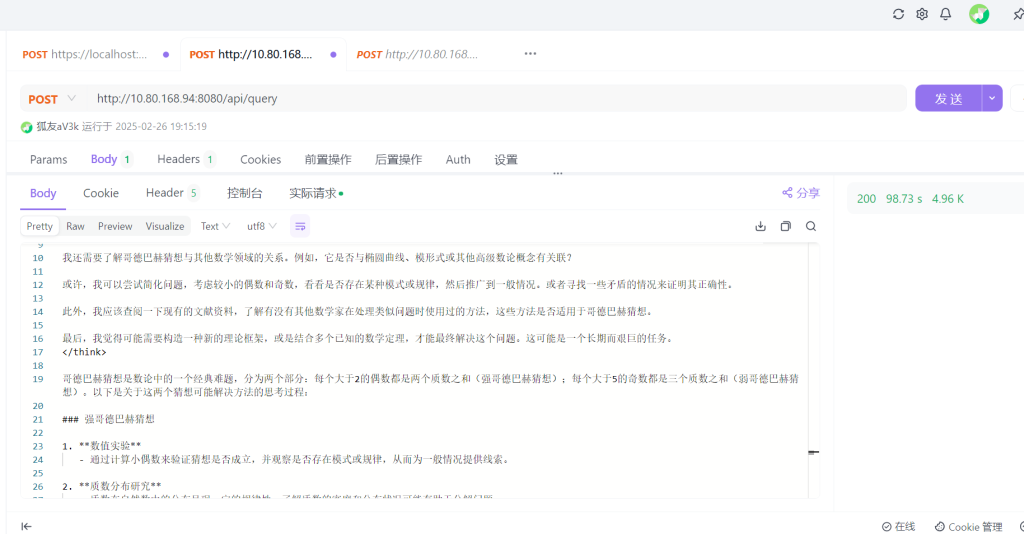
дё»иҰҒжҳҜжғіиҰҒжҸҗдҫӣдёҖдёӘapiпјҢдҫӣиҮӘе·ұзҺ©гҖӮ
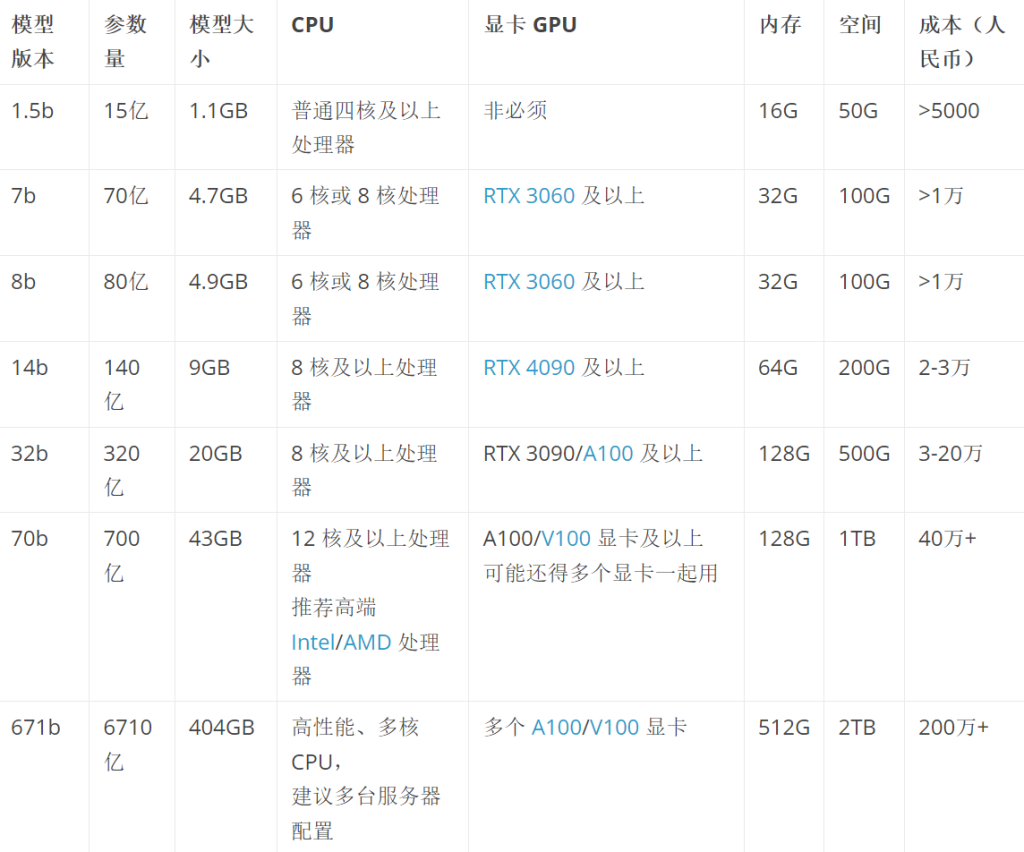
дёҖиҲ¬й…ҚзҪ®йңҖжұӮеҰӮдёӢеӣҫпјҢдҪҶжҳҜеҸҜд»Ҙз”Ёcpuи·‘гҖӮе®һйҷ…дёҠпјҢжҲ‘еңЁй”җйҫҷ8845HSдёҠи·‘14BжЁЎеһӢз»°з»°жңүдҪҷпјҢиҷҪ然ж•ҲзҺҮдёҚй«ҳдҪҶеҹәжң¬еҸҜз”ЁгҖӮиҖҢдё”иҝҷжҳҜиҖғиҷ‘еҲ°еҮ д№ҺзәҜCPUеңЁи·‘пјҲand gpuжҡӮж— еҘҪзҡ„йҖӮй…Қпјү
жӯҘйӘӨеҲҶжҲҗдёӨдёӘйғЁеҲҶпјҢдёҖжҳҜйғЁзҪІпјҢдәҢжҳҜapiжңҚеҠЎгҖӮиҚүеұҘиҷ«йғҪдјҡеҒҡ
жң¬ең°йғЁзҪІ
еҺ»дёӢиҪҪпјҢжүҫиҮӘе·ұзҡ„зі»з»ҹhttps://ollama.com

дёӢиҪҪе®ҢжҲҗеҗҺhttps://ollama.com/searchеҺ»жүҫжЁЎеһӢгҖӮзӣ®еүҚејҖжәҗз»јеҗҲжҖ§иғҪжңҖеҘҪжҳҜdeepseek
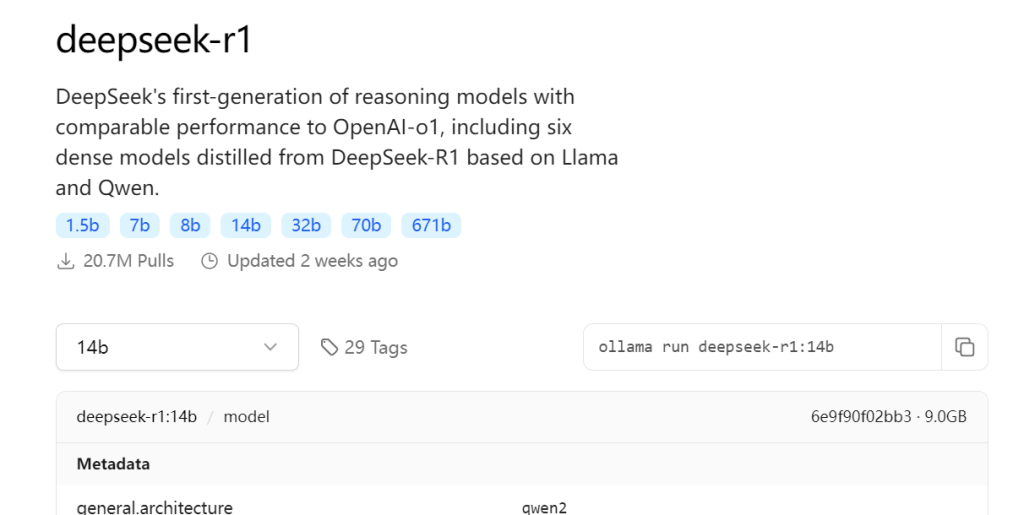
еӨҚеҲ¶е“ӘдёҖиЎҢпјҢokеҸҜд»Ҙи·‘дәҶ
ollama run deepseek-r1:14b
еҜ№иҜқеҚіеҸҜгҖӮ
WebжңҚеҠЎ
ollamaиҙҙеҝғзҡ„жҸҗдҫӣдәҶwebжҺҘеҸЈпјҢRESTful
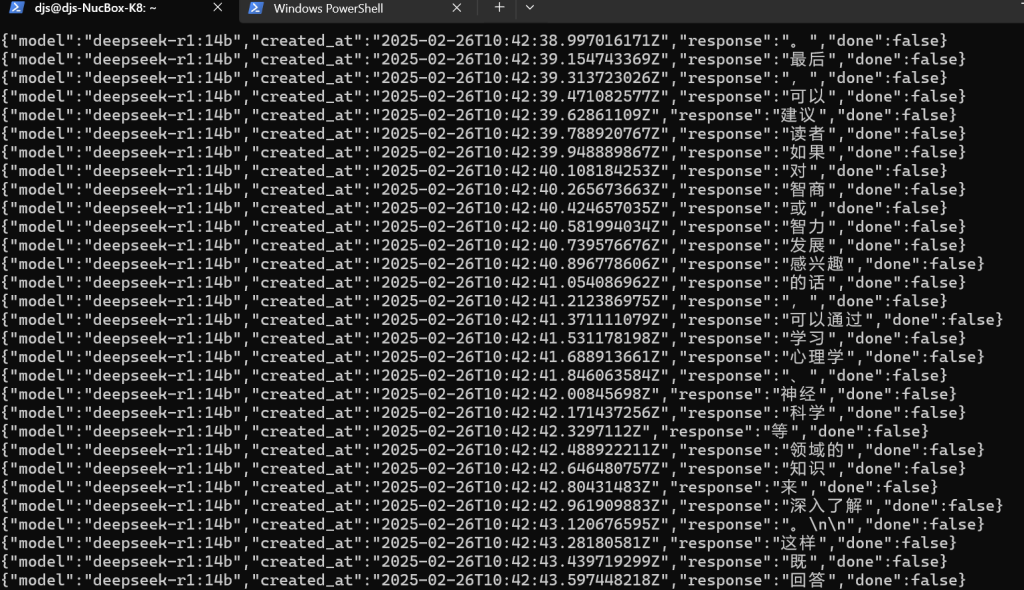
иҝҷдёӘиӮҜе®ҡдёҚжҡҙйңІзҡ„пјҢиҝ”еӣһеҖјжҳҜжөҒејҸзҡ„пјҢз»“жқҹеҗҺдјҡжҸҗзӨәdoneгҖӮ
зЁҚеҫ®еҶҷдёӘпјҲgptпјүpyеүҚз«ҜпјҢйҳІзҒ«еўҷе…ідёҖдёӢеӨ–йғЁе°ұеҸҜд»Ҙи®ҝй—®дәҶгҖӮе®һзҺ°дәҶеӨ–йғЁжҺҘеҸЈе’Ңж•ҙдҪ“иҝ”еӣһгҖӮ
