҶеҢәзҡ„ж„Ҹд№үпјҡ
- RDD дјҡиў«еҲҶеүІдёәиӢҘе№ІдёӘеҲҶеҢәпјҢеҲҶеёғеңЁйӣҶзҫӨзҡ„дёҚеҗҢиҠӮзӮ№дёҠгҖӮ
- еҲҶеҢәдҪҝеҫ—ж•°жҚ®еҸҜд»ҘеңЁдёҚеҗҢиҠӮзӮ№дёҠ并иЎҢи®Ўз®—пјҢжҸҗеҚҮи®Ўз®—ж•ҲзҺҮгҖӮ
еҲҶеҢәзҡ„еҘҪеӨ„пјҡ
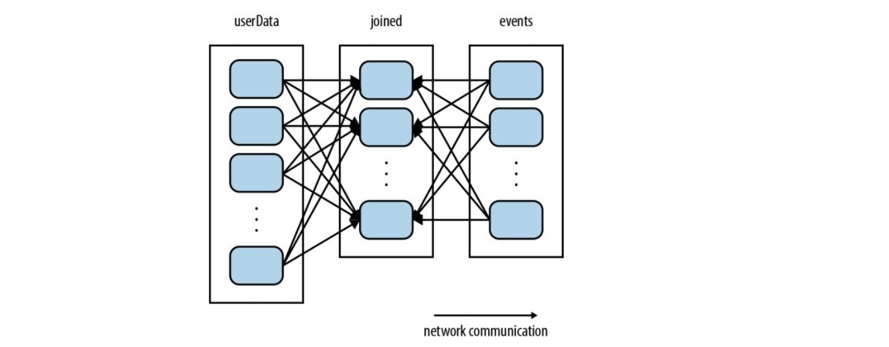
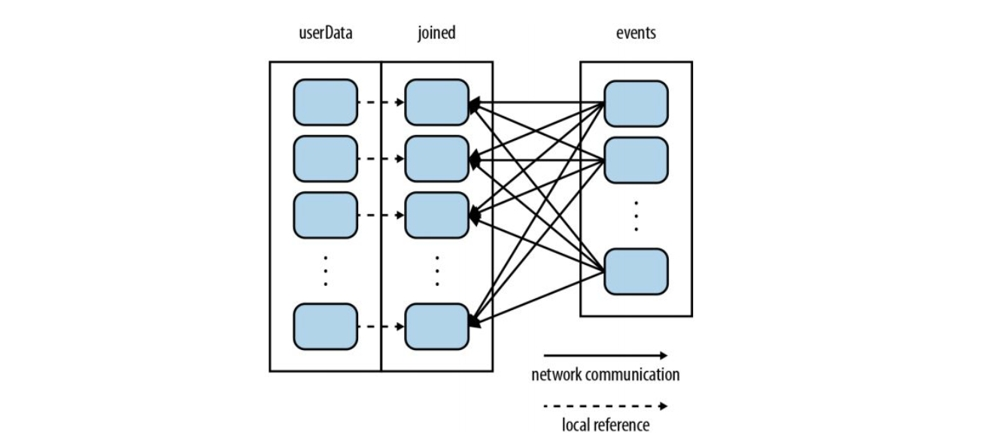
- еҒҮи®ҫжңүдёҖдёӘз”ЁжҲ·дҝЎжҒҜиЎЁпјҲuserDataпјүе’ҢдёҖдёӘзӮ№еҮ»дәӢ件表пјҲeventsпјүпјҢйңҖиҰҒеҜ№дёӨиҖ…иҝӣиЎҢ Join ж“ҚдҪңпјҡ
- еҰӮжһң userData е’Ң events иў«еҲҶеҢәеӯҳеӮЁеңЁдёҚеҗҢиҠӮзӮ№дёҠпјҢJoin ж“ҚдҪңеҸӘйңҖеңЁеҜ№еә”иҠӮзӮ№еҶ…е®ҢжҲҗпјҢеҮҸе°‘дәҶзҪ‘з»ңдј иҫ“ејҖй”ҖгҖӮ
- еҰӮжһңжІЎжңүеҲҶеҢәпјҢJoin ж“ҚдҪңдјҡеҜјиҮҙеӨ§йҮҸзҡ„зҪ‘з»ңйҖҡдҝЎе’Ңж•°жҚ®дј иҫ“пјҢдёҘйҮҚеҪұе“ҚжҖ§иғҪгҖӮ
Spark зҡ„дҫқиө–пјҲDependencyпјү
дҫқиө–зҡ„зұ»еһӢпјҡ
- зӘ„дҫқиө–пјҲNarrow Dependencyпјүпјҡ
- жҜҸдёӘзҲ¶ RDD зҡ„еҲҶеҢәжңҖеӨҡиў«дёҖдёӘеӯҗ RDD зҡ„еҲҶеҢәдҪҝз”ЁгҖӮ
- ж— йңҖ ShuffleпјҢеҸҜд»Ҙ并иЎҢи®Ўз®—гҖӮ
- е®Ҫдҫқиө–пјҲWide Dependencyпјүпјҡ
- жҜҸдёӘзҲ¶ RDD зҡ„еҲҶеҢәеҸҜиғҪиў«еӨҡдёӘеӯҗ RDD зҡ„еҲҶеҢәдҪҝз”ЁгҖӮ
- йңҖиҰҒ ShuffleпјҢи®Ўз®—еӨҚжқӮеәҰиҫғй«ҳгҖӮ
зӘ„дҫқиө–зҡ„дјҳеҠҝпјҡ
- еҸӘйңҖйҮҚз®—дёўеӨұж•°жҚ®зҡ„зҲ¶еҲҶеҢәпјҢж”ҜжҢҒ并иЎҢи®Ўз®—пјҢиҠӮзӮ№жҒўеӨҚж•ҲзҺҮй«ҳгҖӮ
- е®Ҫдҫқиө–йңҖиҰҒйҮҚж–°и®Ўз®—еӨҡдёӘзҲ¶еҲҶеҢәпјҢеҸҜиғҪеҜјиҮҙдёҚеҝ…иҰҒзҡ„еҶ—дҪҷи®Ўз®—гҖӮ
Spark зҡ„ Stage е’Ң DAG
Stage зҡ„еҲ’еҲҶ
- еңЁSpark дёӯпјҢд»»еҠЎдјҡиў«еҲ’еҲҶдёәеӨҡдёӘ йҳ¶ж®өпјҲStageпјүпјҢжҜҸдёӘйҳ¶ж®өеҶ…йғЁе°ҪеҸҜиғҪеӨҡең°еҢ…еҗ«еҸҜд»ҘжөҒж°ҙзәҝеҢ–пјҲPipelineпјүзҡ„ж“ҚдҪңпјҢд»ҘжҸҗеҚҮж•ҲзҺҮгҖӮжүҖд»ҘжҜҸдёӘ Stage еҶ…йғЁеҢ…еҗ«е°ҪеҸҜиғҪеӨҡзҡ„зӘ„дҫқиө–ж“ҚдҪңгҖӮ
- Stage зҡ„иҫ№з•Ңпјҡ
- е®Ҫдҫқиө–дёҠзҡ„ Shuffle ж“ҚдҪңгҖӮ
- е·Ізј“еӯҳзҡ„еҲҶеҢәгҖӮ
DAGпјҲжңүеҗ‘ж— зҺҜеӣҫпјү
- Spark еҹәдәҺ DAG жһ„е»әи®Ўз®—д»»еҠЎпјҢжүҖжңүзҡ„ Transformation ж“ҚдҪңдјҡе…ҲеҪўжҲҗ DAGгҖӮ
- еҪ“ Action ж“ҚдҪңи§ҰеҸ‘ж—¶пјҢDAG иў«еҲ’еҲҶдёәеӨҡдёӘ Stage 并жү§иЎҢгҖӮ
Stage зҡ„жү§иЎҢ
- еңЁдёҖдёӘ Stage еҶ…пјҢжүҖжңүзӘ„дҫқиө–зҡ„ Transformation ж“ҚдҪңдјҡиў«жөҒж°ҙзәҝеҢ–пјҲPipelineпјүжү§иЎҢгҖӮ
- еҘҪеӨ„пјҡеҮҸе°‘еҶ…еӯҳеҚ з”Ёе’Ңдёӯй—ҙз»“жһңеӯҳеӮЁпјҢжҸҗй«ҳжү§иЎҢж•ҲзҺҮгҖӮ
Stage 1пјҡеҺҹе§Ӣж•°жҚ® A йҖҡиҝҮ groupBy иҪ¬жҚўдёә BпјҢ并缓еӯҳдәҶ BгҖӮеӣ дёәе·Із»Ҹзј“еӯҳпјҢеҸҜд»ҘзңӢеҲ°жІЎжңүжү§иЎҢгҖӮ
Stage 2пјҡд»Һзј“еӯҳзҡ„ B ејҖе§ӢпјҢжү§иЎҢ map е’Ң unionпјҢз”ҹжҲҗдёӯй—ҙз»“жһң FгҖӮ
Stage 3пјҡжү§иЎҢ join ж“ҚдҪңпјҲе®Ҫдҫқиө–пјүпјҢе°Ҷ F е’Ңзј“еӯҳзҡ„ B з»“еҗҲпјҢз”ҹжҲҗжңҖз»Ҳз»“жһң GгҖӮ
第дәҢеҚҒдёғз«
Storm
Apache Storm жҳҜдёҖз§ҚеҲҶеёғејҸе®һж—¶жөҒеӨ„зҗҶжЎҶжһ¶пјҢз”ұжҺЁзү№еҸ‘жҳҺпјҢз”ЁдәҺеӨ„зҗҶжәҗжәҗдёҚж–ӯзҡ„жөҒејҸж•°жҚ®гҖӮе®ғж“…й•ҝеҜ№жө·йҮҸж•°жҚ®иҝӣиЎҢе®һж—¶и®Ўз®—пјҢйҖӮеҗҲеӨ„зҗҶйңҖиҰҒеҝ«йҖҹе“Қеә”зҡ„еңәжҷҜпјҢдҫӢеҰӮжҺЁзү№е®һж—¶еӨ„зҗҶз”ЁжҲ·дёҠдј зҡ„еӣҫзүҮгҖҒж—Ҙеҝ—зӣ‘жҺ§гҖҒе®һж—¶з»ҹи®ЎзӯүгҖӮжҜ”еҰӮиҜҙз”ЁжҲ·дёҠдј дёҖе ҶеҫҲеӨ§з…§зүҮпјҢдҪ е°ұеҸҜд»Ҙе…Ҳдј еӣһдёӘзіҠзҡ„пјҢеҶҚж…ўж…ўеҸҳжё…жҷ°пјҲJMomentsд№ҹз”ЁдәҶпјү
иөӣеҚҡж–—иӣҗиӣҗпјҢHadoop е’Ң Storm йғҪжҳҜз”ЁдәҺеӨ§ж•°жҚ®еӨ„зҗҶзҡ„жЎҶжһ¶пјҢдҪҶе®ғ们зҡ„дҫ§йҮҚзӮ№е’Ңеә”з”ЁеңәжҷҜдёҚеҗҢпјҢйғҪжҳҜеҲҶеёғејҸе’ҢиҚЈй”ҷзҡ„гҖӮ
| еұһжҖ§ | Storm | Hadoop |
|---|---|---|
| еӨ„зҗҶж–№ејҸ | е®һж—¶жөҒеӨ„зҗҶ | жү№еӨ„зҗҶ |
| зҠ¶жҖҒз®ЎзҗҶ | ж— зҠ¶жҖҒпјҲеӨ„зҗҶд»»еҠЎеҪјжӯӨзӢ¬з«Ӣпјү | жңүзҠ¶жҖҒпјҲд»»еҠЎз»“жһңдҫқиө–дәҺжҢҒд№…еҢ–зҡ„дёӯй—ҙзҠ¶жҖҒпјү |
| жһ¶жһ„ | еҹәдәҺ ZooKeeper зҡ„дё»д»Һжһ¶жһ„пјҡдё»иҠӮзӮ№пјҡNimbusд»ҺиҠӮзӮ№пјҡSupervisors | дё»д»Һжһ¶жһ„пјҡдё»иҠӮзӮ№пјҡJob Trackerд»ҺиҠӮзӮ№пјҡTask Tracker |
| ж•°жҚ®еӨ„зҗҶиғҪеҠӣ | жҜҸз§’еӨ„зҗҶж•°дёҮжқЎж¶ҲжҒҜпјҲдҪҺ延иҝҹпјү | еӨ„зҗҶжө·йҮҸж•°жҚ®пјҢдҪҶйңҖиҰҒиҖ—иҙ№ж•°еҲҶй’ҹжҲ–ж•°е°Ҹж—¶пјҲй«ҳеҗһеҗҗпјү |
| иҝҗиЎҢжЁЎејҸ | Topology жҢҒз»ӯиҝҗиЎҢпјҢзӣҙеҲ°дәәдёәе…ій—ӯжҲ–еҸ‘з”ҹдёҚеҸҜжҒўеӨҚзҡ„ж•…йҡң | MapReduce дҪңдёҡжҢүйЎәеәҸжү§иЎҢпјҢе®ҢжҲҗеҗҺйҖҖеҮә |
| е®№й”ҷжҖ§ | дё»иҠӮзӮ№пјҲNimbusпјүжҲ–д»ҺиҠӮзӮ№пјҲSupervisorпјүе®•жңәеҗҺеҸҜжҒўеӨҚ | дё»иҠӮзӮ№пјҲJobTrackerпјүе®•жңәеҗҺпјҢжүҖжңүиҝҗиЎҢдёӯзҡ„дҪңдёҡдёўеӨұ |
| еӯҳеӮЁ | дёҚиҙҹиҙЈж•°жҚ®жҢҒд№…еҢ– | дҪҝз”Ё HDFSпјҲеҲҶеёғејҸж–Ү件系з»ҹпјүиҝӣиЎҢж•°жҚ®еӯҳеӮЁ |
- Storm жҳҜжөҒеӨ„зҗҶпјҢе®һж—¶жҖ§ејәпјҢд»»еҠЎж— зҠ¶жҖҒгҖӮ
- йҖӮеҗҲе®һж—¶и®Ўз®—пјҲеҰӮе®һж—¶ж—Ҙеҝ—еҲҶжһҗгҖҒе®һж—¶жҺЁиҚҗгҖҒеңЁзәҝзӣ‘жҺ§зӯүпјүпјҢејәи°ғдҪҺ延иҝҹгҖӮ
- Hadoop жҳҜжү№еӨ„зҗҶпјҢеҗһеҗҗйҮҸеӨ§пјҢд»»еҠЎжңүзҠ¶жҖҒгҖӮ
- йҖӮеҗҲзҰ»зәҝжү№еӨ„зҗҶпјҲеҰӮеӨ§и§„жЁЎж•°жҚ®з»ҹи®ЎгҖҒжңәеҷЁеӯҰд№ и®ӯз»ғзӯүпјүпјҢејәи°ғй«ҳеҗһеҗҗгҖӮ
- з»“еҗҲдҪҝз”ЁпјҡеҸҜд»Ҙз”Ё Hadoop иҝӣиЎҢзҰ»зәҝж•°жҚ®еӯҳеӮЁе’Ңжү№еӨ„зҗҶпјҢз”Ё Storm иҝӣиЎҢе®һж—¶ж•°жҚ®жөҒеӨ„зҗҶпјҢж»Ўи¶ідёҚеҗҢдёҡеҠЎйңҖжұӮгҖӮ
ж ёеҝғжҰӮеҝө
- TupleпјҡStorm зҡ„еҹәжң¬ж•°жҚ®з»“жһ„пјҢжҳҜдёҖдёӘжңүеәҸзҡ„е…ғзҙ еҲ—иЎЁпјҢзұ»дјјдәҺдёҖиЎҢж•°жҚ®гҖӮ
- StreamпјҡдёҖдёӘж— еәҸгҖҒж— йҷҗзҡ„ Tuple еәҸеҲ—пјҢжҳҜ Storm дёӯж•°жҚ®жөҒеҠЁзҡ„ж ёеҝғгҖӮ
- Spoutпјҡж•°жҚ®зҡ„жқҘжәҗпјҢз”ЁдәҺд»ҺеӨ–йғЁж•°жҚ®жәҗпјҲеҰӮ KafkaгҖҒTwitter APIпјүиҜ»еҸ–ж•°жҚ®е№¶з”ҹжҲҗ StreamгҖӮ
- Boltпјҡж•°жҚ®еӨ„зҗҶзҡ„йҖ»иҫ‘еҚ•е…ғпјҢжҺҘ收 Spout жҲ–е…¶д»– Bolt зҡ„ж•°жҚ®пјҢжү§иЎҢи®Ўз®—гҖҒиҝҮж»ӨгҖҒиҒҡеҗҲзӯүж“ҚдҪң并иҫ“еҮәз»“жһңгҖӮ
- TopologyпјҡдёҖдёӘжңүеҗ‘еӣҫпјҢз”ұ Spout е’Ң Bolt з»„жҲҗгҖӮ
- Spout жҳҜиө·зӮ№пјҢиҙҹиҙЈиҜ»еҸ–ж•°жҚ®гҖӮ
- Bolt жҳҜиҠӮзӮ№пјҢиҙҹиҙЈеӨ„зҗҶж•°жҚ®гҖӮ
- Topology жҢҒз»ӯиҝҗиЎҢпјҢзӣҙеҲ°иў«жүӢеҠЁз»ҲжӯўгҖӮ
- д»»еҠЎпјҲTaskпјүпјҡSpout е’Ң Bolt зҡ„е…·дҪ“жү§иЎҢе®һдҫӢпјҢдёҖдёӘд»»еҠЎеҜ№еә”дёҖдёӘзәҝзЁӢгҖӮеӨҡдёӘе®һдҫӢеҸҜд»Ҙ并иЎҢиҝҗиЎҢпјҢжҸҗеҚҮжҖ§иғҪгҖӮ
Storm зҡ„е·ҘдҪңжңәеҲ¶
- ж•°жҚ®жөҒеҠЁпјҡж•°жҚ®д»Һ Spout ејҖе§ӢжөҒе…ҘпјҢз»ҸиҝҮеӨҡдёӘ Bolt зҡ„еӨ„зҗҶеҗҺз”ҹжҲҗжңҖз»Ҳз»“жһңгҖӮ
- е®һж—¶жҖ§пјҡеҫ®и§ӮдёҠжҳҜжү№еӨ„зҗҶпјҲеӨ„зҗҶдёҖжқЎжқЎ TupleпјүпјҢе®Ҹи§ӮдёҠжҳҜжөҒеӨ„зҗҶпјҲиҝһз»ӯеӨ„зҗҶжәҗжәҗдёҚж–ӯзҡ„ж•°жҚ®жөҒпјүгҖӮ
