еЊИжЧ©дї•еЙНпЉМжИСе∞±йГ®зљ≤ињЗињЩдЄ™й°єзЫЃгАВељУжЧґжШѓжЬђеЬ∞йГ®зљ≤пЉМеРОзї≠иѓХдЇЖdockerпЉМdockerдєЯз°ЃеЃЮе•љзФ®пЉМдЄНињЗжИСзЫЃеЙНubuntuзЪДdockerжЧ†ж≥ХpullпЉМдї£зРЖйЕНзљЃйГљеЖЩдЇЖдЊЭзДґдЄНи°МпЉМињЩе∞±иЃ©жИСеЊИеЫ∞жГСдЇЖгАВ
дЄНињЗйЧЃйҐШдЄНе§ІпЉМеѓєдЇОжЬНеК°еЩ®dockerеЯЇжЬђйГљжШѓеЃМеЦДзЪДпЉМйЕНзљЃдєЯж≤°еХ•йЧЃйҐШгАВдї•еРОжИЦиЃЄдЉЪиАГиЩСеЕ®жМВеИ∞жЬНеК°еЩ®дЄКйЭҐеОїпЉМдЄНињЗзО∞еЬ®жИСињШйЬАи¶БеЉАеПСпЉМз≠ЙеКЯиГљеЃМеЦДеРОеЖНжЙУеМЕжМВжЬНеК°еЩ®еЊЧдЇЖгАВй°єзЫЃжЬђиЇЂдЄНйЪЊпЉМе®±дєРжАІиі®жЫіеЉЇпЉИ
жЬђжЦЗжЭ•иЗ™еЉАжЇРй°єзЫЃ https://github.com/zhayujie/chatgpt-on-wechat пЉМеѓєеЕґжПТдїґеЉАеПСгАВ
йГ®зљ≤йЕНзљЃ
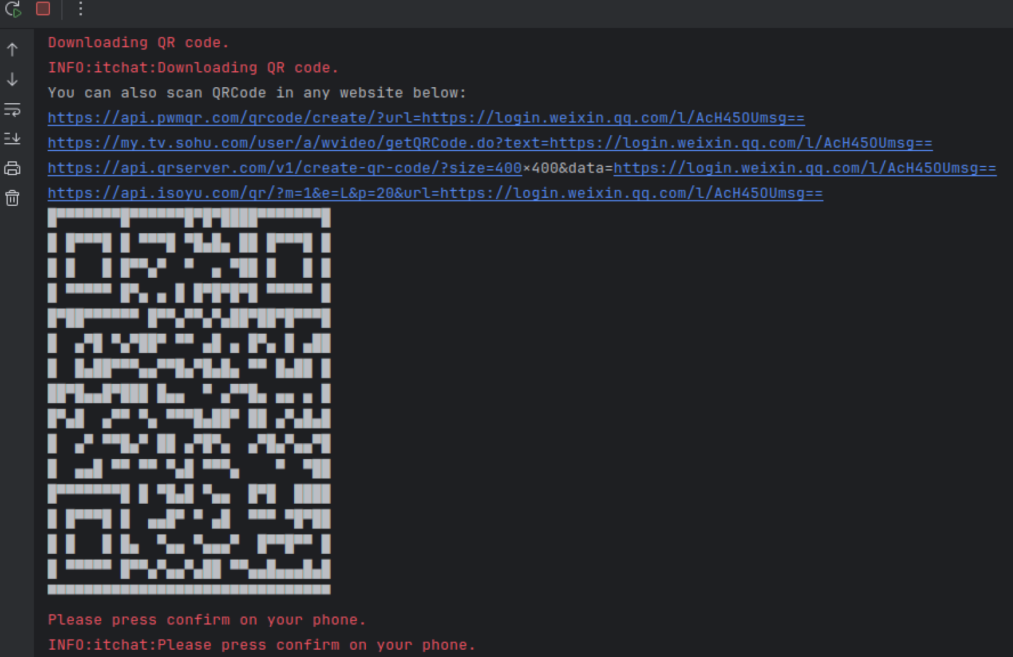
pullдЄЛжЭ•еРОпЉМж†єжНЃrequirements.txtи¶Бж±ВйЕНзљЃгАВеЕЈдљУеПВжХ∞йЕНзљЃиЗ™еЈ±жЙЊжЙЊжЦЗж°£йГљеПѓдї•жЙЊеИ∞гАВжИСйБЗеИ∞дЇЖдЄАдЄ™е∞ПйЧЃйҐШпЉМwebsocketзЙИжЬђињЗжЦ∞еѓЉиЗіеЗљжХ∞еЈ≤зїП襀еИ†жОЙдЇЖпЉМеНЄиљљеРОжМЗеЃЪдЄЛиљљжМЗеЃЪзЙИжЬђwebsocket-clientеН≥еПѓ
еЉАеПСplugins
еЯЇжЬђйАїиЊС
1.жФґеИ∞жґИжБѓ ---> 2.дЇІзФЯеЫЮе§Н ---> 3.еМЕи£ЕеЫЮе§Н ---> 4.еПСйАБеЫЮе§НжЦЗж°£еЖЩзЪДеЊИе•љпЉМдљЖжШѓеПѓжГЬеОЯзЙИжЬђињЗжЧґдЇЖпЉМжИСжМЙзЕІжЦ∞дї£з†БжХізРЖдЄАдЄЛ
ж≥®еЖМ
еѓєдЇОдЄЛйЭҐињЩдЄ™пЉМжПТдїґй¶ЦеЕИж†ЗиѓЖеєґж≥®еЖМпЉМеРМжЧґйЫЖжИРиЗ™Plugin
еЬ®з±їеЃЪдєЙдєЛеЙНйЬАи¶БдљњзФ®@plugins.registerи£Ей•∞еЩ®ж≥®еЖМжПТдїґпЉМеєґе°ЂеЖЩжПТдїґзЪДзЫЄеЕ≥дњ°жБѓпЉМеЕґдЄ≠desire_priorityи°®з§ЇжПТдїґйїШиЃ§зЪДдЉШеЕИзЇІпЉМиґКе§ІдЉШеЕИзЇІиґКйЂШгАВеИЭжђ°еК†иљљжПТдїґеРОеПѓеЬ®plugins/plugins.jsonдЄ≠дњЃжФєжПТдїґдЉШеЕИзЇІгАВ
еєґеЬ®initдЄ≠зїСеЃЪдљ†зЉЦеЖЩзЪДдЇЛдїґе§ДзРЖеЗљжХ∞гАВ
HelloжПТдїґдЄЇдЇЛдїґON_HANDLE_CONTEXTзїСеЃЪдЇЖдЄАдЄ™е§ДзРЖеЗљжХ∞on_handle_contextпЉМеЃГи°®з§ЇдєЛеРОжѓПжђ°зФЯжИРеЫЮе§НеЙНпЉМйГљдЉЪзФ±on_handle_contextеЕИе§ДзРЖгАВ
