ن¸€ه¥—هں؛ن؛ژو ‘èژ“و´¾çڑ„èپٹه¤©وœ؛ه™¨ن؛؛
و¼”ç¤؛视频+و؛گن»£ç پï¼ڑDemo1
ه®çژ°هٹں能ï¼ڑ
ه‰چوœںه‡†ه¤‡

烧ه½•
و ‘èژ“و´¾ه‘¨è¾¹è®¾و–½éه¸¸ه®Œه–„,ن¹ںه°±وک¯è¯´ن½ هڈھ需è¦پهژ»ه®ک网ن¸‹ن¸€ن¸ھه®کو–¹é©±هٹ¨ه™¨ه°±è،Œم€‚SDهچ،ن¹°ه¥½ç‚¹çڑ„,و„ں觉64G+ه°±و¯”较足ه¤ںن؛†م€‚
https://www.raspberrypi.com/software
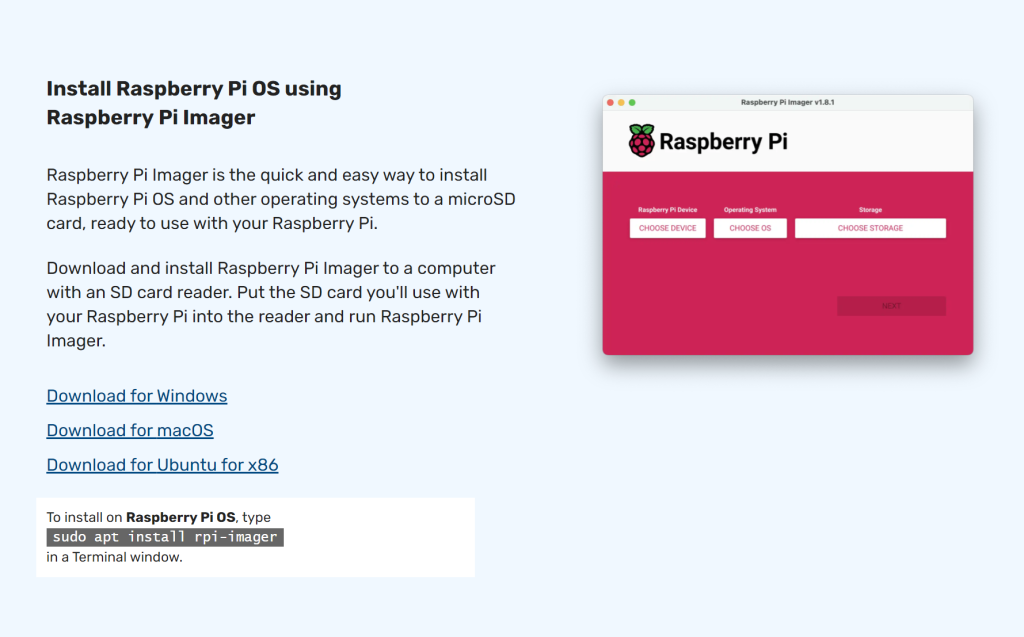
ن¸‹è½½هگژ,选و‹©ن½ çڑ„设ه¤‡ه’Œéœ€è¦په†™ه…¥çڑ„ç³»ç»ںم€‚هکه‚¨هچ،هں؛وœ¬è¯†هˆ«é£ه¸¸ه‡†ï¼Œن¸€ن¸‹ه°±çœ‹ه‡؛و¥ن؛†
هں؛وœ¬é…چن»¶ه®‰è£…
و ‘èژ“و´¾ç؛¢و¸©é€ںه؛¦وپه؟«ï¼Œه› و¤ï¼Œه¥½çڑ„و•£çƒوک¯ه¾ˆوœ‰ه؟…è¦پçڑ„م€‚

هڈچè؟‡و¥ن¸€è´´ه°±ok,ç”ڑ至贴ه؟ƒçڑ„وœ‰هچ،هڈ£م€‚و€»ن¹‹ه°±وک¯éه¸¸ه¥½ç”¨~
WIFI
و³¨و„ڈsjtuçڑ„wifi需è¦پcaè¯پن¹¦ï¼Œو ‘èژ“و´¾é»ک认و²،وœ‰م€‚è؟™é‡Œهژ»وŒ‡ه®ڑè·¯ه¾„هژ»و‰¾هچ³هڈ¯ï¼Œه…·ن½“و–¹و³•هڈ‚考è؟™éƒ¨هˆ†
https://net.sjtu.edu.cn/info/1215/2712.htm
输ه…¥و³•
https://blog.csdn.net/weixin_73412387/article/details/140137267
SSHè؟وژ¥
ه…ˆهœ¨و ‘èژ“و´¾وگهˆ°è‡ھه·±çڑ„ip,ه†چهژ»ه¼€هگ¯م€‚ه¦‚وœو²،وœ‰ه¼€هگ¯ه°±هژ»é…چç½®ن¸ه¼€هچ³هڈ¯م€‚
VNCè؟وژ¥
هڈ‚考و‰‹ه†Œï¼Œه¼€هگ¯sshهگژ,و‰“ه¼€VNC(é»ک认وœ‰ï¼‰ï¼Œو— ه±ڈه¹•و—¶ه€™هڈ¯ن»¥è™ڑو‹ںه±ڈه¹•ï¼Œvncserver-virtual 解ه†³م€‚