- е®№й”ҷжҖ§пјҡеҰӮжһңжҹҗдёӘиҠӮзӮ№пјҲеҰӮ Nimbus жҲ– Supervisorпјүе®•жңәпјҢStorm дјҡиҮӘеҠЁжҒўеӨҚ并д»Һдёӯж–ӯзҡ„дҪҚзҪ®з»§з»ӯиҝҗиЎҢгҖӮ
Zookeeper
Zookeeper жҳҜ Storm йӣҶзҫӨзҡ„еҚҸи°ғжңҚеҠЎпјҢдё»иҰҒеҠҹиғҪеҢ…жӢ¬пјҡ
- з®ЎзҗҶйӣҶзҫӨдёӯзҡ„иҠӮзӮ№пјҲеҰӮ Nimbus е’Ң SupervisorпјүгҖӮ
- е®һзҺ°дёҖиҮҙжҖ§пјҡзЎ®дҝқйӣҶзҫӨдёӯжүҖжңүиҠӮзӮ№еҜ№д»»еҠЎзҡ„зҠ¶жҖҒиҫҫжҲҗдёҖиҮҙгҖӮ
- ж•…йҡңжҒўеӨҚпјҡеҪ“дё»иҠӮзӮ№пјҲNimbusпјүе®•жңәж—¶пјҢZookeeper дјҡйҖүдёҫж–°зҡ„дё»иҠӮзӮ№гҖӮ
第дәҢеҚҒе…«з«
HDFS
HDFS дҪҝз”ЁеңәжҷҜ
йҖӮеҗҲзҡ„еңәжҷҜпјҡ
- еӨ§ж–Ү件еӯҳеӮЁпјҡ
- йҖӮеҗҲеӯҳеӮЁйқһеёёеӨ§зҡ„ж–Ү件пјҲеҰӮ GBгҖҒTB зә§еҲ«пјүгҖӮ
- е°ҸдәҺ 100MB зҡ„е°Ҹж–Ү件еӯҳеӮЁж•ҲзҺҮиҫғдҪҺгҖӮ
- жөҒејҸж•°жҚ®и®ҝй—®пјҡ
- ж•°жҚ®йҖҡеёёжҳҜвҖңдёҖж¬ЎеҶҷе…ҘпјҢеӨҡж¬ЎиҜ»еҸ–вҖқгҖӮ
- дёҚйҖӮеҗҲйў‘з№Ғдҝ®ж”№зҡ„ж•°жҚ®гҖӮдҫӢеҰӮпјҡж—¶еәҸж•°жҚ®пјҲеҰӮ InfluxDB ж•°жҚ®пјүйқһеёёйҖӮеҗҲгҖӮ
- е»ү价硬件пјҲCommodity Hardwareпјүпјҡ
- еҸҜд»Ҙз”ЁеӨ§йҮҸдҪҺжҲҗжң¬зҡ„硬件组жҲҗйӣҶзҫӨпјҢдёҚйңҖиҰҒй«ҳжҖ§иғҪ硬件гҖӮ
- дҪҝз”ЁвҖңеүҜжң¬жңәеҲ¶вҖқпјҲй»ҳи®Ө 3 дёӘеүҜжң¬пјүдҝқиҜҒеҸҜйқ жҖ§гҖӮ
дёҚйҖӮеҗҲзҡ„еңәжҷҜпјҡ
- дҪҺ延иҝҹзҡ„ж•°жҚ®и®ҝй—®пјҡ
- HDFS дё»иҰҒиҝҪжұӮй«ҳеҗһеҗҗйҮҸпјҢиҖҢйқһдҪҺ延иҝҹгҖӮ
- дҫӢеҰӮпјҡдёҖдёӘе·ЁеӨ§зҡ„ж–Ү件еҲҶдёә 1000 дёӘ blockпјҢеҗҢж—¶иҜ»еҸ–ж•ҲзҺҮй«ҳпјӣдҪҶе°Ҹж–Ү件еҚ•зӢ¬иҜ»еҸ–ж•ҲзҺҮдҪҺгҖӮ
- еӨ§йҮҸе°Ҹж–Ү件пјҡ
- жҜҸдёӘж–Ү件йңҖиҰҒи®°еҪ•е…ғж•°жҚ®пјҲmetadataпјүпјҢе°Ҹж–Ү件иҝҮеӨҡдјҡеҜјиҮҙе…ғж•°жҚ®иҶЁиғҖпјҢйҡҫд»Ҙз»ҙжҠӨгҖӮ
- йў‘з№Ғдҝ®ж”№гҖҒеӨҡеҶҷиҖ…еңәжҷҜпјҡ
- HDFS еҸӘж”ҜжҢҒвҖңеҚ•еҶҷиҖ…гҖҒиҝҪеҠ еҶҷвҖқгҖӮ
- дёҚж”ҜжҢҒд»»ж„ҸдҪҚзҪ®зҡ„дҝ®ж”№пјҢеӨҡдёӘеҶҷж“ҚдҪңйңҖиҰҒдёІиЎҢеҢ–пјҢеҪұе“Қж•ҲзҺҮгҖӮ
HDFS жһ¶жһ„
HDFS йҮҮз”Ё Master-SlaveпјҲдё»д»Һпјүжһ¶жһ„пјҢеҲҶдёә NameNode е’Ң DataNodeгҖӮ
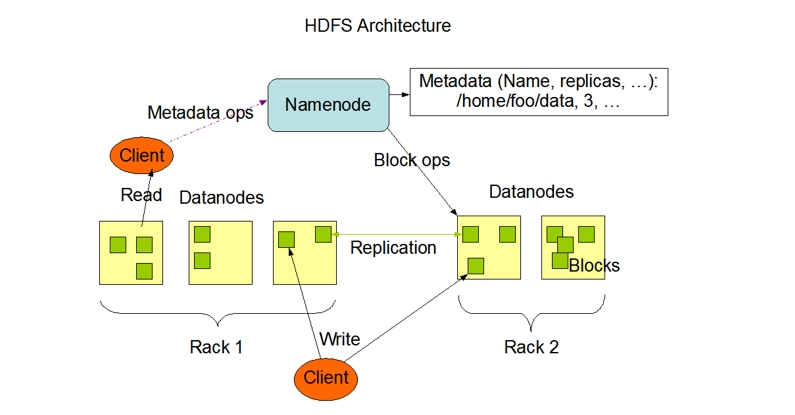
- NameNodeпјҲдё»иҠӮзӮ№пјүпјҡиҙҹиҙЈеӯҳеӮЁ е…ғж•°жҚ®пјҲmetadataпјүпјҢеҰӮж–Ү件еҗҚгҖҒж–Ү件еҲҶеқ—дҝЎжҒҜгҖҒеүҜжң¬дҪҚзҪ®зӯүгҖӮдёҚеӯҳж”ҫе®һйҷ…ж•°жҚ®гҖӮ
- DataNodeпјҲд»ҺиҠӮзӮ№пјүпјҡеӯҳеӮЁе®һйҷ…ж•°жҚ®еқ—пјҲblockпјүгҖӮе‘ЁжңҹжҖ§еҗ‘ NameNode еҸ‘йҖҒ еҝғи·іпјҲheartbeatпјү е’Ң BlockReportпјҢжҠҘе‘ҠиҮӘе·ұеӯҳжҙ»зҠ¶жҖҒеҸҠж•°жҚ®еқ—дҝЎжҒҜгҖӮ
иҜ»ж•°жҚ®жөҒзЁӢпјҡ
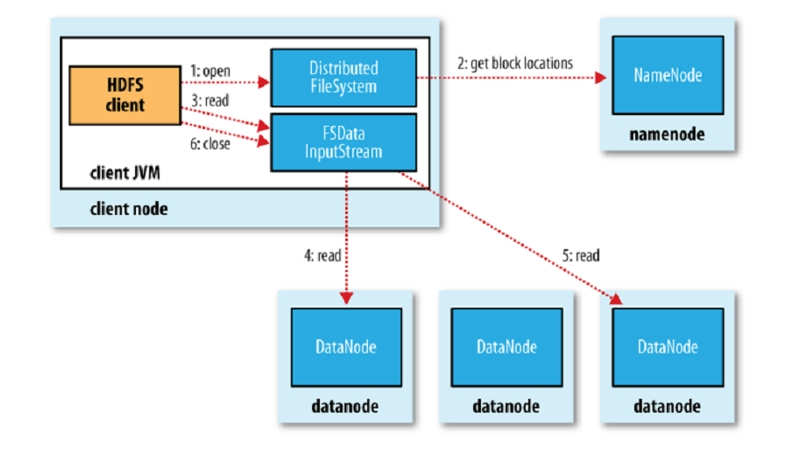
- е®ўжҲ·з«Ҝеҗ‘ NameNode иҜ·жұӮж–Ү件зҡ„е…ғж•°жҚ®пјҲеҰӮж–Ү件еҲҶеқ—дҝЎжҒҜпјҢжҜҸдёӘеқ—зҡ„дҪҚзҪ®пјүгҖӮ
- NameNode иҝ”еӣһж•°жҚ®еқ—зҡ„дҪҚзҪ®дҝЎжҒҜгҖӮ
- е®ўжҲ·з«ҜзӣҙжҺҘд»Һ DataNode иҜ»еҸ–ж•°жҚ®пјҢNameNode дёҚеҸӮдёҺж•°жҚ®дј иҫ“гҖӮ
еҶҷж•°жҚ®жөҒзЁӢпјҡ
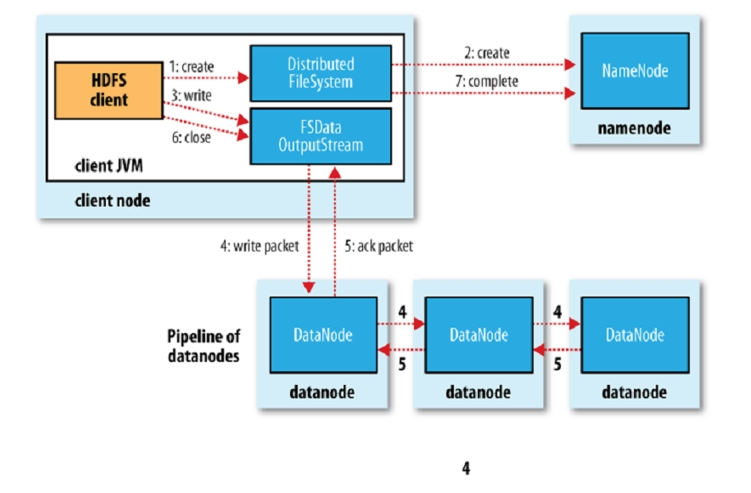
- е®ўжҲ·з«Ҝеҗ‘ NameNode иҜ·жұӮеҶҷжқғйҷҗгҖӮ
- NameNode еҲҶй…Қж•°жҚ®еқ—дҪҚзҪ®гҖӮ
- е®ўжҲ·з«ҜзӣҙжҺҘе°Ҷж•°жҚ®еҶҷе…Ҙ DataNodeпјҢе№¶ж №жҚ®еүҜжң¬зӯ–з•ҘеҗҢжӯҘеҲ°е…¶д»– DataNodeгҖӮ
жіЁж„ҸпјҡNameNode жҳҜ HDFS зҡ„еҚ•зӮ№ж•…йҡңзӮ№пјҢиӢҘ NameNode жҢӮжҺүпјҢж•ҙдёӘзі»з»ҹдёҚеҸҜз”ЁгҖӮеӣ жӯӨйңҖиҰҒеҜ№ NameNode зҡ„е…ғж•°жҚ®иҝӣиЎҢеӨҮд»ҪгҖӮйңҖиҰҒдҪҝз”ЁlogгҖӮ
HDFS зҡ„е…ій”®и®ҫи®Ў
1. еүҜжң¬жңәеҲ¶пјҲReplicaпјүпјҡ
- жҜҸдёӘж•°жҚ®еқ—жңүеӨҡдёӘеүҜжң¬пјҲй»ҳи®Ө 3 дёӘпјүпјҢд»ҘжҸҗй«ҳеҸҜйқ жҖ§е’Ңе®№й”ҷжҖ§гҖӮ
- иҝҮеӨҡж„Ҹе‘ізқҖжү§иЎҢеҶҷж“ҚдҪңж—¶й—ҙдјҡй•ҝпјҢеӨұиҙҘзҡ„жҰӮзҺҮеҸҳеӨ§пјҢдё”йҳ»еЎһгҖӮ
- еүҜжң¬еӯҳж”ҫзӯ–з•ҘпјҲд»Ҙ 3 еүҜжң¬дёәдҫӢпјүпјҡ
- 第дёҖдёӘеүҜжң¬пјҡдјҳе…Ҳеӯҳж”ҫеңЁжҢҮе®ҡзҡ„ DataNode жң¬ең°пјҢеҗҰеҲҷйҡҸжңәеңЁйӣҶзҫӨдёӯйҖүжӢ© дёҖдёӘDataNode .
- 第дәҢдёӘеүҜжң¬пјҡеӯҳж”ҫеңЁдёҚеҗҢжңәжһ¶зҡ„ DataNodeпјҲи·Ёжңәжһ¶еӯҳеӮЁпјүгҖӮ
- 第дёүдёӘеүҜжң¬пјҡеӯҳж”ҫеңЁз¬¬дәҢдёӘеүҜжң¬жүҖеңЁжңәжһ¶зҡ„е…¶д»–иҠӮзӮ№гҖӮ
2. жңәжһ¶ж„ҹзҹҘпјҲRack Awarenessпјүпјҡ
- HDFS йҖҡиҝҮиҜҶеҲ«зҪ‘з»ңжӢ“жү‘з»“жһ„пјҢе°ҶиҠӮзӮ№еҲ’еҲҶдёәдёҚеҗҢзҡ„жңәжһ¶гҖӮ
- дјҳеҢ–еүҜжң¬еӯҳж”ҫзӯ–з•ҘпјҢжҸҗеҚҮж•°жҚ®еҸҜйқ жҖ§е’ҢзҪ‘з»ңеёҰе®ҪеҲ©з”ЁзҺҮгҖӮ
- ж•°жҚ®дј иҫ“зҡ„дјҳе…Ҳзә§пјҡ
- еҗҢиҠӮзӮ№гҖӮ
- еҗҢжңәжһ¶еҶ…зҡ„дёҚеҗҢиҠӮзӮ№гҖӮ
- дёҚеҗҢжңәжһ¶зҡ„иҠӮзӮ№гҖӮ
3. еҝғи·іжңәеҲ¶пјҲHeartbeatпјүпјҡ
- DataNode е®ҡжңҹеҗ‘ NameNode еҸ‘йҖҒеҝғи·іпјҢжҠҘе‘Ҡеӯҳжҙ»зҠ¶жҖҒгҖӮ
- еҝғи·ідёӯеҢ…еҗ«зҠ¶жҖҒж•°жҚ®пјҲеҰӮж•°жҚ®еқ—дҝЎжҒҜпјҢBlockReportпјүпјҢд»ҘеЎ«ж»Ў TCP ж•°жҚ®еҢ…пјҢжҸҗй«ҳзҪ‘з»ңеҲ©з”ЁзҺҮгҖӮеҝғи·ідёҚиғҪжҳҜдё“й—Ёзҡ„дёҖдёӘзәҝзЁӢпјҢзңҹжӯЈзҡ„еҝғи·іеә”иҜҘжҳҜеңЁдҪ зҡ„дё»зәҝзЁӢйҮҢйқўгҖӮ
4. е®үе…ЁжЁЎејҸпјҲSafemodeпјүпјҡ
- NameNode еҗҜеҠЁж—¶иҝӣе…ҘвҖңе®үе…ЁжЁЎејҸвҖқпјҢдёҚе…Ғи®ёеҶҷж“ҚдҪңгҖӮ
- жЈҖжҹҘжүҖжңүж•°жҚ®еқ—жҳҜеҗҰж»Ўи¶іеүҜжң¬ж•°йҮҸиҰҒжұӮпјҢиӢҘдёҚи¶іеҲҷи§ҰеҸ‘еүҜжң¬еӨҚеҲ¶гҖӮ
- зЎ®дҝқзі»з»ҹдёҖиҮҙжҖ§еҗҺйҖҖеҮәе®үе…ЁжЁЎејҸгҖӮ
HDFS зҡ„дјҳеҠҝе’ҢеұҖйҷҗ
дјҳеҠҝпјҡ
- й«ҳеҗһеҗҗйҮҸпјҡйҖӮеҗҲжү№йҮҸеӨ„зҗҶеӨ§ж•°жҚ®гҖӮ
- й«ҳеҸҜйқ жҖ§пјҡйҖҡиҝҮеүҜжң¬жңәеҲ¶е®һзҺ°е®№й”ҷгҖӮ
- еҸҜжү©еұ•жҖ§пјҡж”ҜжҢҒйӣҶзҫӨеҠЁжҖҒжү©еұ•гҖӮ
еұҖйҷҗпјҡ
- дёҚйҖӮеҗҲе°Ҹж–Ү件пјҡеӨ§йҮҸе°Ҹж–Ү件дјҡеҜјиҮҙе…ғж•°жҚ®еӯҳеӮЁе’Ңз®ЎзҗҶзҡ„еҺӢеҠӣгҖӮ
- дёҚж”ҜжҢҒйў‘з№Ғдҝ®ж”№пјҡеҸӘиғҪиҝҪеҠ еҶҷпјҢдё”еҸӘиғҪеҚ•еҶҷиҖ…гҖӮ
- еҚ•зӮ№ж•…йҡңпјҡNameNode жҳҜеҚ•зӮ№ж•…йҡңиҠӮзӮ№пјҢйңҖеҒҡеҘҪеӨҮд»ҪгҖӮ
HDFS зҡ„е®һйҷ…еә”з”ЁеңәжҷҜ
- ж—Ҙеҝ—еӯҳеӮЁпјҡеӨ§йҮҸж—Ҙеҝ—ж•°жҚ®пјҲеҰӮ Web и®ҝй—®ж—Ҙеҝ—гҖҒжңҚеҠЎеҷЁж—Ҙеҝ—пјүеҸҜд»ҘеӯҳеӮЁеңЁ HDFS дёӯпјҢз”ЁдәҺеҗҺз»ӯеҲҶжһҗгҖӮ
- ж•°жҚ®д»“еә“пјҡHDFS жҳҜеӨ§ж•°жҚ®з”ҹжҖҒзі»з»ҹзҡ„ж ёеҝғеӯҳеӮЁз»„件пјҢеёёз”ЁдәҺеӯҳеӮЁзҰ»зәҝеҲҶжһҗж•°жҚ®гҖӮ
- еӨҮд»Ҫж•°жҚ®еӯҳеӮЁпјҡз”ұдәҺ HDFS зҡ„й«ҳеҸҜйқ жҖ§пјҢеҸҜд»Ҙз”ЁдәҺеӯҳеӮЁйҮҚиҰҒж•°жҚ®зҡ„еӨҮд»ҪгҖӮ
- дёҚеҸҜеҸҳж•°жҚ®пјҡи®ўеҚ•гҖҒдәӨжҳ“и®°еҪ•зӯүз”ҹжҲҗеҗҺдёҚеҶҚдҝ®ж”№зҡ„ж•°жҚ®йқһеёёйҖӮеҗҲеӯҳеӮЁеңЁ HDFS дёӯгҖӮ
жіЁж„ҸпјҡеғҸеә“еӯҳпјҲStockпјүзӯүйў‘з№ҒеҸҳеҠЁзҡ„ж•°жҚ®дёҚйҖӮеҗҲзӣҙжҺҘеӯҳеӮЁеңЁ HDFS дёӯпјҢе»әи®®е°ҶеҸҳеҠЁйғЁеҲҶеӯҳеӮЁеңЁеҶ…еӯҳжҲ–ж•°жҚ®еә“дёӯгҖӮ
第дәҢеҚҒд№қз«
HBase
