A1
з»ғд№ д»ҘдёӢдёӨдёӘ Unix е‘Ҫд»Өзҡ„ж“ҚдҪңпјҲж №жҚ® Markus Dickinson зҡ„иҜҫзЁӢж”№зј–пјүпјҡ
- д»Һ
dates_in_may.txtж–Ү件дёӯеҲӣе»әдёҖдёӘеҚ•иҜҚеҲ—иЎЁпјҢиҜҘеҲ—иЎЁжҢүеӯ—жҜҚйЎәеәҸжҺ’еәҸпјҢдҪҶжҺ’еәҸж–№ејҸжҳҜд»ҺеҸіеҲ°е·Ұзҡ„гҖӮдҫӢеҰӮпјҢtinaеә”иҜҘжҺ’еңЁangstд№ӢеүҚгҖӮжҸҗзӨәпјҡе‘Ҫд»ӨrevеҸҜд»ҘжҺҘеҸ—дёҖдёӘж–Ү件дҪңдёәеҸӮ数并еҸҚиҪ¬жҜҸиЎҢзҡ„еӯ—з¬ҰгҖӮе°ҶжүҖжңүе‘Ҫд»ӨеҶҷе…ҘдёҖдёӘж–Ү件пјҢиҫ“еҮәз»“жһңеҶҷе…ҘеҸҰдёҖдёӘж–Ү件гҖӮ - иҮӘеҠЁд»Һ
vm.posж–Ү件дёӯеҲӣе»әдёҖдёӘеҢ…еҗ«иҜҚжҖ§ж ҮжіЁпјҲPOS tagsпјүзҡ„вҖңеӯ—е…ёвҖқпјҢеҚіз”ҹжҲҗдёҖдёӘеҲ—иЎЁпјҢжҜҸиЎҢжңүдёҖдёӘиҜҚжҖ§ж ҮжіЁд»ҘеҸҠе®ғзҡ„еҮәзҺ°йў‘зҺҮгҖӮеҒҮи®ҫжүҖжңүзҡ„еӨ§еҶҷеӯ—жҜҚеӯ—з¬Ұд»ЈиЎЁиҜҚжҖ§ж ҮжіЁпјҢиҖҢе°ҸеҶҷеӯ—жҜҚеӯ—з¬Ұд»ЈиЎЁеҚ•иҜҚпјҲеӣ жӯӨеҸҜд»ҘеҲ йҷӨе°ҸеҶҷеӯ—жҜҚпјүгҖӮ
е®үиЈ…й…ҚзҪ®пјҡMobaXtermпјҢе®ҳзҪ‘дёӢиҪҪеҚіеҸҜ
д»»еҠЎдёҖпјҡйҡҫеәҰвӯҗ
ж–°жүӢжқ‘第дёҖдёӘе°ҸжҖӘ
з®ҖиҰҒжҰӮиҝ°пјҡйҖҶеәҸеҚ•иҜҚиЎЁгҖӮжҖқи·ҜжҳҜе…ҲжҠҠжҜҸдёӘеҚ•иҜҚеҸҳжҲҗзӢ¬з«ӢдёҖиЎҢпјҢеҶҚжҜҸдёҖиЎҢзҡ„еӯ—з¬ҰеҸҚиҪ¬пјҢжҢүз…§еӯ—жҜҚжҺ’еәҸпјҢеҶҚеҸҚиҪ¬еӣһеҺ»пјҢжңҖеҗҺз»“жһңеҶҚиҫ“еҮәеҲ°дёҖдёӘж–Ү件гҖӮ
и§Јзӯ”пјҡ
cat dates_in_may.txt | tr ' ' '\n'| tr 'A-Z' 'a-z'| tr -cd 'a-z\n_'| sed '/^$/d' | rev | sort | rev > a_result.txtйҖҗеҸҘи§ЈйҮҠпјҡ
cat dates_in_may.txtпјҡиҜ»ж–Ү件пјҢе°Ҷж–Ү件еҶ…е®№дҪңдёәиҫ“е…ҘжөҒгҖӮtr ' ' '\n'пјҡжҠҠжҜҸдёӘеҚ•иҜҚеҸҳжҲҗзӢ¬з«Ӣзҡ„дёҖиЎҢtr 'A-Z' 'a-z'пјҡеҝҪи§ҶеӨ§е°ҸеҶҷпјҢе…ЁйғЁеҸҳжҲҗе°ҸеҶҷпјҢеҸӘе…іеҝғе…·дҪ“зҡ„еҚ•иҜҚtr -cd 'a-z\n_'пјҡеҲ йҷӨйҷӨдәҶеӯ—жҜҚжҚўиЎҢдёӢеҲ’зәҝзҡ„еӯ—з¬ҰпјҢеӣ дёәиҖғиҷ‘еҲ°ж•°жҚ®йӣҶдёӯжңү_Sound_Pattern_of_Englishиҝҷж ·зҡ„еҚ•иҜҚгҖӮsed '/^$/d'пјҡеҲ йҷӨз©әиЎҢrevпјҡеҸҚиҪ¬жҜҸдёҖиЎҢеӯ—з¬ҰsortпјҡеҜ№дәҺеҸҚиҪ¬еҗҺеҶ…е®№жҺ’еәҸrevпјҡеҶҚеҸҚиҪ¬еӣһжқҘпјҢе®ҢжҲҗд»»еҠЎ> a_result.txtпјҡжңҖеҗҺдёҖжӯҘпјҢеҶҷе…Ҙж–Ү件дёӯ
жңҖз»Ҳз»“жһңз¬ҰеҗҲйў„жңҹпјҢйғЁеҲҶз»“жһңеҰӮдёӢгҖӮеҸҜд»ҘзңӢеҲ°жҳҜжҢүз…§еҸідҫ§cdжҺ’еәҸзҡ„

д»»еҠЎдәҢпјҡйҡҫеәҰвӯҗвӯҗ
з•Ҙеҫ®еӨҚжқӮдёҖзӮ№пјҢдҪҶд»ҚеұһдәҺз®ҖеҚ•зҡ„иҢғз•ҙ
з®ҖиҰҒжҰӮиҝ°пјҡиҝҮж»ӨеҮәTagпјҢ并з»ҹи®ЎжҺ’еәҸ
еҲҶжһҗпјҡж•°жҚ®еҶ…е®№RTпјҢйңҖиҰҒжҺ’йҷӨеҗ„з§ҚеҘҮеҘҮжҖӘжҖӘзҡ„з¬ҰеҸ·пјҢжңҖз»ҲеҸӘз•ҷдёӢWRB,VBZиҝҷж ·зҡ„гҖӮжіЁж„Ҹпјҡ第дёҖиЎҢдёӯпјҢBOSпјҢNNKд№Ӣзұ»зҡ„зј–з ҒдёҚйңҖиҰҒдҝқз•ҷпјҢжүҖд»ҘйңҖиҰҒе°Ҹеҝғзҡ„жӢҶи§ЈгҖӮ
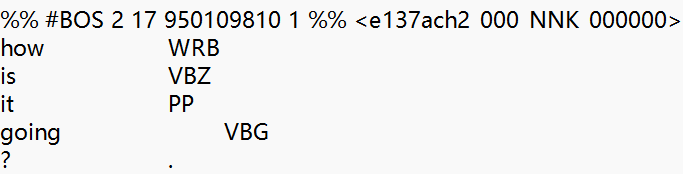
и§Јзӯ”пјҡ
cat vm.pos | tr -d 'a-z0-9[:punct:]' | sed 's/^[ \t]//;s/[ \t]$//' | sed '/^$/d' | grep '^[A-Z]*$' | sort | uniq -c | sort -nr > pos_frequency.txtcat vm.posпјҡиҜ»еҸ–ж–Ү件зҡ„еҶ…е®№гҖӮtr -d 'a-z0-9[:punct:]'пјҡеҲ йҷӨжүҖжңүзҡ„е°ҸеҶҷеӯ—жҜҚпјҲйўҳзӣ®иҜҙдәҶпјүгҖҒж•°еӯ—е’Ңж ҮзӮ№з¬ҰеҸ·пјҢдҝқз•ҷеӨ§еҶҷеӯ—жҜҚгҖӮsed 's/^[ \t]*//;s/[ \t]*$//'пјҡеҺ»йҷӨжҜҸиЎҢзҡ„еүҚеҗҺз©әж јпјҢз”ұдёҠйқўж•°жҚ®еҸҜи§ҒпјҢз©әж јз©әж јйқһеёёеӨҡгҖӮsed '/^$/d'пјҡеҲ йҷӨз©әиЎҢгҖӮgrep '^[A-Z]*$'пјҡжӯӨж—¶жҲ‘们йңҖиҰҒзҡ„ж•°жҚ®иЎҢе·Із»ҸеҸӘеү©дёӢзәҜеӨ§еҶҷеӯ—жҜҚпјҢиҖҢзј–з ҒеҶ…е®№иҝҳеҫҲж··д№ұпјҢжҲ‘们зӯӣйҖү并дҝқз•ҷеҸӘеҢ…еҗ«еӨ§еҶҷеӯ—жҜҚзҡ„иЎҢпјҢеҚіиҜҚжҖ§ж ҮжіЁгҖӮsortпјҡеҜ№иҫ“еҮәзҡ„иҜҚжҖ§ж ҮжіЁжҢүеӯ—е…ёеәҸжҺ’еәҸпјҢеӣ дёәuniq -cеҸӘиғҪз»ҹи®Ўиҝһз»ӯйҮҚеӨҚзҡ„иЎҢгҖӮuniq -cпјҡз»ҹи®ЎжҜҸдёӘиҜҚжҖ§ж ҮжіЁзҡ„еҮәзҺ°ж¬Ўж•°гҖӮsort -nrпјҡж №жҚ®йў‘зҺҮд»Һй«ҳеҲ°дҪҺжҺ’еәҸгҖӮ> pos_frequency.txtпјҡдҝқеӯҳпјҢе®ҢжҲҗд»»еҠЎ
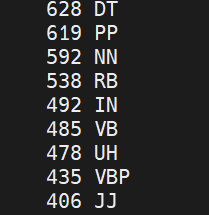
жңҖз»Ҳз»“жһңз¬ҰеҗҲйў„жңҹпјҢйғЁеҲҶз»“жһңеҰӮдёӢпјҢBOSпјҢNNKд№Ӣзұ»зҡ„зј–з ҒжІЎжңүдҝқз•ҷпјҡ
A2
дҪңдёҡиҰҒжұӮпјҡ
з”Ё Unix е‘Ҫд»Ө жқҘе®ҢжҲҗд»ҘдёӢд»»еҠЎпјҢ并ж¶үеҸҠдёӨдёӘиҜӯж–ҷеә“зҡ„жҜ”иҫғеҲҶжһҗпјҡ
- з»ҹи®ЎвҖңзҡ„вҖқзҡ„йў‘зҺҮпјҡ
- жҜ”иҫғ зҝ»иҜ‘жұүиҜӯж–Үжң¬пјҲZCTC_rawпјү е’Ң еҺҹз”ҹжұүиҜӯж–Үжң¬пјҲLCMC_rawпјү дёӯвҖңзҡ„вҖқеҮәзҺ°зҡ„йў‘зҺҮгҖӮ
- еҲҶжһҗвҖңжҳҜвҖҰзҡ„вҖқз»“жһ„зҡ„йў‘зҺҮпјҡ
- жҜ”иҫғ зҝ»иҜ‘ж–°й—»ж–Үжң¬пјҲZCTC дёӯзҡ„ A B C зұ»пјү е’Ң еҺҹз”ҹж–°й—»ж–Үжң¬пјҲLCMC дёӯзҡ„ A B C зұ»пјү дёӯвҖңжҳҜвҖҰзҡ„вҖқз»“жһ„зҡ„йў‘зҺҮгҖӮ
- жҸҗзӨәпјҡ
- йңҖиҰҒдҪҝз”ЁжӯЈеҲҷиЎЁиҫҫејҸжқҘеҢ№й…ҚвҖңжҳҜвҖҰзҡ„вҖқз»“жһ„пјҢдҫӢеҰӮвҖңжҲ‘жҳҜдәӨеӨ§зҡ„вҖқвҖңд»–жҳҜеӨҚж—Ұзҡ„вҖқгҖӮ
- дҪҝз”ЁеҲҶиҜҚеҗҺзҡ„ж–Үжң¬ж–Ү件пјҲLCMC_seg е’Ң ZCTC_segпјүгҖӮ
- з»ҹи®ЎвҖңдёҖ + йҮҸиҜҚвҖқз»“жһ„пјҡ
- ж №жҚ®ж–ҮзҢ®пјҲеҰӮ Hu and Kuebler 2021пјүзҡ„з ”з©¶пјҢзҝ»иҜ‘жұүиҜӯдёӯвҖңдёҖ + йҮҸиҜҚвҖқз»“жһ„зҡ„йў‘зҺҮй«ҳдәҺеҺҹз”ҹжұүиҜӯгҖӮ
- йӘҢиҜҒиҝҷдёҖиҜҙжі•пјҡ
- еҲҶеҲ«з»ҹи®Ў LCMC е’Ң ZCTC дёӯжңҖеёёи§Ғзҡ„ 10 дёӘвҖңдёҖ + йҮҸиҜҚвҖқз»“жһ„еҸҠе…¶йў‘зҺҮгҖӮ
- з»ҹи®ЎжҜҸдёӘиҜӯж–ҷеә“дёӯвҖңдёҖ + йҮҸиҜҚвҖқз»“жһ„зҡ„жҖ»йў‘ж•°гҖӮ
- дҪҝз”ЁеёҰжңүиҜҚжҖ§ж Үзӯҫзҡ„ж–Үжң¬ж–Ү件пјҲLCMC_wordnpos е’Ң ZCTC_wordnposпјүгҖӮ
еҲҶжһҗд»»еҠЎпјҡ
еҜ№дәҺжҲ‘们жқҘиҜҙпјҢж ёеҝғд»»еҠЎе°ұжҳҜдҪҝз”Ё Unix е‘Ҫд»ӨжқҘе®ҢжҲҗж–Үжң¬жҗңзҙўгҖҒеҢ№й…ҚгҖҒи®Ўж•°зӯүж“ҚдҪңпјҢ并记еҪ•жҜҸжқЎе‘Ҫд»Өзҡ„дҪңз”ЁгҖӮеҲҶжһҗж“ҚдҪңзҡ„з»“жһңпјҢ并讨и®әд»…дҪҝз”Ё Unix е‘Ҫд»Өе®ҢжҲҗиҝҷдәӣд»»еҠЎеҸҜиғҪеӯҳеңЁзҡ„еұҖйҷҗжҖ§гҖӮ
д»»еҠЎдёҖпјҡйҡҫеәҰвӯҗ
д»»еҠЎиҰҒжұӮпјҡеҺ»з»ҹи®Ўж–Ү件еӨ№ZCTC_rawе’ҢLCMC_rawдёӢйқўжүҖжңүж–Ү件дёӯвҖңзҡ„вҖқеҮәзҺ°йў‘зҺҮгҖӮ
и§Јзӯ”жҖқи·Ҝпјҡж–Үжң¬еҶ…е®№еҰӮдёӢеӣҫжүҖзӨәпјҢжҲ‘们еҸҜз”Ёgrep -oеҸӘеҢ№й…Қзҡ„йғЁеҲҶпјҢеҚідёҖдёӘвҖңзҡ„вҖқпјҢеҚ•еҶ…е®№зӢ¬жҲҗиЎҢпјҢ然еҗҺеҶҚз»ҹи®ЎиЎҢж•°еҚіеҸҜгҖӮ