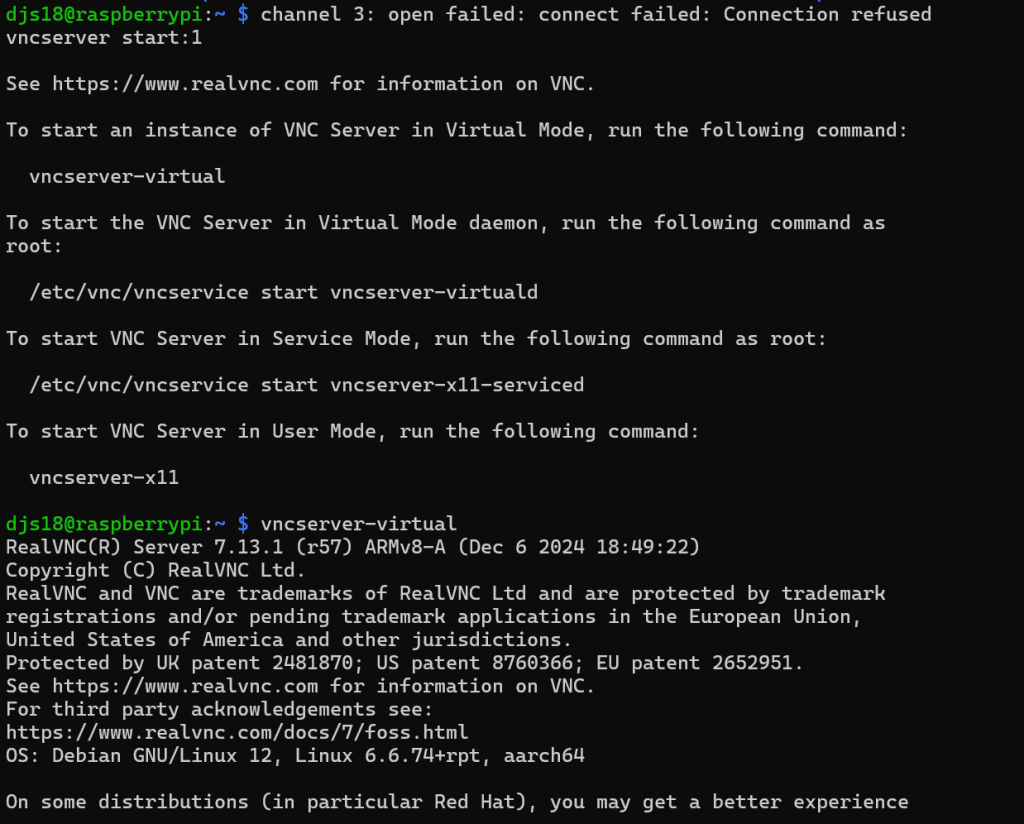
و’و”¾éں³ن¹گ
vncن¹‹é—´è؟وژ¥و—¶ه€™ه£°éں³و€»وک¯ه¼‚ه¸¸و²،هٹو³•و’و”¾ï¼Œو‰€ن»¥éœ€è¦پن½ ن¸چن½؟用و،Œé¢çژ¯ه¢ƒï¼Œç›´وژ¥ssh链وژ¥è®؟é—®وژ§هˆ¶
è؟™é‡Œç”¨ن؛†cmus,ن½؟用ه°±ç›´وژ¥cmus,调و•´ه£°éں³ï¼ڑalsamixer
Linux终端éں³ن¹گو’و”¾ه™¨: cmus – brt2 – هچڑه®¢ه›
ن¾؟وچ·ن¼ 输و–‡ن»¶
scp [هڈ‚و•°] your_file username@remote_host:target
递ه½’ه¤چهˆ¶ç›®ه½•
ه¦‚وœن½ وƒ³ه¤چهˆ¶و•´ن¸ھç›®ه½•هڈٹه…¶ه†…ه®¹ï¼Œهڈ¯ن»¥ن½؟用 -r 选é،¹م€‚ن¾‹ه¦‚,ه°†وœ¬هœ°çڑ„ my_directory ç›®ه½•ه¤چهˆ¶هˆ°è؟œç¨‹ن¸»وœ؛çڑ„ /home/user/ ç›®ه½•ن¸‹ï¼ڑ
scp -r my_directory user@remote_host:/home/user/
وŒ‡ه®ڑ端هڈ£هڈ·
ه¦‚وœè؟œç¨‹ن¸»وœ؛çڑ„ SSH وœچهٹ،è؟گè،Œهœ¨éé»ک认端هڈ£ï¼ˆن¾‹ه¦‚ 2222),ن½ هڈ¯ن»¥ن½؟用 -P 选é،¹وŒ‡ه®ڑ端هڈ£هڈ·ï¼ڑ
scp -P 2222 example.txt user@remote_host:/home/user/
è؟œç¨‹é،¹ç›®ه¼€هڈ‘
ن½؟用çڑ„pycharm,ه¥½ه¤„وک¯و–¹ن¾؟,هڈه¤„وک¯و¯”较ه¤§م€‚ه¦‚وœه†…هکو¯”较ه°‘ه»؛议用vscode
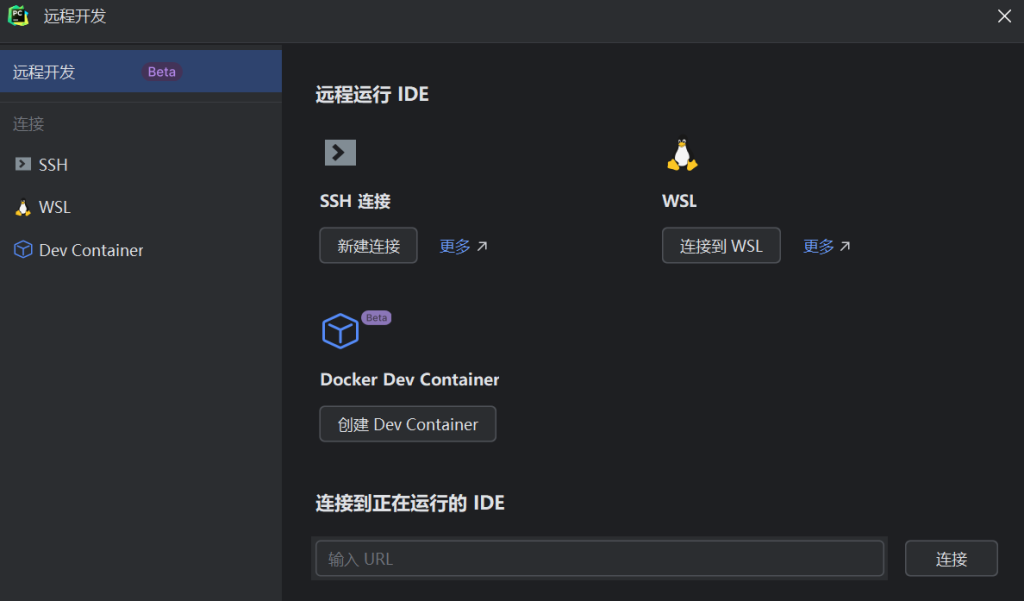
ن½؟用sshè؟وژ¥ن¹‹هگژ,ن¼ڑé»ک认هœ¨ه®¢وˆ·ç«¯ن¸‹è½½pycharmçڑ„هگژ端,هŒ…ن½“ه¤§و¦‚2g,هچ 用ه†…هکهڈ¯ن»¥è°ƒو•´ï¼Œن¸€èˆ¬è®¾ç½®ن¸چ超è؟‡و•´ن½“ه†…هکçڑ„1/3(ن½ هڈ¯ن»¥و‰‹هٹ¨è®¾ç½®ن¸ٹé™گ)