HBase жҳҜдёҖдёӘй«ҳж•Ҳзҡ„еҲҶеёғејҸж•°жҚ®еә“пјҢйҖӮеҗҲеӯҳеӮЁе’ҢеӨ„зҗҶжө·йҮҸзҡ„еҚҠз»“жһ„еҢ–е’Ңйқһз»“жһ„еҢ–ж•°жҚ®пјҢйқһеёёйҖӮеҗҲйңҖиҰҒеҝ«йҖҹиҜ»еҶҷгҖҒеҠЁжҖҒжү©еұ•зҡ„еә”з”ЁеңәжҷҜпјҢеҰӮж—Ҙеҝ—еҲҶжһҗгҖҒж—¶й—ҙеәҸеҲ—ж•°жҚ®еӯҳеӮЁгҖҒзү©иҒ”зҪ‘ж•°жҚ®зӯүпјҢдҪҶдёҚйҖӮеҗҲеӨҚжқӮзҡ„еӨҡиЎЁе…іиҒ”жҹҘиҜўеңәжҷҜгҖӮ
еҰӮжһңжҲ‘们жҠҠ Hadoop жҜ”е–»дёәдёҖдёӘдә‘дёҠзҡ„ж“ҚдҪңзі»з»ҹпјҡ
- HDFSпјҡ жҳҜж–Ү件系з»ҹпјҢиҙҹиҙЈеӯҳеӮЁж•°жҚ®гҖӮ
- MapReduceпјҡ жҳҜдҪңдёҡи°ғеәҰзі»з»ҹпјҢиҙҹиҙЈи®Ўз®—д»»еҠЎзҡ„еҲҶеҸ‘е’Ңжү§иЎҢгҖӮ
- HBaseпјҡ жҳҜж•°жҚ®еә“пјҢзұ»дјј Google зҡ„ BigTableпјҢжҳҜдёҖдёӘдё“й—ЁеӨ„зҗҶеӨ§и§„жЁЎж•°жҚ®зҡ„еҲҶеёғејҸж•°жҚ®еә“гҖӮ
HBase зҡ„зү№зӮ№жҳҜпјҡ
- еӨ„зҗҶеҚҠз»“жһ„еҢ–е’Ңйқһз»“жһ„еҢ–ж•°жҚ®пјҡ дј з»ҹе…ізі»еһӢж•°жҚ®еә“пјҲRDBMSпјүдё»иҰҒеӨ„зҗҶз»“жһ„еҢ–ж•°жҚ®пјҢиҖҢ HBase жӣҙйҖӮеҗҲеӨ„зҗҶеӨ§и§„жЁЎзҡ„еҚҠз»“жһ„еҢ–е’Ңйқһз»“жһ„еҢ–ж•°жҚ®гҖӮ
- еҲҶеёғејҸеӯҳеӮЁдёҺзәҝжҖ§жү©еұ•пјҡ ж•°жҚ®еҸҜд»Ҙж°ҙе№іеҲҮеҲҶеҲ°еӨҡдёӘиҠӮзӮ№дёҠпјҢзі»з»ҹзҡ„жҖ§иғҪе’Ңе®№йҮҸеҸҜд»ҘйҖҡиҝҮеўһеҠ иҠӮзӮ№зәҝжҖ§жү©еұ•гҖӮ
- иҝ‘е®һж—¶иҜ»еҶҷпјҡ е°Ҫз®ЎжҳҜеӨ§ж•°жҚ®йҮҸпјҢHBase дҫқ然еҸҜд»Ҙж”ҜжҢҒиҝ‘д№Һе®һж—¶зҡ„йҡҸжңәиҜ»еҶҷгҖӮ
ж•°жҚ®жЁЎеһӢ
HBase зҡ„ж•°жҚ®жЁЎеһӢдёҺдј з»ҹе…ізі»еһӢж•°жҚ®еә“жңүеҫҲеӨ§дёҚеҗҢ
2.1 иЎЁз»“жһ„дёҺеӯҳеӮЁж–№ејҸ
- жҢүеҲ—еӯҳеӮЁпјҡ
- HBase жҳҜеҹәдәҺеҲ—еӯҳеӮЁзҡ„ж•°жҚ®еә“пјҢдёҚеҗҢеҲ—зҡ„ж•°жҚ®жҳҜеҲҶејҖеӯҳеӮЁзҡ„гҖӮ
- еҲ—еӯҳеӮЁзҡ„еҘҪеӨ„жҳҜи®ҝй—®ж•ҲзҺҮй«ҳпјҢзү№еҲ«жҳҜеҪ“еҸӘйңҖиҰҒиҜ»еҸ–е°‘йҮҸеҲ—ж—¶пјҢдёҚйңҖиҰҒжү«жҸҸж•ҙиЎҢж•°жҚ®гҖӮ
- еҲҶеұӮеӯҳеӮЁпјҡ
- HBase иЎЁдјҡиў«ж°ҙе№іеҲҮеҲҶжҲҗеӨҡдёӘ RegionпјҢжҜҸдёӘ Region жҳҜиЎЁзҡ„дёҖйғЁеҲҶпјҲзұ»дјјдәҺиЎЁзҡ„еҲҶзүҮпјүгҖӮ
- жҜҸдёӘ Region дјҡиҝӣдёҖжӯҘеҲҮеҲҶжҲҗ BlockпјҢ并еӯҳеӮЁеңЁ HDFS дёҠгҖӮ
- иҝҷз§ҚеҲҶеұӮеӯҳеӮЁж–№ејҸеҠ йҖҹдәҶж•°жҚ®жҹҘиҜўпјҡ
- йҖҡиҝҮ Key зҡ„иҢғеӣҙпјҢеҝ«йҖҹе®ҡдҪҚж•°жҚ®еңЁе“ӘдёӘ RegionгҖӮ
- 然еҗҺеңЁ Region дёӯжүҫеҲ°е…·дҪ“зҡ„ BlockпјҢжңҖеҗҺиҜ»еҸ–еҜ№еә”зҡ„ж•°жҚ®гҖӮ
- дё»й”®пјҡ
- жҜҸиЎҢж•°жҚ®йғҪжңүдёҖдёӘе”ҜдёҖзҡ„ Row KeyпјҲдё»й”®пјүгҖӮ
- жүҖжңүиЎҢж №жҚ® Row Key зҡ„еӯ—иҠӮйЎәеәҸжҺ’еәҸеӯҳеӮЁгҖӮ
- жҹҘиҜўж—¶еҝ…йЎ»йҖҡиҝҮдё»й”®и®ҝй—®пјҢдё»й”®зҡ„и®ҫи®ЎиҰҒжңүж„Ҹд№үпјҲеҰӮ URL еҖ’еәҸеӯҳеӮЁпјүгҖӮ
- еёҰзүҲжң¬зҡ„еӨҡз»ҙеӯҳеӮЁпјҡ
- HBase ж”ҜжҢҒеҜ№еҗҢдёҖдёӘеӯ—ж®өеӯҳеӮЁеӨҡдёӘзүҲжң¬зҡ„ж•°жҚ®пјҢжҜҸдёӘзүҲжң¬д»Ҙж—¶й—ҙжҲіеҢәеҲҶгҖӮ
- иҝҷдҪҝеҫ— HBase еҸҜд»ҘжҹҘзңӢжҹҗдёӘж—¶й—ҙзӮ№зҡ„ж•°жҚ®еҝ«з…§пјҢжҲ–иҖ…еңЁдёҚеҗҢзүҲжң¬д№Ӣй—ҙеҲҮжҚўгҖӮ
2.2 еҲ—ж—ҸпјҲColumn Familyпјү
- жҰӮеҝөпјҡ
- HBase зҡ„еҲ—жҳҜйҖҡиҝҮ еҲ—ж—ҸпјҲColumn Familyпјү з»„з»Үзҡ„гҖӮ
- жҜҸдёӘеҲ—ж—ҸеҢ…еҗ«иӢҘе№ІеҲ—пјҲColumn KeysпјүгҖӮеҲ—ж—ҸжҳҜ HBase зҡ„еҹәжң¬еӯҳеӮЁеҚ•дҪҚгҖӮ
- зү№зӮ№пјҡ
- еҲ—ж—Ҹдёӯзҡ„еҲ—еҸҜд»ҘеҠЁжҖҒеўһеҠ пјҢдё”дёҚйңҖиҰҒдёәе·Іжңүж•°жҚ®еЎ«е……й»ҳи®ӨеҖјгҖӮ
- е…ізі»еһӢж•°жҚ®еә“дёӯпјҢеўһеҠ еҲ—йңҖиҰҒдҝ®ж”№ж•ҙдёӘиЎЁзҡ„з»“жһ„пјҢеҸҜиғҪдјҡеҜјиҮҙе·Іжңүж•°жҚ®дёҚдёҖиҮҙпјӣиҖҢеңЁ HBase дёӯпјҢж–°еўһеҲ—дёҚеҪұе“Қе·Іжңүж•°жҚ®гҖӮ
- еҲ—й”®ж јејҸпјҡ
- еҲ—й”®зҡ„ж јејҸдёә
family:qualifierпјҢе…¶дёӯfamilyжҳҜеҲ—ж—ҸеҗҚпјҢqualifierжҳҜеҲ—еҗҚгҖӮ - дҫӢеҰӮпјҡ
- еҲ—ж—Ҹ
languageдёӯеҸӘжңүдёҖдёӘеҲ—й”®пјҢз”ЁдәҺи®°еҪ•зҪ‘йЎөзҡ„иҜӯиЁҖгҖӮ - еҲ—ж—Ҹ
anchorдёӯпјҢжҜҸдёӘеҲ—й”®йғҪжҳҜдёҖдёӘй”ҡзӮ№пјҲanchor еҗҚз§°пјүпјҢеҜ№еә”зҡ„еҖјжҳҜй“ҫжҺҘзҡ„ж–Үжң¬гҖӮ
- еҲ—ж—Ҹ
- еҲ—й”®зҡ„ж јејҸдёә
- иҝһз»ӯеӯҳеӮЁпјҡ
- еҗҢдёҖеҲ—ж—Ҹдёӯзҡ„еҲ—дјҡиҝһз»ӯеӯҳеӮЁпјҢиҝҷж ·еҸҜд»ҘжҸҗй«ҳи®ҝй—®ж•ҲзҺҮгҖӮ
- дҫӢеҰӮпјҢжҹҘиҜўжҹҗдёӘеҲ—ж—Ҹж—¶пјҢдёҚйңҖиҰҒжү«жҸҸж•ҙдёӘиЎЁпјҢеҸӘйңҖжү«жҸҸиҜҘеҲ—ж—Ҹзҡ„ж•°жҚ®гҖӮ
2.3 ж—¶й—ҙжҲідёҺеӨҡзүҲжң¬ж•°жҚ®
- еӨҡзүҲжң¬ж•°жҚ®пјҡ
- HBase зҡ„жҜҸдёӘеҚ•е…ғж јпјҲCellпјүеҸҜд»ҘеӯҳеӮЁеӨҡдёӘзүҲжң¬зҡ„ж•°жҚ®гҖӮ
- зүҲжң¬йҖҡиҝҮж—¶й—ҙжҲіж Үи®°пјҢеҸҜд»ҘдҝқеӯҳжңҖж–°зҡ„ N дёӘзүҲжң¬пјҲN жҳҜз”ЁжҲ·й…ҚзҪ®зҡ„еҖјпјүгҖӮ
- ж—¶й—ҙжҲіжңәеҲ¶пјҡ
- жҜҸж¬ЎеҶҷе…Ҙж•°жҚ®ж—¶пјҢHBase дјҡиҮӘеҠЁдёәж•°жҚ®ж·»еҠ ж—¶й—ҙжҲігҖӮ
- жҹҘиҜўж—¶еҸҜд»ҘжҢҮе®ҡж—¶й—ҙжҲіпјҢиҺ·еҸ–жҹҗдёӘж—¶й—ҙзӮ№зҡ„ж•°жҚ®пјҢжҲ–иҖ…жҹҘзңӢжҹҗдёӘеӯ—ж®өзҡ„еҺҶеҸІеҖјгҖӮ
- зҒөжҙ»жҖ§пјҡ
- дёҚеҗҢеҚ•е…ғж јеҸҜд»ҘжңүдёҚеҗҢж•°йҮҸзҡ„зүҲжң¬гҖӮдҫӢеҰӮпјҢдёҖдёӘеҚ•е…ғж јеҸҜд»Ҙеӯҳ 5 дёӘзүҲжң¬пјҢиҖҢеҸҰдёҖдёӘеҚ•е…ғж јеҸӘжңү 2 дёӘзүҲжң¬гҖӮ
- иҝҷз§ҚжңәеҲ¶еўһејәдәҶж•°жҚ®зҡ„иЎЁиҫҫиғҪеҠӣпјҢжҳҜдј з»ҹе…ізі»еһӢж•°жҚ®еә“ж— жі•е®һзҺ°зҡ„гҖӮ
2.4 Web Table зӨәдҫӢ
URL еҖ’еәҸеӯҳеӮЁпјҡ
- еңЁ Web Table дёӯпјҢURL йҖҡеёёеӯҳеӮЁдёәеҖ’еәҸеҪўејҸгҖӮдҫӢеҰӮпјҡ
еҺҹе§Ӣ URL: www.example.com/page1 еҖ’еәҸ URL: com.example.www/page1 - иҝҷж ·еҸҜд»Ҙе°ҶеҗҢдёҖеҹҹеҗҚзҡ„зҪ‘йЎөеӯҳеӮЁеңЁдёҖиө·пјҢжҸҗй«ҳжҹҘиҜўж•ҲзҺҮгҖӮ
еҲ—ж—Ҹи®ҫи®Ўпјҡ
- еҒҮи®ҫ Web Table жңүдёӨдёӘеҲ—ж—Ҹпјҡ
- иҜӯиЁҖпјҲlanguageпјүпјҡ еӯҳеӮЁзҪ‘йЎөзҡ„иҜӯиЁҖ IDгҖӮ
- й”ҡзӮ№пјҲanchorпјүпјҡ жҜҸдёӘеҲ—й”®иЎЁзӨәдёҖдёӘй”ҡзӮ№пјҢеҖјжҳҜй“ҫжҺҘзҡ„ж–Үжң¬гҖӮ
- иҝҷз§Қи®ҫи®ЎеҸҜд»ҘзҒөжҙ»жү©еұ•пјҢдҫӢеҰӮж–°еўһеҲ—й”®ж—¶пјҢдёҚйңҖиҰҒдҝ®ж”№иЎЁз»“жһ„гҖӮ
3. HBase зҡ„ж“ҚдҪңдёҺзү№зӮ№
3.1 ж“ҚдҪңж–№ејҸ
- дё»й”®и®ҝй—®пјҡ
- жүҖжңүж“ҚдҪңеҝ…йЎ»йҖҡиҝҮдё»й”®пјҲRow KeyпјүиҝӣиЎҢпјҢдё»й”®зҡ„и®ҫи®ЎйқһеёёйҮҚиҰҒгҖӮ
- дё»й”®зҡ„жҺ’еәҸж–№ејҸпјҲжҢүеӯ—иҠӮз ҒжҺ’еәҸпјүдјҡеҪұе“Қж•°жҚ®зҡ„еӯҳеӮЁе’ҢжҹҘиҜўж•ҲзҺҮгҖӮ
- еҶҷж“ҚдҪңпјҡ
- HBase зҡ„еҶҷж“ҚдҪңжҳҜиҝҪеҠ ејҸзҡ„пјҢдёҚдјҡиҰҶзӣ–еҺҹжңүж•°жҚ®гҖӮ
- еҶҷе…Ҙж•°жҚ®ж—¶дјҡиҮӘеҠЁз”ҹжҲҗж—¶й—ҙжҲіпјҢд»ҺиҖҢж”ҜжҢҒеӨҡзүҲжң¬еӯҳеӮЁгҖӮ
- иҜ»ж“ҚдҪңпјҡ
- жҹҘиҜўж—¶еҸҜд»ҘжҢҮе®ҡдё»й”®иҢғеӣҙпјҢжҲ–иҖ…йҖҡиҝҮж—¶й—ҙжҲіиҺ·еҸ–жҹҗдёӘзүҲжң¬зҡ„ж•°жҚ®гҖӮ
3.2 HBase зҡ„дјҳеҠҝ
- еҠЁжҖҒеҲ—пјҡ
- еҲ—ж—Ҹдёӯзҡ„еҲ—еҸҜд»ҘеҠЁжҖҒеўһеҠ пјҢдёҚйңҖиҰҒдҝ®ж”№иЎЁз»“жһ„пјҢдё”дёҚдјҡеҪұе“Қе·Іжңүж•°жҚ®гҖӮ
- иҝҷеҜ№ж•°жҚ®жЁЎеһӢеҸҳеҢ–йў‘з№Ғзҡ„еңәжҷҜйқһеёёеҸӢеҘҪгҖӮ
- й«ҳж•Ҳзҡ„йҡҸжңәиҜ»еҶҷпјҡ
- HBase ж”ҜжҢҒиҝ‘е®һж—¶зҡ„йҡҸжңәиҜ»еҶҷж“ҚдҪңпјҢйҖӮеҗҲйңҖиҰҒйў‘з№Ғжӣҙж–°е’ҢжҹҘиҜўзҡ„еңәжҷҜгҖӮ
- зәҝжҖ§жү©еұ•пјҡ
- ж•°жҚ®еҸҜд»Ҙж°ҙе№іеҲҮеҲҶеҲ°еӨҡдёӘиҠӮзӮ№пјҢзі»з»ҹжҖ§иғҪеҸҜд»ҘйҖҡиҝҮеўһеҠ иҠӮзӮ№зәҝжҖ§жү©еұ•гҖӮ