д»Јз Ғе®һзҺ°пјҡ
# еңЁ LCMC_raw ж–Ү件еӨ№дёӯз»ҹи®ЎвҖңзҡ„вҖқзҡ„йў‘зҺҮ
grep -o 'зҡ„' LCMC_raw/* | wc -l
# еңЁ ZCTC_raw ж–Ү件еӨ№дёӯз»ҹи®ЎвҖңзҡ„вҖқзҡ„йў‘зҺҮ
grep -o 'зҡ„' ZCTC_raw/* | wc -lжңҖз»Ҳз»“жһңеҰӮдёӢпјҢеҸҜд»ҘзңӢеҮәзҝ»иҜ‘ж–Үжң¬дёӯвҖңзҡ„вҖқж•°зӣ®жҳҫи‘—й«ҳдәҺеҺҹз”ҹжұүиҜӯдёӯвҖңзҡ„вҖқж•°зӣ®

- grep -o ‘зҡ„’ LCMC_raw/*пјҡеҢ№й…Қ LCMC_raw ж–Ү件еӨ№дёӯжүҖжңүж–Ү件дёӯзҡ„вҖңзҡ„вҖқгҖӮ
- wc -lпјҡз»ҹи®ЎжҖ»йў‘зҺҮгҖӮ
дҪҶжҳҜиҝҷ并дёҚдёҘи°ЁпјҢеҫҲжҳҫ然жҲ‘们并дёҚжё…жҘҡжҖ»ж•°пјҢжӯӨж—¶зҡ„йў‘зҺҮжҳҫеҫ—жІЎжңүж„Ҹд№үгҖӮдәҺжҳҜдҪҝз”ЁдёӢйқўжҢҮд»Өз»ҹи®ЎжҖ»ж–Үжң¬ж•°пјҢеҸ‘зҺ°дәҢиҖ…ж•°зӣ®еҹәжң¬зӣёеҪ“гҖӮжүҖд»ҘжӯӨж—¶и®Өдёәзҝ»иҜ‘ж–Үжң¬дёӯвҖңзҡ„вҖқж•°зӣ®жҳҫи‘—й«ҳдәҺеҺҹз”ҹжұүиҜӯдёӯвҖңзҡ„вҖқж•°зӣ®

- wc -m LCMC_raw/*пјҡз»ҹи®ЎжҜҸдёӘж–Ү件зҡ„еӯ—з¬Ұж•°пјҢ并еҲ—еҮәжҜҸдёӘж–Ү件зҡ„з»“жһңгҖӮ
- tail -n 1пјҡеҸӘеҸ–жңҖеҗҺдёҖиЎҢзҡ„жҖ»и®ЎпјҲtotalпјүеӯ—з¬Ұж•°гҖӮ
д»»еҠЎдәҢпјҡйҡҫеәҰвӯҗпјҲвӯҗвӯҗвӯҗвӯҗпјү
д»»еҠЎиҰҒжұӮпјҡеңЁLCMC_seg е’Ң ZCTC_segж–Ү件еӨ№дёӢпјҢз»ҹи®ЎвҖқжҳҜвҖҰзҡ„вҖқз»“жһ„зҡ„йў‘зҺҮ
д»»еҠЎеҲҶжһҗпјҡж–Үжң¬е·Із»Ҹиў«еҲҶејҖпјҢзӣ®зҡ„иҝҳжҳҜжӯЈеҲҷеҢ№й…ҚгҖӮзӨәдҫӢеҶ…е®№жҰӮиҝ°дёә A жҳҜ B зҡ„гҖӮеҰӮжһңеҸӘе®һзҺ°иҝҷж ·зҡ„еҶ…е®№еҫҲз®ҖеҚ•гҖӮдҪҶеҰӮдҪ•еҢәеҲҶ A жҳҜ B е’Ң C зҡ„ пјӣ A жҳҜ B пјҢC е’Ң D зҡ„гҖӮиҝҷд»…д»…йҖҡиҝҮжӯЈеҲҷиЎЁиҫҫејҸж— жі•жҸҗеҸ–еҮәжқҘпјҢе…·дҪ“жқҘиҜҙпјҡ
- дәӨеӨ§ жҳҜ иҮӘз”ұ пјҢзҫҺдёҪ е’Ң е’Ңи°җ зҡ„
- дҪ жҳҜ и°Ғ пјҢ жҲ‘ зҡ„ жңӢеҸӢ пјҹ
еҫҲжҳҫ然пјҢ第дёҖеҸҘз¬ҰеҗҲиҰҒжұӮпјҢ第дәҢеҸҘдёҚз¬ҰеҗҲиҰҒжұӮгҖӮиҝҷдёӨеҸҘжІЎжңүеҠһжі•йҖҡиҝҮз®ҖеҚ•зҡ„йҖ»иҫ‘е°ұеҢәеҲ«еҮәжқҘпјҢеҝ…йЎ»иҰҒжҜ”еҰӮиҜҚд№үеҲҶжһҗеҗҺпјҢжүҚжңүеҸҜиғҪеҢәеҲҶеҮәжқҘгҖӮ