еРМжЧґињШжФѓжМБдї•дЄЛеЗ†зІНеЫЮе§НпЉМеЃЮйЩЕжЭ•иѓіпЉМжФґеИ∞еЫЮе§НжЬАжЬЙзФ®пЉМдЄАиИђдєЯзФ®ињЩдЄ™е∞±е§ЯдЇЖ
1.жФґеИ∞жґИжБѓ
—> ON_HANDLE_CONTEXT
2.дЇІзФЯеЫЮе§Н
—> ON_DECORATE_REPLY
3.и£Ей•∞еЫЮе§Н
—> ON_SEND_REPLY
@plugins.register(name="Hello", desc="A simple plugin that says hello", version="0.1", author="lanvent", desire_priority= -1)
class Hello(Plugin):
def __init__(self):
super().__init__()
self.handlers[Event.ON_HANDLE_CONTEXT] = self.on_handle_context
logger.info("[Hello] inited")жФґеИ∞жґИжБѓ
def on_handle_context(self, e_context: EventContext):
if e_context['context'].type != ContextType.TEXT:
returnеЕґдљЩйАїиЊСеЕ®йГ®еЬ®on_handle_contentйЗМйЭҐпЉМеѓєдЇОдЄАдЄ™дЇЛзЙ©пЉМжФґеИ∞жґИжБѓеРОж†єжНЃиЗ™еЈ±йЬАж±ВеИ§жЦ≠йЬАи¶БеУ™дЇЫз±їеЮЛпЉМж†єжНЃеЃЮйЩЕйЬАи¶БзЪДеОїи°•еЕЕ
- TEXT = 1 # жЦЗе≠Ч
- VOICE = 2 # е£∞йЯ≥
- IMAGE = 3 # еЫЊзЙЗ
- FILE = 4 # жЦЗдїґ
- VIDEO = 5 # иІЖйҐС
- SHARING = 6 # еИЖдЇЂ
- IMAGE_CREATE = 10 # еИЫеїЇеЫЊзЙЗеСљдї§
- ACCEPT_FRIEND = 19 # еРМжДПе•љеПЛйЬАж±В
- JOIN_GROUP = 20 # еК†еЕ•зЊ§иБК
- PATPAT = 21 # жЛНдЄАжЛН
- FUNCTION = 22 # еЗљжХ∞и∞ГзФ®
- EXIT_GROUP = 23 # йААеЗЇ
еѓєдЇОеЊЧеИ∞еЕґеЕЈдљУеЖЕеЃєпЉМеИЩжШѓеЬ® e_context["context"].content йЗМйЭҐпЉМжЦЗе≠ЧдЉЪзЫіжО•дЉ†йАТеАЉеН≥жЦЗжЬђеЖЕеЃєпЉМдЄНињЗжИСе∞ЪжЬ™е∞ЭиѓХйЯ≥йҐСжЦЗдїґз±їеЖЕеЃєпЉМе¶ВжЮЬдї£з†Биґ≥е§ЯиІДиМГйВ£еЇФиѓ•жРЇеЄ¶зЪДжШѓеОЯжХ∞жНЃпЉИж†єжНЃдЄЛжЦЗдЉ†йАТзМЬжµЛпЉЙ
дЇІзФЯеЫЮе§Н
дЇЛдїґе§ДзРЖеЗљжХ∞жО•жФґдЄАдЄ™EventContextеѓєи±°e_contextдљЬдЄЇеПВжХ∞гАВe_contextеМЕеРЂдЇЖдЇЛдїґзЫЄеЕ≥дњ°жБѓпЉМеИ©зФ®e_context[‘key’]жЭ•иЃњйЧЃињЩдЇЫдњ°жБѓгАВ