- йҖӮеҗҲеҚҠз»“жһ„еҢ–е’Ңйқһз»“жһ„еҢ–ж•°жҚ®пјҡ
- HBase еҸҜд»ҘеӯҳеӮЁзҒөжҙ»зҡ„ж•°жҚ®жЁЎеһӢпјҢж”ҜжҢҒеӨҚжқӮзҡ„жҹҘиҜўе’ҢеҲҶжһҗгҖӮ
3.3 HBase зҡ„еұҖйҷҗжҖ§
- дёҚж”ҜжҢҒеӨҚжқӮжҹҘиҜўпјҡ
- HBase дёҚж”ҜжҢҒ SQL жҹҘиҜўпјҢж— жі•зӣҙжҺҘжү§иЎҢеӨҚжқӮзҡ„ Join е’ҢиҒҡеҗҲж“ҚдҪңгҖӮ
- йҖӮеҗҲеҚ•иЎЁж“ҚдҪңпјҢдёҚйҖӮеҗҲеӨҡиЎЁе…іиҒ”жҹҘиҜўгҖӮ
- дҫқиө–дё»й”®пјҡ
- жҹҘиҜўеҝ…йЎ»дҫқиө–дё»й”®пјҢдё»й”®и®ҫи®ЎдёҚеҗҲзҗҶеҸҜиғҪеҜјиҮҙжҹҘиҜўж•ҲзҺҮдҪҺдёӢгҖӮ
- ж•°жҚ®жЁЎеһӢеӨҚжқӮпјҡ
- еҲ—ж—Ҹе’ҢеӨҡзүҲжң¬жңәеҲ¶иҷҪ然зҒөжҙ»пјҢдҪҶд№ҹеўһеҠ дәҶж•°жҚ®жЁЎеһӢзҡ„еӨҚжқӮжҖ§гҖӮ
第дёүеҚҒз«
Hive
Hive жҳҜдёҖдёӘеҹәдәҺ Hadoop зҡ„ж•°жҚ®д»“еә“е·Ҙе…·пјҢе®ғеҸҜд»Ҙе°Ҷз»“жһ„еҢ–зҡ„ж•°жҚ®ж–Ү件жҳ е°„дёәж•°жҚ®еә“иЎЁпјҢ并жҸҗдҫӣзұ»дјј SQL зҡ„жҹҘиҜўеҠҹиғҪгҖӮHive зҡ„ж ёеҝғдҪңз”ЁжҳҜе°Ҷ SQL жҹҘиҜўзҝ»иҜ‘жҲҗеә•еұӮзҡ„ MapReduce жҲ– Spark д»»еҠЎиҝӣиЎҢи®Ўз®—пјҢиҖҢж•°жҚ®еӯҳеӮЁеҲҷз”ұ HDFSпјҲHadoop еҲҶеёғејҸж–Ү件系з»ҹпјүиҙҹиҙЈгҖӮдё»иҰҒз”ЁдәҺеӨ§и§„жЁЎж•°жҚ®зҡ„зҰ»зәҝеҲҶжһҗпјҢйҖҡиҝҮзұ» SQL зҡ„жҺҘеҸЈйҷҚдҪҺдәҶ MapReduce зҡ„еӯҰд№ жҲҗжң¬пјҢ并ж”ҜжҢҒеӨҡз§Қж–Үд»¶ж јејҸе’Ңжү©еұ•еҠҹиғҪпјҢHive зҡ„и®ҫи®ЎзҗҶеҝөжҳҜ Schema on ReadпјҢеңЁжҹҘиҜўж—¶жүҚиҝӣиЎҢж•°жҚ®и§Јжһҗе’ҢиҪ¬жҚўпјҢйҖӮеҗҲеӨ„зҗҶжө·йҮҸж•°жҚ®зҡ„еҲҶжһҗеңәжҷҜгҖӮ
\Hive жҳҜдёҖдёӘе°Ҷ SQL иҪ¬жҚўдёә MapReduce/Spark д»»еҠЎзҡ„е·Ҙе…·пјҢз”ҡиҮіеҸҜд»ҘзңӢдҪңжҳҜ MapReduce/Spark зҡ„ SQL е®ўжҲ·з«ҜгҖӮ
жіЁж„Ҹпјҡ Hive 并дёҚйҖӮеҗҲз”ЁдҪңдәӢеҠЎеһӢж•°жҚ®еә“пјҲеҰӮз”өеӯҗе•ҶеҠЎзі»з»ҹзҡ„и®ўеҚ•з®ЎзҗҶпјүпјҢе®ғзҡ„ж ёеҝғзӣ®ж ҮжҳҜй«ҳж•ҲеӨ„зҗҶеӨ§и§„жЁЎж•°жҚ®зҡ„жү№йҮҸеҲҶжһҗд»»еҠЎпјҢйҖӮеҗҲж•°жҚ®д»“еә“е’Ңж•°жҚ®ж№–зҡ„еңәжҷҜгҖӮ
Hive зҡ„зү№зӮ№
- еҸҜжү©еұ•жҖ§Hive ж”ҜжҢҒеҠЁжҖҒжү©еұ•йӣҶзҫӨ规模пјҢйҖҡеёёдёҚйңҖиҰҒйҮҚеҗҜжңҚеҠЎгҖӮ
- 延еұ•жҖ§з”ЁжҲ·еҸҜд»Ҙж №жҚ®йңҖиҰҒе®ҡд№үиҮӘе·ұзҡ„еҮҪж•°пјҲUDFгҖҒUDAFгҖҒUDTFпјүжқҘжү©еұ• Hive зҡ„еҠҹиғҪгҖӮ
- е®№й”ҷжҖ§Hive е…·жңүиүҜеҘҪзҡ„е®№й”ҷжҖ§пјҢеҚідҪҝжҹҗдәӣиҠӮзӮ№еҮәзҺ°й—®йўҳпјҢSQL жҹҘиҜўд»»еҠЎд»Қ然иғҪеӨҹе®ҢжҲҗгҖӮ
Hive дёӯзҡ„еҹәжң¬жҰӮеҝө
1. ETL
ETL жҳҜж•°жҚ®д»“еә“е’ҢеӨ§ж•°жҚ®еӨ„зҗҶдёӯеёёи§Ғзҡ„жөҒзЁӢпјҢд»ЈиЎЁж•°жҚ®зҡ„жҠҪеҸ–пјҲExtractпјүгҖҒиҪ¬жҚўпјҲTransformпјүе’ҢеҠ иҪҪпјҲLoadпјүгҖӮеңЁ Hive дёӯпјҢETL иҝҮзЁӢйҖҡеёёеҢ…жӢ¬д»ҘдёӢжӯҘйӘӨпјҡ
- ж•°жҚ®жҠҪеҸ–пјҲExtractпјү
д»ҺдёҚеҗҢзҡ„ж•°жҚ®жәҗпјҲеҰӮе…ізі»еһӢж•°жҚ®еә“гҖҒж—Ҙеҝ—ж–Ү件зӯүпјүдёӯиҺ·еҸ–ж•°жҚ®пјҢеҸҜд»ҘдҪҝз”Ёе·Ҙе…·еҰӮ Sqoop жҲ–зӣҙжҺҘиҜ»еҸ–ж–Ү件гҖӮ - ж•°жҚ®иҪ¬жҚўпјҲTransformпјү
дҪҝз”Ё HiveQL еҜ№еҺҹе§Ӣж•°жҚ®иҝӣиЎҢжё…жҙ—гҖҒзӯӣйҖүгҖҒиҒҡеҗҲзӯүж“ҚдҪңпјҢдҪҝе…¶з¬ҰеҗҲзӣ®ж Үж•°жҚ®д»“еә“зҡ„ж јејҸгҖӮ - ж•°жҚ®еҠ иҪҪпјҲLoadпјү
е°ҶиҪ¬жҚўеҗҺзҡ„ж•°жҚ®еҠ иҪҪеҲ° Hive иЎЁдёӯпјҢеҸҜйҖҡиҝҮLOAD DATAе‘Ҫд»ӨжҲ–еҲҶеҢәиЎЁжңәеҲ¶е®ҢжҲҗгҖӮ
2. Metadata StoreпјҲе…ғж•°жҚ®еӯҳеӮЁпјү
Hive зҡ„иЎЁз”ұдёӨйғЁеҲҶжһ„жҲҗпјҡж•°жҚ® е’Ң е…ғж•°жҚ®гҖӮ
е…ғж•°жҚ®жҸҸиҝ°дәҶиЎЁдёӯж•°жҚ®зҡ„з»“жһ„е’ҢеёғеұҖпјҢдҫӢеҰӮпјҡ
- ж–Ү件еҢ…еҗ«зҡ„еҲ—ж•°е’ҢеҲ—зҡ„ж•°жҚ®зұ»еһӢ
- ж•°жҚ®ж–Ү件зҡ„еӯҳеӮЁи·Ҝеҫ„
- ж–Ү件зҡ„ж јејҸпјҲеҰӮ CSVгҖҒParquet зӯүпјү
е…ғж•°жҚ®йҖҡеёёеӯҳеӮЁеңЁ Hive зҡ„е…ғж•°жҚ®еӯҳеӮЁз»„件дёӯпјҲеҰӮ MySQL жҲ– Derby ж•°жҚ®еә“пјүгҖӮ
3. ж•°жҚ®еҠ иҪҪ
йҖҡиҝҮе‘Ҫд»Ө LOAD DATA еҸҜд»Ҙеҝ«йҖҹе°Ҷж–Ү件еҠ иҪҪеҲ° Hive иЎЁдёӯгҖӮдҫӢеҰӮпјҡ
LOAD DATA LOCAL INPATH '/home/hadoop/data/emp.txt'
OVERWRITE INTO TABLE emp;жіЁж„Ҹпјҡ
- иҜҘе‘Ҫд»ӨдёҚдјҡзӣҙжҺҘжү§иЎҢж•°жҚ®зҡ„и§ЈжһҗгҖҒиҪ¬жҚўжҲ–еҠ иҪҪпјҲеҚідёҚиҝӣиЎҢ ETL ж“ҚдҪңпјүгҖӮ
- е®ғеҸӘжҳҜе‘ҠиҜү Hive иЎЁзҡ„ж•°жҚ®жқҘжәҗдәҺжҢҮе®ҡж–Ү件пјҢзңҹжӯЈзҡ„и§Јжһҗе’ҢиҪ¬жҚўдјҡеңЁжү§иЎҢ HQL жҹҘиҜўж—¶иҝӣиЎҢгҖӮ
иҝҷз§Қзӯ–з•Ҙзҡ„дјҳзӮ№жҳҜеҠ иҪҪйҖҹеәҰеҝ«пјҢдҪҶеңЁжҹҘиҜўж—¶еҸҜиғҪдјҡзЁҚж…ўгҖӮ
Hive ж”ҜжҢҒзҡ„ж–Үд»¶ж јејҸ
Hive ж”ҜжҢҒеӨҡз§Қж–Үд»¶ж јејҸе’ҢеҺӢзј©ж–№ејҸпјҡ
- TextFileпјҡй»ҳи®Өзҡ„ж–Үжң¬ж–Үд»¶ж јејҸгҖӮ
- SequenceFileпјҡHadoop зҡ„дәҢиҝӣеҲ¶ж–Үд»¶ж јејҸпјҢж”ҜжҢҒеҲҶеқ—еҺӢзј©гҖӮ
- RCFileпјҲRow Columnar FileпјүпјҡиЎҢеҲ—ж··еҗҲеӯҳеӮЁж јејҸпјҢйҖӮеҗҲдәҺжҹҗдәӣжҹҘиҜўеңәжҷҜгҖӮ
- ORCFileпјҲOptimized Row Columnar FileпјүпјҡдјҳеҢ–иЎҢеҲ—еӯҳеӮЁж јејҸпјҢж”ҜжҢҒй«ҳж•ҲеҺӢзј©е’ҢжҹҘиҜўгҖӮ
- Avro FileпјҡдёҖз§Қж”ҜжҢҒжЁЎејҸжј”еҢ–зҡ„ж•°жҚ®еәҸеҲ—еҢ–ж јејҸгҖӮ
- ParquetпјҡдёҖз§ҚеҲ—ејҸеӯҳеӮЁж јејҸпјҢзҺ°е·ІжҲҗдёә Apache зҡ„зӢ¬з«ӢйЎ№зӣ®пјҢе№ҝжіӣз”ЁдәҺи·Ёзі»з»ҹж•°жҚ®дәӨжҚўе’Ңй«ҳж•ҲжҹҘиҜўгҖӮ
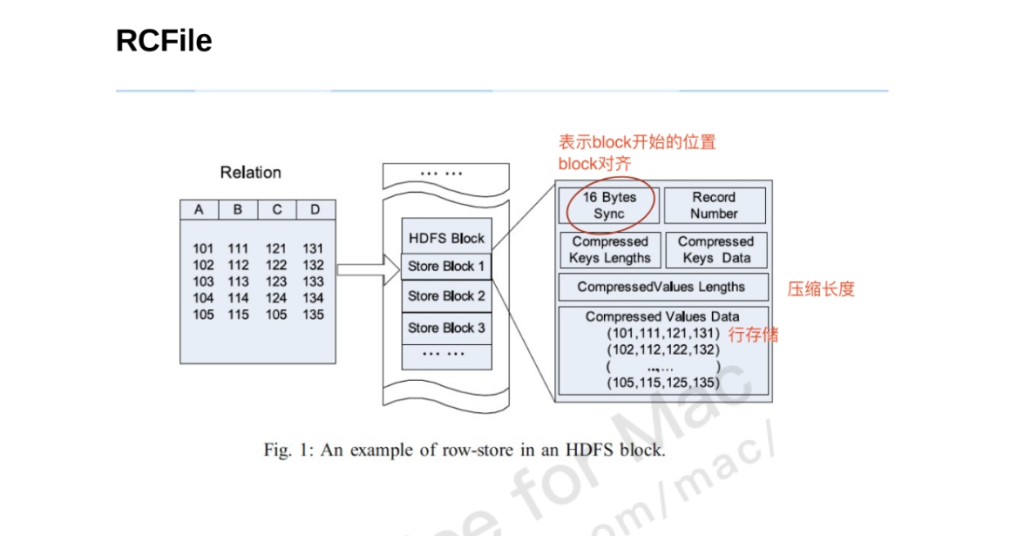
RCFile жҳҜдёҖз§Қж—©жңҹзҡ„иЎҢеҲ—ж··еҗҲеӯҳеӮЁж јејҸпјҢиҷҪ然еңЁдёҖе®ҡзЁӢеәҰдёҠз»“еҗҲдәҶиЎҢеӯҳеӮЁе’ҢеҲ—еӯҳеӮЁзҡ„дјҳзӮ№пјҢдҪҶе®ғзҡ„еҺӢзј©ж–№ејҸд»Қ然д»ҘиЎҢеӯҳеӮЁдёәдё»пјҢеҜјиҮҙеҺӢзј©ж•ҲзҺҮжңүйҷҗгҖӮжҜ”еҰӮдёҠеӣҫABCDеҰӮжһңд»ЈиЎЁдёҚеҗҢзҡ„ж•°жҚ®зұ»еһӢпјҢеҲҷеҸҜиғҪеҜјиҮҙиҝҷз§Қ算法并дёҚй«ҳж•ҲгҖӮ
Hive дёҺдј з»ҹж•°жҚ®еә“зҡ„еҜ№жҜ”
1. Schema on Read vs Schema on Write
- HiveпјҲSchema on Readпјү
Hive еңЁеҠ иҪҪж•°жҚ®ж—¶дёҚдјҡзӣҙжҺҘеҜ№ж•°жҚ®иҝӣиЎҢи§ЈжһҗжҲ–ж ЎйӘҢпјҢиҖҢжҳҜеңЁжү§иЎҢ HQL жҹҘиҜўж—¶жүҚиҝӣиЎҢж•°жҚ®зҡ„жҠҪеҸ–гҖҒиҪ¬жҚўе’ҢеҠ иҪҪгҖӮиҝҷз§Қж–№ејҸйҖӮеҗҲеӨ„зҗҶжө·йҮҸж•°жҚ®пјҢеӣ дёәе®ғйҒҝе…ҚдәҶеҲқе§ӢеҠ иҪҪзҡ„й«ҳ延иҝҹгҖӮ - дј з»ҹж•°жҚ®еә“пјҲSchema on Writeпјү
дј з»ҹе…ізі»еһӢж•°жҚ®еә“пјҲеҰӮ MySQLпјүеңЁжҸ’е…ҘжҲ–еҠ иҪҪж•°жҚ®ж—¶е°ұдјҡиҝӣиЎҢж•°жҚ®ж ЎйӘҢе’ҢиҪ¬жҚўпјҢзЎ®дҝқж•°жҚ®зҡ„дёҖиҮҙжҖ§е’Ңе®Ңж•ҙжҖ§гҖӮиҝҷз§Қж–№ејҸжӣҙйҖӮеҗҲдәӢеҠЎеӨ„зҗҶеңәжҷҜгҖӮ
2. йқўеҗ‘дәӢеҠЎ vs йқўеҗ‘еҲҶжһҗ
- дј з»ҹж•°жҚ®еә“пјҲеҰӮ MySQLпјүпјҡйҖӮеҗҲдәӢеҠЎеӨ„зҗҶпјҢиҰҒжұӮж•°жҚ®дёҖиҮҙжҖ§гҖҒе®һж—¶жҖ§иҫғй«ҳгҖӮ
- HiveпјҡйҖӮеҗҲзҰ»зәҝеҲҶжһҗпјҢйҖҡеёёдёҖж¬ЎеҶҷе…ҘеӨҡж¬ЎиҜ»еҸ–пјҢејәи°ғеӨ§и§„жЁЎж•°жҚ®зҡ„жү№йҮҸеӨ„зҗҶгҖӮ
3. ж•°жҚ®д»“еә“ vs ж•°жҚ®ж№–
- ж•°жҚ®д»“еә“пјҡж•°жҚ®з»ҸиҝҮжё…жҙ—е’Ңе»әжЁЎпјҢйҖӮеҗҲй«ҳзә§еҲҶжһҗж“ҚдҪңгҖӮ
- ж•°жҚ®ж№–пјҡеӯҳеӮЁеҺҹе§Ӣж•°жҚ®пјҢж”ҜжҢҒеӨҡз§Қж јејҸе’Ңе·Ҙе…·и®ҝй—®гҖӮ