иҝҷйҮҢжҲ‘дёҚеҰЁеӨ§иғҶеҒҮи®ҫпјҢйңҖиҰҒзҡ„е°ұжҳҜеҪўеҰӮвҖңA жҳҜ B зҡ„вҖқиҝҷз§Қз®ҖеҚ•еҸҘпјҢиҝҷеңЁдёҖе®ҡзЁӢеәҰдёҠжҳҜеҸҜд»ҘиҜҙжҳҺи¶ӢеҠҝзҡ„гҖӮ
и§Јзӯ”пјҡ
# еңЁ ZCTC_seg ж–Ү件еӨ№дёӯз»ҹи®ЎABCзұ»дёӯвҖңжҳҜ...зҡ„вҖқзҡ„йў‘зҺҮ
grep -Eo 'жҳҜ [^ ]+ зҡ„' ZCTC_seg/ZCTC_A* ZCTC_seg/ZCTC_B* ZCTC_seg/ZCTC_C* | wc -l
# еңЁ LCMC_seg ж–Ү件еӨ№дёӯз»ҹи®ЎABCзұ»дёӯвҖңжҳҜ...зҡ„вҖқзҡ„йў‘зҺҮ
grep -Eo 'жҳҜ [^ ]+ зҡ„' LCMC_seg/LCMC_A* LCMC_seg/LCMC_B* LCMC_seg/LCMC_C* | wc -l- grep -Eo ‘жҳҜ [^ ]+ зҡ„’пјҡжӯЈеҲҷеҢ№й…Қз¬ҰеҗҲиҰҒжұӮзҡ„пјҢиЎЁиҫҫејҸиЎЁзӨәдёӯй—ҙйҷӨдәҶејҖе§Ӣз©әзҡ„дёҖж јпјҢйҮҢйқўеҝ…йЎ»жҳҜйқһз©әж јпјҢиҝҷж ·дҝқиҜҒжҳҜ зҡ„иҝҷз§ҚиҜҚиў«иҜҜе…ҘгҖӮ-EжҳҜдёәдәҶдҪҝз”Ёжү©еұ•жӯЈеҲҷиЎЁиҫҫејҸиҜӯжі•пјҢ-oдёәдәҶеҲҶиЎҢз»ҹи®Ў
- LCMC_seg/LCMC_A* LCMC_seg/LCMC_B* LCMC_seg/LCMC_C*пјҡи§ӮеҜҹж–Үд»¶ж јејҸеҫ—еҲ°зҡ„гҖӮеҺ»LCMC_segж–Ү件еӨ№дёӢпјҢеҫ—еҲ°дёүз§Қж–Ү件пјҢ他们йғҪд»ҘиҮӘе·ұзҡ„зұ»еҲ«жү“еӨҙ
wc -lпјҡз»ҹи®ЎиЎҢж•°пјҢеҫ—еҲ°йў‘зҺҮж•°гҖӮ
з»“жһңеҰӮдёӢпјҢиҜҙжҳҺеҺҹз”ҹж–°й—»дёӯвҖңжҳҜ…зҡ„вҖқеҮәзҺ°иҜ„зҺҮдҪҺдәҺзҝ»иҜ‘ж–Үжң¬гҖӮ

дҪңдёҡдёүпјҡйҡҫеәҰвӯҗвӯҗ
еңЁLCMC_wordnpos е’Ң ZCTC_wordnposж–Ү件еӨ№дёӢпјҢе®ҢжҲҗдёӨ件дәӢ
- еҲҶеҲ«з»ҹи®Ў LCMC е’Ң ZCTC дёӯжңҖеёёи§Ғзҡ„ 10 дёӘвҖңдёҖ + йҮҸиҜҚвҖқз»“жһ„еҸҠе…¶йў‘зҺҮгҖӮ
- з»ҹи®ЎжҜҸдёӘиҜӯж–ҷеә“дёӯвҖңдёҖ + йҮҸиҜҚвҖқз»“жһ„зҡ„жҖ»йў‘ж•°гҖӮ
д»»еҠЎеҲҶжһҗпјҡеҸҜд»ҘзңӢеҲ°пјҢеңЁиҝҷдёӨдёӘж–Ү件еӨ№дёӢзҡ„ж–Ү件пјҢе·Із»ҸеҒҡеҘҪдәҶиҜҚжҖ§ж ҮжіЁпјҢжүҖд»ҘеҸҜд»Ҙе…ҲеҺ»зҪ‘з«ҷжҹҘеҮәдёҖе’ҢйҮҸиҜҚеҲҶеҲ«еҜ№еә”зҡ„POS tagsпјҲдҪңдёҡж–ҮжЎЈдёӯжңүпјүпјҢ然еҗҺжӯЈеҲҷеҚіеҸҜгҖӮз»ҹи®ЎжҖ»ж•°еҲҷз®ҖеҚ•дәҶпјҢзӣҙжҺҘзңӢиЎҢж•°е°ұжҳҜз»“жһңгҖӮ

и§Јзӯ”пјҡ
# жҸҗеҸ–еҺҹз”ҹж–Үжң¬дёӯзҡ„вҖңдёҖ + йҮҸиҜҚвҖқз»“жһ„дёӯжңҖеёёи§Ғзҡ„10дёӘ
grep -Eho " дёҖ/m [^ ]+/q" LCMC_wordnpos/* | sort | uniq -c | sort -nr | head -n 10
# жҸҗеҸ–зҝ»иҜ‘ж–Үжң¬дёӯзҡ„вҖңдёҖ + йҮҸиҜҚвҖқз»“жһ„дёӯжңҖеёёи§Ғзҡ„10дёӘ
grep -Eho " дёҖ/m [^ ]+/q" ZCTC_wordnpos/* | sort | uniq -c | sort -nr | head -n 10
# з»ҹи®ЎеҺҹз”ҹж–Үжң¬дёӯвҖңдёҖ + йҮҸиҜҚвҖқз»“жһ„зҡ„жҖ»йў‘ж•°
grep -Eho " дёҖ/m [^ ]+/q" LCMC_wordnpos/* | wc -l
# з»ҹи®Ўзҝ»иҜ‘ж–Үжң¬дёӯвҖңдёҖ + йҮҸиҜҚвҖқз»“жһ„зҡ„жҖ»йў‘ж•°
grep -Eho " дёҖ/m [^ ]+/q" ZCTC_wordnpos/* | wc -l- grep -Ehoпјҡ-hеҝҪз•Ҙж–Ү件еҗҚз§°пјҢ-Eжү©еұ•жӯЈеҲҷиЎЁиҫҫејҸиҜӯжі•пјҢ-oдёәдәҶеҲҶиЎҢз»ҹи®Ў
- ” дёҖ/m [^ ]+/q”пјҡжҢүз…§иҜҚд№үпјҢйҮҸиҜҚдёә/qпјҢдёәдәҶдҝқиҜҒ第дёҖд№Ӣзұ»зҡ„иҜҚе№Іжү°пјҢеҠ дәҶдёҖдёӘз©әж јиЎЁзӨәеҢәеҲҶгҖӮ
- LCMC_wordnpos/*пјҡзӣ®еҪ•дёӢе…ЁйғЁж–Ү件гҖӮ
- sort | uniq -c | sort -nrпјҡз»ҹи®ЎжҜҸз§Қз»“жһ„зҡ„йў‘зҺҮпјҢ并жҢүйҷҚеәҸжҺ’еҲ—гҖӮ
- head -n 10пјҡз»ҹи®ЎеүҚеҚҒдёӘ
- wc -lпјҡз»ҹи®ЎиЎҢж•°пјҢд№ҹе°ұжҳҜжҖ»ж•°
еҰӮдёӢеӣҫжүҖзӨәпјҢTOP10еҮәзҺ°зҡ„з»„еҗҲеҰӮдёӢпјҢеҸҜд»ҘзңӢеҲ°еҹәжң¬и¶ӢеҠҝжҳҜе·®дёҚеӨҡзҡ„пјҢдҪҶжҳҜзҝ»иҜ‘ж–Үжң¬ дёҖз§Қ еҮәзҺ°зҡ„йў‘зҺҮжҳҺжҳҫиҰҒжӣҙй«ҳгҖӮ
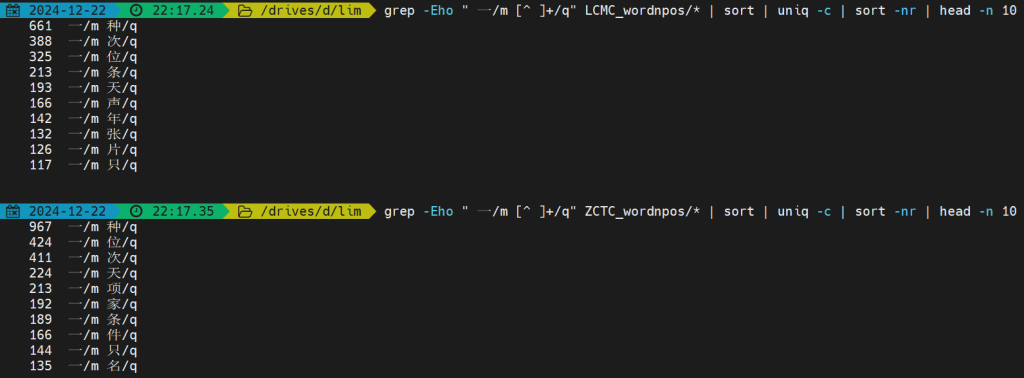
жүҖжңүеҮәзҺ°зҡ„з»„еҗҲеҶ…е®№еҰӮдёӢ

жүҖд»Ҙзҝ»иҜ‘жұүиҜӯдёӯвҖңдёҖ + йҮҸиҜҚвҖқз»“жһ„зҡ„йў‘зҺҮй«ҳдәҺеҺҹз”ҹжұүиҜӯпјҢеҹәжң¬еҫ—еҲ°йӘҢиҜҒпјҲжҖ»ж•°д№ӢеүҚе·Іе®ҢжҲҗз»ҹи®ЎпјҢе№¶ж— жҳҺжҳҫе·®ејӮпјү
A3
йҡҫеәҰпјҡвӯҗвӯҗвӯҗвӯҗ
SJTUи¶…з®—дёҚзҹҘйҒ“дёәд»Җд№ҲдёҚеҸҜд»ҘдҪҝз”ЁдәҶпјҹжҲ‘зҡ„ж•°жҚ®иҝҳеңЁйҮҢйқўе‘ўпјҒпјҹ
дёҖдёӘеҘҪж¶ҲжҒҜжҳҜд№ӢеүҚеҶҷдәҶдёҖзӮ№и®°еҪ•https://www.haruhi.fans/?p=1108пјҢеқҸж¶ҲжҒҜжҳҜдёҚз¬ҰеҗҲжҠҘе‘Ҡж јејҸпјҢе°‘жөӢдәҶеҫҲеӨҡеҫҲеӨҡдёңиҘҝгҖӮ
зӮјдё№пјҢдҪҶжҳҜеҲҶдёә3дёӘйғЁеҲҶпјҡпјҲ1пјүж•°жҚ®йў„еӨ„зҗҶпјӣпјҲ2пјүжЁЎеһӢи®ӯз»ғпјӣпјҲ3пјүжЁЎеһӢиҜ„жөӢ
пјҲ1пјүж•°жҚ®йў„еӨ„зҗҶ
ејҖе§ӢжҳҜдёҖдёӘж•°жҚ®зҡ„жё…жҙ—гҖӮжё…жҙ—иҝҮеҗҺзҡ„ж•°жҚ®ж јејҸеӨ§жҰӮжҳҜжҜҸдёҖдёӘжұүеӯ—д№Ӣй—ҙйғҪжңүдёҖдёӘз©әж јгҖӮиҮідәҺиӢұж–ҮеҚ•иҜҚпјҢжҲ‘д№ҹжҳҜеҰӮжӯӨпјҢеӣ дёәжөӢиҜ•ж•°жҚ®йӣҶеҰӮжӯӨгҖӮдёәдәҶеҸ–еҫ—жӣҙй«ҳзҡ„еҲҶж•°пјҢиҮӘ然иҰҒйқўеҗ‘ж•°жҚ®йӣҶгҖӮ
иҝҷж ·е°ұе®ҢжҲҗдәҶдёҖдёӘз®ҖеҚ•зҡ„жё…жҙ—
пјҲ2пјүжЁЎеһӢи®ӯз»ғ
жҲ‘ејҖе§ӢдҫҝжҳҜжғіиҰҒеҒҡдёҖдёӘжңҖеҘҪзҡ„жЁЎеһӢпјҢи®°еҫ—иҖҒеёҲжҸҗеҲ°еӣ°жғ‘еәҰжңҖдҪҺзҡ„дјҡз»ҷдёӘе°ҸзӨјзү©пјҲиҖҒеёҲиІҢдјјеҝҳдәҶпјҢйӮЈд№ҲжңҖеҘҪиӮҜе®ҡжҳҜиҰҒжңүжңҖеӨ§зҡ„ж•°жҚ®йҮҸпјҢжңҖй«ҳзҡ„еұӮж¬ЎпјҢеҚ з”ЁжӣҙеӨ§еҶ…еӯҳгҖӮдҪҶжҳҜеҶ…еӯҳиҝҮеӨ§дјҡиў«дәӨжҲ‘з®—жқҖдәҶпјҢеұӮиҝҮеӨҡдјҡеҜјиҮҙйқһеёёж…ўгҖӮз»ҸиҝҮдёҖдёӘtrade-offжңҖз»ҲеҰӮдёӢйқўжүҖзӨәпјҢдәӨжҲ‘еҠһ40ж ёжңәеҷЁ40-50еҲҶй’ҹеҸҜд»Ҙи·‘е®Ңи®ӯз»ғгҖӮ
cat data/full/*.txt | ./build/bin/lmplz -o 5 -S 15G > models/full/full2.arpa
пјҲ3пјүжЁЎеһӢиҜ„жөӢ
еҜ№дәҺиҝҷж ·еӨ§зҡ„дёҖдёӘжЁЎеһӢпјҢиҜ„жөӢд№ҹжҳҜиҰҒиҠұйқһеёёеӨҡж—¶й—ҙзҡ„гҖӮиҜ„жөӢдёҖж¬Ўд№ҹиҰҒе°Ҷиҝ‘1hзҡ„ж—¶й—ҙпјҢжңҖз»Ҳеӣ°жғ‘еәҰеӨ§жҰӮ56.еӨҡгҖӮ