هگژç»ه¼€هڈ‘ه°±ه’Œوœ¬هœ°ن½؟用pycharmو²،وœ‰هŒ؛هˆ«ن؛†
é،¹ç›®ه¼€هڈ‘
ه¤§è¯è¨€ه¯¹è¯
让و ‘èژ“و´¾è¯´è¯هˆ†ن¸؛3部هˆ†ï¼Œهˆ†هˆ«وک¯STT(è¯éں³è½¬و–‡ه—)GPT(ه¤§è¯è¨€و¨،ه‹ï¼‰TTS(و–‡ه—转è¯éں³ï¼‰
STT
细هŒ–و¥è¯´هˆ†ن¸؛ن¸¤و¥ï¼Œن¸€وک¯è°ƒç”¨ç³»ç»ںوŒ‡ن»¤ه½•éں³ï¼Œن؛Œوک¯è°ƒç”¨ه؛“وٹٹè¯éں³è½¬و–‡ه—
ه½•éں³ï¼ڑarecord -D {device} -f cd -t wav -d {duration} {file_name}
è¯éں³è½¬و–‡ه—ï¼ڑSenseVoiceوœ¬هœ°و•ˆوœè¶³ه¤ںه¥½ï¼Œن¸”çœپçڑ„وژ¥هڈ£çڑ„钱,ه› و¤ه»؛è®®وœ¬هœ°éƒ¨ç½²م€‚
و¥éھ¤ 1. ه…‹éڑ†é،¹ç›®ه¹¶هˆ›ه»؛ python 3.8+ è™ڑو‹ںçژ¯ه¢ƒ
首ه…ˆه…‹éڑ†ه®کو–¹é،¹ç›®ه¹¶هˆ›ه»؛ن¸€ن¸ھ独立çڑ„ Python è™ڑو‹ںçژ¯ه¢ƒم€‚
git clone https://github.com/FunAudioLLM/SenseVoice.git cd SenseVoice #هˆ›ه»؛ن¸€ن¸ھ独立çڑ„ Python 3.8 è™ڑو‹ںçژ¯ه¢ƒه¹¶و؟€و´»ه®ƒ conda create -n sensevoice python=3.8 conda activate sensevoice
و¥éھ¤ 2. 然هگژه®‰è£…ن¾èµ–é،¹
至و¤ï¼Œè™ڑو‹ںçژ¯ه¢ƒه·²è¢«و؟€و´»م€‚çژ°هœ¨ن¸‹è½½ه¹¶ه®‰è£…é،¹ç›®و‰€ن¾èµ–çڑ„第ن¸‰و–¹è½¯ن»¶هŒ…م€‚
# ه®کو–¹ن¸‹è½½
pip install -r requirements.txt