Hive еңЁжҹҗз§ҚзЁӢеәҰдёҠе…·еӨҮдәҶж•°жҚ®ж№–зҡ„иғҪеҠӣпјҢеӣ дёәе®ғе…Ғи®ёзӣҙжҺҘеӯҳеӮЁеҺҹе§Ӣж•°жҚ®ж–Ү件пјҢ并еңЁжҹҘиҜўж—¶з»ҹдёҖи§ЈжһҗгҖӮ
ж•°жҚ®ж№–дёҺж•°жҚ®д»“еә“зҡ„е…ізі»
- ж•°жҚ®ж№–дҪңдёәж•°жҚ®д»“еә“зҡ„ж•°жҚ®жәҗ
еҺҹе§Ӣж•°жҚ®еӯҳеӮЁеңЁж•°жҚ®ж№–дёӯпјҢж•°жҚ®д»“еә“д»Һж•°жҚ®ж№–дёӯжҸҗеҸ–ж•°жҚ®з”ЁдәҺй«ҳзә§еҲҶжһҗгҖӮ - ж•°жҚ®ж№–еҚіж•°жҚ®д»“еә“
ж•°жҚ®ж№–еҸҜд»ҘзӣҙжҺҘйҖҡиҝҮ SQL жҹҘиҜўи®ҝй—®пјҢжҲҗдёәдёҖдёӘз»ҹдёҖзҡ„еӯҳеӮЁе’ҢеҲҶжһҗе№іеҸ°гҖӮ - ж№–д»“дёҖдҪ“пјҲLakehouseпјү
зғӯж•°жҚ®еӯҳеӮЁеңЁж•°жҚ®д»“еә“дёӯд»ҘжҸҗй«ҳжҹҘиҜўж•ҲзҺҮпјҢеҶ·ж•°жҚ®еӯҳеӮЁеңЁж•°жҚ®ж№–дёӯд»ҘиҠӮзңҒжҲҗжң¬гҖӮиҝҷз§ҚжЁЎејҸиў«з§°дёәж№–д»“дёҖдҪ“пјҢHive еҸҜд»ҘзңӢдҪңжҳҜж—©жңҹе®һзҺ°ж№–д»“дёҖдҪ“зҡ„е·Ҙе…·гҖӮ
第дёүеҚҒдёҖз«
FLINK
Flink жҳҜдёҖдёӘжЎҶжһ¶е’ҢеҲҶеёғејҸеӨ„зҗҶеј•ж“ҺпјҢдё“й—Ёз”ЁдәҺеӨ„зҗҶ жңүзҠ¶жҖҒпјҲstatefulпјүи®Ўз®— зҡ„ ж— з•ҢпјҲunboundedпјү е’Ң жңүз•ҢпјҲboundedпјү ж•°жҚ®жөҒгҖӮ
- жөҒејҸж•°жҚ®пјҲStreamsпјүпјҡ
- ж— з•ҢжөҒпјҲUnbounded Streamsпјүпјҡ ж•°жҚ®жәҗжәҗдёҚж–ӯең°дә§з”ҹпјҢж•°жҚ®жөҒжІЎжңүеӣәе®ҡзҡ„з»“жқҹзӮ№гҖӮжҜ”еҰӮе®һж—¶ж—Ҙеҝ—гҖҒдј ж„ҹеҷЁж•°жҚ®зӯүгҖӮ
- жңүз•ҢжөҒпјҲBounded Streamsпјүпјҡ ж•°жҚ®жөҒжҳҜжңүйҷҗзҡ„пјҢзұ»дјјжү№еӨ„зҗҶгҖӮжҜ”еҰӮдёҖдёӘеӣәе®ҡеӨ§е°Ҹзҡ„ж–Ү件гҖӮ
- е®һж—¶жөҒпјҲReal-time Streamsпјүпјҡ ж•°жҚ®йҡҸзқҖдәӢ件зҡ„еҸ‘з”ҹе®һж—¶еҲ°иҫҫгҖӮ
- еҪ•еҲ¶жөҒпјҲRecorded Streamsпјүпјҡ ж•°жҚ®дёҚжҳҜе®һж—¶еҲ°иҫҫпјҢиҖҢжҳҜд»Һ Kafka зӯүж¶ҲжҒҜйҳҹеҲ—дёӯиҜ»еҸ–еҺҶеҸІж•°жҚ®пјҲFlink еӨ„зҗҶйҖҹеәҰеҸҜиғҪи·ҹдёҚдёҠе®һж—¶ж•°жҚ®ж—¶зҡ„и§ЈеҶіж–№жЎҲпјүгҖӮ
Flink иҰҒи§ЈеҶізҡ„ж ёеҝғй—®йўҳ
- ж•°жҚ®еҲҶеҢәпјҲPartitioningпјүпјҡ
- жңүеӨҡдёӘеӨ„зҗҶеҷЁпјҲз®—еӯҗпјүж—¶пјҢеҰӮдҪ•е°Ҷж•°жҚ®еҲҶеҢәеҲ°дёҚеҗҢиҠӮзӮ№дёҠпјҹпјҲжҜ”еҰӮжҢү key жҲ–规еҲҷе°ҶжҹҗдәӣдәӢ件еҲҶй…ҚеҲ°зү№е®ҡзҡ„иҠӮзӮ№пјү
- д№ұеәҸй—®йўҳпјҲOut-of-order Eventsпјүпјҡ
- ж•°жҚ®еҸҜиғҪдёҚжҳҜжҢүдәӢ件еҸ‘з”ҹж—¶й—ҙзҡ„йЎәеәҸиҝӣе…Ҙзі»з»ҹпјҢжҜ”еҰӮд№қзӮ№й’ҹеӨ„зҗҶе…«зӮ№еҲ°д№қзӮ№зҡ„ж•°жҚ®пјҢдҪҶд№қзӮ№еҚҒдә”еҸҜиғҪиҝҳдјҡ收еҲ°е…«зӮ№еҲ°д№қзӮ№зҡ„ж•°жҚ®гҖӮеҰӮдҪ•дҝқиҜҒжӯЈзЎ®жҖ§пјҹ
- жңүзҠ¶жҖҒзҡ„еӨ„зҗҶпјҲStateful Computationпјүпјҡ
- дәӢ件д№Ӣй—ҙйңҖиҰҒе…іиҒ”еӨ„зҗҶгҖӮдҫӢеҰӮпјҡ
- з”ЁжҲ·зӮ№еҮ»иЎҢдёәи·ҹиёӘпјҡйңҖиҰҒзҹҘйҒ“з”ЁжҲ·дёҠдёҖж¬ЎзӮ№еҮ»зҡ„дҪҚзҪ®гҖӮ
- иҙӯзү©иҪҰпјҡйңҖиҰҒдҝқеӯҳжҜҸдёӘз”ЁжҲ·зҡ„иҙӯзү©иҪҰзҠ¶жҖҒгҖӮ
- дәӢ件д№Ӣй—ҙйңҖиҰҒе…іиҒ”еӨ„зҗҶгҖӮдҫӢеҰӮпјҡ
- иҝҷз§ҚзҠ¶жҖҒйңҖиҰҒиў«дҝқеӯҳе’Ңз®ЎзҗҶпјҢзү№еҲ«жҳҜеҪ“еҶ…еӯҳдёҚи¶іж—¶пјҢзҠ¶жҖҒйңҖиҰҒеҶҷе…ҘзЎ¬зӣҳпјҲеҰӮ RocksDBпјүпјҢ并еңЁйңҖиҰҒж—¶жҒўеӨҚгҖӮ
ж ёеҝғжҰӮеҝө
- Flink зҡ„ж ёеҝғжҰӮеҝөпјҡ
- еҲҶеҢәпјҡ ж•°жҚ®жҢү key еҲҶеҢәеҲ°дёҚеҗҢиҠӮзӮ№пјҢдҝқиҜҒзҠ¶жҖҒдёҖиҮҙжҖ§гҖӮ
- зҠ¶жҖҒпјҡ дҝқеӯҳдәӢ件зҡ„дёӯй—ҙз»“жһңпјҢж”ҜжҢҒеӯҳеӮЁдёҺжҒўеӨҚгҖӮ
- Watermarksпјҡ и§ЈеҶід№ұеәҸй—®йўҳпјҢе®ҡд№ү延иҝҹж—¶й—ҙгҖӮ
- зӘ—еҸЈжңәеҲ¶пјҡ е°ҶжөҒејҸж•°жҚ®еҲҶжү№еӨ„зҗҶгҖӮ
- Flink зҡ„дјҳеҠҝпјҡ
- ж”ҜжҢҒжңүзҠ¶жҖҒзҡ„жөҒејҸи®Ўз®—пјҢиғҪеӨҹе…іиҒ”еүҚеҗҺдәӢ件гҖӮ
- й«ҳж•Ҳзҡ„зҠ¶жҖҒз®ЎзҗҶпјҲеҶ…еӯҳ+зЎ¬зӣҳ+еҝ«з…§пјүгҖӮ
- зҒөжҙ»еӨ„зҗҶд№ұеәҸж•°жҚ®пјҢдҝқиҜҒз»“жһңзҡ„еҮҶзЎ®жҖ§гҖӮ
д»Җд№ҲжҳҜзҠ¶жҖҒпјҲStateпјүпјҹ
- зҠ¶жҖҒзҡ„е®ҡд№үпјҡ
- зҠ¶жҖҒжҳҜзЁӢеәҸеңЁеӨ„зҗҶдәӢ件时йңҖиҰҒи®°дҪҸзҡ„дҝЎжҒҜгҖӮдҫӢеҰӮпјҡ
- з”ЁжҲ·зҡ„иҙӯзү©иҪҰпјҲй”®еҖјеҜ№еӯҳеӮЁпјүгҖӮ
- з”ЁжҲ·зӮ№еҮ»зҡ„и®ҝй—®и·Ҝеҫ„гҖӮ
- Flink дёӯзҡ„зҠ¶жҖҒпјҡ
- Flink зҡ„зҠ¶жҖҒжҳҜжҜҸдёӘдәӢ件еӨ„зҗҶйҖ»иҫ‘зҡ„дёӯй—ҙз»“жһңгҖӮдҫӢеҰӮпјҡ
- еҪ“еүҚдәӢ件еӨ„зҗҶеҲ°е“ӘпјҢеүҚдёҖдёӘдәӢ件жҳҜд»Җд№ҲгҖӮ
- иҝҷдәӣзҠ¶жҖҒйңҖиҰҒеңЁдәӢ件еӨ„зҗҶзҡ„еүҚеҗҺиҝӣиЎҢе…іиҒ”гҖӮ
- зҠ¶жҖҒз®ЎзҗҶзҡ„зү№зӮ№пјҡ
- еӯҳеӮЁдёҺжҒўеӨҚпјҡ еҪ“еҶ…еӯҳдёҚи¶іж—¶пјҢзҠ¶жҖҒдјҡеҶҷеҲ°зЎ¬зӣҳпјҲеҰӮ RocksDBпјүпјҢ并еңЁйңҖиҰҒж—¶д»ҺзЎ¬зӣҳжҒўеӨҚгҖӮ
- CheckpointпјҲжЈҖжҹҘзӮ№пјүпјҡ дёәдәҶе®№й”ҷпјҢFlink е®ҡжңҹеҜ№зҠ¶жҖҒиҝӣиЎҢеҝ«з…§пјҲsnapshotпјүпјҢзЎ®дҝқеҚідҪҝзі»з»ҹеҙ©жәғпјҢд№ҹеҸҜд»Ҙд»ҺжңҖиҝ‘зҡ„жЈҖжҹҘзӮ№жҒўеӨҚгҖӮ
- ејӮжӯҘеҝ«з…§пјҡ еүҚз«Ҝ继з»ӯеӨ„зҗҶдәӢ件пјҢеҗҺз«ҜејӮжӯҘеҶҷе…Ҙеҝ«з…§пјҢйҒҝе…ҚеүҚз«ҜеҒңйЎҝгҖӮ
- еўһйҮҸеҝ«з…§пјҡ жҜҸж¬ЎеҸӘи®°еҪ•еҸҳеҢ–зҡ„зҠ¶жҖҒпјҢйҒҝе…Қе…ЁйҮҸеҝ«з…§еёҰжқҘзҡ„жҖ§иғҪејҖй”ҖгҖӮ
- еҲҶеҢәе’ҢзҠ¶жҖҒз»ҙжҠӨпјҡ
- Flink дјҡж №жҚ® key е°ҶзӣёеҗҢ key зҡ„дәӢ件еҸ‘йҖҒеҲ°еҗҢдёҖдёӘиҠӮзӮ№еӨ„зҗҶпјҢзЎ®дҝқзҠ¶жҖҒеҫ—д»Ҙз»ҙжҠӨпјҲзұ»дјј Nginx зҡ„ IP е“ҲеёҢйҖ»иҫ‘пјүгҖӮ
WatermarksпјҲж°ҙдҪҚзәҝпјү
- Watermarks зҡ„дҪңз”Ёпјҡ
- и§ЈеҶіе°‘йҮҸж•°жҚ®е»¶иҝҹеҲ°иҫҫзҡ„й—®йўҳгҖӮ
- дҫӢеҰӮпјҡжҲ‘们еёҢжңӣеӨ„зҗҶ 8 зӮ№еҲ° 9 зӮ№зҡ„ж•°жҚ®пјҢдҪҶ 9 зӮ№ 2 еҲҶиҝҳжңү 8 зӮ№зҡ„ж•°жҚ®еҲ°иҫҫпјҢеҰӮдҪ•еӨ„зҗҶпјҹ
- Watermarks зҡ„йҖ»иҫ‘пјҡ
- е®ҡд№үдёҖдёӘеҸҜд»ҘжҺҘеҸ—зҡ„延иҝҹж—¶й—ҙпјҲеҰӮ 5 еҲҶй’ҹпјүгҖӮ
- еҰӮжһң延иҝҹж—¶й—ҙеҶ…пјҲеҰӮ 9 зӮ№ 5 еҲҶеүҚпјүж•°жҚ®еҲ°иҫҫпјҢд»Қ然еҸҜд»ҘеӨ„зҗҶдёәеҪ“еүҚзӘ—еҸЈзҡ„ж•°жҚ®гҖӮ
- еҰӮжһңи¶…иҝҮ延иҝҹж—¶й—ҙпјҲеҰӮ 9 зӮ№ 6 еҲҶеҲ°иҫҫпјүпјҢеҸҜд»ҘйҖүжӢ©пјҡ
- е°Ҷж•°жҚ®ж”ҫеҲ°дёӢдёҖдёӘзӘ—еҸЈеӨ„зҗҶгҖӮ
- дёўејғиҝҷжқЎж•°жҚ®гҖӮ
- Watermarks зҡ„е®һзҺ°пјҡ
- жҜҸдёӘж•°жҚ®жәҗдјҡз”ҹжҲҗдёҖдёӘж°ҙдҪҚзәҝпјҢиЎЁзӨәе®ғе·Із»ҸеӨ„зҗҶеҲ°зҡ„ж—¶й—ҙзӮ№гҖӮ
- дёӢжёёз®—еӯҗдјҡж №жҚ®еӨҡдёӘж•°жҚ®жәҗзҡ„жңҖе°Ҹж°ҙдҪҚзәҝпјҢеҶіе®ҡеҪ“еүҚж—¶й—ҙзӘ—еҸЈзҡ„еӨ„зҗҶйҖ»иҫ‘гҖӮ
зӘ—еҸЈжңәеҲ¶пјҲWindowingпјү
- зӘ—еҸЈзҡ„дҪңз”Ёпјҡ
- е°ҶжөҒејҸж•°жҚ®еҲҶжҲҗе°Ҹжү№ж¬ЎпјҢеҲҶжү№еӨ„зҗҶгҖӮжҜҸдёӘжү№ж¬Ўзҡ„ж•°жҚ®еҸ«еҒҡдёҖдёӘзӘ—еҸЈгҖӮ
- дёӨз§ҚзӘ—еҸЈзұ»еһӢпјҡ
- ж—¶й—ҙзӘ—еҸЈпјҲTime-based Windowпјүпјҡ
- жҢүеӣәе®ҡж—¶й—ҙй—ҙйҡ”еӨ„зҗҶж•°жҚ®гҖӮдҫӢеҰӮжҜҸ 30 з§’еӨ„зҗҶдёҖж¬ЎгҖӮ
- и®Ўж•°зӘ—еҸЈпјҲCount-based Windowпјүпјҡ
- жҢүеӣәе®ҡдәӢ件数йҮҸеӨ„зҗҶж•°жҚ®гҖӮдҫӢеҰӮжҜҸ 3 дёӘдәӢ件еӨ„зҗҶдёҖж¬ЎгҖӮ
- жҖ»з»“пјҡ
- зӘ—еҸЈжңәеҲ¶е°ҶжөҒејҸж•°жҚ®еҲ’еҲҶдёәе°Ҹзҡ„жү№ж¬ЎеӨ„зҗҶпјҢд»Һе®Ҹи§ӮдёҠзңӢпјҢжөҒејҸж•°жҚ®е°ұеғҸжҳҜе®һж—¶жү№еӨ„зҗҶгҖӮ
2. Flink зҡ„жһ¶жһ„
- жңүзҠ¶жҖҒи®Ўз®—пјҡ
- жҜҸж¬ЎеӨ„зҗҶдәӢ件时пјҢйҖ»иҫ‘зЁӢеәҸйңҖиҰҒиҜ»еҸ–зҠ¶жҖҒпјҢеҶіе®ҡеҰӮдҪ•еӨ„зҗҶеҪ“еүҚдәӢ件гҖӮ
- зҠ¶жҖҒеӯҳеӮЁеңЁеҶ…еӯҳжҲ–зЎ¬зӣҳдёҠпјҢйў‘з№ҒиҜ»еҶҷгҖӮ