еҰӮжһңзӣ®ж ҮжҳҜеҶІеҮ»жңҖй«ҳзҡ„еҲҶж•°пјҢйӮЈд№ҲиҝҷдёӘиҜӯж–ҷеә“е’ҢжЁЎеһӢзҡ„иғҪеҠӣдёҠйҷҗе°ұиҝҷдёӘж°ҙе№ідәҶпјҢжңҖеӨҡеӣ°жғ‘еәҰдҪҺ1-2гҖӮ4еұӮеҲ°5еұӮжЁЎеһӢ并没жңүеҸҳеҘҪеӨҡе°‘пјҢдҪҶиҠұиҙ№ж—¶й—ҙеҚҙеӨҡдәҶйқһеёёеӨҡпјҢжЁЎеһӢд№ҹеӨ§дәҶеҘҪеҮ еҖҚпјҢиҫҫеҲ°дәҶеҘҪеҮ еҚҒдёӘGгҖӮеҸҜдҫӣи°ғж•ҙзҡ„еҸӮж•°д№ҹдёҚеӨҡгҖӮиҖҢдё”еҰӮжһңжғіиҰҒеҶІеҮ»жӣҙй«ҳеҲҶж•°пјҢжҲ‘е®Ңе…ЁеҸҜд»Ҙз”ЁжӣҙеӨҡж ёжңҚеҠЎеҷЁпјҢжӣҙеӨҡж—¶й—ҙеңЁжҲ‘зҡ„еҹәзЎҖдёҠдҝ®ж”№пјҢиҝҷдёҺжЁЎеһӢи®ӯз»ғдјҳеҢ–зҡ„еҲқиЎ·дјјд№ҺжңүдәӣиҝқиғҢгҖӮ
A4
йҡҫеәҰпјҡвӯҗвӯҗвӯҗвӯҗвӯҗ
е®ҢжҲҗдёҖдёӘдёҖдёӘдёҖдёӘйҖ»иҫ‘еӣһеҪ’йЎ№зӣ®гҖӮ
й…ҚзҪ®зҺҜеўғжҺЁиҚҗиҝҷдёҖзҜҮпјҢи®Ізҡ„еҫҲиҜҰз»ҶгҖӮжҲ‘иҝҳжҳҜжҺЁиҚҗmntжҢӮеңЁеҲ°зі»з»ҹйҮҢйқўдёҖдёӘе…·дҪ“дҪҚзҪ®еҺ»пјҢиҝҷж ·ж–№дҫҝж“ҚдҪңпјҢжҜ”еҰӮиҜҙжҲ‘еңЁEзҡ„cs124ж–Ү件еӨ№зӣ®еҪ•дёӢпјҢйҮҢйқўиҜҰз»ҶжӯҘйӘӨйғҪжңүд»Ӣз»ҚгҖӮ
https://github.com/cs124/pa0-jupyter-tutorial/blob/main/platform/Windows.md
д»»еҠЎд»Ӣз»Қпјҡз®ҖеҚ•жқҘиҜҙе°ұжҳҜеҢәеҲҶеҮәдёҖжқЎж¶ҲжҒҜжҳҜеҗҰaidзҡ„дҝЎжҒҜпјҢ并且йңҖиҰҒжүҫеҲ°е’Ңж•‘жҸҙжңүе…ізҡ„дҝЎжҒҜгҖӮ
дёәжӯӨпјҢжҲ‘们иҰҒеҒҡзҡ„жҳҜеҶҷе…ӯдёӘеҮҪж•°SigmoidпјҢLogistic Loss е’Ң Logistic Regression ClassifierдёӯеӣӣдёӘпјҲ__init__пјҢtrainпјҢclassifyпјҢget_weightsпјүпјҢжңҖеҗҺжЁЎеһӢиҜ„дј°пјҢиҝӣиЎҢеҮҶзЎ®еәҰжөӢиҜ•пјҲи®ӯз»ғйӣҶе’ҢејҖеҸ‘йӣҶдёҠпјүпјҢе’ҢеҗҲзҗҶжҖ§жЈҖжҹҘ
еҮҪж•°
Sigmoid
е°ҶжЁЎеһӢзҡ„зәҝжҖ§иҫ“еҮәпјҲz = W * X + bпјүжҳ е°„еҲ°жҰӮзҺҮиҢғеӣҙ [0, 1]пјҢжҢүз…§жҸҗзӨәдҪҝз”Ёsigmoidе®ҢжҲҗд»»еҠЎгҖӮ
def sigmoid(x: np.ndarray) -> np.ndarray:
s = 1 / (1 + np.exp(-x))
return sLogistic Loss
и®Ўз®—жЁЎеһӢйў„жөӢеҖјдёҺзңҹе®һж Үзӯҫд№Ӣй—ҙзҡ„жҚҹеӨұпјҲдәӨеҸүзҶөжҚҹеӨұпјүгҖӮиҝҷйҮҢдёәдәҶйҳІжӯўlog(0) зҡ„й—®йўҳпјҢжҲ‘们еҠ е…ҘдёҖдёӘеҫҲе°Ҹзҡ„epsilonпјҢжҺҘзқҖж №жҚ®дәӨеҸүзҶөе®ҡд№үе®ҢжҲҗжӯӨеҮҪж•°пјҢжңҖеҗҺиҝ”еӣһдёҖдёӘе№іеқҮеҖјгҖӮдҪҝз”Ёnp.clipпјҲпјүжҳҜдёәдәҶдёҘж јдҝқиҜҒжҰӮзҺҮеӨ„дәҺ(0, 1) д№Ӣй—ҙ
def logistic_loss(y_pred: np.ndarray, y_true: np.ndarray) -> float:
epsilon = 1e-8
y_pred = np.clip(y_pred, epsilon, 1 - epsilon)
# ж №жҚ®е…¬ејҸи®Ўз®—йҖ»иҫ‘жҚҹеӨұ
losses = - (y_true * np.log(y_pred) + (1 - y_true) * np.log(1 - y_pred))
return np.mean(losses)дёӢйқўе°ұеҸҜд»ҘжөӢжөӢжҲ‘们зҡ„жҚҹеӨұдәҶпјҢйў„и®ЎеҖјдёҺзңҹе®һеҖји¶ҠжҺҘиҝ‘пјҢlossи¶ҠдҪҺпјҢеҸҜи§Ғи¶ӢеҠҝиҝҳжҳҜеҫҲжҳҺжҳҫзҡ„гҖӮеҸҜи§Ғе“ӘжҖ•жҳҜ0е’Ң1д№ҹжІЎжңүж— з©·еӨ§жҲ–иҖ…0пјҢеӣ дёәжҲ‘们д№ӢеүҚеҒҡдәҶepsilonзҡ„зјҳж•…гҖӮ