from flask import Flask, request, jsonify, Response
import requests
import json # дҪҝз”Ё JSON и§ЈжһҗиҖҢйқһ eval()
app = Flask(__name__)
# еҒҮи®ҫ Ollama жЁЎеһӢиҝҗиЎҢеңЁжң¬ең°пјҢз«ҜеҸЈдёә 11434
OLLAMA_API_URL = "http://localhost:11434/api/generate"
@app.route('/api/query', methods=['POST'])
def query_model():
try:
# д»ҺиҜ·жұӮдёӯиҺ·еҸ–иҫ“е…Ҙ
data = request.json
model = data.get("model", "deepseek-r1:14b") # й»ҳи®ӨдҪҝз”Ё deepseek-r1:14b жЁЎеһӢ
prompt = data.get("prompt", "")
if not prompt:
return jsonify({"error": "No prompt provided"}), 400
# еҗ‘ Ollama зҡ„ /api/generate еҸ‘йҖҒиҜ·жұӮ
ollama_response = requests.post(
OLLAMA_API_URL,
json={"model": model, "prompt": prompt},
stream=True # ејҖеҗҜжөҒејҸеӨ„зҗҶ
)
# жЈҖжҹҘиҜ·жұӮжҳҜеҗҰжҲҗеҠҹ
if ollama_response.status_code != 200:
return jsonify({"error": f"Ollama API error: {ollama_response.status_code}"}), ollama_response.status_code