- зҠ¶жҖҒз®ЎзҗҶзҡ„е…ій”®зӮ№пјҡ
- зҠ¶жҖҒеӯҳеӮЁдёҺжҒўеӨҚпјҡ
- зҠ¶жҖҒеҸҜиғҪеҫҲеӨ§пјҢеҶ…еӯҳдёҚи¶іж—¶йңҖиҰҒеӯҳеӮЁеҲ°зЎ¬зӣҳпјҲеҰӮ RocksDBпјүгҖӮ
- зі»з»ҹеҙ©жәғеҗҺпјҢд»Һеҝ«з…§дёӯжҒўеӨҚзҠ¶жҖҒгҖӮ
- ејӮжӯҘдёҺеўһйҮҸеҝ«з…§пјҡ
- ејӮжӯҘеҝ«з…§пјҡеүҚз«Ҝ继з»ӯеӨ„зҗҶдәӢ件пјҢеҗҺз«ҜејӮжӯҘеҶҷе…ҘзҠ¶жҖҒгҖӮ
- еўһйҮҸеҝ«з…§пјҡеҸӘи®°еҪ•зҠ¶жҖҒзҡ„еҸҳеҢ–пјҢеҮҸе°‘жҖ§иғҪејҖй”ҖгҖӮ
AI
дәәе·ҘзҘһз»ҸзҪ‘з»ң

жҝҖжҙ»еҮҪж•°пјҡsigmod
Пғ(z)= 1/(1+e^вҲ’z)
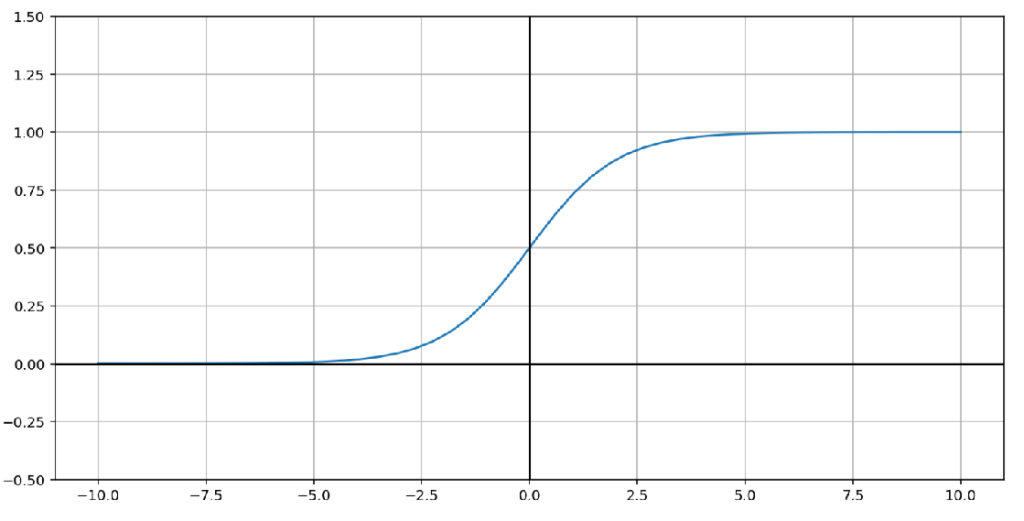
дёәд»Җд№Ҳsigmoidпјҹд»»ж„ҸдёҖдёӘеҮҪж•°йғҪеҸҜд»Ҙиў«жӢҶжҲҗжҳҜиӢҘе№ІдёӘвҖңйҳ¶и·ғеҮҪж•°вҖқпјҲеҲҶж®өеҮҪж•°пјүзҡ„зәҝжҖ§з»„еҗҲпјҢзұ»дјјеӮ…йҮҢеҸ¶ еҸҳжҚўгҖӮдҪҶжҳҜеҲҶж®өеҮҪж•°иЎЁзӨәиө·жқҘжҜ”иҫғйә»зғҰгҖӮsigmoidзҡ„жҖ§иҙЁпјҡ
1. еҸ–еҖјиҢғеӣҙеңЁ0~1д№Ӣй—ҙпјҢйқһеёёйҖӮеҗҲжҰӮзҺҮ
2. дёӯеҝғеҜ№з§°пјҢеңЁx=0еӨ„жўҜеәҰиҫғеӨ§
3. е№іж»‘дё”жұӮеҜјж–№дҫҝпјҢПғвҖІ(z) = Пғ(z)(1вҲ’Пғ(z))
4.йқһзәҝжҖ§пјҢеҸҜд»Ҙеё®еҠ©зҘһз»ҸзҪ‘з»ңжҚ•жҚүж•°жҚ®дёӯзҡ„еӨҚжқӮжЁЎејҸ
еҚ•дёӘзҘһз»Ҹе…ғеҸӘиғҪдә§з”ҹзәҝжҖ§еҶізӯ–иҫ№з•ҢпјҢйҖӮз”ЁдәҺдәҢеҲҶзұ»й—®йўҳгҖӮе®һйҷ…зў°еҲ°зҡ„й—®йўҳеӨҚжқӮеҫ—еӨҡгҖӮ
е…ЁиҝһжҺҘзҘһз»ҸзҪ‘з»ң
зҘһз»ҸзҪ‘з»ңзҡ„иҫ“еҮәдҪҝз”Ёзҡ„жҳҜвҖңзӢ¬зғӯзј–з Ғ(One Hot Encoding)вҖқпјҢиҫ“еҮәжҳҜдёҖдёӘеҗ‘йҮҸпјҢй•ҝеәҰзӯүдәҺеҲҶзұ»зҡ„ж•°йҮҸгҖӮжҜҸ дёӘеҲҶзұ»йғҪз”ұеҗ‘йҮҸдёӯзү№е®ҡзҡ„дҪҚзҪ®жқҘиЎЁзӨә (дёҖдёӘдҪҚзҪ®жҳҜ1пјҢе…¶д»–дҪҚзҪ®дёә0пјҢеҘҪеӨ„пјҡзӣёдә’жӯЈдәӨпјҢеҪјжӯӨзӢ¬з«ӢпјҢдә’дёҚе№Іжү°)
жҰӮеҝөпјҡиҫ“е…ҘеұӮпјҢйҡҗи—ҸеұӮпјҢиҫ“еҮәеұӮгҖӮеҮҖиҫ“е…Ҙ(иҫ“е…Ҙзҡ„еҠ жқғе’Ң)пјҢжҝҖжҙ» (еҲ°дёӢдёҖеұӮзҘһз»Ҹе…ғзҡ„иҫ“еҮә)
- иҫ“е…ҘеұӮпјҡиҝҷжҳҜзҪ‘з»ңзҡ„第дёҖеұӮпјҢжҺҘеҸ—иҫ“е…Ҙж•°жҚ®гҖӮеӣҫеғҸеҲҶзұ»д»»еҠЎдёӯзҡ„жҜҸдёӘеғҸзҙ еҖјдјҡдҪңдёәиҫ“е…ҘеұӮзҡ„дёҖдёӘиҠӮзӮ№гҖӮ
- йҡҗи—ҸеұӮпјҡиҝҷеұӮдҪҚдәҺиҫ“е…ҘеұӮе’Ңиҫ“еҮәеұӮд№Ӣй—ҙпјҢиҙҹиҙЈеӨ„зҗҶж•°жҚ®е№¶жҸҗеҸ–зү№еҫҒгҖӮзҘһз»ҸзҪ‘з»ңзҡ„иғҪеҠӣдё»иҰҒдҫқиө–дәҺйҡҗи—ҸеұӮзҡ„еұӮж•°е’ҢиҠӮзӮ№ж•°гҖӮ
- иҫ“еҮәеұӮпјҡиҝҷжҳҜзҪ‘з»ңзҡ„жңҖеҗҺдёҖеұӮпјҢиҫ“еҮәзҪ‘з»ңзҡ„жңҖз»Ҳз»“жһңгҖӮеҜ№дәҺеҲҶзұ»д»»еҠЎпјҢиҫ“еҮәеұӮйҖҡеёёдјҡз»ҷеҮәжҜҸдёӘзұ»еҲ«зҡ„йў„жөӢеҖјгҖӮ
- жқғйҮҚпјҲзҹ©йҳөпјүиҠӮзӮ№д№Ӣй—ҙзҡ„иҝһжҺҘзәҝжқЎд»ЈиЎЁжқғйҮҚпјҢз”ЁжқҘиЎЁзӨәиҫ“е…Ҙе’Ңиҫ“еҮәд№Ӣй—ҙзҡ„е…ізі»гҖӮжқғйҮҚзҹ©йҳө рқ‘Ҡ(1),рқ‘Ҡ(2),рқ‘Ҡ(3)жҳҜзҘһз»ҸзҪ‘з»ңзҡ„ж ёеҝғеҸӮж•°пјҢи®ӯз»ғзҡ„зӣ®ж Үе°ұжҳҜжүҫеҲ°еҗҲйҖӮзҡ„жқғйҮҚжқҘжңҖе°ҸеҢ–иҜҜе·®гҖӮ
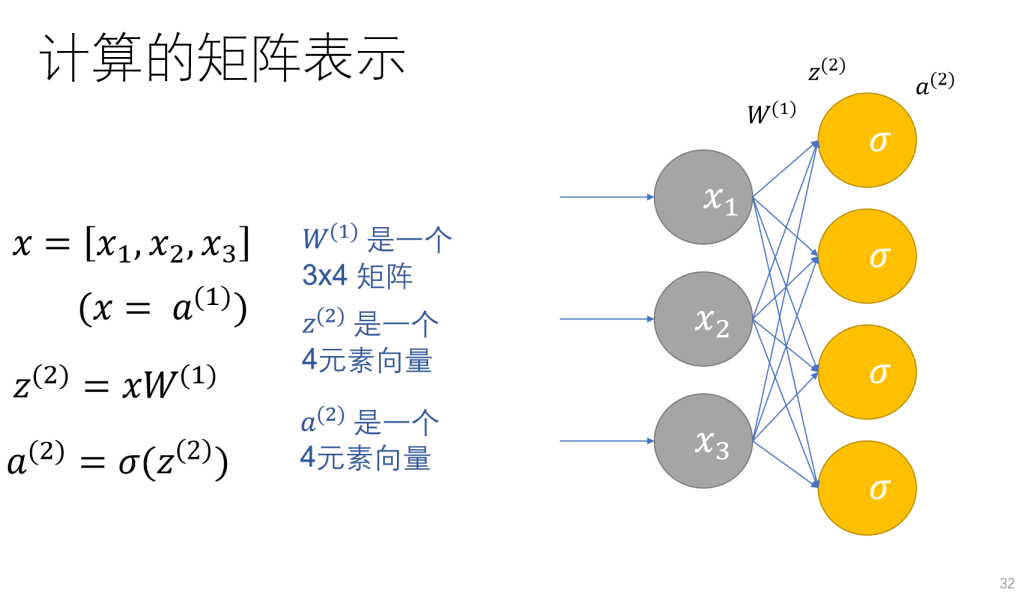
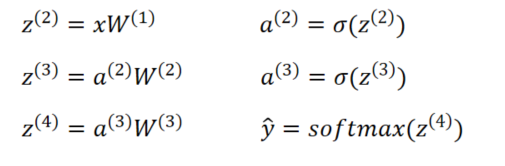
еҜ№дәҺеӨҡеҲҶзұ»й—®йўҳпјҢжңҖеҗҺдёҖеұӮжҳҜдёҖдёӘй•ҝеәҰзӯүдәҺзұ»еҲ«ж•°йҮҸзҡ„еҗ‘йҮҸ
SigmoidеҜ№еӨҡзұ»еҲ«зҡ„жү©еұ•е°ұжҳҜ softmax еҮҪж•°пјҡ
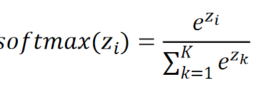
е®ғдјҡдә§з”ҹдёҖдёӘеҗ‘йҮҸпјҢе…¶дёӯзҡ„еҗ„дёӘйЎ№йғҪд»ӢдәҺ 0 еҲ° 1 д№Ӣй—ҙпјҢ并且е®ғ们зҡ„жҖ»е’ҢзӯүдәҺ 1
softmaxеҘҪеӨ„пјҲд№ӢдёҖпјүпјҡжңҖеҗҺзҡ„з»“жһңдјҡжҺҘиҝ‘дәҺзӢ¬зғӯзј–з Ғ
еҜ№дәҺиҝҷдёӘпјҢеҸӮж•°йҮҸ 100480 = пјҲ784 +1пјү*128пјҢеӨҡеҮәжқҘзҡ„дёҖдёӘжҳҜеҒҸзҪ®йЎ№
Denseпјҡе…ЁиҝһжҺҘеұӮпјҢдёӨеұӮй—ҙд»»ж„ҸдёӨдёӘзҘһз»Ҹе…ғй—ҙжңүиҝһжҺҘ
model = Sequential([ Input(shape=(28, 28, ), batch_size=32), Flatten(), Dense(128, activation=’relu’), Dropout(0.2), Dense(10, activation=’softmax’) ])
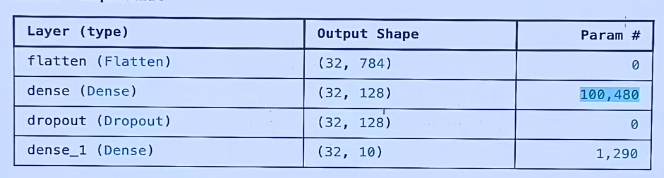
и®ӯз»ғзҘһз»ҸзҪ‘з»ң
и®ҫзҪ®жү№йҮҸbatchзҡ„еҺҹеӣ пјҡ并иЎҢи®Ўз®—дёҖдёӘе’ҢеӨҡдёӘйҖҹеәҰдёҖж ·пјӣеҺҹзҗҶжҳҜжү§иЎҢе®ҢжҜҸдёӘbatchиҝӣиЎҢдёҖдәӣдҝ®жӯЈ(жӢҝеӨҡдёӘзҡ„жҚҹеӨұеҖјзҡ„е№іеқҮ)пјҢжү§иЎҢе®ҢеӨҡдёӘеҶҚдҝ®жӯЈж•ҲжһңжӣҙеҘҪ
еҰӮдҪ•и®ӯз»ғзҘһз»ҸзҪ‘з»ңпјҡжўҜеәҰдёӢйҷҚпјҒ
1. еҒҡеҮәйў„жөӢ 2. и®Ўз®—жҚҹеӨұ 3. и®Ўз®—жҚҹеӨұеҮҪж•°е…ідәҺжқғйҮҚеҸӮж•°зҡ„жўҜеәҰ 4. жҢүз…§зӣёеҸҚзҡ„ж–№еҗ‘жӣҙж–°дёҖжӯҘжқғйҮҚеҸӮж•° 5. иҝӯд»ЈдёҠиҝ°иҝҮзЁӢ

Пғ = Пғ(z)(1вҲ’Пғ(z)) вүӨ 0.25 еҪ“еұӮж•°еўһеӨҡж—¶пјҢеңЁйқ еүҚзҡ„еұӮдёӯпјҢжўҜеәҰе°ұеҸҳеҫ—йқһеёёе°ҸдәҶгҖӮиҝҷе°ұжҳҜвҖңжўҜеәҰж¶ҲеӨұвҖқй—® йўҳгҖӮжӯЈеӣ дёәиҝҷдёӘеҺҹеӣ пјҢе…¶д»–зҡ„жҝҖжҙ»еҮҪж•°(дҫӢеҰӮReLU) еҸҳеҫ—жӣҙеёёи§ҒдәҶ
еҚ·з§ҜзҘһз»ҸзҪ‘з»ңпјҲCNNпјү
зӣ®ж ҮпјҡйҖҡиҝҮеҚ·з§ҜжҸҗеҸ–еұҖйғЁзҡ„зү№еҫҒпјҢдҫӢеҰӮжҸҗеҸ–еӣҫеғҸиҫ№зјҳ
е…ЁиҝһжҺҘзҪ‘з»ңзјәзӮ№пјҡ
1. иҫ“е…Ҙж•°жҚ®зҡ„еҗ„дёӘеҲҶйҮҸжҳҜеҸҜдә’жҚўзҡ„гҖӮд№ҹе°ұжҳҜиҜҙпјҢиҫ“е…ҘеҲҶйҮҸеҪјжӯӨд№Ӣй—ҙжІЎжңүд»»дҪ•зү№е®ҡзҡ„е…ізі»гҖӮдҪҶжҳҜеҜ№дәҺеӣҫ еғҸж•°жҚ®пјҢжЁЎеһӢеә”иҜҘе……еҲҶеҲ©з”Ёе…¶еҶ…еңЁзҡ„еұһжҖ§гҖӮ
2. е…ЁиҝһжҺҘзҪ‘з»ңдјҡдә§з”ҹж•°йҮҸеәһеӨ§зҡ„еҸӮж•°пјҡеҪ©иүІеӣҫеғҸйҖҡеёёдјҡжңүиҮіе°‘(200 Г— 200)еғҸзҙ Г— 3йўңиүІйҖҡйҒ“(RGB) = 120,000дёӘеҸӮж•°гҖӮеҚ•дёӘе…ЁиҝһжҺҘеұӮе°ұйңҖиҰҒ (200x200x3)^2 = 14,400,000,000 дёӘжқғйҮҚпјҒ
еҠЁжңәпјҡйңҖиҰҒжһ„е»әзҡ„зү№еҫҒпјҡиҫ№зјҳ-> еҪўзҠ¶ -> еҪўзҠ¶д№Ӣй—ҙзҡ„е…ізі»пјӣзә№зҗҶ
еҚ·з§Ҝж ё
- еҚ·з§Ҝж ёпјҡеҚ·з§Ҝж ёжҳҜдёҖдёӘжқғйҮҚзҪ‘з»ңпјҢйҖҡеёёз”ЁдәҺеӣҫеғҸеӨ„зҗҶдёӯгҖӮе®ғеғҸдёҖдёӘе°ҸзҪ‘ж јдёҖж ·иҰҶзӣ–еңЁеӣҫеғҸдёҠпјҢжҜҸж¬ЎдёҺеӣҫеғҸдёӯдёҖдёӘеғҸзҙ иҝӣиЎҢи®Ўз®—пјҢйҖҡеёёд»ҘиҝҷдёӘеғҸзҙ дёәдёӯеҝғиҝӣиЎҢж“ҚдҪңгҖӮ
- еҚ·з§Ҝж ёе°әеҜёпјҡеҚ·з§Ҝж ёдёҖж¬ЎеҸҜд»ҘвҖңзңӢеҲ°вҖқзҡ„еғҸзҙ ж•°йҮҸпјӣе…ёеһӢжғ…еҶөдёӢдёәеҘҮж•°пјҢеӣ дёәжңүдёҖдёӘеұ…дёӯеғҸзҙ пјӣеҚ·з§Ҝж ёдёҚдёҖе®ҡйқһиҰҒжҳҜжӯЈж–№еҪўзҡ„гҖӮ
- иҫ№зјҳж•Ҳеә”пјҡеҪ“еҚ·з§Ҝж ёж»‘еҠЁеҲ°еӣҫеғҸиҫ№зјҳж—¶пјҢе®ғдјҡйҒҮеҲ°й—®йўҳпјҢеӣ дёәеӣҫеғҸзҡ„иҫ№зјҳжІЎжңүи¶іеӨҹзҡ„еғҸзҙ жқҘж”ҜжҢҒе®Ңж•ҙзҡ„еҚ·з§Ҝж“ҚдҪңгҖӮдҫӢеҰӮпјҢеҪ“еҚ·з§Ҝж ёжҳҜ 5×5 ж—¶пјҢеӣҫеғҸиҫ№зјҳйғЁеҲҶе‘Ёеӣҙе°ұжІЎжңү 5×5 зҡ„еғҸзҙ еҸҜд»ҘеҸӮдёҺи®Ўз®—гҖӮдҪҝз”ЁеЎ«е……пјҲpaddingпјүгҖӮйҖҡиҝҮеңЁеӣҫеғҸиҫ№зјҳж·»еҠ йўқеӨ–еғҸзҙ пјҲйҖҡеёёдёәйӣ¶пјүпјҢдҪҝеҫ—еҚ·з§Ҝж ёиғҪеӨҹеңЁеӣҫеғҸиҫ№зјҳд№ҹиҝӣиЎҢе®Ңж•ҙзҡ„еҚ·з§Ҝж“ҚдҪңпјҢд»ҺиҖҢйҒҝе…Қиҫ№зјҳж•Ҳеә”гҖӮ
- жӯҘе№…пјҡеҚ·з§Ҝж ёз§»еҠЁзҡ„жӯҘй•ҝгҖӮдҫӢеҰӮпјҢжӯҘе№…дёә 1 ж—¶пјҢеҚ·з§Ҝж ёжҜҸж¬Ўж»‘еҠЁ 1 дёӘеғҸзҙ пјӣжӯҘе№…дёә 2 ж—¶пјҢеҚ·з§Ҝж ёжҜҸж¬Ўи·іиҝҮ 1 дёӘеғҸзҙ пјҢзӣҙжҺҘж»‘еҠЁ 2 дёӘеғҸзҙ гҖӮ