Logistic Regression Classifier
__init__()
еҲқе§ӢеҢ–еҲҶзұ»еҷЁзҡ„еҸӮж•°пјҲеҰӮеӯҰд№ зҺҮгҖҒиҝӯд»Јж¬Ўж•°зӯүпјүе’Ңзү№еҫҒжҸҗеҸ–еҷЁгҖӮ
дҪҶе®һйҷ…дёҠд»–з»ҷзҡ„е·Із»ҸеҫҲеӨҹз”ЁдәҶпјҢжҲ‘并没жңүд»»дҪ•зҡ„ж·»еҠ гҖӮз”ұдәҺжўҜеәҰдёӢйҷҚеҮҪж•°жҳҜдёҚи®ёеҸҳжӣҙзҡ„пјҢйӮЈжҲ‘们иҝҷйғЁеҲҶе…¶е®һиҮӘз”ұеҸ‘жҢҘз©әй—ҙд№ҹ并дёҚеӨҡгҖӮ
train()
и®ӯз»ғйҖ»иҫ‘еӣһеҪ’жЁЎеһӢгҖӮгҖӮexampleе…·дҪ“ж ·еӯҗеңЁдёҠж–ҮжҸҗеҲ°иҝҮпјҢеҸҜд»Ҙи§ҒеҲ°жҳҜдёҖдёӘVec
йӮЈд№ҲпјҢжҲ‘们йңҖиҰҒеҒҡзҡ„жҳҜиҜҚеҗ‘йҮҸеҸҳжҲҗеҸҘеӯҗпјҢеӣ дёәCountVectorizer йңҖиҰҒд»Ҙеӯ—з¬ҰдёІеҪўејҸиҫ“е…Ҙж–Үжң¬ж•°жҚ®пјҢиҖҢдёҚжҳҜеҚ•дёӘеҚ•иҜҚзҡ„еҲ—иЎЁгҖӮlabelsдёҠйқўзңӢеҲ°дәҶпјҢе°ұжҳҜ0е’Ң1пјҢз®ҖеҚ•зІ—жҡҙгҖӮ
Xж №жҚ®дёҠйқўжўҜеәҰдёӢйҷҚеҮҪж•°е®ҡд№үпјҢжҳҜдёҖдёӘnumpy arrayпјҢжҲ‘们иҰҒtoarray()жҠҠд»–иҪ¬еҸҳдёәеҜҶйӣҶзҹ©йҳөпјҢд»ҘдҫҝжҲ‘们еҸҜд»Ҙз”Ёе®ғжқҘиҝӣиЎҢжўҜеәҰдёӢйҷҚгҖӮ
def train(self, examples: List[Example]) -> None:
texts = [" ".join(example.words) for example in examples]
labels = np.array([example.label for example in examples])
self.X = self.vectorizer.fit_transform(texts).toarray()
self.y = labels
self.weights, self.bias = gradient_descent(
X=self.X,
Y=self.y,
batch_size=self.batch_size,
alpha=self.alpha,
num_iterations=self.num_iterations,
print_every=self.print_every,
epsilon=self.epsilon
)classify
з”Ёи®ӯз»ғеҘҪзҡ„жқғйҮҚе’ҢеҒҸзҪ®еҜ№ж–°ж ·жң¬иҝӣиЎҢеҲҶзұ»пјҲ0 жҲ– 1пјүгҖӮ
е…ҲеҗҢзҗҶиҪ¬жҚўдёәtexts,е°Ҷж–Үжң¬иҪ¬еҢ–дёәзү№еҫҒзҹ©йҳө,и®Ўз®—зәҝжҖ§жЁЎеһӢзҡ„иҫ“еҮә z = X * W + b,еҶҚSigmoid еҮҪж•°жҳ е°„еҲ°еҗҲзҗҶиҢғеӣҙпјҢиҝ”еӣһз»“жһңгҖӮ
def classify(self, examples: List[Example],
return_scores: bool = False) -> Union[List[int], List[float]]:
texts = [" ".join(example.words) for example in examples]
X = self.vectorizer.transform(texts).toarray()
z = np.dot(X, self.weights) + self.bias
scores = 1 / (1 + np.exp(-z))
if return_scores:
return scores.tolist()
else:
return [1 if score >= 0.5 else 0 for score in scores]get_weights
иҝ”еӣһи®ӯз»ғеҘҪзҡ„жқғйҮҚеҗ‘йҮҸгҖӮ
def get_weights(self) -> np.ndarray:
return self.weightsз»“жһңпјҡиҝҷдәӣиҜҚйғҪеҫҲз¬ҰеҗҲжҲ‘зҡ„зӣҙи§үгҖӮ
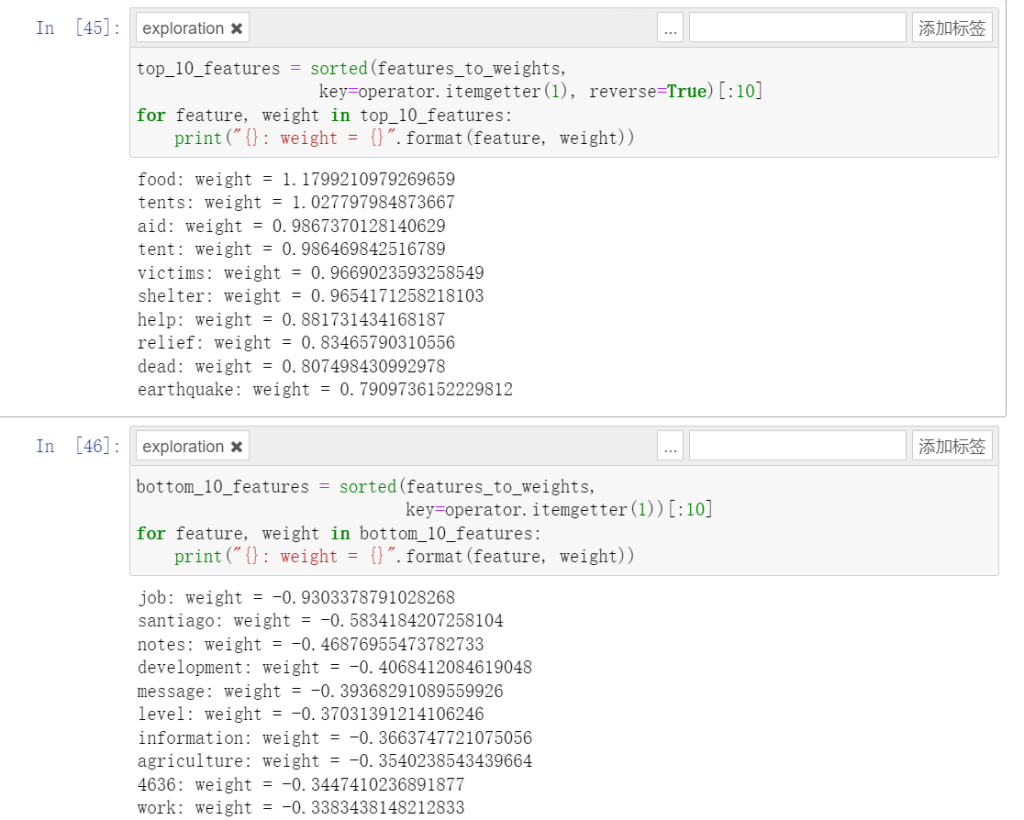
иЎЁзҺ°жқҘзңӢеҖ’д№ҹжӯЈеёёпјҢиҝҷдёӘеҮҶзЎ®еәҰдёҚзҹҘйҒ“жҳҜеҗҰеӨҹеҘҪгҖӮиҝҷе’Ңд»–з»ҷжҲ‘зҡ„з»“жһңеҖ’жҳҜйқһеёёжҺҘиҝ‘
stop_wordпјҢдёҖдәӣеёёи§ҒдҪҶж„Ҹд№үиҫғејұзҡ„иҜҚеҸҜиғҪжңүеҷӘеЈ°пјҢеҺ»жҺүгҖӮдҪҶеҜ№жҲ‘зҡ„з»“жһң并没жңүд»Җд№ҲеҪұе“ҚгҖӮдҪҶжҳҜе®һиҜқиҜҙеҜ№жҲ‘еҸҜиғҪиҝҳжҳҜеүҜдҪңз”ЁпјҢж„ҹи§үеҸҜиғҪжҳҜеӣ дёәеҰӮжһң移йҷӨдәҶеҒңз”ЁиҜҚпјҢеҸҜиғҪдјҡдёўеӨұдёҖдәӣдёҠдёӢж–ҮдҝЎжҒҜгҖӮдҫӢеҰӮпјҢвҖңlikeвҖқ жҲ– вҖңtoвҖқ зӯүиҜҚеҸҜиғҪеңЁдёҠдёӢж–Үдёӯжңүж„Ҹд№үгҖӮ

дҪҶжҳҜеҒҮйҳіжҖ§е’ҢеҒҮйҳҙжҖ§з»“жһңиҝҳжҳҜеӯҳеңЁгҖӮ
д»Һй”ҷиҜҜж ·жң¬жқҘзңӢпјҢFalse Negatives дёӯзҡ„ж–Үжң¬еҫҖеҫҖжҳҜдёҖдәӣиҜӯд№үдёҠеӨҚжқӮзҡ„еҸҘеӯҗпјҢеҸҜиғҪеӣ дёәзјәд№Ҹе…ій”®зү№еҫҒпјҲеҰӮе…ій”®иҜҚпјүжҲ–дёҠдёӢж–ҮдҝЎжҒҜпјҢеҜјиҮҙжЁЎеһӢжңӘиғҪиҜҶеҲ«еҮәе®ғ们еұһдәҺжӯЈзұ»гҖӮ
жҜ”еҰӮ第дёҖжқЎ FNпјҡ"i'd like to get more information about the possibility of"пјҢеҸҜиғҪжҜ”иҫғжЁЎзіҠпјҢ
False Positives дёӯзҡ„ж–Үжң¬йҖҡеёёеҢ…еҗ«дёҖдәӣејәзӣёе…ізҡ„иҜҚжұҮпјҲеҰӮ “food,” “water,” “help,” зӯүпјүпјҢдҪҶиҝҷдәӣиҜҚжұҮеҸҜиғҪеңЁдёҠдёӢж–Үдёӯ并жңӘзңҹжӯЈиЎЁиҫҫзҒҫйҡҫжҲ–зҙ§жҖҘжғ…еҶөпјҢиҖҢжҳҜеҮәзҺ°еңЁе…¶д»–жғ…еўғдёӯгҖӮ
第дёҖжқЎ FPпјҡ"these communities are in areas experiencing chronic food insecurity environmental problems and a general lack of basic services"
жҸҸиҝ°дәҶжҹҗдәӣеӣ°еўғпјҢдҪҶжҳҜе®һйҷ…жҳҜиҙҹзұ»гҖӮжЁЎеһӢеҸҜиғҪеӯҳеңЁжҹҗдәӣиҝҮжӢҹеҗҲпјҹеҜјиҮҙе°Ҷиҙҹзұ»ж ·жң¬иҜҜеҲӨдёәжӯЈзұ»
дёӢйқўдҝ®ж”№еҸӮж•°е°қиҜ•дјҳеҢ–гҖӮ
е…ҲжҳҜе°қиҜ•еҲҶзұ»ж ҮеҮҶз»ҷжҲҗ0.4пјҢе№¶ж— жҳҫи‘—е·®ејӮпјҢзЎ¬иҰҒиҜҙйӮЈе°ұжҳҜз•ҘжңүдёҠеҚҮ
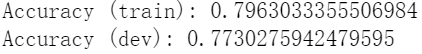

еҪ“жҲ‘ж”№жҲҗ0.6еҗҺпјҢз”ҡиҮіеҮәзҺ°дәҶдёҖе®ҡзҡ„дёӢйҷҚгҖӮзңӢжқҘзӣ®еүҚ0.5д»ҘдёӢеӨ„дәҺдёҖдёӘжҜ”иҫғеҗҲзҗҶзҡ„еҢәй—ҙ