# жөҒејҸиҜ»еҸ– Ollama зҡ„е“Қеә”并жӢјжҺҘе®Ңж•ҙзҡ„з»“жһң
def generate_response():
full_response = ""
try:
for chunk in ollama_response.iter_lines(decode_unicode=True):
if chunk: # зЎ®дҝқ chunk дёҚдёәз©ә
# дҪҝз”Ё json.loads() е®үе…Ёи§Јжһҗ JSON ж•°жҚ®
try:
data = json.loads(chunk)
except json.JSONDecodeError:
yield "[Error: Invalid JSON received from Ollama]\n"
break
# д»Һи§Јжһҗзҡ„ж•°жҚ®дёӯжҸҗеҸ–е“Қеә”зүҮж®ө
response_segment = data.get("response", "")
full_response += response_segment
yield response_segment # е®һж—¶иҝ”еӣһз”ҹжҲҗзҡ„зүҮж®ө
# жЈҖжҹҘжҳҜеҗҰе®ҢжҲҗ
if data.get("done", False):
break
except Exception as e:
yield f"[Error: {str(e)}]\n"
# иҝ”еӣһжөҒејҸе“Қеә”з»ҷе®ўжҲ·з«Ҝ
return Response(generate_response(), content_type='text/plain')
except Exception as e:
# жҚ•иҺ·жүҖжңүе…¶д»–ејӮ常并иҝ”еӣһй”ҷиҜҜдҝЎжҒҜ
return jsonify({"error": str(e)}), 500
if __name__ == '__main__':
app.run(host='0.0.0.0', port=8080)apifoxжөӢдёҖжөӢпјҢйқһеёёеҘҪрҹ‘Қ