- жӯҘе№…и¶ҠеӨ§пјҢиҫ“еҮәеӣҫеғҸзҡ„е°әеҜёи¶Ҡе°ҸгҖӮеӣ дёәеҚ·з§Ҝж ёжҜҸж¬Ўи·іеҫ—жӣҙиҝңпјҢи®Ўз®—зҡ„еҢәеҹҹеҮҸе°‘дәҶпјҢеҜјиҮҙиҫ“еҮәзҡ„з»ҙеәҰеҮҸе°ҸгҖӮ
- йҖҡйҒ“е’Ңж·ұеәҰпјҡйўңиүІе’Ңзү№еҫҒз»ҙеәҰгҖӮжҜҸдёӘеғҸзҙ йҖҡеёёеҢ…еҗ«еӨҡдёӘж•°еҖјпјҲдҫӢеҰӮпјҢRGB еӣҫеғҸдёӯзҡ„зәўиүІгҖҒз»ҝиүІгҖҒи“қиүІйҖҡйҒ“пјүгҖӮиҝҷдәӣж•°еҖјеҸ«еҒҡвҖңйҖҡйҒ“вҖқпјҲchannelsпјүгҖӮ
- RGBеӣҫеғҸ вҖ“ 3йҖҡйҒ“пјҢ CMYKеӣҫеғҸ вҖ“ 4йҖҡйҒ“гҖӮ
- ж·ұеәҰпјҡеӣҫеғҸзҡ„ж·ұеәҰеҚідёәе…¶йҖҡйҒ“ж•°гҖӮеҜ№дәҺ RGB еӣҫеғҸпјҢж·ұеәҰдёә 3пјӣеҜ№дәҺзҒ°еәҰеӣҫеғҸпјҢж·ұеәҰдёә 1гҖӮ
- еҚ·з§Ҝж ёзҡ„ж·ұеәҰпјҡйҖҡйҒ“зҡ„ж•°йҮҸпјҢеҚ·з§Ҝж ёзҡ„ж·ұеәҰйҖҡеёёе’Ңиҫ“е…ҘеӣҫеғҸзҡ„йҖҡйҒ“ж•°зӣёеҗҢгҖӮдҫӢеҰӮпјҡеҜ№дәҺдёҖ дёӘеңЁRGBеӣҫеғҸдёҠзҡ„ 5 Г— 5 зҡ„еҚ·з§Ҝж ёжҖ»е…ұжңү 5 Г— 5 Г— 3 = 75 дёӘжқғйҮҚгҖӮ
- жҜҸдёҖеұӮзҡ„иҫ“еҮәж·ұеәҰпјҡеңЁеҚ·з§ҜзҘһз»ҸзҪ‘з»ңдёӯпјҢжҜҸдёҖеұӮйҖҡеёёдјҡи®ӯз»ғеӨҡдёӘеҚ·з§Ҝж ёгҖӮжҜҸдёӘеҚ·з§Ҝж ёдјҡз”ҹжҲҗдёҖеј зү№еҫҒеӣҫпјҲfeature mapпјүпјҢиҖҢжҜҸдёӘеҚ·з§Ҝж ёзҡ„иҫ“еҮәж·ұеәҰжҳҜ 1
- еҰӮжһңжҹҗдёҖеұӮдҪҝз”ЁдәҶ 10 дёӘеҚ·з§Ҝж ёпјҢйӮЈд№ҲиҜҘеұӮзҡ„иҫ“еҮәж·ұеәҰдёә 10пјҢеӣ дёәжҜҸдёӘеҚ·з§Ҝж ёйғҪдјҡз”ҹжҲҗдёҖеј зү№еҫҒеӣҫгҖӮ
еҚ·з§Ҝж ёзҡ„е·ҘдҪңеҺҹзҗҶпјҡ
еҚ·з§Ҝж ёжң¬иҙЁдёҠжҳҜдёҖдёӘжқғйҮҚзҪ‘з»ңпјҢз”ЁдәҺеӣҫеғҸеӨ„зҗҶгҖӮе®ғеғҸдёҖдёӘе°ҸзҪ‘ж јдёҖж ·иҰҶзӣ–еңЁеӣҫеғҸдёҠпјҢжҜҸж¬ЎдёҺеӣҫеғҸдёӯдёҖдёӘеғҸзҙ иҝӣиЎҢи®Ўз®—пјҢйҖҡеёёд»ҘиҜҘеғҸзҙ дёәдёӯеҝғгҖӮ
- еҚ·з§Ҝж ёдҪҚзҪ®дёҺеӣҫеғҸдәӨдә’пјҡ
- жҜҸдёӘеҚ·з§Ҝж ёйғҪдҪңз”ЁдәҺе®ғжүҖиҰҶзӣ–зҡ„еӣҫеғҸеҢәеҹҹпјҢиҝҷдёӘеҢәеҹҹйҖҡеёёжҳҜзҹ©еҪўжҲ–жӯЈж–№еҪўпјҢеҚ·з§Ҝж ёзҡ„вҖңдёӯеҝғвҖқдјҡиҰҶзӣ–еӣҫеғҸдёӯзҡ„жҹҗдёӘеғҸзҙ гҖӮ
- еңЁеҚ·з§Ҝж“ҚдҪңдёӯпјҢеҚ·з§Ҝж ёйҖҡиҝҮеҠ жқғжұӮе’ҢжқҘиҺ·еҸ–иҜҘдҪҚзҪ®зҡ„зү№еҫҒгҖӮе…¬ејҸдёәпјҡдёӢйқўвҖӢ
е…¶дёӯпјҢWpвҖӢ дёәеҚ·з§Ҝж ёзҡ„жқғйҮҚпјҢрқ‘қрқ‘–рқ‘Ҙрқ‘’рқ‘ҷрқ‘қ жҳҜеӣҫеғҸдёӯеҜ№еә”дҪҚзҪ®зҡ„еғҸзҙ еҖјпјҢрқ‘ғ дёәеҚ·з§Ҝж ёзҡ„еғҸзҙ жҖ»ж•°гҖӮ
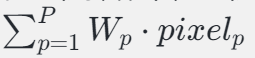
еҚ·з§Ҝж ёзҡ„еә”з”Ёпјҡ
еҚ·з§Ҝж ёдёҚд»…еә”з”ЁдәҺж·ұеәҰеӯҰд№ дёӯзҡ„еҚ·з§ҜзҘһз»ҸзҪ‘з»ңпјҲCNNпјүпјҢд№ҹе№ҝжіӣз”ЁдәҺдј з»ҹзҡ„еӣҫеғҸеӨ„зҗҶжҠҖжңҜдёӯпјҢе…·дҪ“еҢ…жӢ¬пјҡ
- жЁЎзіҠеҢ–пјҲBlurпјүпјҡйҖҡиҝҮеҠ жқғе№іеқҮеғҸзҙ еҖјжқҘжЁЎзіҠеӣҫеғҸгҖӮ
- й”җеҢ–пјҲSharpeningпјүпјҡйҖҡиҝҮзү№е®ҡзҡ„жқғйҮҚпјҢи®©еӣҫеғҸзҡ„иҫ№зјҳжӣҙеҠ жё…жҷ°гҖӮ
- иҫ№зјҳжЈҖжөӢпјҲEdge DetectionпјүпјҡйҖҡиҝҮжЈҖжөӢеӣҫеғҸдёӯзҡ„жҳҫи‘—еҸҳеҢ–пјҢиҜҶеҲ«зү©дҪ“зҡ„иҫ№зјҳгҖӮ
- жө®йӣ•еҢ–пјҲEmbossingпјүпјҡйҖҡиҝҮеўһеҠ еӣҫеғҸзҡ„ж·ұеәҰж„ҹжҲ–3Dж•ҲжһңпјҢиҫҫеҲ°жө®йӣ•ж•ҲжһңгҖӮ
CNN
жұ еҢ–пјҡйҖҡиҝҮе°ҶдёҖеқ—еғҸжҳ е°„дёәеҚ•дёӘеғҸзҙ жқҘйҷҚдҪҺеӣҫеғҸзҡ„е°әеҜёпјҢеҸҜд»Ҙзј©еҮҸеӣҫеғҸзҡ„з»ҙеәҰгҖӮжңүжңҖеӨ§еҖјжұ еҢ–е’Ңе№іеқҮеҖјжұ еҢ–гҖӮ
еҚ·з§ҜзҘһз»ҸзҪ‘з»ңзҡ„дё»иҰҒжҖқжғіпјҡ1.и®©зҘһз»ҸзҪ‘з»ңеӯҰд№ е“ӘдәӣеҚ·з§ҜжңҖжңүз”Ё 2.дҪҝз”ЁзӣёеҗҢзҡ„еҚ·з§Ҝж ёйӣҶеҗҲдҪңз”ЁдәҺж•ҙе№…еӣҫеғҸ(平移дёҚеҸҳжҖ§) 3.еҮҸе°‘еҸӮж•°зҡ„ж•°йҮҸпјҢеҮҸе°ҸвҖңж–№е·®вҖқ(д»ҺвҖңеҒҸе·®-ж–№е·®вҖқе№іиЎЎзҡ„и§’еәҰ)
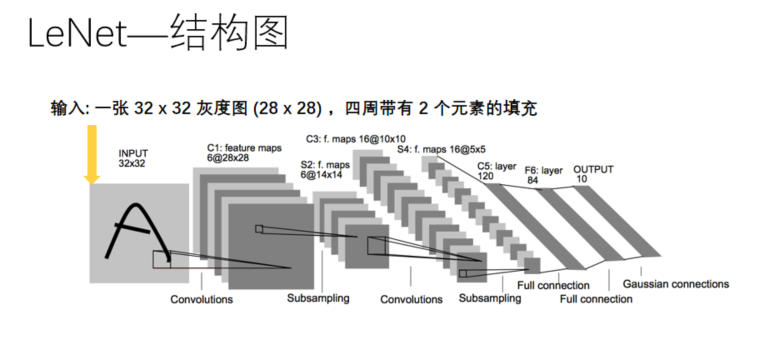
- иҫ“е…ҘеӣҫеғҸдёә32Г—32зҡ„зҒ°еәҰеӣҫгҖӮ
- C1гҖҒC3е’ҢC5жҳҜеҚ·з§ҜеұӮпјҢз”ЁжқҘжҸҗеҸ–зү№еҫҒ并з”ҹжҲҗзү№еҫҒеӣҫгҖӮ
- S2е’ҢS4жҳҜжұ еҢ–еұӮпјҢз”ЁдәҺйҷҚз»ҙ并еҮҸе°‘и®Ўз®—йҮҸгҖӮ
- F6жҳҜе…ЁиҝһжҺҘеұӮпјҢиҙҹиҙЈе°ҶжҸҗеҸ–еҲ°зҡ„зү№еҫҒиҪ¬жҚўдёәжңҖз»Ҳзҡ„еҲҶзұ»иҫ“еҮәгҖӮ
- иҫ“еҮәеұӮз»ҷеҮә10дёӘзұ»еҲ«зҡ„жҰӮзҺҮпјҢиҝӣиЎҢж•°еӯ—еҲҶзұ»гҖӮ
жҖ»жқғйҮҚ
- Conv1:5Г—5(еҚ·з§Ҝж ёе°әеҜё)Г—6(еҚ·з§Ҝж ёдёӘж•°)+6(еҒҸзҪ®йЎ№)=6Г—(5Г—5+1)=6Г—26=156
- Conv3:5Г—5Г—6(еҚ·з§Ҝж ёе°әеҜёГ—иҫ“е…ҘйҖҡйҒ“ж•°)Г—16(еҚ·з§Ҝж ёдёӘж•°)+16(еҒҸзҪ®йЎ№)=16Г—(5Г—5Г—6+1)=16Г—151=2,416
- FC1:5Г—5Г—16(еҚ·з§Ҝж ёе°әеҜёГ—иҫ“е…ҘйҖҡйҒ“ж•°)Г—120(еҚ·з§Ҝж ёдёӘж•°)+120(еҒҸзҪ®йЎ№)= 120Г—(5Г—5Г—16+1)=120Г—401=48,120
- FC2:120(иҫ“е…ҘзҘһз»Ҹе…ғж•°)Г—84(иҫ“еҮәзҘһз»Ҹе…ғж•°)=120Г—84=10,080
- FC3:84(иҫ“е…ҘзҘһз»Ҹе…ғж•°)Г—10(иҫ“еҮәзҘһз»Ҹе…ғж•°)=84Г—10=840
- ALL:156+0+2,416+0+48,120+10,080+840=61,612
иҝҷ笔еҚ•дёӘе…ЁиҝһжҺҘеұӮзҡ„жқғйҮҚйғҪе°‘гҖӮ
йҮҚзӮ№пјҡеҚ·з§ҜеұӮе…·жңүзӣёеҜ№иҫғе°‘зҡ„жқғйҮҚгҖӮ

иҮӘ然иҜӯиЁҖеӨ„зҗҶ
ж–ҮжЎЈзӣёдјјжҖ§еӨ„зҗҶ
еӨ„зҗҶж–ҮжЎЈзӣёдјјжҖ§й—®йўҳзҡ„еёёи§ҒжӯҘйӘӨеҰӮдёӢпјҢдё»иҰҒж¶үеҸҠж–Үжң¬зҡ„йў„еӨ„зҗҶгҖҒзү№еҫҒиЎЁзӨәе’ҢзӣёдјјжҖ§и®Ўз®—гҖӮ
1. еҲҶиҜҚдёҺйў„еӨ„зҗҶ
- иҜӯж–ҷеә“пјҡд№ҹз§°дёәж–Үжң¬ж•°жҚ®пјҢеҢ…еҗ«дәҶжҲ‘们иҰҒеӨ„зҗҶзҡ„жүҖжңүж–ҮжЎЈгҖӮ
- йў„еӨ„зҗҶпјҡжҢҮеҜ№ж–Үжң¬иҝӣиЎҢжё…жҙ—е’Ң规иҢғеҢ–пјҢеҢ…жӢ¬еҺ»йҷӨеҒңз”ЁиҜҚгҖҒж ҮзӮ№з¬ҰеҸ·гҖҒж•°еӯ—зӯүж— е…ідҝЎжҒҜпјҢеёёз”Ёзҡ„е·Ҙе…·еҢ…жӢ¬жӯЈеҲҷиЎЁиҫҫејҸзӯүгҖӮ
- еҲҶиҜҚпјҡе°Ҷж–Үжң¬еҲҮеҲҶжҲҗеҚ•дёӘиҜҚжұҮзҡ„иҝҮзЁӢпјҢеёёи§Ғзҡ„еҲҶиҜҚе·Ҙе…·жңүjiebaгҖҒNLTKзӯүгҖӮ
2. жһ„е»әеӯ—е…ё
д»ҺиҜӯж–ҷеә“дёӯжҸҗеҸ–еҮәжүҖжңүеҮәзҺ°зҡ„иҜҚжұҮпјҢз”ҹжҲҗиҜҚжұҮиЎЁпјҲеӯ—е…ёпјүгҖӮжҜҸдёӘиҜҚжұҮдјҡиў«иөӢдәҲдёҖдёӘе”ҜдёҖзҡ„IDпјҲиҜҚIDпјүпјҢз”ЁдәҺеҗҺз»ӯзҡ„еҗ‘йҮҸеҢ–иЎЁзӨәгҖӮ
3. жһ„е»әиҜҚиўӢжЁЎеһӢ (BOW)
- BOWжЁЎеһӢпјҡиҜҘжЁЎеһӢеҝҪз•ҘиҜҚжұҮйЎәеәҸпјҢд»…з»ҹи®ЎжҜҸдёӘиҜҚеңЁж–Үжң¬дёӯеҮәзҺ°зҡ„йў‘зҺҮгҖӮ
ж јејҸпјҡ(иҜҚID, иҜҚйў‘)пјҢдҫӢеҰӮеҜ№дәҺж–Үжң¬вҖңжҲ‘ зҲұ еӯҰд№ вҖқпјҢиҜҚиўӢжЁЎеһӢеҸҜиғҪеҸҳдёә[(жҲ‘, 1), (зҲұ, 1), (еӯҰд№ , 1)]гҖӮ
4. жһ„е»әTF-IDFиҜҚжқғйҮҚ
- TF-IDFпјҡе…Ёз§°вҖңиҜҚйў‘-йҖҶж–ҮжЎЈйў‘зҺҮвҖқпјҲTerm Frequency-Inverse Document FrequencyпјүгҖӮе®ғиЎЎйҮҸдёҖдёӘиҜҚиҜӯеҜ№дәҺдёҖзҜҮж–ҮжЎЈзҡ„йҮҚиҰҒжҖ§гҖӮ
- TF (Term Frequency)пјҡиҜҚиҜӯеңЁж–ҮжЎЈдёӯеҮәзҺ°зҡ„йў‘зҺҮгҖӮ
- IDF (Inverse Document Frequency)пјҡиҜҚиҜӯеңЁж•ҙдёӘиҜӯж–ҷеә“дёӯзҡ„йҮҚиҰҒжҖ§пјҢи¶Ҡе°‘еҮәзҺ°еңЁе…¶д»–ж–ҮжЎЈдёӯзҡ„иҜҚи¶ҠйҮҚиҰҒгҖӮ
- йҖҡиҝҮTF-IDFи®Ўз®—еҫ—еҲ°жҜҸдёӘиҜҚзҡ„жқғйҮҚпјҢеёёз”ЁдәҺж”№иҝӣBOWжЁЎеһӢпјҢдҪҝеёёи§ҒиҜҚиҜӯзҡ„еҪұе“ҚеҠӣйҷҚдҪҺгҖӮ
5. жһ„е»әN-GramдёҺPhrasesжЁЎеһӢ
- N-GramпјҡжҳҜдёҖз§ҚеҹәдәҺзӘ—еҸЈеӨ§е°Ҹзҡ„еәҸеҲ—жЁЎеһӢпјҢиЎЁзӨәж–Үжң¬дёӯиҝһз»ӯзҡ„NдёӘиҜҚгҖӮжҜ”еҰӮпјҢ2-gramиЎЁзӨәж–Үжң¬дёӯзҡ„иҝһз»ӯдёӨдёӘиҜҚпјҡ