йӮЈд№ҲеҶҚжқҘ0.3пјҢиҮӘ然жҳҫи‘—дёӢйҷҚгҖӮ


е°қиҜ•д»Һmin_dfзқҖжүӢпјҢд№ӢеүҚFNжңүдәӣдёҚе°ұжҳҜзңӢдёҚеҮәжқҘпјҢе°қиҜ•еҸҳеӨ§еҸҳе°ҸзңӢзңӢгҖӮиҝҷдёӘиЎЁзӨәCountVectorizerиҖғиҷ‘йў‘зҺҮзҡ„жңҖдҪҺеҖјгҖӮ
min_dfи®ҫзҪ®дёә10пјҢд»ҺеҮҶзЎ®еәҰжқҘзңӢпјҢemmпјҢno stopword removalзҡ„иҝҷдёӨиҖ…зҡ„еҢәеҲ«еҸҳеӨ§дәҶгҖӮи®ӯз»ғйҖҹеәҰеҸҳзҡ„йқһеёёж„ҹдәәгҖӮ


min_dfи®ҫзҪ®дёә30пјҢиӮүзңјеҸҜи§Ғи®ӯз»ғйҖҹеәҰеҝ«дәҶдёҚе°‘


д№ҹе°қиҜ•иҝҮи®ёеӨҡе…¶е®ғеҸӮж•°пјҢжҜ”еҰӮеӯҰд№ зҺҮпјҢи®ӯз»ғж•°зӯүзӯүгҖӮдҪҶжҳҜе®һйҷ…ж„ҹи§үж„Ҹд№үдёҚеӨ§пјҢAccuracyе’ҢLoss并没жңүжҳҫи‘—еҸҳеҢ–пјҢеҪ“然и®ӯз»ғи®әиҝ°еӨҡпјҢеҸҜиғҪдјҡжӣҙеҘҪдёҖзӮ№зӮ№гҖӮдҪҶжІЎжңүд»Җд№Ҳжң¬иҙЁеҢәеҲ«пјҢеҢәеҲ«еҸӘжҳҜж—¶й—ҙзҡ„й•ҝзҹӯгҖӮ
жүҖд»ҘпјҢеҰӮжһңжғіиҰҒеҫ—еҲ°жӣҙеҘҪзҡ„з»“жһңпјҢе°ұеҰӮдёҠйқўеҲҶжһҗдёҖж ·пјҢйӮЈд№ҲйңҖиҰҒзҡ„еә”иҜҘжҳҜжӣҙеҘҪзҡ„зү№еҫҒжҚ•жҚүпјҢжҚ•жҚүжӣҙж·ұзҡ„иҜҚд№үгҖӮжЁЎеһӢжүҖйҷҗпјҢдјҳеҢ–дёҠзәҝеҰӮжӯӨгҖӮ
A5
йҡҫеәҰпјҡвӯҗвӯҗвӯҗвӯҗвӯҗвӯҗвӯҗ
Part1пјҡSynonyms
еҗҢд№үиҜҚгҖӮжҲ‘们зҡ„д»»еҠЎжҳҜе®ҢжҲҗзӯ”йўҳпјҢжҜ”еҰӮиҜҙжүҫеҲ°жҲҳеЈ«зҡ„зӣёдјјзҡ„иҜҚгҖӮеҺҹзҗҶе°ұжҳҜйӮЈеҮ з§Қи·қзҰ»иЎЁзӨәзӣёдјјеәҰгҖӮиҝҷйҮҢеҸӘйңҖиҰҒе®ҢжҲҗеӣӣдёӘеҮҪж•°пјҢeuclidean_distanceпјҢcosine_similarityпјҢfind_synonymпјҢpart1_written
euclidean_distance
и®Ўз®—дёӨдёӘеҗ‘йҮҸд№Ӣй—ҙзҡ„欧ж°Ҹи·қзҰ»пјҢе°ұжҳҜз©әй—ҙдёӯдёӨзӮ№и·қзҰ»гҖӮ
np.linalg.normе°ұжҳҜз®—жіӣејҸпјҢй»ҳи®ӨжҳҜ第дәҢжіӣејҸд№ҹе°ұжҳҜ欧ж°Ҹи·қзҰ»гҖӮ
def euclidean_distance(v1, v2):
euclidean_dist = np.linalg.norm(v1 - v2)
return euclidean_dist cosine_similarity
и®Ўз®—дёӨдёӘеҗ‘йҮҸд№Ӣй—ҙзҡ„дҪҷејҰзӣёдјјеәҰпјҢи®Ўз®—дёӨдёӘеҗ‘йҮҸзҡ„зӮ№з§ҜпјҢ然еҗҺйҷӨд»Ҙе®ғ们зҡ„жЁЎпјҲеҚіеҗ‘йҮҸзҡ„й•ҝеәҰпјүжқҘеҫ—еҲ°зҡ„гҖӮеӣҫдёҠеӨ§жҰӮе°ұжҳҜдёӨдёӘеҗ‘йҮҸд№Ӣй—ҙзҡ„еӨ№и§’
def cosine_similarity(v1, v2):
dot_product = np.dot(v1, v2)
magnitude_v1 = np.linalg.norm(v1)
magnitude_v2 = np.linalg.norm(v2)
cosine_sim = dot_product / (magnitude_v1 * magnitude_v2)
return cosine_sim find_synonym
е°ұжҳҜејҖе§ӢеҒҡйўҳдәҶпјҢеҺ»ж №жҚ®зӣёдјјеәҰпјҢжүҫеҲ°жӯЈзЎ®зҡ„зӯ”жЎҲгҖӮеҰӮжһңдҪҝз”ЁдҪҷејҰзӣёдјјеәҰпјҢйҖүжӢ©зӣёдјјеәҰжңҖй«ҳзҡ„иҜҚпјӣеҰӮжһңдҪҝ用欧ж°Ҹи·қзҰ»пјҢйҖүжӢ©и·қзҰ»жңҖе°Ҹзҡ„иҜҚгҖӮеҰӮжһңдҪҝз”ЁдҪҷејҰзӣёдјјеәҰпјҲ’cosine_sim’пјүпјҢе°Ҷ best_score и®ҫдёәиҙҹж— з©·еӨ§пјҢеӣ дёәжҲ‘们еёҢжңӣжүҫеҲ°жңҖеӨ§еҖјгҖӮеҰӮжһңдҪҝ用欧еҮ йҮҢеҫ—и·қзҰ»пјҲ’euc_dist’пјүпјҢе°Ҷ best_score и®ҫдёәжӯЈж— з©·еӨ§пјҢеӣ дёәжҲ‘们еёҢжңӣжүҫеҲ°жңҖе°ҸеҖјгҖӮ
def find_synonym(word, choices, embeddings, comparison_metric):
answer = None
best_score = float('-inf') if comparison_metric == 'cosine_sim' else float('inf')
for choice in choices:
if comparison_metric == 'cosine_sim':
score = cosine_similarity(embeddings[word], embeddings[choice])
if score > best_score:
best_score = score
answer = choice
elif comparison_metric == 'euc_dist':
score = euclidean_distance(embeddings[word], embeddings[choice])
if score < best_score:
best_score = score
answer = choice
return answerpart1_written
жЁЎеһӢеҸҜиғҪдјҡйҖүжӢ©вҖңжӮІи§Ӯзҡ„вҖқиҖҢдёҚжҳҜвҖңз§ҜжһҒзҡ„вҖқпјҢеӣ дёәеңЁи®ӯз»ғж•°жҚ®дёӯпјҢвҖңд№җи§Ӯзҡ„вҖқе’ҢвҖңжӮІи§Ӯзҡ„вҖқеҸҜиғҪеңЁеҗ‘йҮҸз©әй—ҙдёӯжӣҙжҺҘиҝ‘пјҢе°Ҫз®Ўе®ғ们зҡ„ж„ҸжҖқзӣёеҸҚгҖӮ
зӯ”жЎҲдёҺйў„жңҹдёҖиҮҙпјҢ第дёҖйғЁеҲҶе®ҢжҲҗгҖӮ