# ه¦‚وœç§ںèµپçڑ„وœچهٹ،ه™¨هœ¨ن¸ه›½ه¤§é™†ï¼Œéœ€è¦پن½؟用ه›½ه†…çڑ„é•œهƒڈ
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com
و¥éھ¤ 3. هگ¯هٹ¨ SenseVoice WebUI
و¨،ه‹و–‡ن»¶éه¸¸ه¤§ï¼Œن¸‹è½½éœ€è¦په¾ˆé•؟و—¶é—´م€‚ه®Œوˆگهگژ,ن½؟用ن»¥ن¸‹ه‘½ن»¤هگ¯هٹ¨وœچهٹ،ï¼ڑ
python webui.py
çژ°هœ¨ï¼Œو‚¨هڈ¯ن»¥é€ڑè؟‡è®؟é—®ه±€هںں网 IP ه’Œç«¯هڈ£هڈ· 7860 è®؟问由gradientه؛“و„ه»؛çڑ„ WebUI 网络ه؛”用程ه؛ڈم€‚
GPT
وœ¬هœ°éƒ¨ç½²هڈ‚考https://www.haruhi.fans/?p=3193م€‚و ‘èژ“و´¾8Gه†…هکه¤§و¦‚هڈ¯ن»¥éƒ¨ç½²ن¸€ن¸ھ1.5Bçڑ„و¨،ه‹
TTS
وœ¬هœ°éƒ¨ç½²ن½؟用ن؛†Piper,و•ˆوœن¸€èˆ¬èˆ¬ï¼Œن½†وک¯è¶³ه¤ںه؟«ن¸”ن¸€èˆ¬و„ڈن¹‰ن¸ٹ能用https://github.com/rhasspy/piper/?tab=readme-ov-file
部署ï¼ڑ
ن¸‰é€‰ن¸€ه¼€هڈ‘هŒ…,选و‹©é€‚هگˆè‡ھه·±çڑ„
هژ»https://github.com/rhasspy/piper/blob/master/VOICES.mdè؟™é‡Œï¼Œé€‰و‹©هگˆé€‚çڑ„و¨،ه‹ï¼Œن¸‹è½½modelه’Œconfig
هˆ’هˆ°وœ€ه؛•ن¸‹éڑڈن¾؟选ن¸€ه¯¹ç»„هگˆï¼Œè²Œن¼¼mediumو•ˆوœه¥½ن¸€ن؛›

ن½؟用ï¼ڑن¼ ه…¥و–‡وœ¬ç»™piper,选و‹©وŒ‡ه®ڑçڑ„و¨،ه‹ه’Œè¾“ه‡؛و–‡ن»¶
echo ‘Welcome to the world of speech synthesis!’ | \
./piper –model zh_CN-huayan-medium.onnx –output_file welcome.wav
و¼”ç¤؛视频
Demo1+و؛گن»£ç پ
ه†چن¸چو£’读ن؛†ًںکًںک,ه£°éں³ه¥½ن؛–ه®…ه•ٹ