EventContext(EventдЇЛдїґз±їеЮЛ, {‘channel’ : жґИжБѓchannel, ‘context’: Context, ‘reply’: Reply})
е§ДзРЖеЗљжХ∞дЄ≠йАЪињЗдњЃжФєe_contextеѓєи±°дЄ≠зЪДдЇЛдїґзЫЄеЕ≥дњ°жБѓжЭ•еЃЮзО∞жЙАйЬАеКЯиГљпЉМжѓФе¶ВжЫіжФєe_context[‘reply’]дЄ≠зЪДеЖЕеЃєеПѓдї•дњЃжФєеЫЮе§НгАВ
def on_handle_context(self, e_context: EventContext):
if e_context['context'].type != ContextType.TEXT:
return
content = e_context['context'].content
if content == "Hello":ињЩйЗМеИ§жЦ≠contentжШѓдЄЇзїЩеЃЪеАЉпЉМдљЖеЃЮйЩЕињШжЬЙеЗ†дЄ™еЃЮзФ®зЪДжО•еП£пЉМеЃЮйЩЕдєЯжШѓpythonйЗМйЭҐзЪДжЦЗе≠Че§ДзРЖпЉМжѓФе¶ВиѓіеЃЮзФ®зЪДеЉАе§іеМЕеРЂпЉМжИЦиАЕж≠£еИЩеМєйЕНпЉМдЊњдЇОињЫдЄАж≠•еМєйЕНеЖЕеЃє
if content.startswith("жߕ胥"):
horoscope_match = re.match(r'^([\u4e00-\u9fa5]{2}?)$', content)
if horoscope_match:еМЕи£ЕеПСйАБ
дї•жИСиЗ™еЈ±еЖЩзЪДдЄАдЄ™зЃАеНХиОЈеПЦеЫЊзЙЗURLдЄЇдЊЛе≠Р
if content == "жЭ•зВєйВ£дЄ™":
url = "https://www.dmoe.cc/random.php"
reply_type = ReplyType.IMAGE_URL if self.is_valid_url(url) else ReplyType.TEXT//иЃЊеЃЪеЫЮе§Нз±їеЮЛпЉМеИ§жЦ≠urlжШѓеР¶еПѓиОЈеПЦ
reply = self.create_reply(reply_type, url) //еИЫеїЇ
e_context["reply"] = reply //иЃЊеЃЪжБҐе§НеЖЕеЃє
e_context.action = EventAction.BREAK_PASS //дЇЛдїґзїУжЭЯпЉМдЄНеЖНзїІзї≠дЉ†йАТ
return
def create_reply(self, reply_type, content):
reply = Reply()
reply.type = reply_type
reply.content = content
return reply- EventAction.CONTINUE: дЇЛдїґжЬ™зїУжЭЯпЉМзїІзї≠дЇ§зїЩдЄЛдЄ™жПТдїґе§ДзРЖпЉМе¶ВжЮЬж≤°жЬЙдЄЛдЄ™жПТдїґпЉМеИЩдЇ§дїШзїЩйїШиЃ§зЪДдЇЛдїґе§ДзРЖйАїиЊСгАВ
- EventAction.BREAK: дЇЛдїґзїУжЭЯпЉМдЄНеЖНзїЩдЄЛдЄ™жПТдїґе§ДзРЖпЉМдЇ§дїШзїЩйїШиЃ§зЪДе§ДзРЖйАїиЊСгАВ