Part2пјҡAnalogies
зұ»жҜ”пјҢa:b вҶ’ aa:bbпјҢжҲ‘们иҝҷйҮҢе®ҢжҲҗдёҖдёӘзұ»жҜ”зҡ„жҺЁжј”пјҢеҺҹзҗҶзұ»дјјдәҺе№іиЎҢеӣӣиҫ№еҪўгҖӮжҜ”еҰӮиҜҙвҖңз”·дәәпјҡеӣҪзҺӢ вҶ’ еҘідәәпјҡеҘізҺӢвҖқ
find_analogy_word()
a , b , aaпјҢжҲ‘们еҺ»жүҫжү“йӮЈдёӘжңҖеҘҪзҡ„bbпјҢеңЁеҖҷйҖүиҜҚеҲ—иЎЁдёӯжүҫеҲ°жңҖиғҪе®ҢжҲҗзұ»жҜ”зҡ„иҜҚпјҲеҲ©з”ЁдҪҷејҰзӣёдјјеәҰдҪңдёәзӣёдјјжҖ§еәҰйҮҸпјүгҖӮе°ұжҳҜе…Ҳе№іиЎҢеӣӣиҫ№еҪўпјҢз®—еҮәжңҹжңӣзҡ„иҫ№пјҢеҶҚжҜ”иҫғзӣёдјјеәҰпјҢйҖүжӢ©дҪҷејҰзӣёдјјеәҰжңҖеӨ§зҡ„гҖӮ
def find_analogy_word(a, b, aa, choices, embeddings):
answer = None
best_score = float('-inf')
analogy_vector = embeddings[b] - embeddings[a] + embeddings[aa]
for choice in choices:
choice_vector = embeddings[choice]
cosine_sim = np.dot(analogy_vector, choice_vector) / (
np.linalg.norm(analogy_vector) * np.linalg.norm(choice_vector)
)
if cosine_sim > best_score:
best_score = cosine_sim
answer = choice
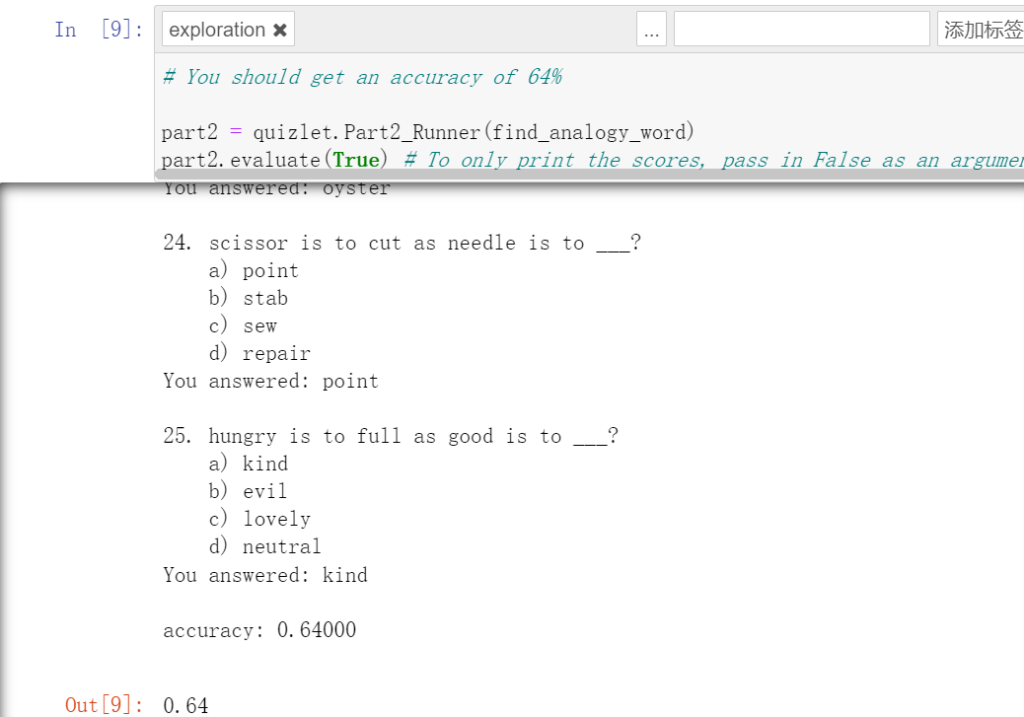
return answerжңҖз»Ҳз»“жһңеҰӮдёӢпјҢдёҺйў„жңҹдёҖиҮҙгҖӮ
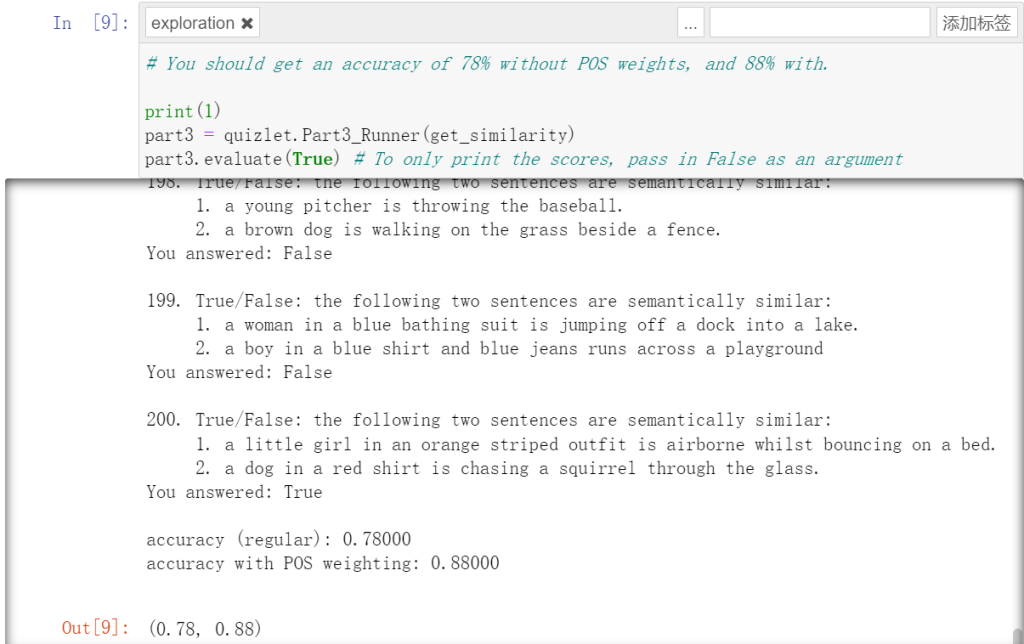
Part 3: Sentence Similarity
иҜӯеҸҘзӣёдјјгҖӮз®ҖеҚ•жқҘиҜҙпјҢз»ҷдҪ дёӨдёӘеҸҘеӯҗпјҢз”Ё0 or 1,жқҘиҜҙжҳҺдёӨдёӘеҸҘеӯҗиҜӯд№үжҳҜеҗҰжҺҘиҝ‘гҖӮжҜ”еҰӮиҜҙвҖңжҲ‘еҗғдәҶйҘӯвҖқе’ҢвҖңйҘӯиў«жҲ‘еҗғдәҶвҖқиҝҷж ·зӣёдјјгҖӮе…·дҪ“е®һзҺ°жқҘиҜҙе°ұжҳҜйҖҡиҝҮдҪҷејҰзӣёдјјеәҰпјҲcosine similarityпјүи®Ўз®—дёӨдёӘеҸҘеӯҗеөҢе…Ҙеҗ‘йҮҸд№Ӣй—ҙзҡ„зӣёдјјеәҰпјҢеҰӮжһңи¶…иҝҮдёҖе®ҡйҳҲеҖјпјҢе°ұи®Өдёә他们зӣёдјјгҖӮиҝҷйҮҢжҳҜе®һзҺ°дёӨдёӘеҮҪж•°пјҢget_embeddingе’Ңget_similarityгҖӮ
е°ҶеҸҘеӯҗиҪ¬еҢ–дёәеҚ•дёӘеҗ‘йҮҸеөҢе…Ҙзҡ„жӯҘйӘӨжңүд»ҘдёӢдёӨз§Қж–№ејҸпјҢиҰҒд№Ҳз®ҖеҚ•жұӮе’ҢпјҢжҠҠеӯҗдёӯжҜҸдёӘеҚ•иҜҚзҡ„еөҢе…Ҙеҗ‘йҮҸзӣёеҠ пјҢеҫ—еҲ°дёҖдёӘжҖ»зҡ„еҸҘеӯҗеҗ‘йҮҸгҖӮиҰҒд№ҲеҹәдәҺиҜҚжҖ§еҠ жқғжұӮе’Ң
get_embedding
е°Ҷиҫ“е…Ҙзҡ„еҸҘеӯҗиҪ¬еҢ–дёәдёҖдёӘеҸҘеӯҗеөҢе…ҘпјҲеҗ‘йҮҸиЎЁзӨәпјүгҖӮеҲқе§ӢеҢ–0еҗ‘йҮҸпјҢеҜ№дәҺwordsеҲҶиҜҚпјҢеҲӨж–ӯжҳҜеҗҰејҖжң—ж №жҚ®иҜӯд№үеҲҶиҜҚпјҢжҳҜзҡ„иҜқе…ҲиҺ·еҸ–жҜҸдёҖдёӘзҡ„иҜҚжҖ§пјҢеҠ жқғжұӮе’ҢпјҢжңҖеҗҺеҪ’дёҖеҢ–гҖӮдёҚжҳҜзҡ„иҜқжҜҸдёӘиҜҚйғҪдёҖж ·пјҢжңҖеҗҺиҝҳжҳҜеҠ жқғжұӮе’ҢгҖӮ
def get_embedding(s, embeddings, use_POS=False, POS_weights=None):
embed = np.zeros(embeddings.vector_size)
words = word_tokenize(s)
if use_POS:
tagged_tokens = nltk.pos_tag(words)
total_weight = 0.0
for word, tag in tagged_tokens:
if word in embeddings and tag in POS_weights:
embed += embeddings[word] * POS_weights[tag]
total_weight += POS_weights[tag]
if total_weight > 0:
embed /= total_weight
else:
count = 0
for word in words:
if word in embeddings:
embed += embeddings[word]
count += 1
if count > 0:
embed /= count
return embedget_similarity
и®Ўз®—дёӨдёӘеҸҘеӯҗзҡ„дҪҷејҰзӣёдјјеәҰгҖӮs1,s2е°ұжҳҜжҲ‘们йӮЈдёӨдёӘеҸҘеӯҗгҖӮ
ејҖе§Ӣе°ҶеҸҘеӯҗ s1 е’Ң s2 иҪ¬жҚўдёәеӣәе®ҡз»ҙеәҰзҡ„еөҢе…Ҙеҗ‘йҮҸ embed1 е’Ң embed2гҖӮжЈҖжҹҘдёӢдҝқиҜҒдёҚжҳҜз©әеҗ‘йҮҸпјҢи®Ўз®—жҲ‘们зҡ„дҪҷејҰзӣёдјјеәҰпјҢиҝ”еӣһеҚіеҸҜгҖӮжҳҜз©әеҗ‘йҮҸе°ұзӣҙжҺҘ0.
def get_similarity(s1, s2, embeddings, use_POS, POS_weights=None):
similarity = 0
embed1 = get_embedding(s1, embeddings, use_POS, POS_weights)
embed2 = get_embedding(s2, embeddings, use_POS, POS_weights)
if np.linalg.norm(embed1) > 0 and np.linalg.norm(embed2) > 0:
similarity = np.dot(embed1, embed2) / (np.linalg.norm(embed1) * np.linalg.norm(embed2))
else:
similarity = 0.0
return similarityеҸҜд»ҘзңӢеҲ°пјҢз»“жһңдёҺйў„жңҹе®Ңе…ЁдёҖиҮҙпјҢиЎЁжҳҺз»ҸиҝҮеҠ жқғжұӮе’Ңеҫ—еҲ°зҡ„ж•ҲжһңжӣҙеҘҪпјҢеҮҶзЎ®еәҰжӣҙй«ҳгҖӮ
Part 4: Exploration
жңүдәҶеүҚйқўзҡ„з§ҜзҙҜпјҢзҺ°еңЁе°ұеҸҜд»ҘжқҘи§ЈеҶіе®һйҷ…й—®йўҳдәҶ
occupation_exploration
йңҖиҰҒе®һзҺ°дёҖдёӘеҮҪж•°пјҢж №жҚ®иҒҢдёҡеҗҚз§°еҲ—иЎЁе’ҢиҜҚеөҢе…ҘжЁЎеһӢпјҢжүҫеҲ°дёҺеҚ•иҜҚ “man” д»ҘеҸҠ “woman” жңҖзӣёдјјзҡ„5дёӘиҒҢдёҡгҖӮиҒҢдёҡд№Ӣй—ҙзҡ„зӣёдјјеәҰдҪҝз”ЁдҪҷејҰзӣёдјјеәҰиҝӣиЎҢиЎЎйҮҸгҖӮ
е…ҲжЈҖжҹҘжҳҜеҗҰжҳҜmanе’ҢwomanпјҢжҳҜзҡ„иҜқ继з»ӯжҸҗеҸ–иҜҚеҗ‘йҮҸгҖӮ然еҗҺеҜ№дәҺеҗҲ规зҡ„иҒҢдёҡпјҢеҲҶеҲ«и®Ўз®—дҪҷејҰзӣёдјјеәҰпјҢж·»еҠ еҲ°зӣёдјјеәҰеҲ—иЎЁпјҢжңҖеҗҺжҺ’еәҸеҫ—еҲ°дәҶеүҚ5зҡ„иҒҢдёҡ
def occupation_exploration(occupations, embeddings):
top_man_occs = []
top_woman_occs = []
if 'man' not in embeddings or 'woman' not in embeddings:
raise ValueError("Embeddings for 'man' and 'woman' are required.")
man_embedding = embeddings['man']