"жҲ‘ зҲұ"гҖҒ"зҲұ еӯҰд№ "гҖӮ - PhrasesжЁЎеһӢпјҡйҖҡиҝҮN-GramжЁЎеһӢеҸ‘зҺ°жңүж„Ҹд№үзҡ„зҹӯиҜӯпјҲеҰӮвҖңеӨҸеӯЈ иҒ”иөӣвҖқпјүпјҢ并е°ҶиҝҷдәӣзҹӯиҜӯи§ҶдёәдёҖдёӘиҜҚгҖӮйҖҡиҝҮдёӢеҲ’зәҝиҝһжҺҘпјҲдҫӢеҰӮвҖңеӨҸеӯЈ_иҒ”иөӣвҖқпјүпјҢеўһејәжЁЎеһӢеҜ№еёёи§ҒиҜҚз»„зҡ„иҜҶеҲ«гҖӮ
6. дҪҝз”ЁGensimжһ„е»әLDAжЁЎеһӢ
- LDA (Latent Dirichlet Allocation)пјҡдёҖз§Қдё»йўҳжЁЎеһӢпјҢйҖҡиҝҮе®ғеҸҜд»ҘдёәжҜҸзҜҮж–ҮжЎЈз”ҹжҲҗдё»йўҳжҰӮзҺҮеҲҶеёғпјҢ并йҖҡиҝҮжҢҮе®ҡдё»йўҳж•°жқҘжүҫеҲ°жҜҸзҜҮж–ҮжЎЈзҡ„жҪңеңЁдё»йўҳгҖӮ
- LSI (Latent Semantic Indexing)пјҡеҸҰдёҖз§Қеёёз”Ёзҡ„дё»йўҳе»әжЁЎж–№жі•пјҢйҖҡиҝҮSVDеҲҶи§ЈеҜ№ж–ҮжЎЈиҝӣиЎҢйҷҚз»ҙпјҢеҶҚйҖҡиҝҮдҪҷејҰзӣёдјјеәҰжқҘи®Ўз®—ж–ҮжЎЈзӣёдјјжҖ§гҖӮ
7. и®Ўз®—ж–ҮжЎЈзӣёдјјжҖ§
- еҹәдәҺTF-IDFжҲ–LDAзӯүжЁЎеһӢзҡ„иҫ“еҮәпјҢи®Ўз®—дёҚеҗҢж–ҮжЎЈд№Ӣй—ҙзҡ„зӣёдјјеәҰгҖӮеёёи§Ғзҡ„и®Ўз®—ж–№жі•жңүдҪҷејҰзӣёдјјеәҰпјҢе®ғиЎЎйҮҸдёӨдёӘеҗ‘йҮҸеӨ№и§’зҡ„дҪҷејҰеҖјпјҢеҚіж–ҮжЎЈд№Ӣй—ҙзҡ„зӣёе…іеәҰгҖӮ
ж–Үжң¬иҪ¬жҚўдёәж•°еҖјпјҡBOWдёҺиҜҚеҗ‘йҮҸиЎЁзӨә
е°Ҷж–Үжң¬иҪ¬еҢ–дёәж•°еҖјеҪўејҸжҳҜиҮӘ然иҜӯиЁҖеӨ„зҗҶдёӯе…ій”®зҡ„дёҖжӯҘгҖӮеёёи§Ғзҡ„ж–№жі•жңүпјҡ
- иҜҚиўӢжЁЎеһӢ (BOW)пјҡз®ҖеҚ•ең°и®°еҪ•жҜҸдёӘиҜҚеңЁж–Үжң¬дёӯеҮәзҺ°зҡ„ж¬Ўж•°пјҢеҝҪз•ҘйЎәеәҸгҖӮйҖӮеҗҲдәҺз»“жһ„з®ҖеҚ•зҡ„ж–Үжң¬еҲҶжһҗгҖӮ
- иҜҚеҗ‘йҮҸ (Word2Vec, GloVe)пјҡжҜҸдёӘиҜҚйҖҡиҝҮи®ӯз»ғз”ҹжҲҗдёҖдёӘй«ҳз»ҙеҗ‘йҮҸпјҢиЎЁзӨәиҜҚиҜӯзҡ„иҜӯд№үдҝЎжҒҜгҖӮйҖӮз”ЁдәҺеӨҚжқӮиҜӯеўғдёӢзҡ„ж–Үжң¬еҲҶжһҗгҖӮ
еә”з”ЁпјҡйҖҡиҝҮдёҖз»ҙеҚ·з§ҜжҸҗеҸ–зү№еҫҒ
- дёҖз»ҙеҚ·з§ҜпјҡеңЁж–Үжң¬еҲҶзұ»дёӯпјҢйҖҡеёёз”ЁеҚ·з§ҜзҘһз»ҸзҪ‘з»ңпјҲCNNпјүжқҘеӨ„зҗҶж–Үжң¬гҖӮйҖҡиҝҮеҚ·з§ҜеұӮпјҢеҸҜд»ҘжҸҗеҸ–еӨҡдёӘеҚ•иҜҚд№Ӣй—ҙзҡ„е…ізі»пјҢд»ҺиҖҢиҺ·еҫ—ж–Үжң¬зҡ„зү№еҫҒиЎЁзӨәпјҢиҝӣиЎҢеҲҶзұ»гҖӮ
TextCNNдёҺSimpleCNNзҡ„еҢәеҲ«
- SimpleCNNпјҡйҖҡеёёжҢҮзҡ„жҳҜеҹәзЎҖзҡ„еҚ·з§ҜзҘһз»ҸзҪ‘з»ңпјҢе…¶еҚ·з§Ҝж ёеӨ§е°ҸпјҲfilter sizeпјүйҖҡеёёжҳҜеӣәе®ҡзҡ„пјҢжүҖжңүеҚ·з§Ҝж“ҚдҪңдҪҝз”ЁзӣёеҗҢзҡ„зӘ—еҸЈеӨ§е°ҸгҖӮ
- TextCNNпјҡдёәж–Үжң¬еӨ„зҗҶи®ҫи®Ўзҡ„еҚ·з§ҜзҘһз»ҸзҪ‘з»ңпјҢдҪҝз”ЁдәҶеӨҡз§ҚдёҚеҗҢеӨ§е°Ҹзҡ„еҚ·з§Ҝж ёпјҲдҫӢеҰӮпјҢ1xNгҖҒ2xNгҖҒ3xNзӯүпјүгҖӮйҖҡиҝҮе°ҶдёҚеҗҢеӨ§е°ҸеҚ·з§Ҝж ёзҡ„з»“жһңиҝӣиЎҢжӢјжҺҘпјҢTextCNNиғҪеӨҹжҚ•жҚүеҲ°ж–Үжң¬дёӯзҡ„еӨҡе°әеәҰзү№еҫҒпјҢжӣҙеҠ йҖӮеҗҲж–Үжң¬ж•°жҚ®гҖӮ
еҫӘзҺҜзҘһз»ҸзҪ‘з»ңпјҲRNNпјү
RNNпјҲеҫӘзҺҜзҘһз»ҸзҪ‘з»ңпјүжҳҜдёҖз§Қз”ЁдәҺеӨ„зҗҶеәҸеҲ—ж•°жҚ®зҡ„зҘһз»ҸзҪ‘з»ңз»“жһ„пјҢе®ғйҖҡиҝҮж—¶й—ҙжӯҘйҖҗжӯҘеӨ„зҗҶиҫ“е…Ҙж•°жҚ®пјҢ并е°ҶеҪ“еүҚзҡ„иҫ“е…ҘдёҺдёҠдёҖж—¶еҲ»зҡ„йҡҗи—ҸзҠ¶жҖҒз»“еҗҲпјҢжқҘз”ҹжҲҗеҪ“еүҚж—¶еҲ»зҡ„иҫ“еҮәгҖӮе…¶ж ёеҝғжҖқжғіжҳҜеҫӘзҺҜиҝһжҺҘпјҢдҪҝеҫ—жЁЎеһӢиғҪеӨҹи®°дҪҸд№ӢеүҚзҡ„дҝЎжҒҜпјҢд»ҺиҖҢжңүж•ҲеӨ„зҗҶж—¶й—ҙеәҸеҲ—ж•°жҚ®пјҲеҰӮж–Үжң¬гҖҒиҜӯйҹізӯүпјүгҖӮ
SimpleRNNпјҡеҹәжң¬жғіжі•пјҡдҪҝз”ЁеүҚйқўеҫ—еҲ°зҡ„з»“жһңпјҢдә§з”ҹеҗҺйқўзҡ„иҫ“еҮәгҖӮеқҸеӨ„жҳҜдёҚиғҪ并иЎҢпјҢй•ҝеәҸеҲ—ж•Ҳжһңе·®гҖӮ
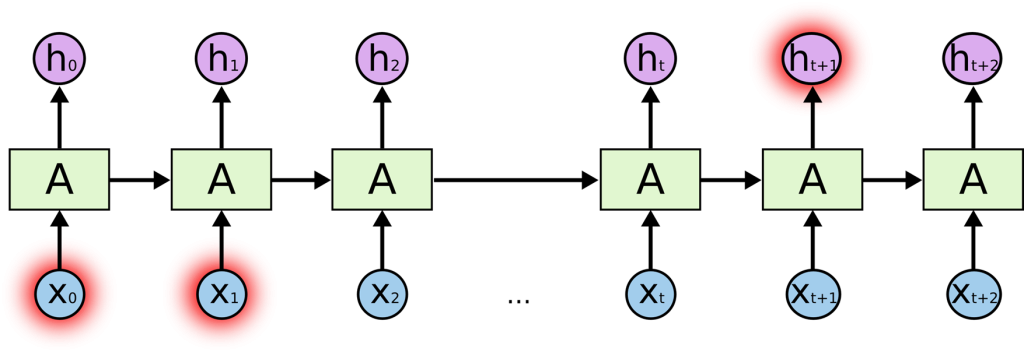
LSTMпјҡLSTMйҖҡиҝҮеј•е…ҘвҖңйҒ—еҝҳй—ЁвҖқвҖңиҫ“е…Ҙй—ЁвҖқе’ҢвҖңиҫ“еҮәй—ЁвҖқжқҘжҺ§еҲ¶дҝЎжҒҜжөҒеҠЁпјҢиҝҷдҪҝеҫ—е®ғиғҪеӨҹжңүж•Ҳең°и§ЈеҶіжўҜеәҰж¶ҲеӨұе’ҢжўҜеәҰзҲҶзӮёй—®йўҳпјҢжҚ•жҚүй•ҝжңҹдҫқиө–дҝЎжҒҜгҖӮLSTMиғҪеӨҹйҖүжӢ©жҖ§ең°вҖңеҝҳи®°вҖқжҲ–вҖңи®°дҪҸвҖқдҝЎжҒҜпјҢеӣ жӯӨеҜ№дәҺиҫғй•ҝеәҸеҲ—зҡ„еӨ„зҗҶж•ҲжһңжӣҙеҘҪгҖӮ
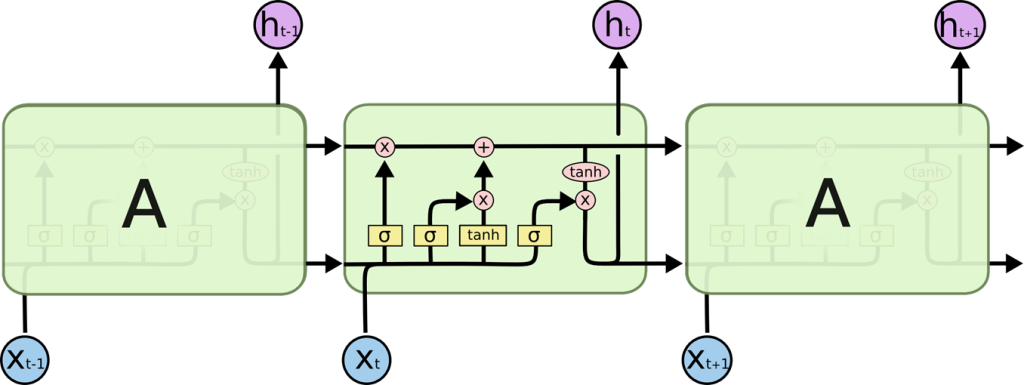
RNNзҡ„зјәзӮ№пјҡдёҚиғҪ并иЎҢпјҢжҖ»жҳҜдҫқиө–еүҚдёҖж¬Ўиҫ“е…Ҙзҡ„з»“жһңдҪңдёәиҝҷдёҖж¬Ўиҫ“е…Ҙзҡ„зү№еҫҒд№ӢдёҖпјҲдәҺжҳҜжңүдәҶ transformerпјү
йҒ—еҝҳй—ЁпјҢй•ҝеәҸеҲ—ж•Ҳжһңе·®гҖӮ
еҒҮи®ҫжҲ‘们йҖҡиҝҮи®ӯз»ғпјҢеҫ—еҲ°дәҶдёӢдёҖдёӘиҜҚзҡ„дёҚеҗҢеҸҜиғҪжҖ§пјҢд»ҘеҸҠеҜ№еә”зҡ„жҰӮзҺҮпјҢжҲ‘们еҰӮдҪ•дҝқиҜҒжҜҸдәәеҫ—еҲ°зҡ„еҖјдёҚеҗҢпјҹ
вҖ”вҖ”и®ҫзҪ®дёҖдёӘжё©еәҰпјҢжё©еәҰи¶Ҡй«ҳпјҢи¶ҠжңүеҸҜиғҪдёҚйҖүжӢ©жҰӮзҺҮжңҖй«ҳзҡ„иҜҚиҜӯгҖӮ
ChatGPT
дёҖж¬ЎеҸӘз”ҹжҲҗдёҖдёӘиҜҚгҖӮ
еҒҮи®ҫжҲ‘们йҖҡиҝҮи®ӯз»ғпјҢеҫ—еҲ°дәҶдёӢдёҖдёӘиҜҚзҡ„дёҚеҗҢеҸҜиғҪжҖ§пјҢд»ҘеҸҠеҜ№еә”зҡ„жҰӮзҺҮпјҢжҲ‘们еҰӮдҪ•дҝқиҜҒжҜҸдәәеҫ—еҲ°зҡ„еҖјдёҚеҗҢпјҹ
вҖ”вҖ”и®ҫзҪ®дёҖдёӘжё©еәҰпјҢжё©еәҰи¶Ҡй«ҳпјҢи¶ҠжңүеҸҜиғҪдёҚйҖүжӢ©жҰӮзҺҮжңҖй«ҳзҡ„иҜҚиҜӯгҖӮ
жҰӮзҺҮжҳҜеҰӮдҪ•еҫ—еҲ°зҡ„пјҹ
еҒҮи®ҫжҲ‘们еҫ—еҲ°дәҶе…ідәҺвҖңcatвҖқзҡ„иҜӯж–ҷеә“пјҢйҰ–е…ҲжҲ‘们з»ҹи®ЎжҜҸдёӘеӯ—жҜҚеҮәзҺ°зҡ„ж¬Ўж•°пјҢ然еҗҺи®©aжЁЎеһӢдә§з”ҹдёҖдәӣвҖңеҚ•иҜҚвҖқпјҢжҳҫ然иҝҷдёӘеҚ•иҜҚ并дёҚеӯҳеңЁдәҺеӯ—е…ёйҮҢпјҢжүҖд»ҘжҲ‘们иҝҳйңҖиҰҒе…іжіЁеӯ—жҜҚдёҺеӯ—жҜҚй—ҙзҡ„е…ізі»пјҢжҜ”еҰӮqеҗҺйқўз»ҸеёёеҮәзҺ°uпјҢеҶҚиҝӣиЎҢи®ӯз»ғпјҢе°ұеҸҜд»Ҙдә§з”ҹдёҖдәӣжӯЈзЎ®зҡ„еҚ•иҜҚгҖӮ(n-gram)
дә§з”ҹеҚ•иҜҚеҗҺпјҢжҲ‘们еңЁиҜҚе’ҢиҜҚд№Ӣй—ҙеҒҡеҗҢж ·зҡ„и®ӯз»ғпјҢдҪҶжҳҜиҜҚиҜӯзҡ„дёӘж•°иҝңеӨ§дәҺеӯ—з¬Ұж•°пјҢжүҖд»ҘйңҖиҰҒиҝӣиЎҢйҷҚз»ҙеӨ„зҗҶгҖӮ(transformer)
Transformer
transformerзҡ„дә§з”ҹпјҡ
еңЁCNNпјҢдёӯжҲ‘们用е°ҸеҚ·з§Ҝж ёжҸҗеҸ–е°ҸиҢғеӣҙзү№еҫҒпјҢз”ЁеӨҡеұӮеҚ·з§ҜжҸҗеҸ–й•ҝиҢғеӣҙзү№еҫҒпјҢй—®йўҳжҳҜдёҚиғҪзңӢеҮәиҜҚзҡ„йЎәеәҸпјҢиҖҢдё”еҫҲйҡҫеҸҚеә”еүҚйқўиҜҚеҜ№еҗҺйқўиҜҚзҡ„еҪұе“ҚпјӣдәҺжҳҜдә§з”ҹRNNеҸҠLSTMпјҢйҖҡиҝҮе°ҶдёҠдёҖж¬Ўиҫ“е…ҘеҸҳжҲҗдёӢдёҖж¬Ўзҡ„иҫ“еҮәпјҢиҝҷж ·еҸҜд»ҘдҝқжҢҒиҜҚдёҺиҜҚд№Ӣй—ҙзҡ„е…ізі»пјҢзјәзӮ№жҳҜдёҚиғҪ并иЎҢжү§иЎҢгҖӮдәҺжҳҜдә§з”ҹTransformer
Transformerжһ¶жһ„пјҡ
е·Ұдҫ§дёәзј–з ҒеҷЁпјҲиҫ“е…ҘдёҖеҸҘиҜқпјҢиҫ“еҮәдёҖдёІзү№еҫҒпјүпјҢеҸідҫ§дёәи§Јз ҒеҷЁпјҲз”Ёзү№еҫҒдә§з”ҹз»“жһңпјүпјҢеҸҰеӨ–йңҖиҰҒеӨҡдёӘзј–з ҒеҷЁеөҢеҘ—
дёәд»Җд№ҲйңҖиҰҒеӨҡеӨҙи®°еҝҶеҠӣпјҡиҮӘ然иҜӯиЁҖжңүжӯ§д№үгҖӮжіЁж„ҸеҠӣйңҖиҰҒйҖҡиҝҮжҹҘиҜўзҹ©йҳөQгҖҒй”®зҹ©йҳөKгҖҒеҖјзҹ©йҳөVи®Ўз®—пјҢеҫ—еҲ°дёҖдёӘжіЁж„ҸеҠӣзҹ©йҳө
дёәд»Җд№ҲжҺ©з ҒпјҡеҗҺйқўзҡ„дёңиҘҝиҝҳжІЎз”ҹжҲҗпјҢжҠҠеҗҺеҚҠиҫ№йҒ®дҪҸ
еүҚйҰҲзҪ‘з»ңеұӮзҡ„дҪңз”Ёпјҡеј•е…ҘйқһзәҝжҖ§пјҢдёҚ然f1(f2(f3(f4(x))))пјҢиҝҷд№ҲеӨҡдёӘзәҝжҖ§еҮҪж•°е®һйҷ…дёҠе°ұзӣёеҪ“дәҺдёҖдёӘзәҝжҖ§еҮҪж•°
жіЁж„ҸеҠӣпјҡд»ҺеӨ§йҮҸдҝЎжҒҜдёӯжңүйҖүжӢ©ең°зӯӣйҖүеҮәе°‘йҮҸйҮҚиҰҒдҝЎжҒҜ并иҒҡз„ҰеҲ°иҝҷдәӣйҮҚиҰҒдҝЎжҒҜдёҠпјҢеҝҪз•ҘеӨ§еӨҡдёҚйҮҚиҰҒзҡ„дҝЎ жҒҜгҖӮ
дёәдәҶеҸҚеә”иҜҚиҜӯйЎәеәҸеҜ№еҸҘеӯҗзҡ„еҪұе“ҚпјҢеҸҜд»ҘдҪҝз”ЁдҪҚзҪ®зј–з Ғ

зӣёиҫғдәҺLSTMзҡ„дјҳзӮ№пјҡзј–з ҒеҷЁеҸҜд»Ҙ并иЎҢи®Ўз®—