- EventAction.BREAK_PASS: дЇЛдїґзїУжЭЯпЉМдЄНеЖНзїЩдЄЛдЄ™жПТдїґе§ДзРЖпЉМиЈ≥ињЗйїШиЃ§зЪДе§ДзРЖйАїиЊСгАВ
returnеРОеЃМжИР
еЃЮжИШжУНзїГ
жПТдїґжФѓжМБзГ≠жЫіжЦ∞пЉМйЕНеРИ#reloadp еН≥еПѓгАВдљЖжЬЙжЧґиОЂеРН姱賕пЉМ姱賕дЄАиИђжШѓдї£з†БеЖЩйФЩдЇЖпЉМе¶ВжЮЬз°ЃиЃ§ж≤°йФЩйВ£дєИе∞±йЗНеРѓй°єзЫЃеРІ
дЄАеЉ†еЫЊ
ж≠§йУЊжО•linkеРОдЉЪзЫіжО•ињФеЫЮеЫЊзЙЗжХ∞жНЃпЉМжАїдљУйАїиЊСзЃАеНХ
if content == "жЭ•зВєйВ£дЄ™":
url = "https://www.dmoe.cc/random.php"
reply_type = ReplyType.IMAGE_URL if self.is_valid_url(url) else ReplyType.TEXT//иЃЊеЃЪеЫЮе§Нз±їеЮЛпЉМеИ§жЦ≠urlжШѓеР¶еПѓиОЈеПЦ
reply = self.create_reply(reply_type, url) //еИЫеїЇ
e_context["reply"] = reply //иЃЊеЃЪжБҐе§НеЖЕеЃє
e_context.action = EventAction.BREAK_PASS //дЇЛдїґзїУжЭЯпЉМдЄНеЖНзїІзї≠дЉ†йАТ
returnleetcode
pythonжЦЗдїґеЉХзФ®жАїжШѓиЃ©жИСе§іе§ІпЉМеѓєдЇОpyпЉМеЉХзФ®и≤МдЉЉйГљжШѓж†єжНЃеЈ•дљЬзЫЃељХжЭ•зЪДгАВеИЖжЦЗдїґзЪДpyдЉЪеѓЉиЗіеЉХзԮ姱賕йЧЃйҐШгАВеѓєж≠§пЉМжИСдЄУйЧ®еИЫеїЇдЇЖдЄАдЄ™utilsжЦЗдїґе§єпЉМдЄУйЧ®жФЊжИСзЪДзИђиЩЂ
зИђиЩЂеКЯе§ЂињШдЄНеИ∞еЃґпЉМињЩйЗМcopyдЇЖдїЦдЇЇзЪДпЉМеРОзї≠жХ∞жНЃзФ±жИСе§ДзРЖгАВXMLжХ∞жНЃ+getдЄНзЯ•дЄЇдљХдЄНеМЕеРЂжИСеЃЮйЩЕзЬЛиІБзЪДпЉМжИЦиЃЄжШѓдїАдєИеПНжЙТжО™жЦљпЉИпЉЯпЉМдЄЛжђ°еЖНдЄУйЧ®йЗНжЦ∞жРЮе•љзИђиЩЂпЉИ
йАїиЊСиОЈеПЦзљСй°µжХ∞жНЃпЉМзИђеПЦеѓєеЇФеЖЕеЃєгАВжИСеЖНеѓєжХ∞жНЃе§ДзРЖпЉМжЙУеМЕжИРжґИжБѓеПСйАБзЪДж†ЉеЉПгАВе§ЦйГ®и∞ГзФ®ж≠§еЗљжХ∞е∞±зЫіжО•иОЈеЊЧдЇЖжЦЗжЬђпЉМжИСеЖНињФеЫЮеН≥еПѓ
if content == "жѓПжЧ•дЄАйҐШ":
reply_type = ReplyType.TEXT
content = fetch_today_question()
reply = self.create_reply(reply_type , content)
e_context['reply'] = reply
e_context.action = EventAction.BREAK_PASS
returnжХИжЮЬеПѓдї•пЉМйЕНеРИеЃЪжЧґеЩ®жМЙжЧґеБЪйҐШпЉИ