woman_embedding = embeddings['woman']
man_similarities = []
woman_similarities = []
for occ in occupations:
if occ in embeddings:
occ_embedding = embeddings[occ]
similarity_to_man = np.dot(man_embedding, occ_embedding) / (np.linalg.norm(man_embedding) * np.linalg.norm(occ_embedding))
similarity_to_woman = np.dot(woman_embedding, occ_embedding) / (np.linalg.norm(woman_embedding) * np.linalg.norm(occ_embedding))
man_similarities.append((similarity_to_man, occ))
woman_similarities.append((similarity_to_woman, occ))
man_similarities.sort(key=lambda x: x[0], reverse=True)
woman_similarities.sort(key=lambda x: x[0], reverse=True)
top_man_occs = [occ for _, occ in man_similarities[:5]]
top_woman_occs = [occ for _, occ in woman_similarities[:5]]
return top_man_occs, top_woman_occspart4_written
дёҖдәӣиҒҢдёҡжӣҙжҺҘиҝ‘вҖңз”·дәәвҖқпјҢиҖҢеҸҰдёҖдәӣиҒҢдёҡжӣҙжҺҘиҝ‘вҖңеҘідәәвҖқпјҢиҝҷеҸҚжҳ дәҶзӨҫдјҡдёӯеӯҳеңЁзҡ„жҖ§еҲ«еҲ»жқҝеҚ°иұЎгҖӮеҸҜиғҪжҳҜеӣ дёәз”ЁдәҺи®ӯз»ғиҜҚеҗ‘йҮҸзҡ„ж•°жҚ®дёӯеҢ…еҗ«дәҶиҝҷдәӣеҒҸи§ҒпјҢеҜјиҮҙжЁЎеһӢеӯҰд№ еҲ°дәҶиҝҷдәӣе…іиҒ”гҖӮ
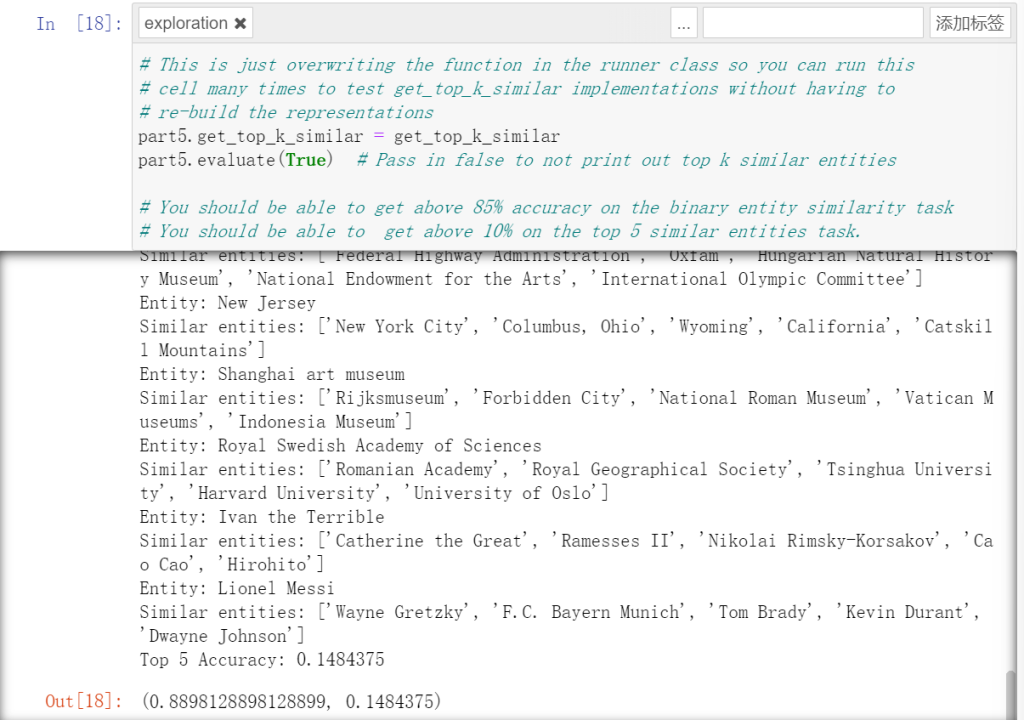
Part 5: Entity Representation
дҪҝз”Ё е‘ҪеҗҚе®һдҪ“иҜҶеҲ«жЁЎеһӢ (NER Model) д»Һ Wikipedia зҡ„ж–ҮжЎЈдёӯжҸҗеҸ–е‘ҪеҗҚе®һдҪ“ (Named Entities)гҖӮдҫӢеҰӮпјҢBarack Obama жҳҜдёҖдёӘе‘ҪеҗҚе®һдҪ“пјҢзұ»еҲ«дёәвҖңдәәеҗҚвҖқгҖӮжҸҗеҸ–е‘ҪеҗҚе®һдҪ“еҗҺпјҢз ”з©¶е“Әдәӣе®һдҪ“еҪјжӯӨзӣёдјјгҖӮ
extract_named_entities
з»ҷдёҖж®өж–Үжң¬пјҢдҪҝз”Ё SpaCy зҡ„иҮӘ然иҜӯиЁҖеӨ„зҗҶеҠҹиғҪжҸҗеҸ–е‘ҪеҗҚе®һдҪ“гҖӮ
з”ЁnlpеҜ№иұЎпјҢжҠҠжҲ‘们зҡ„ж®өиҗҪиҪ¬еҢ–дёәSpaCyж–ҮжЎЈпјҢж–ҮжЎЈжҸҗеҸ–ж–ҮжЎЈдёӯзҡ„е‘ҪеҗҚе®һдҪ“并иҝ”еӣһгҖӮ
def extract_named_entities(paragraph):
global nlp
spacy_paragraph = nlp(paragraph)
named_entities = list(spacy_paragraph.ents)
return named_entities, spacy_paragraphcompute_entity_representation
дёәжҜҸдёӘе®һдҪ“жһ„е»әдёҖдёӘиЎЁзӨәеҗ‘йҮҸпјҢдҪҝз”ЁжҸҸиҝ°дёӯзҡ„иҜҚеөҢе…Ҙи®Ўз®—е®һдҪ“зҡ„е№іеқҮеҗ‘йҮҸпјҢ收йӣҶжүҖжңүз¬ҰеҗҲжқЎд»¶зҡ„иҜҚзҡ„еөҢе…Ҙеҗ‘йҮҸпјҢ并计算е®ғ们зҡ„е№іеқҮеҖјгҖӮ
йҒҚеҺҶжҸҸиҝ°дёӯзҡ„жҜҸдёӘиҜҚпјҢжЈҖжҹҘе…¶жҳҜеҗҰдёәеҒңз”ЁиҜҚпјҢ并еңЁеөҢе…Ҙеӯ—е…ёдёӯгҖӮ
def compute_entity_representation(description, embeddings):
vector = None
word_vectors = []
for token in description:
if not token.is_stop and token.text.lower() in embeddings:
word_vectors.append(embeddings[token.text.lower()])
if word_vectors:
vector = np.mean(np.array(word_vectors), axis=0)
return vectorget_top_k_similar
и®Ўз®—з»ҷе®ҡе®һдҪ“еөҢе…ҘдёҺдёҖз»„еҖҷйҖүе®һдҪ“еөҢе…Ҙд№Ӣй—ҙзҡ„зӣёдјјжҖ§пјҢиҝ”еӣһжңҖзӣёдјјзҡ„еүҚ k дёӘе®һдҪ“гҖӮ
йҰ–е…ҲеҜ№е®һдҪ“еөҢе…Ҙе’ҢеҖҷйҖүеөҢе…ҘиҝӣиЎҢеҪ’дёҖеҢ–пјҢдҪҝз”Ё NumPy зҡ„зҹ©йҳөд№ҳжі•и®Ўз®—дҪҷејҰзӣёдјјеәҰпјҢжңҖеҗҺж №жҚ®зӣёдјјеәҰжҺ’еәҸ并йҖүжӢ©еүҚ k дёӘжңҖзӣёдјјзҡ„е®һдҪ“гҖӮ
def get_top_k_similar(entity_embedding, choices, top_k):
similar_entities = []
if not choices:
return similar_entities
choice_names = list(choices.keys())
choice_embeddings = np.array(list(choices.values()))
entity_embedding_norm = entity_embedding / np.linalg.norm(entity_embedding)
choice_embeddings_norm = choice_embeddings / np.linalg.norm(choice_embeddings, axis=1, keepdims=True)
similarities = np.matmul(choice_embeddings_norm, entity_embedding_norm)
top_k_indices = np.argsort(similarities)[::-1][:top_k]
similar_entities = [choice_names[i] for i in top_k_indices]
return similar_entitiesз»“жһңйқһеёёеҘҪпјҢз¬ҰеҗҲиҰҒжұӮгҖӮеӨ§дәҺдәҶд»–зҡ„иҰҒжұӮ
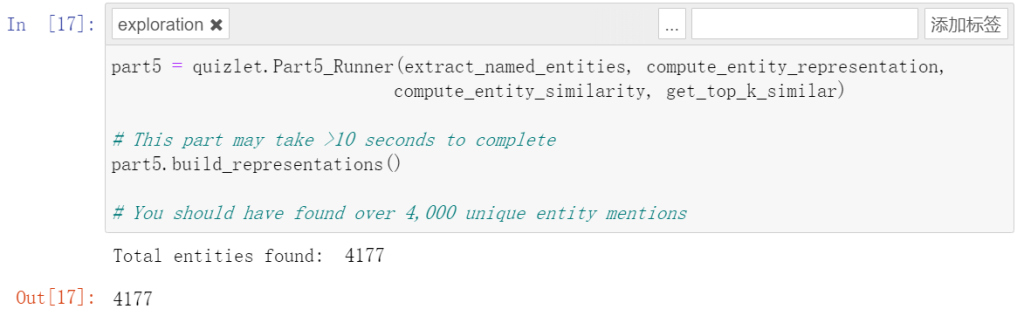
дёӢйқўзҡ„еҮҶзЎ®еәҰе’ҢеҲҶж•°д№ҹйғҪйҒҘйҒҘйўҶе…ҲпјҢд»»еҠЎжҲҗеҠҹиҗҪдёӢ帷幕гҖӮ
еӨ§и®әж–Ү
йҡҫеәҰпјҡвӯҗвӯҗпјҲвӯҗвӯҗвӯҗвӯҗвӯҗвӯҗвӯҗвӯҗпјү
йҮҮз”ЁдәҶжҳҹзҒ«еӨ§жЁЎеһӢпјҢдёәд»Җд№Ҳе‘ўпјҹеӣ дёәд»–е…Қиҙ№йўқеәҰжңҖеӨҡдәҶпјҢжЁЎеһӢиҝҳжҜ”иҫғеҘҪз”ЁгҖӮ
жҲ‘зҡ„и®ЎеҲ’жҳҜеҜ№дәҺдёүз§ҚдёҚеҗҢзҡ„д»»еҠЎпјҢдёҖз§ҚжҳҜж–Үз« еҶ…е®№жў—жҰӮпјҢдёҖз§ҚжҳҜе°Ҹзәўд№Ұж–ҮжЎҲз”ҹжҲҗпјҢдёҖз§ҚжҳҜжҙ»еҠЁзӯ–еҲ’гҖӮдёәд»Җд№ҲйҖүжӢ©иҝҷдёүз§Қе‘ўпјҢжҳҜеӣ дёәиҝҷдёүз§ҚеҜ№еә”зҡ„ж–Үжң¬з”ҹжҲҗзӯ–з•ҘгҖӮж–Үз« еҶ…е®№жў—жҰӮиҰҒжұӮеҶ…е®№зІҫзЎ®пјҢйҒөеҫӘеҺҹж–Үпјӣе°Ҹзәўд№Ұж–ҮжЎҲз”ҹжҲҗйңҖиҰҒдёҖе®ҡзҡ„жү©еұ•пјҢдҪҶд№ҹиҰҒдҝқиҜҒеҺҹжңүеҶ…е®№зҡ„иҰҶзӣ–пјӣжҙ»еҠЁзӯ–еҲ’жҸҗзӨәеҶ…е®№иҫғе°‘пјҢеӨ§йғЁеҲҶдёәиҮӘз”ұеҸ‘жҢҘгҖӮ